Embed Size (px)
Citation preview

Review for Midterm 2Review for Midterm 2
Shahram GhandeharizadehShahram Ghandeharizadeh

Midterm 2Midterm 2
Scheduled for April 30Scheduled for April 30thth
4 papers4 papers Variant indexes.Variant indexes. Access path selection.Access path selection. Overview of query optimization.Overview of query optimization. Mining Association Rules.Mining Association Rules. Paper on cache management is not included Paper on cache management is not included
because it was covered by your project.because it was covered by your project.
Midterm 2 is worth 35% of your grade.Midterm 2 is worth 35% of your grade.

Variant IndexesVariant Indexes
A read-mostly database that is updated A read-mostly database that is updated infrequently.infrequently.
Complex indexes to speedup queries.Complex indexes to speedup queries. Focuses on physical designs to enhance Focuses on physical designs to enhance
performance.performance.

Example Data WarehouseExample Data Warehouse
Key Observations:Key Observations: A handful of products, A handful of products,
a PROD table with tens a PROD table with tens of rows.of rows.
Many millions of rows Many millions of rows for SALES tables.for SALES tables.
CidCidPidPidDayDayAmtAmtdollar_costdollar_costUnit_salesUnit_sales
SALESSALES
PidPidNameNameSizeSizeWeightWeightPackage_typePackage_type
PRODPRODDayDayWeekWeekMonthMonthYearYearHollidayHollidayWeekdayWeekday
TIMETIME

A B+-Tree on Major HolidaysA B+-Tree on Major Holidays
A B+-tree index on different holidays of the A B+-tree index on different holidays of the SALES table.SALES table.
Joe, Big Mac, Lab day, …Joe, Big Mac, Lab day, …
Mary, Fries, Pres day, …Mary, Fries, Pres day, …
Harry, Big Mac, Pres day, …Harry, Big Mac, Pres day, …
Henry, Big Mac, Pres day, …Henry, Big Mac, Pres day, …
Jane, Happy Meal, Pres day, …Jane, Happy Meal, Pres day, …
Shideh, Happy Meal, Pres day, …Shideh, Happy Meal, Pres day, …
Kam, Happy Meal, Pres day, …Kam, Happy Meal, Pres day, …
Bob, Big Mac, Pres day, …Bob, Big Mac, Pres day, …
(Pres day, (1,2), (1, 3), (1, 4), (2,1), ….(Pres day, (1,2), (1, 3), (1, 4), (2,1), …. B+-treeB+-treeLeaf pageLeaf page
Value ListValue List

A B+-Tree on Major HolidaysA B+-Tree on Major Holidays
A B+-tree index on different holidays of the A B+-tree index on different holidays of the SALES table.SALES table.
Joe, Big Mac, Lab day, …Joe, Big Mac, Lab day, …
Mary, Fries, Pres day, …Mary, Fries, Pres day, …
Harry, Big Mac, Pres day, …Harry, Big Mac, Pres day, …
Henry, Big Mac, Pres day, …Henry, Big Mac, Pres day, …
Jane, Happy Meal, Pres day, …Jane, Happy Meal, Pres day, …
Shideh, Happy Meal, Pres day, …Shideh, Happy Meal, Pres day, …
Kam, Happy Meal, Pres day, …Kam, Happy Meal, Pres day, …
Bob, Big Mac, Pres day, …Bob, Big Mac, Pres day, …
(Pres day, (1,2), (1, 3), (1, 4), (2,1), ….(Pres day, (1,2), (1, 3), (1, 4), (2,1), …. B+-treeB+-treeLeaf pageLeaf page
Value ListValue List RID ListRID List

Conjunctive QueriesConjunctive Queries
Count number of Big Mac Sales on Count number of Big Mac Sales on “President’s Day” assuming a B+-tree on “President’s Day” assuming a B+-tree on product (pid) and day of SALESproduct (pid) and day of SALES
With RID-ListsWith RID-Lists Get the Value-List for “Big Mac” using the B+-Get the Value-List for “Big Mac” using the B+-
tree, obtain RID-List1.tree, obtain RID-List1. Get the Value-List for “President’s Day” using Get the Value-List for “President’s Day” using
the B+-tree, obtain RID-List2.the B+-tree, obtain RID-List2. Compute set-intersect of RID-List1 and RID-List2Compute set-intersect of RID-List1 and RID-List2 Count the number of RIDs in the intersection set.Count the number of RIDs in the intersection set.
Is there a better way? Is there a better way? Yes, use bit-maps and logical bit-wise operands.Yes, use bit-maps and logical bit-wise operands.

