Embed Size (px)
Citation preview
RecurrentNeuralNetworks(RNNs)
Roi Yehoshua3/9/2018

Eliahu Khalastchi
Agenda
2
} RepresentingSequences
} StructureofRNNs
} ComputingactivationsinRNNs
} TrainingRNNs(BackpropagationThroughTime)
} Theproblemofvanishinggradients
} LSTMs
} PracticalApplicationsofRNNs
Eliahu Khalastchi
RecurrentNeuralNetworks(RNNs)
3
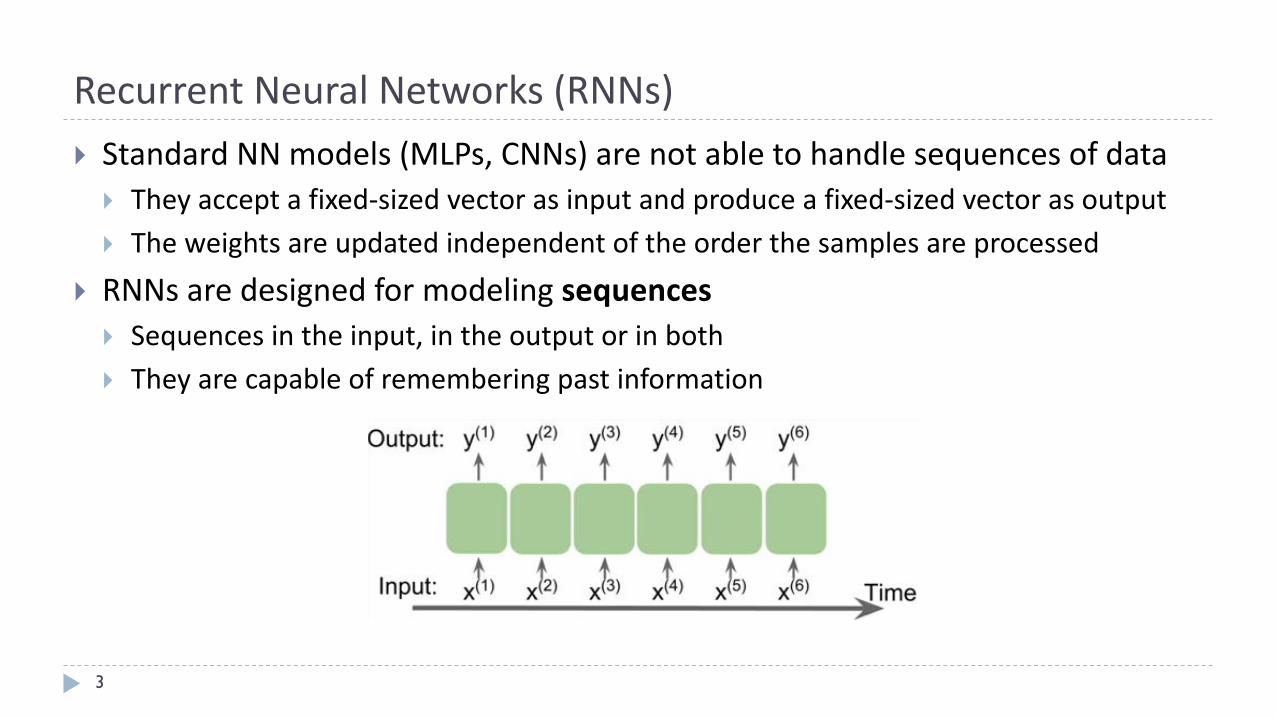
} StandardNNmodels(MLPs,CNNs)arenotabletohandlesequencesofdata} Theyacceptafixed-sizedvectorasinputandproduceafixed-sizedvectorasoutput
} Theweightsareupdatedindependentoftheorderthesamplesareprocessed
} RNNsaredesignedformodelingsequences} Sequencesintheinput,intheoutputorinboth
} Theyarecapableofrememberingpastinformation
Eliahu Khalastchi
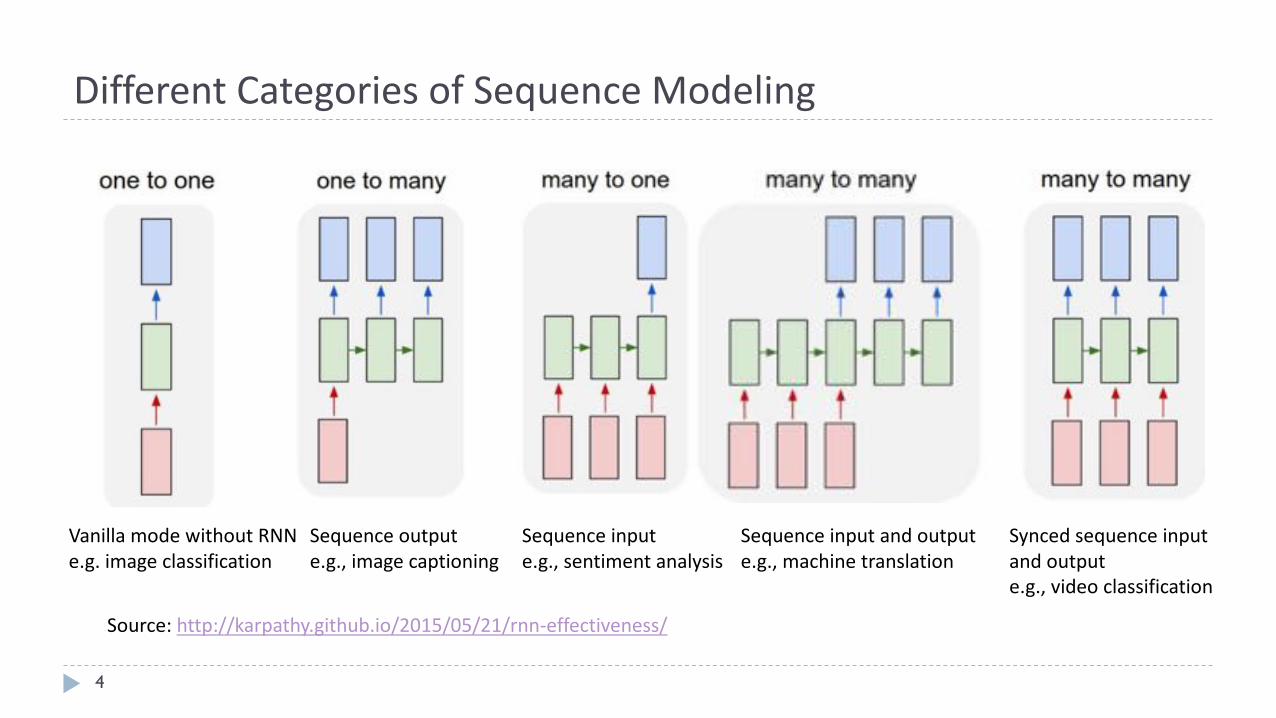
DifferentCategoriesofSequenceModeling
4
Sequenceoutpute.g.,imagecaptioning
Sequenceinpute.g.,sentimentanalysis
Syncedsequenceinputandoutpute.g.,videoclassification
Sequenceinputandoutpute.g.,machinetranslation
VanillamodewithoutRNNe.g.imageclassification
Source:http://karpathy.github.io/2015/05/21/rnn-effectiveness/
Eliahu Khalastchi
