Embed Size (px)
Citation preview

03~379~~ 53.00 + 0.00 Copyright .c 1990 Pergamon Press plc
TUTORIAL
PHYSICAL DATABASE DESIGN ASPECTS OF RELATIONAL DBMS IMPLEMENTATIONS
FRANZ HABERHALJER
Institute of ParalleI and ~ist~but~ sigh-Perfo~ance Computers (IPVR), university of Stuttgart, Azenbergstr. 12, D-7080 Stuttgart 1, F.R.G.
(Received 15 July 1988; in revkedform 2 November 1989; received for pubiicafion 3 Janunry 1990)
Abstract-There are no standards for storage structures in relational DBMSs (RDBMSs). RDBMS- implementors can choose from the whole variety of structures and decide which options and parameters the physical database designer should have. RDBMSs provide non-procedural, set-oriented query languages. The generation of access plans is automatically done by the RDBMS; programers cannot explicitly control the use of access paths. Yet an appropriate access path configuration has to be supplied by the physical database designer in order to run the application programs efficiently.
In this paper general deficiencies and advantages of RDBMSs are exhibited, implementation details affecting physical database design decisions are highlighted, four sample commercial systems are reviewed in some detail, and general conclusions for physical design in RDBMSs are drawn.
&=.v words: Relational database systems. database system architecture, database system performance, physical database design
1. INTRODUCTION
Compared to “classical” DBMSs, many relational DBMSs (RDBMSs) support only a small number of physical storage structures. This is one reason for the complaints about bad performance of RDBMSs. More recent systems, especially commercial systems designed for high-~rfo~ance production appli- cations, offer more options allowing a far more flexible tuning. Standardization efforts [l, 21 for a relational query language (SQL) do not include any concepts for the specification of physical storage structures. Most vendors expanded the standard CREATE TABLE-statement by optional clauses re- lated to storage structure definitions and added a secondary access path structure called INDEX, which-dependent on its implementation-supports one or more access types, e.g. direct access using an attribute value or a value range. Frequently a system enforced uniqueness constraint on an attribute can only be ~~blish~ by the definition of a unique index on this attribute.
Although there are solutions for isolated problems, there is no comprehensive methodology for the entire physical design step. Data compression [3], vertical [4,5] and horizontal [6] data partitioning, reorganiz- ation issues [7,8], and especially access path selection [9-161 are well investigated areas. Surveys on physical design can be found in [17-201.
But most of the approaches suggested so far are only of limited applicability. Certain statistical
properties, e.g. uniform distribution and indepen- dence of attribute values, are commonly assumed for the database and the workload [21]. Frequently the number of secondary storage accesses is the sole or at least dominating cost measure, though today’s transaction processing systems often have large database buffers and are CPU-bound rather than I/O-bound. Multit~~ng en~ronmen~, buffer management, concurrency control, communication and OS-overhead are frequently neglected, though they have a major performance impact. Thus a detailed knowledge of the target DBMS’s implementation and dynamic behaviour is a pre- requisite for an effective physical design. One also needs specific information about the hardware en- vironment and the operating system services used by the DBMS.
in the subsequent sections we will first highlight some implemen~tion details of RDBMSs that inffu- ence physical design decisions, then show for several commercial systems which design options and parameters are available, and finally summarize how well the principal physical design techniques are supported by present systems. We will focus on commercial, centralized, disk based RDBMSs supporting SQL, which have been developed as relational systems and not only received an additional relational query component. Other architectures like distributed DBMSs, main memory DBMSs or data- base machines require some different or extended considerations.
37.5

376 Tutorial
2. IMPLE~NTATION CONCEPTS FOR RDBMS COMPONENTS
2.1. Storage structures, access method and re- organization
Usually logical schema objects are mate~alized on storage devices using a mapping through several layers of physical schema objects visible to the physi- cal database designer. This mapping differs somewhat for the different RDBMSs. Figure 1 shows a frame- work model for the mapping structure using an extended entity-relationship model. In the next section this framework is applied to four sample systems. Models for internal storage structures are described in [22-251.
A logical table consisting of one or more attributes is mapped to a physical table by the definition of storage formats for the attributes, a mapping rule for tuples to physical records, and the de~nition of primary and secondary access paths. All current systems map each logical table to a single physical table, although replication, fragmentation, etc. are well-approved techniques and can help to alleviate certain types of performance problems. Each logical attribute has a co~esponding physical attribute. The physical representation of an attribute may be differ- ent from its logical format. Criteria for the physical representation of data may be the costs for the conversion from the physical to the logical format and vice versa, the sorting overhead (cost for compar- ing two sort key values), the representable value ranges for numerical data, the accuracy of real
Fig. I. Mapping logical schema objects to devices.
@S I ww
number representations (exact decimal encoded or approximate binary encoded numerics) or the space requirements (application of compression tech- niques). Partially the systems supply conversion routines, but some provide only exits to user-defined routines which can encode and decode the whole tuple or the contents of certain fields. Some systems add physical attributes, e.g. timestamps or logical sequence numbers which are used as unique keys. Usually these attributes have a logical representation and may be queried, but cannot be updated.
Most RDBMSs store all attributes of one tuple contiguously, i.e. there is no option for vertical fragmentation. However, SQL allows dynamic schema modifications like the definition of new columns. This can result in implicit vertical partition- ing for existing tuples. Although the ordering of the attribute specifications in a table definition is ir- relevant for the logical schema, one should be aware that most systems store the attributes in just that sequence, since tables are defined by a statement combining logical and physical schema aspects. Different orders may result in slightly different performance [26].
For space requirement calcuIations during physical design, average and maximal tuple lengths must be evaluated. Therefore the attribute and tuple storage formats must be known. The total tuple length consists of the physical attribute lengths plus some organizational data. Null values need not be exphc- itly stored. The info~ation on null values can be stored in organizational data. Physical records must usually fit into a singIe page, records spanning page boundaries are rarely supported. This limits the maximal tuple length and can result in much Frag- mentation for large tuples. For tuples longer than approximately half the page length a whole page is allocated. Very long data can be stored either using a large page size or using a special data type (long field) for which there may be some usage restrictions, e.g. it cannot be used in selection predicates.
Associated with each physical table is one primary access path which determines where a tuple is stored. Vertical and horizontal partitions could be defined. While vertical partitioning is rarely supported by RDBMSs, horizontal partitioning is indispensable for systems supporting large databases with high- performance and availability requirements. If the disk access rate induced by accesses to a large table exceeds the maximum service rate of a single disk the table must be horizontally partitioned and each partition must be stored on another disk. Tuples may be stored using a first-fit algorithm, in entry- sequenced order-in this case the loading sequence is an important parameter-or an address transform- ation technique thashing) may be used. On the other hand, tuples may be clustered according to an attribute value materializing a sort sequence (sorted cluster), or according to a common parent in a 1 :n relationship materializing a logical access path (value

Tutorial 317
cluster). Several tables may have one primary access path in common. This may be used to achieve an inter-table clustering. The connection between a cluster structure and the data can be more or less strong. In some systems (usually those using cluster structures supplied by the file system) cluster struc- tures can be defined only when the table is created. In other systems such structures may be defined and dropped dynamically, but without a reorganization only those tuples inserted during the lifetime of the cluster structures are indeed clustered. Some systems, however. perform an implicit ~organization of the table clustering ail data. Clustered indexes may be dense or non-dense. In a dense index each key value is found in the index leaf level pages, whereas in non-dense indexes only the lowest or the highest key within each data page is found in the index. A non-dense index can require one index level less whereas a dense index allows a faster scanning of the key values.
