Embed Size (px)
Citation preview

PHRASE-LEVEL AUDIO SEGMENTATION OF JAZZ IMPROVISATIONSINFORMED BY SYMBOLIC DATA
Jeff Gregorio and Youngmoo E. KimDrexel University, Dept. of Electrical and Computer Engineering
{jgregorio, ykim}@drexel.edu
ABSTRACT
Computational music structure analysis encompasses anymodel attempting to organize music into qualitativelysalient structural units, which can include anything in theheirarchy of large scale form, down to individual phrasesand notes. While much existing audio-based segmenta-tion work attempts to capture repetition and homogeneitycues useful at the form and thematic level, the time scalesinvolved in phrase-level segmenation and the avoidanceof repetition in improvised music necessitate alternate ap-proaches in approaching jazz structure analysis. Recently,the Weimar Jazz Database has provided transcriptions ofsolos by a variety of eminent jazz performers. Utilizinga subset of these transcriptions aligned to their associatedaudio sources, we propose a model based on supervisedtraining of a Hidden Markov Model with ground-truth statesequences designed to encode melodic contours appearingfrequently in jazz improvisations. Results indicate that rep-resenting likely melodic contours in this way allows a low-level audio feature set containing primarily timbral andharmonic information to more accurately predict phraseboundaries.
1. INTRODUCTION
Music structure analysis is an active area of research withinthe Music Information Retrieval (MIR) community withutility extending to a wide range of MIR applications in-cluding song similarity, genre recognition, audio thumb-nailing, music indexing systems, among others. Musicalstructure can be defined in terms of any qualitatively salientunit, from large scale form (e.g. intro, verse, chorus, etc.),to melodic themes and motifs, down to individual phrasesand notes.
Paulus [8] categorizes existing approaches to audio-based structural analysis according to perceptual cues as-sumed to have central importance in determination ofstructure, namely into those based on repetition, novelty,and homogeneity. A music structure analysis task typi-cally involves a boundary detection step, where individualsections are assumed to be homogeneous, and transitions
c© Jeff Gregorio and Youngmoo E. Kim. Licensed undera Creative Commons Attribution 4.0 International License (CC BY 4.0).Attribution: Jeff Gregorio and Youngmoo E. Kim. “Phrase-level AudioSegmentation of Jazz Improvisations Informed by Symbolic Data”, 17thInternational Society for Music Information Retrieval Conference, 2016.
between sections associated with a high degree of novelty.Novelty is assumed to be indicated by large changes in oneor more time-series feature representations that may corre-spond to perceptually-salient shifts in timbre, rhythm, har-mony, or instrumentation. Predicted boundaries can thenbe used to obtain segments which can be grouped accord-ing to similarity in the employed feature space(s). Alter-natively, repetition-based methods may be used to identifyrepeated segments and boundaries directly.
Due to the difficulty in reliabily estimating individualnote onsets and pitches, much existing work on music seg-mentation at the phrase level has been limited to single in-struments in the symbolic domain. In a meta-analysis ofsymbolic phrase segmentation work, Rodrıguez Lopez [7]showed that two of the best performing rule-based mod-els in comparative studies include Cambouropoulos’s Lo-cal Boundary Detection Model (LBDM) [2] and Temper-ley’s Grouper [11]. Both relate to Gestalt discontinuityprinciples, placing phrase boundaries using heuristics de-rived in part from features of consecutive note onset times,including inter-onset intervals (IOI) and offset-onset in-tervals (OOI). The LBDM model additionally uses pitchcontour information, assuming discontinuity strength is in-creased by large inter-pitch intervals (IPI). Grouper alsoincorporates knowledge of metrical context and assumes aprior distribution of phrase lengths.
The proposed work focuses on musical structure at thephrase level, specifically identification of phrase bound-aries from audio signals. Though we do not directly pre-dict note onsets, durations, or pitches available in sym-bolic representations, we take advantage of audio-alignedMIDI transcriptions in the supervised training of a Hid-den Markov Model (HMM). Using a primarily timbral andharmonic audio feature represenation, we hope to aid inthe prediction of phrase boundaries by exploiting correla-tions between timbral/harmonic cues and common melodicphrase contours represented in the dataset.
