Embed Size (px)
Citation preview

Real-Time Multi-Core Virtual Machine Scheduling in Xen
Sisu Xi† Meng Xu‡ Chenyang Lu† Linh T.X. Phan‡ Christopher Gill† Oleg Sokolsky‡ Insup Lee‡
†Washington University in St. Louis‡University of Pennsylvania
Abstract—Recent years have witnessed two major trendsin the development of complex real-time embedded systems.First, to reduce cost and enhance flexibility, multiple systemsare sharing common computing platforms via virtualizationtechnology, instead of being deployed separately on physicallyisolated hosts. Second, multicore processors are increasinglybeing used in real-time systems. The integration of real-timesystems as virtual machines (VMs) atop common multicoreplatforms raises significant new research challenges in meetingthe real-time performance requirements of multiple systems. Thispaper advances the state of the art in real-time virtualizationby designing and implementing RT-Xen 2.0, a new real-timemulticore VM scheduling framework in the popular Xen virtualmachine monitor (VMM). RT-Xen 2.0 realizes a suite of real-timeVM scheduling policies spanning the design space. We implementboth global and partitioned VM schedulers; each scheduler can beconfigured to support dynamic or static priorities and to run VMsas periodic or deferrable servers. We present a comprehensiveexperimental evaluation that provides important insights intoreal-time scheduling on virtualized multicore platforms: (1) bothglobal and partitioned VM scheduling can be implemented inthe VMM at moderate overhead; (2) at the VMM level, whilecompositional scheduling theory shows partitioned EDF (pEDF)is better than global EDF (gEDF) in providing schedulabilityguarantees, in our experiments their performance is reversed interms of the fraction of workloads that meet their deadlines onvirtualized multicore platforms; (3) at the guest OS level, pEDFrequests a smaller total VCPU bandwidth than gEDF based oncompositional scheduling analysis, and therefore using pEDF atthe guest OS level leads to more schedulable workloads in ourexperiments; (4) a combination of pEDF in the guest OS andgEDF in the VMM – configured with deferrable server – leads tothe highest fraction of schedulable task sets compared to otherreal-time VM scheduling policies; and (5) on a platform with ashared last-level cache, the benefits of global scheduling outweighthe cache penalty incurred by VM migration.
I. INTRODUCTION
Complex real-time systems are moving from physically iso-lated hosts towards common multicore computing platformsshared by multiple systems. Common platforms bring signif-icant benefits, including reduced cost and weight, as well asincreased flexibility via dynamic resource allocation. However,the integration of real-time systems as virtual machines (VM)on a common multicore computing platform brings significantchallenges in simultaneously meeting the real-time perfor-mance requirements of multiple systems, which in turn requirefundamental advances in the underlying VM scheduling at thevirtual machine monitor (VMM) level.
As a step towards real-time virtualization technology formulticore processors, we have designed and implementedRT-Xen 2.0, a multicore real-time VM scheduling frame-work in Xen, an open-source VMM that has been widelyadopted in embedded systems [1]. While earlier efforts onreal-time scheduling in Xen [2]–[5] focused on single-core
schedulers, RT-Xen 2.0 realizes a suite of multicore real-timeVM scheduling policies spanning the design space. We haveimplemented both global and partitioned VM schedulers (rt-global and rt-partition); each scheduler can be configured tosupport dynamic or static priorities and to run VMs under peri-odic or deferrable server schemes. Our scheduling frameworktherefore can support eight combinations of real-time VMscheduling policies, which enable us to perform comprehensiveexploration of and experimentation with real-time VM schedul-ing on multicore processors. Moreover, RT-Xen 2.0 supportsmultiple resource interfaces for VMs, which enable designersto calculate and specify the resource demands of VMs to theunderlying RT-Xen 2.0 scheduler, thereby incorporating resultsof compositional schedulability theory [6]–[8] into a multicorevirtualization platform.
We have conducted a series of experiments to evaluate theefficiency and real-time performance of RT-Xen 2.0 with Linuxand the LITMUSRT [9] patch as the guest OS. Our empiricalresults provide insights on the design and implementation ofreal-time VM scheduling:
• Both global and partitioned real-time VM schedulingcan be realized within Xen at moderate overhead.
• At the VMM level, while compositional schedulabilityanalysis shows that partitioned EDF (pEDF) outper-forms global EDF (gEDF) in terms of schedulabilityguarantees for tasks running in VMs, experimentallygEDF often outperforms pEDF in terms of the fractionof workloads actually schedulable on a virtualizedmulticore processor.
• At the guest OS level, pEDF requests a smaller totalVCPU bandwidth than gEDF based on compositionalschedulability analysis, and therefore using pEDF inthe guest OS leads to more schedulable workloads.The combination of pEDF in the guest OS and gEDFin the VMM therefore results in the best experimentalperformance when using a periodic server.
• When pEDF is used as the guest OS scheduler, gEDFin the VMM – configured with deferrable server –leads to the highest fraction of schedulable task setsunder system overload compared to other real-timeVM scheduling policies.
• On a platform with a shared last-level cache, the ben-efits of global scheduling outweigh the cache penaltyincurred by VM migration.
The rest of this paper is structured as follows: In SectionII we first introduce background information on Xen. Wethen describe the design and implementation of the multicorereal-time scheduling framework in RT-Xen 2.0 in SectionIII. Section IV presents our experimental evaluation. After

reviewing other related work in Section V, we conclude thepaper in Section VI.
II. BACKGROUND
We first review the scheduling architecture in Xen, and thendiscuss the compositional schedulability analysis (CSA) thatserves as the theoretical basis for the design of our multicoreVMM scheduling framework, RT-Xen 2.0.
A. Scheduling in Xen
Xen [10] is a popular open-source virtualization platform thathas been developed over the past decade. It provides a layercalled the virtual machine monitor (VMM) that allows multipledomains (VMs) to run different operating systems and toexecute concurrently on shared hardware. Xen has a specialdomain, called domain 0, that is responsible for managing allother domains (called guest domains).
Fig. 1: Xen scheduling architecture.
Figure 1 illustrates the scheduling architecture in Xen. Asshown in the figure, each domain has one or more virtualCPUs (VCPUs), and tasks within the domain are scheduledon these VCPUs by the domain’s OS scheduler. The VCPUsof all domains are scheduled on the physical CPUs (PCPUs),or cores, by the VMM scheduler. At runtime, each VCPU canbe in either a runnable or a non-runnable (blocked by I/O oridle) state. When there are no runnable VCPUs to execute,the VMM scheduler schedules an idle VCPU. By default, Xenboots one idle VCPU per PCPU.
VMM schedulers in Xen. There are three VMM schedulersin Xen: credit, credit2 and simple EDF (SEDF). The creditscheduler is the default one, and uses a proportional sharescheme, where each domain is associated with a weight(which encodes the share of the CPU resource it will receive,relative to other domains), and a cap (which encodes themaximum CPU resource it will receive). The credit scheduleris implemented using a partitioned queue, and uses a heuristicload balancing scheme: when the PCPU’s run queue only hasone VCPU with credit left, the PCPU “steals” VCPUs fromother run queues to rebalance the load. The credit2 scheduleralso assigns a weight per domain, but does not support capsand is not CPU-mask aware. As a result, it cannot limit eachdomain’s CPU resource, nor can it dedicate cores to domains.Unlike the credit and credit2 schedulers, the SEDF schedulerschedules domains based on their interfaces (defined as periodand budget) using an EDF-like scheduling policy. However,SEDF is not in active development and is planned to be“phased out and eventually removed” from Xen [11].
B. Compositional Schedulability Analysis
RT-Xen 2.0 supports resource interfaces for VMs based onmulticore compositional schedulability analysis (CSA) [8] forresource allocation. This is enabled by a natural mapping
between Xen and a two-level compositional scheduling hi-erarchy in CSA: each domain corresponds to an elementarycomponent, and the system (a composition of the domainsunder the VMM scheduler) corresponds to the root componentin CSA. Using this approach, we can represent the resourcerequirements of each domain as a multiprocessor periodicresource (MPR) interface, µ = 〈Π,Θ,m′〉, which specifiesa resource allocation that provides a total of Θ executiontime units in each period of Π time units, with a maximumlevel of parallelism m′. Each interface µ = 〈Π,Θ,m′〉 canbe mapped to m′ VCPUs whose total resource demand is atleast equal to the resource supply of the interface. The VCPUsof the domains are then scheduled together on the PCPUsby the VMM scheduler. Based on the VCPUs and the VMMscheduling semantics, we can also derive an interface for thesystem (i.e., root component), which can be used to check theschedulability of the system or to determine the number ofcores needed to schedule the system.
In this paper, we compute the interface of a domain usinga state-of-the-art interface computation method correspondingto the scheduling algorithm used by the domain. Specifically,the interfaces of domains under pEDF or partitioned DeadlineMonotonic (pDM) are computed using the interface computa-tion method in [6]. The interfaces under gEDF are computedusing the multicore interface computation method describedin [7]. Finally, since there are currently no methods for gDM,we also propose a new method for computing the interfacesunder gDM, which is described in detail in the Appendix A.
III. DESIGN AND IMPLEMENTATION
In this section, we first describe the design principles behindthe multicore real-time scheduling framework of RT-Xen 2.0,and then we discuss our implementation in detail.
