Embed Size (px)
Citation preview

Pittsburgh Genome Resource RepositoryCommunity Meeting
June 16th, 201512-3 pm

Agenda
• 12:00-1:00 State of the PGRR Jacobson/Barmada/Chandran/Blood/Miller
• Intro and Datatypes and Datasets• Compute nodes accessible; tools available• Data Supercell and Data Staging for BAM files• New functionality in PGRR portal since launch• GenomOncology software and recent changes• Current status of NCI Cloud Pilots and Cancer Genome
Commons• What is the future of PGRR?

Agenda• 1:00- 2:00 Flash Talks• Six ten minute “Flash Talks” by investigators using the TCGA data – each 5
minute presentation with 5 minutes of questions/discussion. • Paul Cantalupo - From Contamination to Discovery: the Virome of 3,000
TCGA Participants• Xinghua Lu - Tumor Specific causal inference reveals a functional map
between cancer genome alterations and transcriptomic programs • Kevin McDade - Data driven evaluation of bioinformatics workflow quality• Nolan Priedigkeit Leveraging TCGA primary cancers by sequencing their
recurrences• Kevin Levine – Gaining clinical insight from TCGA exomes and genomes• Da Yang - Impairment of miRNA biogenesis: A new hallmark of cancer

Agenda• 2:00 – 2:45 Adding Value to PGRR• Open Discussion of New tools, Additional Data, Additional Efforts that may be
valuable to the community.
• Adding additional UPMC clinical data?• New analytic tools (CLC Bio, cBIO, transMART)• Getting standard pipelines working • Reinvigorating relationship with UPMC Enterprise Analytics• Other datasets?
• 2:45 – 3:00 Wrap Up/Prioritization • Prioritize new features/changes/additions for 2015-2016• PGRR team to provide draft project plan for 2015-2016 as follow up to the meeting

Goals for the Meeting
• Share information on current state of PGRR• Discuss use of resource and potential improvements
(new tools, new data, new functionality)• Discuss problems with resource and how we can
address them• Share experience of investigators with TCGA data• Disseminate information on NCI projects that may
provide alternatives to PGRR starting in Spring 2016• Co-construct PGRR project plan for the next year

Accomplishments
• Developed platform for data and metadata acquisition and management
• Deployed at SaM and PSC• Downloading data including BAM files; Some
datasets are already complete• Optimized hardware performance; improved
networking and communications• Created initial methods for staging data

Investment
• Institute for Personalized Medicine and University of Pittsburgh Cancer Institute
• Total investment = ~540K over 2 years– Human Effort - 162K over 2 years (% effort from 13
different people across DBMI, SaM and PSC) and lots of donated effort
– Hardware (SaM and PSC) – 254K over 2 years– Software – 128K for GO license and dev efforts
• Thank you to Jeremy Berg, Maryann Donovan and Mike Becich for their support

Data types and Volume Num_FilesSize (TB)Total 556298 314.4071

Recent Data Management Updates
• Acquisition now entirely moved to PSC side• Automated BAM download request data selection• Automated post-download BAM files upload to
PGRR storage and metadata creation• Added Portal Repository Search page• Dual metadata format support: RDF store
(Virtuoso) and relational database (PostgreSQL).• Improved search capabilities by moving
production metadata backend to PostgreSQL

Portal Search Repository

Moved Backend from Virtuoso to PostgreSQL Database
Num of Records To Retrieve Virtuoso on SAM PostgreSQL on PSC
51 2.6 0.4
2001 3.3 0.4
5000 4.5 0.4
10000 6.1 0.5
Number of triples: 18,558,650
Number of distinct records (same subject): 540,534

6
The Data Exacell (DXC):Data Infrastructure Building Blocks for
Coupling Analytics and Data
12

Enabling Data Analyticsin Research, Government, and Industry
CAMPUSES RESEARCHERS INSTRUMENTSGOVERNMENT PRIVATE
SECTOR
SHERLOCK:GRAPH ANALYTICS
BLACKLIGHT: SHARED MEMORY FOR GENERAL ANALYTICS
TIOGA*: DATABASE
AND WEB
SERVERS
DATA SUPERCELL:FAST, COST-EFFECTIVE,
RELIABLE STORAGE
(AS OFNOVEMBER 2014)

