Embed Size (px)
Citation preview

Quantum ESPRESSO Performance Benchmark and Profiling
March 2010

Note
• The following research was performed under the HPC Advisory Council activitiesAdvisory Council activities
– Participating vendors: AMD, Dell, Mellanox
Compute resource - HPC Advisory Council Cluster Center– Compute resource - HPC Advisory Council Cluster Center
• For more info please refer to
ll d ll /h d– www.mellanox.com, www.dell.com/hpc, www.amd.com
– http://www.quantum-espresso.org
2

Quantum ESPRESSO
• Quantum ESPRESSO stands for opEn Source Package for Research
in Electronic Structure, Simulation, and Optimization
• It is an integrated suite of computer codes for electronic-structure
calculations and materials modeling at the nanoscale
• It is based on
– Density-functional theory
– Plane waves
– Pseudopotentials (both norm-conserving and ultrasoft)
• Open source under the terms of the GNU General Public License
3

Objectives
• The presented research was done to provide best practices
Quantum ESPRESSO performance benchmarking– Quantum ESPRESSO performance benchmarking
• Performance tuning with different communication libraries and compilers
• Interconnect performance comparisons
– Understanding Quantum ESPRESSO communication patterns
– Power-efficient simulations
• The presented results will demonstrate
– Balanced compute system enables
• Good application scalability
• Power saving
4

Test Cluster Configuration
• Dell™ PowerEdge™ SC 1435 24-node cluster
• Quad-Core AMD Opteron™ 2382 (“Shanghai”) CPUsQuad Core AMD Opteron 2382 ( Shanghai ) CPUs
• Mellanox® InfiniBand ConnectX® 20Gb/s (DDR) HCAs
• Mellanox® InfiniBand DDR SwitchMellanox® InfiniBand DDR Switch
• Memory: 16GB memory, DDR2 800MHz per node
• OS: RHEL5U3, OFED 1.5 InfiniBand SW stackOS: RHEL5U3, OFED 1.5 InfiniBand SW stack
• MPI: OpenMPI-1.3.3, MVAPICH2-1.4, Platform MPI 5.6.7
• Application: Quantum ESPRESSO 4 1 2Application: Quantum ESPRESSO 4.1.2
• Benchmark Workload
– Medium size DEISA benchmark AUSURF112
5
Medium size DEISA benchmark AUSURF112
