Embed Size (px)
Citation preview

Project 3
CS652 Information Extraction and Information Integration

Project3
Presented by:
Reema Al-Kamha
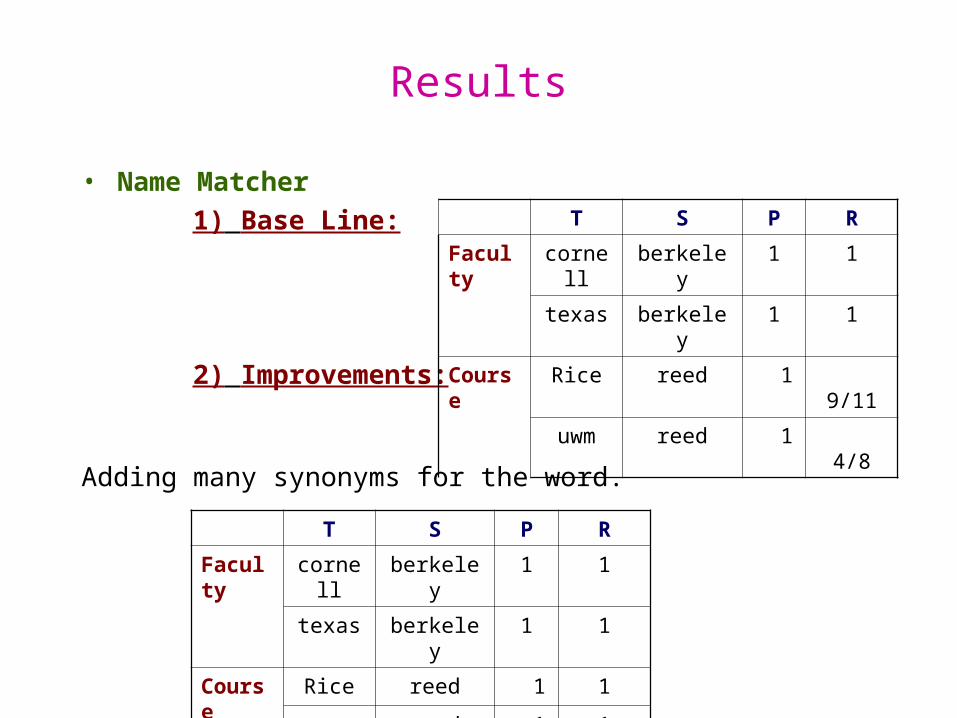
Results
• Name Matcher
1) Base Line:
2) Improvements:
T S P R
Faculty cornell berkeley 1 1
texas berkeley 1 1
Course Rice reed 1 9/11
uwm reed 1 4/8
Adding many synonyms for the word.
T S P R
Faculty cornell berkeley 1 1
texas berkeley 1 1
Course Rice reed 1 1
uwm reed 1 1

Results
• NB Model
1)Base Line: I treated the continents
of each row as one token .
2)Improvements:
T S P R
Faculty cornell berkeley 1 1/10
texas berkeley 1 2/10
Course Rice reed 1 1/11
uwm reed 1 2/8
T S P R
Faculty cornell berkeley 1 6/10
texas berkeley 1 6/10
Course Rice reed 1 6/11
uwm reed 1/5 5/8
Combination
T S P R
Faculty cornell berkeley 1 6/10
texas berkeley 1 6/10
Course Rice reed 1 1/11
uwm reed 1 2/8

Comments• I do not figure out how to distinguish start _time and end_time.
• I parse each row in XML to tokens.
• I got ride from all stop words (also got ride from .,;#.in vocabulary vector
• I get ride from suffix like Introduction to Intro.
• I do not insert the files that are in source but not in target.
• Sometimes I extract the key words in the documents and treat the document as if it only contains these words like in ward attribute.
• For some files attributes like code Attribute, I separate the numeric part from the letter part to let the code match subject in course application, and then I drop the numeric part.
• I had a lot of difficulties in using Java for this project because it was very slow.

