Embed Size (px)
Citation preview

Quantifying the Energy Efficiency of FFT onHeterogeneous Platforms
Yash Ukidave, Amir Kavyan Ziabari, Perhaad Mistry, Gunar Schirner and David KaeliDepartment of Electrical & Computer Engineering, Northeastern University, Boston, USA
{yukidave, aziabari, pmistry, schirner, kaeli}@ece.neu.edu
Abstract—Heterogeneous computing using Graphic ProcessingUnits (GPUs) has become an attractive computing model given theavailable scale of data-parallel performance and programmingstandards such as OpenCL. However, given the energy issuespresent with GPUs, some devices can exhaust power budgetsquickly. Better solutions are needed to effectively exploit thepower efficiency available on heterogeneous systems. In thispaper we evaluate the power-performance trade-offs of differentheterogeneous signal processing applications. More specifically,we compare the performance of 7 different implementations ofthe Fast Fourier Transform algorithms. Our study covers discreteGPUs and shared memory GPUs (APUs) from AMD (LlanoAPUs and the Southern Islands GPU), Nvidia (Fermi) and Intel(Ivy Bridge). For this range of platforms, we characterize thedifferent FFTs and identify the specific architectural featuresthat most impact power consumption. Using the 7 FFT kernels,we obtain a 48% reduction in power consumption and up toa 58% improvement in performance across these different FFTimplementations. These differences are also found to be targetarchitecture dependent. The results of this study will help thesignal processing community identify which class of FFTs aremost appropriate for a given platform. More important, wehave demonstrated that different algorithms implementing thesame fundamental function (FFT) can perform vastly differentbased on the target hardware and associated programmingoptimizations.
Keywords—OpenCL; FFT; Power; GPUs;
I. INTRODUCTION
The data-parallel performance of GPU architectures canbe used to obtain large speedups in computation for differentdomains such as scientific computing, biomedical imaging andsignal processing applications [24]. Standardized programmingframeworks such as OpenCL have simplified programming forGPU architectures and gained popularity among developers.Even though large performance gains have been reported forcomputations on GPUs [23], the power budget of these GPUsused in such applications is very high [29]. This is evident fromthe fact that the maximum Thermal Design Power (TDP) ofthe latest generation of GPUs from Nvidia (Kepler GTX 680)is close to the last generation (Fermi GTX 580) at 200W [21].
In the domain of Digital Signal Processing (DSP), theDiscrete Fourier Transform (DFT) has been a widely usedTime-Frequency domain transform algorithm. The DFT hasbeen used extensively in the fields of image processing, datacompression, spectral analysis and radar communications. TheFast Fourier Transform (FFT) is a fast version of the DFTalgorithm, reducing the DFT’s time complexity to O(NlogN)from O(N2), where N is the number of input data points. Ahigh performance FFT is key to meet performance demands
in Real-Time and DSP applications. A number of differentimplementations of the FFT algorithm have been developed toenhance the algorithm runtime.
Motivated by the increasing power consumption of het-erogeneous systems being used in signal processing, thispaper examines the power and execution performance of theFFT algorithm. The paper compares implementations of theCooley-Tukey, Stockham, Sande-Tukey and Multi-Radix FFTs.Our FFT implementations use OpenCL as the programmingframework.
In this paper, we evaluate the relationship between exe-cution and power performance of different FFT implementa-tions, across different GPUs and fused architectures APUs.GPU resource usage such as write unit stalls, registers andmemory access patterns are studied to understand the powerconsumption of the application [16].
By characterizing both power and execution performancetogether, we can determine the most appropriate FFT imple-mentation given a specific platform. DSP developers can utilizethis knowledge of power and performance to carefully focustheir efforts on a specific application. The contributions of thispaper can be summarized as follows.
• We characterize performance and power consumptiontrends across 7 different FFT implementations target-ing both discrete GPUs and shared memory APUs.
• Using actual system measurements, we identify thealgorithmic and architectural factors that affect powerconsumption of the applications on heterogeneousdevices.
II. BACKGROUND AND MOTIVATION
A. Heterogeneous Applications using OpenCL
Open Compute Language (OpenCL) is an emerging soft-ware framework for programming heterogeneous devices [15].OpenCL is an industry standard maintained by Khronos, a non-profit technology consortium. The adoption rate of OpenCLhas been increased by major vendors such as Apple, AMD,ARM, NVIDIA, Intel, Imagination, Qualcomm and S3.
The OpenCL program has host code that executes on aCPU and is responsible for the setup of data and schedul-ing execution on a compute device (such as a GPU). Thearchitecture is shown in Figure 1. The code that executeson a compute device is called a kernel. In-depth informationfor implementing OpenCL based heterogeneous applicationsis provided in [9].

Fig. 1. OpenCL Host Device Architecture
Application libraries developed using OpenCL can be tunedfor devices from different vendors for performance whilemaintaining the basic program structure. Signal processingapplications such as the FFT need to be tuned for performanceaccording to the platform architecture. Different implementa-tions of FFT can be selected in order to achieve superior perfor-mance on a particular heterogeneous device architecture [10],[30].
B. Power Performance of Heterogeneous Applications
Power consumption of a GPU has been studied by re-searchers to understand and develop energy efficient GPUdesigns [26], [31]. At peak performance, the maximum powerconsumed by a CPU and the latest high-end GPU is 100Wand 200W, respectively. Energy-efficient heterogeneous com-puting pushes the need to study the power performance of anapplication on a heterogeneous device such as the GPU.
A number of heterogeneous applications developed inCUDA [19] have been studied to know their power consump-tion [18], [29]. In this paper, we leverage the cross-platformnature of OpenCL to study power consumption of a singleapplication across different heterogeneous devices.
III. FAST FOURIER TRANSFORM
Every discrete function f(x) of finite length can be de-scribed as a set of potentially infinite sinusoidal functions. Thisrepresentation is known as frequency domain representation ofthe function, F (u). The relation between these two functionsis represented by Discrete Fourier Transform (DFT).
F{f(x)} = F (u) =1
N
N−1∑x=0
f(x)WuxN (1)
F−1{F (u)} = f(x) =N−1∑u=0
F (u)W−uxN (2)
Where WN = e−j2π
N is called the Twiddle Factor and N isthe number of input data points.
The Equation 1 defines the forward DFT computation overa finite time signal f(x). The inverse DFT computation overa frequency function F (u) is shown in Equation 2.