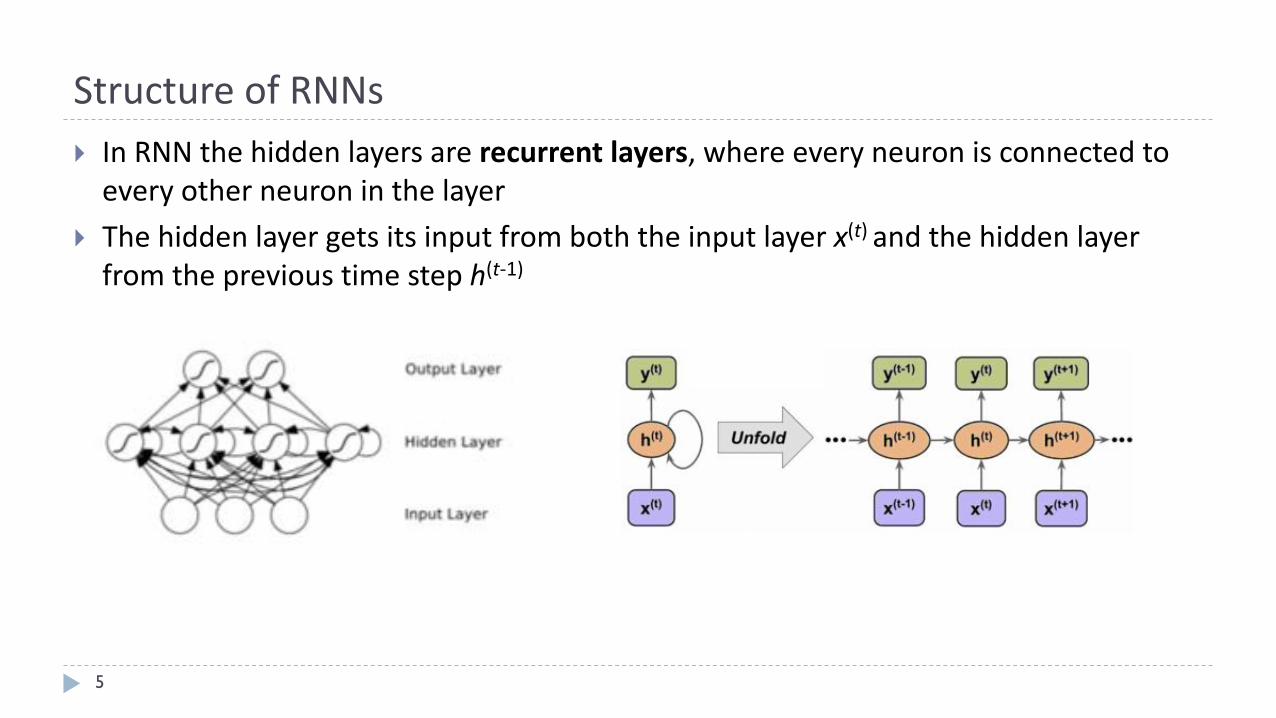
StructureofRNNs
5
} InRNNthehiddenlayersarerecurrentlayers,whereeveryneuronisconnectedtoeveryotherneuroninthelayer
} Thehiddenlayergetsitsinputfromboththeinputlayerx(t)andthehiddenlayerfromtheprevioustimesteph(t-1)
Eliahu Khalastchi
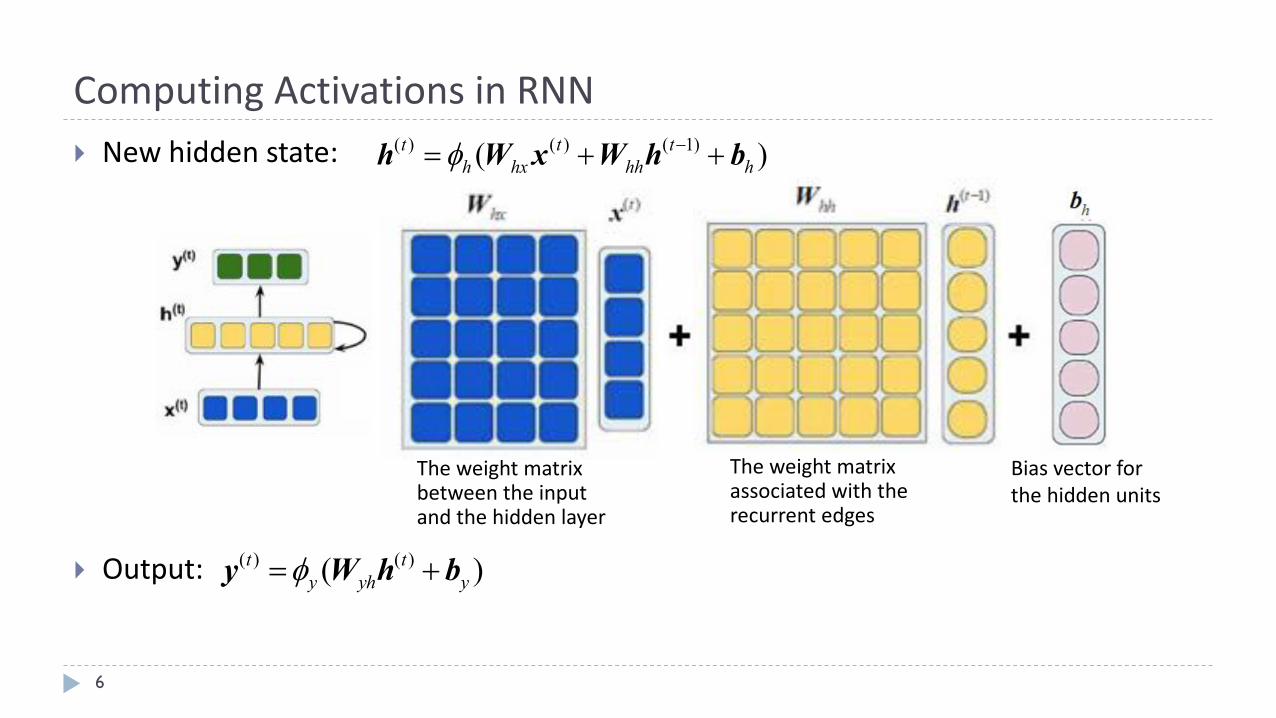
} Newhiddenstate:
} Output:
ComputingActivationsinRNN
6
Theweightmatrixbetweentheinputandthehiddenlayer
Theweightmatrixassociatedwiththerecurrentedges
Biasvectorforthehiddenunits
( ) ( ) ( 1)( )t t th hx hh hf -= + +h W x W h b
( ) ( )( )t ty yh yf= +y W h b
Eliahu Khalastchi
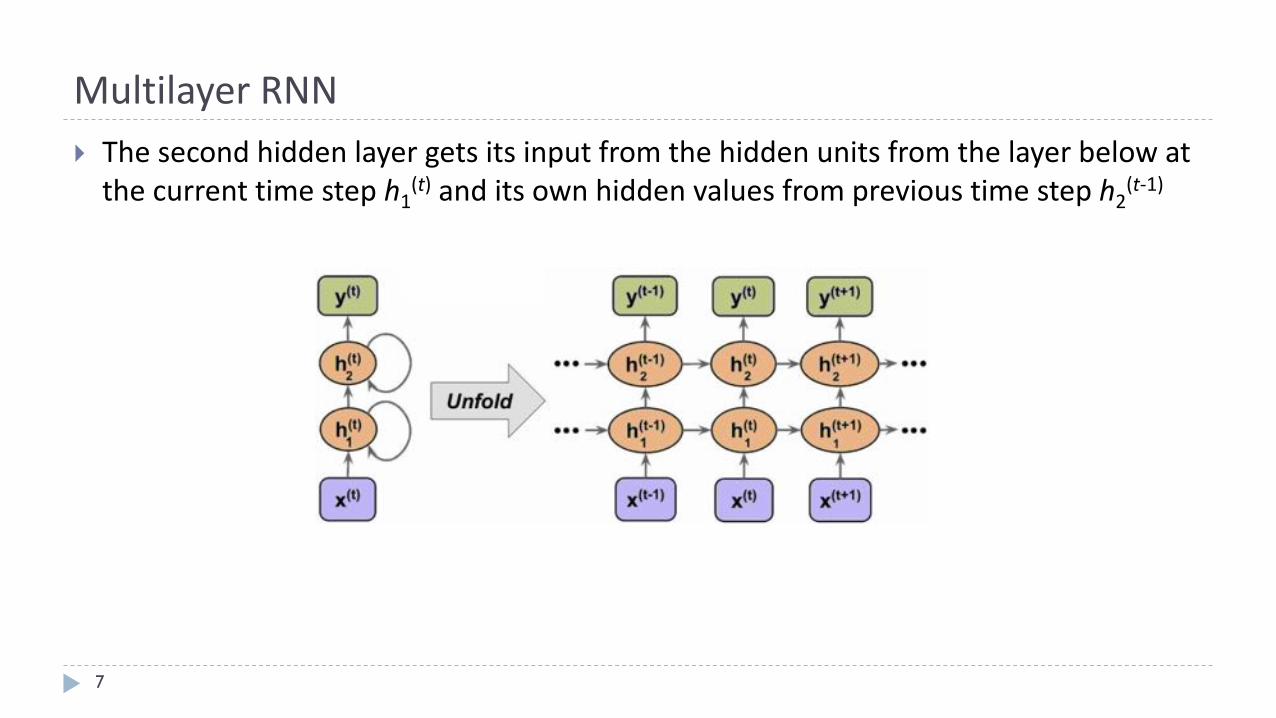
} Thesecondhiddenlayergetsitsinputfromthehiddenunitsfromthelayerbelowatthecurrenttimesteph1(t) anditsownhiddenvaluesfromprevioustimesteph2(t-1)
MultilayerRNN
7

Eliahu Khalastchi
RepresentationalPowerofRNNs
8
} Regularfeed-forward neuralnetworks arenot Turing-Complete} Theycanrepresentanysinglemathematicalfunctionbutdon’thaveanyabilitytoperform
loopingorothercontrolflowoperations
} RNNsareTuring-Complete [Killan andSiegelmann,1996]
} Theycansimulatearbitraryprograms
