Embed Size (px)
Citation preview

Reducing Indirect Function Call
Overhead In C++ Programs
Brad Calder and Dirk Grunwald(Email:{calder, grunwald}(?cs. colorado. edu)
Department of Computer Science,Campus Box 430, University of Colorado,
Boulder, CO 80309-0430
Abstract
Modern computer architectures increasingly depend onmechanisms that estimate fhture control flow decisionsto increase performance. Mechanisms such as speculative
execution and prefetching are becoming standard architec-tural mechanisms that rely on control flow prediction to
prefetch and speculatively execute future instructions. At
the same time, computer programmers are increasinglyturning to object-oriented languages to increase their pro-ductivity. These languages commonly use run time dis-
patching to implement object polymorphism. Dispatch-
ing is usually implemented using an indirect finction call,which presents challenges to existing control flow predic-tion techniques.
We have measured the occurrence of indirect functioncalls in a collection of C++ programs. We show that, al-though it is more important to predict branches accurately,indirect call prediction is also an important factor in someprograms and will grow in importance with the growth ofobject-oriented programming. We examine the improve-ment offered by compile-time optimization and static anddynamic prediction techniques, and demonstrate how com-pilers can use existing branch prediction mechanisms toimprove performance in C++ programs. Using these meth-ods with the programs we examined, the number of in-structions between mispredicted breaks in control can bedoubled on existing computers.
Keywords: Object oriented programming, optimization,profile-based optimization, customization
1 Introduction
The design of computer architectures and languages aretightly entwined. For example, the advent of register dis-placement addressing enabled efficient implementation of
Perrnksion to copy without fee ell or part of this material isgranted provided that the copies sro not made or distributed fordirect commercial advsntage, the ACM copyright notice and the
title of the publication end its date appaar, and notice is giventhet copying is by permission of the Association for ComputingMachinery. To copy otherwise, or to republish, requiras a fea
and/or specific permission.
POPL 94- 1/94, Portland Oregon, USA
~ 1994 ACM o-89791 -636-9/04~1 ..$3.s0
Algol and the increased use of COBOL emphasized the useof BCD arithmetic. Likewise, the C and FORTRAN lan-guages have become ubiquitous, strongly influenced RISCprocessor design. Object-oriented programming has re-cently gained popularity, illustrated by the wide-spreadpopularity of C++. Object-oriented languages exercise dif-ferent aspects of computer architectures to support theobject-oriented programming style. In this paper, we ex-amine how indirect fi.mction calls, used to support objectpolymorphism, influence the pefiormance of an efficientobject oriented language. Modern architectures using deepinstruction pipelines and speculative execution rely on pre-dictable control flow changes, and indirect function callscause unpredictable changes in program control flow. Forexample, the DEC Alpha AXP 21064 processor, one of thefirst widely-available deeply pipelined superscalar micro-processors, stalls for 10 instructions if the processor mis-predicts the flow of control. This increases if the mispre-dicted target is not in the instruction cache and must befetched. As systems increasingly rely on speculative exe-cution [19, 16], the importance of control flow predictionwill increase.
In most programs, conditional branches introduce themain uncertainty in program flow, and architectures use avariety of branch prediction techniques to reduce instruc-tion cache misses and to insure instructions are availablefor the processor pipeline. Most fimction calls specifi ex-plicit call targets, and thus most fimction calls can be triv-ially predicted. Control flow prediction is just as importantin object-oriented programs, but these languages tend touse indirect finction calls, where the address of the calltarget is loaded horn memory. Fisher et al [12] said indi-rection fimction calls ”... are unavoidable breaks in controland there are few compiler or hardware tricks that couldallow instruction-level parallelism to advance past them”.By accurately predicting the calling address, the processorcan reduce instruction stalls and prefetch instructions.
Our results show that accurately predicting the be-havior of indirect function calls can largely eliminate thecontrol-flow rnisprediction penalty for using static-typedobject-oriented languages such as C++. Figure 1 showsthe normalized execution time for a variety of C++ pro-grams. We measured the number of instructions executed
397

by each program, and collected information concerning theconditional branches and indirect fimction calls executedby each program. Although we measured the programson a DECstation-5000, we simulated the branch mispre-diction characteristics of a deeply pipelined superscalararchitecture, similar to the DEC Alpha AXP 21064.
For each program, each bar indicates the number ofmachine cycles spent executing instructions and sufferingfrom the delay imposed by mispredicting control flow un-der different assumptions. A value of ’1’ indicates the pro-gram spends no additional time due to delays, while avalue of ’2’ indicates the program would execute twice asslowly. The left-most bar indicates the delay that wouldbe incurred if every control flow change was incorrectlypredicted or there was no prediction. The next bar indi-cates the increase in execution if only conditional branches
are predicted, using static profile based prediction. Thenext three bars indicate the decrease in execution timeif branches and indirect function calls are correctly pre-dicted, using three different techniques described in thispaper. For the programs we measured, we found we couldimprove performance 270-24% using these simple tech-niques; the final improvement depends on the numberof indirect function calls, how program libraries are usedand the underlying architecture. Architectures that havedeeper pipelines or that issue more instructions per cyclewould evince greater improvement.
We are interested in reducing the cost of indirect func-tion calls (I-calls) for modern architectures. If a compilercan determine a unique or likely call target, indirect func-tion calls can be converted to direct calls for unique calltargets. Likewise, compilers may choose to inline likely orunique call targets. Inlining I-calls not only reduces thenumber of function calls, it exposes opportunities for otheroptimizations such as better register allocation, constantfolding, code scheduling and the like. However, type in-ferencing for C++ programs is an N_P-hard problem [221,and will be difficult to integrate into existing compilers, be-cause accurate type inference requires information aboutthe entire type hierarchy. This information is typically notavailable until programs are linked, implying that type-determination algorithms will require link-time optimiza-tion.
We are interested in more subtle optimizations thathave a modest, albeit respectable, performance improve-ment. Many of the optimization and code transforms relyon modifjing an existing program executable and the pos-sibility y of assisting the compiler with profile-based opti-mization. When we began this study, we asked the fol-lo%ing questions:
Could we predict how frequently compiler-basedmethods could eliminate indirect function calls?
How accurate is profile-based prediction? Are dy-namic prediction methods more accurate?
Can we use existing branch prediction hardware topredict indirect function calls?
●
●
How effective are combinations of prediction tech-niques?
What type of other compiler optimizations can be ap-plied towards indirect function calls, in order to im-prove their performance?
