Embed Size (px)
Citation preview

Probabilistic Planning For Symbiotic Autonomy InDomestic Robots
Nuno Laurentino Mendes
Thesis to obtain the Master of Science Degree in
Electrical and Computer Engineering
Supervisors: Prof. Rodrigo Martins de Matos Ventura,Prof. Plinio Moreno Lopez
Examination CommitteeChairperson: Prof. Joao Fernando Cardoso Silva Sequeira
Supervisor: Prof. Rodrigo Martins de Matos VenturaMember of the Committee: Prof. Francisco Antonio Chaves Saraiva de Melo
November 2017


Abstract
Having robots interact with humans in domestic environments, while completing household tasks,requires a whole new degree of autonomy and reasoning. Typically, these kind of environments maypush the robot’s capabilities (i.e. robot has to pick an object on an unreachable location). Likewise,some actions performed by the robot agent have a higher success rate due to its domain knowledge.Cooperation between humans and robots can overcome these issues, resulting in a higher amount ofpossible tasks for the robot. This is an example of Symbiotic Autonomy.
In this scenario, at some point the robot has the option to do some action by himself or to ask forhelp in case it’s better for both agents - in the short or long-term.
The proposed approach uses a planning framework based on probabilistic logic programming, theHYPE planner, which gathers at every step, observations from the environment, generating a groundedMarkov Decision Process problem from the described domain and deciding the action he should take inorder to maximize its performance on this environment. Furthermore, this architecture is benchmarkedon a simulation environment from generated observations as well as in a house with a robot and realhuman agents.
Keywords: Symbiotic Autonomy, Planning Under Uncertainty, Probabilistic Logic Programming
3


Resumo
A existencia de robos que interagem com pessoas em ambientes domesticos, requere um novo graude autonomia e raciocınio. Tipicamente, este tipo de ambientes desafia as capacidades do robot (p.e.ter de apanhar um objecto que se encontra inacessıvel). Da mesma forma, algumas accoes realizadaspelo agente robotico tem uma maior probabilidade de successo devido ao seu conhecimento do am-biente. A Cooperacao entre humanos e robos pode ajudar a ultrapassar estes problemas, resultandonum maior numero de tarefas possıveis para o robot. Este e um exemplo de Autonomia Simbiotica.
Neste cenario, existe um momento em que o robot tem a opcao de realizar uma acao por ele proprioou pedir ajuda a um agente humano caso esta escolha os beneficie de igual forma - a curto ou longoprazo.
Para lidar com este tipo de problemas e proposta a utilizacao de um sistema de planeamento ba-seado no planeador HYPE, que em cada passo adquire observacoes vindas do ambiente, gerando umproblema de decisao markoviano com variaveis de estado determinadas por estas mesmas observacoesa partir do domınio descrito e, decidindo a acao que deve tomar de forma a maximizar a sua perfor-mance neste ambiente. Finalmente, este sistema e testado num ambiente de simulacao com observacoesgeradas previamente, bem como numa situacao real com agentes humanos e um robot.
Palavras-Chave: Autonomia Simbiotica, Planeamento Sob Incerteza, Programacao LogicaProbabilıstica
5


Contents
List of Tables 11
List of Figures 13
Acronyms 15
1 Introduction 171.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 171.2 Problem Description . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
1.2.1 Problem Statement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 201.2.2 Approach . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 201.2.3 Contributions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
1.3 Work Outline . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2 Background 232.1 Logical Programming . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.1.1 Prolog . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 232.1.2 Probabilistic Logical Programming . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
2.1.2.1 Distributional Clauses . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 252.1.2.2 Dynamic Distributional Clauses . . . . . . . . . . . . . . . . . . . . . . . 262.1.2.3 Related Methods . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
2.2 Decision Theory and Planning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 272.2.1 Markov Decision Processes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 272.2.2 Solving Markov Decision Processes . . . . . . . . . . . . . . . . . . . . . . . . . . 282.2.3 Dynamic Programming . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
2.2.3.1 Value Iteration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 302.2.4 Monte Carlo Learning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 312.2.5 Factored Markov Decision Processes . . . . . . . . . . . . . . . . . . . . . . . . . 322.2.6 HYPE Planner . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
2.2.6.1 Implementing Hybrid Episodic Planner (HYPE) Domains & Problems . . 342.2.7 Related Logical Probabilistic Planners . . . . . . . . . . . . . . . . . . . . . . . . . 35
2.3 Social Robotics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 362.3.1 Domestic Robots . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 362.3.2 Symbiotic Autonomy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
2.3.2.1 Agent’s Limitations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 372.3.2.2 Help Types . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 372.3.2.3 Help Cost . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 372.3.2.4 Availability . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
7

2.3.2.5 Trust in Help Requests . . . . . . . . . . . . . . . . . . . . . . . . . . . . 382.3.3 Related Approaches . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
3 Robot Using Symbiotic Autonomy on Domestic Environments 413.1 Describing the Domestic Environment Domain . . . . . . . . . . . . . . . . . . . . . . . . 413.2 Methodology . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 413.3 Hierarchical Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
3.3.1 Time Invariant Predicates . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 433.4 Wandering Domain Description . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 443.5 Mission Domain Description . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 473.6 Software Architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
4 Evaluation 534.0.1 Physical Setup . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
4.0.1.1 Robot Platform . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 534.0.1.2 ISRoboNet@Home - Home Environment Testbed . . . . . . . . . . . . . 54
4.1 Simulation Benchmark Setup . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 544.1.1 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.2 Experimental Procedure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
5 Discussion 575.1 Analyzing reliability of Symbiotic Autonomy on Domestic Environments . . . . . . . . . . . 575.2 Looking into the High Level Architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . 575.3 System Design Approach . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 585.4 Usability of the Dynamic Distributional Clauses . . . . . . . . . . . . . . . . . . . . . . . . 585.5 Is HYPE a good choice for solving real-time planning problems? . . . . . . . . . . . . . . 59
6 Conclusion 616.1 Future Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
Bibliography 63
A Appendix 67A.1 1st Test on Wandering Domain . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67A.2 2nd Test on Mission Domain . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70A.3 3rd Test on Mission Domain . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
8


10

List of Tables
3.1 Description of predicates that are static with respect to time changes and that are thesame in both subdomains of the model. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
3.2 Time variant predicates used for the wandering domain. . . . . . . . . . . . . . . . . . . . 443.3 Actions that can be performed by the robot on the wandering domain of the domestic
environment. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 453.4 Time variant predicates used for the mission domain. . . . . . . . . . . . . . . . . . . . . . 483.5 Actions that can be executed by the robot on the mission domain of the domestic environ-
ment. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
4.1 First case study results on the Wandering Domain. . . . . . . . . . . . . . . . . . . . . . . 554.2 Second case study results on the Mission Domain. . . . . . . . . . . . . . . . . . . . . . . 554.3 Third case study results on the Mission Domain. . . . . . . . . . . . . . . . . . . . . . . . 56
A.1 State of the world in the first step. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67A.2 State of the world in the second step. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68A.3 State of the world in the third step. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68A.4 State of the world in the fourth step. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69A.5 State of the world in the fifth step. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69A.6 State of the world in the first step. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70A.7 State of the world in the second step. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70A.8 State of the world in the third step. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71A.9 State of the world in the first step. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71A.10 State of the world in the second step. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72A.11 State of the world in the third step. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72A.12 State of the world in the fourth step. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73A.13 State of the world in the fifth step. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73A.14 State of the world in the sixth step. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
11


List of Figures
1.1 On the left, it is shown a match between two teams in the human size robot soccer league.On the right, it is shown a run of the Robocup@Home tournament. These events occurredin Leipzig, 2016. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
1.2 SocRob@Home team logo and ISRoboNet@Home Testbed. . . . . . . . . . . . . . . . . 201.3 The Venn diagram above shows 3 different areas of interest that are encapsulated by the
proposed framework: Logical Programming, Probabilistic Inference and Planning. Thetheoretical ground for this dissertation is logical programming. An example of a logicalprogramming language is Prolog, for instance. Following the same line of thought, proba-bilistic inference gives mathematical tools to discover the likelihood of a particular event.Planning uses Decision Theoretic tools in order to find which decision should be made oneach step of a process. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.1 Overview of a simple Markov Decision Process for domestic environments, described forthe robotic agent. There are only two states in this process, and they are colored yellow.Actions are colored blue and red and have the same cost. Outcomes of each actionare enumerated from its name along with its explicit probability of occurring. Rewardsare obtained when the robot reaches each individual state and are represented as greendiamonds with respective values inside. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
2.2 Backup diagram of dynamic programming while using Bellman Backups. . . . . . . . . . . 302.3 Schematic of a Reinforcement Learning (RL) agent operation. . . . . . . . . . . . . . . . . 322.4 Dynamic Bayesian Network (DBN) describing part of the factored Markov Decision Pro-
cess for the robot. The illustrated state here is the robot location. It can be either of thesethree values: ”kitchen table”, ”sofa”or ”bed”. The actions are illustrated along the arrows:”wait”, ”navigate”or ”respond”. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
2.5 Cobot robots that roam around Carnegie Mellon University (CMU) Gates’ computer sci-ence building. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
3.1 Schematic of the domain architecture. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 433.2 High level diagram of the execution workflow. . . . . . . . . . . . . . . . . . . . . . . . . . 513.3 High level overview of the communication between hardware systems. . . . . . . . . . . . 52
4.1 Mbot, the robot that was used for the real world benchmarks. . . . . . . . . . . . . . . . . 534.2 On the left image, it can be seen a topological map of the ISRoboNet@Home testbed. On
the right image, it is shown the map used by the robot for navigation and localization. . . . 544.3 Robot in a real world benchmark, on the mission domain situation, with a real human
giving external sensor information with a QR code. On the left, the robot is in the initialsofa location; on the center the robot is simulating a coke grasp; on the right, the robot isin the bed location, also next to robert and trying to deliver the object to him. . . . . . . . 56
13


Acronyms
AI Artificial Intelligence. 15, 21
BN Bayesian Network. 30, 37
CMU Carnegie Mellon University. 34, 36, 37
DBN Dynamic Bayesian Network. 18, 30
DC Distributional Clause. 23, 24
DDC Dynamic Distributional Clause. 24, 31, 33, 37, 40, 42, 43, 56, 57, 60
DSR Domestic Service Robot. 15–17
DT Decision Theory. 17, 18
FOL First Order Logic. 21
GPSR General Purpose Service Robot. 15
HYPE Hybrid Episodic Planner. 19, 31, 32, 37, 39, 40, 57–60
ICAPS-IPC International Conference on Automated Planning and Scheduling International PlanningCompetition. 18, 19, 33, 60
KB Knowledge Base. 23, 24
MCL Monte Carlo Learning. 29, 31
MDP Markov Decision Process. 17–19, 25–30, 32, 34, 39, 55, 56, 59, 60
PDDL Planning Domain Definition Language. 36
PDL Planning Description Language. 18
PLPL Probabilistic Logical Programming Language. 18, 21, 24, 37
POMDP Partially Observable Markov Decision Process. 18, 25, 37
PPDDL Probabilistic Planning Domain Description Language. 18, 57
PRADA Probabilistic Action-sampling in DBN’s Planning Algorithm. 33
15

RDDL Relational Dynamic Influence Diagram Language. 18, 57
RL Reinforcement Learning. 30
ROS Robot Operating System. 15, 56
SA Symbiotic Autonomy. 17, 19, 37, 38, 48, 55
SMR Social Mobile Robot. 15
16

Chapter 1
Introduction
1.1 Motivation
It has been robotic’s long term goal and also, dream, to have Social Mobile Robots (SMRs) and inparticular Domestic Service Robots (DSRs) that can assist humans in their daily domestic tasks. Thisarea is a subfield of social robotics which will likely have a considerable impact on society, not onlyby improving people’s psychological and physical state, but also by giving them spare time which canbe spent doing other activities. This includes robots: assisting senior citizens on tasks they can nolonger execute on their own (like cooking, cleaning or organizing medical pills, for example); carrying outtasks for people with disabilities; and helping or dealing with house chores that are too cumbersome orrepetitive for people.
Fortunately, this research area has been pushed forward by recent developments in machine learningor more generally artificial intelligence. This includes developments on robot’s skills like computer vision,mobile base navigation, environment mapping, speech processing and recognition, robotic manipulationand also, human robot interaction.
This momentum on robotics research has so far introduced multiple tools for roboticists: in softwarewith the introduction of Robot Operating System (ROS)1, and in hardware as stable consumer graderobot platforms become available from mainstream companies. In turn, public awareness and interest isincreasing with the rise of robotics competitions. A prime example is Robocup2, the major internationalrobotics competition, fostering Artificial Intelligence (AI) and robotics research. Its role is to providestandardized testing environments and tasks in order to properly benchmark developed technologiesby researchers all over the world. All of this while encouraging competitions and sharing of knowledgebetween these international teams. Therefore, as these areas improve, the goal of having a GeneralPurpose Service Robot (GPSR)3 becomes imminent.
1To know more, check: http://www.ros.org/2For more information see http://www.robocup.org/3This is also a name for a specific task in Robocup. Its purpose is to evaluate how all the different robot skills perform together
on a set of possible benchmarks.
17

