Embed Size (px)
Citation preview

March 2018
Quantum Chemistry (QC) on GPUs

2
Overview of Life & Material Accelerated Apps
MD: All key codes are GPU-accelerated
Great multi-GPU performance
Focus on dense (up to 16) GPU nodes &/or large # of
GPU nodes
ACEMD*, AMBER (PMEMD)*, BAND, CHARMM, DESMOND, ESPResso,
Folding@Home, GPUgrid.net, GROMACS, HALMD, HTMD, HOOMD-
Blue*, LAMMPS, Lattice Microbes*, mdcore, MELD, miniMD, NAMD,
OpenMM, PolyFTS, SOP-GPU* & more
QC: All key codes are ported or optimizing
Focus on using GPU-accelerated math libraries,
OpenACC directives
GPU-accelerated and available today:
ABINIT, ACES III, ADF, BigDFT, CP2K, GAMESS, GAMESS-
UK, GPAW, LATTE, LSDalton, LSMS, MOLCAS, MOPAC2012,
NWChem, OCTOPUS*, PEtot, QUICK, Q-Chem, QMCPack,
Quantum Espresso/PWscf, QUICK, TeraChem*
Active GPU acceleration projects:
CASTEP, GAMESS, Gaussian, ONETEP, Quantum
Supercharger Library*, VASP & more
green* = application where >90% of the workload is on GPU

3
MD vs. QC on GPUs
“Classical” Molecular Dynamics Quantum Chemistry (MO, PW, DFT, Semi-Emp)Simulates positions of atoms over time;
chemical-biological or chemical-material behaviors
Calculates electronic properties; ground state, excited states, spectral properties,
making/breaking bonds, physical properties
Forces calculated from simple empirical formulas (bond rearrangement generally forbidden)
Forces derived from electron wave function (bond rearrangement OK, e.g., bond energies)
Up to millions of atoms Up to a few thousand atoms
Solvent included without difficulty Generally in a vacuum but if needed, solvent treated classically (QM/MM) or using implicit methods
Single precision dominated (FP32) Double precision is important (FP64)
Uses cuFFT, CUDA Uses cuBLAS, cuFFT, Tensor/Eigen Solvers, OpenACC
GeForce (Workstations), Tesla (Servers) Tesla recommended
ECC off ECC on

4
Accelerating Discoveries
Using a supercomputer powered by the Tesla
Platform with over 3,000 Tesla accelerators,
University of Illinois scientists performed the first
all-atom simulation of the HIV virus and discovered
the chemical structure of its capsid — “the perfect
target for fighting the infection.”
Without gpu, the supercomputer would need to be
5x larger for similar performance.

5
GPU-Accelerated Quantum Chemistry Apps
Abinit
ACES III
ADF
BigDFT
CP2K
DIRAC
GAMESS-US
Gaussian
GPAW
FHI-AIMS
LATTE
LSDalton
MOLCAS
Mopac2012
NWChem
Green Lettering Indicates Performance Slides Included
GPU Perf compared against dual multi-core x86 CPU socket.
Quantum SuperChargerLibrary
RMG
TeraChem
UNM
VASP
WL-LSMS
Octopus
ONETEP
Petot
Q-Chem
QMCPACK
Quantum Espresso

ABINIT

ABINIT on GPUS
Speed in the parallel version:
For ground-state calculations, GPUs can be used. This is based on
CUDA+MAGMA
For ground-state calculations, the wavelet part of ABINIT (which is BigDFT) is
also very well parallelized : MPI band parallelism, combined with GPUs

BigDFT

Courtesy of BigDFTteam @ CEA

Courtesy of BigDFTteam @ CEA

Courtesy of BigDFTteam @ CEA

Courtesy of BigDFTteam @ CEA

Courtesy of BigDFTteam @ CEA

Courtesy of BigDFTteam @ CEA

February 2018
GAMESS

16
GAMESS valinomycin rimp2 energyon V100 vs P100 (PCIe 16GB)
(Untuned on Volta)Running GAMESS
The blue node contains Dual Intel Xeon E5-2690 [email protected] [3.5GHz
Turbo] (Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2690 [email protected] [3.5GHz Turbo] (Broadwell) CPUs + Tesla P100 PCIe (16GB) or V100 PCIe
(16GB) GPUs0.0002
0.0016
0.0019
0.0021
0.00130.0014
0.0015
0.0000
0.0005
0.0010
0.0015
0.0020
0.0025
1 Broadwellnode
1 node +1x P100PCIe per
node
1 node +2x P100PCIe per
node
1 node +4x P100PCIe per
node
1 node +1x V100PCIe per
node
1 node +2x V100PCIe per
node
1 node +4x V100PCIe per
node
1/se
conds
6.5X
8.0X
9.5X
10.5X
7.0X7.5X

