Embed Size (px)
Citation preview

Physis: An Implicitly Parallel Framework for Stencil Computa;ons
Naoya Maruyama RIKEN AICS (Formerly at Tokyo Tech)
GTC12, May 2012
1
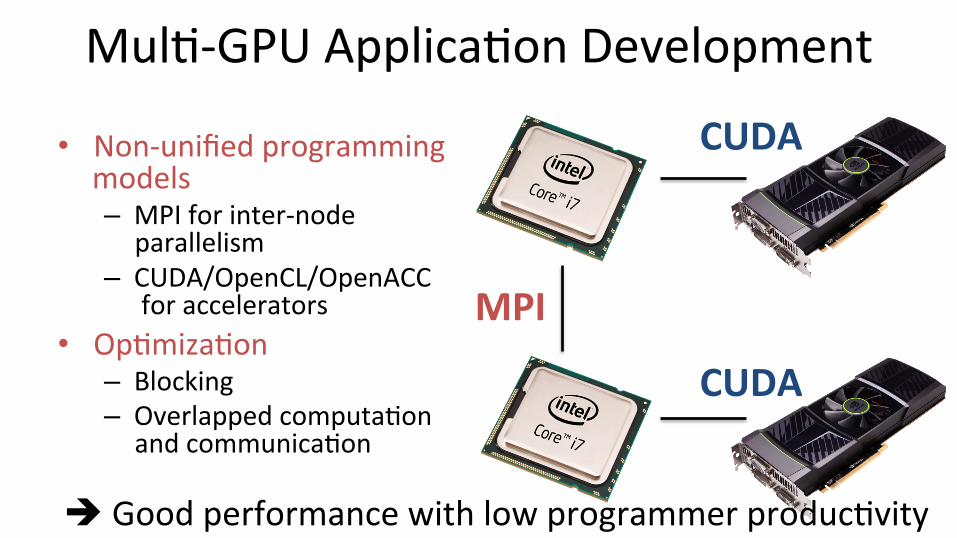
Mul;-‐GPU Applica;on Development
• Non-‐unified programming models – MPI for inter-‐node
parallelism – CUDA/OpenCL/OpenACC
for accelerators • Op;miza;on
– Blocking – Overlapped computa;on
and communica;on
CUDA
CUDA
MPI
è Good performance with low programmer produc;vity

Goal High performance, highly produc;ve programming for heterogeneous clusters
Approach
High level abstrac9ons for structured parallel programming – Simplifying programming models – Portability across plaWorms – Does not sacrifice too much performance
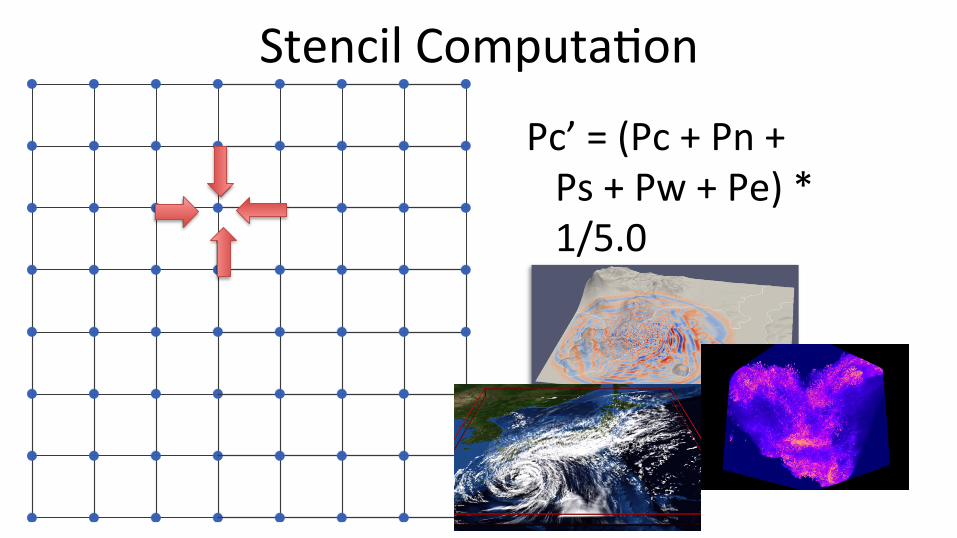
Stencil Computa;on
Pc’ = (Pc + Pn +
Ps + Pw + Pe) * 1/5.0
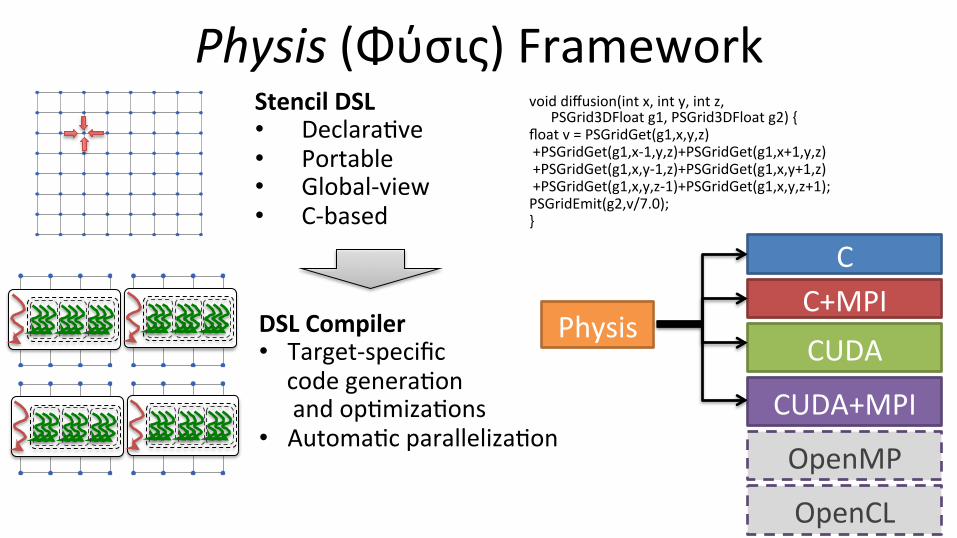
Physis (Φύσις) Framework
Stencil DSL • Declara;ve • Portable • Global-‐view • C-‐based
void diffusion(int x, int y, int z, PSGrid3DFloat g1, PSGrid3DFloat g2) { float v = PSGridGet(g1,x,y,z) +PSGridGet(g1,x-‐1,y,z)+PSGridGet(g1,x+1,y,z) +PSGridGet(g1,x,y-‐1,z)+PSGridGet(g1,x,y+1,z) +PSGridGet(g1,x,y,z-‐1)+PSGridGet(g1,x,y,z+1); PSGridEmit(g2,v/7.0); }