Figure 1.1: On the left, it is shown a match between two teams in the human size robot soccer league.On the right, it is shown a run of the Robocup@Home tournament. These events occurred in Leipzig,2016.
It is in this context that Robocup@Home4 [vBCH+16] appears (among others, e.g., Robocup@Work,Robocup Rescue, etc.), fostering research on DSRs and having the main goal of developing service andassistive technologies with relevance for future personal domestic applications.
During the event, a set of robot capabilities are tested on specialized environments. Major categoriesinclude: perception, human robot interaction, mapping, navigation under highly dynamic environmentsand last, but not the least, robotic manipulation. It is interesting to note that even if tests are specialized,it does not mean they focus on single skills. Furthermore, all these tests feature scenarios where therobot has to use most of its capabilities in order to successfully accomplish the provided tasks. Yet,even if the robot has the majority of these systems working properly, it still has to reason what to dowith them. For this reason, task planning is absolutely necessary as a coordination mechanism tosuccessfully complete goals on these environments.
Even though most of this modules have matured to a point that render them usable on non controlledenvironments, like robotics competitions, the same cannot be said to the area of task planning. Most ofthe teams still rely exclusively on state machines in order to provide basic reasoning to the robot. Thereasons for using state machines (e.g., SMACH5) on these type of domains, in spite of a fully fledgedtask planner, can be reduced to three factors:
• Easy to structure and design;
• Stable Software Packages, as integrated debug and monitoring tools are provided out of the box,making them reliable and predictable.
• Tasks are structured in a way that makes planning seem like an overengineered solution to aspecific problem.
However, this approach has several problems:
• Scaling to real world problems can be difficult, as state machines become increasingly complicatedand hard to understand as the number of possible transitions increase;
• There is not a natural way to handle uncertainty coming from actions or observations and whenthey are adapted to do that, the resulting state machine appears hammered to solve a specificproblem;
4For more information see http://www.robocupathome.org/5Find more about it on http://wiki.ros.org/smach
18

• Real world does not have a structured nature, rendering state machines incapable to acutely rep-resent it.
For the reasons above, planning appears as an alternative to control the robot behavior with thehope that it increases its autonomy. Furthermore, Decision Theory (DT) provides the basic mathematicalframework in order to solve these planning problems, with or without uncertainty on its domains, capableof maximizing reward signals over time and/or completing goals. Applying this knowledge into robotics,the domestic environment can be modeled as a Markov Decision Process (MDP), taking into account theuncertainty on agent’s action effects and rewards given for reaching some state. With this framework,the agent can decide at any time which action it should take in order to maximize this reward.
Other rather important detail is that these DSRs often face several limitations on the actions theymust perform and how they perceive the surrounding environment. Nevertheless, there are multipleways to overcome these limitations, ranging from better sensors and actuators, to agents that seek helpfrom other agents to reach their goals. However, the first solution is not always feasible: the robot couldnot withstand more weight; there is not a sensor precise enough for the application ; or more commonly,the budget does not accommodate any extra hardware/software to be integrated. Whereas the latter canbe a cheaper and simpler solution for coping with these constraints. Under these circumstances, therobot agent should try to do most of the actions by himself, keeping its autonomy, but should ask for helpwhenever the success rate for a specific action is too low and the cost for asking human cooperation isbearable. This is an example of Symbiotic Autonomy (SA), where the robot has to take on tasks frompeople on the domestic environment, but can also ask for their help whenever it is necessary.
In general, the help that these robotic agents can receive is not restricted to physical actions, likegrabbing a cup and giving it back to the robot, for example. Therefore, a human agent can also helpthe robot in many other ways, like giving him a better estimate of his position, giving him a preferablepath to cross if there is some temporary physical restriction or by telling where is the object he is islooking for. Most of these pains are easily solved by these human agents, wandering around on theseenvironments.
All things considered, by formalizing and solving this problem, the followed approach can be gener-alized to handle other kinds of domains where there is uncertainty in the world model and rewards forexecuting some action along with other human agents in the environment.
1.2 Problem Description
All things considered, the main topic of this dissertation concerns the effort from SocRob@Home team6
to provide action reasoning on domestic environments (namely on the ISRoboNet testbed) to the Mbotrobot. SocRob@Home is part of SocRob project at Institute for Systems and Robotics, responsiblefor research in the areas of mobile service robots in multiple domains of interest, like domestic andhealthcare facilities. During research duties, the developed technologies are benchmarked on roboticcompetitions among other highly reputable teams across the world.
6http://socrob.isr.ist.utl.pt/
19

Figure 1.2: SocRob@Home team logo and ISRoboNet@Home Testbed.
1.2.1 Problem Statement
Taking into account all tasks the mobile robot must complete in domestic scenarios and the existinguncertainty on outcomes of agent’s actions (may them be its own actions or its requests for help), thisagent should make decisions that lead it to the best outcome possible, given any possible situationachieved, on a countable sequence of steps. So the objective is to integrate a planner which canattain that, into a real robot. The planner should be able to deal with discrete and continuous actioneffects while being able to cope with new information given to it (i.e. new objects or people in theenvironment from one step to another). So, can symbiotic autonomy increase the robot’s autonomyby improving the number of completed delivery missions on the domestic environment?
1.2.2 Approach
In order to achieve this behavior, the agent should have a world model of the domestic environment7,including possible states and respective rewards along with actions available to be performed by therobot. In fact, to model these domains in an efficient manner, there are the following tools capable ofhandling uncertainty on their domains:
• MDP or Partially Observable Markov Decision Process (POMDP): the classical approach, followingwell known mathematical procedures.
• DBN: by drawing the world model, along with the correspondent probability distributions, on aclassical structure of probability theory8.
• Planning Description Language (PDL): Using declarative languages such as Probabilistic Plan-ning Domain Description Language (PPDDL) [YL04] or Relational Dynamic Influence DiagramLanguage (RDDL) [San10] to describe the world model, according to a set of syntax and semanticrules. They are normally used in competitions like International Conference on Automated Plan-ning and Scheduling International Planning Competition (ICAPS-IPC)9, decoupling the plannerfrom the language used to describe the world model.
• Probabilistic Logical Programming Languages (PLPLs): the world model is formalized on a com-pletely capable logical programming language and the solver comes as a builtin of the program-ming language.
7This is not absolutely necessary if the problem is solved using other methods from DT like reinforcement learning, for example.8OpenMarkov is a common tool used for this purpose. See more at http://www.openmarkov.org/9Discover more about these type of competitions here: http://www.icaps-conference.org/index.php/Main/Competitions
20

For the tools listed above, it was choosen the latter as a building block of the framework, namelythe HYPE planner [NBDR15]. The model must incorporate the possibility that the robot interacts withhumans and the other way around, whenever is necessary, giving mutual cooperation capabilities tothese agents. To emphasize this requirement, it must be capable to demonstrate advanced behaviors,particularly SA as an alternative to complete tasks on the domestic environment.
1.2.3 Contributions
We propose a pipeline for probabilistic logical planning using Dynamic Distributional Clauses for model-ing the house environment and HYPE planner for robot’s decision making, distributed as a ROS package,in domestic robots that includes symbiotic autonomy as a defining behavior of these robots.
1.3 Work Outline
In summary, the present dissertation is structured as follows:
• On the second chapter, it is explained all the basis needed to understand how the proposed frame-work has been put together. Starting from logical programming and finding its roots on first orderlogic, through newer probabilistic logic programming paradigms and its respective extensions. Fur-ther along the line, it is made a brief introduction to MDPs, domain modeling tools and finally plan-ning, following a discussion on the classical solving methods and newer alternatives coming fromICAPS-IPC. On the end of this topic, it is discussed introduced HYPE planner as it is the buildingblock of the proposed approach. It is a great idea to view and more importantly, understand figure1.3 to get the big picture of how these pieces fit together.
Figure 1.3: The Venn diagram above shows 3 different areas of interest that are encapsulated by the pro-posed framework: Logical Programming, Probabilistic Inference and Planning. The theoretical groundfor this dissertation is logical programming. An example of a logical programming language is Prolog, forinstance. Following the same line of thought, probabilistic inference gives mathematical tools to discoverthe likelihood of a particular event. Planning uses Decision Theoretic tools in order to find which decisionshould be made on each step of a process.
21

Consequently, it is explained what is the concept of Symbiotic Autonomy as well as the relatedwork on this area.
• Then, on the third chapter, it is discussed the implementation of the framework. Afterwards, thedomain used on this task is explained, that is both robot and human agents acting in the sceneand the testbed, simulating a domestic environment. Finally, the planning framework architectureis explained, as well as each one of its procedures.
• The fourth chapter is about the evalutation of the pipeline on simulation and in the real world.Starting from a description of the robot, in terms of its relevant hardware and software modulesand ending in the testbed. Results from the planning framework are collected, not only fromsimulation scenarios but also from the real test scenario with real agents.
• Then, there is also a discussion about the results obtained. In particular, the following questionsare answered:”Does the framework produce meaningful results?” ; ”Is the framework usable in realenvironments?”. Not only are these questions answered, but also some remarks are made aboutthe lessons learned.
• In the last chapter, a conclusion is made about what was achieved in this thesis.
22

Chapter 2
Background
On this chapter, it is introduced some general concepts which are fundamental to understand the prob-lem at hand. These concepts are divided into three parts. The first section concerns logical reasoning:starting from First Order Logic (FOL) and its role as inspiration for logical programming languages whichtriggered the first wave of intensive AI research and brought significant funding from both public andprivate sectors, in the seventies. Then, it discussed a new framework based on logical programming todescribe uncertain domains called PLPL and its recent possible extension which uses dynamic distribu-tional clauses. This extension provides the ability to model logical predicates as probabilistic distributionsand also make them vary along different time steps.The second part focuses on decision and planning problems and finding optimal ways to solve them ifthat is possible on polynomial complexity. It is also discussed aproximate ways to solve them based onsampling. To finish this part, the connection between PLPL and planning is made along with all detailsnecessary to understand it.Finally, on the third and last part of this chapter it is made a brief overview of social robotics and itsrelation with symbiotic autonomy.
2.1 Logical Programming
Logical programming was the cause of popular excitement during the first wave of AI. It started in thelate 60’s and early 70’s, when the first logical programming languages were developed. Prolog was oneof those programming languages. It currently sits as the 32nd most popular 1 programming language.
2.1.1 Prolog
Prolog is a logical programming language first introduced by Alain Colmerauer and Philippe Roussel[CR96], in 1972, that was designed to simulate the man-machine communication system in naturallanguage. The goal was also to integrate logic as a declarative knowledge representation language witha procedural representation of knowledge.
The ensemble of facts and clauses (in definitions 1 and 2, respectively) and queries are built out ofterms, its single data type. Terms can be complex or simple, if they are composed by logical variablesor constants (Atoms or Numbers). Variables start with an upper case letter while constants start with alower case letter. As it is said before, what makes this programming language different than others isthe fact that it is declarative, it does not describe the control flow of the program, only the logic of the
1According to the TIOBE index, October 2017
23

computation. This logic is expressed by means of relations between objects, and its execution is startedby running a query over the program’s knowledge base. Programs are compiled by using a combinationof facts and clauses which are in turn, transformed to a knowledge base (definition 3).
Definition 1 (Clause) Is a first order formula, represented by an implication clause that is read from theright to the left. The leftmost member is called the Head and the set of facts to the right are called theBody. This Body can contain both disjunctions and/or conjunctions of facts.
Definition 2 (Fact) Is a grounded (no variables) clause with an empty Body.
Examples of a fact and a clause are shown in snippets 2.1 and 2.2, respectively.
location(O, X)← has(Y, O), location(Y, X). (2.1)
robot(mbot). (2.2)
Definition 3 (Knowledge Base) It is a collection of facts and relations which are loaded into program’smemory, when it is executed.
New rules can be created by joining a combination of facts, increasing the information about theworld. It is also important to know that when a prolog program is started, it loads all the clauses andfacts into its Knowledge Base. Then, to interact with it, the user needs to query it. These queries can becompletely grounded, with variables or even containing both the terms. The query provided to the prologinterpreter is handled through the rules and facts present in the knowledge base using the Unification-Resolution mechanism with a backtracking flow model control, returning ’Yes’, if the solver can prove thequery clause with all the remaining clauses in the database, or ’No’, if the solver cannot prove it with theavailable information about the world. It can also show all the possible unifications with variables it foundwhile running that same query.
It is also important to mention that Prolog is built upon the Closed World Assumption, which says thatall knowledge about the world is present in the database. The result provided by the interpreter must beseen as an attempt of the programming language to prove that the asked query is true in some modelof the world. So if the solver returns a ’No’ answer, it does not necessarily mean that the query clauseis false, just that the solver cannot prove it with the available information about the world.
A simple prolog example relevant to the problem that is being treated can be seen in snippet 2.3.
robot(mbot).
object(coke).
region(kitchen).
region(bathroom).
has(robot, coke).
located(mbot, kitchen). (2.3)
From the previous simple program, it is interesting to make multiple queries about its knowledgebase. One can query ?- region(X), in order to get every possible region term. It is also possible to queryabout the robot location, ?- located(mbot, X); in this case, the answer is obvious, as there is already anexplicit fact about it in the knowledge base. But, imagine the location of the coke is also important for
24

the problem. Since the robot has the object, its location will be the same. So, in order to replicate theprevious behaviour, the following clause was introduced into the knowledge base.
located(X, Y)← has(A, X), robot(A), located(A, Y).
(2.4)
It is now possible to get information about coke’s location.
There are currently multiple Prolog implementations and each one has its own advantages, limita-tions and support. Currently, the most popular are SWI Prolog and Yap Prolog2. The work developedalong this thesis uses the latter.
A good book on Prolog and logic programming in general is [NM90], which should be consulted inorder to get more information about this topic.
2.1.2 Probabilistic Logical Programming
2.1.2.1 Distributional Clauses
Distributional Clauses 3 [NDLDR14] [NDLDR16] - inspired by Sato’s Distribution Semantics [Sat95] - arean extension of logic programming which can represent random variables as probability distributions. Itincludes typical probability distributions: uniform, gaussian, discrete finite choice, poisson, beta, etc. Theformal syntax of Distributional Clauses (DCs) are normal Prolog definite clauses, but with few addons:
x ∼ D ← b1, ..., bn. (2.5)
Where x is the random variable, represented as a Prolog term; D is the probability distribution, whichcan also include other terms. Until now, every term explained is contained on the head of the clause. ButDCs also include a body: b1, ..., bn, where bk are literal terms. The body should have a valid substitutionin order to generate variable x, and each grounding of the body will generate an instance of x. Thesespecial clauses can also include logical variables (when written in capitalized format) in both the bodyand the head, giving it an higher dimension of abstraction.
Another important detail is the operator ', in snippet 2.6, which is used to get the outcome of somerandomly distributed variable. It is necessary when referencing the value of some random variable in abody of a DC.
y ∼ val(true)←' (x) = true. (2.6)
In the previous example clause, the random variable y will be sampled according to the deterministicvalue true, if the random variable x has the value true.
After adding some DCs into a Prolog program, it is now called a distributional program. The pro-gram will generate a distribution over possible worlds from the information given by all clauses in theKnowledge Base (KB). The inference procedure is the following:
1. Initialize possible worlds, W, as an empty set;
2. For every DC, find an unique substition of the body and if it is possible, sample a value from thehead’s distribution and add it to W.
2The latter can be found in http://www.swi-prolog.org/ and the former in https://www.dcc.fc.up.pt/~vsc/Yap/3Implementation by Davide Nitti is available on https://github.com/davidenitti/DC
25

