Embed Size (px)
Citation preview

Resource &Process Management

Resource Management
Every distributed system consists of a number of resources interconnected by a network.
Set of available resources in a distributed system seem like a single virtual system to the user.
A resource manager schedules the processes in a distributed system to make use of the system resources in a manner that resource usage, response time, network congestion, and scheduling overhead are optimized.
Scheduling of process can be done in three ways:– Task assignment approach– Load balancing approach– Load sharing approach

Desirable Features of Scheduling Algorithm
No priori knowledge about the processes– Else users have to specify resource requirements of
processes on submission for execution
Dynamic in nature– Process assignment based on current load of system not on
fixed static policy– Preemptive process migration facility
Quick decision making capability– Use heuristic methods requiring less computational effort
Balanced system performance and scheduling overhead– Tradeoff – global information / higher cost & timely
processing of information

Stability– Processor thrashing happens when scheduling decisions
taken independently or on basis of obsolete data & processes in transit to a lightly loaded node are not taken into account.
Scalability– Probe only m out of N nodes for selecting a host.
Fault tolerance– Should have decentralized decision making capability &
consider only available nodes for scheduling
Fairness of service– Use load sharing rather than load balancing. A node shares
its resources as long as its users are not significantly affected.

Task Assignment Approach
Find an optimal assignment for tasks of an individual process.
Assumptions– Process split into cohesive tasks with minimum
coupling– Amount of computation required by each task &
speed of each processor known– Cost of processing each task on every node is
known.– IPC costs between every pair of tasks is known.– Resource requirements, available resources,
precedence relationships among tasks known.– Reassignment of tasks not possible.

Task Assignment Approach
Goals– Minimization of IPC– Quick turn around time– High degree of parallelism– Efficient utilization of system resources
Drawbacks– Characteristics of all processes should be known
in advance– Does not take care of dynamically changing state
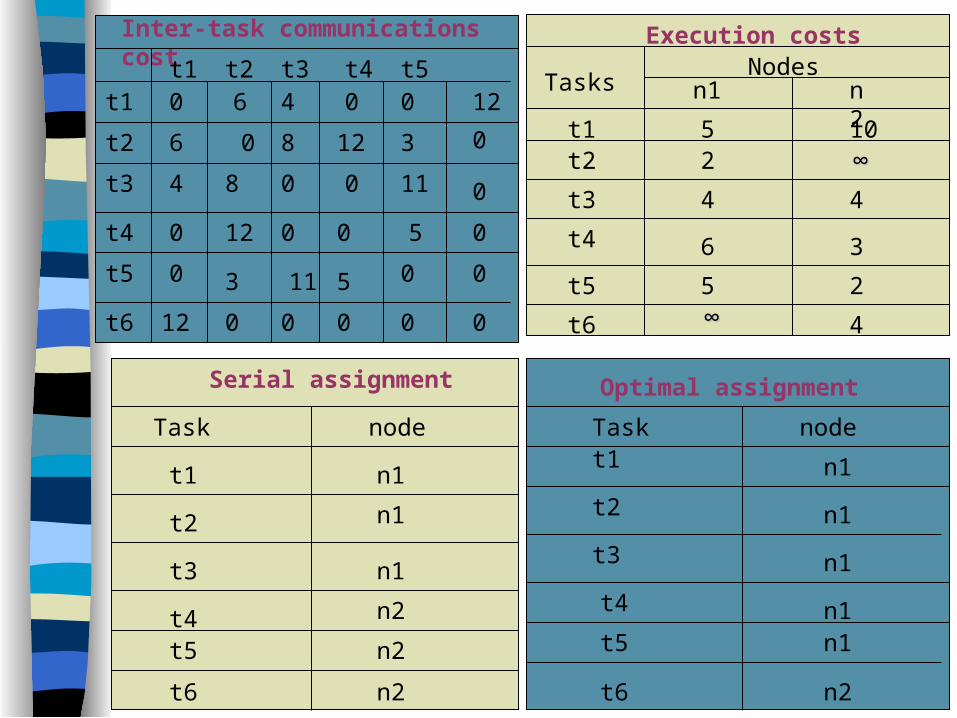
Serial assignment
Task node
t1
t2
t3
t4t5
t6
n1
n1
n1
n2n2n2
Optimal assignment
Task nodet1
t2
t3
t5
t4
t6
n1
n2
n1
n1
n1n1
t6
11
Inter-task communications cost
t1
t2
t3
t4
t5
t6
t1 t2 t3 t4 t512
12
0
6
4
6 4 0
0
0
0
0
0
0
0
0
0000
0
0
5
11
312
8
8
123
0
0
0
0
5
Execution costsNodes
n1 n2
Tasks
105t1t2
t3
t4
t5
t6
2
4 4
6 3
5 2
4∞∞
∞∞

