Embed Size (px)
Citation preview

Principles for Safe and Automated Middleware Specializations for Distributed
Real-time Embedded Systems
Department of Electrical Engineering & Computer Science
Vanderbilt University, Nashville, TN, USA
Ph.D. Dissertation DefenseApril 2, 2012
Akshay Dabholkar [email protected]
www.dre.vanderbilt.edu/~aky
Research supported by NSF CAREER CNS# 0845789, Vanderbilt Discovery
http://www.dre.vanderbilt.edu/~aky/docs/Dissertation.pdf

2
Presentation Road Map
Motivation Overview of Solution Approach: Automated
Middleware Specialization Process Research Area Focus Safe Middleware
Adaptation for Real-Time Fault-Tolerance Research Contributions Concluding Remarks
Context: Distributed Real-time Embedded (DRE) Systems
Large-scale, system-of-systems Operation in resource-
constrained environments• Memory-constraints• Low Processor speeds, Power
availability• Component/Process/Processor failures
Stringent and simultaneous QoS demands• Efficient Resource Utilization• Timeliness• High Reliability
Examples• Intelligent Transportation Systems (ITS)• Inventory Control Systems• NASA’s Magnetospheric Multi-scale
mission (MMS)
3(Images courtesy: Google)

Overcoming Variability in DRE System Domain Concerns
Group Failover
Semantics
Maximize Throughpu
t
Resource Constrain
ed
Real Time Updates
Reconfigurable Conveyor Belt System
Intelligent Transportation System
Direct Application
Generalization
Development via General-purpose Middleware
• Feature-rich• Satisfies wide
range of DRE systems
• Uses extensible frameworks
• CORBA, .NET, J2EE, etc.Performance Requirements Reliability Requirements

Impediments to Using General-purpose Middleware General-purpose middleware
supports a wide range of DRE applications
However, individual DRE applications have streamlined requirements
Antagonistic Design Forces • Excessive features due to
wide applicability• Unnecessary overhead due
to high flexibility and configurability
• Moreover, focus is on horizontal decomposition into layers• Incurs time and space
overhead due to rigid layered processing
• Application concerns are tangled across middleware modularization boundaries

Preferred Approach to Overcome Generality in Middleware
Real-Time Fault
Tolerance
Maximize Throughpu
t
Resource Constrain
ed
Reconfigurable Conveyor Belt System
Intelligent Transportation System
Direct Application
Generalization
Specialization
Specific Application
Real Time Updates
Performance Requirements Reliability Requirements
Doesn’t mean develop
middleware from scratch

What is Middleware Specialization?
Resolves the tension between Generality and Specificity Creates specialized forms of middleware for each system by
Pruning away unnecessary features based on application requirements Augmenting application-specificity by embedding their semantics Optimizing performance by moving away from the rigid layered
processing by creating specialized processing paths Adapting at runtime to enable safe failure mitigation in real-time
Customized Middleware Stack Standards-based, General-
purpose, Layered Middleware Architecture
Specialization
Container
ClientOBJREF
in argsoperation()out args +
return
IDLSTUBS
ORBINTERFACE
IDLSKEL
Object Adapter
ORB CORE GIOP/IIOP/ESIOPS
Component(Servant)
Se
rvices
ProtocolInterface
ComponentInterface
ServicesInterface
DII
DSI

Taxonomy of Middleware Specialization Techniques
8
Dimensions can be combined to synthesize new specialization techniques
Overlapping dimensions share concepts e.g. MDE/AOP includes both feature pruning & augmentation and can be used for customization as well as tuning
Serves as a guideline for synthesis of tools for design, V&V, analysis of specializations
Three dimensional Taxonomy of Middleware
Specializations
How?
What?
When?
Taxonomy of specializations developed based on literature survey

Assessment of Taxonomy of Middleware Specialization Techniques
Group of techniques that perform a common function
9
DSMLs, Feature Diagrams, IDL used to capture application concerns (e.g., Bypass)
MDE, AOP used in generating rules for specialization (e.g., Bypass)
Pre-postulated, Just-in-time (e.g., Caesar, AFM, AspectOpenORB, JAsCO, PROSE, Abacus)
MDE (e.g., Modelware), Reflection (e.g., AspectOpenORB) used to deduce specialization
context
Augment, Prune middleware sources (e.g., Bypass, CIDE, AHEAD, FOCUS)
DSML, IDL used to map concerns to code artifacts (e.g., AHEAD, Bypass )

Taxonomy-induced Middleware Specialization Lifecycle
Taxonomy gives rise to a specialization lifecycle
10
DSMLs, Feature Diagrams, IDL used to capture application concerns (e.g., Bypass)
MDE, AOP used in generating rules for specialization (e.g., Bypass)
Pre-postulated, Just-in-time (e.g., Caesar, AFM, AspectOpenORB, JAsCO, PROSE, Abacus)
MDE (e.g., Modelware), Reflection (e.g., AspectOpenORB) used to deduce specialization
context
Transformation
Deduction
Specification
Generation
SpecializationLifecycle
Inference
Adaptation
Augment, Prune middleware sources (e.g., Bypass, CIDE, AHEAD, FOCUS)
DSML, IDL used to map concerns to code artifacts (e.g., AHEAD, Bypass )

Taxonomy-induced Middleware Specialization Lifecycle
Must deal with variability over the specialization lifecycle Multiple steps involved
11
Specify and Reason about the desired application features
Generate the middleware transformation rules that realize the specializations
Adapt middleware safely and predictably to changes in runtime conditions
Detect the context from the application models that drives specialization opportunities
Transformation
Deduction
Specification
Generation
SpecializationLifecycle
Inference
Adaptation
Transform middleware into specialized forms
Infer the specializations applicable to the context and actual middleware features desired
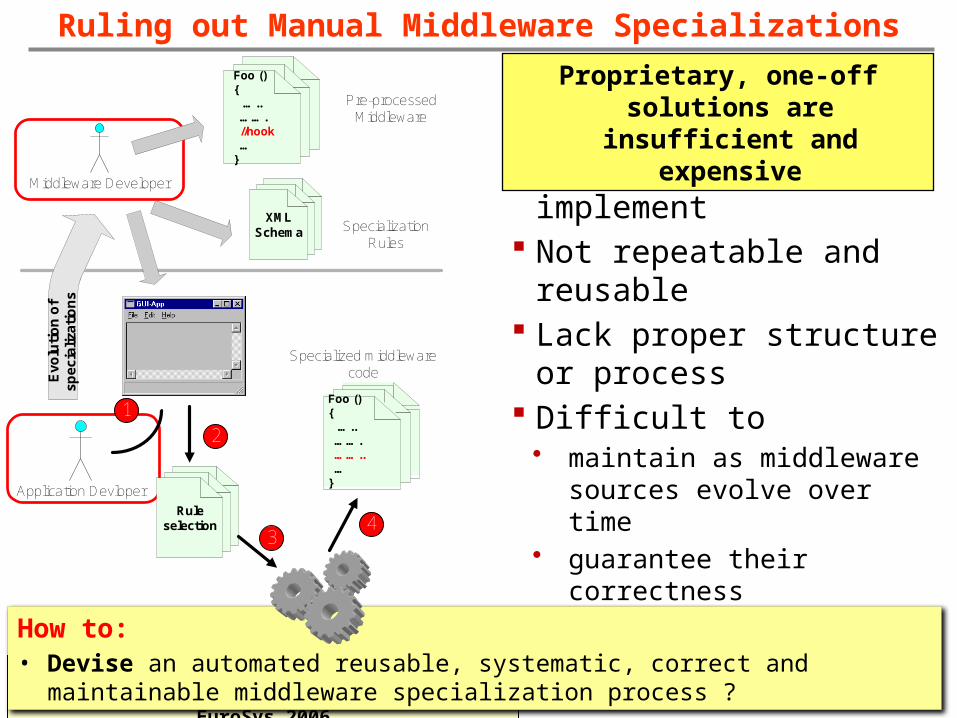
Ruling out Manual Middleware Specializations
Cumbersome to implement Not repeatable and reusable Lack proper structure or
process Difficult to
• maintain as middleware sources evolve over time
• guarantee their correctness• extend to other middleware
technologies
12
XML Schema Specialization
Rules
Foo (){ ….. ……. //hook …}
Middleware Developer
Application Devloper
Foo (){ ….. ……. …….. …}
Rule selection
Pre-processed Middleware
1
2
34
Specialized middleware codeE
volu
tio
n o
f s
pe
cial
iza
tio
ns
Proprietary, one-off solutions are insufficient
and expensive
FOCUS: A. Krishna et al., “Context-Specific Middleware Specialization Techniques …”,
EuroSys 2006
How to:• Devise an automated reusable, systematic, correct and maintainable
middleware specialization process ?

