Embed Size (px)
Citation preview

Publish and SubscribeThe Information Bus®—An Architecture for Extensible Distributed Systems
Oki, Pfluegl, Siegel, Skeen. 1993.
Matching Events in a Content-based Subscription System
Aguilera, Strom, Sturman, Astley, Chandra. 1999.
Dan Sandler | COMP 520 | October 7, 2004

Distributed Systems in the Real World
So far: Tools for building distributed systems
Focused on certain problems Redundancy Distribution Marshalling and communication
Less attention paid to others Discoverable systems Maintainable, upgradeable systems

Generative Programming in Linda
Review: Linda Typed data organized
into tuples Stored indefinitely in
global “tuple space” Tuples requested by
partial specification Anonymous
communicationTUPLE SPACE

Problems in Tuple Space
Open Issues Unbounded storage
requirements of tuple space
Tuple contents weak on flexibility, metadata, discoverability
General tuple-searching can be complex, slow
TUPLE CLUTTER

Take-aways from Linda
The content itself connects senders to receivers
Participants have no other formal relationship
Let’s explore this model further
Publish and Subscribe
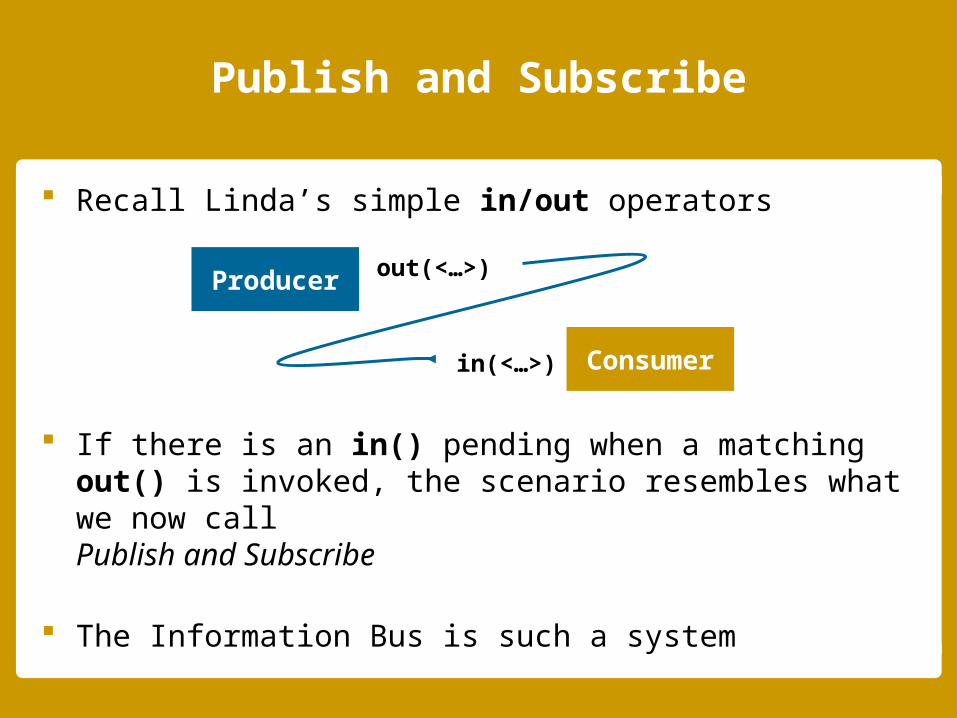
Recall Linda’s simple in/out operators
If there is an in() pending when a matching out() is invoked, the scenario resembles what we now call Publish and Subscribe
The Information Bus is such a system
Producer out(<…>)
Consumerin(<…>)

The Information Bus
Goal: develop real-time, “24/7” systems Circuit fabrication Securities trading systems
Specific requirements derived from these situations Continuous operation Legacy systems integration “Dynamic system evolution”