Muhammed Al-Muhammed
• Two schema matching techniques were implemented, Name-matching and NB in Java.
• In general the type of the data help in achieving a good matching results.
• Two improvements done. More in the conclusion.
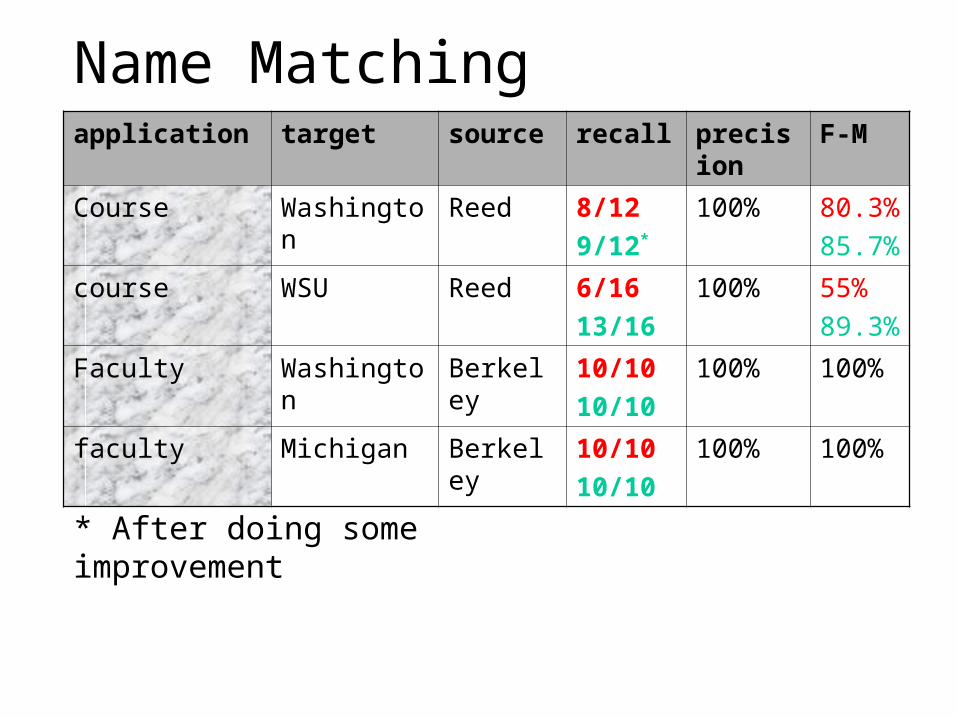
Name Matchingapplication target source recall precision F-M
Course Washington Reed 8/12
9/12*
100% 80.3%
85.7%
course WSU Reed 6/16
13/16
100% 55%
89.3%
Faculty Washington Berkeley 10/10
10/10
100% 100%
faculty Michigan Berkeley 10/10
10/10
100% 100%
* After doing some improvement
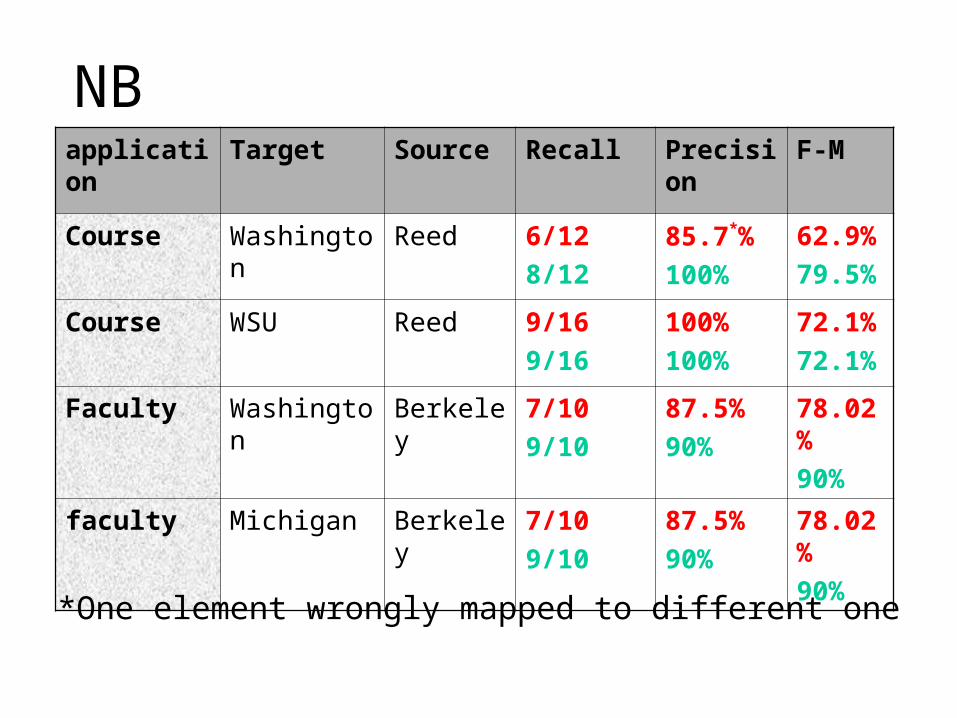
NBapplication Target Source Recall Precision F-M
Course Washington Reed 6/12
8/12
85.7*%
100%
62.9%
79.5%
Course WSU Reed 9/16
9/16
100%
100%
72.1%
72.1%
Faculty Washington Berkeley 7/10
9/10
87.5%
90%
78.02%
90%
faculty Michigan Berkeley 7/10
9/10
87.5%
90%
78.02%
90%
*One element wrongly mapped to different one