3. If it is impossible to generate more worlds, the program ends.
4. It is now possible to make probabilistic inferences from the sampled world.
After all the above steps are complete, probabilistic inferences are made by querying the Prologprogram over all possible worlds.
An example of a distributed clause describing the robot location is shown in snippet 2.7. It modelsthe robot location as a random variable and it is governed by a uniform distribution of possible values.On this case, the values are regions: kitchen, bed and sofa.
location(robot) ∼ uni f orm(kitchen, bed, so f a)← true. (2.7)
This clause translates as: the robot is either on the kitchen, bed or sofa with the same probabilityand the probabilities’ sum equals to one (uniform distribution).
2.1.2.2 Dynamic Distributional Clauses
Dynamic Distributional Clauses (DDCs) [NDLDR16] adds more expressiveness to DCs by introducingtemporal modeling. This is done by adding a subscript (as shown in snippet 2.8) to the previously definedrandom variables. This way, it is possible to describe logical interpretations that can evolve over timeperiods. In order to have this kind of dynamic clauses, random variables just need to have a time indexassociated with their program terms.
xt+1 ∼ D ← b1, ..., bn. (2.8)
In order to have a correct Prolog program with DDCs, the random variables must be defined:
• in the initial timestep, t = 0, also known as the prior distribution.
• the transition model, which describes how a random variable evolves through successive timesteps.
Example 2.7 can now be extended with the proper model, as seen in snippet 2.9. So, the robot willalways be in the same place as time passes.
location(robot)t+1 ∼ val(X)←' (location(robot)t) = X. (2.9)
The previous clause is translated as: the location of robot at the current time step, with value X, willbe sampled deterministically and equal to X, on the next time step.
2.1.2.3 Related Methods
When other alternatives were up for discussion to model the domestic environment with possible humaninteractions:
• The prime example of a PLPL is Problog [DRKT07] from De Raedt et al. The authors devisedthe programming language as a probabilistic extension of the original Prolog. On this language,a Problog program defines a distribution over Prolog programs. Also, each clause specifies theprobability of belonging to a randomly sampled program. The ultimate goal is to make probabilis-tic inferences by running Problog queries into the KB. In contrast with DDCs which are used inthese work, Problog lacks sampling from continuous probability distributions and builtin support fordiscrete timed logical interpretations.
26

• Another interesting work was done by Milch et al. in [MMR+07]. They proposed and developeda language syntax in order to procedurally describe probabilistic models that have an unknownnumber of objects. The language is called BLOG (from Bayesian Logic) and it is able to han-dle bayesian models in a compact manner. An inference engine was also developed based onsampling methods over possible worlds. Though, it lacked the expressiveness of a programminglanguage that is featured when using the Prolog engine.
2.2 Decision Theory and Planning
2.2.1 Markov Decision Processes
It is important to formalize a model that can capture the uncertainty contained on domestic environmentswith robots. These robotic agents must make optimal decisions (or approximately optimal) while knowingthat their actions can possibly lead to multiple exclusive outcomes.
A classical method is to formalize these domains as MDPs [SB98] [BT96] [Put14]. This kind ofprocesses have been extensively studied by Decision Theory research and have a broad range of ap-plications: economics, routing, general game playing, operations research and also robotics.
An interesting feature of MDPs is that information about the current state is sufficient to completelycharacterize the decision problem at the current step. However, it is important to remark that while thesemodels can capture the uncertainty of the world, the source of the latter comes from the stochasticnature of action effects. For example, if I decide to move to my right to point A, there’s a chance I couldend up in B instead. Though, there are also models that can incorporate uncertainty on the current stateare called POMDPs, being a generalization of MDPs. An example of that behavior could be the human’smood, modeled as a state: happy or sad; and having another agent guess that state by observing thatsame human. The human’s mood would be considered a probabilistic distribution of being happy andbeing sad. Though, they will not be featured on this thesis.
A process of this genre has a set of states, S, which can be discrete: finite or infinite; or continuous.Along the current work, the spotlight is on discrete states, although the proposed framework is expressiveenough to handle continuous states.
In order to transition from one state to another, the agent uses an applicable action from the actionspace, A. When the agent transitions to a new state, it receives a reward, returned as a function of itscurrent state, action taken at this step and also the new transitioned state.
The main law of these processes is the so called Markov Property (in property 1) which mathemati-cally translates what has been said earlier.
Property 1 (Markov Property) The conditional probability of future state depends exclusively on thecurrent state and it is independent of all previous states.
P(st+1|st) = P(st+1|st, ..., s1) (2.10)
The previous property applies for example in Hidden Markov Models or MDPs, as seen in definition4.
Definition 4 (Markov Process) A process where Property 1 holds is called a Markov Process. Onthese processes, the following equation holds:
P(st+1|st, at) = P(st+1|st, at..., s1, a1) (2.11)
27

The probabilities given by equation 2.11 are known by state transition probabilities and are commonlyrepresented on a matrix, if the state-action space is finite. Under the assumption of equation 2.11, allthe past history of states and actions is irrelevant in order to find the next state the agent will be in, whenit executes some specific action. It only depends on the current state.
In order to fully capture information given by the model and explicitly introduce the fact that the agenthas to make decisions, it is necessary to make a generalization for MDPs.
Definition 5 (Markov Decision Process) A Markov Process where an agent has to make decisions. Itis characterized by the tuple < S, A, T, R >:
• S, set of states.
• A, set of possible actions.
• T, state transition model.
• R, reward function.
A simplified version of this thesis MDP is shown in figure 2.1. This short example shows how MDPscan describe domestic environments with robots.
Figure 2.1: Overview of a simple Markov Decision Process for domestic environments, described for therobotic agent. There are only two states in this process, and they are colored yellow. Actions are coloredblue and red and have the same cost. Outcomes of each action are enumerated from its name alongwith its explicit probability of occurring. Rewards are obtained when the robot reaches each individualstate and are represented as green diamonds with respective values inside.
On the previous example, there are two states: nobody has the coke; and robert has the coke. Therobot can be in either of these states. When it is on the former, it receives a reward of minus two; andplus five on the latter. But, it has two actions when it is on the former: the robot can pick and deliver thecoke with its own manipulator; or ask for Lynda’s help to deliver the coke to Robert. Each one of theseactions has different probabilities of reaching the two available states. Since both of them cost the same,the rational decision for the robot would be to ask for help, as it has a higher probability of reaching thestate where Robert has the coke can. When the robot reaches this state, planning ends, as there is notany possible action to perform and it is the goal of the process.
2.2.2 Solving Markov Decision Processes
Having the problem statement formally defined, it is now time to discuss on how to solve them. Theobjective here is to maximize the Return, in definition 6, from the current state to the goal or on aspecified horizon.
28

Definition 6 (Return) defined as the discounted reward from the current state, while following somepolicy, in definition 7, on a specified number of steps, infinite or finite. γ is the discount factor and it isbounded between 0 and 1. t index is the current episode.
Gt =∞
∑k=0
γkrk (2.12)
The discount factor γ can make the rewards awarded far into the future less valuable. This factor ismeant to simulate inflation as it appears in economics. It motivates the agent to take actions that leadto increased immediate rewards. In parallel, it is also a way of overcoming the difficulty of planning on ainfinite horizon.
Definition 7 (Policy) is a function π(a|s), which gives the probability that an agent has of taking actiona while on state s. A policy can also be deterministic, if in every state there is one and only one actionwith probability equal to one.
An example of an optimal policy which is stochastic: Paper, Rock and Scissors game, or guessingthe result of a coin flip.
A policy can be classified as:
• Complete: if there is a mapping for every state in S.
• Partial: if a policy is not complete.
• Closed: if an agent starting from the current state, s0, is able follow the current policy without everneeding to replan.
It is now appropriate to talk about the concepts of State-value and Action-value functions, in defini-tions 8 and 9 respectively, and how closely are they tied with the current policy. Using loose terminology,they are a measure of how good a state is for the agent, while following some particular policy.
Definition 8 (State-value function) is the expected long term return of a state s while following somepolicy π on the following future.
vπ(s) = Eπ
[Gt|St = s
](2.13)
Definition 9 (Action-value function) is the expected long term return of a state s and after taking someaction a, while following some policy π on the following future.
qπ(s, a) = Eπ
[Gt|St = s, At = a
](2.14)
2.2.3 Dynamic Programming
The goal of solving MDPs is to find the Optimal Policy 10 for every possible state. One way to find it, isby using dynamic programming. Basically, it is a method for solving complex problems by turning theminto subproblems and combining the solutions of them. Since these subproblems occur many times, onecan cache their result and reuse it to solve the main problem.
29

Definition 10 (Optimal Policy) , π∗ is a Policy which has the highest state-value function possible fora particular problem, the optimal State-value function. It is also important to mention that it can existmultiple optimal deterministic policies for the same optimal State-value function.
So, equation 2.15 is used to dynamically solve MDP. It is normaly called the Bellman Equationfor vπ. Another equation exists for calculating qπ. Using the latter provides faster convergence, but anhigher amount of memory used, since it is necessary to store values for each state-action pair, instead ofstoring exclusively state values. This happens because one has to store more values for the combinationof state and possible applicable actions than just storing values for each state, exclusively.
vπ(s) = ∑a∈A
π(a|s) ∑s′∈S
p(s′|s, a)[r(s′, a, s) + γvπ(s′)
](2.15)
In order to better understand how 2.15 makes the update of the state-value and action-value function,it is usual to draw a tree diagram, the Backup Diagram in figure 2.2, which encompasses these variablesacross successor states from the root, the initial state s0. It is organized in successive layers of vk
π untila goal or the end of an horizon is reached.
Figure 2.2: Backup diagram of dynamic programming while using Bellman Backups.
The figure shows how the bellman equation recursively backs up values (using the rewards andtransition model, in order to get the expected value) from the leaf nodes to the root. It starts and endswith state nodes and, each level has state nodes or state-action nodes and they alternate level fromlevel.
It happens that finding an optimal policy for a MDP is a task which can be done in polynomial time[LDK95] when formulated as a linear program. Though, due to the curse of dimensionality, it will takelonger as the number of states and actions increase exponentially. Also getting an optimal policy for allthe state space on a MDP is a P-complete problem [PT87].
The classical method to solve MDPs is based on this programming paradigm. It is recognized by thename of Value Iteration, subsection 2.2.3.1.
2.2.3.1 Value Iteration
This algorithm [Ber87] is based on the Bellman Optimality Equation 2.16.
v∗(s) = maxa∈A ∑s′∈S
p(s′|s, a)[r(s′, a, s) + γv∗(s′)
](2.16)
The line of reasoning is to iteratively run the previous equation for every state in the MDP. Thiscomplete procedure is repeated until some condition is verified. The usual conditions are:
• θ-convergence algorithm 1. It just compares the current state-value function for the currentiteration with the one at the previous step. If some state has state-value bigger than θ, then it has
30

not θ-converged yet;
Algorithm 1: θ-convergence of the state-value function of MDP.
input: State space S.State-value functions Vk and Vk−1 .
forall s in S doif |Vk[s]−Vk−1[s]| > θ then
return Falseend
endreturn True
• Maximum number of iterations;
• Timeout.
Algorithm 2: Value Iteration for a generic MDP with the θ-convergence criteria.
input : MDP, < S, A, T, R >.θ, convergence threshold.γ, discount factor.
output: π∗, the θ-optimal policy.V∗, the θ-optimal state-value function.
k← 0∀s ∈ S, V∗k (s)← 0repeat
k← k + 1forall s in S do
V∗k (s) = maxa∈A ∑s′∈S p(s′|s, a)[r(s′, a, s) + γV∗k−1(s′)]
end
until V∗k has θ-convergedforall s in S do
π∗(s) = argmaxa ∑s′∈S p(s′|s, a)[r(s′, a, s) + γV∗k−1(s′)]
endreturn π∗, V∗k
The Optimal Policy can only be obtained with full certainty, if one is using the θ-convergence criteriaand θ parameter is set to zero. However, this is not always possible, as the number of states can be toolarge or there are time constraints to solve the MDP. So, one must resort to local maxima of the statevalue function. One way to obtain them is by using sampling techniques as seen in the following section.
2.2.4 Monte Carlo Learning
Unlike algorithm 2 which is based on dynamic programming, Monte Carlo Learning (MCL) [SB98] is asample based method that involves learning the optimal policy from episodic experience. Additionally,it does not even need an explicit model of the world (i.e., the transition model and the reward function).Though, a blackbox simulator of it is needed. Figure 2.3 describes an agent following this behaviour. Theagent’s job is to find and execute the best action, given the current situation. Afterwards, the simulatorgives a sample of the new state and a reward. This process is repeated until it fulfills some previouslydefined condition.
31