The B-tree-family 1271 has become a standard access method allowing clustering, but there are subtle implementation details that can have a dra- matic performance impact. Different B-tree node split algorithms yield, for example, a very different space utilization for the same insert-delete patterns. For tuples inserted in sort sequence, it may be as low as 50% if the standard algorithm is used, but there are other split algorithms. If a local ~ist~bution scheme is applied, which defers node splits until two sibling nodes are full and then splits these two nodes into three, space utilization is 66% in the worst case. Another approach is to simply suppress redistri- bution of tuples if a boundary page split is triggered by an insert at one end of the key’s value range (at-end-slack)~ With this algorithm space utilization after sequential inserts may be up to 100%. In the first case twice as many pages must be read for a sequential scan through the table than with 100% utilization. On the other hand, in the last case there are many page splits required to process subsequent random inserts or updates expanding tuples. In some systems it is possible to specify a certain amount of space that is left free during an initial sequential load or a reorganization.
B-trees result in in&a-page dusters, the quality of inter-page clustering depends on the algorithm for the allocation of leaf (data)-pages. Inter-page clustering is necessary for the use of efficient I/O-operations for sequential scans {reading several pages with one physical I/O or asynchronously reading pages ahead). Load utilities usually build a B-tree bottom-up (the root of a tree is at the top, according to the usual graphical repr~ntation). The data pages are allo- cated and loaded first, and then the index is built from the leaf pages up to the root page. Afterwards a B-tree grows top-down using the split and merge algorithms. Therefore there is a good inter-page clustering after the data have been loaded: the data- pages are physically stored in their logical sequence.
When a page is split the new page is allocated e.g. behind the last currently allocated page: the logical and physical sequence of data pages diverge. Thus the inter-page clustering suffers if many inserts are dispersed over the whole key value range resulting in many page splits because there is not enough free space within the pages. This can be improved if every nth page is left free during loading so that it can be used for page splits in its neighbourhood. B-trees provide dynamic reorganization, but the problems described sometimes still make a reorganization by unload/reload necessary.
Additional secondary access paths to single tables may be defined-auxiliary storage structures usually supporting faster retrieval at the expense of ad- ditional storage and update costs. Indexes may be used to support direct and/or (sorted) sequential access based on an attribute value. Secondary access paths are sometimes (most systems in which there is a one-to-one relationship between tables and files do that) implements as special, system-maintained tables with the secondary key attributes and an additional attribute designating a tupie identifier. This identifier can be either the tupie’s primary key or an identifier for the page on which the tuple or a reference to the tuple is stored, usually the page- number within the address space, concatenated with a tupie sequence number relative to the page. The addressing scheme influences the tradeoff between retrieval savings and additional index maintenance expenses, and thus the practicability of an index for a certain workload. Primary key values require no updates if a page is split, but for retrieval the primary access path must be used, this requires additional page accesses. If a page addressing scheme is used, retrieval is faster since the primary access path is bypassed, but, on the other hand, page splits can require updates in ail existing indexes if no pre- cautions are taken. Defining a home page for a tupie and storing a reference to the actual page if the tupie leaves this page is one approach. If too many tupies have left their home pages a reorganization should be performed. The index tables themselves also can have different primary access paths.
Index implementations may be classified by the retrieval types they support. Hash-based indexes (scatter fables) support very efficient retrieval using exact match predicates, whereas tree-based indexes support a somewhat less efficient retrieval for these predicates but also support (sorted) retrieval using range predicates.
Another kind of access paths are materialized logical access pa&s. In the relational model, relation- ships between tables are represented by values and exploited by the join-operator. In the logical schema there are no structural links such as pointers. Never- theless it is possible to support the join-operator by materiaiiting the join result using a special primary access path for several tables in common which clusters the tuples of these tables according to the

378 Tutorial
join attribute. However, there is a requirement for RDBMSs to support structural integrity constraints such as referential integrity [28,2]. If such constraints are defined, relationships between tables can be sup- ported by the introduction of pointers on the physical schema level. The early System R included such a feature called link (291.
In some applications database buffer sizes have reached a size at which the active parts of the database are kept in main memory. An appropriate choice of access paths does not only save disk-I/OS, but also reduces CPU-requirements since less instruc- tions are required for main storage searches. But most of the implemented storage structures are still oriented towards secondary storage. It should be considered to supply main storage structures which are created when an object is loaded into the buffer, maintained while it is kept in the buffer, and dropped when it is replaced.
Tables, primary and secondary access path struc- tures are allocated within linear, page-structured address spaces, which consist of one or more OS-files each. Address spaces can have substructures to separ- ate several tables or to separate tables and indexes. If (primary) index pages are imbedded between the data pages an address space scan requires more I/OS than a scan over an address space (substructure) contain- ing only data pages. In general it is appropriate to store tables and their indexes on different disk volumes to reduce seek distances. This may be achieved by allocating tables and indexes in different address spaces or address space substructures con- sisting of files residing on different disk volumes.
In some systems there is a one-to-one relationship between tables, address spaces and files, i.e. for each table there exists one file. When a table is created the DBMS automatically creates the corresponding file which is often dynamic by extent. At first some amount of continuous storage called primary extent is allocated, then each time free space is exhausted another amount of continuous storage called sec- ondary extent is allocated. Extent sizes are derived from specifications or defaults in the CREATE TABLE-statement. The device on which the file is allocated can usually be explicitly specified. These systems often use file system primary access paths. The file is deleted when the table is dropped.
If an address space consists of more than one file, each file usually has a hxed size. The files are created and initialized with a DBMS-utility and are then explicitly added to an address space or one of its substructures. Within an address space the DBMSs frequently allocate space to tables and auxiliary structures also based on extents.
Sufficient space must be allocated for the data, primary and secondary access path structures. Also some free space to accommodate growth has to be provided within these structures and/or within the address spaces. Free space allocation influences when a reorganization due to degraded clustering or exces-
sive fragmentation is appropriate. Space that was previously occupied by deleted tuples or tables some- times cannot be reused immediately, a whole page must become empty or an address space reorganiz- ation must be performed before this space can be reclaimed.
2.2. Optimizers, access plans and statistics
RDBMSs provide non-procedural, set-oriented interfaces. An optimizer is used to generate an appro- priate access plan for each query. For physical design it is necessary to predict which access plan an opti- mizer will generate in a specific configuration, since it makes no sense to define an index which the optimizer refuses to use. There may be additional expensive processing steps required in some index configur- ations such as the creation of auxiliary tables or sorting steps that can be avoided in others. For many relational operators there are several algorithms with different pros and cons and many implemen- tation options. Some RDBMSs implement only one algorithm, others implement several and let the optimizer choose the most appropriate one for each
query. In this context there are two important features
that have obviously a strong impact on access path selection. The first is the number of access paths that can be used to check several predicates on a single table. There are two basic methods: using a single access path or using multiple access paths. For a conjunction of predicates a single index may be used for tuple retrieval applying one predicate (this may be a conjunction of predicates if there is an index on several concatenated attributes) while the other predicates are checked for the retrieved tuples; for a disjunction of predicates this is not possible, here the first alternative is a scan over the whole table. The other approach is to use more than one index. For each index a list of tuple identifiers satisfying a predicate which can be evaluated using the index is formed. These lists are intersected/merged into a final sorted list, which is used to retrieve the corresponding tuples.
The second feature is the availability of several join methods [30]. Their performance is very sensitive to the table sizes, the join cardinality, the availability of indexes on the join columns and the available buffer size (311. The sort merge join method shows a more balanced behaviour than the nested loop method which is superior in many cases, provided that it is supported by the necessary indexes. The recently proposed hash-based join methods [32,33] are especially well-suited for large database buffers, but are not yet implemented in commercially available systems. The availability or unavailability of an index for a join-operation may result in performance differ- ences of more than an order. If an index is not appropriate with respect to the total workload it may pay to create it temporarily for the processing of a single query [34].