conclusions
• In general NB is better than NM• Two small improvements - Numerical ratio for the name matching - Building expected patterns for the data. “ help in improving NB matching”• Combining the two methods was helpful
but the results still not significant enough to argue for the combination.

Tim – Project 3 Results Name Matcher Improvements
• Word Similarity Function– Convert to lower case
– Combine:• Levenshtien edit distance – normalized to give %
• similar_text() – % of characters the same
– Soundex
– Longest Common Subsequence • Checks for substring
• Normalized to give %

Naïve Bayes Improvements
• Classify data instances– Use regular expession classifiers– 24 general classes
• Correspond to datatypes
• No domain specific classes
• long_string, small_int, big_int, short_all_caps, med_all_caps, init_cap, init_caps, …, short_string
– Used only Course data to create REs

Course Results
Domain: Course Test 1 Test 2 All 10 Tests (%)
P R P R P R F
Name Matcher Base 8/8 8/9 7/7 7/9 100 83 91
Naïve Bayes Base 3/9 3/9 5/9 5/9 48 48 48
Combined 3/3 3/9 4/4 4/9 100 41 58
Name Macher Improved 9/9 9/9 9/9 9/9 99 97 98
Naïve Bayes Improved 5/9 5/9 7/9 7/9 57 57 57
Combined 9/9 9/9 9/9 9/9 97 97 97

Faculty Results
Domain: Faculty Test 1 Test 2 All 10 Tests (%)
P R P R P R F
Name Matcher Base 10/10 10/10 10/10 10/10 100 100 100
Naïve Bayes Base 3/10 3/10 3/10 3/10 30 30 30
Combined 3/3 3/10 3/3 3/10 100 30 46
Name Macher Improved 10/10 10/10 10/10 10/10 100 100 100
Naïve Bayes Improved 5/10 5/10 8/10 8/10 73 73 73
Combined 10/10 10/10 10/10 10/10 100 100 100

Schema Matching
Helen Chen
CS652 Project 3
06/14/2002

Results from Name Matcher
Application Target Source # of Attr.
# of missing Attr.
Matched Recall Precision
Course wsh uwm 12 1 11 (8)* 11/11 11/11
Course wsu uwm 16 7 9 (8)* 9/9 9/9
Faculty wsh texas 10 0 10 10/10 10/10
Faculty mch texas 10 0 10 10/10 10/10
* The number in () is the # of matched before improvement

Results from Naïve Bayes
Application Target Source # of Attr. # of Missing Attr.
Recall Precision
Course wsh uwm 12 1 5/11 5/11
Course wsu uwm 16 7 5/9 5/9
Faculty wsh texas 10 0 5/10 5/7
Faculty mch texas 10 0 5/10 5/7