} Theycanrepresentanymappingbetweeninputandoutputsequences
Eliahu Khalastchi
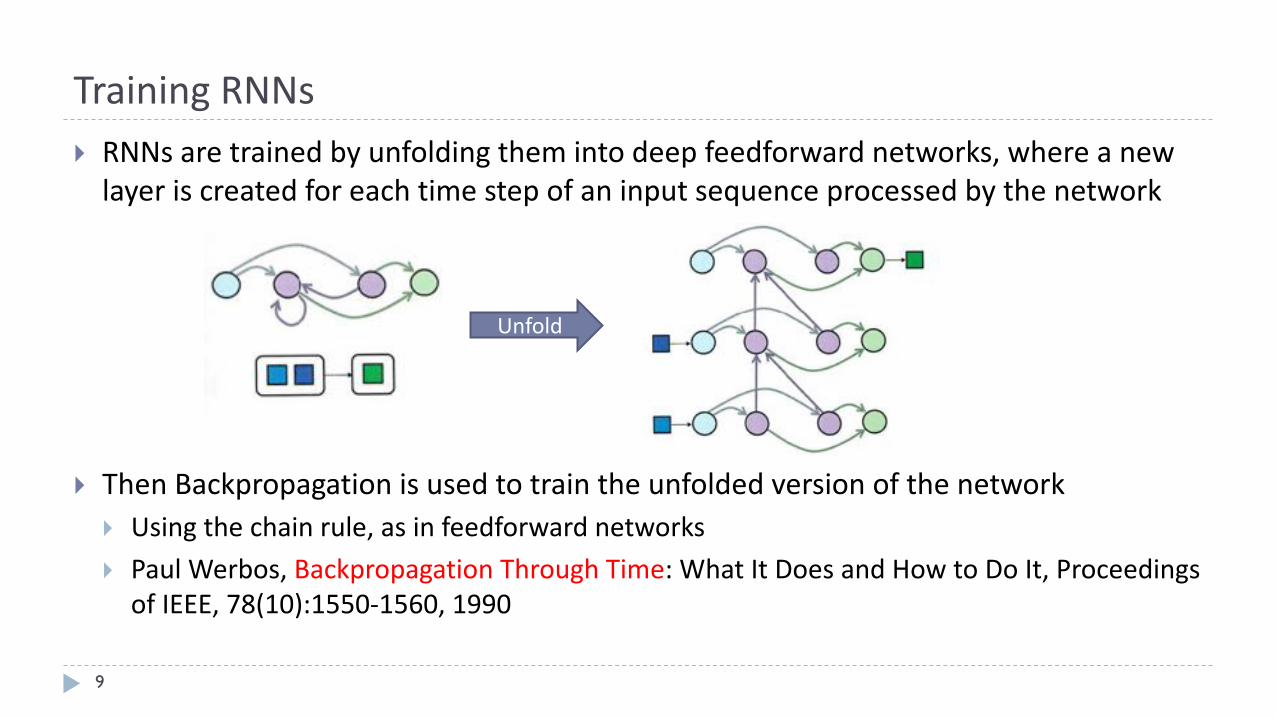
TrainingRNNs
9
} RNNsaretrainedbyunfoldingthemintodeepfeedforward networks,whereanewlayeriscreatedforeachtimestepofaninputsequenceprocessedbythenetwork
} ThenBackpropagationisusedtotraintheunfoldedversionofthenetwork} Usingthechainrule,asinfeedforward networks
} PaulWerbos,BackpropagationThroughTime:WhatItDoesandHowtoDoIt,ProceedingsofIEEE,78(10):1550-1560,1990
Unfold

Eliahu Khalastchi
BackpropagationThroughTime(BPTT)
10
} TheoveralllossListhesumofallthelossfunctionsattimest =1tot =T:
} Thelossattimet dependsonthehiddenunitsatallprevioustimesteps(1..t)
} W canbeeitherWhh orWhx
} BPTTcanbecomputationallyexpensiveasthenumberoftimestepsincreases
( )
1
Tt
tL L
=
=å
( ) ( ) ( ) ( ) ( )
( ) ( ) ( )1
t t t t kt
t t kk
L L=
é ùæ ö¶ ¶ ¶ ¶ ¶= × × ×ê úç ÷¶ ¶ ¶ ¶ ¶è øë û
åy h hW y h h W
( ) ( )
( ) ( 1)1
t it
k ii k
-= +
¶ ¶=
¶ ¶Õh hh h
Eliahu Khalastchi
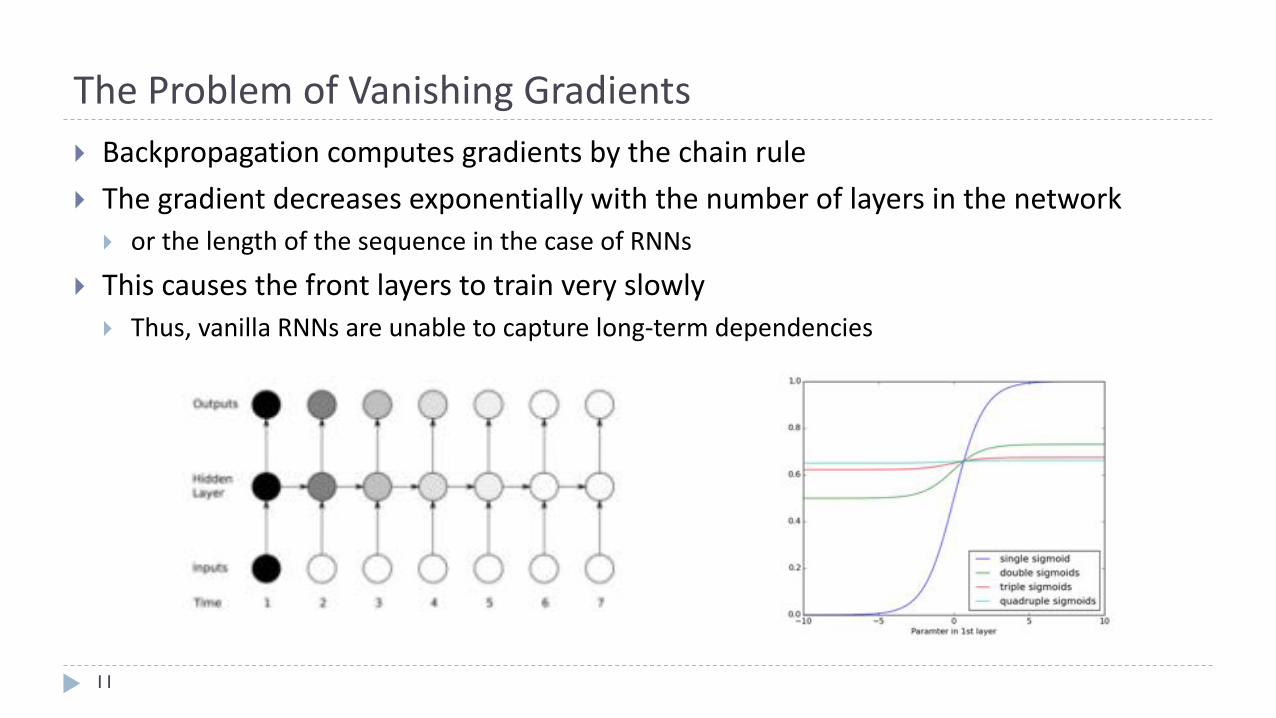
TheProblemofVanishingGradients
11
} Backpropagationcomputesgradientsbythe chainrule
