Embed Size (px)
Citation preview

Progress in Computa0onal Seman0cs: Structured Distribu0ons and their
Applica0ons
Eduard Hovy Carnegie Mellon University

NLP has had an amazing history • Started in the late 1950s with MT • Today:
– General web search (Baidu, Google, Yahoo!...)
– General MT of understandable quality – Usable speech recogni0on (Apple’s SIRI…) – Robust dynamic R&D community (maybe 10,000+ university-‐ and corporate-‐style researchers?)
– Ongoing R&D funding
• So, where next?

What can NLP do well today?
• Surface-‐level preprocessing (POS tagging, word segmenta0on, NE extrac0on, etc.): 94%+
• Shallow syntac0c parsing: 92%+ for English (Charniak, Collins, Lin) and deeper analysis (Smith)
• IE: ~40% for well-‐behaved topics (MUC, ACE) • Speech: ~80% large vocab; 40%+ open vocab, noisy input
• IR: 40%+ (TREC) • MT: ~70% depending on what you measure • Summariza7on: ? (~60% for extracts; TAC) • QA: ? (~60% for factoids; TREC)
90s–
00s–
80s–
80–90s 80–90s
80s–
90–00s
00s–

What can NLP not do today?
• Do general-‐purpose text genera7on • Deliver long/complex answers
– e.g., extrac0ng, merging, and summarizing web info
• Handle extended dialogues • Read, remember, and learn (extend own knowledge) • Use pragma7cs (style, emo0on, user profile…) • Deliver seman7cs—either in theory or in prac0ce
– (not even seman0c analysis of mul0ple sentences)
• Contribute to a theory of Language (in Linguis0cs or Neurolinguis0cs) or Informa7on (in Signal Processing)
• etc…

Why? Maybe because NLP s0ll works at the word level
• Most NLP is nota7on transforma7on: – IF [word and/or features] à [transformed result] – Features: part of speech label (noun, verb…), seman0c type (person, loca5on…), simple sen0ment value (pos, neg…), etc.
• Sta0s0cs / machine learning is currently the main paradigm
• Too liFle thinking about knowledge and founda7ons – Most work is algorithm hacking or small-‐problem explora0on (the HOW, not the WHY)

Where next? My bet is on seman0cs
• Today: illusion that NLP systems ‘understand’ through – clever problem decomposi0on – use of resources like WordNet, online dic0onaries, PropBank…
• To do more than surface-‐level transforma0on, system needs knowledge that is not explicitly in the input: – Some external informa0on resources – Some fuzzy matching for almost-‐iden0cal cases – Some inference capability

What is seman0cs?
dream green ideas furiously colorless • Syntax: rules of grammar
colorless green ideas dream furiously • Seman7cs: meaning
5red old men dream peacefully • Pragma7cs: meaning anchored in context
• Important concepts: – Lexical seman7cs: meaning of each word alone – Composi7onal hypothesis: can compose meanings to build larger meaning, recursively

Some seman0c phenomena Somewhat easier Bracke0ng (scope) of predica0ons Word sense selec0on (incl. copula) NP structure: geni0ves, modifiers… Concepts: ontology defini0on Concept structure (incl. frames and
thema0c roles) Coreference (en00es and events) Pronoun classifica0on (ref, bound, event,
generic, other) Iden0fica0on of events Temporal rela0ons (incl. discourse and
aspect) Manner rela0ons Spa0al rela0ons Direct quota0on and reported speech
More difficult Quan0fier phrases and numerical
expressions Compara0ves Coordina0on Informa0on structure (theme/rheme) Focus Discourse structure Other adverbials (epistemic modals,
eviden0als) Iden0fica0on of proposi0ons (modality) Opinions and subjec0vity Pragma0cs/speech acts Polarity/nega0on Presupposi0ons Metaphors

Outline
1. Introduc0on 2. Need for usable computa0onal seman0cs 3. Distribu0onal models 4. Challenges and explora0ons 5. An applica0on

