Embed Size (px)
Citation preview

MASTER THESISThesis submitted in partial fulfillment of the requirements for the de-gree of Master of Science in Engineering at the University of AppliedSciences Technikum Wien - Degree Program Game Engineering andSimulation Technology
Reducing Driver Overhead in OpenGL, Direct3Dand Mantle
By: Simon Dobersberger, BScStudent Number: 1310585003
Supervisors: DI Stefan ReinalterDI Dr. Gerd Hesina
Vienna, May 28, 2015

Declaration
“I confirm that this paper is entirely my own work. All sources and quotations have been fullyacknowledged in the appropriate places with adequate footnotes and citations. Quotations havebeen properly acknowledged and marked with appropriate punctuation. The works consultedare listed in the bibliography. This paper has not been submitted to another examination panelin the same or a similar form, and has not been published. I declare that the present paper isidentical to the version uploaded.“
Place, Date Signature

Kurzfassung
Der Overhead, welcher vor allem durch die Verwendung des Grafikkartentreibers zustandekommt, ist einer der Hauptgründe für Performance-Probleme in komplexen 2D und 3D App-likationen wie in etwa Spielen. Die Reduzierung von Draw Calls und Zustandsänderungen derGrafik-Pipeline führen dazu, dass mehr Objekte gleichzeitig in einer Szene dargestellt werdenkönnen. OpenGL, Direct3D und Mantle verfügen über zahlreiche Features um sich diesemProblem anzunehmen. Diese Masterarbeit dient der Vorstellung und Analyse dieser Technikenund vergleicht sie untereinander mit den einzelnen APIs.
Schlagworte: Rendering, Treiber Overhead, Performance, 3D

Abstract
Driver overhead is one of the main reasons for performance problems in complex 2D and 3Dapplications like games. By reducing the number of draw calls and state switches the programbecomes capable of rendering more objects per frame. OpenGL, Direct3D and Mantle provideseveral features tackling these problems. This thesis introduces and analyses most of thesetechniques and compares them with other APIs.
Keywords: Rendering, Driver Overhead, Performance, 3D

Acknowledgements
I would like to express my greatest gratitude to my mother and my stepfather for supportingme all the time during my studies at the UAS Technikum Vienna. I would also like to thank mysupervisor who motivated me with his lessons and always replied quickly with helpful advicewhen I had any kind of problem. Also, I would like to thank all my friends and family memberswho helped me with their feedback and support.

Contents
1. Driver Overhead 1
2. OpenGL 22.1. OpenGL is a State Machine . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22.2. Analysis of Modern OpenGL Techniques . . . . . . . . . . . . . . . . . . . . . . . 32.3. Instancing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82.4. Batching . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82.5. Sorting . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92.6. Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3. Direct3D 123.1. Analysis of Modern Direct3D 11 Techniques . . . . . . . . . . . . . . . . . . . . . 123.2. Direct3D 12 Outlook . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 243.3. Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
4. AMD Mantle 304.1. Execution Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 314.2. Generalized Resources . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 314.3. Memory Management . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 324.4. Monolithic Pipelines . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 334.5. Resource Binding Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 354.6. Resource Preparation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 354.7. Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
5. Comparison of Modern OpenGL and Direct3D Techniques on PC 375.1. Ace3D Engine . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 375.2. Test System . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 435.3. OpenGL - DSA versus Non-DSA . . . . . . . . . . . . . . . . . . . . . . . . . . . 445.4. Massive Untextured Object Rendering . . . . . . . . . . . . . . . . . . . . . . . . 465.5. Massive Textured Object Rendering . . . . . . . . . . . . . . . . . . . . . . . . . 545.6. Third Party API Tests . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 595.7. Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
6. Comparison of Modern OpenGL Techniques on the Tegra K1 GPU 626.1. Test System . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 626.2. Third Party API Tests . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63

6.3. Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
7. Conclusion & Outlook 657.1. Fields of Application . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 657.2. Future Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
8. Bibliography 69
9. List of Figures 73
10.List of Tables 74
11.List of abbreviations 75
A. OpenGL Backend 76
B. Direct3D Backend 96

1. Driver Overhead
There are many ways to optimize the performance of the graphics hardware. One of today’smain problems is the high number of draw calls and state switches that are needed for renderingmultiple objects on the screen. APIs that handle graphical output like Direct3D or OpenGLfeature several methods for sending vertex data to the Graphics Processing Unit (GPU). Thesedraw commands generate a performance overhead for the driver. Therefore, AMD is currentlyworking on their own API called Mantle, which reduces the number of draw calls in programswhere performance is critical like games or 3D simulations. Microsoft also announced to tacklethis problem with the next version of DirectX (DX12).
1

2. OpenGL
OpenGL, which is managed by the Khronos Group, already offers multiple ways for reducingdraw calls by providing features like Array Textures, Bindless Textures as well as functionslike glMultiDrawElements and glMultiDrawArraysIndirect. In case of glMultiDrawArraysIndirectthe rendering is managed by the GPU itself. The API also provides features like PersistentlyMapped Buffers for minimizing memory usage. Another way of reducing driver overhead is bysimplifying OpenGL calls via Direct State Access. [1]
There are also programming techniques that help to address this problem, e.g. by sortingdraw commands or instancing. Using shaders, textures and vertex data for multiple objectsreduces the need for resending data to the GPU for each mesh.
The following sections explain most of these features and techniques in detail.
2.1. OpenGL is a State Machine
OpenGL, especially regarding the older versions, is called a state machine or a stateful API.That is because it uses a lot of switches that have to be set before transferring data, settingtexture attributes and other operations. It also provides functions for pushing and poppingthe current state on/from stack. OpenGL uses a client-server architecture meaning that theapplication is considered the client whereas the hardware, which theoretically could reside onanother physical machine, is the server. Thereby, there are two kinds of states GL server stateand GL client state. However, with the introduction of display lists and vertex buffers objects theusage of client states becomes obsolete because the vertex data resides on the server itself.Therefore, functions like glEnableClientState() are listed as removed features in the current coreprofile specification (OpenGL 4.5) [2].
Listing 2.1: Example code for changing the texture minification filter in OpenGL
glActiveTexture (GL_TEXTURE0 ) ;glBindTexture (GL_TEXTURE_2D , textureId ) ;glTexParameteri (GL_TEXTURE_2D , GL_TEX_MIN_FILTER , GL_LINEAR ) ;
Prior to changing the parameter of a texture, the application has to activate the correct textureslot and bind the id of the texture, as shown in listing 2.1. However, this means that developershave to keep track of active states before doing any kind of operation which could lead to error-prone programming behaviour or code. Another disadvantage of this kind of method is that
2

such operations become verbose. Therefore, OpenGL introduced a feature called direct stateaccess which is described in detail in section 2.2.7. [13]
2.2. Analysis of Modern OpenGL Techniques
This section considers several rendering techniques. This includes OpenGL functions that arepart of the core API since version 3.x or 4.x.
2.2.1. Vertex Buffer Objects
OpenGL provides several types of buffers which represent a memory storage of linear alloca-tions. During the glGenBuffers() call a handle or rather name in the form of an unsigned integeris reserved which can be used to refer to the buffer later on. As shown as in listing 2.2 the func-tion does not need to know the type of buffer yet. It is also possible to create multiple buffers atonce. [3]
Listing 2.2: Example code for creating a buffer object
GLuint buffer ;glGenBuffers (1 , &buffer ) ;
Before usage, it has to be bound to the context with glBindBuffer(). Only now, when thebuffer is bound for the first time, the name gets associated with a buffer object. At this pointOpenGL also needs to know the purpose of the buffer. This section focuses on the usage as anGL_ARRAY_BUFFER which stores the vertex data of an 2D/3D object like positions, normals,colors and UVs. The memory of the buffer is located on the server or rather GPU, for whichreason the data has to be transferred. This can be done by passing parameters for the buffertype, size, client side data and type of buffer usage with the glBufferData() call. The listing 2.3shows an example of uploading data, so that it can be used for the vertex attributes in the vertexshader. [1]
Listing 2.3: Example code for using a vertex buffer object to upload vertex data
/ / Generate VBO f o r ve r t i ces , normals and t e x t u r e coord ina tesGLuint vbo ;glGenBuffers (1 , &vbo ) ;/ / Bind VBO i n order to useglBindBuffer (GL_ARRAY_BUFFER , vbo ) ;/ / Generate b u f f e r data setglBufferData (GL_ARRAY_BUFFER , numVertices ∗ sizeof (VertexData ) , vertices ,
GL_STATIC_DRAW ) ;/ / Unbind b u f f e r
3

glBindBuffer (GL_ARRAY_BUFFER , 0) ;
GL_STATIC_DRAW is a hint for the OpenGL API that describes the access to data storageand may have an impact on the buffer performance. There are nine different types of hints thatcan be broken down into the following parts:
• STATIC, DYNAMIC and STREAM specify how often the buffer will be used and modified.
• DRAW, READ and COPY describe the nature of that access.
Thanks to vertex buffer objects the vertex data resides directly on the server of the OpenGLimplementation. Therefore, it does not have to be transferred every frame, which reduces theoverhead and transfer times.
2.2.2. Vertex Array Objects
Vertex array objects are a way to tell the API how the vertex data is structured and how it shouldbe used in the vertex shader. The generation and binding are similar to buffer objects and usethe functions glGenVertexArrays() and glBindVertexArray(). It also uses unsigned integers asnames to refer to the objects. The application tells the OpenGL implemenation the format andstructure of the data by calling glVertexAttribPointer() using the following parameters:
• Vertex attribute index
• Size
• Type of data (float, integer, etc.)
• Should the values be normalized when using integers or bytes?
• Stride
• Offset
It is important to note that the appropriate vertex buffer object has to be bound before the call,so that the vertex array object knows where the data lies. Finally, glEnableVertexAttribArray()activates the vertex attribute so that it can be used by the shader. By using vertex array objectsthe information about the vertex data structure is saved and only needs to be stored once atstart-up and not before each draw call. This reduces CPU overhead and the binding of thevertex buffer object is not required anymore. [1] [3]
4

Listing 2.4: Example code for setting the vertex attributes in the VAO
/ / Generate VAOGLuint vao ;glGenVertexArrays (1 , &vao ) ;/ / Bind VAOglBindVertexArray (vao ) ;/ / Bind VBO so t h a t the VAO knows where the data i s loca tedglBindBuffer (GL_ARRAY_BUFFER , vbo ) ;/ / Pos i t i onsglVertexAttribPointer (0 , 3 , GL_FLOAT , GL_FALSE , sizeof (VertexData ) , 0) ;glEnableVertexAttribArray ( 0 ) ;/ / NormalsglVertexAttribPointer (1 , 3 , GL_FLOAT , GL_FALSE , sizeof (VertexData ) ,
reinterpret_cast<void∗>(sizeof (VertexPosition ) ) ) ;glEnableVertexAttribArray ( 1 ) ;/ / UVsglVertexAttribPointer (2 , 2 , GL_FLOAT , GL_FALSE , sizeof (VertexData ) ,
reinterpret_cast<void∗>(sizeof (VertexPosition ) + sizeof (VertexNormals ) ) );
glEnableVertexAttribArray ( 2 ) ;glBindVertexArray ( 0 ) ;
2.2.3. Array Textures
Instead of binding a single texture for each mesh, OpenGL also provides a way of bindingmultiple textures at the same time without the use of texture units and glActiveTexture. Arraytextures are provided for 1D, 2D and cubemap textures and greatly improve the number oftextures that are available in a shader. A single element of an array texture is often referred toas layer. 2D array textures are basically the same as 3D textures. However, there is no filteringbetween the layers. Basically this feature replaces the use of texture atlases as long as there isenough room for textures in the array and on the GPU. Thus switching states and calling drawcommands for meshes that use different textures is minimized. [3]
2.2.4. Bindless Textures
The programmer may take it even further and completely eradicate the need for texture bind-ings. This technique is called bindless textures and is an ARB extension in the OpenGL 4.4release. Basically the size limit for array textures does not matter anymore because there isno need to bind textures or texture arrays. Instead, OpenGL provides a texture handle thatis accessible within the shader as a uniform variable and can be used like any other variable.Thus the driver overhead for binding textures is gone as well as the limitation for the numbers
5

of textures that can be used by a shader at a time. The functions for this feature are calledglGetTextureHandleARB and glMakeTextureHandleResidentARB. The handle itself is an 64-bitinteger value that is passed to the shader by using glUniformHandleui64ARB. [7][8][9]
2.2.5. Multi Draw Indirect
Multi Draw Indirect (MDI) helps reducing the number of draw calls and the driver overheadeven further. Instead of sending the data for each draw command from the CPU, the GPUcan handle all of that itself. By using either glDrawArraysIndirect or glDrawElementsIndirecteach procedure call provides multiple draws that are stored in buffer objects. Therefore, largebatches of drawing commands can be accessed directly from the GPU itself. [9][10]
All the information for the draw calls is stored in a void pointer array which consists of struc-tures that basically have to look as follows[12]:
typedef struct{
uint count;
uint primCount;
uint first;
uint baseInstance;
} DrawArraysIndirectCommand;
By looking at this structure it becomes clear that this technique may also be used to ren-der multiple instances of an mesh. Therefore, indirect draw calls replaces or rather extendsinstancing.[11]
2.2.6. Persistently Mapped Buffers - PMBs
Usually a program allocates temporary memory to store new buffer data that needs to be trans-ferred to the GPU’s buffer storage. Using glBufferSubData that data is written to OpenGL’smemory. On the other side glGetBufferSubData reads or rather copies the data to some re-served memory. Instead of using extra memory space the OpenGL program may use a featurecalled mapping. glMapBufferRange returns a pointer to the buffer’s storage itself and thereforedoes not require any temporary memory. The function requires at least one access bit thattells OpenGL whether the mapping is used for reading or writing data to the storage. However,using OpenGL commands while the buffer is mapped isn’t possible. Thus the buffer needs tobe unmapped by calling glUnmapBuffer.
Since OpenGL 4.4 unmapping the buffer is not necessary anymore thanks to persistent buffermapping. GL_MAP_PERSISTENT_BIT tells OpenGL that the buffer storage is going to beaccessed by GPU as well as the CPU. However, that means that the program has to take careof synchronization issues itself.
One way to achieve this is by using the following function:
6

glMemoryBarrier(GL_CLIENT_MAPPED_BUFFER_BARRIER_BIT);
This either tells OpenGL that the buffer storage may be used now or ensures that the mem-ory is coherently visible. For reading purposes the program either needs to call glFinish orcreate a fence by using glFenceSync. The fence orders OpenGL to complete all of its currentcommands.
Another way is to add the GL_MAP_COHERENT_BIT bit to the access parameter of theglMapBufferRange function. The data will be visible to OpenGL as well as the program itselfautomatically. However, glFinish or glFenceSync still need to be used for syncing commands.[9]
2.2.7. DSA - Direct State Access
OpenGL is a stateful API. That means that it is necessary to switch and bind states for cer-tain operations, e.g. editing textures, writing to buffers and draw commands. The usage oftechniques like array textures, bindless textures or multi draw indirect reduces the amount ofrequired state changes. However, for example it still takes states and multiple lines of code tosimply change the filtering option of an texture.
OpenGL 4.5 introduces an extension called GL_ARB_direct_state_access. This enables theprogram to use buffer and texture ids directly as arguments for OpenGL calls instead of bindingthem.
The following code is written without Direct State Access:
glActiveTexture(GL_TEXTURE0);
glBindTexture(GL_TEXTURE_2D, textureId);
glTexParameteri(GL_TEXTURE_2D, GL_TEX_MIN_FILTER, GL_LINEAR);
First, the right texture unit needs to be activated. Secondly, the program needs to bind the righttexture. After these two steps, it is possible to change the filtering option for the given texture.
By using the new extension the code changes as follows:
glTextureParameteri(textureId, GL_TEXTURE_2D, GL_TEX_MIN_FILTER,
GL_LINEAR);
The new function glTextureParameteri provides a parameter for setting the texture filtering tolinear in only one command. That does not mean that there are no state switches or any otherperformance improvements at this point. However, it improves the control over the OpenGLprogram and its overall robustness because there is no need for state switches anymore. ThusDSA theoretically only simplifies the implementation of other techniques like multithreading.[13]
7

2.3. Instancing
Instancing describes the technique of rendering multiple objects with one draw call. By us-ing the same vertex data, the OpenGL API can theoretically render an unlimited number ofmeshes. The big advantage of instancing is that there is only one glDraw*() call. For example,when the application should render one million blades of grass, the command for drawing thevery simple geometry of the mesh would have to be sent one million times using glDrawAr-rays() or glDrawElements() calls. Each call takes a certain amount of CPU time, while the GPUis already finished rendering the last grass blade. Therefore, the CPU overhead for sendingdraw commands is reduced to a minimum by this technique and the rendering performanceof an CPU bound application improves immensely. There is also an older version of instanc-ing which comes with the GL_ARB_draw_instanced extension in OpenGL version 3.1. How-ever, there is no support for vertex buffer data and developers had to use texture and uniformbuffer objects to achieve instancing. The features described in this section are all part of theGL_ARB_instanced_array extension which was added in OpenGL 3.3. [4][5]
The API provides several methods to identify each instance in the shader and change its ap-pearance accordingly. First of all, the gl_instanceID variable is available in GLSL. It representsthe zero-based index of the currently drawn instance from the same draw call. Thanks to thisvariable, it is possible compute each instance differently. For example, it is possible to offset thevertex position by the gl_instanceID, access certain uniform data, look up values in a texture oruse an array texture for fetching individual textures.
Another feature for providing different data for each instance is the glVertexAttribDivisor()function. Thanks to that, the API knows how often the vertex attributes are going to be usedbefore accessing the next values in the buffer. For example, the application could render a largeamount of 2D sprites or particles with instancing and store the individual position of each quadin a vertex buffer. By setting the divisor for the attribute to one, each instance will use its ownposition data. glVertexAttribDivisor() requires OpenGL version 3.3 or higher.
2.4. Batching
There are times where instancing is not a valid option for developers. The technique doesnot work for meshes with different vertex data and shaders. It is also important to note thatinstancing is not supported by older systems that do not support OpenGL 3.1/3.3 and theGL_ARB_instanced_array extension. In that situation another technique called batching couldbe used to reduce the number of draw calls. It describes the process of putting primitives ofmultiple geometry objects together and thus call the draw commands as few times as possible.Cozzi and Riccio [5] refer to three different methods of batching: combine, combine + elementand dynamic.
8

2.4.1. Combine
The idea behind this method is to transfer the data of multiple geometry objects into a singleset of buffer objects. Furthermore, they are rendered by using only one draw call. However,the method comes with some disadvantages, such as the fact that the objects have to use thesame shader. That means that only similar objects are able to be grouped together, althoughit is important to note that for the usage of different textures a texture atlas, array textures orbindless textures could be used. Another problem is that it is not possible to move the batchedmeshes independently anymore because the model/world matrix is applied to the whole batch.Culling also becomes more difficult because all objects are either rendered or not. Therefore, itis important to only batch objects that are relatively close to each other.
2.4.2. Combine + Element
This approach tackles the problem of culling batched objects by keeping all indices in a dynamicGL_ELEMENT_ARRAY buffer object. When the geometry objects should be rendered to thescene, the application copies their indices into the large dynamic element buffer. Hence, culledobjects are removed from it and partly culled ones are drawn individually. However, that alsomeans that the batch’s buffer objects contain the transformed geometry of all loaded meshes,which increases the memory usage. Another disadvantage is that this method only works forgrouping static objects.
2.4.3. Dynamic
The dynamic method works by filling vertex and element buffers during runtime. Multiple geom-etry objects that use the same shader, material, uniforms, etc. are packed together, after thetransformations and the skinning have been computed. Thus, the overhead of the draw callsis reduced even for non-static objects. On the contrary, the CPU has to compute the vertexdata instead of the shader. After that, the data has to be transferred to the buffer, which alsotakes some memory bandwidth. Cozzi and Riccio [5] recommend to conduct performance testsbefore using this approach.
2.5. Sorting
Batching describes a technique that focuses on vertex data and buffer objects. In contrast, sort-ing is about the bucketing of rendering states like shaders, textures and uniforms. Ericson [6]introduces a method called sort-based draw call bucketing which he describes as easy to im-plement and that allows effortless experimentation by using a standard sorting algorithm. Thisapproach was used in games like God of War 3 and Heavenly Sword for the Sony Playstation 3.For the bucketing an array of key-value pairs is created. Each value element contains an offsetor a pointer to the actual draw call data, whereas the key consists of the various states. The
9

latter one is represented by an unsigned variable like an unsigned integer. The type dependson the size of the state data that is stored in the key. After filling the array with all the drawcommands, it is sorted by using quicksort or any other type of sorting algorithm. Developerscan choose freely how the key data looks like, but in the following example it consists of thisstate information:
• Fullscreen layer: It describes the type of layer that is used for the rendering like the gameor HUD layer.
• Viewport: Each scene may consist of multiple viewports for providing features like split-screen multiplayer.
• Viewport layer: Again, as described in the fullscreen layer, each viewport consists ofmultiple layers.
• Translucency: The scene may contain opaque or translucent geometry that needs to begrouped together as well.
• Depth sorting: Translucent objects need to be sorted based on their depth. Opaqueobjects may be sorted as well to aid z-culling.
• Material: This contains the ID to the used material that contains the object’s shaders,textures and different passes.
The depth sorting and material may be switched around to reduce the number of state switchesfor opaque geometry. By using a certain number of bits for each state information, the possiblemaximum number of such states can be considered. The most important information is storedat the position of the most significant bit. This goes on until the last category fills the key up tothe least significant bit. Therefore, in this example the whole key structure looks like in figure 1
which consists of 64 bits.
Figure 1.: An example of a key structure used for bucketing. c©Ericson
The author also describes the approach of adding rendering commands directly into the array.Therefore, operations such as rendering in wireframe mode or clearing the depth buffer can becalled when processing the array. The key data is extended by adding a single bit after thetranslucency category that tells the application if the remaining bits contain either informationabout the depth and material or a special rendering command. The result may look like in theexample in figure 2.
10

Figure 2.: An example of a key structure with special draw commands. c©Ericson
2.6. Conclusion
AMD’s Mantle and Microsoft’s DirectX 12 are not the only APIs which are focusing on reducingdriver overhead. OpenGL already provides many ways for minimizing the number of draw calls,state changes and texture binds. The Khronos Group is also working on simplifying the API byadding Direct State Access. Features like MDI and instancing may increase the complexity ofan application, but are modern ways to provide the draw data to the GPU.
11

3. Direct3D
The Direct3D rendering API is developed by Microsoft and part of the DirectX API which alsoprovides input, audio and other components to create multimedia content like video games.DirectX only runs on Microsoft’s systems which are to date (2015-04-02) Windows, WindowsPhone and XBox. This chapter focuses on the Direct3D 11 API, while mentioning the changesto the older Direct3D versions 9 and 10. It also gives an outlook to the new Direct3D 12 APIwhich includes console-like rendering features like AMD Mantle to reduce the number of drawcalls and the CPU overhead.
3.1. Analysis of Modern Direct3D 11 Techniques
This section introduces some of the modern Direct3D 11 and 11.x techniques which alreadyprovide features to reduce the driver or rather CPU overhead.
3.1.1. Multithreaded Rendering
Since Direct3D 9 Microsoft works on improving the multithreading capabilities of its render-ing API [14]. Therefore, it introduced the D3DCREATE_MULTITHREADED flag that can beadded to the IDirect3D9::CreateDevice() method alongside other construction parameters. Thiscauses the Direct3D 9 API to make the IDirect3DDevice9 thread-safe. However, Microsoft doesnot recommend this setting because it leads to significant synchronisation overhead.
With Direct3D 10 Microsoft added the so-called API layers [15]. They consist of the corelayer that provides a low overhead for high-frequency calls as well as other optional lay-ers which contain additional functionality. Similar to the D3DCREATE_MULTITHREADEDflag these layers are created by calling the D3D10CreateDevice() function with the ap-propriate D3D10_CREATE_DEVICE_FLAG parameters. Thus, the API provides a flagto create a thread-safe layer or rather the layer is constructed per default and de-velopers may decide to opt-out and use a single-threaded ID3D10Device with theD3D10_CREATE_DEVICE_SINGLE_THREADED flag. This means that Direct3D 10 providesall thread synchronisation features by default like critical sections and mutex locks.
Direct3D 11 also enables multithreading capabilities by default. However, Microsoftgreatly improved the provided functionality and efficiency of the synchronisation in Direct3D[14]. Similar to version 10 the D3D11_CREATE_DEVICE_SINGLETHREADED flag tells theD3D11CreateDevice() function that the developer wants to exclude the multithreading features.The ID3D11Device interface provides completely thread-safe resource creation methods with-
12

out the need of synchronisation commands. Thus, this overhead has been removed from theAPI and the device may ne accessed by multiple threads. Additionally, Microsoft introducedthe ID3D11DeviceContext interface which decouples the rendering from the resource creationfunctionality. The ID3D11Device only provides methods to identify the capabilities of a displayadapter and to create resources like shaders or textures. In contrast, the device context is usedto set the rendering stages, clearing views and calling draw commands. The interface is notthread-safe and therefore may only be used by a single thread at a time. The API differentiatesbetween two context types:
• Immediate context
• Deferred context
Immediate Context
This type of context directly interacts with the GPU driver. The ID3D11Device may onlyhave one single immediate context that is stored in the pointer that is provided as a param-eter to the D3D11CreateDevice() function. Another way to get the context is by calling theID3D11Device::GetImmediateContext() method. It immediately renders either by using theDraw*() methods or by providing a command list that was recorded before. This can be used toperform several kinds of tasks:
• The same rendering operations are used multiple times on different sets of data.
• A list of commands is recorded while the game is busy with other tasks like loading a levelto improve the performance later on.
• The creation of rendering commands is split between multiple threads.
The latter task is performed by using a deferred context which is described in the next section.
Deferred Context
The purpose of the deferred context is to record rendering commands that are executed bythe immediate context later on. Microsoft advises to refrain from using this kind of contextfor single-threaded applications [16]. It is important to note that the state of the immediatecontext does not have any kind of impact on a deferred context. The Direct3D API providesthe ID3D11Device::CreateDeferredContext() method to create such a context. It is most likelycalled by the worker thread, which is also shown in the listing 3.1.
13

Listing 3.1: Example code of using a deferred context within a worker thread
HRESULT hr ;ID3D11DeviceContext∗ deferredContext = NULL ;hr = device−>CreateDeferredContext (0 , &deferredContext ) ;deferredContext−>IASetInputLayout (layout ) ;deferredContext−>IASetPrimitiveTopology (
D3D11_PRIMITIVE_TOPOLOGY_TRIANGLELIST ) ;deferredContext−>IASetVertexBuffers (0 , 1 , vertexBuffer , stride , 0) ;deferredContext−>VSSetShader (vertShader , NULL , 0) ;deferredContext−>PSSetShader (pixShader , NULL , 0) ;deferredContext−>Draw (vertexCount , 0) ;
As soon as the worker thread has finished drawing the deferred context stores its renderingcommands into a command list that was mentioned in the previous section 3.1.1. Therefore,the main thread or rather the immediate context is able to render the pre-recorded commandsto the screen.
Listing 3.2: Example code of storing the command list within a worker thread
ID3D11CommandList∗ commandList = NULL ;HRESULT hr ;hr = deferredContext−>FinishCommandList (FALSE , &commandLists [threadId ] ) ;
Listing 3.3: Example code of executing the command lists within the main thread
for (size_t i = 0; i < numThreads ; ++i ){
immediateContext−>ExecuteCommandList (commandLists [i ] , TRUE ) ;}
This procedure reduces the driver overhead by minimizing the number of draw calls. There-fore, especially the needed CPU time is decreased to improve performance.
14

3.1.2. Dynamic Shader Linkage
Prior to Direct3D 11 there have been mainly two different types of shader approaches as de-scribed by Gee [17]. First, the application could use a different kind of shader for each task suchas normal mapping, displacement mapping, point lighting, directional lighting and so on. Thismeans developers have to write specific vertex, pixel, tessellation, etc. shaders. Therefore,each one is compiled and linked, which increases load times or may induce stuttering duringgameplay. Another disadvantage of the specialization is the driver overhead which is producedby the number of shader switches in the rendering pipeline.
The other approach introduces the usage of a so-called uber shader which could also be re-ferred to as a general purpose shader. The advantage of this method is that all the functionalityis in one place. Therefore, the shader could be used by a large number of scene objects withoutthe need of state changes. This also addresses the problem of compilation and linking duringgameplay because the best case scenario states that these operations only have to be done forone shader at the beginning. However, the complexity of such a shader is higher and thereforemore error-prone. The register usage also becomes worse because by using different branchesthe GPU always assumes the worst-case path. Microsoft [18] also describes this problem asthe inefficient use of general purpose registers, which causes a slow-down compared to thespecialization method.
Listing 3.4: Example code of using dynamic branches in a general purpose pixel shader
float4 PSMain ( PS_INPUT Input ) : SV_TARGET
{if (lightType == 1){
/ / Do po in t l i g h t render ing}else if (lightType == 2){
/ / Do spot l i g h t render ing}else if (lightType == 3){
/ / Do d i r e c t i o n a l l i g h t render ing}
}
Microsoft addresses this by introducing dynamic linkage in shader model 5 of the Direct3D11 API. By using an object-oriented approach the shader code can be separated into inter-faces, classes and virtual functions. Therefore, only the currently needed shader code has tobe bound at runtime. Direct3D 11 provides the ID3D11ClassLinkage interface that has the pur-pose of sharing variables and types between multiple shaders. It stores instances of classes
15

which are of the type ID3D11ClassInstance into an array that is passed as an argument to aID3D11DeviceContext::*SSetShader call. Microsoft [19] distinguishes between interfaces andclasses.
Interfaces are similar to abstract base classes in C++. They declare virtual methods that haveto be implemented by the class that inherits such an interface.
Listing 3.5: Example code of an HLSL interface
interface iLight
{float3 LightAmbient (float3 vNormal ) ;float3 LightDiffuse (float3 vNormal ) ;float3 LightSpecular (float3 vNormal , int specPow ) ;
} ;
interface iMaterial
{float3 GetAmbientColor (float2 vTexcoord ) ;float3 GetDiffuseColor (float2 vTexcoord ) ;int GetSpecularPower ( ) ;
} ;
Classes can inherit from zero to one other classes as well as any number of interfaces. Theyhave to implement the virtual methods of the interfaces, whereas the definition of the methodscan either be done in the class declaration itself or separated at any later point of the shadercode. Aside from that, developers can also declare member variables within the class.
Listing 3.6: Example code of an HLSL class inheriting an interface
class cAmbientLight : iLight
{float3 m_vLightColor ;float3 LightAmbient (float3 vNormal ) ;float3 LightDiffuse (float3 vNormal ) { return (float3 ) 0 ; }float3 LightSpecular (float3 vNormal , int specPow ) { return (float3 ) 0 ; }
} ;
float3 cAmbientLight : : IlluminateAmbient (float3 vNormal ){
return m_vLightColor ;}
16

