Embed Size (px)
Citation preview

Provably Secure Competitive Routing against Proactive Byzantine
Adversaries via Reinforcement Learning
Baruch Awerbuch David Holmer Herbert Rubens∗
Abstract
An ad hoc wireless network is an autonomous self-organizing system of mobile nodes connected by wire-less links where nodes not in direct range communicatevia intermediary nodes. Routing in ad hoc networks is achallenging problem as a result of highly dynamic topol-ogy as well as bandwidth and energy constraints. TheSwarm Intelligence paradigm has recently been demon-strated as an effective approach for routing in smallstatic network configurations with no adversarial inter-vention. These algorithms have also been proven to berobust and resilient to changes in node configuration.However, none of the existing routing algorithms canwithstand a dynamic proactive adversarial attack, wherethe network may be completely controlled by byzantineadversaries.
The routing protocol presented in this work at-
tempts to provide throughput competitive route selec-
tion against an adversary which is essentially unlimited;
more specifically, the adversary benefits from complete
collusion of adversarial nodes, can engage in arbitrary
byzantine behavior and can mount arbitrary selective
adaptive attacks, dynamically changing its attack with
each new packet. In this work, we show how to use
the Swarm Intelligence paradigm and Distributed Rein-
forcement Learning in order to develop provably secure
routing against byzantine adversaries. A proof of the
convergence time of our algorithm is presented as well
as preliminary simulation results.
1 Introduction
The motivation for this work is to design ro-bust routing for wired overlay networks or mobilead hoc wireless networks (MANET’s). Althoughrouting in ad hoc wireless networks has unique as-pects, many of the security problems faced in ad
∗Authors are with the Computer Science Department,Johns Hopkins University, Baltimore, Maryland. baruch,dave, [email protected] Technical Report 5/16/2003.
hoc routing protocols are similar to those faced bywired networks. Wireless security issues are moreacute, due to the inherent vulnerabilities of a wire-less environment and are the focus of this paper;however our ideas are applicable to wired overlaynetworks as well.
In general, routing protocols are susceptible toa wide variety of attacks. A malicious node mayadvertise false routing information, try to redirectroutes, or perform a denial of service attack byengaging a node in resource consuming activitiessuch as routing packets in a loop. Furthermore,due to their cooperative nature and the broadcastmedium, ad hoc wireless networks are more vul-nerable to attacks in practice [27].
A great deal of work has been done in termsof guaranteeing practical security considerations inexisting network protocols. In practice, adversarialattacks observed and documented in ad hoc net-works might not be overly sophisticated. The easeof access to the medium has allowed extremely ba-sic attacks to cause a great deal of damage. Con-sequently, such attacks can be thwarted by simpleyet effective methods. For example: a mis-routingattack can be easily detected by authenticating thepacket path; consistent traffic blocking can eventu-ally be detected; a single adversary that does notcollude can be detected by its neighbors; trustedservers or sensors an be used to monitor truth-fulness of link state databases, etc. For each ofthese important special cases, a lot of great workwas done, which is extremely important in prac-tice. However, existing work does not come any-where close in either addressing the sophisticatedattacks arising in our dynamic adversarial model,or attempting to prove analytical bounds on packetloss.
Our Contribution: The goal of this paper is todesign an on-demand flooding-free routing proto-col in a dynamic byzantine adversarial environ-
1

ment. We propose a generic framework for rout-ing protocols which are appropriate for networksoperating under this extremely strong adversarialmodel. Such strong models have not been consid-ered in the literature to the best of our knowledge.In fact, one does not even need to consider the fullpower of byzantine attacks. Even relatively benignadaptive dynamic denial of service attacks are al-ready sufficient to break most existing algorithmicwork. (In section 2.6, we briefly describe why DOSattacks are so devastating.)
What is remarkable about our result is the abil-ity to prove near-optimality bounds under com-pletely arbitrary adversarial behavior, with es-sentially no assumptions about either the net-work, or the underlying security infrastructure.We use techniques similar to the “Swarm Intel-ligence” and Distributed Reinforcement Learningparadigm. Swarm Intelligence is a set of learningand biologically-inspired approaches to solve hardoptimization problems using distributed coopera-tive agents. Motivation comes from work whichexplored the behaviors of ants and how they coor-dinate each others selections of routes based on apheromone secretion.
As in [50], one can imagine a model of net-work routing, such that the network is populatedby artificial ants (packets) that make use of thetrail laying principle; at each node an ant encoun-ters on the journey to its destination, it leaves anamount of pheromone which evaporates with time,but is an increasing function of the frequency oftraversal of that location. The ant then selects thenext node on its journey on the basis of the localpheromone distribution [50]. The routing decisionis determined by these pheromone distributions.
In our Byzantine routing approach, we act sim-ilarly: the process of route detection and faultavoidance is carried out by a distributed processof “learning” fault free paths, in spite of deceptivetechniques pursued by adversaries. The routingprocess creates and adjusts a probability distribu-tion at each node for the node’s neighbors. Theprobability associated with a neighbor reflects therelative likelihood of that neighbor forwarding andeventually delivering the packet to the destination.
It may appear that our Byzantine-inspired rout-ing model may lead to impractical algorithms intypical (non-Byzantine) settings. However, ant-
inspired routing algorithms were developed andtested in real network environments by BritishTelecomm and NTT for both wired and wirelessnetworks with superior results [13, 56, 18, 14, 48,50, 11, 21]. AntNet, a particular such algorithm,was tested in routing for data communication net-works [13]. The algorithm performed better thanOSPF, distributed Bellman-Ford with various dy-namic metrics, and various modifications of short-est path with a dynamic cost metric [9, 48].
2 Network and Security Model
In the following section we describe both our net-work and security models and any assumptionsthat we make. We also fully explain the adversarialmodel that we consider in this work and the chal-lenges to mitigating the adversarial threats fromboth an algorithmic and security stand point.
2.1 Network Assumptions
Bi-directional communication channels.Our protocol does not require bi-directionalcommunication on all links in the network, but itwill seek only bi-directional routes from sendersto receivers. Bi-directional communication is alsoa requirement of most wireless MAC protocols,including 802.11 [2] and MACAW [10]. We focuson providing a secure routing protocol, whichaddresses threats to the ISO/OSI network layer.
No knowledge of the network topology. Asmentioned before, topology databases may be com-pletely corrupt. We only assume that nodes thatjoin the network flood their authenticated identitythru the whole network, so each node knows thepotential “membership” in the network.
We do not specifically address attacks againstlower layers. For example, the physical layer canbe disrupted by jamming, and MAC protocols suchas 802.11 can be disrupted by attacks using thespecial RTS/CTS packets. Though MAC proto-cols can detect packet corruption, we do not con-sider this a substitute for cryptographic integritychecks [55]. While our protocol is not trying toprevent any of these attacks, it should be able toovercome such attacks.
2

2.2 Security Assumptions
Authentication and Symmetric Crypto-graphic Primitives. We assume existence ofefficient cryptographic primitives. This requirespairwise shared keys between the sender and othernodes in the network 1 which are establishedon-demand. The public-key infrastructure usedfor authentication can be either completely dis-tributed (as described in [29]), or Certificate Au-thority (CA) based. In the latter case, a dis-tributed cluster of peer CA’s sharing a commoncertificate and revocation list can be deployed toimprove the CA’s availability. However, the issuesof establishing authentication mechanisms are be-yond the scope of this paper.
No trusted parties assumed. This work doesnot assume the existence of any trusted servers orrouters. In this work we consider only the sourceand the destination to be trusted. The only as-sumption is that any intermediate node on thepath between the source and destination can beauthenticated and can participate in the protocol.Nodes that can not be authenticated do not par-ticipate in the protocol.
2.3 Considered Attacks
Even authenticated nodes may exhibit byzantinebehavior at times. The goal of our protocol is notto explicitly detect byzantine behavior (which isessentially impossible) but rather to avoid byzan-tine participants in such a way that the trafficlosses are nearly optimal.
We define byzantine behavior as any action byan authenticated node that results in disruptionor degradation of the routing service. We assumethat an intermediate node can exhibit such behav-ior either alone or in collusion with other nodes.More generally, we use the term fault to refer toany disruption that causes significant loss or delayin the network. A fault can be caused by byzan-tine behavior, external adversaries, lower layer in-fluences, and certain types of normal network be-havior such as bursting traffic.
1We discourage group shared keys since this is an invi-tation for impersonation in a cooperative environment.
An adversary or group of adversaries can inter-cept, modify, or fabricate packets, create routingloops, drop packets selectively (often referred toas a black hole), artificially delay packets, routepackets along non-optimal paths, or make a pathlook either longer or shorter than it is. All theabove attacks result in disruption or degradationof the routing service. In addition, they can induceexcess resource consumption which is particularlyproblematic in wireless networks.
One strong attack, referred to as a wormhole[28], is where two attackers establish a path andtunnel packets from one to another. Our proto-col addresses this attack by treating the worm-hole as a single link which will be avoided if it ex-hibits byzantine behavior, but does not prevent thewormhole formation. Also, we do address tradi-tional denial of service attacks which are character-ized by packet injection with the goal of resourceconsumption. The following Section 2.4 providessystematic description of all attacks handled.
2.4 Adversary models overview
We now provide the list of all the possible adver-sarial models captured by our work. We wouldlike to classify adversaries based on a number ofdimensions. In each dimension, we rank the ad-versaries based on its power. We then address theadversary which is the “strongest” in each dimen-sion. No prior work provided a bounds on packetsloss under such a stringent adversarial model.
Malignancy of the attacks. A benign adver-sary can drop packets, e.g. exercise a remote De-nial of Service (DOS) attack, but cannot infiltraterouters and cannot not engage in active attackssuch as modifying or mis-routing (tunnelling) mes-sages or acknowledgements.
Static malicious adversary is the next level up inthe adversarial hierarchy. This class of attacks al-lows the adversary to permanently control a staticsubset of the routers. An adversarial network node(router) may employ the following attacks:
• Libel: assigning the blame to its neighbors forthe failure to transmit or receive packets.
• Impersonation: pretending to be somebodyelse.
3