} Thegradientdecreasesexponentiallywith the numberoflayersinthenetwork} orthelengthofthesequenceinthecaseofRNNs
} Thiscausesthefrontlayerstotrainveryslowly} Thus,vanillaRNNsareunabletocapturelong-termdependencies
Eliahu Khalastchi
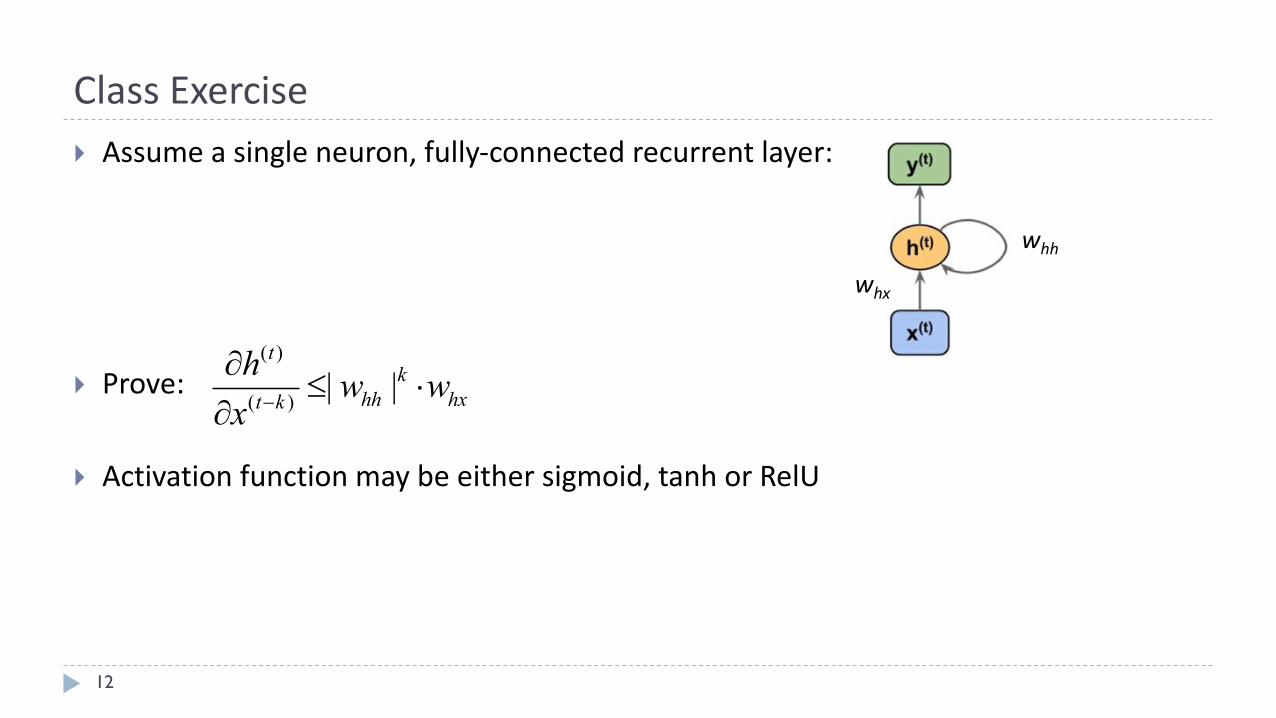
ClassExercise
12
} Assumeasingleneuron,fully-connectedrecurrentlayer:
} Prove:
} Activationfunctionmaybeeithersigmoid,tanh orRelU
( )
( ) | |t
khh hxt k
hw w
x -
¶£ ×
¶
whh
whx

Eliahu Khalastchi
TruncatedBPTT(TBPTT)
13
} AmodifiedversionofBPTTsuggestedbyIlya Sutskever in2013:
1. Presentasequenceofk1 timestepsofinputandoutputpairstothenetwork
2. PerformanBPTTupdatebackfork2 timesteps
3. Repeat
} Example:Splita1,000-longsequenceinto50sequenceseachoflength20andtreateachsequenceoflength20asaseparatetrainingcase
} k2 shouldbelargeenoughtocapturethetemporalstructureintheproblem} butsmallenoughtoavoidvanishinggradients
} Problem:thenetworkisblindtodependenciesthatspanmorethank2 timesteps
Eliahu Khalastchi
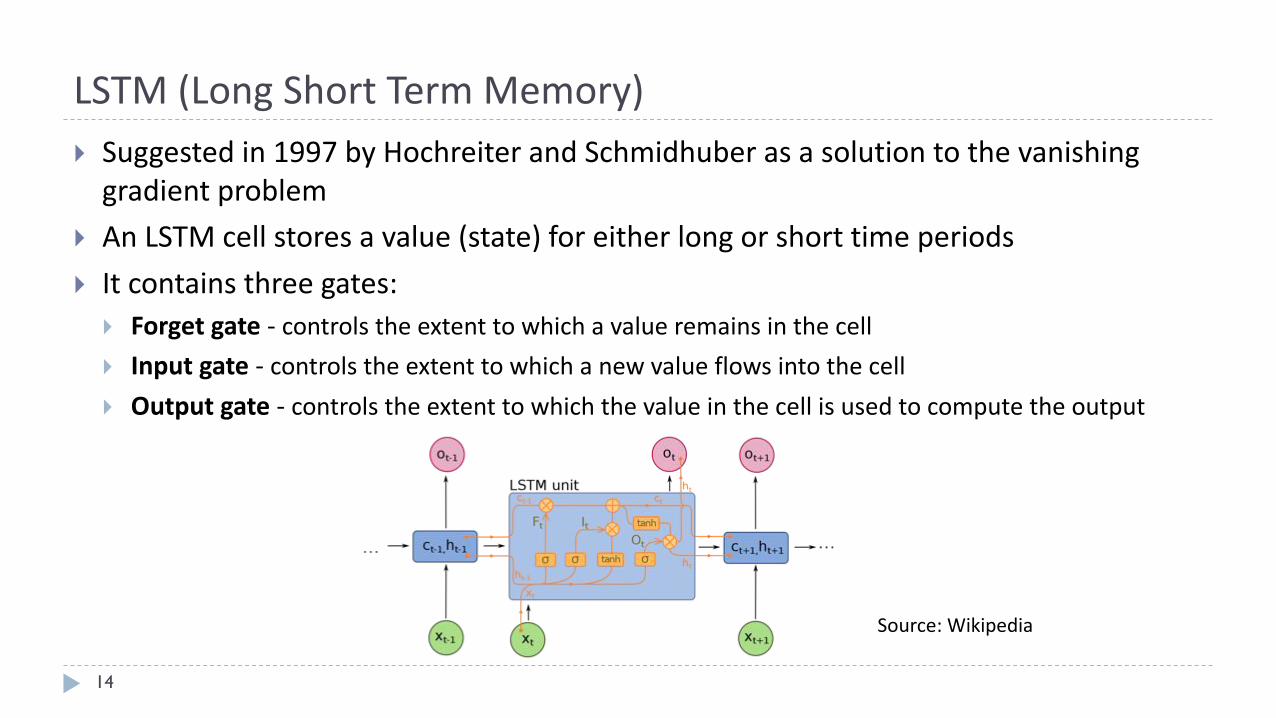
LSTM(LongShortTermMemory)
14
} Suggestedin1997byHochreiter andSchmidhuber asasolutiontothevanishinggradientproblem