Comments
• Name matcher works fine in the given two domains with appropriate dictionary– Add stemming words, synonyms, etc. in the dictionary, make the words
case insensitive
• Naïve Bayes is not a good schema matching method in the given domains– Use words instead of tuples as token– Use thesaurus (count stemming words and synonyms as one token, ignore
cases)
• Improvements can be done– Use value characteristics (String length, numeric ratio, space ratio)
– Use Ontology

Yihong’s Project 3
• Course Domain:– Rice, 11 Washington, 12; (11/11 directly mapped)
– Rice, 11 WSU, 16; (9/11 directly mapped, 1/11 indirectly mapped, 1/11 not mapped)
• Faculty Domain – Cornell, 10 Washington, 10; (10/10 directly
mapped)
– Cornell, 10 Michigan, 10; (10/10 directly mapped)

Name Matcher
• Base line situation– Synonym list for each attribute name by training
– Add most common synonyms and abbreviations
– Compare with case-insensitive
• Improvement situation– Add more synonyms using WordNet
– String similarity computation
– Add a new category as “UNKNOWN”

Naïve Bayes
• Base line situation
– Each entry in Raw_text as a training unit
• Improvement situation– Remove stopwords
– Cluster special strings
– String similarity computation
– Add a new category as “UNKNOWN”
– Training size experiment
0.3
0.35
0.4
0.45
0.5
0.55
0.6
0 100 200 300 400 500 600
washington->rice
wsu->rice

Results Conclusion
Course Domain Faculty Domain
Rice
Washington
Rice
WSU
Cornell Washington
Cornell Michigan
P(11/11) R(11/11) P(11/11) R(9/9) P(10/10) R(10/10) P(10/10) R(10/10)
Name Matcher Base Line 8/11 8/11 8/11 8/9 10/10 10/10 10/10 10/10
Naïve Bayes Base Line 3/11 3/11 3/11 3/9 3/10 3/10 3/10 3/10
Combined 8/11 8/11 8/11 8/9 10/10 10/10 10/10 10/10
Name Matcher Improved 11/11 11/11 10/11* 9/9 10/10 10/10 10/10 10/10
Naïve Bayes Improved 6/11 6/11 6/11* 6/9 7/10 7/10 8/10 8/10
Combined 11/11 11/11 10/11* 9/9 10/10 10/10 10/10 10/10
Combination: random selection weighted by experimental accuracies