Bitmap IndexesBitmap Indexes
Use a bitmap to represent the existence of a Use a bitmap to represent the existence of a record with a certain attribute value.record with a certain attribute value.
Example: If a record has the indexed Example: If a record has the indexed attribute value “Big Mac” then its attribute value “Big Mac” then its corresponding entry in the bitmap is set to corresponding entry in the bitmap is set to one. Otherwise, it is a zero.one. Otherwise, it is a zero.
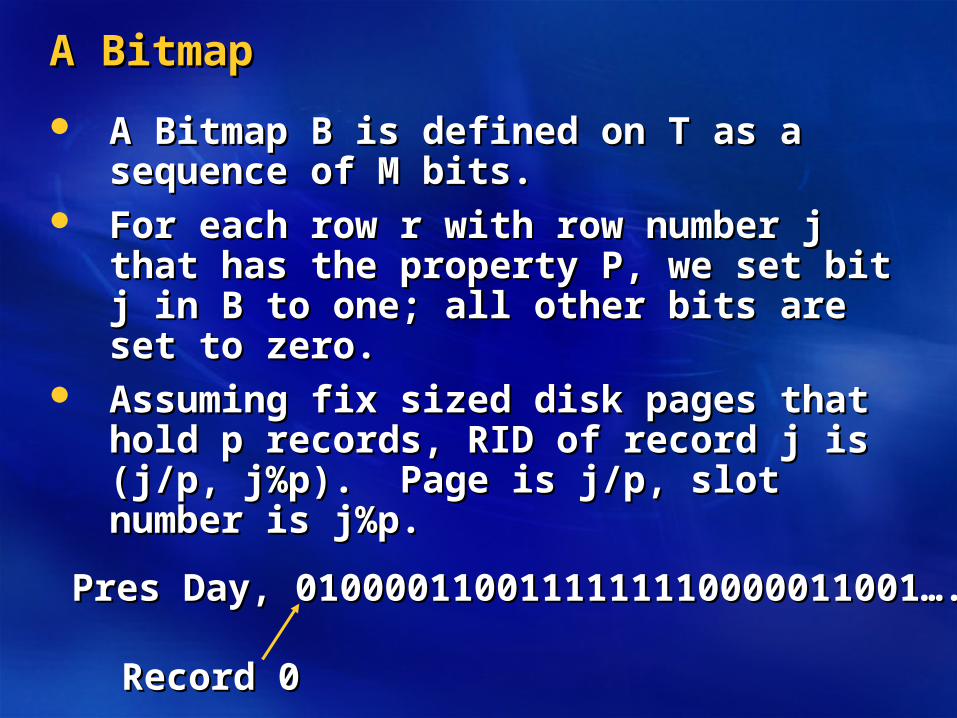
A BitmapA Bitmap
A Bitmap B is defined on T as a sequence of A Bitmap B is defined on T as a sequence of M bits.M bits.
For each row r with row number j that has For each row r with row number j that has the property P, we set bit j in B to one; all the property P, we set bit j in B to one; all other bits are set to zero.other bits are set to zero.
Assuming fix sized disk pages that hold p Assuming fix sized disk pages that hold p records, RID of record j is (j/p, j%p). Page is records, RID of record j is (j/p, j%p). Page is j/p, slot number is j%p.j/p, slot number is j%p.
Pres Day, 0100001100111111110000011001…..Pres Day, 0100001100111111110000011001…..
Record 0Record 0

A BitmapA Bitmap
A Bitmap B is defined on T as a sequence of A Bitmap B is defined on T as a sequence of M bits.M bits.
For each row r with row number j that has For each row r with row number j that has the property P, we set bit j in B to one; all the property P, we set bit j in B to one; all other bits are set to zero.other bits are set to zero.
Assuming fix sized disk pages that hold p Assuming fix sized disk pages that hold p records, RID of record j is (j/p, j%p). Page is records, RID of record j is (j/p, j%p). Page is j/p, slot number is j%p.j/p, slot number is j%p.
Pres Day, 0100001100111111110000011001…..Pres Day, 0100001100111111110000011001…..
Record 1Record 1