2. MOTIVATION
In the audio domain, most existing structural segmenta-tion work attempts to model to large scale form. The selfdistance matrix (SDM) is a useful representation in thismodality, where entries SDM(i, j) = d(xi,xj) representthe distance between all combinations of feature vectorsxi and xj by some distance metric d. This representationlends itself well to identifiable patterns associated with ho-
482
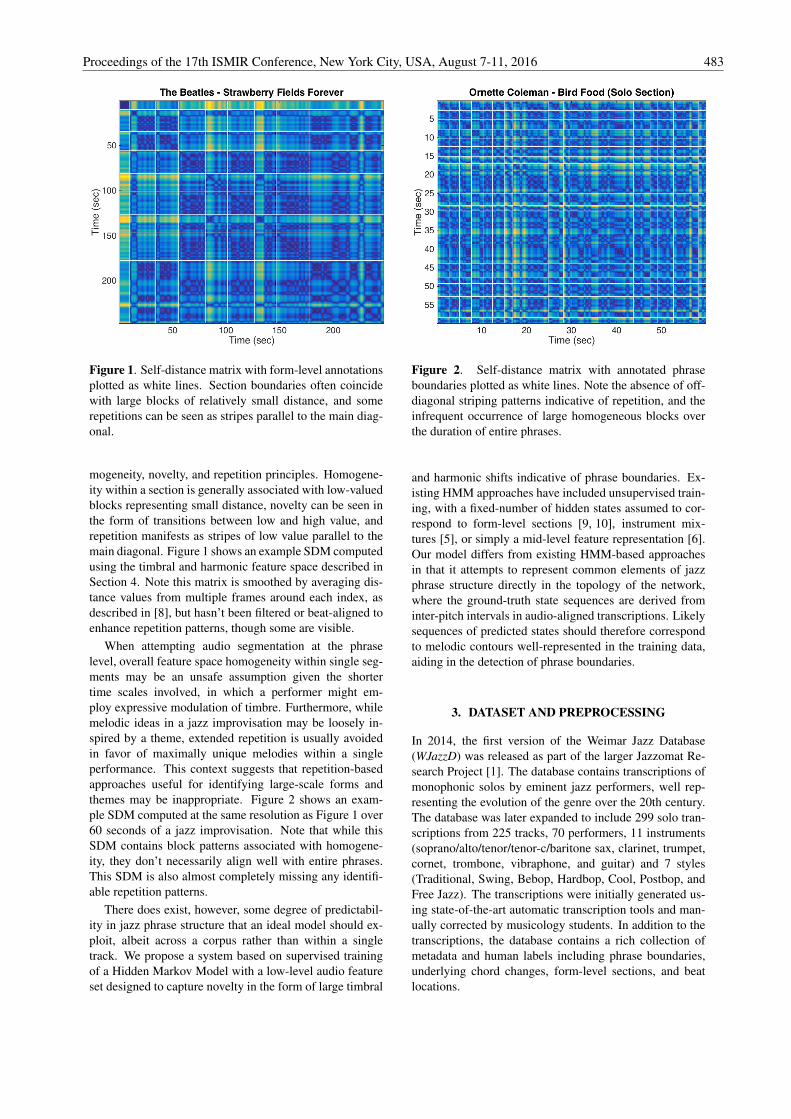
Figure 1. Self-distance matrix with form-level annotationsplotted as white lines. Section boundaries often coincidewith large blocks of relatively small distance, and somerepetitions can be seen as stripes parallel to the main diag-onal.
mogeneity, novelty, and repetition principles. Homogene-ity within a section is generally associated with low-valuedblocks representing small distance, novelty can be seen inthe form of transitions between low and high value, andrepetition manifests as stripes of low value parallel to themain diagonal. Figure 1 shows an example SDM computedusing the timbral and harmonic feature space described inSection 4. Note this matrix is smoothed by averaging dis-tance values from multiple frames around each index, asdescribed in [8], but hasn’t been filtered or beat-aligned toenhance repetition patterns, though some are visible.