} AnLSTMcellstoresavalue(state)foreitherlongorshorttimeperiods
} Itcontainsthreegates:} Forgetgate- controlstheextenttowhichavalueremainsinthecell
} Inputgate- controlstheextenttowhichanewvalueflowsintothecell} Outputgate- controlstheextenttowhichthevalueinthecellisusedtocomputetheoutput
Source: Wikipedia
Eliahu Khalastchi
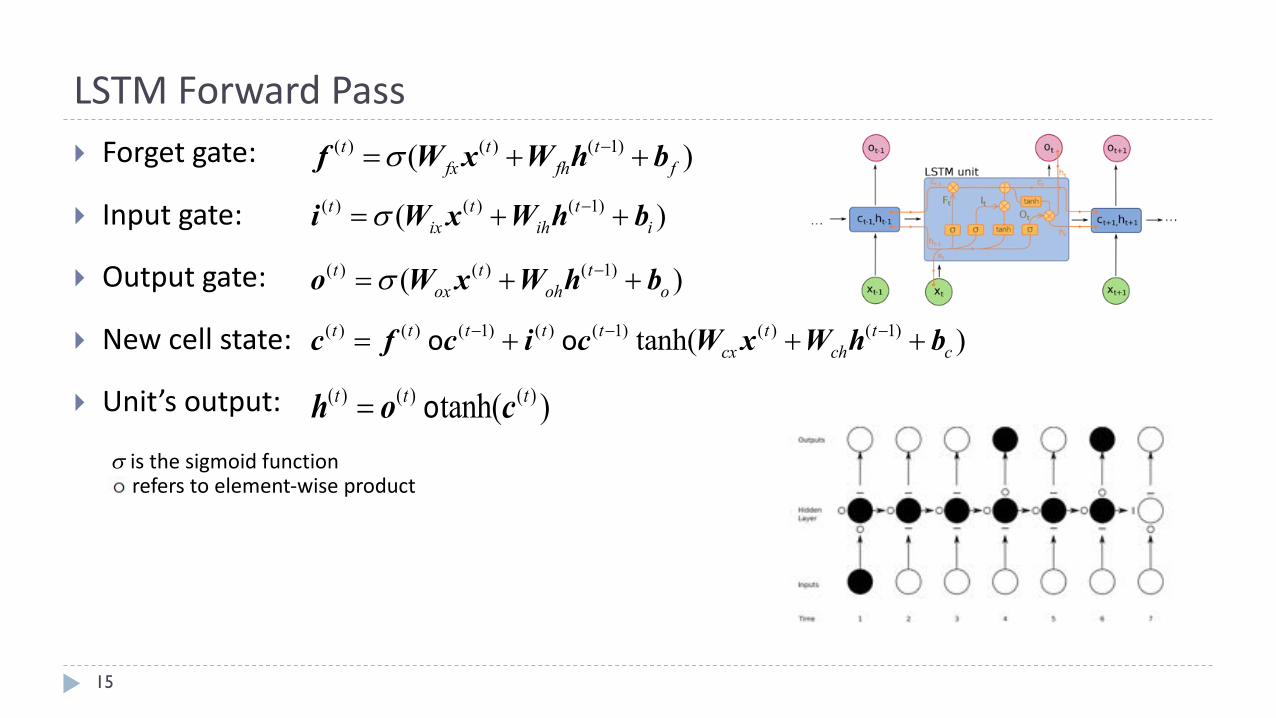
LSTMForwardPass
15
} Forgetgate:
} Inputgate:
} Outputgate:
} Newcellstate:
} Unit’soutput:
( ) ( ) ( 1)( )t t tfx fh fs -= + +f W x W h b
( ) ( ) ( 1)( )t t tix ih is -= + +i W x W h b
( ) ( ) ( 1)( )t t tox oh os -= + +o W x W h b
( ) ( ) ( 1) ( ) ( 1) ( ) ( 1)tanh( )t t t t t t tcx ch c
- - -= + + +o oc f c i c W x W h b
( ) ( ) ( )tanh( )t t t= oh o cs isthesigmoidfunctionreferstoelement-wiseproduct

Eliahu Khalastchi
TrainingLSTMs
16
} AnLSTMnetwork(anRNNcomposedofLSTMunits)istrainedwith BPTT
} Thesubsequentcellstateisasum ofthecurrentstatewithnewinput
} ThishelpsLSTMspreserveaconstanterrorwhenitisbackpropagated atdepth
} Thecellslearnwhentoallowdatatoenter,leaveorbedeletedthroughtheiterativeprocessofbackpropagating errorandadjustingweightsviagradientdescent
