Embed Size (px)
Citation preview

Prioritizing Local Inter-Domain Communication in Xen
Sisu Xi, Chong Li, Chenyang Lu, and Christopher GillCyber-Physical Systems LaboratoryWashington University in St. Louis
IEEE/ACM International Symposium on Quality of Service, 2013

2
Multiple computing elements Cost! Weight! Power! Communicate via dedicated network or real-time networks
Use fewer computing platforms to integrate independently developed systems via virtualization
Motivation

3
Multiple computing elements Cost! Weight! Power! Communicate via dedicated network or real-time networks
Use fewer computing platforms to integrate independently developed systems via virtualization
Motivation
Physically Isolated Hosts -> Common Computing Platforms
Network Communication -> Local Inter-Domain Communication
Guarantee QoS with Virtualization???

4
System Model and Contributions We focus on
Xen as the underlying virtualization software Single core for each virtual machine on a multi-core platform Local Inter-Domain Communication (IDC) No modification to the guest domain besides the Xen patch
Contributions Real-Time Communication Architecture (RTCA) in Xen Reduces high priority IDC latency from ms to us in the presence of
low priority IDC

5
B
Background – Xen Overview
A
NIC
VMM Scheduler
Core Core Core Core Core Core
VCPU
netfront
Domain 1
VCPU
NIC driver
softnet_data
netback
Domain 0
VCPU
netfront
Domain 2
… …

6
Part I – VMM Scheduler: Limitations Default credit scheduler
Schedule VCPUs in round-robin order RT-Xen scheduling framework
Schedule VCPUs by priority Server based mechanism, each VCPU has (budget, period)
However If execution time < 0.5 ms, VCPU budget is not consumed
Solution Dual quanta: ms for scheduling, while us for time accounting
“Realizing Compositional Scheduling through Virtualization”, Real-Time and Embedded Technology and Application Symposium (RTAS), 2012
“RT-Xen: Towards Real-Time Hypervisor Scheduling in Xen”, ACM International Conferences on Embedded Software (EMSOFT), 2011

7
Part I – VMM Scheduler: Evaluation
VMM Scheduler: RT-Xen VS. Credit
C 5C 0 C 1 C 3 C 4
Dom 3
Dom 4
Dom 0
Dom 1
Dom 2
Linux 3.4.2100% CPU
sent pkt every 10ms5,000 data points
C 2
Dom 9
Dom 10
…
When Domain 0 is not busy, the VMM scheduler dominates the IDC performance for higher priority domains

8
Part I – VMM Scheduler: Enough???
VMM Scheduler
C 5C 0 C 1 C 2 C 4C 3
Dom 3
Dom 4
Dom 5
Dom 0 Dom 1 Dom 2
100% CPU
…
…
…
9
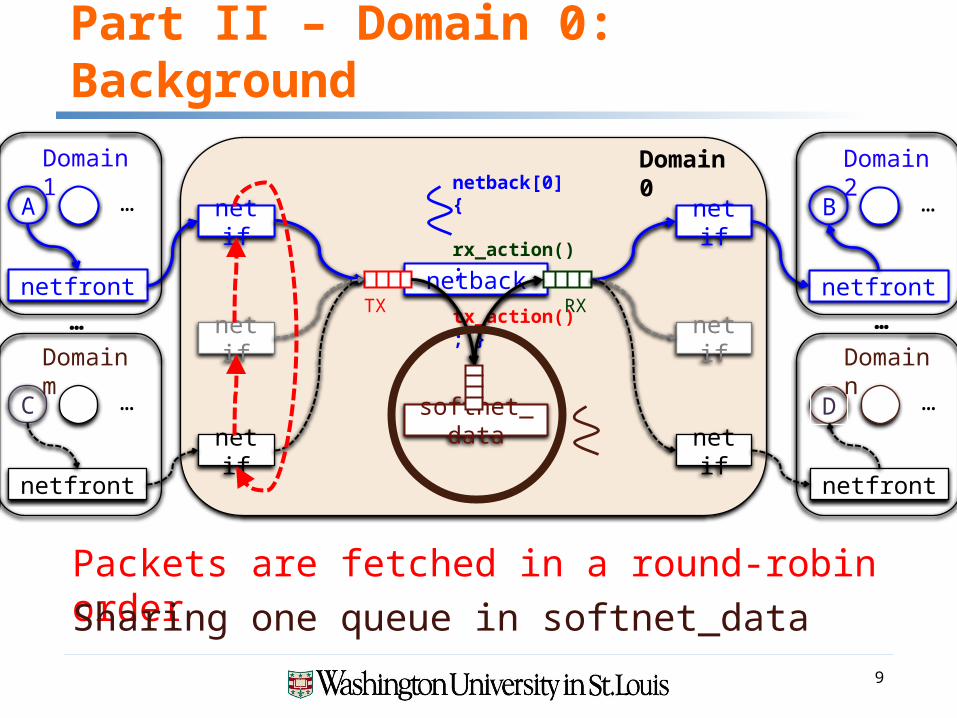
Part II – Domain 0: Background
C D
A
netfront
Domain 1 Domain 0
… B
netfront
Domain 2
…netif netif
TX RXnetback
netback[0] { rx_action(); tx_action(); }
netfront
Domain m
…
netfront
Domain n
…
… …netif
netif netif
netif
softnet_data
Packets are fetched in a round-robin order
Sharing one queue in softnet_data