March 2018
Gaussian 16

18
GAUSSIAN 16
Using OpenACC allowed us to continue
development of our fundamental
algorithms and software capabilities
simultaneously with the GPU-related
work. In the end, we could use the
same code base for SMP, cluster/
network and GPU parallelism. PGI's
compilers were essential to the
success of our efforts.
Mike Frisch, Ph.D.President and CEOGaussian, Inc.
Parallelization Strategy
Within Gaussian 16, GPUs are used for a small fraction of code that consumes a large
fraction of the execution time. T e implementation of GPU parallelism conforms
to Gaussian’s general parallelization strategy. Its main tenets are to avoid changing
the underlying source code and to avoid modif cations which negatively af ect CPU
performance. For these reasons, OpenACC was used for GPU parallelization.
T e Gaussian approach to parallelization relies on environment-specif c parallelization frameworks and tools: OpenMP for shared-memory, Linda for cluster and network parallelization across discrete nodes, and OpenACC for GPUs.
T e process of implementing GPU support involved many dif erent aspects:
Identifying places where GPUs could be benef cial. T ese are a subset of areas which
are parallelized for other execution contexts because using GPUs requires f ne grained
parallelism.
Understanding and optimizing data movement/storage at a high level to maximize
GPU ef ciency.
Gaussian, Inc.340 Quinnipiac St. Bldg. 40Wallingford, CT 06492 [email protected]
Gaussian is a registered trademark of Gaussian, Inc. All other trademarks and registered trademarks are the properties of their respective holders. Specif cations subject to change without notice.
Copyright © 2017, Gaussian, Inc. All rights reserved.
Roberto GompertsNVIDIA
Michael FrischGaussian
Brent LebackNVIDIA/PGI
Giovanni ScalmaniGaussian
Project Contributors
PGI Accelerator Compilers with OpenACCPGI compilers fully support the current OpenACC standard as well as important extensions to it. PGI is an important contributor to the ongoing development of OpenACC.
OpenACC enables developers to implement GPU parallelism by adding compiler directives to their source code, of en eliminating the need for rewriting or restructuring. For example, the following Fortran compiler directive identif es a loop which the compiler should parallelize:
! $ a c c p a r a l l e l l o o p
Other directives allocate GPU memory, copy data to/from GPUs, specify data to remain on the GPU, combine or split loops and other code sections, and generally provide hints for optimal work distribution management, and more.
T e OpenACC project is very active, and the specif cations and tools are changing fairly rapidly. T is has been true throughout the lifetime of this project. Indeed, one of its major challenges has been using OpenACC in the midst of its development. T e talented people at PGI were instrumental in addressing issues that arose in one of the very f rst uses of OpenACC for a large commercial sof ware package.
Specifying GPUs to Gaussian 16
T e GPU implementation in Gaussian 16 is sophisticated and complex but using it is simple and straightforward. GPUs are specif ed with
1 additional Link 0 command (or equivalent Default.Route f le entry/command line option). For example, the following commands tell
Gaussian to run the calculation using 24 compute cores plus 8 GPUs+8 controlling cores (32 cores total):
%CPU= 0 - 3 1 Request 32 CPUs for the calculation: 24 cores for computation, and 8 cores to control GPUs (see below). %GPUCPU= 0 - 7 = 0 - 7 Use GPUs 0-7 with CPUs 0-7 as their controllers.
Detailed information is available on our website.
PGI’s sophisticated prof ling and performance evaluation tools were vital to the success of the ef ort.
ValinomycinFrequency. APFD 6-311+G(2d,p)
7X speedup on 8X P100 GPUs
Hardware: HPE Apollo 6500 server with dual Intel Xeon E5-2680 v4 CPUs (2.40GHz; 14 cores/chip, 28 cores total), 256GB memory and 8 Tesla P100 GPU boards (autoboost clocks). Gaussian source code compiled with PGI Accelerator Compilers (17.7) with OpenACC (2.5 standard).
A Leading Computation Chemistry Code
19
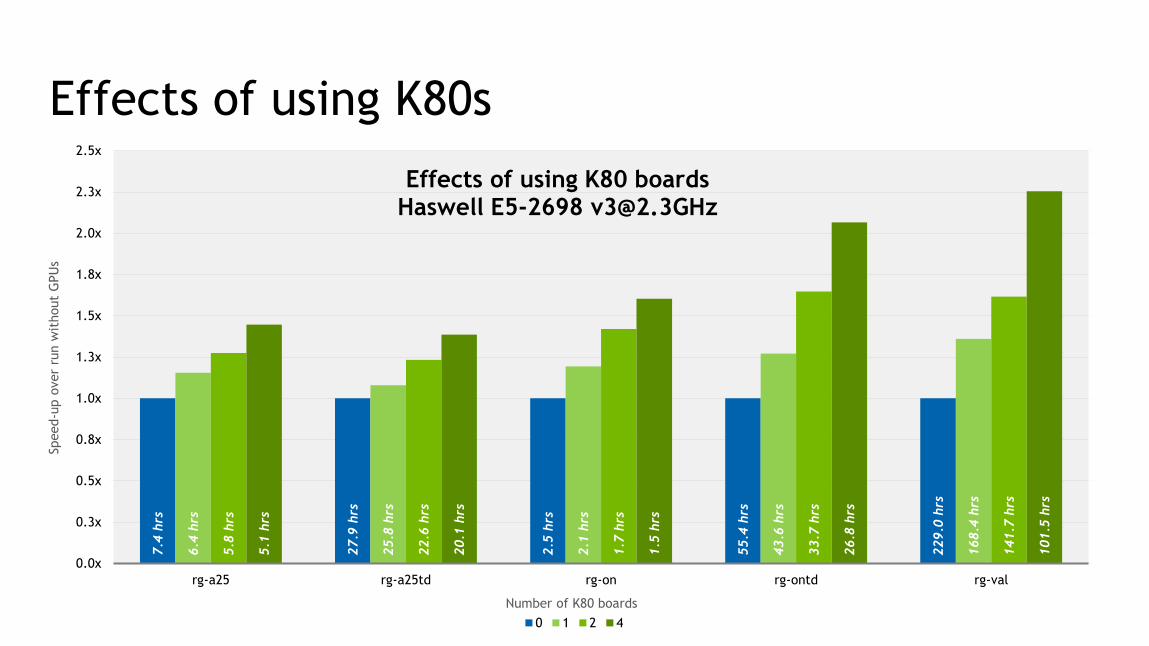
Effects of using K80s7.4
hrs
27.9
hrs
2.5
hrs
55.4
hrs
229.0
hrs
6.4
hrs
25.8
hrs
2.1
hrs
43.6
hrs
168.4
hrs
5.8
hrs
22.6
hrs
1.7
hrs
33.7
hrs
141.7
hrs
5.1
hrs
20.1
hrs
1.5
hrs
26.8
hrs
101.5
hrs
0.0x
0.3x
0.5x
0.8x
1.0x
1.3x
1.5x
1.8x
2.0x
2.3x
2.5x
rg-a25 rg-a25td rg-on rg-ontd rg-val
Speed-u
p o
ver
run w
ithout
GPU
s
Number of K80 boards
Effects of using K80 boardsHaswell E5-2698 [email protected]
0 1 2 4
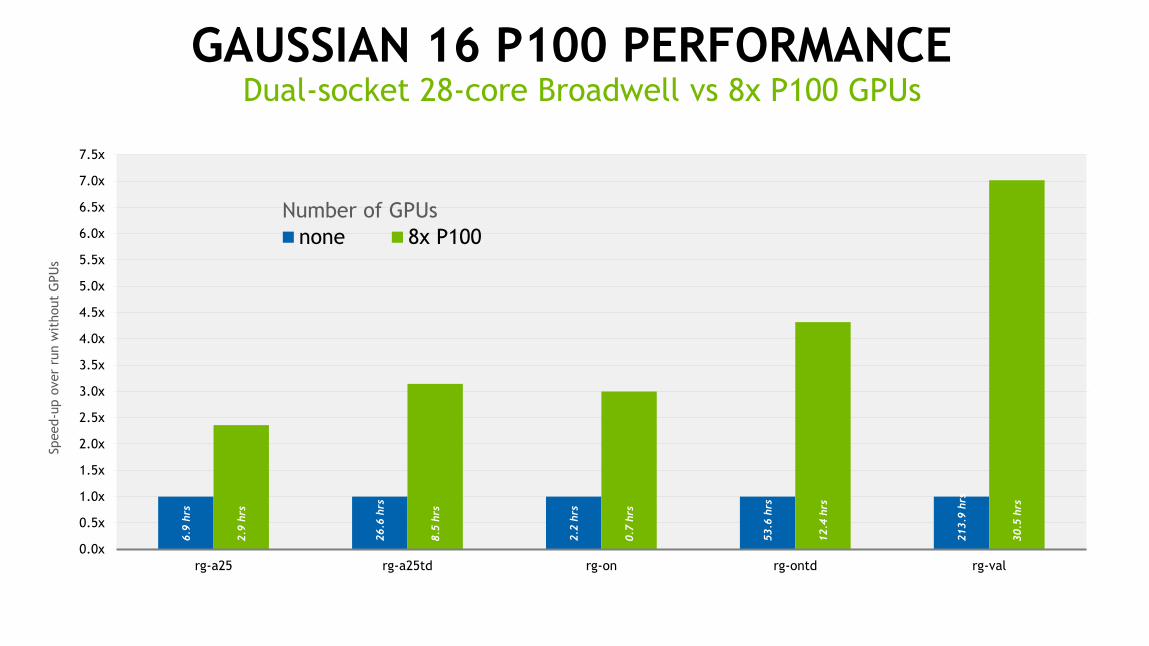
20
GAUSSIAN 16 P100 PERFORMANCE
6.9
hrs
26.6
hrs
2.2
hrs
53.6
hrs
213.9
hrs
2.9
hrs
8.5
hrs
0.7
hrs
12.4
hrs
30.5
hrs
0.0x
0.5x
1.0x
1.5x
2.0x
2.5x
3.0x
3.5x
4.0x
4.5x
5.0x
5.5x
6.0x
6.5x
7.0x
7.5x
rg-a25 rg-a25td rg-on rg-ontd rg-val
Speed-u
p o
ver
run w
ithout
GPU
s
Number of GPUs
none 8x P100
Dual-socket 28-core Broadwell vs 8x P100 GPUs

21
GPU-ACCELERATED GAUSSIAN 16 AVAILABLE
• Gaussian is a Top Ten HPC (Quantum Chemistry) Application.
• 80-85% of use cases are GPU-accelerated (Hartree-Fock and DFT: energies, 1st derivatives (gradients) and 2nd derivatives for ground & excited states). More functionality to come.
• K40, K80, P100 support; B.01 release.
• No pricing difference between Gaussian CPU and GPU versions.
• Existing Gaussian 09 customers under maintenance contract get (free) upgrade.
• Existing non-maintenance customers required to pay upgrade fee.
• To get the bits or to ask about the upgrade fee, please contact Gaussian, Inc.’s Jim Hess, Operations Manager; [email protected].
100% PGI OpenACC Port (no CUDA)

22
rg-a25 on K80s
Running Gaussian version 16
The blue node contains Dual Intel Xeon E5-2698 [email protected] (Haswell) CPUs
The green nodes contain Dual Intel Xeon E5-2698 [email protected] (Haswell) CPUs + Tesla K80 (autoboost) GPUs
Alanine 25. Two steps: Force and Frequency. APFD 6-31G*
nAtoms = 259, nBasis = 2195
7.4 hrs 6.4 hrs 5.8 hrs 5.1 hrs0.0x
0.2x
0.4x
0.6x
0.8x
1.0x
1.2x
1.4x
1.6x
1 Haswell node 1 node +1x K80 per node
1 node +2x K80 per node
1 node +4x K80 per node
Speed-u
p v
s D
ual H
asw
ell
rg-a25

23
rg-a25td on K80s
Running Gaussian version 16
The blue node contains Dual Intel Xeon E5-2698 [email protected] (Haswell) CPUs
The green nodes contain Dual Intel Xeon E5-2698 [email protected] (Haswell) CPUs + Tesla K80 (autoboost) GPUs
Alanine 25. Two Time-Dependent (TD) steps: Force and Frequency. APFD 6-31G*
nAtoms = 259, nBasis = 2195
27.9 hrs 25.8 hrs 22.6 hrs 20.1 hrs0.0x
0.2x
0.4x
0.6x
0.8x
1.0x
1.2x
1.4x
1.6x
1 Haswell node 1 node +1x K80 per node
1 node +2x K80 per node
1 node +4x K80 per node
Speed-u
p v
s D
ual H
asw
ell
rg-a25td

24
rg-on on K80s
Running Gaussian version 16
The blue node contains Dual Intel Xeon E5-2698 [email protected] (Haswell) CPUs
The green nodes contain Dual Intel Xeon E5-2698 [email protected] (Haswell) CPUs + Tesla K80 (autoboost) GPUs
GFP ONIOM. Two steps: Force and Frequency. APFD/6-
311+G(2d,p):amber=softfirst)=embednAtoms = 3715 (48/3667), nBasis = 813
2.5 hrs 2.1 hrs 1.7 hrs 1.5 hrs0.0x
0.2x
0.4x
0.6x
0.8x
1.0x
1.2x
1.4x
1.6x
1.8x
1 Haswell node 1 node +1x K80 per node
1 node +2x K80 per node
1 node +4x K80 per node
Speed-u
p v
s D
ual H
asw
ell
rg-on

25
rg-ontd on K80s
Running Gaussian version 16
The blue node contains Dual Intel Xeon E5-2698 [email protected] (Haswell) CPUs
The green nodes contain Dual Intel Xeon E5-2698 [email protected] (Haswell) CPUs + Tesla K80 (autoboost) GPUs
GFP ONIOM. Two Time-Dependent (TD) steps: Force and Frequency. APFD/6-311+G(2d,p):amber=softfirst)=embed
nAtoms = 3715 (48/3667), nBasis = 813
55.4 hrs 43.6 hrs 33.7 hrs 26.8 hrs0.0x
0.5x
1.0x
1.5x
2.0x
2.5x
1 Haswell node 1 node +1x K80 per node
1 node +2x K80 per node
1 node +4x K80 per node
Speed-u
p v
s D
ual H
asw
ell
rg-ontd