To date, our experimentation has demonstrated that al-though object-oriented libraries support object polymor-phism, the target of most indirect function calls can be ac-curately predicted, either fi-om prior runs of the programor during a program’s execution. Furthermore, many ex-isting C++ programs can be optimized naively by a linker,using information about the C++ type system. The opti-mization we examine involves converting an indirect func-tion call that only calls a unique function name into adirect fimction call. For more sophisticated compilers withlink-time code generation, significant optimization oppor-tunities exist. Lastly, a compiler optimization that we termI-call if conversion can be used to increase the performanceof indirect function calls. This information can be used bya simple profile-based binary modification to improve ex-ecution on existing C++ programs by 2-24% on modernarchitectures.
We measured the behavior of a variety of publicly avail-able C++ programs, collecting information on instructioncounts and function calls. This information is also part ofa larger study to quantiti the differences between C++ andconventional C programs [71. In this study, we show thatcall prediction is important for many C++ programs andshow to what extent static, dynamic and compile-directedmethods can reduce indirect function call overhead. Wealso demonstrate the opportunity for profile-based opti-mization in the C++ programs we measured. These op-timization can profitably be applied to existing archi-tectures that incur significant control-flow mispredictionpenalties.
The results we present are divided into two portions;the first considers applying hardware branch predictionmechanisms to existing C++ programs, while the secondconsiders additional profile based optimizations that canbe applied to C++ programs. In !2, we discuss some rel-evant prior work. In $3, we describe the experimentalmethodology we used and describe the programs we in-strumented and measured. In $4 we compare the variousI-call prediction mechanisms we studied and summarizehow we can improve the performance of ezisting C++ pro-grams.
2 Prior Work
A considerable amount of research has been conductedin reducing the overhead of method calls in dynamicallytyped object-oriented languages. Many of the solutionsrelevant in that domain apply to the optimization of com-piled languages using I-calls, as in C++. We will discussthese shortly. Furthermore, numerous researchers haveexamined the similar issue of reducing branch overhead.
398

No PredictionBranches OnlyBranches & IcallsBranches, l-calls & UniqueBranches, l-calls, Unique & IF Conv
)___(
— .
regress Doc
‘) (2
.——
I (2.32) (2.35) (1.
~T
—
Idl Idraw
)_
——
3roff Morpher Rtsh
Figure 1: Normalized Execution Time of Various C++ Programs, Including Expected Instructions and Stalls Due toMispredicted Control Flow, For A Computer Similar to DEC Alpha AXP 21064.
399

Since both function calls and branches alter the controlflow, there is considerable overlap in our work, yet sub-stantial differences as well. One such difference is that aconditional branch has only two possible targets, while anindirect function call can have a large number of potentialtargets. We have measured programs with 191 differentsubroutines called from a single indirect fimction call. Thismakes branches easier to predict. Some dynamic branchprediction mechanisms achieve w 95% – 97% predictionaccuracy [21, 27, 29]. This level of accuracy is needed forsuper-scalar processors issuing several instructions per cy-cle [281.
The most relevant prior work was on predicting thedestination of indirect function calls conducted by DavidWall [26] while examining limits to instruction level paral-lelism. He states ‘iLittle work has been done on predicting
the destinations of indirect jumps, but it might pay off in
instruction-level parallelism.” He simulates static profilebased prediction and infinite and finite dynamic last callprediction, and finds they accurately predict I-call destina-tions; however, the benefit of I-call prediction was minimalbecause he only examined C and Fortran programs. We gobeyond his research by (1) showing that I-call predictionis important for C++ programs, (2) that compile-time opti-mization can be combined with static profile based predic-tion to increase a programs performance, (3) that simpletechniques yield very accurate I-call prediction rates and,(4) we do a more in-depth comparison between differentstatic and dynamic mechanisms for doing I-call prediction.
2.1 Compiler Optimization
Two classes of compiler-oriented optimization are mostrelevant to our research. A large body of research existsin dataflow analysis to determine the set of possible calltargets for a given call site. Ryder[24] presented a methodfor computing the call-graph, or set of functions, that maybe called by each call site using dataflow equations. Morerecent work by Burke [4] and Hall[131 has refined this tech-nique. All of this work characterized programs where pro-cedure values may be passed as function parameters. Oth-ers, including Hall [13], also examine functional programs.More recently Pande and Ryder[221 have shown that in-ferring the set of call targets for call sites in languageswith the C++ type system is a NP-hard problem.
In this paper, we seek to minimize pipeline stalls usinginformation concerning the frequency of calling specific callsites. Unless the previous algorithms can determine aunique call target, more information is needed for I-callprediction. However, the results of this study indicatesthat single call targets occur frequently, and the techniquesin e.g., Ryder [22] may be very successful in practice. Toour knowledge, there has been little work in speci&ngthe probability of specific call targets being called usingdataflow techniques.
By comparison, there has been considerable work inadaptive runtime systems to reduce the cost of polymor-
phism in dynamically typed languages. Most recent, andforemost, in these efforts is the work by the SELF project[8, 9, 14] on customization of method dispatches and exten-sive optimization of method lookup. SELF is a dynamicly-typed language, providing a rich set of capabilities notpresent in statically-typed languages such as C++. How-ever, statically-typed languages such as C++ are very effi-cient, using a constant-time method dispatch mechanism.Statically-type object-oriented languages are popular be-cause less compiler effort is needed to achieve reasonableperformance and the object-oriented programming styleencourages software resources and structured software li-braries.
Customization and other optimization have producedconsiderable performance improvement in the SELF im-plementation. In many ways, we are extending some ofthe optimization explored by the SELF project to the C++language. However, we must rely on hardware for “cus-tomization” (e.g., prediction hardware) rather than soft-ware, because most C++ implementations are already veryefficient. For example, an indirect function call in C++takes seven instructions on a DECstation - reducing thiscost to greatly improve the performance of an applicationis difficult. We also feel that the results of our research willbenefit prototyping languages such as SELF and SmallTalkas those languages are further optimized for modern ar-chitectures. There are also secondary effects to these opti-mization. In certain cases, our code transformations willallow fimction inlining, facilitating further optimization.
2.2 Branch Prediction
There are a number of mechanisms to ameliorate the ef-fect of uncertain control flow changes, including staticand dynamic branch prediction, branch target buffers, de-layed branches, prefetching both targets, early branch res-olution, branch bypassing and prepare-to-branch mecha-nisms [181. Conventional branch prediction studies typ-ically assume there are two possible branch targets for agiven branch point, because multi-target branches occurinfrequently in most programs. Rather than present acomprehensive overview of the field, we focus on methodsrelated to the techniques we consider in this paper.
Some architectures employ static prediction hints us-ing either profile-derived information, information de-rived flom compile time analysis or information about thebranch direction or branch opcode [25, 20, 21. Wall[261found profile-driven static prediction to be reasonably ac-curate for indirect function calls. Fisher and Freuden-berger [12] found profile-derived static prediction to beeffective for conditional branches, but they hypothesizethat inter-run variations occurred because prior input didnot cover sufficient execution paths, and our results pro-vide support for their hypothesis. In general, profile basedprediction techniques outperform compile-time predictiontechniques or techniques that use hueristics based onbranch prediction or instruction opcodes.