13
Presentation Road Map
Motivation Overview of Solution Approach: Automated
Middleware Specialization Process Research Area Focus Safe Middleware
Adaptation for Real-Time Fault-Tolerance Research Contributions Concluding Remarks
14
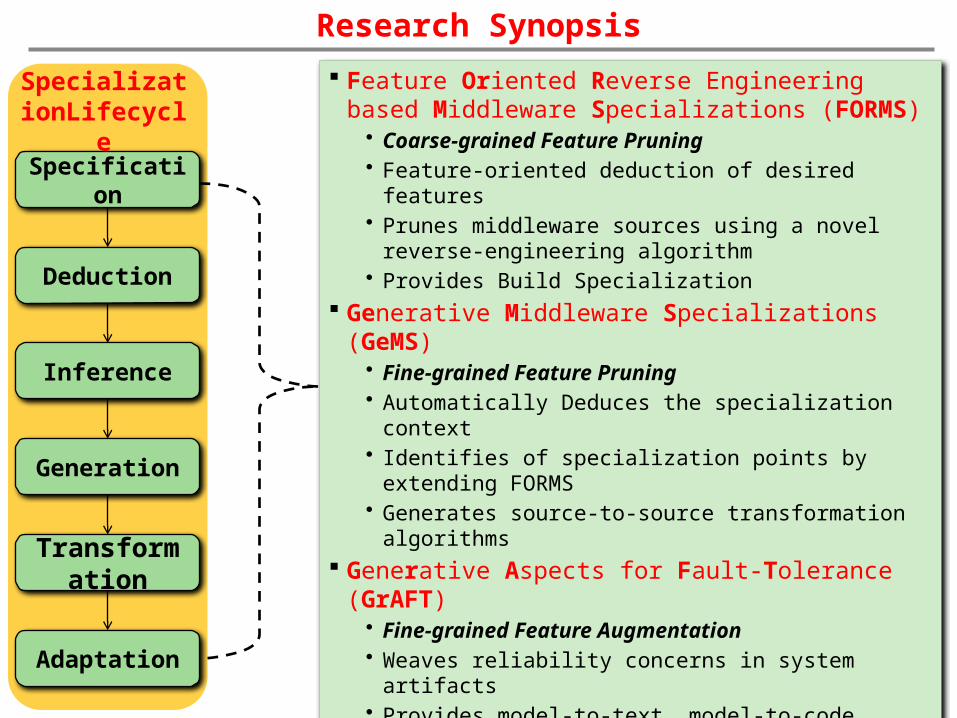
Research Synopsis
Feature Oriented Reverse Engineering based Middleware Specializations (FORMS)
• Coarse-grained Feature Pruning• Feature-oriented deduction of desired features• Prunes middleware sources using a novel reverse-
engineering algorithm• Provides Build Specialization
Generative Middleware Specializations (GeMS)• Fine-grained Feature Pruning• Automatically Deduces the specialization context• Identifies of specialization points by extending
FORMS• Generates source-to-source transformation
algorithms Generative Aspects for Fault-Tolerance
(GrAFT)• Fine-grained Feature Augmentation• Weaves reliability concerns in system artifacts• Provides model-to-text, model-to-code
transformations Safe Middleware Adaptation for Real-Time
Fault-Tolerance (SafeMAT)• Fine-grained middleware adaptation to
failures while maintaining safety, predictability and improving resource utilizations within the hard real-time constraints
Transformation
Deduction
Specification
Generation
SpecializationLifecycle
Inference
Adaptation

15
Research Synopsis
Feature Oriented Reverse Engineering based Middleware Specializations (FORMS)
• Coarse-grained Feature Pruning• Feature-oriented deduction of desired features• Prunes middleware sources using a novel reverse-
engineering algorithm• Provides Build Specialization
Generative Middleware Specializations (GeMS)• Fine-grained Feature Pruning• Automatically Deduces the specialization context• Identifies of specialization points by extending
FORMS• Generates source-to-source transformation
algorithms Generative Aspects for Fault-Tolerance
(GrAFT)• Fine-grained Feature Augmentation• Weaves reliability concerns in system artifacts• Provides model-to-text, model-to-code
transformations Safe Middleware Adaptation for Real-Time
Fault-Tolerance (SafeMAT)• Fine-grained middleware adaptation to
failures while maintaining safety, predictability and improving resource utilizations within the hard real-time constraints
Transformation
Deduction
Specification
Generation
SpecializationLifecycle
Inference
Adaptation

Challenge 1: Horizontal v/s Vertical Middleware Decomposition Middleware is traditionally decomposed
along the horizontal dimension into layers
However, applications only use a subset of features within each middleware layer
Application domains expect vertical decomposition along domain concerns
Moreover, application domain concerns are tangled across middleware modularization boundaries
It becomes hard to specify the desired features for middleware specialization and decompositionHow to:
• Reason about the middleware features desired by the application/application family?
• Modularize of middleware along domain concerns (i.e., Vertical Decomposition) without refactoring the middleware code?