• Mis-routing: sending a message in the wrongdirection.
• Topology-distortion: incorrectly advertisingtopology information to draw traffic into it-self (dropping it later).
• Ack-distortion: attempting to send fake ac-knowledgements to confuse the protocol
and, basically do anything else an adversary canthink of to confuse and disrupt routing algorithm.
Proactive malicious adversaries: is the ultimateadversary that we would like to confront. It maytake control of different routers at different times,getting in and out, completely at will, in spiteof these routers being previously authenticated.While a router or edge is “possessed” by an ad-versary, it executes any of the byzantine or DOSattacks above.
Collusion power of adversary. The easiestcase involves no collusion: each adversarial routeracts on its own. The hardest possible case thatwe would like to handle in this paper is completecollusion: all adversarial routers act as a team, en-gaging in simultaneous collusion with other routerswhich are under adversarial control (e.g., enabling“tunnelling” or “wormhole” attacks, as well as“switching blame” between compromised routersfor the purpose of avoiding detection.)
Adaptivity/Intelligence of the adversary.The easiest model is that of a completely staticadversary. This adversary designs a static faultpattern ahead of time, while knowing the algo-rithm, but without knowing any coin flips usedby the algorithm. It applies some pattern of at-tacks to all the packets on a given router (edge).It completely destroys all static deterministic orrandomized algorithms, such as min-hop routingpath, random path, random selection among alledge-disjoint paths, etc.) However, some of theexisting work on byzantine routing handles suchan adversary, e.g, [7].
Oblivious dynamic adversary designs a dynamicfault pattern ahead of time, with full knowledge ofthe routing algorithm, but without knowledge ofany coin flips used by the algorithm. It applies thesame attacks to all the packets on a given router
(edge). This adversary can completely destroy anydeterministic routing algorithm e.g, [7], that at-tempts to collect traffic statistics and choose thenext path based on lowest fault rate on previouslysampled paths, e.g., RON [5]. The only known al-gorithm that can succeed against this type of ad-versary is a “learning” style algorithm as in [8];however it only works for DOS attacks and fails inthe case of byzantine behavior.
Adaptive adversary adapts the fault patternbased on the past, after gaining full knowledge ofall past decisions, including the past coin flips usedby the algorithm. It applies same attacks to allthe current packets on a given router (edge). Thistype of adversary will destroy all existing routingalgorithms including [8].
Adaptive selective adversary is the ultimate ad-versary that we would like to consider in this pa-per. This type of adversary selectively attackspackets on a given router (edge). This adversarybenefits from knowledge of the traffic pattern (in-cluding packet contents) in all compromised andand non-compromised routers; this includes allcurrent traffic and all past traffic history
2.5 System and Security challenges
Authentication is of little use. Although onemight assume that, once authenticated, a nodeshould be trusted, there are many scenarios wherethis is not appropriate. For example, when ad hocnetworks are used in a public Internet access sys-tem (airports or conferences), users are authenti-cated by the Internet service provider, but this au-thentication does not imply trust between the in-dividual users of the service. Also, mobile wirelessdevices can be more easily compromised (e.g. lackof physical security), so complete trust should notbe assumed. Thus, we focus on providing routingsurvivability under a dynamic “proactive” [22] ad-versarial model, where dynamically changing sub-sets of intermediate nodes can perform arbitrarybyzantine attacks such as creating routing loops,misrouting packets on non-optimal paths, or se-lectively dropping packets (black hole). Only thesource and destination nodes are assumed to betrusted.
4

Maintaining link-state databases is expen-sive and not useful. While this sounds counter-intuitive, the standard proactive “link-state” rout-ing model, where topology updates are beingbroadcast through the network, is not applicable tothis type of byzantine setting. Indeed, nothing pre-vents byzantine nodes from claiming perfect con-nectivity with every node in the network and thencompletely destroying all traffic. It is provablyimpossible under certain circumstances, for exam-ple when a majority of the nodes are malicious,to attribute a byzantine fault occurring along apath to a specific node, even using expensive andcomplex byzantine agreement. Consequently, thetopology database used in link state methods can-not be trusted and, strictly speaking, is useless inthis context.
On-demand operation needed. On-demandrouting protocols [44, 30, 7] are an attractive al-ternative since such protocols can test the reliabil-ity of network components based on actual traffic.They are also attractive, regardless of trust issues,for wireless environments because they initiate aroute discovery process only when data packetsneed to be routed, thus saving energy in the un-used areas of the network. Discovered routes arethen typically cached until they go unused for aperiod of time, or break as a result of topologychanges.
Flooding should be avoided. One unattrac-tive feature of on-demand protocols [44, 30, 7]is the occasional flooding of broadcast messagesthrough the entire network in order to discoverroutes from the sender to the receiver. In net-works with infrequent traffic or low mobility thecost of an on-demand flood is extremely small com-pared to the constant overhead of link-state up-dates. However, it would be extremely desirable toeliminate flooding altogether from on-demand pro-tocols; we will refer to such solutions as flooding-free.
2.6 Algorithmic challenges
Past performance is no guarantee of futuresuccess. The problem is that we are making de-cisions “online”, where the online algorithm needs
to service requests by selecting actions while hav-ing only information regarding past requests, andno (or very limited) information regarding the fu-ture requests. There are no stochastic assump-tions about the way the adversary is acting or thesequence of fault patterns generated. Moreover,it is also assumed that there is a powerful adver-sary that generates the worst input sequence forthe online algorithm. A fundamental question re-garding online algorithms is how to evaluate theirperformance. It is rare, and in some cases outrightimpossible that one deterministic algorithm alwaysoutperforms another deterministic algorithm. Oneclassical method has been to assume a stochas-tic model regarding the environment, and com-pare the performance of different algorithms on thesame model. However, in an adversarial setting,there is no reason why the adversary should fol-low the rules of the stochastic model we invented- if anything, the adversary will do exactly the theopposite of what our model would predict. (Thereis no reason to hope that the adversary will notknow our model.)
One may be tempted to think that converging tothe best fixed route may be easily accomplished byutilizing a “greedy” heuristic: keep track of pasterror rates on different links, and simply select thepath with the smallest overall failure rate, namelythe sum of the failure rates of its links. For exam-ple, existing work on routing in overlay networks,such as RON [5] runs a greedy strategy of windowsof a specific size. The intuition is very strong:extrapolate the past failure pattern into the fu-ture. This may work if failure pattern is staticor if there is a statistical model of failures. How-ever this method fails quite spectacularly in thecase of dynamic adversaries. For example, con-sider 100 options of choosing a relay point betweenthe sender and receiver, which define 100 differentpaths. At time i path i (modulo 100) is undercontrol of the adversary, and is failing all pack-ets; at all other times the path is perfect. Thegreedy algorithm will always pick the worst path,even though at any moment in time only 1% of thepaths are faulty.
To see the principle flaw in this greedy strategy,consider the performance of an investor who triesto follow the best performing stock on the stockmarket, with the naive assumption that “past per-
5

formance is a guarantee of future results”. In fact,in an adversarial setting, e.g., the stock market, itmay very well be the case that past performancecorrelates negatively with future results, and algo-rithms must not be fooled into this easy trap.
Our path selection must withstand compet-itive analysis. In general, there may not be anideal fault-free path, but yet there may be the bestpath in terms of accumulated loss on that path.Our goal is to make path selections, such that ouroverall performance is comparable to that of the“best path”.
Our goal is thus to find a robust randomizedalgorithm that works well on all inputs, in thesense that the expected behavior of our algorithmis comparable to the optimum fixed path on eachinput. Our goal is to design a distributed algo-rithm for sending messages on paths with the over-all smallest loss ratio. The contribution of thispaper is a novel distributed algorithm for routeselection and its proof of optimality in the sensethat the total number of messages lost in our algo-rithm exhibits a very small additive gap with op-timum prescient route assignment. The optimumassignment is made with complete knowledge ofadversary actions, in the past, current, and future,and has infinite computational power. The onlyrestriction on the optimum route is that it mustchange somewhat less frequently.
The loss of performance of the algorithm that weare seeking should be based on competitive analy-sis [51]. We compare the performance of our onlinealgorithms to the best static offline. Namely theoffline algorithm selects a fixed path and uses itduring all time steps. Our results bound the dif-ference between the cost of the best static offlineand our online algorithms. This difference is alsoreferred to in the learning literature as regret.
For example, consider a wireless network withpotentially 200 users, around 1000 potential wire-less links and a guarantee of existence of one fixedpath of 7 hops between sender and receiver thathas an average link fault rate of 0.01 %, i.e. 99.99%of the time the whole path is reliable. The onlyproblem is selecting one out of around 2007 pos-sible paths, while only having information aboutpast experiments over these paths. In this case,one can construct a counter-example in which
greedy may never succeed in delivering a singlemessage, i.e. has a 100% fault rate, in spite ofthoroughly selecting the best of the 2007 paths sofar! The explanation to this counter-intuitive factis that any deterministic algorithm can be easilyfooled by an adversary, forcing it to pick the cur-rently worst path that always fails.
In contrast, the “competitive” randomized algo-rithm that we are seeking should be able to “zeroin” on the reliable path, or at least get comparableperformance. The algorithm we are seeking shouldguarantee, for any adversarial behavior (subjectto the adversary’s “pledge” to keep some path oflength 7 hops being 99.99% reliable on each link), afault rate of just below 7 ·0.01% = 0.07% over longsequences (this is averaged over the coin tosses ofour algorithm).
Randomness is not a guarantee of success.Another “quick fix” is to try to select a randompath. There is a misconception in the communitythat selecting one of many node-disjoint paths, orselecting a random path will somehow guaranteesuccess. (The stock-market equivalent of this be-lief is asserting that a stock index such as the NAS-DAQ 100 cannot go down by much.) There issomething appealing about random strategies inthe sense that they allow the spreading of risk;what is wrong with the above quick fix is that thereis no attempt to adapt the probabilities. In fact, itis easy to generate counter-examples to either oneof these policies. For example, consider a faultyedge leading into a dense subnetwork; generatingpaths at random pretty much guarantees hittingthis faulty edge.
Multiple paths do not guarantee success.In has been generally recognized that sendingpackets along “multiple paths” is more “fault-tolerant” than sending packets over a single path.However, it is easy to come up with a exampleinvolving a collection of edge-disjoint paths (e.g.,disjoint paths in an expander where the error prob-ability is constant) such that each path has at leastone fault, and yet a random path is likely to nothave any fault with high probability.
6