The Fast Fourier Transform refers to a class of algorithmsthat uses divide-and-conquer techniques to efficiently compute
the Discrete Fourier Transform of the input signal. For a 1-Dimensional(1D) array of input data size N , the FFT algorithmbreaks the array into a number of equally sized sub-arrays andperforms computation on these sub-arrays. Dividing the inputsequence in the FFT algorithm is called decimation and hastwo major classifications which cover all variations of FFTalgorithms.
1) Decimation in Time (DIT)2) Decimation in Frequency (DIF)
The decimation in time (DIT) algorithm splits the N-pointdata sequence into two N
2 -point data sequences f1(N) andf2(N), for even and odd numbered input samples, respectively.The decimation in frequency (DIF) algorithm is split into twosequences, for the first N
2 and last N2 data points, respectively.
More details regarding the structure of both the FFT algorithmscan be found in [7].
The most basic implementation of the DIT-based FFT isthe Recursive Radix 2 FFT. The algorithm recursively dividesthe N
2 length odd and even arrays into smaller arrays untilthe length of the array is one. It calculates the DFT of eachsingle point and finally synthesizes the resulting N points intoa single array. In OpenCL programming, this method requireslog2N stages or kernel calls. For example, 10 kernel calls arerequired for an input of 1024 input data points.
The Multi-Radix FFT (MR) is an example of one possiblevariant of the divide-and-conquer technique used in the DIFand DIT algorithms. The MR FFT uses a combination ofdifferent radix sizes for efficient computation.
Seven different implementations of the FFT algorithm areevaluated in this work. Table I provides a summary of eachimplementation and its attributes. The different implementa-tions are characterized by attributes such as the number ofkernel calls required, method of calculation of twiddle fac-tors, requirements involving bit-reversals and memory accesspatterns.
A. FFT Implementations
Next, we discuss each of the 7 different implementations ofthe FFT algorithms described in Table I. The implementationsare compared based on their design and executioncharacteristics when mapped to heterogeneous devices.
A. Radix-2 FFT (FFT R2)The Radix-2 implementation is based on the Recursive-Radix-2 FFT described in Section III. At each stage of the algorithm,a Radix-2 computation is performed on two data points. Thiscomputation is performed using a single work-item in anOpenCL kernel. The implementation uses multiple kernelcalls to complete the computation. The general FFT Radix-2computation requires two complex multiplications and twocomplex additions.
B. Multi-Radix-Multi-Call FFT (MR-MC)The implementation uses multiple kernel calls similar toRadix-2 FFT. But instead of just using Radix-2 computation
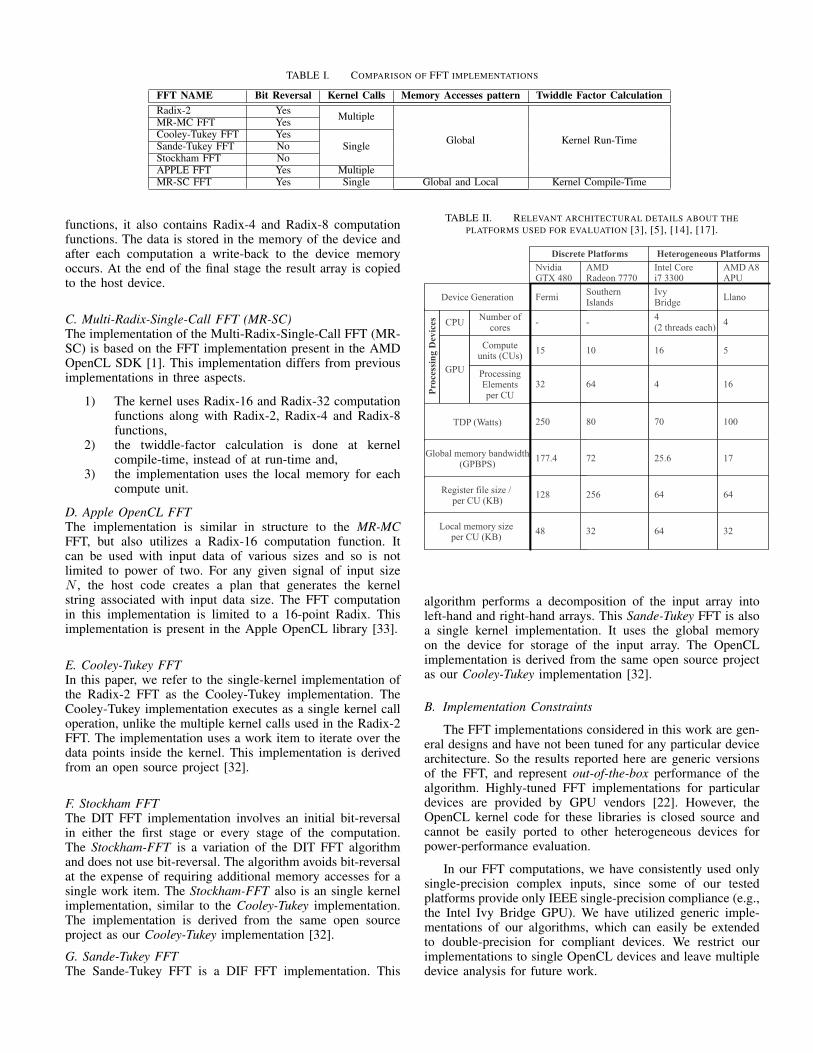
TABLE I. COMPARISON OF FFT IMPLEMENTATIONS
FFT NAME Bit Reversal Kernel Calls Memory Accesses pattern Twiddle Factor CalculationRadix-2 Yes Multiple
Global Kernel Run-Time
MR-MC FFT YesCooley-Tukey FFT Yes
SingleSande-Tukey FFT NoStockham FFT NoAPPLE FFT Yes MultipleMR-SC FFT Yes Single Global and Local Kernel Compile-Time
functions, it also contains Radix-4 and Radix-8 computationfunctions. The data is stored in the memory of the device andafter each computation a write-back to the device memoryoccurs. At the end of the final stage the result array is copiedto the host device.
C. Multi-Radix-Single-Call FFT (MR-SC)The implementation of the Multi-Radix-Single-Call FFT (MR-SC) is based on the FFT implementation present in the AMDOpenCL SDK [1]. This implementation differs from previousimplementations in three aspects.