Evolution is hard
Capacity for change must be planned from the beginning
Systems may need to “evolve” in many ways New kinds of data New applications (services, clients) Fault recovery and scalability can be considered
evolution
Remember: Evolution must occur without interruption of service

Architecture of the Information Bus
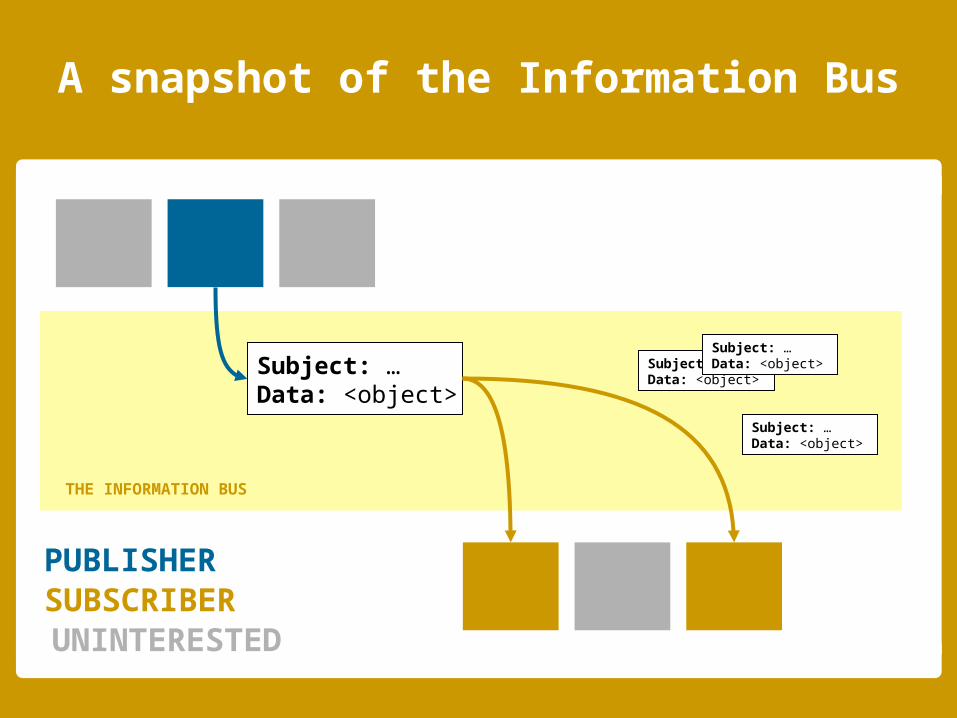
Clients may publish data objects under a specific subject
Clients may subscribe to one or more subjects to receive data
Note: The bus broadcasts all published data to all participating hosts
A snapshot of the Information Bus
Subject: …Data: <object>
THE INFORMATION BUS
SUBSCRIBERPUBLISHER
UNINTERESTED
Subject: …Data: <object>
Subject: …Data: <object>
Subject: …Data: <object>

Properties of the Information Bus
P1. Minimal core semantics Recall the “end to end argument” – complexity at a
low level is usually either insufficient…or overkill
Two styles of communication: Remote method invocation Publish/subscribe
Two kinds of objects: Data (things sent on the bus) Services and Clients (things that use the bus)

Properties of the Information Bus (cont.)
P2. Self-describing objects We might call this “introspection” today
Given an object, we can ask at run-time for object type, property types and values, method signatures, etc.
All participants and data play by these rules
Effect: loose coupling and run-time discovery

Properties of the Information Bus (cont.)
P3. “Dynamic classing” A fancy way of expressing the ability of the
system implementation to be changed at run-time
Without interruption of the system: New classes can be defined New code can be introduced
This is clearly necessary for evolvability

Properties of the Information Bus (cont.)
P4. Anonymous communication The hallmark of publish-and-subscribe
Data objects are sent and received based on content alone Details of the participants are irrelevant In this system, the content which controls
subscription is a “subject” string No other part of the data is involved in delivering the
object to subscribers Subjects typically organized with hierarchy
(cf. Usenet groups: rice.owlnews.comp520)