( ) ( ) ( 1) ( ) ( 1) ( ) ( 1)tanh( )t t t t t t tcx ch c
- - -= + + +o oc f c i c W x W h b
( )( )
( 1) ...t
tt-
¶= +
¶c fc
Eliahu Khalastchi
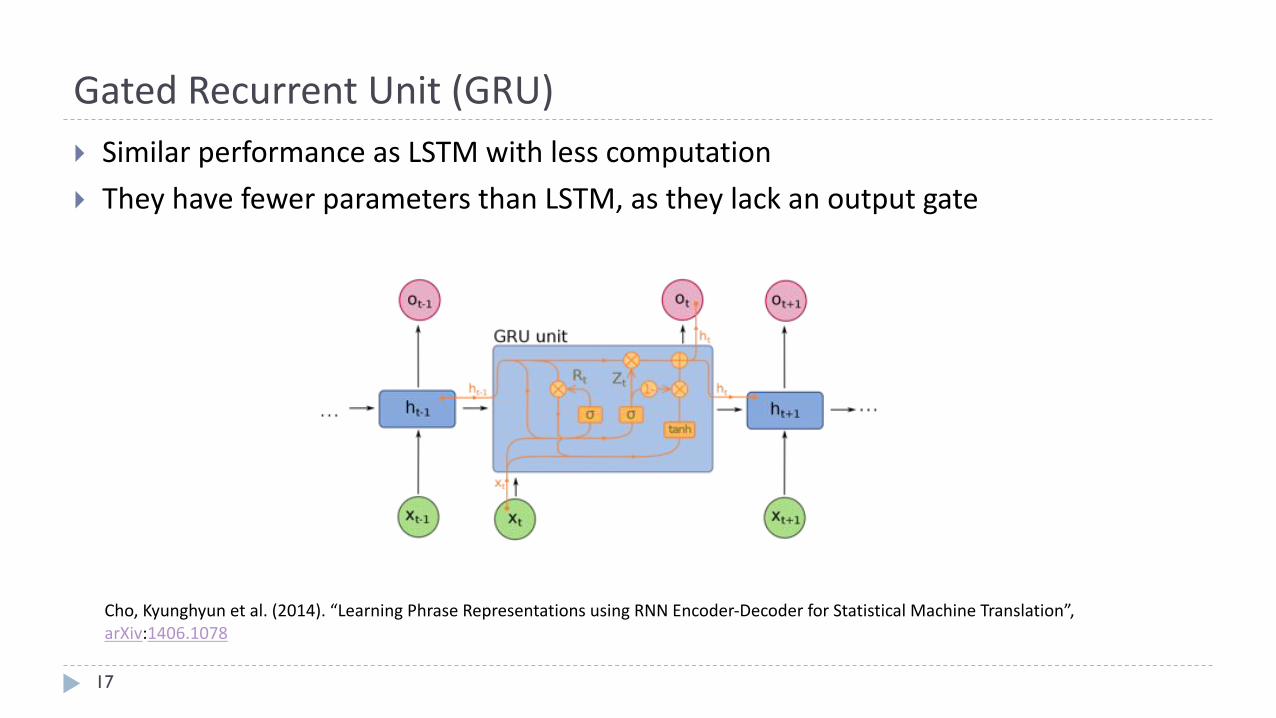
GatedRecurrentUnit(GRU)
17
} SimilarperformanceasLSTMwithlesscomputation
} TheyhavefewerparametersthanLSTM,astheylackanoutputgate
Cho,Kyunghyun etal.(2014).“LearningPhraseRepresentationsusingRNNEncoder-DecoderforStatisticalMachineTranslation”,arXiv:1406.1078
Eliahu Khalastchi
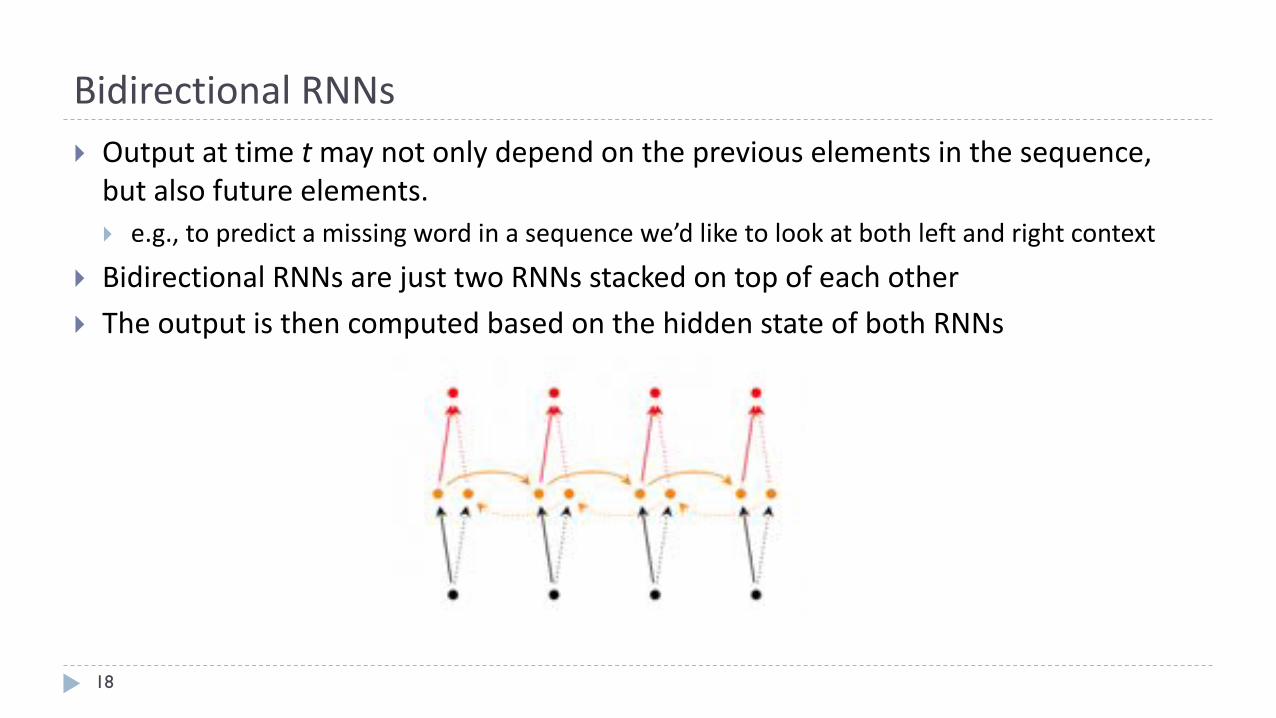
BidirectionalRNNs
18
} Outputattimetmaynotonlydependonthepreviouselementsinthesequence,butalsofutureelements.} e.g.,topredictamissingwordinasequencewe’dliketolookatbothleftandrightcontext
} BidirectionalRNNsarejusttwoRNNsstackedontopofeachother
} Theoutputis thencomputedbasedonthehiddenstateofbothRNNs

Eliahu Khalastchi
PracticalApplicationsofRNNs
19
} Machinetranslation} GoogleusesLSTMsforGoogleTranslate
} QuestionAnswering} AppleusesLSTMforSiri,AmazonusesLSTMforAlexa
} VariousNLPtasks} Part-of-speechtagging,named-entityrecognition,sentimentanalysis,etc.