1) The kernel uses Radix-16 and Radix-32 computationfunctions along with Radix-2, Radix-4 and Radix-8functions,
2) the twiddle-factor calculation is done at kernelcompile-time, instead of at run-time and,
3) the implementation uses the local memory for eachcompute unit.
D. Apple OpenCL FFTThe implementation is similar in structure to the MR-MCFFT, but also utilizes a Radix-16 computation function. Itcan be used with input data of various sizes and so is notlimited to power of two. For any given signal of input sizeN , the host code creates a plan that generates the kernelstring associated with input data size. The FFT computationin this implementation is limited to a 16-point Radix. Thisimplementation is present in the Apple OpenCL library [33].
E. Cooley-Tukey FFTIn this paper, we refer to the single-kernel implementation ofthe Radix-2 FFT as the Cooley-Tukey implementation. TheCooley-Tukey implementation executes as a single kernel calloperation, unlike the multiple kernel calls used in the Radix-2FFT. The implementation uses a work item to iterate over thedata points inside the kernel. This implementation is derivedfrom an open source project [32].
F. Stockham FFTThe DIT FFT implementation involves an initial bit-reversalin either the first stage or every stage of the computation.The Stockham-FFT is a variation of the DIT FFT algorithmand does not use bit-reversal. The algorithm avoids bit-reversalat the expense of requiring additional memory accesses for asingle work item. The Stockham-FFT also is an single kernelimplementation, similar to the Cooley-Tukey implementation.The implementation is derived from the same open sourceproject as our Cooley-Tukey implementation [32].
G. Sande-Tukey FFTThe Sande-Tukey FFT is a DIF FFT implementation. This
TABLE II. RELEVANT ARCHITECTURAL DETAILS ABOUT THEPLATFORMS USED FOR EVALUATION [3], [5], [14], [17].
algorithm performs a decomposition of the input array intoleft-hand and right-hand arrays. This Sande-Tukey FFT is alsoa single kernel implementation. It uses the global memoryon the device for storage of the input array. The OpenCLimplementation is derived from the same open source projectas our Cooley-Tukey implementation [32].
B. Implementation Constraints
The FFT implementations considered in this work are gen-eral designs and have not been tuned for any particular devicearchitecture. So the results reported here are generic versionsof the FFT, and represent out-of-the-box performance of thealgorithm. Highly-tuned FFT implementations for particulardevices are provided by GPU vendors [22]. However, theOpenCL kernel code for these libraries is closed source andcannot be easily ported to other heterogeneous devices forpower-performance evaluation.
In our FFT computations, we have consistently used onlysingle-precision complex inputs, since some of our testedplatforms provide only IEEE single-precision compliance (e.g.,the Intel Ivy Bridge GPU). We have utilized generic imple-mentations of our algorithms, which can easily be extendedto double-precision for compliant devices. We restrict ourimplementations to single OpenCL devices and leave multipledevice analysis for future work.

Fig. 2. Power measurement setup for discrete GPU and shared memory APU
IV. EXPERIMENTAL SETUP & METHODOLOGY
In this section, we describe the platforms used for evalua-tion of power and execution performance. We also describe themethodology used for power measurements for the differentplatforms used.
A. Platforms for Evaluation
We perform measurements and testing on four different testplatforms. These platforms include two discrete GPU devices(i.e., an NVIDIA GTX 480 and an AMD Radeon HD 7770)and two fused architecture devices (an Intel Core i7-3770 IvyBridge processor and an AMD A8-3850).
The NVIDIA GTX 480 belongs to the Fermi family ofGPUs and the AMD HD 7770 belongs to the Southern Islandsfamily of GPUs. The fused architecture devices combine theCPU and GPU on a single die. The AMD Fused deviceuses an x86 CPU and Evergreen family GPU. The Intel i7-3770 processor uses a x86-based CPU and Intel Series-4000embedded GPU. The fused architectures offer lower latenciesfor algorithms tightly integrated between the CPU and GPUsuch as the FFT [28]. The architecture details of the platformsused for our measurements are provided in Table II.
B. Measurement of Power Consumption
Power consumption for the GPU is measured using a Kill-a-Watt power meter. The GPU is connected via the PCI-Express to the main system board, but is powered usinga dedicated external power supply (FSP Booster X5). ThePCI express slot of the GPU draws very small quantities ofpower [4]. The major source of power to the GPU is theexternal power supply unit. Kasichayanula et al. also used theexternal power supply of a GPU to validate their proposedpower model [13]. The power meter is attached to the externalpower supply to record the readings. The external supply helpsin noting the idle and peak power consumption of the GPU.
Fig. 4. Performance of FFT implementations measured in MBlocks/sec,averaged over all the devices and block sizes.
Our power measurement setup for discrete platforms is shownin Figure 2a.
Power measurements for fused devices are done using asimilar Kill-a-Watt meter, but attached to the main powersupply of the system. This methodology is less accurate thanour method used for discrete devices. However, since the GPUis on the same die as the processor, we cannot isolate the fusedGPU. The discrete GPU is not present in the system duringpower measurements for fused devices.
V. EXPERIMENTAL RESULTS
We evaluate the computational performance and power-performance of the FFT implementations on the platformsdiscussed earlier in Section IV-A. We will discuss the rela-tionship between the power consumption and FFT algorithms,in regards to the program structure and architectural featuresof the devices.
A. Execution Performance of FFT Implementations
The execution performance of the 7 different FFT imple-mentations is evaluated in Figure 3. Performance is measuredin blocks/sec for every implementation. Each block of dataconsists of N inputs, each input data point being a complexsingle precision number. For an input of size N, the FFTperforms 5×N log2 N floating point operations (FLOPs) [34].We present results for 3 different block-sizes (N = 64K, 1Mand 8M). The performance of different FFT implementationsacross the different devices and block-sizes is shown in Fig-ure 3. FFT implementations improve in performance withincreasing block size. Figure 4 summarizes the compute perfor-mance of each of the FFTs, averaged over all the devices andblock size. The comparative performance of FFTs and vendorprovided FFT implementations is also shown in Figure 4.cuFFT is a FFT implementation provided by Nvidia designedusing CUDA [22]. clAmdFFT is a FFT library designed inOpenCL for AMD GPUs and APUs [2].
In general, the MR-SC, MR-MC, Sande-Tukey and AppleFFTs perform better than the other FFT implementations, pro-cessing more than 500 Mblocks/sec. Their performance variesacross block sizes and devices. The MR-MC FFT performs upto 1000 MBlocks/sec for N = 1M and up to 1800 MBlocks/secfor N = 8M.
