Embed Size (px)
Citation preview

Properties of Community Data
in Ecology
Adapted from Ecological Statistical Workshop, FLC, Daniel Laughlin

Community Data Summary
• Community data matrices
• Species on gradients
• Problems with community data
• Normality assumptions
Key questions to keep in the back of your mind:1. How do species abundances relate to each other?2. How do species relate to environmental gradients?

Community data matrices
or Molecular marker
(abundance orpresence/absenceused as a measure ofspecies performance)
Independentsample units
Traits
SPARSE

Full Community Dataset
n = # of sampleunits (plots)
p = # of species
t = # of traits
e = # of environmentalvariables orfactors
d = # of dimensions
n x p n x e n x t n x d
t x p t x e
e x p
plots inspecies space plots in envir
spaceplots intrait space
plots inreducedspeciesspace
traits in species space
used for species inenvironmental space (A’E) traits in envir
space
d x pspecies in reducedplot space
Ordination can address more questions than how plots differ in composition…
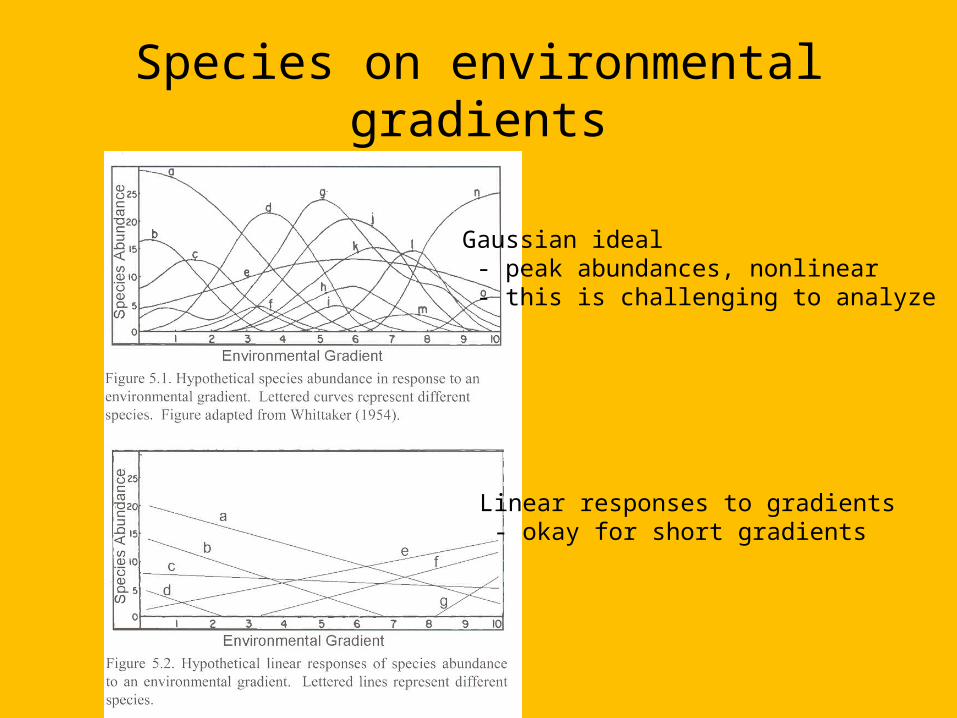
Species on environmental gradients
Gaussian ideal - peak abundances, nonlinear - this is challenging to analyze
Linear responses to gradients - okay for short gradients

Major Problems with Community Data
1. Species responses have the “zero truncation problem”
2. Curves are “solid” due to the action of many other factors
3. Response curves can be complex
4. High beta diversity
5. Nonnormal species distributions

Major Problems with Community Data
• species responses truncated at zero • only zeros are possible beyond limits• no info on how unfavorable the environment is for a species
• “curves” are typically solid envelopes rather than curves• species is usually less abundant than its potential (even zeros are possible)
1. Zero truncation 2. “Solid” curves

Major Problems with Community Data
3. Complex curves-polymodal, asymmetric, discontinuous
Average lichen cover on twigs in shore pine bogs in SE Alaska.