A. Design Principles
To leverage multicore platforms effectively in real-time virtual-ization, we designed RT-Xen 2.0 to cover three dimensions ofthe design space: global and partitioned scheduling; dynamicand static priority schemes; and two server schemes (deferrableand periodic) for running the VMs. In summary, RT-Xen 2.0supports:
• a scheduling interface that is compatible with a rangeof resource interfaces (e.g., [7], [12], [13]) used incompositional schedulability theory;
• both global and partitioned schedulers, called rt-globaland rt-partition, respectively;
• EDF and DM priority schemes for both schedulers;
• for each scheduler, a choice of either a work-conserving deferrable server or a periodic server.
We next discuss each dimension of the design space,focusing on how theory and platform considerations influencedour design decisions.
Scheduling interface. In RT-Xen 2.0, the scheduling interfaceof a domain specifies the amount of resource allocated to thedomain by the VMM scheduler. In a single-core virtualizationsetting, each domain has only one VCPU and thus, its schedul-ing interface can be defined by a budget and a period [3]. In

contrast, each domain in a multicore virtualization setting canhave multiple VCPUs. As a result, the scheduling interfaceneeds to be sufficiently expressive to enable resource allocationfor different VCPUs at the VMM level. At the same time, itshould be highly flexible to support a broad range of resourceinterfaces, as well as different distributions of interface band-width to VCPUs (to be scheduled by the VMM scheduler),according to CSA theory.
Towards the above, RT-Xen 2.0 defines the schedulinginterface of a domain to be a set of VCPU interfaces, whereeach VCPU interface is represented by a budget, a period, anda cpu mask (which gives the subset of PCPUs on which theVCPU is allowed to run), all of which can be set independentlyof other VCPUs. This scheduling interface has several benefits:(1) it can be used directly by the VMM scheduler to schedulethe VCPUs of the domains; (2) it can be configured to supportdifferent resource interfaces from the CSA literature, suchas MPR interfaces [7], deterministic MPR interfaces [12],and multi-supply function interfaces [13]; (3) it is compatiblewith different distributions of interface bandwidth to VCPUbudgets, such as one that distributes budget equally amongthe VCPUs [7], or one that provides the maximum bandwidth(equal to 1) to all but one VCPU [12]; and finally (4) it enablesthe use of CPU-mask-aware scheduling strategies, such asone that dedicates a subsets of PCPUs to some VCPUs andschedules the rest of the VCPUs on the remaining PCPUs [12].
Global vs. partitioned schedulers. Different multicoreschedulers require different implementation strategies andprovide different performance benefits. A partitioned scheduleronly schedules VCPUs in its own core’s run queue and henceis simple to implement; in contrast, a global schedulerschedules all VCPUs in the system and thus is more complexbut can provide better resource utilization. We support bothby implementing two schedulers in RT-Xen 2.0: rt-globaland rt-partition.1 The rt-partition scheduler uses a partitionedqueue scheme, whereas the rt-global scheduler uses a globalshared run queue that is protected by a spinlock.2 For eachscheduler, users can switch between dynamic priority (EDF)and static priority (DM) schemes on the fly.
Server mechanisms. Each VCPU in RT-Xen 2.0 is associatedwith a period and a budget, and is implemented as aserver: the VCPU is released periodically and its budget isreplenished at the beginning of every period. It consumes itsbudget when running, and it stops running when its budgetis exhausted. Different server mechanisms provide differentways to schedule the VCPUs when the current highestpriority VCPU is not runnable (i.e., has no jobs to execute)but still has unused budget. For instance, when implementedas a deferrable server, the current VCPU defers its unusedbudget to be used at a later time within its current period ifit becomes runnable, and the highest-priority VCPU among
1In our current platform, all cores share an L3 cache, thus limiting thepotential benefits of cluster-based schedulers; however, we plan to considercluster-based schedulers in our future work on new platforms with multiplemulticore sockets.
2An alternative approach to approximating a global scheduling policy isto employ partitioned queues that can push/pull threads from each other [14](as adopted in the Linux Kernel). We opt for a simple global queue designbecause the locking overhead for the shared global queue is typically smallin practice, since each host usually runs only relatively few VMs.
the runnable VCPUs is scheduled to run. In contrast, whenimplemented as a periodic server, the current VCPU continuesto run and consume its budget (as if it had a backgroundtask executing within it). As shown by our experimentalresults in Section IV-F, results can be quite different whendifferent servers are used, even if the scheduler is the same.We implemented both rt-global and rt-partition as deferrableservers, and can configure them as periodic servers by runninga lowest priority CPU-intensive task in a guest VCPU.
B. Implementation
We first introduce the run queue structure of the rt-globalscheduler, followed by that of the rt-partition scheduler whichhas a simpler run queue structure. We then describe the keyscheduling functions in both schedulers.
Run queue structure. Figure 2 shows the structure of theglobal run queue (RunQ) of the rt-global scheduler, which isshared by all physical cores. The RunQ holds all the runnableVCPUs, and is protected by a global spin-lock. Within thisqueue, the VCPUs are divided into two sections: the firstconsists of the VCPUs with a nonzero remaining budget,followed by the second which consists of VCPUs that haveno remaining budget. Within each section, the VCPUs aresorted based on their priorities (determined by a chosen priorityassignment scheme). We implemented both EDF and DMpriority schemes in RT-Xen 2.0. A run queue of the rt-partitionscheduler follows the same structure as the RunQ, except thatit is not protected by a spin-lock, and the rt-partition schedulermaintains a separate run queue for each core.
Fig. 2: rt-global run queue structure.
Scheduling functions: The scheduling procedure consists oftwo steps: first, the scheduler triggers the scheduler-specificdo schedule() function to make scheduling decisions; then, ifnecessary, it triggers the context switch() function to switchthe VCPUs, and after that, a context saved() function to putthe currently running VCPU back into the run queue (only inshared run queue schedulers).
Algorithm 1 shows the pseudo-code of the do schedule()function of the rt-global scheduler under an EDF priorityscheme (i.e., gEDF). In the first for loop (Lines 5–10), itreplenishes the budgets of the VCPUs and rearranges theVCPUs in the RunQ appropriately. In the second for loop(Lines 11–18), it selects the highest-priority runnable VCPU(snext) that can be executed. Finally, it compares the deadlineof the selected VCPU (snext) with that of the currently runningVCPU (scurr), and returns the VCPU to be executed next(Lines 19–24).
There are two key differences between RT-Xen 2.0 and thesingle-core scheduling algorithm in RT-Xen [2]: (1) the secondfor loop (Lines 11–18) guarantees that the scheduler isCPU-mask aware; and (2) if the scheduler decides to switchVCPUs (Lines 22–24), the currently running VCPU (scurr) is

Algorithm 1 do schedule() function for rt-global under EDF.1: scurr ← the currently running VCPU on this PCPU2: idleVCPU ← the idle VCPU on this PCPU3: snext← idleVCPU4: burn budget(scurr)5: for all VCPUs in the RunQ do6: if VCPU’s new period starts then7: reset VCPU.deadline, replenish VCPU.budget8: move VCPU to the appropriate place in the RunQ9: end if
10: end for11: for all VCPUs in the RunQ do12: if VCPU.cpu mask & this PCPU 6= 0 then13: if VCPU.budget > 0 then14: snext← VCPU15: break16: end if17: end if18: end for19: if
(snext = idleVCPU or snext.deadline > scurr.deadline
)and (scurr 6= idleVCPU) and (scurr.budget > 0)and vcpu runnable(scurr) then
20: snext← scurr21: end if22: if snext 6= scurr then23: remove snext from the RunQ24: end if25: return snext to run for 1 ms
not inserted back into the run queue; otherwise, it could begrabbed by another physical core before its context is saved(since the run queue is shared among all cores), which wouldthen make the VCPU’s state inconsistent. For this reason,Xen adds another scheduler-dependent function named con-text saved(), which is invoked at the end of a context switch()to insert scurr back into the run queue if it is still runnable.Note that both do schedule() and context saved() need to grabthe spin-lock before running; since this is done in the Xenscheduling framework, we do not show this in Algorithm 1.
Another essential function of the scheduler is thewake up() function, which is called when a domain receivesa packet or a timer fires within it. In the wake up() functionof the rt-global scheduler, we only issue an interrupt if thereis a currently running VCPU with a lower priority than thedomain’s VCPUs, so as to reduce overhead and to avoidpriority inversions. We also implemented a simple heuristicto minimize the cache miss penalty due to VCPU migrations:whenever there are multiple cores available, we assign thepreviously scheduled core first.
The do schedule() function of the rt-partition scheduler issimilar to that of the rt-global scheduler, except that (1) itdoes not need to consider the CPU mask when operating on alocal run queue (because VCPUs have already been partitionedand allocated to PCPUs based on the CPU mask), and (2) ifthe scheduler decides to switch VCPUs, the currently runningVCPU scurr will be immediately inserted back into the runqueue. In addition, in the wake up() function, we compareonly the priority of the woken up VCPU to the priority of thecurrently running VCPU, and perform a switch if necessary.
We implemented both rt-global and rt-partition schedulersin C. We also patched the Xen tool for adjusting the parameters
of a VCPU on the fly. Our modifications were done solelywithin Xen. The source code of RT-Xen 2.0 and the data usedin our experiments are both available online (not shown dueto double blind review).