10
Part II – Domain 0: RTCA
Packets are fetched by priority, up to batch size
A
netfront
Domain 1 Domain 0
… A
netfront
Domain 2
…netif netif
TX RXnetback
netback[0] { rx_action(); tx_action(); }
… …
softnet_dataB
netfront
Domain m
…
netif
netifnetfront
Domain n
…
…
netif
netif
B
Queues are separated by priority in softnet_data

11
Part II – Domain 0: Evaluation Setup
VMM Scheduler
C 5C 0 C 1 C 2 C 4C 3
Dom 0 Dom 1 Dom 2
100% CPUOriginal vs. RTCA
Dom 3
Dom 4
Dom 5
Interference
Medium
Heavy
Light
Base
…
…
…
sent pkt every 10ms5,000 data points

12
Part II – Domain 0: Latency
When there is no interference, IDC performance is comparable
Original Domain 0 performs poorly in all cases• Due to priority inversion within Domain 0
RTCA with batch size 1 performs best• We eliminate most of the priority inversions
RTCA with larger batch sizes perform worse under IDC interference
IDC Latency between Domain 1 and Domain 2 in presence of low priority IDC (us)

13
Part II – Domain 0: Latency
When there is no interference, IDC performance is comparable
Original Domain 0 performs poorly in all cases• Due to priority inversion within Domain 0
RTCA with batch size 1 performs best• we eliminate most of the priority inversions
RTCA with larger bath sizes perform worse under IDC interference
By reducing priority inversion in Domain 0, RTCA can effectively mitigate impacts of low priority IDC on the latency of high priority IDC
IDC Latency between Domain 1 and Domain 2 in presence of low priority IDC (us)

14
Part II – Domain 0: Throughput
A small batch size leads to significant reduction in high priority IDC latency and improved IDC throughput under interfering traffic
iPerf Throughput between Dom 1 and Dom 2

15
Other Approaches and Future Work Shared Memory Approach [XWAY, XenLoop, Xensocket]
Required modification to guest OS or applications
Traffic Control in Linux [www.lartc.org] Applied within one device. Cannot directly be applied on IDC
Future Work Multi-Core VM scheduling Network Interface Card (NIC) Rate control Co-ordinate with VMM scheduler

16
Conclusion
Hardware
VMM Scheduler
VCPU
netfront
Domain 1
VCPU
softnet_data
netback
Domain 0
VCPU
netfront
Domain 2
VMM scheduler alone cannot guarantee IDC latency RTCA: Real-Time Communication Architecture RTCA + RT-Xen reduces high priority IDC latency from ms to
us in the presence of low priority IDC https://sites.google.com/site/realtimexen/
Thank You!Questions?

17
Backup Slides

18
Why IDC? Why Xen? Embedded Systems
Integrated Modular Avionics• ARINC 653 Standard• Honeywell claims that IMA design can save 350 pounds of weight on a
narrow-body jet: equivalent to two adults• http://www.artist-embedded.org/docs/Events/2007/IMA/Slides/
ARTIST2_IMA_WindRiver_Wilson.pdf
Full Virtualization based ARINC 653 partitionSanghyun Han, Digital Avionics Systems Conference (DASC), 2011
ARINC 653 HypervisorVanderLeest S.H., Digital Avionics Systems Conference (DASC), 2010

20
End-to-End Task Performance
VMM Scheduler: Credit vs. RT-Xen
C 5C 0 C 1 C 2 C 4C 3
Dom 11
Dom 12
Dom 13
Interference
Medium
Heavy
Light
Dom 0
Dom 1 Dom 2
100% CPUOriginal vs. RTCA
T1(10, 2)
T2(20, 2)
T1(10, 2)
T3(20, 2)
T1(10, 2)
T4(30, 2)
Dom 1 & Dom 2• 60% CPU each
Dom 3 to Dom 10• 10% CPU each• 4 pairs bouncing
packets
Dom 3Dom 4
Dom 5Dom 6
Dom 7Dom 8
Dom 9Dom 10
Base

