Embed Size (px)
Citation preview

Programming for Linguists
An Introduction to Python15/12/2011

A sequence of values
They are similar to lists:the values can be any typethey are indexed by integers
Syntactically a tuple is a comma-separated list of values:t = 'a', 'b', 'c', 'd', 'e'
Tuples

Although it is not necessary, it is common to enclose tuples in parenthesest = ('a', 'b', 'c', 'd', 'e’)
To create a tuple with a single element, you have to include a final comma:t1 = 'a’,type(t1)

Note: a value in parentheses is not a tuple !t2 = (‘a’)type(t2)
With no argument, the tuple ( ) function creates a new empty tuple
t = tuple( )

If the argument is a sequence (string, list or tuple), the result is a tuple with the elements of the sequence:
t = tuple(‘lupins’)print t
Most list operators also work on tuples:
print t[0]print t[1:3]

BUT if you try to modify one of the elements of the tuple, you get an error message
t[0] = ‘A’
You can’t modify the elements of a tuple: a tuple is immutable !

You can replace one tuple with another
t = ('A',) + t[1:]print t

It is often useful to swap the values of two variables, e.g. swap “a” with “b”
temp=a a=b b=temp
Tuple Assignment

More elegant with a tuple assignment
a,b = b,a
The number of variables on the left and the number of values on the right have to be the same !
a, b = 1,2,3ValueError: too many values to unpack

For example: split an email address into a user name and a domain
address = ‘[email protected]’username, domain = address.split('@')print usernameprint domain
The return value from split(‘@’) is a list with two elements
The first element is assigned to username, the second to domain.

Strictly speaking, a function can only return one value
If the value is a tuple, the effect is the same as returning multiple values
Tuples as Return Values

For example:
def min_max(t):return min(t), max(t)
max( ) and min( ) are built-in functions that find the largest and smallest elements of a sequence
min_max(t) computes both and returns a tuple of two values

.items ( ) function used on dictionaries we saw last week actually returns a list of tuples, e.g.
>>> d = {'a':0, 'b':1, 'c':2}>>> d.items( )[('a', 0), ('c', 2), ('b', 1)]
Dictionaries and Tuples

This way you can easily access both keys and values separately:
d = {'a':0, 'b':1, 'c':2}for letter, number in d.items( ):
print letterprint number

Example: sorting a list of words by their word length
def sort_by_length(words):list1=[ ]for word in words:
list1.append((len(word), word))
list1.sort(reverse=True)ordered_list=[ ] for length, word in list1:
ordered_list.append(word) return ordered_list

NLTK and the InternetA lot of text on the web is in the form
of HTML documents
To access them, you first need to specify the correct locationurl = “http://nltk.googlecode.com/svn/trunk/doc/book/ch03.html”
Then use the urlopen( ) functionfrom urllib import urlopenhtmltext = urlopen(url).read( )

NLTK provides a function nltk.clean_html( ), which takes an HTML string and returns raw text, e.g.rawtext = nltk.clean_html(htmltext)
In order to use other NLTK methods, you can then tokenize the raw text
tokens=nltk.wordpunct_tokenize(rawtext)

NLTK’s WordPunctTokenizer takes as an argument raw text and returns a list of tokens (words + punctuation marks)
If you want to use the functions we used on the texts from nltk.book on your own texts, use the nltk.Text( ) functionmy_text = nltk.Text(tokens)my_text.collocations( )

Note: if you are used to working with characters in a particular local encoding (ë, è,…), you need to include the string '# -*- coding: <coding> -*-' as the first or second line of your script, e.g.
# -*- coding: utf-8 -*-
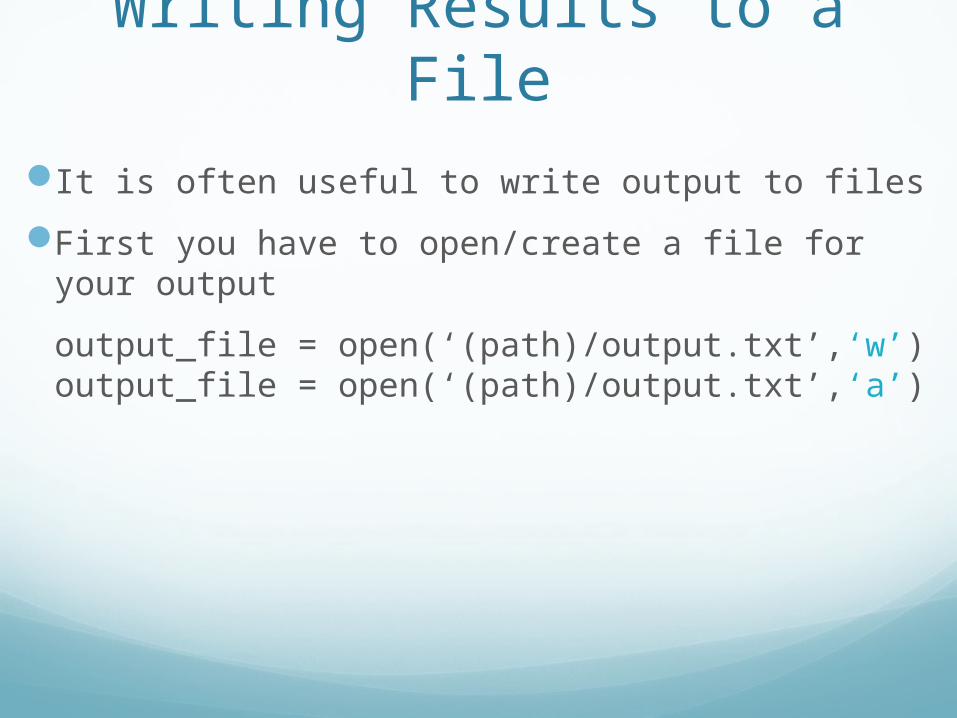
Writing Results to a File
It is often useful to write output to files
First you have to open/create a file for your output
output_file = open(‘(path)/output.txt’,‘w’)output_file = open(‘(path)/output.txt’,‘a’)

