Embed Size (px)
Citation preview

Planning for Failure in Cloud Applications
Wade WegnerTwitter: @WadeWegnerBlog: http://www.wadewegner.com/
AZR333

Who am I?
Chief Technology Oficer at Aditi TechnologiesFormerly a Windows Azure Technical EvangelistBlog: http://www.wadewegner.com/Twitter: http://twitter.com/WadeWegnerGithub: https://github.com/wadewegner

Planning for Failure in Cloud Applications
Design For FailureRecent cloud outagesBuilding blocks
Infrastructure abstractionAutomation
Architectural options to mitigate failuresConclusions

Takeaways
Outline of architectural options for designing highly-available, fault-tolerant applicationsBest practices for implementation of these architectural optionsMulti-Availability Zone (AZ) & Fault Domain, Multi-Region, and Multi-Cloud
Architectural optionsConsiderations / pros and cons of these options

Why plan for failure?
Notable recent outages:
AWS – Thursday, 4/21/2011Windows Azure – Wednesday, 2/29/2012AWS – Thursday, 6/14/2012AWS – Friday, 6/29/2012Windows Azure – Thursday, 7/26/2012

Why plan for failure?
It will happen!

Terminology
Fault ToleranceDesigns incorporating redundancy and replication to enable systems to continue operating properly (perhaps at a degraded level) if one or more components fails
High Availability (HA)Fault Tolerant systems are measured by their Availability in terms of planned and unplanned service outages for end users
Disaster Recovery (DR)The process, policies, and procedures related to restoring critical systems after a catastrophic event

SLAs
99% availability = 3.65 days of downtime99.5% = 1.83 days of downtime99.9% = 8.76 hours of downtime99.95% = 4.38 hours of downtime99.99% = 53 minutes of downtime99.999% = 5.26 minutes of downtime

Compounding SLAs
Windows Azure Compute (2 instances) = 99.95%SQL Azure = 99.9%Windows Azure Storage = 99.9%
Total SLA4.38 hours + 8.76 hours + 8.76 hours21.9 hours
Target: 99.75%

A moment about “the Cloud” …
A frame for discussing the cloud:
A cloud is a physical data center behind an API endpointThink of a cloud as a “resource pool” that you can access via APIA cloud is not …
Windows AzureAmazon Web Services
A cloud is defined by the isolation of the resources

A Cloud is …
Windows Azure North Central RegionAWS US East (North Virginia) Region
This is important moving forward as we talk about DR and HA …

What does HA require?
No single points of failureMultiple web serversMultiple load balancersData replication
Graceful failover when individual components fail (and they will)

Disaster Recovery
Disaster recovery is about preparing for and recovering from a disaster.
Hardware or softwareNetwork or power outagePhysical damage to a buildingHuman error… or something else!
Invest time and resources to plan, prepare, rehearse, document, train, and update processes to deal with events.Continual process of analysis and improvement

Typical DR approach
Duplication of infrastructure to ensure the availability of spare capacity in a disaster scenario
Procured, installed, and maintained so that it’s readSignificant physical distance apart to ensure isolation from faultsTypically under-utilized or over-provisioned

DR with the Cloud
Essential to consider the best use of services and features that support data migration and durable storage; restore data when disaster strikesScale up as needed
Windows AzureRegionsFault Domains
Amazon Web ServicesRegionsAvailability Zones

Design For Failure
Large scale failures in the cloud are rare but happenApplication owners are ultimately responsible for availability and recoverabilityBalance cost and complexity of HA efforts against risk(s) you’re willing to bearCloud infrastructure has made DR and HA remarkably affordable versus past options
Multi-serverMulti-availability zone / fault domainMulti-regionMulti-cloud

Overcoming Multi-Cloud Pain Points
APIs differDifferent sets of resourcesDifferent formats, encodings, and versions
Abstractions and features differNetwork architectures differ: VLANs, security groups, NAT, Ips, ACLs, …Storage architectures differ: local/attachable disks, backup, snapshots, …Hypervisors, machine images … cost models, billing, reporting, …
Each cloud is unique in some/many/all respects, with different access mechanisms and varying functionalities provided by the managed resources.