• Gold surface (112 atoms)
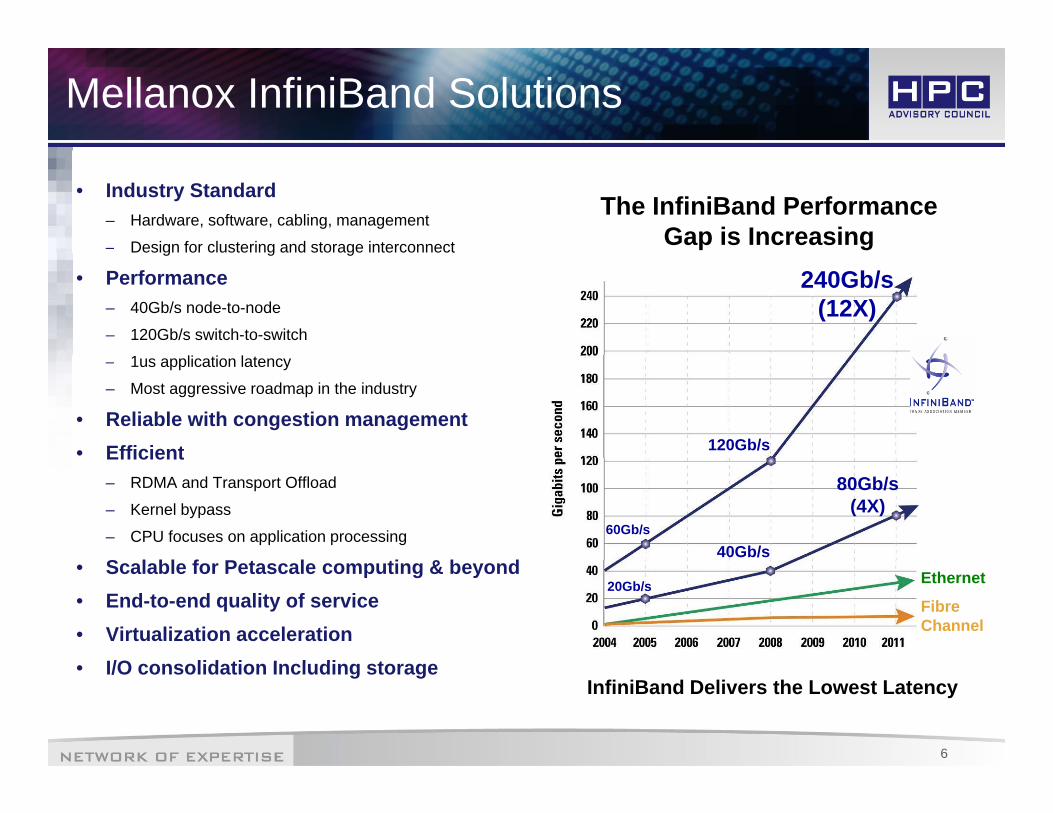
Mellanox InfiniBand Solutions
• Industry Standard– Hardware, software, cabling, management
– Design for clustering and storage interconnect
The InfiniBand Performance Gap is Increasingg g g
• Performance– 40Gb/s node-to-node
– 120Gb/s switch-to-switch
1 li i l
240Gb/s (12X)
– 1us application latency
– Most aggressive roadmap in the industry
• Reliable with congestion management• Efficient 120Gb/sEfficient
– RDMA and Transport Offload
– Kernel bypass
– CPU focuses on application processing
S l bl f P t l ti & b d
60Gb/s40Gb/s
80Gb/s (4X)
• Scalable for Petascale computing & beyond• End-to-end quality of service• Virtualization acceleration
I/O lid ti I l di t
Fibre Channel
Ethernet20Gb/s
6
• I/O consolidation Including storageInfiniBand Delivers the Lowest Latency

Quad-Core AMD Opteron™ Processor
• Performance– Quad-Core
• Enhanced CPU IPCDual ChannelReg DDR2
• 4x 512K L2 cache• 6MB L3 Cache
– Direct Connect Architecture• HyperTransport™ Technology
8 GB/S
8 GB/S
• HyperTransport Technology • Up to 24 GB/s peak per processor
– Floating Point• 128-bit FPU per core
4 FLOPS/ lk kPCI-E® Bridge
PCI-E® Bridge
8 GB/S 8 GB/S
• 4 FLOPS/clk peak per core– Integrated Memory Controller
• Up to 12.8 GB/s• DDR2-800 MHz or DDR2-667 MHz
Bridge
I/O Hub
USB
PCI
8 GB/S
• Scalability– 48-bit Physical Addressing
• Compatibility– Same power/thermal envelopes as 2nd / 3rd generation AMD Opteron™ processor
PCI
7
Same power/thermal envelopes as 2 / 3 generation AMD Opteron processor
7 November5, 2007

Dell PowerEdge Servers helping Simplify IT
• System Structure and Sizing Guidelines– 24-node cluster build with Dell PowerEdge™ SC 1435 Servers
S ti i d f Hi h P f C ti i t– Servers optimized for High Performance Computing environments
– Building Block Foundations for best price/performance and performance/watt
• Dell HPC Solutions– Scalable Architectures for High Performance and Productivity
– Dell's comprehensive HPC services help manage the lifecycle requirements.