High beta diversity
• Beta diversity = the difference in community composition between communities along an environmental gradient or among communities within a landscape

Whittaker’s (1972) Beta Diversity
γ = number of species in composite sample (total number of species)ά = average species richness in the sample units
No formal units, but can be thought of as ‘number of distinct communities”
The one is subtracted to make zero beta diversity correspond to zero variation in species turnover.
Rule of thumb:βw < 1 are low, βw > 5 are high

Are species distributions normal?
• Univariate normality (it’s what we’re used to)
• Bivariate normality (it’s easy to visualize)
– Idealized community data– Real community data
• Multivariate normality (straightforward extension of bivariate normality to multiple dimensions)

Univariate normality
Normality can be assessed by:skewness (asymmetry), andkurtosis (peakiness)
Skew = 0Kurtosis = 0

Skewness
• Community data will nearly always be positively skewed due to lots of zeroes
• Linear models require |skew| < 1
• Assess skewness of data in PCORD (Row and Column Summary)

Positively skewed distribution typical of community data
PLHE
-0.1 0 .1 .2 .3 .4 .5 .6 .7
HYVI
0 .05 .1 .15
HYIN
-0.2 0 .2 .4 .6 .8 1

Bivariate Normality
Viewsfromabove

Bivariate Species Distributions
Idealized Gaussian species response curves
positive association negative association
bivariate distribution is non-linear dust bunny distribution-plotting one species against another (lots of points near orgin and along axes)

Bivariate Species Distributions
Realistic data with “solid” response curves
positive association negative association
dust bunny distributiondust bunny distribution
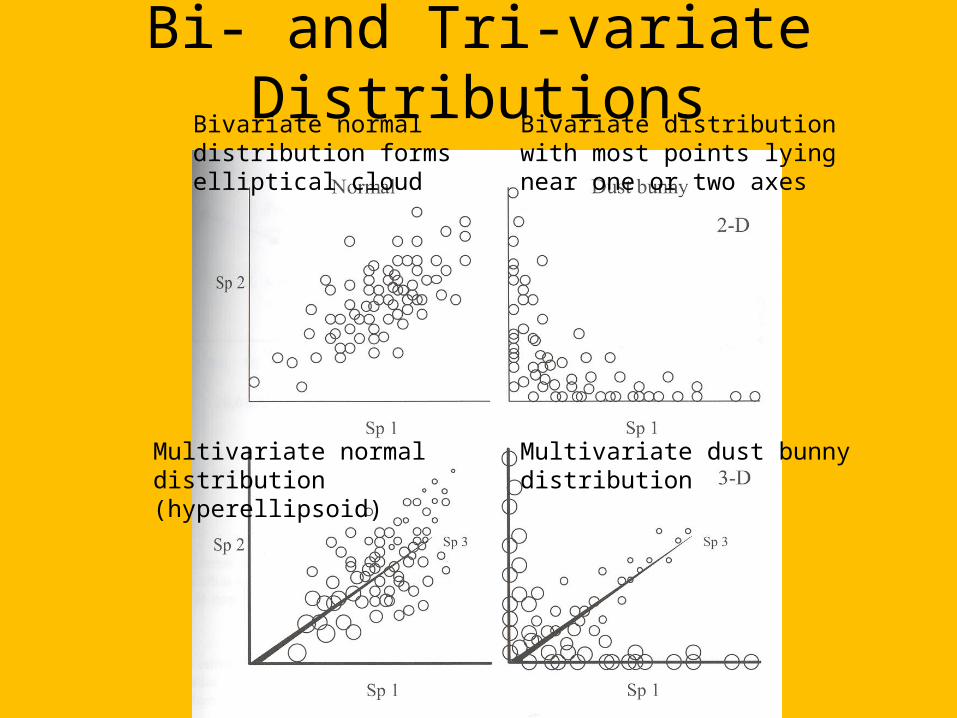
Bi- and Tri-variate DistributionsBivariate normal distribution forms elliptical cloud
Bivariate distribution with most points lying near one or two axes
Multivariate normal distribution (hyperellipsoid)
Multivariate dust bunny distribution

Dust bunny in 3-D species space
Environmental gradients form strong non-linear shape in species space

A: cluster within the cloud of points (stands) occupying vegetation space.
B: 3 dimensional abstract vegetation space: each dimension represents an element (e.g. proportion of a certain species) in the analysis (X Y Z axes).
A, the results of a classification approach (here attempted after ordination) in which similar individuals are grouped and considered as a single cell or unit.
B, the results of an ordination approach in which similar stands nevertheless retain their unique properties and thus no information is lost (X1 Y1 Z1 axes).
Key Point: Abstract space has no connection with real space from which the records were initially collected.

Multivariate Normality
• Linear algebra easily extends these concepts into multiple dimensions
• Most multivariate methods assume multivariate normality (linear ordination methods)
• Ecological data are seriously abnormal• Thus, we will often require different
methods





