Figure 2.3: Schematic of a RL agent operation.
Again, it is not possible to deterministically calculate the state-values, as the model is unknown to theagent, so he must resort to estimates, using the sum of the rewards gained on every episode containingthis state, averaged over all the completed episodes which have that same state.
Moreover, since the agent is trying to find the optimal policy, it should not always take actions whichgave it the best expected rewards in previous episodes, as the state-values can have a high amount ofbias in them. So, he must mix exploitation of the current policy with exploration of unknown states inorder to converge to the optimal policy.
This computational paradigm has been followed in many successful RL algorithms, like Q-Learningand SARSA [SB98] and more recent ones using Deep Neural Networks like Deep Q-learning [MKS+15][MKS+13].
2.2.5 Factored Markov Decision Processes
When learning the theory behind MDPs, it is often easier to describe them using its explicit representa-tion. It is called explicit because the transition probabilities are discriminated for every possible state ofthe world model. The same applies for goals and actions.
However, this type of representation does not scale to bigger problems, as the state space is oftentoo big to be enumerated. So, an alternative way to model MDPs exists, and the reasoning behind it isto represent each state by a combination of multiple attributes of the world model.
This representation was introduced by [BDH99]. On this specification, each state is composed ofmultiple factors, normally referred as state variables. Each factor has its own domain and the total spacesize is the combination of all possible values for each state variable.
The main advantage of having this kind of representation is that each probabilistic transition can beseparately represented by a DBN.
In order to understand what a DBN is, one must explain what is a Bayesian Network (BN). BNsare a class of probabilistic graphical models which represent dependencies of variables with directedgraphs. It contains nodes, which represent state variables, and edges between them, expressing acausal dependency between them. Every node has a conditional probability table that expresses theserelations mentioned above. A BN can represent a set of factored models that are time invariant. If atemporal dependence exists, DBNs can be used to model them. They are represented as a two stepBN, one on the current time step and the other on the next time step, with the same variables on each.Temporal dependences are represented by edges from variables on the first timeslice to variables onthe second timeslice. There is not any edge between variables on the first time step. However, it canexist edges between variables on the second time step. They are meant to represent effects that have acommon cause.
These factored representations are used to describe the domains further along this thesis. An exam-
32

ple of a factored MDP, which was actually used to model the location of the robot in the house is showedin 2.4:
Figure 2.4: DBN describing part of the factored Markov Decision Process for the robot. The illustratedstate here is the robot location. It can be either of these three values: ”kitchen table”, ”sofa” or ”bed”.The actions are illustrated along the arrows: ”wait”, ”navigate” or ”respond”.
2.2.6 HYPE Planner
While searching for an appropriate planner that would take advantage of logical programming, multipleoptions were possible (see discussion in section 2.2.7). But, in the end, the choice fell upon HYPEalgorithm [NBDR15] (pseudocode is shown in algorithm 3), a state of the art planner completely writtenin Prolog. Some of its most important features include domains with an unknown number of variablesand handling both discrete and continuous state and/or action spaces. All of this is accomplished afterdescribing the domain, using DDCs on a Prolog program, and following a set of syntax rules (see section2.2.6.1 for more information about these rules).
Unlike other classical algorithms based on dynamic programming, HYPE takes advantage of MCLin order to overcome the curse of dimensionality and build the state-value function. Since others thatfollow this approach do not use information about the transition model, HYPE incorporates importancesampling in order to take advantage of that same model.
Also, and similarly to Q-learning [SB98], it follows an off-policy strategy to update the state valuefunction. This means that the value of the optimal action is learnt without following the current policy. Itsimplementation uses an ε-greedy strategy to sample an action from the current state, i.e. with probability1− ε chooses the action with the highest action-value estimate, otherwise, samples a random actionaccording to an uniform distribution.
The algorithm takes advantage of logical interpretations for representing states in the domain. Theselogical interpretations are ground facts that define a possible world. Finally, the algorithm gives a policyfor the specified horizon. Though, in our methodology, we replan on every step of the robot planning/ex-
33

ecution cycle.
Algorithm 3: HYPE algorithm for solving MDP problems, as shown in [NBDR15].
Function HYPE recursive (d, smt , m)
input : d, horizon.sm
t , state of the world at timestep t in episode m.m, episode number.
output: Vm(st), the state-value estimate for s in episode m.if d = 0 then
return 0endforall action a in applicable(sm
t ) do
Qmd (s
mt , a) = r(sm
t , a) + γ∑m∈M wmVm
d−1(smt+1)
∑m∈M wm
endam
t ← ε-greedy(st, Qmd )
Sample smt+1 ∼ T(st+1|sm
t , amt )
Vmd (sm
t )← r(smt , am
t ) + γ HYPE recursive(d− 1, smt+1, m)
Put in memory (smt , Vm
d (smt ), d)
return Vmd (sm
t )
The wi parameter is a weight function for episode i at state sit+1. These weights explore the transition
model. A thorough explanation of the weight function is shown in the original publication [NBDR15].The state-value function is calculated using a recursive procedure and is initialized with zeroes for
each possible state.
2.2.6.1 Implementing HYPE Domains & Problems
In order to write a syntactically correct HYPE domain, it is necessary to follow some rules:
1. Decide whether is preferable to use an implicit or explicit representation of the MDP. If an explicitmodel is chosen, there only exists one predicate at each timed step.
2. Identify needed predicates which are necessary to describe the MDP and goal predicate(s). Imag-ine, for example, that an agent has the goal of reaching the kitchen:
stopt ←' (location(agent)t) = kitchen. (2.17)
3. Enumerate all possible actions in the domain and explain when they are available to be used.Actions should describe what states they are applicable. A simple example is shown below, de-scribing when the action deliver is available to be used:
applicable(deliver(coke, lynda))t ←' (have(coke)t) = agent,' (near(lynda)t) = true. (2.18)
4. Choose the proper rewards: they can be function of specific interpretation 2.19, action 2.20 oreven both 2.21. It can also be used to give a reward when the goal is reached 2.22. Though, it isimportant to mention that rewards are mutually exclusive. So, this can be a serious limitation if thedomain designer chooses a factored state representation.
reward(10)t ←' (have(coke)t) = lynda. (2.19)
34

reward(−10)t ← deliver(coke, lynda)t. (2.20)
reward(−4)t ←' (near(lynda)t) = true, deliver(coke, lynda)t. (2.21)
reward(10)t ← stopt. (2.22)
5. Describe the transition model of the domain using DDCs. It uses a structure similar to SituationCalculus. So, when some action is executed, it must dictate what will change and also whatremains the same. An example is, for instance, the movement action of an agent and its effects onothers around him:
location(agent)t+1 ∼ f inite([0.8 : hall, 0.2 : kitchen])← action(navigate(hall)). (2.23)
location(lynda)t+1 ∼ val(Region)← action(navigate(Y)),' (location(lynda)t) = Region. (2.24)
6. Instatiate a problem by grounding the current predicates with their respective values or probabilitydistributions.
7. Try to find which hyperparameters (episode horizon, discount factor, exploration bias, numberof episodes, etc) give the best domain results by differential parameter tuning under simulationbenchmarks.
2.2.7 Related Logical Probabilistic Planners
In order to have our robot freely behaving in the domestic environment, it was necessary a probabilisticplanner. Then, the robot would be able to determine rational actions it could perform in order to completemissions assigned to it. The planner needed to have support for DDCs (language that the robot’s domainwas modeled in), continuous probabilistic distributions and temporal logical predicates. The followingalternatives were considered:
• In [VdBTVODR10], den Broeck et al. presented a decision theorethic extension of Problog with thename DT-Problog. It included a set of syntax rules that was expressive enough to describe simpleplanning problems. It includes two integrated algorithms for solving them: an approximate solverwhich is faster but non-optimal; and an exact one which can take a lot longer in order to converge.They express actions as decision facts and rewards as utility attributes. However, the languagelacks support for timed indexed predicates, so there is no way to express temporal transition oflogical predicates. Also, it does not support continuous facts and decisions which can be essentialin robotics problems.
• Another related approach is proposed in [LT10] by Land and Toussaint. They make use of NoisyIndeterministic Deictic rules in order to learn abstract representations of the world. In turn, thoserules are integrated into a planner by the name of Probabilistic Action-sampling in DBN’s PlanningAlgorithm (PRADA), which was developed by the same authors and takes advantage of probabilis-tic inference in order to handle probabilistic action effects. Finally, this architecture was appliedinto a 3D manipulation task and likewise to the domains of ICAPS-IPC. They lack however the
35

expressiveness of a programming language Prolog and they are not able to describe continuousprobabilistic distributions.
2.3 Social Robotics
2.3.1 Domestic Robots
There have been a lot of attempts to introduce robots in domestic environments. But the most successfulcase is in vacuum cleaning industry. There are now multiple inexpensive robots that autonomously cleanhouse floors. Still, the majority of interesting tasks in household domains are incredibly difficult to performin real scenarios within tight schedules.
Tasks in domestic environments integrate multiple skills like perception, grasping or others whichare incredibly difficult to perform on separate benchmarks. Normally, they have high accuracy but arenot time efficient or even the other way around. Robot grasping is one of those skills, but with otherproblems: reliable robotic manipulators are not affordable to the average citizen. The problem here isthat most of these tasks requires the robot to interact physically with one or more objects in the scene.
Examples of these hard tasks exist in laundry folding [MVDBF+12] and in pancake cooking [BKK+11],for example. The pipelines developed to accomplish their objectives are highly specialized and the robotsare expensive to the average consumer.
In order to overcome this problem, the work developed here gives robot the opportunity to ask forhelp to other people in the house. This extension should improve the robot’s accuracy in tasks he hastrouble doing by himself.
2.3.2 Symbiotic Autonomy
In this section, it will be discussed the research already developed in the field of Symbiotic Autonomy,which is at the core of the main problem to be solved. In reality, most of the research efforts on this areahave been conducted by Rosenthal in [RBV10], from CORAL group (in CMU), led by Professor ManuelaVeloso.
In robotics and similar to biology, when there is a symbiotic relationship, all agents are usually per-forming their own asynchronous actions, and each agent is influenced by the outcome of the otheragents’ actions. However, all agents can actively cooperate with each other, by communicating, re-questing and providing help. As said earlier, agents with this type of relationship can ask or receive helpfrom each other on actions they could not have performed by themselves, overcoming their limitations.Each agent can help the other one by: performing an action for the first agent; increasing the first agent’scapability to perform an action.
By interacting in an environment with multiple human agents and possible actions usable by the mo-bile robot agent, establishes this situation as a planning problem. So, each agent has a cost associatedto his state and action made. Hence, each agent will perform the set of actions that minimize the cost ofeach others’ state in order to achieve the goal.
As already referred in section 2.3.1, it seems useful to introduce the concept of capability : theprobability of an agent to complete an action [RBV10]. If this probability is zero, it is impossible thatthis agent can successfully perform the respective action. Conversely, if the probability is bigger thanzero, but lower than one, there is a chance that this action would not be completed by the agent. If theprobability is equal to one, the agent can always perform this action successfully. This information canbe encoded in the transition model of a MDP.
36

As it is not possible for a robot to be able to perform all actions in tasks that he is supposed to finish,due to the complex nature of the real world, this approach can be shown as an advantageous alternativeto successfuly complete most of the tasks assigned to the mobile robot agent [RBV10]. On the otherhand, and as discussed before, this approach raises new problems related to probabilistic planning, asthe models of the world become much more complex. This fact needs to be properly handled to give thebest results possible in the current task. Furthermore, the cost of asking for help to a human agent mustbe accurately determined, and may even be different to each individual human agent [RV12], addinganother level of difficulty to this problem.
2.3.2.1 Agent’s Limitations
When a robot is wandering around an environment completing its tasks, it may experience a failure atsome point, because of some limitation it could have. There are a lot of possible causes that can leadto unexpected outcomes. When talking about its limitations, they can be separated in:
• Action Execution: the robot does not have a manipulator, or it will fail to grasp some object on aspecific scenario. Another example could be its incapability to pass through stairways, or use anelevator.
• Perception Errors: the robot has difficulty identifying objects and people on a task. He could alsohave bad sensors which induce localization problems.
• Insuficient Cognition: these are the harder to overcome; An example is an agent that does notunderstand he will have to press a specific button in order to call an elevator.
2.3.2.2 Help Types
Hence, and in order to overcome the limitations described above the agent can request for help to peoplein the scene. So, the following types of help actions can be described:
• Actor’s Action Replacement: the agent asks a nearby agent to perform some physical action forhim. The human could pick an object and give it to the robot or he could lift him and carry it througha stairway.
• Information Gathering Action: the robot can ask for clarification about some uncertain measurewhich is relevant for its current state. An example of this behaviour could be a human correctingthe robot’s pose estimate on a map.
• Policy Demonstration Action: the human agent teaches the robot how he can interact in theenvironment in order to produce some effect in the world. This type of help action can augmentthe agent’s capability in the long term, but with a higher cost. The human can teach the robot totouch the elevator button in order to get to another floor. He can also teach him to pick objects bydemonstration.
2.3.2.3 Help Cost
Whenever the agent needs to make a decision in the environment, he must plan in advance if it is betterto perform some action by himself or should he ask for help. The decision process takes into accounteach of the different costs to make the optimal decision. However, there are a couple of factors thatshould be taken into account when calculating the cost of requesting some human agent for help. Thosecan be:
37

