Embed Size (px)
Citation preview

Reliable I/O on the Grid
Douglas Thain and Miron Livny
Condor ProjectUniversity of Wisconsin

Outline
A Practical Problem• Half-Interactive Jobs• Solution: The Grid Console
Philosophical Musings A New System: Kangaroo

Problem:“Half-Interactive” Jobs
Users want to submit batch jobs to the Grid, but still be able to monitor the output interactively.
But, network failures are expected as a matter of course, so keeping the job running takes priority over getting output.
Examples:• INFN: Collider event simulation and
reconstruction with CMS• NCSA: Modelling with Gaussian

Existing Toolsare not Sufficient
Installing a uniform world-wide DFS is not feasible. Even if it were:• NFS: disconnect causes delay• AFS: close() can fail?!?
Condor• Vanilla: dependent on file system.• Standard: disconnect causes rollback.
GASS• Staging mode: no incremental output.• Append mode: no easy failure recovery.

Solution: The Grid Console
Trap reads and writes on stdio and send them via RPCs to be executed at the home site.
If connection is lost, just keep writing to disk but retry connection periodically.
If re-made, send all spooled data back and then continue operation.
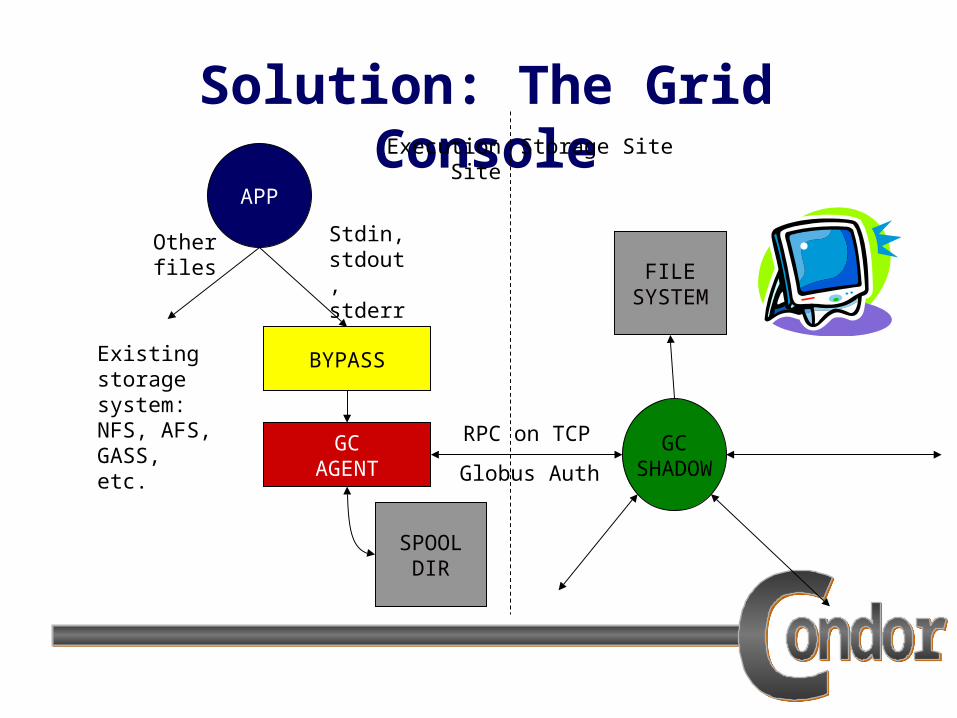
Solution: The Grid Console
APP
GCSHADOW
Execution Site Storage Site
BYPASS
GCAGENT
FILESYSTEM
SPOOLDIR
RPC on TCP
Stdin, stdout, stderr
Existing storage system: NFS, AFS, GASS, etc.
Other files
Globus Auth

Observations onthe Grid Console
Interfaces well with existing systems:• Applied to vanilla Condor(G) jobs.• Works on any dynamically-linked program.
Undesired properties:• Only applies to standard streams.• Job is blocked during recovery mode.
Strange property:• Disconnected mode might be faster than
connected mode!• Can we have it both ways?