17
Resolution 1: Feature Oriented Reverse Engineering based Middleware Specializations (FORMS)
FORMS: Automated Inference of desired Middleware Features
• Utilizes a lookup table that provides PIM-to-PSM mapping
FORMS: Closure Computation• Coarsely Prunes the middleware by finding the
feature modules using a novel closure computation algorithm by recursively inspecting source code dependencies
FORMS: Feature-Oriented Requirements Reasoning
• Utilizes a Feature Oriented Decision Tree
FORMS: Build Specialization• Specialize/Prune the middleware build
configurations and generate binaries using MPC perl scripts
Adaptation
Deduction
Transformation
Generation
Inference
Specification
Specialization Lifecycle
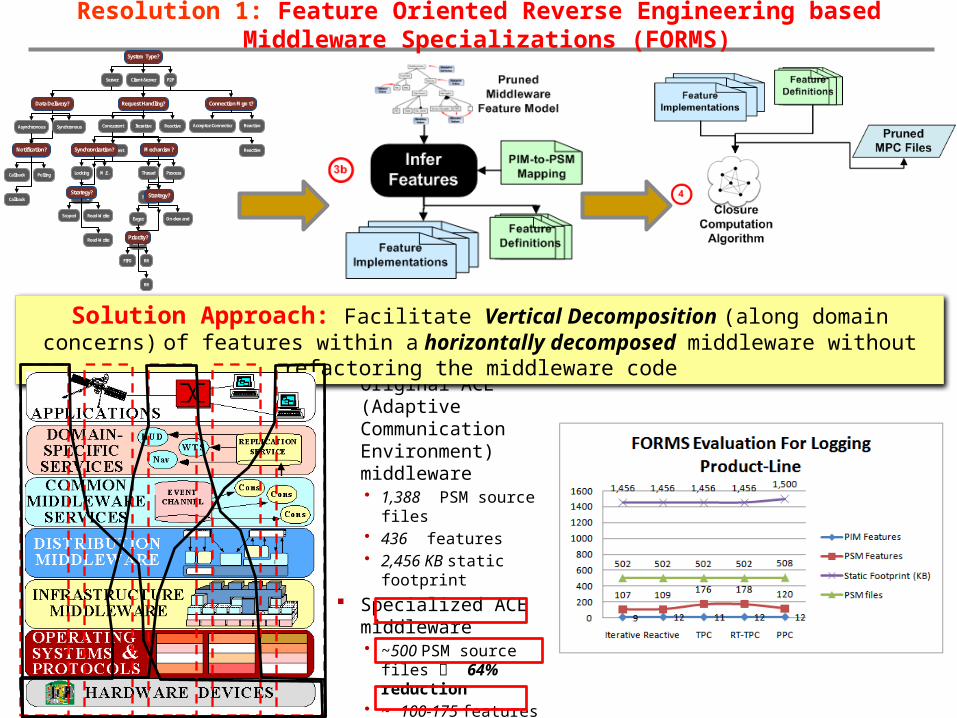
Resolution 1: Feature Oriented Reverse Engineering based Middleware Specializations (FORMS)
Original ACE (Adaptive Communication Environment) middleware • 1,388 PSM source files• 436 features• 2,456 KB static footprint
Specialized ACE middleware• ~500 PSM source files
64% reduction• ~ 100-175 features
60-76% reduction• ~ 1,500 KB footprint
41% reduction
RR
EagerRead-Write
ThreadLocking
Concurrent
Client-Server
Reactive
Callback
Asynchronous
Solution Approach: Facilitate Vertical Decomposition (along domain concerns) of features within a horizontally decomposed middleware without
refactoring the middleware code
System Type?
Server
RRFIFO
On-demandEagerRead-WriteScoped
ProcessThreadM.E.LockingPollingCallback
ReactiveIterativeConcurrentSynchronousAsynchronous
P2PClient-Server
Priority?
Strategy?Strategy?
Mechanism?Synchronization?Notification?
Request Handling?Data Delivery? Connection Mgmt?
Acceptor-Connector Reactive
Adaptation
Specification
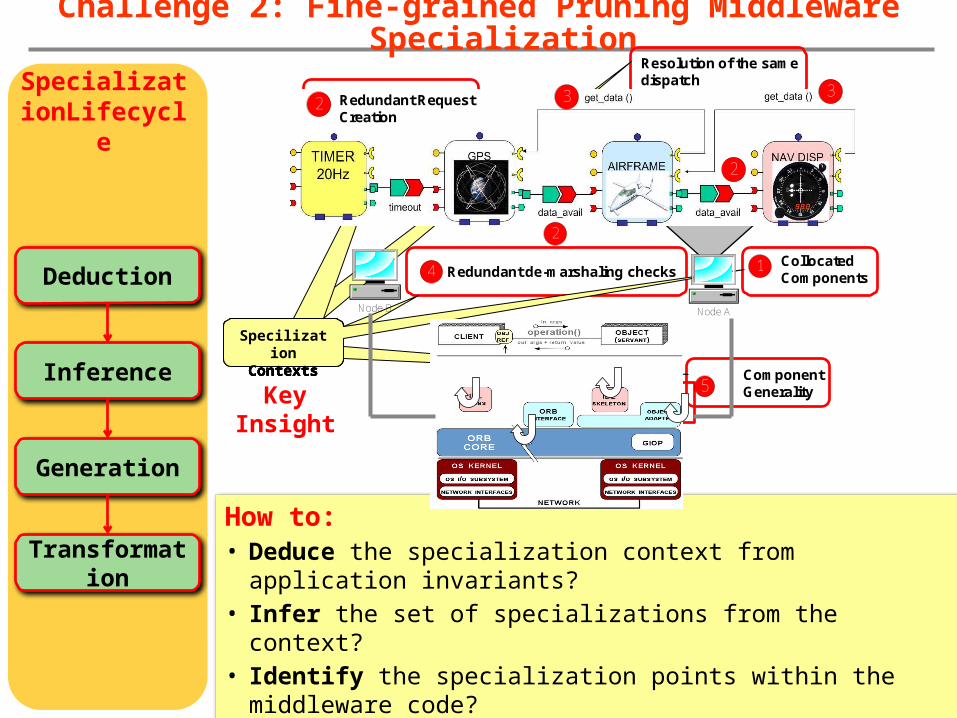
Challenge 2: Fine-grained Pruning Middleware Specialization
Node ANode B
1 Collocated Components
2 Redundant Request Creation
2
2
3
Resolution of the same dispatch
4 Redundant de-marshaling checks
5Component Generality
3
How to:• Deduce the specialization context from application
invariants?• Infer the set of specializations from the context?• Identify the specialization points within the middleware
code?• Generate the specializations to improve developer
productivity?• Transform the middleware sources by executing
specializations?
Generation
SpecializationLifecycle
Deduction
Inference
Transformation
Specilization ContextsSpecilization ContextsSpecilization ContextsSpecilization ContextsSpecilization Contexts
Key Insight
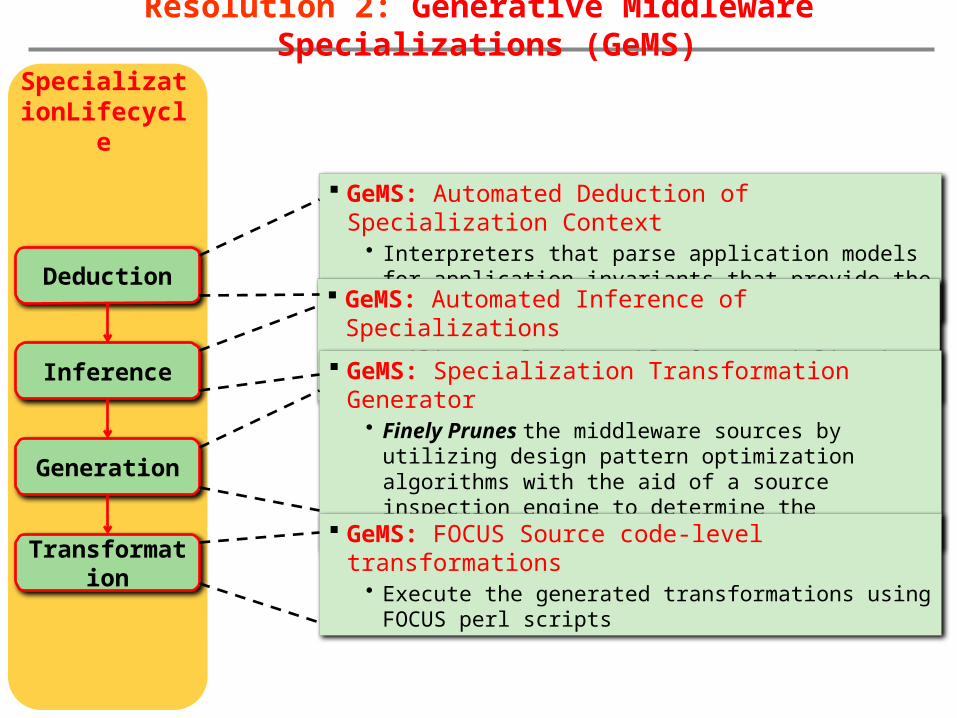
GeMS: Automated Deduction of Specialization Context
• Interpreters that parse application models for application invariants that provide the context to drive specializations
Resolution 2: Generative Middleware Specializations (GeMS)
GeMS: Automated Inference of Specializations• Utilizes a lookup table for specializations that apply
GeMS: Specialization Transformation Generator• Finely Prunes the middleware sources by utilizing
design pattern optimization algorithms with the aid of a source inspection engine to determine the specialization points
GeMS: FOCUS Source code-level transformations
• Execute the generated transformations using FOCUS perl scripts
Specification
Adaptation
Generation
SpecializationLifecycle
Deduction
Inference
Transformation
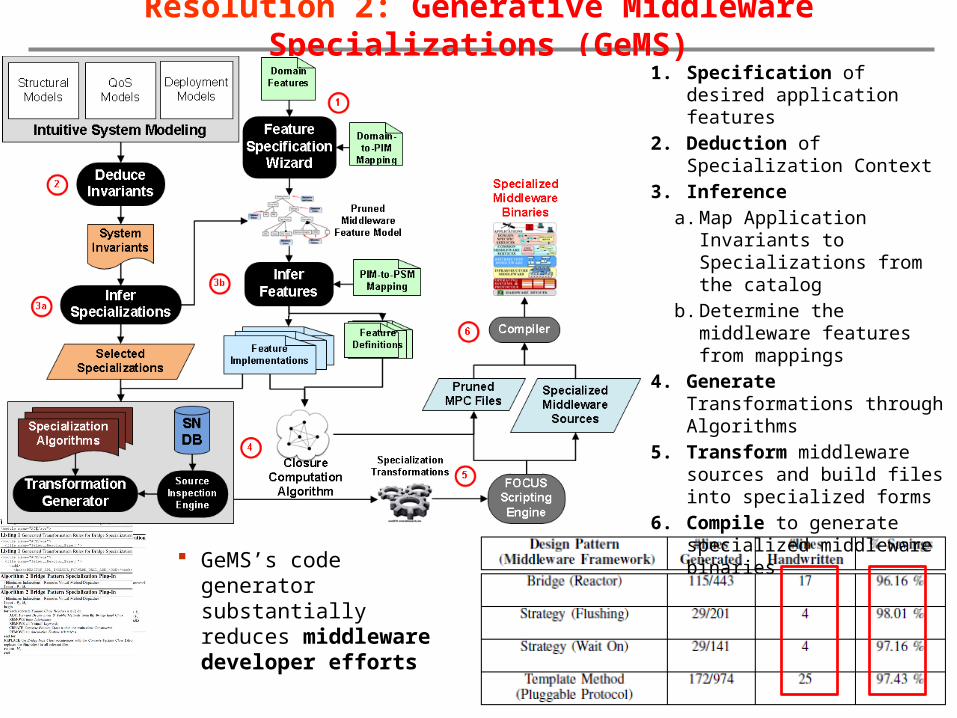
Resolution 2: Generative Middleware Specializations (GeMS)1. Specification of desired
application features2. Deduction of
Specialization Context3. Inference
a. Map Application Invariants to Specializations from the catalog
b. Determine the middleware features from mappings
4. Generate Transformations through Algorithms
5. Transform middleware sources and build files into specialized forms
6. Compile to generate specialized middleware binaries
GeMS’s code generator substantially reduces middleware developer efforts