IV. EMPIRICAL EVALUATION
In this section, we present our experimental evaluation of RT-Xen 2.0. We have five objectives for our evaluation: (1) to eval-uate the scheduling overhead of the rt-global and rt-partitionschedulers compared to the default Xen credit scheduler; (2)to experimentally evaluate the schedulability of the systemunder different combinations of schedulers at the guest OS andVMM levels; (3) to evaluate the real-time system performanceunder RT-Xen 2.0 schedulers in overload situations; (4) tocompare the performance of the deferrable server scheme andthe periodic server scheme; and (5) to evaluate the impact ofcache on global and partitioned schedulers.
A. Experiment Setup
We perform our experiments on an Intel i7 x980 machine,with six cores (PCPUs) running at 3.33 GHz. We disablehyper-threading and SpeedStep to ensure constant CPU speed,and we shut down all other non-essential processes during ourexperiments to minimize interference. The scheduling quantumfor RT-Xen 2.0 is set to 1 ms. Xen 4.3 is patched with RT-Xen2.0 and installed with a 64-bit Linux 3.9 Kernel as domain0, and a 64-bit Ubuntu image with a para-virtualized LinuxKernel as the guest domain. For all experiments, we bootdomain 0 with one VCPU and pin this VCPU to one core;the remaining five cores are used to run the guest domains.In addition, we patch the guest OS with LITMUSRT [9] tosupport EDF scheduling.
For the partitioned scheduler at the guest OS level andthe VMM level, we use a variant of the best-fit bin-packingalgorithm for assigning tasks to VCPUs and VCPUs to cores,respectively. Specifically, for each domain, we assign a taskto the VCPU with the largest current bandwidth3 among allexisting VCPUs of the domain that can feasibly schedule thetask. Since the number of VCPUs of the domain is unknown,we start with one VCPU for the domain, and add a new VCPUwhen the current task could not be packed into any existingVCPU. At the VMM level, we assign VCPUs to the availablecores in the same manner, except that (1) in order to maximizethe amount of parallelism that is available to each domain,we try to avoid assigning VCPUs from the same domain tothe same core, and (2) under an overload condition, when thescheduler determines that it is not feasible to schedule thecurrent VCPU on any core, we assign that VCPU to the corewith the smallest current bandwidth, so as to balance the loadamong cores.
We perform the same experiments as above using the creditscheduler, with both the weight and the cap of each domainconfigured to be the total bandwidth of its VCPUs. (Recallthat the bandwidth of a VCPU is the ratio of its budget to itsperiod.) The CPU-mask of each VCPU was configured to be1-5 (same as in the rt-global scheduler).
3The maximum bandwidth of a VCPU is 1, since we assume that it canonly execute on one core at a time.

0 500 1000 1500 2000 2500 30000
0.2
0.4
0.6
0.8
1
Overhead (ns)
Fra
ctio
n of
eve
nts
←rt−global
rt−partition→
←credit
credit, 99%: 2057, max: 68117rt−global, 99%: 1831, max: 37395rt−partition, 99%: 994, max: 4096
(a) do schedule
0 500 1000 1500 2000 2500 30000
0.2
0.4
0.6
0.8
1
Overhead (ns)
Fra
ctio
n of
eve
nts
←rt−globalrt−partition→
credit→
credit, 99%: 2171, max: 36365rt−global, 99%: 3266, max: 69476rt−partition, 99%: 2819, max: 5953
(b) context switch
0 500 1000 1500 2000 2500 30000
0.2
0.4
0.6
0.8
1
Overhead (ns)
Fra
ctio
n of
eve
nts
←rt−global
rt−global, 99%: 1224, max: 18576
(c) context saved
Fig. 3: CDF plots for scheduling overhead for different schedulers over 30 seconds.
B. Workloads
In our experiments, tasks are created based on the base taskprovided by LITMUSRT. To emulate a desirable execution timefor a task in RT-Xen 2.0, we first calibrate a CPU-intensivejob to take 1 ms in the guest OS (when running without anyinterference), then scale it to the desirable execution time. Foreach task set, we run each experiment for 60 seconds, andrecord the deadline miss ratio for each task using the st tracetool provided by LITMUSRT.
Following the methodology used in [15] to generate real-time tasks, our evaluation uses synthetic real-time task sets.The tasks’ periods are chosen uniformly at random between350ms and 850ms, and the tasks’ deadlines are set equalto their periods. The tasks’ utilizations follow the mediumbimodal distribution, where the utilizations are distributeduniformly over [0.0001, 0.5) with probability of 2/3, or [0.5,0.9] with probability of 1/3. Since there are five cores forrunning the guest domains, we generate task sets with totalutilization ranging from 1.1 to 4.9, with a step of 0.2. Fora specific utilization, we first generate tasks until we exceedthe specified total task utilization, then we discard the lastgenerated task and use a “pad” task to make the task setutilization match exactly the specified utilization. For each ofthe 20 task set utilizations, we use different random seeds togenerate 25 task sets for each bimodal distribution. In total,there are 20 (utilization values) × 25 (random seeds) = 500task sets in our experiments.
Each generated task is then distributed into four differentdomains in a round-robin fashion. We apply compositionalscheduling analysis to compute the interface of each domain,and to map the computed interface into a set of VCPUs to bescheduled by the VMM scheduler. In our evaluation, we useharmonic periods for all VCPUs. We first evaluate the real-time schedulers using CPU-intensive tasks in the experiments,followed by a study on the impacts of cache on the differentreal-time schedulers using cache-intensive tasks with largememory footprints (Section IV-G).
C. Scheduling Overhead
In order to measure the overheads for different schedulers, weboot 4 domains, each with 4 VCPUs. We set each VCPU’sbandwidth to 20%, and distribute the VCPUs to 5 PCPUs forthe rt-partition scheduler in a round-robin fashion; for the rt-global and credit schedulers, we allow all guest VCPUs to runon all 5 PCPUs. We run a CPU-intensive workload with a totalutilization of 3.10. We use the EDF scheme in both rt-global
and rt-partition schedulers, as the different priority schemesonly differ in their placement of a VCPU in the RunQ. Inthe Xen scheduling framework, there are three key functionsrelated to schedulers as described in Section III-B. We measurethe overheads as the time spent in the do schedule function asscheduling latency, the time spent in the context switch, andthe time spent in the context saved. Note that context savedis necessary only in rt-global schedulers, as they have sharedqueues. For rt-partition and credit schedulers, the runningVCPU is inserted back to run queue in do schedule function.To record these overheads, we modify xentrace [16] and useit to record data for 30 seconds.
Figure 3 shows CDF plots of the time spent in the threefunctions for different schedulers. Since 99% of the valuesare smaller than 3 microseconds (except for rt-global in thecontext switch function, which is 3.266 microseconds), we cutthe X-axis at 3 microseconds for a clear view, and include the99% and maximum values in the legend for each scheduler.We observe the following:
First, as is shown in Figure 3a, the rt-global schedulerincurred a higher scheduling latency than the rt-partitionscheduler. This is because the rt-global scheduler experiencedthe overhead to grab the spinlock, and it had a run queue thatwas 5 times longer than that of the rt-partition scheduler. Thecredit scheduler performed better than the rt-global schedulerin the lower 60%, but performed worse in the higher 40%of our measurements. We attribute this to the load balancingscheme in the credit scheduler, which must check all otherPCPUs’ RunQs to “steal” VCPUs.
Second, Figure 3b shows that the context switch overheadsfor all three schedulers were largely divided into two phases:approximately 50% of the overhead was around 200 nanosec-onds, and the remaining was more than 1500 nanoseconds.We find that the first 50% (with lower overhead) ran withoutactually performing context switches, since Xen defers theactual context switch until necessary: when the schedulerswitches from a guest VCPU to the IDLE VCPU, or fromthe IDLE VCPU to a guest VCPU with its context still intact,the time spent in the context switch function is much shorterthan a context switch between two different guest VCPUs.We can also observe that context switch in rt-global has ahigher overhead. We attribute this to the global schedulingpolicy, where the VMM scheduler moves VCPUs around allPCPUs, and would cause more preemptions than a partitionedscheduling policy like rt-partition.
Third, Figure 3c shows the time spent in the context savedfunction for the rt-global scheduler. Recall that this function

is NULL in the rt-partition and credit schedulers, since thecurrent VCPU is already inserted back into the run queue bythe do schedule function. We observe that, for the rt-globalscheduler, around 90% of the overhead was 200 nanosecondsor less, and the 99% value was only 1224 nanoseconds. Weattribute this to the extra overhead of grabbing the spinlock toaccess the shared run queue in the rt-global scheduler.
Overall, in 99% of the cases, the overhead of all threefunctions (do schedule, context switch, and context saved)for all schedulers was smaller than 4 microseconds. Sincewe use a 1 ms scheduling quantum for both the rt-globaland the rt-partition schedulers, an overhead of 4 microsecondscorresponds to a resource loss of only 1.2% per schedulingquantum. Notably, in contrast to an OS scheduler – whichis expected to handle a large number of tasks – the VMMscheduler usually runs fewer than 100 VCPUs as each VCPUtypically demands much more resources than a single task.As a result, the run queue is typically much shorter, andthe overhead for grabbing the lock in a shared run queue istypically smaller than in an OS scheduler.