Philosophical Musings What have we done? Hidden errors
• Job is not designed to deal with unusual error conditions:
– Write -> disconnected?– Close -> host not found?
Hidden latency• Job is not designed to deal with slow I/O. It
assumes that I/O ops are low latency, or at least appear to be.
• GC could be better at this.

Philosophical Musings, #2 These problems are one and the same:
• Hiding errors: Retry, report the error to a third party, and use another resource to satisfy the request.
• Hiding latency: Use another resource to satisfy the request in the background, but if an error occurs, there is no channel to report it.
Reliability is not a binary property.• A slow link can be just as damaging to
throughput as a disconnection.

Philosophical Musings, #3 A traditional OS deals with these same
problems when it uses memory to buffer disk operations.
Let’s apply the same principle to the Grid: Use memory and disk to satisfy unscheduled I/O operations in the background.
Introducing Kangaroo- A user-level data movement system that ‘hops’ files piecemeal from node to node on the Grid.
- A background process that will ‘fight’ for your jobs’ I/O needs.
- A ‘damage control’ specialist that will give errors to a third party but never admit failure to the job.
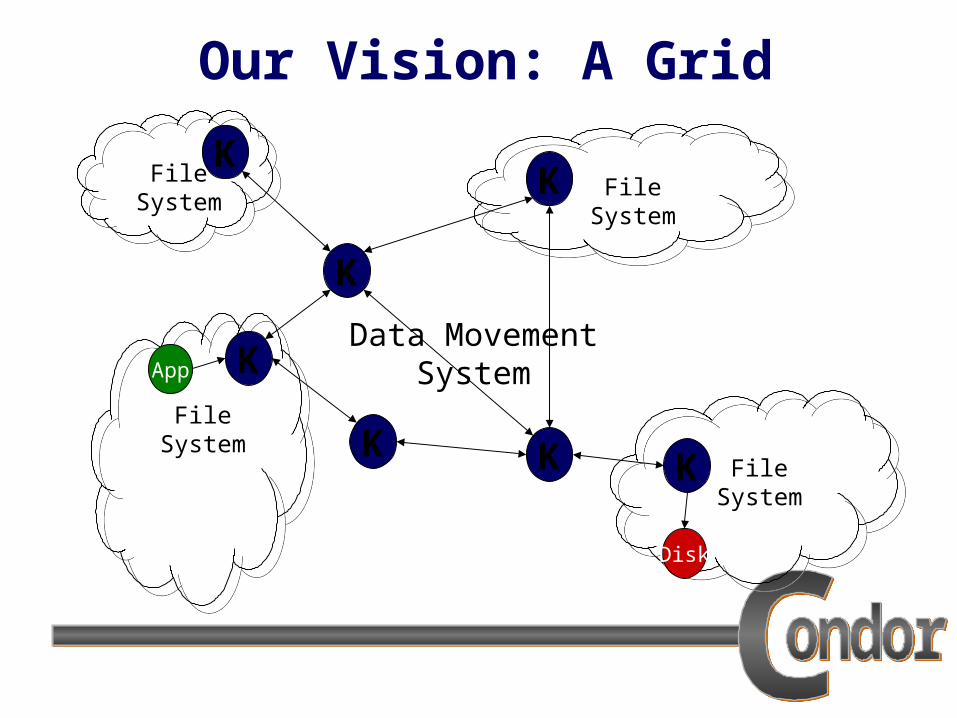
Our Vision: A Grid
FileSystem
FileSystem
FileSystem
FileSystem
KKK
K
K
KK
Data MovementSystemApp
Disk

Kangaroo Prototype We have built a first-try Kangaroo that
validates the central ideas of error and latency hiding.
Emphasis on high-level reliability and throughput, not on low-level optimizations.
First, work to improve writes, but leave room in the design to improve reads.