Approach: Data Management• /supercell SLASH2 Wide-Area Filesystem (PSC and Pitt)
– TCGA data downloaded to SLASH2 filesystem backed by DXC storage– All TCGA data can be local to PSC, all the time– Smaller data (e.g. VCF files) always local to Pitt and PSC– Large data (BAM files) can be replicated to be local to Pitt as needed– Always maintains a single view of complete TCGA to Pitt and PSC resources
• Metadata Tracking (PSC and Pitt) – PGRR software developed by Pitt pulls metadata from NCI repositories– Updates metadata stored in DXC databases– Store and manage TCGA metadata– Provides version control of TCGA data
• IPM Portal (Pitt)– Queries DXC databases for TCGA metadata– Allows researchers to search and locate files of interest for analysis– Notifies researchers of changes to data sets they are tracking

PGRR-TCGA Directory Structure

Approach: Data Analysis• GenomOncology (Pitt)
– Loads Level 2 TCGA (non-BAM, e.g, VCF) data from SLASH2 filesystem– Gets metadata from DXC databases– Provides GUI analysis framework for interactive analysis of TCGA data
• SaM Compute Resources (Pitt)– Enable researchers to use Pitt commercial software, e.g. CLCBio, GenomOncology– Allow Pitt researchers to use existing scripts and analysis frameworks configured and
supported on Pitt resources (e.g. Frank)• PSC Compute Resources
– Enable specialized analyses requiring DXC analytical engines (e.g Blacklight)• E.g. large shared memory systems for structural variation analysis or de novo assembly
– Enable large-scale analyses across entire TCGA dataset, including BAM files• UPMC Data Warehouse: re-identifies a subset of the TCGA sequence data and merges
with rich clinical phenotype data for integrative analysis

PittIPM Portalvirtuoso.sam.pitt.edu login0a
login0b
PSC
Pitt (IPM, UPCI)
Source (e.g. NCI, CGHub)TCGA
GOtcga.sam.pitt.edu
bl2
BAM
BAM
mobydisk280 TB
/bl2100 TB
10 G
bit (
thro
ttle
d to
2 G
bit)
Net
wor
k
Repl
icati
on
Metadata
BAMNon-BAM
Non-BAM
Non-BAM
MDSsupercell-mds0
~8 TB*~300 TB*
*Growing to ~1 PB of BAM data and 33 TB of non-BAM data
PGRR
UPMC
Pitt direct network link to UPMC
Enterprise Data Warehouse
clinicalseq
Metadata(PostreSQL)
DXC database node dxcdb01.psc.edu
IOS: 37 TBsupercell1
Non-BAM IOS: 100 TB
supercell0
Frankn0 n1 n2 n3
Blacklightfirehose6.psc.edu
IOS: 352 TB
dxcsbb01
app1
CLCBioNon-BAM
Non-BAM
IOS: 391 TB
sense51
IOS: 352 TB
dxcsbb02
Non-BAM
Non-BAM
Non-BAM
M Data Exacell Storage Single view of all TCGA data under /supercell filesystemIOS = I/O serverMDS = metadata server

Demo: Calling Tumor Variants from Replicated TCGA Data on /supercell/tcga Filesystem
1.Pitt researcher identifies relevant BAM files through IPM portal
2.Researcher requests these data be replicated to Pitt /supercell I/O servers
3.Requested files replicate to Pitt I/O servers4.Researcher runs variant calling workflows on
TCGA data using existing analysis scripts and tools at Pitt
clinical-omics

Pitt researcher identifies relevant BAM files through IPM portal
tumor_file = /supercell/tcga/ov/TCGA-13-2060/TCGA-13-2060-01/WXS/CGHub_Illumina/fe2e5645-e958-4e5a-a84c-2024a73d2227/TCGA-13-2060-01A-01W-0799-08_IlluminaGA-DNASeq_capture.bam
normal_file = /supercell/tcga/ov/TCGA-13-2060/TCGA-13-2060-10/WXS/CGHub_Illumina/0c52e122-5890-4aed-a8c3-20b919c4128b/TCGA-13-2060-10A-01W-0799-08_IlluminaGA-DNASeq_capture.bam

Researcher requests these data be replicated to Pitt SLASH2 I/O servers
msctl repl-add:ice@PITT:* $tumor_file
msctl repl-add:ice@PITT:* $normal_file