Tutorial 379
The quality of the access plan depends on the optimizer. Some optimizers evaluate access plans only using the query structure and the extension of the database, whereas more sophisticated optimizers do also consider the intension of the database de- scribed in more or Iess detail by some statistical data. Statistical data, especiafly on attribute vaiue distri- butions, e.g. the number of different values, are often available only if an index is defined on this attribute. Statistical data are usually updated on demand. Statistics updates are not for free. They require scan- and for some statistics sort-steps which are very expensive for large databases. There are also ap- proaches using sampling techniques [35,36]. But neglecting statistics updates especially after a signifi- cant amount of inserts can result in very bad query performance. Statistics can also help to deter- mine when parts of the database should be reorgan- ized, though reorganizations are often scheduled periodically.
An optimizer must make several assumptions and rough estimates. Common assumptions which are frequently used for the query clause selectivity esti- mates 1211, are the uniform distribution assumption for attribute values and the assumption that different attributes are not correIated. [34] shows how in- accuracies in cost functions used by an optimizer influence its access path selection decisions and thus query performance. There are also situations in which the optimizer fails to generate an optimal access plan because of flaws in the optimizing strategies. There is, for example, a performance bug found in some systems, which has been introduced with the solution of the Halloween problem: an index on an attribute updated by a query is never used as an access path for this query, though the query is no instance of the Halloween problem and thus the index could and should be used [I&37].
There are two approaches for query optimization. On one hand, queries are compiled and the resulting machine language access modules are executed. For embedded query languages these access modules can be generated by a precompiler and stored by the RDBMS. Optimi~tion is based on the database state at compilation time. Changes, for example the drop- ping of an index, may invalidate an access module, which is recompiled when it is accessed. A statistics update usually also invalidates precompiled access modules. Some systems do not automatically in- validate access plans if an index is added, a statistics update must be scheduled manually to make the index usuable for existing programs. Another prob- lem are query variables, because their actual values cannot be considered at compilation time. Thus default selectivities e.g. for range predicates are as- sumed which can be quite different from the actual values. On the other hand, queries can be interpreted. But with this approach there is much overhead introduced for frequently executed queries; a query plan buffer can be used to limit this overhead.
Some vendors exhibit their optimizing strategies thus allowing a tuning of the queries (which is subject to change in subsequent DBMS releases). Perform- ance differences of an order between semantically equivalent queries are not unusual [38]. A typical problem is the adoption of query clause sequences and nestings in access plans [39,40]. Future systems will allow the user to give the optimizer some ad- ditional hints on the properties of a query. But on the other hand the best approach especially for perform- ance critical applications running precompiled queries (contesting with ad hoc queries and rapid prototyping apphcations) would be to query the optimizer for possible access plans, to force it to generate certain ones, to measure their per- formance, and then to use the actually best one for production purposes-and not the one expected to be the best. Such a feature has been implemented in the System R* for an evaluation of its query optimizer f34).
In DBDSCEN [ 11,41,42] an interesting approach was tried for an index selection tool. The workload is specified by a set of SQL statements. The tool modifies catalog and statistics to pretend the database and the index configuration being considered, and uses the resulting cost estimates from the optimizer to select a set of useful indexes.
2.3. Locking
All systems offer different levels of isoIation (level l-dirty read, level 2-curser stability, level 3-repeatable read) [43]. A certain level of isolation may be requested for single DML- statements, for whole programs or for transaction types. In addition to system locking, tables may be locked explicitly.
Besides the isolation level, locking granularity is a design parameter. A locking granule may be a single record, a page, a table or an address space. Some- times a default locking granularity for a single table or all tables in an address space may be specified by DDL statements which can be overridden by DML statements. The smaller the locking granule is, the more concurrency is possible but also the more overhead is needed to acquire the locks and to store the lock-information for the same amount of data. Thus some systems have an escalation feature which automatically uses a larger locking granule for a query, if there are too many locks expected for a fine granule.
A problem that must not be neglected is lock contention within indexes. Systems using page lock- ing offer options to limit the fan-out of an index page being locked: either the number of index entries per page can be reduced by filling index pages only to a specified limit (but with this method the index efficiency may also suffer from the reduced clustering) or one physical index page can be divided into several logical pages which can be locked separately.

380 Tutorial
2.4. Catalog management
The catalog is an important resource for an RDBMS. It easily can become a performance bottle- neck. Important aspects are access times to catalog items and locking. Thus many systems have imple- mented special catalog storage structures and locking mechanisms. The appropriate locking granule is a record. Another approach is to implicitly commit DDL-statements locking many catalog items. In general it is a good idea to reduce the number of catalog accesses. Several systems do not close address spaces and files if they are currently not used, i.e. they buffer the corresponding control blocks, some as an option, others by default.
2.5. Buffer management
Considering the database buffer [44] is essential for RDBMS physical design because, for example, intra-page clustering effects are established through the buffer. The available buffer size also influences whether it is cheaper to check a predicate using an address space scan than using an index scan, thus making the index obsolete.
The RDBMS usually provides its own buffer which may be centralized, partitioned into several buffers, be it by data and control block types, by address spaces or by disk volumes, but some systems simply use the operating system file buffers. The mapping of physical schema objects to buffer partitions is a physical design parameter in some systems.
Most systems use a more or less modified LRU algorithm for buffer replacement, though there are other promising proposals [31]. Mechanisms which detect sequential access patterns and process them in a special manner are already implemented. They perform an asynchronous prefetching of pages which are expected to been referenced soon, they make use of chained I/O, and they avoid the sequential flooding of the buffer by aging pages read sequentially faster than pages accessed at random, for which a higher probability of re-referencing is assumed. A prerequisite for the applicability of these mechanisms is a good inter-page clustering of the data.
2.6. Logging
Logging issues [45,46] also can influence physical design decisions. In a system doing page logging, an intra-page clustering of data being updated by one transaction reduces the amount of log data generated and thus favours clustering, whereas in a system doing record logging clustering results in no gain with respect to logging. Forcing updated pages to disk during commit also favours intra-page clustering more than write-ahead-logging [42].
A beneficial feature are non-audited tables which may be used for permanent auxiliary tables or for temporary tables which are created and dropped within the same transaction.
If each transaction flushes the log buffer when it commits, the resulting l/O-rate to the log device may limit the throughput in systems with high transaction processing rates to about 30 transactions per second. Systems using group commit [47,48] will reach this limit only with much higher rates.
2.7. TP-monitor, operating system and hardware configuration
TP-monitor, operating system and hardware con- figuration determine cost parameters and resource limits.
There are many DBMS-/OS-interfaces (49,501. Query processing usually requires the interaction of several OS-processes (application program process and one or more DBMS processes). Interprocess commu- nication is never cheap, message handling and context switches cost many instructions. Thus message bundling and features allowing a process to address code and data in several address spaces [51] are used to avoid context switches. Usually DBMS-processes are scheduled by the OS-scheduler. Within DBMS-pro- cesses an internal multi-threading can be performed. The database buffer may be pageable resulting in double or even triple paging phenomena, or fixed in real memory. The DBMS can also do its own main memory management for some amount of storage.
An important interface between DBMS and OS is the file system interface. Some DBMSs use a low-level interface to simple file organizations only to make their DBMS-code device independent. Others use more complex file organizations, e.g. key-sequenced datasets, to avoid the re-implementation of .existing components. At least one vendor tried the approach probably yielding the best performance, which is to implement a special file system and to integrate it into the operating system (37,521.
In a DBMS using a standard UNIX file system with its dynamic block allocation mechanism one file access may require up to 4 disk I/OS and physical contiguity of logical adjacent blocks cannot be guar- anteed [53], though allocating fixed size database files on new formatted disks circumvents the latter prob- lem. Contemporary UNIX-systems use the Berkeley fast file system which uses larger block sizes (usually 8 kbyte) and which tries to allocate file-blocks with respect to disk-cylinders and thus improves perform- ance. If the RDBMS supports the use of UNIX-“raw devices” (541 this problem is solved by bypassing the UNIX file system. Extent-based file systems do not suffer from these problems.