Other features of the Information Bus
What else is going on in the bus?
Object discovery
Point-to-point remote method invocation
Legacy data conversion
Discovery protocol
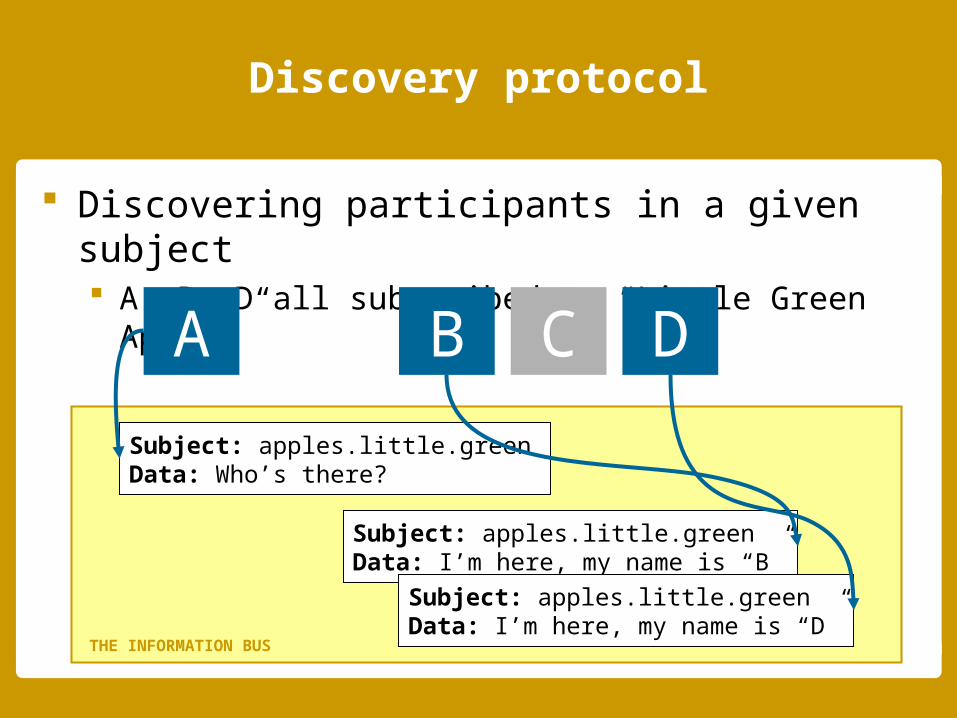
Discovering participants in a given subject A, B, D all subscribed to “Little Green Apples”
A B C D
Subject: apples.little.greenData: Who’s there?
Subject: apples.little.greenData: I’m here, my name is “B”
Subject: apples.little.greenData: I’m here, my name is “D”
THE INFORMATION BUS