400

Some architectures use dynamic prediction, either us-ing tables or explicit branch registers. A branch target
buffer (BTB) [17, 23] is a small cache holding the addressof branch sites and the address of branch targets. Thereare myriad variations on the general idea. Typically thecache contains from 32 to 512 entries and may be 2 or 4-way associative. The address of a branch site is used as atag in the BTB, and matching data is used to predict thebranch. Some designs include decoded instructions as wellas the branch target. Other designs eliminate the branchtarget address, obeerving that most branches only go oneof two ways (taken/not taken).
Still other designs eliminate the tag, or branch siteaddress horn the table. These designs use the branch siteaddress as an index into a table of prediction bits. Thisinformation can actually be the prediction information foranother branch. However, there’s at least a 50q0 chance theprediction information is correct, and this can be improvedsomewhat [5]. The most common variants of table-baseddesigns are l-bit techniques that indicate the direction ofthe most recent branch mapping to a given prediction bit,and 2-bit techniques that yield much better performancefor programs with loops [25, 17, 20]. The advantage ofthese bit-table techniques is that they keep track of verylittle information per branch site and are very effective inpractice.
Lastly some computers use explicit branch target ad-
dress registers (BTARs) to specifi the branch target [11, 1].This has numerous advantages, because branch instruc-tions are very compact and easily decoded. BTARs canbe applied to both conditional branches and function calls,and the instructions loading branch targets can be movedout of loops or optimized in other ways. Furthermore, ad-dresses specified by explicit branch targetregisters provideadditional hints to instruction caches, and those instruc-tions can be prefetched and decoded early. However, mostproposed implementations provide only 4-8 BTARs[l]. Thecontents of these registers will probably not be savedacross fimction calls. Thus, instructions manipulating theBTARs must occur early in the instruction stream to effec=tively use BTARs.
At first glance, some of these techniques, such as bit-table techniques, do not appear applicable to I-call predic-tion, because indirect function calls can jump to a numberof call targets. Later, we show how profile-based I-call if
conversion can use these mechanisms.
3 Experimental Design
Our comparison used trace-based simulation. We in-strumented a number of C++ programs, listed in Table 1,using a modified version of the QPT[31 program tracingtool. We emphasized programs using existing C++ class li-braries or that structured the application in a modular, ex-tensible fashion normally associated with object-orienteddesign. A more extensive comparison between the charac-teristics of C and C++ programs can be found in [7]. Em-
pirical computer science is a labour-intensive undertaking.The programs were compiled and processed on DECstation5000’s. Three C++ compilers (Gnu G++, DEC C++, AT&TC++ V3.O.2) were required to successfully compile all pro-grams; much of this occurred because the C++ languageis not standardized. This collection of programs, when in-strumented, consumed % lGb of disk space. Despite thegood performance of the QPT tracing tool for conventionalprograms, it offers little trace compression in programsusing indirect calls.
We constructed a simulator to analyze the programtraces. ‘l?vpically the simulator was run once to collect
..”
information on call and branch targets, and a second timeto use prediction information fi-om the prior run. For oneprogram (GROFF), we compared predictions using inputfrom differing runs to better assess the robustness of ourresults.
We modified QPT to indicate what caused a basic-blocktransition (a direct branch. indirect branch or fall-through)and record whether a fimction call was caused by a director indirect call. For most programs, we were also able toindicate what fimctions were C++ methods. 1 We classifiedunpredictable breaks in control into three classes: a 2Brsis a conditional branch, a >2Brs is a branch with multipledestinations, usually arising from switch or case state-ments. and an I-call is an indirect function call. Table 2lists the number of occurrences for each type of unpre-dictable break in control for the different programs. Weshow three entries for GROFF because we use these threeexecutions for coverage analysis later. Entries in the col-umn “Sites From Trace” lists the number of branch or callsites of that type encountered during the program execu-tion. For example, DOC actually has 2,367 indirect func-tion calls, but we only encountered 1,544 of those calls dur-ing the program execution. The heading “Occurvwnces
During Execution” lists the number of times breaks ofthat type appear during program execution. Thus, therewere 5,310,059 indirect fimction calls when we tracedDOC. Approximately 99% of the indirect calls were to C++methods, except in GROFF, where 95% were to methods.
4 Performance comparison
There are many metrics that can be used to compareI-call prediction and combined I-call and branch predictiontechniques. Table 3 shows the number of instructions be-
tween breaks (NIBBs) without branch or I-call prediction.We tracked only breaks in control flow that will cause along pipeline delay. These breaka are conditional branchesand indirect calls. Returns also cause a long pipeline stall,but returns can be accurately predicted by using a returnstack [151, and we did not track these. We assume that un-conditional branches, procedure calls and assigned gotosare accurately predicted. These control-transfer instruc-tions, conditional branches and I-calls can also cause an
‘We couldnot extract this information for IDL, which wascompiledbyDEC C++
401

Name
CONGRESS
Doc
GROFF
IDL
IDRAW
MORPHER
RTSH
Description
Interpreter for a PROLOG-like language. Input was one of the examples distributedwith CONGRESSfor configuration management.Interactive text formatter, based on the InterViews 3.1 library Input was briefly editinga 10 page document.Groff Version 1.7 — A version of the “ditroff text formatter. One input was a collectionof manual pages, another input was a 10-page paper.Sample backend for the Interface Definition Language system distributed by the ObjectManagement Group. Input was a sample IDL- specification for the Fresco graphics Ilibrary.Interactive structured graphics editor, based on the InterViews 2.6 library Examplewas drawing and editing a figure.Structured graphics “morphing” demonstration, based on the InterViews 2.6 library.Example was a morphed “running man” example distributed with the program.
Ray Tracing Shell – An interactive ray tracing environment, with a TC~K user inter-face and a C++ graphics library Example was a small ray traced image distributed withthe program.
Table 1: C++ Programs Instrumented
instruction misfetch penalty because they mustbe decodedbefore the instruction stream knows the instruction type.Thus, the instruction fetch unit may incorrectly fetch thenext instruction, rather than the target destination. Inanother paper [6], we show how these misfetch penaltiescan be avoided using extra instruction type bits andfor asimple instruction type prediction table, coupled with thetechniques discussed in this paper.
If we are only considering conditional branches and in-direct calls. We would expect the parameters in Table 3 tobe similar for C and C++ programs. To the contrary, wefound that our sample C++ programs had a higher numberof instructions between breaka, indicating that C++ pro-grams tend to either be more predictable than C programsor, they use a different linguistic construct for conditionallogic. For example, consider a balanced-tree implementa-tion in C and C++. A C programmer might implement asingle procedure to balance a tree, passing in several flagsto control the actual balancing. A C++ programmer, on theother hand, would tend to use inheritance and the objectmodel to provide similar functionality. Thus, it is not sur-prising that C++ programs tend to have more procedurecalls and fewer conditional operations [71.
