Embed Size (px)
Citation preview

Project No. 4Information discovery using
Stochastic Context-Free Grammars(SCFG)
Wei Du Ranjan Santra
May 16 2001

Why SCFG ?
More Powerful
– evolution processes of mutation, insertion, deletion
– interaction between basepairs
C A A AG A G A C G G C A U C G G C U A
GACGCAAGUCUCGGAAACGA

Problems can be solved by SCFG
• Scoring problem– compute P(x|G)– inside algorithm
• Alignment problem– find the most likely generating path – Cocke-Younger-Kasami (CYK) algorithm
• Training problem– parameter re-estimation– inside-outside algorithm

Normal Form for SCFG
• SCFGs can have unlimited symbols on the right hand side of the production
S ABC(0.9) A a(0.5) B b(0.8) C c(0.6)
• Chomsky Normal Form – requires all production rules to be of the form
W XY or W a
S AD (0.9)D BC (1.0)A a (0.5)B b (0.8)C c (0.6)

Example Grammar
A BA (0.4)
A CA (0.2)
A a (0.3)
A g (0.1)
B CA (0.4)
B g (0.3)
B t (0.3)
C CA (0.6)
C t (0.2)
C c (0.2)
A B C
a 0.3 0.0 0.0
g 0.1 0.3 0.0
t 0.0 0.3 0.2
c 0.0 0.0 0.2
G E
A
A B C
A 0.0 0.0 0.0
B 0.0 0.0 0.0
C 0.0 0.0 0.0
T B
A B C
0.4 0.0 0.0
0.0 0.0 0.0
0.0 0.0 0.0
C
A B C
0.2 0.0 0.0
0.4 0.0 0.0
0.6 0.0 0.0
grammar matrix

Inside Algorithm
Compute (i, j,)
– the probability of a subtree rooted with the non-terminal deriving the subword (xi… xj)
(i, j, ) = P( * xi… xj|G)
– computed recursively in a bottom up fashion starting with subwords of length one.
M M j-1
(i, j, ) = (i,k,y) (k+1,j,z)t (y,z) y=1 z=1 k=I

Inside Algorithm
• Basic Idea:– calculate P start with subsequences of
length 1– then subsequences of length 2– … … – continue working on longer and longer
subsequences– until, a probability is determined for the
complete parse tree rooted at the start non-terminal

Example for Inside Algorithm
• Input sequence: tag • Non-terminals: A B C
1. calculate P for subsequences of length 1
2. calculate P for subsequences of length 2
A t A a A g
B t B a B g
C t C a C g
B ta
A ag B ta B ag C ta C ag
3. calculate P for subsequences of length 3A tag
Copy from matrix E
A BA B ta A g A CA C ta A g
B CA C t A a
A ta

Outside Algorithm
Compute (i, j,)
– the probability that starting from the start non-terminal the non-terminal v is generated, and the string not dominated by it is (x1…xi-1) to the left and (xj+1…xL) to the right.
(i,j,v) = P( S * x1… xi-1vxj+1… xL|G).

Outside Algorithm
Compute (i, j,)
– computed recursively starting with the largest excluded subsequence
i-1
(i,j,v) = (k,i-1,z) (k,j,y) ty(z,v) + y z k=1
L
(j+1,k ,z) (i,k,y) ty(v,z). y z k=j+I
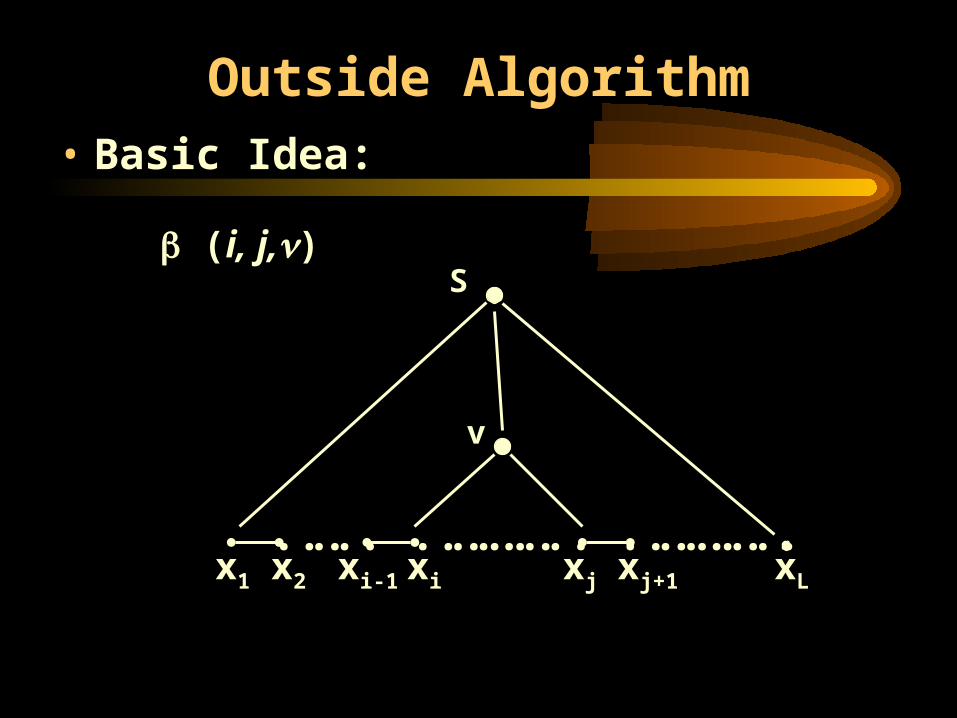
Outside Algorithm• Basic Idea:
...... ... ...x1 x2 xi-1 xi
... ...xj xj+1
... ... ... ...xL
S
v
(i, j,)

Outside Algorithm• Basic Idea:
...... ... ...x1 xk xi-1
...xj
... ... ...xL
S
z
(i, j,)
...xi
v
... ......
y
... ...... ...