When attempting audio segmentation at the phraselevel, overall feature space homogeneity within single seg-ments may be an unsafe assumption given the shortertime scales involved, in which a performer might em-ploy expressive modulation of timbre. Furthermore, whilemelodic ideas in a jazz improvisation may be loosely in-spired by a theme, extended repetition is usually avoidedin favor of maximally unique melodies within a singleperformance. This context suggests that repetition-basedapproaches useful for identifying large-scale forms andthemes may be inappropriate. Figure 2 shows an exam-ple SDM computed at the same resolution as Figure 1 over60 seconds of a jazz improvisation. Note that while thisSDM contains block patterns associated with homogene-ity, they don’t necessarily align well with entire phrases.This SDM is also almost completely missing any identifi-able repetition patterns.
There does exist, however, some degree of predictabil-ity in jazz phrase structure that an ideal model should ex-ploit, albeit across a corpus rather than within a singletrack. We propose a system based on supervised trainingof a Hidden Markov Model with a low-level audio featureset designed to capture novelty in the form of large timbral
Figure 2. Self-distance matrix with annotated phraseboundaries plotted as white lines. Note the absence of off-diagonal striping patterns indicative of repetition, and theinfrequent occurrence of large homogeneous blocks overthe duration of entire phrases.
and harmonic shifts indicative of phrase boundaries. Ex-isting HMM approaches have included unsupervised train-ing, with a fixed-number of hidden states assumed to cor-respond to form-level sections [9, 10], instrument mix-tures [5], or simply a mid-level feature representation [6].Our model differs from existing HMM-based approachesin that it attempts to represent common elements of jazzphrase structure directly in the topology of the network,where the ground-truth state sequences are derived frominter-pitch intervals in audio-aligned transcriptions. Likelysequences of predicted states should therefore correspondto melodic contours well-represented in the training data,aiding in the detection of phrase boundaries.
3. DATASET AND PREPROCESSING
In 2014, the first version of the Weimar Jazz Database(WJazzD) was released as part of the larger Jazzomat Re-search Project [1]. The database contains transcriptions ofmonophonic solos by eminent jazz performers, well rep-resenting the evolution of the genre over the 20th century.The database was later expanded to include 299 solo tran-scriptions from 225 tracks, 70 performers, 11 instruments(soprano/alto/tenor/tenor-c/baritone sax, clarinet, trumpet,cornet, trombone, vibraphone, and guitar) and 7 styles(Traditional, Swing, Bebop, Hardbop, Cool, Postbop, andFree Jazz). The transcriptions were initially generated us-ing state-of-the-art automatic transcription tools and man-ually corrected by musicology students. In addition to thetranscriptions, the database contains a rich collection ofmetadata and human labels including phrase boundaries,underlying chord changes, form-level sections, and beatlocations.
Proceedings of the 17th ISMIR Conference, New York City, USA, August 7-11, 2016 483
3.1 MIDI to Audio Alignment
The lack of availability of the original audio tracks used assource material for the database’s transcriptions presentssome difficulty in taking full advantage of the possibili-ties for supervised machine learning methods using acous-tic features. Toward this end, we were able to obtain 217of 225 tracks containing the solo(s) as transcribed. Meta-data available in WJazzD indicate the starting and end-ing timestamps of the solo sections at a 1-second reso-lution, which is insufficient for determining ground truthfor phrase boundaries associated with note onset times.Additionally, pulling audio files from various sources in-troduces further uncertainty, as many tracks appear onboth original releases and compilations which may differslightly in duration or other edits.