Adaptation
Resolution 2: Performance Metrics Evaluation of FORMS+GeMS Cumulative benefits of applying both FORMS and GeMS
when applied to The ACE ORB (TAO) specifically the ORB and POA frameworks
Static footprint is the size of compiled shared middleware library
Dynamic footprint is the combined average size of runtime executables of BasicSP application components each of which is running on a specialized middleware (TAO) version
10-15% savings if applied on individual specialization basis Substantial footprint reductions are mainly a result of
applying the FORMS closure computations Runtime performance improvements are mainly due to
GeMS framework optimizations
22
Specification
Generation
SpecializationLifecycle
Deduction
Inference
Transformation
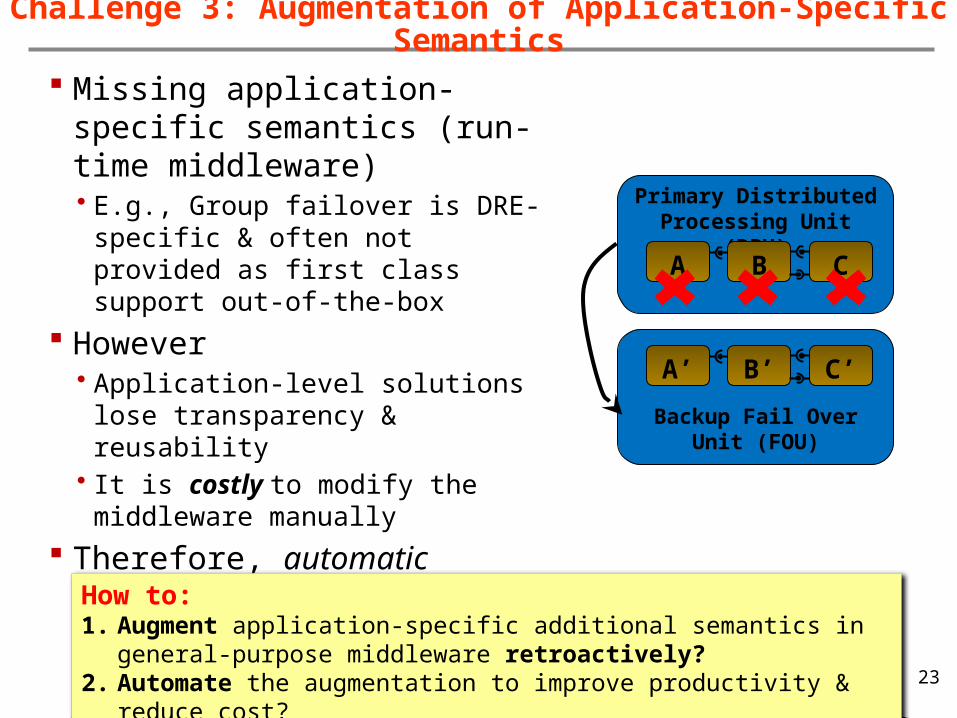
Challenge 3: Augmentation of Application-Specific Semantics
Missing application-specific semantics (run-time middleware)• E.g., Group failover is DRE-specific &
often not provided as first class support out-of-the-box
However• Application-level solutions lose
transparency & reusability• It is costly to modify the middleware
manually
Therefore, automatic middleware instrumentation required to augment application-specificity
23
How to:1. Augment application-specific additional semantics in general-
purpose middleware retroactively?2. Automate the augmentation to improve productivity & reduce
cost?
Backup Fail Over Unit (FOU)
Primary Distributed Processing Unit
(DPU)A B C
A’ B’ C’

Inference
Adaptation
Resolution 3: Generative Aspects for Fault-Tolerance (GrAFT)
24
GrAFT: Aspect C++ Generator • Generates the application-specific semantics in
form of aspect code for fault handling and masking to enable transparent group failover
Deduction
Specification
Transformation
Generation
SpecializationLifecycle
GrAFT: Modeling Environment and Transformations
• Fine Grained Feature Augmentation• Provides model-to-text, model-to-code
transformations
GrAFT: Source code-level transformations• Finely Augments these application-specific
semantics in system artifacts by weaving in the generated aspects with application and client stubs

Resolution 3: Generative Aspects for Fault-Tolerance (GrAFT)
Specify Application-specific semantics of Group Failover
Parse application models and determine the components that require group failover semantics
Generate the fault detection, masking, and failover code through exception handling mechanisms
Weave in AspectC++ code in the generated code in the respective component stubs
25
Reconfigurable Conveyor Belt
System
GrAFT’s code generator completely eliminates middleware developer efforts

Relevant PublicationsFORMS Publications
1. FORMS: Feature-Oriented Reverse Engineering-based Middleware Specialization for Product-Lines, JSW 2011
2. Middleware Specialization for Product-lines using Feature Oriented Reverse Engineering, ITNG 2010
3. Developing and Evaluating a Taxonomy of Modularization Techniques for Middleware Specialization, ACoM 2008
4. Towards a Holistic Approach for Integrating Middleware with Software Product Lines Research, McGPLE 2008
First Author26
Second Author
GeMS Publications1. GeMS: An Automated Middleware
Specialization Process for Distributed Real-time and Embedded Systems, Elsevier-JSA 2012 (in submission)
2. A Generative Middleware Specialization Process for Distributed Real-time and Embedded Systems, ISORC 2011
3. Architecture-Driven Context-Specific Middleware Specializations for Distributed Real-time and Embedded Systems, LCTES-WIP 2010
4. An Approach to Middleware Specialization for Cyber Physical Systems, WCPS 2009
GrAFT Publications1. Fault-tolerance for Component-based Systems – An Automated Middleware
Specialization Approach, ISORC 20092. CQML: Aspect-oriented Modeling for Modularizing & Weaving QoS Concerns in
Component-based Systems, ECBS 20093. Towards A QoS Modeling & Modularization Framework for Component-based
Systems, AQuSerM 20084. MoPED: A Model-based Provisioning Engine for Dependability in Component-
based Distributed Real-time Embedded Systems, ECBS 2011

27
Presentation Road Map
Motivation Overview of Solution Approach: Automated
Middleware Specialization Process Research Area Focus Safe Middleware
Adaptation for Real-Time Fault-Tolerance Research Contributions Concluding Remarks

Motivation: Addressing Failures in System-of-Systems
Safety-critical applications such as in avionics, automotive, industrial automation domains• Composed of system-of-systems• Must handle variety of failures stemming from the
composition• Certified to be schedulable and guaranteed to meet
stringent QoS
However, individual subsystems have• Closed nature• Static execution schedules• Resource-constrained• Often over-provisioned in terms of allocated time
and required capacity of resources to guarantee predictability in worst-case scenarios
How to handle failures in system-of-systems in the context of• Closed and over-provisioned, individual
subsystems• Stringent real-time QoS assurance
28