User Interface Like the GC, attach standard applications
with Bypass.• A tool for trapping UNIX I/O operations
and routing them through new code.• Works on any dynamically-linked,
unmodified program. Examples:
• setenv LD_PRELOAD pfs_agent.so• vi kangaroo://coral.cs.wisc.edu/etc/hosts• gcc gsiftp://ftp/input.c -o kangaroo://host/out
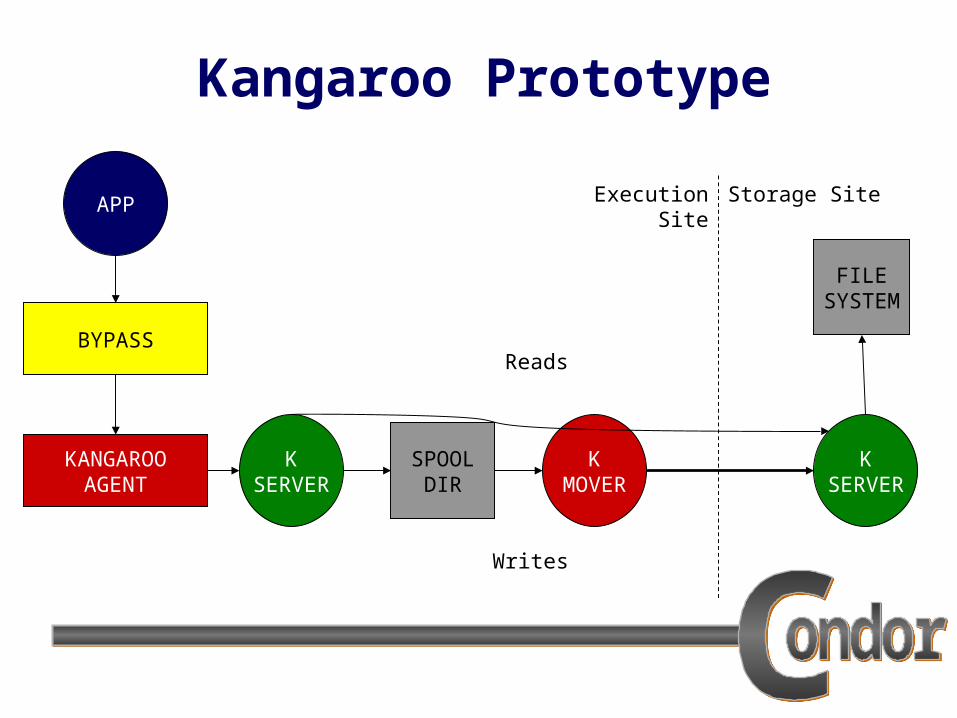
Kangaroo Prototype
APP
KANGAROOAGENT
KSERVER
SPOOLDIR
KMOVER
KSERVER
FILESYSTEM
Execution Site Storage Site
BYPASS
Writes
Reads