To obtain ground truth, we trim the original tracks ac-cording to provided solo timestamps and employ a toolcreated by Dan Ellis [4] which uses Viterbi alignment onbeat-tracked versions of original audio and resynthesizedMIDI to modify and output an aligned MIDI file. Upon in-spection, 90 extracted solos produced a suitable alignmentthat required minimal manual corrections. We parse thedatabase and handle conversion to and from MIDI formatin Matlab using the MIDI Toolbox [3], making extensiveuse of the convenient note matrix format and pianoroll vi-sualizations.
4. AUDIO FEATURES
To represent large timbral shifts, we use spectral flux andcentroid features derived from the short-time Fourier trans-form (STFT), and spectral entropy derived from the powerspectral density (PSD) of the audio tracks, sampled at22050Hz with a FFT size of 1024 samples, Hamming win-dowed, with 25% overlap. Due to our interest in the leadinstrument only, features are computed on a normalizedportion of the spectrum between 500− 5000Hz to removethe influence of prominent bass lines while preserving har-monic content of the lead instrument.
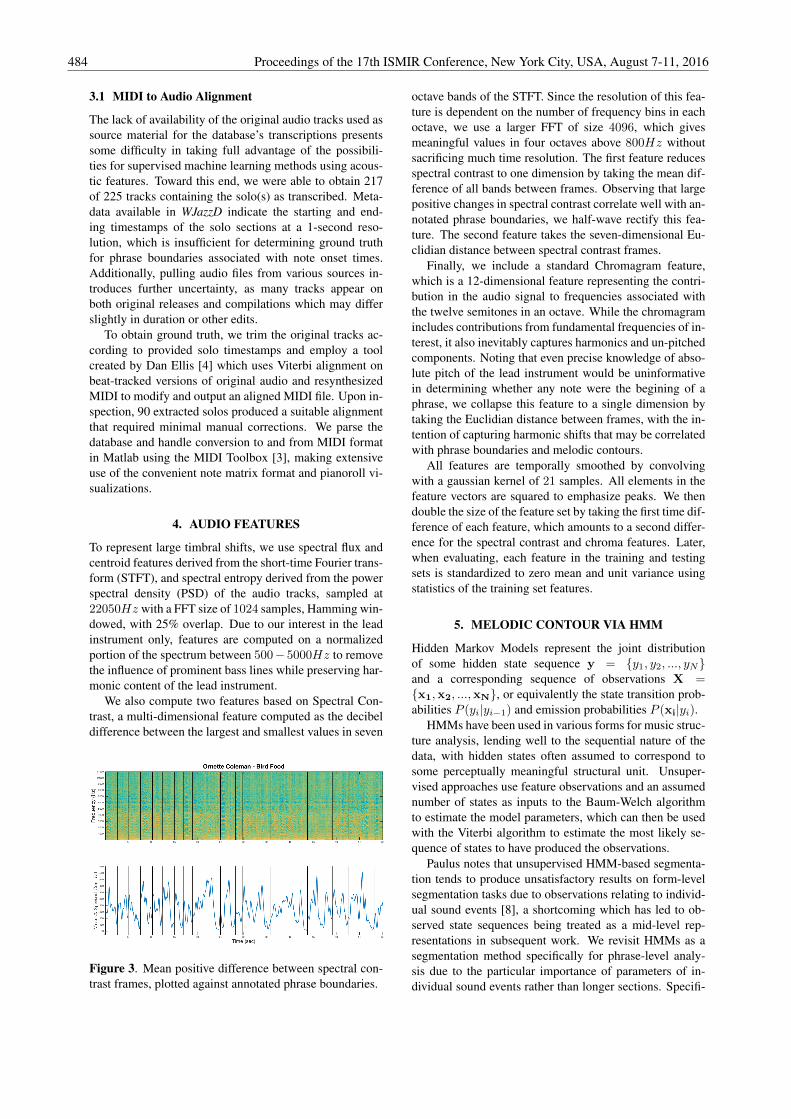
We also compute two features based on Spectral Con-trast, a multi-dimensional feature computed as the decibeldifference between the largest and smallest values in seven
Figure 3. Mean positive difference between spectral con-trast frames, plotted against annotated phrase boundaries.