The I/O-subsystem hardware and its configuration (channels, controllers, strings, disks, etc.) determine service-rate/response-time characteristics and thus affect the allocation of files on disk volumes. If a disk fails or is set offline, a database which is partitially stored on that disk should still be partially accessible, i.e. the DBMS should be able to process queries which do not need to reference data on a disk not being online.

Tutorial 381
3. PHYSICAL SCHEMA OPTIONS IN COMMERCIAL RDBMSs
3.1. hgres (RTI)
The commercial Ingres [SS, 561 evolved from one of the first RDBMS research prototypes developed at the University of California, Berkeley [57]. It is now available for a large variety of operating sys- tems including several UNIX-derivates, VAX/VMS, VM/CMS and even MS-DOS. In its release 6 major architectural changes were performed to support multiprocessor hardware and to improve online transaction processing performance.
Ingres supports variable length strings with up to 2000 ASCII characters, binary encoded integers and floating point numbers, and two special data types date and money.
Primary access paths are entry-sequence (called heap), ISAM (a tree structure with a static directory), B-tree and hashing.
Actually B-trees are used only as a dense index on the data, the data themselves are stored on data pages for which there is a relationship to the index leaf pages. Each index leaf page has an associated data page into which new tuples are inserted. If a data page fills up a new data page is associated with the respective index leaf page. Tuples are not re- distributed during index leaf page splits. Thus the resulting clustering is not optimal. The space on a not-associated data page cannot be reused immedi- ately, even if all tuples on the page are deleted; a reorganization is necessary.
Ingres uses 2 kbyte pages, the maximum tuple length is 2008 bytes. Optionally compression sup-
n
LizI Location
Fig. 2. Mapping hierarchy of Ingres.
pressing traiiing blanks in all character columns can be applied, otherwise tuples are stored with a fixed length. Fill factors which control free space allocation within pages during a table reorganization can be specified.
Secondary indexes are implemented as special tables for which in turn primary access paths can be selected. This allows, for example, the use of scatter tables as secondary access paths by creating a hashed secondary index.
Each table (and thus each secondary index) is stored in a separate file. The files are allocated using areas which abstract from the operating system concept directory and which are specified through locationnames. In release 6, tables can be distributed over several areas (on several disk volumes). This distribution is performed automatically by the sys- tem. For each table with multiple locations every 16 pages are circularly allocated using the first location, then the second and so on.
The optimizer can use detailed statistics which are generated optionally. For example, attribute value frequencies can be counted for a specified number of value ranges.
Ingres’ locking ~~ula~ty is page or tabIe depend- ing on the optimizer’s estimate for the number of required page locks. The amount to which B-tree index pages are filled can be controlled to reduce lock contention.
Up to release 5 each front-end process running a user-interface created its own backend-process per- forming the database-operations when a user con- nected to Ingres. Each backend had its own database buffer, the operating system file buffer was used to share data between the backend processes.
In release 6 there is an m : n-relationship between frontend and database server processes. The database buffer is shared among all servers. In this release write-ahead-logging and group commit are imple- mented. On UNIX-systems a raw-device can be used for the log. Redo-logging is optional and may be enabled per table.
3.2. Oracle (Oracie Corp.)
Oracle [58] is also available for many different operating systems.
Oracle supports variable length strings of up to 240 characters. A special data type long is supplied, which may be used to store up to 64 kbyte data, but which cannot be used in Jeremiah, expressions or functions. The tuple size is not limited to the page size, but there can be at most 254 columns in a table. Numerical data are stored as fixed-point numbers with variable precision (up to 19 digits) and scale internally represented as base 100 floating point numbers. Also a data type date is supplied.
An Oracle database is made up of one or more address spaces called partitions, which consist of one or more files each. These partitions are preallocated using an utility. On UNIX-systems raw-devices can

382 Tutorial
1 n
1 1
Data Index Segment Ssgment
ri 13
1
cl Segment
Fig. 3. Mapping hierarchy of Oracle.
be used. When a table is created, two segments are created-one for the data and one for all indexes on that table. Space for these segments is allocated using an extent-based scheme. The size of the primary and the secondary extents, and the maximum number of extents may be specified for each segment in a macro-definition termed space definition, which is used in the CREATE TABLE-statement. Data and index segments of one table are placed in the same partition. Space occupied by deleted tuples can only be reused to store new tuples if a whole page becomes empty. Oracle uses a page size of 1 kbyte under UNIX, 2 kbyte under VAX/VMS and 4 kbyte under VM/CMS.
Oracle supports entry sequence and a special pri- mary access path structure called cluster, which may be used to physically cluster related data of several tables on a common attribute. These inter-table value-clusters are materialized joins. Clusters may also be used to store single tables in order to build value clusters. Each value of the common attribute, the cluster key, defines a group. The cluster key attributes are extracted from the tuples and each value is stored only once in front of its group. For each group a certain amount of space is reserved- one page by default, an integral fraction of it, if specified. Implicitly there is an index created on the cluster key. Clusters can be used to improve join performance or to efficiently store tuples with long, non-unique attribute values.
Secondary indexes are implemented as B-trees with default prefix and suffix compression which can be switched off. Pages are not totally filled, some amount of free space may be specified to be reserved for updates expanding tuples. Tuple identifiers termed rowih consist of the concatenated logical page number, sequence number relative to the page, and the partition number (not stored in secondary indexes).
Query optimization is based only on the query structure and the index configuration.
A version-based synchronization-algorithm is used. Readers are never blocked; if an object is accessed for which there is an uncommited update, its value is retrieved from the before-image.
3.3. DB2 (IBM)
DB2 [Sl] is a RDBMS for mainframes running the MVS operating system.
DB2 supports fixed and variable length character strings with up to 254 single-byte characters or 127 double-byte characters. There are also character data types which are only limited by the maximum tuple length which is almost the page size. Fixed-point decimals with at most 15 digits precision, floating point numbers and binary encoded 2- and 4-byte integers are provided for numerical data.
When a table is created, application-defined exit routines may be specified, which are called whenever a tuple is inserted, updated or retrieved. These routines may be used e.g. for compression purposes.
DB2 provides entry sequence and clustered indexes as primary access paths and non-clustered indexes as secondary access paths. There is some amount of free space allocated during an initial load or a reorganiz- ation. By default there are 5% within data pages and 10% within index pages left empty. Optionally single pages may be totally left empty in regular distances to lower clustering degression through inserts. Space occupied by dropped tables cannot be reused until an address space reorganization is performed.
DB2 uses address spaces which can hold one or more tables (tablespace) or an index structure (index- space). The page size is either 4 or 32 kbyte. An address space may be either simple or partitioned. A simple address space can contain several tables and consists of up to 32 VSAM ESDSs (entry sequenced data sets) which must be all online when the address space is accessed. By the use of an entry-sequenced primary access path for several tables in one address space a hierarchical clustering may be achieved at load time. This clustering is not maintained and may degrade during update processing. A partitioned address space can contain only a single table with data partitioned by key ranges among up to 64 partitions. Partitions may be independently set on- and offline and can be reorganized individually.
Address spaces can be allocated on groups of disk volumes called storage groups. For each address space it may be specified whether it and its underlying
Tutorial 383
VSAM datasets will be kept open if they are currently not used.
Each address space is assigned to a buffer pool. There are three 4 kbyte buffer pools and one 32 kbyte buffer pool. The number of frames in a buffer pool varies between a minimum and a maximum value. Sequentially processed pages are prefetched, they are replaced prior to randomly accessed pages, and pages that contain several records, from which is known in advance that they will be accessed, are usually fixed in the buffer until all records are processed.
For table spaces a locking granularity can be specified. It may be either table space or page. For indexes, a logical leaf page size can be specified (default 1 kbyte) which defines the locking granular- ity. DB2 logs record level undo-/redo-information.