2.7 Contribution of this paper
General statement. The main result of this pa-per is a routing protocol that combines all the fol-lowing features:
• on-demand operation: energy is not wastedlearning/maintaining topology informationfor the areas which are not affected, or whilethere is no traffic in the network.
• flooding-free routing: no flooding is takingplace even during heavy traffic. Each packetis sent over a selected path of certain boundedlength to its destination.
• near-optimum loss: for every adversarial pat-tern our algorithms achieves near-optimal losson that sequence.
The routing protocol presented in this work at-tempts to provide throughput competitive routeselection against an adversary which is (essen-tially) not limited; more specifically, the adver-sary benefits from complete collusion of adversar-ial nodes, can engage in arbitrary byzantine be-havior and can mount arbitrary selective adaptiveattacks, dynamically changing its attack with eachnew packet.
It appears from the description of the model thatno possible solution exists against such a strongadversary. Indeed our model does allow the ad-versary to compromise the whole network. Now,once the adversary is completely in control of ev-erybody, it appears that our algorithm cannot pos-sibly accomplish any packet deliveries. If the ad-versary wiped out the whole network than surelythe failure to communicate is not being attributedto a naive routing algorithm, but rather to theinformation-theoretic inability to accomplish com-munication by any algorithm. In this case, our al-gorithm should be “off the hook”. More dangerousto us are situations where a “post-mortem” anal-ysis indicates that it was indeed possible to routethe messages by a “reasonable benchmark” strat-egy, but our algorithm in fact failed to match theperformance of such reasonable strategy in termsof overall packet loss.
Quantitative definition of optimality. Infor-mally, we pick as a benchmark a fixed strategy
(best fixed path) that knows the pattern of the at-tack of the dynamic adversary, and has optimizedits selection in advance. In fact, a stronger versionof our results can be proved, by picking a some-what stronger dynamic benchmark, which will infact be allowed to change, albeit less frequentlythan the algorithm (this is described below). Westill need to formally define the “best path”.
Definition 2.1 We consider a path to be instanceoptimal if, for a given schedule of adversarial infil-tration/attacks on routers/network edges, proces-sors, it minimizes, among all possible paths, theaverage number of faults, attacks, message dis-tortions or other adversarial action on a packet’spath. Let this sum be the called hypothetical lossof a path.
Definition 2.2 The Hypothetical regretof a rout-ing strategy is the worst case normalized difference,over all possible adversarial actions between thefollowing two factors:
• the actual loss of our routing strategy, and
• the above hypothetical loss of instance-optimal path.
Notice that the benchmark strategy and ourstrategy are both evaluated on the same input in-stance, namely the particular instance of adversar-ial behavior. The difference is that our algorithmdoes not know the adversarial behavior, while thebenchmark strategy was custom-tailored for thisinstance.
Our algorithm is outlined in Sec. 3 and formallydescribed in section B. The following theorem isan informal statement of Thm. A.1.
Theorem 2.3 For all ε > 0, the algorithm accom-plishes regret upper-bounded by ε.
Extension to dynamic benchmarks. Thestatement of Thm. 2.3 can be strengthened todynamic benchmarks. Let us make the followingnotations: E is the set of the edges in the net-work, and εsa is an arbitrarily chosen constant, dis degree of the network, and H is the length ofrouting paths being considered, and εsa, εex is the
7

error tolerance parameters that we choose (e.g,,εsa = εex = 0.01).
More precisely, we will allow our dynamic bench-mark to change every τben = T·τpha packets, where
τpha = Ω(|E|
εsa) and T =
H2
εex2· log d.
In contrast, our algorithm will changes its policyeach τpha packets. In other words, we expect ouralgorithm to “learn” the best path after T phases,each phase lasting τpha packets. Consider a sched-ule of possessed processors (i.e., a time-table in-dicating at which time each router is being pos-sessed), which is unknown to our routing strategy,but may be known to somebody else. The state-ment of Thm. 2.3 applies in this case as well.
3 Major ideas of our algorithm
The algorithm we present is executed at eachsource node with respect to a specific destination.The actual data packets are source routed and thesource route is protected using an onion encryp-tion technique described in Section 4. Every sourceis maintaining its own graph and probabilities ofreaching specific destinations. This information isnot shared between nodes because of the byzan-tine adversarial model which is assumed. Sourcenodes only rely on other nodes in the network toforward packets and return acknowledgments. Itis also assumed that the nodes may choose notto forward the packets or not to return acknowl-edgements and the source adjusts its probabilitydistribution accordingly. It is important to notethat this approach does not rely on intermediarynodes to make hop by hop routing decisions as inother approaches, since those approaches are sureto fail under this strong model. The following de-scription provides an overview of the major ideasof our algorithm.
The main idea of this algorithm is the use of a“Distributed Reinforcement Learning” technique.Specifically, each node is attempting to pick a par-ent edge towards the source. The set of all parentedges forms a tree rooted at the source. The pack-ets are sent on the unique path in this tree from thesender (the root) to the receiver, and are being ac-knowledged by the receiver. However, a potentialfailure may decompose the path into two parts:
the part closest to the source that succeeded toacknowledge the packet, and the rest of the paththat failed to return an acknowledgement. We nowadjust the choice of parent edges as follows. Thepart of the path that succeeds in acking reinforcesits confidence in the parent, while the other part ofthe path reduces its confidence. The parent will bechosen probabilistically based on the confidencesacquired.
The intuition is that confidence in the parentreflects not only the reliability of the link betweenchild and parent, but also the fact that the parentis “intelligent” enough to pick the right (grand)-parent. In this context, there is no way to distin-guish byzantine nodes from nodes that are unluckyin choosing their parent. Notice that by authenti-cating all messages, byzantine nodes are limited intheir ability to mislead the source since some edgecontrolled by the adversary must be exposed to thesource, each time an edge fails. The adversary canchoose not to expose itself, and indeed this compli-cates the proof somewhat. We need to show thatthe adversary has nothing to gain from taking con-trol of an edge, and then not killing packets on thisedge. By using a probabilistic distribution over theparent edges we generate a probability distributionover all source-rooted trees, such that probabilityof each tree is growing exponential in its perfor-mance. This discriminates edges controlled by theadversary, and “reinforces” edges where the adver-sary is absent. More intuition can be obtained bywork on non-stochastic multi-armed bandit [6] andits distributed analog in [8].
We outline below the main components of ouralgorithm, postponing formal presentation to Sec-tion B and its proof to section C.
Transforming a graph into a layered di-rected graph. Without loss of generality, we as-sume that we can transform the original undirectednetwork graph (e.g., see Fig. 1) into a directedlayered graph, with the receiver being in layer 0of this graph (Fig, 2). All the nodes that can po-tentially reach the receiver in i hops (or less), for0 ≤ i ≤ H are represented in layer i of the graph.Here H is the upper bound on hop count of a rout-ing path. The directed edges connect these repre-sentative nodes in layer i to representative nodesin layer i − 1. If the topology of the graph is not
8

s
a
r
b
c
Figure 1: The original network.
s3 s2
c3
a3 a2
b2
s4 s1
c1
r0
Figure 2: Layered graph w.r.t. receiver r (in layer0).
known, the assumption is that the topology of thegraph is full interconnection, in which case all thenodes have representatives in all the layers. If thetopology is partially known, then a node may stillhave representatives in more than one layer.
In order to get an intuition of our algorithm, it iseasiest to imagine the original graph as a layeredgraph with respect to the destination. However,our algorithm and claims of optimality do applyfor any graph. (See Section B.1.)
Establishing a feedback mechanism forthe packets. We request that each packet beacknowledged using a secure acknowledgementscheme by the destination. The adversary can def-initely interfere with either the packet or the ackpropagation process. However, any adversarial ac-tion can be summarized as follows: the source hasreceived an ack from some intermediate node, indi-cating the first parent edge on the path (we call itthe separator that appears to have failed. All theedges leading to parents on the path from senderto receiver prior to the separator are called lucky.All the edges leading to parents on the path from
sender to receiver beyond the separator edge arecalled unlucky. (See Sec. B.2.)
Quantitatively ranking the incoming edges.Imagine that instead trying to optimize the processof the source trying to reach destination, we try tooptimize the process of all the nodes in the networksending ack packets (“ants”) trying to reach thesource in the reverse direction of the edges. Eachnode will be selecting this best edge on its pathtowards the sender. Let us call such edge a “parentedge”. The set of parent edges forms a routing treerooted at the source. Routing from source to thedestination is performed over the tree from its root(source) towards the destination, from parents totheir children on the path.
As in [8], the nodes rank their adjacent edgesbased on the percentage of “luck” they bring.The greedy strategy (which does not work) wouldbe picking edges in decreasing order of luckiness.However, picking edges based on the exponent ofluckiness, say βx, where β < 1 is a small number,and x is luckiness percentage, will essentially yieldoptimal performance. The value of β is crucial forthe performance of our algorithm. Low values of βresult in our decision sequence resembling that ofthe greedy algorithm, and thus will be vulnerableto adversarial attacks. On the other hand, valuesof β which are close to 1 will cause the algorithmto respond slowly to changes. The optimal valueof β can be determined using the “best expert”framework of [33, 15]. (See Sec. B.3.)
Final policy: distribution over outgoingedges. Our final policy is determined by eachnode making a probabilistic decision on an out-going edge, selecting the edge which has the bestchance of reaching the receiver. Our policy will dis-criminate packets based on the packet’s hop count.The routing policy is maintaining a “time-to-live”count c, initially set toH. When the packet arrivesat a node v with hop count c, the receiving node vdecrements c by 1, and then chooses the probabil-ity distribution over its outgoing edges. The ideais to set the probability over the outgoing edges toemulate the probability distribution over incom-ing edges defining a probability distribution of di-rected rooted trees, with the source being the rootof each tree. While this provides a route towards
9