Overcoming Multi-Cloud Pain Points
Design using generic concepts (e.g. “durable storage”) yet deploy using cloud specifics (e.g. “EBS volumes”)Have tools that translate your concepts to cloud-specific ones (e.g. scripts/recipes that choose the correct provider for the desired resource)Think of how to share resources across clouds (i.e. data sharing)

Infrastructure Abstraction & Automation
Architecture & Application PortabilityAllows simplified deployments across multiple regions/clouds
Automated DeploymentsReproducible configurations with change control (avoids manual configuration errors)Cost effective
Advanced Server and Deployment MonitoringAutomated Scaling and Operations

HA/DR Checklist for Risk Mitigation
Determine who owns the architecture, DR process, and testing.Develop expertise in house and/or get outside help.Conduct a risk assessment for each application.Specify your target Recovery Time Objective and Recovery Point Objective.Design for Failure starting with application architecture.Implement HA best practices, balancing cost, complexity, and risk.
Automate infrastructure for consistency and reliability.Abstract applications for flexibility and portability.
Document operational processes and automations.Test the failover … then test it again.Release the Chaos Monkey.

General HA Best Practices
Avoid single points of failureAlways place (at least) one of each component (load balancers, app servers, databases, …) in at least two AZs or fault domainsMaintain sufficient capacity to absorb AZ / fault domain failures
Reserved Instances – guarantee capacity is available in a separate region/cloud.
Replicate data across AZs and backup or replicate across clouds/regions for failoverSetup monitoring, alerts, and operations to identity and automate problem resolution or failover processDesign stateless applications for resilience to reboot / relaunch