A DB2 utility collects statistics on tables, table- spaces and indexes. Besides statistics on the number of tuples in a table, the number of pages used to store these tuples and some statistics on value distributions for indexed attributes and the indexes themselves which are used for query optimization, there are statistics that support the scheduling of reorganiz- ations. For example, the amount of space wasted by dropped tables that cannot be reused until a table- space reorganization, the number of tuples that have left their home pages, the average number of pages between successive leaf pages within a sequential scan through an index, and the number of times a tuple in an index scan is not on the same page as the prior ones are recorded.
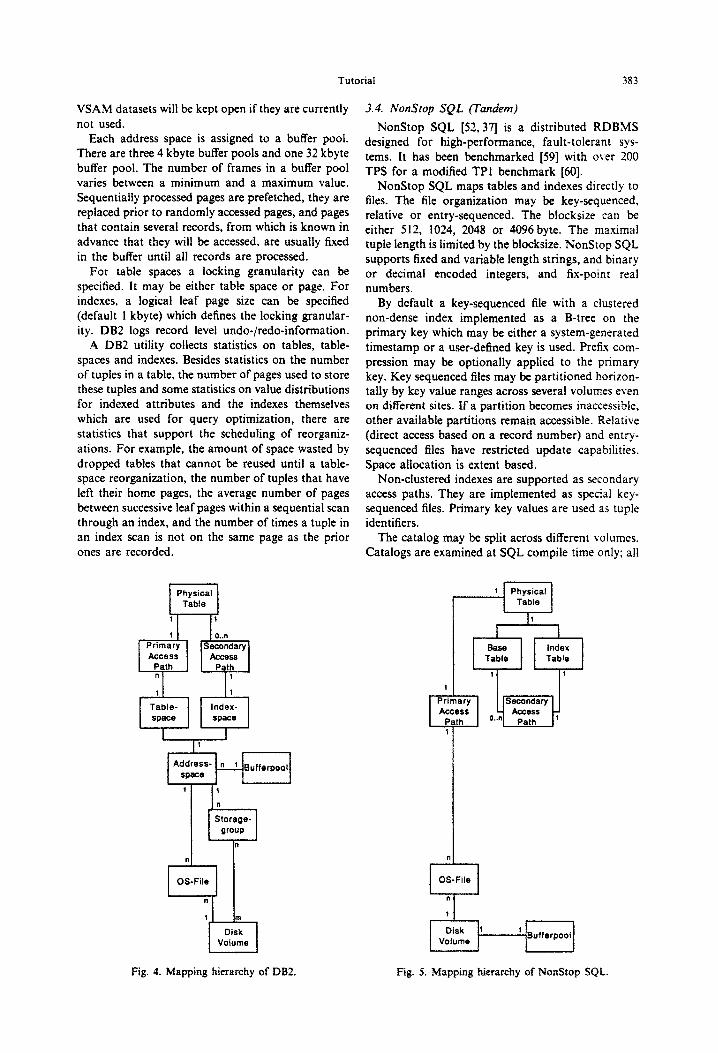
3.4. Nonhp SQL (Tandem)
NonStop SQL [52,371 is a distributed RDBMS designed for high-performance, fault-tolerant sys- tems. It has been benchmarked [59] with over 200 TPS for a modified TPI benchmark [60].
Nonstop SQL maps tables and indexes directly to files. The file organization may be key-sequenced, relative or entry-sequenced. The blocksize can be either 512, 1024, 2048 or 4096 byte. The maxima1 tuple length is limited by the blocksize. Nonstop SQL supports fixed and variable length strings, and binary or decimal encoded integers, and fix-point real numbers.
By default a key-sequenced file with a clustered non-dense index implemented as a B-tree on the primary key which may be either a system-generated timestamp or a user-defined key is used. PreKx com- pression may be optionally applied to the primary key. Key sequenced files may be partitioned horizon- tally by key value ranges across several volumes even on different sites. If a partition becomes inaccessible, other available partitions remain accessible. Relative (direct access based on a record number) and entry- sequenced files have restricted update capabilities. Space allocation is extent based.
Non-clustered indexes are supported as secondary access paths. They are implemented as special key- sequenced files. Primary key values are used as tuple identifiers.
The catalog may be split across different volumes. Catalogs are examined at SQL compile time only; all
Physical Table U 1 1
n
Storage-
~~
group
n
n
Fig. 4. Mapping hierarchy of DB2.
OS-File 5Y t , n
1
, ‘ I f
Fig, 5. Mapping hierarchy of NonStop SQL.

384 Tutorial
information necessary at run time is found in the access plan and in a file header. A timestampbased algorithm is used to check plan validity.
Nonstop SQL uses sampling to generate statistics for large tables (> 4 Mbyte). Besides some size statis- tics for each attribute the number of unique values, the second highest and the second lowest value are stored.
File accesses are performed by disk server pro- cesses. Each disk volume is managed by a set of disk servers sharing one buffer pool. These server pro- cesses receive single variable queries containing seiec- tion and projection predicates. They return their results to the requesting application processes which perform joins and aggregations.
Usually record locking is done with primary key values used as lock identifiers. Larger locking granules (key value ranges) may be defined for a table by specifying the length of a primary key prefix which is then used as lock identifier.
4. PHYSICAL DESIGN IN RDBMSs
Several principles are applied in physical database design:
Supporting database operations by using appro- priate access methods and storage structures. The clustering of data, i.e. storing related data physically close together to reduce processing overhead. The partitioning of data, i.e. storing related data apart to reduce contention. The ~pli~tion of data.
Clustering and partitioning are two conflicting principles for the placement of physical objects. Both principles may be applied on different levels.
For clustering several types of localities can be defined. The gain is larger when more data occur- rences are clustered within one locality. The smallest locality is a page. Clustering related data on pages saves I/OS, reduces the number of page level locks, and the number of required buffer frames. A larger locality is adjacent pages (on the same track or cylinder of a disk votume). Clustering with regard to this locality avoids disk seeks and allows the efficient use of chained I/O-operations. The clustering of several objects within address spaces and/or files saves open operations.
Several types of single and multiuser contention can be avoided by storing data apart. Page level lock contention can be reduced if concurrently accessed data are stored on different pages. The same is true for address spaces. Disk arm movement can be reduced by storing files containing data and files containing indexes to these data or files that contain data which are frequently accessed in an interleaved manner on different disk volumes. For the same reason it may be appropriate to reserve a whole
volume for a heavily-used dataset, even if it requires only a fraction of its capacity.
Access path selection is restricted to the access path types and the parameterization options supplied by the RDBMS. Usually entry sequence and some kind of B-tree are supplied as primary access paths. Only a few systems support hashing. Some kind of ciuster- ing is supported in each system but no system allows full control. Frequently an aggregated storing of tables (inter-table clustering) is not possible. A bad primary access path selection can only be corrected by unloading and reloading a table and recreating ail its indexes. This can be quite expensive.
Horizontal partitioning is supported by some sys- tems to split large or heavily accessed tables across several disk volumes to avoid contention and to improve availability. The mapping of tables and indexes to devices is more or less under the DBA’s control.
Vertical partitioning is not supported, though re- lational query languages would allow support on the physical level, because all required attributes must be specified in a query. Vertical partitioning is appropri- ate e.g. for tables with a few frequently and many infrequently accessed attributes or for tables with a large overall tuple size resulting in much frag mentation if the DBMS does not support records spanning page boundaries.
A logical table or partitions of it could be repli- cated using several physical tables with different storage structures. The query optimizer could then estimate which replicate of a table yields the lowest access costs and could generate a corresponding access plan. But this feature is not supported by the present RDBMSs. Replication on the logical schema level is more difficult to maintain, since logicai schema modifications can require program modifications.
A dense index may be viewed (and used) as a replicated vertical partition of a table in systems that do not access the data if all required attributes are found in the index.
All systems supply B-tree based secondary access paths. Other types of secondary access paths, e.g. multilists or inverted lists, are not used. Secondary access paths can be dynamically created and dropped ~thout affecting the programs. Thus errors and flaws in the index con~guration may be fixed with Iimited effort.