3.1.3. Texture Arrays
Direct3D 11 offers texture arrays to bind large amounts of data and reduce the number of textureswitches. OpenGL also supports this feature as described in section 2.2.3. Texture arraysenable developers to use instancing to render a large amount of different textured objects.Another approach to reduce the number of switches is the creation of texture atlases whichcontain multiple textures. As long as all objects in the texture array have the same dimensionsand formats, it is possible to combine both methods. [20]
The implementation of texture arrays is very similar to normal textures and uses the sameID3D11Texture*D interface. The D3D11_TEXTURE*D_DESC structure contains all informa-tion the API needs to create a texture object. This also includes the ArraySize member whichdescribes the size of the array which exists in the form of homogeneous image data. The tex-ture object can be bound to the pixel shader stage via a Shader Resource View (SRV) whichis created using a D3D11_SHADER_RESOURCE_VIEW_DESC structure. This contains infor-mation about the used texture type via the D3D11_SRV_DIMENSION ViewDimension memberas well as an union which specifies the resource.
Listing 3.7: Example code of the creation of a texture2D array
std : : vector<D3D11_SUBRESOURCE_DATA> imageData ;imageData .resize (2048) ;
/ / Create subresource data f o r each image i n the t e x t u r e ar rayfor (size_t i = 0; i < 2048; i++){
imageData [i ] . pSysMem = image .getPixelsPtr ( ) ;imageData [i ] . SysMemPitch = size .x ∗ 4;imageData [i ] . SysMemSlicePitch = 0;
}
D3D11_TEXTURE2D_DESC textureDesc ;textureDesc .Width = size .x ;textureDesc .Height = size .y ;textureDesc .MipLevels = 1;textureDesc .ArraySize = 2048; / / Texture ar ray w i th maximum s izetextureDesc .Format = DXGI_FORMAT_R8G8B8A8_UNORM ;textureDesc .SampleDesc .Count = 1;textureDesc .SampleDesc .Quality = 0;textureDesc .Usage = D3D11_USAGE_DEFAULT ;textureDesc .BindFlags = D3D11_BIND_SHADER_RESOURCE ;textureDesc .CPUAccessFlags = 0;textureDesc .MiscFlags = 0;
/ / Create t e x t u r e resource wi th an ar ray o f subresource data
17

mDevice−>CreateTexture2D(&textureDesc , &imageData [ 0 ] , &textureData .texture ) ;
D3D11_SHADER_RESOURCE_VIEW_DESC srvDesc ;srvDesc .Format = textureDesc .Format ;srvDesc .ViewDimension = D3D11_SRV_DIMENSION_TEXTURE2DARRAY ;srvDesc .Texture2DArray .ArraySize = textureDesc .ArraySize ;srvDesc .Texture2DArray .FirstArraySlice = 0;srvDesc .Texture2DArray .MipLevels = textureDesc .MipLevels ;srvDesc .Texture2DArray .MostDetailedMip = 0;
mDevice−>CreateShaderResourceView (textureData .texture , &srvDesc , &textureData .resourceView ) ;
It is important to note that for texture arrays the ID3D11Device::CreateTexture*D() methodexpects a pointer to a D3D11_SUBRESOURCE_DATA structure array. Microsoft [21] limits themaximum number of array slices to 2048 for Direct3D 11.
The HLSL shader uses the Texture*DArray type for texture arrays which are sampled byproviding an additional dimension to the location parameter of the TextureObject::Sample()method.
3.1.4. Instancing
Instancing is also discussed in the corresponding section of the OpenGL chapter 2.3. However,there are differences that need additional consideration. Especially in Direct3D 9 the approachworks differently than in Direct3D 10 or OpenGL 3.x.
Direct3D 9
The older API version does not support instancing as a core feature. However, there are stillways to render multiple instances more efficiently than rendering them with individual drawcalls, thus reducing the overhead. Microsoft [22] describes this method for indexed and non-indexed geometry. Both types use vertex buffers to store geometry data as well as per-objectinstance data. The latter one contains per-instance data like positions or material information.Microsoft recommends to structure the data as shown in figure 3 (indexed geometry) and figure4 (non-indexed geometry).
18
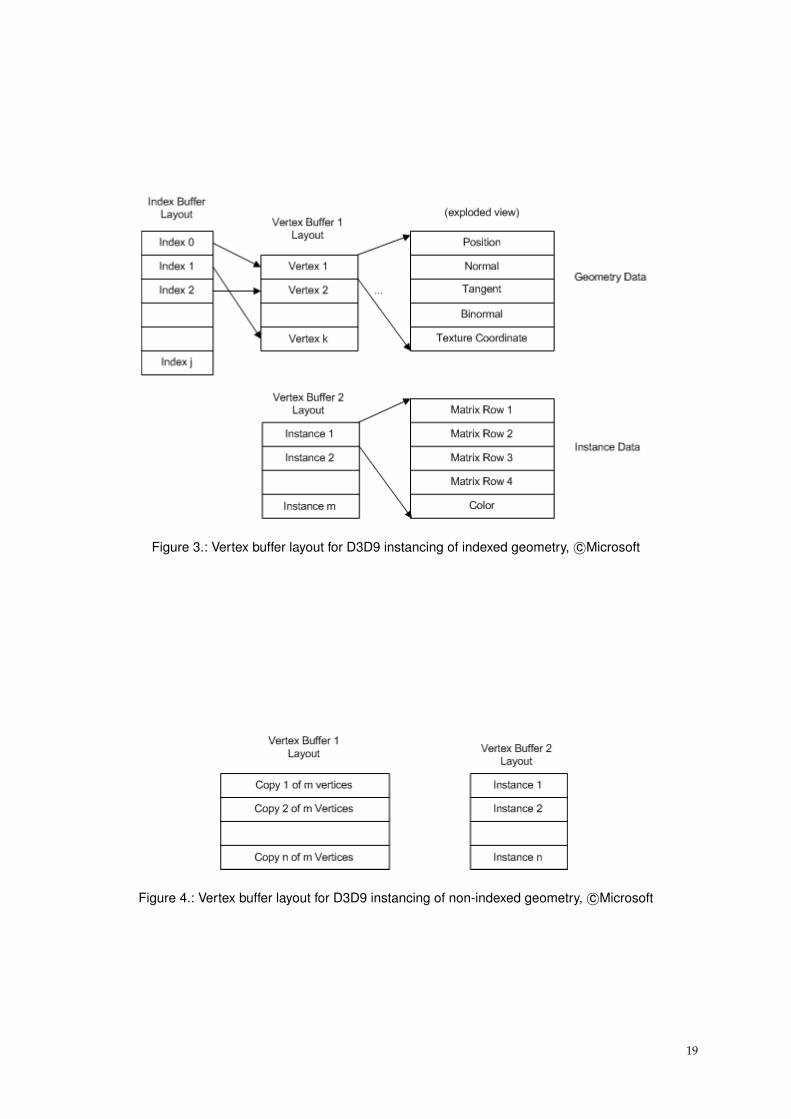
Figure 3.: Vertex buffer layout for D3D9 instancing of indexed geometry, c©Microsoft
Figure 4.: Vertex buffer layout for D3D9 instancing of non-indexed geometry, c©Microsoft
19

The Direct3D 9 API does not provide a function or method like DrawInstanced(). Instead,Microsoft uses vertex buffer streams and shaders to implement instancing. This is not sup-ported by the fixed-function pipeline and requires the vertex shader model 3.0. The API pro-vides the D3DVERTEXELEMENT9 type that is used to describe the vertex attributes used bythe shader. It also allows developers to the declare which vertex buffer stream contains thecorresponding data. The call to the IDirect3DDevice9::SetStreamSourceFreq() method is theequivalent to the glVertexAttribDivisor() function used by the OpenGL API. Additionally, theD3DSTREAMSOURCE_INDEXEDDATA and D3DSTREAMSOURCE_INSTANCEDATA con-stants tell the method which type of data is stored in the stream by using the bitwise ORoperator with the divisor. The latter one describes how many instances use the same set ofdata. Finally, the IDirect3DDevice9::SetStreamSource() method binds the vertex buffer and thevertex attribute declarations.
Listing 3.8: Example code of setting up the indexed vertex buffer streams
/ / Geometry datadevice−>SetStreamSourceFreq (0 , 1) ;device−>SetStreamSource (0 , vertexBufferGeometry , 0 , D3DXGetDeclVertexSize (
vertexBufferDeclGeometry , 0) ) ;
/ / Ins tance datadevice−>SetStreamSourceFreq (1 , verticesPerInstance ) ;device−>SetStreamSource (1 , vertexBufferInstanceData , 0 ,
D3DXGetDeclVertexSize ( vertexBufferDeclInstance , 1) ) ;
When using non-indexed vertex data the parameters for setting the stream source frequencychange. The constants and bitwise OR operator are left out. Instead, the method simply usesthe vertex buffer index as the first and the number of vertices used for each instance as thesecond parameter.
Listing 3.9: Example code of setting up the non-indexed vertex buffer streams
/ / Geometry datadevice−>SetStreamSourceFreq (0 , (D3DSTREAMSOURCE_INDEXEDDATA | numInstances ) )
;device−>SetStreamSource (0 , vertexBufferGeometry , 0 , D3DXGetDeclVertexSize (
vertexBufferDeclGeometry , 0) ) ;
/ / Ins tance datadevice−>SetStreamSourceFreq (1 , (D3DSTREAMSOURCE_INSTANCEDATA | 1) ) ;device−>SetStreamSource (1 , vertexBufferInstanceData , 0 ,
D3DXGetDeclVertexSize ( vertexBufferDeclInstance , 1) ) ;
20

It is important to note that after the usage of instancing, the frequency of the stream sourceshave to be set to 1 by the IDirect3DDevice9::SetStreamSourceFreq() method.
When using this technique for non-indexed vertex data there is no support for hardwareacceleration and it only works with software vertex processing. This approach also needs theapplication to create a copy of the vertex data for each instance in the geometry vertex buffer,which increases the memory usage of the GPU.
Direct3D 10
Starting with version 10 of the DirectX SDK, Microsoft supports instancing as a core fea-ture of the rendering API. Thus, drawing multiple instances can be done by using theID3D10DeviceContext::DrawInstanced() or ID3D10DeviceContext::DrawIndexedInstanced()method. There is no need for vertex buffer streams. Similar to the previous version this ap-proach uses two different buffers. Direct3D 10 does not differentiate between several buffertypes anymore. Instead, each buffer object uses the ID3D10Buffer interface.
• Geometry Buffer: Contains all geometry data that is identical for all instances
• Instance Buffer: Contains all per-object data that changes with each instance
Basically, the layout of the buffers used in the Direct3D 9 method could be re-used. Therefore,it is possible to use the same structure as shown in figure 3 for indexed geometry data. However,for non-indexed geometry data there is no need to create copies of that data as shown in figure4 anymore.
The Intel Corporation [23] published an article that describes the usage of the new approach.As mentioned before, the structure of the buffers is nearly identical to the method used inversion 9 of the API. Two buffer objects are bound to the input assembler stage, holding thegeometry and per-instance data as shown in figure 5.
21

Figure 5.: Buffer and input assembler layout for non-indexed D3D10 instancing, c©Intel Corporation
The layout of the input data is described in an array of D3D10_INPUT_ELEMENT_DESCelements. It contains information about the used name and index which are associated with theHLSL semantics as well as the format and byte offset. However, the most important membersare
• the index of the input assembler slot which specifies where the data of the appropriatebuffer is stored,
• the input slot class that comes with the D3D10_INPUT_CLASSIFICATION enumerationand describes when the data should be used and
• the instance data step rate which specifies how many instances are drawn before usingthe next set of data, where 0 means that there is no stepping at all [24].
Listing 3.10: Example code of describing the layout of the vertex input data
static const D3D10_INPUT_ELEMENT_DESC instanceLayout [ ] ={
{"POSITION" , 0 , DXGI_FORMAT_R32G32B32_FLOAT , 0 , 0 ,D3D10_INPUT_PER_VERTEX_DATA , 0 } ,
{"TEXCOORD" , 0 , DXGI_FORMAT_R32G32_FLOAT , 0 , 12 ,D3D10_INPUT_PER_VERTEX_DATA , 0 } ,
{"INSTANCE_POSITION" , 0 , DXGI_FORMAT_R32G32B32_FLOAT , 1 , 0 ,D3D10_INPUT_PER_INSTANCE_DATA , 1 } ,
} ;
22

The instance data is specified by using D3D10_INPUT_PER_INSTANCE_DATA as the inputclassifier and by using the associated index of the buffer as shown in listing 3.10. In this examplethe string INSTANCE_POSITION defines a custom HLSL semantic that is used to identify theper-instance position in the vertex shader stage.
The ID3D10Device::IASetVertexBuffers() method binds multiple buffers to the device and canbe used to specify individual strides and offsets for each one of them. Setting the sources andfrequency of vertex buffer streams is not necessary anymore.
Listing 3.11: Example code of binding buffers for instancing
/ / Create two b u f f e r s ( geometry and ins tance b u f f e r )ID3D10Buffer∗ buffers [ 2 ] ;buffers [ 0 ] = geometryBuffer ;buffers [ 1 ] = instanceBuffer ;UINT strides [ 2 ] ;strides [ 0 ] = sizeof (VertexData ) ;strides [ 1 ] = sizeof (InstanceData ) ;UINT offsets [ 2 ] = { 0 , 0 } ;device−>IASetVertexBuffers (
0 , / / S t a r t i n g i npu t s l o t2 , / / Bu f fe r countbuffers ,strides ,offsets
) ;
device−>IASetInputLayout (instanceLayout ) ;
By providing the ID3D10Device::DrawInstanced() method, developers are able to decidewhich and how many instances should be rendered by the GPU.
Listing 3.12: Prototype of the DrawInstanced() method
void DrawInstanced (UINT VertexCountPerInstance ,UINT InstanceCount ,UINT StartVertexLocation ,UINT StartInstanceLocation
) ;
As mentioned in section 2.3 the OpenGL API provides a gl_instanceID variable to iden-tify the currently drawn instance in the shader stages. The Direct3D 10 API introduces aSV_InstanceID semantic similar to its OpenGL counterpart. This could be used to fetch val-ues from a texture or a constant buffer instead of storing the data in the instance buffer.
23

The ID3D10Device::DrawInstanced() and ID3D10Device::DrawIndexedInstanced() methodsprovide a consistent interface for using the instancing technique. By improving the instanc-ing capabilities of the Direct3D API Microsoft enables developers to render multiple instanceswithout any additional draw calls.
3.2. Direct3D 12 Outlook
Direct3D 12 is the new version of Microsoft’s graphics API. As described by Sandy [25] it offersnew interfaces and techniques for rendering games in a more console-like way. The level ofhardware abstraction is much lower, thus reducing the overhead for CPUs and GPUs. Themost important features introduced with Direct3D 12, which are analysed in the next sections,are as followed.
• Descriptor tables
• Pipeline state objects
• Command lists and bundles, featuring a new of way of work submission
The API has similarities to AMD Mantle that also tries to reduce or rather remove the driveroverhead by providing a console-like approach. The Mantle API is described in more detail inchapter 4.
3.2.1. Descriptor Heaps & Tables
This technique enables the application to re-use resources and reduce the number of bindcommands. Descriptors, descriptor heaps and descriptor tables give developers more controlover the resource binding process and the correspondent memory management. Therefore, itbecomes possible to apply optimizations that otherwise the driver would not know about. How-ever, it is important to note that more control could easily lead to errors and mismanagement ofresources.
Descriptors
The Direct3D 12 API references resources via so-called descriptors as described by Coppock[26]. It defines several parameters for resources that can be used by the rendering pipeline.The descriptor only consists of raw data on the GPU that contains information about
• the type of resource,
• a description of the used format,
• the mip count in the case of textures and
• a pointer to the data.
24

Previous versions of the rendering API did not provide access to descriptors directly. Instead,the driver was responsible for managing the creation and placement in the descriptor heaps andthe process of referencing them correctly for the next draw command. However, in Direct3D 12developers are responsible for these processes and their optimization.
Descriptors are available to the following resources that are not part of a pipeline state object.
• Shader Resource Views
• Unordered Access Views
• Constant Buffer Views
• Samplers
Descriptor Heaps
Descriptors are stored in descriptor heaps which provide the memory for them and remove theneed for continuous allocations. Thanks to the new API developers are now able to organizethose heaps by themselves to account for specific use cases. For example, if the applicationsets a new view for the next draw command, the driver copies the appropriate descriptors theposition of the heap where the GPU is currently reading from. The size of the heap depends ofthe used GPU hardware. For lower power devices which are limited to a certain heap size it ispossible to create multiple heaps. However, descriptor heap switching causes the GPU to flush,which is why its usage should be reduced to a minimum. Descriptor heaps can be optimized tore-use as much descriptors as possible instead when switching resources to reduce the numberof descriptors or rather descriptor tables.
Descriptor Tables
Descriptor tables are basically just an index and a size on the heap. Therefore, it is not nec-essary to represent them as API objects and do not need to be created or destroyed. Theyare used by the shader stages to gain access to certain descriptors which are referenced byindex. Microsoft [27] also describes them as a sub-range of descriptor heaps and states thatthe operation of switching tables is as cheap as identifying a region in the heap to the hardware.The usage of very large descriptor tables enables developers to use a bindless approach likein OpenGL as introduced in chapter 2.2.4. For example, shaders are able to access textures byusing an index provided by the material data, which makes the binding of textures obsolete.
25

Figure 6.: Descriptor Heap Model, c©Microsoft
The Direct3D 12 API also enables the application to use multiple descriptor tables per shaderstage and change the update frequency. This means that it is possible to iterate over one tablewith each draw command while another table containing constant data remains static. However,it is important to note that this approach is only available on modern hardware.
3.2.2. Pipeline State Objects
As described by Microsoft [28] the rendering pipeline consists of several components that readand manipulate data. Developers are able to change the results by adding programmableshaders or changing the state of certain pipeline stages. However, this leads to a large numberof high-level objects and state switches that cause a decrease in rendering performance. Thus,Direct3D 12 introduces pipeline state objects to eliminate this overhead. The technique issimilar to the monolithic pipeline introduced by AMD as a part of their Mantle API, which isdescribed in more detail in section 4.4.
Pipeline state objects or rather PSOs are immutable Direct3D 12 objects that consist of com-ponents like the input assembler, rasterizer, vertex shader, pixel shader or output merger. Thesestages and their states are set once when they are created, thus enabling the GPU and driversto optimize the graphics processing. This increases the performance of a draw call itself by re-moving the need to recompute the hardware state based on the rendering and pipeline settings.Instead, the application could use multiple PSOs for different rendering tasks.
Coppock [29] states that by providing a single point instead of multiple individual stage objectsthat the hardware mismatch overhead is removed. By translating the rendering commandsdirectly into GPU instructions there is no need for additional flow control overhead. This enables
26

the application to render more draw calls without decreasing the performance of the process.
Figure 7.: D3D 11 and 12 Pipeline Comparison, c©Intel
It is important to note that not all state objects are part of the PSO. Certain states like theviewport or the scissor rectangle are set without affecting the pipeline state object.
PSOs are represented by the ID3D12PipelineState interface and are created for ren-dering tasks by using the ID3D12Device::CreateGraphicsPipelineState() method that takesa large D3D12_GRAPHICS_PIPELINE_STATE_DESC structure as a parameter that de-scribes the stages and states of the pipeline. The PSO is set by calling theID3D12GraphicsCommandList::SetPipelineState() method in a command list or bundle.
3.2.3. Command Lists and Bundles
In Direct3D 11 Microsoft established the usage of immediate and deferred contexts as de-scribed in section 3.1.1. This enables the application to use multiple threads to create commandlists which are then executed by the immediate context on the main or rather rendering thread.However, there is still room for improvement because the approach comes with a lot of serialoverhead as described by Coppock [30]. This type of overhead is caused by the driver to ensurecoherent data when the order of the commands is important. Another reason is the trackingof states for each context, which increases memory usage. The third and last cause is thememory tracking needed for managing discarded buffers which are affecting other commandlists.
Microsoft [31] improves the concept of multithreaded rendering by re-designing the processof work submission. The new version of Direct3D removes the immediate context and theconnection to a specific device. This also includes the need for deferred contexts. Instead,rendering commands are directly submitted to command lists. Like deferred contexts they arenot thread-safe and Microsoft recommends to have one list per thread. It is also possible to usea command list multiple times if its previous execution on the GPU has been finished.
27

Command lists are submitted to command queues which are similar to an imme-diate context. However, the queue provides more control, especially over synchro-nization. As descibed by Microsoft [32] the ID3D12Device::GetDefaultCommandQueue()method returns the default command queue that is created with the device’s initial-ization. After each thread has finished recording its command lists they are sub-mitted to the queue by calling either ID3D12CommandQueue::ExecuteCommandList() orID3D12CommandQueue::ExecuteCommandLists(). By using the latter method multiple listscan be submitted at once, thus creating a lower overhead. The Direct3D 12 API providesthe ID3D12Device::CreateCommandQueue() method to create multiple command queues andspecify their usage scenario with the D3D12_COMMAND_LIST_TYPE enumeration. Themethod supports three different kinds of queues:
• Direct: Accepts any kind of command.
• Compute: Accepts compute and copy commands.
• Copy: Accepts copy commands.
Another feature introduced by the Direct3D 12 API is the usage of command bundles. Anapplication can decide to create such bundles for grouping draw commands and use themacross multiple command lists. Command bundles can be recorded for later use and ex-ecuted multiple times. This approach provides an easier way to manage the recording ofcommand lists. Furthermore, it enables the driver to pre-process and optimize the bundle,thus increasing the efficiency of the contained rendering commands. A command bundlecan be created by calling the ID3D12Device::CreateCommandAllocator() method and provid-ing D3D12_COMMAND_LIST_TYPE_BUNDLE for the bundle type argument. Once they havefinished their recording of rendering commands, other command lists may add their executionwith the ID3D12GraphicsCommandList::ExecuteBundle() method. It is important to note that itis not possible to submit a command bundle to a command queue directly.
28

3.3. Conclusion
The Direct3D 11 API offers a variety of features to reduce the rendering overhead. Microsoftespecially focuses on multithreaded rendering, which enables developers to use modern multi-core systems for their advantage. The approach is easy to implement because the interfaceof deferred contexts is identical to the immediate context used by single-threaded applications.However, the great flexibility comes with additional driver overhead that the next version of theSDK is taking care of. Direct3D 12 offers command lists and bundles to account for the problemscreated by the usage of deferred contexts. Dynamic shader linkage offers the possibility tocreate a more dynamic pipeline, but it is important to note that switching class instances toooften might create another bottleneck. Some other features like texture arrays, instancing,descriptors and pipeline state objects are similar to features offered by other APIs like OpenGLor Mantle.
29

4. AMD Mantle
Mantle is an API developed by Advanced Micro Devices (AMD). It provides the tools for low-level rendering functionality for the developer and is an alternative to other APIs like OpenGLand Direct3D. It was first announced at a press conference in fall 2013 and should provide DICEwith an console-like rendering API for reducing CPU overhead in games [33].
AMD has also been working with other game developers and providing the Mantle API forthem. Therefore, the following games and engines support the Mantle API to date (2015-03-17) [34]:
• Battlefield Hardline
• Dragon Age: Inquisition
• Plants vs. Zombies Garden Warfare
• Civilization: Beyond Earth
• CRYENGINE by Crytek
• Battlefield 4 by EA/DICE
• Thief by Eidos-Montreal/Square-Enix
• Star Citizen by Roberts Space Industries
• Nitrous game engine by Oxide
• Sniper Elite 3 by Rebellion Developments
However, during GDC 2015 at San Francisco AMD announced that there will be no publicSDK and the API will only be available to selected partners. Instead, developers should focuson DirectX 12 or the new Vulkan API (previously called glNext) that is going to be specified laterin 2015. The Mantle API is going to be the foundation for the Vulkan API that works for multiplehardware vendors and platforms. [35]
AMD plans to support the open and cross-platform Vulkan API by providing parts of theMantle API like reduced driver overhead and power consumption, support for multi-core CPUsand features like split-frame rendering [36].
The following sections describe and analyse the core features of the Mantle API.
30

4.1. Execution Model
In general a GPU contains multiple engines which have the purpose of executing differentrendering or compute commands provided by the command buffer. Normally these buffersare created by the GPU driver and stored in queues until they are pulled by the hardware.
Figure 8.: Mantle Execution Model, c©AMD
The Mantle API enables developers to create commands for the engines, store them in com-mand buffers and managing synchronization between them by themselves. Therefore, it alsobecomes possible to generate these buffers via multithreading. [37]
4.2. Generalized Resources
Rendering APIs like Direct3D or OpenGL provide many different types of resources like vertexbuffers, index buffers, textures, etc. They give hints to the GPU driver which type of memorylocation should be used. The Mantle API doesn’t differentiate between those resource types,which is why the developer has a more general access to GPU memory. [37]
Figure 9.: Generalized Resources, c©AMD
31

4.3. Memory Management
The Mantle API gives developers explicit control over the GPU memory. It also completelydecouples memory from API objects like textures and buffers. Instead of letting the graphicsdriver allocate the memory, the API handles them as CPU-side data objects. Therefore, itbecomes easier to recycle memory, reduce the memory footprint and manage the creation ofa huge number of objects. There is only a differentiation between images and memory. In thebackground Mantle uses a virtual memory system which enables the developer to re-map thepage tables for those allocations. With this feature AMD wants to provide a way to make theusage of partially resident textures or tiled resources possible and easier. [37] [38]
Listing 4.1: Example code of such a memory allocation
GR_MEMORY_ALLOC_INFO allocationInfo = { } ;allocationInfo .memPriority = GR_MEMORY_PRIORITY_NORMAL ;allocationInfo .size = numPages ∗ gpuPageSize ;allocationInfo .alignment = 0;allocationInfo .heapCount = 1;allocationInfo .heaps [ 0 ] = firstHeapChoiceId ;GR_RESULT result = grAllocMemory (device , &allocationInfo , memory ) ;
The code in listing 4.1 allocates a certain amount of virtual pages or rather GPU memorywhich is aligned to the hardware-dependant page size of the heap. That is because eachplatform has one or more heaps that are available to the application. They differentiate in theirsize, access flags, performance ratings and other properties which are important factors whenthe application decides about the heap priorities. However, these queries are not accurateregarding the heap size because there is always the possibility of other applications trying touse the same heap or special system constraints. Thus, AMD recommends to use this estimateas a way of avoiding oversubscribed memory. [39]
32

Listing 4.2: Example code of querying the heap’s properties
GR_RESULT result ;/ / Ret r ieve number o f memory heapsGR_UINT heapCount = 0;result = grGetMemoryHeapCount (device , &heapCount ) ;/ / A l l oca te memory f o r heap i n f oGR_MEMORY_HEAP_PROPERTIES∗ pHeapInfo = new GR_MEMORY_HEAP_PROPERTIES [
heapCount ] ;/ / Ret r ieve i n f o f o r each heapfor (GR_UINT i = 0; i < heapCount ; i++){
GR_SIZE dataSize = sizeof (GR_MEMORY_HEAP_PROPERTIES ) ;result = grGetMemoryHeapInfo (device , i ,
GR_INFO_TYPE_MEMORY_HEAP_PROPERTIES ,&dataSize , &pHeapInfo [i ] ) ;
}
The CPU memory allocated by the graphics driver is also visible to developers, which is help-ful when dealing with multi-threaded operations [37]. This doesn’t happen by default and nor-mally the memory is not accessible to the CPU. Therefore, it has to be mapped with the functiongrMapMemory() and the heap needs to have the GR_MEMORY_HEAP_CPU_VISIBLE prop-erty flag enabled [39].
4.4. Monolithic Pipelines
It is important to understand that each pipeline has to be created only once in the application.They are programmable thanks to shader objects which may be written in an binary interme-diate language (IL) format or compiled from high-level shader languages. During the pipelinecreation these objects are converted to a native GPU shader format. Therefore, they can bedestroyed as soon as all pipelines are ready. Shader objects are created by the function gr-CreateShader(). The idea behind this is to create, compile and link only one shader objectfor a certain task and re-use it for multiple pipelines. Thus, the start-up and load times of theapplication can be reduced. The other parts of the pipeline are described by state data whichare separated into static and dynamic states.
• Static State: Has to be set when constructing the pipeline like the tessellator, rasterizer orinput assembler state.
• Dynamic State: The configurable part which has to be set in command buffer like indexdata, viewport state or color blender state.
The so-called monolithic pipeline is an special object that combines the fixed function andshader-based stages. It represents the graphics pipeline and the flow and communication
33

between the different stages. The construction of the pipeline also allows the Mantle API tooptimize the given shader. The Mantle API uses command buffers for rendering which can takethe pipelines like any other dynamic state. Therefore, the developer may create different typesof pipelines to solve special tasks. However, a pipeline always needs at least a vertex and pixelshader as well as a hull and domain shader when using tessellation. [39]
Listing 4.3 shows how such a pipeline construction can be done. This example includes
• vertex and pixel shaders,
• an input assembler,
• a rasterizer,
• a color blender test & output and
• a depth-stencil test & output.
Listing 4.3: Example code of creating a rendering pipeline.
GR_RESULT result ;/ / Setup resource mapping f o r ver tex fe t chGR_DESCRIPTOR_SLOT_INFO resMapping = { } ;resMapping .slotObjectType = GR_SLOT_SHADER_RESOURCE ;resMapping .shaderEntityIndex = 0;GR_GRAPHICS_PIPELINE_CREATE_INFO pipelineInfo = { } ;/ / Vertex shader stage i n f opipelineInfo .vs .shader = compiledVertexShader ;pipelineInfo .vs .descriptorSetMapping [ 0 ] . descriptorCount = 1;pipelineInfo .vs .descriptorSetMapping [ 0 ] . pDescriptorInfo = &resMapping ;pipelineInfo .vs .dynamicMemoryViewMapping .slotObjectType = GR_SLOT_UNUSED ;/ / P i xe l shader stage i n f opipelineInfo .ps .shader = compiledPixelShader ;pipelineInfo .ps .dynamicMemoryViewMapping .slotObjectType = GR_SLOT_UNUSED ;/ / Fixed f u n c t i o n s ta te setuppipelineInfo .iaState .topology = GR_TOPOLOGY_TRIANGLE_LIST ;pipelineInfo .rsState .depthClipEnable = GR_FALSE ;pipelineInfo .cbState .logicOp = GR_LOGIC_OP_COPY ;pipelineInfo .cbState .target [ 0 ] . blendEnable = GR_FALSE ;pipelineInfo .cbState .target [ 0 ] . channelWriteMask = 0xF ;pipelineInfo .cbState .target [ 0 ] . format .channelFormat = GR_CH_FMT_R8G8B8A8 ;pipelineInfo .cbState .target [ 0 ] . format .numericFormat = GR_NUM_FMT_UNORM ;pipelineInfo .dbState .format .channelFormat = GR_CH_FMT_R32G8 ;pipelineInfo .dbState .format .numericFormat = GR_NUM_FMT_DS ;/ / Create p i p e l i n eGR_PIPELINE pipeline = GR_NULL_HANDLE ;result = grCreateGraphicsPipeline (device , &pipelineInfo , &pipeline ) ;
34