} Speechrecognition} Android’sspeechrecognizerisbasedonLSTMRNNs(since2012)
} Generatingimagedescriptions} Generatingtext
} iOS QuickType auto-completionusesLSTM
} Handwritingrecognition} LSTMswonthe ICDARhandwritingcompetition(2009)
Eliahu Khalastchi
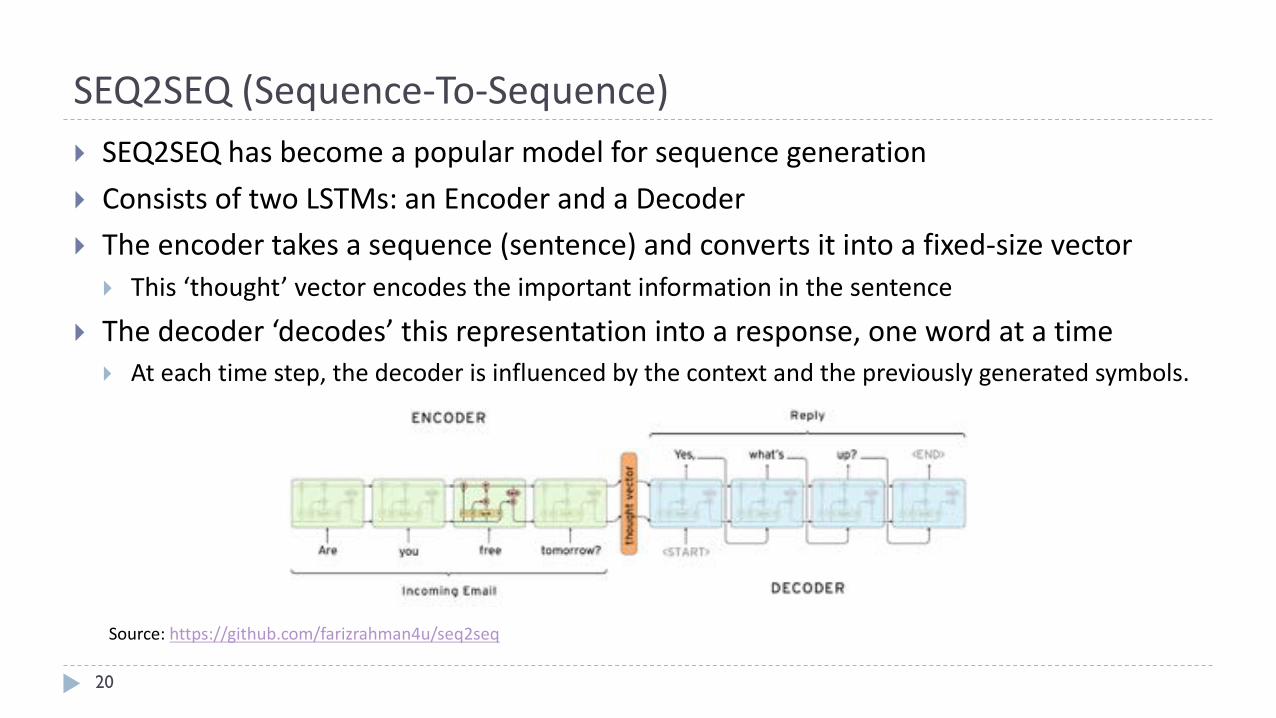
SEQ2SEQ(Sequence-To-Sequence)
20
} SEQ2SEQhasbecomeapopularmodelforsequencegeneration
} ConsistsoftwoLSTMs:anEncoderandaDecoder
} Theencodertakesasequence(sentence)andconvertsitintoafixed-sizevector} This‘thought’vectorencodestheimportantinformationinthesentence
} Thedecoder‘decodes’thisrepresentationintoaresponse,onewordatatime} Ateachtimestep,thedecoderisinfluencedbythecontextandthepreviouslygeneratedsymbols.
Source:https://github.com/farizrahman4u/seq2seq
Eliahu Khalastchi
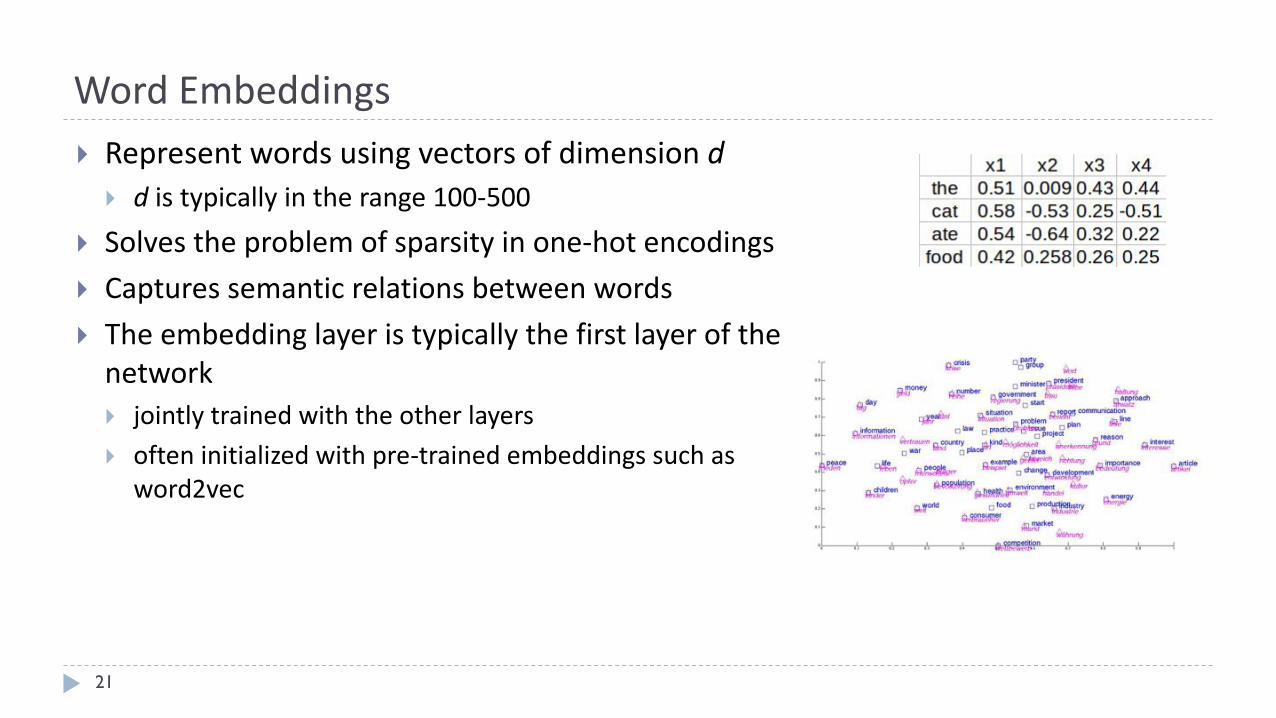
WordEmbeddings
21
} Representwordsusingvectorsofdimensiond} d istypicallyintherange100-500
} Solvestheproblemofsparsity inone-hotencodings
} Capturessemanticrelationsbetweenwords
} Theembeddinglayeristypicallythefirstlayerofthenetwork} jointlytrainedwiththeotherlayers
} ofteninitializedwithpre-trainedembeddingssuchasword2vec
Eliahu Khalastchi
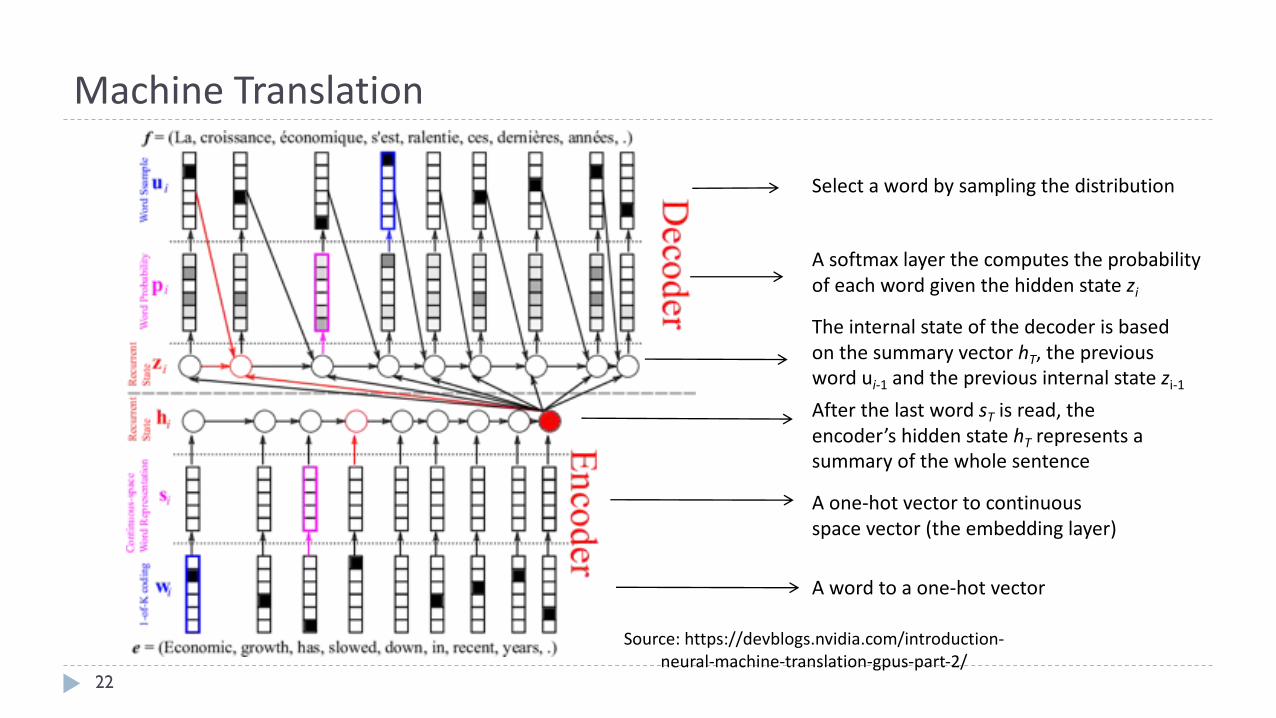
MachineTranslation
22
Source:https://devblogs.nvidia.com/introduction-neural-machine-translation-gpus-part-2/
Awordtoaone-hotvector
Aone-hotvectortocontinuousspacevector(theembeddinglayer)
AfterthelastwordsT isread,theencoder’shiddenstatehT representsasummaryofthewholesentence
TheinternalstateofthedecoderisbasedonthesummaryvectorhT,thepreviouswordui-1 andthepreviousinternalstatezi-1
Selectawordbysamplingthedistribution
Asoftmax layerthecomputestheprobabilityofeachwordgiventhehiddenstatezi

Eliahu Khalastchi
GeneratingImageDescriptions
23
} TogetherwithConvolutional NeuralNetworks,RNNshavebeenusedto generatedescriptions forunlabeledimages
Karpathy andFei-Fei,DeepVisual-SemanticAlignmentsforGeneratingImageDescriptions(2015)Source: http://cs.stanford.edu/people/karpathy/deepimagesent/

Eliahu Khalastchi
GeneratingImageDescriptions– Step1
24