Serial assignment execution cost
t11 + t21 + t31 + t42+ t52+ t62 = 5+2+4+3+2+4 = 20
Serial assignment communication cost
c14 + c15 + c16 + c24 + c25 + c26+ c34+ c35+ c36
=0+0+12+12+3+0+0+11+0 = 38 Serial assignment total cost = 20+38 = 58
Optimal assignment execution cost
t11 + t21 + t31 + t41+ t51+ t62 = 5+2+4+6+5+4 = 26
Optimal assignment communication cost
c16 + c26 + c36 + c46 + c56 = 12 +0+0+0+0 = 12
Optimal assignment total cost = 26+12 = 38

Cut Set– A set of edges of a graph which, if removed (or "cut"),
disconnects the graph (i.e., forms a disconnected graph).
Minimum cut set– A cut is minimum if the size of the cut is not larger than the
size of any other cut.
Optimal Assignment using Minimal Cutset

Optimal Assignment using Minimal Cutset
t1
t2 t6
n2
t3
t5
t4n1
54
6
12
8
12
4
3
2 53
6
4
5
2
4
10
11
Minimum cost cut
∞∞

Load Balancing Approach
Balance the total system load by transparently transferring the workload from heavily loaded nodes to lightly loaded nodes to maximize the total system throughput.

Classification of Load Balancing Algorithms
Static Dynamic
Deterministic
Probabilistic
Centralized
Distributed
Cooperative
Non - cooperative
Load Balancing Algorithms

Static– Decisions are hard-coded into an algorithm with a
priori knowledge of system.– Use average behavior of system, ignoring current
state of the system.– Simpler
Dynamic– React to the system state that changes
dynamically.– Have greater performance benefits

Static Algorithms Deterministic
– Uses information about the properties of the nodes and the characteristics of the processes to be scheduled to allocate processes to nodes. E.g. Task assignment approach
– Difficult to implement but efficient
Probabilistic– Uses information regarding static attributes of the
system such as number of nodes, processing capability of each node, network topology etc to allocate nodes to processes.
– Easier to implement but poor performance

Dynamic Algorithms Centralized
– Single node, centralized server node collects system state information and is responsible for scheduling.
– Efficient as knows both load at each node & number of processes requiring service.
– K+1 replications of server to survive k faults. Consistency?– Use reinstantiation.K entities monitor single server to detect
its failure. On failure new server brought up. Occasional delay in service.
Distributed– Uses k physically distributed entities that work as local
controller, where each is responsible for making scheduling decisions for processes of a predetermined set of nodes.
– In a fully distributed system each node acts as a local controller.

Dynamic Algorithms
Cooperative– Distributed entities cooperate with each other to
make scheduling decisions. – More complex and involve larger overhead.
Non-cooperative– Individual entities act as autonomous entities and
make scheduling decision independently.– Less stable.

Load Balancing Algorithm
All processes are distributed among nodes of the system to equalize workload among nodes.
Design Issues – Load estimation policy– Process transfer policy– State information exchange policy– Location policy– Priority assignment policy– Migration limitation policy

Load Estimation Policy
How to estimate workload of a particular node on the system?– Total number of processes on node (Remaining
service time: memoryless, pastrepeats, distribution)– Resource demands of processes– Instruction mixes of these processes– Architecture & speed of node’s processor
Above methods not suitable because of existence of daemon processes
Thus, use CPU utilization measured by observing CPU state.