D. Multi-core Real-Time Performance of Credit Scheduler
We conduct experiments to compare the real-time performanceof the default credit scheduler in Xen and our RT-Xen 2.0schedulers. All guest domains run the pEDF scheduler in theguest OS. For the credit scheduler, we configure each domain’scredit and cap as the sum of all its VCPU’s bandwidths, asdescribed in Section IV-A. For comparison, we also plot theresults for the gEDF and gDM schedulers in RT-Xen 2.0 usinga periodic server.
1.1 1.5 1.9 2.3 2.7 3.1 3.5 3.9 4.3 4.7 0
0.2
0.4
0.6
0.8
1
Task Set Utilization
Fra
ctio
n o
f sc
hed
ula
ble
tas
kset
s
guest OS (pEDF), VMM (gEDF)guest OS (pEDF), VMM (gDM)guest OS (pEDF), VMM (credit)
Fig. 4: credit vs. RT-Xen 2.0 schedulers
Figure 4 shows the results. With the credit scheduler, evenwhen the total workload utilization is as low as 1.1, 10 % of thetask sets experienced deadline misses, which clearly demon-strates that the credit scheduler is not suitable for schedulingVMs that contain real-time applications. In contrast, our real-time VM schedulers based on the gEDF and gDM policiescan meet the deadlines of all task sets at utilizations as highas 3.9. This result highlights the importance of incorporatingreal-time VM schedulers in multicore hypervisors such as Xen.In the following subsections, we compare different real-timeVM scheduling policies in RT-Xen 2.0.
E. Comparison of Real-Time Scheduling Policies
We now evaluate different real-time VM scheduling policiessupported by RT-Xen 2.0. We first compare their capabilityto provide theoretical schedulability guarantees based oncompositional scheduling analysis. We then experimentally
evaluate their capability to meet the deadlines of real-time tasks in VMs on a real multi-core machine. Thisapproach allows us to compare the theoretical guarantees andexperimental performance of real-time VM scheduling, aswell as the real-time performance of different combinationsof real-time scheduling policies at the VMM and guest OSlevels. In both theoretical and experimental evaluations, weused the medium-bimodal distribution, and we performedthe experiments for all 25 task sets per utilization under thert-global and rt-partition schedulers.
Theoretical guarantees. To evaluate the four scheduling poli-cies at the VMM level, we fix the guest OS scheduler to beeither pEDF or gEDF, and we vary the VMM scheduler amongthe four schedulers, pEDF, gEDF, pDM and gDM. For eachconfiguration, we perform the schedulability test for every taskset.
Performance of the four schedulers at the VMM level: Fig-ures 5(a) and 5(b) show the fraction of schedulable task setsfor the four schedulers at the VMM level with respect to thetask set utilization when fixing pEDF or gEDF as the guestOS scheduler, respectively. The results show that, when we fixthe guest OS scheduler, the pEDF and pDM schedulers at theVMM level can provide theoretical schedulability guaranteesfor more task sets than the gDM scheduler, which in turnoutperforms the gEDF scheduler, for all utilizations. Note thatthe fraction of schedulable task sets of the pEDF scheduleris the same as that of the pDM scheduler. This is becausethe set of VCPUs to be scheduled by the VMM is the samefor both pDM and pEDF schedulers (since we fixed the guestOS scheduler), and these VCPUs have harmonic periods; asa result, the utilization bounds under both schedulers are bothequal to 1 [17]. The results also show that the partitionedschedulers usually outperformed the global schedulers in termsof theoretical schedulability.
Combination of EDF schedulers at both levels: Figure 5(c)shows the fraction of schedulable task sets for each taskset utilization under four different combinations of the EDFpriority assignment at the guest OS and the VMM levels. Theresults show a consistent order among the four combinationsin terms of theoretical schedulability (from best to worst):(pEDF, pEDF), (gEDF, pEDF), (pEDF, gEDF), and (gEDF,gEDF).
Experimental evaluation on RT-Xen 2.0. From the abovetheoretical results, we observed that pEDF and gEDF havethe best and the worst theoretical performance at both levels.Henceforth, we focus on EDF results in the experimentalevaluation. We have not observed statistically distinguishabledifferences between DM and EDF scheduling in their empiricalperformance, and the DM results follows similar trends to EDFscheduling. We include the DM results in the appendix forcompleteness.
Experimental vs. theoretical results: Figures 6(a) and 6(b)show the fractions of schedulable task sets that were predictedby the CSA theory and that were observed on RT-Xen 2.0for the two EDF schedulers at the VMM level, when fixingpEDF or gEDF as the guest OS scheduler, respectively. Weexamine all 25 task sets for each level of system, and we findthat whenever a task set used in our evaluation is schedulable

1.1 1.5 1.9 2.3 2.7 3.1 3.5 3.9 4.3 4.7 0
0.2
0.4
0.6
0.8
1
Fra
ctio
n o
f sc
hed
ula
ble
tas
k se
ts
Task Set Utilization
VMM (pEDF)VMM (pDM)VMM (gDM)VMM (gEDF)
(a) Guest OS (pEDF)
1.1 1.5 1.9 2.3 2.7 3.1 3.5 3.9 4.3 4.7 0
0.2
0.4
0.6
0.8
1
Fra
ctio
n o
f sc
hed
ula
ble
tas
k se
ts
Task Set Utilization
VMM (pEDF)VMM (pDM)VMM (gDM)VMM (gEDF)
(b) Guest OS (gEDF)
1.1 1.5 1.9 2.3 2.7 3.1 3.5 3.9 4.3 4.7 0
0.2
0.4
0.6
0.8
1
Fra
ctio
n o
f sc
hed
ula
ble
tas
k se
ts
Task Set Utilization
guest OS (pEDF), VMM (pEDF)guest OS (gEDF), VMM (pEDF)guest OS (pEDF), VMM (gEDF)guest OS (gEDF), VMM (gEDF)
(c) EDF for both Guest OS and VMM
Fig. 5: Theoretical results: schedulability of different schedulers at the guest OS and the VMM levels.
1.1 1.5 1.9 2.3 2.7 3.1 3.5 3.9 4.3 4.7 0
0.2
0.4
0.6
0.8
1
Task Set Utilization
Fra
ctio
n of
sch
edul
able
task
sets
gEDF (RT−Xen)pEDF (RT−Xen)pEDF (CSA Theory)gEDF (CSA Theory)
(a) Guest OS with pEDF
1.1 1.5 1.9 2.3 2.7 3.1 3.5 3.9 4.3 4.7 0
0.2
0.4
0.6
0.8
1
Task Set Utilization
Fra
ctio
n of
sch
edul
able
task
sets
gEDF (RT−Xen)pEDF (RT−Xen)pEDF (CSA Theory)gEDF (CSA Theory)
(b) Guest OS with gEDF
1.1 1.5 1.9 2.3 2.7 3.1 3.5 3.9 4.3 4.7 0
0.2
0.4
0.6
0.8
1
Task Set Utilization
Fra
ctio
n o
f sc
hed
ula
ble
tas
kset
s
guest OS (pEDF), VMM (gEDF)guest OS (pEDF), VMM (pEDF)guest OS (gEDF), VMM (gEDF)guest OS (gEDF), VMM (pEDF)
(c) Experimental results of EDF schedulers
Fig. 6: Experimental vs. theoretical results: schedulability of different schedulers at the guest OS and the VMM levels.
according to the theoretical analysis, it is also schedulableunder the corresponding scheduler on RT-Xen 2.0 in ourexperiments. In addition, for both pEDF and gEDF schedulers,the fractions of schedulable task sets observed on RT-Xen2.0 are always larger than or equal to those predicted by thetheoretical analysis. The results also show that, in contrast tothe trend predicted in theory, the gEDF scheduler at the VMMlevel can often schedule more task sets empirically than thepEDF scheduler. We attribute this to the pessimism of thegEDF schedulability analysis when applied to the VMM level,but gEDF is an effective real-time scheduling policy in practicedue to its flexibility to migrate VMs among cores.
Combination of EDF schedulers at both levels: Figure 6(c)shows the fraction of empirically schedulable task sets atdifferent levels of system utilization under four differentcombinations of EDF policies at the guest OS and VMMlevels. The results show that, at the guest OS level, the pEDFscheduler always outperform the gEDF scheduler. Further, ifwe fix pEDF (gEDF) for the guest OS scheduler, the gEDFscheduler at the VMM level can often schedule more task setsthan the pEDF scheduler.
1.1 1.5 1.9 2.3 2.7 3.1 3.5 3.9 4.3 4.7 0
2
4
6
Avg
to
tal b
and
wid
th o
f V
CP
Us
Task Set Utilization
←
available resource bandwidth
guest OS (gEDF)guest OS (pEDF)
Fig. 7: Average total VCPU bandwidth comparison.
To explain the relative performance of pEDF and gEDF
in a two-level scheduling hierarchy, we investigate the corre-sponding set of VCPUs that are scheduled by the VMM whenvarying the guest OS scheduler. For the same task set, theVCPUs of a domain under the pEDF and gEDF schedulerscan be different; hence, the set of VCPUs to be scheduledby the VMM can also be different. Figure 7 shows the totalbandwidth of all the VCPUs that are scheduled by the VMM– averaged across all 25 task sets – at each level of systemutilization for the pEDF and gEDF schedulers at the guest-OSlevel. The horizontal line represents the total available resourcebandwidth (with 5 cores).