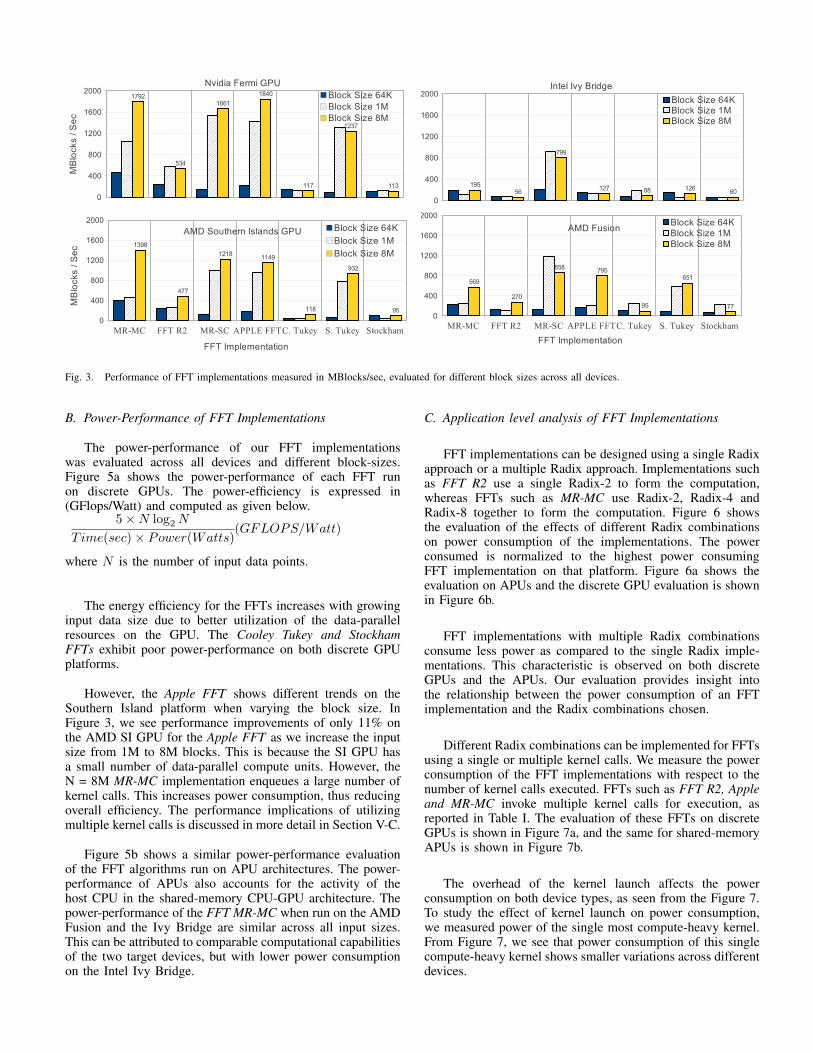
Fig. 3. Performance of FFT implementations measured in MBlocks/sec, evaluated for different block sizes across all devices.
B. Power-Performance of FFT Implementations
The power-performance of our FFT implementationswas evaluated across all devices and different block-sizes.Figure 5a shows the power-performance of each FFT runon discrete GPUs. The power-efficiency is expressed in(GFlops/Watt) and computed as given below.
5×N log2 N
Time(sec)× Power(Watts)(GFLOPS/Watt)
where N is the number of input data points.
The energy efficiency for the FFTs increases with growinginput data size due to better utilization of the data-parallelresources on the GPU. The Cooley Tukey and StockhamFFTs exhibit poor power-performance on both discrete GPUplatforms.
However, the Apple FFT shows different trends on theSouthern Island platform when varying the block size. InFigure 3, we see performance improvements of only 11% onthe AMD SI GPU for the Apple FFT as we increase the inputsize from 1M to 8M blocks. This is because the SI GPU hasa small number of data-parallel compute units. However, theN = 8M MR-MC implementation enqueues a large number ofkernel calls. This increases power consumption, thus reducingoverall efficiency. The performance implications of utilizingmultiple kernel calls is discussed in more detail in Section V-C.
Figure 5b shows a similar power-performance evaluationof the FFT algorithms run on APU architectures. The power-performance of APUs also accounts for the activity of thehost CPU in the shared-memory CPU-GPU architecture. Thepower-performance of the FFT MR-MC when run on the AMDFusion and the Ivy Bridge are similar across all input sizes.This can be attributed to comparable computational capabilitiesof the two target devices, but with lower power consumptionon the Intel Ivy Bridge.
C. Application level analysis of FFT Implementations
FFT implementations can be designed using a single Radixapproach or a multiple Radix approach. Implementations suchas FFT R2 use a single Radix-2 to form the computation,whereas FFTs such as MR-MC use Radix-2, Radix-4 andRadix-8 together to form the computation. Figure 6 showsthe evaluation of the effects of different Radix combinationson power consumption of the implementations. The powerconsumed is normalized to the highest power consumingFFT implementation on that platform. Figure 6a shows theevaluation on APUs and the discrete GPU evaluation is shownin Figure 6b.
FFT implementations with multiple Radix combinationsconsume less power as compared to the single Radix imple-mentations. This characteristic is observed on both discreteGPUs and the APUs. Our evaluation provides insight intothe relationship between the power consumption of an FFTimplementation and the Radix combinations chosen.
Different Radix combinations can be implemented for FFTsusing a single or multiple kernel calls. We measure the powerconsumption of the FFT implementations with respect to thenumber of kernel calls executed. FFTs such as FFT R2, Appleand MR-MC invoke multiple kernel calls for execution, asreported in Table I. The evaluation of these FFTs on discreteGPUs is shown in Figure 7a, and the same for shared-memoryAPUs is shown in Figure 7b.
The overhead of the kernel launch affects the powerconsumption on both device types, as seen from the Figure 7.To study the effect of kernel launch on power consumption,we measured power of the single most compute-heavy kernel.From Figure 7, we see that power consumption of this singlecompute-heavy kernel shows smaller variations across differentdevices.