RMI brokering
Finding a participant to invoke methods Like the discovery protocol
A B C D
Subject: apples.little.greenData: I want to make a method call.
Subject: apples.little.greenData: Sure, my address is “2”
Subject: apples.little.greenData: Sure, my address is “4”
THE INFORMATION BUS
1 2 3 4
Adapters
Subject: …Data: <object>
THE INFORMATION BUS
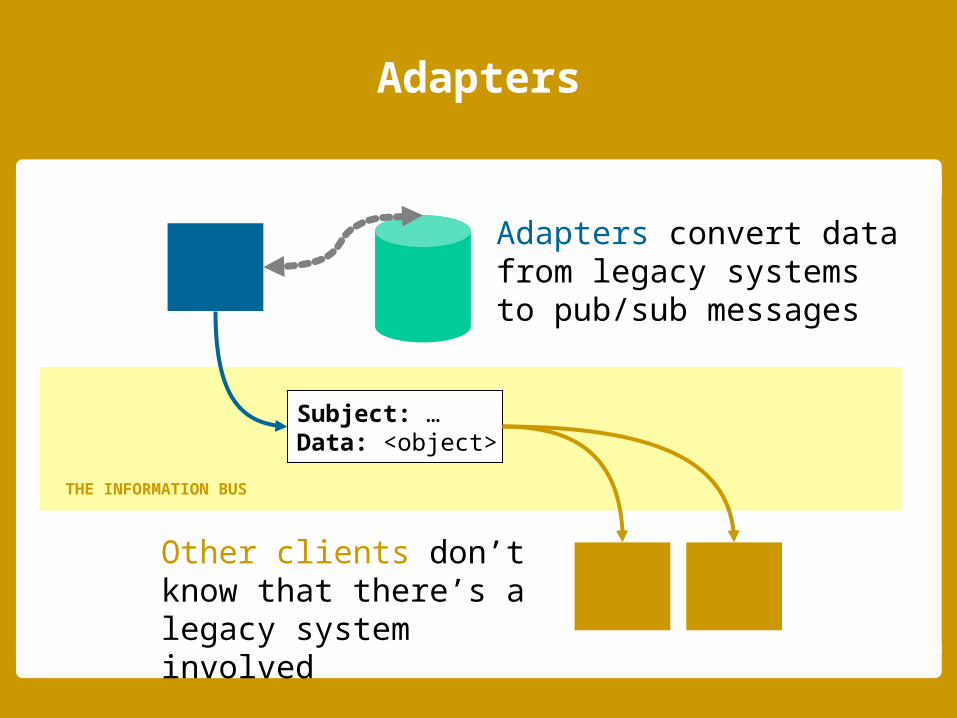
Adapters convert data from legacy systems to pub/sub messages
Other clients don’t know that there’s a legacy system involved

Dynamic System Evolution
New clients can be brought on-line at any time Subscribe to current subjects Publish objects of conventional type Publish objects of novel type and implementation Create new subjects for subscription
Existing subscriptions unaffected

Problems solved by the Information Bus
System is available, evolvable Maintenance may be performed on-line New services and clients can be rolled out
incrementally, without downtime
Is subject-based subscription a limitation? Simple subject easier to test than arbitrary tuple
signatures
Let’s look closer at this “matching problem”

Matching Events in a Content-based Subscription System
Scenario: The content-based pub/sub system
Like the Information Bus: subscriptions based on content, rather than a membership list
A participant has (potentially) many subscriptions
A participant receives (potentially) many “publications”

The Matching Problem
Each participant must test each event to see which subscriptions it matches
Attribute-based subscription model Each event may have multiple attributes, some or
all of which may be tested Example subscriptions:
Fruit=“apple”; Size=“little”; Color=“green”
Fruit=“apple”; Size=*; Color=“red” Fruit=*; Size=“little”; Color=*
* == “don’t care” (match anything)

The Matching Problem
Trivially, this problem is linear in the number of subscriptions
By adding multiple attributes, it’s now linear in the number of attributes too
Can we do better than the naïve matching implementation?

The Exact Attribute Problem
Consider a special case of this problem
Each attribute is to be matched exactly (Alternatives: substring match, lexicographic
comparison, etc.)