In the remaining tables, we only show the mean NIBBfor each program and use the harmonic mean of the NIBBas a summary. We also use the percent of breaks pre-
dicted (YoBP) to understand how well various techniquespredict breaks. This metric, or the more common mis-prediction rate, is commonly used to compare branch pre-diction mechanisms. However, note that the %BP metricdoes not account for the density of breaks in a program.For example, there may be a single conditional branch ina 100,000,000 instruction program. While the the branchmay always be mispredicted, the number of instructionsbetween breaks remains high. Therefore, it is useful tolook at both the NIBB and %BP when comparing predic-
tion techniques across different programs,
4.1 Bounds on Compile-time i-Call Prediction
We were interested in determining how well interprocedu-ral dataflow analysis could predict indirect method calls[22] and we compared these results to profile-based staticprediction methods. Method names in C++ are encodedwith a unique type signature. If a linker knew the in-tended type signature at a call site,2 and there was a sin-gle function with that signature, then no other functioncould be appropriate for that call site and the indirect callcould be replaced by a direct call. We call this the Unique
Name measure, and feel it represents a lower bound onwhat could be accomplished by a dataflow optimization al-gorithm – in practice, a dataflow method should be moreaccurate, because a symbol table in UNIX system typicallyincludes methods horn classes that are never invoked. Atthe other extreme, we recorded the number of Single Tar-
get I-call sites, or I-call sites that record a single call targetduring a trace. Compiler directed I-call prediction is mostuseful if a single target can be selected. In the number oftraces we recorded, the Single Target measure representsan upper bound on the target prediction we could expectfrom dataflow-based prediction algorithms. Both Unique
Name and Single Target values measure the number ofdynamic occurrences. In general, our results indicate sig-nificant promise from static analysis of C++ programs. Inparticular, because it is so effective and simple to imple-ment, we feel the Unique Name measure should be inte-grated into existing compilers and linkers.
2Currently,compilersdon’t provide this information at call sites,butthisinformation is easy to capture.
402
IzE??J&congress I 1,817
Ldoc 5,398groff-1 1,974
groff-2 2,110
groff-3 2,370idl 1,011idraw 6,473morpher 4,050rtsh 1,390
FromICalls
309
1,544671722
759525
2,2791,200
59
‘ace OccurrencesD(> 2Brs 2Brs ICalls
4 18,352,179 j 342,2666 48,536,165 5,310,0599 4,525,946 214,2199 6,047,864 205,487
10 7,977,220 304,9486 11,809,125 2,991,355
12 18,699,046 1,490,4606 6,613,548 425,0723 52,357,435 5,547,705
mgExec> 2Brs
43,59313,58563,11670,75994,29838,15751,6647,807
489
ionInstructions
152,658,312406,673,89837,655,94946,416,49563,641,709
151,419,127184,930,70052,131,648
822,054,191
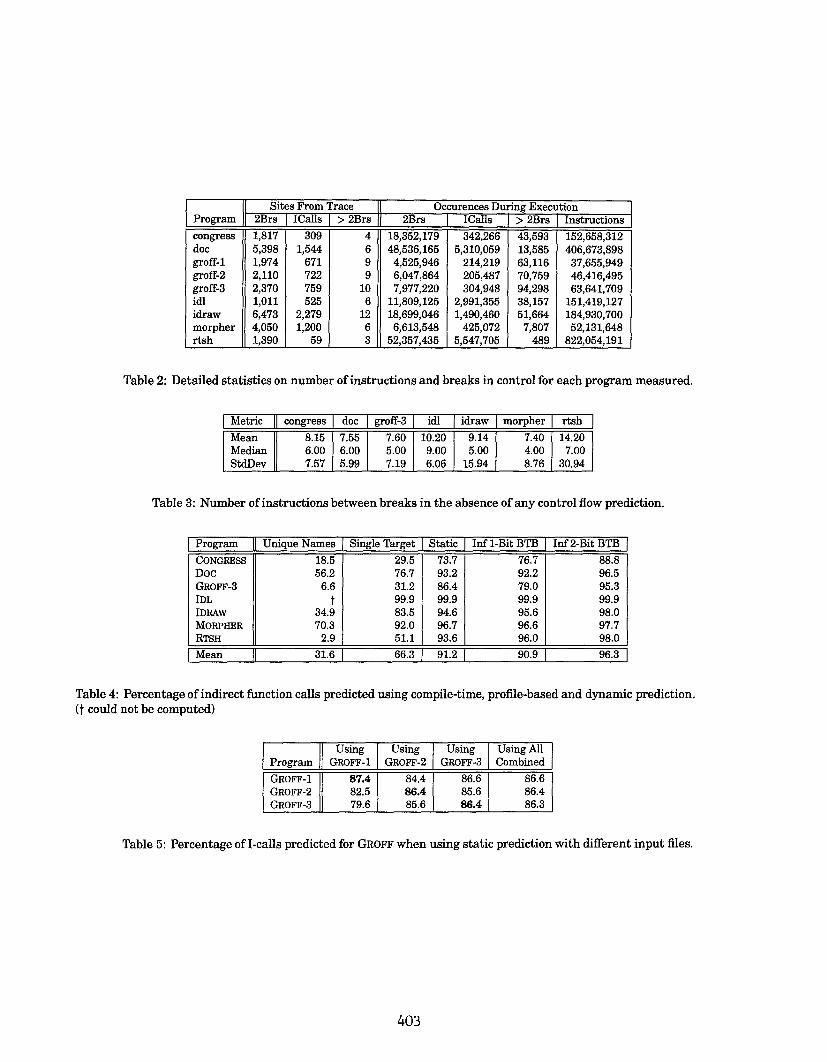
Table 2: Detailed statistics on number of instructions and breaks in control for each program measured.
Metric congress doc groff-3 idl idraw morpher rtsh
Mean 8,15 7.55 7.60 10.20 9.14 7.40 14.20Median 6.00 6.00 5.00 9.00 5.00 4.00 7.00StdDev 7.57 5.99 7.19 6.06 15.94 8.76 30.94
Table 3: Number of instructions between breaks in the absence of any control flow prediction.