Requested files replicate to Pitt I/O servers

Researcher runs variant calling workflows on TCGA data using existing analysis scripts and tools at Pitt
java -jar $MUTECT --analysis_type MuTect -L $BED --reference_sequence $REF --input_file:normal $normal_file --input_file:tumor $tumor_file --out cancer.out –vcf cancer.vcf

Scheduled data replication• Working on enabling co-scheduling of compute jobs on Frank with
TCGA data replication to local Pitt I/O servers– Researchers submit a list of files they need to analyze from Frank
compute nodes along with their batch job– Batch job does not start until all necessary files are replicated on local Pitt
I/O servers– Only a single copy of files are visible within /supercell, but multiple copies
exist, and Frank compute nodes will use the local Pitt copy automatically• Considering allowing advance data replication requests within
PGRR portal• Data replication only needed if using Frank compute nodes. Frank
login nodes and CLCBio can see and use all data regardless of physical location

Available nodes @ SaM
• For PGRR investigators interested in using Frank (HPC cluster at SaM), access to the shared queue is the default, however shared is rather busy at the moment (averaging 93% utilization)– 4 nodes (n0 - n3) have been set aside for the use of Health
Sciences faculty (known, informally, as the “genomics” nodes) – 48 core/128GB RAM each
– jobs can be routed to these nodes by adding the -l advres=genomics flag to your qsub command, or by using the #PBS -l advres=genomics directive in the header of your script
– all 4 genomics nodes are connected to /supercell via ethernet– n3 has an infiniband connection directly to /supercell
• Additional capacity coming soon (Health Sciences cluster upgrade online by end of year)

Available tools
• Many common tools are already available on Frank to work with NGS data– BWA, CLCbio Genomics Server, GATK, HOMER,
MapSplice, MutSig, Picard, SNVer, SOAPindel, SOAPsnp, STAR, admixmap, bamtools, bcftools, beagle, bedtools, bfast, bioperl, blast, blast+, bowtie, cdbfasta, circos, cufflinks, cutadapt, delly, fastq_screen, fastqc, hugeseq, igv, merlin, mesa, miRDeep, mira, mutec, ngsqctoolkit, plink, prinseq, R (with some bioconductor libraries), rna-seqc, rnaseqmut, sailfish, samtools, seqclean, shrimp, simwalk, snap, snptest, somaticsniper, sratoolkit, star, svdetect, swiftlink, tophat, trinity, vcftools, velvet
• If a tool you need is not available, submit a helpdesk ticket at http://core.sam.pitt.edu - the SaM staff will review the request and get back to you

Available tools - caveats
• Note that whole pipelines (like HOMER) take considerably longer to install, and may not work in a shared system, or may only partially work
• Tools with graphical interfaces are also probably not going to work on the cluster (as the command line interface is text-based), and will take considerable time and effort to install if they are usable– If you are looking for graphical interfaces, consider either
the CLCbio Genomics Workbench (which is integrated with the Frank cluster), the Pitt Galaxy installation (http://galaxy.sam.pitt.edu), or the GenomOncology interface

Available nodes @ SaM
• For PGRR investigators interested in using Frank (HPC cluster at SaM), access to the shared queue is the default, however shared is rather busy at the moment (averaging 93% utilization)– 4 nodes (n0 - n3) have been set aside for the use of Health
Sciences faculty (known, informally, as the “genomics” nodes)– jobs can be routed to these nodes by adding the following flag
to your qsub command: -l advres=genomics or by using the #PBS -l advres=genomics directive in the header of your script
– all 4 genomics nodes are connected to /supercell via ethernet– n3 has an infiniband connection directly to /supercell

Available tools
• Many common tools are already available on Frank to work with NGS data– BWA, CLCbio Genomics Server, GATK, HOMER, MapSplice,
MutSig, Picard, SNVer, SOAPindel, SOAPsnp, STAR, admixmap, bamtools, bcftools, beagle, bedtools, bfast, bioperl, blast, blast+, bowtie, cdbfasta, circos, cufflinks, cutadapt, delly, fastq_screen, fastqc, hugeseq, igv, merlin, mesa, miRDeep, mira, mutec, ngsqctoolkit, plink, prinseq, R (with some bioconductor libraries), rna-seqc, rnaseqmut, sailfish, samtools, seqclean, shrimp, simwalk, snap, snptest, somaticsniper, sratoolkit, star, svdetect, swiftlink, tophat, trinity, vcftools, velvet
• If a tool you need is not available, submit a helpdesk ticket at http://core.sam.pitt.edu - the SaM staff will review the request and get back to you