– Integrated, Tested and Validated Architectures
• Workload Modeling– Optimized System Size, Configuration and Workloads p y , g
– Test-bed Benchmarks
– ISV Applications Characterization
8
– Best Practices & Usage Analysis

Dell PowerEdge™ Server Advantage
• Dell™ PowerEdge™ servers incorporate AMD Opteron™ and Mellanox ConnectX InfiniBand to provide leading edge performance and reliability
• Building Block Foundations for best price/performance andBuilding Block Foundations for best price/performance and performance/watt
• Investment protection and energy efficient• Longer term server investment valueg• Faster DDR2-800 memory• Enhanced AMD PowerNow!• Independent Dynamic Core Technologyp y gy• AMD CoolCore™ and Smart Fetch Technology• Mellanox InfiniBand end-to-end for highest networking performance
9
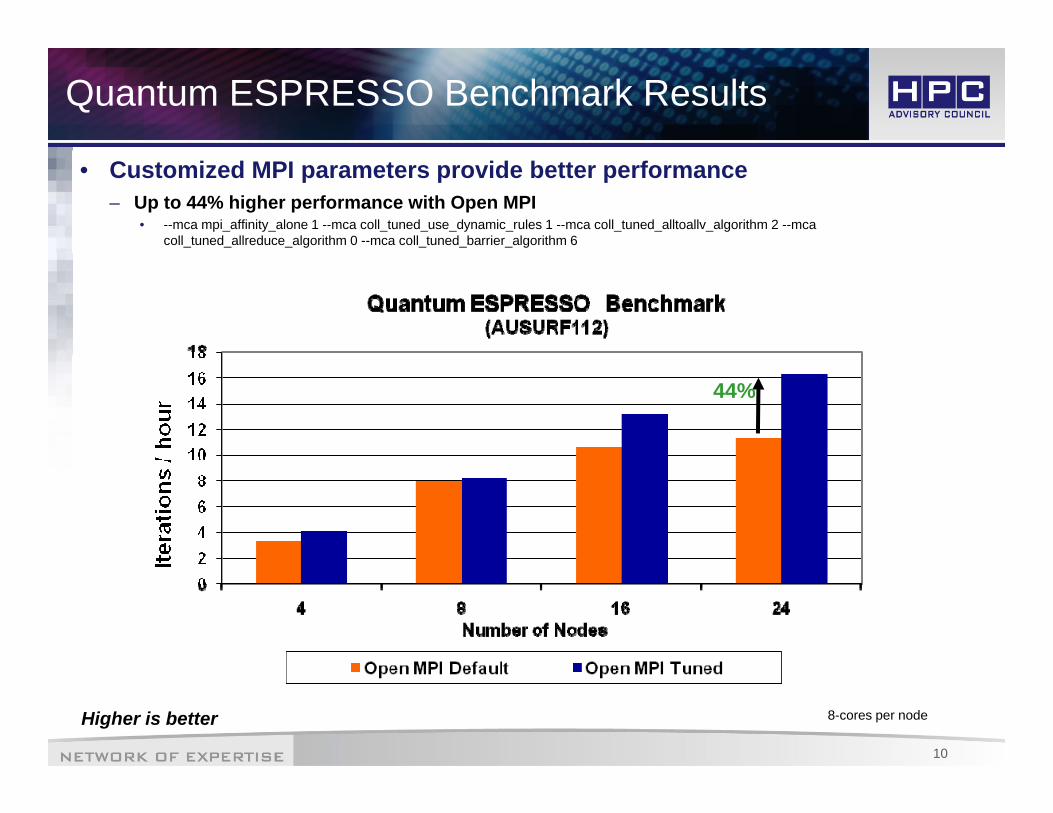
Quantum ESPRESSO Benchmark Results