General DR Scenarios
Backup and Restore“Pilot Light” for Simple RecoveryWarm Standby SolutionMulti-site SolutionMulti-cloud Solution
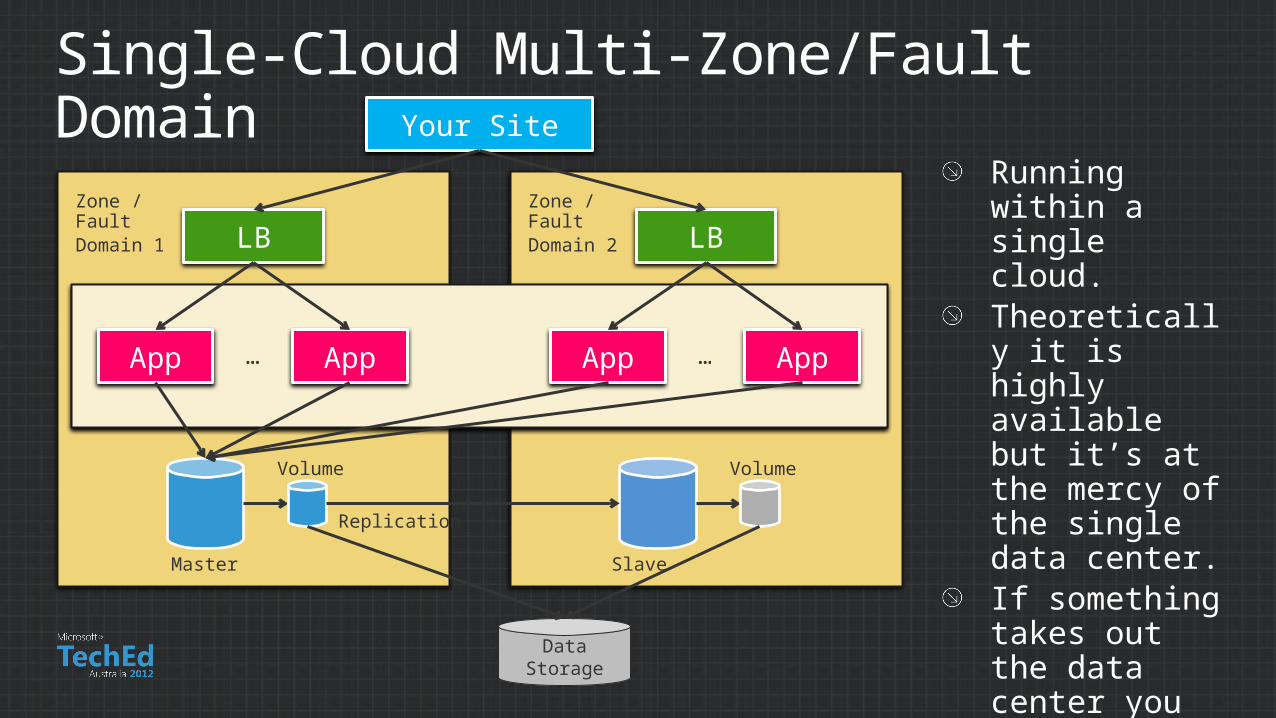
Single-Cloud Multi-Zone/Fault Domain
Running within a single cloud.Theoretically it is highly available but it’s at the mercy of the single data center.If something takes out the data center you lose.
Your Site
Data Storage
LB
AppApp
Master
…
Volume
Zone /FaultDomain 1 LB
AppApp …
Volume
Zone /FaultDomain 2
Slave
Replication
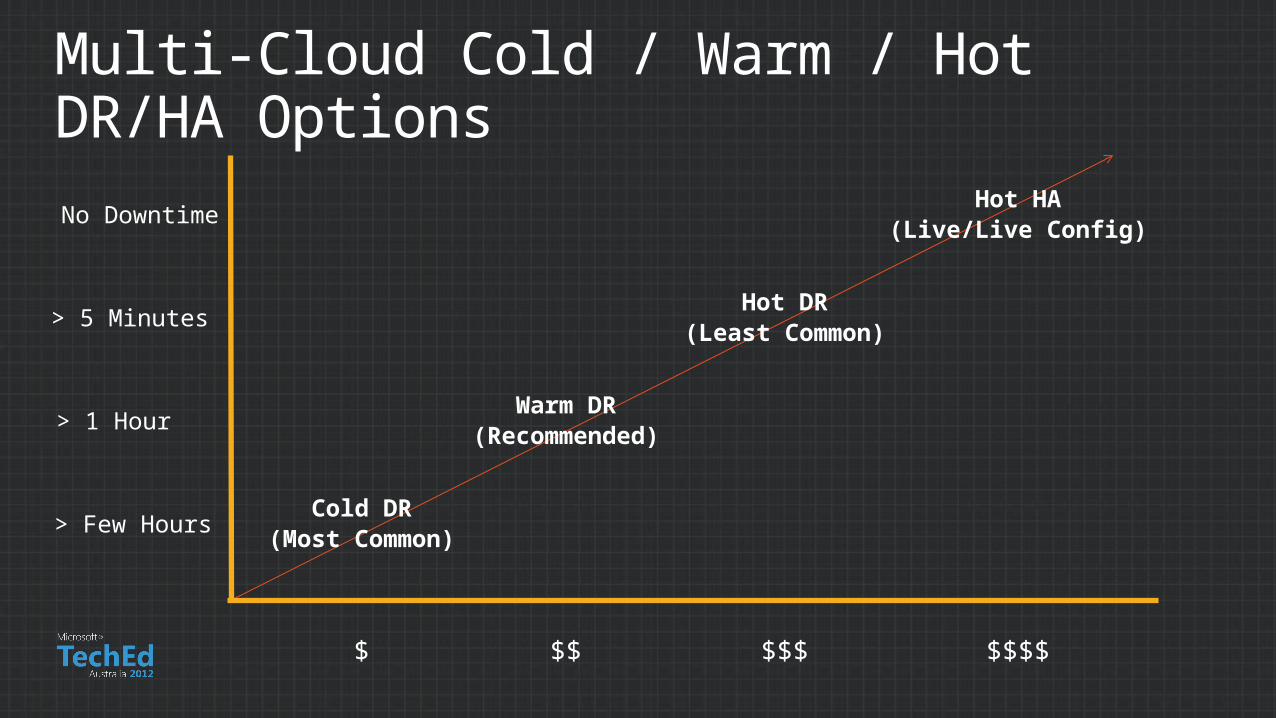
Multi-Cloud Cold / Warm / Hot DR/HA Options
$ $$ $$$ $$$$
> Few Hours
> 1 Hour
> 5 Minutes
No Downtime
Cold DR(Most Common)
Warm DR(Recommended)
Hot DR(Least Common)
Hot HA(Live/Live Config)