David Marble
CS 652
Project 3
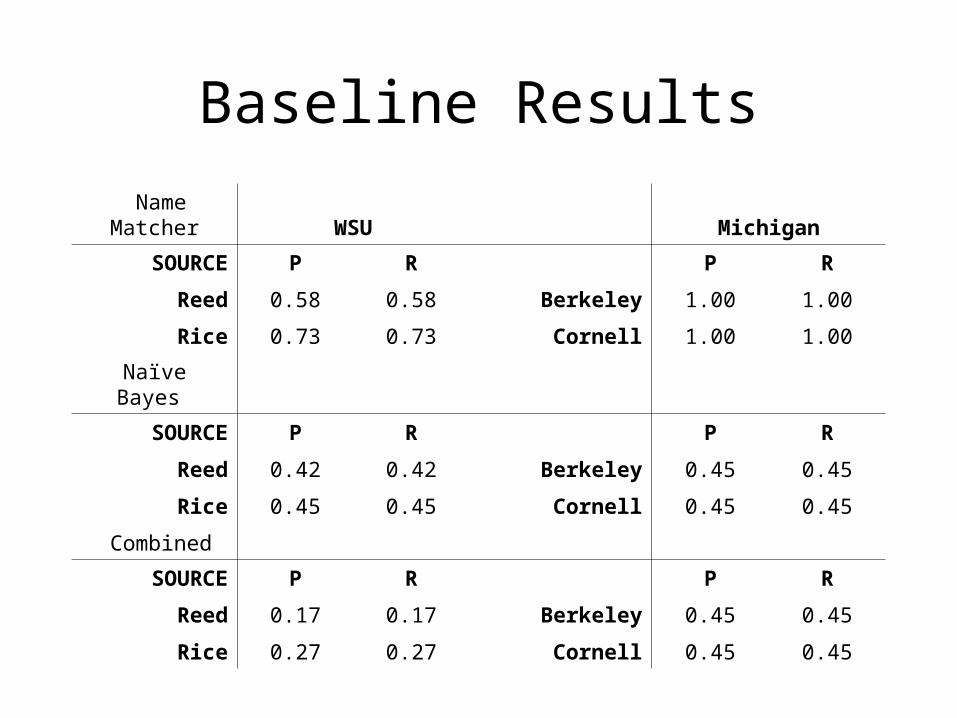
Baseline Results
Name Matcher WSU Michigan
SOURCE P R P R
Reed 0.58 0.58 Berkeley 1.00 1.00
Rice 0.73 0.73 Cornell 1.00 1.00
Naïve Bayes
SOURCE P R P R
Reed 0.42 0.42 Berkeley 0.45 0.45
Rice 0.45 0.45 Cornell 0.45 0.45
Combined
SOURCE P R P R
Reed 0.17 0.17 Berkeley 0.45 0.45
Rice 0.27 0.27 Cornell 0.45 0.45
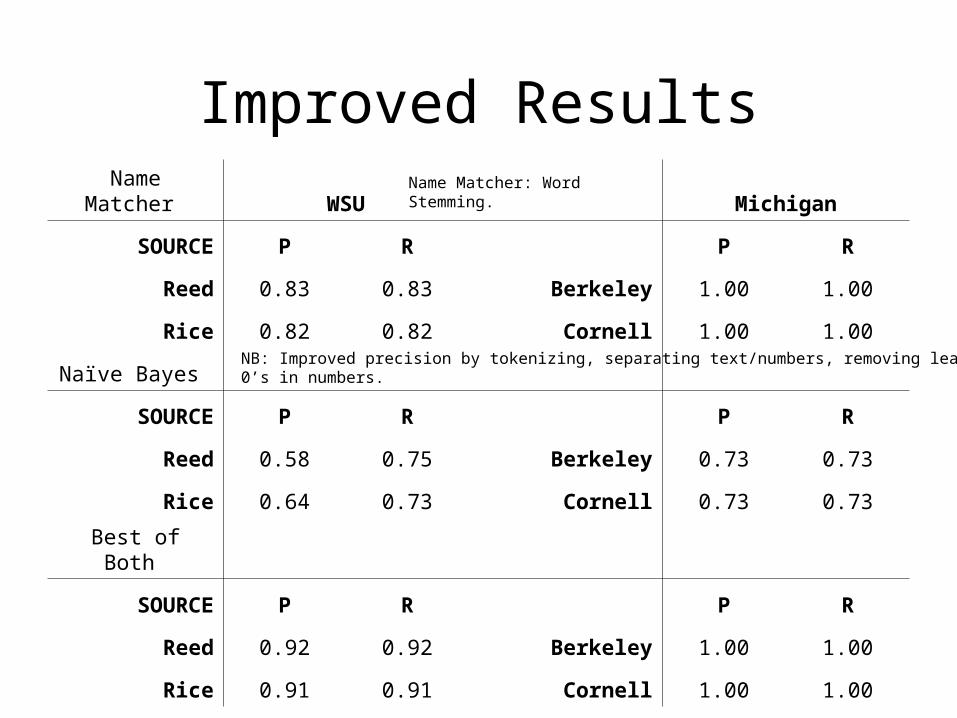
Improved Results
NB: Improved precision by tokenizing, separating text/numbers, removing leading 0’s in numbers.
Name Matcher: Word Stemming.Name Matcher WSU Michigan
SOURCE P R P R
Reed 0.83 0.83 Berkeley 1.00 1.00
Rice 0.82 0.82 Cornell 1.00 1.00
Naïve Bayes
SOURCE P R P R
Reed 0.58 0.75 Berkeley 0.73 0.73
Rice 0.64 0.73 Cornell 0.73 0.73
Best of Both
SOURCE P R P R
Reed 0.92 0.92 Berkeley 1.00 1.00
Rice 0.91 0.91 Cornell 1.00 1.00

Comments
• WSU happened to be the “weird” one.– Building names completely different– Faculty with odd last names, only a few first
names matched (not a lot of training names)
• Telephone #’s only matched when changing digits to “digit” instead of value.
• Start time, end time dilemma – why can’t schools run their schedule like BYU?