• Customized MPI parameters provide better performance– Up to 44% higher performance with Open MPI
• --mca mpi_affinity_alone 1 --mca coll_tuned_use_dynamic_rules 1 --mca coll_tuned_alltoallv_algorithm 2 --mca coll_tuned_allreduce_algorithm 0 --mca coll_tuned_barrier_algorithm 6
44%
10
Higher is better 8-cores per node
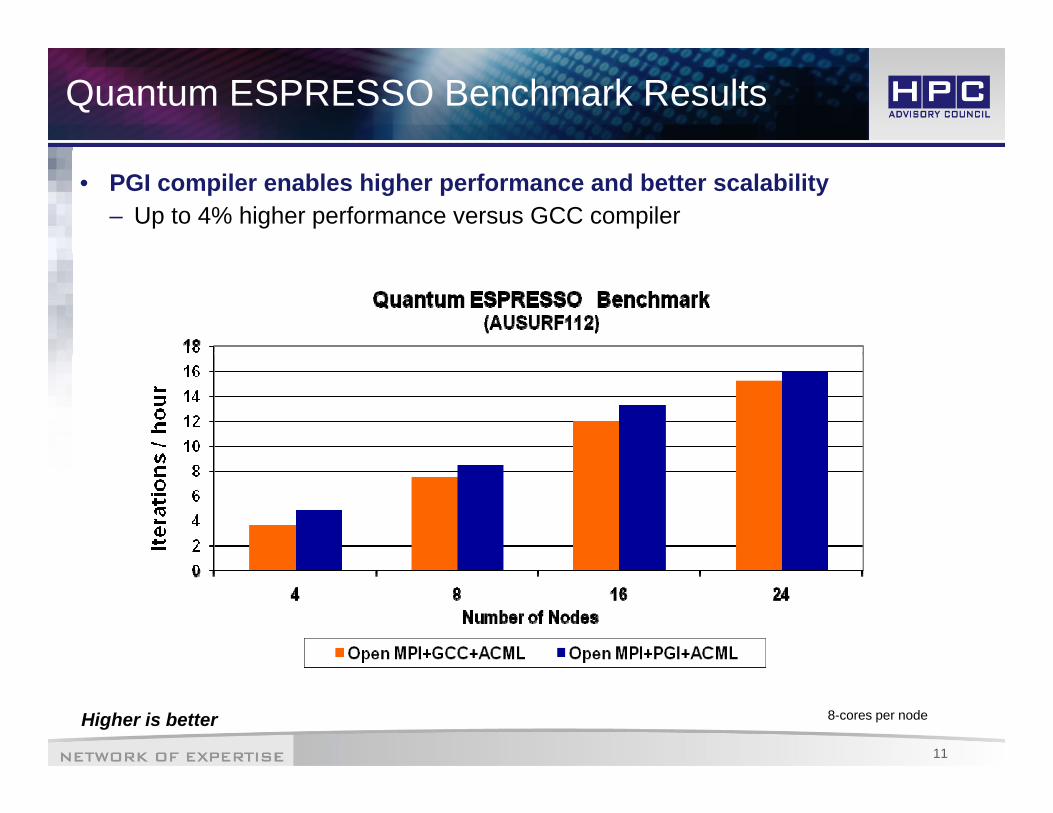
Quantum ESPRESSO Benchmark Results
• PGI compiler enables higher performance and better scalability– Up to 4% higher performance versus GCC compiler
11
Higher is better 8-cores per node
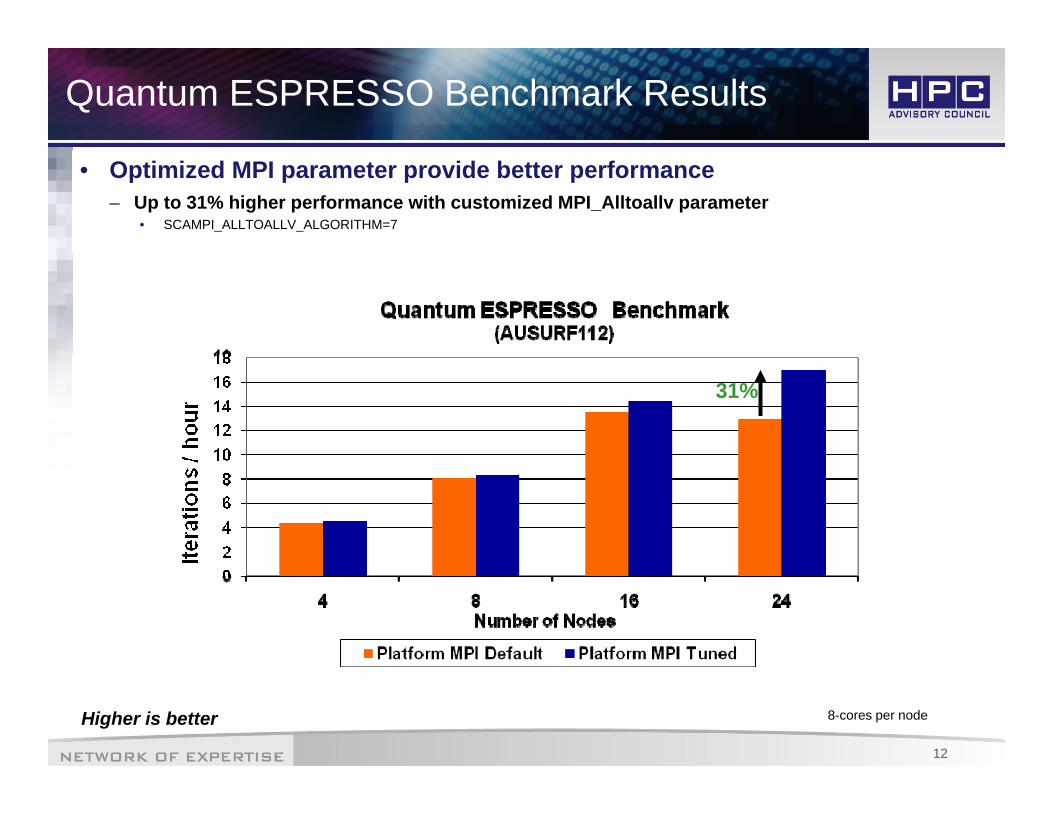
Quantum ESPRESSO Benchmark Results
• Optimized MPI parameter provide better performance– Up to 31% higher performance with customized MPI_Alltoallv parameter
• SCAMPI_ALLTOALLV_ALGORITHM=7
31%
12
Higher is better 8-cores per node
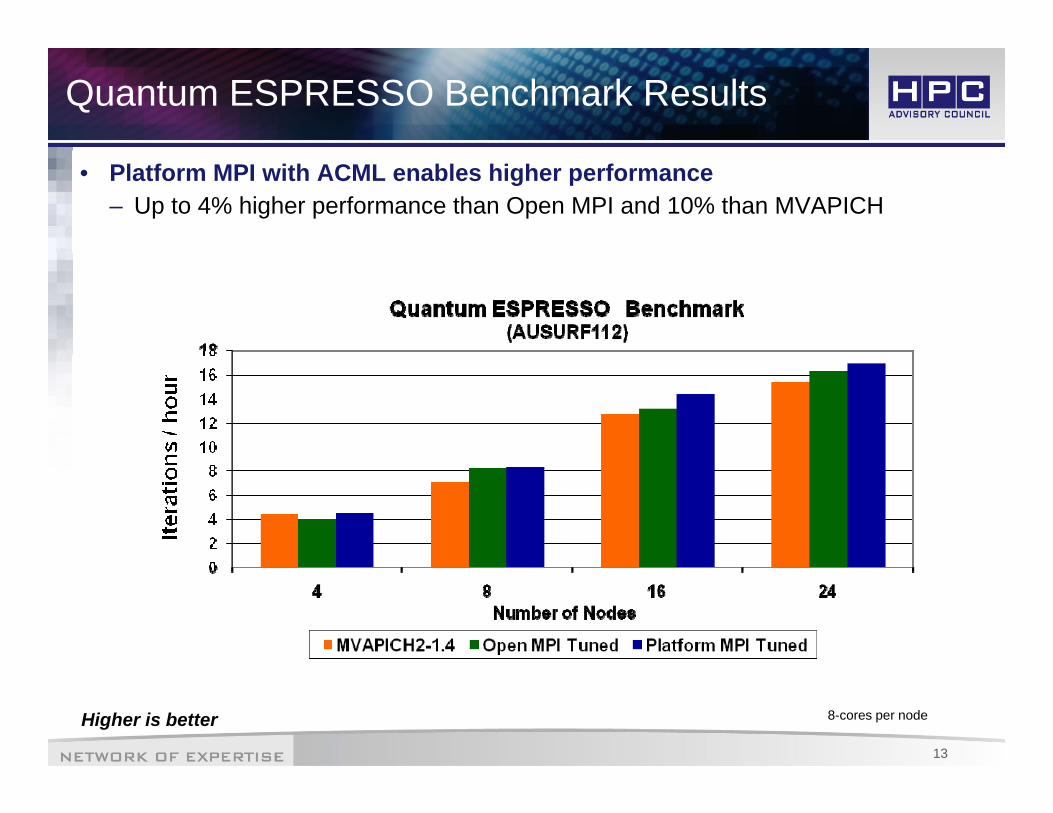
Quantum ESPRESSO Benchmark Results