About GenomOncology• GO Clinical Workbench
– Clinical interpretation driven by FDA, NCCN, ASCO and MyCancerGenome
– Customized reporting tailored to your Laboratory and Client needs– Scalable, Pathology friendly workflow to ensure compliance
• GenomAnalytics– Discovery / Research platform - analyze thousands of genomes
simultaneously to identify causal variants and create your own knowledge base.

GenomAnalytics for TCGA Analysis
• GenomAnalytics serves as an interactive graphical interface to TCGA variation data stored at SaM– Users without computer science background can analyze
data in an intuitive manner
– Interface allows users to look at hundreds of samples simultaneously within or across cancer subtypes and across multiple data types giving an integrated analysis
– System has been optimized to rapidly query data so data can be filtered in real time allowing users to fully explore an analysis

The GenomAnalytics Platform

System Updates
New Functionality• Somatic status filtering allows
users to restrict analysis to somatic only varaints
• Validation interface to support studies aimed at comparing experimental samples to known datasets
• New reporting interface allows analysis of data using R and generation of Excel or PDF reports
GO Application New Server • GO Application migrated to
new, higher performance server• Export performance increased• All tumor SNV and INDEL data
reloaded, along with ½ matched normal samples
• All RNAseqV2 data load• Additional matched-normal and
other data-types will continue to be loaded into application

TCGA and the Cloud?
• Change in NCI/dbGAP Policy• Development of Cancer Genome
Commons• NCI Cloud Pilots

Change in NIH dbGAP Policy• “Investigators who wish to use cloud computing for storage and analysis will need to indicate in
their Data Access Request (DAR) that they are requesting permission to use cloud computing and identify the cloud service provider or providers that will be employed. They also will need to describe how the cloud computing service will be used to carry out their proposed research. The institution’s signing official, principal investigator, IT Director, and any other personnel approved by NIH to access the data will be responsible for ensuring the protection of the data. The NIH will hold the institution, not the cloud service provider, responsible for any failure in the oversight of using cloud computing services for controlled-access data.”
• Position Statement on Use of Cloud Computing:– http://
gds.nih.gov/pdf/NIH_Position_Statement_on_Cloud_Computing.pdf
• New Security Best Practices:– http
://www.ncbi.nlm.nih.gov/projects/gap/pdf/dbgap_2b_security_procedures.pdf

National Cancer InstituteU.S. DEPARTMENT OF HEALTH AND HUMAN SERVICESNational Institutes of Health
NCI Cancer Genomics Cloud Pilots (and Genomic Data
Commons)
Tanja Davidsen, Ph.D.Center for Biomedical Informatics and Information Technology
(CBIIT)National Cancer Institute
May 12, 2015

• Goal to unify fragmentary repositories at NCI• TCGA, TARGET and CGCI have their own data repositories
(DCCs)• Sequencing data: BAM files at CGhub while VCF/MAF
files at DCC
Center For Cancer Genomics (CCG) Genomics Data Commons (GDC)

• Harmonize diverse standards
• BAMs aligned to various references
• Mutations are called by various tools
Genomics Data Commons (GDC)

• University of Chicago, PI: Dr. Robert Grossman• Go live date: Late Spring 2016 • Not a commercial cloud: Free to download data
Genomics Data Commons (GDC)

Standard Model of Computational Analysis
Local Data
U N I V E R S I T YU N I V E R S I T Y
Locally Developed Software
Publicly AvailableSoftware
Local storage andcompute resources
Network Download
Public Data

Co-located Compute & Data
API
Data AccessSecurityResource
Access
Core Data(TCGA)
User Data
Computational Capacity
Standard toolsUser uploaded tools

The Cloud Pilots in Context
QA/QCValidation
Aggregation
Authoritative NCI Reference Data Set
Data Coordinating Center
NCI Genomic Data Commons
NCI Clouds
High PerformanceComputing
Search/Retrieve
Download
Analysis