The figure shows that gEDF as the guest OS schedulerresults in a higher average total VCPU bandwidth comparedto pEDF; therefore, the extra resource that the VMM allocatesto the VCPUs (compared to that was actually required by theirtasks) is much higher under gEDF. Since the resource that isunused by tasks of a higher priority VCPU cannot be used bytasks of lower-priority VCPUs when VCPUs are implementedas periodic servers, more resources were wasted under gEDF.In an overloaded situation, where the underlying platformcannot provide enough resources at the VMM level, the lower-priority VCPUs will likely miss deadlines. Therefore the poorperformance of gEDF at the guest OS level results from thecombination of pessimistic resource interfaces based on theCSA and the non-work-conserving nature of periodic server.We study deferrable server, a work-conserving mechanism forimplementing VCPUs, in Section IV-F
In contrast, when we fix the guest OS scheduler to be eitherpEDF or gEDF, the set of VCPUs that is scheduled by theVMM is also fixed. As a result, we observe more VCPUs beingschedulable on RT-Xen 2.0 under the gEDF scheduler thanunder the pEDF scheduler at the VMM level (c.f., Figure 6(c)).This is consistent with our earlier observation, that the gEDFscheduler can often schedule more task sets than the pEDFscheduler empirically because of the flexibility to migrate VMs
1.1 1.5 1.9 2.3 2.7 3.1 3.5 3.9 4.3 4.7 0
0.2
0.4
0.6
0.8
1
Task Set Utilization
Fra
ctio
n o
f sc
hed
ula
ble
tas
kset
s
gEDF (Deferrable Server)gEDF (Periodic Server)pEDF (Deferrable Server)pEDF (Periodic Server)
(a) Guest OS with pEDF
1.1 1.5 1.9 2.3 2.7 3.1 3.5 3.9 4.3 4.7 0
0.2
0.4
0.6
0.8
1
Task Set Utilization
Fra
ctio
n o
f sc
hed
ula
ble
tas
kset
s
gEDF (Deferrable Server)gEDF (Periodic Server)pEDF (Deferrable Server)pEDF (Periodic Server)
(b) Guest OS with gEDF
1.1 1.5 1.9 2.3 2.7 3.1 3.5 3.9 4.3 4.7 0
0.2
0.4
0.6
0.8
1
Task Set Utilization
Fra
ctio
n o
f sc
hed
ula
ble
tas
kset
s
guest OS (pEDF), VMM (gEDF)guest OS (gEDF), VMM (gEDF)guest OS (pEDF), VMM (pEDF)guest OS (gEDF), VMM (pEDF)
(c) Deferrable Server’s Performance
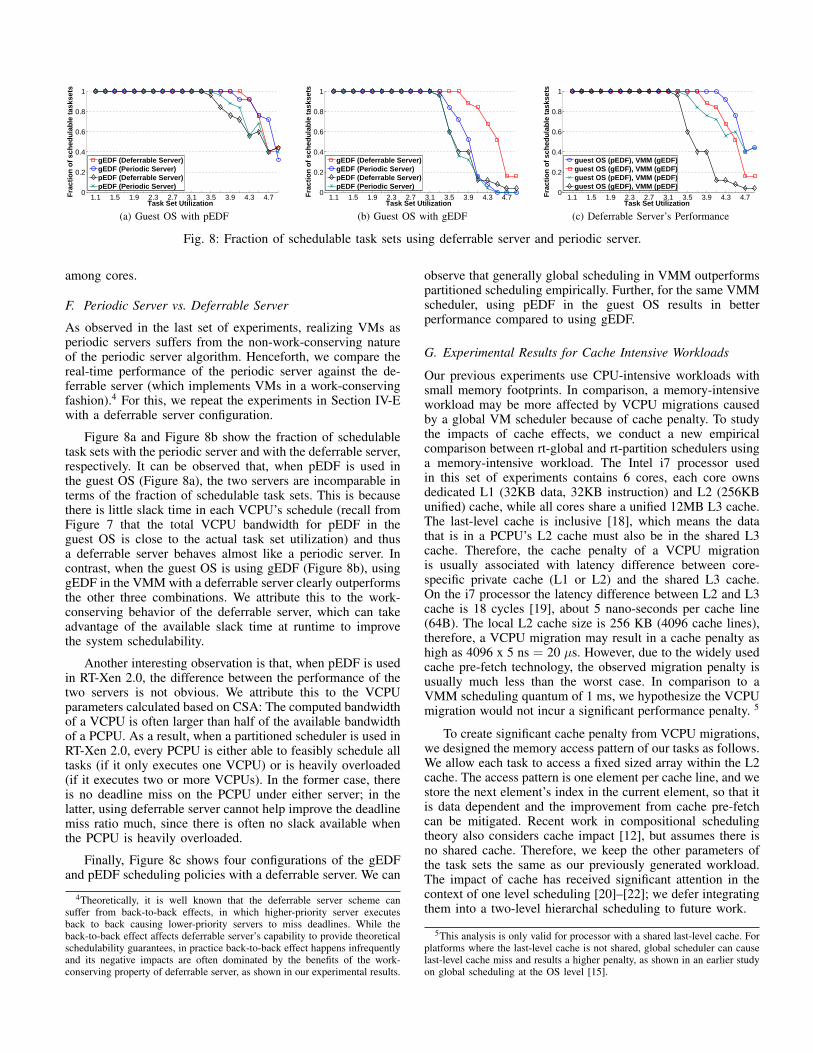
Fig. 8: Fraction of schedulable task sets using deferrable server and periodic server.
among cores.
F. Periodic Server vs. Deferrable Server
As observed in the last set of experiments, realizing VMs asperiodic servers suffers from the non-work-conserving natureof the periodic server algorithm. Henceforth, we compare thereal-time performance of the periodic server against the de-ferrable server (which implements VMs in a work-conservingfashion).4 For this, we repeat the experiments in Section IV-Ewith a deferrable server configuration.
Figure 8a and Figure 8b show the fraction of schedulabletask sets with the periodic server and with the deferrable server,respectively. It can be observed that, when pEDF is used inthe guest OS (Figure 8a), the two servers are incomparable interms of the fraction of schedulable task sets. This is becausethere is little slack time in each VCPU’s schedule (recall fromFigure 7 that the total VCPU bandwidth for pEDF in theguest OS is close to the actual task set utilization) and thusa deferrable server behaves almost like a periodic server. Incontrast, when the guest OS is using gEDF (Figure 8b), usinggEDF in the VMM with a deferrable server clearly outperformsthe other three combinations. We attribute this to the work-conserving behavior of the deferrable server, which can takeadvantage of the available slack time at runtime to improvethe system schedulability.
Another interesting observation is that, when pEDF is usedin RT-Xen 2.0, the difference between the performance of thetwo servers is not obvious. We attribute this to the VCPUparameters calculated based on CSA: The computed bandwidthof a VCPU is often larger than half of the available bandwidthof a PCPU. As a result, when a partitioned scheduler is used inRT-Xen 2.0, every PCPU is either able to feasibly schedule alltasks (if it only executes one VCPU) or is heavily overloaded(if it executes two or more VCPUs). In the former case, thereis no deadline miss on the PCPU under either server; in thelatter, using deferrable server cannot help improve the deadlinemiss ratio much, since there is often no slack available whenthe PCPU is heavily overloaded.
Finally, Figure 8c shows four configurations of the gEDFand pEDF scheduling policies with a deferrable server. We can
4Theoretically, it is well known that the deferrable server scheme cansuffer from back-to-back effects, in which higher-priority server executesback to back causing lower-priority servers to miss deadlines. While theback-to-back effect affects deferrable server’s capability to provide theoreticalschedulability guarantees, in practice back-to-back effect happens infrequentlyand its negative impacts are often dominated by the benefits of the work-conserving property of deferrable server, as shown in our experimental results.
observe that generally global scheduling in VMM outperformspartitioned scheduling empirically. Further, for the same VMMscheduler, using pEDF in the guest OS results in betterperformance compared to using gEDF.
G. Experimental Results for Cache Intensive Workloads
Our previous experiments use CPU-intensive workloads withsmall memory footprints. In comparison, a memory-intensiveworkload may be more affected by VCPU migrations causedby a global VM scheduler because of cache penalty. To studythe impacts of cache effects, we conduct a new empiricalcomparison between rt-global and rt-partition schedulers usinga memory-intensive workload. The Intel i7 processor usedin this set of experiments contains 6 cores, each core ownsdedicated L1 (32KB data, 32KB instruction) and L2 (256KBunified) cache, while all cores share a unified 12MB L3 cache.The last-level cache is inclusive [18], which means the datathat is in a PCPU’s L2 cache must also be in the shared L3cache. Therefore, the cache penalty of a VCPU migrationis usually associated with latency difference between core-specific private cache (L1 or L2) and the shared L3 cache.On the i7 processor the latency difference between L2 and L3cache is 18 cycles [19], about 5 nano-seconds per cache line(64B). The local L2 cache size is 256 KB (4096 cache lines),therefore, a VCPU migration may result in a cache penalty ashigh as 4096 x 5 ns = 20 µs. However, due to the widely usedcache pre-fetch technology, the observed migration penalty isusually much less than the worst case. In comparison to aVMM scheduling quantum of 1 ms, we hypothesize the VCPUmigration would not incur a significant performance penalty. 5
To create significant cache penalty from VCPU migrations,we designed the memory access pattern of our tasks as follows.We allow each task to access a fixed sized array within the L2cache. The access pattern is one element per cache line, and westore the next element’s index in the current element, so that itis data dependent and the improvement from cache pre-fetchcan be mitigated. Recent work in compositional schedulingtheory also considers cache impact [12], but assumes there isno shared cache. Therefore, we keep the other parameters ofthe task sets the same as our previously generated workload.The impact of cache has received significant attention in thecontext of one level scheduling [20]–[22]; we defer integratingthem into a two-level hierarchal scheduling to future work.