• Platform MPI with ACML enables higher performance– Up to 4% higher performance than Open MPI and 10% than MVAPICH
13
Higher is better 8-cores per node
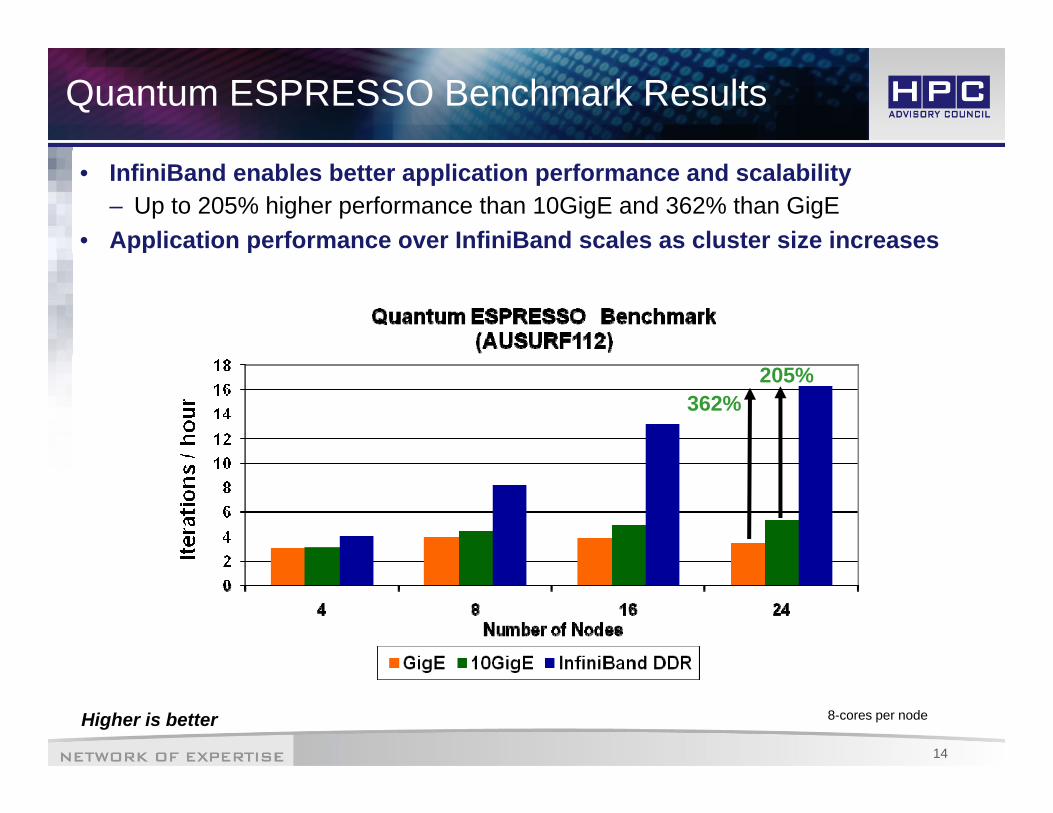
Quantum ESPRESSO Benchmark Results
• InfiniBand enables better application performance and scalability– Up to 205% higher performance than 10GigE and 362% than GigE
• Application performance over InfiniBand scales as cluster size increases
205%362%
14
Higher is better 8-cores per node

Power Cost Savings with Different Interconnect
• Dell economical integration of AMD CPUs and Mellanox InfiniBand– To achieve same number of Quantum ESPRESSO jobs over GigE– InfiniBand saves power up to $5450 versus 10GigE and $9646 versus GigE– Yearly based for 24-node cluster
• As cluster size increases, more power can be saved
$9646
$5450$5450
15
$/KWh = KWh * $0.20For more information - http://enterprise.amd.com/Downloads/svrpwrusecompletefinal.pdf