Outside Algorithm• Basic Idea:
...... ... ...x1
xk
...xj+1
... ... ...xL
S
v
(i, j,)
...xi
z
... ......
y
... ...... ...xj

CYK Algorithm
• Basic Idea:– find the most likely generating path
starting with subsequences of length 1– then subsequences of length 2– … … – continue working on longer and longer
subsequences– until, a path is determined for the
complete parse tree rooted at the start non-terminal

Example for CYK Algorithm
• Input sequence: tag • Non-terminals: A B C
1. Find path for subsequences of length 1
2. Find path for subsequences of length 2
A t A a A g
B t B a B g
C t C a C g
B ta
A ag B ta B ag C ta C ag
3. Find path for subsequences of length 3A tag
Copy from matrix E
A BA B ta A g
B CA C t A a
A ta

References
1. [Brown and Wilson, 1995] Brown, M.P.S. and Wilson, C. Rna pseudoknot modeling using intersections of stochastic context free grammars with applications to database search. In Hunter, L. and Klein, T., editors. Pacific Synposium on Biocomputing, pages 109-1252. [Brown 1999] Brown, M.P.S., “RNA Modeling Using Stochastic Context-Free Grammars”, ph.D thesis.3. [Eddy and Durbin, 1994] Eddy, S. R. and Durbin, R. (1994). RNA sequence analysis using covariance models. NAR, 22:2079-2088.4. [Krogh et al., 1994] Krogh, A., Brown, M., Mian, I. S., Sjolander, K., and Haussler, D. Hidden Markov models in computational biology: Applications to protein modeling. JMB, 235:1501-1531.5. [Lowe and Eddy, 1999] Lowe, T. and Eddy, S. A computational screen for methylation guide snornas in yeast. Science, 283:1168-1171.6. [Sakakibara et al., 1994] Sakakibara, Y., Brown, M., Hughey, R., Mian, I. S., Sjolander, K., Underwood, R. C., and Haussler, D. Stochastic context-free grammars for tRNA modeling. NAR, 22:5112-5120.7. [Underwood, 1994] Underwood, R. C. Stochastic context-free grammars for modeling three spliceosomal small nuclear ribonucleic acids. Master thesis, University of California, Santa Cruz.

A Test System
• User interfaces
• Compute P(x|G)
• Find Viterbi path
Primary target: modeling a small sequence using SCFG



Display Grammar Window


Calculating Probability for “tag”

Calculating Probability for “tgacg”
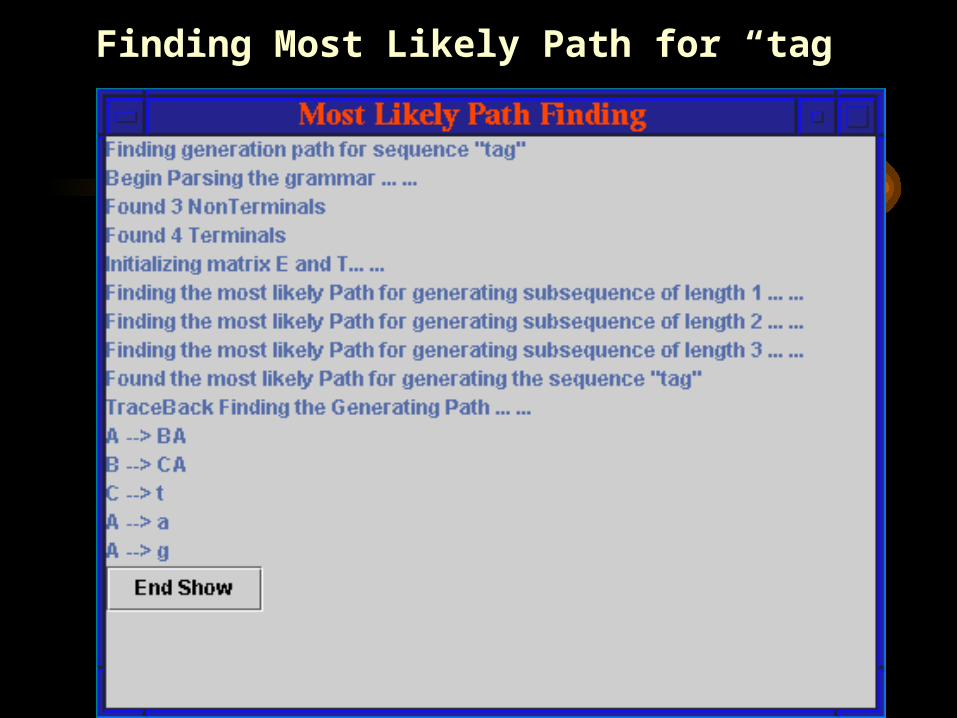
Finding Most Likely Path for “tag”

Finding Most Likely Path for “tgacg”

Finding Most Likely Path for “tgtacggta”

Training Algorithm
• Basic Idea:– an original grammar, G, which can model a family
of sequence, but not good enough– feed it with sequence x– compute the probability of P(x|G)– adjust the G to be G`





