the source, we want to route towards the receiver.
However, to formally specify the routing func-tion from the sender to the receiver, we need todefine a probability distribution over the outgoingedges of each node. Routing works as follows: startat the source and iteratively pick an outgoing edgefrom the current node according to the prescribededge probabilities until the sink is reached.
One might think that the same probabilities as-signed to incoming edges can not be used for goingin the opposite direction, which is definitely incor-rect. This transformation from incoming to outgo-ing probabilities is performed via matrix multipli-cation, similar to Bellman-Ford algorithms. Thisalgorithm is called the Weight Pushing algorithm.It was developed by Mehryar Mohri in the contextof speech recognition [39], and used in this contextin [58]. (See Sec. B.4).
Sampling unexplored territory. A subtle butimportant component of the algorithm is its abil-ity to sample edges in the network, since thisis the only way it is able to detect changes inthe adversarial fault pattern, and to sample rela-tively “stale” portions of the network. This meansthat the algorithm is occasionally (and probabilis-tically) deviating from the optimal routes in orderto make sure that feedback is obtained from eachedge in the network. This is reminiscent of theclassical multi-armed bandit algorithms in [6] andits extension to network routing in [8], but our im-plementation here is quite different.
This deviation is accomplished by forcing the al-gorithm to pass, with small probability, which iscompletely under our control, over a completelyrandom edge, using a different set of outgoingprobabilities. This set of probabilities is computedvia the same Weight Pushing algorithm, but start-ing with the edge being sampled as the sink, andmoving back towards the source. Once we cross theedge, we start moving towards the receiver withthe usual outgoing probabilities.
Let us give some intuition on why this is de-sirable. By allowing β to be small the algorithmwill move quickly to the least fault path, but willonly utilize even slightly less reliable paths withlow probability. In order to ensure that the algo-rithm is making correct decisions, it continuously
needs to have updated feedback on the other pathsin the network. This is accomplished by randomsampling. Ideally, if every data packet was used asa sampling packet, meaning the sampling rate was100%, the algorithm would have extremely highloss rates from exploring faulty paths, but wouldhave extremely accurate estimates of the currentreliability of paths in the network. On the otherhand if the algorithm only samples paths with 1%of its traffic, then it will be slightly slower in de-tecting changes, but will be sending a higher per-centage of its packets over links that do not fail.
It is important to note that the algorithm sam-ples with actual data packets and not small ex-ploratory test packets. This is critically importantsince we are working under a strong byzantine ad-versarial model. It is assumed that if we send testpackets, the adversaries will be aware that we aretesting links and allow the packets to pass throughthe network. This would increase our probabilityof selecting the adversarial controlled links. By uti-lizing real data packets, the only way for the adver-sary to ”draw us in” would be to allow enough datapackets to successfully pass through its links, thatits links appeared more reliable then other linksin the network. However, our goal is to deliverpackets from the source to the destination. If theadversary chooses to deliver these packets, thenit is not exhibiting adversarial behavior. If theadversary decides to increase its fault rate as weincrease the rate at which we utilize its links, thealgorithm will immediately respond since it wouldnot be receiving acks for packets.
4 Byzantine Fault Detection
Our detection algorithm is based on using acknowl-edgments (acks) of the data packets. If a validack is not received within a timeout, it is assumedthat the packet has been lost. Note that this def-inition of loss includes both malicious and non-malicious causes. A loss can be caused by packetdrop due to buffer overflow, packet corruption dueto interference, a malicious attempt to modify thepacket contents, or any other event that preventseither the packet or the ack from being receivedand verified within the timeout. We would like toemphasize that our protocol provides fault avoid-ance and never disconnects nodes from the net-
10

work. Thus, the impact of false positives, due tonormal events such as bursting traffic, is drasti-cally reduced. This provides a much more flexiblesolution than one where nodes are declared faultyand excluded from the network.
4.1 Fault Detection Overview
Our fault detection protocol requires the desti-nation and each intermediate node to return anack to the source, for every successfully receiveddata packet. We use shared keys between thesource and each intermediate node as a basis forour cryptographic primitives in order to avoid theprohibitively high cost of using public key cryp-tography on a per packet basis. These pairwiseshared keys can be established on-demand via akey exchange protocol such as Diffie-Hellman [20],authenticated using digital signatures.
4.2 Source Route Specification
The mechanism for specifying the source route ona packet is essential for the correct operation ofthe protocol. The source route is specified as alist of addresses, where the order of the addressesindicates the path which the packet will traverse.The list is “onion” encrypted [57]. Each route isspecified by an address indicating the next hop, anHMAC of the packet (not including the list), andthe encrypted remaining list. Both the HMAC andthe encrypted remaining list are computed withthe shared key between the source and that node.An HMAC [4] using a one-way hash function suchas SHA1 [1] and a standard block cipher encryp-tion algorithm such as AES [3] can be used.
When a node receives a packet it verifies theHMAC of the packet and decrypts the remain-der of the source route using its shared key withthe source. If the HMAC verifies, the node pro-ceeds to forward the packet to the next hop. Sincethe source route is onion encrypted the intermedi-ate nodes are only aware of the next hop and donot know the full path that the packet will tra-verse. This prevents the adversary from strategi-cally dropping packets which are intended to tra-verse specific nodes. It can drop packets based onthe selected next hop, but this will only incrimi-nate the adversary, thus decreasing the probability
that the source selects it as a forwarding node.
4.3 Acknowledgment Specification
If the adversary can drop individual acks, it can in-criminate any arbitrary link along the path. In or-der to prevent this, each node does not send its ackimmediately, but waits for the ack from the nextnode and combines them into one ack. In otherwords, acks are accumulated from the destinationback to the source. For any successfully delivereddata packet, the source should receive a single ac-knowledgement allowing it to verify the successfuldelivery of the packet as well as the path which thepacket traversed. Each ack consists of the identi-fier of the node, the identifier of the data packetthat is being acknowledged, the ack received fromthe next node encrypted with the key shared bythis node and the source, and an HMAC of thenew combined ack.
If no ack is received within a timeout, the nodestops waiting, and creates and sends its ack. Thetimeouts are set up in such a way that if there is afailure, all the acks before the failure point can becombined without other timeouts occurring. Thisis accomplished by setting the ack timeout at eachnode to be the upper bound of the round-trip fromit to the destination. Upon receipt of an ack, thesource checks the acks from each node by succes-sively verifying the HMACs and decrypting thenext ack. The source either verifies all the acksup through the destination, or discovers a loss onthe link following the last ack.
By using the above specification, it is simple toattribute losses to links. A loss is attributed to aset of links when the source successfully receivedand verified an ack from an intermediary node, butdoes not from the destination. Blame is assignedto the nodes between the last received ack and thedestination node. Those nodes are penalized forpoor parent selection.
5 Implementation Results
In order to substantiate the claims made in thiswork, simulations were conducted to investigatethe convergence time of the algorithm. The simu-lations were conducted by developing a simple pro-
11
gram which would simulate the decision makingprocess of the algorithm and examine its perfor-mance against adversarial inputs. The simulationconsisted of a source selecting a path to the desti-nation at each unit of time. An adversarial modelwould then select which nodes at the current unitof time were faulty. The packet would traverse thegraph and receive positive feedback from the des-tination if there were no faulty nodes on the path,or from the last non-faulty node before the packetwas dropped. Using this feedback the algorithmwould adjust its probabilities and compute a newpath for the next packet.
Source Destination
0.05
0.10 0.04
0.03
1 3
5
42
0
Figure 3: Simple Simulation Topology
Beta = 0.5 Sample Rate = 0.10
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1 1001 2001 3001 4001 5001 6001 7001 8001 9001 10001
Packets Sent
Perc
en
t o
n L
ink 0 to 1
0 to 2
1 to 3
1 to 4
2 to 3
2 to 4
3 to 5
4 to 5
Figure 4: Simple Configuration Results
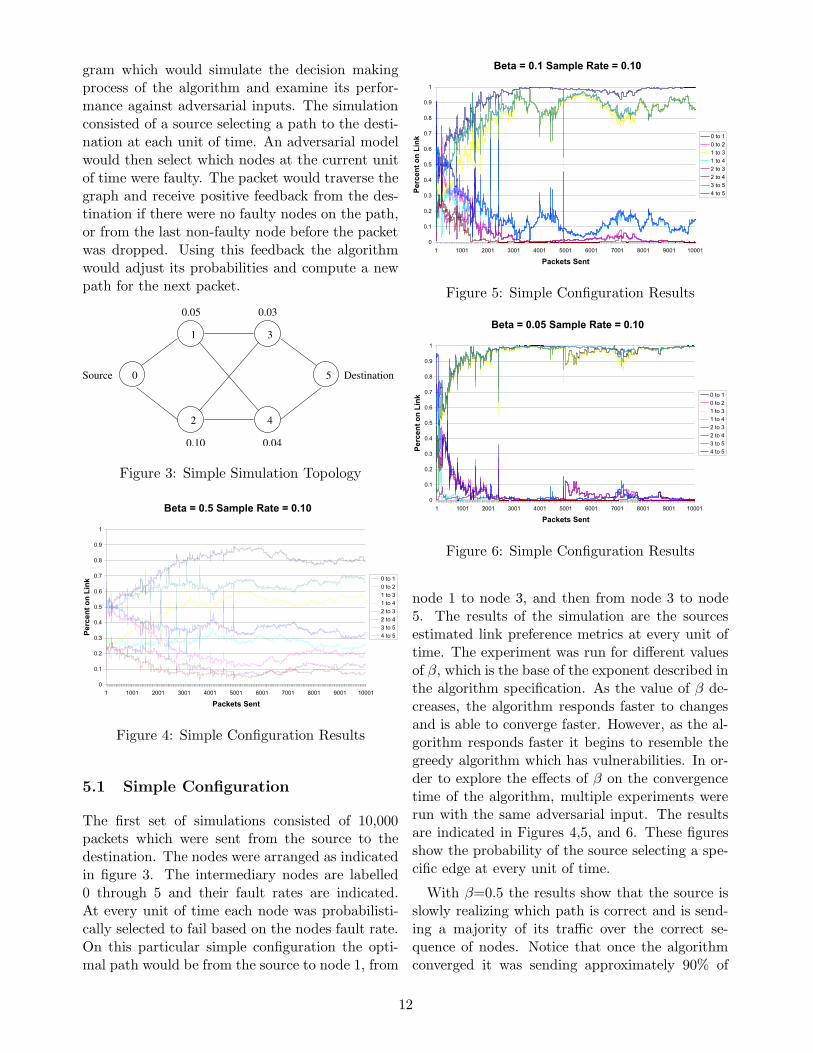
5.1 Simple Configuration
The first set of simulations consisted of 10,000packets which were sent from the source to thedestination. The nodes were arranged as indicatedin figure 3. The intermediary nodes are labelled0 through 5 and their fault rates are indicated.At every unit of time each node was probabilisti-cally selected to fail based on the nodes fault rate.On this particular simple configuration the opti-mal path would be from the source to node 1, from
Beta = 0.1 Sample Rate = 0.10
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1 1001 2001 3001 4001 5001 6001 7001 8001 9001 10001
Packets Sent
Perc
en
t o
n L
ink 0 to 1
0 to 2
1 to 3
1 to 4
2 to 3
2 to 4
3 to 5
4 to 5
Figure 5: Simple Configuration Results
Beta = 0.05 Sample Rate = 0.10
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1 1001 2001 3001 4001 5001 6001 7001 8001 9001 10001
Packets Sent
Pe
rce
nt
on
Lin
k 0 to 1
0 to 2
1 to 3
1 to 4
2 to 3
2 to 4
3 to 5
4 to 5
Figure 6: Simple Configuration Results
node 1 to node 3, and then from node 3 to node5. The results of the simulation are the sourcesestimated link preference metrics at every unit oftime. The experiment was run for different valuesof β, which is the base of the exponent described inthe algorithm specification. As the value of β de-creases, the algorithm responds faster to changesand is able to converge faster. However, as the al-gorithm responds faster it begins to resemble thegreedy algorithm which has vulnerabilities. In or-der to explore the effects of β on the convergencetime of the algorithm, multiple experiments wererun with the same adversarial input. The resultsare indicated in Figures 4,5, and 6. These figuresshow the probability of the source selecting a spe-cific edge at every unit of time.
With β=0.5 the results show that the source isslowly realizing which path is correct and is send-ing a majority of its traffic over the correct se-quence of nodes. Notice that once the algorithmconverged it was sending approximately 90% of
12
Beta = 0.05 Sample Rate = 0.01
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1 1001 2001 3001 4001 5001 6001 7001 8001 9001 10001
Packets Sent
Pe
rcen
t o
n L
ink 0 to 1
0 to 2
1 to 3
1 to 4
2 to 3
2 to 4
3 to 5
4 to 5
Figure 7: Simple Configuration Results
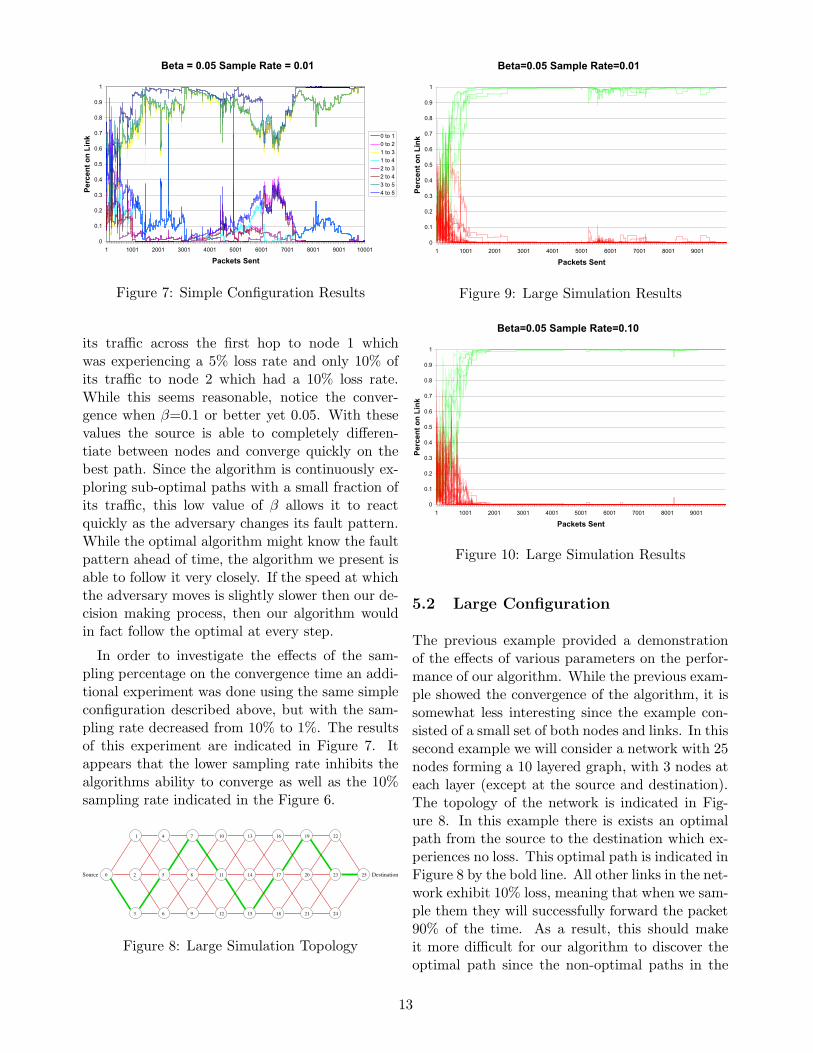
its traffic across the first hop to node 1 whichwas experiencing a 5% loss rate and only 10% ofits traffic to node 2 which had a 10% loss rate.While this seems reasonable, notice the conver-gence when β=0.1 or better yet 0.05. With thesevalues the source is able to completely differen-tiate between nodes and converge quickly on thebest path. Since the algorithm is continuously ex-ploring sub-optimal paths with a small fraction ofits traffic, this low value of β allows it to reactquickly as the adversary changes its fault pattern.While the optimal algorithm might know the faultpattern ahead of time, the algorithm we present isable to follow it very closely. If the speed at whichthe adversary moves is slightly slower then our de-cision making process, then our algorithm wouldin fact follow the optimal at every step.
In order to investigate the effects of the sam-pling percentage on the convergence time an addi-tional experiment was done using the same simpleconfiguration described above, but with the sam-pling rate decreased from 10% to 1%. The resultsof this experiment are indicated in Figure 7. Itappears that the lower sampling rate inhibits thealgorithms ability to converge as well as the 10%sampling rate indicated in the Figure 6.
0
4
5
7
8
9
10
11 14
16
17
19
20
21
22
23
24
25
1
2
3 6 15
13
DestinationSource
12 18
Figure 8: Large Simulation Topology
Beta=0.05 Sample Rate=0.01
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1 1001 2001 3001 4001 5001 6001 7001 8001 9001
Packets Sent
Pe
rce
nt
on
Lin
k
Figure 9: Large Simulation Results
Beta=0.05 Sample Rate=0.10
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1 1001 2001 3001 4001 5001 6001 7001 8001 9001
Packets Sent
Perc
en
t o
n L
ink
Figure 10: Large Simulation Results
5.2 Large Configuration
The previous example provided a demonstrationof the effects of various parameters on the perfor-mance of our algorithm. While the previous exam-ple showed the convergence of the algorithm, it issomewhat less interesting since the example con-sisted of a small set of both nodes and links. In thissecond example we will consider a network with 25nodes forming a 10 layered graph, with 3 nodes ateach layer (except at the source and destination).The topology of the network is indicated in Fig-ure 8. In this example there is exists an optimalpath from the source to the destination which ex-periences no loss. This optimal path is indicated inFigure 8 by the bold line. All other links in the net-work exhibit 10% loss, meaning that when we sam-ple them they will successfully forward the packet90% of the time. As a result, this should makeit more difficult for our algorithm to discover theoptimal path since the non-optimal paths in the
13