Process Transfer Policy
Whether to execute a process remotely or locally?
Decide node is lightly or heavily loaded?
Threshold value - limiting value of a nodes workload
Static policy– Each node has a predefined threshold value
depending on its processing capability
Dynamic policy– Threshold value is calculated from average
workload of all nodes and a predefined constant

Node should accept remote process if it does not significantly affect service to local processes & it should transfer local process elsewhere if it improves performance of rest of its processes.
Single threshold value may lead to useless process transfers. May result in process thrashing.
In double threshold, policy new processes are accepted only in under loaded region.
Overloaded
Under loaded
Threshold
Single-threshold policy
Overloaded
Normal
Under loaded
Low mark
High mark
Double-threshold policy

Location Policy
To which node a selected process should be sent?
Threshold– Probe nodes randomly to check whether node is able to
receive the process– If yes then transfer the process, else another node is selected
randomly. This continues until probe limit is reached, else process is executed at originating node.
Shortest– L distinct nodes are chosen at random & polled to determine
its load. Process is transferred to node having minimum load unless its workload value prohibits to accept the process.
– If none of polled nodes accept process, it is executed at originating node.
– Discontinue probing whenever a node with zero load is encountered

Bidding– Each node can act as manager (send process) and contractor
(receive process)– Managers broadcast request for bid, contractors respond with
bids (prices based on capacity of the contractor node) and manager selects the best offer
– Winning contractor is notified and asked if it accepts bid or not. If bid is rejected, bidding is started again.
– Full autonomy to nodes (contractors/ managers)– Big communication overhead &– Difficult to decide a good pricing policy
Pairing– Reduce variance of load only between pairs of nodes– Two nodes that differ greatly in load are temporarily paired
with each other and migration starts– The pair is broken as soon as the migration is over – Each node asks some randomly chosen node to form a pair– On receiving rejection, randomly selects another node for
pairing– A node only tries to find a partner if it has at least two
processes

State Information Exchange Policy
How to exchange load information among nodes?
Periodic broadcast– Each node broadcasts its state information after
every time T– Heavy network traffic & poor scalability
Broadcast when state changes– Avoids fruitless messages by broadcasting state
only on arrival or departure of a process– Optimize by broadcasting only when state switches
to under loaded or over loaded region.

On-demand exchange– Node broadcasts a State-Information-Request
message when its state switches from normal to either under loaded or overloaded region.
– Other nodes which can co-operate with it in load balancing process reply with their own state information to the requesting node
Exchange by polling– Random polling used rather than broadcasting– Polling stops on finding suitable partner or poll
limit is reached

Priority Assignment Policy
How to set priority of execution of local and remote processes?
Selfish
– Local processes are given higher priority than remote processes.
Altruistic
– Remote processes are given higher priority than local processes.
Intermediate
– When number of local processes is greater or equal to number of remote processes, local processes are given higher priority. Otherwise, remote processes are given higher priority.

Migration Limiting Policy
How many times a process can migrate?
Uncontrolled– A process may be migrated any number of times.– Causes instability
Controlled– Use a migration count to fix a limit on the number of
time a process can migrate– Irrevocable migration policy: migration count is fixed
to 1– Migration count k: allow multiple process migrations
to adapt to dynamically changing states of nodes.

Load Balancing vs. Load Sharing
Load balancing algorithms attempt to equalize loads among nodes.
Load-balancing algorithms transfer tasks at a higher rate, thus incurring higher overhead. Also big overhead is generated by gathering exact state information.
Load balancing is not achievable since number of processes in a node is always fluctuating and temporal unbalance among the nodes exists every moment.
Load-sharing is much simpler than load-balancing since it only attempts to ensure that no node is idle when heavily node exists.

Load Sharing Approach
Load estimation policy– Simply counts total number of processes (or CPU
Utilization)
Process transfer policy– All-or-nothing strategy - threshold value 1– Nodes can receive process when it has no process,
and send process when it has more than 1 process– Threshold value set to 2 to avoid node being idle
while waiting for acquiring process.
Priority assignment policy & Migration limitation policy same as in Load balancing

Location policy
Sender initiated location policy– Heavily loaded nodes search for lightly loaded nodes– When node becomes overloaded, it either
broadcasts or randomly probes other nodes to find a node that is able to receive remote processes
– Initiated on process arrival
Receiver initiated location policy– Lightly loaded nodes search for heavily loaded nodes – When node becomes under loaded, it either
broadcasts or randomly probes other nodes indicating its willingness to receive remote processes
– Initiated on process departure– Require preemptive process migration