DSL Compiler • Target-‐specific
code genera;on and op;miza;ons
• Automa;c paralleliza;on
Physis
C C+MPI CUDA
CUDA+MPI
OpenMP
OpenCL

DSL Overview • C + custom data types and intrinsics • Grid data types
– PSGrid3DFloat, PSGrid3DDouble, etc. • Dense Cartesian domain types
– PSDomain1D, PSDomain2D, and PSDomain3D • Intrinsics
– Run;me management – Grid object management (PSGridFloat3DNew, etc) – Grid accesses (PSGridCopyin, PSGridGet, etc) – Applying stencils to grids (PSGridMap, PSGridRun) – Grid reduc;ons (PSGridReduce)

Wri;ng Stencils • Stencil Kernel – C func;ons describing a single flow of scalar execu;on on one grid element
– Executed over specified rectangular domains void diffusion(const int x, const int y, const int z, PSGrid3DFloat g1, PSGrid3DFloat g2, float t) { float v = PSGridGet(g1,x,y,z) +PSGridGet(g1,x-‐1,y,z)+PSGridGet(g1,x+1,y,z) +PSGridGet(g1,x,y-‐1,z)+PSGridGet(g1,x,y+1,z) +PSGridGet(g1,x,y,z-‐1)+PSGridGet(g1,x,y,z+1); PSGridEmit(g2,v/7.0*t); } Issues a write to grid g2 Offset must be constant