Thanks to the one time construction of the pipelines, shaders do not need to be compiled dur-ing gameplay, which reduces stuttering and CPU overhead. Instead, the pipeline can be savedand loaded without high performance costs because of the already pre-compiled shaders. [37]
4.5. Resource Binding Model
The binding of resources is a task that takes a lot of time when rendering larger amounts of ob-jects. The traditional model works by using certain slots where resources are getting stored be-fore rendering. For example, older versions of OpenGL use GL_TEXTURE0, GL_TEXTURE1,GL_TEXTURE2, etc. to bind one or more textures to the rendering pipeline and use the posi-tion for accessing them via uniform variables in the shader. However, modern OpenGL featuresa way to use pointers or rather handles without the need of binding them before use, whichis explained closely in section 2.2.4. This is part of the so-called bindless model. The MantleAPI improves that concept by providing descriptor sets that can be used in multiple pipelines.Changing resources in these sets does not require the API to re-bind them completely. Instead,it uses pointers to a subset of resources which can be modified from the outside. This enablesthe developer to keep the amount of bindings to a minimum, thus reducing CPU overhead. [37]
4.6. Resource Preparation
The Mantle API gives developers more power over the preparation and management of re-sources. This means that they have to make sure that textures are loaded before reading them,certain GPU caches are flushed and other operations are done. In short, the application isresponsible for taking care of possible race conditions and data hazards. However, the benefitis that the hardware and especially the CPU do not have to care for these things by themselves.The developer also has more control about when state changes occur because they have to beexplicitly called and reported to the Mantle API. [37]
There are two different types of states that can be tracked and changed by the applica-tion. They match the generalized resource types described in section 4.2. Consequently,there are GR_MEMORY_STATE and GR_IMAGE_STATE values. Initially, resources are in theGR_MEMORY_STATE_DATA_TRANSFER or GR_IMAGE_STATE_DATA_TRANSFER state aswell as the GR_IMAGE_STATE_UNINITIALIZED when using images that could be used ascolor or depth-stencil targets. When the application changes the state of a resource, it adds antransition command to the command buffer. [39]
35

Listing 4.4: Example of memory preparation.
/ / Prepare f i r s t 100 bytes o f memory ob jec t f o r shader read a f t e r dataupload
GR_MEMORY_STATE_TRANSITION transition = { } ;transition .mem = mem ;transition .oldState = GR_MEMORY_STATE_DATA_TRANSFER ;transition .newState = GR_MEMORY_STATE_GRAPHICS_SHADER_READ_ONLY ;transition .offset = 0;transition .regionSize = 100;/ / Record s ta te t r a n s i t i o n i n command b u f f e rgrCmdPrepareMemoryRegions (cmdBuffer , 1 , &transition ) ;
Listing 4.5: Example of image preparation.
/ / Prepare image f o r shader read a f t e r i t was rendered toGR_IMAGE_STATE_TRANSITION transition = { } ;transition .image = image ;transition .oldState = GR_IMAGE_STATE_TARGET_RENDER_ACCESS_OPTIMAL ;transition .newState = GR_IMAGE_STATE_GRAPHICS_SHADER_READ_ONLY ;transition .subresourceRange .aspect = GR_IMAGE_ASPECT_COLOR ;transition .subresourceRange .baseMipLevel = 0;transition .subresourceRange .mipLevels = GR_LAST_MIP_OR_SLICE ;transition .subresourceRange .baseArraySlice = 0;transition .subresourceRange .arraySize = GR_LAST_MIP_OR_SLICE ;/ / Record s ta te t r a n s i t i o n i n command b u f f e rgrCmdPrepareImages (cmdBuffer , 1 , &transition ) ;
4.7. Conclusion
With Mantle AMD provides a low-level API that can reduce the CPU and memory overhead. Itallows the developer to have great control over the GPU processes like memory management,pipelines or state changes. It also tries to be as general and simple as possible regarding thegeneralized resources and usage of memory. The Mantle API improves concepts provided byother APIs like the bindless model to reduce the need of binding resources to the pipeline asmuch as possible. These concepts and ideas are going to be used in the new Vulkan API byproviding a solid foundation.
36

5. Comparison of Modern OpenGL and Direct3DTechniques on PC
5.1. Ace3D Engine
The Ace3D engine was developed by the author Simon Dobersberger. It has been used for twoyears during the master studies at the UAS Technikum Vienna for the purpose of providing asolid base for exercises, projects and experiments. This includes several tasks like running arti-ficial intelligence algorithms, playing sound events provided via FMOD studio or implementing adeferred shading pipeline with post-processing effects. The engine is written in C++ and easilyextensible thanks to an entity component system and an event system. Thus, the various partsare loosely coupled and mostly do not depend on each other.
For the following tests it has been stripped of all features to provide a light-weighted frame-work for focusing on the rendering aspects. The engine contains mainly two different renderbackends for testing and comparing modern OpenGL and Direct3D features.
5.1.1. Target Platforms
The number of target platforms of the Ace3D engine and the rendering tests are narroweddown to one because the only hardware and software available to perform the following tasksare integrated in a Windows 8.1 PC. This environment supports the OpenGL as well as theDirectX API and has access to high-performing CPU and GPU components. Another platformavailable for testing modern API features is the NVIDIA Shield Tablet which is covered in chapter6. However, it does not provide access to the DirectX API due to the fact that the device usesAndroid as the operating system.
As explained in chapter 4 it is not possible to perform testing for AMD Mantle. The API isbeing discontinued and will not be released as a public SDK.
Direct3D 12 is another API which can not be supported because it is not officially availableyet. To date (2015-04-08) it has been silently integrated into the Windows 10 Technical Preview(build 10041), but the lack of GPU drivers and the beta status of the new Windows versionprohibits the delivery of valid test results [40].
5.1.2. Entity Component System
The Ace3D engine uses an entity component approach instead of inheritance. The more tra-ditional method is to define classes for different types of game objects which inherit logic from
37

their parent classes. Each entity has its own update and render methods that are called everyframe. This type of entity system is used by engines like the Unreal Engine 3 which uses anActor base class that offers a set of functionality for rendering, animation, physics and so on.Unreal Engine 4 also implies this type of entity system as shown in listing 5.1.
Listing 5.1: Example of a header file for a door actor in Unreal Engine 4.
#pragma once
#include "GameFramework/Actor.h"
#include "DoorActor.generated.h"
UCLASS ( )class MYRPG_API ADoorActor : public AActor
{GENERATED_BODY ( )
public :/ / Const ructor , s e t t i n g d e f a u l t valuesADoorActor ( ) ;
virtual void BeginPlay ( ) override ;
virtual void Tick (float DeltaSeconds ) override ;
bool NeedsKey ;
bool IsOpen ;} ;
As further explained by Pruehs [41] this object oriented approach comes with a lot of disad-vantages. First, the game object classes come with a lot of overhead caused by inheritance.That does not only include the virtual tables for virtual destructors and update methods, but alsomembers and logic of base classes that are passed on. Another problem is the vast number ofclasses needed to implement every single object in the game that could also lead to root classesof unreasonable size or code that is copied to multiple leaf classes. This also leads to errorscaused by changes in the base classes that conflicts the behaviour of the children. Therefore,every developer working with the system has to know all dependencies. It also becomes quitecomplicated to consider dependencies and the execution order of the entities. A less technicaldisadvantage is the static development process enforced by this approach. For every new gameobject, change or idea the application needs to be modified by the programmer, thus increasingthe workload of the team.
38

The other approach introduces a so-called component that provides an encapsulated pieceof logic or state. Instead of game objects being directly defined by their classes and inher-itance, they are represented by their components. Therefore, it is possible to easily add orremove certain parts of the logic during the development process or even during runtime. Thisenables the development team to use a data-driven approach that is more independent of theirprogrammers.
Figure 10.: Components define the entity
The entity component system used in the Ace3D engine is similar to the method describedby Pruehs [42]. Components only represent the current state of an entity and do not possesany kind of logic. Therefore, they are declared in POD structures to keep them as small andeasily manageable as possible. The engine does not provide an entity class. Instead, entitiesare represented by an ID and the sum of their components. The game logic and all functionalityis found in entity systems that are updated each frame. For example, in the update methodthe rendering system gets all mesh components and renders each one in a for-loop. Thisalso means that the components could be split and given to multiple threads to optimize theperformance. However, a problem of the component-based approach is the communication
39

between entities, for example when two objects are colliding. Therefore, Ace3D offers an eventmanager which enables the system to fire events and register listeners to exchange informationand execute related tasks in other entity systems.
5.1.3. Rendering System
The RenderSystem class is responsible for managing the different tests and determines thetype of rendering commands needed. These commands are not called directly. Instead, theengine uses different rendering backends that are wrapped around the API calls. Therefore,the rendering system does not know anything about the used API and is completely decoupledfrom any OpenGL or Direct3D calls. The two backends are included via header files that bothprovide the same interface. Preprocessor symbols (USE_GL and USE_D3D) which are definedin different build targets, decide which backend class should be used during compile time.Thus, the appropriate rendering backend is called by the system without any additional runtimeoverhead created by if-statements.
Listing 5.2: The correct rendering backend is included by the preprocessor.
#ifdef USE_GL#include "RenderBackendGL.h"
#elif USE_D3D#include "RenderBackendD3D11.h"
#endif
The different rendering tests are run individually by calling the appropriate methods of thebackend. There are no if-statements to decide which test should be executed. Again, thisprevents additional runtime overhead and the test results completely depend on the renderingbackends themselves.
5.1.4. OpenGL Backend
The implementation of the OpenGL API uses many modern techniques provided by the 3.xand 4.x versions. The definitions of the OpenGL backend have been added to the appendix A.The rendering pipeline does not work with any kind of client side data. Therefore, all vertices,indices, matrices and object are uploaded to corresponding buffer objects and accessed inthe vertex and fragment shader stages. To reduce the number of necessary buffer binds thebackend uses vertex array object to provide the same input layout for all draw calls. The vertexand index data is bound to the VAO before each draw call. This also serves the purpose ofimitating the setup of the Direct11 API. The OpenGL backend also does not use any kind ofindividual uniform calls. Instead, it uses multiple uniforms buffers like the constant buffers inMicrosoft’s API. For the naive test case of using an individual buffer for each object the backendalso implements the usage of non-DSA methods. This enables a comparison between the two
40

approaches. However, most other function calls use DSA. The OpenGL side of the engine alsoimplements bindless textures to compare the approach to texture arrays.
5.1.5. Direct3D 11 Backend
The Direct3D 11 backend uses the d3d11.h header file which is part of the Windows 8/8.1 SDK.Thus, the Ace3D engine is completely independent of the older DirectX SDK from June 2010.The definitions of the Direct3D 11 backend are also part of the appendix and can be looked at inchapter B. All vertex, index and constant data is uploaded to ID3D11Buffer objects. There arealso two constant buffers which are used to upload either global and static data like the viewprojection matrix or per object and dynamic data like model matrices, material diffuse colorsand texture indices for texture arrays. The input layout is set once and depends on the usedshaders.
5.1.6. Third-Party Libraries
The Ace3D engine uses several third-party libraries for the tests. They provide additional func-tionality that is not crucial for the measurement of the application and do not influence results.
• SFML 2.2: Texture loading as well as OpenGL window creation and buffer swapping
• glew: OpenGL extension loading
• glm: OpenGL math library
• Assimp: Importing 3D models and scenes
5.1.7. Timers
The Ace3D engine provides several timer classes for measuring CPU and GPU times.Therefore, they are also used for the following tests. The timers start just before theclearScreen() call that clears the backbuffers via the glClear(GL_COLOR_BUFFER_BIT |GL_DEPTH_BUFFER_BIT); function or ID3D11DeviceContext::ClearXXXView() method. Afterall draw calls have been sent to the pipeline and the buffers and shaders have been unbound,the timer is stopped queries the time needed for the last frame. The GPU timers for OpenGLand Direct3D11 are based on the NvTimers class that is included in the NVIDIA GameWorksOpenGL samples. However, the functionality has been edited and all dependencies for externallibraries like GLFW as well as the other classes provided in the samples have been removed.The timer has been fully integrated into the engine and also works with the Direct3D backend.
OpenGL Timer
The GPU time is measured with glQuery*() functions. As described in the official specification[43] of the ARB_timer_query extension, timer query objects provide accurate timing functional-
41

ity for the GPU hardware. Normal CPU timers are not synchronized with the GPU commandsand therefore not useful for profiling. OpenGL query objects provide asynchronous time pollswithout stalling the rendering pipeline. The GPU timer used by the engine utilizes multiple queryobjects to account for the possibility of a time query not being finished at the end of the frame.
Listing 5.3: Sample code of the OpenGL GPU timer’s interface.
/ / Generate b u f f e r o f quer ies once at the s t a r t o f the a p p l i c a t i o n .void init ( ){glGenQueries (TIMER_COUNT∗TIMESTAMP_QUERY_COUNT , mQueries [ 0 ] ) ;
}
/ / Query the timestamp when s t a r t i n g the counter .void start ( ){getResults ( ) ; / / Add pending t im ings from prev ious framesmNextTimeStampQuery++;mNextTimeStampQuery = (mNextTimeStampQuery >= TIMER_COUNT ) ? 0 :
mNextTimeStampQuery ;glQueryCounter (mQueries [mNextTimeStampQuery ] [ TIMESTAMP_QUERY_BEGIN ] ,
GL_TIMESTAMP ) ;}
/ / Query the timestamp when stopp ing the counter .void stop ( ){glQueryCounter (mQueries [mNextTimeStampQuery ] [ TIMESTAMP_QUERY_END ] ,
GL_TIMESTAMP ) ;mTimeStampQueryInFlight [mNextTimeStampQuery ] = true ;
}
The timer uses the internal timestamp of the GPU by querying the GL_TIMESTAMP enumer-ation as seen in listing 5.3. The query objects are used like a circular buffer to give each queryenough time to finish. The timer also sets a flag when it is stopped to notify the rest of the classthat the query is waiting for its result. Thus, the loop in the getResults() method does not checkthe idle ones as seen in listing 5.4.
42

Listing 5.4: Sample code of the OpenGL GPU timer’s interface.
void getResults ( ){for (unsigned int i = 0; i < TIMER_COUNT ; i++){if (mTimeStampQueryInFlight [i ] ){GLuint available = false ;glGetQueryObjectuiv (mQueries [i ] [ TIMESTAMP_QUERY_END ] ,
GL_QUERY_RESULT_AVAILABLE , &available ) ;
if (available ){GLuint64 timeStart , timeEnd ;glGetQueryObjectui64v (mQueries [i ] [ TIMESTAMP_QUERY_BEGIN ] ,
GL_QUERY_RESULT , &timeStart ) ;glGetQueryObjectui64v (mQueries [i ] [ TIMESTAMP_QUERY_END ] ,
GL_QUERY_RESULT , &timeEnd ) ;
/ / Add elapsed t imemElapsedCycles += float (double (timeEnd − timeStart ) ∗ 1.e−6) ;mTimeStampQueryInFlight [i ] = false ;
mStartStopCycles++;mCycles++;
}}
}}
It is important to note that checking for GL_QUERY_RESULT_AVAILABLE does not stall theapplication, whereas GL_QUERY_RESULT implicitly flushes the OpenGL pipeline as describedin the OpenGL manual [44]. The timer may check again later and the application can startrendering another frame. However, that also means that not all queries are finished when theprogram stops. Therefore, the timer also counts the number of the ones that are really finishedand can be used to calculate the correct frame time average.
5.2. Test System
The setup consists of an PC equipped with an Intel i5-3450 (3.1 Ghz), a NVIDIA GeforceGTX770 (2 GB GDDR5) and 8 gigabytes of DDR3 system memory. The used Geforce driverversion is 350.12.
43
5.3. OpenGL - DSA versus Non-DSA
As explained in section 2.2.7 direct state access does not provide any performance improve-ments by itself. However, the new interfaces help to improve the structure of the application andto keep the code clean. It is also important to note that this reduces the number of API func-tion calls drastically. Thus, DSA could decrease the overhead created by dispatching OpenGLfunctions and it gives the GPU driver room for improvement. Therefore, this test is designed toshow if DSA has any kind of impact on an application.
The test scenario consists of rendering a large number of untextured cubes. The enginedoes not use any kind of performance improving technique like instancing or multi draw indirect.Each object translates into one draw call and has its own vertex data buffers. The input layout isdescribed by a global vertex array object and the associated vertex and index buffer objects arebound to it before each glDrawElements() call. All objects use the same diffuse shader whichconsists of a vertex and a fragment stage.
Figure 11.: The test renders 32,768 objects in 800x600.
Measurement
The test was performed for 60 seconds and renders a three dimensional field of 32 x 32 x 32cubes. That makes a total number of 32,768 objects. The following test results are provided bymeasuring the CPU and GPU time needed for the rendering process in milliseconds.
44

Mode CPU time per frame (ms) GPU time per frame (ms)
Non-DSA 21.91 10.21
DSA 18.05 8.37
Table 1.: OpenGL DSA Sample
Discussion
The results show that DSA really reduces the amount of overhead that is created by bindingobjects and textures via several OpenGL commands. The CPU time is decreased by nearly fourmilliseconds or rather 18%. Even the GPU saves almost two milliseconds and accordingly also18% of rendering time. Assuming that DSA also reduces the start-up time of the application,this specific test proves the importance of revising the structure of the API and providing a sliminterface. This also enables the driver to optimize the commands and decreases the numberof unnecessary binding and unbinding calls that are caused by error. It is important to notethat the test already reduces the number of bindings to a minimum. Buffers, vertex arrays andshaders are bound only once at the beginning and the end of the rendering process.
Listing 5.5: Update loop of the rendering system.
void RenderSystem : : update ( ){CPU_TIMER_SCOPE ( ) ;GPU_TIMER_SCOPE ( ) ;
mBackend .clearScreen ( ) ;mBackend .enableBindings ( ) ; / / Binds shader , ve r tex ar ray ( and uni form
b u f f e r )for (auto& meshIt : mWorld−>getMeshComponents ( ) ){mBackend .render (meshIt .first , ∗mWorld ) ;
}mBackend .disableBindings ( ) ;mBackend .swapBuffers ( ) ;
}
Direct state access does not remove calls to bind the vertex array or the shader becausethere are no glDraw*() commands. Modern OpenGL still uses a large amount of states as wellas handles and functions, instead of classes and structs like the Direct3D API. Therefore, thenumber of draw call arguments would be too large and confusing. The DSA extension provides
45

an interface that is more similar to the Direct3D API and a clean code structure. Therefore, it isused for all the following tests and non-DSA results will be ignored.
5.4. Massive Untextured Object Rendering
This test scenario emphasizes the driver overhead created by dispatching a massive amountof draw calls per frame and using a low resolution. It compares OpenGL and Direct3D as wellas several rendering techniques provided by the APIs like instancing and multi draw indirect.
Figure 12.: The test renders 91,125 objects in 800x600.
5.4.1. Individual versus Global Vertex Buffers
The comparison between the different usage of buffer objects concentrates on the overheadcreated by changing them for each draw call. Each mesh component has its own buffer ID orID3D11Buffer object that is initialized at the beginning of the application in the RenderBack-end::initMesh() method. However, it is also possible to upload the vertex and index data to asingle set of buffers via the RenderBackend::initMeshesSingleBuffered() method to reduce thenumber of buffer bounds. This increases the complexity of the memory management tough, forexample when the buffer data needs to be updated.
46

Listing 5.6: Draw calls for rendering with per object buffers versus global set of buffers
/ / Direct3D 11/ / Per ob jec t b u f f e r smContext−>DrawIndexed (meshComp .indices .size ( ) ∗ 3 , 0 , 0) ;/ / Global se t o f b u f f e r smContext−>DrawIndexed (meshComp .indices .size ( ) ∗ 3 , indexOffset , vertexOffset
) ;
/ / OpenGL/ / Per ob jec t b u f f e r sglDrawElements (GL_TRIANGLES , meshComp .indices .size ( ) ∗ 3 , GL_UNSIGNED_INT ,
0) ;/ / Global se t o f b u f f e r sglDrawElementsBaseVertex (GL_TRIANGLES , meshComp .indices .size ( ) ∗ 3 ,
GL_UNSIGNED_INT , (void∗ )indexOffset , vertexOffset ) ;
As shown in listing 5.6 the APIs provide different types of draw calls to simplify the usage of aglobal set of buffers. The ID3D11DeviceContext::DrawIndex() method offers offset parameterswhich enables the application to use a single set of buffers without changing the buffer state orinput layout. Similary, OpenGL offers the glDrawElementsBaseVertex() function that is part ofthe core API since version 3.2.
Measurement
The test was performed for 120 seconds and renders a total number of 91,125 cubes. Theyare arranged in a three dimensional field of 45 x 45 x 45 objects. The results are measuredin milliseconds and show the average time per frame for the CPU and the GPU needed by therendering system.
Mode CPU time per frame (ms) GPU time per frame (ms)
OpenGL Per Object Buffer 51.09 24.51
OpenGL Global Buffer 27.24 12.95
Direct3D 11 Per Object Buffer 54.34 28.67
Direct3D 11 Global Buffer 17.22 8.77
Table 2.: Buffer Comparison
47

Discussion
As seen in the comparison the overhead created by the per object buffers is too large to offer apleasant gaming experience when rendering large numbers of objects. By batching the data, asingle set of buffers can be used for multiple objects. In the OpenGL implementation the changecuts the frame time into a half. The Direct3D 11 test increases the performance even more: TheCPU and GPU time per frame are reduced to nearly 30%. The results are as expected becausethe number of draw calls and buffer bindings have been reduced, which especially affects theCPU. The GPU also has less overhead because the vertex data can be accessed via a singlebuffer. This method is also more cache-friendly because all the attributes are stored in a linearway, instead of being scattered around the GPU memory.
The test results show a great performance boost by using a single pair of vertex and indexbuffers. However, in most games it is difficult to store all data in that way. The application hasto react to the player’s interactions, which creates a lot of dynamic objects that are dissimilar toeach other. Thus, the overhead and complexity for managing the vertex data increases, whichintroduces problems when using techniques like culling. It also limits the available memorybandwidth for other operations like texture steaming. Therefore, as described in section 2.4,batching is a valid option for reducing the number of draw calls and making use of as few buffersas possible. By grouping static objects that are close to each other, some disadvantages canbe removed. For example, culling a group of stones as soon as all of them are hidden behind awall. However, this may increase the workload for level designers, if they have to manually packobjects into batches. Theoretically, the idea behind that method is also applicable to Direct3Drendering backends.
5.4.2. Instancing
Instancing enables the application to render all cubes based on the same vertex data andeffectively reduces the number of draw calls to one. The per object data is provided via ainstance buffer that contains all model/world matrices as well as the material diffuse color. Thelatter one is sent to the framgment/pixel shader stage via the flat or noninterpolate keywords.
Measurement
For this test 91,125 objects are rendered in a three-dimensional field of 45 x 45 x 45 cubes. Theaverage CPU and GPU times are measured in milliseconds and represent the time needed bythe rendering system.
48
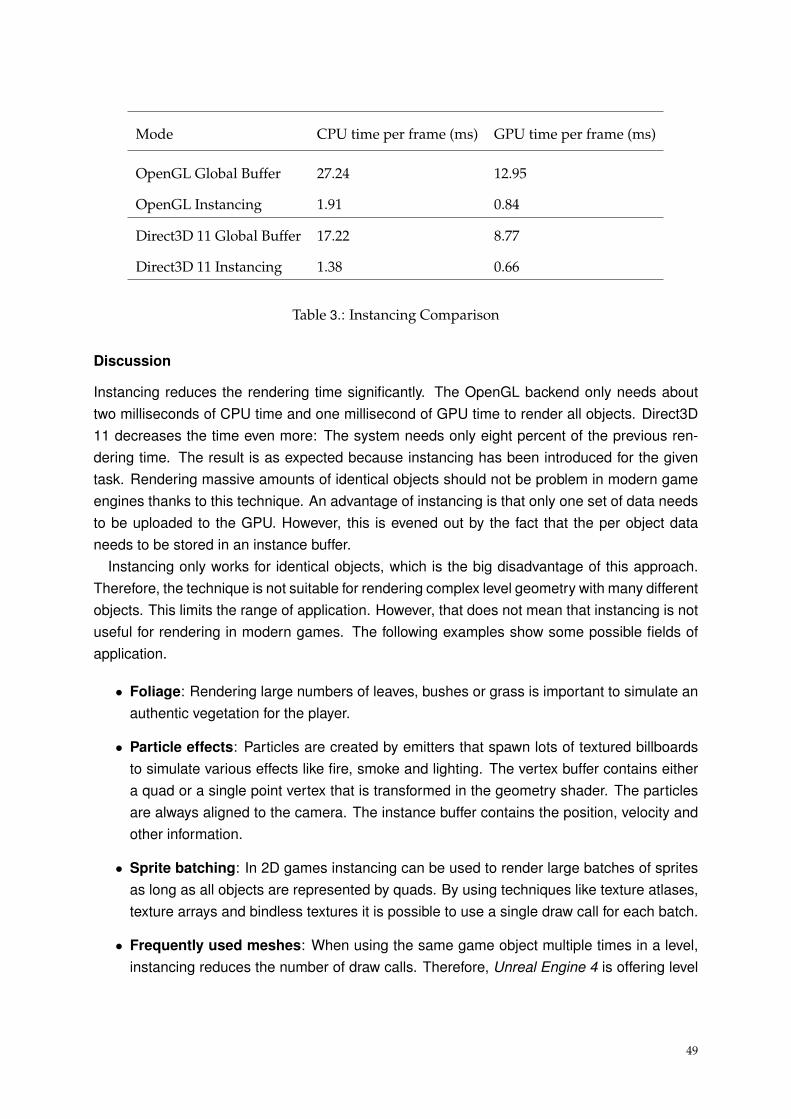
Mode CPU time per frame (ms) GPU time per frame (ms)
OpenGL Global Buffer 27.24 12.95
OpenGL Instancing 1.91 0.84
Direct3D 11 Global Buffer 17.22 8.77
Direct3D 11 Instancing 1.38 0.66
Table 3.: Instancing Comparison
Discussion
Instancing reduces the rendering time significantly. The OpenGL backend only needs abouttwo milliseconds of CPU time and one millisecond of GPU time to render all objects. Direct3D11 decreases the time even more: The system needs only eight percent of the previous ren-dering time. The result is as expected because instancing has been introduced for the giventask. Rendering massive amounts of identical objects should not be problem in modern gameengines thanks to this technique. An advantage of instancing is that only one set of data needsto be uploaded to the GPU. However, this is evened out by the fact that the per object dataneeds to be stored in an instance buffer.
Instancing only works for identical objects, which is the big disadvantage of this approach.Therefore, the technique is not suitable for rendering complex level geometry with many differentobjects. This limits the range of application. However, that does not mean that instancing is notuseful for rendering in modern games. The following examples show some possible fields ofapplication.
• Foliage: Rendering large numbers of leaves, bushes or grass is important to simulate anauthentic vegetation for the player.
• Particle effects: Particles are created by emitters that spawn lots of textured billboardsto simulate various effects like fire, smoke and lighting. The vertex buffer contains eithera quad or a single point vertex that is transformed in the geometry shader. The particlesare always aligned to the camera. The instance buffer contains the position, velocity andother information.
• Sprite batching: In 2D games instancing can be used to render large batches of spritesas long as all objects are represented by quads. By using techniques like texture atlases,texture arrays and bindless textures it is possible to use a single draw call for each batch.
• Frequently used meshes: When using the same game object multiple times in a level,instancing reduces the number of draw calls. Therefore, Unreal Engine 4 is offering level
49

designers the option to use instanced meshes. For example, a warehouse with a largenumber of crates benefits greatly from the use of instancing.
5.4.3. Multi Draw Indirect & Multithreaded Rendering
This approach is described in section 2.2.5 as well as in section 3.1.1. The multi draw indirecttechnique in OpenGL is similar to the interface provided by deferred contexts in Direct3D 11.Both approaches enable the application to gather a large amount of rendering commands andsend them as a single draw call to the graphics hardware. The advantage in comparison toinstancing is that individual vertex and index data can be used for each object. In Direct3D 11it is even possible to record commands for buffers, shaders, input layouts and other parts of therendering pipeline.
The OpenGL backend uses a DrawElementsIndirectCommand structure to store all relevantdraw call data for the glMultiDrawElementsIndirect() call. The Ace3D engine uses a buffer oftype GL_DRAW_INDIRECT_BUFFER to upload all the commands to the GPU. It is persis-tently mapped to a pointer by providing the GL_MAP_PERSISTENT_BIT argument. Anotherbit given to the map function is GL_MAP_COHERENT_BIT which tells the API that it needs tobe synchronized with graphics hardware.
Listing 5.7: Creation of a command buffer to store all draw calls.
glCreateBuffers (1 , &mIndirectDrawBuffer ) ;glNamedBufferStorage (mIndirectDrawBuffer , world .getMeshComponents ( ) .size ( ) ∗
sizeof (DrawElementsIndirectCommand ) , 0 , GL_MAP_WRITE_BIT |GL_MAP_PERSISTENT_BIT | GL_DYNAMIC_STORAGE_BIT | GL_MAP_COHERENT_BIT ) ;
mCommandBuffer = static_cast<DrawElementsIndirectCommand∗>(glMapNamedBufferRange (
mIndirectDrawBuffer ,0 ,world .getMeshComponents ( ) .size ( ) ∗ sizeof (DrawElementsIndirectCommand ) ,GL_MAP_WRITE_BIT | GL_MAP_PERSISTENT_BIT | GL_MAP_COHERENT_BIT
) ) ;
The buffer can also be filled by multiple threads at a time. Therefore, the OpenGL backendalso provides the functionality to use multithreading and split the gathering of draw commands.All the data needed for this process is stored in work items which are created at start-up. Theengine uses C++11 threads to accomplish this task as seen in listing 5.8.
50