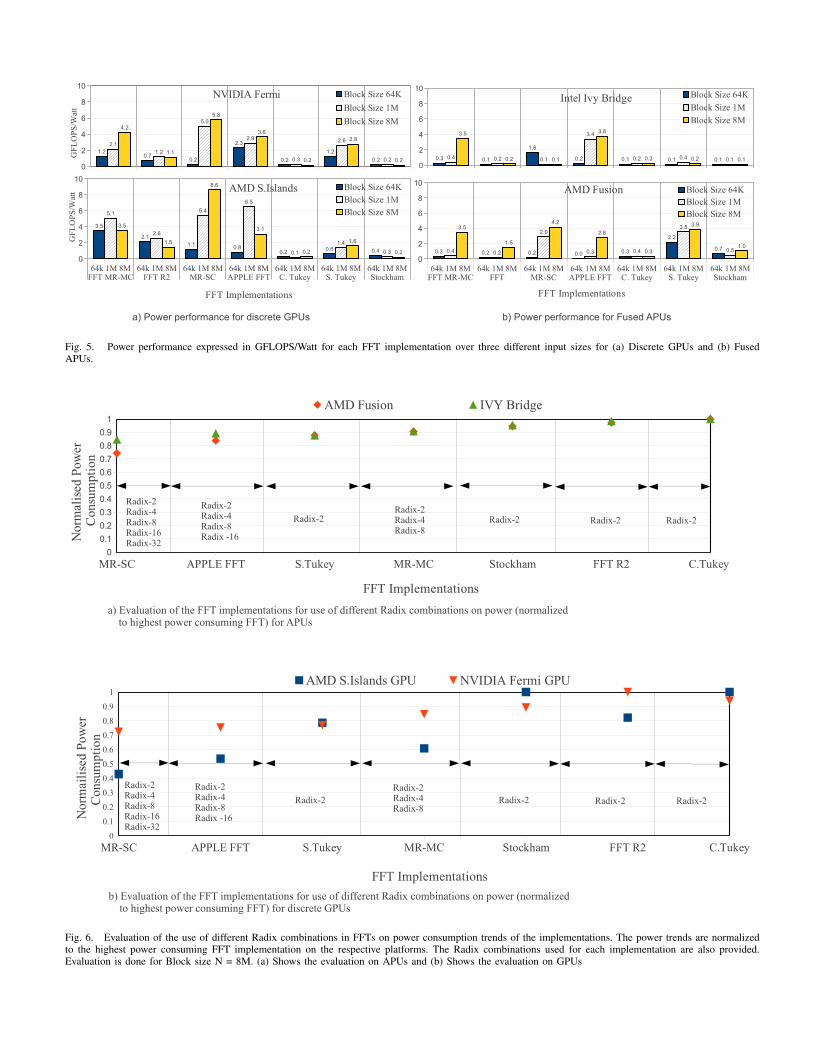
Fig. 5. Power performance expressed in GFLOPS/Watt for each FFT implementation over three different input sizes for (a) Discrete GPUs and (b) FusedAPUs.
Fig. 6. Evaluation of the use of different Radix combinations in FFTs on power consumption trends of the implementations. The power trends are normalizedto the highest power consuming FFT implementation on the respective platforms. The Radix combinations used for each implementation are also provided.Evaluation is done for Block size N = 8M. (a) Shows the evaluation on APUs and (b) Shows the evaluation on GPUs
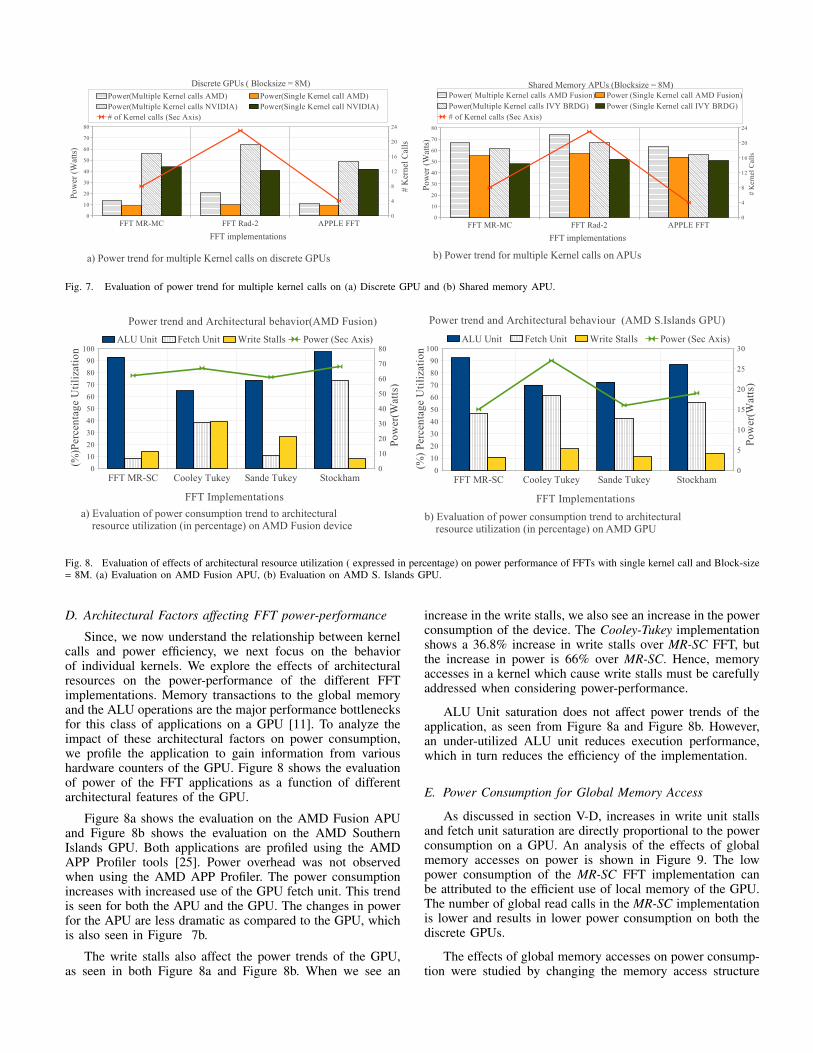
Fig. 7. Evaluation of power trend for multiple kernel calls on (a) Discrete GPU and (b) Shared memory APU.
Fig. 8. Evaluation of effects of architectural resource utilization ( expressed in percentage) on power performance of FFTs with single kernel call and Block-size= 8M. (a) Evaluation on AMD Fusion APU, (b) Evaluation on AMD S. Islands GPU.