Applying Stencils to Grids • Map: Creates a stencil closure that encapsulates stencil and grids
• Run: Itera;vely executes stencil closures PSGrid3DFloat g1 = PSGrid3DFloatNew(NX, NY, NZ); PSGrid3DFloat g2 = PSGrid3DFloatNew(NX, NY, NZ); PSDomain3D d = PSDomain3DNew(0, NX, 0, NY, 0, NZ); PSStencilRun(PSStencilMap(diffusion,d,g1,g2,0.5), PSStencilMap(diffusion,d,g2,g1,0.5), 10);
Grouping by PSStencilRun à Target for kernel fusion op;miza;on
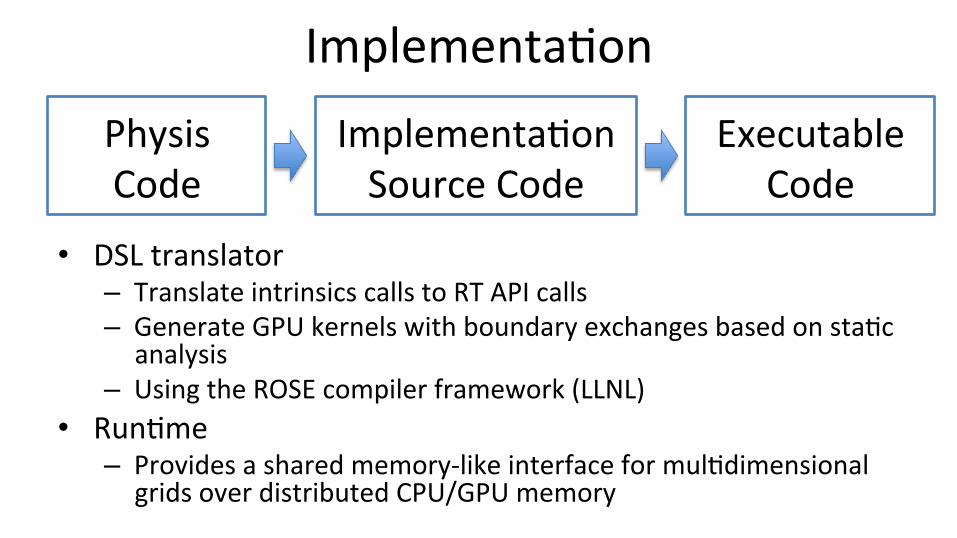
Implementa;on
• DSL translator – Translate intrinsics calls to RT API calls – Generate GPU kernels with boundary exchanges based on sta;c
analysis – Using the ROSE compiler framework (LLNL)
• Run;me – Provides a shared memory-‐like interface for mul;dimensional
grids over distributed CPU/GPU memory
Physis Code
Implementa;on Source Code
Executable Code
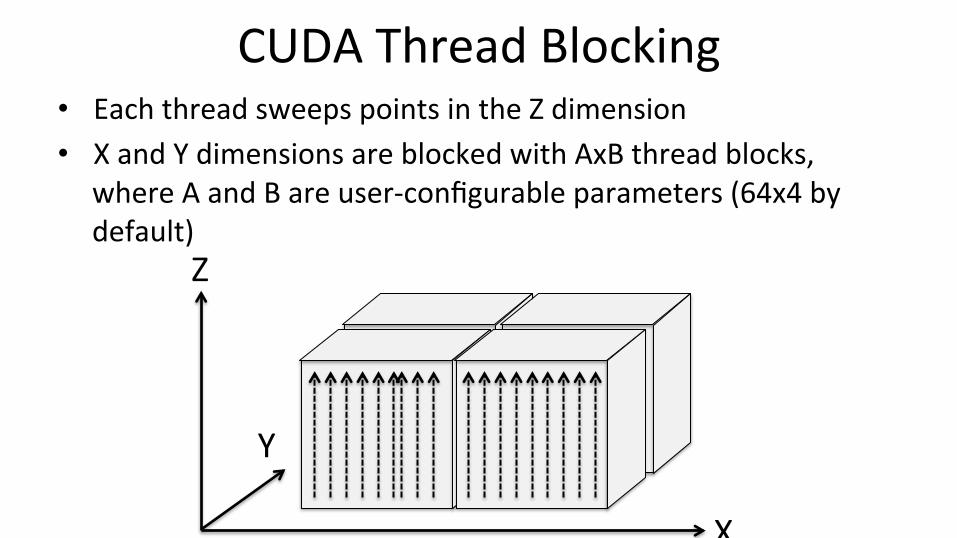
CUDA Thread Blocking • Each thread sweeps points in the Z dimension • X and Y dimensions are blocked with AxB thread blocks,
where A and B are user-‐configurable parameters (64x4 by default)
X
Z
Y