NEED FOR USABLE COMPUTATIONAL SEMANTICS

Two major types of seman0cs in NLP
• Proposi0onal (logic-‐based) – Origin in mathema0cal logic – Statements describe asser0ons about the world – Usually built by hand
• Distribu0onal (sta0s0cs-‐based) – Origin in large-‐scale word co-‐occurrences – Word groupings describe quasi-‐seman0c items (topics, etc.)
– Data built by machine

1. Tradi0onal proposi0onal seman0cs • Proposi0ons are logical statements about events, en00es, and quali0es in the domain – These elements are related, to form seman0c networks – Representa0on in two styles: logical clauses or frames – Rep. includes terms and operators ( , AND, NOT…), nes0ng – Oren, the elements are defined in an ontology
Ε
( e0 (atack e0 x0 x1 x2) (not e0) (Kurds x0) (military-‐unit x1) (member-‐of x1 x4) (Turkish-‐Army x4) (Iraq x2))
Ε
Clauses: Kurds did not aFack a military unit of the Turkish Army in Iraq
Frame:
(e0 :type atack :agent Kurds :pa0ent (x1 :type military-‐unit :member-‐of Turkish Army) :polarity NEG :loc Iraq)

Difficul0es for denota0onal models
The green table is strong
( e0) (have-‐property e0 x0) (table x0) (green x0) (strong x0)
(x0 (:type table) (:color green) (:strength +5))
Logic:
Frame:
Ε What is a table? What is ‘greenness’? What is ‘strength’? What is this mapping?
?

The trouble with tradi0onal seman0cs
1. Symbols themselves are ‘empty’ – No content for symbols in the nota0on: one cannot within the proposi5ons work with their content
– For example, interac0ons between nega0on, modali0es, etc., on par0cular aspects of content remains hidden
2. Symbols are discrete – Yet meanings are shaded, spread in a con0nuum toward different direc0ons of nuance
3. Seman7c theories show no direct connec7ons with psycholinguis7c or cogni7ve phenomena – No obvious explana0ons for confusions, forgexng, degrees of processing complexity, etc.

• Basic model from Firth: { Tk, (wk1,sk1), (wk2,sk2), … , (wkn,skn) }
bank1 = {(money 0.7) (deposit 0.4) (loan 0.2) …} bank2 = {(depend 0.3) (help 0.1) (lean 0.4) …} bank3 = {(turn 0.3) (veer 0.1) (angle 0.1 ) …}
• Word associa0ons can represent words, word clusters, sentences, documents, even whole topics – Values create a con0nuum of seman0c distance – IR works because it uses this weak form of seman0cs!
• Essen0ally this is clustering in lexical space, using some distance measure: freq counts, }.idf, PMI…
2. Distribu0onal ‘seman0cs’ “You shall know a word by the company it keeps”—Firth (1957)

Distribu0onal seman0cs in NLP
• Increasingly, NLP researchers are simply using the frequency distribu5ons of associated words as the (de facto) ‘seman0cs’ of a word – Build the ‘word families’ of the target element (word, wordsense, phrase, topic, etc.)
– Some0mes differen0ate between ler and right contexts – General approach: treat as ‘the same’ or ‘matching’ all the en00es (wordsenses, etc.) whose associated word families are the same
– Values in distribu0on give con0nuum of seman0c distance
• Many applica0ons: – Wordsense disambigua0on, MT, sen0ment recogni0on, entailment, paraphrase discovery…

KWIC incessant noise and bustle had abated. It seemed everyone was up after dawn the storm suddenly abated. Ruth was there waiting when Thankfully, the storm had abated, at least for the moment, and
storm outside was beginning to abate, but the sky was still ominous Fortunately, much of the fuss has abated, but not before hundreds of , after the shock had begun to abate, the vision of Benedict's
been arrested and street violence abated, the ruling party stopped he declared the recession to be abating, only hours before the
‘soft landing’ in which inflation abates but growth continues moderate the threshold. The fearful noise abated in its intensity, trailed
ability. However, when the threat abated in 1989 with a ceasefire in bag to the ocean. The storm was abating rapidly, the evening sky ferocity of sectarian politics abated somewhat between 1931 and storm. By dawn the weather had abated though the sea was still angry
the dispute showed no sign of abating yesterday. Crews in
17

Problems with distribu0onal models
1. Not discrete enough: – Topic/word models have no clear boundaries – There’s no good way to evaluate LDA (etc.) output because in principle a topic can be refined infinitely
2. Not composi7onal (so: not a real seman7cs): – No nes0ng of structures – How to ‘add’ two distribu0ons?
3. No operators (nega0on, modality, etc.)