5This analysis is only valid for processor with a shared last-level cache. Forplatforms where the last-level cache is not shared, global scheduler can causelast-level cache miss and results a higher penalty, as shown in an earlier studyon global scheduling at the OS level [15].

1.1 1.5 1.9 2.3 2.7 3.1 3.5 3.9 4.3 4.7 0
0.2
0.4
0.6
0.8
1
Task Set Utilization
Fra
ctio
n o
f sc
hed
ula
ble
tas
kset
s
gEDFpEDF
Fig. 9: Cache-intensive workloads (guest OS with pEDF)
We use pEDF in the guest OS so that the cache penaltyare attributed only to the VMM-level schedulers. We comparethe real-time performance of the gEDF and pEDF VMMschedulers. As shown in Figure 9, gEDF again outperformspEDF despite the cache penalty. This confirms the benefits ofa global scheduling policy outweighs the cache penalty causedby the VCPU migration on a multicore platformed with sharedlast-level cache.
V. RELATED WORK
Since our RT-Xen 2.0 scheduling framework is shaped byboth theoretical and practical considerations, we discuss relatedwork in both the theory and the systems domain.
A. Theory perspective
There exists a large body of work on hierarchical schedulingfor single-processor platforms (see e.g., [6], [23]–[25]), whichconsiders both DM and EDF schemes. In RT-Xen 2.0, we usethe method in [6] to derive the interfaces under partitioned DMand partitioned EDF schedulers.
Recently, a number of compositional scheduling techniquesfor multicore platforms have been developed (e.g., [7], [12],[13], [26]–[28]), which provide different resource models forrepresenting the interfaces. For instance, an MPR interface [7]abstracts a component using a period, a budget within eachperiod, and a maximum level of concurrency, whereas a multi-supply function interface [13] uses a set of supply boundfunctions. Our evaluations on RT-Xen 2.0 were performedusing the MPR model for the domains’ interfaces [7], but theRT-Xen 2.0 scheduling framework is compatible with mostother interfaces, such as [12], [13] and their variations asdiscussed in Section III. In the future RT-Xen 2.0 can serveas an open source platform for the community to experimentwith different hierarchical schedulability analysis.
B. Systems perspective
The implementation of hierarchical scheduling has been inves-tigated for various platforms, including (1) native platforms,(2) Xen, and (3) other virtualization platforms. We describeeach category below:
Native platforms: There are several implementations ofhierarchical scheduling within middleware or OS kernels [29]–[34]. In these implementations, all levels of the schedulinghierarchy are implemented in one (user or kernel) space. Incontrast, RT-Xen 2.0 implements schedulers in the VMMlevel, and leverages existing real-time schedulers in the guest
OS, thereby achieving a clean separation between the twolevels of scheduling. Furthermore, leveraging compositionalschedulability analysis, RT-Xen 2.0 also enables guestdomains to hide their task-level details from the underlyingplatform, since it only requires a minimal scheduling interfaceabstraction from the domains.
Other Xen approaches: Several recent efforts have addedreal-time capabilities to Xen. For example, Lee et al. [35]and Zhang et al. [36] provides a strict-prioritization patchfor the credit scheduler so that real-time domains can alwaysget resource before non-real-time domains, and Govindan etal. [5] mitigates priority inversion when guest domains areco-scheduled with domain 0 on a single core. Yoo et al. [4]used similar ideas to improve the credit scheduler on theXen ARM platform. While these works employed heuristicsto enhance the existing schedulers, RT-Xen 2.0 delivers areal-time performance based on compositional schedulabilityanalysis and provides a new real-time scheduling frameworkthat is separate from the existing schedulers.
Other virtualization approaches: There are othervirtualization technologies that rely on architectures otherthan Xen. For instance, KVM [37] integrates the VMM withthe host OS, and schedules VCPUs together with other tasksin the host OS. Hence, in principle, any real-time multicoreLinux scheduler [15], [38]–[41] could be configured toapply two-level hierarchical scheduling in KVM, but withlimited server mechanism support. As an example, Checconiet al. [42] implemented a partitioned-queue EDF schedulerfor scheduling multicore KVM virtual machines, usinghard constant-bandwidth servers for the VCPUs and globalfixed-priority scheduling for the guest OS scheduler. The samegroup also investigated the scheduling of real-time workloadsin virtualized cloud infrastructures [43]. Besides KVM, themicro-kernel like L4/Fiasco [44] can also be used to achievehierarchical scheduling, as demonstrated by Yang et al. [45]using a periodic server implementation. Lackorzynski etal. [46] exported the task information to the host scheduler inorder to address the challenge of mixed-criticality systems ina virtualized environment. Hartig et al. [47] studied a multi-resource multi-level problem to optimize energy consumption.Crespo et al. [48] proposed a bare-metal VMM based on apara-virtualization technology similar to Xen for embeddedplatforms, which uses static (cyclic) scheduling. In contrast,RT-Xen 2.0 provides a scheduling framework spanning thedesign space in terms of global and partitioned scheduling,dynamic and static priority, periodic and deferrable servers.We also provide an comprehensive experimental study ofdifferent combinations of scheduling designs.
VI. CONCLUSIONS AND FUTURE WORK
We have designed and implemented RT-Xen 2.0, a new real-time multicore VM scheduling framework in the Xen virtualmachine monitor (VMM). RT-Xen 2.0 realizes global andpartitioned VM schedulers, and each scheduler can be con-figured to support dynamic or static priorities, and to runVMs as periodic or deferrable servers. Through a compre-hensive experimental study, we show that both global andpartitioned VM scheduling can be implemented in the VMMat moderate overhead. Moreover, at the VMM scheduler level,in compositional schedulability theory pEDF is better than

gEDF in schedulability guarantees, but in our experimentstheir actual performance is reversed in terms of the fraction ofworkloads that meet their deadlines on virtualized multicoreplatforms. At the guest OS level, pEDF requests a smallertotal VCPU bandwidth than gEDF based on compositionalschedulability analysis, and therefore using pEDF in the guestOS level leads to more schedulable workloads on a virtualizedmulticore processor. The combination of pEDF in guest OSand gEDF in the VMM therefore resulted the best experimentalperformance. Finally, on a platform with a shared last-levelcache, the benefits of global scheduling outweigh the cachepenalty incurred by VM migration.
REFERENCES
[1] “The Xen Project’s Hypervisor for the ARM architecture,” http://www.xenproject.org/developers/teams/arm-hypervisor.html.
[2] S. Xi, J. Wilson, C. Lu, and C. Gill, “RT-Xen: Towards Real-TimeHypervisor Scheduling in Xen,” in EMSOFT. ACM, 2011.
[3] J. Lee, S. Xi, S. Chen, L. T. X. Phan, C. Gill, I. Lee, C. Lu, andO. Sokolsky, “Realizing Compositional Scheduling Through Virtual-ization,” in RTAS. IEEE, 2012.
[4] S. Yoo, K.-H. Kwak, J.-H. Jo, and C. Yoo, “Toward under-millisecondI/O latency in Xen-ARM,” in Proceedings of the Second Asia-PacificWorkshop on Systems. ACM, 2011, p. 14.
[5] S. Govindan, A. R. Nath, A. Das, B. Urgaonkar, and A. Sivasubra-maniam, “Xen and Co.: Communication-aware CPU Scheduling forConsolidated Xen-based Hosting Platforms,” in VEE, 2007.
[6] I. Shin and I. Lee, “Compositional Real-Time Scheduling Framework,”in RTSS, 2004.
[7] A. Easwaran, I. Shin, and I. Lee, “Optimal virtual cluster-basedmultiprocessor scheduling,” Real-Time Syst., vol. 43, no. 1, pp.25–59, Sep. 2009. [Online]. Available: http://dx.doi.org/10.1007/s11241-009-9073-x
[8] ——, “Optimal Virtual Cluster-Based Multiprocessor Scheduling,”Real-Time Systems, 2009.
[9] “LITMUS-RT,” http://www.litmus-rt.org/.[10] P. Barham, B. Dragovic, K. Fraser, S. Hand, T. Harris, A. Ho, R. Neuge-
bauer, I. Pratt, and A. Warfield, “Xen and the Art of Virtualization,”ACM SIGOPS Operating Systems Review, 2003.
[11] “Credit Scheduler,” http://wiki.xen.org/wiki/Credit Scheduler.[12] M. Xu, L. T. X. Phan, I. Lee, O. Sokolsky, S. Xi, C. Lu, and C. D.