Program Unique Names Single Target Static Inf l-Bit BTB Inf 2-Bit BTB
CONGRRSS 18.5 29.5 73.7 76.7 88.8Doc 56.2 76.7 93.2 92.2 96.5GROFF-3 6.6 31.2 86.4 79.0 95.3IDL t 99.9 99.9 99.9 99.9IDRAW 34.9 83.5 94.6 95.6 98.0MORFHER 70.3 92.0 96.7 96.6 97.7RTSH 2.9 51.1 93.6 96.0 98.0
Mean 31.6 66.3 91.2 90.9 96.3
Table 4: Percentage of indirect function calls predicted using compile-time, profile-based and dynamic prediction.(t could not be computed)
Using using Using Using AllProgram GROFF-1 GROFF-2 GROFF-3 Combined
GROFF-1 87.4 84.4 86.6 86.6
GROFF-2 82.5 86.4 85.6 86.4GROFF-3 79.6 85.6 86.4 86.3
Table 5: Percentage of I-calls predicted for GROFF when using static prediction with different input files.
403
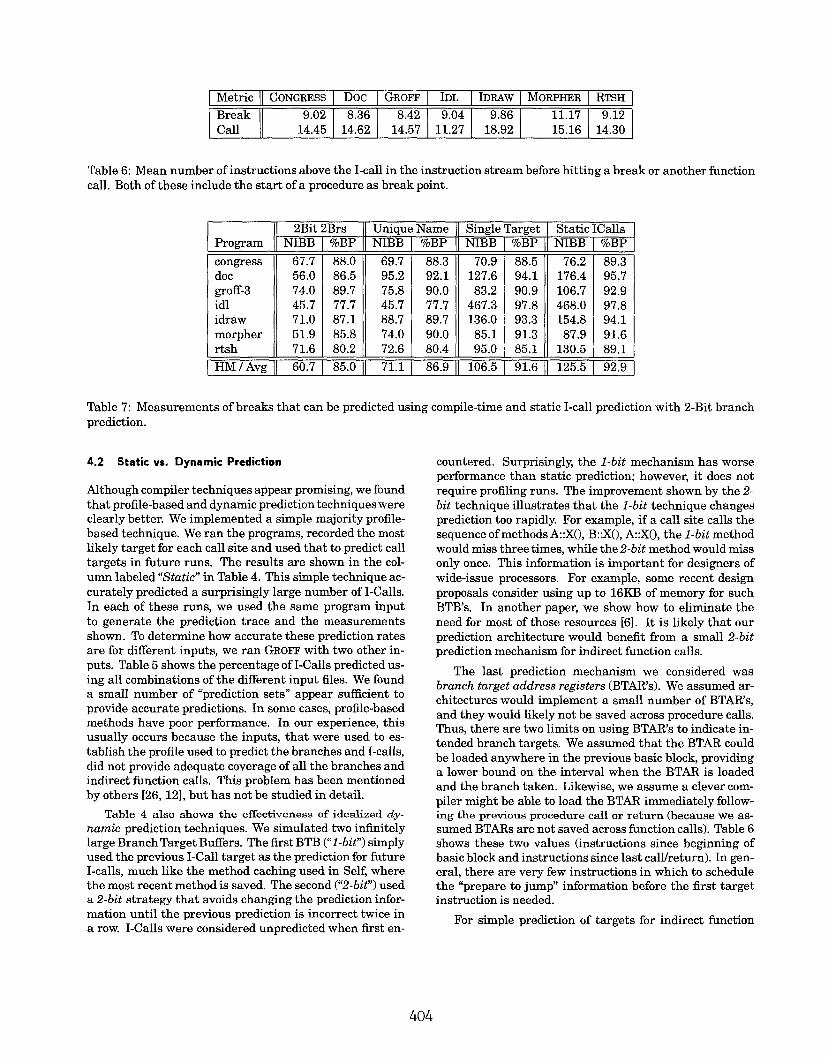
Metric CONGRESS Doc GROFF IDL IDRAW MORPHER RTSH
Break 9.02 8.36 8.42 9.04 9.86 11.17 9.12
Call 14.45 14.62 14.57 11.27 18.92 15.16 14.30
Table6: Meannumber ofinstructions above the I-call intheinstruction stream before hitting abreakor another finctioncall. Both of these include thestati ofaprocedure as break pint.
EiiiIiE
~
congress 67.7
doc 56.0groff-3 74.0idl 45,7idraw 71.0morpher 51.9rtsh 71.6
HM 1Avg 60.7
Brs I Uniuue Name II Single Target \ Static ICalls%BP II NIBB \ %BP I NIBB
88.0 II 69.7 I 88.3 II 70.9
I86.5 95.2 92.1 127.689.7 75.8 90.0 83.277.7 45.7 77.7 467.387.1 88.7 89.7 136.085.8 74.0 90.0 85.180.2 72.6 80.4 95.0
85.0 71.1 86.9 106.5
EmtEIEE88.5 \\ 76.2
194.1 176.490.9 106.797.8 468.093.3 154.891.3 87.985.1 130.5
~
%BP
89.395,792.997.894.191.689.1
92.9
Table 7: Measurements of breaka that can be predicted using compile-time and static I-call prediction with 2-Bit branchprediction.
4.2 Static vs. Dynamic Prediction
Although compiler techniques appear promising, we foundthat profile-based and dynamic prediction techniques wereclearly better. We implemented a simple majority profile-based technique. We ran the programs, recorded the mostlikely target for each call site and used that to predict calltargets in future runs. The results are shown in the col-umn labeled “Static” in Table 4. This simple technique ac-curately predicted a surprisingly large number of I-Calls.In each of these runs, we used the same program inputto generate the prediction trace and the measurementsshown. To determine how accurate these prediction ratesare for different inputs, we ran GROFF with two other in-puts. Table 5 shows the percentage of I-Calls predicted us-ing all combinations of the different input files. We founda small number of “prediction sets” appear sufficient toprovide accurate predictions. In some cases, profile-basedmethods have poor performance. In our experience, thisusually occurs because the inputs, that were used to es-tablish the profile used to predict the branches and I-calls,did not provide adequate coverage of all the branches andindirect function calls. This problem has been mentionedby others [26, 12], but has not be studied in detail.
Table 4 also shows the effectiveness of idealized dy-namic prediction techniques. We simulated two infinitelylarge Branch Target Buffers. The first BTB Vi-bit”) simplyused the previous I-Call target as the prediction for fhtureI-calls, much like the method caching used in Self, wherethe most recent method is saved. The second (“2-bit”) useda 2-bit strategy that avoids changing the prediction infor-mation until the previous prediction is incorrect twice ina row. I-Calls were considered unpredicted when first en-
countered. Surprisingly, the l-bit mechanism has worseperformance than static prediction; however, it does notrequire profiling runs. The improvement shown by the 2-bit technique illustrates that the l-bit technique changesprediction too rapidly. For example, if a call site calls thesequence of methods A.:X(), B::X(), A:X(), the l-bit methodwould miss three times, while the 2-bit method would missonly once. This information is important for designers ofwide-issue processors. For example, some recent designproposals consider using up to 16KB of memory for suchBTB’s. In another paper, we show how to eliminate theneed for most of those resources [6]. It is likely that ourprediction architecture would benefit from a small 2-bit
prediction mechanism for indirect fi.mction calls.