For seman0cs: What would we like? • Combine proper7es of proposi7onal seman7cs and distribu7onal approach
• From tradi0onal logic-‐based KR: – Formal proposi0ons consis0ng of symbols – Each symbol represents a concept or rela0on – Can compose symbols into complex representa0ons
• From modern sta0s0cal NLP: – Vectors of word distribu0ons, with weights – Each symbol carries its ‘content’ explicitly – Symbol contents that are not discrete
• With links to other fields: – Conform with psycholinguis0c and cogni0ve findings – Provide basis for Informa0on Theory measures of info content

DISTRIBUTIONAL MODELS

3 Approaches
1. Vectors – Easy to build and use – Many simple similarity/distance metrics
2. Embeddings – No terms, just vector of latent values/dimensions – Learn values using neural network, new for each task
3. Tensors – Generalize vectors, making rela0ons explicit
bank1 = {(money 0.7) (deposit 0.4) (loan 0.2) …}

Vector space distance measures 1

Vector space distance measures 2

Embeddings • Instead of vector with predefined representa0on terms, use
vector of latent values/dimensions:
• Train values with neural network – Different embedding representa0on for each task – Vector contents not interpretable – Generally beter performance than explicit word vectors
• Originally from image processing – Examples: Bengio et al., Collobert and Weston
• Public resources: – SENNA collec0on (Collobert and Weston) – Word2vec sorware (Mikolov et al.)

Tensors: Structured Distribu0onal Seman0c Model (SDSM)
• Hypothesis: Structuring the distribu0onal vector gives greater seman7c expressability and interpretability – Break up the vector into a tensor (a set of vectors, one for each rela0on):
X = { (w1 S1) (w2 S2) (w3 S3) (w4 S4) …}
X = {X1 :r1 ((w1 S1) (w3 S3 …) :r2 ((w2 S2) (w5 S5) …) :r3 ((w4 S4) (w6 S6) …) …}
dog = {[breed: (collie 0.4) (labrador 0.6) …] [agent-‐of: (bark 0.5) (pant 0.2) …] [pa5ent-‐of: (feed 0.2) (pet 0.3) …] [owner-‐of: (bone 0.3) …] …}

Relevant past work • Linear (vector) distribu0ons:
– Topic Models and other uses of LSA: Deerwester et al., 1990; Landauer et al., 1998
– Topic Signatures: Lin and Hovy, COLING 2000; Agirre et al., 2000 – Probabilis0c LSA and other variants – Topic models by LDA: Blei et al., 2003
• Structured distribu0ons: – Lin and Pantel, 2003 – Navigli, 2008 – Erk and Pado, 2008 – Baroni and Lenci, 2010 – Turney and Pantel, 2010 – Many others…
• Embeddings: – Collobert and Weston, 2007 – Bengio et al. – Socher and Manning – Mikolov et al. – Others…

Vectors, embeddings, or tensors? A dilemma
• Vectors are easy to make, and can be composed in various ways, but they don’t have nes0ng structure, so no seman0cs
• Embeddings compose easily and give best empirical results, but they are not interpretable and also have no internal structure
• Tensors have structure and are interpretable, but they may not compose above a certain level