Listing 5.8: Command gathering method executed by each thread.
void RenderBackend : : gatherCommandsThread (unsigned int threadId , unsigned int
startIndex , unsigned int num ){for (size_t i = startIndex ; i < startIndex + num ; i++){WorkItem workItem = mWorkList [i ] ;mCommandBuffer [i ] . count = workItem .meshComp−>indices .size ( ) ∗ 3;mCommandBuffer [i ] . instanceCount = 1;mCommandBuffer [i ] . firstIndex = workItem .indexOffset ;mCommandBuffer [i ] . baseVertex = workItem .vertexOffset ;mCommandBuffer [i ] . baseInstance = i ;
}}
The Direct3D 11 backend creates one or more deferred contexts and gathers the render-ing commands in ID3D11CommandList objects. The single-threaded approach uses such acontext on the main thread to simulate the MDI functionality provided by the OpenGL API.
Listing 5.9: Rendering commands are stored into the command list and executed.
void RenderBackend : : renderIndirect ( ){if (mCommandBuffer == NULL ) / / Check f o r cached command l i s t{mDeferredContext−>FinishCommandList (true , &mCommandBuffer ) ;
}mContext−>ExecuteCommandList (mCommandBuffer , false ) ;
}
Similar to the OpenGL backend the command list can also be created by multiple threads.After each deferred context has been set up, they gather all draw calls from the work items.As soon as all threads have finished, the immediate context in the main thread executes thecommand lists. Thus, technically the multithreaded approach used by the Direct3D 11 backenduses one draw call per thread.
In both backends there is also the possibility to cache all command buffers and lists. This isuseful for static data or data that does not change very often.
Measurement
This test compares eight different rendering modes and consists of drawing 45 x 45 x 45 orrather 91,125 cubes in a three dimensional grid. The results represent the average renderingtime needed per frame by the CPU and the GPU.
51
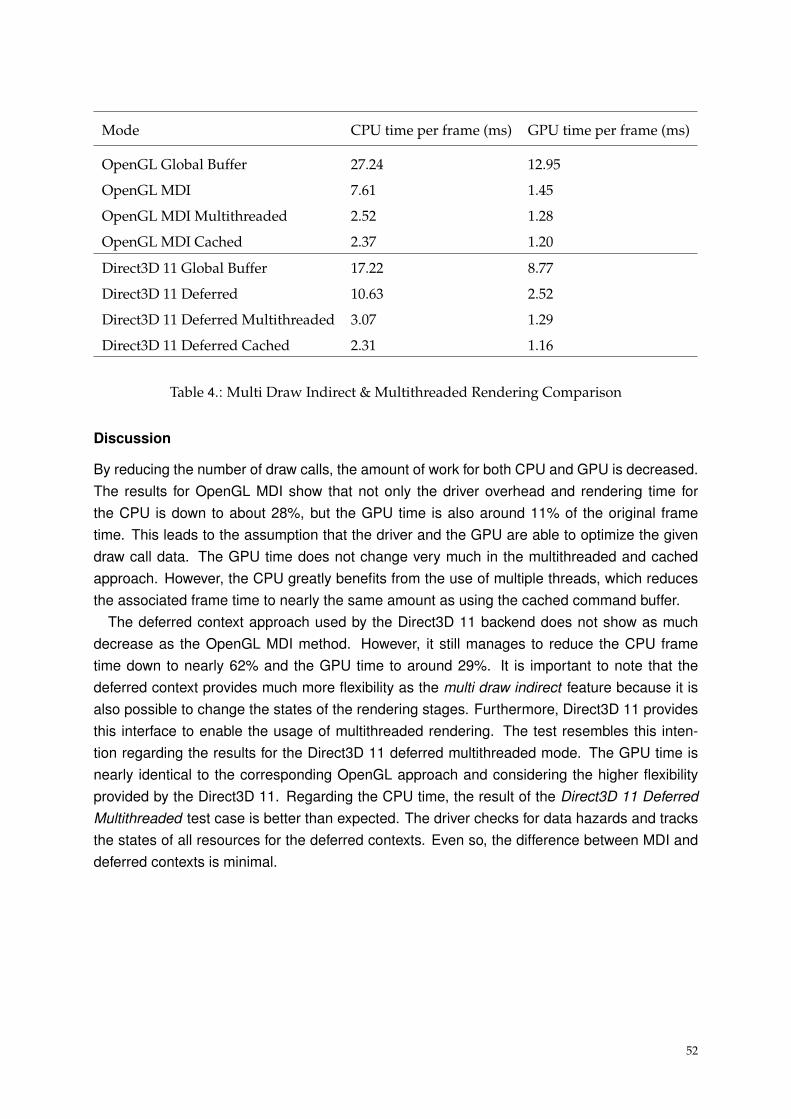
Mode CPU time per frame (ms) GPU time per frame (ms)
OpenGL Global Buffer 27.24 12.95
OpenGL MDI 7.61 1.45
OpenGL MDI Multithreaded 2.52 1.28
OpenGL MDI Cached 2.37 1.20
Direct3D 11 Global Buffer 17.22 8.77
Direct3D 11 Deferred 10.63 2.52
Direct3D 11 Deferred Multithreaded 3.07 1.29
Direct3D 11 Deferred Cached 2.31 1.16
Table 4.: Multi Draw Indirect & Multithreaded Rendering Comparison
Discussion
By reducing the number of draw calls, the amount of work for both CPU and GPU is decreased.The results for OpenGL MDI show that not only the driver overhead and rendering time forthe CPU is down to about 28%, but the GPU time is also around 11% of the original frametime. This leads to the assumption that the driver and the GPU are able to optimize the givendraw call data. The GPU time does not change very much in the multithreaded and cachedapproach. However, the CPU greatly benefits from the use of multiple threads, which reducesthe associated frame time to nearly the same amount as using the cached command buffer.
The deferred context approach used by the Direct3D 11 backend does not show as muchdecrease as the OpenGL MDI method. However, it still manages to reduce the CPU frametime down to nearly 62% and the GPU time to around 29%. It is important to note that thedeferred context provides much more flexibility as the multi draw indirect feature because it isalso possible to change the states of the rendering stages. Furthermore, Direct3D 11 providesthis interface to enable the usage of multithreaded rendering. The test resembles this inten-tion regarding the results for the Direct3D 11 deferred multithreaded mode. The GPU time isnearly identical to the corresponding OpenGL approach and considering the higher flexibilityprovided by the Direct3D 11. Regarding the CPU time, the result of the Direct3D 11 DeferredMultithreaded test case is better than expected. The driver checks for data hazards and tracksthe states of all resources for the deferred contexts. Even so, the difference between MDI anddeferred contexts is minimal.
52
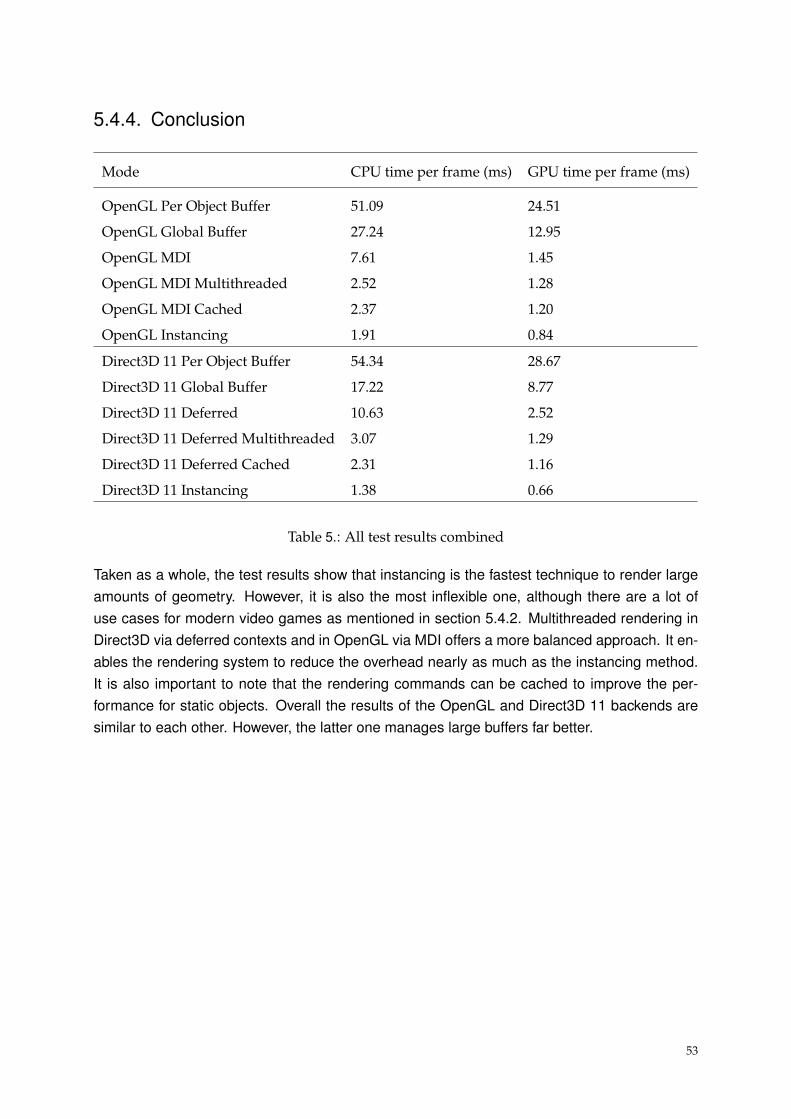
5.4.4. Conclusion
Mode CPU time per frame (ms) GPU time per frame (ms)
OpenGL Per Object Buffer 51.09 24.51
OpenGL Global Buffer 27.24 12.95
OpenGL MDI 7.61 1.45
OpenGL MDI Multithreaded 2.52 1.28
OpenGL MDI Cached 2.37 1.20
OpenGL Instancing 1.91 0.84
Direct3D 11 Per Object Buffer 54.34 28.67
Direct3D 11 Global Buffer 17.22 8.77
Direct3D 11 Deferred 10.63 2.52
Direct3D 11 Deferred Multithreaded 3.07 1.29
Direct3D 11 Deferred Cached 2.31 1.16
Direct3D 11 Instancing 1.38 0.66
Table 5.: All test results combined
Taken as a whole, the test results show that instancing is the fastest technique to render largeamounts of geometry. However, it is also the most inflexible one, although there are a lot ofuse cases for modern video games as mentioned in section 5.4.2. Multithreaded rendering inDirect3D via deferred contexts and in OpenGL via MDI offers a more balanced approach. It en-ables the rendering system to reduce the overhead nearly as much as the instancing method.It is also important to note that the rendering commands can be cached to improve the per-formance for static objects. Overall the results of the OpenGL and Direct3D 11 backends aresimilar to each other. However, the latter one manages large buffers far better.
53
5.5. Massive Textured Object Rendering
This section compares the different modes introduced in the previous section 5.4 by renderinga large amount of textured objects. It also introduces different techniques for handling texturedata like texture arrays and bindless textures. Again, the Ace3D engine is used for these testsand provides two different backends for the Direct3D and OpenGL APIs. To reduce the start-uptime of the application all objects use the same image data which is loaded only once. However,for each cube an individual texture object or rather texture and shader view resource is created.Therefore, the engine has to switch over large amounts of resources and provide unambiguousresults to compare the different rendering techniques. That is also the reason why the size ofthe texture has been kept at 32 x 32 pixels and the application does not use any mipmaps.
Figure 13.: The test renders 46.656 textured objects in 800x600.
5.5.1. Individual Texture Binding
This test compares the different modes introduced in section 5.4 and focuses on the costsof binding individual textures. For this reason the engine binds the corresponding texture ob-ject or shader resource view for every single draw call. Techniques like instancing or multidraw indirect cannot be used for this test because it is not possible to send the texture re-sources that way. The Direct3D 11 backend uses the default sampler state which is providedby the ID3D11Device::CreateSamplerState() method as long as the first parameter is NULL.The OpenGL backend does the same by not changing any of the texture parameters and by notproviding a sampler object.
54

Measurement
In this test case the engine renders a three-dimension field of 36 x 36 x 36 or rather 46.656textured cubes. It is performed for 120 seconds and measures the frame time of the CPU andGPU.
Mode CPU time per frame (ms) GPU time per frame (ms)
OpenGL Per Object Buffer 52.72 25.48
OpenGL Global Buffer 33.19 15.76
Direct3D 11 Per Object Buffer 49.45 29.26
Direct3D 11 Global Buffer 22.69 14.08
Direct3D 11 Deferred 42.55 18.70
Direct3D 11 Deferred Multithreaded 22.26 8.34
Direct3D 11 Deferred Cached 10.62 6.42
Table 6.: Binding each texture individually
Discussion
Although the number of rendered cubes is smaller than in the previous tests in section 5.4, theframe times have increased on average. The usage of a single global buffer still reduces theoverhead, but the additional texture operations prevent a smooth frame rate of 60 hertz whichtranslates to 16.66 milliseconds per frame. The usage of a deferred context increases thetimes significantly. The especially high CPU overhead can only be countered by multithreading,although the GPU time can be reduced to around 60% thanks to deferred contexts. A cachedcommand list in Direct3D 11 manages to provide the best results, but there still remains a lotof overhead. Apart from that, the OpenGL API seems to handle texture switches not as well asMicrosoft’s one.
In conclusion this test case shows that texturing without any modern rendering features liketexture arrays or a bindless resource approach are not suitable for rendering large amounts ofdifferently textured objects.
5.5.2. Texture Arrays
This test case uses texture arrays to provide a large number of textures for the fragment andpixel shader stages. Therefore, the Ace3D engine is able to use instancing and MDI to ren-der batches of objects. Their size depends on the number of textures that can be placed ina single texture array. The GL_MAX_ARRAY_TEXTURE_LAYERS OpenGL query as well as
55

the D3D11_REQ_TEXTURE2D_ARRAY_AXIS_DIMENSION Direct3D 11 query return a max-imum possible size of 2048 layers per array. For each object the engine checks, if the texturearray needs to be switched to reduce the number of unnecessary texture binds. This appliesfor the per object buffer, global buffer and deferred rendering modes.
Measurement
As seen in the previous test, the engine renders 46.656 objects in the form of a three-dimensionfield of 36 x 36 x 36 textured cubes. The test is always run for 120 seconds and the resultsshow the average frame time of the CPU and GPU.
Mode CPU time per frame (ms) GPU time per frame (ms)
OpenGL Per Object Buffer 27.10 12.62
OpenGL Global Buffer 13.61 6.07
OpenGL MDI 3.56 0.82
OpenGL MDI Multithreaded 1.50 0.81
OpenGL MDI Cached 1.41 0.71
OpenGL Instancing 1.07 0.46
Direct3D 11 Per Object Buffer 28.95 17.82
Direct3D 11 Global Buffer 13.47 7.37
Direct3D 11 Deferred 6.73 1.36
Direct3D 11 Deferred Multithreaded 3.24 0.87
Direct3D 11 Deferred Cached 1.49 0.75
Direct3D 11 Instancing 0.94 0.44
Table 7.: Binding texture arrays
Discussion
The results show that texture arrays increase the performance of the application significantly.Especially the deferred contexts of the Direct3D 11 backend seem to manage far better. How-ever, MDI is still faster on average: The OpenGL technique has much less CPU overhead andperforms around 50% of the time needed by deferred contexts. The only exceptions are theMDI cached and deferred cached modes which show that the difference lies in the method ofrecording the rendering commands.
The disadvantage of texture arrays is that all textures have to be of the same size and format.For example, it is not possible to store the high resolution 2048 x 2048 character textures andthe 256 x 256 textures for small props into one array. This also applies to 32-bit diffuse maps
56

and 8-bit height maps. However, there are certain use cases which greatly benefit from theusage of texture arrays.
• Shadow mapping: Texture arrays can be used to store equally sized shadow maps,which is very useful for techniques like cascaded shadow mapping. It solves the problemof perspective aliasing by providing varying numbers of shadow maps depending on thefrustum depth. This means that shadows in front of the player have been split into multipletextures to show a small portion of them at a high resolution. Cascaded shadow mappingis especially useful for large surfaces like the terrain of an open-world game.
• Terrains: All of the height and layer information is stored in textures. By splitting theminto equally-sized sections, it is possible to create larger, high-resolution terrains.
• Texture groups: Similar to texture atlases, it is possible to pack multiple textures into asingle array to reduce the number of necessary switches.
• Sprite animations: Instead of using large sprite sheets and calculate the UV coordinatesof each animation frame, they are referenced by their index in the texture array. This workssimilar to a flip-book.
5.5.3. OpenGL - Texture Arrays versus Bindless Textures
Another technique that is currently only available for the OpenGL backend is called bindlesstextures. The extension is also described in section 2.2.4 and enables the application to usespecific handles instead of texture (array) bindings. Microsoft’s API introduces a similar featurein Direct3D 12 in the form of descriptors. OpenGL provides texture handles in the form of 64-bitunsigned integers which are converted to the appropriate sampler*D type in the GLSL shader.
Measurement
The parameters are identical to the texture array test in section 5.5.2. Therefore, the OpenGLbackend renders 46.656 textured cubes in a field of 36 x 36 x 36 objects. The CPU and GPUtimes in the results are the average amount of milliseconds needed to render one frame.
57
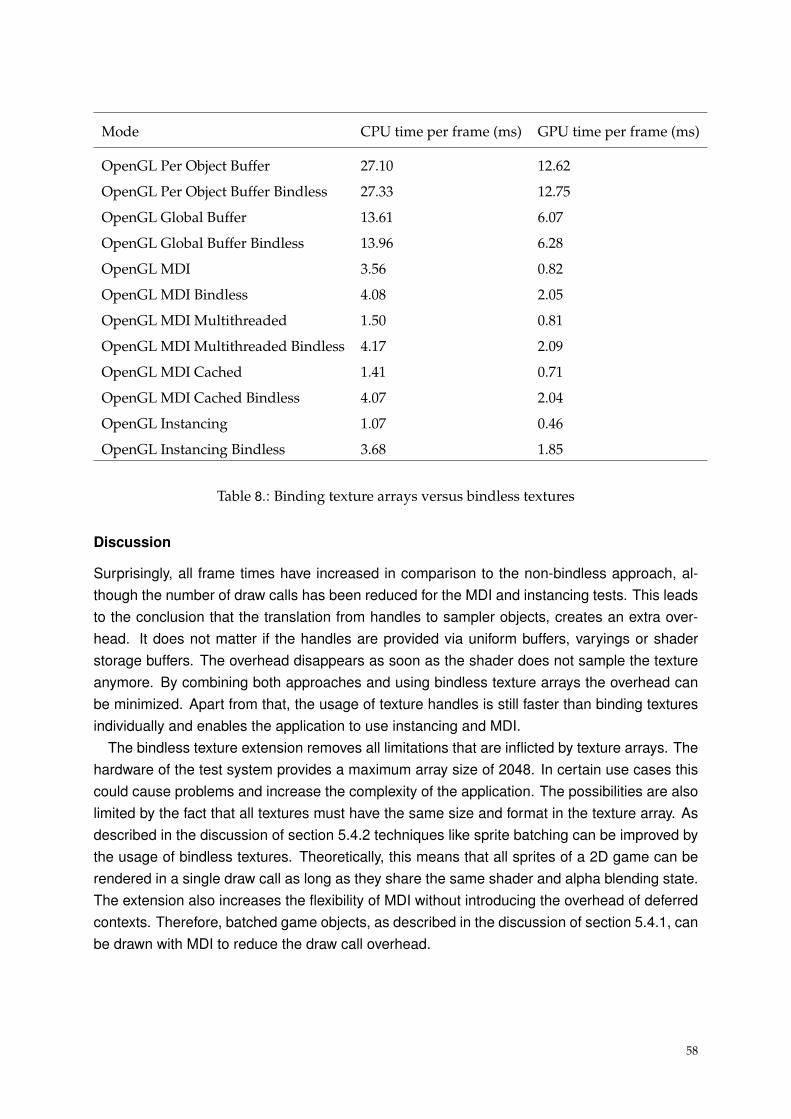
Mode CPU time per frame (ms) GPU time per frame (ms)
OpenGL Per Object Buffer 27.10 12.62
OpenGL Per Object Buffer Bindless 27.33 12.75
OpenGL Global Buffer 13.61 6.07
OpenGL Global Buffer Bindless 13.96 6.28
OpenGL MDI 3.56 0.82
OpenGL MDI Bindless 4.08 2.05
OpenGL MDI Multithreaded 1.50 0.81
OpenGL MDI Multithreaded Bindless 4.17 2.09
OpenGL MDI Cached 1.41 0.71
OpenGL MDI Cached Bindless 4.07 2.04
OpenGL Instancing 1.07 0.46
OpenGL Instancing Bindless 3.68 1.85
Table 8.: Binding texture arrays versus bindless textures
Discussion
Surprisingly, all frame times have increased in comparison to the non-bindless approach, al-though the number of draw calls has been reduced for the MDI and instancing tests. This leadsto the conclusion that the translation from handles to sampler objects, creates an extra over-head. It does not matter if the handles are provided via uniform buffers, varyings or shaderstorage buffers. The overhead disappears as soon as the shader does not sample the textureanymore. By combining both approaches and using bindless texture arrays the overhead canbe minimized. Apart from that, the usage of texture handles is still faster than binding texturesindividually and enables the application to use instancing and MDI.
The bindless texture extension removes all limitations that are inflicted by texture arrays. Thehardware of the test system provides a maximum array size of 2048. In certain use cases thiscould cause problems and increase the complexity of the application. The possibilities are alsolimited by the fact that all textures must have the same size and format in the texture array. Asdescribed in the discussion of section 5.4.2 techniques like sprite batching can be improved bythe usage of bindless textures. Theoretically, this means that all sprites of a 2D game can berendered in a single draw call as long as they share the same shader and alpha blending state.The extension also increases the flexibility of MDI without introducing the overhead of deferredcontexts. Therefore, batched game objects, as described in the discussion of section 5.4.1, canbe drawn with MDI to reduce the draw call overhead.
58
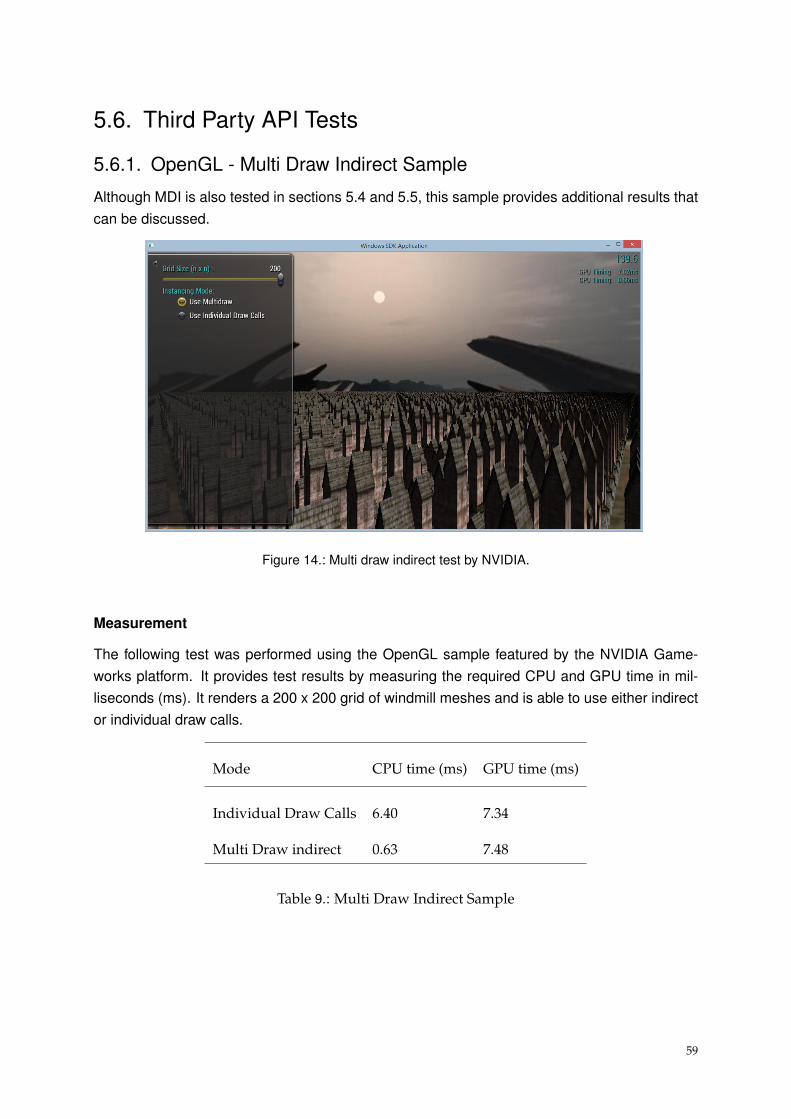
5.6. Third Party API Tests
5.6.1. OpenGL - Multi Draw Indirect Sample
Although MDI is also tested in sections 5.4 and 5.5, this sample provides additional results thatcan be discussed.
Figure 14.: Multi draw indirect test by NVIDIA.
Measurement
The following test was performed using the OpenGL sample featured by the NVIDIA Game-works platform. It provides test results by measuring the required CPU and GPU time in mil-liseconds (ms). It renders a 200 x 200 grid of windmill meshes and is able to use either indirector individual draw calls.
Mode CPU time (ms) GPU time (ms)
Individual Draw Calls 6.40 7.34
Multi Draw indirect 0.63 7.48
Table 9.: Multi Draw Indirect Sample
59

Discussion
The test results confirm the advantage of using this technique and show how much CPU time isused up by individual draw calls and driver overhead. The needed time is reduced significantlyto around 10% by using Multi Draw Indirect. The GPU takes 0.14 ms longer for processing oneframe because it has to provide all the rendering commands by itself. However, the amount oftime needed is minimal.
5.6.2. OpenGL - Instancing
Similar to the MDI test in section 5.6.1 these results help by providing additional feedback.
Figure 15.: Instancing test by NVIDIA.
Measurement
This test is provided by the NVIDIA Gameworks platform and is a part of the OpenGL samples.It measures the frames per seconds for three different types of instancing.
• No instancing: Individual draw calls and uniforms.
• Shader: Uses batches of 100 objects for the draw calls and uniforms.
• Hardware: Uses real instancing with a single draw call.
The application renders 274,625 as well as one million textured boxes in a three-dimensionalfield. Each instance has its own position, rotation and material color.
60

Mode Frames per second
No instancing 14.3
Shader 281.9
Hardware 182.1
Table 10.: GameWorks Instancing Sample - 274,625 objects
Mode Frames per second
No instancing 7.5
Shader 86.8
Hardware 51.4
Table 11.: GameWorks Instancing Sample - 1,000,000 objects
Discussion
The two tests show that instancing and batching increase the performance significantly. How-ever, despite the reduced amount of draw calls the instancing approach produces more over-head for the instancing data that is accessed in the shader. Therefore, the test appears to beGPU-bound on the test system.
5.7. Conclusion
The benchmarks show that there are many different approaches to reduce the driver overheadof an engine. Developers have to choose the appropriate method for their application by pro-filing and testing their applications. Some features like instancing and MDI may reduce theamount of draw calls, but need additional setup and are not as flexible. They can also increasethe bandwith usage as well as the used GPU memory. Direct3D 12, Vulkan and Mantle mayremove those problems by adding more control that enables developers to optimize their gamesand simulations.
61

6. Comparison of Modern OpenGL Techniqueson the Tegra K1 GPU
On July 22, 2014 NVIDIA Corporation launched the NVIDIA Shield Tablet. It belongs to the fam-ily of Shield devices which also includes the previously released NVIDIA Shield Portable. TheShield Tablet is a high-performance mobile device which comes with the Tegra K1 processorwhich consists of the Kepler architecture. Therefore, it is based on the same technology that isused for dedicated GPUs in PCs. The tablet provides OpenGL 4.5 support and is suited to per-form tests with the newest API extensions like ARB_multi_draw_indirect, ARB_bindless_textureor ARB_instanced_array. Thus, the tablet can be used to play modern video games like Trine2, Half-Life 2 or Portal. It also features the streaming of games from the cloud via GRID or thePC via GameStream as well as hardware video capture thanks to ShadowPlay. [45]
NVIDIA offers the Tegra Android Development Pack to enable developers to port their gameseasily to Tegra devices. It contains all software tools that are required to build Android gameslike the Android SDK and NDK, Nsight Tegra for Visual Studio, etc. [46]
This makes it possible to port some of the tests from chapter 5 to the Shield Tablet device.Therefore, two different tests from the Ace3D engine are run to compare the modern OpenGLtechniques:
• Massive object rendering
• Dynamic object streaming
6.1. Test System
The NVIDIA Shield Tablet consists of a Tegra K1 graphics processor with 192 cores and a 2.2GHz ARM Cortex A15 quad-core CPU. The device also provides 2 GB of DDR3L RAM and16-32 GB flash memory. The test device runs Android 5.0.1 with OTA (over the air) version2.2.1. The tests are run by using all 4 cores of the quad-core CPU and the highest performancesettings.
62

6.2. Third Party API Tests
6.2.1. OpenGL - Multi Draw Indirect Sample
The sample used for this test is the same as in section 5.6.1 and is provided by the NVIDIAGameworks platform.
Measurement
The test results are compared by their required CPU and GPU time in milliseconds (ms). Unlikethe PC benchmark this benchmark only renders a 100 x 100 grid of windmill meshes becauseof the weaker hardware.
Mode CPU time (ms) GPU time (ms)
Individual Draw Calls 19.05 24.70
Multi Draw indirect 8.03 24.83
Table 12.: Multi Draw Indirect Sample - NVIDIA Shield Tablet
Discussion
Regarding the test results Multi Draw Indirect reduces the CPU overhead significantly. In com-parison the CPU time is down to approximatley 42% or 11.02 ms. At the same time the GPUtime increases by only 0.13 ms, which is nearly non-relevant. This approach could improvequality and performance of modern mobile games on the NVIDIA Tegra devices quite a lot, forexample by using the extra CPU time for more complex games.
6.2.2. OpenGL - Instancing
The test project is identical to the one used in section 5.6.2 which is provided by the NVIDIAGameworks platform. It compares the performance of using three different kinds of renderingtechniques.
• No instancing: Uses no instancing at all.
• Shader: Uses batches of 100 objects to send the data and draw calls to the shader.
• Hardware: Uses hardware instancing by dispatching all draw data with one function call.
63