The last prediction mechanism we considered wasbranch target address registers (BTAR’s). We assumed ar-chitectures would implement a small number of BTAR’s,and they would likely not be saved across procedure calls.Thus, there are two limits on using BTAR’s to indicate in-tended branch targets. We assumed that the BTAR couldbe loaded anywhere in the previous basic block, providinga lower bound on the interval when the BTAR is loadedand the branch taken. Likewise, we assume a clever com-piler might be able to load the BTAR immediately follow-ing the previous procedure call or return (because we as-sumed BTARs are not saved across function calls). Table 6shows these two values (instructions since beginning ofbasic block and instructions since last call/return). In gen-eral, there are very few instructions in which to schedulethe “prepare to jump” information before the first targetinstruction is needed.
For simple prediction of targets for indirect function
404

calls, we found:
● Dynamic methods using the 2-bit branch target
buffer were the most effective technique we consid-ered. However, this style of prediction maybe expen-sive to implement.
● By combining a simpler branch prediction technique
with BTB’s for indirect function calls, the resourcedemands become more realistic.
● Static profile-driven prediction was very accurate,and is used in the remainder of this paper.
4.3 Using Profiles to Eliminate Indirect Function Calls
Our prior measurements have shown the percentage ofI-calls predicted using these different techniques. By com-parison, Table 7 shows the percent of total breaks pre-dicted. Using static prediction with prior profiles for I-callsaccurately predicts half of the remaining breaks in control,doubling the number of instructions between breaks (as-suming that the breaks are evenly distributed). RecallFigure 1. In this figure conditional branches and indirectfimction calls are predicted using the static profile-basedtechnique just described. The second bar for each pro-gram indicates the additional delays incurred by breaksfrom indirect function calls and mispredicted conditionalbranches. While the third bar, eliminates delays hornstatically predicted indirect function calls. For architec-tures providing BTB’s, the delay would be slightly smaller.Clearly, predicting branches is the foremost priority, butpredicting indirect calls removes a substantial number ofbreaks.
The success of profile-based static prediction also indi-
cates that many methods could be successfidly compiledinline, even without compile-time type analysis. We canconvert an indirect function call, e.g.,ob j ec t -> f oo ( ) ;to a conditional procedure call with a run-time type check
if (typeof(ob-ject) == A )
object -z A:: fooo;else
object –> fooo;
This transformation is useful for three reasons. First,once this code transformation has been performed, fimc-tion call A: : f oo ( ) can be inlined. Secondly, If there isa high likelyhood of calling A: : f oo ( ), this code sequenceis less expensive on most RISC architectures, using on 4-5 instructions rather than 5-8. Lastly if an architectureprovides branch prediction but does not support predictionfor indirect fimction calls, the transformed code can avoidmany misprediction penalties. Existing branch predictionhardware may be able to improve on strictly profile-basedprediction because it can accommodate bursts of calls to asecondary call target.
Although inliningflmctions is useful, it does not alwaysreduce program execution time [10]. However, many indi-rect fimction calls in C++ tend to be very short, becauseprogrammers are more likely to employ proper data encap-sulation techniques. We believe automatic inlining will bemore useful for C++ than C. Further, on most architec-tures, the converted indirect- fimction call is more efficientif there is a high Iikelyhood of calling the most commonfunction (A: : f oo ( ) above).
We constructed the following cost models for handlingI-calls and used this to optimize I-calls in more detail.Assume the cost of a direct method call, Cdmc, is 2 in-structions. This comes from an extra instruction neededto compute the object pointer which is passed to the call in-struction. The cost of an indirect method call, Cimc, is 7 in-structions, and is because of the extra instructions neededto compute the pointer addresses and fbture branch tar-get. The cost of an “i~ Cif, as shown in the previousexample, is 3 instructions, including an indirect load forthe object pointer, a load of a constant and the comparison.The penalty for mispredicting a conditional branch or an
indirect finction call, Cmiss, is 10 instruction times. Thisis because we assume mispredicted breaks can cause a 10cycle pipeline delay. From this we get the cost for indirectmethod calls with no prediction to be
Since the indirect call is not predicted, it is considered tobe mispredicted. By comparison, with the static profile-based prediction mechanism as discussed in the previoussection, the cost becomes
cp..d~ct(p) = Came + (1– P) Cma$$ .
if there is a P?ZOprobability of accurately predicting the calltarget for a call site. The cost for converting an indirectmethod call to an ‘i~ as done above, would be
however, we can use the existing profile information tocompute ‘Q, the percentage of the second most likely calltarget being selected. Note that Q has to be less than orequal to min(P,( l-P)), else it would be the most likely targetselected. It is interesting to note that Q might be a highpercentage of the remaining I-calls. For example, we mayhave P = 40%, with the next most likely branch occurringQ = 35% of the time. This means that 35/(100 – 40), or58% of the remaining 60% of I-calls are correctly predicted.Thus, the cost for converting an indirect ftmction call to an‘if’ construct is actually
Cti..-ij(P, ~) = Cit + Pcdmc +
(1- P)(Cm+.$ + Cp.edict(~/(1 - p))) .