Gill, “Cache-Aware Compositional Analysis of Real-Time MulticoreVirtualization Platforms,” in RTSS, 2013.
[13] E. Bini, G. Buttazzo, and M. Bertogna, “The Multi Supply FunctionAbstraction for Multiprocessors,” in RTCSA. IEEE, 2009.
[14] S. Barush and B. Brandenburg, “Multiprocessor feasibility analysis ofrecurrent task systems with specified processor affinities,” in RTSS,2013.
[15] A. Bastoni, B. B. Brandenburg, and J. H. Anderson, “An EmpiricalComparison of Global, and Clustered Multiprocessor EDF Schedulers,”in RTSS. IEEE, 2010.
[16] D. Gupta, R. Gardner, and L. Cherkasova, “Xenmon: Qos Monitoringand Performance Profiling Tool,” Hewlett-Packard Labs, Tech. Rep.HPL-2005-187, 2005.
[17] G. C. Buttazzo, “Rate monotonic vs. edf: judgment day,” Real-TimeSyst., vol. 29, no. 1, pp. 5–26, Jan. 2005. [Online]. Available:http://dx.doi.org/10.1023/B:TIME.0000048932.30002.d9
[18] “Intel 64 and IA-32 Architectures Optimization Reference Man-ual,” http://www.intel.com/content/dam/www/public/us/en/documents/manuals/64-ia-32-architectures-optimization-manual.pdf.
[19] “Intel Ivy Bridge 7-Zip LZMA Benchmark Results,” http://www.7-cpu.com/cpu/IvyBridge.html.
[20] W. Lunniss, S. Altmeyer, C. Maiza, and R. I. Davis, “Integrating CacheRelated Pre-emption Delay Analysis into EDF Scheduling,” in RTAS,2013.
[21] S. Altmeyer, R.I. Davis, and C. Maiza, “Improved Cache Related Pre-emption Delay Aware Response Time Analysis for Fixed Priority Pre-emptive Systems,” Real-Time Systems, 2012.
[22] H. Yun, G. Yao, R. Pellizzoni, M. Caccamo, and L. Sha, “MemGuard:Memory Bandwidth Reservation System for Efficient PerformanceIsolation in Multi-core Platforms,” in RTAS, 2013.
[23] Z. Deng and J. Liu, “Scheduling Real-Time Applications in an OpenEnvironment,” in RTSS, 1997.
[24] A. Easwaran, M. Anand, and I. Lee, “Compositional Analysis Frame-work Using EDP Resource Models,” in RTSS, 2007.
[25] M. Behnam, I. Shin, T. Nolte, and M. Nolin, “SIRAP: A Synchroniza-tion Protocol for Hierarchical Resource Sharing in Real-Time OpenSystems,” in EMSOFT, 2007.
[26] H. Leontyev and J. H. Anderson, “A Hierarchical MultiprocessorBandwidth Reservation Scheme with Timing Guarantees,” Real-TimeSystems, 2009.
[27] S. Groesbrink, L. Almeida, M. de Sousa, and S. M. Petters, “Towardscertifiable adaptive reservations for hypervisor-based virtualization,” inRTAS, 2014.
[28] G. Lipari and E. Bini, “A Framework for Hierarchical Scheduling onMultiprocessors: From Application Requirements to Run-Time Alloca-tion,” in RTSS. IEEE, 2010.
[29] J. Regehr and J. Stankovic, “HLS: A Framework for Composing SoftReal-Time Schedulers,” in RTSS, 2001.
[30] Y. Wang and K. Lin, “The Implementation of Hierarchical Schedulersin the RED-Linux Scheduling Framework,” in ECRTS, 2000.
[31] F. Bruns, S. Traboulsi, D. Szczesny, E. Gonzalez, Y. Xu, and A. Bilgic,“An Evaluation of Microkernel-Based Virtualization for EmbeddedReal-Time Systems,” in ECRTS, 2010.
[32] T. Aswathanarayana, D. Niehaus, V. Subramonian, and C. Gill, “Designand Performance of Configurable Endsystem Scheduling Mechanisms,”in RTAS, 2005.
[33] B. Lin and P. A. Dinda, “Vsched: Mixing batch and interactive virtualmachines using periodic real-time scheduling,” in Proceedings of the2005 ACM/IEEE conference on Supercomputing, 2005.
[34] M. Danish, Y. Li, and R. West, “Virtual-CPU Scheduling in the QuestOperating System,” in RTAS, 2011.
[35] M. Lee, A. Krishnakumar, P. Krishnan, N. Singh, and S. Yajnik,“Supporting Soft Real-Time Tasks in the Xen Hypervisor,” in ACMSigplan Notices, 2010.
[36] W. Zhang, S. Rajasekaran, T. Wood, and M. Zhu, “MIMP: Deadlineand Interference Aware Scheduling of Hadoop Virtual Machines,”in IEEE/ACM International Symposium on Cluster, Cloud and GridComputing, 2014.
[37] “Kernel Based Virtual Machine,” http://www.linux-kvm.org.[38] G. Gracioli, A. A. Frohlich, R. Pellizzoni, and S. Fischmeister, “Im-
plementation and evaluation of global and partitioned scheduling in areal-time os,” Real-Time Systems, 2013.
[39] B. B. Brandenburg and J. H. Anderson, “On the Implementation ofGlobal Real-Time Schedulers,” in RTSS. IEEE, 2009.
[40] J. M. Calandrino, H. Leontyev, A. Block, U. C. Devi, and J. H.Anderson, “LITMUS-RT: A Testbed for Empirically Comparing Real-Time Multiprocessor Schedulers,” in RTSS, 2006.
[41] T. Cucinotta, G. Anastasi, and L. Abeni, “Respecting Temporal Con-straints in Virtualised Services,” in COMPSAC, 2009.
[42] F. Checconi, T. Cucinotta, D. Faggioli, and G. Lipari, “HierarchicalMultiprocessor CPU Reservations for the Linux Kernel,” OSPERT,2009.
[43] T. Cucinotta, F. Checconi, G. Kousiouris, D. Kyriazis, T. Varvarigou,A. Mazzetti, Z. Zlatev, J. Papay, M. Boniface, S. Berger et al.,“Virtualised e-learning with real-time guarantees on the irmos platform,”in Service-Oriented Computing and Applications (SOCA). IEEE, 2010.
[44] “Fiasco micro-kernel,” http://os.inf.tu-dresden.de/fiasco/.[45] J. Yang, H. Kim, S. Park, C. Hong, and I. Shin, “Implementation of
compositional scheduling framework on virtualization,” SIGBED Rev,2011.
[46] A. Lackorzynski, A. Warg, M. Volp, and H. Hartig, “Flattening hierar-chical scheduling,” in EMSOFT. ACM, 2012.
[47] H. Hartig, M. Volp, and M. Hahnel, “The case for practical multi-resource and multi-level scheduling based on energy/utility,” in RTCSA,2013.
[48] A. Crespo, I. Ripoll, and M. Masmano, “Partitioned Embedded Archi-tecture Based on Hypervisor: the XtratuM Approach,” in EDCC, 2010.
[49] M. Bertogna, M. Cirinei, and G. Lipari, “Schedulability analysis ofglobal scheduling algorithms on multiprocessor platforms,” Parallel andDistributed Systems, IEEE Transactions on, vol. 20, no. 4, pp. 553–566,2009.

APPENDIX A: COMPOSITIONAL ANALYSIS UNDER GLOBALDEADLINE MONOTONIC SCHEDULING
In this appendix, we present a compositional analysis methodfor components under the gDM scheduling algorithm, whichis needed to derive the interfaces of domains in RT-Xen 2.0(c.f. Section II-B). Here, we adopt the MPR model [7] torepresent a component’s interface due to its simplicity andflexibility; however, the method can easily be extended to othermultiprocessor resource models.
First, recall that an MPR µ = 〈Π,Θ,m′〉 represents a unit-capacity multiprocessor resource that provides Θ executiontime units every Π time units with concurrency at most m′.Its bandwidth is Θ
Π , and its supply bound function, sbfµ(t),which specifies the minimum resource supply of µ over anytime interval of length t, is given by [7]:
sbfµ(t) =
0, if t′ < 0
b t′
ΠcΘ + max{
0,m′x− (m′Π−Θ)},
if t′ ≥ 0 and x ∈ [1, y]
b t′
ΠcΘ + max{
0,m′x− (m′Π−Θ)}− (m′ − β),
if t′ ≥ 0 and x 6∈ [1, y](1)
where t′ = t − (Π − d Θm′ e), x = (t′ − Πb t
′
Πc); y = Π − Θm′ ,
and β = Θ −m′b Θm′ c. Further, µ is called an optimal MPR
interface of a component C if it has the smallest bandwidthamong all MPR models that can guarantee the schedulabilityof C.
To compute an optimal MPR interface of a componentunder gDM, we first develop its schedulability test undergDM. Our test improves (in most cases) upon the state-of-the-art schedulability test proposed by Bertogna et al. [49] byconsidering an extended problem window.
Consider a component C with a workload τ ={τ1, . . . , τn
}that is scheduled under gDM on a multi-core
platform with m unit-speed cores, where each τi is a periodictask with period pi, worst-case execution time ei, and deadlinedi, for all 1 ≤ i ≤ n. Without loss of generality, we assumethat τi has higher priority than τj (which implies di ≤ dj) ifi < j.