Measurement
The test results describe the frames rendered per second. The test renders 216,000 texturedobjects which are constantly changing their position, rotation and shading color.
Mode Frames per second
No instancing 7.5
Shader 25.4
Hardware 33.4
Table 13.: Instancing Sample - NVIDIA Shield Tablet
Discussion
Unlike the test results in section 5.6.2 this shows that hardware instancing indeed helps re-ducing additional driver overhead. However, the batching of the draw calls alone increases theperformance to nearly 340% in comparison to the no instancing mode.
6.3. Conclusion
In conclusion both tests not only show that overhead has a large impact on mobile devices, butalso that hardware like the Tegra K1 chip by NVIDIA begins closing the gap between PC andmobile hardware. The support of APIs like OpenGL 4.5 makes it possible to play games likeHalf-Life 2 on Shield devices. However, tests like the MDI test in section 6.2.1 indicate that thereis still much more room for improvement. Techniques like this may reduce the CPU overhead,but the GPU still takes much longer.
64

7. Conclusion & Outlook
Driver overhead is a problem for games developers that should not be ignored. Although driversmake it possible to run applications on several hardware configurations, it still takes up a lot ofrendering time. Consoles show that a more low-level approach helps resolving overhead is-sues by giving developers more control. Thus, AMD has started working on their Mantle API,which triggered a small revolution in the graphics API section of the game development sector.Mantle enables the application to handle resources and memory more easily by themselves ina console-like way. The API is not going to be released to the public, but it serves as the foun-dation for the new Vulkan API. However, modern OpenGL also provides extensions to reducethe overhead created by the driver. Bindless textures, MDI, DSA, instancing and many morefeatures enable a more simple and overhead-friendly way of graphics programming. Direct3Dis going to provide bindless resources in the form of descriptors in version 12 of Microsoft’s Di-rectX API. Multithreaded rendering is a feature that offers a flexible way to use multiple threadsto record API commands that can then be executed by the main thread. However, the testsshow that this comes with a certain overhead in Direct3D 11 caused by the usage of deferredcontexts. Thus, Microsoft introduces command lists and bundles in the next version of its APIthat are used instead to counter this problem. The outlook is best described as optimistic andnew APIs like Direct3D 12 and Vulkan will certainly help to improve performance for the futuregeneration of games.
Benchmarking shows that the reduction of overhead often comes with the cost of losingflexibility. However, it does indeed have a significant impact on the performance of the renderingprocess. Developers have to perform tests by themselves to decide which features providesatisfactory results for their specific use case. The same applies for mobile devices like theNVIDIA Shield tablet that introduces modern APIs like OpenGL 4.5 to this section. However, atthis moment it is still uncertain how hardware like the Tegra K1 chip is going to be supported bythe device manufacturers.
7.1. Fields of Application
Chapter 5 introduces several rendering techniques and some possible fields of applications.This section evaluates their value for modern games to conclude this thesis.
65

7.1.1. Single Buffer Usage
As described in the discussion of section 5.4.1 it is difficult to pack all of the vertex data into asingle set of buffers. The management this data introduces additional overhead and increasesthe complexity of the application. This also leads to problems when using techniques likeocclusion or frustum culling. It becomes difficult to dynamically manipulate certain objects inthe scene. Therefore, this technique is mostly suitable for creating batches of similar objects,which could be done by the level designer of the game project. The following examples showsome possible fields of application.
• Open world games: Rendering large numbers of individual objects in the game worldintroduces a massive amount of different buffer sets, which increases the driver overheadof the application. This can be solved by creating batches for groups of stones, trees andother parts of the level that are close to each other.
• Rooms: Occlusion culling could be used to hide the geometry of a room to increase theperformance of the game. Therefore, static objects like the furniture can be stored inper-room buffers.
7.1.2. Instancing
Section 5.4.2 introduces several scenarios which benefit from the usage of instancing like fo-liage, particle effects, sprite batching and frequently used meshes. Instancing requires all ob-jects to use the same geometry, although it is possible to manipulate the vertex data in thegeometry and tessellation shader stages. This means that the range of application is limited.Still, the described scenarios are applicable to many games as shown in the following examples.
• Shoot ’em ups & bullet hell shooters: These games are part of the shooter genre. Theyare often rendered in 2D and use a massive amount of bullet sprites. Instancing enablesthe application to perform at a smooth frame rate.
• Open world games: Thanks to instancing vegetation like grass can be rendered with lessoverhead. Instance attributes like the bend factor, color, position and size are stored inthe per-instance buffers and are accessed in the shader stages.
• Voxel engines: The world in games like Minecraft consists of many blocks or similarobjects. Although packing static voxels into a single object to reduce the overhead is avalid approach, dynamic instances still require a large amount of individual draw calls.This can be solved by using the instancing technique.
7.1.3. Multi Draw Indirect
The MDI extension enables OpenGL applications to store several draw commands into a buffer.Ideally, the draw call data resides in GPU memory, which is used by the rendering pipeline.
66

However, it is not possible to switch the states in between each draw call. Therefore, onlygame objects that are using the same set of buffers, textures and shaders are drawn withless overhead. The extension improves the concept of single buffer usage and batching andenhances the previously described scenarios in section 7.1.1. It also introduces the possibilityof using multithreading to gather all draw commands to improve the performance even further.
7.1.4. Deferred Contexts
Similar to MDI, deferred contexts are used by the Direct3D API to gather rendering commandsin multiple threads and execute them with less overhead. The technique uses the same inter-face as the immediate context, which makes it possible to use multithreaded rendering withoutadding too much complexity. Data hazards and state switches are managed by the driver tosimplify the usage. However, this introduces additional overhead. Theoretically, there is noreason to not use deferred contexts and multithreaded rendering in modern games. Still, it isrecommended to perform tests for each application.
7.1.5. Texture Arrays
Texture arrays can be used for shadow mapping, terrains, texture groups and sprite animationas described in the discussion of section 5.5.2. The area of application is limited by the fact thatall textures in an array must have the same size and format. This makes it difficult to use themas an all-round solution for modern games. However, it is possible to use texture arrays in thefollowing examples.
• 2D games: Many modern indie and mobile games are rendered in 2D. Simple spriteanimations that are baked into textures can be accessed more easily by using texturearrays.
• Open world games: Large terrains and modern shadow mapping require the usage oflarge numbers of similar textures. By storing them into texture arrays, the number of stateswitches is reduced.
• Voxel engines: Texture arrays enable the application to render several types of voxels atonce without any state switches. The per-object data contains the texture array index tosample the correct texture for each instance.
7.1.6. Bindless Textures
As described in the discussion of section 5.5.3 the bindless texture extension removes the im-posed restrictions of texture arrays in OpenGL. The test results show that the usage of residenttextures, which are referenced via specific handles, create a small overhead. However, thereare nearly no limitations, which implies that this technique is applicable to all textures of a mod-ern video game. Still, it is recommended to perform occasional tests and also use bindless
67

texture arrays. The extension especially improves the usage of sprites in 2D games. Texturehandles are represented as per-object attributes, which are stored in the instance buffer. Thissignificantly increases the amount of sprites that can be drawn per batch via instancing.
7.2. Future Work
The Direct3D 12 and Vulkan APIs, which are developed by Microsoft and the Khronos Group,give developers more control over rendering operations and the management of hardware re-sources. However, this does not mean that there is going to be no overhead anymore. Controlleads to a more error-prone behaviour that could cause problems like fragmentation and badcache usage. Therefore, the introduction of the APIs will also be the beginning of new discus-sions about these topics.
68

8. Bibliography
[1] Khronos Group: OpenGL Software Development Kit documentation. https://www.opengl.org/sdk/docs/man4/ (visited 2014-12-10)
[2] Khronos Group: The OpenGL Graphics System: A Specification Version 4.5 (Core Profile).February 2, 2015
[3] Sellers, G., Wright, I. R., Haemel, N.: OpenGL Superbible, Comprehensive Tutorial andReference. Addison-Wesley, Sixth Edition, 160–165 (2014)
[4] Sellers, G., Wright, I. R., Haemel, N.: OpenGL Superbible, Comprehensive Tutorial andReference. Addison-Wesley, Sixth Edition, 237–250 (2014)
[5] Cozzi, P., Riccio, C.: OpenGL Insights. Taylor & Francis Group, 358–362 (2012)
[6] Ericson, C.: Order your graphics draw calls around! http://realtimecollisiondetection.net/blog/?p=86 (visited 2015-04-01)
[7] Khronos Group: OpenGL Registry - Bindless Textures Specification. https://www.opengl.org/registry/specs/ARB/bindless_texture.txt (visited 2014-12-12)
[8] Lichtenbelt, B.: Announcing OpenGL 4.4. SIGGRAPH (2013)
[9] McDonald, J., Everitt, C.: Beyond Porting - How Modern OpenGL can Radically ReduceDriver Overhead. Steam Dev Days (2014)
[10] Gateau, S.: Batching for the masses: One glCall to draw them all. SIGGRAPH (2013)
[11] NVIDIA Corporation: NVIDIA Gameworks documentation - Multi-Draw Indirect. http://docs.nvidia.com/gameworks/index.html (visited 2014-12-10)
[12] Khronos Group: OpenGL Registry - Multi Draw Indirect Specification. https://www.opengl.org/registry/specs/ARB/multi_draw_indirect.txt (visited 2014-12-12)
[13] Hart, E.: OpenGL 4.x and Beyond. GPU Technology Conference (2013)
[14] Microsoft: Threading Differences between Direct3D Versions. https://msdn.microsoft.com/en-us/library/windows/desktop/ff476890(v=vs.85).aspx (visited 2015-04-02)
[15] Microsoft: API Layers (Direct3D 10). https://msdn.microsoft.com/en-us/library/windows/desktop/bb205068(v=vs.85).aspx (visited 2015-04-02)
69

[16] Microsoft: Introduction to a Device in Direct3D 11. https://msdn.microsoft.com/en-us/library/windows/desktop/ff476880(v=vs.85).aspx (visited 2015-04-02)
[17] Gee, K.: Introduction to the Direct3D 11 Graphics Pipeline. Nvision 08 (2008)
[18] Microsoft: Dynamic Linking. https://msdn.microsoft.com/en-us/library/windows/desktop/ff471420(v=vs.85).aspx (visited 2015-04-03)
[19] Microsoft: Interfaces and Classes. https://msdn.microsoft.com/en-us/library/windows/desktop/ff471421(v=vs.85).aspx (visited 2015-04-03)
[20] Microsoft: Introduction To Textures in Direct3D 11. https://msdn.microsoft.com/en-us/library/windows/desktop/ff476906(v=vs.85).aspx (visited 2015-04-21)
[21] Microsoft: Resource Limits (Direct3D 11). https://msdn.microsoft.com/en-us/library/windows/desktop/ff819065(v=vs.85).aspx (visited 2015-04-21)
[22] Microsoft: Efficiently Drawing Multiple Instances of Geometry (Direct3D 9). https://msdn.microsoft.com/en-us/library/windows/desktop/bb173349(v=vs.85).aspx (visited 2015-04-04)
[23] Intel Corporation: Rendering grass with Instancing in DirectX* 10. https://software.intel.com/en-us/articles/rendering-grass-with-instancing-in-directx-10 (visited 2015-04-05)
[24] Microsoft: D3D10_INPUT_ELEMENT_DESC structure. https://msdn.microsoft.com/en-us/library/windows/desktop/bb205316(v=vs.85).aspx (visited 2015-04-05)
[25] Sandy, M.: DirectX 12. DirectX Developer Blog. http://blogs.msdn.com/b/directx/archive/2014/03/20/directx-12.aspx (visited 2015-04-09)
[26] Coppock, M.: Direct3D 12 Overview Part 4: Heaps and Tables. In-tel Developer Zone. https://software.intel.com/en-us/blogs/2014/08/07/direct3d-12-overview-part-4-heaps-and-tables (visited 2015-04-10)
[27] Microsoft: Descriptor Tables. https://msdn.microsoft.com/en-us/library/dn899113(v=vs.85).aspx (visited 2015-04-10)
[28] Microsoft: Pipelines and Shaders with Direct3D 12. https://msdn.microsoft.com/en-us/library/dn899200(v=vs.85).aspx (visited 2015-04-10)
[29] Coppock, M.: Direct3D 12 Overview Part 2: Pipeline State Object.Intel Developer Zone. https://software.intel.com/en-us/blogs/2014/07/23/direct3d-12-overview-part-2-pipeline-state-object (visited 2015-04-10)
[30] Coppock, M.: Direct3D 12 Overview Part 6: Command Lists. Intel Developer Zone. https://software.intel.com/en-us/blogs/2014/08/22/direct3d-12-overview-part-6-command-lists(visited 2015-04-11)
70

[31] Microsoft: Design Philosophy of Command Queues and Command Lists. https://msdn.microsoft.com/en-us/library/dn899114(v=vs.85).aspx (visited 2015-04-11)
[32] Microsoft: Executing and synchronizing command lists. https://msdn.microsoft.com/en-us/library/dn899124(v=vs.85).aspx (visited 2015-04-11)
[33] Altavilla, D.: AMD and DICE To Co-Develop Console Style API ForRadeon Graphics. Forbes. http://www.forbes.com/sites/davealtavilla/2013/09/30/amd-and-dice-to-co-develop-console-style-api-for-radeon-graphics/ (visited 2015-03-17)
[34] Advanced Micro Devices (AMD): AMD’s Revolutionary Mantle. http://www.amd.com/en-gb/innovations/software-technologies/mantle (visited 2015-03-17)
[35] Advanced Micro Devices (AMD): On APIs and the future of Mantle.http://community.amd.com/community/amd-blogs/amd-gaming/blog/2015/03/02/on-apis-and-the-future-of-mantle (visited 2015-03-17)
[36] Advanced Micro Devices (AMD): One of Mantle’s Futures: Vulkan. http://community.amd.com/community/amd-blogs/amd-gaming/blog/2015/03/03/one-of-mantles-futures-vulkan(visited 2015-03-17)
[37] Advanced Micro Devices (AMD): Mantle: Empowering 3D Graphics Innovation. White pa-per (2014-03)
[38] Advanced Micro Devices (AMD): Mantle - Introducing a new API for Graphics. GDC SanFrancisco (2014)
[39] Advanced Micro Devices (AMD): Mantle Programming Guide and API reference. Revision1.0 (2014-03-6)
[40] Al-Riyami, F.: You can now try out DirectX 12 for yourself on theWindows 10 Technical Preview! Winbeta. http://www.winbeta.org/news/you-can-now-try-out-directx-12-yourself-windows-10-technical-preview (visited 2015-04-08)
[41] Pruehs, N.: Game Models - A Different Approach. http://www.npruehs.de/game-models-a-different-approach-i/ (visited 2015-04-13)
[42] Pruehs, N.: Game Models - A Different Approach (Part 2). http://www.npruehs.de/game-models-a-different-approach-part-2/ (visited 2015-04-13)
[43] Khronos Group: OpenGL Registry - Timer Query Specification. https://www.opengl.org/registry/specs/ARB/timer_query.txt (visited 2015-04-18)
[44] Khronos Group: OpenGL Software Development Kit documentation - glGetQueryObject.https://www.opengl.org/sdk/docs/man3/xhtml/glGetQueryObject.xml (visited 2015-04-18)
71

[45] NVIDIA Newsroom: NVIDIA Launches World’s Most Ad-vanced Tablet Built for Gamers. http://nvidianews.nvidia.com/news/nvidia-launches-world-s-most-advanced-tablet-built-for-gamers-2775407 (visited 2015-04-07)
[46] NVIDIA Gameworks: Tegra Android Development Pack. https://developer.nvidia.com/tegra-android-development-pack (visited 2015-04-08)
72

9. List of Figures
Figure 1. Example of a key sort structure . . . . . . . . . . . . . . . . . . . . . . . . . . . 10Figure 2. Example of an extended key sort structure . . . . . . . . . . . . . . . . . . . . 11Figure 3. Vertex buffer layout for indexed D3D9 instancing . . . . . . . . . . . . . . . . . 19Figure 4. Vertex buffer layout for non-indexed D3D9 instancing . . . . . . . . . . . . . . 19Figure 5. Buffer and input assembler layout for non-indexed D3D10 instancing . . . . . . 22Figure 6. Descriptor Heap Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26Figure 7. D3D 11 & 12 Pipeline Comparison . . . . . . . . . . . . . . . . . . . . . . . . . 27Figure 8. Mantle Execution Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31Figure 9. Generalized Resources . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31Figure 10. Entity component system . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39Figure 11. DSA rendering test . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44Figure 12. Untextured rendering test . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46Figure 13. Untextured rendering test . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54Figure 14. MDI test . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59Figure 15. Instancing test . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
73

10. List of Tables
Table 1. OpenGL DSA Sample . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45Table 2. Buffer Comparison . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47Table 3. Instancing Comparison . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49Table 4. Multi Draw Indirect & Multithreaded Rendering Comparison . . . . . . . . . . . 52Table 5. All test results combined . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53Table 6. Binding each texture individually . . . . . . . . . . . . . . . . . . . . . . . . . . . 55Table 7. Binding texture arrays . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56Table 8. Binding texture arrays versus bindless textures . . . . . . . . . . . . . . . . . . 58Table 9. Multi Draw Indirect Sample . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59Table 10. GameWorks Instancing Sample - 274,625 objects . . . . . . . . . . . . . . . . . 61Table 11. GameWorks Instancing Sample - 1,000,000 objects . . . . . . . . . . . . . . . . 61Table 12. Multi Draw Indirect Sample - NVIDIA Shield Tablet . . . . . . . . . . . . . . . . 63Table 13. Instancing Sample - NVIDIA Shield Tablet . . . . . . . . . . . . . . . . . . . . . 64
74

11. List of abbreviations
GPU Graphics Processor Unit
CPU Central Processing Unit
DSA Direct State Access
API Application Programming Interface
SRV Shader Resource View
MDI Multi Draw Indirect
GLSL OpenGL Shading Language
HLSL High Level Shading Language
75

A. OpenGL Backend
#ifdef USE_GL#include "RenderBackendGL.h"
#include "TransformComponent.h"
#include "MeshComponent.h"
#include "Texture.h"
#include "TextureLoader.h"
#include <iostream >#include <thread >#include <SFML\ Graphics . hpp>#include <SFML\ System . hpp>#include <glm \ ex t . hpp>
RenderBackend : : RenderBackend ( ){}
RenderBackend : : ~RenderBackend ( ){}
void RenderBackend : : createContext (const glm : : uvec2& windowSize ){mScreenSize = windowSize ;
sf : : ContextSettings settings ;settings .antialiasingLevel = 0;settings .depthBits = 24;settings .stencilBits = 8;
mWindow = new sf : : RenderWindow (sf : : VideoMode (mScreenSize .x , mScreenSize .y ), "Master Rendering" , sf : : Style : : None , settings ) ;
mWindow−>setVerticalSyncEnabled (false ) ;mWindow−>setMouseCursorVisible (false ) ;sf : : Mouse : : setPosition (sf : : Vector2i (mScreenSize .x / 2 , mScreenSize .y / 2) ,
∗mWindow ) ;
76

settings = mWindow−>getSettings ( ) ;std : : cout << "depth bits:" << settings .depthBits << std : : endl ;std : : cout << "stencil bits:" << settings .stencilBits << std : : endl ;std : : cout << "antialiasing level:" << settings .antialiasingLevel << std : :
endl ;std : : cout << "version:" << settings .majorVersion << "." << settings .
minorVersion << std : : endl ;
GLenum err = glewInit ( ) ;if (GLEW_OK != err ){
/∗ Problem : g l e w I n i t f a i l e d , something i s s e r i o u s l y wrong . ∗ /fprintf (stderr , "Error: %s\n" , glewGetErrorString (err ) ) ;
}
glEnable (GL_CULL_FACE ) ;glCullFace (GL_BACK ) ;
/ / Enable depth t e s t i n gglEnable (GL_DEPTH_TEST ) ;
/ / Set c l ea r co l o rglClearColor ( 0 .5f , 0.5f , 0.8f , 0.0f ) ;
glViewport (0 , 0 , mScreenSize .x , mScreenSize .y ) ;
glm : : vec3 position = glm : : vec3 ( 0 .0f ) ;glm : : vec3 forward = glm : : vec3 ( 0 .0f , 0.0f , 1.0f ) ;glm : : vec3 right = glm : : vec3 ( 1 .0f , 0.0f , 0.0f ) ;glm : : vec3 up = glm : : vec3 ( 0 .0f , 1.0f , 0.0f ) ; / / glm : : cross ( r i g h t , forward ) ;
glm : : mat4 projectionMatrix = glm : : perspective (glm : : radians (60 .0f ) ,static_cast<float>(mScreenSize .x ) / static_cast<float>(mScreenSize .y ) ,
0.1f , 1000.0f ) ;glm : : mat4 viewMatrix = glm : : lookAt (position , position + forward , up ) ;mViewProjectionMatrix = projectionMatrix ∗ viewMatrix ;
}
void RenderBackend : : initTextures (TextureLoader∗ textureLoader ){sf : : Image image ;image .loadFromFile ("media/test_point.png" ) ;glm : : uvec2 size = glm : : uvec2 (image .getSize ( ) .x , image .getSize ( ) .y ) ;
for (auto& textureIt : textureLoader−>getTextures ( ) )
77

{textureIt−>size = size ;unsigned int& id = textureIt−>id ;
glCreateTextures (GL_TEXTURE_2D , 1 , &id ) ;/ / Load t e x t u r e from p i x e l sglTextureStorage2D (id , 1 , GL_RGBA8 , size .x , size .y ) ;glTextureSubImage2D (id , 0 , 0 , 0 , size .x , size .y , GL_RGBA ,
GL_UNSIGNED_BYTE , image .getPixelsPtr ( ) ) ;
#ifdef USE_GL_BINDLESStextureIt−>handle = glGetTextureHandleARB (id ) ;glMakeTextureHandleResidentARB (textureIt−>handle ) ;
#endif
}}
void RenderBackend : : initTextureArrays (TextureLoader∗ textureLoader ){sf : : Image image ;image .loadFromFile ("media/test_point.png" ) ;glm : : uvec2 size = glm : : uvec2 (image .getSize ( ) .x , image .getSize ( ) .y ) ;std : : vector<Texture∗>& textures = textureLoader−>getTextures ( ) ;size_t textureNum = textures .size ( ) ;size_t arrayIndex = 0;GLuint id = 0;
#ifdef USE_GL_BINDLESSGLuint64 bindlessHandle = 0;
#endif
for (size_t i = 0; i < textureNum ; i++){Texture& texture = ∗textures [i ] ;
if (arrayIndex == 0){glCreateTextures (GL_TEXTURE_2D_ARRAY , 1 , &id ) ;GLuint arraySize = glm : : min<GLuint>(2048 , textureNum − i ) ;glTextureStorage3D (id , 1 , GL_RGBA8 , size .x , size .y , arraySize ) ;
#ifdef USE_GL_BINDLESSbindlessHandle = glGetTextureHandleARB (id ) ;
#endif
TextureArrayData textureArrayData = { id , arraySize } ;mTextureArrayDataList .push_back (textureArrayData ) ;
78

}
glTextureSubImage3D (id , 0 , 0 , 0 , arrayIndex , size .x , size .y , 1 , GL_RGBA ,GL_UNSIGNED_BYTE , image .getPixelsPtr ( ) ) ;
texture .size = size ;texture .id = id ;texture .arrayIndex = arrayIndex ;
#ifdef USE_GL_BINDLESStexture .handle = bindlessHandle ;
#endif
arrayIndex++;
if (arrayIndex >= 2048 | | i == textureNum − 1){
#ifdef USE_GL_BINDLESSglMakeTextureHandleResidentARB (texture .handle ) ;
#endif
arrayIndex = 0;}
}}
void RenderBackend : : initMesh (unsigned int id , ComponentWorld& world ){MeshComponent& meshComp = world .getMeshComponents ( ) [id ] ;
#ifdef USE_GL_DSA/ / Generate VBO f o r ve r t i ces , normals and t e x t u r e coord ina tesGLuint vbo ;glCreateBuffers (1 , &vbo ) ;meshComp .vbo = vbo ;
/ / Generate b u f f e r data setglNamedBufferData (vbo , meshComp .vertices .size ( ) ∗ sizeof (VertexData ) , &
meshComp .vertices [ 0 ] , GL_STATIC_DRAW ) ;
/ / Generate VBO f o r i nd i cesGLuint ibo ;glCreateBuffers (1 , &ibo ) ;meshComp .ibo = ibo ;
/ / Generate b u f f e r data set f o r i nd i cesglNamedBufferData (ibo , meshComp .indices .size ( ) ∗ sizeof (glm : : uvec3 ) , &
meshComp .indices [ 0 ] , GL_STATIC_DRAW ) ;
79

#else
/ / Generate VBO f o r ve r t i ces , normals and t e x t u r e coord ina tesGLuint vbo ;glGenBuffers (1 , &vbo ) ;meshComp .vbo = vbo ;/ / Bind VBO i n order to useglBindBuffer (GL_ARRAY_BUFFER , vbo ) ;/ / Generate b u f f e r data setglBufferData (GL_ARRAY_BUFFER , meshComp .vertices .size ( ) ∗ sizeof (VertexData
) , &meshComp .vertices [ 0 ] , GL_STATIC_DRAW ) ;glBindBuffer (GL_ARRAY_BUFFER , 0) ;
GLuint ibo ;glGenBuffers (1 , &ibo ) ;meshComp .ibo = ibo ;/ / Bind VBO f o r i nd i ces i n order to useglBindBuffer (GL_ELEMENT_ARRAY_BUFFER , ibo ) ;/ / Generate b u f f e r data set f o r i nd i cesglBufferData (GL_ELEMENT_ARRAY_BUFFER , meshComp .indices .size ( ) ∗ sizeof (glm
: : uvec3 ) , &meshComp .indices [ 0 ] , GL_STATIC_DRAW ) ;glBindBuffer (GL_ELEMENT_ARRAY_BUFFER , 0) ;
#endif
}
void RenderBackend : : initInstanceBaseMesh (unsigned int id , ComponentWorld&world )
{MeshComponent& meshComp = world .getMeshComponents ( ) [id ] ;
/ / Generate VBO f o r ve r t i ces , normals and t e x t u r e coord ina tesglCreateBuffers (1 , &mVbo ) ;
/ / Generate b u f f e r data setglNamedBufferData (mVbo , meshComp .vertices .size ( ) ∗ sizeof (VertexData ) , &
meshComp .vertices [ 0 ] , GL_STATIC_DRAW ) ;
/ / Generate VBO f o r i nd i cesglCreateBuffers (1 , &mIbo ) ;
/ / Generate b u f f e r data set f o r i nd i cesglNamedBufferData (mIbo , meshComp .indices .size ( ) ∗ sizeof (glm : : uvec3 ) , &
meshComp .indices [ 0 ] , GL_STATIC_DRAW ) ;}
80

void RenderBackend : : initMeshesSingleBuffered (ComponentWorld& world ){std : : vector<VertexData> vertexData ;std : : vector<UVector3> indexData ;
for (auto& meshIt : world .getMeshComponents ( ) ){MeshComponent& meshComp = meshIt .second ;vertexData .insert (vertexData .end ( ) , meshComp .vertices .begin ( ) , meshComp .
vertices .end ( ) ) ;indexData .insert (indexData .end ( ) , meshComp .indices .begin ( ) , meshComp .
indices .end ( ) ) ;}
/ / Generate VBO f o r ve r t i ces , normals and t e x t u r e coord ina tesglCreateBuffers (1 , &mVbo ) ;/ / Generate b u f f e r data setglNamedBufferData (mVbo , vertexData .size ( ) ∗ sizeof (VertexData ) , &
vertexData [ 0 ] , GL_STATIC_DRAW ) ;
/ / Generate VBO f o r i nd i cesglCreateBuffers (1 , &mIbo ) ;/ / Generate b u f f e r data set f o r i nd i cesglNamedBufferData (mIbo , indexData .size ( ) ∗ sizeof (glm : : uvec3 ) , &indexData
[ 0 ] , GL_STATIC_DRAW ) ;}
void RenderBackend : : initInstanceData (ComponentWorld& world ){std : : vector<PerObjectData> instanceData ;instanceData .resize (world .getMeshComponents ( ) .size ( ) ) ;size_t index = 0;
for (auto& meshIt : world .getMeshComponents ( ) ){TransformComponent& transformComp = world .getTransformComponents ( ) [
meshIt .first ] ;glm : : mat4 modelMatrix = glm : : translate (glm : : mat4 ( 1 .0f ) , transformComp .
position ) ;#ifdef USE_GL_BINDLESS
instanceData [index ] = { modelMatrix , meshIt .second .color , meshIt .second .texture−>arrayIndex , meshIt .second .texture−>handle } ;
#else
instanceData [index ] = { modelMatrix , meshIt .second .color , meshIt .second .texture−>arrayIndex } ;
81