Effort to democratize access to NCI genomics data
Managed through CBIIT in partnership with the Center for Cancer Genomics (CCG)
– Coordinating with the Genomic Data Commons (GDC)
Three contracts awarded to– Broad Institute– Institute for Systems Biology– Seven Bridges Genomics
Period of performance: Sept 2014 – Sept 2016– https://cbiit.nci.nih.gov/ncip/nci-cancer-genomics-cloud-pilots – Anticipated launch date: January 2016
Project Structure

• Design• Designs must be released under a non-viral, open source license
• Extensibility• Initial clouds will focus on a set of “core datatypes”• Extend to additional datatypes without major refactoring of the
existing system
• Sustainability• Cost assessments for operating at current scale and at 10/100
fold increases in storage, compute and usage
• Security• FISMA moderate system, FedRAMP certified cloud provider,
Trusted Partnership • Open v/s Controlled access data
Considerations

• Core Data• All three awardees will host a common core data set from
TCGA• DNA-Seq binary alignment (BAM) files• RNA-Seq FASTQ and BAM files• SNP array (.cel) files• Somatic and germline mutation calls for each sample (.vcf, .maf)• Clinical data
• Each awardee will include at least one additional TCGA data set
• Broad: validation BAMs, miRNAseq, and methyl-seq• ISB: miRNAseq, and all L3 data (mRNA/miRNA expression, copy-
number, DNA methylation, protein RPPA)• Seven Bridges: whole genome and exome DNA-Seq FASTQ,
miRNAseq data, and methyl-seq
Research and Technical Objectives

Project Schedule and Deliverables
SelectionSelection Design/Build I
Design/Build I Design/Build IIDesign/Build II EvaluationEvaluation
6 Months
Initial Design and Development
6 Months
Initial Design and Development
9 Months
Completion of Design, Development and Implementation
9 Months
Completion of Design, Development and Implementation
9 Months
Provide cloud to researchersNCI evaluationsCommunity evaluations
9 Months
Provide cloud to researchersNCI evaluationsCommunity evaluations

• Core datasets
• Use Cases• Running preloaded pipeline on TCGA data
• Uploading and processing user data
• Uploading and running custom algorithms
• Serve both biologists and bioinformaticians
• Workflow Language• Common Workflow Language (CWL) is being considered
• Docker containers• For improved portability and reproducibility
• Using emerging GA4GH standards
• Authorization and Authentication process
Common to all three Cloud Pilots

• PI: Gad Getz• Collaborators: University California Berkeley,
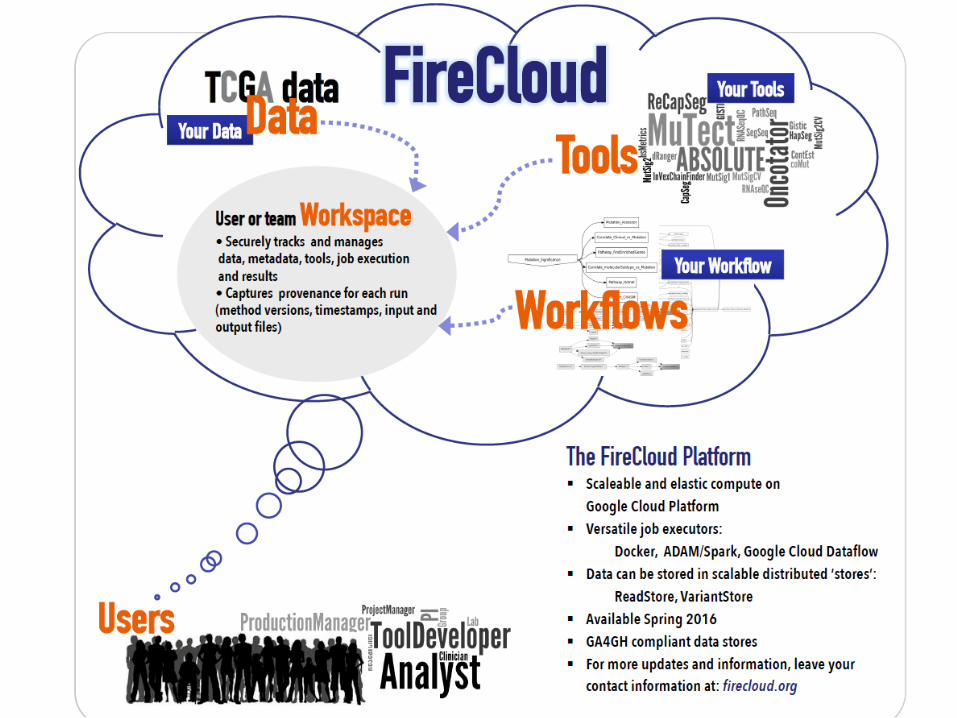
University California Santa Cruz • Cloud Platform: Google• Unique Technologies Used: ADAM/Spark• Tools Incorporated: Firehose • Cloud Pilot Website: http://firecloud.org
Broad Cloud Pilot