5. SUMMARY AND CONCLUSIONS
In total there are many design options available in commercial RDBMSs, but each system supplies only a subset of these options. Some options seem to have been introduced as ad hoc solutions for performance problems in previous versions. In many systems there are obscure restrictions and dependencies between option and parameter choices. Vendors give in their manuals only very few and general hints on the

Tutorial 385
optimal usage of the options. If there are hints, the reasons and limitations are frequently missing. Descriptions of storage structures and processing algorithms are rare, but would be very valuable for physical design. There is also no information on the OS interfaces of the sample RDBMSs. Systematic benchmarking [61-63] can be used to analyze per- formance characteristics of DBMSs.
Non-standard applications require a more appro- priate data model than the relational and especially an efficient support on the physical schema layer. There are several research prototypes of object- oriented and extensible DBMSs [64-68]. These sys- tems offer new features on the physical schema level, but again there is only little support for their selection [69].
Currently there is no comprehensive methodology for physical design. Thus physical design is largely based on the designer’s experience and his knowledge of the target system, and many database administra- tors, especially of smaller installations, are overtaxed.
For practical use, physical design tools are re- quired, which-based on a certain methodology- guide a designer systematically through the design process, which indicate for each design step what has to be decided, and which allow a qualitative and quantitative evaluation of possible design alternatives.
Such tools are currently being developed at the University of Stuttgart. First results will be presented in a forthcoming paper.
AcknonYedgemenr-This work was supported by the Deutsche Forschungsgemeinschaft (D.F.G.) under Grant Re660/1-I.
REFERENCES
[I] American National Standards Institute. Database language SQL. Document ANSI X.3.135-1986 (1986).
[2] Database Language SQL2 (Working Draft). IS0 TC97 SC21 WG3, July (1987).
[3] D. Severance. A practitioner’s guide to data base compression. fnformufion Sysrems %(l), 51-62 (1983).
[4] S. T. March. Techniques for structuring database records. ACM Compuf. Suru. 15(l). 45-79 (1983).
(51 S. Navathe, S. Ceri, G. Wiederhold and J. Dou. Vertical partitioning algorithms for database design. ACM Trans. Database Systems 9(4), 680-710.
[6] S. Ceri, M. Negri and C. Pelagatti. Horizontal data partitioning in database design. Proc. ACM SIGMOD 1~. Con/: on Munugemenl of Dufa, pp. 128-136 (1982).
[7] D. S. Batory. Optimal file designs and reorganization points. ACM Trans. Darabase Systems 7( 1). 60-81 (1982).
[8] G. H. Sockut and R. P. Goldberg. Database re- organisation-principles and practice. ACM Compur. Sure. lI(4). 371-395 (1979).
[9] R. Bonanno, D. Maio and P. Tiberio. An approxi- mation algorithm for secondary index selection in relational database physical design. The Comput. J. 28(4), 398405 (1985).
[IO] F. Bonfatti, D. Maio and P. Tiberio. A separability- based method for secondary index selection in physical database design. Methodology and Tools for Data Base
WI
[I31
[I41
1151
[I61
El81
1191
WI
WI
WI
f231
[241
WI
1261
[271
1281
f291
(301
f311
1321
Design (S. Ceri. Ed.), pp. 148-160 North-Holland, Amsterdam (1983). S. J. Finkelstein, M. Schkolnick and P. Tiberio. Physical database design for relational databases. ACM Trans. Database Systems 13(l), 91-128 (1988). M. Hatzopoulos and J. G. Kollias. A dynamic model for the optimal selection of secondary indexes. In/or- marion Systems 8(3), 159-164 (1983). S. T. March. A mathematical programming approach to the selection of access paths for large multiuser data bases. Decision Sci. 14(4), 564-587 (1983). D. Motzkin. The design of optimal access paths for relational databases. Infirmarion Systems It(Z). 203-213 (1987). M. Schkolnick and P. Tiberio. Estimating the cost of updates in a relational database. ACM Trans. Darabuse Svstems 10(2), 163-179 (1985). K.-Y. Whang, G. Wiederhold’and D. Sagalowicz. The property of separability and its application to physical database design. Query Processing in Database Sysrems (W. Kim, D. S. Reiner and D. S. Batory. Eds), pp. 297-317. Springer, New York (1985). C. C. Fleming and B. von Halle, Handbook of Relational Databme Design. Addison-Wesley, Reading, Mass. (1989). S. T. March, Physical database design: techniques for improved database performance. Query Processing in Darabase Systems, (W. Kim, D. S. Reiner and D. S. Batory, Eds), pp. 279-296 (1985). M. Schkolnick. A survey of physical design method- ology and techniques. Proc. 4h Int. Conf on Veer) Large Databases, Berlin, pp. 474-487 (1978). T. J. Teory and J. P. Fry. Design of Database Srruc- tures. Prentice-Hail, Englewood Cliffs, New Jersey (1982). S. Christodoulakis. Implications of certain assumptions in database performance evaluation. ACM Trans. Database Systems 9(2). 163-186 (1984). D. S. Bate-ry. Modeling the storage architectures of commercial database systems. ACM Trans. Database Systems 10(4), 463-528 (1985). D. S. Batory. Progress toward automating the develop ment of database system software. Query Processing in Dotabuse Systems (W. Kim, D. S. Reiner and D. S. Batory, Eds), pp. 261-278 Springer, New York (1985). J. V. Carlis and S. T. March. A descriptive model of physical database design problems and solutions. Proc. Inr. Conf: on Data Engineering, Los Angeles, pp. 253-260 (1984). S. T. March, J. V. Carlis and M. Wilens. Frame memory: a storage architecture to support rapid design of efficient databases. ACM Trans. Databate S_vsremr 6(3). 441463 (1981). Tandem, SQL Programming Techniques-Program- ming Considerations Using Nonstop SQL, July (1987). D. Comer. The ubiquitous B-tree. ACM Compur. Sure. 11(2), 121-137 (1979). E. F. Codd. Is your DBMS really relational? Computerworld Ckt. (1985). M. M. Astrahan and M. W. Blasgen et aI. System R: relational approach to database management. ACM Trans. Derubuse Sysrems l(6), 97-137 (1976). M. W. Blasgen and K. P. Eswaran. Storage and access in relational data bases. IBM Svsrems J. 16(4). 363-377 , (1977). G. M. Sacco and M. Schkolnick. Buffer management in relational database systems. ACM Trans. Database Systems ll(4). (1986). - D. J. Dewitt, R. H. Katz, F. Olken, L. D. Shapiro, M. Stonebraker and D. Wood. Implementation Techniques for Main Memory Database Systems. Proc. ACM SIGMOD Inr. ConJ on Managemenr of Dofa, pp. l-8 (1984).

386 Tutorial
(331 L. D. Shapiro. Join processing in database systems with large main memories. ACM 7?unr. Dorubase Systems 1 l(3), (1986).
[34] L. F. Mackert and G. M. Lohman. R* Optimizer validation and performance evaluation for local queries. Proc. ACM SIGMOD Int. Conf: on Manage- ment of Data, pp. 84-95 (1986). _ _
1351 M. M. Astrahan. M. Schkolnick and K.-Y. Whann. . . Approximating the number of unique values of a’n attribute without sorting. Information Systems 12(I). I I-15 (1987).
[36] G. Piatetsky-Shapiro and C. Connell. Accurate esti- mation of the number of tuples satisfying a condition. Proc. ACM SIGMOD Int. Conf. Management of Data, pp. 256-276 (1984).
[37] The Tandem Database Group. Nonstop SQL, a dis- tributed, high-performance, high-availability imple- mentation of SQL. zhd Int. Workshop on High Performance Transaction Systems, Asilomar (1987).
[38] W. Bludau. Leistungsuntersuchungen an dem relation- _ _ alen Datenbanksystem SQL/DS. Spezielle Berichte der Kernforschunzsanlaze Jillich 391. March (1987).