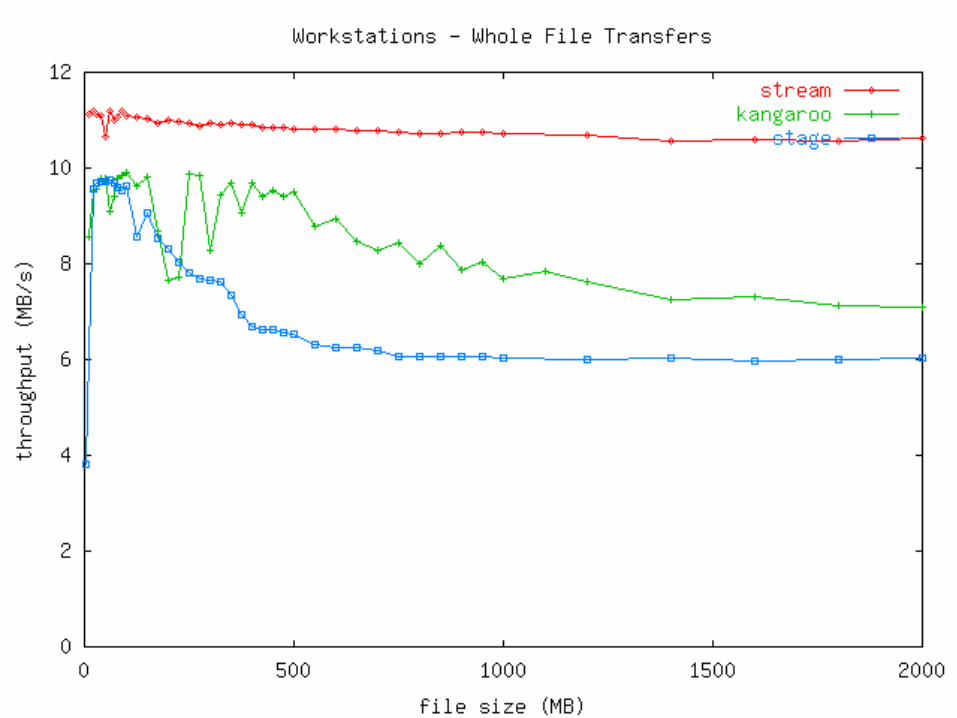
Microbenchmark:File Transfer
Create a large output file at the execution site, and send it to a storage site.
Ideal conditions: No competition for cpu, network, or disk bandwidth.
Three methods:• Stream output directly to target.• Stage output to disk, then copy to
target.• Kangaroo