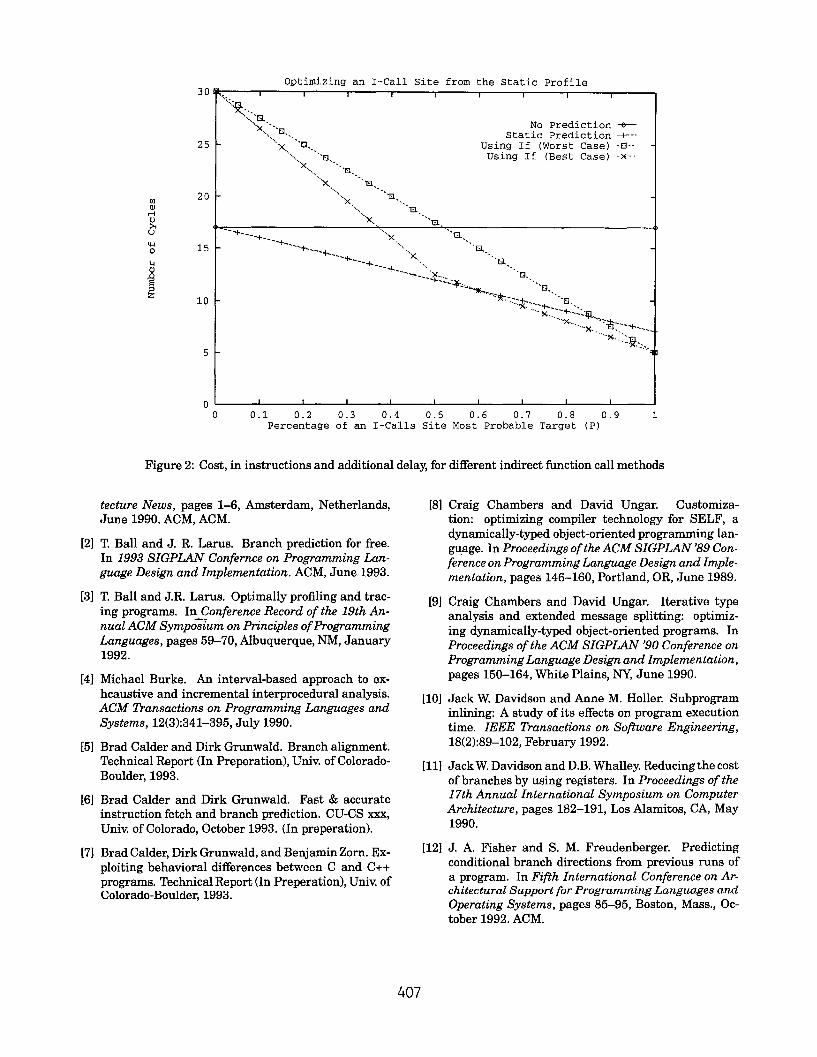
Figure 2 shows the costs for C&p-edict (the horizon-tal line), c=~,dici (the lower line) and the boundaries for
405

Ca.e–~f (P, Q) for Q = rnin(P, (1 – P)) the best case, and
Q = 0.0 the worst case. In the worst case, our “if con-version” is the same as CU8e–it (P). This is a hypotheti-cal case when there are so many second most likely tar-gets that Q is approximately equal to zero percent. Inthe graph the best case if conversion, Cs..–-,t (P, Q) for
Q = m~n(p, (1 – P)), is achieved when an I-call site hasonly 2 targets. This can only happen when P >= 0.5.So when P < 0.5, at best Q can only equal P, and theremaining 1 – (P + Q) I-call targets cannot be predicted.This is the reason the line in the graph for the best case ifconversion changes slope at P = 0.5. From the graph, onecan see that it is always a benefit to do static I-call predic-tion. Given the values for C~f, Cdmc, Cmi$,and CimCthatwe used, when P = 0.6, depending on how accurate onecan predict the second most likely target Q, it can be bet-ter to do the if conversion on the I-call rather than onlypredicting the most likely target. From the graph, onecan see that, Cti, c--if(P) eventually hIteI%eCtS Cpredict (P),
where it is always beneficial to do the if conversion onan architecture that provides static prediction. With ourarchitecture assumptions, this occurs at P = 0.86. Thelines c~~redict and Cu,.–i j (P) (WOrst Case) also eventu-ally intersect, where it is always beneficial to do the ifconversion on an architecture that does not movide staticprediction. With our architecture assumptions, this occursat P = 0.52. Thus, doing the if conversion on an architec-ture that does not provide static prediction gives the user,in a sense, the benefit of static prediction. As mentioned,the architecture we’ve considered is similar to the DigitalAXP 21064. Other architectures, including the Intel Pen-tium, also issue two instructions per clock, and some newlyannounced architectures, such as the IBM RIOS-11 issueup to eight instructions per cycle. On these architectures,the advantage of “if-conversion” occurs with much lowerprobabilities for P.
In general, prediction information can greatly reducethe penalty for indirect function calls. As noticed fromthe graph it is always beneficial to predict the destinationfor an I-call. Accurate profile-based measurements exposeother optimizations when the accuracy of predicting themost frequently called function exceeds 80-90%. Table 4shows this occurs for many of the programs we measured.This transformation also provides opportunity for inliningthe body of the function, allowing the compiler to customizethe parameters to the function, avoid register spills andthe like.
The right-most bar for each program shown in Figure 1
shows the effect of applying this transformation where ap-propriate, based on our model, for each call site in theprograms. By comparison, the second bar horn the rightshows the benefit of using prediction and unique nameelimination, without using the if conversion. Althoughthe advantage is small, similar costtbenefit analysis canbe used to determine the advantage of additional functioninlining. Note, there will be a greater advantage in usingthe if conversion when the architecture does not supportstatic prediction.
5 Conclusions and Future Work
As object-oriented programs become more common, therewill be an increasing need to optimize indirect fimctioncalls. This will become even more important as processorpipeline depths increase and superscalar instruction issueand speculative execution become more common. Exist-ing branch prediction mechanisms accurately prediction95%–97% of conditional branches. Because branch predic-tion is so successful, accurate prediction of the remainingbreaks in control-flow becomes increasingly important asprocessors begin to issue more instructions concurrently.Eliminating the misprediction penalty for indirect functioncalls in C++ programs can remove 10% of the remainingbreaks in control in a C++ program.
We found that static profile-based prediction mecha-nisms worked well for the collection of existing C++ pro-grams we examined. We saw additional improvements bycombining compiler optimization techniques (unique nameelimination and ‘if conversion’) with static indirect call pre-diction. The information from profile-based prediction isaIso useful for other code transformations, such as inlin-ing and better register scheduling. Our results show thatwe get an average of 10VOimprovement in the number ofinstructions executed for a program by using our I-callpredictionloptimization techniques.
We recommend that compilers for highly pipelined,speculative execution architectures : use profile-basedstatic prediction methods to optimize C++ programs, uselink-time information to remove indirect function calls,and customize call-sites using ‘if conversion’ based on pro-file information. Furthermore, we hope the architectureand benchmarking community expands benchmark suitesto include modern programming languages such as C++,Modula-3 and the like, because these languages exercisedifferent architectural features than C or Fortran pro-grams.
Acknowledgements
We would like to thank Ben Zorn, John Feehrer and thereviewers for comments on the paper. We’d also like tothank James Larus for developing QPT and helping ussolve the various problems we encountered applying it tosuch large programs. This work was funded in part byNSF grant No. ASC-9217394, and is part of a continuedeffort to make languages such as C++ suitable for scientificcomputing.
References
[1] Robert Alverson, David Callahan, Daniel Cummings,Brian Koblenz, Allan Porterfield, and Burton Smith.The tera computer system. In Proc. 17th Annual Sym-
posium on Computer Architecture, Computer Archi-
406
[2]
[3]
[4]
[5]
[61
[71
wo
30
25
20
15
10
5
0
Optimizing an I-Call Site from the Static Profile%*.:. 1 1 t 1 1 f 1 1 [
““’g:;;..a
“’’’x:;,-’ .❑ No Prediction 4--. . . Static Prediction -+-......
x. “m.. Using If (Worst Case) -U--‘....., ‘-’a.. Using If (Best Case) x-.