#endif
index++;}
/ / Generate VBO f o r ins tance dataglCreateBuffers (1 , &mInstanceVbo ) ;
/ / Generate b u f f e r data setglNamedBufferData (mInstanceVbo , sizeof (PerObjectData ) ∗ instanceData .size
( ) , &instanceData [ 0 ] , GL_DYNAMIC_DRAW ) ;}
void RenderBackend : : initShader ( ){mShader .init ("Diffuse.vert" , "Diffuse.frag" ) ;
/ / L ink shadermShader .linkProg ( ) ;
mShader .storeUniformBlockIndex ("StaticMatrices" ) ;glUniformBlockBinding (mShader .id ( ) , mShader .getUniformBlockIndex ("
StaticMatrices" ) , staticMatricesIndex ) ;mShader .storeUniformBlockIndex ("DynamicBuffer" ) ;glUniformBlockBinding (mShader .id ( ) , mShader .getUniformBlockIndex ("
DynamicBuffer" ) , dynamicBufferIndex ) ;
#ifndef USE_GL_BINDLESSmShader .storeUniformLocation ("uColorTex" ) ;glProgramUniform1i (mShader .id ( ) , mShader .getUniformLocation ("uColorTex" ) ,
0) ;#endif
#ifdef USE_GL_DSAglCreateVertexArrays (1 , &mVao ) ;
/ / Setup ver tex a t t r i b u t e sglEnableVertexArrayAttrib (mVao , 0) ;glEnableVertexArrayAttrib (mVao , 1) ;glEnableVertexArrayAttrib (mVao , 2) ;
/ / Setup the formatsglVertexArrayAttribFormat (mVao , 0 , 3 , GL_FLOAT , GL_FALSE , 0) ;glVertexArrayAttribFormat (mVao , 1 , 3 , GL_FLOAT , GL_FALSE , sizeof (glm : : vec3
) ) ;
82

glVertexArrayAttribFormat (mVao , 2 , 2 , GL_FLOAT , GL_FALSE , sizeof (glm : : vec3) ∗ 2) ;
/ / L ink them upglVertexArrayAttribBinding (mVao , 0 , 0) ;glVertexArrayAttribBinding (mVao , 1 , 1) ;glVertexArrayAttribBinding (mVao , 2 , 2) ;
/ / Generate g loba l matr ices uni form b u f f e r ob jec tglCreateBuffers (1 , &mStaticMatricesUbo ) ;glNamedBufferData (mStaticMatricesUbo , sizeof (glm : : mat4 ) , NULL ,
GL_STATIC_DRAW ) ;glNamedBufferSubData (mStaticMatricesUbo , 0 , sizeof (glm : : mat4 ) , glm : :
value_ptr (mViewProjectionMatrix ) ) ;
glCreateBuffers (1 , &mDynamicBufferUbo ) ;glNamedBufferData (mDynamicBufferUbo , sizeof (PerObjectData ) , NULL ,
GL_STREAM_DRAW ) ;#else
/ / Bind VAOglBindVertexArray (mVao ) ;
glEnableVertexAttribArray ( 0 ) ;glEnableVertexAttribArray ( 1 ) ;glEnableVertexAttribArray ( 2 ) ;
glVertexAttribFormat (0 , 3 , GL_FLOAT , GL_FALSE , 0) ;glVertexAttribFormat (1 , 3 , GL_FLOAT , GL_FALSE , sizeof (glm : : vec3 ) ) ;glVertexAttribFormat (2 , 2 , GL_FLOAT , GL_FALSE , sizeof (glm : : vec3 ) ∗ 2) ;
glVertexAttribBinding (0 , 0) ;glVertexAttribBinding (1 , 1) ;glVertexAttribBinding (2 , 2) ;
glBindVertexArray ( 0 ) ;
/ / Generate g loba l matr ices uni form b u f f e r ob jec tglGenBuffers (1 , &mStaticMatricesUbo ) ;glBindBuffer (GL_UNIFORM_BUFFER , mStaticMatricesUbo ) ;glBufferData (GL_UNIFORM_BUFFER , sizeof (glm : : mat4 ) , NULL , GL_STATIC_DRAW ) ;glBufferSubData (GL_UNIFORM_BUFFER , 0 , sizeof (glm : : mat4 ) , glm : : value_ptr (
mViewProjectionMatrix ) ) ;
glGenBuffers (1 , &mDynamicBufferUbo ) ;glBindBuffer (GL_UNIFORM_BUFFER , mDynamicBufferUbo ) ;
83

glBufferData (GL_UNIFORM_BUFFER , sizeof (PerObjectData ) , NULL ,GL_STREAM_DRAW ) ;
glBindBuffer (GL_UNIFORM_BUFFER , 0) ;#endif
}
void RenderBackend : : initInstancingShader ( ){mShader .init ("DiffuseInstancing.vert" , "DiffuseInstancing.frag" ) ;
/ / L ink shadermShader .linkProg ( ) ;
mShader .storeUniformBlockIndex ("StaticMatrices" ) ;glUniformBlockBinding (mShader .id ( ) , mShader .getUniformBlockIndex ("
StaticMatrices" ) , staticMatricesIndex ) ;
glCreateVertexArrays (1 , &mVao ) ;
/ / Setup ver tex a t t r i b u t e sglEnableVertexArrayAttrib (mVao , 0) ;glEnableVertexArrayAttrib (mVao , 1) ;glEnableVertexArrayAttrib (mVao , 2) ;glEnableVertexArrayAttrib (mVao , 3) ;glEnableVertexArrayAttrib (mVao , 4) ;glEnableVertexArrayAttrib (mVao , 5) ;glEnableVertexArrayAttrib (mVao , 6) ;glEnableVertexArrayAttrib (mVao , 7) ;glEnableVertexArrayAttrib (mVao , 8) ;
/ / Setup the formatsglVertexArrayAttribFormat (mVao , 0 , 3 , GL_FLOAT , GL_FALSE , 0) ;glVertexArrayAttribFormat (mVao , 1 , 3 , GL_FLOAT , GL_FALSE , sizeof (glm : : vec3
) ) ;glVertexArrayAttribFormat (mVao , 2 , 2 , GL_FLOAT , GL_FALSE , sizeof (glm : : vec3
) ∗ 2) ;glVertexArrayAttribFormat (mVao , 3 , 4 , GL_FLOAT , GL_FALSE , 0) ;glVertexArrayAttribFormat (mVao , 4 , 4 , GL_FLOAT , GL_FALSE , sizeof (glm : : vec4
) ) ;glVertexArrayAttribFormat (mVao , 5 , 4 , GL_FLOAT , GL_FALSE , sizeof (glm : : vec4
) ∗ 2) ;glVertexArrayAttribFormat (mVao , 6 , 4 , GL_FLOAT , GL_FALSE , sizeof (glm : : vec4
) ∗ 3) ;glVertexArrayAttribFormat (mVao , 7 , 4 , GL_FLOAT , GL_FALSE , sizeof (glm : : vec4
) ∗ 4) ;
84

glVertexArrayAttribIFormat (mVao , 8 , 1 , GL_UNSIGNED_INT , sizeof (glm : : vec4 )∗ 5) ;
#ifdef USE_GL_BINDLESSglVertexArrayAttribLFormat (mVao , 9 , 1 , GL_UNSIGNED_INT64_ARB , sizeof (glm : :
vec4 ) ∗ 5 + sizeof (GLuint ) ) ;#endif
/ / L ink them upglVertexArrayAttribBinding (mVao , 0 , 0) ;glVertexArrayAttribBinding (mVao , 1 , 1) ;glVertexArrayAttribBinding (mVao , 2 , 2) ;glVertexArrayAttribBinding (mVao , 3 , 3) ;glVertexArrayAttribBinding (mVao , 4 , 4) ;glVertexArrayAttribBinding (mVao , 5 , 5) ;glVertexArrayAttribBinding (mVao , 6 , 6) ;glVertexArrayAttribBinding (mVao , 7 , 7) ;glVertexArrayAttribBinding (mVao , 8 , 8) ;
#ifdef USE_GL_BINDLESSglVertexArrayAttribBinding (mVao , 9 , 9) ;
#endif
/ / Set d i v i s o rglVertexArrayBindingDivisor (mVao , 3 , 1) ;glVertexArrayBindingDivisor (mVao , 4 , 1) ;glVertexArrayBindingDivisor (mVao , 5 , 1) ;glVertexArrayBindingDivisor (mVao , 6 , 1) ;glVertexArrayBindingDivisor (mVao , 7 , 1) ;glVertexArrayBindingDivisor (mVao , 8 , 1) ;
#ifdef USE_GL_BINDLESSglVertexArrayBindingDivisor (mVao , 9 , 1) ;
#endif
/ / Generate g loba l matr ices uni form b u f f e r ob jec tglCreateBuffers (1 , &mStaticMatricesUbo ) ;glNamedBufferData (mStaticMatricesUbo , sizeof (glm : : mat4 ) , NULL ,
GL_STATIC_DRAW ) ;glNamedBufferSubData (mStaticMatricesUbo , 0 , sizeof (glm : : mat4 ) , glm : :
value_ptr (mViewProjectionMatrix ) ) ;}
void RenderBackend : : initCommandBuffer (ComponentWorld& world ){#ifdef USE_GL_DSA
glCreateBuffers (1 , &mIndirectDrawBuffer ) ;
85

glNamedBufferStorage (mIndirectDrawBuffer , world .getMeshComponents ( ) .size ( )∗ sizeof (DrawElementsIndirectCommand ) , 0 , GL_MAP_WRITE_BIT |
GL_MAP_PERSISTENT_BIT | GL_DYNAMIC_STORAGE_BIT ) ;mCommandBuffer = static_cast<DrawElementsIndirectCommand∗>(
glMapNamedBufferRange (mIndirectDrawBuffer ,0 ,world .getMeshComponents ( ) .size ( ) ∗ sizeof (DrawElementsIndirectCommand ) ,GL_MAP_WRITE_BIT | GL_MAP_PERSISTENT_BIT
) ) ;#else
glGenBuffers (1 , &mIndirectDrawBuffer ) ;glBindBuffer (GL_DRAW_INDIRECT_BUFFER , mIndirectDrawBuffer ) ;glBufferStorage (GL_DRAW_INDIRECT_BUFFER , world .getMeshComponents ( ) .size ( )
∗ sizeof (DrawElementsIndirectCommand ) , 0 , GL_MAP_WRITE_BIT |GL_MAP_PERSISTENT_BIT | GL_DYNAMIC_STORAGE_BIT ) ;
mCommandBuffer = static_cast<DrawElementsIndirectCommand∗>(glMapBufferRange (
GL_DRAW_INDIRECT_BUFFER ,0 ,world .getMeshComponents ( ) .size ( ) ∗ sizeof (DrawElementsIndirectCommand ) ,GL_MAP_WRITE_BIT | GL_MAP_PERSISTENT_BIT
) ) ;glBindBuffer (GL_DRAW_INDIRECT_BUFFER , 0) ;
#endif
}
void RenderBackend : : initCommandBufferThreads (ComponentWorld& world ){mMaxThreads = std : : thread : : hardware_concurrency ( ) ;
if (mMaxThreads == 0){printf ("Command Buffer Thread Initialization: Hardware does not support
threading." ) ;exit ( 1 ) ;
}
#ifdef USE_GL_DSAglCreateBuffers (1 , &mIndirectDrawBuffer ) ;glNamedBufferStorage (mIndirectDrawBuffer , world .getMeshComponents ( ) .size ( )
∗ sizeof (DrawElementsIndirectCommand ) , 0 , GL_MAP_WRITE_BIT |GL_MAP_PERSISTENT_BIT | GL_DYNAMIC_STORAGE_BIT | GL_MAP_COHERENT_BIT ) ;
mCommandBuffer = static_cast<DrawElementsIndirectCommand∗>(glMapNamedBufferRange (
86

mIndirectDrawBuffer ,0 ,world .getMeshComponents ( ) .size ( ) ∗ sizeof (DrawElementsIndirectCommand ) ,GL_MAP_WRITE_BIT | GL_MAP_PERSISTENT_BIT | GL_MAP_COHERENT_BIT
) ) ;#else
glGenBuffers (1 , &mIndirectDrawBuffer ) ;glBindBuffer (GL_DRAW_INDIRECT_BUFFER , mIndirectDrawBuffer ) ;glBufferStorage (GL_DRAW_INDIRECT_BUFFER , world .getMeshComponents ( ) .size ( )
∗ sizeof (DrawElementsIndirectCommand ) , 0 , GL_MAP_WRITE_BIT |GL_MAP_PERSISTENT_BIT | GL_DYNAMIC_STORAGE_BIT | GL_MAP_COHERENT_BIT ) ;
mCommandBuffer = static_cast<DrawElementsIndirectCommand∗>(glMapBufferRange (
GL_DRAW_INDIRECT_BUFFER ,0 ,world .getMeshComponents ( ) .size ( ) ∗ sizeof (DrawElementsIndirectCommand ) ,GL_MAP_WRITE_BIT | GL_MAP_PERSISTENT_BIT | GL_MAP_COHERENT_BIT
) ) ;glBindBuffer (GL_DRAW_INDIRECT_BUFFER , 0) ;
#endif
}
void RenderBackend : : populateWorkList (ComponentWorld& world ){unsigned int numMeshes = world .getMeshComponents ( ) .size ( ) ;mWorkList .clear ( ) ;mWorkList .resize (numMeshes ) ;auto it = world .getMeshComponents ( ) .begin ( ) ;unsigned int vertexOffset = 0;unsigned int indexOffset = 0;
for (size_t i = 0; i < numMeshes ; i++ , ++it ){mWorkList [i ] = { &it−>second , vertexOffset , indexOffset } ;vertexOffset += it−>second .vertices .size ( ) ;indexOffset += it−>second .indices .size ( ) ∗ 3;
}}
void RenderBackend : : initContext (GPUTimer∗ gpuTimer ){glBindBufferBase (GL_UNIFORM_BUFFER , staticMatricesIndex ,
mStaticMatricesUbo ) ;glBindBufferBase (GL_UNIFORM_BUFFER , dynamicBufferIndex , mDynamicBufferUbo )
;
87

}
void RenderBackend : : enableBindings ( ){mShader .bind ( ) ;
#ifndef USE_GL_DSAglBindBuffer (GL_UNIFORM_BUFFER , mDynamicBufferUbo ) ;
#endif
glBindVertexArray (mVao ) ;}
void RenderBackend : : disableBindings ( ){glBindVertexArray ( 0 ) ;
#ifndef USE_GL_DSAglBindBuffer (GL_UNIFORM_BUFFER , 0) ;
#endif
mShader .unbind ( ) ;}
void RenderBackend : : clearScreen ( ){glClear (GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT ) ;
}
void RenderBackend : : render (unsigned int id , ComponentWorld& world ){TransformComponent& transformComp = world .getTransformComponents ( ) [id ] ;MeshComponent& meshComp = world .getMeshComponents ( ) [id ] ;glm : : mat4 modelMatrix = glm : : translate (glm : : mat4 ( 1 .0f ) , transformComp .
position ) ;#ifdef USE_GL_DSA
#ifdef USE_GL_BINDLESS
PerObjectData perObjectData = { modelMatrix , meshComp .color , meshComp .texture−>arrayIndex , meshComp .texture−>handle } ;
#elsePerObjectData perObjectData = { modelMatrix , meshComp .color , meshComp .
texture−>arrayIndex } ;
if (meshComp .texture && mBoundTextureId != meshComp .texture−>id ){glBindTextureUnit (0 , meshComp .texture−>id ) ;mBoundTextureId = meshComp .texture−>id ;
}#endif
88

glNamedBufferSubData (mDynamicBufferUbo , 0 , sizeof (PerObjectData ) , &perObjectData ) ;
/ / Setup the b u f f e r sourcesglVertexArrayVertexBuffer (mVao , 0 , meshComp .vbo , 0 , sizeof (VertexData ) ) ;glVertexArrayVertexBuffer (mVao , 1 , meshComp .vbo , 0 , sizeof (VertexData ) ) ;glVertexArrayVertexBuffer (mVao , 2 , meshComp .vbo , 0 , sizeof (VertexData ) ) ;glVertexArrayElementBuffer (mVao , meshComp .ibo ) ;
#else
#ifdef USE_GL_BINDLESS
PerObjectData perObjectData = { modelMatrix , meshComp .color , meshComp .texture−>arrayIndex , meshComp .texture−>handle } ;
#elsePerObjectData perObjectData = { modelMatrix , meshComp .color , meshComp .
texture−>arrayIndex } ;
if (meshComp .texture && mBoundTextureId != meshComp .texture−>id ){glActiveTexture (GL_TEXTURE0 ) ;glBindTexture (GL_TEXTURE_2D , meshComp .texture−>id ) ;glUniform1i (mShader .getUniformLocation ("uColorTex" ) , 0) ;mBoundTextureId = meshComp .texture−>id ;
}#endifglBufferSubData (GL_UNIFORM_BUFFER , 0 , sizeof (PerObjectData ) , &
perObjectData ) ;/ / Setup the b u f f e r sourcesglBindVertexBuffer (0 , meshComp .vbo , 0 , sizeof (VertexData ) ) ;glBindVertexBuffer (1 , meshComp .vbo , 0 , sizeof (VertexData ) ) ;glBindVertexBuffer (2 , meshComp .vbo , 0 , sizeof (VertexData ) ) ;glBindBuffer (GL_ELEMENT_ARRAY_BUFFER , meshComp .ibo ) ;
#endif
glDrawElements (GL_TRIANGLES , meshComp .indices .size ( ) ∗ 3 , GL_UNSIGNED_INT ,0) ;
}
void RenderBackend : : renderSingleBuffered (ComponentWorld& world ){unsigned int vertexOffset = 0;unsigned int indexOffset = 0;
#ifdef USE_GL_DSA/ / Setup the b u f f e r sourcesglVertexArrayVertexBuffer (mVao , 0 , mVbo , 0 , sizeof (VertexData ) ) ;glVertexArrayVertexBuffer (mVao , 1 , mVbo , 0 , sizeof (VertexData ) ) ;glVertexArrayVertexBuffer (mVao , 2 , mVbo , 0 , sizeof (VertexData ) ) ;
89

glVertexArrayElementBuffer (mVao , mIbo ) ;
#else
/ / Setup the b u f f e r sourcesglBindVertexBuffer (0 , mVbo , 0 , sizeof (VertexData ) ) ;glBindVertexBuffer (1 , mVbo , 0 , sizeof (VertexData ) ) ;glBindVertexBuffer (2 , mVbo , 0 , sizeof (VertexData ) ) ;glBindBuffer (GL_ELEMENT_ARRAY_BUFFER , mIbo ) ;
#endif
for (auto& meshIt : world .getMeshComponents ( ) ){TransformComponent& transformComp = world .getTransformComponents ( ) [
meshIt .first ] ;MeshComponent& meshComp = meshIt .second ;glm : : mat4 modelMatrix = glm : : translate (glm : : mat4 ( 1 .0f ) , transformComp .
position ) ;#ifdef USE_GL_DSA
#ifdef USE_GL_BINDLESS
PerObjectData perObjectData = { modelMatrix , meshComp .color , meshComp .texture−>arrayIndex , meshComp .texture−>handle } ;
#elsePerObjectData perObjectData = { modelMatrix , meshComp .color , meshComp .
texture−>arrayIndex } ;
if (meshComp .texture && mBoundTextureId != meshComp .texture−>id ){glBindTextureUnit (0 , meshComp .texture−>id ) ;mBoundTextureId = meshComp .texture−>id ;
}#endif
glNamedBufferSubData (mDynamicBufferUbo , 0 , sizeof (PerObjectData ) , &perObjectData ) ;
#else
#ifdef USE_GL_BINDLESS
PerObjectData perObjectData = { modelMatrix , meshComp .color , meshComp .texture−>arrayIndex , meshComp .texture−>handle } ;
#elsePerObjectData perObjectData = { modelMatrix , meshComp .color , meshComp .
texture−>arrayIndex } ;
if (meshComp .texture && mBoundTextureId != meshComp .texture−>id ){glActiveTexture (GL_TEXTURE0 ) ;glBindTexture (GL_TEXTURE_2D , meshComp .texture−>id ) ;
90

glUniform1i (mShader .getUniformLocation ("uColorTex" ) , 0) ;mBoundTextureId = meshComp .texture−>id ;
}#endif
glBufferSubData (GL_UNIFORM_BUFFER , 0 , sizeof (PerObjectData ) , &perObjectData ) ;
#endif
glDrawElementsBaseVertex (GL_TRIANGLES , meshComp .indices .size ( ) ∗ 3 ,GL_UNSIGNED_INT , (void∗ )indexOffset , vertexOffset ) ;
vertexOffset += meshComp .vertices .size ( ) ;indexOffset += meshComp .indices .size ( ) ∗ 3;
}}
void RenderBackend : : renderInstanced (unsigned int baseId , ComponentWorld&world )
{MeshComponent& meshComp = world .getMeshComponents ( ) [baseId ] ;
glVertexArrayElementBuffer (mVao , mIbo ) ;/ / Setup the b u f f e r sourcesglVertexArrayVertexBuffer (mVao , 0 , mVbo , 0 , sizeof (VertexData ) ) ;glVertexArrayVertexBuffer (mVao , 1 , mVbo , 0 , sizeof (VertexData ) ) ;glVertexArrayVertexBuffer (mVao , 2 , mVbo , 0 , sizeof (VertexData ) ) ;/ / Setup the ins tance b u f f e r sourcesglVertexArrayVertexBuffer (mVao , 3 , mInstanceVbo , 0 , sizeof (PerObjectData ) )
;glVertexArrayVertexBuffer (mVao , 4 , mInstanceVbo , 0 , sizeof (PerObjectData ) )
;glVertexArrayVertexBuffer (mVao , 5 , mInstanceVbo , 0 , sizeof (PerObjectData ) )
;glVertexArrayVertexBuffer (mVao , 6 , mInstanceVbo , 0 , sizeof (PerObjectData ) )
;glVertexArrayVertexBuffer (mVao , 7 , mInstanceVbo , 0 , sizeof (PerObjectData ) )
;glVertexArrayVertexBuffer (mVao , 8 , mInstanceVbo , 0 , sizeof (PerObjectData ) )
;#ifdef USE_GL_BINDLESS
glVertexArrayVertexBuffer (mVao , 9 , mInstanceVbo , 0 , sizeof (PerObjectData ) );
glDrawElementsInstanced (GL_TRIANGLES , meshComp .indices .size ( ) ∗ 3 ,GL_UNSIGNED_INT , 0 , world .getMeshComponents ( ) .size ( ) ) ;
#else
for (size_t i = 0; i < mTextureArrayDataList .size ( ) ; i++){
91

glBindTextureUnit (0 , mTextureArrayDataList [i ] . textureId ) ;glDrawElementsInstancedBaseInstance (GL_TRIANGLES , meshComp .indices .size
( ) ∗ 3 , GL_UNSIGNED_INT , 0 , mTextureArrayDataList [i ] . arraySize , i ∗2048) ;
}#endif
}
void RenderBackend : : addDrawCommand (unsigned int id , ComponentWorld& world ){MeshComponent& meshComp = world .getMeshComponents ( ) [id ] ;
mCommandBuffer [mCommandIndex ] . count = meshComp .indices .size ( ) ∗ 3;mCommandBuffer [mCommandIndex ] . instanceCount = 1;mCommandBuffer [mCommandIndex ] . firstIndex = mCommandIndexOffset ;mCommandBuffer [mCommandIndex ] . baseVertex = mCommandVertexOffset ;mCommandBuffer [mCommandIndex ] . baseInstance = mCommandIndex ;
mCommandVertexOffset += meshComp .vertices .size ( ) ;mCommandIndexOffset += meshComp .indices .size ( ) ∗ 3;++mCommandIndex ;
}
void RenderBackend : : renderIndirect ( ){glVertexArrayElementBuffer (mVao , mIbo ) ;
/ / Setup the b u f f e r sourcesglVertexArrayVertexBuffer (mVao , 0 , mVbo , 0 , sizeof (VertexData ) ) ;glVertexArrayVertexBuffer (mVao , 1 , mVbo , 0 , sizeof (VertexData ) ) ;glVertexArrayVertexBuffer (mVao , 2 , mVbo , 0 , sizeof (VertexData ) ) ;
/ / Setup the ins tance b u f f e r sourcesglVertexArrayVertexBuffer (mVao , 3 , mInstanceVbo , 0 , sizeof (PerObjectData ) )
;glVertexArrayVertexBuffer (mVao , 4 , mInstanceVbo , 0 , sizeof (PerObjectData ) )
;glVertexArrayVertexBuffer (mVao , 5 , mInstanceVbo , 0 , sizeof (PerObjectData ) )
;glVertexArrayVertexBuffer (mVao , 6 , mInstanceVbo , 0 , sizeof (PerObjectData ) )
;glVertexArrayVertexBuffer (mVao , 7 , mInstanceVbo , 0 , sizeof (PerObjectData ) )
;glVertexArrayVertexBuffer (mVao , 8 , mInstanceVbo , 0 , sizeof (PerObjectData ) )
;
92

glBindBuffer (GL_DRAW_INDIRECT_BUFFER , mIndirectDrawBuffer ) ;#ifdef USE_GL_BINDLESS
glVertexArrayVertexBuffer (mVao , 9 , mInstanceVbo , 0 , sizeof (PerObjectData ) );
glMultiDrawElementsIndirect (GL_TRIANGLES , GL_UNSIGNED_INT , 0 ,mCommandIndex , 0) ;
#else
for (size_t i = 0; i < mTextureArrayDataList .size ( ) ; i++){glBindTextureUnit (0 , mTextureArrayDataList [i ] . textureId ) ;glMultiDrawElementsIndirect (GL_TRIANGLES , GL_UNSIGNED_INT ,
reinterpret_cast<void∗>(i ∗ 2048 ∗ sizeof (DrawElementsIndirectCommand ) ) , mTextureArrayDataList [i ] . arraySize ,0) ;
}#endif
glBindBuffer (GL_DRAW_INDIRECT_BUFFER , 0) ;}
void RenderBackend : : clearCommandBuffers ( ){mCommandIndex = 0;mCommandVertexOffset = 0;mCommandIndexOffset = 0;
}
void RenderBackend : : renderIndirectThreaded (ComponentWorld& world ){std : : vector<std : : thread> threads ;threads .reserve (mMaxThreads ) ;unsigned int numItems = mWorkList .size ( ) ;unsigned int currentStartId = 0;
for (size_t i = 0; i < mMaxThreads ; i++){unsigned int count = numItems / mMaxThreads ;if (numItems − count == 1){count++;
}threads .push_back (std : : thread(&RenderBackend : : gatherCommandsThread , this
, i , currentStartId , count ) ) ;currentStartId += count ;
}
93

for (size_t i = 0; i < mMaxThreads ; i++){threads [i ] . join ( ) ;
}
glVertexArrayElementBuffer (mVao , mIbo ) ;
/ / Setup the b u f f e r sourcesglVertexArrayVertexBuffer (mVao , 0 , mVbo , 0 , sizeof (VertexData ) ) ;glVertexArrayVertexBuffer (mVao , 1 , mVbo , 0 , sizeof (VertexData ) ) ;glVertexArrayVertexBuffer (mVao , 2 , mVbo , 0 , sizeof (VertexData ) ) ;
/ / Setup the ins tance b u f f e r sourcesglVertexArrayVertexBuffer (mVao , 3 , mInstanceVbo , 0 , sizeof (PerObjectData ) )
;glVertexArrayVertexBuffer (mVao , 4 , mInstanceVbo , 0 , sizeof (PerObjectData ) )
;glVertexArrayVertexBuffer (mVao , 5 , mInstanceVbo , 0 , sizeof (PerObjectData ) )
;glVertexArrayVertexBuffer (mVao , 6 , mInstanceVbo , 0 , sizeof (PerObjectData ) )
;glVertexArrayVertexBuffer (mVao , 7 , mInstanceVbo , 0 , sizeof (PerObjectData ) )
;glVertexArrayVertexBuffer (mVao , 8 , mInstanceVbo , 0 , sizeof (PerObjectData ) )
;
glBindBuffer (GL_DRAW_INDIRECT_BUFFER , mIndirectDrawBuffer ) ;#ifdef USE_GL_BINDLESS
glVertexArrayVertexBuffer (mVao , 9 , mInstanceVbo , 0 , sizeof (PerObjectData ) );
glMultiDrawElementsIndirect (GL_TRIANGLES , GL_UNSIGNED_INT , 0 , numItems , 0);
#else
for (size_t i = 0; i < mTextureArrayDataList .size ( ) ; i++){glBindTextureUnit (0 , mTextureArrayDataList [i ] . textureId ) ;glMultiDrawElementsIndirect (GL_TRIANGLES , GL_UNSIGNED_INT ,
reinterpret_cast<void∗>(i ∗ 2048 ∗ sizeof (DrawElementsIndirectCommand ) ) , mTextureArrayDataList [i ] . arraySize ,0) ;
}#endif
glBindBuffer (GL_DRAW_INDIRECT_BUFFER , 0) ;}
94

void RenderBackend : : gatherCommandsThread (unsigned int threadId , unsigned int
startIndex , unsigned int num ){for (size_t i = startIndex ; i < startIndex + num ; i++){WorkItem workItem = mWorkList [i ] ;mCommandBuffer [i ] . count = workItem .meshComp−>indices .size ( ) ∗ 3;mCommandBuffer [i ] . instanceCount = 1;mCommandBuffer [i ] . firstIndex = workItem .indexOffset ;mCommandBuffer [i ] . baseVertex = workItem .vertexOffset ;mCommandBuffer [i ] . baseInstance = i ;
}}
void RenderBackend : : swapBuffers ( ){mWindow−>display ( ) ;
}
void RenderBackend : : destroyContext ( ){glDeleteVertexArrays (1 , &mVao ) ;glDeleteBuffers (1 , &mVbo ) ;glDeleteBuffers (1 , &mIbo ) ;glDeleteBuffers (1 , &mInstanceVbo ) ;glDeleteBuffers (1 , &mStaticMatricesUbo ) ;glDeleteBuffers (1 , &mDynamicBufferUbo ) ;glDeleteBuffers (1 , &mIndirectDrawBuffer ) ;
mWindow−>close ( ) ;}
void RenderBackend : : destroyTextures (TextureLoader∗ textureLoader ){for (auto& textureIt : textureLoader−>getTextures ( ) ){if (glIsTexture (textureIt−>id ) ){
#ifdef USE_GL_BINDLESSif (glIsTextureHandleResidentARB (textureIt−>handle ) ){glMakeTextureHandleNonResidentARB (textureIt−>handle ) ;
}#endif
95

glDeleteTextures (1 , &textureIt−>id ) ;}
}}
void RenderBackend : : destroyBuffers (unsigned int id , ComponentWorld& world ){MeshComponent& meshComp = world .getMeshComponents ( ) [id ] ;GLuint vbo = meshComp .vbo ;glDeleteBuffers (1 , &vbo ) ;GLuint ibo = meshComp .ibo ;glDeleteBuffers (1 , &ibo ) ;
}#endif
B. Direct3D Backend
#ifdef USE_D3D#include "RenderBackendD3D11.h"
#include "TransformComponent.h"
#include "MeshComponent.h"
#include "Texture.h"
#include "TextureLoader.h"
#include "GPUTimerD3D11.h"
#include <SFML\ Graphics . hpp>#include <iostream >#include < s t r i n g >#include <thread >#include <d3dcompiler . h>
RenderBackend : : RenderBackend ( ){}
RenderBackend : : ~RenderBackend ( ){}
96

void RenderBackend : : initWindows ( ){#define FULL_SCREEN false
WNDCLASSEX wc ;DEVMODE dmScreenSettings ;int posX , posY ;
/ / Get an ex te rna l p o i n t e r to t h i s ob jec t .ApplicationHandle = this ;
/ / Get the ins tance of t h i s a p p l i c a t i o n .mHinstance = GetModuleHandle (NULL ) ;
/ / Give the a p p l i c a t i o n a name .mApplicationName = L"Master Rendering" ;
/ / Setup the windows c lass wi th d e f a u l t s e t t i n g s .wc .style = CS_HREDRAW | CS_VREDRAW | CS_OWNDC ;wc .lpfnWndProc = WndProc ;wc .cbClsExtra = 0;wc .cbWndExtra = 0;wc .hInstance = mHinstance ;wc .hIcon = LoadIcon (NULL , IDI_WINLOGO ) ;wc .hIconSm = wc .hIcon ;wc .hCursor = LoadCursor (NULL , IDC_ARROW ) ;wc .hbrBackground = (HBRUSH )GetStockObject (HOLLOW_BRUSH ) ;wc .lpszMenuName = NULL ;wc .lpszClassName = mApplicationName ;wc .cbSize = sizeof (WNDCLASSEX ) ;
/ / Reg is te r the window c lass .RegisterClassEx(&wc ) ;
/ / Setup the screen s e t t i n g s depending on whether i t i s running i n f u l lscreen or i n windowed mode .
if (FULL_SCREEN ){
/ / Determine the r e s o l u t i o n o f the c l i e n t s desktop screen .mScreenSize .x = GetSystemMetrics (SM_CXSCREEN ) ;mScreenSize .y = GetSystemMetrics (SM_CYSCREEN ) ;
/ / I f f u l l screen set the screen to maximum s ize o f the users desktopand 32 b i t .
97

memset(&dmScreenSettings , 0 , sizeof (dmScreenSettings ) ) ;dmScreenSettings .dmSize = sizeof (dmScreenSettings ) ;dmScreenSettings .dmPelsWidth = (unsigned long )mScreenSize .x ;dmScreenSettings .dmPelsHeight = (unsigned long )mScreenSize .y ;dmScreenSettings .dmBitsPerPel = 32;dmScreenSettings .dmFields = DM_BITSPERPEL | DM_PELSWIDTH | DM_PELSHEIGHT
;
/ / Change the d i sp lay s e t t i n g s to f u l l screen .ChangeDisplaySettings(&dmScreenSettings , CDS_FULLSCREEN ) ;
/ / Set the p o s i t i o n o f the window to the top l e f t corner .posX = posY = 0;
}else
{/ / Place the window i n the middle o f the screen .posX = (GetSystemMetrics (SM_CXSCREEN ) − mScreenSize .x ) / 2 ;posY = (GetSystemMetrics (SM_CYSCREEN ) − mScreenSize .y ) / 2 ;
}
/ / Create the window wi th the screen s e t t i n g s and get the handle to i t .mHwnd = CreateWindowEx (WS_EX_APPWINDOW , mApplicationName , mApplicationName
,WS_CLIPSIBLINGS | WS_CLIPCHILDREN | WS_POPUP ,posX , posY , mScreenSize .x , mScreenSize .y , NULL , NULL , mHinstance , NULL ) ;
/ / Br ing the window up on the screen and set i t as main focus .ShowWindow (mHwnd , SW_SHOW ) ;SetForegroundWindow (mHwnd ) ;SetFocus (mHwnd ) ;
/ / Hide the mouse cursor .ShowCursor (false ) ;
return ;}
LRESULT CALLBACK RenderBackend : : MessageHandler (HWND hwnd , UINT umsg , WPARAM
wparam , LPARAM lparam ){switch (umsg ){
/ / Check i f a key has been pressed on the keyboard .case WM_KEYDOWN :
98