network only experience marginal loss. This sim-ulation consisted of a source attempting to deliver10,000 packets to the destination. The graphs inFigures 9 and 10 show the results when we are per-forming random sampling with 1% and 10% of ourpackets respectively. In this experiment β equal to0.05 was used.
The results indicate that the algorithm is ableto successfully converge on the optimal path af-ter approximately 1000 packets are sent. Oncethe algorithm learned the best path it was able tosend approximately 99% of its traffic successfullyto the destination. The graph visually indicatesthis by showing the sources link preferences at ev-ery unit of time. When the simulation begins thesource considers all of the links in the network tobe equal and then learns their reliability by send-ing traffic across the links and receiving feedback.As the number of packets (or trials) increases thesources knowledge of the network continuously be-comes more accurate. This is evident as the re-liable paths become separated from the less reli-able paths and selected with near 100% probabil-ity. Since the source is continuously sampling theless desirable edges it is able to respond quickly tochanges in the adversarial fault pattern.
6 Existing Work
Existing Algorithmic Work: The only al-gorithmic results that possibly work under thisstrong adversarial model are based on a computa-tional learning framework [33, 15]. Near optimallearning algorithms, with reliable global informa-tion for finding a shortest path in a graph, whereat each time a different known cost is assigned toeach edge, were studied in [33, 15]; these solu-tions have an exponential computational overhead.Polynomial computational overhead schemes wererecently suggested by [58, 31]. The solutions in[33, 15] and [58, 31] correspond to “link-state”routing, and the case where the adversary can onlyexercise dynamic DOS attacks, but cannot cheat.Byzantine behavior causes such algorithms to col-lapse. Most recently, “on-demand” routing againstan oblivious adversary was suggested in [8]. In thismodel, an adversary cannot cheat and the patternof cheating and blocking is assumed to be oblivi-ous, i.e., this work does not handle dynamic DOS
attacks.
Reinforcement Learning: Interest in applica-tions of ant-based routing in MANETs has risenand many recent papers have addressed the subject[35, 9]. Gunes et al [36] considers ant-based ap-proach to routing in MANETs, with a completelyreactive algorithm. Marwaha et al. [49] studies ahybrid approach using both AODV and reactiveAnt-based exploration. Baras et al [9] describes anew algorithm that utilizes the inherent broadcastnature of wireless networks to multicast controland signaling packets (ants). ARAMA [35] usesanalogous approach. Work on Swarm Intelligenceis described in [34, 13, 56, 18, 14, 48, 50, 11, 21,35, 9].
Networking/Security: A substantial researcheffort has gone into the development of securerouting algorithms both for wireless MANETs andoverlay networks. The following A number of rout-ing algorithms have been proposed for wirelessMANET’s; these protocols can generally be cat-egorized as either proactive or reactive. They in-clude DSDV [43], AODV [44], DSR [30], and sev-eral others. Many researchers focused on securingclasses of (wired) routing protocols such as link-state [25, 16, 61, 23] and distance-vector [54]. Oth-ers addressed in detail the security issues of well-known protocols such as OSPF [41] and BGP [53].
As mentioned in [25], source authentication ismore of a concern in routing than confidentiality.Papadimitratos and Haas showed in [42] how im-personation and replay attacks can be preventedfor on-demand routing by disabling route cachingand providing end-to-end authentication using anHMAC [4] primitive which relies on the existenceof security associations between sources and desti-nations. Dahill et al. [19] focus on providing hop-by-hop authentication for the route discovery stageof two well-known on-demand protocols: AODV[44] and DSR [30], relying on digital signatures.Other significant works include SEAD [26] andAriadne [28] that provide efficient secure solutionsfor the DSDV [43] and DSR [30] routing proto-cols, respectively. While SEAD uses one-way hashchains to provide authentication, Ariadne uses avariant of the Tesla [46] source authentication tech-nique to achieve similar security goals.
14