Now you have to write your output to the file you just opened
list = [1, 2, 3]output_file.write(str(list) + "\n”)
When you write non-text data to a file you must convert it to a string first
Do not forget to close the file when you are doneoutput_file.close( )

NLTK and automatic text classification
Classification is the computational task of choosing the correct class label for a given input text, e.g.deciding whether an email is spam or
notdeciding what the topic of a news article is
(e.g. sports, politics, financial,…)authorship attribution

Framework (1)Gather a training corpus:
in which a categorization is possible using metadata, e.g.information about the author(s): name,
age, gender, locationinformation about the texts’ genre: sports,
humor, romance, scientific

Framework (2)Gather a training corpus:
for which you need to add the metadata yourself, e.g.annotation of content-specific
information: add sentiment labels to utterances
annotation of linguistic features: add POS tags to text
Result: a dataset with predefined categories

Framework (3)Pre-processing of the dataset, e.g.
tokenization, removing stop words
Feature selection: which features of the text could be informative for your classification task, e.g.lexical features: words, word bigrams,...character features: n-gramssyntactic features: POS tagssemantic features: role labelsothers: readability scores, TTR, wl, sl,…

Framework (4)Divide your dataset in a training set and
a test set (usually 90% vs 10%)
Feature selection metrics:based on frequencies: most frequent featuresbased on frequency distributions per
category: most informative featuresin NLTK: Chi-square, Student's t test,
Pointwise Mutual Information, Likelihood Ratio, Poisson-Stirling, Jaccard index, Information Gain
use them only on training data! (overfitting)

Framework (5)For document classification: each
document in the dataset is represented by a separate instance containing the features extracted from the training data
The format of your instances depends on the classifier you want to use
Select your classifier: in NLTK: Naive Bayes, Decision Tree, Maximum Entropy, link to Weka

Framework (6)Train the classifier using the training
instances you created in the previous step
Test your trained model on previously unseen data: the test set
Evaluate your classifier’s performance: accuracy, precision, recall and f-scores, confusion matrix
Perform error analysis

A Case StudyClassification task: classifying movie reviews into positive and negative reviews
1. Import the corpus from nltk.corpus import movie_reviews
2. Create a list of categorized documentsdocuments = [(list(movie_reviews.words(fileid)), category) for category in movie_reviews.categories( ) for fileid in movie_reviews.fileids(category)]

print documents[:2]
3. Shuffle your list of documents randomlyfrom random import shuffleshuffle(documents)
4. Divide your data in training en testtrain_docs = documents[:1800]test_docs = documents[1800:]
5. We only consider word unigram features here, so make a dictionary of all (normalized) words from the training data

train_words = { }for (wordlist, cat) in train_docs:
for w in wordlist:w = w.lower( )if w not in train_words:
train_words[w] = 1else:
train_words[w] += 1
print len(train_words)

6. Define a feature extraction function
def extract_features(wordlist): document_words = set(wordlist) features = { } for word in document_words:
word = word.lower( ) if word in train_words:
features[word] = (word in document_words)
return features
print extract_features(movie_reviews.words('pos/cv957_8737.txt'))

7. Use your feature extraction function to extract all features from your training and test set
train_feats = [(extract_features(wordlist), cat) for (wordlist,cat)
in train_docs]test_feats = [(extract_features(wordlist), cat) for (wordlist,cat)
in test_docs]

7. Train e.g. NLTK’s Naïve Bayes classifier on the training set
from nltk.classify import NaiveBayesClassifierclassifier = NaiveBayesClassifier.train(train_feats)predicted_labels = classifier.batch_classify([fs for (fs, cat) in test_feats])
8. Evaluate the model on the test set
print nltk.classify.accuracy(classifier, test_feats)classifier.show_most_informative_features(20)

For Next WeekFeedback on the past exercises
Some extra exercises
If you have additional questions or problems, please e-mail me by Wednesday
The evaluation assignment will be announced

Ex 1)Choose a website. Read it in in Python using the urlopen function, remove all HTML mark-up and tokenize it. Make a frequency dictionary of all words ending with ‘ing’ and sort it on its values (decreasingly).
Ex 2) Write the raw text of the text in the previous exercise to an output file.

Ex 3)Write a script that performs the same classification task as we saw today using word bigrams as features instead of single words.

Thank you





