• PI: Ilya Shmulevich• Collaborators: Google, SRA International • Cloud Platform: Google• Unique Technologies Used: Google Genomics
Platform• Tools Incorporated: Regulome explorer, Gene Spot
• Focus on interactive data visualization, exploration and analysis
• Cloud Pilot Website: http://cgc.systemsbiology.net/
Institute for Systems Biology (ISB) Cloud Pilot

Interactive tools• explore all tumors or a subset• define custom “cohorts”• focus on specific molecular data
types or platforms
Programmatic access• REST APIs for Cloud Storage • SQL-like queries for BigQuery • GA4GH API for Google Genomics
Tutorials• IPython notebooks • RStudio (Rmd) files

• PI: Deniz Kural• Collaborators: None• Cloud Platform: Amazon Web Services• Unique Technologies Used: SBG platform • Tools Incorporated: > 30 public pipelines
• https://igor.sbgenomics.com/lab/public/pipelines/
• Cloud Pilot Website: http://www.cancergenomicscloud.org
Seven Bridges Genomics Cloud Pilot


What is the future of PGRR?
• At some point in the future, CGC and clouds may provide sufficient (or better) access
• It may take time (even after they are open for business) to have a stable, well-supported environment
• We still don’t know much about things like data provenance
• We recommend that everyone try the cancer clouds and provide feedback if possible
• We will need to determine at what point PGRR will no longer be beneficial

Discussion
• Adding additional UPMC clinical data?• New analytic tools (CLC Bio, cBIO, transMART)• Getting standard pipelines working • Reinvigorating relationship with UPMC
Enterprise Analytics• Other datasets?

Adding additional clinical data
• Clinical data in TCGA is very limited snapshot• Errors have been identified• Should we consider improving on additional
data?• Would TCGA even accept an update?• What if we want to have more than an update
(e.g. new data elements)?

CLCbio Genomics Server v8
• New CLCbio server supports new, better integrated RNAseq, InDels and Structural Variant detection, and Low Frequency Variant discovery tools, new phylogenetics tools, and mapping of variants onto 3D protein structures

cBio
• We are considering (almost a certainty) installing a local version of the cBio portal for working with our local TCGA data (and UPMC clinical data)

PSC’s Blacklight (SGI Altix® UV 1000)Massive Coherent Shared Memory Computer
• 2×16 TB of cache-coherent shared memory, 4096 cores
• High bandwidth, low latency interprocessor communication
• ideal for memory or data-intensive analysis
– E.g. de novo assembly, structural variant analysis
• Other large shared memory nodes and fast I/O systems coming as part of DXC and XSEDE projects

Getting Access to PSC resources
• Send email to me ([email protected])• Depending on research requirements, compute allocations
can be obtained through DXC or XSEDE projects• PSC helps install required software packages (many
bioinformatics packages already available)• Obtain the locations of TCGA files in /supercell from PGRR
portal• PSC helps you create a script for your analysis pipeline• Submit batch scripts, directly accessing /supercell/tcga
from PSC compute nodes















![arXiv:2004.07399v1 [eess.IV] 16 Apr 2020 › pdf › 2004.07399v1.pdf · 40 magnification from The Cancer Genome Atlas (TCGA) dataset, the largest public repository of histopathology](https://img.pdfslide.us/doc/110x75/5f03e1c37e708231d40b3b1d/arxiv200407399v1-eessiv-16-apr-2020-a-pdf-a-2004-40-magniication.jpg)