26
rg-val on K80s
Running Gaussian version 16
The blue node contains Dual Intel Xeon E5-2698 [email protected] (Haswell) CPUs
The green nodes contain Dual Intel Xeon E5-2698 [email protected] (Haswell) CPUs + Tesla K80 (autoboost) GPUs
Valinomycin. Two steps: Force and Frequency. APFD 6-311+G(2d,p)
nAtoms = 168, nBasis = 2646
229.0 hrs 168.4 hrs 141.7 hrs 101.5 hrs0.0x
0.5x
1.0x
1.5x
2.0x
2.5x
1 Haswell node 1 node +1x K80 per node
1 node +2x K80 per node
1 node +4x K80 per node
Speed-u
p v
s D
ual H
asw
ell
rg-val

27
Gaussian 16 Supported Platforms
• 4-way collaboration; Gaussian, Inc., NVIDIA (& PGI) and HPE
• HPE, NVIDIA and PGI is the development platform
• All released/certified x86_64 versions of Gaussian 16 use the PGI compilers
• Certified versions of Gaussian 16 use Intel only for Itanium, XLF for some IBM platforms, Fujitsu compilers for some SPARC-based machines and PGI for the rest (including some Apple products)
• GINC is collaborating with IBM, PGI (and NVIDIA) to release an OpenPower version of Gaussian that also uses the PGI compiler
• See Gaussian Supported Platforms for more details: http://gaussian.com/g16/g16_plat.pdf

28
CLOSING REMARKS
Significant Progress has been made in enabling Gaussian on GPUs with OpenACC
OpenACC is increasingly becoming more versatile
Significant work lies ahead to improve performance
Expand feature set:
PBC, Solvation, MP2, triples-Corrections

29
ACKNOWLEDGEMENTS
Development is taking place with:
Hewlett-Packard (HP) Series SL2500 Servers (Intel® Xeon® E5-2680 v2 (2.8GHz/10-core/25MB/8.0GT-s QPI/115W, DDR3-1866)
NVIDIA® Tesla® GPUs (V100)
PGI Accelerator Compilers (18.x) with OpenACC (2.5 standard)
3/8/2018

GPAW

Increase Performance with Kepler
Running GPAW 10258
The blue nodes contain 1x E5-2687W CPU (8
Cores per CPU).
The green nodes contain 1x E5-2687W CPU (8
Cores per CPU) and 1x or 2x NVIDIA K20X for
the GPU.
0
0.5
1
1.5
2
2.5
3
3.5
Silicon K=1 Silicon K=2 Silicon K=3
Sp
eed
up
Co
mp
are
d t
o C
PU
On
ly
1.4
2.5
1.5
2.7
1.6
3.0
1 1 1

Increase Performance with Kepler
0
0.5
1
1.5
2
2.5
3
Silicon K=1 Silicon K=2 Silicon K=3
Sp
eed
up
Co
mp
are
d t
o C
PU
On
ly
1.7x
2.2x
2.4x
Running GPAW 10258
The blue nodes contain 1x E5-2687W CPU (8
Cores per CPU).
The green nodes contain 1x E5-2687W CPUs (8
Cores per CPU) and 2x NVIDIA K20 or K20X for
the GPU.

Increase Performance with Kepler
Running GPAW 10258
The blue nodes contain 2x E5-2687W CPUs (8
Cores per CPU).
The green nodes contain 2x E5-2687W CPUs (8
Cores per CPU) and 2x NVIDIA K20 or K20X for
the GPU.
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
Silicon K=1 Silicon K=2 Silicon K=3
Sp
eed
up
Co
mp
are
d t
o C
PU
On
ly
1.3x
1.4x
1.4x

Used with
permission from
Samuli Hakala




38

39

40

41

42

43

LSDALTON

45
Janus Juul Eriksen, PhD Fellow
qLEAP Center for Theoretical Chemistry, Aarhus University
“
OpenACC makes GPU computing approachable for
domain scientists. Initial OpenACC implementation
required only minor effort, and more importantly,
no modifications of our existing CPU implementation.
“
LSDALTON
Large-scale application for calculating high-accuracy molecular energies
Lines of Code
Modified
# of Weeks
Required
# of Codes to
Maintain
<100 Lines 1 Week 1 Source
Big Performance
7.9x8.9x
11.7x
ALANINE-113 ATOMS
ALANINE-223 ATOMS
ALANINE-333 ATOMS
Speedup v
s C
PU
Minimal Effort
LS-DALTON CCSD(T) ModuleBenchmarked on Titan Supercomputer (AMD CPU vs Tesla K20X)
https://developer.nvidia.com/openacc/success-stories

NWChem

NWChem 6.3 Release with GPU Acceleration
Addresses large complex and challenging molecular-scale scientific
problems in the areas of catalysis, materials, geochemistry and
biochemistry on highly scalable, parallel computing platforms to
obtain the fastest time-to-solution
Researchers can for the first time be able to perform large scale
coupled cluster with perturbative triples calculations utilizing the
NVIDIA GPU technology. A highly scalable multi-reference coupled
cluster capability will also be available in NWChem 6.3.
The software, released under the Educational Community License
2.0, can be downloaded from the NWChem website at
www.nwchem-sw.org

System: cluster consisting
of dual-socket nodes
constructed from:
• 8-core AMD Interlagos
processors
• 64 GB of memory
• Tesla M2090 (Fermi)
GPUs
The nodes are connected
using a high-performance
QDR Infiniband interconnect
Courtesy of Kowolski, K.,
Bhaskaran-Nair, at al @
PNNL, JCTC (submitted)
NWChem - Speedup of the non-iterative calculation for various configurations/tile sizes

Kepler, Faster Performance (NWChem)
0
20
40
60
80
100
120
140
160
180
CPU Only CPU + 1x K20X CPU + 2x K20X
Tim
e t
o S
olu
tio
n (
sec
on
ds
)
165
81
54
Uracil
Uracil Molecule
Performance improves by 2x with one GPU and by 3.1x with 2 GPUs

March 2018
Quantum Espresso 5.4.0

51
QUANTUM ESPRESSO
CUDA Fortran gives us the full
performance potential of the CUDA
programming model and NVIDIA GPUs.
!$CUF KERNELS directives give us
productivity and source code
maintainability. It’s the best of both
worlds.
Filippo SpigaHead of Research Software EngineeringUniversity of CambridgeQuantum Chemistry Suite
www.quantum-espresso.org
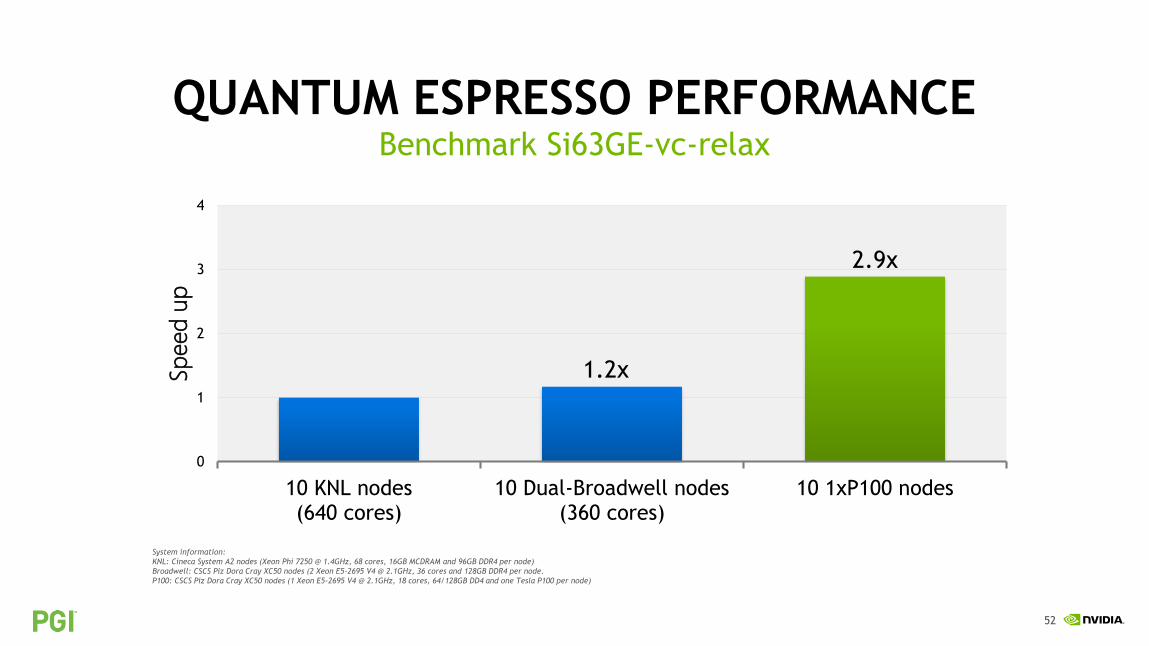
52
0
1
2
3
4
10 KNL nodes(640 cores)
10 Dual-Broadwell nodes(360 cores)
10 1xP100 nodes
Sp
eed
up
QUANTUM ESPRESSO PERFORMANCEBenchmark Si63GE-vc-relax
System information:
KNL: Cineca System A2 nodes (Xeon Phi 7250 @ 1.4GHz, 68 cores, 16GB MCDRAM and 96GB DDR4 per node)
Broadwell: CSCS Piz Dora Cray XC50 nodes (2 Xeon E5-2695 V4 @ 2.1GHz, 36 cores and 128GB DDR4 per node.
P100: CSCS Piz Dora Cray XC50 nodes (1 Xeon E5-2695 V4 @ 2.1GHz, 18 cores, 64/128GB DD4 and one Tesla P100 per node)
1.2x
2.9x