Marti et al. [37] address a problem similar to theone we consider, survivability of the routing servicewhen nodes selectively drop packets. They takeadvantage of the wireless cards promiscuous modeand have trusted nodes monitoring their neighbors.Links with an unreliable history are avoided in or-der to achieve robustness. Although the idea ofusing the promiscuous mode is interesting, this so-lution does not work well in multi-rate wireless net-works because nodes might not hear their neigh-bors forwarding communication due to differentmodulations. In addition, this method is not ro-bust against collaborating adversaries.
Collaborating adversaries can be handled bynew work of Mittal and Vigna (CCS 2002) [38]which places “sensors” in various locations, mon-itoring both topology updates as well as networktraffic in order to detect adversarial behavior. Inorder to decide whether a routing update is ma-licious or not, a router needs to have reliable,nonlocal topology information. Reliance on ex-ternal sensors is needed, because, unfortunately,RIP routers do not have this information. It isnecessary to check every possible path (there areexponentially many of them) from every router toevery other router, since adversaries may engagein selective message blocking. The obvious draw-back is the introduction of the sensors; second isreliance of their reliability. Also, message overheadof the algorithm grows with (potentially exponen-tial) number of paths.
The problem of source authentication for rout-ing protocols was explored using digital signatures[41] or symmetric cryptography based methods:hash chains [25], chains of one-time signatures [61]or HMAC [23]. Intrusion detection is another topicthat researchers focused on, for generic link-state[60, 47] or OSPF [59].
Perlman [45] designed the Network-layer Pro-tocol with Byzantine Robustness (NPBR) whichaddresses denial of service at the expense of flood-ing and digital signatures. The problem of byzan-tine nodes that simply drop packets (black holes)in wired networks is explored in [17, 12]. The ap-proach in [17] is to use a number of trusted nodesto probe their neighbors, assuming a limited modeland without discussing how probing packets aredisguised from the adversary. A different tech-nique, flow conservation, is used in [12]. Based on
the observation that for a correct node the num-ber of bytes entering a node should be equal to thenumber of bytes exiting the node (within a thresh-old), the authors suggest a scheme where nodesmonitor the flow in the network. This is done byrequiring each node to have a copy of the routingtable of their neighbors and reporting the incom-ing and outgoing data. Although interesting, thescheme does not work when two or more adversar-ial nodes collude.
Using digital signatures to verify packet pathshas been considered for distance vector, link stateadvertisements and BGP [52, 40, 32]. Other workattempts to reduce the performance overhead asso-ciated with securing routing protocols using digitalsignatures in context of efficiency and security ofupdates in link state routing (Hauser et al. [24]).
7 Conclusion
In this work we have presented an online algo-rithm which is based on the Swarm Intelligenceparadigm and Distributed Reinforcement Learn-ing approach. Through mathematical analysis andsimulation results we have shown the algorithmscompetitive performance under a strong adversar-ial model consisting of dynamic proactive adver-sarial attacks, where the network may be com-pletely controlled by byzantine adversaries.
The results of this work indicate validity of ourapproach and motivate the need for future workin this direction. We intend on implementing thisprotocol in a more realistic simulation environmentand exploring the effects of both mobility and moresophisticated active adversarial attacks on the al-gorithm.
References
[1] Secure Hash Standard (SHA1). Num-ber FIPS 180-1. National Institute forStandards and Technology (NIST), 1995.http://www.itl.nist.gov/fipspubs/fip180-1.htm.
[2] ANSI/IEEE Std 802.11, 1999 Edition. 1999.http://standards.ieee.org/catalog/olis/lanman.html.
[3] Advanced Encryption Standard (AES). Number FIPS197. National Institute for Standards and Technology(NIST), 2001. http://csrc.nist.gov/encryption/aes/.
[4] The Keyed-Hash Message Authentication Code(HMAC). Number FIPS 198. National Insti-
15

tute for Standards and Technology (NIST), 2002.http://csrc.nist.gov/publications/fips/index.html.
[5] David G. Andersen, Hari Balakrishnan, M. FransKaashoek, and Robert Morris. Resilient overlay net-works. In Proceedings 18th ACM SOSP, Banff, Canada,10 October 2001.
[6] Peter Auer, Nicolo Cesa-Bianchi, Yoav Freund, andRobert E. Schapire. Gambling in a rigged casino: theadversarial multi-armed bandit problem. In Proceed-ings of the 36th Annual Symposium on Foundationsof Computer Science, pages 322–331. IEEE ComputerSociety Press, Los Alamitos, CA, 1995.
[7] Baruch Awerbuch, Dave Holmer, Cristina Nita-Rotaru, and Herb Rubens. An on-demand secure rout-ing protocol resilent to byzantine failures. In WirelessSecurity Workshop Proceedings, September 2002.
[8] Baruch Awerbuch and Yishay Mansour. Online learn-ing of reliable network paths. In PODC, 2003. to ap-pear.
[9] John S. Baras and Harsh Mehta. Dynamic adaptiverouting in manets. In Procedings of Annual ARL CTASymposium, 2003.
[10] Vaduvur Bharghavan, Alan J. Demers, Scott Shenker,and Lixia Zhang. MACAW: A media access proto-col for wireless LAN’s. In SIGCOMM, pages 212–225,1994.
[11] E. Bonabeau, F. Henaux, S. Guerin, D. Snyers,P. Kuntz, and G. Theraulaz. Routing in telecommuni-cations networks with “smart” ant-like agents. In Intel-ligent Agents for Telecommunications Applications ’98(IATA’98), 1998.
[12] Kirk A. Bradley, Steven Cheung, Nick Puketza,Biswanath Mukherjee, and Ronald A. Olsson. Detect-ing disruptive routers: A distributed network monitor-ing approach. In IEEE Symposium on Security andPrivacy, 1998.
[13] G. Di Caro and M. Dorigo. AntNet: a mobileagents approach to adaptive routing. Technical ReportIRIDIA/97-12, Universite Libre de Bruxelles, Belgium.
[14] Gianni Di Caro and Marco Dorigo. Antnet: Dis-tributed stigmergetic control for communications net-works. Journal of Artificial Intelligence Research,9:317–365, 1998.
[15] Nicolo Cesa-Bianchi, Yoav Freund, David P. Helmbold,David Haussler, Robert E. Schapire, and Manfred K.Warmuth. How to use expert advice. pages 382–391,1993. To appear, Journal of the Association for Com-puting Machinery.
[16] Steven Cheung. An efficient message authenticationscheme for link state routing. In The 13th Annual Com-puter Security Applications Conference, pages 90–98,December 1997.
[17] Steven Cheung and Karl Levitt. Protecting routing in-frastructures from denial of service using cooperativeintrusion detection. In New Security Paradigms Work-shop, 1997.
[18] P. Druschel D. Subramaniam and J. Chen. Ants andreinforcement learning : A case study in routing indynamic networks. In Proceedings of IEEE MILCOM,Atlantic City, NJ, 1997.
[19] B. Dahill, B.N. Levine, C. Shields, and E. Royer. Asecure routing protocol for ad hoc networks. TechnicalReport 01-37, Department of Computer Scinece, Uni-versity of Massachusetts, August 2001.
[20] W. Diffie and M. E. Hellman. New directions in cryp-tography. IEEE Trans. Inform. Theory, IT-22:644–654,November 1976.
[21] Marco Dorigo, Vittorio Maniezzo, and Alberto Col-orni. The Ant System: Optimization by a colony ofcooperating agents. IEEE Transactions on Systems,Man, and Cybernetics Part B: Cybernetics, 26(1):29–41, 1996.
[22] Yair Frankel, Peter Gemmell, Philip D. MacKenzie,and Moti Yung. Optimal resilience proactive public-keycryptosystems. In IEEE Symposium on Foundations ofComputer Science, pages 384–393, 1997.
[23] Michael T. Goodrich. Efficient and secure networkrouting algorithms. Provisional patent filing., January2001.
[24] Ralf Hauser, Antoni Przygienda, and Gene Tsudik. Re-ducing the cost of security in link state routing. InIn Internet Society Symposium on Network and Dis-tributed Systems Security,, pages 93–99.
[25] Ralf Hauser, Tony Przygienda, , and Gene Tsudik. Re-ducing the cost of security in link-state routing. InSymposium of Network and Distributed Systems Secu-rity, 1997.
[26] Yih-Chun Hu, David B. Johnson, and Adrian Perrig.SEAD: Secure efficient distance vector routing for mo-bile wireless ad hoc networks. In The 4th IEEE Work-shop on Mobile Computing Systems and Applications.IEEE, June 2002.
[27] Yih-Chun Hu, Adrian Perrig, and David B. Johnson.Ariadne: A secure on-demand routing protocol for adhoc networks. Technical Report TR01-383, Depart-ment of Computer Science, Rice University, December2001.
[28] Yih-Chun Hu, Adrian Perrig, and David B. Johnson.Ariadne: A secure on-demand routing protocol for adhoc networks. In The 8th ACM International Confer-ence on Mobile Computing and Networking, September2002. To appear.
[29] J.-P. Hubaux, L. Buttyan, and S. Capkun. The questfor security in mobile ad hoc networks. In The 2ndACM Symposium on Mobile Ad Hoc Networking andComputing, October 2001.
[30] David B. Johnson, David A. Maltz, and Josh Broch.DSR: The Dynamic Source Routing Protocol for Multi-Hop Wireless Ad Hoc Networks. in Ad Hoc Networking,chapter 5, pages 139–172. Addison-Wesley, 2001.
[31] Adam Kalai and Santosh Vempala. Geometric al-gorithms for online optimization, 2003. unpublishedmanuscript.
16