D. Architectural Factors affecting FFT power-performance
Since, we now understand the relationship between kernelcalls and power efficiency, we next focus on the behaviorof individual kernels. We explore the effects of architecturalresources on the power-performance of the different FFTimplementations. Memory transactions to the global memoryand the ALU operations are the major performance bottlenecksfor this class of applications on a GPU [11]. To analyze theimpact of these architectural factors on power consumption,we profile the application to gain information from varioushardware counters of the GPU. Figure 8 shows the evaluationof power of the FFT applications as a function of differentarchitectural features of the GPU.
Figure 8a shows the evaluation on the AMD Fusion APUand Figure 8b shows the evaluation on the AMD SouthernIslands GPU. Both applications are profiled using the AMDAPP Profiler tools [25]. Power overhead was not observedwhen using the AMD APP Profiler. The power consumptionincreases with increased use of the GPU fetch unit. This trendis seen for both the APU and the GPU. The changes in powerfor the APU are less dramatic as compared to the GPU, whichis also seen in Figure 7b.
The write stalls also affect the power trends of the GPU,as seen in both Figure 8a and Figure 8b. When we see an
increase in the write stalls, we also see an increase in the powerconsumption of the device. The Cooley-Tukey implementationshows a 36.8% increase in write stalls over MR-SC FFT, butthe increase in power is 66% over MR-SC. Hence, memoryaccesses in a kernel which cause write stalls must be carefullyaddressed when considering power-performance.
ALU Unit saturation does not affect power trends of theapplication, as seen from Figure 8a and Figure 8b. However,an under-utilized ALU unit reduces execution performance,which in turn reduces the efficiency of the implementation.
E. Power Consumption for Global Memory Access
As discussed in section V-D, increases in write unit stallsand fetch unit saturation are directly proportional to the powerconsumption on a GPU. An analysis of the effects of globalmemory accesses on power is shown in Figure 9. The lowpower consumption of the MR-SC FFT implementation canbe attributed to the efficient use of local memory of the GPU.The number of global read calls in the MR-SC implementationis lower and results in lower power consumption on both thediscrete GPUs.
The effects of global memory accesses on power consump-tion were studied by changing the memory access structure
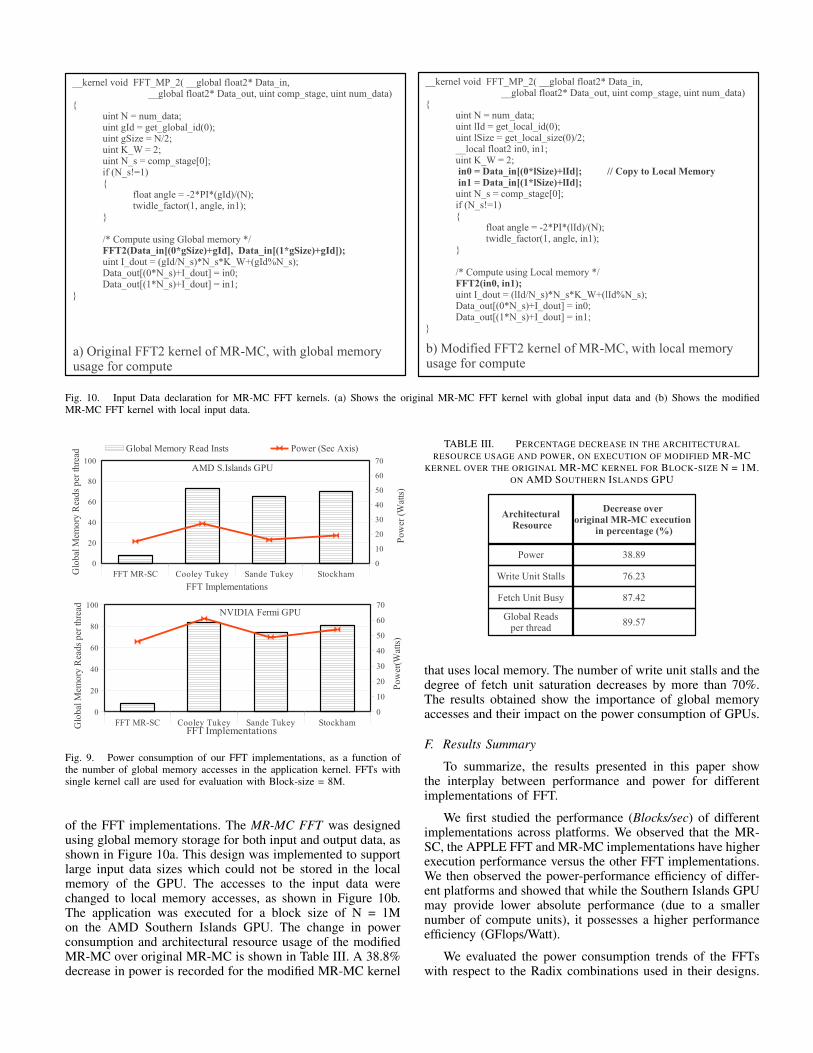
Fig. 10. Input Data declaration for MR-MC FFT kernels. (a) Shows the original MR-MC FFT kernel with global input data and (b) Shows the modifiedMR-MC FFT kernel with local input data.
Fig. 9. Power consumption of our FFT implementations, as a function ofthe number of global memory accesses in the application kernel. FFTs withsingle kernel call are used for evaluation with Block-size = 8M.
of the FFT implementations. The MR-MC FFT was designedusing global memory storage for both input and output data, asshown in Figure 10a. This design was implemented to supportlarge input data sizes which could not be stored in the localmemory of the GPU. The accesses to the input data werechanged to local memory accesses, as shown in Figure 10b.The application was executed for a block size of N = 1Mon the AMD Southern Islands GPU. The change in powerconsumption and architectural resource usage of the modifiedMR-MC over original MR-MC is shown in Table III. A 38.8%decrease in power is recorded for the modified MR-MC kernel
TABLE III. PERCENTAGE DECREASE IN THE ARCHITECTURALRESOURCE USAGE AND POWER, ON EXECUTION OF MODIFIED MR-MC
KERNEL OVER THE ORIGINAL MR-MC KERNEL FOR BLOCK-SIZE N = 1M.ON AMD SOUTHERN ISLANDS GPU
that uses local memory. The number of write unit stalls and thedegree of fetch unit saturation decreases by more than 70%.The results obtained show the importance of global memoryaccesses and their impact on the power consumption of GPUs.