Challenge 4: How to Safely and Predictably Adapt to Failures?
Fault tolerance solutions need additional resources, but• No additional resources are available
due to over-provisioning• Rigid execution schedules severely
constrain the extent of runtime failure adaptability in real-time
• Cannot compromise on system safety• Redesigning and reimplementing the
individual subsystems is not an option due to economic forces
Since system-of-systems are being formed, we need to think holistically about how to handle faults within this concept.
29
Primary Distributed Processing Unit
(DPU)A B C
Backup Fail Over Unit (FOU)
A1 B1 C1
Backup Fail Over Unit (FOU)
A2 B2 C2
?
Resource-Constrained X Over-Provisioned

Challenge 4: How to Safely and Predictably Adapt to Failures? Side Effects of Over-provisioning
Most of the time resources remain under-utilized Large amount of processor utilization and time
slack within each allocated task quantum that can be better leveraged for adaptive fault management
Therefore it is important to, • Identify availability of unused resources at runtime• Do No Harm Provision fast and resource-aware
failure adaptation to ensure safety and predictability while obeying real-time constraints
Key Insight Existence of significant slack in over-provisioned individual subsystems
30
Primary Distributed Processing Unit
(DPU)A B C
Backup Fail Over Unit (FOU)
A1 B1 C1
Backup Fail Over Unit (FOU)
A2 B2 C2
?
How to:1. Identify the opportunities for slack in the DRE execution schedule2. Design safe and predictable dynamic failure adaptation3. Validate system safety in the context of DRE system fault tolerance

31
Related Research: Middleware Adaptation TechniquesCategory Related Research (Middleware Adaptation Techniques)
Adaptive Passive Replication Systems
S. Pertet et. al., Proactive Recovery in Distributed CORBA Applications, in Proceedings of the IEEE International Conference on Dependable Systems & Networks (DSN 2004), Italy, 2004P. Katsaros et. al., Optimal Object State Transfer – Recovery Policies for Fault-tolerant Distributed Systems, in Proceedings of the IEEE International Conference on Dependable Systems & Networks (DSN 2004), Italy, 2004Z. Cai et. al., Utility-driven Proactive Management of Availability in Enterprise-scale Information Flows, In Proceedings of the ACM/IFIP/USENIX Middleware Conference (Middleware 2006), Melbourne, Australia, November 2006L. Froihofer et. al., Middleware Support for Adaptive Dependability, In Proceedings of the ACM/IFIP/USENIX Middleware Conference (Middleware 2007), Newport Beach, CA, November 2007
Load-Aware Adaptations of Fault-tolerance Configurations
T. Dumitras et. al., Fault-tolerant Middleware & the Magical 1%, In Proceedings of the ACM/IFIP/USENIX Middleware Conference (Middleware 2005), Grenoble, France, November 2005O. Marin et. al., DARX: A Framework for the Fault-tolerant Support of Agent Software, In Proceedings of the IEEE International Symposium on Software Reliability Engineering (ISSRE 2003), Denver, CO, November 2003S. Krishnamurthy et. al., An Adaptive Quality of Service Aware Middleware for Replicated Services, in IEEE Transactions on Parallel & Distributed Systems (IEEE TPDS), 2003
Runtime adaptations to reduce failure recovery times
Change of replication
styles, reduced degree of
active replication

32
Related Research: Real-time Fault-Tolerant Middleware & Software Health Management
Category Related Research (Real-time Fault-Tolerant Middleware)
Real-time Fault-tolerant Systems
D. Powell et. al., Distributed Fault-tolerance: Lessons from Delta-4, In IEEE MICRO, 1994K. H. Kim et. al., The PSTR/SNS Scheme for Real-time Fault-tolerance Via Active Object Replication & Network Surveillance, In IEEE Transactions on Knowledge & Data Engineering (IEEE TKDE), 2000S. Krishnamurthy et. al., Dynamic Replica Selection Algorithm for Tolerating Timing Faults, In the IEEE International Conference on Dependable Systems & Networks (DSN 2001), 2001H. Zou et. al., A Real-time Primary Backup Replication Service, in IEEE Transactions on Parallel & Distributed Systems (IEEE TPDS), 1999
Schedulability analysis to schedule
backups in case primary replica fails,
faster processing
times
Category Related Research (Software Health Management)
Software Health Management
A. Dubey, et. al., A deliberative reasoner for model-based software health management, In the International Conference on Autonomic and Autonomous Systems, 2012, A. Srivastava et. al., The case for software health management, In the IEEE International Conference on Space Mission Challenges for Information Technology (SMCIT), 2011
Detect , Diagnose and Reason only
known failures with
predefined failover
strategies

Adaptive Fault Tolerance (AFT) approaches improve overall resource utilizations, however• Mostly applied to soft real-time applications• Require additional resources consuming
precious time from the real-time schedule• Excessively dynamic
Related Research: Middleware Composition Techniques
33
Category Related Research (Middleware Composition)
CORBA-based Fault-tolerant Middleware Systems
P. Felber et. al., Experiences, Approaches, & Challenges in Building Fault-tolerant CORBA Systems, in IEEE Transactions on Computers, May 2004T. Bennani et. al., Implementing Simple Replication Protocols Using CORBA Portable Interceptors & Java Serialization, in Proceedings of the IEEE International Conference on Dependable Systems & Networks (DSN 2004), Italy, 2004P. Narasimhan et. al., MEAD: Support for Real-time Fault-tolerant CORBA, in Concurrency & Computation: Practice & Experience, 2005
QoS-specific Middleware Customizations
Wolf et al., “Supporting Component-based Failover Units in Middleware for Distributed Real-time and Embedded Systems”, Elsevier JSA 2010Wang et al., “Total Quality of Service Provisioning in Middleware and Applications”, Elsevier JMM 2003Balasubramanian et al., “Evaluating Techniques for Dynamic Component Updating”, DOA 2005
Middleware building blocks
for fault-tolerant systems
Focus only on composing one QoS at a time
Software Health Management (SHM) approaches ensure safe and predictable adaptations, however• Apply to only errors in components
implementations known a priori• Support only predefined failover strategies• Are resource agnostic

Resolution 4: Safe Middleware Adaptation for Real-Time Fault Tolerance (SafeMAT)
Safe Middleware Adaptation for Real-Time Fault-Tolerance (SafeMAT)
• Fine-grained middleware adaptation to failures while maintaining safety, predictability and improving resource utilizations within the hard real-time constraints
How do we safely adapt middleware to runtime failures while maintaining predictability in
real-time?
Deduction
Inference
Transformation
Generation
Specification
Adaptation
SpecializationLifecycle
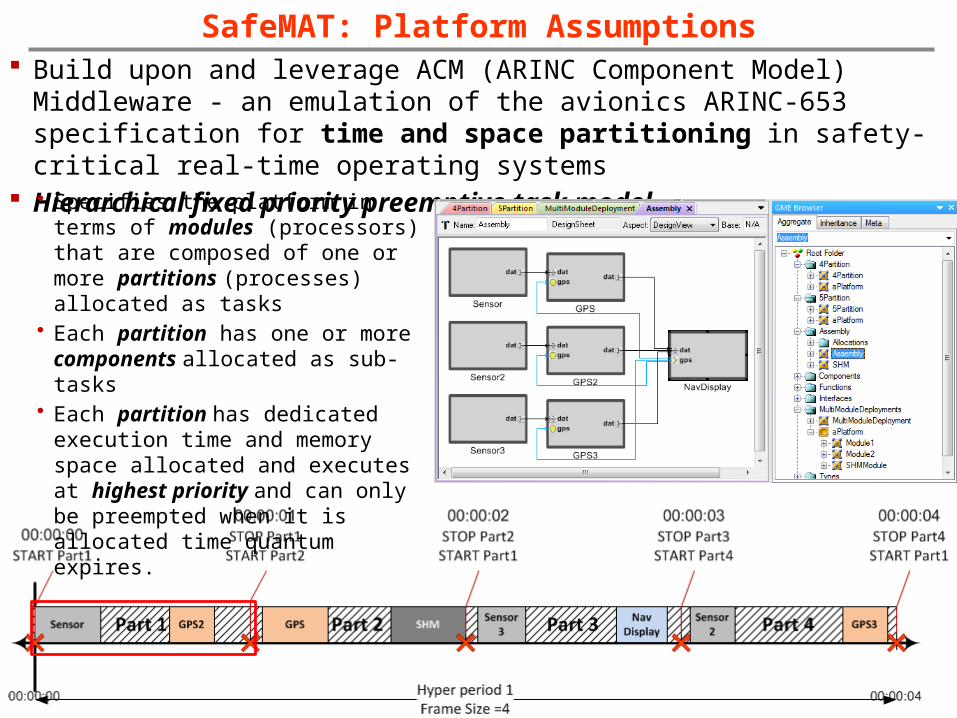
SafeMAT: Platform Assumptions Build upon and leverage ACM (ARINC Component Model) Middleware - an
emulation of the avionics ARINC-653 specification for time and space partitioning in safety-critical real-time operating systems
Hierarchical fixed priority preemptive task model
35
• Specifies the platform in terms of modules (processors) that are composed of one or more partitions (processes) allocated as tasks
• Each partition has one or more components allocated as sub-tasks
• Each partition has dedicated execution time and memory space allocated and executes at highest priority and can only be preempted when it is allocated time quantum expires.