Craig Parker

Baseline Results
• Course 1– Recall = .6– Precision = 1
• Course 1– Recall = .66– Precision = 1
• Faculty– Recall = .8– Precision = 1

Modified Results
• Course 1– Recall = .7– Precision = 1
• Course 1– Recall = .78– Precision = 1
• Faculty– Recall = .8– Precision = 1

Discussion
• Modification of Name Matching involved a number of substring comparisons.
• Modifications improved results for both Course tests.
• Modifications did not change results for Faculty tests.
• Naïve Bayesian Classifier not well suited for all types of data (buildings, sections, phone numbers)

Schema Matching results
Lars Olson

Baseline test data
• Test 1 (Course: Washington Reed)– R = 3/9 (33%), P = 3/3 (100%)– room, title, days
• Test 2 (Course: Washington Rice)– R = 4/9 (44%), P = 4/4 (100%)– room, credits, title, days
• Test 3 (Faculty: Washington Berkley)– R = 8/10 (80%), P = 8/8 (100%)– name, research, degrees, fac_title, award, year, building,
title
• Test 4 (Faculty: Washington Cornell) (identical to Test 3)

After Improvements
• Test 1 (Course: Washington Reed)– Name matcher: R = 8/9 (89%), P = 8/8 (100%) (missed
schedule_line reg_num)
– Bayes: R = 4/9 (44%), P = 4/12 (33%) (also missed schedule_line)
• Test 2 (Course: Washington Rice)– Name matcher: R = 9/9 (100%), P = 9/9 (100%)
– Bayes: R = 4/9 (44%), P = 4/12 (33%)
• Test 3 (Faculty: Washington Berkley | Cornell)– Name matcher: R = 10/10 (100%), P = 10/10 (100%)
– Bayes: R = 8/10 (80%), P = 8/10 (80%)

Comments
• Improvements made:– Name matcher:
• Remove all symbols (e.g. ‘_’) from string
• Build thesaurus based on training set
– Bayes learner:• Attempt 1: classify all numbers together
• Attempt 2: replace all digits with ‘#’
• Idea: FSA tokenizer (to recognize phone numbers #######, times ##:##)
• Difficulties:– What are the correct matches? (e.g. restrictions comments)
– Aggregate matches were not included in recall measures

Jeff Roth
Project 3

Basic Results
Course - Target = Reed
Training = Rice, uwm, Washington
Source = wsu
Naïve Bayes: 7 / 12 correct, 6 / 16 FP
Name Classifier: 12 / 15 correct, 0 / 19 FP
Faculty - Target = Berkley
Training = Cornell, Texas, Washington
Source = Michigan
Naïve Bayes: 6 / 10 correct, 3 / 10 FP
Name Classifier: 14 / 14 correct, 0 / 14 FP
Course - Target = Rice
Training = Reed, uwm, Washington
Source = wsu
Naïve Bayes: 7 / 10 * correct, 5 / 16 FP
Name Classifier: 12 / 13 correct, 0 / 19 FP
Faculty - Target = Cornell
Training = Berkley, Texas, Washington
Source = Michigan
Naïve Bayes: 5 / 10 correct, 3 / 10 FP
Name Classifier: 14 / 14 correct, 0 / 14 FP

“Improved” Naïve Bayes
Course - Target = Reed
Training = Rice, uwm, Washington
Source = wsu
Naïve Bayes: 7 / 12 correct, 7 / 16 FP
Faculty - Target = Berkley
Training = Cornell, Texas, Washington
Source = Michigan
Naïve Bayes: 6 / 10 correct, 3 / 10 FP
Course - Target = Rice
Training = Reed, uwm, Washington
Source = wsu
Naïve Bayes: 7 / 10 * correct, 5 / 16 FP
Faculty - Target = Cornell
Training = Berkley, Texas, Washington
Source = Michigan
Naïve Bayes: 5 / 10 correct, 3 / 10 FP
Improvements:1. Classification = argmax (Log(P(vj) + Σ log(P(ai | vj))) - included in basic2. If a word in classification doc has no match,
classification = 1 / (2 * |vocabulary|) - no help3. Divide by number of words in test doc and find global max - scratched

