Embed Size (px)
Citation preview

Reinforcement LearningExploration vs Exploitation
Marcello Restelli
March–April, 2015

MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
Exploration vs Exploitation Dilemma
Online decision making involves a fundamental choice:
Exploitation: make the best decision given currentinformationExploration: gather more information
The best long–term strategy may involve short–termsacrificesGather enough information to make the best overalldecisions

MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
Examples
Restaurant SelectionExploitation: Go to favorite restaurantExploration: Try a new restaurant
Online Banner AdvertisementsExploitation: Show the most successful advertExploration: Show a different advert
Oil DrillingExploitation: Drill at the best known locationExploration: Drill at a new location
Game PlayingExploitation: Play the move you believe is bestExploration: Play an experimental move
Clinical TrialExploitation: Choose the best treatment so farExploration: Try a new treatment

MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
Common Approaches in RL
ε–Greedy
at =
{a∗t with probability 1− εrandom action with probability ε
SoftmaxBias exploration towards promising actionsSoftmax action selection methods grade actionprobabilities by estimated valuesThe most common softmax uses a Gibbs (orBoltzmann) distribution:
π(a|s) =e
Q(s,a)τ
e∑
a′∈AQ(s,a′)τ
τ is a “computational” temperature:τ → ∞: P = 1
|A|τ → 0: greedy
MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
Multi–Arm Bandits (MABs)
A multi–armed bandit is a tuple〈A,R〉A is a set of N possible actions(one per machine = arm)R(r |a) is an unknown probabilitydistribution of rewards given theaction chosenAt each time step t the agentselects an action at ∈ AThe environment generates areward rt ∼ R(·,a)
The goal is to maximizecumulative reward:
∑Tt=1 rt

MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
Regret
The action–value is the mean reward for action a
Q(a) = E[r |a]
The optimal value V ∗ is
V ∗ = Q(a∗) = maxa∈A
Q(a)
The regret is the opportunity loss for one step
lt = E[V ∗ −Q(at )]
The total regret is the total opportunity loss
Lt = E
[T∑
t=1
V ∗ −Q(at )
]Maximize cumulative reward ≡ minimize total regret

MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
Counting Regret
The count Nt (a) is expected number of selections foraction aThe gap ∆a is the difference in value between actiona and optimal action a∗, ∆a = V ∗ −Q(a)
Regret is a function of gaps and the counts
Lt = E
[T∑
t=1
V ∗ −Q(at )
]=
∑a∈A
E[Nt (a)](V ∗ −Q(a))
=∑a∈A
E[Nt (a)](∆a)
A good algorithm ensures small counts for large gapsProblem: gaps are not known!

MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
Greedy Algorithm
We consider algorithms that estimate Qt (a) ≈ Q(a)
Estimate the value of each action by Monte–Carloevaluation
Qt (a) =1
Nt (a)
T∑t=1
rt1(at = a)
The greedy algorithm selects action with highest value
a∗t = arg maxa∈A
Qt (a)
Greedy can lock onto a suboptimal action forever⇒ Greedy has linear total regret

MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
ε–Greedy Algorithm
The ε–greedy algorithm continues to explore foreverWith probability 1− ε select a = arg maxa∈A Q(a)With probability ε select a random action
Constant ε ensures minimum regret
lt ≥ε
|A|∑a∈A
∆a
⇒ ε–greedy has linear total regret
MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
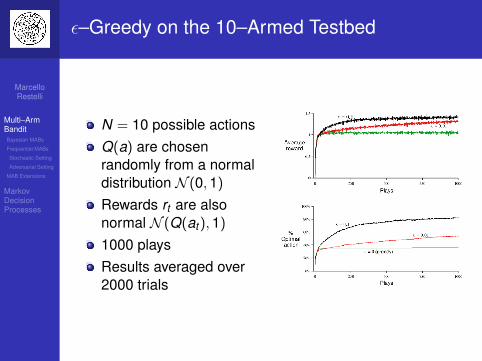
ε–Greedy on the 10–Armed Testbed
N = 10 possible actionsQ(a) are chosenrandomly from a normaldistribution N (0,1)
Rewards rt are alsonormal N (Q(at ),1)
1000 playsResults averaged over2000 trials
MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
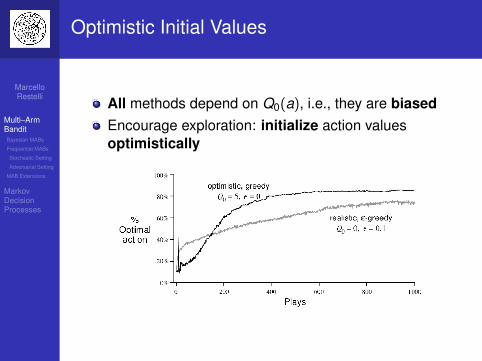
Optimistic Initial Values
All methods depend on Q0(a), i.e., they are biasedEncourage exploration: initialize action valuesoptimistically

MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
Decaying εt–Greedy Algorithm
Pick a decay schedule for ε1, ε2, . . .Consider the following schedule
c > 0d = min
a|∆a>0∆a
εt = min{
1,c|A|d2t
}Decaying εt–greedy has logarithmic asymptotic totalregret!Unfortunately, schedule requires advance knowledgeof gapsGoal: find an algorithm with sublinear regret for anymulti–armed bandit (without knowledge of R)

MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
Two Formulations
Bayesian formulation(Q(a1),Q(a2), . . . ) are random variables with priordistribution (f1, f2, . . . )Policy: choose an arm based on the priors (f1, f2, . . . )and the observation historyTotal discounted reward over an infinite horizon:
Vπ(f1, f2, . . . ) = Eπ
{ ∞∑t=0
βtRπ(t)|f1, f2, . . .
}(0 < β < 1)
Frequentist formulation(Q(a1),Q(a2), . . . ) are unknown deterministicparametersPolicy: choose an arm based on the observationhistoryTotal reward over a finite horizon of length T

MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
Bandit and MDP
Multi-armed bandit as a class of MDPN independent arms with fully observable states[Z1(t), . . . ,ZN(t)]One arm is activated at each timeActive arm changes state (known Markov process)and offers reward Ri (Zi (t))Passive arms are frozen and generate no reward
Why is sampling stochastic processes with unknowndistributions an MDP?
The state of each arm is the posterior distribution fi (t)(information state)For an active arm, fi (t + 1) is updated from fi (t) and thenew observationFor a passive arm, fi (t + 1) = fi (t)
Solving MAB using DP: exponential complexity w.r.t. N

MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
Gittins Index
The index structure of the optimal policy [Gittins’74]Assign each state of each arm a priority indexActivate the arm with highest current index value
ComplexityArms are decoupled (one N-dim to N separate 1-dimproblems)Linear complexity with NForward inductionPolynomial (cubic) with the state space size of a singlearmComputational cost is too high for real-time use
Approximations of the Gittins indexThompson sampling
Incomplete learning
MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
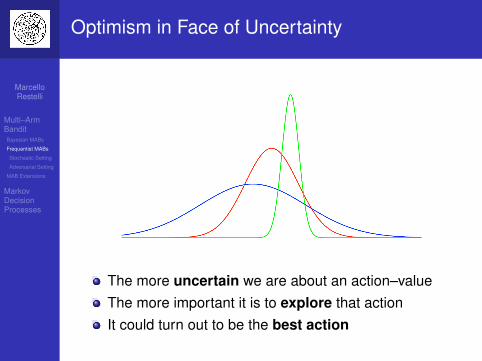
Optimism in Face of Uncertainty
The more uncertain we are about an action–valueThe more important it is to explore that actionIt could turn out to be the best action

MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
Lower Bound
The performance of any algorithm is determined bysimilarity between optimal arm and other armsHard problems have similar–looking arms withdifferent meansThis is formally described by the gap ∆a and thesimilarity in distributions KL(R(·|a)||R(·,a∗))
TheoremLai and Robbins Asymptotic total regret is at leastlogarithmic in number of steps
limt→∞
Lt ≥ log t∑
a|∆a>0
∆a
KL(R(·|a)||R(·,a∗))

MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
Upper Confidence Bounds
Estimate an upper confidence Ut (a) for each actionvalueSuch that Q(a) ≤ Qt (a) + Ut (a) with high probabilityThis depends on the number of items N(a) has beenselected
Small Nt (a)⇒ large Ut (a) (estimated value isuncertain)Large Nt (a)⇒ small Ut (a) (estimated value isaccurate)
Select action maximizing Upper Confidence Bound(UCB)
at = arg maxa∈A
Q(a) + U(a)

MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
Hoeffding’s Inequality
TheoremHoeffding’s Inequality Let X1, . . . ,Xt be i.i.d. randomvariables in [0,1], and let X t = 1
T∑T
t=1 Xt be the samplemean. Then
P[E[X ] > X t + u] ≤ e−2tu2
We will apply Hoeffding’s Inequality to rewards of the banditconditioned on selecting action a
P[Q(a) > Qt (a) + Ut (a)] ≤ e−2Nt (a)Ut (a)2

MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
Calculating Upper Confidence Bounds
Pick a probability p that true value exceeds UCBNow solve for Ut (a)
e−2Nt (a)Ut (a)2= p
Ut (a) =
√− log p2Nt (a)
Reduce p as we observe more rewards, e.g., p = t−4
Ensures we select optimal actions as t →∞
Ut (a) =
√2 log tNt (a)

MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
UCB1
This leads to the UCB1 algorithm
at = arg maxa∈A
Q(a) +
√2 log tNt (a)
TheoremAt time T , the expected total regret of the UCB policy is atmost
E[LT ] ≤ 8 log T∑
a|∆a<∆a∗
1∆a
+
(1 +
π2
3
)∑a∈A
∆a
MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
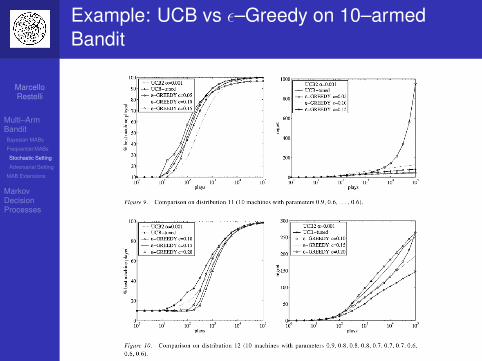
Example: UCB vs ε–Greedy on 10–armedBandit

MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
Other Upper Confidence Bounds
Upper confidence bounds can be applied to otherinequalities
Bernstein’s inequalityEmpirical Bernstein’s inequalityChernoff inequalityAzuma’s inequality. . .

MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
The Adversarial Bandit Setting
N armsAt each round t = 1, . . . ,T
The learner chooses It ∈ 1, . . . ,NAt the same time the adversary selects reward vectorrt = (r1,t , . . . , rN,t ) ∈ [0,1]N
The learner receives the reward rIt ,t , while the rewardsof the other arms are not received

MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
Variation on SoftmaxEXP3.P
It is possible to drive regret down by annealing τ
EXP3.P: Exponential weight algorithm for explorationand exploitationThe probability of choosing arm a at time t is
π(a|t) = (1− β)wt (a)∑
a′∈Awt (a′)+
β
|A|
wt+1(a) =
wt (a)e(−η rt (a)
πt (a)
)if arm a is pulled at t
wt (a) otherwise
η > 0 and β > 0 are the parameters of the algorithmRegret: E[LT ] ≤ O(
√T |A| log |A|)

MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
MAB with Infinitely Many Arms
Unstructured set of actionsUCB Arm-Increasing Rule
Structured set of actionsLinear BanditsLipschitz BanditsUnimodalBandits in trees

MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
The Contextual Bandit Setting
At each round t = 1, . . . ,TThe world produces some context s ∈ SThe learner chooses It ∈ 1, . . . ,NThe world reacts with reward RIt ,tThere is no dynamics
Learn a good policy (low regret) for choosing actionsgiven contextIdeas
Run a different MAB for each distinct contextPerform generalization over contexts

MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
Exploration–Exploitation in MDPs
Multi–armed bandit are one–step decision–makingproblemsMDPs represent sequential decision–making problemsWhat exploration–exploitation approaches can be usedin MDPs?How to measure the efficiency of an RL algorithm informal terms?

MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
Sample Complexity
LetM be an MDP with N states, K actions, discountfactor γ ∈ [0,1) and a maximal reward Rmax > 0Let A be an algorithm that acts in the environment,producing experience: s0,a0, r1, s1,a1, r2, . . .
Let V At = E[
∑∞τ=0 γ
τ rt+τ |s0,a0, r1, . . . , st−1,at−1, rt , st ]
Let V ∗ be the value function of the optimal policy
Definition [Kakade,2003]Let ε > 0 be a prescribed accuracy and δ > 0 be anallowed probability of failure. The expressionη(ε, δ,N,K , γ,Rmax ) is a sample complexity bound foralgorithm A if independently of the choice of s0, withprobability at least 1− δ, the number of timesteps such thatV A
t < V ∗(st )− ε is at most η(ε, δ,N,K , γ,Rmax ).

MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
Efficient Exploration
DefinitionAn algorithm with sample complexity that is polynomial in1ε , log 1
δ ,N,K ,1
1−γ ,Rmax is called PAC-MDP (probablyapproximately correct in MDPs)

MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
Exploration StrategiesPAC–MDP Efficiency
ε–greedy and Boltzmann are not PAC-MDP efficient.Their sample complexity is exponential in the numberof states
Other approaches with exponential complexity:variance minimization of action–valuesoptimistic value inizializationstate bonuses: frequency, recency, error, . . .
Example of PAC–MDP efficient approaches:model–based: E3, R–MAX, MBIEmodel–free: Delayed Q–learning
Bayesian RL: optimal exploration strategyonly tractable for very simple problems

MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
Explicit–Exploit–or–Explore (E3) AlgorithmKearns and Singh, 2002
Model–based approach with polynomial samplecomplexity (PAC–MDP)
uses optimism in the face of uncertaintyassumes knowledge of maximum reward
Maintains counts for state and actions to quantifyconfidence in model estimates
A state s is known if all actions in s have beensufficiently often executed
From observed data, E3 constructs two MDPsMDPknown: includes known states with (approximatelyexact) estimates of P and R (drives exploitation)MDPunknown: MDPknown without reward + special state s′
where the agent receives maximum reward (drivesexploration)

MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
E3 Sketch
Input: State sOutput: Action aif s is known then
Plan in MDPknownif resulting plan has value above some threshold then
return first action of planelse
Plan in MDPunknownreturn first action of plan
end ifelse
return action with the least observations in send if
MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
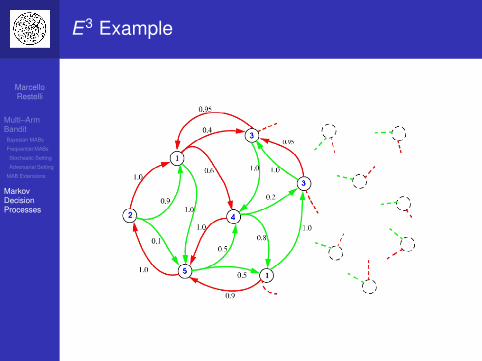
E3 Example
MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
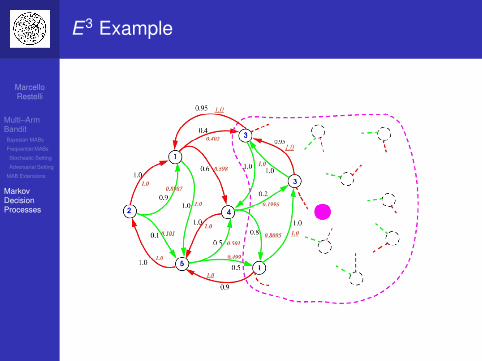
E3 Example
MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
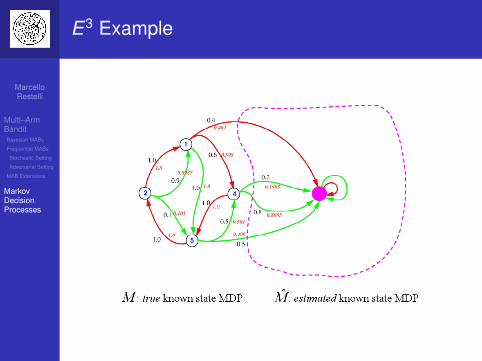
E3 Example

MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
R–MAXBrafman and Tennenholtz, 2002
Similar to E3: implicit instead of explicit explorationBased on reward function
RR−MAX (s,a) =
{R(s,a) c(s,a) ≥ m(s,a known)
Rmax c(s,a) < m(s,a unknown)
Sample Complexity: O(|S|2|A|ε3(1−γ)6
)

MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
Limitations of E3 and R–MAX
E3 and R–MAX are called “efficient” because itssample complexity scales only polynomially in thenumber of statesIn natural environments, however, this number of statesis enormous: it is exponential in the number of statevariablesHence E3 and R–MAX scale exponentially in thenumber of state variablesGeneralization over states and actions is crucial forexploration
Relational Reinforcement Learning: try to modelstructure of environmentsKWIK-R–MAX: extension of R–MAX that is polynomialin the number of parameters used to approximate thestate transition model

MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
Delayed Q–learning
Optimistic initializationGreedy action selectionQ–learning updates in batches (no learning rate)Updates only if values significantly decrease
Sample complexity: O(|S||A|
ε4(1−γ)8
)

MarcelloRestelli
Multi–ArmBanditBayesian MABs
Frequentist MABs
Stochastic Setting
Adversarial Setting
MAB Extensions
MarkovDecisionProcesses
Bayesian RL
Agent maintains a distribution (belief) b(m) over MDPmodels m.
typically, MDP structure is fixed; belief over theparametersbelief updated after each observation(s,a, r , s′) : b → b′
only tractable for very simple problemsBayes–optimal policy π∗ = arg maxπ Vπ(b, s)
no other policy leads to more rewards in expectationw.r.t. prior distribution over MDPssolves the exploration–exploitation tradeoff implicitly:minimizes uncertainty about the parameters, whileexploiting where it is certainis not PAC-MDP efficient!













![Routine Characterization of mAbs and Other Proteins.ppt...Microsoft PowerPoint - Routine Characterization of mAbs and Other Proteins.ppt [Compatibility Mode] Author dasalbpo Created](https://img.pdfslide.us/doc/110x75/609800d8c087cb5300199da6/routine-characterization-of-mabs-and-other-microsoft-powerpoint-routine-characterization.jpg)