Speaker, Date
TeraChem 1.5K

TrpCage6-31GRHF
1604 bfn284 atoms
TrpCage6-31G**
RHF2900 bfn
284 atoms
Ru ComplexLANL2DZ
B3LYP4512 bfn
1013 atoms
BPTISTO-3G
RHF2706 bfn
882 atoms
Olestra6-31G*
RHF3181 bfn
453 atoms
Olestra6-31G*
BLYP3181 bfn
453 atoms
3.7x
2.8x 3.3x
2.7x2.3x
2.8x
All timings for complete energyand gradient Calculations
K80 = 1 GPU on Board, not both
Slide courtesy of PetaChem LLC / Todd Martinez

55
TERACHEM 1.5K; TRIPCAGE ON TESLA K40S
0
40
80
120
160
200
2 x Xeon E5-2697 [email protected] + 1 xTesla K40@875Mhz (1 node)
2 x Xeon E5-2697 [email protected] + 2 xTesla K40@875Mhz (1 node)
2 x Xeon E5-2697 [email protected] + 4 xTesla K40@875Mhz (1 node)
2 x Xeon E5-2697 [email protected] + 8 xTesla K40@875Mhz (1 node)
TeraChem 1.5K; TripCage on Tesla K40s & IVB CPUs(Total Processing Time in Seconds)

56
TERACHEM 1.5K; TRIPCAGE ON TESLA K40S & HASWELL CPUS
0
40
80
120
160
200
2 x Xeon E5-2698 [email protected] + 1 x TeslaK40@875Mhz (1 node)
2 x Xeon E5-2698 [email protected] + 2 x TeslaK40@875Mhz (1 node)
2 x Xeon E5-2698 [email protected] + 4 x TeslaK40@875Mhz (1 node)
TeraChem 1.5K; TripCage on Tesla K40s & Haswell CPUs(Total Processing Time in Seconds)

57
TERACHEM 1.5K; TRIPCAGE ON TESLA K80S & IVB CPUS
0
40
80
120
2 x Xeon E5-2697 [email protected] + 1 x Tesla K80 board(1 node)
2 x Xeon E5-2697 [email protected] + 2 x Tesla K80 boards(1 node)
2 x Xeon E5-2697 [email protected] + 4 x Tesla K80 boards(1 node)
TeraChem 1.5K; TripCage on Tesla K80s & IVB CPUs(Total Processing Time in Seconds)

58
TERACHEM 1.5K; TRIPCAGE ON TESLA K80S & HASWELL CPUS
0
30
60
90
120
2 x Xeon E5-2698 [email protected] + 1 x Tesla K80board (1 node)
2 x Xeon E5-2698 [email protected] + 2 x Tesla K80boards (1 node)
2 x Xeon E5-2698 [email protected] + 4 x Tesla K80boards (1 node)
TeraChem 1.5K; TripCage on Tesla K80s & Haswell CPUs(Total Processing Time in Seconds)

59
TERACHEM 1.5K; BPTI ON TESLA K40S & IVB CPUS
0
2000
4000
6000
8000
10000
12000
2 x Xeon E5-2697 [email protected] + 1 xTesla K40@875Mhz (1 node)
2 x Xeon E5-2697 [email protected] + 2 xTesla K40@875Mhz (1 node)
2 x Xeon E5-2697 [email protected] + 4 xTesla K40@875Mhz (1 node)
2 x Xeon E5-2697 [email protected] + 8 xTesla K40@875Mhz (1 node)
TeraChem 1.5K; BPTI on Tesla K40s & IVB CPUs(Total Processing Time in Seconds)

60
TERACHEM 1.5K; BPTI ON TESLA K80S & IVB CPUS
0
2000
4000
6000
8000
2 x Xeon E5-2697 [email protected] + 1 x Tesla K80board (1 node)
2 x Xeon E5-2697 [email protected] + 2 x Tesla K80boards (1 node)
2 x Xeon E5-2697 [email protected] + 4 x Tesla K80boards (1 node)
TeraChem 1.5K; BPTI on Tesla K80s & IVB CPUs(Total Processing Time in Seconds)
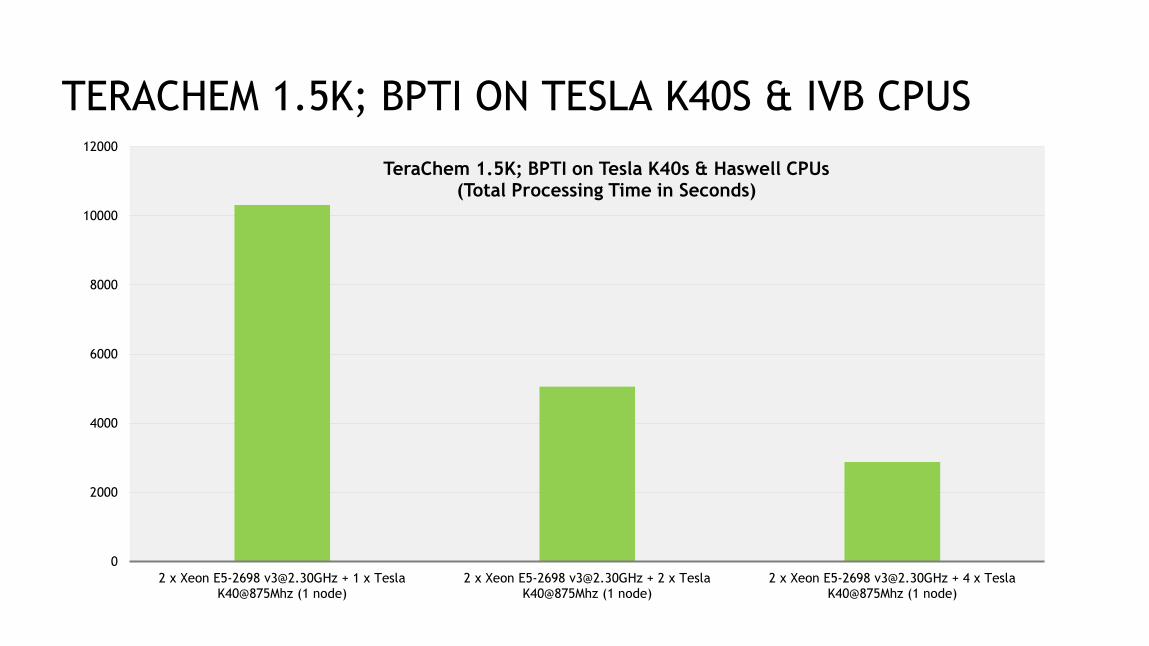
61
TERACHEM 1.5K; BPTI ON TESLA K40S & IVB CPUS
0
2000
4000
6000
8000
10000
12000
2 x Xeon E5-2698 [email protected] + 1 x TeslaK40@875Mhz (1 node)
2 x Xeon E5-2698 [email protected] + 2 x TeslaK40@875Mhz (1 node)
2 x Xeon E5-2698 [email protected] + 4 x TeslaK40@875Mhz (1 node)
TeraChem 1.5K; BPTI on Tesla K40s & Haswell CPUs(Total Processing Time in Seconds)

62
TERACHEM 1.5K; BPTI ON TESLA K80S & HASWELL CPUS
0
2000
4000
6000
2 x Xeon E5-2698 [email protected] + 1 x Tesla K80 board(1 node)
2 x Xeon E5-2698 [email protected] + 2 x Tesla K80boards (1 node)
2 x Xeon E5-2698 [email protected] + 4 x Tesla K80boards (1 node)
TeraChem 1.5K; BPTI on Tesla K80s & Haswell CPUs(Total Processing Time in Seconds)