Example: 7-‐point Stencil GPU Code __device__ void kernel(const int x,const int y,const int z,__PSGrid3DFloatDev *g, __PSGrid3DFloatDev *g2) { float v = (((((( *__PSGridGetAddrNoHaloFloat3D(g,x,y,z) + *__PSGridGetAddrFloat3D_0_fw(g,(x + 1),y,z)) + *__PSGridGetAddrFloat3D_0_bw(g,(x -‐ 1),y,z)) + *__PSGridGetAddrFloat3D_1_fw(g,x,(y + 1),z)) + *__PSGridGetAddrFloat3D_1_bw(g,x,(y -‐ 1),z)) + *__PSGridGetAddrFloat3D_2_bw(g,x,y,(z -‐ 1))) + *__PSGridGetAddrFloat3D_2_fw(g,x,y,(z + 1))); *__PSGridEmitAddrFloat3D(g2,x,y,z) = v; } __global__ void __PSStencilRun_kernel(int offset0,int offset1,__PSDomain dom, __PSGrid3DFloatDev g,__PSGrid3DFloatDev g2) { int x = blockIdx.x * blockDim.x + threadIdx.x + offset0, y = blockIdx.y * blockDim.y + threadIdx.y + offset1; if (x < dom.local_min[0] || x >= dom.local_max[0] || (y < dom.local_min[1] || y >= dom.local_max[1])) return ; int z; for (z = dom.local_min[2]; z < dom.local_max[2]; ++z) { kernel(x,y,z,&g,&g2); } }

Example: 7-‐point Stencil CPU Code sta;c void __PSStencilRun_0(int iter,void **stencils) { struct dim3 block_dim(64,4,1); struct __PSStencil_kernel *s0 = (struct __PSStencil_kernel *)stencils[0]; cudaFuncSetCacheConfig(__PSStencilRun_kernel,cudaFuncCachePreferL1); struct dim3 s0_grid_dim((int )(ceil(__PSGetLocalSize(0) / ((double )64))),(int )(ceil(__PSGetLocalSize(1) / ((double )4))),1); __PSDomainSetLocalSize(&s0 -‐> dom); s0 -‐> g = __PSGetGridByID(s0 -‐> __g_index); s0 -‐> g2 = __PSGetGridByID(s0 -‐> __g2_index); int i; for (i = 0; i < iter; ++i) {{ int fw_width[3] = {1L, 1L, 1L}; int bw_width[3] = {1L, 1L, 1L}; __PSLoadNeighbor(s0 -‐> g,fw_width,bw_width,0,i > 0,1); } __PSStencilRun_kernel<<<s0_grid_dim,block_dim>>>(__PSGetLocalOffset(0), __PSGetLocalOffset(1),s0 -‐> dom, *((__PSGrid3DFloatDev *)(__PSGridGetDev(s0 -‐> g))), *((__PSGrid3DFloatDev *)(__PSGridGetDev(s0 -‐> g2)))); } cudaThreadSynchronize(); }
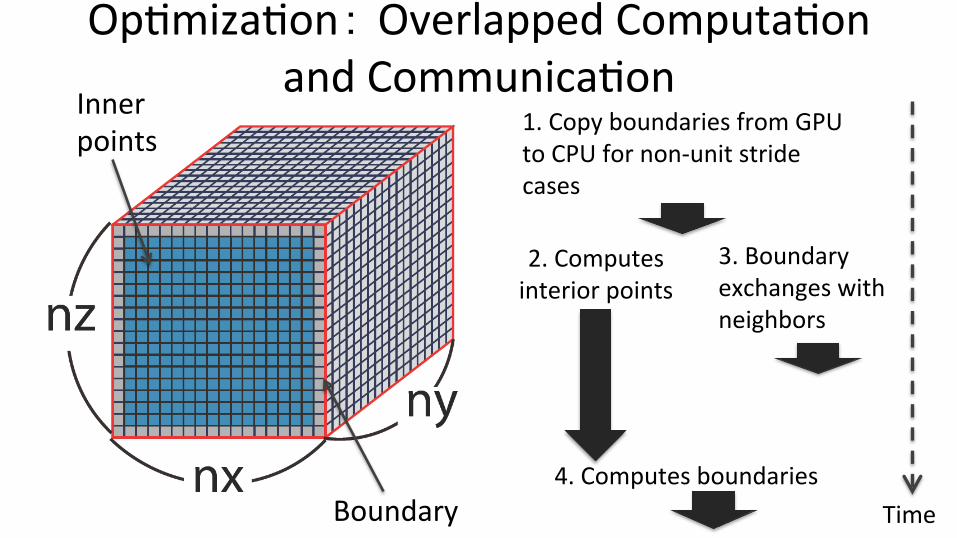
Op;miza;on: Overlapped Computa;on and Communica;on
Boundary
Inner points
1. Copy boundaries from GPU to CPU for non-‐unit stride cases
2. Computes interior points
3. Boundary exchanges with neighbors
4. Computes boundaries Time