Quantum ESPRESSO Benchmark Summary
• Tuned MPI parameters provides better performance– Both Open MPI and Platform MPI gain extra performance by adjusting parameters
• PGI compiler with ACML enables higher performance than GCCPGI compiler with ACML enables higher performance than GCC
• Interconnect comparison shows– InfiniBand delivers superior performance in every cluster size versus GigE and 10GigE
– Performance advantage extends as cluster size increases
• InfiniBand enables power saving – Up to $9646/year power savings versus GigE and $5450 versus 10GigE
• Dell™ PowerEdge™ server blades provides– Linear scalability (maximum scalability) and balanced system
B i i I fi iB d i d AMD• By integrating InfiniBand interconnect and AMD processors
– Maximum return on investment through efficiency and utilization
16
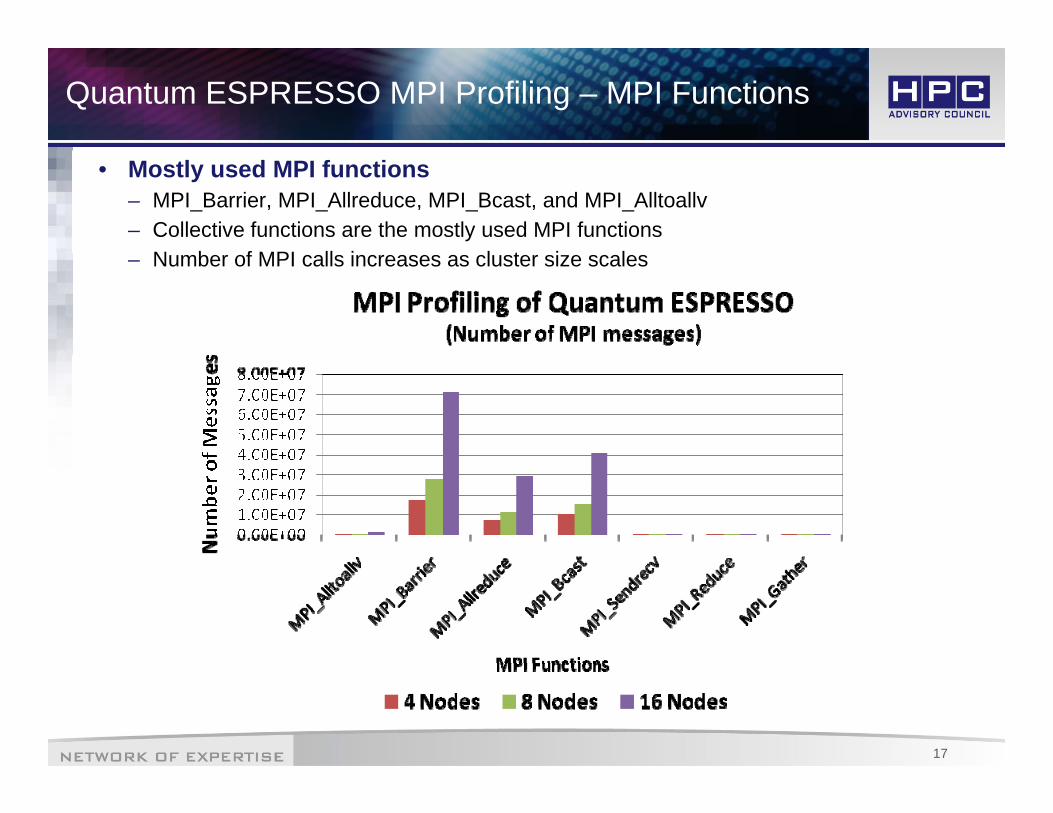
Quantum ESPRESSO MPI Profiling – MPI Functions