March 2018
Beyond VASP 5.4.4 Development

64
VASP
For VASP, OpenACC is the way forward
for GPU acceleration. Performance is
similar to CUDA, and OpenACC
dramatically decreases GPU
development and maintenance efforts.
We’re excited to collaborate with
NVIDIA and PGI as an early adopter of
Unified Memory.
Prof. Georg KresseComputational Materials PhysicsUniversity of Vienna
PhotoThe Vienna Ab Initio Simulation Package
65
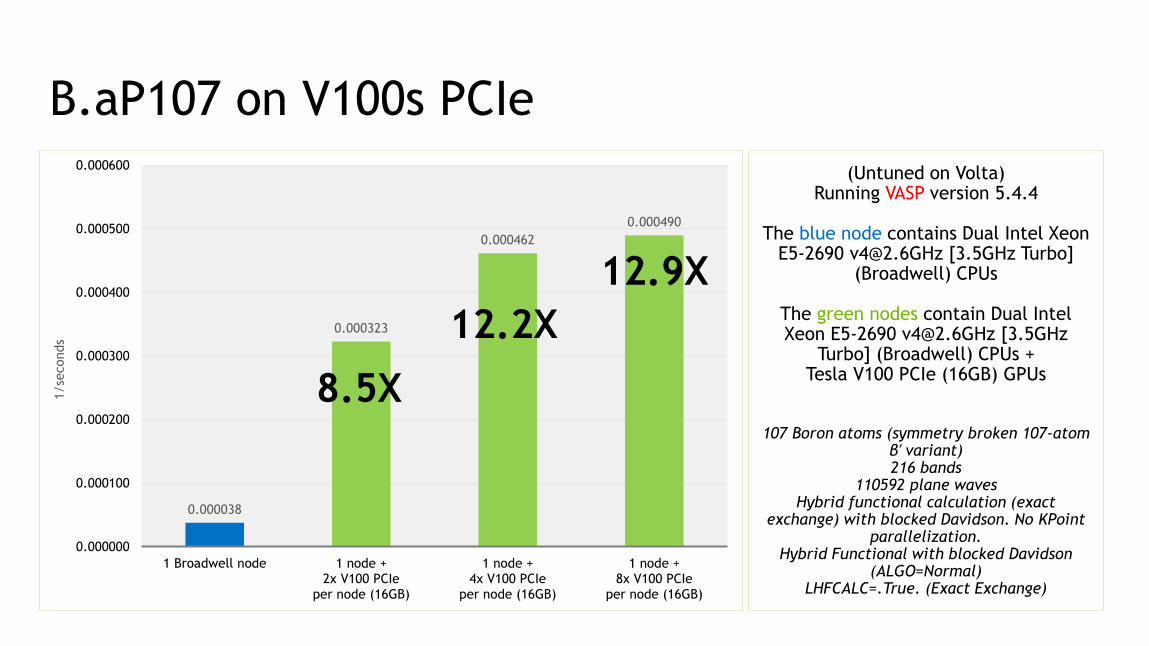
B.aP107 on V100s PCIe
0.000038
0.000323
0.000462
0.000490
0.000000
0.000100
0.000200
0.000300
0.000400
0.000500
0.000600
1 Broadwell node 1 node +2x V100 PCIe
per node (16GB)
1 node +4x V100 PCIe
per node (16GB)
1 node +8x V100 PCIe
per node (16GB)
1/se
conds
(Untuned on Volta)Running VASP version 5.4.4
The blue node contains Dual Intel Xeon E5-2690 [email protected] [3.5GHz Turbo]
(Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2690 [email protected] [3.5GHz
Turbo] (Broadwell) CPUs + Tesla V100 PCIe (16GB) GPUs
107 Boron atoms (symmetry broken 107-atom β′ variant)216 bands
110592 plane wavesHybrid functional calculation (exact
exchange) with blocked Davidson. No KPointparallelization.
Hybrid Functional with blocked Davidson (ALGO=Normal)
LHFCALC=.True. (Exact Exchange)
8.5X
12.2X
12.9X
66
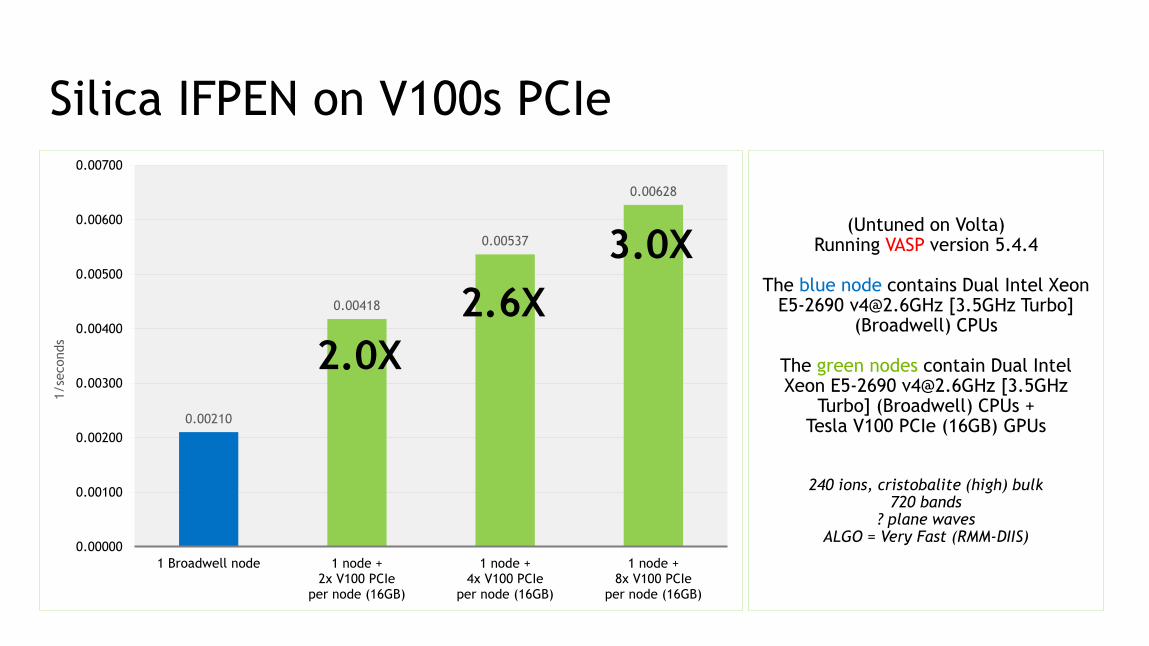
Silica IFPEN on V100s PCIe
0.00210
0.00418
0.00537
0.00628
0.00000
0.00100
0.00200
0.00300
0.00400
0.00500
0.00600
0.00700
1 Broadwell node 1 node +2x V100 PCIe
per node (16GB)
1 node +4x V100 PCIe
per node (16GB)
1 node +8x V100 PCIe
per node (16GB)
1/se
conds
(Untuned on Volta)Running VASP version 5.4.4
The blue node contains Dual Intel Xeon E5-2690 [email protected] [3.5GHz Turbo]
(Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2690 [email protected] [3.5GHz
Turbo] (Broadwell) CPUs + Tesla V100 PCIe (16GB) GPUs
240 ions, cristobalite (high) bulk720 bands
? plane wavesALGO = Very Fast (RMM-DIIS)
2.0X
2.6X
3.0X

67
VASP Dev Version OpenACC Performance
Reasons for performance gain:
• OpenACC port covers more VASP routines
• OpenACC port planned top down, with complete analysis of the call tree
• OpenACC port leverages improvements in latest VASP Fortran source base
silica IFPEN, RMM-DIIS on P100
40 cores 1 2 4
0
1
2
3
4
5
MPI Ranks / Nr. of P100 SXM2 NVLINK
Speed-u
p
vasp_std (5.4.4)
vasp_gpu (5.4.4)
OpenACC port

68
VASP Dev Version OpenACC Performance
VASP with OpenACC is an ongoing project. The developers in Vienna are integrating some OpenACC into their code base and there are plans to continue porting in that direction. Given that there is ongoing work, chances are the next
major release will contain some of the results of this work. But from NV’s side, we can neither comment on any release
schedule for VASP in general, nor on any feature set for upcoming releases.

February 2018
VASP 5.4.4
70
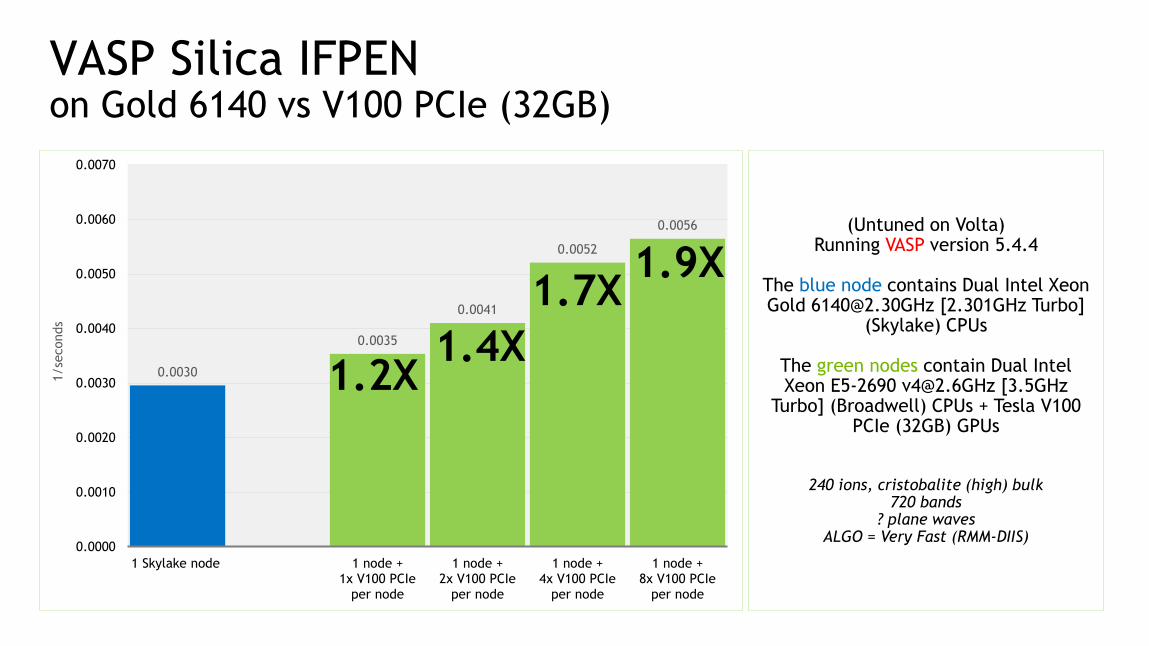
VASP Silica IFPENon Gold 6140 vs V100 PCIe (32GB)
(Untuned on Volta)Running VASP version 5.4.4
The blue node contains Dual Intel Xeon Gold [email protected] [2.301GHz Turbo]
(Skylake) CPUs
The green nodes contain Dual Intel Xeon E5-2690 [email protected] [3.5GHz
Turbo] (Broadwell) CPUs + Tesla V100 PCIe (32GB) GPUs
240 ions, cristobalite (high) bulk720 bands
? plane wavesALGO = Very Fast (RMM-DIIS)
0.0030
0.0035
0.0041
0.0052
0.0056
0.0000
0.0010
0.0020
0.0030
0.0040
0.0050
0.0060
0.0070
1 Skylake node 1 node +1x V100 PCIe
per node
1 node +2x V100 PCIe
per node
1 node +4x V100 PCIe
per node
1 node +8x V100 PCIe
per node
1/se
conds
1.7X
1.2X1.4X
1.9X