Op;miza;on Example: 7-‐Point Stencil CPU Code for (i = 0; i < iter; ++i) { __PSStencilRun_kernel_interior<<<s0_grid_dim,block_dim,0, stream_interior>>> (__PSGetLocalOffset(0),__PSGetLocalOffset(1),__PSDomainShrink(&s0 -‐> dom,1), *((__PSGrid3DFloatDev *)(__PSGridGetDev(s0 -‐> g))), *((__PSGrid3DFloatDev *)(__PSGridGetDev(s0 -‐> g2)))); int fw_width[3] = {1L, 1L, 1L}; int bw_width[3] = {1L, 1L, 1L}; __PSLoadNeighbor(s0 -‐> g,fw_width,bw_width,0,i > 0,1); __PSStencilRun_kernel_boundary_1_bw<<<1,(dim3(1,128,4)),0, stream_boundary_kernel[0]>>>(__PSDomainGetBoundary(&s0 -‐> dom,0,0,1,5,0), *((__PSGrid3DFloatDev *)(__PSGridGetDev(s0 -‐> g))), *((__PSGrid3DFloatDev *)(__PSGridGetDev(s0 -‐> g2)))); __PSStencilRun_kernel_boundary_1_bw<<<1,(dim3(1,128,4)),0, stream_boundary_kernel[1]>>>(__PSDomainGetBoundary(&s0 -‐> dom,0,0,1,5,1), *((__PSGrid3DFloatDev *)(__PSGridGetDev(s0 -‐> g))), *((__PSGrid3DFloatDev *)(__PSGridGetDev(s0 -‐> g2)))); … __PSStencilRun_kernel_boundary_2_fw<<<1,(dim3(128,1,4)),0, stream_boundary_kernel[11]>>>(__PSDomainGetBoundary(&s0 -‐> dom,1,1,1,1,0), *((__PSGrid3DFloatDev *)(__PSGridGetDev(s0 -‐> g))), *((__PSGrid3DFloatDev *)(__PSGridGetDev(s0 -‐> g2)))); cudaThreadSynchronize(); } cudaThreadSynchronize(); }