General algorithm
Pre-process all subscriptions into a “matching tree” Like a decision tree of attribute tests Goal: If multiple subscriptions have the same
attribute requirements, only test that attribute once for all subscriptions
Similar problem: matching multiple strings in text consider each char of each string an attribute
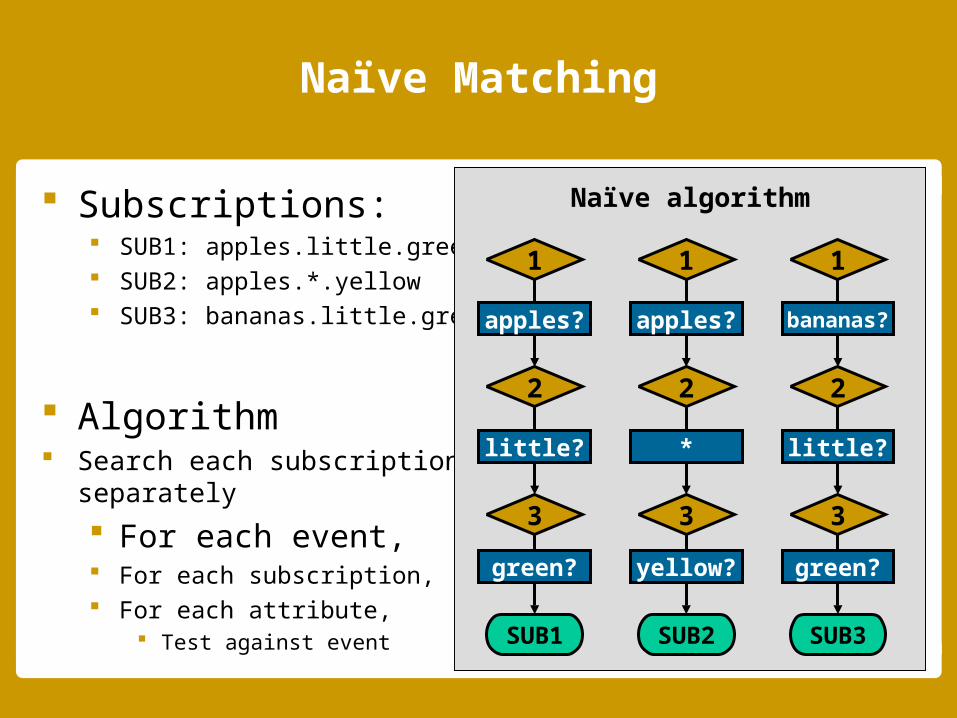
Naïve Matching
Subscriptions: SUB1: apples.little.green SUB2: apples.*.yellow SUB3: bananas.little.green
Algorithm Search each subscription
separately
For each event, For each subscription, For each attribute,
Test against event
Naïve algorithm
1
2
3
SUB1
apples?
little?
green?
1
2
3
SUB2
apples?
*
yellow?
1
2
3
SUB3
bananas?
little?
green?
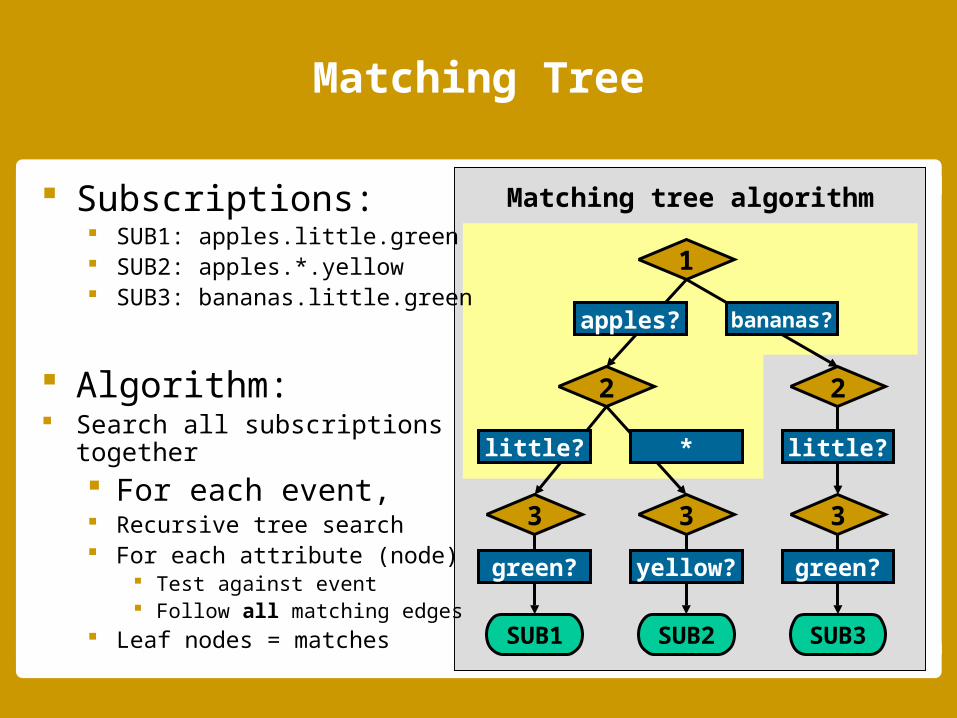
Matching Tree
Subscriptions: SUB1: apples.little.green SUB2: apples.*.yellow SUB3: bananas.little.green
Algorithm: Search all subscriptions
together For each event, Recursive tree search For each attribute (node)
Test against event Follow all matching edges
Leaf nodes = matches
Matching tree algorithm
2
3
SUB1
little?
green?
1
3
SUB2
apples?
*
yellow?
2
3
SUB3
little?
green?
bananas?