[39] R. Ganski andH. KTT. Wong. Optimization ofnested queries revisited. Proc. ACM SIGMOD Int. Co& on Management of Data, pp. 23-33 (1987).
[40] W. Kim. On optimizing an SQL-like nested query. ACM Trans. Database Systems 7(3), 443-469 (1982).
[41] S. J. Finkelstein, M. Schkolnick and P. Tiberio. DBDSGN-a nhvsical database desizn tool for svstem R. IEEE Data&e Engng Bull. 5(1),-9-l I (1982j.
(421 M. Schkolnick and P. Tiberio. Considerations in devel- oping a design tool for relational DBMS. Proe. IEEE COMPSAC Conf, pp. 228-235, Chicago (1979).
[43] J. Gray. Notes on Data Base Operating Systems, Vol. 60. Lecture Notes on Computer Science, pp. 394-481. Springer, New York (1978).
[44] W. Effelsberg and T. HHrder. Principles of database buffer management. ACM Trans. Database Systems 9(4), 560-595 (1984).
[45] T. Harder and A. Reuter. Principles of transaction- oriented database recovery. ACM Comput. Sure. 15(4), 287-317 (1983).
[46] A. Reuter. Performance analysis of recovery techniques. ACM Trans. Database Systems 9(4), 526-556 (1984).
[47] D. Gawlick and D. Kinkade. Varieties of concurrency control in IMSIVS fast nath. IEEE Database Enpna June (1985). *
VI
[48] P. Helland, H. Sammer, J. Lyon, R. Carr, P. Garrett and A. Reuter. Group commit timers and high volume transaction systems. Proc. 2nd Int. Workshop on High Performance Transaction Systems (1987).
[49] T. HBrder. Die Einbettung eines Datenbanksystems in eine Betriebssystemumgebung. Dutenbanktechnofogie, (J. Niedereichholz, Ed). pp. 9-24. Teubner-Verlag, Stuttgart (1979).
[50] M. Stonebraker. Operating system support for data- base management. Commun. ACM U(7), (1981).
(511 Special Issue on DB2. IBM Systems I. u(2), (1984).
[52] A. Barr and F. Putzolu. High performance SQL through low-level system integration. Proc. ACM SIGMOD Int. Conf on Management of Data, pp. 342-349 (1988).
[53] K. Thompson. UNIX Implementation. Bell Labora- tories (1978).
(541 M. J. Bach. The Design of the UNIX Operating System. Prentice-Hall, Englewood Cliffs, New Jersey (1986).
[55] Relational Technology Inc. INGRES/SQL Reference Manual, Release 5.0, L.VIX, August (1986).
[56] Relational Technology Inc. INGRESISQL Re/erence Manual. Release 6. UNIX. Avril (1989).
[571 M. Stonebraker (Ed.) The INGRES Papers, Anatomy of a Relational Database System. Addison-Wesley, Reading, Mass. (1986).
[58] Oracle Corporation Europe. Oracle Database Adminis- trator’s Guide, Version 5.1, August (1986).
[59] The Tandem Performance Group. A benchmark of Nonstop SQL on the debit credit transaction. Proc. ACM SIGMOD Int. Conf on Management of Data, pp. 337-341 (1988).
[60] Anon et al. A measure of transaction processing power. Datamation 31, April (1985).
[61] H.-Y. Hwang and Y. T. Yu. An analytical method for estimating and interpreting query time. Proc. 13th Int. Conf. on Very Large Databases, Brighton. pp. 347-358 (1987).
[62] C. Turbyflll. Comparative Benchmarking of Relational Database Svstems. Ph.D. Thesis. Cornell University (1988). -
[63] S. B. Yao, A. R. Hevner and H. Young-Meyers. Analysis of database system architectures using bench- marks. IEEE Trans. Software Engng 13(a), 709-725 (1987).
[64] D. S. Batory, J. R. Bamett, J. F. Garza and K. P. Smith et al. GENESIS: an extensible database management system. IEEE Trans. Software Engng 14(11), 171 I-1730 (1988).
[65] M. J. Carey, D. J. Dewitt and D. Frank et ol. The architecture of the EXODUS extensible DBMS. Proc. 1986 Int. Workshop on Object Oriented Database Systems, pp. 52-65 (1986).
[66] T. Harder, K. Meyer-Wegener. B. Mitschang and A. Sikeler. PRIMA-a DBMS prototype supporting engineering applications. Proc. 13th Int. Conf. on Very Large Databases, Brighton, pp. 43342 (1987).
[67] P. Schwarz, W. Chang and J. C. Freytag et al. Extensibility in the Starburst database system. Proc. 1986 Int. Workshop on Object Oriented Databose Systems, pp. 85-92 (1986).
[68] M. R. Stonebraker. The design of the POSTGRES storage system. Proc. 13th Int. Con/. on Very Large Databases, Brighton, pp. 289-300 (1987).
[69] K. Abramowicz. Wissensbasierte Werkzeuge zur Leistungsoptimienmg objektorientierter Datenbank- systeme. Datenbanksysteme in Btiro, Technik und Wissenschaft, GIjSI-Fachtagwtg, IFB 204 (T. H;irder, Ed.), pp. 368-372 (1989).
APPENDIX
DDL-Commands for Schema Creation
In the sequel the syntax of DDL-commands for the creation of physical schemata in the sample systems is presented. This overview is intended only to give a compact impression of the similarities and the differences in these systems, but neither to provide the syntax in full detail, nor to describe all the dependencies between and the restrictions imposed on specific options or parameters.
Explanation of metacharacters
I
/select at least one, jselect exactly one,
[ Jselect optionally one,

Tutorial 387
[seporaror . .] Optionally repeat previous selection separated by separaror, italics parameter, bold default.
Ingres (release 6)
CREATE TABLE TableName ({ Column Name Data Type
WITH NULL
NOT NULL [WITH DEFAULTINOT DEFAULT] 1 119 . . .I) [AS Subselect]
PITH
DataType :: = INTEGER1 1 INTEGER21 INTEGER4ISMALLINTjINTEGER
FLOAT41 FLOAT8 1 FLOAT
MONEY 1 DATE
LOCATION = (LocationName [, . . .I) [NOIJOURNALING
[NOIDUPLICATES
r CHAR(n)lC(n)lVARCHAR(n IVCHAR(n) 1
CREATE [UNIQUE] INDEX IndexName ON TableName ({ ColumnName [ASCI DESC]}[, . . .])
1 STRUCTURE= {[C]BTREEI[C]ISAMI[C]HASHI[C]HEAP}
[WITH KEY = (ColumnNume [, . . .])
LOCATION = (LocarionName[, . AllocationSpecification
.I) I
TO [UNIQUE][ON]( ColumnName [ASC I DESC]}[, . . .)]
REORGANIZE
TRUNCATED
AllocationSpectfication
[WITH NEWLOCATION = (LocationName [, . . .]) OLDLOCATION = (LocationName [, . . .]) 1
LOCATION = (LocutionName [. . . .])
StorageStructure :: = [C]BTREEI[CjISAMI[C]HASHI[qHEAPj[C]HEAPSORT
FILLFACTOR = n
MINPAGES = n
AllocationSpecljication :: = MAXPAGES = n
LEAFFILL = n
NONLEAFFILL = n
Oracle (Release 5.1)
CREATE TABLE TableName ({ColumnNume DataType INOT NULLIII, . . .I) (SPACE SpaceMacroiam;] _‘- -- [CLUSTER ClusterName (ColumnName 1. . . 31 iAS SelectStmt] ’
Da,al?pe:: = [ NUME=~;..)

388 Tutorial
CREATE WNIQUE] INDEX IndexName ON TableName (ColumnName [, . . .])