CHALLENGES AND EXPLORATIONS

Building the SDSM: The PropStore
• Contents: – Words, lemmas, supertags, POS tags – [words x words x syntac0c rela0ons] – Current size (English): ~4 billion triples in 800 databases (~2TB) – Mul0ply indexed for rapid retrieval and vector/tensor assembly
• 3 languages: – English: Currently used all of Simple Wikipedia + parts of Wikipedia +
parts of ClueWeb-‐09 – Spanish: Spanish Wikipedia + AnCora corpus and senses – Chinese: Chinese Wikipedia
• We build the PropStore: Can extract arbitrarily complex structures and their counts
Goyal et al., ACL 2013

Construc0on procedure 1. Take a lot of domain text 2. Parse every sentence (dependency parse) 3. (Convert the syntac0c and prep rela0ons
to seman0c ones) 4. Cut up the dependency tree into [head-‐rel-‐mod] triples 5. (If needed, combine triples into proposi0ons) 6. Save every triple/prop:
[rel head mod 1 doc-‐id sent-‐id] 7. When done, add together all the iden0cal triples/props:
[rel head mod total ((doc-‐id1 sent-‐id1) (doc-‐id2 sent-‐id2) …)] 8. Regroup as needed (e.g., sort under the heads):
[head (rel (mod1 total1) (mod2 total2) …) ((doc-‐id1 sent-‐id1)…)] (rel (mod1 total1) (mod2 total2) …) ((doc-‐id1 sent-‐id1)…)]
(eat nsubj dog 15 (…)) (eat nsubj child 34 (…)) (eat nsubj Joe 2 (…)) (eat dobj salad 24 (…)) (eat dobj meat 195 (…)) (eat dobj pizza 35 (…)) (eat instr fork 93 (…)) (eat instr chops0ck 54 (…)) (eat instr knife 101 (…)) (eat instr hand 12 (…)) …

Moving toward seman0cs
dog = {[breed: (collie 0.4) (labrador 0.6) …] [nsubj: (bark 0.5) (pant 0.2) …] [dobj: (feed 0.2) (pet 0.3) …] [owner-‐of: (bone 0.3) …] …} Gramma0cal or
seman0c roles?
Word/sentence/topic or concept?
Words or concepts?
‘Strength’ or probability?
DOG1 = {[breed: (collie 1.0)] [name: (“Lassie” 1.0)] [dobj: (perform 0.3) feed 0.2) …] [owner-‐of: (bone 0.3) …] …}
EVENT1 = { [type: eat1] [agent: DOG1] [pa5ent: BONE12] [loc: PARK15] …}
How to compose?

Inves0ga0ng structured distribu0ons
• Our research agenda: – Strength or probability?
• What counts/probabili0es to use? How to normalize? – How to compose elements into larger ‘meanings’?
• How ‘high’ can one compose? What composi0on machinery works best?
– Becoming seman7c: words or concepts? • Word-‐senses, not words? Seman0c rela0ons?
– What about data sparsity? • How to compress the empty space? Are embeddings beter?
– Evalua0on: Test them in applica7ons

• Basic term weights normalized three ways: – Row Norm: – Full Norm: – Collapsed Vector Norm:
• Composi0on of terms in complex structures: – Compose triple-‐sized units and propagate head upward
1. Strengths or probabili0es?

2. Composing elements into larger ‘meanings’
• Want to define an ‘algebra of meaning deriva0on’: just like physicists compute the behavior of the external world, we want to compute the ‘external’ meanings of word composi5ons: A <– B ¤ C
• Problem: “brown” ¤ “cow” is not just a brownish cowishness, but is a cow with color brown whose breed is not Friesian but probably Brahmin or HerDordshire: how does “brown” know to modify the breed when it combines with “cow”?