““x..., “’D........x.., “m..
,....,x
-’m . ..,..., “m..
““’x. ..,, “m.<b.-- +---+
4>‘x “m-. --+--- . .
-’t---- “....,i. ‘“Q,.
---+ ‘“x,--- + -.. .,, ‘“Q.-1- . .
----l. -.-’x .... “Q..-=%...% “’5..
“-..*-,-6-“n.-“-x .:::+---%, -+:>:““”-x. ...
~-..x.:’-&--+---
“’”’x...;;.g,.,>- -
~J
1 I 1 1 1 1 1 1 1
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1Percentage of an I-Calls Site Most Probable Target (P)
Figure 2: Cost, in instructions and additional delay for different indirect function call methods
tecture News, pages 1-6, Amsterdam, Netherlands,June 1990.ACM,ACM.
T. Ball and J. R. Larus. Branch prediction for flee.1n1993SIGPLAN Confernce on Programming Lan-
guageDesignand Implementation. ACM, June 1993.
T. Ball andJ.R. Larus. Optimally profilingandtrac-ing programs. In Conference Record of the 19thAn-
nualACMSympo~um on Principles ofProgramming
Languages,pages 59–70,Albuquerque, NM,January1992.
Michael Burke. An interval-based approachto ex-haustive and incremental interprocedural analysis.ACM Transactions on Programming Languages and
Systems, 12(3):341–395, July 1990.
Brad Calderand Dirk Grunwald. Branch alignment.Technical Report (In Preperation), Univ. of Colorado-Boulder, 1993,
Brad Calder and Dirk Grunwald. Fast & accurateinstruction fetch and branch prediction. CU-CS xxx,Univ. of Colorado, October 1993. (In preperation).
Brad Calder, Dirk Grunwald, and Benjamin Zorn. Ex-ploiting behavioral differences between C and C++programs. Technical Report (In Preperation), Univ. ofColorado-Boulder, 1993.
[81
[91
[10]
[11]
[121
Craig Chambers and David Ungar. Customiza-tion: optimizing compiler technology for SELF, adynamically-typed object-oriented programming lan-guage. In Proceedings of the ACM SIGPLAN ’89 Con-
ference on Programming Language Design and Imple-
mentation, pages 146-160, Portland, OR, June 1989.
Craig Chambers and David Ungar. Iterative typeanalysis and extended message splitting: optimiz-ing dynamically-typed object-oriented programs. InProceedings of the ACM SIGPLAN ’90 Conference on
Programming Language Design and Implementation,
pages 150-164, White Plains, NY, June 1990.
Jack W. Davidson and Anne M. Holler. Subprograminlining: A study of its effects on program executiontime. IEEE Transactions on Software Engineering,
18(2):89–102, February 1992.
Jack W. Davidson and D.B. Whalley. Reducing the costof branches by using registers. In Proceedings of the
17th Annual International Symposium on Computer
Architecture, pages 182–191, Los Alamitos, CA, May1990.
J. A. Fisher and S. M. Freudenberger. Predictingconditional branch directions from previous runs ofa program. In Fifth International Conference on Ar-
chitectural Support for Programming Languages and
Operating Systems, pages 85–95, Boston, Mass., Oc-tober 1992. ACM.
407

[131
[14]
[15]
[16]
[171
[18]
[191
[20]
[21]
[22]
[23]
[24]
[25]
Mary W. Hall and Ken Kennedy. Efficient call graphanalysis. Letters on Programming Languages and
Systems, 1(3):227-242, September 1992.
Urs Holzle, Craig Chambers, and David Unger. Op-timizating dynamically-typed object-orientred lan-guages with polymorphic inlines caches. In ECCOP
’91 Proc. Springer-Verlag, July 1991.
David R. Kaeli and Philip G. Emma. Branch historytable prdiction of moving target branches due to sub-routine returns. In 18th Annual International Sym-
posium of Computer Architecture, pages 34-42. ACM,May 1991.
M. S. Lam and R. P. Wilson. Limits of control flowon parallelism. In 19th Annual International Sym-
posium of Computer Architecture, pages 46-57, GoldCoast, Australia, May 1992. ACM.
Johnny K. F. Lee and Alan Jay Smith. Branch predic-tion strategies and branch target buffer design. IEEE
Computer, pages 6-22, January 1984.
David J. Lilja. Reducing the branch penalty inpipelined processors. IEEE Computer, pages 47–55,July 1988.
M. S. Lam M. D. Smith, M. Horowitz. Efficient super-scalar performance through boosting. In Fifth Inter-
national Conference on Architectural Support for Pro-
gramming Languages and Operating Systems, pages248–259, Boston, Mass., October 1992. ACM.
Scott McFarling and John Hennessy. Reducing thecost of branches. In 13th Annual Internationa~ Sym-
posium of Computer Architecture, pages 396-403.ACM, 1986.
S.-T. Pan, K. So, and J. T. Rahmeh. Improving theaccuracy of dynamic branch prediction using branchcorrelation. In Fifth International Conference on Ar-
chitectural Support for Programming Languages and
Operating Systems, pages 76-64, Boston, Mass., Oc-tober 1992. ACM.
Hemant D. Pande and Barbera G. Ryder. Static typedetermination for C++. Technical Report LCSR-TR-197, Rutgers Univ., February 1993.
Chris Perleberg and Alan Jay Smith. Branch targetbuffer design and optimization. IEEE Transactions
on Computers, 42(4):396-412, April 1993.
Barbera G. Ryder. Constructing the call graph of aprogram. IEEE Transactions on Software Engineer-
ing, SE-5(3):216-226, May 1979.
J. E. Smith. A study of branch prediction strategies.In 8th Annual International Symposium of Computer
Architecture. ACM, 1981.
[26]
[27]
[28]
[29]
D. W. Wall. Limits of instruction-level parallelism.In Fourth International Conference on Architectural
Support for Programming Languages and Operating
Systems, pages 176-188, Boston, Mass., 1991. ACM.
Tse-Yu Yeh and Yale N. Patt. Alternative implemen-tations of two-level adaptive branch predictions. In19th Annual International Symposium of Computer
Architecture, pages 124-134, Gold Coast, Australia,May 1992. ACM.
Tse-Yu Yeh and Yale N. Patt. A comprehensive in-struction fetch mechanism for a processor support-ing speculative execution. In 19th Annual Interna-
tional Symposium on Microarchitecture, pages 129–139, Portland, Or, December 1992. ACM.
Tse-Yu Yeh and Yale N. Patt. A comparison of dy-namic branch predictors that use two levels of branchhistory In 20th Annual International Symposium of
Computer Architecture,
CA, May 1993. ACM.pages 257–266: San Diego,
408