A BitmapA Bitmap
A Bitmap B is defined on T as a sequence of A Bitmap B is defined on T as a sequence of M bits.M bits.
For each row r with row number j that has For each row r with row number j that has the property P, we set bit j in B to one; all the property P, we set bit j in B to one; all other bits are set to zero.other bits are set to zero.
Assuming fix sized disk pages that hold p Assuming fix sized disk pages that hold p records, RID of record j is (j/p, j%p). Page is records, RID of record j is (j/p, j%p). Page is j/p, slot number is j%p.j/p, slot number is j%p.
Pres Day, 0100001100111111110000011001…..Pres Day, 0100001100111111110000011001…..
Record 2Record 2

A B+-Tree on Major HolidaysA B+-Tree on Major Holidays
A B+-tree index on different holidays of the A B+-tree index on different holidays of the SALES table.SALES table.
Joe, Big Mac, Lab day, …Joe, Big Mac, Lab day, …
Mary, Fries, Pres day, …Mary, Fries, Pres day, …
Harry, Big Mac, Pres day, …Harry, Big Mac, Pres day, …
Henry, Big Mac, Pres day, …Henry, Big Mac, Pres day, …
Jane, Happy Meal, Pres day, …Jane, Happy Meal, Pres day, …
Shideh, Happy Meal, Pres day, …Shideh, Happy Meal, Pres day, …
Kam, Happy Meal, Pres day, …Kam, Happy Meal, Pres day, …
Bob, Big Mac, Pres day, …Bob, Big Mac, Pres day, …
(Pres day, 01111111….(Pres day, 01111111….B+-treeB+-tree
Leaf pageLeaf page

Conjunctive QueriesConjunctive Queries
Count number of Big Mac Sales on “President’s Count number of Big Mac Sales on “President’s Day” assuming a B+-tree on product (pid) and day Day” assuming a B+-tree on product (pid) and day of SALESof SALES
With RIDWith RID Get the Value-List for “Big Mac” using the B+-tree, obtain Get the Value-List for “Big Mac” using the B+-tree, obtain
RID-List1.RID-List1. Get the Value-List for “President’s Day” using the B+-tree, Get the Value-List for “President’s Day” using the B+-tree,
obtain RID-List2.obtain RID-List2. Compute set-intersect of RID-List1 and RID-List2Compute set-intersect of RID-List1 and RID-List2 Count the number of RIDs in the intersection set.Count the number of RIDs in the intersection set.
With bit mapsWith bit maps Get the Value-List for “Big Mac” using the B+-tree, obtain Get the Value-List for “Big Mac” using the B+-tree, obtain
bit-map1.bit-map1. Get the Value-List for “President’s Day” using the B+-tree, Get the Value-List for “President’s Day” using the B+-tree,
obtain bit-map2.obtain bit-map2. Recall Existence Bitmap (EBM) identify rows that exist.Recall Existence Bitmap (EBM) identify rows that exist. Let RES = logical AND of bit-map1, bit-map2, and EBM.Let RES = logical AND of bit-map1, bit-map2, and EBM. Count the number of bits set to one to identify how many Count the number of bits set to one to identify how many
Big Macs were sold on “President’s Day”.Big Macs were sold on “President’s Day”.

Variant IndexesVariant Indexes
Midterm 2 ignores:Midterm 2 ignores: MEDIAN, N-TILE, Column-Product as aggregates.MEDIAN, N-TILE, Column-Product as aggregates. Section 5.Section 5.

Access Path SelectionAccess Path Selection
Formulates a cost prediction for each access Formulates a cost prediction for each access plan, using the following cost formula:plan, using the following cost formula:
COST = Page fetches + W * (RSI Calls)COST = Page fetches + W * (RSI Calls)
W is an adjustable weighting factor between W is an adjustable weighting factor between I/O and CPU.I/O and CPU.
RSI calls is an approximation for CPU RSI calls is an approximation for CPU utilization.utilization.
Assumptions:Assumptions: WHERE tree is considered to be in conjunctive WHERE tree is considered to be in conjunctive
normal form,normal form, Every disjunct is called a boolean factor.Every disjunct is called a boolean factor.