Methods of composi0on
• Basic idea: Compare task performance of computed composi0on against naturally composed elements to learn best composi0on func0on(s)
• Vectors: Simple algebra to add or mul0ply counts or scores; complex quantum techniques (Mitchell and Lapata; Reddy; Erk and Pado; Baroni and Lenci; Grefenstete et al.; …)
• Embeddings: Neural networks (Socher et al.; Dasigi and Hovy):

Tensors: Measuring similarity of structured ‘meanings’
Big goal: Is “he died” = “he kicked the bucket”? Goal: Capture lexical similarity between two parse trees: • Compare parse trees simultaneously for syntac0c tree structure +
seman0c word vectors
• Tradi0onal tree kernels count common syntac0c substructures, but with discrete matching of node labels
• Distribu0onal matches compare vectors for words, but ignore structure

Vector Tree Kernel • Approach:
– Enumerate all common walks between the two trees • Speedup algorithm: Define bijec0ve mapping from common walks to walks on the product graph
– Define Vector Tree Kernel func0on that combines tree posi0on and node vector informa0on
• Walks with similar words in similar posi0on are similar • Distribu0onal vectors give lexical similarity
– Word vector representa0on: • SENNA embeddings (Collobert and Weston)
– Advantages: • Incorporates both syntax and seman0cs • Allows many-‐to-‐one/one-‐to-‐many mappings
• Evalua0on: – Three rather different NLP tasks:
• Sentence polarity iden0fica0on • Paraphrase detec0on • Metaphor iden0fica0on
Srivastava and Hovy, EMNLP 2013 and ACL 2014

3. (Latent) seman0c rela0ons • Ideally, use seman0c rela0ons
– Which ones? How many? – Open linguis0c debate
• (case roles, FrameNet, etc.) – No robust seman0c parsers
• (SRL too limited) – All previous work uses syntax (nsubj, dobj, etc.)
• Proposed solu0on: Latent seman0c rela0ons – No need to specify which rela0ons—system will find them
– Can easily specify how many you want, and cross-‐validate op0mal number
– Our method: no need for any external annota0ons
Jauhar et al., COLING 2014

Latent Rela0on Analysis • Like LSA, but focus on rela0ons between pairs of words:
– LSA groups words into similar topics – LRA groups word pairs into similar rela0ons
• Use rela0on paterns, like “is a kind of”: – football is a kind of sport – apple is a kind of fruit – spoon is a kind of utensil
• Select ‘meaningful’ word pairs from cross product of 4500 common English words in Gigaword + Wikipedia
• LRA (Turney, 2005) learns analogical reasoning by harves0ng these paterns: – Apply SVD to patern matrix to produce latent dimensions – Select K = 130 top singular values (empirically op0mized)
?X is a kind of ?Y

Results (seman0c tensors)
• Evalua0on: Apply latent seman0c rela0on tensors to two lexical seman0c tasks:
• This model outperforms others in evalua0on
– Word similarity – WS-‐353: carpenter : wood :: mason : [feather | stone | drinking…] ?
– Synonym selec0on – ESL: rug ?= {sofa | carpet | chair…}
Model
WS-‐353 (Spear-‐man’s ρ)
ESL (%
accuracy)
Random 0.0 25
DSM 17.9 28
synSDSM 31.5 27
SENNA 51.0 38
LR-‐SDSM 58.6 51

How many dimensions? • Rela0ons redefined in terms of latent dimensions • Expt: Rela0on classifica0on
– SemEval-‐2012 Task 2 dataset • 933 word-‐pairs in 9 classes; Ex: Part-‐Whole —> engine::car
• Op0mal range: 100–150 latent dimensions for both tasks
Random Vector Diff.
Vectors SENNA Latent Rela5on SDSM Add Mul Add Mul
Prec. 0.11 0.27 0.42 0.38 0.49 0.42 0.43
Recall 0.11 0.34 0.45 0.44 0.52 0.46 0.48
F-‐1 0.11 0.29 0.43 0.38 0.50 0.43 0.44
Acc. 11.0 34.3 44.9 44.3 51.5 45.6 47.5

How many latent dimensions? • Rela0ons redefined in terms of latent dimensions • Op0mal range: 100–150 latent dimensions for both tasks