SafeMAT: System Model and Fault Handling
Component Execution States• Active – all ports are operational• Semi-Active – required ports operational,
provided ports disabled• Inactive – none of the ports are operational
Fail-Stop failures Semi-Active replication due to hard
real-time constraints and to avoid state synchronization overhead• One primary replica – active state –
handles all client requests• Multiple backup replicas – semi-active state
– only process client’s requests; not produce any output.
Failure Granularity• Component• Component Group• Partition (process)• Module (processor)
36
Two primary sources of failure for each component port • Logical Failure – component failure due to
internal software, concurrency & environmental faults, latent bugs in the developer code
• Critical Failure – process/processor failures, undetected component failures
Failover Strategies• Logical Failure – failover to alternate
backup replica only• Critical Failure – failover to identical or
alternate backup replicas
Replica Placement • Identical Replica – Always deploy to
different partition than primary• Alternate Replica – Can be deployed within
same partition
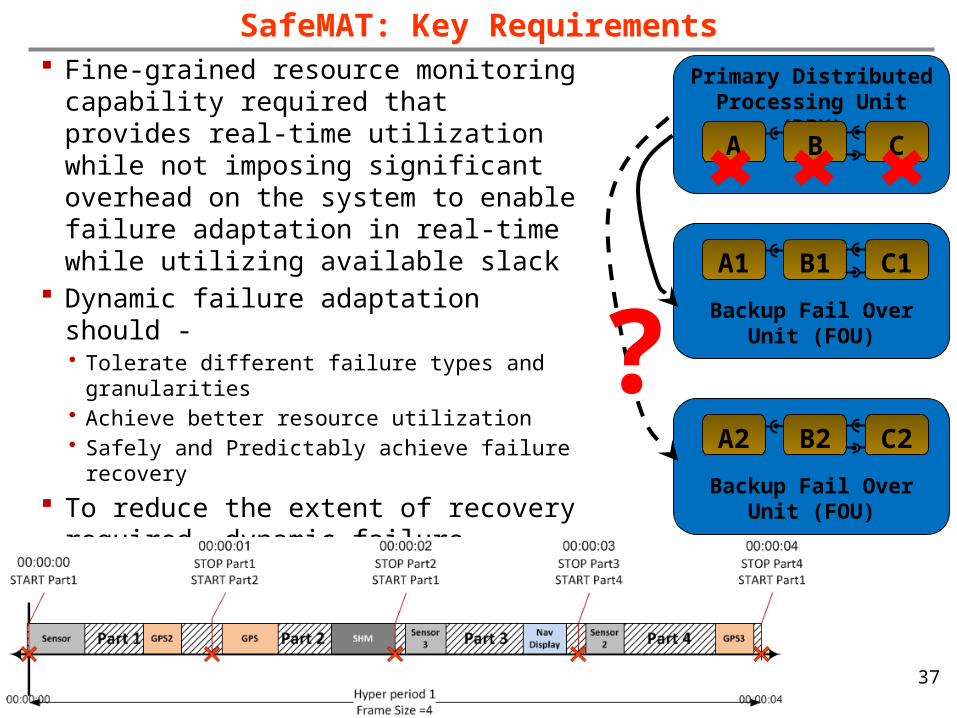
SafeMAT: Key Requirements Fine-grained resource monitoring capability
required that provides real-time utilization while not imposing significant overhead on the system to enable failure adaptation in real-time while utilizing available slack
Dynamic failure adaptation should -• Tolerate different failure types and granularities• Achieve better resource utilization• Safely and Predictably achieve failure recovery
To reduce the extent of recovery required, dynamic failure adaptation should be• Be Fast & Lightweight• Obey hard real-time constraints (predictability)• Flexible (account for failure type, granularity, replica
placements)
37
Primary Distributed Processing Unit
(DPU)A B C
Backup Fail Over Unit (FOU)
A1 B1 C1
Backup Fail Over Unit (FOU)
A2 B2 C2
?

ACM Middleware: Architecture
System Level • Module Scheduler• Alarm Aggregator• Diagnoser• Deliberative Reasoner (DR)
Module Level • Partition Creator• Partition Scheduler • Module Initializer
Partition Level• CLHM• Partition Initializer• Components
38A. Dubey, G. Karsai, and N. Mahadevan, “A component
model for hardreal-time systems: CCM with ARINC-653,” SPE 2011

SafeMAT: Architecture
System Level • Module Scheduler• System Resource Manager (sRM)• Failure Handler• Alarm Aggregator• Diagnoser• Resource Aware Deliberative Reasoner
(RADaR)
Module Level • Partition Scheduler • Module Resource Monitor (mRM)• Failure Handler
Partition Manager Level• Partition Launcher• Partition Resource Monitor in compute
mode (pRMc)• Failure Handler
Partition Level• CLHM• Partition Resource Monitor in notify
mode (pRMn)• Components
39
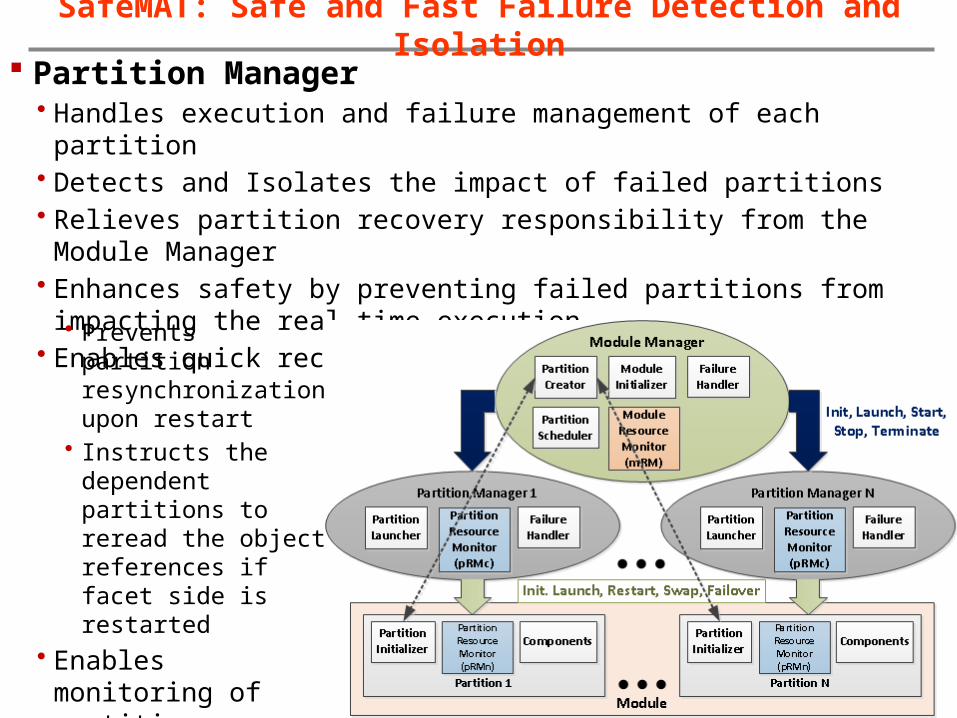
SafeMAT: Safe and Fast Failure Detection and Isolation Partition Manager
• Handles execution and failure management of each partition • Detects and Isolates the impact of failed partitions• Relieves partition recovery responsibility from the Module Manager• Enhances safety by preventing failed partitions from impacting the real-time
execution • Enables quick recovery by coordinating with RADaR
40
• Prevents partition resynchronization upon restart
• Instructs the dependent partitions to reread the object references if facet side is restarted
• Enables monitoring of partition resource utilizations through pRMc