21
End-to-End Task Performance
By combining the RT-Xen VMM scheduler and the RTCA Domain 0 kernel, we can deliver end-to-end real-time performance to tasks involving both computation and communication

22
Backup – Baseline

23
Domain-0
Domain-U
(1). XEN Virtual Networksocket(AF_INET, SOCKET_DGRAM, 0);socket(AF_INET, SOCKET_STREAM, 0);
sendto(…)recvfrom(…)
VMM
app
kernel
TCP
IP
Netback Driver
UDP
INET
TCP
IP
Netfront Driver
UDP
INET
Transparent Isolation General Migration
X PerformanceX Data IntegrityX Multicast

24
Domain-U
(2). XWay, VEE’08
VMM
XWAY switch
TCP
IP
XWAYprotocol
NetfrontXWAY driver
UDP
INET
app
kernel
socket(AF_INET, SOCKET_DGRAM, 0);socket(AF_INET, SOCKET_STREAM, 0);
sendto(…)recvfrom(…)
Transparent ? Performance Dynamic Create/Destroy Live Migration
X Connect OverheadX Patch Guest OSX No UDPX Complicated
25
Domain-U
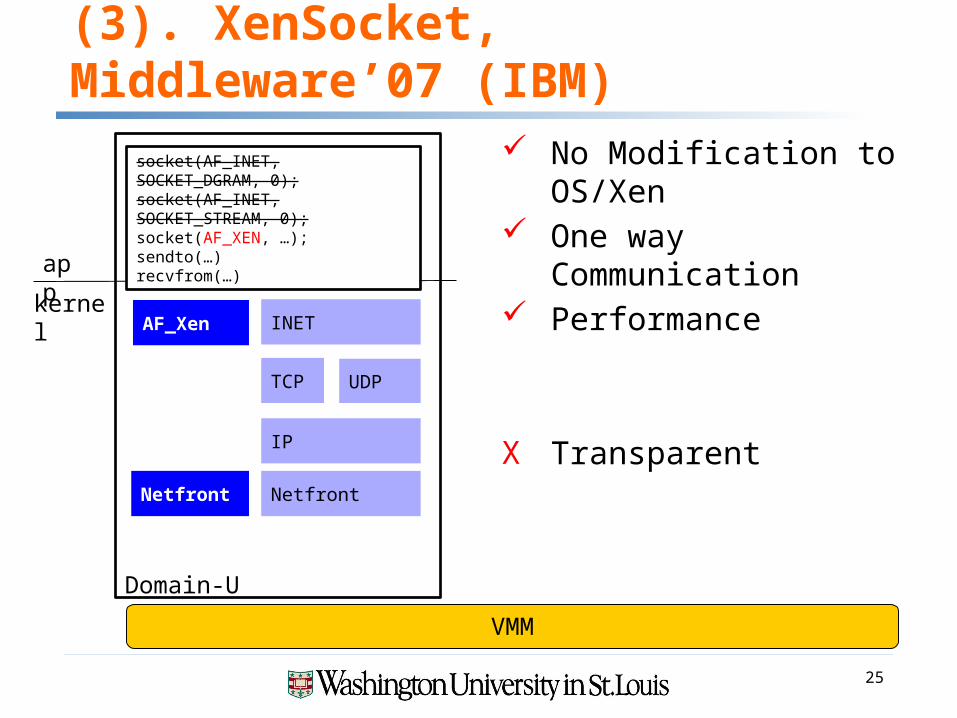
(3). XenSocket, Middleware’07 (IBM)
VMM
app
kernel
socket(AF_INET, SOCKET_DGRAM, 0);socket(AF_INET, SOCKET_STREAM, 0);socket(AF_XEN, …);sendto(…)recvfrom(…)
TCP
IP
Netfront
UDP
INETAF_Xen
Netfront
No Modification to OS/Xen One way Communication Performance
X Transparent

26
Domain-U
(4). XenLoop, HPDC’08 (Binghamton)
VMM
app
kernel
socket(AF_INET, SOCKET_DGRAM, 0);socket(AF_INET, SOCKET_STREAM, 0);
sendto(…)recvfrom(…)
TCP
IP
Netfront
UDP
INET
XenLoop
No Modification to OS/Xen Transparent Performance Migration
X OverheadX Isolation ?X Dynamic teardown ?

A
netfront
Domain-1 Domain-0
… A
netfront
Domain-2
…netif netif
… …
softnet_data
NIC driver
multiple kthreads
B
netfront
Domain-m
…
netif
netifnetfront
Domain-n
…
…
netif
netif
B
TX RXnetback
TX RXnetback
TX RXnetback
priority kthreads
highest priority





