[32] S. Kent, C. Lynn, J. Mikkelson, and K. Seo. Realworld performance and deployment issues. In SecureBorder Gateway Protocol (SecureBGP). In Proceedingsof the Symposium on Network and Distributed SystemSecurity, February 2000.
[33] Nick Littlestone and Manfred K. Warmuth. Theweighted majority algorithm. Information and Com-putation, 108:212–261, 1994. A preliminary version ap-peared in FOCS 1989.
[34] M. Littman and J. Boyan. A distributed reinforcementlearning scheme for network routing. In Proceedings ofthe International Workshop on Applications of NeuralNetworks to Telecommunications. Alspector, J., Good-man, R. and Brown, T. X. (Ed.), pages 45–51, 1993.
[35] U. Sorges M. Gunes and I. Bouazizi. The ant colonybased routing algorithm for manets. In Proc. of the2002 ICPP Workshop on Ad Hoc Networks (IWAHN2002), pages 79–85. IEEE Computer Society Press,2002.
[36] U. Sorges M. Gunes and I. Bouazizi. ara - the antcolony based routing algorithm for manets. In Proc.of the 2002 ICPP Workshop on Ad Hoc Networks(IWAHN 2002), pages 79–85. IEEE Computer SocietyPress Stephan Olariu edt., 2002.
[37] S. Marti, T. Giuli, K. Lai, and M. Baker. Mitigatingrouting misbehavior in mobile ad hoc networks. In The6th ACM International Conference on Mobile Comput-ing and Networking, August 2000.
[38] Vishal Mittal and Giovanni Vigna. Sensor-based intru-sion detection for intra-domain distance-vector rout-ing. In Proceedings of the CCS, pages 127 – 137. ACM,2002.
[39] Mehryar Mohri. General algebraic frameworks and al-gorithms for shortest distance problems. Technical Re-port 81219-10TM, ATT Labs-Research, 1998.
[40] S. Murphy and M. Badger. Digital signature protectionof the ospf routing protocol, 1996.
[41] S. L. Murphy and M. R. Badger. Digital signature pro-tection of the OSPF routing protocol. In Symposiumon Networks and Distributed Systems Security, 1996.
[42] P. Papadimitratos and Z.J. Haas. Secure routing formobile ad hoc networks. In SCS Communication Net-works and Distributed Systems Modeling and Simula-tion Conference, pages 27–31, January 2002.
[43] Charles E. Perkins and Pravin Bhagwat. Highly dy-namic destination-sequenced distance-vector routing(DSDV) for mobile computers. In ACM SIGCOMM’94Conference on Communications Architectures, Proto-cols and Applications, 1994.
[44] Charles E. Perkins and Elizabeth M. Royer. Ad hocNetworking, chapter Ad hoc On-Demand Distance Vec-tor Routing. Addison-Wesley, 2000.
[45] Radia Perlman. Network Layer Protocols with Byzan-tine Robustness. PhD thesis, MIT LCS TR-429, Octo-ber 1988.
[46] Adrian Perrig, Ran Canetti, Dawn Song, and DougTygar. Efficient and secure source authentication formulticast. In Network and Distributed System SecuritySymposium, February 2001.
[47] Diheng Qu, Brian M. Vetter, Feiyi Wang, RavindraNarayan, S. Felix Wu, Y. Frank Jou, Fengmin Gong,and Chandru Sargor. Statistical anomaly detection forlink-state routing protocols. In IEEE Symposium onSecurity and Privacy (5 Minutes), May 1997.
[48] O. E. Holland R. Schoonderwoerd and J. L. Bruten.Ant-like agents for load balancing in telecommunica-tions networks. In Proc. First ACM International Con-ference on Autonomous Agents, Marina del Rey, Cali-fornia, pages 209–216, 1997.
[49] C. K. Tham S. Marwaha and D. Srinivasan. Mobileagents based routing protocol for mobile ad hoc net-works. In in Proceedings of IEEE Globecom,, 2002.
[50] Ruud Schoonderwoerd, Owen E. Holland, Janet L.Bruten, and Leon J. M. Rothkrantz. Ant-based loadbalancing in telecommunications networks. AdaptiveBehavior, (2):169–207, 1996.
[51] Sleator and Tarjan. Amortized efficiency of list up-date and paging rules. Communication of the ACM,28(2):202–208, 1985.
[52] B. Smith and J. Garcia-Luna-Aceves. Securing the bor-der gateway routing protocol. In Proc. Global Inter-net’96, London, UK, 20-21 November 1996., 1996.
[53] B. Smith and J.J. Garcia-Luna-Aceves. Efficient secu-rity mechanisms for the border gateway routing proto-col. Computer Communications (Elsevier), 21(3):203–210, 1998.
[54] Bradley R. Smith, Shree Murthy, and J.J. Garcia-Luna-Aceves. Securing distance-vector routing proto-cols. In Symposium on Networks and Distributed Sys-tems Security, 1997.
[55] Jonathan Stone and Craig Partridge. When the CRCand TCP checksum disagree. In ACM SIGCOM, Au-gust/September 2000.
[56] Devika Subramanian, Peter Druschel, and JohnnyChen. Ants and reinforcement learning: A case studyin routing in dynamic networks. In IJCAI (2), pages832–839, 1997.
[57] Paul F. Syverson, David M. Goldschlag, andMichael G. Reed. Anonymous connections and onionrouting. In IEEE Symposium on Security and Privacy,1997.
[58] Eiji Takimoto and Manfred K. Warmuth. Path ker-nels and multiplicative updates. In COLT Proceedings,2002.
[59] S.F. Wu, H.C. Chang, D. Qu, F. Wang F. Jou, F. Gong,C. Sargor, and R. Cleaveland. JiNao: Design and im-plementation of a scalable intrusion detection systemfor the OSPF routing protocol. Journal of ComputerNetworks and ISDN Systems, 1999.
[60] Shyhtsun F. Wu, Fei yi Wang, Brian M. Vetter,W. Rance Cleaveland, Y. Frank Jou, Fengmin Gong,and Chandramouli Sargor. Intrusion detection for link-state routing protocols. In IEEE Symposium on Secu-rity and Privacy, 1997.
[61] K. Zhang. Efficient protocols for signing routing mes-sages. In Symposium on Networks and Distributed Sys-tems Security, 1998.
17

Appendix
A The Formal Model
A.1 Routing strategy.
Consider an overlay network G(V,E) with a sources and receiver r, and a hop count H. At each inte-ger time t ∈ N, source sends packet to the receiverover a path of H hops at the most. We normalizeour time units in such a way that transmission ofa packet over H hops takes 1 unit of time at themost.
Let Π(s, r) be collection of paths from s to r.A H-routing algorithm consists of, for each timet ∈ N, a routing policy πt.
A deterministic routing strategy specifies a map-ping, for each t ∈ N,
πt : V × V h → E
whose arguments are:
• current router v ∈ V
• prefix of the current routing path Π′ ∈ V h,that leads from source s to v
and whose value, e = π(v, t,Π′) is an outgoingedge e = (v → u) ∈ E which is the next edgeto be taken by the packet. A probabilistic routingstrategy specifies a mapping
ζ : V × V h ×E → (0, 1)
which specifies the probability ζ(v, t,Π′, e) ofcontinuing on edge e, after arriving at router vthrough routing path Π′.
The deterministic routing strategy is a specialcase of the probabilistic strategy, and thus in therest of the paper we describe probabilistic strate-gies. The description of the strategy, namely map-ping ζ, is carried in the packet.
A routing strategy is memoryless if it is indepen-dent of path traversed by the packet. An algorithmis τ -stationary if its strategy is changing at mostonce in τ steps.
A.2 Adversary Model
We denote by A the strategy of the adversary. Ateach moment in time t ∈ N, the adversary picks asubset of nodes under its control, VA(t) ⊂ V . LetUA(t) ∈ E be the subset of edges incident to VA(t).
For each node v and each time t, we define
λA(e, t) =
1 if e ∈ UA(t)1 otherwise
(1)
For each time t ∈ N, the adversary picks aninfiltration strategy
λA : N→ 2E
of the subset of edges, and a blocking strategy
γA : N×E × V H ×P → 0, 1
whose arguments are:
• current time t ∈N
• current edge e ∈ UA(t) under adversarial con-trol
• prefix of the current routing path Π′ ∈ V H ,that leads from source s to v
• specific routing strategy πt ∈ P used by therouting algorithm
and whose value γA(t, e,Π′, π) ∈ 0, 1 is the de-cision whether to block the packet or not to blockit. Namely,
γA(t, e,Π′, π) =
1 if e ∈ Ut and e blocks at time t0 otherwise
Note that e /∈ Ut means that e is not controlledby adversary and there is no way to block thispacket.
The values γA(t, e,Π′, π) are generally notknown to the algorithm. Certainly, acknowledgingback to the source the result of each transmissionwill alleviate this problem, unless the acks are be-ing blocked or forged by the adversary controllingthe intermediate routers. However, acking every
18

packet, on each hop is extremely inefficient. Con-sequently, we allow the routing algorithm to spec-ify, as part of the routing strategy, that receipt ofpackets at the destination are being acknowledgedback to the source.
A.3 Evaluating the algorithm
Formalizing the benchmark cost. Considernow our benchmark strategy ΠA against a givenadversary A that must be fixed in some interval,say (0, τben). Specifically, this strategy consists ofa path Π = (e1, e2, . . . , eH) picked by the bench-mark algorithm. For any 0 ≤ t ≤ τben, define theinstantaneous faultiness of such path
λ(Π, t) =H
∑
i=0
λA(ej , t)
Best path ΠA is minimizing loss for A:
ΠA = argminΠExpt∈0,τben[λ+(Π, t)]
and our benchmark is Expt∈0,τben[λ(ΠA, t)].
Formalizing the algorithm cost. Letour algorithm B pick pick path ΠB(t) =(e1( t), e
2(t), . . . , ej−1(t)) to edge e at layer jat time t. Note that the loss factor for our pathat time t, for an edge e is
ψ(ΠB(t)) = 1−j
∏
i=1
(1− γA(t, ej(t),Πj(t), π))
The algorithms average loss isExpt∈0,τalg
[ψ(Π(t))].
The error term. Our loss is maximum, overallselection of A and all selection of ΠA of
δB = maxA,ΠA
Expt∈0,τalg[ψ(ΠB(t))− λ(ΠA, t]
Theorem A.1 The algorithm B in section B ac-complishes δB ≤ ε for all ε in window τalg =
τben · τpha. Here,
τpha = Ω(|E|
εsa) (2)
T =H2
εex2· log d (3)
B Details of the Algorithm
B.1 Transforming a graph into a lay-ered directed graph
Suppose that a packet starts at source s, and whiletraversing the network carries a hop count. Whenpacket arrives to node v after traversing i hops, weconsider the packet as if it arrives at “virtual” nodevH−i. We can consider a directed levelled acyclic“virtual” graph G′(V ′, E′) where
V ′ = vi|v ∈ V, i ≤ H
andE′ = vi → ui+1|(u, v) ∈ E
Suppose we have a sender s, a receiver r, and ahop count H.
V 0 ← s0repeat j = 0 downto H − 1
V j+1 ← vj+1 | ∃uj ∈ Vj , (u, v) ∈ E
Ej+1 ← vj+1 → uj | ∃uj ∈ Vj , (u, v) ∈ E
remove all edges/vertices unreachable from sH
Figure 11: Algorithm for constructing layered graph.
We observe that a directed levelled graph G′
of depth H simulates any communication wherepacket traverses a bounded number of hops H ≤|V |. Thus, for the rest of the paper, we consider,without loss of generality, our network graph to belevelled, directed, acyclic, and every node is reach-able from the source.
Now, we will imagine a node s and r which werefer to as the “source” and “sink” nodes respec-tively. The sink node r will be placed in layer 0 ofthe graph.
B.2 Feedback mechanism
For each packet sent at phase at time t, let Π(t)be the collection of nodes traversed by this packet.
19