• Mostly used MPI functions– MPI_Barrier, MPI_Allreduce, MPI_Bcast, and MPI_Alltoallv– Collective functions are the mostly used MPI functions
N b f MPI ll i l t i l– Number of MPI calls increases as cluster size scales
17
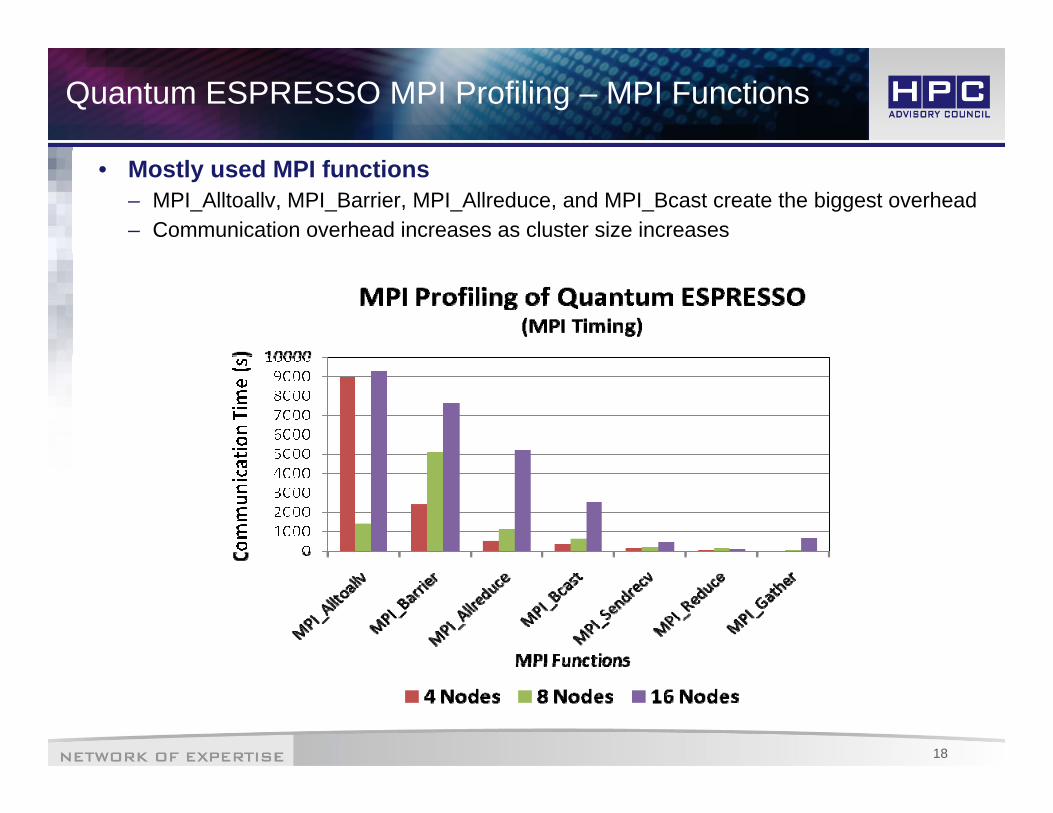
Quantum ESPRESSO MPI Profiling – MPI Functions
• Mostly used MPI functions– MPI_Alltoallv, MPI_Barrier, MPI_Allreduce, and MPI_Bcast create the biggest overhead– Communication overhead increases as cluster size increases
18
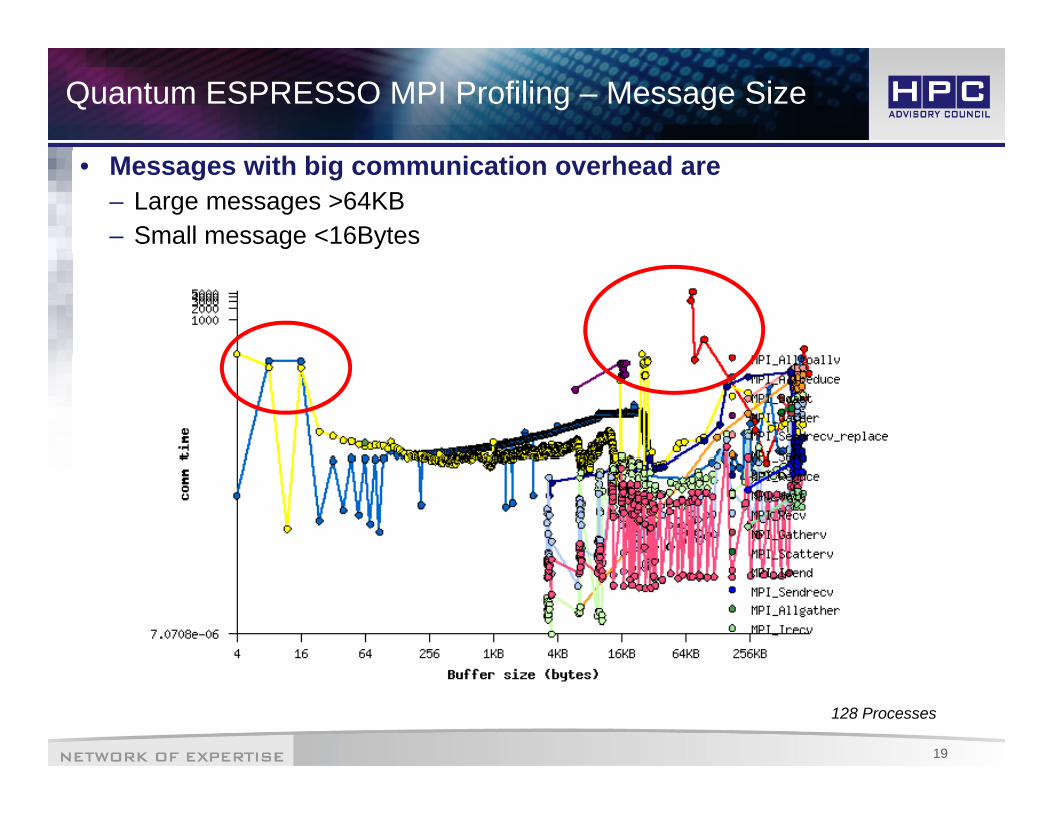
Quantum ESPRESSO MPI Profiling – Message Size
• Messages with big communication overhead are– Large messages >64KB – Small message <16Bytes
19
128 Processes

Quantum ESPRESSO Profiling Summary
• Quantum ESPRESSO was profiled to identify its communication
patternsp
– MPI collective functions create the biggest communication overhead
– Number of messages increases with cluster sizeg
• Interconnects effect to Quantum ESPRESSO performance
– Most messages are either large than 64KB or smaller than 16BytesMost messages are either large than 64KB or smaller than 16Bytes
– Both bandwidth and latency is critical to application performance
• Balanced system CPU memory Interconnect that match each• Balanced system – CPU, memory, Interconnect that match each
other capabilities, is essential for providing application efficiency
20

Thank YouHPC Ad i C ilHPC Advisory Council
2121
All trademarks are property of their respective owners. All information is provided “As-Is” without any kind of warranty. The HPC Advisory Council makes no representation to the accuracy and completeness of the information contained herein. HPC Advisory Council Mellanox undertakes no duty and assumes no obligation to update or correct any information presented herein





