Mapping latent rela0ons
• Can handle many / all kinds of unusual word pairs, even unusual rela0ons
• So what about the rela0ons we know? – Mul0dimensional scaling plot of known seman0c rela0ons shows recognizable clusters – Dataset: SemEval 2012 Task 2 – Seem to cluster as we expect
Correla0on distance between classifier weights for different rela0ons
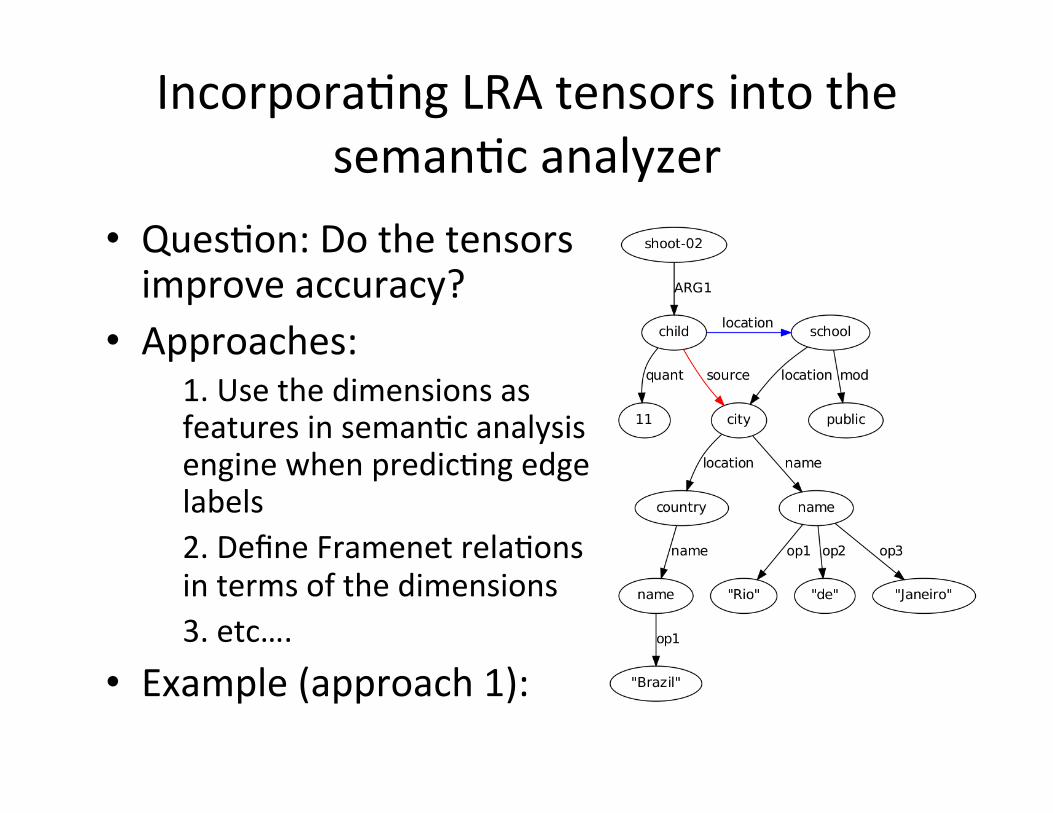
Incorpora0ng LRA tensors into the seman0c analyzer
• Ques0on: Do the tensors improve accuracy?
• Approaches: 1. Use the dimensions as features in seman0c analysis engine when predic0ng edge labels 2. Define Framenet rela0ons in terms of the dimensions 3. etc….
• Example (approach 1):

4. Sparsity: Dimensionality reduc0on • Problem: PropStore cube is only 2% full! This space is huge
– The 240k defining dimension is too large! • Tried various techniques
– SVD • Matrix (2-‐d tensor) SVD • On structured word co-‐occur matrix
– N-‐mode tensor SVD • Extension to matrix SVD: tensor N-‐mode flatening • New tensor the core tensor, analogous to a conven0onal singular value matrix • Un contains the orthonormal vectors spanning the column space of matrix D(n)
– Tucker Decomposi0on • Best results achieved: around 600–800 defini0on dimensions