For εac fraction of all packets, each node will (in-directly) ack this packet, and the path will be par-titioned into sub-paths Π(t) = Π+(t) · Π−(t), sothat edges (vj , vj−1) ∈ Π+(t) have acked, whileedges (vj , vj−1) ∈ Π−(t) have failed to ack.
We also divide time into phases T1, T2, . . . TT,each of length τpha, so that t ∈ Ti is τpha · i ≤ t ≤τpha · (i+ 1).
Let Ti(e) = t ∈ T |e ∈ Π(t) be the set oftimes edge e appears on the path, and, similarlylet T +
i (e) = t ∈ T |e ∈ Π+(t) be the set of timesedge e appears on the path and succeeded to ack,and let T −
i (e) = t ∈ T |e ∈ Π+(t) be the numberof times e failed to ack. We define the “faultiness”of edge (x, y) at time t as
v0 ← srepeat j = 0 downto H
choose vj+1 ← u with prob. π(v, u, Ti)
Figure 12: Algorithm for phase Ti.
ψ(x, y, t) =
1 if (x, y) ∈ Π−(t)0 if (x, y) ∈ Π+(t)undefined otherwise
(4)
and we defined the average of a function f(t)that is defined at times t1, . . . tk in phase Ti as
Expt∈Ti[f(t)] =1
k
k∑
i=1
f(ti) (5)
Also, the average of a function over phases, fromphase 1 till phase j of a function f(i) will be
Expi∈0,i[f(j)] =1
j
j∑
i=1
f(i) (6)
Define average grade for (x, y) in a phase j as
ψ(x, y, Tj) = Expt∈Tj−1[ψ(x, y, Ti]) (7)
and let the average cumulative weight be
Ψ(x, y, Ti) = Expi∈0,i−1[ψ(x, y, Tj ]) (8)
This construction is used in [8].
B.3 Selecting Incoming probabilities
and the weight of the link (x, y) is updated as
ξ(x, y, Ti)← βΨ(x,y,Ti)) (9)
Finally, each node v sets a probability of its in-coming edges as
π(v, u, Ti)←ξ(v, u, Ti)
∑
w∈I(v)
ξ(v, w, Ti)(10)
This construction is used in [8].
B.4 Final policy: distribution over out-going edges
Specifically, given π, and a receiver r, we need toconstruct the outgoing edges probability distribu-tion
ζr : E → (0, 1)
The meaning of probability ζr(e) is that, whilerouting messages to r, regardless of source s, eachnode v chooses an outgoing edge e = (v → u) ∈for u ∈ O(v) (where O(v) are outgoing edges of v(with probability proportional to ζ(e).
Our policy will be discriminating packets basedon packet’s hops count. The routing policy is keep-ing a “time-to-live” count c, initially set to H.When the packet arrives to a node v with hopcount c, the receiving node v decrements c by 1,
and then chooses probability distribution ζ(c)r (u)
over its going edges.
Note that picking an incoming edge for eachnode defines a probability measure on the set oftrees, routed at the sink r. For a given phase i,a probabilistic strategy π : E → (0, 1) assigningmeasure π(e) to incoming edge e ∈ I(v), as in eqn.10. The meaning of it is that v selects e as itspreferred parent in a routing tree routed at sources with probability ζ(e). Given any destination r,the current path from r to s in the routing tree isthe routing strategy used by s to route to r.
However, in order to accomplish routing func-tion in a distributed manner, we need to translate
20

these collection of trees with accompanying proba-bilities into probability over outgoing edges. Thereis a dual interpretation of the same routing policybased on a probability distribution over the outgo-ing edges.
Note that ζr(e) can be computed from π in lin-ear time, using a Bellman-Ford style algorithm, inwhich we propagate “back” the probabilities in-duced by π.
Specifically, let ζ(0)r (v) be initialized as
ζ(0)r (v) =
0 if v 6= r1 if v = r
(11)
we we can compute ζ(j)r (u) from the recurrence
ζ(j)r (u) =
∑
v∈O(u)
ζ(j−1)r (v) · π(v, u) (12)
Now, the outgoing probabilities for a node u inlayer j as
ζ(u, v) =ζ(j−1)r (v) · π(v, u)
∑
v∈O(u)
ζ(j−1)r (v) · π(v, u)
(13)
This construction is adopted from [39], and [58].
Below, we provide the code for this the algo-rithm (which is run at the source node); see Fig.13. It uses variable π(u, v) which is incoming prob-ability of edge (u, v). Its output are outgoingprobabilities ζ i(v, u). This construction is adoptedfrom [39], and [58].
B.5 Sampling the unexplored territory
Also, we can consider
ζr|e : E → (0, 1)
with the meaning of probability ζ(e)r|e is that,while routing message from s to r, and conditionedon passing thru edge e, each node v chooses anoutgoing edge e = (v → u) ∈ for u ∈ O(v) (whereO(v) are outgoing edges of v (with probability pro-portional to ζ(e)r|e.
Note that ζ(e)r|(u,v) can be computed accordingto following:
Initializationζ0(v)← 0 ∀ v 6= rζ0(r)← 1repeat i = 0 to i = H
ζi(v, u) = ζi(u) · π(v, u)ζi+1(u) =
∑
(u,v)∈E ζi(v, u)
Path Generationi← Hvi ← s /* start at the source */repeat H times
select vi−1 ← u with prob. ζi−1(vi,u)ζi−1(vi)
i← i− 1
Figure 13: Links state version of the algorithm. Theabove algorithm is performed at the source and at eachintermediate node.
ζ(e)r|(u,v) =
ζ(e)u if e precedes (u, v)1 if e = (u, v)ζ(e)r if e follows (u, v)
(14)
That is, in layers before u we route towards u.Once we reach node u we route on (u, v) with prob.1. After crossing (u, v) we route towards r.
Consider now probability
ζε(e) = (1− ε)ζr(e) +∑
e∈E
ε
|E|· ζr|e(e)
This corresponds to using ζr for (1− ε) fractionof the time, and using ζr|e with random e for ε
|E|of the time. Let us choose ε = εsa. This is thefinal probability distribution used by our routingalgorithm.
This technique has not been used in this form inthe literature. It is inspired by [8] and the originalwork of Auer et al [6].
C Proof of Near-Optimality ofLoss Fraction (Sketch)
For the analysis we will relate the number of timesa node v was disconnected from the source s toits distance from the source. The proof would
21

be by induction on the distance from the source.Consider first the operation of experts in differentphases.
The following bound is derived using techniquesin [33, 8]. Define the adversarial pattern
λ(e, t) =
1 if e is adversarrail at time t0 otherwise
(15)
Given a path Π = (e1, e2 . . . eH) at time t, definelossiness of this path as the number of edges on thispaths under adversary control
λ(π, t) =H
∑
i=1
λ(ei, t)
Theorem C.1 There exists a randomized algo-rithm, BEX(v), that selects edge, at phase j, fromv to u ∈ I(v) with probability proportional to
βExpi∈0,j−1[Ψ(v,u,Ti)]
such that for any sequence of T phases at node v,holds
Expi∈0,i[Ψ(BEX(v)] ≤ O(
√
log d
T)+
minu∈I(v)
Expi∈0,T[λ(v, u, Ti) + Ψ(BEX(u), Ti)]
Proof. The optimal prescient algorithm has theopportunity to pick, among all u ∈ I(v), fixed par-ent u∗ minimizing
Expi∈0,T[λ(v, u, Ti) + ψ(BEX(u, Ti)]
and accomplish loss of at most
Expi∈0,i[v, u∗, Ti] ≤ λ(v, u∗, Ti) + Ψ(BEX(u), Ti)
The best expert algorithm BEX(v) is trying tominimize its loss associated with parent selection,and option u∗ is one of the options available toit. However, due to its online decision makingprocess, best experts learns adapts to best pos-sible option while suffering an additive regret of
O(
√
log d
T) (i.e., its loss is O(
√
log d
T) higher) on
sequence of T steps. The proof of the additivebound on regret follows from an argument similarto [33]. ut
The following lemma is using a proof techniquesimilar to [8].
Lemma C.2 Let v be a node at distance j from sand W an arbitrary spanning tree Then,
Expi∈0,T[Ψ(BEX, v, Ti)] ≤
Expi∈0,T[λ(W, v, Ti)] + j ·
√
log d
T
Proof. The proof is by induction on j. For j = 1the claim is trivial. For j = 2 we are simply run-ning the BEX algorithm and the bound is directlyfrom Theorem C.1. Assume the claim hold for jand show it for j + 1. Let I(v) be the neighbors ofv in level j. By the induction hypothesis, we havethat u ∈ I(v) is disconnected from s at most
Expi∈0,T[Ψ(BEX, v, Ti)] ≤
Expi∈0,T[λ(W, v, Ti)] + j ·
√
log d
T)
Let uW be the parent of v in W. Note that vhas the options of choosing uW; by doing so, thefraction of times v will get disconnected is at most
Expi∈0,T[λ(W, uW, Ti)] + j ·
√
log d
T)
By choosing uW, the fraction of times that v willget disconnected is upper bounded by the sum offraction of times uW gets disconnected and edgefrom v to uW gets disconnected, which is, by def-inition, at most Expi∈0,T[λ(v, uW, Ti]. Thus, weget
Expi∈0,T[λ(W, uW, Ti) + λ(v, uW, Ti] + j ·
√
log d
T
≤ Expi∈0,T[λ(W, uW, Ti)] + (j + 1) ·
√
log d
T)
The claim follows.
ut
22









![Routing Protocols for Vehicular Adhoc Networks …cisjournal.org/journalofcomputing/archive/vol5no1/vol5no1_4.pdf · reactive approaches for routing [17]. Proactive approaches maintain](https://img.pdfslide.us/doc/110x75/5ac806c47f8b9a42358bf316/routing-protocols-for-vehicular-adhoc-networks-approaches-for-routing-17.jpg)


![Practical and Provably Secure Onion Routing · 2012-07-16 · Practical and Provably Secure Onion Routing [IEEE CSF '12] Practical and Provably Secure OR - Esfandiar Mohammadi Anonymous](https://img.pdfslide.us/doc/110x75/5f03aa957e708231d40a2ccb/practical-and-provably-secure-onion-routing-2012-07-16-practical-and-provably.jpg)
