As usual, the demand of a task τi in any time interval oflength t is the amount of computation that must be completedwithin that interval to guarantee that all jobs of τi withdeadlines within the interval are schedulable. Under gDM, thisdemand is upper-bounded by [49]:
dbfi(t)def= Ni(t)ei + COi(t) (2)
where Ni(t) =⌊t+di−ei
pi
⌋and COi(t) = min{ei, t + di −
ei − Ni(t)pi}. Here, COi(t) denotes the maximum carry-outdemand of τi in any time interval [a, b) with b− a = t, whichis the maximum demand of a job of τi that is released priorto b but has deadline after b.
To verify the schedulability of a task τk, suppose that Jk isa job of τk that has the highest response time among all τk’sjobs. We define the problem window of Jk as [a, b), wherea is the release time of Jk, and b is the earliest time at orafter its deadline when at least one core is idle. Let t = b− a.
We categorize the execution workload of each task τi (where1 ≤ i ≤ n) during the problem window [a, b) into two classes:(1) the workload of τi during the time intervals in [a, b) overwhich τk is running; and (2) the workload of τi during theintervals in [a, b) over which τk is not running.
Observe that the total execution workload of type (1) ofall higher-priority tasks of τk is upper-bounded by mek, sinceonly m cores are executing the taskset. Further, let Ii,2 be themaximum workload of type (2) of τi, and Ii,2 be the maximumworkload of τi in the problem window [a, b) excluding itscarry-out workload, for all 1 ≤ i ≤ n. Then, by definition,both Ik,2 and Ik,2 are upper-bounded by t− dk, whereas bothIi,2 and Ii,2 are upper-bounded by t− ek for all i 6= k (sinceat least one core is idle at time b, and b is greater than or equalto Jk’s deadline). Hence,
Ik,2 = min{dbfk(t)− ek − COk(t), t− dk};Ik,2 = min{dbfk(t)− ek, t− dk};Ii,2 = min{dbfi(t)− COi(t), t− ek},∀i 6= k;
Ii,2 = min{dbfi(t), t− ek},∀i 6= k.
Since at least one core is idle at time b, there are at mostm− 1 tasks whose carry-out workloads contribute to the totalcarry-out workload of τ in [a, b). Let mk be the minimumbetween m − 1 and the number of higher-priority tasks ofτk. Then, the total carry-out workload of τ in [a, b) is upper-bounded by
∑i∈Lk
(Ii,2− Ii,2), where Lk is the set of indicesof mk higher-priority tasks τi of τk with the largest values ofIi,2 − Ii,2. Based on the above observations, we deduce thatthe worst-case demand of τ that must be satisfied to guaranteethe schedulability of Jk is bounded by:
DEM(t,m) = mek +
k∑i=1
Ii,2 +∑i:i∈Lk
(Ii,2 − Ii,2). (3)
As a result, we infer the following schedulability test:
Theorem 1: A component C with a task set τ ={τ1, ..., τn}, where τi = (pi, ei, di), is schedulable under gDMby a multiprocessor resource model R with m cores if, for eachtask τk ∈ τ and for all t > dk, DEM(t,m) ≤ sbfR(t), whereDEM(t,m) is given by Eq. (3) and sbfR(t) is the minimumresource supply of R over any interval of length t.
When R is a fully available multiprocessor platform with munit-capacity cores, sbfR(t) = mt. Thus, by simply replacingsbfR(t) with mt in Theorem 1, we obtain the improvedgDM schedulability test under a fully available multiprocessorplatform with unit-capacity m cores.
Based on Theorem 1, we can establish the gDM schedula-bility test for components when using MPR interfaces, givenin Theorem 2.
Theorem 2: A component C with a workload τ ={τ1, ..., τn}, where τi = (pi, ei, di), is schedulable under gDMby an MPR model µ = 〈Π,Θ,m′〉 if for each task τk ∈ τand for all dk ≤ t ≤ tmax, DEM(t,m′) ≤ sbfµ(t), whereDEM(t,m′) is given by Eq. (3), sbfµ(t) is given by Eq. (1),and
tmax =CΣ +m′ek − dk(Θ
Π − UT ) + U +BΘΠ − UT
, (4)

1.1 1.5 1.9 2.3 2.7 3.1 3.5 3.9 4.3 4.7 0
0.2
0.4
0.6
0.8
1
Task Set Utilization
Fra
ctio
n o
f sc
hed
ula
ble
tas
kset
s
gDM (Deferrable Server)gDM (Periodic Server)pDM (Deferrable Server)pDM (Periodic Server)
(a) Guest OS with pEDF
1.1 1.5 1.9 2.3 2.7 3.1 3.5 3.9 4.3 4.7 0
0.2
0.4
0.6
0.8
1
Task Set Utilization
Fra
ctio
n o
f sc
hed
ula
ble
tas
kset
s
gDM (Deferrable Server)gDM (Periodic Server)pDM (Deferrable Server)pDM (Periodic Server)
(b) Guest OS with gEDF
1.1 1.5 1.9 2.3 2.7 3.1 3.5 3.9 4.3 4.7 0
0.2
0.4
0.6
0.8
1
Task Set Utilization
Fra
ctio
n o
f sc
hed
ula
ble
tas
kset
s
guest OS (pEDF), VMM (gDM)guest OS (gEDF), VMM (gDM)guest OS (pEDF), VMM (pDM)guest OS (gEDF), VMM (pDM)
(c) Deferrable Server’s Performance
Fig. 10: Fraction of schedulable task sets using deferrable server and periodic server.
where CΣ is the sum of the m′−1 largest ei among all τi ∈ τ ,U =
∑ni=1(di − ei) eipi , and B = Θ
Π
(2 + 2(Π− Θ
m′ )).
Proof: By the definition of Lk, the number of tasks whoseindices are in Lk is no more than k. Therefore,
∑i:i∈Lk
(Ii,2−Ii,2) ≤
∑ki=1(Ii,2 − Ii,2). As a result,
DEM(t,m′)def= m′ek +
k∑i=1
Ii,2 +∑
i:i∈Lk
(Ii,2 − Ii,2) (5)
≤ m′ek +k∑
i=1
Ii,2 +k∑
i=1
(Ii,2 − Ii,2) = m′ek +k∑
i=1
Ii,2.
(6)
Since Ii,2 ≤ t− ek, we obtain DEM(t,m′) ≤ m′ek + n(t−ek). From the definition of
∑ki=1(Ii,2 − Ii,2), we imply that∑k
i=1(Ii,2 − Ii,2) ≤ CΣ, where CΣ is the sum of the m′ − 1
largest ei among all τi ∈ τ . Further, Ii,2 = min{dbfi(t) −COi(t), t − ek} ≤ dbfi(t) − COi(t). By definition of dbfi(t)in Eq. 2, we have
dbfi(t)− COi(t) =⌊ t+ di − ei
pi
⌋ei
≤ t+ di − eipi
ei = teipi
+ (di − ei)eipi
.
Recall that UT =∑ki=1
eipi
and U = (di − ei) eipi . Combinethe above with Eq. (6), we have
DEM(t,m′) ≤ m′ek + CΣ +
k∑i=1
(dbfi(t)− COi(t)
)≤ m′ek + CΣ +
k∑i=1
(teipi
+ (di − ei)eipi
)≤ m′ek + CΣ + tUT + U.
From Eq. (2) in [7], we additionally have sbfµ(t) ≥ ΘΠ t−B,
where B = ΘΠ (2 + 2(Π− Θ
m′ )).
Based on the above results, if Theorem 1 is violated for atask τk, then DEM(t,m′) > sbfµ(t), which implies
m′ek + CΣ + tUT + U >Θ
Πt−B.
The above is equivalent to t < tmax, where
t <CΣ +m′ek − dk(Θ
Π − UT ) + U +BΘΠ − UT
def= tmax
Therefore, when t ≥ tmax, DEM(t,m′) ≤ sbfµ(t) for eachτk ∈ τ . Hence, we only need to check the condition ofDEM(t,m′) ≤ sbfµ(t) for all dk ≤ t < tmax for everytask τk ∈ τ . This means that τ is schedulable by µ undergDM if for each task τk ∈ τ , for all dk ≤ t ≤ tmax,DEM(t,m′) ≤ sbfµ(t). Hence, the theorem follows.
Based on Theorem 2, we can now generate the optimalinterface of a domain under gDM based on its workload in thesame manner as the interface generation under gEDF in [7].In addition, we can also transform the obtained interface of adomain into a set of VCPUs for the domain (which will bescheduled by the VMM scheduler) using the MPR interface-to-tasks transformation described in [7]. The parameters ofthe VCPUs of each domain can now be used to performthe scheduling at the VMM level within RT-Xen 2.0 (c.f.Section III).
APPENDIX B: RESULTS FOR DM SCHEDULING POLICIES
We include the results for gDM and pDM in Figure 10 forcompleteness. We can draw same conclusions as in Figure 8:when guest OS is using pEDF, deferrable and periodic serversare incomparable in their performance; when guest OS is usinggEDF, a deferrable server with gDM in the VMM clearlyoutperforms the other combinations. Finally, a combination ofpEDF in guest OS and gDM in VMM results in the highestfraction of schedulable task sets.