71
VASP Silica IFPENon Gold 6140 vs V100 SXM2 (32GB)
(Untuned on Volta)Running VASP version 5.4.4
The blue node contains Dual Intel Xeon Gold [email protected] [2.301GHz Turbo]
(Skylake) CPUs
The green nodes contain Dual Intel Xeon E5-2698 [email protected] [3.6GHz
Turbo] (Broadwell) CPUs + Tesla V100 SXM2 (32GB) GPUs
240 ions, cristobalite (high) bulk720 bands
? plane wavesALGO = Very Fast (RMM-DIIS)
0.0030
0.0036
0.0043
0.0054
0.0058
0.0000
0.0010
0.0020
0.0030
0.0040
0.0050
0.0060
0.0070
1 Skylake node 1 node +1x V100 SXM2
per node
1 node +2x V100 SXM2
per node
1 node +4x V100 SXM2
per node
1 node +8x V100 SXM2
per node
1/se
conds
1.8X
1.2X1.4X
1.9X

72
VASP Silica IFPENon Platinum 8180 vs V100 PCIe (32GB)
(Untuned on Volta)Running VASP version 5.4.4
The blue node contains Dual Intel Xeon Platinum [email protected] [2.501GHz
Turbo] (Skylake) CPUs
The green nodes contain Dual Intel Xeon E5-2690 [email protected] [3.5GHz
Turbo] (Broadwell) CPUs + Tesla V100 PCIe (32GB) GPUs
240 ions, cristobalite (high) bulk720 bands
? plane wavesALGO = Very Fast (RMM-DIIS)
0.0036
0.0041
0.0052
0.0056
0.0000
0.0010
0.0020
0.0030
0.0040
0.0050
0.0060
0.0070
1 Skylake node 1 node +2x V100 PCIe
per node
1 node +4x V100 PCIe
per node
1 node +8x V100 PCIe
per node
1/se
conds
1.4X
1.1X
1.6X

73
VASP Silica IFPENon Platinum 8180 vs V100 SXM2 (32GB)
(Untuned on Volta)Running VASP version 5.4.4
The blue node contains Dual Intel Xeon Platinum [email protected] [2.501GHz
Turbo] (Skylake) CPUs
The green nodes contain Dual Intel Xeon E5-2698 [email protected] [3.6GHz
Turbo] (Broadwell) CPUs + Tesla V100 SXM2 (32GB) GPUs
240 ions, cristobalite (high) bulk720 bands
? plane wavesALGO = Very Fast (RMM-DIIS)
0.0036
0.0043
0.0054
0.0058
0.0000
0.0010
0.0020
0.0030
0.0040
0.0050
0.0060
0.0070
1 Skylake node 1 node +2x V100 SXM2
per node
1 node +4x V100 SXM2
per node
1 node +8x V100 SXM2
per node
1/se
conds
1.5X
1.2X
1.6X
74
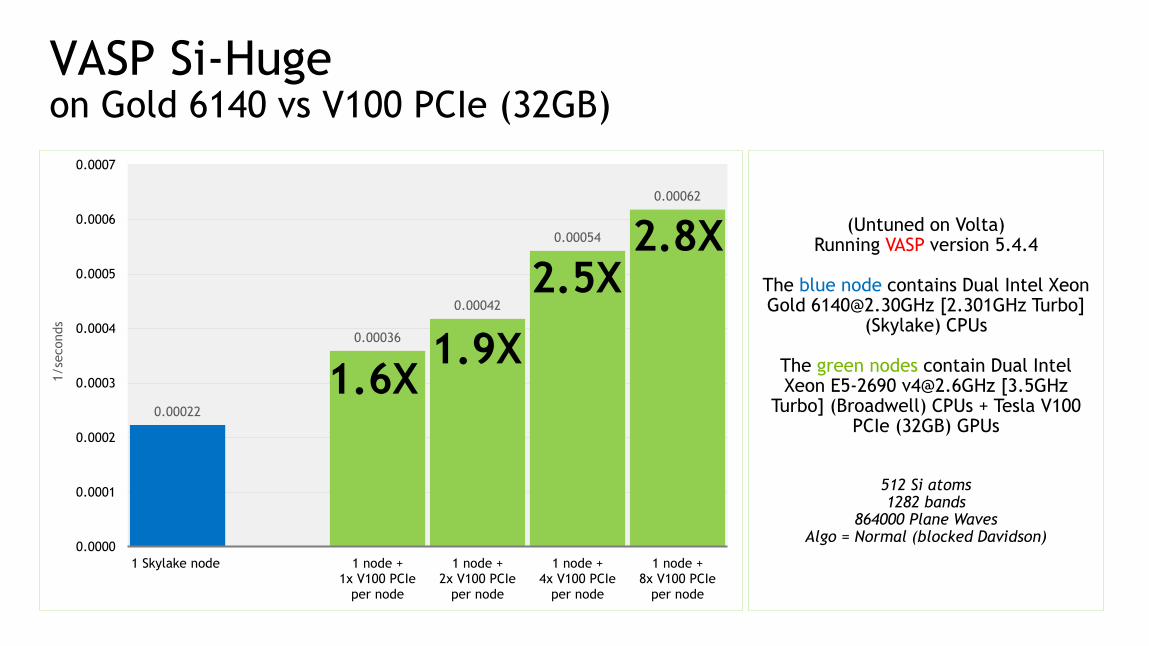
VASP Si-Hugeon Gold 6140 vs V100 PCIe (32GB)
(Untuned on Volta)Running VASP version 5.4.4
The blue node contains Dual Intel Xeon Gold [email protected] [2.301GHz Turbo]
(Skylake) CPUs
The green nodes contain Dual Intel Xeon E5-2690 [email protected] [3.5GHz
Turbo] (Broadwell) CPUs + Tesla V100 PCIe (32GB) GPUs
512 Si atoms1282 bands
864000 Plane WavesAlgo = Normal (blocked Davidson)
0.00022
0.00036
0.00042
0.00054
0.00062
0.0000
0.0001
0.0002
0.0003
0.0004
0.0005
0.0006
0.0007
1 Skylake node 1 node +1x V100 PCIe
per node
1 node +2x V100 PCIe
per node
1 node +4x V100 PCIe
per node
1 node +8x V100 PCIe
per node
1/se
conds
2.5X
1.6X1.9X
2.8X
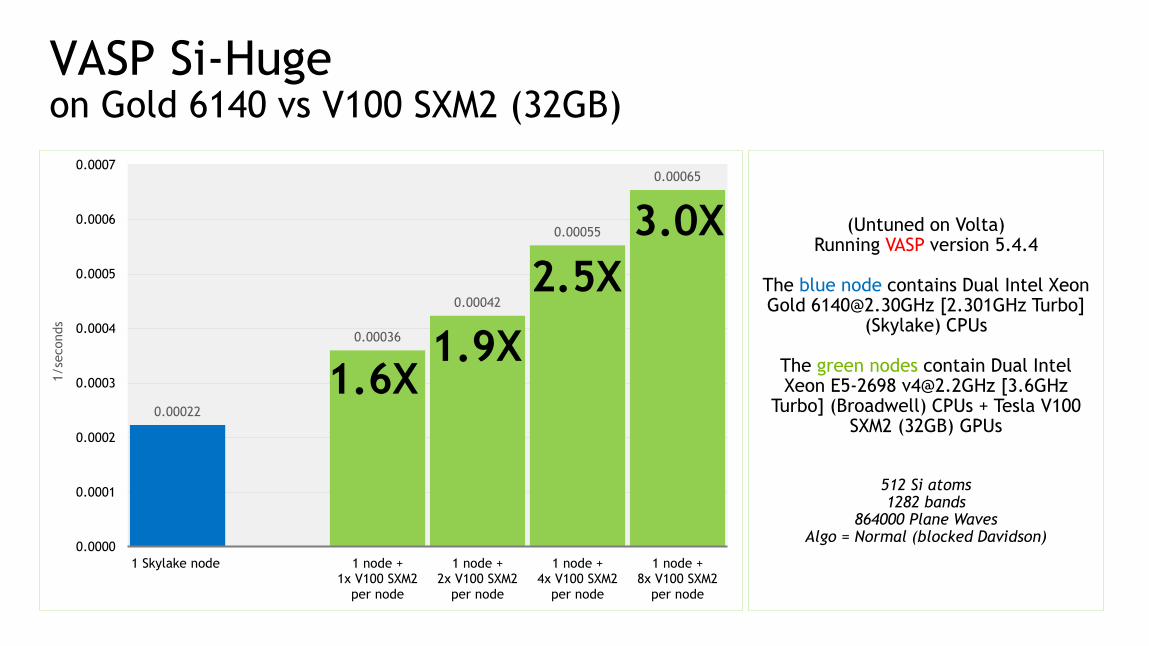
75
VASP Si-Hugeon Gold 6140 vs V100 SXM2 (32GB)
(Untuned on Volta)Running VASP version 5.4.4
The blue node contains Dual Intel Xeon Gold [email protected] [2.301GHz Turbo]
(Skylake) CPUs
The green nodes contain Dual Intel Xeon E5-2698 [email protected] [3.6GHz
Turbo] (Broadwell) CPUs + Tesla V100 SXM2 (32GB) GPUs
512 Si atoms1282 bands
864000 Plane WavesAlgo = Normal (blocked Davidson)
0.00022
0.00036
0.00042
0.00055
0.00065
0.0000
0.0001
0.0002
0.0003
0.0004
0.0005
0.0006
0.0007
1 Skylake node 1 node +1x V100 SXM2
per node
1 node +2x V100 SXM2
per node
1 node +4x V100 SXM2
per node
1 node +8x V100 SXM2
per node
1/se
conds
2.5X
1.6X1.9X
3.0X