N~s~s~~~T [P<lfFREE nl 1 E Nc~~~p~E~s 1 [ROWS = n]
CREATE CLUSTER ClusterName ({ ChsrerColumn DataType}[, . . .]) [SPACE SpaceMacroName] [SIZE LogicalBlockSize] [COMPRESS 1 NOCOMPRESS]
CREATE PARTITION PartitionName
ALTER PARTITION PartitionName ADD FILE ‘OSFileName’
CREATE SPACE [DEFINITION] SpaceMacroName [DATAPAGES ([INITIAL n][, INCREMENT n][, MAXEXTENTS n][, PCTFREE n I)] [INDEXPAGES ([INITIAL n][, INCREMENT n I[, MAXEXTENTS n])] [PARTITION [PartitionName]
DB2 (release 1.2)
CREATE TABLE TableName ((ColumnName DataType
[
(NOT FULL][FIELDPROD EditRoutine (constant [, . . .])] NOT NULL WITH DEFAULT 1 ~[ ,... ])
[IN I [DatabaseName]TableSpaceName
DATABASE DatabaseName > I
[VALIDPROC Tuple ValidationRoutine] [EDITPROC TupleEditRoutine]
CHAR (n) 1 VARCHAR(n) ) LONG VARCHAR
GRAPHIC (n)l VARGRAPHIC (n)l LONG VARGRAPHIC 1 DataType:: = SMALLINTI INTEGER
FLOAT
DECIMAL (precision, [scale])
CREATE TABLESPACE TableSpaceName IN DatabaseName [AllocationSpeciJication] (NUMPARTS NumberOfPartitions [({PART PartitionNumber AllocationSpecijcation}[, . . .])I
[BUFFERPOOL [ B;;l][LOCKSIZE { ,gAcE I ](CLOSE YES
NO I
[DSETPASS VSAMPassword]
CREATE [UNIQUE] INDEX IndexName
ON TableName ((ColumnName
[AllocationSpecifieation] [CLUSTER [({PART PartitionNumber VALUES (constant [ , . . .]) [AllocationSpecificotion]j[, . . .])]
[SUBPAGES n][BUFFERPOOL
[DSETPASS VSAMPassword]
CREATE STOGROUP StorageGroupName Volumes (VolumeSerialNo [, . . .]) VCAT VSAMCatalogName [PASSWORD VSAMPassword]
AllocationSpecification :: =
VCAT VSAMCatalogName
I
PRIQTY n
SECQTY n “ING STOGROUP StorageGroupName
FREEPAGE n PCTFREE n
Tutorial 389
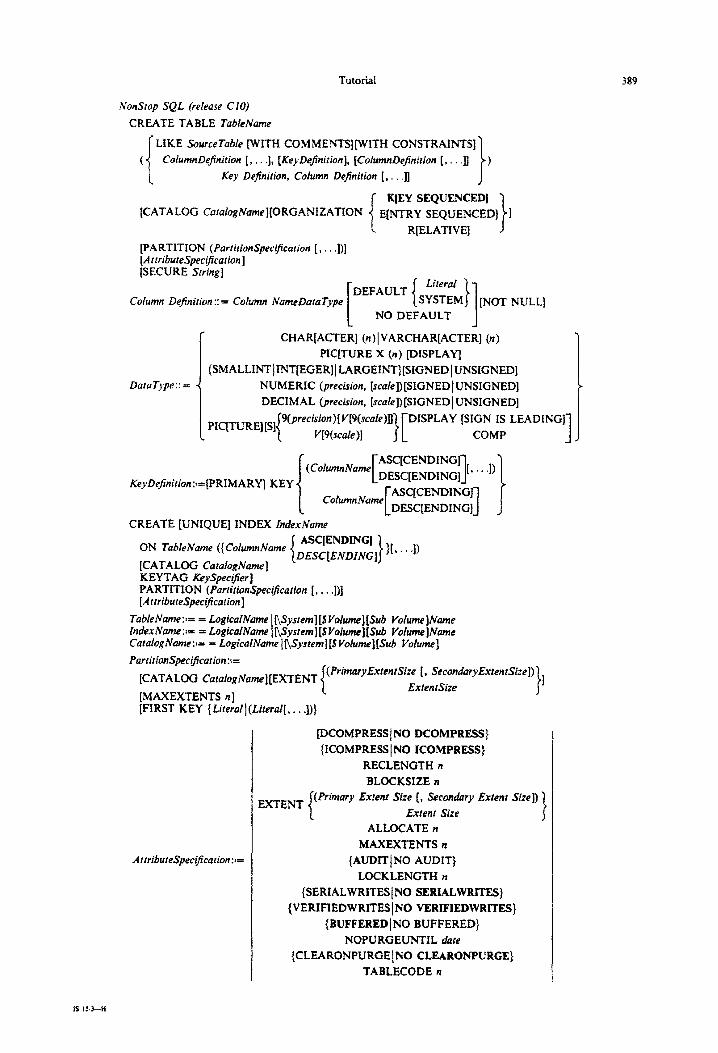
Nonstop SQL (release ClO)
CREATE TABLE TableName
I
LIKE SolcrceTa@e PITH COMME~S]~I~ CONSTRAINTS]
f ColumnDefinition [, . . .I, [KeyDefinition], [CofumnDPfnirion [, . . .I] )
Key Definition, Column Definition [, . , .]]
i
KlEY SEQUENCEDl [CATALOG Cura~og~~e][ORGANIZATtON E[~RY SEQUENCED] ]
RIELATIVE]
[PARTITION (PartirionSpeciFcurion [, . . .])I [AtrributeSpecificarion] [SECURE String]
Cofumfi De$nition :: = Column NameDntaType
[
DEFAULT Literal
( }I
SYSTEM [NOT NUIsL]
NO DEFAULT
~SMALLINT~IN~EGER]~LARGEI~~[SIGNED~UNSIGNED]
DaraType :: = NUMERIC (precision, [s&e]) [SIGNED\ UNSIGNED]
DECIMAL (precision, [scak]) [SIGNEDI UNSIGNED]
CHAR[ACTER] (n)lVARCHAR[ACTER] (n)
PIC[TURE X (n) [DISPLAY]
PICfrURE] [S] 9(precision){V[9(scalefll DISPLAY [SIGN IS LEADING]
V[9(scaie )] COMP 1
(ColumnName ASC’CENDING1 KeyDejinition:1=[PRIMARY] KEY [ DESC[ENDING] 1 [’ ’ ’ ‘I)
I CREATE [UNIQUE] INDEX IndexName
ON TaMeName ({ ColumnName
[CATALOG CatufugName] I
AWENDING It. 1. .1j DESC[ENDING] I
KEYTAG ileySpec~@er] PARTITION (Par~itionSpeLtifjo~ [, . . $1 [AtnibuleSpecifcolion ]
TableName:f= = LogicalName ~Sysrem][$Yolume][Sub Volume]Name IndexName:= = LogicalName nSystemJ[$Voiume][Sub Volume]Name CatalogNames= = LogicalName InSyrtem][$ Volume][Sub Vohme]
Par?ifio~S~ci~ea~ion:~=
[CATALOG CarofogName][EXTENT (PrimaryExrenrSize [, SeeonakryExtentSize])
ExtentSize I
[MAXEXTENTS n] [FIRST KEY {Lirerall(Literal[, . . .]))
.&:ributeSpecificorion :I=
[C~COMPRESS 1~0 DCOMPRES~~
{ ICOMPRESS IN0 ICOMPRESS)
RECLENGTH n
3LOCKSIZE n
MAXEXTENTS n
{AUDIT I NO AUDIT)
LOCKLENGTH n
{ SERIALWRITES / NO SERIALWRITES)
{VERIFllEDWRITES~NO VERIFIEDWRrrES)
{BUFFERED 1 NO BUFFERED}
NOPURGEUNTIL date
{CLEARONPURGEINO CLEARONPURGE)
TABLECODE n
(Primary Extent Size [, Secondary Extent Size])
Exkmt Size
ALLOCATE n





