{/ / I f a key i s pressed send i t to the i npu t ob jec t so i t can record
t h a t s t a t e ./ / m_Input−>KeyDown ( ( unsigned i n t ) wparam ) ;return 0;
}
/ / Check i f a key has been released on the keyboard .case WM_KEYUP :{
/ / I f a key i s re leased then send i t to the i npu t ob jec t so i t canunset the s ta te f o r t h a t key .
/ / m_Input−>KeyUp ( ( unsigned i n t ) wparam ) ;return 0;
}
/ / Any other messages send to the d e f a u l t message handler as oura p p l i c a t i o n won ’ t make use of them .
default :{return DefWindowProc (hwnd , umsg , wparam , lparam ) ;
}}
}
void RenderBackend : : createContext (const glm : : uvec2& windowSize ){using namespace DirectX ;HRESULT result ;
mScreenSize = windowSize ;initWindows ( ) ;
DXGI_SWAP_CHAIN_DESC sd ;ZeroMemory(&sd , sizeof (sd ) ) ;sd .BufferCount = 1;sd .BufferDesc .Width = mScreenSize .x ;sd .BufferDesc .Height = mScreenSize .y ;sd .BufferDesc .Format = DXGI_FORMAT_R8G8B8A8_UNORM ;sd .BufferDesc .RefreshRate .Numerator = 0;sd .BufferDesc .RefreshRate .Denominator = 1;sd .BufferDesc .ScanlineOrdering = DXGI_MODE_SCANLINE_ORDER_UNSPECIFIED ;sd .BufferDesc .Scaling = DXGI_MODE_SCALING_UNSPECIFIED ;sd .BufferUsage = DXGI_USAGE_RENDER_TARGET_OUTPUT ;sd .OutputWindow = mHwnd ;
99

sd .SampleDesc .Count = 1;sd .SampleDesc .Quality = 0;sd .Windowed = TRUE ;sd .SwapEffect = DXGI_SWAP_EFFECT_DISCARD ;
D3D_FEATURE_LEVEL FeatureLevelsRequested = D3D_FEATURE_LEVEL_11_0 ;UINT numLevelsRequested = 1;D3D_FEATURE_LEVEL FeatureLevelsSupported ;
result = D3D11CreateDeviceAndSwapChain (NULL ,D3D_DRIVER_TYPE_HARDWARE ,NULL ,0 ,&FeatureLevelsRequested ,numLevelsRequested ,D3D11_SDK_VERSION ,&sd ,&mSwapChain ,&mDevice ,&FeatureLevelsSupported ,&mContext ) ;
const D3D_FEATURE_LEVEL lvl [ ] = { D3D_FEATURE_LEVEL_11_1 ,D3D_FEATURE_LEVEL_11_0 ,
D3D_FEATURE_LEVEL_10_1 , D3D_FEATURE_LEVEL_10_0 ,D3D_FEATURE_LEVEL_9_3 , D3D_FEATURE_LEVEL_9_2 , D3D_FEATURE_LEVEL_9_1 } ;
UINT createDeviceFlags = 0;#ifdef _DEBUG
createDeviceFlags |= D3D11_CREATE_DEVICE_DEBUG ;#endif
mDevice = nullptr ;result = D3D11CreateDeviceAndSwapChain (nullptr , D3D_DRIVER_TYPE_HARDWARE ,
nullptr , createDeviceFlags , lvl , _countof (lvl ) , D3D11_SDK_VERSION , &sd, &mSwapChain , &mDevice , &FeatureLevelsSupported , &mContext ) ;
if (result == E_INVALIDARG ){result = D3D11CreateDeviceAndSwapChain (nullptr , D3D_DRIVER_TYPE_HARDWARE
, nullptr , createDeviceFlags , &lvl [ 1 ] , _countof (lvl ) − 1 ,D3D11_SDK_VERSION , &sd , &mSwapChain , &mDevice , &FeatureLevelsSupported , &mContext ) ;
}
100

ID3D11Texture2D∗ pBackBuffer ;
/ / Get a p o i n t e r to the back b u f f e rresult = mSwapChain−>GetBuffer (0 , __uuidof (ID3D11Texture2D ) , (LPVOID∗ )&
pBackBuffer ) ;if (FAILED (result ) ){MessageBox (mHwnd , L"Context creation" , L"Error" , MB_OK ) ;
}
/ / Create a render−t a r g e t viewresult = mDevice−>CreateRenderTargetView (pBackBuffer , NULL , &
mRenderTargetView ) ;if (FAILED (result ) ){MessageBox (mHwnd , L"Context creation" , L"Error" , MB_OK ) ;
}
D3D11_TEXTURE2D_DESC depthBufferDesc ;
/ / I n i t i a l i z e the d e s c r i p t i o n o f the depth b u f f e r .ZeroMemory(&depthBufferDesc , sizeof (depthBufferDesc ) ) ;
/ / Set up the d e s c r i p t i o n o f the depth b u f f e r .depthBufferDesc .Width = mScreenSize .x ;depthBufferDesc .Height = mScreenSize .y ;depthBufferDesc .MipLevels = 1;depthBufferDesc .ArraySize = 1;depthBufferDesc .Format = DXGI_FORMAT_D24_UNORM_S8_UINT ;depthBufferDesc .SampleDesc .Count = 1;depthBufferDesc .SampleDesc .Quality = 0;depthBufferDesc .Usage = D3D11_USAGE_DEFAULT ;depthBufferDesc .BindFlags = D3D11_BIND_DEPTH_STENCIL ;depthBufferDesc .CPUAccessFlags = 0;depthBufferDesc .MiscFlags = 0;
/ / Create the t e x t u r e f o r the depth b u f f e r using the f i l l e d outd e s c r i p t i o n .
result = mDevice−>CreateTexture2D(&depthBufferDesc , NULL , &mDepthStencilBuffer ) ;
if (FAILED (result ) ){MessageBox (mHwnd , L"Context creation" , L"Error" , MB_OK ) ;
}
101

D3D11_DEPTH_STENCIL_DESC depthStencilDesc ;
/ / I n i t i a l i z e the d e s c r i p t i o n o f the s t e n c i l s t a t e .ZeroMemory(&depthStencilDesc , sizeof (depthStencilDesc ) ) ;
/ / Set up the d e s c r i p t i o n o f the s t e n c i l s t a t e .depthStencilDesc .DepthEnable = true ;depthStencilDesc .DepthWriteMask = D3D11_DEPTH_WRITE_MASK_ALL ;depthStencilDesc .DepthFunc = D3D11_COMPARISON_LESS ;
depthStencilDesc .StencilEnable = true ;depthStencilDesc .StencilReadMask = 0xFF ;depthStencilDesc .StencilWriteMask = 0xFF ;
/ / S t e n c i l opera t ions i f p i x e l i s f r o n t −f ac ing .depthStencilDesc .FrontFace .StencilFailOp = D3D11_STENCIL_OP_KEEP ;depthStencilDesc .FrontFace .StencilDepthFailOp = D3D11_STENCIL_OP_INCR ;depthStencilDesc .FrontFace .StencilPassOp = D3D11_STENCIL_OP_KEEP ;depthStencilDesc .FrontFace .StencilFunc = D3D11_COMPARISON_ALWAYS ;
/ / S t e n c i l opera t ions i f p i x e l i s back−f ac ing .depthStencilDesc .BackFace .StencilFailOp = D3D11_STENCIL_OP_KEEP ;depthStencilDesc .BackFace .StencilDepthFailOp = D3D11_STENCIL_OP_DECR ;depthStencilDesc .BackFace .StencilPassOp = D3D11_STENCIL_OP_KEEP ;depthStencilDesc .BackFace .StencilFunc = D3D11_COMPARISON_ALWAYS ;
/ / Create the depth s t e n c i l s t a t e .result = mDevice−>CreateDepthStencilState(&depthStencilDesc , &
mDepthStencilState ) ;if (FAILED (result ) ){MessageBox (mHwnd , L"Context creation" , L"Error" , MB_OK ) ;
}
/ / Set the depth s t e n c i l s t a t e .mContext−>OMSetDepthStencilState (mDepthStencilState , 1) ;
D3D11_DEPTH_STENCIL_VIEW_DESC depthStencilViewDesc ;
/ / I n i t a i l z e the depth s t e n c i l view .ZeroMemory(&depthStencilViewDesc , sizeof (depthStencilViewDesc ) ) ;
/ / Set up the depth s t e n c i l view d e s c r i p t i o n .depthStencilViewDesc .Format = DXGI_FORMAT_D24_UNORM_S8_UINT ;depthStencilViewDesc .ViewDimension = D3D11_DSV_DIMENSION_TEXTURE2D ;
102

depthStencilViewDesc .Texture2D .MipSlice = 0;
/ / Create the depth s t e n c i l view .result = mDevice−>CreateDepthStencilView (mDepthStencilBuffer , &
depthStencilViewDesc , &mDepthStencilView ) ;if (FAILED (result ) ){MessageBox (mHwnd , L"Context creation" , L"Error" , MB_OK ) ;
}
/ / Bind the viewmContext−>OMSetRenderTargets (1 , &mRenderTargetView , mDepthStencilView ) ;
D3D11_RASTERIZER_DESC rasterDesc ;
/ / Setup the r a s t e r d e s c r i p t i o n which w i l l determine how and what polygonsw i l l be drawn .
rasterDesc .AntialiasedLineEnable = false ;rasterDesc .CullMode = D3D11_CULL_BACK ;rasterDesc .DepthBias = 0;rasterDesc .DepthBiasClamp = 0.0f ;rasterDesc .DepthClipEnable = true ;rasterDesc .FillMode = D3D11_FILL_SOLID ;rasterDesc .FrontCounterClockwise = false ;rasterDesc .MultisampleEnable = false ;rasterDesc .ScissorEnable = false ;rasterDesc .SlopeScaledDepthBias = 0.0f ;
/ / Create the r a s t e r i z e r s t a t e from the d e s c r i p t i o n we j u s t f i l l e d out .result = mDevice−>CreateRasterizerState(&rasterDesc , &mRasterState ) ;if (FAILED (result ) ){MessageBox (mHwnd , L"Context creation" , L"Error" , MB_OK ) ;
}
/ / Now set the r a s t e r i z e r s t a t e .mContext−>RSSetState (mRasterState ) ;
/ / Setup the v iewpor tmViewport .Width = static_cast<float>(mScreenSize .x ) ;mViewport .Height = static_cast<float>(mScreenSize .y ) ;mViewport .MinDepth = 0.0f ;mViewport .MaxDepth = 1.0f ;mViewport .TopLeftX = 0;mViewport .TopLeftY = 0;
103

mContext−>RSSetViewports (1 , &mViewport ) ;
/ / Setup the p r o j e c t i o n mat r i x .float fieldOfView = DirectX : : XMConvertToRadians (60 .0f ) ;float screenAspect = static_cast<float>(mScreenSize .x ) / static_cast<float
>(mScreenSize .y ) ;
/ / Create the p r o j e c t i o n mat r i x f o r 3D render ing .mViewProjectionMatrix = XMMatrixPerspectiveFovLH (fieldOfView , screenAspect
, 0.1f , 1000.0f ) ;initViewMatrix ( ) ;
mViewProjectionMatrix = DirectX : : XMMatrixTranspose (mViewProjectionMatrix ) ;}
void RenderBackend : : initTextures (TextureLoader∗ textureLoader ){mDevice−>CreateSamplerState (NULL , &mSamplerState ) ;
mTextureDataList .resize (textureLoader−>getTextures ( ) .size ( ) ) ;size_t index = 0;
sf : : Image image ;image .loadFromFile ("media/test_point.png" ) ;DirectX : : XMUINT2 size = DirectX : : XMUINT2 (image .getSize ( ) .x , image .getSize
( ) .y ) ;
for (auto& textureIt : textureLoader−>getTextures ( ) ){textureIt−>size = size ;textureIt−>id = index ;textureIt−>arrayIndex = 0;
D3D11_TEXTURE2D_DESC textureDesc ;textureDesc .Width = size .x ;textureDesc .Height = size .y ;textureDesc .MipLevels = 1;textureDesc .ArraySize = 1;textureDesc .Format = DXGI_FORMAT_R8G8B8A8_UNORM ;textureDesc .SampleDesc .Count = 1;textureDesc .SampleDesc .Quality = 0;textureDesc .Usage = D3D11_USAGE_DEFAULT ;textureDesc .BindFlags = D3D11_BIND_SHADER_RESOURCE ;textureDesc .CPUAccessFlags = 0;textureDesc .MiscFlags = 0;
104

D3D11_SUBRESOURCE_DATA initData ;initData .pSysMem = image .getPixelsPtr ( ) ;initData .SysMemPitch = size .x ∗ 4;initData .SysMemSlicePitch = 0;
HRESULT result = mDevice−>CreateTexture2D(&textureDesc , &initData , &mTextureDataList [index ] . texture ) ;
if (FAILED (result ) ){MessageBox (mHwnd , L"Texture Creation" , L"Error" , MB_OK ) ;
}
D3D11_SHADER_RESOURCE_VIEW_DESC srvDesc ;srvDesc .Format = textureDesc .Format ;srvDesc .ViewDimension = D3D11_SRV_DIMENSION_TEXTURE2D ;srvDesc .Texture2D .MipLevels = textureDesc .MipLevels ;srvDesc .Texture2D .MostDetailedMip = 0;
result = mDevice−>CreateShaderResourceView (mTextureDataList [index ] .texture , &srvDesc , &mTextureDataList [index ] . resourceView ) ;
if (FAILED (result ) ){MessageBox (mHwnd , L"SRV Creation" , L"Error" , MB_OK ) ;
}
index++;}
}
void RenderBackend : : initTextureArrays (TextureLoader∗ textureLoader ){mDevice−>CreateSamplerState (NULL , &mSamplerState ) ;
size_t textureNum = textureLoader−>getTextures ( ) .size ( ) ;size_t index = 0;size_t arrayIndex = 0;
sf : : Image image ;image .loadFromFile ("media/test_point.png" ) ;DirectX : : XMUINT2 size = DirectX : : XMUINT2 (image .getSize ( ) .x , image .getSize
( ) .y ) ;size_t perTextureSize = size .x ∗ size .y ∗ 4;std : : vector<D3D11_SUBRESOURCE_DATA> imageData ;imageData .resize (2048) ;
105

for (auto& textureIt : textureLoader−>getTextures ( ) ){textureIt−>size = size ;textureIt−>id = mTextureDataList .size ( ) ;textureIt−>arrayIndex = arrayIndex ;
imageData [arrayIndex ] . pSysMem = image .getPixelsPtr ( ) ;imageData [arrayIndex ] . SysMemPitch = size .x ∗ 4;imageData [arrayIndex ] . SysMemSlicePitch = 0;
index++;arrayIndex++;
if (arrayIndex >= 2048 | | index == textureNum ){TextureData textureData ;
D3D11_TEXTURE2D_DESC textureDesc ;textureDesc .Width = size .x ;textureDesc .Height = size .y ;textureDesc .MipLevels = 1;textureDesc .ArraySize = arrayIndex ;textureDesc .Format = DXGI_FORMAT_R8G8B8A8_UNORM ;textureDesc .SampleDesc .Count = 1;textureDesc .SampleDesc .Quality = 0;textureDesc .Usage = D3D11_USAGE_DEFAULT ;textureDesc .BindFlags = D3D11_BIND_SHADER_RESOURCE ;textureDesc .CPUAccessFlags = 0;textureDesc .MiscFlags = 0;
HRESULT result = mDevice−>CreateTexture2D(&textureDesc , &imageData [ 0 ] ,&textureData .texture ) ;
if (FAILED (result ) ){MessageBox (mHwnd , L"Texture Creation" , L"Error" , MB_OK ) ;
}
D3D11_SHADER_RESOURCE_VIEW_DESC srvDesc ;srvDesc .Format = textureDesc .Format ;srvDesc .ViewDimension = D3D11_SRV_DIMENSION_TEXTURE2DARRAY ;srvDesc .Texture2DArray .ArraySize = textureDesc .ArraySize ;srvDesc .Texture2DArray .FirstArraySlice = 0;srvDesc .Texture2DArray .MipLevels = textureDesc .MipLevels ;srvDesc .Texture2DArray .MostDetailedMip = 0;
106

result = mDevice−>CreateShaderResourceView (textureData .texture , &srvDesc , &textureData .resourceView ) ;
if (FAILED (result ) ){MessageBox (mHwnd , L"SRV Creation" , L"Error" , MB_OK ) ;
}
textureData .arraySize = arrayIndex ;mTextureDataList .push_back (textureData ) ;arrayIndex = 0;
}}
}
void RenderBackend : : initMesh (unsigned int id , ComponentWorld& world ){using namespace DirectX ;MeshComponent& meshComp = world .getMeshComponents ( ) [id ] ;
/ / Vertex dataD3D11_BUFFER_DESC vertexBufferDesc ;vertexBufferDesc .Usage = D3D11_USAGE_DEFAULT ;vertexBufferDesc .ByteWidth = sizeof (VertexData ) ∗ meshComp .vertices .size ( )
;vertexBufferDesc .BindFlags = D3D11_BIND_VERTEX_BUFFER ;vertexBufferDesc .CPUAccessFlags = 0;vertexBufferDesc .MiscFlags = 0;
D3D11_SUBRESOURCE_DATA VertexInitData ;VertexInitData .pSysMem = &meshComp .vertices [ 0 ] ;VertexInitData .SysMemPitch = 0;VertexInitData .SysMemSlicePitch = 0;
ID3D11Buffer∗ vbo ;HRESULT result = mDevice−>CreateBuffer(&vertexBufferDesc , &VertexInitData ,
&vbo ) ;if (FAILED (result ) ){MessageBox (mHwnd , L"Mesh creation" , L"Error" , MB_OK ) ;
}meshComp .vbo = vbo ;
/ / Index dataD3D11_BUFFER_DESC indexBufferDesc ;
107

indexBufferDesc .Usage = D3D11_USAGE_DEFAULT ;indexBufferDesc .ByteWidth = sizeof (UVector3 ) ∗ meshComp .indices .size ( ) ;indexBufferDesc .BindFlags = D3D11_BIND_INDEX_BUFFER ;indexBufferDesc .CPUAccessFlags = 0;indexBufferDesc .MiscFlags = 0;
D3D11_SUBRESOURCE_DATA IndexInitData ;IndexInitData .pSysMem = &meshComp .indices [ 0 ] ;IndexInitData .SysMemPitch = 0;IndexInitData .SysMemSlicePitch = 0;
ID3D11Buffer∗ ibo ;result = mDevice−>CreateBuffer(&indexBufferDesc , &IndexInitData , &ibo ) ;if (FAILED (result ) ){MessageBox (mHwnd , L"Mesh creation" , L"Error" , MB_OK ) ;
}meshComp .ibo = ibo ;
}
void RenderBackend : : initInstanceBaseMesh (unsigned int id , ComponentWorld&world )
{using namespace DirectX ;MeshComponent& meshComp = world .getMeshComponents ( ) [id ] ;
/ / Vertex dataD3D11_BUFFER_DESC vertexBufferDesc ;vertexBufferDesc .Usage = D3D11_USAGE_DEFAULT ;vertexBufferDesc .ByteWidth = sizeof (VertexData ) ∗ meshComp .vertices .size ( )
;vertexBufferDesc .BindFlags = D3D11_BIND_VERTEX_BUFFER ;vertexBufferDesc .CPUAccessFlags = 0;vertexBufferDesc .MiscFlags = 0;
D3D11_SUBRESOURCE_DATA VertexInitData ;VertexInitData .pSysMem = &meshComp .vertices [ 0 ] ;VertexInitData .SysMemPitch = 0;VertexInitData .SysMemSlicePitch = 0;
HRESULT result = mDevice−>CreateBuffer(&vertexBufferDesc , &VertexInitData ,&mVertexBuffer ) ;
if (FAILED (result ) ){MessageBox (mHwnd , L"Mesh creation" , L"Error" , MB_OK ) ;
108

}
/ / Index dataD3D11_BUFFER_DESC indexBufferDesc ;indexBufferDesc .Usage = D3D11_USAGE_DEFAULT ;indexBufferDesc .ByteWidth = sizeof (UVector3 ) ∗ meshComp .indices .size ( ) ;indexBufferDesc .BindFlags = D3D11_BIND_INDEX_BUFFER ;indexBufferDesc .CPUAccessFlags = 0;indexBufferDesc .MiscFlags = 0;
D3D11_SUBRESOURCE_DATA IndexInitData ;IndexInitData .pSysMem = &meshComp .indices [ 0 ] ;IndexInitData .SysMemPitch = 0;IndexInitData .SysMemSlicePitch = 0;
result = mDevice−>CreateBuffer(&indexBufferDesc , &IndexInitData , &mIndexBuffer ) ;
if (FAILED (result ) ){MessageBox (mHwnd , L"Mesh creation" , L"Error" , MB_OK ) ;
}}
void RenderBackend : : initMeshesSingleBuffered (ComponentWorld& world ){using namespace DirectX ;std : : vector<VertexData> vertexData ;std : : vector<UVector3> indexData ;
for (auto& meshIt : world .getMeshComponents ( ) ){MeshComponent& meshComp = meshIt .second ;vertexData .insert (vertexData .end ( ) , meshComp .vertices .begin ( ) , meshComp .
vertices .end ( ) ) ;indexData .insert (indexData .end ( ) , meshComp .indices .begin ( ) , meshComp .
indices .end ( ) ) ;}
/ / Vertex dataD3D11_BUFFER_DESC vertexBufferDesc ;vertexBufferDesc .Usage = D3D11_USAGE_DEFAULT ;vertexBufferDesc .ByteWidth = sizeof (VertexData ) ∗ vertexData .size ( ) ;vertexBufferDesc .BindFlags = D3D11_BIND_VERTEX_BUFFER ;vertexBufferDesc .CPUAccessFlags = 0;vertexBufferDesc .MiscFlags = 0;
109

D3D11_SUBRESOURCE_DATA VertexInitData ;VertexInitData .pSysMem = &vertexData [ 0 ] ;VertexInitData .SysMemPitch = 0;VertexInitData .SysMemSlicePitch = 0;
HRESULT result = mDevice−>CreateBuffer(&vertexBufferDesc , &VertexInitData ,&mVertexBuffer ) ;
if (FAILED (result ) ){MessageBox (mHwnd , L"Mesh creation" , L"Error" , MB_OK ) ;
}
/ / Index dataD3D11_BUFFER_DESC indexBufferDesc ;indexBufferDesc .Usage = D3D11_USAGE_DEFAULT ;indexBufferDesc .ByteWidth = sizeof (UVector3 ) ∗ indexData .size ( ) ;indexBufferDesc .BindFlags = D3D11_BIND_INDEX_BUFFER ;indexBufferDesc .CPUAccessFlags = 0;indexBufferDesc .MiscFlags = 0;
D3D11_SUBRESOURCE_DATA IndexInitData ;IndexInitData .pSysMem = &indexData [ 0 ] ;IndexInitData .SysMemPitch = 0;IndexInitData .SysMemSlicePitch = 0;
result = mDevice−>CreateBuffer(&indexBufferDesc , &IndexInitData , &mIndexBuffer ) ;
if (FAILED (result ) ){MessageBox (mHwnd , L"Mesh creation" , L"Error" , MB_OK ) ;
}}
void RenderBackend : : initInstanceData (ComponentWorld& world ){using namespace DirectX ;
std : : vector<PerObjectData> instanceData ;instanceData .resize (world .getMeshComponents ( ) .size ( ) ) ;size_t index = 0;
for (auto& meshIt : world .getMeshComponents ( ) ){
110

TransformComponent& transformComp = world .getTransformComponents ( ) [meshIt .first ] ;
XMMATRIX modelMatrix = XMMatrixIdentity ( ) ;modelMatrix = XMMatrixTranslation (transformComp .position .x ,
transformComp .position .y , transformComp .position .z ) ;modelMatrix = XMMatrixTranspose (modelMatrix ) ;instanceData [index ] = { modelMatrix , meshIt .second .color , meshIt .second .
texture−>arrayIndex } ;index++;
}
/ / Ins tance dataD3D11_BUFFER_DESC instanceBufferDesc ;instanceBufferDesc .Usage = D3D11_USAGE_DYNAMIC ;instanceBufferDesc .ByteWidth = sizeof (PerObjectData ) ∗ instanceData .size ( )
;instanceBufferDesc .BindFlags = D3D11_BIND_VERTEX_BUFFER ;instanceBufferDesc .CPUAccessFlags = D3D11_CPU_ACCESS_WRITE ;instanceBufferDesc .MiscFlags = 0;
D3D11_SUBRESOURCE_DATA instanceInitData ;instanceInitData .pSysMem = &instanceData [ 0 ] ;instanceInitData .SysMemPitch = 0;instanceInitData .SysMemSlicePitch = 0;
HRESULT result = mDevice−>CreateBuffer(&instanceBufferDesc , &instanceInitData , &mInstanceBuffer ) ;
if (FAILED (result ) ){MessageBox (mHwnd , L"Instance buffer creation" , L"Error" , MB_OK ) ;
}}
void RenderBackend : : initCommandBuffer (ComponentWorld& world ){mDevice−>CreateDeferredContext (0 , &mDeferredContext ) ;
mDeferredContext−>OMSetDepthStencilState (mDepthStencilState , 1) ;mDeferredContext−>OMSetRenderTargets (1 , &mRenderTargetView ,
mDepthStencilView ) ;mDeferredContext−>RSSetState (mRasterState ) ;mDeferredContext−>RSSetViewports (1 , &mViewport ) ;
mDeferredContext−>VSSetShader (mVertexShader , NULL , 0) ;mDeferredContext−>PSSetShader (mPixelShader , NULL , 0) ;
111

mDeferredContext−>IASetInputLayout (mLayout ) ;
/ / Set ver tex b u f f e r s t r i d e and o f f s e t .unsigned int stride = sizeof (VertexData ) ;unsigned int offset = 0;ID3D11Buffer∗ vbo = mVertexBuffer ;
/ / Set the ver tex b u f f e r to a c t i v e i n the i npu t assembler so i t can berendered .
mDeferredContext−>IASetVertexBuffers (0 , 1 , &vbo , &stride , &offset ) ;
ID3D11Buffer∗ ibo = mIndexBuffer ;
/ / Set the index b u f f e r to a c t i v e i n the i npu t assembler so i t can berendered .
mDeferredContext−>IASetIndexBuffer (ibo , DXGI_FORMAT_R32_UINT , 0) ;
unsigned int instanceStride = sizeof (PerObjectData ) ;unsigned int instanceOffset = 0;ID3D11Buffer∗ instanceVbo = mInstanceBuffer ;
/ / Set the ins tance b u f f e r to a c t i v e i n the i npu t assembler so i t can berendered .
mDeferredContext−>IASetVertexBuffers (1 , 1 , &instanceVbo , &instanceStride ,&instanceOffset ) ;
/ / Set the type of p r i m i t i v e t h a t should be rendered from t h i s ver texbu f fe r , i n t h i s case t r i a n g l e s .
mDeferredContext−>IASetPrimitiveTopology (D3D11_PRIMITIVE_TOPOLOGY_TRIANGLELIST ) ;
mDeferredContext−>VSSetConstantBuffers (0 , 1 , &mStaticMatrixBuffer ) ;}
void RenderBackend : : initCommandBufferThreads (ComponentWorld& world ){mMaxThreads = std : : thread : : hardware_concurrency ( ) ;
if (mMaxThreads == 0){MessageBox (mHwnd , L"Gather Draw Commands Threaded" , L"Hardware does not
support threading." , MB_OK ) ;exit ( 1 ) ;
}
112

mThreadDataList .resize (mMaxThreads ) ;
for (size_t i = 0; i < mMaxThreads ; i++){mThreadDataList [i ] . commandBuffer = NULL ;
ID3D11DeviceContext∗ deferredContext ;mDevice−>CreateDeferredContext (NULL , &deferredContext ) ;mThreadDataList [i ] . deferredContext = deferredContext ;
deferredContext−>OMSetDepthStencilState (mDepthStencilState , 1) ;deferredContext−>OMSetRenderTargets (1 , &mRenderTargetView ,
mDepthStencilView ) ;deferredContext−>RSSetState (mRasterState ) ;deferredContext−>RSSetViewports (1 , &mViewport ) ;deferredContext−>VSSetShader (mVertexShader , NULL , 0) ;deferredContext−>PSSetShader (mPixelShader , NULL , 0) ;deferredContext−>IASetInputLayout (mLayout ) ;
/ / Set ver tex b u f f e r s t r i d e and o f f s e t .unsigned int stride = sizeof (VertexData ) ;unsigned int offset = 0;ID3D11Buffer∗ vbo = mVertexBuffer ;
/ / Set the ver tex b u f f e r to a c t i v e i n the i npu t assembler so i t can berendered .
deferredContext−>IASetVertexBuffers (0 , 1 , &vbo , &stride , &offset ) ;
ID3D11Buffer∗ ibo = mIndexBuffer ;
/ / Set the index b u f f e r to a c t i v e i n the i npu t assembler so i t can berendered .
deferredContext−>IASetIndexBuffer (ibo , DXGI_FORMAT_R32_UINT , 0) ;
unsigned int instanceStride = sizeof (PerObjectData ) ;unsigned int instanceOffset = 0;ID3D11Buffer∗ instanceVbo = mInstanceBuffer ;
/ / Set the ins tance b u f f e r to a c t i v e i n the i npu t assembler so i t can berendered .
deferredContext−>IASetVertexBuffers (1 , 1 , &instanceVbo , &instanceStride ,&instanceOffset ) ;
/ / Set the type of p r i m i t i v e t h a t should be rendered from t h i s ver texbu f fe r , i n t h i s case t r i a n g l e s .
113

deferredContext−>IASetPrimitiveTopology (D3D11_PRIMITIVE_TOPOLOGY_TRIANGLELIST ) ;
deferredContext−>VSSetConstantBuffers (0 , 1 , &mStaticMatrixBuffer ) ;}
}
void RenderBackend : : populateWorkList (ComponentWorld& world ){unsigned int numMeshes = world .getMeshComponents ( ) .size ( ) ;mWorkList .clear ( ) ;mWorkList .resize (numMeshes ) ;auto it = world .getMeshComponents ( ) .begin ( ) ;unsigned int vertexOffset = 0;unsigned int indexOffset = 0;
for (size_t i = 0; i < numMeshes ; i++ , ++it ){mWorkList [i ] = { &it−>second , vertexOffset , indexOffset } ;vertexOffset += it−>second .vertices .size ( ) ;indexOffset += it−>second .indices .size ( ) ∗ 3;
}}
void RenderBackend : : initShader ( ){HRESULT result ;mVertexShader = 0;mPixelShader = 0;
/ / Create ver tex shaderID3DBlob∗ vertexBlob ;result = D3DReadFileToBlob (L"../ReleaseD3D11/DiffuseVS.cso" , &vertexBlob ) ;if (FAILED (result ) ){MessageBox (mHwnd , L"DiffuseVS.cso" , L"Vertex Shader Read Error" , MB_OK ) ;
}result = mDevice−>CreateVertexShader (vertexBlob−>GetBufferPointer ( ) ,
vertexBlob−>GetBufferSize ( ) , NULL , &mVertexShader ) ;if (FAILED (result ) ){MessageBox (mHwnd , L"DiffuseVS.cso" , L"Vertex Shader Compile Error" ,
MB_OK ) ;}D3D11_INPUT_ELEMENT_DESC inputDesc [ ] = {
114