Complexity of the matching tree
Why is this better?
By inspection, the matching tree tends to have fewer tests than the trivial implementation
Fewer nodes, that is, assuming there’s some overlap in attribute values among your subscriptions
Still linear in number of subscriptions, however

Complexity of the matching tree (cont.)
Deeper insight
For the exact-matching problem, the number of branches you can follow is at most 2 i.e. some event’s attri = “X”; you can only follow “X”
and *
It gets better, however If there are no * subscriptions for attri, you will follow 0
or 1 branches Intuition: more like a traditional search tree

Complexity of the matching tree (cont.)
Time complexity shown to be O(N1-λ) (The expected complexity for random events) λ related to number of non-* edges in the
matched path; can be as high as ½ Intuition: the more exact tests there are, the
fewer branches you will follow
Other complexity characteristics Space complexity: linear Pre-computation: linear
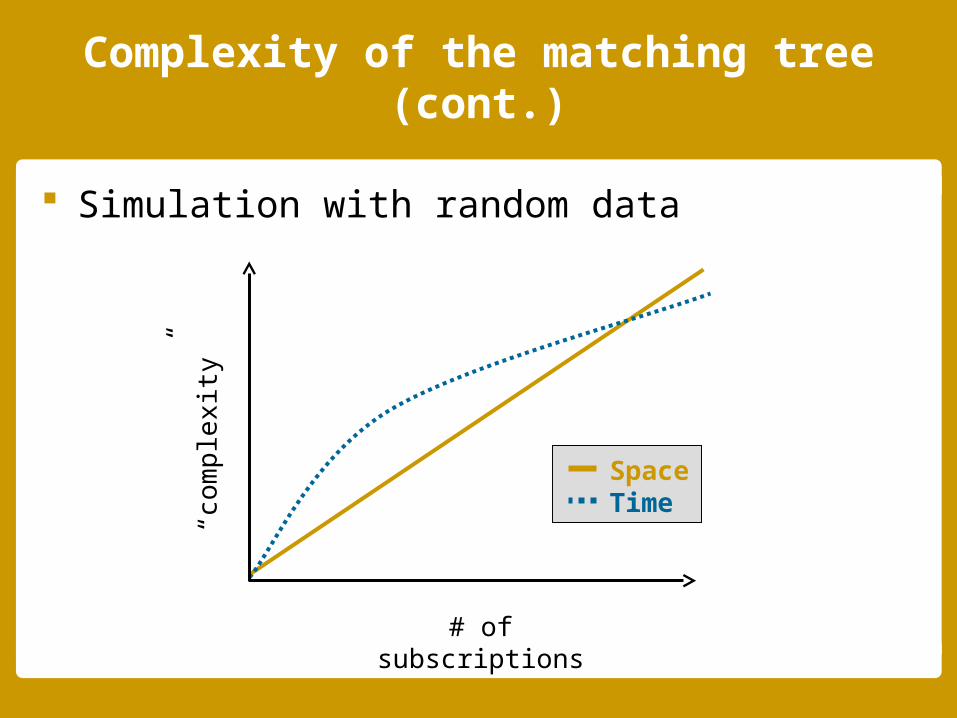
Complexity of the matching tree (cont.)
Simulation with random data
SpaceTime
# of subscriptions
“com
ple
xit
y”