SafeMAT: Distributed Resource Monitor (DRM)
Framework Components• Single System Resource Monitor (sRM)• Multiple Module Resource Monitors (mRM)• Multiple Partition Resource Monitors in
either compute (pRMc) or notify (pRMn) modes
Resource Liveness Monitoring• Auxiliary to failure handlers that monitor
exit statuses of partitions and their managers - dual monitoring capability
• Periodically collects liveness statuses from each of its own monitors to determine partition, partition manager, module failures
41
Configuration• Ability to monitor CPU utilizations at various
granularities of processor, process, component group, component and thread
• Can operate in reactive (on-demand) or periodic (collect history) modes
• Can report utilizations of only specific entities RADaR is interested in
Discovering Resource Allocations• Dynamically discover the exact runtime
allocations of threads to components, components to partitions, and partitions to modules to enable fast monitoring
Monitors Utilization and Liveness of distributed resources

SafeMAT: Enabling Hierarchical Failure Adaptation (HFA)
Component Failure Type• Logical• Critical
Various Failure Granularities due to Hierarchically Scheduled Real-time System• Component• Component Group (e.g. Subsystem)• Partition• Module
Primary-Backup Deployment Topology• Only alternate backup replicas on same partition as
primary• Identical backup replicas always on different partition• Both identical & alternate backup replicas on different
partition as primary• Same module • Different module
42
Adapt failover targets based upon failure type, granularity and backup replica placement
Capable of handling simultaneous module, partition, logical and critical component failures

SafeMAT: The Hierarchical Failover Adaptation (HFA) Algorithm Invoked whenever any of the
DRM and/or the SLHM frameworks detect a failure
To provide quick and efficient failover• sRM proactively pre-computes the
sorted list of least utilized backups • Sends the sorted list to the RADaR
piggybacked with the failed primaries
Hands over control to the SLHM which decides when to initiate failover that depends upon• # failures system can withstand• Time for system to stabilize (usually
at least a Hyperperiod long)
Ability to • Intelligently mitigate simultaneous
failures in an hierarchical fashion• Choose failover target not just
based on current utilization but also based on historical averages 43

SafeMAT: Empirical Evaluation
Inertial Measuring Unit (IMU)• 4 subsystem types • 7 primaries, 4 backups• 55 components• All secondary subsystems
are semi-actively replicated
ADIRU subsystem can withstand 2 accelerometer component failures
GPS and ADIRU subsystem run at 0.1 Hz and 1 Hz respecitvely
PFC fetches GPS data at 0.1 Hz
Display fetches PFC data at 1 Hz 44
A. Dubey, N. Mahadevan, and G. Karsai, “The inertial measurement
unit example: A software health management case study,” ISIS Tech. Rep., Vanderbilt University, 02/2012

SafeMAT: Performance Metric Evaluation (PME) – Runtime Utilization Overhead
We executed the IMU system for 100 iterations for faulty scenarios for both ACM-SHM and SafeMAT
We artificially introduced failures at 15, 20, 30, 35 iterations in the GPS Processor, Accelerometers 6, 5 and 4 respectively such that the values outputted by them are exceedingly high
SafeMAT added only 2-6% utilization overhead on the top of ACM-SHM
Do No Harm SafeMAT added negligible runtime utilization overhead thereby not overloading the system while performing better failure recovery within the available utilization slack 45

SafeMAT: Performance Metric Evaluation (PME) – Runtime Failover Overhead
Impact of Replica Placement We used the Boeing’s BasicSP
scenario to demonstrate the impact of replica placement
We altered the deployments of the backup replicas in three ways - • Same Partition• Different Partition, Same Module• Different Partition, Different Module
4646

SafeMAT: Performance Metric Evaluation (PME) – Runtime Failover Overhead
Impact of Replica Placement We used the Boeing’s BasicSP
scenario to demonstrate the impact of replica placement
We altered the deployments of the backup replicas in three ways -• Same Partition• Different Partition, Same Module• Different Partition, Different Module
SafeMAT roughly added 63-70%
4747
work over ACM-SHM when recovering only one component at a time

SafeMAT: Performance Metric Evaluation (PME) – Runtime Failover Overhead
Impact of Recovery Group Size We tested for different subsystems
within the IMU and BasicSP scenarios SafeMAT added only 9-15% runtime
failover overhead over groups of components
Recovery Times are dependent upon• Size of component group• Component deployments within the failover
group• Amount of network communication within the
DRM
Costs are amortized for large group sizes than individual components
No missed deadlines, application jitter was unaffected
Do No Harm SafeMAT added negligible runtime failover overhead thereby maintaining the predictability of the overall system 48

49
Presentation Road Map
Motivation Overview of Solution Approach: Automated
Middleware Specialization Process Research Area Focus Safe Middleware
Adaptation for Real-Time Fault-Tolerance Research Contributions Concluding Remarks
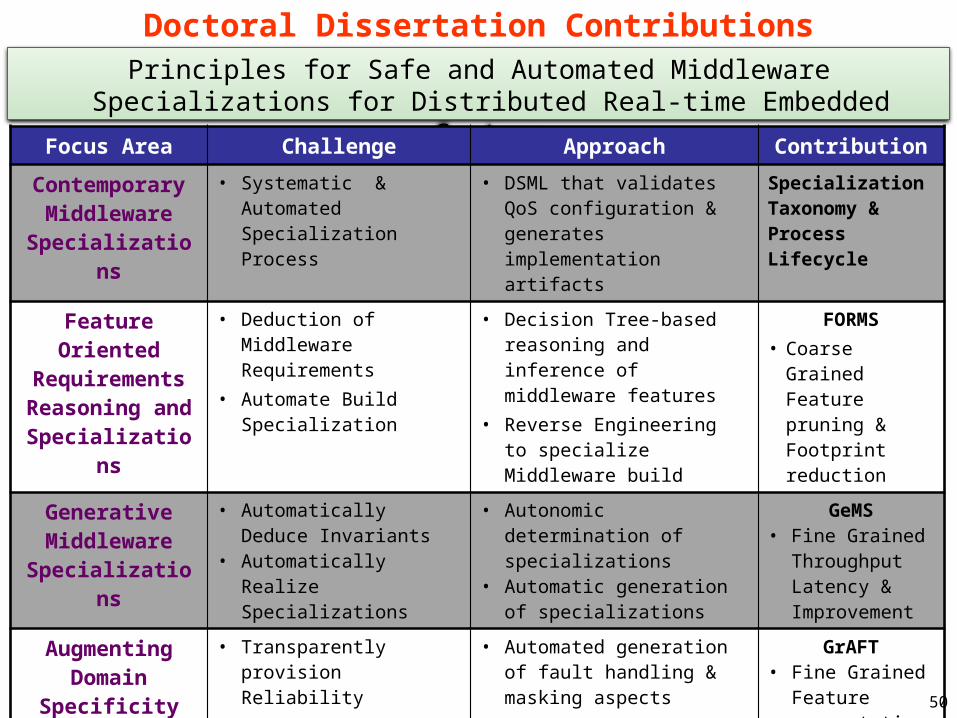
Doctoral Dissertation ContributionsPrinciples for Safe and Automated Middleware Specializations for
Distributed Real-time Embedded Systems
Focus Area Challenge Approach Contribution
Contemporary Middleware
Specializations
• Systematic & Automated Specialization Process
• DSML that validates QoS configuration & generates implementation artifacts
Specialization Taxonomy & Process Lifecycle
Feature Oriented Requirements Reasoning and Specializations
• Deduction of Middleware Requirements
• Automate Build Specialization
• Decision Tree-based reasoning and inference of middleware features
• Reverse Engineering to specialize Middleware build
FORMS• Coarse Grained
Feature pruning & Footprint reduction
Generative Middleware
Specializations
• Automatically Deduce Invariants
• Automatically Realize Specializations
• Autonomic determination of specializations
• Automatic generation of specializations
GeMS• Fine Grained
Throughput Latency & Improvement
Augmenting Domain
Specificity
• Transparently provision Reliability
• Automated generation of fault handling & masking aspects
GrAFT• Fine Grained
Feature augmentation
Safe Specializations
• Safely and predictably provision Reliability
• Predictably adapt to different failure types, granularity and deployment in real-time constraints
SafeMAT• Fine Grained
Resource-Aware Adaptations
50