Multi-Cloud Cold DR
Only provisioned environment is primary.Not good if rapid recovery is required.Slow to replicate data to other cloud.Slow to bring database to an operational state.
Your Site
Data Storage
LB
AppApp
Master
…
Volume
Cloud 1
LB
AppApp
Slave
…
Volume
Cloud 2
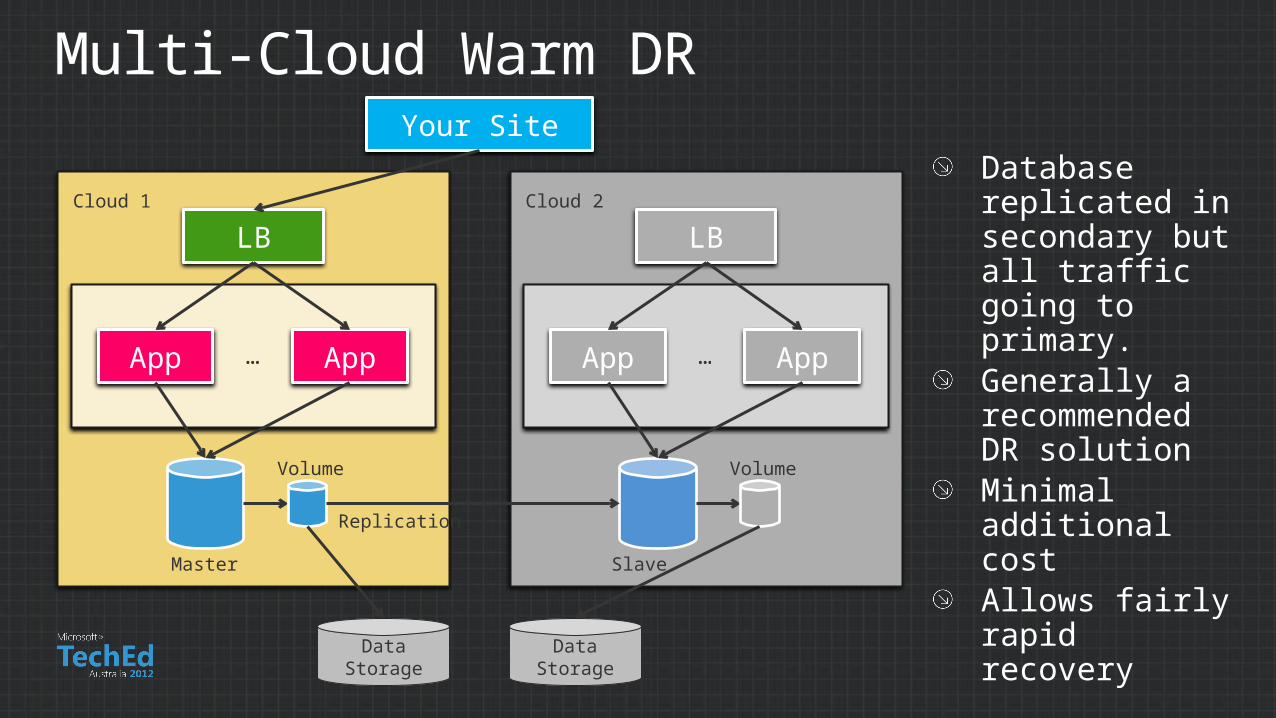
Multi-Cloud Warm DR
Database replicated in secondary but all traffic going to primary.Generally a recommended DR solutionMinimal additional costAllows fairly rapid recovery
Your Site
Data Storage
LB
AppApp
Master
…
Volume
Cloud 1
LB
AppApp …
Volume
Cloud 2
Slave
Replication
Data Storage
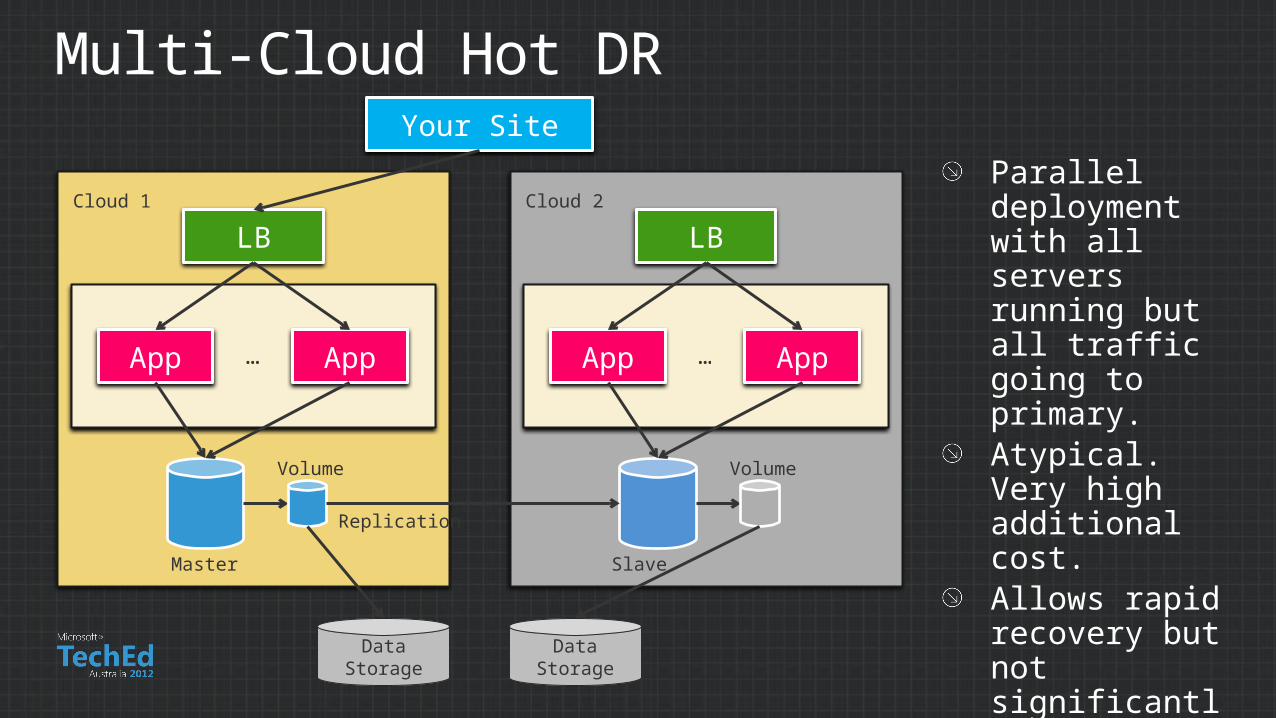
Multi-Cloud Hot DR
Parallel deployment with all servers running but all traffic going to primary.Atypical. Very high additional cost.Allows rapid recovery but not significantly faster than “warm” configuration.