• Time the human agent takes to perform that action. The time of a human is more valuablethan the robot’s. They can be mass produced and their purpose is to fulfill people’s desires or toreplace humans in repetitive and menial tasks.
• Number of times the robot requested help to an agent. A person will get tired of the robot soonif they are always receiving help requests. So each cumulative request to the same person getsmore expensive to the robot.
• Complexity of the help request. The cost also depends on the type of help request. Helptypes were already defined in section 2.3.2.2. The general rule attributes the highest cost toPolicy Demonstration Actions and the lowest to Information Gathering Actions. However, there areexceptions and in those scenarios, a case by case study must be assessed.
• Emotional state of a human agent. Human agents are not always in the best mood to be re-quested for help. And the worst part is that emotions are normally hard to infer just by looking at aperson. So, only by interacting with them (in a conversation, for example), they can discover moreabout their emotional state.
• Personal’s taste for robots. Not all people feel the same about human robot interactions. Thereit will exist people that will ignore robots. Hence, the robot must be able to infer each human agentresistance to the interaction.
2.3.2.4 Availability
Another important detail is how to determine a person availability. Previous studies on human availabilityto help a robot were developed by Rosenthal et al in [RVD12]. They attributed fixed locations to eachperson which had their individual work schedules.
However, human availability depends on multiple factors (apart from perception issues related towhat they are doing in the current situation). It includes most of the topics from section 2.3.2.3 whichtranslates to a complicated inference problem.
2.3.2.5 Trust in Help Requests
The last topic described here is related to the trust in human agents help. Typical scenarios could be:”Did I receive an apple from Person A?” or ”Should I trust the position estimate from Person B?”; This is-sue could be remediated using distributed verification from other agents [RVD12], or even crowdsourcingthe help request review.
Though, most of these topics were not taken into account when modeling the symbiotic interactionbetween robots and humans. The majority of the time was spent testing and correcting errors on thedomain, so it is important that future work is developed on this area.
2.3.3 Related Approaches
The prime example of the concept is project CoBot [VBCR15], in [RBV10], where the mobile robot agentautonomously navigates between floors of CMU’s Gates Center for Computer Science, escorts visitorsto scheduled meetings and fulfills other needs which they might have. In this task, the visitor is notfamiliar with the building’s layout and the robot is unable to do activities which might require physicalmanipulation of objects. Similarly, the robot could lose track of its exact location on the map. On theother hand, the human agent can easily manipulate objects around him and locate its exact positiongiven a visual map, while the mobile robot can plan optimal paths to multiple locations if its location is
38

accurate. Given the previous conditions, the authors meshed the capabilities of each agent to overcometheir limitations. They analyzed the convenience provided and its reliability to prevent delays on thevisitor schedule while minimizing the help requests to other humans to increase its autonomy. Multiplepolicies executed by robot were analyzed by real world data. The domain description language used forthis task was Planning Domain Definition Language (PDDL) with probabilistic extensions.
Figure 2.5: Cobot robots that roam around CMU Gates’ computer science building.
Moreover, similar work was developed in efficient object search [VMVL16], by Veiga et al. They usedprobabilistic logic (this was accomplished while using Problog) to represent object locations as beliefs.Additionaly, the object search decision module was modeled after a POMDP, in order to find objectsin the minimum time possible. The information about the environment was stored in a semantic mapand was updated repeatedly whenever it was acquired new data from sensors. That semantic mapincluded probabilistic rules to update its knowledge about the environment. Additionaly, they used anoffline POMDP solver in order to make decisions on the environment. Finally, they implemented theirsoftware pipeline into the Mbot platform. In contrast, this work focus on fully integrating PLPLs into adomestic environment with possible human interaction (using symbiotic autonomy) in order to completepick and delivery missions. The robotic platform for this task was the same.
Antunes et al. proposed a probabilistic planning approach in order to decode human verbal instruc-tions to robot actions [AJS+16]. A pipeline was created which has the following important parts: seman-tic reasoning for human verbal instructions; goals and formulation; and robotic actuation. The proposedarchitecture was implemented and tested on the Icub robotic platform. This scenario includes multiplesources of knowledge: prior information; semantic knowledge from verbal instructions; and lastly, knowl-edge from real world perception. It uses PRADA probabilistic planner as a method to determine the bestgrounded action in each possible situation the robot encounters. In contrast, the system developed hereintegrates DDCs into the domain description.
Bogdan et al. used probabilistic programming to learn affordance models which can express relationsbetween objects [MMN+17]. The learned model was then incorporated into a planner in order to solvegoals expressed in verbal language. They focused on PLPL in order to represent real world objectrelations in spite of using something like BNs which are unable to represent them. For that purpose,they took advantage of DDCs from Nitti et al. [NDLDR16]. Their pipeline consisted on: first, learning anappropriate affordance model and then, generalizing it to a state transition model; in order to finally useit on real world benchmarks by means of a planner. This planner was a naive sample based planner
39

without policy improvement. Lastly, their software architecture was implemented in the Icub roboticplatform. The work presented on this dissertation builds upon the same PLPL from Nitti et al. and usesthe integrated planner HYPE in order to model and plan in the designed world model. Then, the softwarearchitecture is implemented on top of the Mbot robotic platform.
Finally, the concept of SA could be introduced on the recent project about collaborative robots, theSpace CoBot project [RV16]. The project aims to integrate collaborative robots in microgravity environ-ments such as the International Space Station. Tasks on these environments require similar motor andsensorial skills as those of domestic robots. However, uncertainty about the robot’s surroundings andactions still exist, and other limitations could harm task performance, in general. SAs could be used toincrease task success.
40

Chapter 3
Robot Using Symbiotic Autonomy onDomestic Environments
3.1 Describing the Domestic Environment Domain
In order to take advantage of MDP properties, the domestic environment was modeled taking into ac-count uncertainty on robot’s action effects. The task takes place in ISRoboNet@Home testbed whichsimulates a real domestic environment. The transition and reward models were obtained from em-pirical evidence that would come out of the HYPE planner. The domain is subdivided in two differ-ent domains, making up a hierarchical domain and simplifying the planning mechanism to producebetter real world performance. The following case study tries to reproduce similar tasks that couldhappen on a domestic environment. Since the domains are implemented as prolog code premises,its whole inclusion on this report would occupy too much space. So, the explanations made on thischapter focus more on a high level perspective of action models and sources of uncertainty. Never-theless, the reader is advised to read the respective code that is included on the following repositoryhttps://github.com/littlebrat/Master-Thesis.
3.2 Methodology
The following sequence of steps were used in order to obtain the resulting domain:
1. The first necessary step for modeling a MDP domain is to clearly identify the objective of thedecision agent. On the proposed scenario, the robot’s objective was to deliver an object to anotherhuman in the house.
2. Clearly describe agent’s capabilities and limitations that are relevant to the desired goal. The robotis able to freely move in the domestic environment; can participate in conversations with otherhumans. It can also use its robotic manipulator to interact with objects, but has a low probability ofbeing effective. Thus, the robot’s limitation is related to action execution.
3. Identify which information the robot needs to keep track of, in order to make informed decisions onthe domestic environment. The state will be a combination of multiple dynamical logical predicates.States will also be the result of the grounding of the initial observations. It is assumed that therobot has full information about its state. Thus, the domain is fully observable and there is not anyuncertainty about its state.
41

4. Using a step-by-step approach, and starting from the goal, identify the state predicate and anaction which can lead to the current state. Additionally, it is necessary to define the DDC whichactually modifies the value of the state predicate when that action is used. This procedure startsfrom the goal, which in this case was that person X had object Y and that person X wanted object Y.Afterwards, it is introduced the action deliver/2 and the predicate have/11. The predicate have/1has an argument which is the object and its value could be any of the following: none, robot orperson.
5. In order to test the developed model, it was created a sandbox testing tool which one can inputthe starting state, then send actions and check if the next step result is correct. This is done byverifying the probability distribution of each grounded state predicate in the domain from one stepto another. Since the model is still deterministic, there will be only zeros and ones.
6. This process is done until every possible scenario is covered in the domain. This is an exhaustiveprocedure, since for every action, one must describe the effect for each state predicate, even if itremains constant.
7. Afterwards, the same iterative process is done in the same order, but now with the intent of intro-ducing stochastic effects into each DDCs. Everytime a change is made to a DDC, it is necessaryto run the sandbox testing tool in order to manually confirm that the probabilities of reaching thenext state are correct. Now, the action deliver/2 has a minor probability of dropping the object intothe floor, instead of just deterministically delivering it to another person.
8. When the above step is done, rewards (and costs) are added into the model. Since HYPE hastrouble dealing with state predicates and rewards, it was established that every action had a costwhich was initially assigned to the same amount of time it took to perform that action. The rewardwas given when the goal was reached.
9. It is now time to tune the rewards and probabilities of the DDCs in order to get the appropriateactions from the planner. It was generated a number of tests which should cover the majority ofimportant events the robot could face in a real domestic environment.
10. Now, it is necessary to tune the parameters of the planner in order to get the correct actions whileminimizing the time it took to plan. This was done by reducing the horizon of the planner and thenumber of samples it used.
This method was used specifically to model the domestic environment domain but it can be used todescribe any other domain for the HYPE planner.
3.3 Hierarchical Overview
The designed task consists on a robot that wanders around the domestic household and carries outassigned tasks by the house’s family members. The robot expects a reward every time it receives amission or accomplishes the goal of an assigned task. The robot can only have one assigned mission ata given situation. Every single action the robot executes has a different given cost and can have multipleexclusive effects on the world. This effects are the result of stochastic processes, given the uncertaintyin the real world. This schematic was successfully implemented by building an hierarchical model asseen on figure 3.1, in order to reduce the time it took to give correct results. The model was divided in
1This notation means that the predicate is identified according to the number of arguments it has.
42

two because the reward was awarded far into the future from the first step. So, the planner rarely got theexpected action and would get caught in local maxima.
Figure 3.1: Schematic of the domain architecture.
3.3.1 Time Invariant Predicates
The following table describes every predicate which remains static along the running time of the de-scribed domain. They exist for sole purpose of supporting other dynamic state predicates.
Predicate Arguments Descriptionperson Name Represents a person with Name as identifier.region Name Describes a region in the map with Name as identifier.object Name Identifies an object on the world with Name identifier.robot Name Tags the robot called Name.agent Name An agent identified as Name could be a robot, person or object.
movable agent Name A movable agent identifiable by Name is an agent which has move-ment capabilities. This means that an object is not a movable agent.
other agent Name It is an agent called by Name apart from the robot. In other words,objects and people are other agents.
want Name,Type The agent called Name wishes Object.goal Desire It identifies Desire as a goal.
Table 3.1: Description of predicates that are static with respect to time changes and that are the samein both subdomains of the model.
43

3.4 Wandering Domain Description
On this domain, the robot is wandering around the domestic environment while awaiting for requestsgiven by other human agents. The robot can hear people calling for him (i.e. ”Robot come here!” ).Additionally, he is always aware of the location of each agent in the scene (including himself), and theirposition is static (apart from the robot). Additionally, when the robot moves to another room which has aperson in it, there is a chance that he will be near that same person. Furthermore, the robot can engagein conversation with a person if the latter has called him earlier and is near him. While on conversation,the human may request an object, assigning a mission to him upon the respective validation. Availablepredicates which comprise the full joint state are described in table 3.2 along with the possible actionsthat can be performed by the robot in table 3.3. When a mission is assigned to the robot, the currentworking domain switches to the Mission Domain.
Predicate Arguments Possible Values Descriptiondynamic state - {idle, conversation(Name)} Indicates the operation mode of the
robot. It can be in either two differ-ent states: idle, where it stays still fora defined period of time; or in con-versation with a person identified asName.
called - {none, Name} It can indicate one of two things: no-body called the robot (here repre-sented by none), or that some per-son with Name called it.
located Name {Region} This predicate defines the location ofagent identified as Name in the map.It has the value of Region in whichthe agent is located.
near Name {true, false} It indicates that the robot is near (ornot) of person identified as Name.
listened - {(none,none), (Name, Goal) } This predicate indicates that therobot listened (or not) to a Goalcommand from person identified asName.
mission - {none, Desire} It represents the current goal of therobot. It can have two types of val-ues: none, if it does not have anygoal yet; or Desire, if it already hasa goal defined.
Table 3.2: Time variant predicates used for the wandering domain.
44