Conference Publications4. Akshay Dabholkar, Abhishek Dubey and Aniruddha Gokhale (Oct 2012) Reliable
Distributed Real-time and Embedded Systems Through Safe Middleware Adaptation (In submission to) 31st International Symposium on Reliable Distributed Systems (SRDS 2012), Irvine, California, USA
5. Akshay Dabholkar, and Aniruddha Gokhale (March 2011) A Generative Middleware Specialization Process for Distributed Real-time and Embedded Systems Proceedings of the 14th IEEE International Symposium on Object/Component/Service-oriented Real-time Distributed Computing (ISORC 2011), Newport Beach, CA, USA
6. Akshay Dabholkar, and Aniruddha Gokhale (April 2010) Middleware Specialization for Product-lines using Feature Oriented Reverse Engineering Proceedings of the 7th International Conference on Information Technology : New Generations (ITNG 2010), Las Vegas, NV, USA.
Summary of Publications & Presentations
51
Journal Publications1. Akshay Dabholkar, Abhishek Dubey and Aniruddha Gokhale (2012) SafeMAT: Safe
Middleware Adaptation for Predictable Fault-Tolerant Distributed Real-time and Embedded Systems (In submission)
2. Akshay Dabholkar, and Aniruddha Gokhale (2012). AutoGeMS: An Automated and Generative Middleware Specializations Process for Distributed Real-time and Embedded Systems, (Submitted to) Elsevier Journal of Software Architecture (JSA 2012).
3. Akshay Dabholkar, and Aniruddha Gokhale.(April 2011). FORMS: Feature-Oriented Reverse Engineering-based Middleware Specialization for Product-Lines, Journal of Software Special Issue on Middleware and Network Application (JSW 2011), Vol.6, No.4
First Author

Conference Publications (cont.)7. Sumant Tambe, Akshay Dabholkar, and Aniruddha Gokhale (April 2011) MoPED: A
Model-based Provisioning Engine for Dependability in Component-based Distributed Real-time Embedded Systems. Proceedings of the 18th IEEE International Conference and Workshops on the Engineering of Computer Based Systems (ECBS 2011), Las Vegas, NV, USA
8. Sumant Tambe,Akshay Dabholkar, and Aniruddha Gokhale (April 2009). CQML: Aspect-oriented Modeling for Modularizing and Weaving QoS Concerns in Component-based Systems, Proceedings of the 16th Annual IEEE International Conference and Workshop on the Engineering of Computer Based Systems (ECBS 2009), San Francisco, CA, USA.
9. Sumant Tambe, Akshay Dabholkar, and Aniruddha Gokhale (March 2009). Fault-tolerance for Component-based Systems – An Automated Middleware Specialization Approach, Proceedings of The 12th IEEE International Symposium on Object-oriented Real-time distributed Computing (ISORC 2009), Tokyo, Japan.
10.Nilabja Roy, Akshay Dabholkar, Natham Hamm, Larry Dowdy, and Douglas Schmidt (Sep 2008). Modeling Software Contention using Colored Petri Nets Proceedings of the 16th Annual Meeting of the IEEE International Symposium on Modeling, Analysis, and Simulation of Computer and Telecommunication Systems (MASCOTS 2008), Baltimore, MD, USA.
52Second Author
Technical Reports11.Sumant Tambe,Akshay Dabholkar, Amogh Kavimandan, and Aniruddha Gokhale
(June 2007) A Platform Independent Component QoS Modeling Language for Distributed
Real-time and Embedded Systems. Technical Report ISIS-07-809, Institute for Software
Integrated Systems, Vanderbilt University, Nashville, TN, USA.
Summary of Publications & Presentations

First Author Second Author
Workshop Publications12.Akshay Dabholkar, and Aniruddha Gokhale (March 2011). Safe Specialization of
the LwCCM Container for Simultaneous Provisioning of Multiple QoS, Proceedings of OMG’s Workshop on Real-time, Embedded and Enterprise-Scale Time-Critical Systems (OMG RTWS 2011), Washington DC, USA.
13.Akshay Dabholkar, and Aniruddha Gokhale (June 2009). An Approach to Middleware Specialization for Cyber Physical Systems, Proceedings of The 2nd International Workshop on Cyber-Physical Systems (WCPS 2009), Co-located with ICDCS 2009 pp. 73–79 Montreal, Quebec, Canada.
14.Akshay Dabholkar, and Aniruddha Gokhale (Oct 2008). Developing and Evaluating a Taxonomy of Modularization Techniques for Middleware Specialization Proceedings of the 2nd OOPSLA Workshop on Assessment of Contemporary Modularization Techniques (ACoM), Nashville, TN, USA.
15.Aniruddha Gokhale, Akshay Dabholkar, and Sumant Tambe (Oct 2008). Towards a Holistic Approach for Integrating Middleware with Software Product Lines Research Proceedings of the GPCE Workshop on Modularization, Composition and Generative Techniques in Product Line Engineering, (McGPLE), Nashville, TN, USA.
16.Sumant Tambe, Akshay Dabholkar, and Aniruddha Gokhale, & Amogh Kavimandan (Sep 2008). CQML: A QoS Modeling and Modularization Framework for Component-based Systems, Proceedings of the 3rd EDOC Workshop Advances in Quality of Service Management, (AQuSerM), München, Germany.
53
Summary of Publications & Presentations

Poster Publications17. Akshay Dabholkar, and Aniruddha Gokhale (April 2010). Architecture-Driven Context-
Specific Middleware Specializations for Distributed Real-time and Embedded Systems Proceedings of the ACM SIGPLAN/SIGBED Conference on Languages, Compilers and Tools for Embedded Systems (LCTES-WIP-PS), Stockholm, Sweden
18. Akshay Dabholkar, Sumant Tambe and Aniruddha Gokhale (April 2009). An Systematic Approach to Middleware Specialization for Cyber Physical Systems Published in the Proceedings of the Cyber Physical Systems Week 2009 San Francisco CA, USA.
19. Akshay Dabholkar, and Aniruddha Gokhale (July 2008). Towards Employing End-to-End Middleware Specialization Techniques Proceedings of OMG’s Annual Real-time and Embedded Systems workshop (OMG RTWS) Washington, DC, USA.
20. Joe Hoffert, Akshay Dabholkar, Aniruddha Gokhale, & Douglas Schmidt (March 2007). Enhancing Security in Ultra-Large Scale (ULS) Systems using Domain-specific Modeling. Spring 2007 Conference for Team for Research in Ubiquitous Secure Technology (TRUST), Berkeley, CA.
54First Author Second Author
Summary of Publications & Presentations

Lack of common reasoning vocabulary and systematic specialization process• Middleware Specialization Taxonomy and Lifecycle
Process
Forward Engineering though systematic and elegant does not vertically decompose middleware implementations along domain concerns Feature Oriented Reverse Engineering based
Middleware Specializations (FORMS)
Generative techniques based on source code analysis offer a promising approach for automating the specialization process• Generative Middleware Specializations (GeMS)• Generative Aspects for Fault-Tolerance (GrAFT)
Middleware Adaptation to runtime failures needs to be safe and predictable in order to be viable for hard real-time systems• Safe Middleware Adaptations for Real-Time Fault
Tolerance (SafeMAT)
Concluding Remarks

56
Questions





