Combination
Course - Target = Reed
Training = Rice, uwm, Washington
Source = wsu
Name Classifier: 13 / 15 correct, 0 / 19 FP
Faculty - Target = Berkley
Training = Cornell, Texas, Washington
Source = Michigan
Name Classifier: 14 / 14 correct, 0 / 14 FP
Course - Target = Rice
Training = Reed, uwm, Washington
Source = wsu
Name Classifier: 12 / 13 correct, 0 / 19 FP
Faculty - Target = Cornell
Training = Berkley, Texas, Washington
Source = Michigan
Name Classifier: 14 / 14 correct, 0 / 14 FP
Combination algorithm:1. Match source to target if both Naïve Bayes and name matcher agreed2. Match remaining unmatched target elements to source by name matcher3. Match any remaining unmatched target elements to source by Naïve Bayes

Schema Matching by Using Name Matcher and Naïve Bayesian Classifier (NB)
Cui TaoCS652 Project 3

Name Matcher
Application Mapping Precision Recall
Course UWMWashington
9/9 9/9
WSUWashington
9/9 9/9
Faculty TexasWashington
10/10 10/10
MichiganWashington
10/10 10/10
• Tokenization of names SectionNr Section, Nr; Start_time Start, time
• Expansion of short-forms, acronyms nr number, bldg building, rm room, sect section crse or crs course• Thesaurus of synonyms, hypernyms, acronyms
Nr Code, restriction limit, etc• Ignore cases
• Heuristic name matching (Cupid)Heuristic name matching (Cupid)

Naïve Bayesian Classifier• Improvement:
– Use tokens instead of tuples• Name:
– “Richard Anderson”, “Thomas Anderson”, “Thomas F. Coleman”;
– “Thomas”, “Richard”, “Anderson”, “F.”, “Coleman”.
• Building, degree, research, etc
– Eliminate stopwords– Stemming words: shared
substring at least 80% long in the whole word
– Ignore case
• Problems:– Names, building, etc
– Numbers: room, time,
code
– Keyword confusions:
research, award, title
– Different systems: room,
section number, etc
– Phone numbers (Can not
match by NB, but easy to
find the match by using
pattern recognition)
Application Mapping Precision Recall
Course UWMWashington
5/10 5/9
WSUWashington
6/7 6/9
Faculty TexasWashington
8/8 8/10
MichiganWashington
8/8 8/10

Conclusion
• Combine them together: – How: conflict follow name matcher– Result: all 100%
• Name matcher: works better for this application
• NB: may work better in indirect mappings