Compu;ng Interior Points
Boundary Exchange
Compu;ng Boundary Planes Concurrently

Evalua;on • Performance and produc;vity • Sample code – 7-‐point diffusion kernel (#stencil: 1) – Jacobi kernel from Himeno benchmark (#stencil: 1) – Seismic simula;on (#stencil: 15)
• PlaWorm – Tsubame 2.0
• Node: Westmere-‐EP 2.9GHz x 2 + M2050 x 3
• Dual Infiniband QDR with full bisec;on BW fat tree
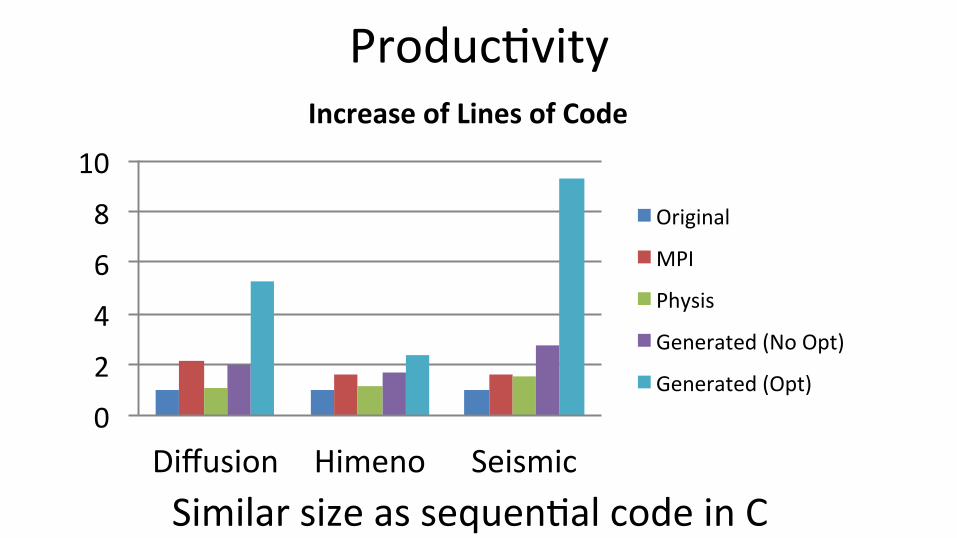
Produc;vity
0"
2"
4"
6"
8"
10"
Diffusion" Himeno" Seismic"
Increase(of(Lines(of(Code(
Original"
MPI"
Physis"
Generated"(No"Opt)"
Generated"(Opt)"
Similar size as sequen;al code in C
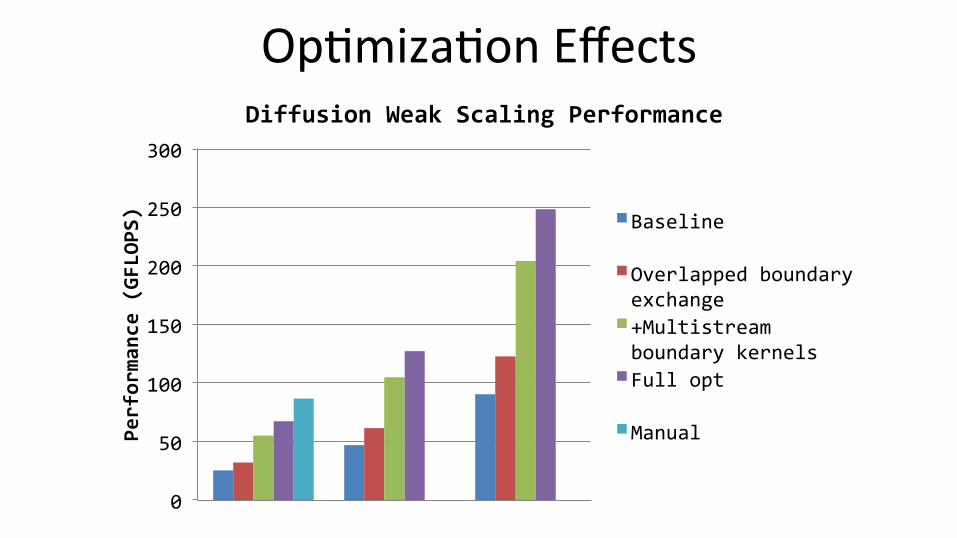
Op;miza;on Effects
0
50
100
150
200
250
300 Performance (GFLOPS)
Diffusion Weak Scaling Performance
Baseline
Overlapped boundary exchange +Multistream boundary kernels Full opt
Manual
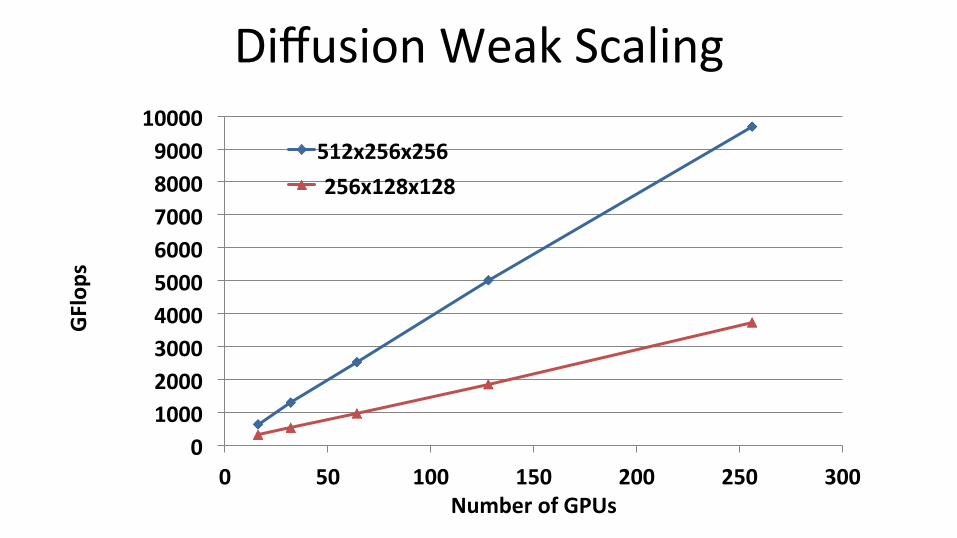
Diffusion Weak Scaling
0 1000 2000 3000 4000 5000 6000 7000 8000 9000
10000
0 50 100 150 200 250 300
GFlop
s
Number of GPUs
512x256x256 256x128x128
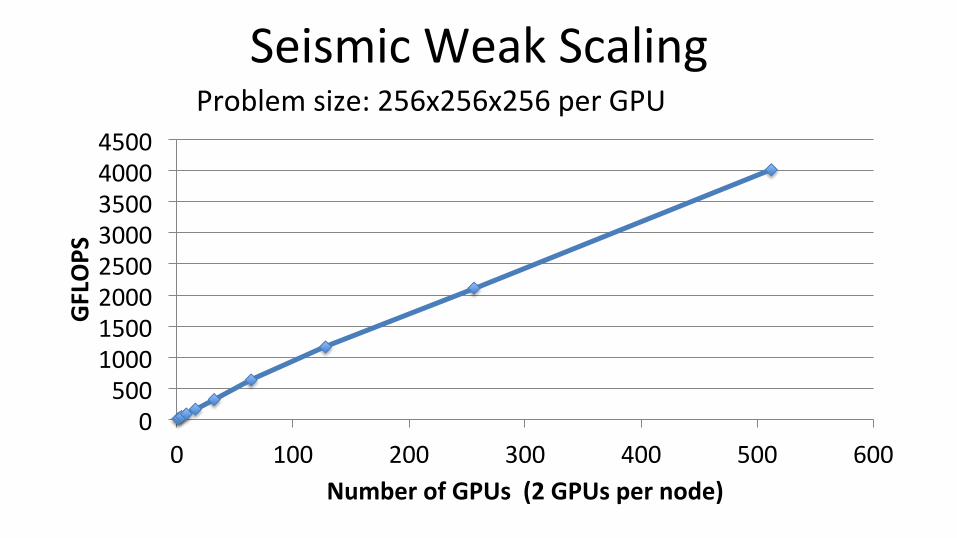
Seismic Weak Scaling
0 500 1000 1500 2000 2500 3000 3500 4000 4500
