Embed Size (px)
Citation preview

Quasi-Synchronous Grammars
Alignment by Soft Projection of Syntactic Dependencies
David A. Smith and Jason EisnerCenter for Language and Speech Processing
Department of Computer ScienceJohns Hopkins University

Synchronous Grammars
Synchronous grammars elegantly model P(T1, T2, A) Conditionalizing for
Alignment Translation
Training? Observe parallel trees? Impute trees/links? Project known trees…
Im Anfang war das Wort
In the beginning was the word

Projection
Train with bitext Parse one side Align words Project dependencies Many to one links? Non-projective and
circular dependencies? Proposals in Hwa et al.,
Quirk et al., etc.
Im Anfang war das Wort
In the beginning was the word

Divergent Projection
Auf Fragediese bekommenichhabe leider Antwortkeine
I did not unfortunately receive an answer to this question
NULL
monotonic
nullhead-swapping
siblings

Free Translation
Tschernobyl könnte dann etwas später an die Reihe kommen
Then we could deal with Chernobyl some time later
Bad dependencies
Parent-ancestors?
NULL

Dependency Menagerie

Overview
Divergent & Sloppy Projection Modeling Motivation Quasi-Synchronous Grammars (QG) Basic Parameterization Modeling Experiments Alignment Experiments

QG by Analogy
HMM: noisy channel generating states
MEMM: direct generativemodel of states
CRF: undirected,globally normalized
Target
Source
Source
Target

I really mean “conference paper”.
Words with Senses
I presented thehave paper about
Ich habe die Veröffentlichung über… präsentiertdas Papier mit
with
Now senses in a particular (German) sentence
Veröffentlichung

Quasi-Synchronous Grammar
QG: A target-language grammar that generates translations of a particular source-language sentence.
A direct, conditional model of translation as P(T2, A | T1)
This grammar can be CFG, TSG, TAG, etc.

Generating QCFG from T1
U = Target language grammar nonterminals V = Nodes of given source tree T1
Binarized QCFG: A, B, C U; α, β, γ 2∈ ∈ V
<A, α> <B, β> <C, γ>⇒ <A, α> w⇒
Present modeling restrictions |α| ≤ 1 Dependency grammars (1 node per word) Tie parameters that depend on α, β, γ “Model 1” property: reuse of senses. Why?
“senses”

Modeling Assumptions
Im Anfang war das Wort
the beginning was the word
At most 1 sense per
English word
Dependency Grammar: one
node/word
Allow sense “reuse”
Tie params for all tokens of
“im”
In

Dependency Relations
+ “none of the above”
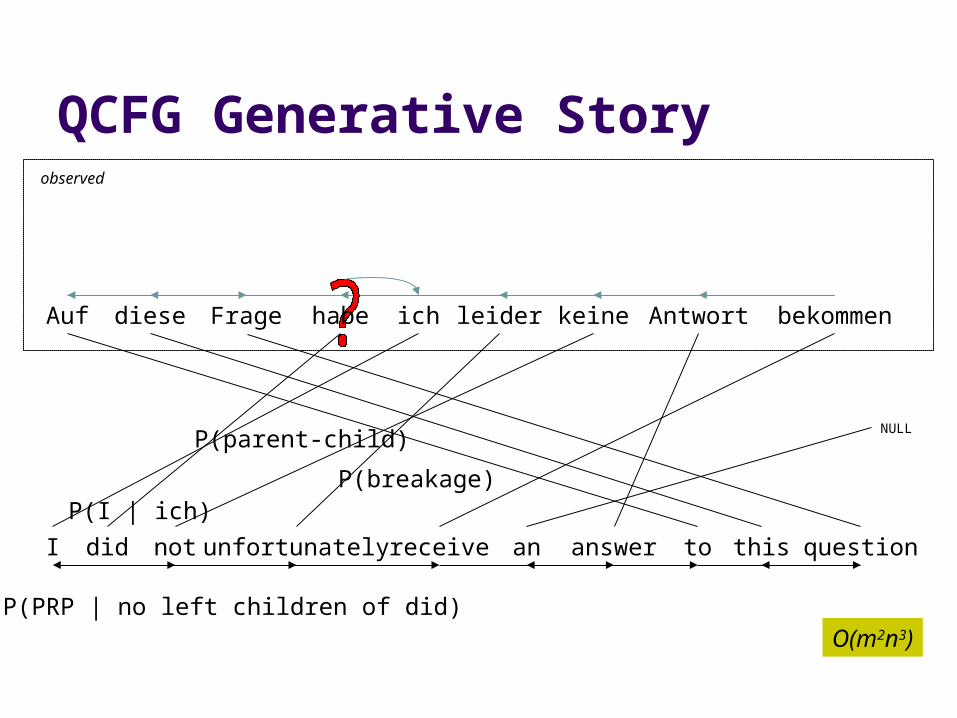
QCFG Generative Storyobserved
Auf Fragediese bekommenich leider Antwortkeine
I did not unfortunately receive an answer to this question
NULL
habe
P(parent-child)
P(PRP | no left children of did)
P(I | ich)
O(m2n3)
P(breakage)

Training the QCFG
Rough surrogates for translation performance How can we best model target given source? How can we best match human alignments?
German-English Europarl from SMT05 1k, 10k, 100k sentence pairs German parsed w/Stanford parser EM training of monolingual/bilingual parameters For efficiency, select alignments in training (not
test) from IBM Model 4 union

Cross-Entropy Results
05
1015202530354045
CE at 1k CE at10k
CE at100k
NULL+parent-child
+child-parent
+same node
+all breakages
+siblings
+grandparent
+c-command