State information exchange policy
Broadcast when state changes– In sender-initiated/ receiver-initiated location policy
a node broadcasts State Information Request when it becomes overloaded/ under loaded
Poll when state changes– Randomly asks different nodes for state
information until find an appropriate one or probe limit is reached

Process Management
Process allocation– Which process should be assigned to which
processor
Process Migration– Movement of process from its current location to
new processor
Threads– Fine grain parallelism

Process Migration
Load balancing (load sharing) policy determines:– if process needs to be migrated from one node to
another.– which process needs to be migrated– what is the node to which process is to be moved
Process migration mechanism deals with the actual transfer of the process

Migration can be– Non preemptive– Preemptive
Process migration involves 3 steps:– Selection of process that should be migrated– Selection of the destination node.– Actual transfer of selected process.

Desirable Features of Good Process Migration Mechanism
Transparency– Object access level - access to objects (such as
files and devices) by process can be done in location -independent manner.
– System call and inter-process communication – System calls should be location independent & redirection of messages should be transparent
Minimal residual dependencies – Migrated process should not depend on the node it
migrated from; else previous node is still loaded & process will fail if the previous node fails.

Minimal interference – In process execution by minimizing freezing time
Efficiency– minimize time required to migrate a process, cost of
locating an object, cost of supporting remote execution after migration
Robustness– Failure of any node other than current, should not
affect the execution of the process
Communication between co-processes of a job– Communication between co-processes should be
directly possible irrespective of their location

Process Migration Mechanism
Sub activities– freezing the process on its source node and
restarting it at destination node– moving the process’s address space– forwarding messages meant for the migrant
process– handling communication between cooperating
processes that are separated

Freezing and Restarting Mechanism
Take snapshot of process’s state on its source node & reinstate it on the destination node
Immediate and delayed blocking of the process depending on kind of system call being executed
Fast and slow I/O operations– Wait for completion of fast I/O operations– Resume slow I/O operation at destination

Information about open files – names, identifiers, access modes, current positions of file pointers, etc.– System wide unique identifiers– Identify files by their pathnames
• Use of links to remote files• Reconstruct complete pathname
– Do not transfer replicated files & use local files as far as possible
Reinstating the process on its destination node– Process given temporary identifier at destination node– On completing migration, new copy’s identifier changed to
original, new copy unfrozen, old copy deleted.

Address Space Transfer Mechanism
Information to be transferred– Process’s state
• contents of registers, program counter, I/O buffers, interrupt signals
– Process’s address space • code, data & stack
Address space transfer mechanisms– Total freezing– Pretransferring– Transfer on reference

Total Freezing
Process’s execution is stopped while transferring the address space
Simplest but slowest
Transfer ofaddress space
Sourcenode
Destinationnode
Execution Suspended
Migrationdecision
Execution resumed
Freezingtime
Total Freezing

Pretransferring (Precopying)
Address space is transferred while the process is still running on the source node
After the transfer, the modified pages are picked up Freezing time is reduced Migration time may increase due to possibility of redundant
transfer of same pages
Transfer ofaddress space
Sourcenode
Destinationnode
Execution Suspended
Migrationdecision
Execution resumed
Freezingtime
Pretransferring

Transfer on Reference
Process starts executing at destination before the address space is migrated
Pages are fetched from the source node as required Freezing time very less Process continues to impose load on source node Failure of source node results in failure of process
On-demandtransfer
Sourcenode
Destinationnode
Execution Suspended
Migrationdecision
Freezingtime
Transfer-on-reference
Execution resumed

Message Forwarding Mechanism
Three types of messages:– Type1: Received when the process execution is
stopped on the source node and has not restarted on the destination node
– Type2: Received on the source node after the execution started on destination node
– Type3: Sent to the migrant process after it started execution on destination node

Mechanism of resending the message– Message type 1 and 2 are returned to sender or
dropped – Sender retries after locating the new node – Type 3 message directly sent to new node– Message forwarding mechanism is not transparent
Origin site mechanism– Each site keeps information about current locations
of all processes created on it.– All messages are sent to origin site– Origin site forwards messages to process’s current
location– If origin site fails, forwarding mechanism fails– Continuous load on the origin site

Link traversal mechanism– Message queue created at origin for type1 – All messages in queue sent to destination as part of
migration procedure– To redirect messages of type 2 and 3,on migration,
link of destination is left on source node– Process can’t be located if any node in chain of
links fail
Link update mechanism– Processes communicate over location independent
link mechanisms– During transfer phase, the source node sends link
update messages to the kernels controlling all of the migrant process’s communication partners.