0 100 200 300 400 500 600
GFLOPS
Number of GPUs (2 GPUs per node)
Problem size: 256x256x256 per GPU
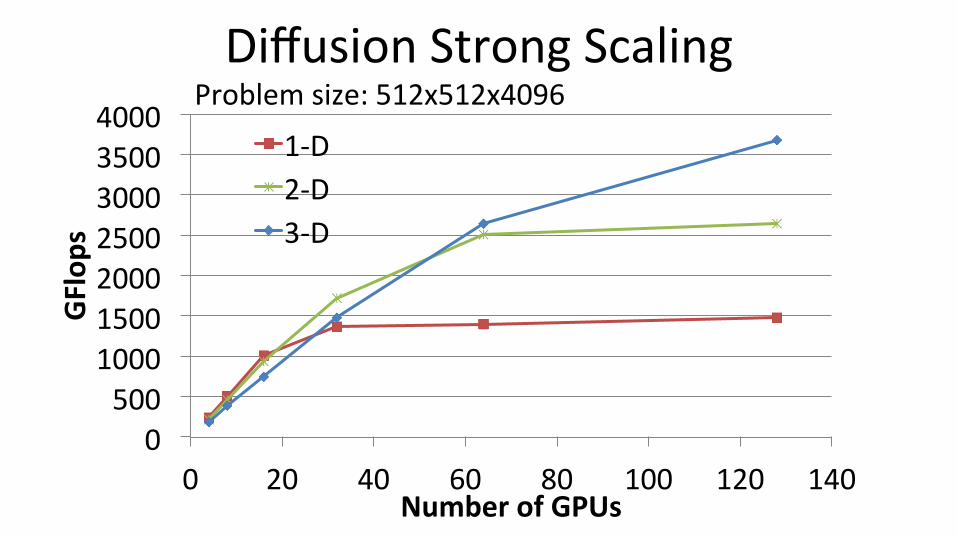
Diffusion Strong Scaling
0 500
1000 1500 2000 2500 3000 3500 4000
0 20 40 60 80 100 120 140
GFlop
s
Number of GPUs
1-‐D 2-‐D 3-‐D
Problem size: 512x512x4096
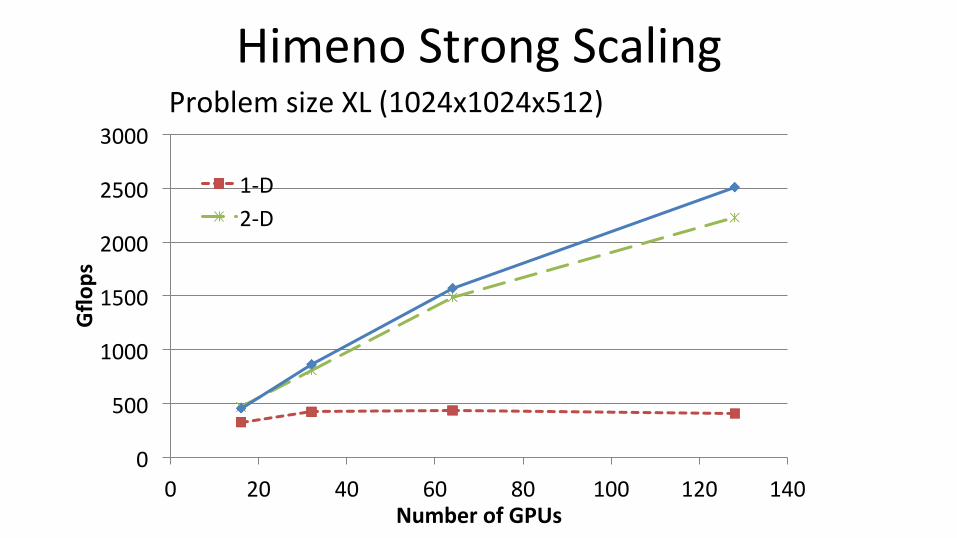
Himeno Strong Scaling
0
500
1000
1500
2000
2500
3000
0 20 40 60 80 100 120 140
Gflo
ps
Number of GPUs
1-‐D 2-‐D
Problem size XL (1024x1024x512)

Conclusion • High-‐level abstrac;ons for stencil compua;ons
– Portable – Declara;ve – Automa;c paralleliza;on
• Future work – Fault tolerance by automated checkpoin;ng – More performance tuning
• 3.5D blocking [Nguyen, 2010] – Support of other architectures
• OpenMP/OpenCL ongoing • Por;ng to the K Computer
• Acknowledgments – JST CREST, FP3C, NVIDIA – The ROSE project by Dan Quinlan et al. of LLNL

Further Informa;on • Code is available at http://github.com/naoyam/physis
• Maruyama et al., “Physis: Implicitly Parallel Programming Model for Stencil Computa;ons on Large-‐Scale GPU-‐Accelerated Supercomputers,” SC’11, 2011.