AER Results
05
1015202530354045
AER at1k
AER at10k
AER at100k
parent-child
+child-parent
+same node
+all breakages
+siblings
+grandparent
+c-command
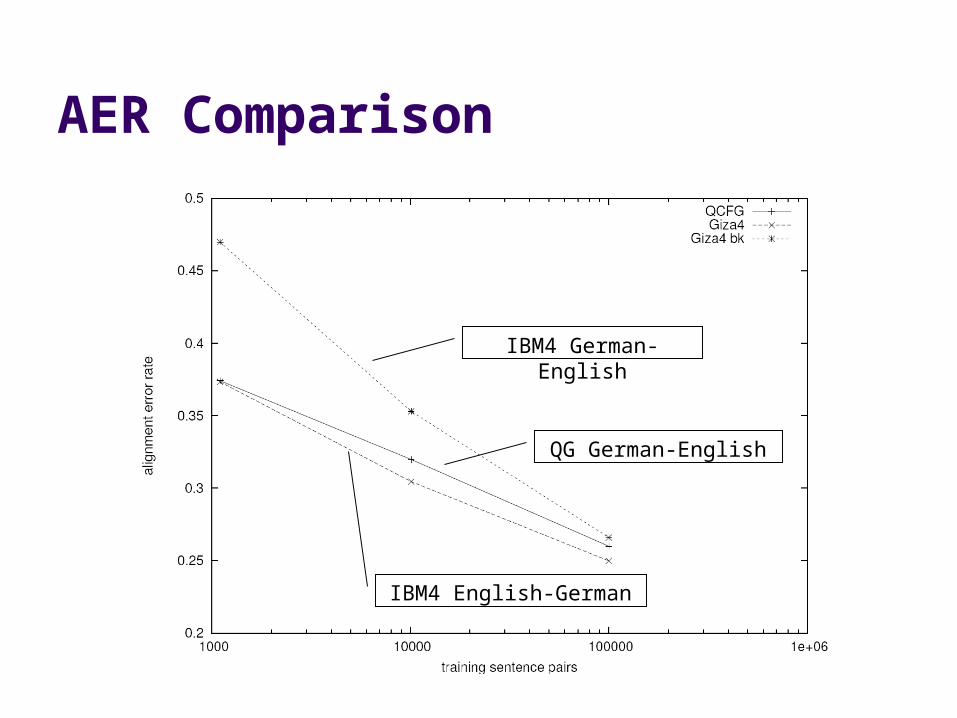
AER Comparison
IBM4 German-English
QG German-English
IBM4 English-German

Conclusions
Strict isomorphism hurts for Modeling translations Aligning bitext
Breakages beyond local nodes help most “None of the above” beats simple head-swapping
and 2-to-1 alignments Insignificant gains from further breakage
taxonomy

Continuing Research
Senses of more than one word should help Maintaining O(m2n3)
Further refining monolingual features on monolingual data
Comparison to other synchronizers Decoder in progress uses same direct model
of P(T2 ,A | T1) Globally normalized and discriminatively trained

Thanks
David Yarowsky Sanjeev Khudanpur Noah Smith Markus Dreyer David Chiang Our reviewers The National Science Foundation

Synchronous Grammar as QG
Target nodes correspond to 1 or 0 source nodes
∀ <X0, α0> <X⇒ 1, α1> … <Xk, αk> ( i ≠ j) α∀ i ≠ αj unless αi = NULL
( i > 0) α∀ i is a child of α0 in T1 , unless αi = NULL
STSG, STAG operate on derivation trees Cf. Gildea’s clone operation as a quasi-
synchronous move

Say What You’ve Said

Projection Synchronous grammars can explain s-t relation
May need fancy formalisms, harder to learn Align as many fragments as possible: explain fragmentariness when target
language requirements override Some regular phenomena: head-swapping, c-command (STAG), traces Monolingual parser Word alignment Project to other language Empirical model vs. decoding P(T2,A|T1) via synchronous dep. Grammar
How do you train? Just look at your synchronous corpus … oops. Just look at your parallel corpus and infer the synchronous trees … oops. Just look at your parallel corpus aligned by Giza and project dependencies over to
infer synchronous tree fragments. But how do you project over many-to-one? How do you resolve nonprojective links in
the projected version? And can’t we use syntax to align better than Giza did, anyway? Deal with incompleteness in the alignments, unknown words (?)

Talking Points Get advantages of a synchronous grammar without
being so darn rigid/expensive: conditional distribution, alignment, decoding all taking syntax into account
What is the generative process? How are the probabilities determined from
parameters in a way that combines monolingual and cross-lingual preferences?
How are these parameters trained? Did it work? What are the most closely related ideas and why is
this one better?


Cross-Entropy Results
Configuration CE at 1k CE at 10k CE at 100k
NULL 60.86 53.28 46.94
+parent-child 43.82 22.40 13.44
+child-parent 41.27 21.73 12.62
+same node 41.01 21.50 12.38
+all breakages 35.63 18.72 11.27
+siblings 34.59 18.59 11.21
+grandparent 34.52 18.55 11.17
+c-command 34.46 18.59 11.27

AER Results
Configuration AER at 1k AER at 10k AER at 100k
parent-child 40.69 39.03 33.62
+child-parent 43.17 39.78 33.79
+same node 43.22 40.86 34.38
+all breakages 37.63 30.51 25.99
+siblings 37.87 33.36 29.27
+grandparent 36.78 32.73 28.84
+c-command 37.04 33.51 27.45





