76
VASP Si-Hugeon Platinum 8180 vs V100 PCIe (32GB)
(Untuned on Volta)Running VASP version 5.4.4
The blue node contains Dual Intel Xeon Platinum [email protected] [2.501GHz
Turbo] (Skylake) CPUs
The green nodes contain Dual Intel Xeon E5-2690 [email protected] [3.5GHz
Turbo] (Broadwell) CPUs + Tesla V100 PCIe (32GB) GPUs
512 Si atoms1282 bands
864000 Plane WavesAlgo = Normal (blocked Davidson)
0.00026
0.00036
0.00042
0.00054
0.00062
0.0000
0.0001
0.0002
0.0003
0.0004
0.0005
0.0006
0.0007
1 Skylake node 1 node +1x V100 PCIe
per node
1 node +2x V100 PCIe
per node
1 node +4x V100 PCIe
per node
1 node +8x V100 PCIe
per node
1/se
conds
2.1X
1.4X1.6X
2.4X

77
VASP Si-Hugeon Platinum 8180 vs V100 SXM2 (32GB)
(Untuned on Volta)Running VASP version 5.4.4
The blue node contains Dual Intel Xeon Platinum [email protected] [2.501GHz
Turbo] (Skylake) CPUs
The green nodes contain Dual Intel Xeon E5-2698 [email protected] [3.6GHz
Turbo] (Broadwell) CPUs + Tesla V100 SXM2 (32GB) GPUs
512 Si atoms1282 bands
864000 Plane WavesAlgo = Normal (blocked Davidson)
0.00026
0.00036
0.00042
0.00055
0.00065
0.0000
0.0001
0.0002
0.0003
0.0004
0.0005
0.0006
0.0007
1 Skylake node 1 node +1x V100 SXM2
per node
1 node +2x V100 SXM2
per node
1 node +4x V100 SXM2
per node
1 node +8x V100 SXM2
per node
1/se
conds
2.1X
1.4X1.6X
2.5X

78
VASP B.hR105on Gold 6140 vs V100 PCIe (32GB)
(Untuned on Volta)Running VASP version 5.4.4
The blue node contains Dual Intel Xeon Gold [email protected] [2.301GHz Turbo]
(Skylake) CPUs
The green nodes contain Dual Intel Xeon E5-2690 [email protected] [3.5GHz
Turbo] (Broadwell) CPUs + Tesla V100 PCIe (32GB) GPUs
105 Boron atoms (β-rhombohedral structure)216 bands
110592 plane wavesHybrid Functional with blocked Davicson
(ALGO=Normal)LHFCALC=.True. (Exact Exchange)
0.0015
0.0047
0.0067
0.0112
0.0120
0.0000
0.0020
0.0040
0.0060
0.0080
0.0100
0.0120
0.0140
1 Skylake node 1 node +1x V100 PCIe
per node
1 node +2x V100 PCIe
per node
1 node +4x V100 PCIe
per node
1 node +8x V100 PCIe
per node
1/se
conds
7.5X
3.1X
4.5X
8.0X

79
VASP B.hR105on Gold 6140 vs V100 SXM2 (32GB)
(Untuned on Volta)Running VASP version 5.4.4
The blue node contains Dual Intel Xeon Gold [email protected] [2.301GHz Turbo]
(Skylake) CPUs
The green nodes contain Dual Intel Xeon E5-2698 [email protected] [3.6GHz
Turbo] (Broadwell) CPUs + Tesla V100 SXM2 (32GB) GPUs
105 Boron atoms (β-rhombohedral structure)216 bands
110592 plane wavesHybrid Functional with blocked Davicson
(ALGO=Normal)LHFCALC=.True. (Exact Exchange)
0.0015
0.0049
0.0071
0.0119
0.0133
0.0000
0.0020
0.0040
0.0060
0.0080
0.0100
0.0120
0.0140
1 Skylake node 1 node +1x V100 SXM2
per node
1 node +2x V100 SXM2
per node
1 node +4x V100 SXM2
per node
1 node +8x V100 SXM2
per node
1/se
conds
7.9X
3.3X
4.7X
8.9X

80
VASP B.hR105on Platinum 8180 vs V100 PCIe (32GB)
(Untuned on Volta)Running VASP version 5.4.4
The blue node contains Dual Intel Xeon Platinum [email protected] [2.501GHz
Turbo] (Skylake) CPUs
The green nodes contain Dual Intel Xeon E5-2690 [email protected] [3.5GHz
Turbo] (Broadwell) CPUs + Tesla V100 PCIe (32GB) GPUs
105 Boron atoms (β-rhombohedral structure)216 bands
110592 plane wavesHybrid Functional with blocked Davicson
(ALGO=Normal)LHFCALC=.True. (Exact Exchange)
0.0017
0.0047
0.0067
0.0112
0.0120
0.0000
0.0020
0.0040
0.0060
0.0080
0.0100
0.0120
0.0140
1 Skylake node 1 node +1x V100 PCIe
per node
1 node +2x V100 PCIe
per node
1 node +4x V100 PCIe
per node
1 node +8x V100 PCIe
per node
1/se
conds
6.6X
2.8X
3.9X
7.1X

81
VASP B.hR105on Platinum 8180 vs V100 SXM2 (32GB)
(Untuned on Volta)Running VASP version 5.4.4
The blue node contains Dual Intel Xeon Platinum [email protected] [2.501GHz
Turbo] (Skylake) CPUs
The green nodes contain Dual Intel Xeon E5-2698 [email protected] [3.6GHz
Turbo] (Broadwell) CPUs + Tesla V100 SXM2 (32GB) GPUs
105 Boron atoms (β-rhombohedral structure)216 bands
110592 plane wavesHybrid Functional with blocked Davicson
(ALGO=Normal)LHFCALC=.True. (Exact Exchange)
0.0017
0.0049
0.0071
0.0119
0.0133
0.0000
0.0020
0.0040
0.0060
0.0080
0.0100
0.0120
0.0140
1 Skylake node 1 node +1x V100 SXM2
per node
1 node +2x V100 SXM2
per node
1 node +4x V100 SXM2
per node
1 node +8x V100 SXM2
per node
1/se
conds
7.0X
2.9X
4.2X
7.8X

October 2017
VASP 5.4.4

83
Silica IFPEN on V100s PCIe
0.00210
0.00418
0.00537
0.00628
0.00000
0.00100
0.00200
0.00300
0.00400
0.00500
0.00600
0.00700
1 Broadwell node 1 node +2x V100 PCIe
per node (16GB)
1 node +4x V100 PCIe
per node (16GB)
1 node +8x V100 PCIe
per node (16GB)
1/se
conds
(Untuned on Volta)Running VASP version 5.4.4
The blue node contains Dual Intel Xeon E5-2690 [email protected] [3.5GHz Turbo]
(Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2690 [email protected] [3.5GHz
Turbo] (Broadwell) CPUs + Tesla V100 PCIe (16GB) GPUs
240 ions, cristobalite (high) bulk720 bands
? plane wavesALGO = Very Fast (RMM-DIIS)
2.0X
2.6X
3.0X

84
Silica IFPEN on V100s SXM2
0.00210
0.00423
0.00541
0.00580
0.00000
0.00100
0.00200
0.00300
0.00400
0.00500
0.00600
0.00700
1 Broadwell node 1 node +2x V100 SXM2
per node (16GB)
1 node +4x V100 SXM2
per node (16GB)
1 node +8x V100 SXM2
per node (16GB)
1/se
conds
(Untuned on Volta)Running VASP version 5.4.4
The blue node contains Dual Intel Xeon E5-2698 [email protected] [3.6GHz Turbo]
(Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2698 [email protected] [3.6GHz
Turbo] (Broadwell) CPUs + Tesla V100 SXM2 (16GB) GPUs
240 ions, cristobalite (high) bulk720 bands
? plane wavesALGO = Very Fast (RMM-DIIS)
2.0X
2.6X
2.8X

85
Si-Huge on V100s PCIe
0.00017
0.00045
0.00057
0.00065
0.00000
0.00010
0.00020
0.00030
0.00040
0.00050
0.00060
0.00070
1 Broadwell node 1 node +2x V100 PCIe
per node (16GB)
1 node +4x V100 PCIe
per node (16GB)
1 node +8x V100 PCIe
per node (16GB)
1/se
conds
(Untuned on Volta)Running VASP version 5.4.4
The blue node contains Dual Intel Xeon E5-2690 [email protected] [3.5GHz Turbo]
(Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2690 [email protected] [3.5GHz
Turbo] (Broadwell) CPUs + Tesla V100 PCIe (16GB) GPUs
512 Si atoms1282 bands
864000 Plane WavesAlgo = Normal (blocked Davidson)
2.6X
3.4X
3.8X

86
Si-Huge on V100s SXM2
0.00017
0.00044
0.00056
0.00067
0.00000
0.00010
0.00020
0.00030
0.00040
0.00050
0.00060
0.00070
0.00080
1 Broadwell node 1 node +2x V100 SXM2
per node (16GB)
1 node +4x V100 SXM2
per node (16GB)
1 node +8x V100 SXM2
per node (16GB)
1/se
conds
(Untuned on Volta)Running VASP version 5.4.4
The blue node contains Dual Intel Xeon E5-2698 [email protected] [3.6GHz Turbo]
(Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2698 [email protected] [3.6GHz
Turbo] (Broadwell) CPUs + Tesla V100 SXM2 (16GB) GPUs
512 Si atoms1282 bands
864000 Plane WavesAlgo = Normal (blocked Davidson)
2.6X3.3X
4.0X

87
SupportedSystems on V100s PCIe
0.0037
0.0068
0.0087
0.0000
0.0010
0.0020
0.0030
0.0040
0.0050
0.0060
0.0070
0.0080
0.0090
0.0100
1 Broadwell node 1 node +2x V100 PCIe
per node (16GB)
1 node +4x V100 PCIe
per node (16GB)
1/se
conds
(Untuned on Volta)Running VASP version 5.4.4
The blue node contains Dual Intel Xeon E5-2690 [email protected] [3.5GHz Turbo]
(Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2690 [email protected] [3.5GHz
Turbo] (Broadwell) CPUs + Tesla V100 PCIe (16GB) GPUs
267 ions788 bands
762048 plane wavesALGO = Fast (Davidson + RMM-DIIS)
1.8X
2.4X