} Thenetworkisfirsttrainedtoalignimageregionswithwordsnippetsofthedescriptions
} RegionalConvoluatioal NeuralNetwork(RCNN)ispre-trainedonImageNet todetectobjectsinimages} Imagesarerepresentedasasetofh-dimensionalvectorsvi
} ABidirectionalRecurrentNeuralNetwork(BRNN)istrainedontexttocomputewordembeddings} Wordsarealsorepresentedash-dimensionalvectorsst
} ThedotproductviTst reflectsthesimilaritybetweenregionvi andwordst
} Theobjectivefunctionistogetthebestalignment

Eliahu Khalastchi
GeneratingImageDescriptions– Step2
25
} TheRNNtakesaseriesofinputwords(e.g,START,“straw”,“hat”...),andaseriesofoutputwords(e.g.,“straw”,“hat”,END)
} TheRNNistrainedtocombineaword(xt)andthepreviouscontext(ht-1)topredictthenextword(yt)
} Theimagerepresentationisusedtoinitializethehiddenstate} Thecostfunctionistomaximizethelogprobabilityoftheassignedlabels(i.e.aSoftmax classifier)
} Topredictasentence:} Theimagerepresentationbv iscomputed} h0 issetto0andx1 issettotheSTARTvector} Thenetworkcomputesthedistributionoverthefirstwordy1} Awordissampledfromthedistributionanditsembeddingvectoris
setasx2} ThisprocessisrepeateduntiltheENDtokenisgenerated

Eliahu Khalastchi
Summary
26
} RNNsareneuralnetworksthatdealwithsequencedata} Trainingrecurrentnetsisoptimizationoverprograms,notfunctions} RNNsarebecomingapervasiveandcriticalcomponenttointelligentsystems
} withmanypracticalapplications
} Manyvariants} LSTM,GRU,Bi-DirectionalLSTM,DeepRNNs
} Furtherreadings} TheUnreasonableEffectivenessofRecurrentNeuralNetworks
http://karpathy.github.io/2015/05/21/rnn-effectiveness/} UnderstandingLSTMNetworks
https://colah.github.io/posts/2015-08-Understanding-LSTMs/} TrainingaNeuralMachineTranslationnetworkinTensorFlow
https://www.tensorflow.org/tutorials/seq2seq
http://www.cs.biu.ac.il/~yehoshr1/

















![in news video networks for artificial Arabic text recognition … · alternative hidden Markov models (HMMs) [ 13, 14], recurrent neural networks (RNNs) [ 18, 19], their combination](https://img.pdfslide.us/doc/110x75/5f7cb7d075dc1156d60ea5ad/in-news-video-networks-for-artificial-arabic-text-recognition-alternative-hidden.jpg)