octave bands of the STFT. Since the resolution of this fea-ture is dependent on the number of frequency bins in eachoctave, we use a larger FFT of size 4096, which givesmeaningful values in four octaves above 800Hz withoutsacrificing much time resolution. The first feature reducesspectral contrast to one dimension by taking the mean dif-ference of all bands between frames. Observing that largepositive changes in spectral contrast correlate well with an-notated phrase boundaries, we half-wave rectify this fea-ture. The second feature takes the seven-dimensional Eu-clidian distance between spectral contrast frames.
Finally, we include a standard Chromagram feature,which is a 12-dimensional feature representing the contri-bution in the audio signal to frequencies associated withthe twelve semitones in an octave. While the chromagramincludes contributions from fundamental frequencies of in-terest, it also inevitably captures harmonics and un-pitchedcomponents. Noting that even precise knowledge of abso-lute pitch of the lead instrument would be uninformativein determining whether any note were the begining of aphrase, we collapse this feature to a single dimension bytaking the Euclidian distance between frames, with the in-tention of capturing harmonic shifts that may be correlatedwith phrase boundaries and melodic contours.
All features are temporally smoothed by convolvingwith a gaussian kernel of 21 samples. All elements in thefeature vectors are squared to emphasize peaks. We thendouble the size of the feature set by taking the first time dif-ference of each feature, which amounts to a second differ-ence for the spectral contrast and chroma features. Later,when evaluating, each feature in the training and testingsets is standardized to zero mean and unit variance usingstatistics of the training set features.
5. MELODIC CONTOUR VIA HMM
Hidden Markov Models represent the joint distributionof some hidden state sequence y = {y1, y2, ..., yN}and a corresponding sequence of observations X ={x1,x2, ...,xN}, or equivalently the state transition prob-abilities P (yi|yi−1) and emission probabilities P (xi|yi).
HMMs have been used in various forms for music struc-ture analysis, lending well to the sequential nature of thedata, with hidden states often assumed to correspond tosome perceptually meaningful structural unit. Unsuper-vised approaches use feature observations and an assumednumber of states as inputs to the Baum-Welch algorithmto estimate the model parameters, which can then be usedwith the Viterbi algorithm to estimate the most likely se-quence of states to have produced the observations.
Paulus notes that unsupervised HMM-based segmenta-tion tends to produce unsatisfactory results on form-levelsegmentation tasks due to observations relating to individ-ual sound events [8], a shortcoming which has led to ob-served state sequences being treated as a mid-level rep-resentations in subsequent work. We revisit HMMs as asegmentation method specifically for phrase-level analy-sis due to the particular importance of parameters of in-dividual sound events rather than longer sections. Specifi-
484 Proceedings of the 17th ISMIR Conference, New York City, USA, August 7-11, 2016

cally, we postulate that phrases drawn from the jazz vocab-ulary follow predictable melodic contours, and incorporat-ing ground-truth knowledge of the distribution and tem-poral evolution of these contours as observed in a largedataset of phrases through supervised training may help inidentification of phrase boundaries.
6. EXPERIMENTS
We first evaluate a 2-state HMM, with states yi ∈ {0, 1}corresponding to the absence or presence (respectively) ofthe lead instrument during the ith audio frame. Thougha 2-state graphical model is trivial and offers no advan-tages over any other supervised classification method, weinclude it here simply as a basis for comparison with themulti-state models to evaluate the efficacy of adding statesbased on ground-truth pitch contour.
To estimate an upper bound on expected performanceof our audio-based models, we evaluate two symbolic seg-mentation models using features of precisely known notepitches and onset times. First, we evaluate the LocalBoundary Detection Model (LBDM) implementation of-fered by the MIDI Toolbox [3]. The LBDM outputs a con-tinuous boundary strength, which we use to tune a bound-ary prediction threshold for maximum f-score via crossvalidation. Second, we train a 2-state HMM, where themodel state yi then corresponds to the ith note rather thanthe ith audio frame, and takes the value 1 if the note is thefirst in a phrase, and 0 otherwise. Observations xi similarlycorrespond to features of individual note events includingthe IOI, OOI, and IPI. Results of the symbolic segmenta-tion models are shown in Table 1(a).