Action Arguments Description Costnavigate Region The robot will navigate to a specified Region on its map. 8
wait - The robot waits until new action is executed. 5respond Person, ready to help The robot acknowledges a call from Person. 7respond Person, confirm mission, Desire The robot confirms the Desire request from Person. 7
Table 3.3: Actions that can be performed by the robot on the wandering domain of the domestic envi-ronment.
In order to truly understand the devised model it is important to explain some of the DDCs which aredefined in the domain. One of them is the navigate/1 action:
e f f ect navigate(Name)t ∼ f inite([0.85 : NewPlace, 0.15 : none])←
robot(Name), action(navigate(NewPlace)).
e f f ect navigate(Other)t ∼ val(none)←
person(Other).
It was necessary to introduce the intermediary state predicate effect navigate/1 in order to modifythe location of both person or human when holding an object, otherwise the object would remain in thesame place. Though in this case, neither people or objects can move to other places, as can be seen inthe previous DDC (the clause related to the object is similar to this one). The robot can either move to anew place with high probability or remain in the same location with a slight probability. The following twoclauses just generate the new location of each agent according to the effect navigate/1 state predicate.
located(Name)t+1 ∼ val(NewPlace)←
movable agent(Name), region(NewPlace),
' (e f f ect navigate(Name)t) = NewPlace.
located(Name)t+1 ∼ val(OldPlace)←
movable agent(Name), region(OldPlace),
' (e f f ect navigate(Name)t) = none,
' (located(Name)t) = OldPlace.
Since it is necessary to enumerate what happens to every state predicate in the model when anaction is performed, the effect navigate/1 will have a DDC for every possible action. The followingclauses show exactly that:
45

e f f ect navigate(Name)t ∼ val(none)←
robot(Name), action(wait).
e f f ect navigate(Name)t ∼ val(none)←
robot(Name), person(Other),
action(respond(Other, ready to help)).
e f f ect navigate(Name)t ∼ val(none)←
robot(Name), person(Other), goal(Message),
action(respond(Other, con f irm mission, Message)).
The action navigate is the only action which can modify the robot’s location from one step to another.This is a simplification of the wandering domain and it is not true in following section. This exact pro-cedure is followed in order to describe the remaining combination of actions and state predicates. Theonly exception to this rule is the state predicate near:
near(Other)t ∼ f inite([0.7 : true, 0.3 : f alse])←
robot(Name), person(Other),
' (located(Name)t) = Place,
' (located(Other)t) = Place.
near(Other)t ∼ val( f alse)←
robot(Name), person(Other),
' (located(Name)t) = Place1,
' (located(Other)t) = Place2,
not(Place1 = Place2).
The near/1 is only dependent on the current values of the state predicate located/1. Also, the robotcan be near (or not) to every agent in the domain (excluding himself). So, the number of grounded in-stances can quickly grow with the number of people and objects in the domain. Additionally, an availableaction is defined as applicable in that time step if it satisfies the body, of its action clause. For example,the action respond/2 has the following clause:
46

applicable(respond(Other, ready to help))t ←
person(Other),
' (near(Other) : t) = true.
It is only available when the robot is near to other person. It also has the following cost:
rewardt ∼ val(−7)←
action(respond(Other, ready to help)).
Finally, the goal of the domain is reached when:
stopt ←
goal(Purpose),
' (missiont) = Purpose.
And the agent receives a reward:
rewardt ∼ val(100)←
stopt.
These short snippets of prolog code serve to demonstrate how was modeled the domestic envi-ronment domain with symbiotic autonomy and how it differs from the object push test from the originalarticle in [NBDR15].
3.5 Mission Domain Description
The mission domain includes a pick-up challenge for the robot, assigned before by a human in thedomestic environment. It includes a complete action description which enables him to pick and deliverthe object himself or request help to another human while implicitly waiting to receive it. It also describesa special rule which penalizes requests for help to the same human that requested the object. It isimportant to mention that in our scenario a human cannot deny a request for help and its cost is thesame for all available people in the house (apart for the human who requested the object in the firstplace). This behavior could be improved, but in this case, the description of the domain would have ahigher degree of complexity and it would take a longer time to plan which was already a limiting factorfor the current design. The predicates of the robot state and actions are also described in tables 3.4and 3.5, respectively. Similarly to the last domain, the location of every agent in the scene is known,including the object, though now every agent in the domain can move from its original location. Finally,the mission will persist until the human who requested the object is in possession of it, switching to theWandering Domain upon completion.
47

Predicate Arguments Possible Values Descriptionlocated Name {Region} This predicate defines the location of
agent identified as Name in the map. Ithas the value of Region in which theagent is located.
near Name {true, false} It indicates that the robot is near (or not)of person identified as Name.
mission - {none, Desire} It represents the current goal of the robot.It can have two types of values: none, if itdoes not have any goal yet; or Desire, if italready has a goal defined.
have Type {Name, none} A movable agent identified as Name (ornot) has the object with Type.
asked - {(none, none), (Type, Name)} The robot asked for help to person identi-fied as Name to pick object Type.
Table 3.4: Time variant predicates used for the mission domain.
Action Arguments Description Costnavigate Region The robot will navigate to a specified Region on its map. 7
wait - The robot waits until new action is executed. 5grasp Object The robot picks Object. 25deliver Object, Person The robot delivers Object to Person. 6
ask help Object, Person The robot requests help from Person in order to get Object. 6receive Object, Person The robot receives Object from Person. 6
Table 3.5: Actions that can be executed by the robot on the mission domain of the domestic environment.
This domain is rather similar to the previous one, since it previously was just one domain. Thoughit was simplified by reducing the number of state predicates available to be grounded. Also, now everyagent can move from one place to another (though objects cannot freely move without assistance froma human or the robot). The same clauses apply for the robot movement, but now a person can alsomove, so their clauses need to be replaced. Though, the person’s movement is conditioned by the valueof one state predicate: asked/0. It indicates if the robot requested help to this person in order to fetch anobject. The action ask help/2 triggers that change in the state predicate.
askedt+1 ∼ val((Type, Other))←
object(Type), person(Other),
' (near(Other)t) = true,
action(ask help(Type, Other)).
This state transition is completely deterministic. But in reality, it should not be like that and thehuman agent could have the possibility to refuse the help request. But, this was the followed approachto reduce the complexity of the domain. The help request becomes fulfilled when the robot has theobject it wanted:
48

askedt+1 ∼ val((none, none))←
object(Type), person(Other), robot(Name),
' (askedt) = (Type, Other),
' (have(Type)t) = Name.
And if the robot still is not in possession of the object, the request will remain active:
askedt+1 ∼ val((Type, Other))←
object(Type), person(Other),
' (askedt) = (Type, Other),
' (have(Type)t) = none.
askedt+1 ∼ val((Type, Other))←
object(Type), person(Other), person(Other2),
' (askedt) = (Type, Other),
' (have(Type)t) = Other2.
The robot can only request for help if it is near the person he wants to ask for help and if it is notalready in possession of the wanted object. The movement of the person who has been requested tohelp is directed to the object location. The person will get the object when it is near him and then deliverit back to the robot (the person will move to the robot’s location if he is not in the same place as it). Theperson performance is completely deterministic. The most important clauses related to these behaviorare shown below:
e f f ect navigate(Other)t ∼ val(Place1)←
person(Other), region(Place1), region(Place2), object(Type),
' (askedt) = (Type, Other),
' (have(Type)t) = none,
' (located(Type)t) = Place1,
' (located(Other)t) = Place2,
not(Place1 = Place2).
49

have(Type)t+1 ∼ val(Other)←
object(Type), person(Other), region(Place),
' (have(Type)t) = none,
' (askedt) = (Type, Other),
' (located(Type)t) = Place,
' (located(Other)t) = Place.
e f f ect navigate(Other)t ∼ val(Place1)←
person(Other), region(Place1), region(Place2), object(Type), robot(Name),
' (located(Name)t) = Place1,
' (located(Other)t) = Place2,
' (have(Type)t) = Other,
' (askedt) = (Type, Other),
not(Place1 = Place2).
When the person has the object is near to the robot, the latter has the oportunity to get the objectfrom him, by using the action receive/2. The other alternative the robot has is to pick the object byhimself, when using the action grasp/1 , given by the following clause:
have(Type)t+1 ∼ f inite([0.7 : Name, 0.3 : none])←
object(Type), person(Other), robot(Name),
' (have(Type)t) = none,
' (askedt) = (none, none),
' (near(Type)t) = true,
action(grasp(Type)).
Also important is the discussion about the action/state state space of each planning problem. Sincethe previous model only describe the flow of a world domain, the number of possible actions and possiblestates will depend on a specific grounding of the problem. In our case, it will depend on the number ofpeople, rooms and objects in the house environment. The domain’s evaluation includes three peopleand locations, plus an object.
3.6 Software Architecture
Now, the robot has a domestic environment model which features interactions with humans on pickand delivery missions. The domain covers SA concepts and uses the planner to perform actions onthis environment. Though, it is also necessary to integrate that information into the robot so that it canuse the domain knowledge and decide at every step what action to execute. This involves joining thefollowing systems: robot sensors, domain knowledge, hype planner and robot actuators. The resulting
50

architecture will be able to evaluate if SA improves the robot effectiveness on domestic environments.
The developed architecture (in figure 3.2) is composed of the following components:
• Monitor Module: receives external sensor data from multiple sources, processes and combines itwith internal sensor data to form the joint state at each time step of the run. In order to procedurallyaccomplish this goal, the internal state is continuously tracked and modified according to the resultof each action. Regular expressions were used in order to parse the external sensor data. Themodule is also responsible for generating the grounded MDP problem from the joint state andcleaning the previous one. When a problem is generated, it calls the next Module;
• HYPE Module: just a python wrapper for calling the HYPE planner with the desired domain andparameters: number of samples and episode depth.
• Executor Module: it receives the action to be performed from the previous module, parses it andsends a ROS action message to the respective action server. It was used a movebase server whichwas already integrated on the robot in order to send the robot to previously recorded waypoints onthe map.
Figure 3.2: High level diagram of the execution workflow.
On each cycle, the robot plans for a previously defined number of steps ahead, given the current ob-servation data. So the current state and action space is given by the grounding of that same observationdata. Though, from one step to another, the planning is done all over again. This is a critical limitationof this architecture and further work should focus on recycling the best policy obtained on the previousstep.
In order to improve the performance of the developed module (the planner frequently causes CPUhogging), the workload was distributed between two computers on a single ROS network, using a remotemaster on the laptop which was responsible for running the HYPE Module, as shown in figure 3.3. Therest of the ROS network ran on the robot’s on-board computer.
51

Figure 3.3: High level overview of the communication between hardware systems.
52

Chapter 4
Evaluation
This chapter describes the methods used for benchmarking the proposed case study and their respectiveresults. The first part describes the real world benchmark setup, robot and domestic environment,whereas on the second part, it is described the simulation benchmark, based on synthetic sensor datafrom possible scenarios in the domestic environment. This includes an observation set given to theprogram on each benchmark test and the results for that same test.
4.0.1 Physical Setup
4.0.1.1 Robot Platform
An omni-directional 4-wheeled robot with a torso and rotating head. It is configured with two laser rangefinders (front and back of its base), Kinect 1 camera on the front of the head, plus an additional AsusXtion PRO Live camera and a directional microphone Røde VideoMic Pro on top of its head for speechrecognition. It also includes a robotic manipulator Robai Cyton Gamma 1500 which was not used dueto hardware and software problems at the time.
Figure 4.1: Mbot, the robot that was used for the real world benchmarks.
53

4.0.1.2 ISRoboNet@Home - Home Environment Testbed
Located in Instituto de Sistemas e Robotica, Lisbon. Serves as a benchmarking tool for robot’s perfor-mance while on domestic environments. In figure 4.2, it includes a kitchen, bedroom, dining and livingroom, all fully furnished with commonly found appliances from IKEA store. This makes it easy to recre-ate similar environments on different laboratories and competitions across the world or in simulationenvironments, like Gazebo.
Figure 4.2: On the left image, it can be seen a topological map of the ISRoboNet@Home testbed. Onthe right image, it is shown the map used by the robot for navigation and localization.
4.1 Simulation Benchmark Setup
First and foremost, all tests were performed on a single machine, equipped with an Intel i7 4700MQCPU, 8 GB of RAM, on Ubuntu 16.04 KDE as operating system. The tests were performed on isolatedenvironments with docker containers, so that they could be easily reproduced with minimum work onother computers or robotic platforms. The computer ran the tests while having the minimum amountof resources needed to operate. This means the computer was left alone to run these tests. Everybenchmark test was executed 5 times to have a better estimate of its expected action choice, action-value estimates and its variance. Similarly, it was measured the time it took to return some output, withthe same statistical estimators as before. It is also important to mention that a minimal number of testswere interrupted by the prolog’s engine core dumps and so, their execution was ignored.
The description of the task consists of three parts:
1. On the first part, the robot is idle in the sofa location and the robot’s goal is to find missions fromnearby people. Suddenly, he is called by Robert. So, he should move to Robert’s location (which isthe bed). Afterwards, he should engage in conversation with Robert, in order to confirm the initialcall and ask what he needs. At this point, Robert requests a coke beverage and the robot shouldacknowledge this request.
2. The second part relates to the mission domain where the robot needs to deliver the coke to Robert.At some point, he will have two mutually exclusive action choices: ask for help to get the coke; orgrasp it and deliver it himself. But, in this case, the coke is already in the same location as Robertand the robot and, the latter is near it. So, the expected result should be the robot grasping anddelivering the object himself, without any assistance.
3. The third part is similar to the previous one, but now the coke is in the kitchen table instead of the
54

bed. So, the robot should move to the kitchen table location and request assistance to Lynda sothat he can return to bed location and deliver the object to Robert.
4.1.1 Results
The purpose of these results was to test how the robot would behave given different scenarios, takinginto account its own limitations and capabilities, and deciding appropriately when to ask for help or not.The other studied variable was the time it took to plan, in each step of the decision process.
Results of the previously described simulation benchmark were obtained with 300 episodes/samplesand a maximum of 10 steps on a running episode with γ = 0.9. The observation data that was given ineach step of the program is described on the appendix: A. The three following tables 4.1, 4.2 and 4.3represent each test referred before.
Step # Best Action Time (s)1 wait 1802 navigate(bed) 2193 respond(ready to help, robert) 2024 respond(robert, confirm mission, want(robert,coke)) 147
Table 4.1: First case study results on the Wandering Domain.
Since the robot still does not have a mission he starts on the wandering domain. On the first step,the robot starts without having anybody calling him up for help. So, it decides the best action was to waitin the same spot instead of spending time wandering around the house, waisting energy. But, on thesecond step, the robot is called by robert which is in a different division of the house. It determines thebest action is to leave the sofa in order to get to robert which is in the bed location. On the remaining twosteps, the robot arrives at the bed division, standing close to robert, acknowledges the call and confirmsthe given mission request, after given the proper mission request from him. These results prove that therobot can receive help requests from human agents in the domestic environment. Talking now aboutthe other variable: time. The time it took to plan was lower on the first and last steps. This happenedbecause the planner had fewer states to explore. From the second step onward, the time it took to plandecreased as the number of possible states from the current one to the goal decreased. In each sample,the planner stops earlier if it reaches the goal condition.
Step # Best Action Time (s)1 grasp(coke) 2632 deliver(coke, robert) 109
Table 4.2: Second case study results on the Mission Domain.
The second experiment continues from the execution of the first one. So, the results shown heredemonstrate the robot’s behavior on the mission domain. Robot’s mission is to deliver the coke can toRobert. The robot, Robert and the coke can are all in the bed location and the robot is near to others. Onthe first step, it had the possibility to execute multiple actions, including picking the coke can by itself orto move to other house divisions where it could ask for help to Lynda or Melanie to get the coke can. Therobot determined that the best action would be to pick the coke can with its physical manipulator, despiteits low accuracy. On the second and final step, the robot delivered the coke can to Robert, finishing themission assigned to it. This experiment was shorter, timewise, since it only took two steps to complete.The decreasing planning time trend is maintained.
55