Co-processes Handling
Need to provide efficient communication between a parent process and sub-processes
Mechanism for handling co-processes– Disallow separation of co-processes
• Disallow migration of processes that wait for their children to complete
• Ensure that when parent process migrates all its child process also migrates with it
– Home node origin• Communication between parent process & its
children processes take place via home node

Process Migration in Heterogeneous System
Data translation required if source CPU & destination CPU formats are different
Use External data representation
Serializing : change particular machine format to XDR format
Example -- Floating point representation• Exponent and mantissa

Handling Exponent & Mantissa
Number of bits used for exponent & mantissa varies in processors
XDR should have at least as many bits in the exponent (mantissa) as the longest exponent (mantissa) of any processor.
Restrict size of numbers used by processes
Restrict migration to only nodes whose representation size is at least as large as that of source node’s processor

Advantages of Process Migration
Reducing average response time of processes by balancing workload
Higher throughput Speeding up individual jobs by concurrent execution Utilizing resources effectively Reducing network traffic by migrating processes closer
to resource Improving system reliability by migrating critical
processes to more reliable node Improving system security by migrating sensitive
processes to more secure node

Threads
In certain cases, a single application may need to run several tasks at the same time
Create a new process for each task– Time consuming
Use a single process with multiple threads

Single and Multithreaded Processes

Processes Processes are independent execution units that contain
their own state information, use their own address spaces, and only interact with each other via IPC.
Inter-process communication is expensive Context Switch expensive Secure: one process cannot corrupt another process

Threads
A single process might contain multiple threads.
All threads of a process share:– memory (program code and global data)– open file/socket descriptors– signal handlers and signal dispositions– working environment (current directory, user ID)
Each thread has it’s own:– Thread ID (integer)– Stack, Registers, Program Counter
Heavyweight Process = Process; Lightweight Process = Thread

Why Threads? Threads can be created more easily than new processes
All threads within a process share the same state and same memory space, and thus can communicate with each other directly.
A context change between threads is cheaper than the operating system's context change between processes
Resource sharing can be achieved more efficiently.
Allow parallelism to be combined with sequential execution & blocking system calls.
There is no protection between threads of a process as they share same address space.

Server Models
Single thread process– Blocking system calls with no parallelism
Finite state machine– Parallelism with non blocking system calls
Group of threads– Parallelism with blocking system calls– Server built with single dispatcher thread &
multiple worker threads

Models for Organizing Threads
Dispatcher thread
Worker Thread
Request
Worker Thread
Request
T TT
1 2 3 Each type of request being handled by a different thread.
Request
T TTOutput generated by first thread used for processing by second thread.
Dispatcher Worker Model Team Model
Pipeline Model

Threads Design Issues
Threads creation– Static– Dynamic
Threads termination
Thread synchronization– Mutex variable : Binary Semaphore that is either in
locked or unlocked state.– Condition variables (wait & signal) associated with
mutex variable