F. Results Summary
To summarize, the results presented in this paper showthe interplay between performance and power for differentimplementations of FFT.
We first studied the performance (Blocks/sec) of differentimplementations across platforms. We observed that the MR-SC, the APPLE FFT and MR-MC implementations have higherexecution performance versus the other FFT implementations.We then observed the power-performance efficiency of differ-ent platforms and showed that while the Southern Islands GPUmay provide lower absolute performance (due to a smallernumber of compute units), it possesses a higher performanceefficiency (GFlops/Watt).
We evaluated the power consumption trends of the FFTswith respect to the Radix combinations used in their designs.

We found that the implementations using multiple Radixcombinations consumed less power.
To understand the relationship between OpenCL implemen-tations and power consumption, we conducted further studiesto observe the power overhead imposed by additional kernelcalls. Our results, as expected, showed that the number ofkernel calls affects the power consumed.
Once the effects of kernel calls were isolated, we proceededto study the FFT implementations which had a single kernelcall. We profiled the OpenCL kernels for both AMD platformsto study which architectural feature affects performance to thegreatest extent. We observed that the utilization of the fetchunit and the occurrence of write stalls followed similar trendsin terms of the power consumed. To validate this hypothesis,we implemented versions of the kernels using local memory.This reduced the utilization of the fetch units, which yieldedsubstantial power savings. While, this is a popular OpenCLoptimization [12], the effects of these optimizations on powerare highly relevant for data-parallel platforms.
VI. RELATED WORK
The importance of the FFT in DSP applications has leadto a number of high quality studies devoted to performanceoptimizations. Prior work on FFT optimizations for multi-coreCPU platforms has produced a number of high-performancelibraries available today [8], [30]. Performance optimizationstudies for GPU platforms include Govindaraju et al. [10],Volkov et al. [35], and Nukada et al. [18]. These studiesreport on substantial performance improvements, but are re-stricted to Nvidia platforms since they predate OpenCL andheterogeneous devices. The popularity of GPUs in the HPC(High Performance Computing) space has also lead to theinclusion of FFT benchmarks in cluster benchmark suites suchas SHOC [6].
Performance optimization of GPU applications is an activearea of research. A number of different optimization techniqueshave been proposed to improve the utilization of the memorybandwidth and the compute units on modern GPUs [12], [27],[36]. We extend these studies by including power in ouranalysis and also discuss a wider range of algorithms andplatforms.
Power consumption for GPUs has been studied for multipleapplications using both, experimental methods where poweris measured on running systems, and using power models.Using power models for GPUs [11], [13], [16] allows architectsto explore the design space, while being aware of energyconsumption. Power models are validated against experimentsusing microbenchmarks [13], [29]. Power modeling research iscomplimentary to our work since our goal is to experimentallyexamine a wider range of very recent platforms such as IvyBridge and Southern Islands - there presently are no powermodels available for these recent devices.
GPUs from Nvidia provide specialized hardware and driversupport for power measurement in the Nvidia ManagementLibrary(NVML) [20]. This methodology provides finer-grainedmeasurements [13]. However due to the large number ofplatforms from multiple vendors that were used in this paper,we decided utilize consistent and vendor-neutral interfaces tomeasure power.
VII. CONCLUSION
In this paper we have characterized the balance betweenexecution performance, implementation techniques and thepower consumption for different FFT algorithms. We analyzedthe execution and power performance of seven FFT implemen-tations on a variety of discrete and fused platforms.
Our primary evaluation shows a variation of up to 55.3% inthe power-performance of selected FFTs algorithms on discreteGPUs and up to a 84% variation on APUs. We investigatedthe effects of design attributes such as radix combinations usedin an FFT implementation on power consumption. We find an35% decrease in power on APUs and up to 55% decrease inpower on discrete GPUs for FFTs that employ multiple Radixcombinations. The choice of a particular FFT algorithm canthus affect the power consumption at large input sizes. We alsoobserved a strong relationship between power consumption andthe number of kernel calls for the FFT implementations.
We have also explored the architectural factors affectingpower consumption on GPUs. The evaluation shows a strongcorrelation between power consumption, write stalls and fetchunit saturation on the GPUs. This correlation is seen forboth GPUs and APUs. The results show an 20% increasein saturation of the fetch unit along with an 13W (55%)increase in power consumption on AMD Southern IslandsGPU. As expected, while ALU utilization does not affectpower consumption, execution performance of the applicationdegrades due to an under-utilized ALU.
We have also evaluated the effects of performance op-timizations such as, tuning global memory accesses for thepower consumption of the GPU. For the use of local memoryover global memory, we see a decrease of 38% in power andan 75% reduction in write unit stalls and fetch unit saturation.
We believe that our study can help developers identify thepotential of kernel development from a power-aware aspectfor heterogeneous computing. Our analysis methodology caneasily be applied to study other data-parallel algorithms. Ourwork helps to explain differences across different implemen-tations of FFTs and gain a better understanding of the powerand performance characteristics of heterogeneous platforms.
VIII. FUTURE WORK
There are several avenues for future work. We would liketo extend our work to study multi-dimensional FFTs and theFFTW (Fastest Fourier Transform in the West) algorithm [8]implementation in OpenCL for analysis on different platforms.We would also like to perform energy efficiency analysis onembedded SoC designs which contain heterogeneous devices.Another interesting path for our work is the analysis of energyefficiency in a multi-GPU environment such as clusters.
ACKNOWLEDGMENT
We would like to thank Analog Devices Inc., AMD andNvidia for supporting this research work. We would like tothank Robert Peloquin and Jiang Wu from Analog DevicesInc. for lending their expertise on FFT design and providingtheir comments and feedback on the research work. This workwas supported in part by an NSF ERC Innovation Award EEC-0946463.

REFERENCES
[1] AMD SDK (formerly ATI Stream). Website. Online available athttp://developer. amd. com/gpu/AMDAPPSDK/Pages/default. aspx.
[2] AMDhttp://www.bealto.com/gpu-fft fft.html. clAmdfft, OpenCL FFTlibrary from AMD.
[3] P. Boudier and G. Sellers. Memory System on Fusion APUs. In AMDFusion Developer Summit, 2011.
[4] S. Collange, D. Defour, and A. Tisserand. Power Consumption of Gpusfrom a Software Perspective. Computational Science–ICCS 2009, pages914–923, 2009.