Step # Best Action Time (s)1 navigate(kitchen table) 3262 ask help(coke, lynda) 2923 navigate(bed) 2644 receive(coke, lynda) 1825 deliver(coke, robert) 105
Table 4.3: Third case study results on the Mission Domain.
The third and final scenario shows the robot’s behavior on the mission domain, following the firstexperiment final state. The goal is the same as the previous case, but now the coke can is in anotherhouse division, the kitchen table. The robot and human agents are still in the same place. In the firststep of this problem, the robot will have to make a decision similar to the previous scenario. It can go tothe kitchen in order to grasp the object or ask for Lynda’s help; or it can go to the sofa division to ask forMelanie’s help. The robot’s decision is to move to the kitchen. Afterwards, it decides the best decisionis to ask for Lynda’s help. Since the human agent behavior is also modeled on the domain, the robotknows how the human is expected to behave when he is helping the robot. So, on the following steps,the robot follows a policy which will culminate on it delivering the coke to Robert. Though, an unexpectedbehavior occured, as the robot left the room after asking for Lynda’s help, making her run after it. Thisis domain design bug as it shows a greedy behavior from the robot’s part. The planning time follows thesame trend as on the previous case studies, decreasing with each step of execution.
4.2 Experimental Procedure
The experimental case studies were executed with help from people that were present in the lab at thetime (test subjects). Then, test subjects would show QR codes to the robot which represented the exter-nal sensor information the robot would receive in a real scenario (as shown in figure 4.3). These physicalexperiments are just a proof of concept of the planned design, since sensor information was prefabri-cated. Tests were made to replicate the behavior which was obtained on simulation scenario. Finally,this experiment was filmed and can be found on https://www.youtube.com/watch?v=Q3rLRO0bsqA.
Figure 4.3: Robot in a real world benchmark, on the mission domain situation, with a real human givingexternal sensor information with a QR code. On the left, the robot is in the initial sofa location; on thecenter the robot is simulating a coke grasp; on the right, the robot is in the bed location, also next torobert and trying to deliver the object to him.
56

Chapter 5
Discussion
5.1 Analyzing reliability of Symbiotic Autonomy on Domestic En-vironments
The introduction of SA on the robot’s domestic task gives alternative action possibilities in order toaccomplish some specific task on this environment. This translates into synchronous interactions withhuman agents. Human’s action effects have an higher probability of leading to certain outcomes. Thisappears in contrast with the actions of the robot which sometimes lead to different states according to aprobability function. However, this comes with the cost of possibly annoying the person being requestedfor assistance. Not only that but the amount of times it requests help to the same person are a reason ofconcern. These costs are taken into account in the description of the domain. Though, the relationshipis not one sided, even if the robot asks for help, the human agent can also request help to get someobject on the house. Looking into both sides, it is clear that there is a symbiotic interaction between thetwo agents where both benefit from helping each other. In short, robotic platforms can be more reliableif they trust some expert to execute some action instead.
Another important issue is how natural does the interaction between the human and the robot feel.Right now, the whole human behavior is predictable, deterministic and without any kind decision makingtaken into account. The reason is that the focus of this thesis was on having the whole system properlyworking, so there is room for improvement on human-robot interaction.
5.2 Looking into the High Level Architecture
The number of states and actions in the developed domain depended on the grounding result from theobservation data. Consequently, the domain is able to incorporate any number of human agents orobjects in the domestic environment. So, when the modeling of the domain finished, it turned out thatthe planner could not handle the initial and simpler observation data which included three human agentsand one object.
This meant that the planner would take too long to solve planning problems. To cope with this issue,a method was devised: organizing the domain into an hierarchical MDP. This way, planning domainsare simpler in terms of possible actions and states, but the overall purpose of the system is maintained.This method provided a better response in terms of expected actions the robot would take for eachencountered situation.
It is important to mention that external observations the robot got were simulated by QR codes. Thishappened because of time constraints of development. So an important step now would be to incorpo-
57

rate real world data into the system. Also related, the compilation of observations was made based onpredictable events released from the environment. This method was chosen instead of discretizing timeinto a set of steps, simplifying the perception module of the system. Though, in the future, it would beinteresting to synchronize every sensor data into the ROS graph network.
5.3 System Design Approach
So there is one question that should be made now: is this system capable of performing in real worldtasks, and if so, is it scalable? Well, if a model of the world was available and the agent could take intoaccount all the uncertainty in the world, it would exist a problem related to the curse of dimensionality. Soit is not possible to perform planning by antecipation, So, in that sense, using online planning can dealwith that issue. The main concern here is that in most cases, a model of the world is not available. Sothere are two alternatives: taking advantage of a human agent to find an approximate model of the worldor; using reinforcement learning to make decisions on this unknown environment while receiving rewardsfrom it, and even trying to find the model by experience. When using the first method, the human hasto study the environment carefully in order to identify probabilistic causalities between states, actionsand its effects. Also, he must engineer a reward function that should model how the agent shouldbehave on this environment. The previous method is not scalable as it requires an enormous amountof human effort. In practice, if one already knows how the agent should behave on an environment,it is often easier to make state machines which are real-time and more reliable, with the same effort.The second option of using reinforcement learning is more of an end-to-end (and specially with theadvances of Deep Reinforcement Learning) system that requires less effort of human expertise, sinceit autonomously learns the environment structure. But, a common drawback of these approaches isthe amount of time necessary to train agents in order to have the optimal policy or world model. Oneexample is [LPK+16], which trains multiple real robotic manipulators to pick and place objects. Thoughin our case, the robot has to interact with human agents during long periods of time in order to haveenough experimental data to learn the best policy for that scenario. Having these robots that try to learnoptimal policies on real scenarios is expensive as it requires real human agents to be available for longperiods of time.
5.4 Usability of the Dynamic Distributional Clauses
DDCs have plenty of potential to represent domains with higher degrees of complexity. They are ableto represent predicates that change along time sequences and also variables distributed on a continu-ous space. Additionally, they offer common probability distributions to model these variables. It is alsopossible the usage of static functions for making external calculations that do not depend on the MDPproblem. Equally important is that by taking advantage of a programming language, that is turing com-plete, as a way to model domains, makes for an higher level of expressivity that it is just not possiblewith other description languages.
Hence, looking into these gains, it would seem like a valid design choice to represent MDPs with thislanguage, instead of using PPDDL or RDDL, for instance. However, when picking DDC, one must takeinto account the following drawbacks.
• One of the major negatives aspects of DDC is that it is largely inspired by situation calculus. Thisleads to the frame problem. For every predicate that remains unchanged after performing someaction, a new rule has to be written. This quickly increases the amount of code written as the
58

number of possible predicates and actions gets higher. As consequence, a lot of errors on thedescription of domains appear. Coupled with the high amount of rules written, it is really hard totrack the origin of these errors, and the absence of debugging tools does not help as well.
• The implementation of this language was made on top of prolog. In fact, there are so many differentimplementations of prolog that in 1995 was published a standard to uniformize the structure ofthe language. Implementations that follow this standard are ISO/IEC 13211-1 compliant. As aresult, the prolog programming community is largely fractured and declining over time. Whensome error occurs, it is generally hard to find a solution, as the problem could be related to aspecific prolog implementation. DDCs is built with YAP prolog, a rather popular version. It isfrustratingly common to have core dumps on execution of a program, making this language (in itscurrent state) not proper for robotic applications. As rule of thumb, reliable robotic systems shouldrely on frameworks that have fast responses and easily recover from failures or unexpected events.
• This is not much of a drawback itself, but more of a discussion on why one should choose todescribe planning domains with DDCs instead of PPDDL or RDDL. Originally, the formers cameup in order to standardize planning domains, so researchers could focus on finding better planningalgorithms, while having a common platform to benchmark them. On the other side, DDC iscapable of describing domains in ways the others are not. It is the reader’s job to interpret what ismost important for their own planning research.
• In particular to this implementation, there is a lot of clutter code that needs to be included in aprogram in order to run prolog programs. An end user of DDC should not have to worry about thistype of details. So, as it stands, the programming interface is not really user-friendly.
5.5 Is HYPE a good choice for solving real-time planning prob-lems?
Withstanding the time constraints imposed by robotic’s problems, HYPE planner provides a lot of flexibil-ity by being able to dynamically introduce new predicates into planning problems as the domain changes.This includes new people or objects on the domain, for example. It performs decisions based on the cur-rent available information if the problem mantains the same knowledge base and structure. This featureis possible because it only finds a policy for the current state, and not for all the existent state space,since it is an online planner. One should not confuse online planning with real-time planning. The termonline means that planning is performed on the moment it receives information from the environment.This appears in contrast with the majority of other planners which normally calculate the optimal policyfor all possible state space, and that function is used on execution time, choosing the correct state-actionmapping, if the policy is deterministic. This procedure is often called offline planning. Regardless, HYPEplanner is not real-time since it does not guarantee a response within an acceptable temporal windowor deadline.
Nevertheless, there are guarantees that given an infinite amount of time and the current state in-formation, an optimal action is found. But, this is not good enough for robotics. An action solutionshould always be found on an acceptable task time. So, on its current state, HYPE is not an appropriateplanner to deal with these type of problems, given its time constraints. Other planners should be consid-ered when dealing with robotics domains that include some uncertainty on its domain, as PROST 1 or
1PROST, Keller and Geisser, is the winning planner from 2011/2014 ICAPS’ International Planning Competitions, on the MDPboolean track.
59

POMDPX NUS2 for instance.Another important topic is the high amount of parameter tuning necessary to find the best action-
value function. This happens because HYPE has a lot of hyperparameters, transforming the problemof planning into an optimization problem of finding the best parameter set for every specific planningproblem. The high variance of the results also do not help on the task of finding them.
It is not possible to define rewards as the sum of multiple state factors. So, it is necessary to dis-criminate the reward for a complete world. This fact could easily lead to errors. Also, if there is worldwhich can unify with multiple rewards, it will only be considered the first that appears on the text file. Thesolution for this problem was to exclusively use actions and goal states as possible reward sources.
Finally, other shortcoming of HYPE is that it can not model multi-agent domains. So, in order to modelhuman agents in the domestic environment, it was assumed they had a static and known stochasticpolicy.
2POMDPX NUS, Ye, Wu, Zhang, Hsu, and Lee, won the 2014 ICAPS’ International Planning Competition, on the POMDPboolean track.
60

Chapter 6
Conclusion
On this work, it was proposed a framework for domestic robots using probabilistic logic programming withdynamic distributional clauses for solving MDPs as one time decision problems. The robot uses thesetools in order to decide which action to take at each time step while trying to maximize its expectedreward on the domestic environment.
It is proposed an hierarchical MDP domain divided into two: one where the robot is wandering inthe environment waiting for some request of assistance, and all actions are executed by this agent; andanother where the robot has to complete some mission assigned from the first domain. This last domainprovides the robot the chance to ask for assistance to another human in order to perform some actionhe had low probability of successfully carrying out.
The set of state predicates, applicable actions, rewards and rules of the domain are described interms of dynamic distributional clauses. A problem is generated from these rules by grounding theobservation set, given proprioceptive and exteroceptive information.
Finally, HYPE solver is called to solve this one time decision problem, giving as result the actionwith the highest state-action value, from the sampling procedure, along with the reward from executingthat action. The robot parses the information from the program and executes the corresponding actionon the real world while waiting to observe new information from it. This cycle continues until the goalof planning problem is reached, switching back again to the first domain where the robot is wanderingaround, looking for missions from human agents.
Nevertheless, the results obtained by the designed system were disappointing, since there is alwaysone thing that fails throughout its operation and it takes a really long time to react to the environment.
6.1 Future Work
This thesis contributed to research in Symbiotic Autonomy between robots and humans in domesticenvironments while using a probabilistic programming language. However, if one wants to follow thisline of research, it is really important to have fully working modules on the robot’s own pool of hardwareand software. Since, the developed work only made use of the robot’s speech and movement, it wouldbe interesting to replace the simulated actions of grasping and delivering objects with a real roboticmanipulator that would react accordingly with the appropriate situation. Another important feature wouldbe to incorporate real perception modules which can generate the expected observation data. It shouldinclude the following:
• Speech Recognition: responsible for the conversational part of the task, exactly when the agentreceives the mission assignment.
61

• Agent’s Location Tracker: in order to know each agent’s location in real time.
• Person Recognition: it is needed to identify each person in the robot’s knowledge base. It canalso be useful to introduce new people into the domain’s problem. Finally, it can be used to checkif the robot is near to other agent.
All these improvements would make the benchmark much more realistic compared to a real domesticenvironment.
Talking now about one of the obvious shortcomings of the present software architecture, which is thetime it takes to plan in any given situation. It would be an interesting research opportunity to integrate astate of the art planner into the developed module and compare its performance on a similar domain. Iwould propose PROST [KE12], given its records on past ICAPS-IPCs.
Another important shortcoming of the current architecture is the planner’s incompatibility for modelingdomains with multiple inteligent agents. In a real domestic environment, every agent is taking individualasynchronous decisions. A proposal for a research path would be to develop a new planner with similarcharacteristics to HYPE (i.e. using a similar programming language, and including DDCs), but withasynchronous multi-agent 1 decision making support for MDPs.
1There is already a planning competition on these types of domains. See more about it here: http://agents.fel.cvut.cz/codmap/
62