AN APPLICATION

Goal: Detect anomalous events
• Novel = first report, not seen before, not co-‐referen0al – Ingredients: similarity fn, event history, co-‐reference, …
• Anomalous = unexpected or surprising event, whether 1st or subsequent men0on – Ingredients: frame parsing, event history, seman0c similarity fn, co-‐reference, …
Event Novel? Anomalous?
Two Syrian soldiers shot by rebels (1st men0on) Yes (new) No (expected)
Two soldiers in Syria shot by rebels (5th men0on) No (old) No (expected)
Congresswoman Gifford shot in Arizona (1st men0on) Yes (new) Yes (surprising)
Shoo0ng of Congresswoman in Arizona (5th men0on) No (old) Yes (surprising)

Must go beyond single slot-‐fillers • Anomaly occurs with an unexpected or unusual combina0on of seman0c role fillers at the right level
• Cannot just look at lexical level; level of generality of slot fillers is important: – [Two soldiers] [shoo0ng] [one another] => normal – [People] [shoo0ng] [one another] => normal
– [Soldiers] [shoo0ng] [in a military camp] => normal – [Soldiers] [shoo0ng] [anywhere] => normal
– [Two soldiers of the same country] [shoo0ng] [one another] => not too abnormal
• Cannot look at slot fillers in isola7on: combina0on is important: – [Two soldiers of the same country] [shoo0ng] [one another] [in a military camp] => not normal

Approach: Neural Event Model NEM
• Approach: – Iden0fy event plus its core facets – Represent words using distribu0onal seman0cs
• Experiment with embeddings, tensors, etc. – Train RNN to recognize typical facet combina0ons – For new event, apply RNN to measure degree of ‘unusualness’
• Corpus and evalua0on: – Created corpus from weird news headlines – Validated with Amazon MTurk
Dasigi and Hovy, COLING 2014

Training data Gigaword Headlines
• US Senate vote on Bonsia “internal” mater says Juppe
• Japanese expect profits to recover arer dismal year
• Otawa gives a new chance to refugees threatened with deporta0on
• Gulf Air sees record year, expands to Asia
“Weird” news headlines
• Missing woman found dead behind bookcase
• Sea lion bites at least 14 at California lagoon
• India weaponizes world’s hotest chili
• Man recovering arer being shot by his dog
Source: NBC News www.nbcnews.com/news/weird-‐news/, 3684 headlines

Confirming the test data
• Gave test data (incl. weird news) to human annotators from MTurk
• HIT required choosing one of four op0ons for each event: – Highly unusual if the event seemed too strange to be true
– Strange if the event seemed unusual but plausible
– Normal – Cannot say if the informa5on provided is not sufficient to make a decision
Number of events 1003
Number of annotators 22
Avg events per annotator 344
Normal 56.3%
Strange 28.6%
Highly Unusual 10.3%
Cannot Say 4.8%
4-way IAA (α) 0.34
3-way IAA (α) 0.56

Baselines • Can the same results be obtained by simpler means? • Experiment 1: Language model preferences:
– Built two LMs (for normal and anomalous sentences) – Datasets same as the ones used for training NEM – Classified each sentence according to which model likes it beter:
• Experiment 2: Perplexity: – Built LM from large corpus – Compared perplexi0es – No clear perp. difference between
normal and anomalous sentences
Language Models NEM
Classifica0on accuracy 49.6 65.4
Anomaly precision 39.5 56.5

Neural Event Model
• Event structure obtained by SRL • Two-‐stage RNN training:
1. Each role filler from the NPs 2. En0re sentence from the fillers
• Anomaly decision: Logis0c regression at top, to classify if event is anomalous

Training 1: Argument composi0on • Phase 1: Recursive Neural Networks (Goller and Küchler, 1996;
Socher et al., 2012) – RNN is a structured deep neural network backed by a tree structure – Training done using back-‐propaga0on – Parameters for each argument: Warg, barg, Sarg, V
• Training objec0ve similar to Contras0ve Es0ma0on (Smith and Eisner, 2005): replace a part of a normal sentence to achieve an abnormal one: – s = score(Two Israeli helicopters
killed 17 soldiers) – s = score(Two persuade helicopters
killed 17 soldiers)
• [Back]propagate to make sure the abnormal one is scored less