Macrobenchmark:Image Processing
Post-processing of satellite image data: Need to compute various enhancements and produce output for each.• Read input image• For I=1 to N
– Compute transformation of image– Write output image
Example:• Image size about 5 MB• Compute time about 6 sec• IO-cpu ratio .91 MB/s
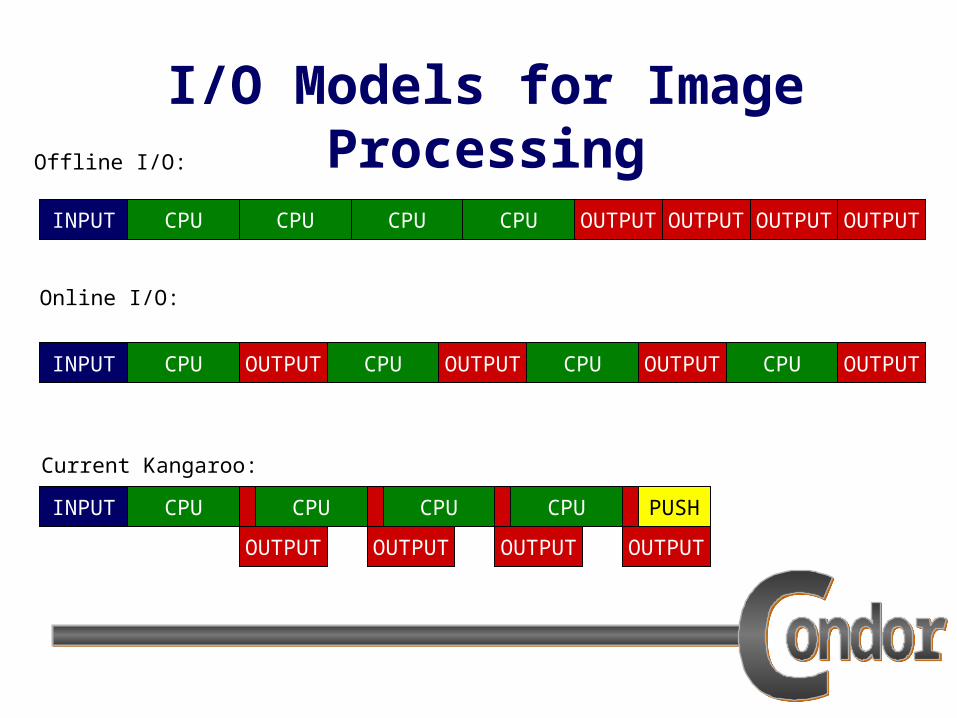
I/O Models for Image Processing
OUTPUT OUTPUT
CPU
OUTPUT
Online I/O:
Offline I/O:
Current Kangaroo:
INPUT
OUTPUT
CPU CPU CPU
OUTPUTOUTPUTCPU OUTPUTINPUT OUTPUTCPU CPU CPU
OUTPUT OUTPUTCPU OUTPUTINPUT OUTPUTCPUCPU CPU
PUSH
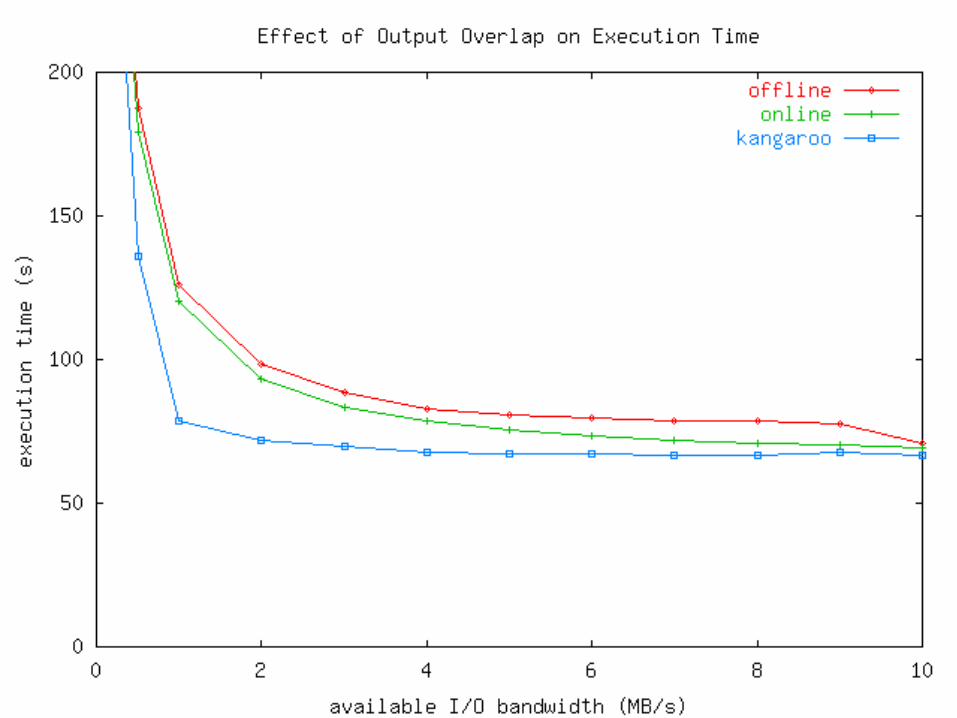

Summary of Results
At the micro level, our prototype provides reliability with reasonable performance.
At the macro level, I/O overlap gives reliability and speedups (for some applications.)
Kangaroo allows the application to survive on its real I/O needs: .91 MB/s. Without it, there is ‘false pressure’ to provide fast networks.

Research Problems Virtual Memory
• A K-node has one input, one output, and a memory/disk buffer. How should we move data to maximize throughput?
File System• Existing spool directory is clumsy and
inefficient. Need a fs optimized for 1-write, 1-read, 1-delete.
Fine-Grained Scheduling• Reads should have priority over writes. This
is easy at one node, but multiple nodes?

Conclusion The Grid is BYOFS. Error hiding and latency hiding are
tightly-knit problems. The solution to both is to overlap I/O and
computation. The benefits of high-level overlap can
outweigh any low-level inefficienies.

Conclusion Need more info?
• {thain|miron}@cs.wisc.edu• http://www.cs.wisc.edu/condor/bypass
Demo time:• Wednesday, 9-12 AM• Room 3381 CS
Questions now?





