Your Site
Data Storage
LB
AppApp
Master
…
Volume
Cloud 1
LB
AppApp …
Volume
Cloud 2
Slave
Replication
Data Storage
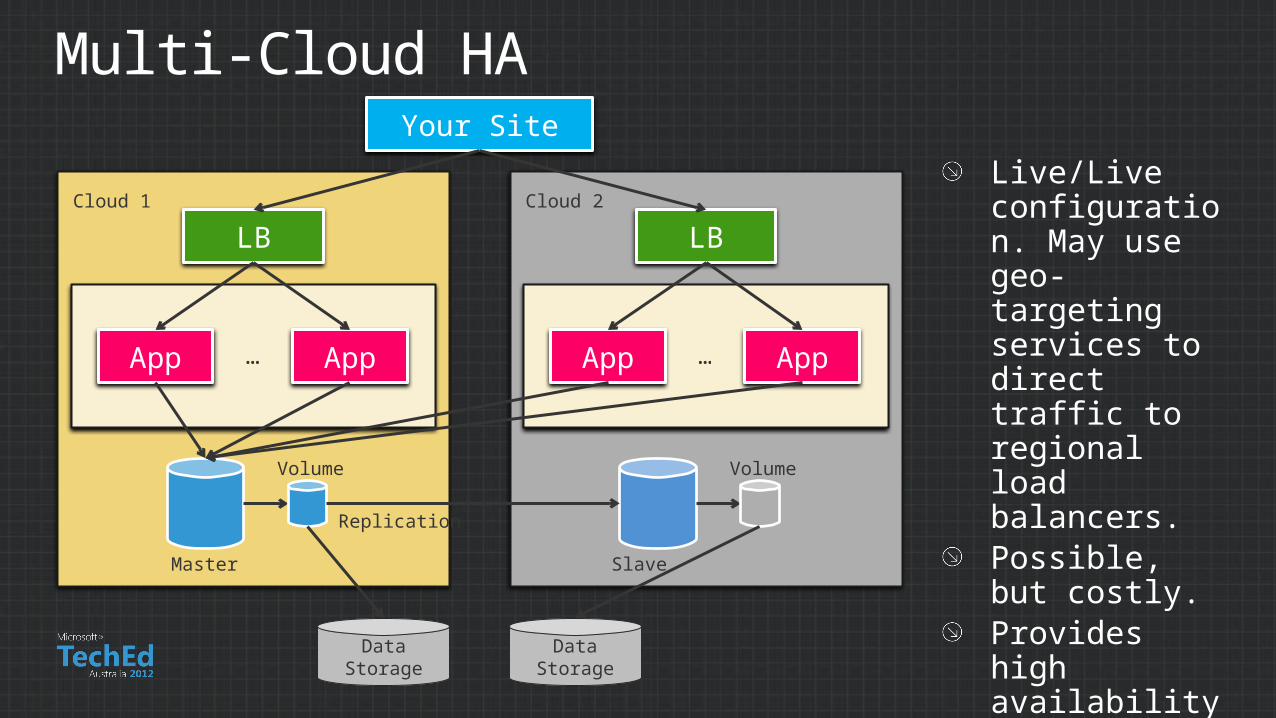
Multi-Cloud HA
Live/Live configuration. May use geo-targeting services to direct traffic to regional load balancers.Possible, but costly.Provides high availability, but complex to implement and manage.
Your Site
Data Storage
LB
AppApp
Master
…
Volume
Cloud 1
LB
AppApp …
Volume
Cloud 2
Slave
Replication
Data Storage

How do I make my service immortal?
Be pessimistic: Design for FailureEmbrace the cloud mentality: Unprecedented featuresHave it your way: No single architecture fits all casesCrawl then walk: Build HA within cloud, then expand

© 2012 Microsoft Corporation. All rights reserved. Microsoft, Windows, Windows Vista and other product names are or may be registered trademarks and/or trademarks in the U.S. and/or other countries.The information herein is for informational purposes only and represents the current view of Microsoft Corporation as of the date of this presentation. Because Microsoft must respond to changing market conditions, it should not be interpreted to be a commitment on the
part of Microsoft, and Microsoft cannot guarantee the accuracy of any information provided after the date of this presentation. MICROSOFT MAKES NO WARRANTIES, EXPRESS, IMPLIED OR STATUTORY, AS TO THE INFORMATION IN THIS PRESENTATION.





