How?How?
Enumerating the different execution plans,Enumerating the different execution plans, Estimate the cost of performing each plan,Estimate the cost of performing each plan, Pick the cheapest plan.Pick the cheapest plan.
Definition of cost is as follows:Definition of cost is as follows:COST = Page fetches + W * (RSI Calls)COST = Page fetches + W * (RSI Calls)

Clustered BClustered B++-Tree-Tree
A B+-tree on the gpa attributeA B+-tree on the gpa attribute
Bob, 21, 3.7, CSMary, 24, 3, ECE
Tom, 20, 3.2, EE
Kathy, 18, 3.8, LS
Kane, 19, 3.8, MELam, 22, 2.8, ME
Chang, 18, 2.5, CS Vera, 17, 3.9, EE
Louis, 32, 4, LS
Martha, 29, 3.8, CS
James, 24, 3.1, ME
Pat, 19, 2.8, EE
Chris, 22, 3.9, CSChad, 28, 2.3, LS
Leila, 20, 3.5, LS Shideh, 16, 4, CS
(3.7, (3, 1))
(3.8, (3,2))
(3.8, (3,3))
(3.9, (4,2))
(4, (4,3))
(3.8, (3,4))
(3.9, (4,1))
(4, (4,4))
(2.3, (1, 1))
(2.5, (1,2))
(2.8, (1,3))
(3.1, (2,2))
(3.2, (2,3)
(2.8, (1,4))
(3, (2,1))
(3.5, (2,4))
3.6

Non-Clustered BNon-Clustered B++-Tree-Tree
A random I/O for every qualifying recordA random I/O for every qualifying record
Bob, 21, 3.7, CS
Mary, 24, 3, ECE
Tom, 20, 3.2, EE
Kathy, 18, 3.8, LS
Kane, 19, 3.8, ME
Lam, 22, 2.8, ME
Chang, 18, 2.5, CS
Vera, 17, 3.9, EE
Louis, 32, 4, LS
Martha, 29, 3.8, CS
James, 24, 3.1, ME
Pat, 19, 2.8, EE
Chris, 22, 3.9, CS
Chad, 28, 2.3, LS
Leila, 20, 3.5, LS
Shideh, 16, 4, CS
(3.7, (1, 1))
(3.8, (3,2))
(3.8, (2,1))
(3.9, (2,4))
(4, (3,1))
(3.8, (1,4))
(3.9, (4,1))
(4, (4,4))
(2.3, (4, 2))
(2.5, (2,3))
(2.8, (2,2))
(3.1, (3,3))
(3.2, (1,3)
(2.8, (3,4))
(3, (1,2))
(3.5, (4,3))
3.6

QuestionsQuestions
How are relations and segments related? If How are relations and segments related? If slide #4, you state segments may contain slide #4, you state segments may contain more than one relation, and then the next more than one relation, and then the next bullet says “at most one relation per bullet says “at most one relation per segment.”. What is going on?segment.”. What is going on?

QuestionsQuestions
How are relations and segments related? If How are relations and segments related? If slide #4, you state segments may contain slide #4, you state segments may contain more than one relation, and then the next more than one relation, and then the next bullet says “at most one relation per bullet says “at most one relation per segment.”. What is going on?segment.”. What is going on?
Best clarified with an example:Best clarified with an example: Segment 1 may contain the Emp, Dept, and Segment 1 may contain the Emp, Dept, and
Revenues tables/relations.Revenues tables/relations. The Emp relation can be assigned to Segment 1 The Emp relation can be assigned to Segment 1
only. It may NOT be assigned to both Segments only. It may NOT be assigned to both Segments 1 and 2.1 and 2.

QuestionsQuestions
The cost of retrieving a range of records The cost of retrieving a range of records from a clustered B+-tree: Should not this be from a clustered B+-tree: Should not this be (depth_of_B+-tree + F(pred) * TCARD) or (depth_of_B+-tree + F(pred) * TCARD) or something related to the depth of the tree something related to the depth of the tree rather than NINDX, since you only have to rather than NINDX, since you only have to navigate through to the leaf nodes once and navigate through to the leaf nodes once and do a record scan once you’ve reached the do a record scan once you’ve reached the correct leaf node?correct leaf node?
•NINDX(I), the number of pages in index I.NINDX(I), the number of pages in index I.•TCARD(T), the number of pages in the TCARD(T), the number of pages in the segment that hold tuples of relation T.segment that hold tuples of relation T.

QuestionQuestion
Should not the cost for a non-clustered B+-Should not the cost for a non-clustered B+-tree also involve the depth of the tree rather tree also involve the depth of the tree rather than NINDX?than NINDX?
•NINDX(I), the number of pages in index I.NINDX(I), the number of pages in index I.•TCARD(T), the number of pages in the TCARD(T), the number of pages in the segment that hold tuples of relation T.segment that hold tuples of relation T.