Thread scheduling– Preemptive/ Non Preemptive Priority assignment facility– Flexibility to vary quantum size dynamically– Handoff scheduling
• Directly switch CPU to thread specified by currently running thread.
– Affinity scheduling• Thread is scheduled on the CPU it last ran on in the hope
that part of the address space is still in the CPU’s cache
Signal handling– A signal is handled properly by creating a separate exception
handler thread in each process.– Signals are prevented from getting lost by assigning each
thread its own private global variables for signaling exception condition.
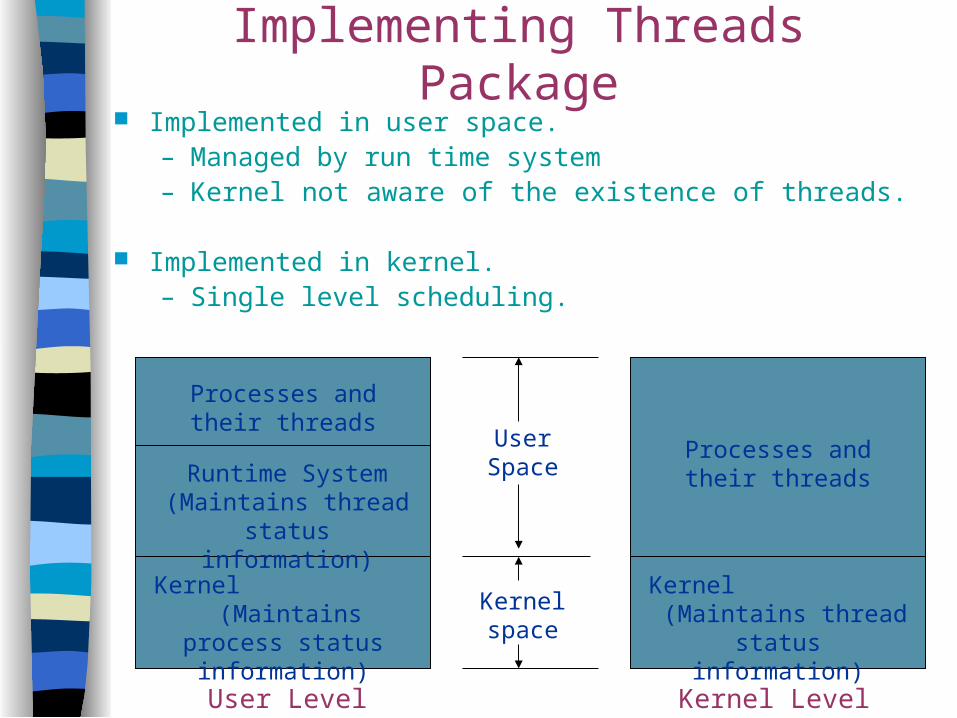
Implementing Threads Package Implemented in user space.
– Managed by run time system– Kernel not aware of the existence of threads.
Implemented in kernel.– Single level scheduling.
Processes and their threads
Runtime System (Maintains thread status
information)
Kernel (Maintains process status information)
Processes and their threads
Kernel (Maintains thread status
information)
Kernel space
User Space
User Level Kernel Level

User-level vs. Kernel-level
Advantages of User – level implementation– Threads package can be implemented on top of an existing
OS that does not support threads.– Users can use customized scheduling algorithms– Context switching faster as done by runtime system without
involving kernel.– Scalability of kernel level approach is poor.
Disadvantages– When a thread blocks, all threads of its process are stopped &
kernel schedules another process to run.– Use of round robin scheduling policy to time share CPU
cycles among threads on quantum by quantum basis is not possible, as there is no clock interrupts within single process.

DCE Threads
Threads standard - POSIX (Portable Operating system Interface for Computer Environments) – P threads
Implementations of POSIX– DCE threads– GNU threads
DCE provides a set of user-level library procedures for creation, termination, synchronization of threads.

Thread Management in DCE
Create– Create new thread in address space of calling
thread Exit
– Terminate calling thread. Join
– Calling thread blocks itself until thread specified in join command terminates.
Detach– Used by parent to disown a child thread.
Cancel– Used by thread to kill another thread.

Real Time Distributed Systems Real Time System: Any computer system where the
correct behavior of these systems depend not only on the result of its computations, but also on the time at which the results are produced. Aims at minimizing response time.
Real-time systems require timely responses to events– even under failure conditions– even under extreme load conditions

Soft vs. Hard Real Time Systems Soft real time System - Compute output response as fast as
possible, but no specific deadlines that must be met. If deadline is not met, system still works but with degraded performance. Ex. Games, Washing Machine, Camcorder.
Hard real time system - Output response must be computed by specified deadline or system fails. Ex. Missile guidance system, nuclear power stations, car engine control system.
Profit
time
release time
deadline
0
+
-
Profit
time
release time
deadline
0
+
-
Soft Real Time System Hard Real Time System

Real-time system– When an external device generates a stimulus for
computer, it must respond to it before a certain deadline.
– Stimuli can be periodic, aperiodic or sporadic
Dev
C
Dev
C
Dev
C
Dev
C
Dev
C
Dev
CC
Actuator
Sensor
Externaldevice
Computer
Network
A distributed real-time computer system