Project 3: Schema Matching
Alan Wessman

Baseline Results
• Course test set: UWM
• Faculty test set: Texas
Reed Rice Berkeley CornellName matcher 3/15 4/15 10/10 10/10NB 3/15 5/15 2/10 2/10
Course Faculty
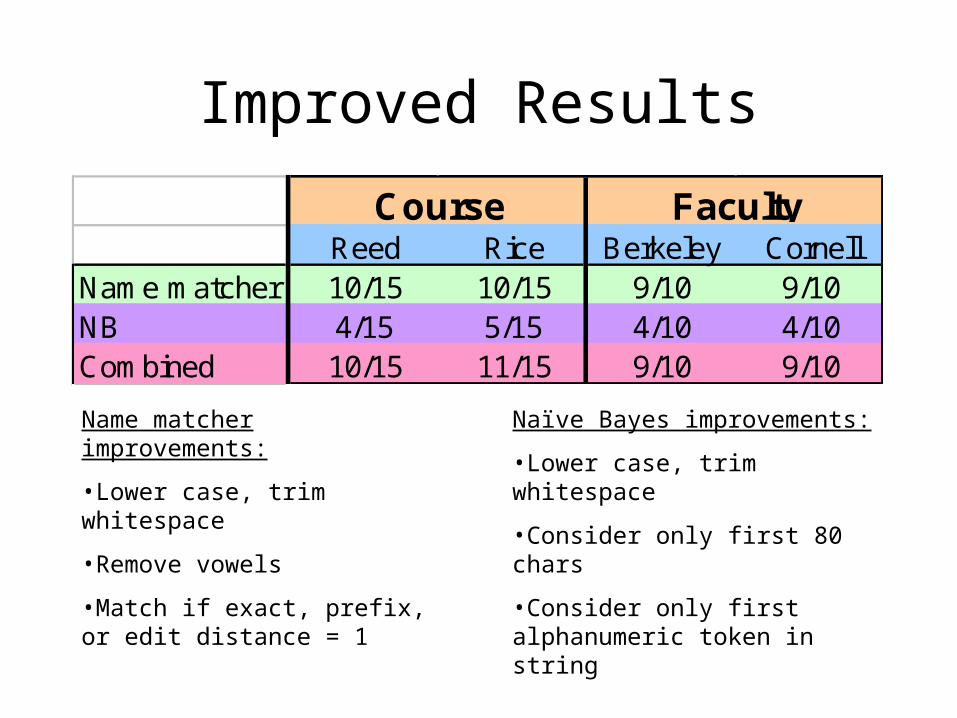
Improved Results
Reed Rice Berkeley CornellName matcher 10/15 10/15 9/10 9/10NB 4/15 5/15 4/10 4/10Combined 10/15 11/15 9/10 9/10
Course Faculty
Name matcher improvements:
•Lower case, trim whitespace
•Remove vowels
•Match if exact, prefix, or edit distance = 1
Naïve Bayes improvements:
•Lower case, trim whitespace
•Consider only first 80 chars
•Consider only first alphanumeric token in string

Commentary
• Improved name matcher effective– But performance decreases if too general
• Naïve Bayes not very useful– Fails when different attributes have similar values
(start_time, end_time, room, section_num)
– Fails when same attribute has different values or formats across data sources (room, comments)
• “Sophisticated” string classifier for NB failed miserably; worse than baseline so I threw it out!

CS 652 Project #3Schema Element Mapping -- By Yuanqiu (Joe) Zhou
ApplicatoinTarget Schema
Num of Target
Elements
Source Schema
Num of Source
Elements
Num of expected mapping
Recall Precision
Course UWM 15 WSU 16 10 6/10 6/13
Course Washington 12 WSU 16 10 7/10 7/13
Faculty Texas 10 Michigan 10 10 8/10 8/10
Faculty Washingotn 10 Michigan 10 10 8/10 8/10
Base Line Experimental Results

CS 652 Project #3Schema Element Mapping -- By Yuanqiu (Joe) Zhou
Improvement (at least tried) Name Matcher
Using simple text transformation functions, such as sub-string, prefix and abbreviation
NB ClassifierPositive Word Density ( does work at all, )Regular expressions for common data types, such as time, small
integers and large integers Combination
Favor name matcher over NB classifierNB classifier can be used to break the tie by name matcher (such
as sect section, sect section_note)

CS 652 Project #3Schema Element Mapping -- By Yuanqiu (Joe) Zhou
ApplicatoinTarget Schema
Num of Target
Elements
Source Schema
Num of Source
Elements
Num of expected mapping
RecallPrecisio
n
Course UWM 15 WSU 16 10 10/10 10/10
Course Wash 12 WSU 16 10 10/10 10/10
Faculty Texas 10 Michigan 10 10 10/10 10/10
Faculty Wash 10 Michigan 10 10 10/10 10/10
Experimental Results with Improvements

CS 652 Project #3Schema Element Mapping -- By Yuanqiu (Joe) Zhou
• High precisions and recalls result mostly from improvements to Name Match
• Improvements to NB classifier did not contribute too much (only correct one missed mapping for one course application)
• NB classifier is not suited to distinguish the elements with similar data type (such as time and number) or the elements sharing many common values
• Reducing the size of training data can achieve the same precision and recall with less running time
Comments





