Bibliography
[AJS+16] Alexandre Antunes, Lorenzo Jamone, Giovanni Saponaro, Alexandre Bernardino, andRodrigo Ventura. From human instructions to robot actions: Formulation of goals,affordances and probabilistic planning. In Robotics and Automation (ICRA), 2016 IEEEInternational Conference on, pages 5449–5454. IEEE, 2016.
[BDH99] Craig Boutilier, Thomas Dean, and Steve Hanks. Decision-theoretic planning: Struc-tural assumptions and computational leverage. Journal of Artificial Intelligence Re-search, 11(1):94, 1999.
[Ber87] Dimitri P Bertsekas. Dynamic programming: Deterministic and stochastic models.Prentice-Hall, 1987.
[BKK+11] Michael Beetz, Ulrich Klank, Ingo Kresse, Alexis Maldonado, Lorenz Mosenlechner,Dejan Pangercic, Thomas Ruhr, and Moritz Tenorth. Robotic roommates making pan-cakes. In Humanoid Robots (Humanoids), 2011 11th IEEE-RAS International Confer-ence on, pages 529–536. IEEE, 2011.
[BT96] Dimitri P Bertsekas and John N. Tsitsiklis. Neuro-dynamic programming. Athena Sci-entific, 1996.
[CR96] Alain Colmerauer and Philippe Roussel. The birth of prolog. In History of programminglanguages—II, pages 331–367. ACM, 1996.
[DRKT07] Luc De Raedt, Angelika Kimmig, and Hannu Toivonen. Problog: A probabilistic prologand its application in link discovery. In IJCAI, 2007.
[KE12] Thomas Keller and Patrick Eyerich. Prost: Probabilistic planning based on uct. InICAPS, 2012.
[LDK95] Michael L Littman, Thomas L Dean, and Leslie Pack Kaelbling. On the complexityof solving markov decision problems. In Proceedings of the Eleventh conference onUncertainty in artificial intelligence, 1995.
[LPK+16] Sergey Levine, Peter Pastor, Alex Krizhevsky, Julian Ibarz, and Deirdre Quillen. Learn-ing hand-eye coordination for robotic grasping with deep learning and large-scale datacollection. The International Journal of Robotics Research, page 0278364917710318,2016.
[LT10] Tobias Lang and Marc Toussaint. Planning with noisy probabilistic relational rules.Journal of Artificial Intelligence Research, 39(1):1–49, 2010.
[MKS+13] Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou,Daan Wierstra, and Martin Riedmiller. Playing atari with deep reinforcement learning.arXiv preprint arXiv:1312.5602, 2013.
63

[MKS+15] Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc GBellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al.Human-level control through deep reinforcement learning. Nature, 518(7540):529–533,2015.
[MMN+17] Bogdan Moldovan, Plinio Moreno, Davide Nitti, Jose Santos-Victor, and Luc De Raedt.Relational affordances for multiple-object manipulation. Autonomous Robots, pages1–26, 2017.
[MMR+07] Brian Milch, Bhaskara Marthi, Stuart Russell, David Sontag, Daniel L Ong, and An-drey Kolobov. Blog: Probabilistic models with unknown objects. Statistical relationallearning, page 373, 2007.
[MVDBF+12] Stephen Miller, Jur Van Den Berg, Mario Fritz, Trevor Darrell, Ken Goldberg, and PieterAbbeel. A geometric approach to robotic laundry folding. The International Journal ofRobotics Research, 31(2):249–267, 2012.
[NBDR15] Davide Nitti, Vaishak Belle, and Luc De Raedt. Planning in discrete and continuousmarkov decision processes by probabilistic programming. In Joint European Confer-ence on Machine Learning and Knowledge Discovery in Databases. Springer, 2015.
[NDLDR14] Davide Nitti, Tinne De Laet, and Luc De Raedt. Relational object tracking and learning.In Robotics and Automation (ICRA), 2014 IEEE International Conference on, pages935–942. IEEE, 2014.
[NDLDR16] Davide Nitti, Tinne De Laet, and Luc De Raedt. Probabilistic logic programming forhybrid relational domains. Machine Learning, 103(3):407–449, 2016.
[NM90] Ulf Nilsson and Jan Małuszynski. Logic, programming and Prolog. Wiley Chichester,1990.
[PT87] Christos H Papadimitriou and John N Tsitsiklis. The complexity of markov decisionprocesses. Mathematics of operations research, 12(3):441–450, 1987.
[Put14] Martin L Puterman. Markov decision processes: discrete stochastic dynamic program-ming. John Wiley & Sons, 2014.
[RBV10] Stephanie Rosenthal, Joydeep Biswas, and Manuela Veloso. An effective personalmobile robot agent through symbiotic human-robot interaction. In Proceedings of the9th International Conference on Autonomous Agents and Multiagent Systems: vol-ume 1-Volume 1, pages 915–922. International Foundation for Autonomous Agentsand Multiagent Systems, 2010.
[RV12] Stephanie Rosenthal and Manuela Veloso. Monte carlo preference elicitation for learn-ing additive reward functions. In RO-MAN, 2012 IEEE, pages 886–891. IEEE, 2012.
[RV16] Pedro Roque and Rodrigo Ventura. Space cobot: a collaborative aerial robot for indoormicrogravity environments. IEEE/RSJ International Conference On Intelligent RobotsAnd Systems (IROS), 2016.
[RVD12] Stephanie Rosenthal, Manuela Veloso, and Anind K Dey. Is someone in this officeavailable to help me? Journal of Intelligent & Robotic Systems, 66(1):205–221, 2012.
64

[San10] Scott Sanner. Relational dynamic influence diagram language (rddl): Language de-scription. Unpublished ms. Australian National University, page 32, 2010.
[Sat95] Taisuke Sato. A statistical learning method for logic programs with distribution se-mantics. In Proceedings of the 12th International Conference on Logic Programming(ICLP’95, pages 715–729. MIT Press, 1995.
[SB98] Richard S Sutton and Andrew G Barto. Reinforcement learning: An introduction, vol-ume 1. MIT press Cambridge, 1998.
[vBCH+16] Loy van Beek, Kai Chen, Dirk Holz, Loreto Martinez Luz Sanchez, Mauricio Mata-moros, Hideoki Nagano, Caleb Rascon, Josemar Rodrigues de Souza, Maja Rud-inac, and Sven Wachsmuth. RoboCup@Home 2016: Rules and Regulations. http:
//www.robocupathome.org/rules/2016_rulebook.pdf, 2016.
[VBCR15] Manuela M Veloso, Joydeep Biswas, Brian Coltin, and Stephanie Rosenthal. Cobots:Robust symbiotic autonomous mobile service robots. In IJCAI, 2015.
[VdBTVODR10] Guy Van den Broeck, Ingo Thon, Martijn Van Otterlo, and Luc De Raedt. Dtproblog: Adecision-theoretic probabilistic prolog. In Proceedings of the twenty-fourth AAAI con-ference on artificial intelligence, pages 1217–1222. AAAI Press, 2010.
[VMVL16] Tiago S Veiga, Pedro Miraldo, Rodrigo Ventura, and Pedro U Lima. Efficient objectsearch for mobile robots in dynamic environments: Semantic map as an input for thedecision maker. In Intelligent Robots and Systems (IROS), 2016 IEEE/RSJ Interna-tional Conference on, pages 2745–2750. IEEE, 2016.
[YL04] Hakan LS Younes and Michael L Littman. Ppddl1. 0: An extension to pddl for express-ing planning domains with probabilistic effects. Techn. Rep. CMU-CS-04-162, 2004.
65

66

Appendix A
Appendix
A.1 1st Test on Wandering Domain
External ObservationsPredicate Valuelocated(mbot)t so f alocated(robert)t bedlocated(lynda)t kitchen tablelocated(melanie)t so f alistenedt (none, none)calledt nonenear(robert)t f alsenear(lynda)t f alsenear(melanie)t f alse
Internal Observationsdynamic statet idlemissiont none
Table A.1: State of the world in the first step.
67

External ObservationsPredicate Valuelocated(mbot)t so f alocated(robert)t bedlocated(lynda)t kitchen tablelocated(melanie)t so f alistenedt (none, none)calledt robertnear(robert)t f alsenear(lynda)t f alsenear(melanie)t f alse
Internal Observationsdynamic statet idlemissiont none
Table A.2: State of the world in the second step.
External ObservationsPredicate Valuelocated(mbot)t bedlocated(robert)t bedlocated(lynda)t kitchen tablelocated(melanie)t so f alistenedt (none, none)calledt robertnear(robert)t truenear(lynda)t f alsenear(melanie)t f alse
Internal Observationsdynamic statet idlemissiont none
Table A.3: State of the world in the third step.
68

External ObservationsPredicate Valuelocated(mbot)t bedlocated(robert)t bedlocated(lynda)t kitchen tablelocated(melanie)t so f alistenedt (robert, want(robert, coke))calledt nonenear(robert)t truenear(lynda)t f alsenear(melanie)t f alse
Internal Observationsdynamic statet conversation(robert)missiont none
Table A.4: State of the world in the fourth step.
External ObservationsPredicate Valuelocated(mbot)t bedlocated(robert)t bedlocated(lynda)t kitchen tablelocated(melanie)t so f alistenedt (none, none)calledt nonenear(robert)t truenear(lynda)t f alsenear(melanie)t f alse
Internal Observationsdynamic statet idlemissiont want(robert, coke)
Table A.5: State of the world in the fifth step.
69

A.2 2nd Test on Mission Domain
External ObservationsPredicate Valuelocated(mbot)t bedlocated(robert)t bedlocated(lynda)t kitchen tablelocated(melanie)t so f alocated(coke)t bednear(robert)t truenear(lynda)t f alsenear(melanie)t f alsenear(coke)t truehave(coke)t none
Internal Observationsasked (none, none)
Table A.6: State of the world in the first step.
External ObservationsPredicate Valuelocated(mbot)t bedlocated(robert)t bedlocated(lynda)t kitchen tablelocated(melanie)t so f alocated(coke)t bednear(robert)t truenear(lynda)t f alsenear(melanie)t f alsenear(coke)t truehave(coke)t mbot
Internal Observationsasked (none, none)
Table A.7: State of the world in the second step.
70

External ObservationsPredicate Valuelocated(mbot)t bedlocated(robert)t bedlocated(lynda)t kitchen tablelocated(melanie)t so f alocated(coke)t bednear(robert)t truenear(lynda)t f alsenear(melanie)t f alsenear(coke)t truehave(coke)t robert
Internal Observationsasked (none, none)
Table A.8: State of the world in the third step.
A.3 3rd Test on Mission Domain
External ObservationsPredicate Valuelocated(mbot)t bedlocated(robert)t bedlocated(lynda)t kitchen tablelocated(melanie)t so f alocated(coke)t kitchen tablenear(robert)t truenear(lynda)t f alsenear(melanie)t f alsenear(coke)t f alsehave(coke)t none
Internal Observationsasked (none, none)
Table A.9: State of the world in the first step.
71

External ObservationsPredicate Valuelocated(mbot)t kitchen tablelocated(robert)t bedlocated(lynda)t kitchen tablelocated(melanie)t so f alocated(coke)t kitchen tablenear(robert)t f alsenear(lynda)t truenear(melanie)t f alsenear(coke)t truehave(coke)t none
Internal Observationsasked (none, none)
Table A.10: State of the world in the second step.
External ObservationsPredicate Valuelocated(mbot)t kitchen tablelocated(robert)t bedlocated(lynda)t kitchen tablelocated(melanie)t so f alocated(coke)t kitchen tablenear(robert)t f alsenear(lynda)t truenear(melanie)t f alsenear(coke)t truehave(coke)t none
Internal Observationsasked (coke, lynda)
Table A.11: State of the world in the third step.
72

External ObservationsPredicate Valuelocated(mbot)t bedlocated(robert)t bedlocated(lynda)t bedlocated(melanie)t so f alocated(coke)t bednear(robert)t truenear(lynda)t truenear(melanie)t f alsenear(coke)t truehave(coke)t lynda
Internal Observationsasked (coke, lynda)
Table A.12: State of the world in the fourth step.
External ObservationsPredicate Valuelocated(mbot)t bedlocated(robert)t bedlocated(lynda)t bedlocated(melanie)t so f alocated(coke)t bednear(robert)t truenear(lynda)t truenear(melanie)t f alsenear(coke)t truehave(coke)t mbot
Internal Observationsasked (none, none)
Table A.13: State of the world in the fifth step.
73

External ObservationsPredicate Valuelocated(mbot)t bedlocated(robert)t bedlocated(lynda)t bedlocated(melanie)t so f alocated(coke)t bednear(robert)t truenear(lynda)t truenear(melanie)t f alsenear(coke)t truehave(coke)t robert
Internal Observationsasked (none, none)
Table A.14: State of the world in the sixth step.
74



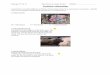

![Verifiable Autonomy - University of Liverpool - …cgi.csc.liv.ac.uk/~maryam/slides/AVWorkshop15-Fisher.pdf[ typically modal, temporal, probabilistic logics ] Formal Verification](https://img.pdfslide.us/doc/110x75/5cf7160f88c993d5258d0b4f/verifiable-autonomy-university-of-liverpool-cgicsclivacukmaryamslidesavworkshop15-.jpg)
