Design Issues
Clock Synchronization
Event-Triggered vs. Time-Triggered systems– Event-triggered systems
• When significant event happens, it is detected by sensor and interrupts the attached CPU
• Can fail when many events happen at same time (event shower)
– Time-triggered systems• A clock interrupt occurs every T

Fault Tolerance– System should be able to cope with maximum
number of faults and maximum load at the same time.
Predictability– System should meet all of its deadlines, even at peak
load– Worst case execution time of each of the system
calls is calculable
Language Support– Requires specialized real time languages– Maximum execution time of every task can be
computed at compile time e.g. cannot support while loop, recursion
– Variable clock, containing current time should be available.
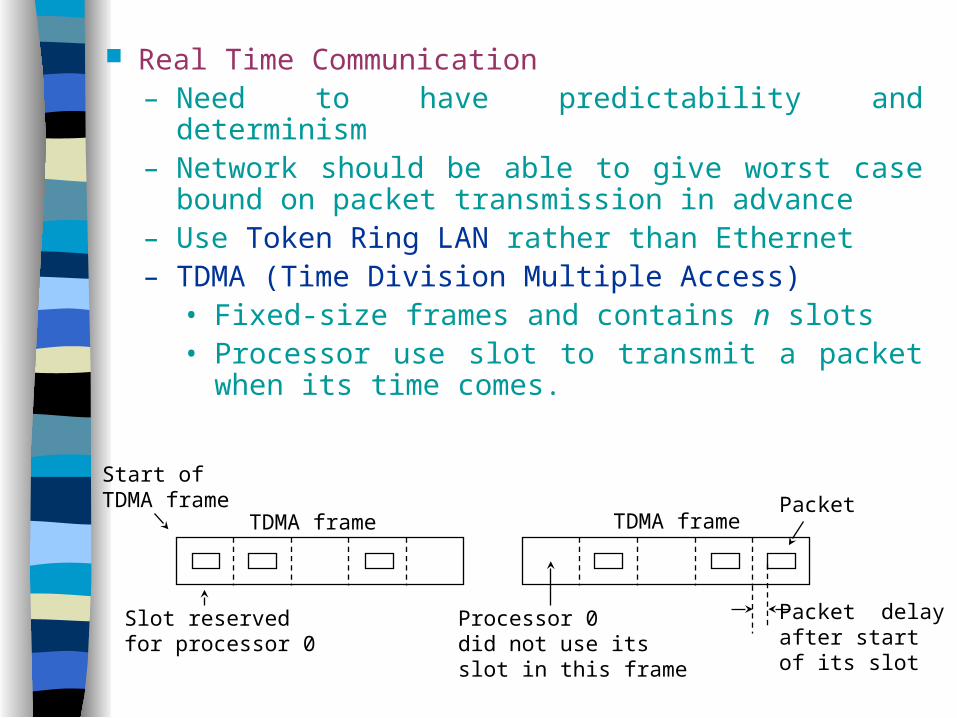
Real Time Communication – Need to have predictability and determinism– Network should be able to give worst case bound on
packet transmission in advance– Use Token Ring LAN rather than Ethernet– TDMA (Time Division Multiple Access)
• Fixed-size frames and contains n slots• Processor use slot to transmit a packet when its
time comes.
Start of TDMA frame
TDMA frame
Slot reservedfor processor 0
TDMA frame
Processor 0did not use itsslot in this frame
Packet
Packet delayafter startof its slot

Time Triggered Protocol– Assumes all clocks are synchronized.– Every node maintains global state of system –
current mode, global time, bit map giving current system membership.
Start ofpacket
Mode ACK Data CRC
Initialize Used tochangemode
Checks sender’sglobal state & packet bits
Control

Real-Time Scheduling
– Hard real time vs. soft real time
– Preemptive vs. non-preemptive scheduling
– Dynamic vs. static
– Centralized vs. decentralized

Dynamic Scheduling
Rate monotonic algorithm– Each task is assigned a priority equal to its
execution frequency
Earliest deadline first– Event is sorted by deadline, closest deadline first
Least laxity– Chooses the task with the least laxity

Static Scheduling
1
2 4
6
3 5
7 8 9 10
A
BResponse
Stimulus
1 2 3 4 5 6
7 8 9 10
1 3 5 2 4 6
7 8 9 10
Time Time
Stimulus Stimulus
Response Response





