Optimizations
Collapse multiple “don’t care” edges into a single edge Rationale: Many subscriptions “don’t care” about
most attributes of data (60% speedup in simulation)
Pre-compute “successor nodes” Short-circuit parts of the matching tree in special
situations
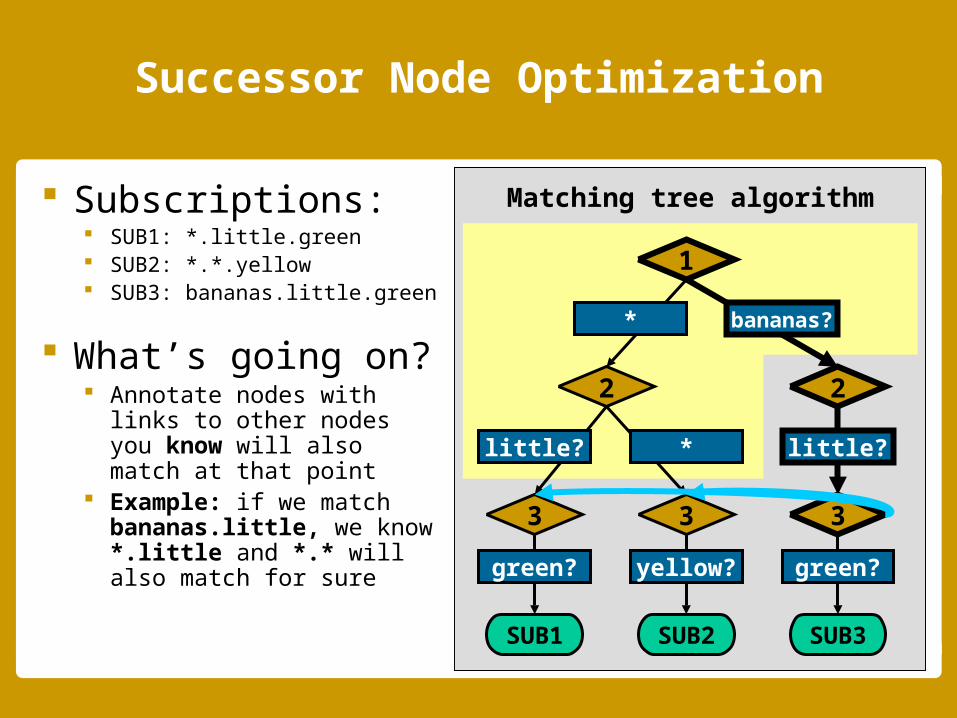
Successor Node Optimization
Subscriptions: SUB1: *.little.green SUB2: *.*.yellow SUB3: bananas.little.green
What’s going on? Annotate nodes with
links to other nodes you know will also match at that point
Example: if we match bananas.little, we know *.little and *.* will also match for sure
Matching tree algorithm
2
3
SUB1
little?
green?
1
3
SUB2
*
*
yellow?
2
3
SUB3
little?
green?
bananas?

Summary and Discussion
Publish/subscribe: participants connected only by exchanged data Flexible, loose connections — an evolvable system No Linda-like storage
(but you could implement a storage service in a pub/sub system)
So what about the matching problem? It only exists in broadcast pub/sub
Each participant sees each event Question: Is this realistic?
Trend: multicast instead of broadcast Subscription lists — more administration, but potentially
better publication performance P2P?





