Training 2: Event composi0on • Phase 2: Tried auto-‐encoding: no success • Supervised: Learn to differen0ate between anomalous events and normal ones – Logis0c regression with event embedding as features – Back-‐propaga0on to learn event composi0on parameters so as to classify anomaly
– Parameters: Wevent bevent Levent – e = g(CV || CArg0 || CArg1 || CArgM-‐LOC || CArgM-‐TMP)

Classifica0on results • Binary classifier tested against human annota0ons
• Cannot Say removed from test data, Strange and Highly Unusual merged
• Precision of random classifier in classifying anomaly expected to be 41% (percentage of events labeled anomalous)

Some qualita0ve results System labeled anomalous
• Test Data – Dog with college degree (A0)
appears (V) in court (LOC) – Woman (A0) eats (V) ex's
goldfish (A1) arer spat (TMP)
• IC Corpus – Group that bombed Madrid
(A0) linked (V) to Al-‐Qaeda, Morocco atacks (A1)
– Town council member (A0) shot (V) as car bomb kills three (TMP)
System labeled normal
• Test Data – Redcross Interna0onal
commitee (A0) quit (V) Hongkong (A1) arer 1997 (TMP)
– 58 (A0) wounded (V) in Azerbaijan revolt (LOC)
• IC Corpus – Three Pales0nian militants (A1)
killed (V) by Israeli troops (A0) in Gaza (LOC)
– Heavy figh0ng (A0) reported (V) in breakaway Somaliland (LOC)

Comparison with human competence using MACE
• Model performance tested against human annotators
• MACE: Uses EM to infer (latent) true labels and annotator “competence” given observed labels
• Model predic0ons compared to annotators:
Image Source: Learning Whom to Trust with MACE, Hovy et al., NAACL 2013
Equals lowest-‐ranked human
MACE

Unsupervised model • Also trained autoencoder with objec0ve func0on to minimize Euclidean distance between input and reconstruc0on
• In anomalousness order, from 1000 sentences (mixed normal and anomalous, in-‐domain and weird news): – Woman makes threat to delay flight – Woman admits selling 2 kids for 1 bird , $175 – India , Bangladesh agree on water-‐sharing pact – Woman gets call about her own funeral – Doctor fires pa0ent who wouldn’t sign pe00on – China bestows May Day gongs on ‘model worker’ business owners – Two Sikorsky troop carriers collided as they were flying to the
occupied zone in south Lebanon over northern Israel – Bulgarian Socialists to elect new leader – A US soldier shot 12 US soldiers and wounded another 30 in a US Army
Base , Ft Hood

Conclusions • New seman0cs: Combine older logic-‐style and newer word
distribu0on-‐style representa0ons into single form – Scale-‐independent nota0on – A seman0c model that requires both linguis0c and machine-‐learning/computa0onal input
• Needs careful and formal defini0on of seman0cs: – Theore0cal connec0ons to Formal Seman0cs – Proper treatment of synonymy and composi0on – Algebra-‐like machinery for concept manipula0on (composi0on, nega0on, etc.)
– Generalize Topic Models and Topic Signatures
• Needs empirical tes0ng in various NLP and KR applica0ons: – Tasks: Parsing, (co)reference, WSD, etc. – Applica0ons: QA, Machine Reading, IR, etc. – Reasoning and inference in KR – Seman0c Web research

THANK YOU!










![Author: Yunqing Xia, Zhongda Xie, Qiuge Zhang, Huiyuan ...tcci.ccf.org.cn/conference/2014/ppts/nlpcc/ppt174.pdf · ranking: Statistical term dependency: Gao [4] linkage dependency](https://img.pdfslide.us/doc/110x75/6044724d4cdab960ac22caac/author-yunqing-xia-zhongda-xie-qiuge-zhang-huiyuan-tcciccforgcnconference2014pptsnlpcc.jpg)

