[5] S. Damaraju, V. George, S. Jahagirdar, T. Khondker, R. Milstrey,S. Sarkar, S. Siers, I. Stolero, and A. Subbiah. A 22nm IA multi-CPU and GPU System-on-Chip. In 2012 IEEE International Solid-StateCircuits Conference, volume 44, pages 56–57. IEEE, Feb. 2012.
[6] A. Danalis, G. Marin, C. McCurdy, J. S. Meredith, P. C. Roth,K. Spafford, V. Tipparaju, and J. S. Vetter. The Scalable HeterogeneousComputing (SHOC) benchmark suite. In ACM International ConferenceProceeding Series; Vol. 425, 2010.
[7] P. Duhamel and M. Vetterli. Fast fourier transforms: A tutorial reviewand a state of the art. Signal Processing, 19(4):259–299, Apr. 1990.
[8] M. Frigo and S. Johnson. The Design and Implementation of FFTW3.Proceedings of the IEEE, 93(2):216–231, Feb. 2005.
[9] B. Gaster, L. Howes, D. R. Kaeli, P. Mistry, and D. Schaa. Heteroge-neous Computing with OpenCL. Morgan Kaufmann,2011, 2011.
[10] N. Govindaraju, B. Lloyd, Y. Dotsenko, B. Smith, and J. Manferdelli.High performance discrete Fourier transforms on graphics processors. In2008 SC - International Conference for High Performance Computing,Networking, Storage and Analysis, pages 1–12. IEEE, Nov. 2008.
[11] S. Hong and H. Kim. An analytical model for a GPU architecture withmemory-level and thread-level parallelism awareness. ACM SIGARCHComputer Architecture News, 37(3):152, June 2009.
[12] B. Jang, D. Schaa, P. Mistry, and D. Kaeli. Exploiting MemoryAccess Patterns to Improve Memory Performance in Data-ParallelArchitectures. IEEE Transactions on Parallel and Distributed Systems,22(1):105–118, Jan. 2011.
[13] K. Kasichayanula, D. Terpstra, P. Luszczek, S. Tomov, S. Moore, andG. D. Peterson. Power Aware Computing on GPUs. In Published atSAAHPC’12, 2012.
[14] M. Mantor and M. Houston. AMD Graphic Core Next, Low Power HighPerformance Graphics & Parallel Compute. AMD Fusion DeveloperSummit, 2011.
[15] A. Munshi. The OpenCL specification version 1.1 . Khronos OpenCLWorking Group, 2010.
[16] H. Nagasaka, N. Maruyama, A. Nukada, T. Endo, and S. Matsuoka.Statistical power modeling of GPU kernels using performance counters.In International Conference on Green Computing, pages 115–122.IEEE, Aug. 2010.
[17] J. Nickolls and W. J. Dally. The GPU Computing Era. IEEE Micro,30(2):56–69, Mar. 2010.
[18] A. Nukada, Y. Ogata, T. Endo, and S. Matsuoka. Bandwidth intensive
3-D FFT kernel for GPUs using CUDA. In 2008 SC - InternationalConference for High Performance Computing, Networking, Storage andAnalysis, number November, pages 1–11. IEEE, Nov. 2008.
[19] NVIDIA. CUDA programming Guide, version 4.2.[20] NVIDIA. Nvidia Management Library (NVML).[21] NVIDIA. Whitepaper on NVIDIA GeForce GTX 680. Technical report.[22] Nvidia. Cufft library, 2010.[23] J. D. Owens, M. Houston, D. Luebke, S. Green, J. E. Stone, and J. C.
Phillips. GPU Computing. 2008.[24] M. Pharr and R. Fernando. GPU Gems 2: Programming Techniques For
High-Performance Graphics And General-Purpose Computation. 2005.[25] B. Purnomo and T. Lead. OpenCL Application Analysis and Opti-
mization with AMD APP Profiler and Kernel Analyzer. AMD FusionDeveloper Summit, 2011.
[26] M. Rofouei, T. Stathopoulos, S. Ryffel, W. Kaiser, and M. Sarrafzadeh.Energy-Aware High Performance Computing with Graphic ProcessingUnits. In Proceedings of the 2008 conference on Power awarecomputing and systems, pages 11—-11. USENIX Association, 2008.
[27] S. Ryoo, C. I. Rodrigues, S. S. Baghsorkhi, S. S. Stone, D. B. Kirk, andW.-m. W. Hwu. Optimization principles and application performanceevaluation of a multithreaded GPU using CUDA. In PPoPP ’08:Proceedings of the 13th ACM SIGPLAN Symposium on Principles andpractice of parallel programming, pages 73–82, New York, NY, USA,2008. ACM.
[28] K. L. Spafford, J. S. Meredith, S. Lee, D. Li, P. C. Roth, and J. S. Vetter.The tradeoffs of fused memory hierarchies in heterogeneous computingarchitectures. In Proceedings of the 9th conference on Computing
Frontiers - CF ’12, page 103, New York, New York, USA, 2012. ACMPress.
[29] R. Suda and D. Q. Ren. Accurate Measurements and Precise Modelingof Power Dissipation of CUDA Kernels toward Power Optimized HighPerformance CPU-GPU Computing. In 2009 International Conferenceon Parallel and Distributed Computing, Applications and Technologies,pages 432–438. Ieee, Dec. 2009.
[30] P. N. Swarztrauber. Multiprocessor FFTs. Parallel Computing, 5(1-2):197–210, July 1987.
[31] K. H. Tsoi and W. Luk. Power profiling and optimization for hetero-geneous multi-core systems. ACM SIGARCH Computer ArchitectureNews, 39(4):8, Dec. 2011.
[32] http://code.google.com/p/simulation-opencl/source/checkout. FFT Al-gorithms in OpenCL.
[33] http://developer.apple.com/library/mac/samplecode/OpenCLFFT/Introduction. Apple Implementation of FFT using OpenCL.
[34] C. Van Loan. Computational Frameworks for the Fast Fourier Trans-form. Society for Industrial and Applied Mathematics, Jan. 1992.
[35] V. Volkov and B. Kazian. Fitting FFT onto the G80 Architecture, 2008.[36] S. Williams, A. Waterman, and D. Patterson. Roofline: an insightful
visual performance model for multicore architectures. Communicationsof the ACM, 52(4), 2009.





