{ "POSITION" , 0 , DXGI_FORMAT_R32G32B32_FLOAT , 0 , 0 ,D3D11_INPUT_PER_VERTEX_DATA , 0 } ,
{ "NORMAL" , 0 , DXGI_FORMAT_R32G32B32_FLOAT , 0 ,D3D11_APPEND_ALIGNED_ELEMENT , D3D11_INPUT_PER_VERTEX_DATA , 0 } ,
{ "TEXCOORD" , 0 , DXGI_FORMAT_R32G32_FLOAT , 0 ,D3D11_APPEND_ALIGNED_ELEMENT , D3D11_INPUT_PER_VERTEX_DATA , 0 }
} ;size_t numElements = sizeof (inputDesc ) / sizeof (inputDesc [ 0 ] ) ;result = mDevice−>CreateInputLayout (inputDesc , numElements , vertexBlob−>
GetBufferPointer ( ) , vertexBlob−>GetBufferSize ( ) , &mLayout ) ;if (FAILED (result ) ){MessageBox (mHwnd , L"Input description error" , L"Invalid input layout" ,
MB_OK ) ;}
/ / Create p i x e l shaderID3DBlob∗ pixelBlob ;D3DReadFileToBlob (L"../ReleaseD3D11/DiffusePS.cso" , &pixelBlob ) ;result = mDevice−>CreatePixelShader (pixelBlob−>GetBufferPointer ( ) ,
pixelBlob−>GetBufferSize ( ) , NULL , &mPixelShader ) ;if (FAILED (result ) ){MessageBox (mHwnd , L"DiffusePS.cso" , L"Pixel Shader Compile Error" , MB_OK
) ;}
/ / Create constant b u f f e r f o r matr ices i n shaderD3D11_BUFFER_DESC matrixBufferDesc ;matrixBufferDesc .Usage = D3D11_USAGE_DYNAMIC ;matrixBufferDesc .ByteWidth = sizeof (DirectX : : XMMATRIX ) ;matrixBufferDesc .BindFlags = D3D11_BIND_CONSTANT_BUFFER ;matrixBufferDesc .CPUAccessFlags = D3D11_CPU_ACCESS_WRITE ;matrixBufferDesc .MiscFlags = 0;matrixBufferDesc .StructureByteStride = 0;
D3D11_SUBRESOURCE_DATA initData ;initData .pSysMem = &mViewProjectionMatrix ;initData .SysMemPitch = 0;initData .SysMemSlicePitch = 0;
result = mDevice−>CreateBuffer(&matrixBufferDesc , &initData , &mStaticMatrixBuffer ) ;
if (FAILED (result ) )
115

{MessageBox (mHwnd , L"Static matrices" , L"Failed create buffer" , MB_OK ) ;
}/ / Set constant b u f f e r i n con tex tmContext−>VSSetConstantBuffers (0 , 1 , &mStaticMatrixBuffer ) ;
/ / Create constant b u f f e r f o r dynamic matr ices i n shaderD3D11_BUFFER_DESC dynBufferDesc ;dynBufferDesc .Usage = D3D11_USAGE_DYNAMIC ;dynBufferDesc .ByteWidth = sizeof (PerObjectData ) ;dynBufferDesc .BindFlags = D3D11_BIND_CONSTANT_BUFFER ;dynBufferDesc .CPUAccessFlags = D3D11_CPU_ACCESS_WRITE ;dynBufferDesc .MiscFlags = 0;dynBufferDesc .StructureByteStride = 0;
D3D11_SUBRESOURCE_DATA initDynData ;initDynData .pSysMem = &mPerObjectData ;initDynData .SysMemPitch = 0;initDynData .SysMemSlicePitch = 0;
result = mDevice−>CreateBuffer(&dynBufferDesc , &initDynData , &mDynamicBuffer ) ;
if (FAILED (result ) ){MessageBox (mHwnd , L"Per Object Data" , L"Failed create buffer" , MB_OK ) ;
}}
void RenderBackend : : initInstancingShader ( ){HRESULT result ;mVertexShader = 0;mPixelShader = 0;
/ / Create ver tex shaderID3DBlob∗ vertexBlob ;result = D3DReadFileToBlob (L"../ReleaseD3D11/DiffuseInstancingVS.cso" , &
vertexBlob ) ;if (FAILED (result ) ){MessageBox (mHwnd , L"DiffuseInstancingVS.cso" , L"Vertex Shader Read Error
" , MB_OK ) ;}
116

result = mDevice−>CreateVertexShader (vertexBlob−>GetBufferPointer ( ) ,vertexBlob−>GetBufferSize ( ) , NULL , &mVertexShader ) ;
if (FAILED (result ) ){MessageBox (mHwnd , L"DiffuseInstancingVS.cso" , L"Vertex Shader Compile
Error" , MB_OK ) ;}D3D11_INPUT_ELEMENT_DESC inputDesc [ ] = {
{ "POSITION" , 0 , DXGI_FORMAT_R32G32B32_FLOAT , 0 , 0 ,D3D11_INPUT_PER_VERTEX_DATA , 0 } ,
{ "NORMAL" , 0 , DXGI_FORMAT_R32G32B32_FLOAT , 0 ,D3D11_APPEND_ALIGNED_ELEMENT , D3D11_INPUT_PER_VERTEX_DATA , 0 } ,
{ "TEXCOORD" , 0 , DXGI_FORMAT_R32G32_FLOAT , 0 ,D3D11_APPEND_ALIGNED_ELEMENT , D3D11_INPUT_PER_VERTEX_DATA , 0 } ,
{ "MODEL_MATRIX" , 0 , DXGI_FORMAT_R32G32B32A32_FLOAT , 1 , 0 ,D3D11_INPUT_PER_INSTANCE_DATA , 1 } ,
{ "MODEL_MATRIX" , 1 , DXGI_FORMAT_R32G32B32A32_FLOAT , 1 ,D3D11_APPEND_ALIGNED_ELEMENT , D3D11_INPUT_PER_INSTANCE_DATA , 1 } ,
{ "MODEL_MATRIX" , 2 , DXGI_FORMAT_R32G32B32A32_FLOAT , 1 ,D3D11_APPEND_ALIGNED_ELEMENT , D3D11_INPUT_PER_INSTANCE_DATA , 1 } ,
{ "MODEL_MATRIX" , 3 , DXGI_FORMAT_R32G32B32A32_FLOAT , 1 ,D3D11_APPEND_ALIGNED_ELEMENT , D3D11_INPUT_PER_INSTANCE_DATA , 1 } ,
{ "MATERIAL_DIFFUSE" , 0 , DXGI_FORMAT_R32G32B32A32_FLOAT , 1 ,D3D11_APPEND_ALIGNED_ELEMENT , D3D11_INPUT_PER_INSTANCE_DATA , 1 } ,
{ "TEXTURE_HANDLE" , 0 , DXGI_FORMAT_R32_UINT , 1 ,D3D11_APPEND_ALIGNED_ELEMENT , D3D11_INPUT_PER_INSTANCE_DATA , 1 }
} ;size_t numElements = sizeof (inputDesc ) / sizeof (inputDesc [ 0 ] ) ;result = mDevice−>CreateInputLayout (inputDesc , numElements , vertexBlob−>
GetBufferPointer ( ) , vertexBlob−>GetBufferSize ( ) , &mLayout ) ;if (FAILED (result ) ){MessageBox (mHwnd , L"Input description error" , L"Invalid input layout" ,
MB_OK ) ;}
/ / Create p i x e l shaderID3DBlob∗ pixelBlob ;D3DReadFileToBlob (L"../ReleaseD3D11/DiffuseInstancingPS.cso" , &pixelBlob ) ;result = mDevice−>CreatePixelShader (pixelBlob−>GetBufferPointer ( ) ,
pixelBlob−>GetBufferSize ( ) , NULL , &mPixelShader ) ;if (FAILED (result ) ){
117

MessageBox (mHwnd , L"DiffuseInstancingPS.cso" , L"Pixel Shader Compile
Error" , MB_OK ) ;}
/ / Create constant b u f f e r f o r matr ices i n shaderD3D11_BUFFER_DESC matrixBufferDesc ;matrixBufferDesc .Usage = D3D11_USAGE_DYNAMIC ;matrixBufferDesc .ByteWidth = sizeof (DirectX : : XMMATRIX ) ;matrixBufferDesc .BindFlags = D3D11_BIND_CONSTANT_BUFFER ;matrixBufferDesc .CPUAccessFlags = D3D11_CPU_ACCESS_WRITE ;matrixBufferDesc .MiscFlags = 0;matrixBufferDesc .StructureByteStride = 0;
D3D11_SUBRESOURCE_DATA initData ;initData .pSysMem = &mViewProjectionMatrix ;initData .SysMemPitch = 0;initData .SysMemSlicePitch = 0;
result = mDevice−>CreateBuffer(&matrixBufferDesc , &initData , &mStaticMatrixBuffer ) ;
if (FAILED (result ) ){MessageBox (mHwnd , L"Static matrices" , L"Failed create buffer" , MB_OK ) ;
}/ / Set constant b u f f e r i n con tex tmContext−>VSSetConstantBuffers (0 , 1 , &mStaticMatrixBuffer ) ;
}
void RenderBackend : : initContext (GPUTimer∗ timer ){timer−>setContext (mDevice , mContext ) ;
/ / I n i t i a l i z e the message s t r u c t u r e .ZeroMemory(&mMsg , sizeof (MSG ) ) ;
}
void RenderBackend : : enableBindings ( ){
/ / Set the ver tex and p i x e l shaders t h a t w i l l be used to render t h i st r i a n g l e .
mContext−>VSSetShader (mVertexShader , NULL , 0) ;mContext−>PSSetShader (mPixelShader , NULL , 0) ;mContext−>IASetInputLayout (mLayout ) ;mContext−>PSSetSamplers (0 , 1 , &mSamplerState ) ;
118

/ / Set the type of p r i m i t i v e t h a t should be rendered from t h i s ver texbu f fe r , i n t h i s case t r i a n g l e s .
mContext−>IASetPrimitiveTopology (D3D11_PRIMITIVE_TOPOLOGY_TRIANGLELIST ) ;
/ / Set constant b u f f e r i n con tex tmContext−>VSSetConstantBuffers (1 , 1 , &mDynamicBuffer ) ;mContext−>PSSetConstantBuffers (0 , 1 , &mDynamicBuffer ) ;
}
void RenderBackend : : disableBindings ( ){mContext−>IASetInputLayout (NULL ) ;mContext−>VSSetShader (NULL , NULL , 0) ;mContext−>PSSetShader (NULL , NULL , 0) ;
}
void RenderBackend : : clearScreen ( ){
/ / Handle the windows messages .if (PeekMessage(&mMsg , NULL , 0 , 0 , PM_REMOVE ) ){TranslateMessage(&mMsg ) ;DispatchMessage(&mMsg ) ;
}
const float clearColor [ 4 ] = { 0.5f , 0.5f , 0.8f , 0.0f } ;mContext−>ClearRenderTargetView (mRenderTargetView , clearColor ) ;mContext−>ClearDepthStencilView (mDepthStencilView , D3D11_CLEAR_DEPTH , 1.0f
, 0) ;}
void RenderBackend : : render (unsigned int id , ComponentWorld& world ){TransformComponent& transformComp = world .getTransformComponents ( ) [id ] ;MeshComponent& meshComp = world .getMeshComponents ( ) [id ] ;
/ / Set ver tex b u f f e r s t r i d e and o f f s e t .unsigned int stride = sizeof (VertexData ) ;unsigned int offset = 0;ID3D11Buffer∗ vbo = meshComp .vbo ;ID3D11Buffer∗ ibo = meshComp .ibo ;
/ / Set the ver tex b u f f e r to a c t i v e i n the i npu t assembler so i t can berendered .
mContext−>IASetVertexBuffers (0 , 1 , &vbo , &stride , &offset ) ;
119

/ / Set the index b u f f e r to a c t i v e i n the i npu t assembler so i t can berendered .
mContext−>IASetIndexBuffer (ibo , DXGI_FORMAT_R32_UINT , 0) ;
mPerObjectData .modelMatrix = DirectX : : XMMatrixIdentity ( ) ;mPerObjectData .modelMatrix = DirectX : : XMMatrixTranslation (transformComp .
position .x , transformComp .position .y , transformComp .position .z ) ;mPerObjectData .modelMatrix = DirectX : : XMMatrixTranspose (mPerObjectData .
modelMatrix ) ;mPerObjectData .materialDiffuse = meshComp .color ;mPerObjectData .textureHandle = meshComp .texture−>arrayIndex ;D3D11_MAPPED_SUBRESOURCE mappedResource ;HRESULT result ;result = mContext−>Map (mDynamicBuffer , 0 , D3D11_MAP_WRITE_DISCARD , 0 , &
mappedResource ) ;if (FAILED (result ) ){MessageBox (mHwnd , L"Dynamic Buffer" , L"Buffer map error" , MB_OK ) ;
}memcpy (mappedResource .pData , &mPerObjectData , sizeof (PerObjectData ) ) ;mContext−>Unmap (mDynamicBuffer , 0) ;
if (meshComp .texture && mBoundTextureId != meshComp .texture−>id ){mContext−>PSSetShaderResources (0 , 1 , &mTextureDataList [meshComp .texture
−>id ] . resourceView ) ;mBoundTextureId = meshComp .texture−>id ;
}
mContext−>DrawIndexed (meshComp .indices .size ( ) ∗ 3 , 0 , 0) ;}
void RenderBackend : : renderSingleBuffered (ComponentWorld& world ){unsigned int vertexOffset = 0;unsigned int indexOffset = 0;
/ / Set ver tex b u f f e r s t r i d e and o f f s e t .unsigned int stride = sizeof (VertexData ) ;unsigned int offset = 0;ID3D11Buffer∗ vbo = mVertexBuffer ;ID3D11Buffer∗ ibo = mIndexBuffer ;
120

/ / Set the ver tex b u f f e r to a c t i v e i n the i npu t assembler so i t can berendered .
mContext−>IASetVertexBuffers (0 , 1 , &vbo , &stride , &offset ) ;
/ / Set the index b u f f e r to a c t i v e i n the i npu t assembler so i t can berendered .
mContext−>IASetIndexBuffer (ibo , DXGI_FORMAT_R32_UINT , 0) ;
for (auto& meshIt : world .getMeshComponents ( ) ){TransformComponent& transformComp = world .getTransformComponents ( ) [
meshIt .first ] ;MeshComponent& meshComp = meshIt .second ;
mPerObjectData .modelMatrix = DirectX : : XMMatrixIdentity ( ) ;mPerObjectData .modelMatrix = DirectX : : XMMatrixTranslation (transformComp .
position .x , transformComp .position .y , transformComp .position .z ) ;mPerObjectData .modelMatrix = DirectX : : XMMatrixTranspose (mPerObjectData .
modelMatrix ) ;mPerObjectData .materialDiffuse = meshComp .color ;D3D11_MAPPED_SUBRESOURCE mappedResource ;HRESULT result ;result = mContext−>Map (mDynamicBuffer , 0 , D3D11_MAP_WRITE_DISCARD , 0 , &
mappedResource ) ;if (FAILED (result ) ){MessageBox (mHwnd , L"Dynamic Buffer" , L"Buffer map error" , MB_OK ) ;
}memcpy (mappedResource .pData , &mPerObjectData , sizeof (PerObjectData ) ) ;mContext−>Unmap (mDynamicBuffer , 0) ;
if (meshComp .texture && mBoundTextureId != meshComp .texture−>id ){mContext−>PSSetShaderResources (0 , 1 , &mTextureDataList [meshComp .
texture−>id ] . resourceView ) ;mBoundTextureId = meshComp .texture−>id ;
}
mContext−>DrawIndexed (meshComp .indices .size ( ) ∗ 3 , indexOffset ,vertexOffset ) ;
vertexOffset += meshComp .vertices .size ( ) ;indexOffset += meshComp .indices .size ( ) ∗ 3;
}}
121

void RenderBackend : : renderInstanced (unsigned int baseId , ComponentWorld&world )
{MeshComponent& meshComp = world .getMeshComponents ( ) [baseId ] ;
/ / Set ver tex b u f f e r s t r i d e and o f f s e t .unsigned int stride = sizeof (VertexData ) ;unsigned int offset = 0;ID3D11Buffer∗ vbo = mVertexBuffer ;ID3D11Buffer∗ ibo = mIndexBuffer ;
unsigned int instanceStride = sizeof (PerObjectData ) ;unsigned int instanceOffset = 0;ID3D11Buffer∗ instanceVbo = mInstanceBuffer ;
/ / Set the ver tex b u f f e r to a c t i v e i n the i npu t assembler so i t can berendered .
mContext−>IASetVertexBuffers (0 , 1 , &vbo , &stride , &offset ) ;
/ / Set the index b u f f e r to a c t i v e i n the i npu t assembler so i t can berendered .
mContext−>IASetIndexBuffer (ibo , DXGI_FORMAT_R32_UINT , 0) ;
/ / Set the ins tance b u f f e r to a c t i v e i n the i npu t assembler so i t can berendered .
mContext−>IASetVertexBuffers (1 , 1 , &instanceVbo , &instanceStride , &instanceOffset ) ;
for (size_t i = 0; i < mTextureDataList .size ( ) ; i++){mContext−>PSSetShaderResources (0 , 1 , &mTextureDataList [i ] . resourceView ) ;mContext−>DrawIndexedInstanced (meshComp .indices .size ( ) ∗ 3 ,
mTextureDataList [i ] . arraySize , 0 , 0 , i ∗ 2048) ;}
}
void RenderBackend : : addDrawCommand (unsigned int id , ComponentWorld& world ){MeshComponent& meshComp = world .getMeshComponents ( ) [id ] ;if (meshComp .texture && mBoundTextureId != meshComp .texture−>id ){mDeferredContext−>PSSetShaderResources (0 , 1 , &mTextureDataList [meshComp .
texture−>id ] . resourceView ) ;mBoundTextureId = meshComp .texture−>id ;
}
122

mDeferredContext−>DrawIndexedInstanced (meshComp .indices .size ( ) ∗ 3 , 1 ,mCommandIndexOffset , mCommandVertexOffset , mCommandIndex ) ;
mCommandVertexOffset += meshComp .vertices .size ( ) ;mCommandIndexOffset += meshComp .indices .size ( ) ∗ 3;mCommandIndex++;
}
void RenderBackend : : renderIndirect ( ){if (mCommandBuffer == NULL ){HRESULT result = mDeferredContext−>FinishCommandList (true , &
mCommandBuffer ) ;if (FAILED (result ) ){MessageBox (mHwnd , L"Finishing command list" , L"Command list error" ,
MB_OK ) ;exit ( 1 ) ;
}}
mContext−>ExecuteCommandList (mCommandBuffer , false ) ;}
void RenderBackend : : renderIndirectThreaded (ComponentWorld& world ){std : : vector<std : : thread> threads ;threads .reserve (mMaxThreads ) ;unsigned int numItems = mWorkList .size ( ) ;unsigned int currentStartId = 0;
for (size_t i = 0; i < mMaxThreads ; i++){unsigned int count = numItems / mMaxThreads ;if (numItems − count == 1){count++;
}threads .push_back (std : : thread(&RenderBackend : : gatherCommandsThread , this
, i , currentStartId , count ) ) ;currentStartId += count ;
}
for (size_t i = 0; i < mMaxThreads ; i++)
123

{threads [i ] . join ( ) ;mContext−>ExecuteCommandList (mThreadDataList [i ] . commandBuffer , false ) ;mThreadDataList [i ] . commandBuffer−>Release ( ) ;mThreadDataList [i ] . commandBuffer = NULL ;
}}
void RenderBackend : : gatherCommandsThread (unsigned int threadId , unsigned int
startIndex , unsigned int num ){ID3D11DeviceContext∗ deferredContext = mThreadDataList [threadId ] .
deferredContext ;
for (size_t i = startIndex ; i < startIndex + num ; i++){WorkItem workItem = mWorkList [i ] ;if (workItem .meshComp−>texture && mBoundTextureId != workItem .meshComp−>
texture−>id ){deferredContext−>PSSetShaderResources (0 , 1 , &mTextureDataList [workItem
.meshComp−>texture−>id ] . resourceView ) ;mBoundTextureId = workItem .meshComp−>texture−>id ;
}deferredContext−>DrawIndexedInstanced (workItem .meshComp−>indices .size ( )
∗ 3 , 1 , workItem .indexOffset , workItem .vertexOffset , i ) ;}
deferredContext−>FinishCommandList (true , &mThreadDataList [threadId ] .commandBuffer ) ;
}
void RenderBackend : : clearCommandBuffers ( ){if (mCommandBuffer != NULL ){mCommandBuffer−>Release ( ) ;mCommandBuffer = NULL ;
}
mCommandIndex = 0;mCommandVertexOffset = 0;mCommandIndexOffset = 0;
}
124

void RenderBackend : : swapBuffers ( ){HRESULT result = mSwapChain−>Present (0 , 0) ;if (FAILED (result ) ){MessageBox (mHwnd , L"Swap" , L"Buffer swap error" , MB_OK ) ;exit ( 1 ) ;
}}
void RenderBackend : : destroyContext ( ){
/ / Before s h u t t i n g down set to windowed mode or when you re lease the swapchain i t w i l l throw an except ion .
if (mSwapChain ){mSwapChain−>SetFullscreenState (false , NULL ) ;
}
if (mRasterState ){mRasterState−>Release ( ) ;mRasterState = 0;
}
if (mDepthStencilView ){mDepthStencilView−>Release ( ) ;mDepthStencilView = 0;
}
if (mDepthStencilState ){mDepthStencilState−>Release ( ) ;mDepthStencilState = 0;
}
if (mDepthStencilBuffer ){mDepthStencilBuffer−>Release ( ) ;mDepthStencilBuffer = 0;
}
if (mRenderTargetView )
125

{mRenderTargetView−>Release ( ) ;mRenderTargetView = 0;
}
if (mContext ){mContext−>Release ( ) ;mContext = 0;
}
if (mDevice ){mDevice−>Release ( ) ;mDevice = 0;
}
if (mSwapChain ){mSwapChain−>Release ( ) ;mSwapChain = 0;
}
/ / Release the mat r i x constant b u f f e r .if (mStaticMatrixBuffer ){mStaticMatrixBuffer−>Release ( ) ;mStaticMatrixBuffer = 0;
}
if (mDynamicBuffer ){mDynamicBuffer−>Release ( ) ;mDynamicBuffer = 0;
}
if (mInstanceBuffer ){mInstanceBuffer−>Release ( ) ;mInstanceBuffer = 0;
}
if (mVertexBuffer ){mVertexBuffer−>Release ( ) ;
126

mVertexBuffer = 0;}
if (mIndexBuffer ){mIndexBuffer−>Release ( ) ;mIndexBuffer = 0;
}
if (mCommandBuffer ){mCommandBuffer−>Release ( ) ;mCommandBuffer = 0;
}
/ / Release the layou t .if (mLayout ){mLayout−>Release ( ) ;mLayout = 0;
}
/ / Release the p i x e l shader .if (mPixelShader ){mPixelShader−>Release ( ) ;mPixelShader = 0;
}
/ / Release the ver tex shader .if (mVertexShader ){mVertexShader−>Release ( ) ;mVertexShader = 0;
}
for (size_t i = 0; i < mThreadDataList .size ( ) ; i++){if (mThreadDataList [i ] . deferredContext ){mThreadDataList [i ] . deferredContext−>Release ( ) ;mThreadDataList [i ] . deferredContext = 0;
}}
}
127

void RenderBackend : : destroyTextures (TextureLoader∗ textureLoader ){for (auto& textureData : mTextureDataList ){textureData .texture−>Release ( ) ;textureData .resourceView−>Release ( ) ;
}}
void RenderBackend : : destroyBuffers (unsigned int id , ComponentWorld& world ){MeshComponent& meshComp = world .getMeshComponents ( ) [id ] ;
if (meshComp .ibo ){meshComp .ibo−>Release ( ) ;
}
if (meshComp .vbo ){meshComp .vbo−>Release ( ) ;
}}
void RenderBackend : : initViewMatrix ( ){using namespace DirectX ;XMFLOAT3 up , position , lookAt ;float yaw , pitch , roll ;XMMATRIX rotationMatrix ;
/ / Setup the vec to r t h a t po in t s upwards .up .x = 0.0f ;up .y = 1.0f ;up .z = 0.0f ;
/ / Setup the p o s i t i o n o f the camera i n the world .position .x = 0.0f ;position .y = 0.0f ;position .z = 0.0f ;
/ / Setup where the camera i s look ing by d e f a u l t .lookAt .x = 0.0f ;
128

lookAt .y = 0.0f ;lookAt .z = 1.0f ;
/ / Set the yaw (Y ax is ) , p i t c h (X ax is ) , and r o l l (Z ax is ) r o t a t i o n s i nrad ians .
pitch = 0.0f ∗ 0.0174532925f ;yaw = 0.0f ∗ 0.0174532925f ;roll = 0.0f ∗ 0.0174532925f ;
/ / Create the r o t a t i o n mat r i x from the yaw , p i t ch , and r o l l values .rotationMatrix = XMMatrixRotationRollPitchYaw (pitch , yaw , roll ) ;
/ / Transform the lookAt and up vec to r by the r o t a t i o n mat r i x so the viewi s c o r r e c t l y ro ta ted a t the o r i g i n .
XMStoreFloat3(&lookAt , XMVector3TransformCoord (XMLoadFloat3(&lookAt ) ,rotationMatrix ) ) ;
XMStoreFloat3(&up , XMVector3TransformCoord (XMLoadFloat3(&up ) ,rotationMatrix ) ) ;
/ / T rans la te the ro ta ted camera p o s i t i o n to the l o c a t i o n o f the viewer .lookAt = XMFLOAT3 (position .x + lookAt .x , position .y + lookAt .y , position .z
+ lookAt .z ) ;
/ / F i n a l l y create the view mat r i x from the three updated vec to rs .mViewProjectionMatrix ∗= XMMatrixLookAtLH (XMLoadFloat3(&position ) ,
XMLoadFloat3(&lookAt ) , XMLoadFloat3(&up ) ) ;}
/ / Process windows messagesLRESULT CALLBACK WndProc (HWND hwnd , UINT umessage , WPARAM wparam , LPARAM
lparam ){switch (umessage ){
/ / Check i f the window i s being destroyed .case WM_DESTROY :{PostQuitMessage ( 0 ) ;return 0;
}
/ / Check i f the window i s being closed .case WM_CLOSE :{PostQuitMessage ( 0 ) ;
129
return 0;}
/ / A l l o ther messages pass to the message handler i n the system c lass .default :{return ApplicationHandle−>MessageHandler (hwnd , umessage , wparam ,
lparam ) ;}
}}
#endif
130





