88
SupportedSystems on V100s SXM2
0.0037
0.0068
0.0087
0.0100
0.0000
0.0020
0.0040
0.0060
0.0080
0.0100
0.0120
1 Broadwell node 1 node +2x V100 SXM2
per node (16GB)
1 node +4x V100 SXM2
per node (16GB)
1 node +8x V100 SXM2
per node (16GB)
1/se
conds
(Untuned on Volta)Running VASP version 5.4.4
The blue node contains Dual Intel Xeon E5-2698 [email protected] [3.6GHz Turbo]
(Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2698 [email protected] [3.6GHz
Turbo] (Broadwell) CPUs + Tesla V100 SXM2 (16GB) GPUs
267 ions788 bands
762048 plane wavesALGO = Fast (Davidson + RMM-DIIS)
1.8X
2.4X
2.7X

89
NiAl-MD on V100s PCIe
0.0031
0.0063
0.0068
0.0000
0.0010
0.0020
0.0030
0.0040
0.0050
0.0060
0.0070
0.0080
1 Broadwell node 1 node +2x V100 PCIe
per node (16GB)
1 node +4x V100 PCIe
per node (16GB)
1/se
conds
(Untuned on Volta)Running VASP version 5.4.4
The blue node contains Dual Intel Xeon E5-2690 [email protected] [3.5GHz Turbo]
(Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2690 [email protected] [3.5GHz
Turbo] (Broadwell) CPUs + Tesla V100 PCIe (16GB) GPUs
500 ions3200 bands
729000 plane wavesALGO = Fast (Davidson + RMM-DIIS)
2.0X2.2X
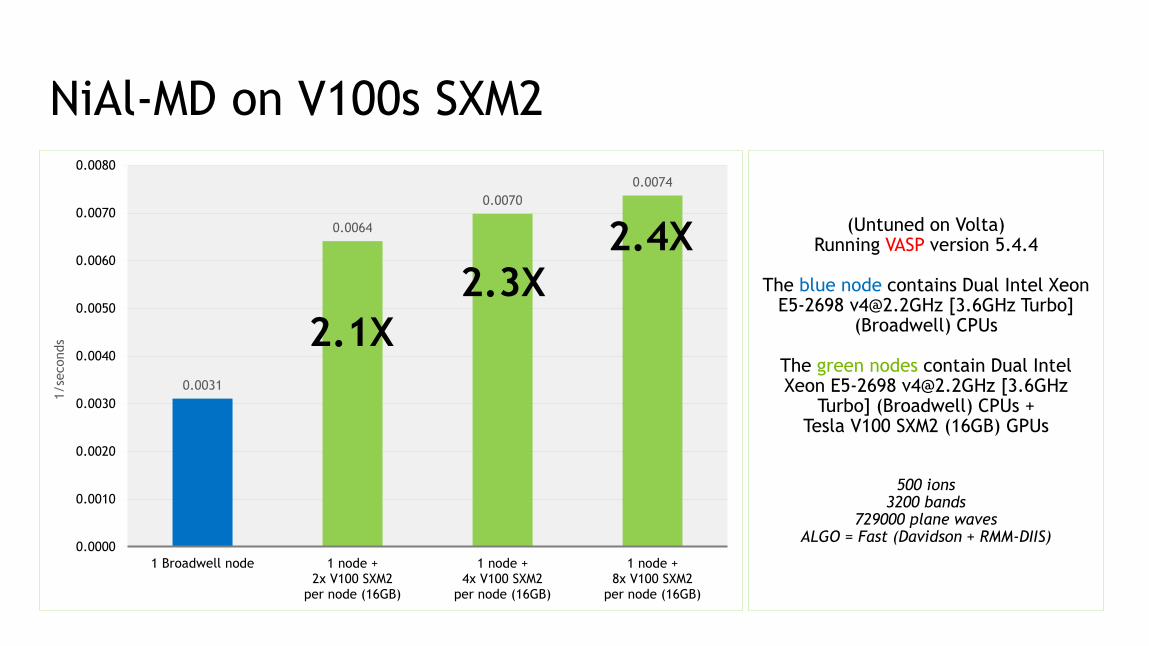
90
NiAl-MD on V100s SXM2
0.0031
0.0064
0.0070
0.0074
0.0000
0.0010
0.0020
0.0030
0.0040
0.0050
0.0060
0.0070
0.0080
1 Broadwell node 1 node +2x V100 SXM2
per node (16GB)
1 node +4x V100 SXM2
per node (16GB)
1 node +8x V100 SXM2
per node (16GB)
1/se
conds
(Untuned on Volta)Running VASP version 5.4.4
The blue node contains Dual Intel Xeon E5-2698 [email protected] [3.6GHz Turbo]
(Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2698 [email protected] [3.6GHz
Turbo] (Broadwell) CPUs + Tesla V100 SXM2 (16GB) GPUs
500 ions3200 bands
729000 plane wavesALGO = Fast (Davidson + RMM-DIIS)
2.1X
2.3X2.4X

91
B.hR105 on V100s PCIe
0.0008
0.0077
0.0112
0.0119
0.0000
0.0020
0.0040
0.0060
0.0080
0.0100
0.0120
0.0140
1 Broadwell node 1 node +2x V100 PCIe
per node (16GB)
1 node +4x V100 PCIe
per node (16GB)
1 node +8x V100 PCIe
per node (16GB)
1/se
conds
(Untuned on Volta)Running VASP version 5.4.4
The blue node contains Dual Intel Xeon E5-2690 [email protected] [3.5GHz Turbo]
(Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2690 [email protected] [3.5GHz
Turbo] (Broadwell) CPUs + Tesla V100 PCIe (16GB) GPUs
105 Boron atoms (β-rhombohedral structure)216 bands
110592 plane wavesHybrid Functional with blocked Davicson
(ALGO=Normal)LHFCALC=.True. (Exact Exchange)
9.6X
14.0X14.9X

92
B.hR105 on V100s SXM2
0.0008
0.0079
0.0116
0.0128
0.0000
0.0020
0.0040
0.0060
0.0080
0.0100
0.0120
0.0140
1 Broadwell node 1 node +2x V100 SXM2
per node (16GB)
1 node +4x V100 SXM2
per node (16GB)
1 node +8x V100 SXM2
per node (16GB)
1/se
conds
(Untuned on Volta)Running VASP version 5.4.4
The blue node contains Dual Intel Xeon E5-2698 [email protected] [3.6GHz Turbo]
(Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2698 [email protected] [3.6GHz
Turbo] (Broadwell) CPUs + Tesla V100 SXM2 (16GB) GPUs
105 Boron atoms (β-rhombohedral structure)216 bands
110592 plane wavesHybrid Functional with blocked Davicson
(ALGO=Normal)LHFCALC=.True. (Exact Exchange)
9.9X
14.5X
16.0X

93
B.aP107 on V100s PCIe
0.000038
0.000323
0.000462
0.000490
0.000000
0.000100
0.000200
0.000300
0.000400
0.000500
0.000600
1 Broadwell node 1 node +2x V100 PCIe
per node (16GB)
1 node +4x V100 PCIe
per node (16GB)
1 node +8x V100 PCIe
per node (16GB)
1/se
conds
(Untuned on Volta)Running VASP version 5.4.4
The blue node contains Dual Intel Xeon E5-2690 [email protected] [3.5GHz Turbo]
(Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2690 [email protected] [3.5GHz
Turbo] (Broadwell) CPUs + Tesla V100 PCIe (16GB) GPUs
107 Boron atoms (symmetry broken 107-atom β′ variant)216 bands
110592 plane wavesHybrid functional calculation (exact
exchange) with blocked Davidson. No KPointparallelization.
Hybrid Functional with blocked Davidson (ALGO=Normal)
LHFCALC=.True. (Exact Exchange)
8.5X
12.2X
12.9X

94
B.aP107 on V100s SXM2
0.000038
0.000324
0.000465
0.000523
0.000000
0.000100
0.000200
0.000300
0.000400
0.000500
0.000600
1 Broadwell node 1 node +2x V100 SXM2
per node (16GB)
1 node +4x V100 SXM2
per node (16GB)
1 node +8x V100 SXM2
per node (16GB)
1/se
conds
(Untuned on Volta)Running VASP version 5.4.4
The blue node contains Dual Intel Xeon E5-2698 [email protected] [3.6GHz Turbo]
(Broadwell) CPUs
The green nodes contain Dual Intel Xeon E5-2698 [email protected] [3.6GHz
Turbo] (Broadwell) CPUs + Tesla V100 SXM2 (16GB) GPUs
107 Boron atoms (symmetry broken 107-atom β′ variant)216 bands
110592 plane wavesHybrid functional calculation (exact
exchange) with blocked Davidson. No KPointparallelization.
Hybrid Functional with blocked Davidson (ALGO=Normal)
LHFCALC=.True. (Exact Exchange)
8.5X
12.2X
13.8X

March 2018
Quantum Chemistry (QC) on GPUs

96
GPU-Accelerated Molecular Dynamics Apps
ACEMD
AMBER
CHARMM
DESMOND
ESPResSO
Folding@Home
GENESIS
GPUGrid.net
GROMACS
HALMD
HOOMD-Blue
HTMD
Green Lettering Indicates Performance Slides Included
GPU Perf compared against dual multi-core x86 CPU socket.
LAMMPS
mdcore
MELD
NAMD
OpenMM
PolyFTS





