QuestionQuestion
Should not the cost for a non-clustered B+-Should not the cost for a non-clustered B+-tree also involve the depth of the tree rather tree also involve the depth of the tree rather than NINDX?than NINDX? It should include the depth of the tree.It should include the depth of the tree. NINDX must be included because the leaf pages NINDX must be included because the leaf pages
of the B+-tree must be visited for the qualifying of the B+-tree must be visited for the qualifying records.records.
•NINDX(I), the number of pages in index I.NINDX(I), the number of pages in index I.•TCARD(T), the number of pages in the TCARD(T), the number of pages in the segment that hold tuples of relation T.segment that hold tuples of relation T.

QuestionsQuestions
Why is the cost of a merge-scan NINDX(R) + Why is the cost of a merge-scan NINDX(R) + NINDX(S) rather than the sum of segment NINDX(S) rather than the sum of segment scans of R and S, since you still have to visit scans of R and S, since you still have to visit every page that contains tuples of R and S?every page that contains tuples of R and S?
•NINDX(I), the number of pages in index I.NINDX(I), the number of pages in index I.•TCARD(T), the number of pages in the TCARD(T), the number of pages in the segment that hold tuples of relation T.segment that hold tuples of relation T.

QuestionsQuestions
Why is the cost of a merge-scan NINDX(R) + Why is the cost of a merge-scan NINDX(R) + NINDX(S) rather than the sum of segment NINDX(S) rather than the sum of segment scans of R and S, since you still have to visit scans of R and S, since you still have to visit every page that contains tuples of R and S?every page that contains tuples of R and S? The merge-scan employs the sorted order of the The merge-scan employs the sorted order of the
entries in the leaf pages of the B+-tree index entries in the leaf pages of the B+-tree index structures.structures.
•NINDX(I), the number of pages in index I.NINDX(I), the number of pages in index I.•TCARD(T), the number of pages in the TCARD(T), the number of pages in the segment that hold tuples of relation T.segment that hold tuples of relation T.

Overview of Query OptimizationOverview of Query Optimization
Extends discussion to:Extends discussion to: Correlation queries, use of outer-join to “flatten” Correlation queries, use of outer-join to “flatten”
nested queries.nested queries. Raises more questions than providing answers.Raises more questions than providing answers.
A good starting point for:A good starting point for: A practitioner who wants to build an optimizer for a A practitioner who wants to build an optimizer for a
relational DBMS.relational DBMS. A Ph.D. student interested in writing a dissertation in A Ph.D. student interested in writing a dissertation in
the area of query optimization techniques.the area of query optimization techniques.

Mining Association RulesMining Association Rules
Objective: Discover association Rule over Objective: Discover association Rule over basket data.basket data.
Motivation: valuable for cross-marketing Motivation: valuable for cross-marketing and attached mailing applications.and attached mailing applications. Example: 98% of customers who purchase tires Example: 98% of customers who purchase tires
and auto accessories also get automotive and auto accessories also get automotive services done.services done.
Key contributions:Key contributions: Fast algorithms: Fast algorithms:
Apriori, AprioriTid, and AprioriHybridApriori, AprioriTid, and AprioriHybrid
Pay attention to terminology, definitions, and Pay attention to terminology, definitions, and the general framework.the general framework.

Database SystemsDatabase Systems
This course has introduced you to:This course has introduced you to: A storage manager and its use, BDB.A storage manager and its use, BDB. Spatial indexing, R-Trees.Spatial indexing, R-Trees. Parallel DBMS.Parallel DBMS. Alternative technologies for applications that do Alternative technologies for applications that do
not require ACID transactions.not require ACID transactions. Google FS, MapReduce, etc.Google FS, MapReduce, etc.
Optimization techniques for relational DBMSs.Optimization techniques for relational DBMSs. Knowledge Discovery.Knowledge Discovery. Efficient query processing techniques.Efficient query processing techniques. RAID and Use of flash memory in enterprises:RAID and Use of flash memory in enterprises:
Steve Kleiman’s lecture.Steve Kleiman’s lecture.

Database SystemsDatabase Systems
Many important topics remain:Many important topics remain: Data mining, Data cubes, Data visualization Data mining, Data cubes, Data visualization
techniques.techniques.
Papers are from 1990s: Neumerous follow-Papers are from 1990s: Neumerous follow-on papers!on papers!





