To directly encode melodic contour in the networktopology for the multi-state, audio-based HMMs, we ex-tract ground-truth state sequences based on quantizationlevels of the observed inter-pitch interval (IPI) in the tran-scription. The following indicate the state of the networkfollowing each IPI, where the state remains for the durationof the note, rounded to the nearest audio frame:
5-State yi =
0 lead instrument absent1 first phrase note2 IPI < 0
3 IPI = 0
4 IPI > 0
7-State yi =
0 lead instrument absent1 first phrase note2 IPI < −53 −5 ≤ IPI < 0
4 IPI = 0
5 0 < IPI ≤ 5
6 IPI > 5
The 5-state model simply encodes increas-ing/decreasing/unison pitch in the state sequence. The7-state model further quantizes increasing and decreasingpitch into intervals greater than and less than a perfectfourth. Each HMM requires a discrete observation se-quence, so the 10-dimensional audio feature set describedin Section 4 is discretized via clustering using a GaussianMixture Model (GMM) with parameters estimated viaExpectation-Maximization (EM).
We note that in the solo transcriptions, there are manyexamples of phrase boundaries that occur between twonotes played legato (i.e. the offset-onset interval is zero orless than the time duration of a single audio frame). Whenparsing the MIDI data and associated boundary note an-notations to determine the state sequence for each audioframe, in any such instance where state 1 is not precededby state 0, we force a 0-1 transition to allow the model toaccount for phrase boundaries that aren’t based primarilyon temporal discontinuity cues.
7. RESULTS
Evaluation of each network is performed via six fold cross-validation, where each fold trains the model on five stylesas provided by the WJazzD metadata, and predicts on theremaining style. We note that WJazzD encompasses sevenstyles, but the 90 examples successfully aligned to corre-sponding audio tracks did not include any traditional jazz.Though the sequence of states predicted by the model in-clude the contour-based states, our reported results onlyconsider accuracy in predicting a transition to state 1 in allcases.
Precision, recall, and f-score metrics reported in form-level segmentation experiments typically consider a truepositive to be a boundary identified within 0.5 and 3 sec-onds of the ground truth. Considering the short time scalesinvolved with phrase-level segmentation, we report metricsconsidering a true positive to be within one beat and onehalf beat, as determined using each solo’s average tempo
Model Pn Rn Fn
LBDM 0.7622 0.7720 0.7670HMM, 2-State 0.8225 0.8252 0.8239
(a) Symbolic models
Model P1B R1B F1B
HMM, 2-State 0.6114 0.5584 0.5837HMM, 5-State 0.5949 0.6586 0.6251HMM, 7-State 0.6116 0.6565 0.6333
(b) Audio models, true positive within one beat of annotation
Model P0.5B R0.5B F0.5B
HMM, 2-State 0.4244 0.3876 0.4052HMM, 5-State 0.4039 0.4472 0.4245HMM, 7-State 0.4212 0.4521 0.4361
(c) Audio models, true positive within half beat of annotation
Table 1. Segmentation results
Proceedings of the 17th ISMIR Conference, New York City, USA, August 7-11, 2016 485
annotation provided by WJazzD. For reference, the meantime per beat in the 90 aligned examples is 0.394 seconds,with a standard deviation of 0.178 seconds. All beat dura-tions were less than 1 second.
We report precision, recall, and f-score computed overall examples, all folds, and 5 trials. Reported results use30 Gaussian components as discrete observations in theaudio-based models, and 5 components for the symbolicmodel, and are summarized in Table 1. For greater insightinto the model’s performance in different stylistic contexts,we also present the cross-validation results across the sixstyles in Figure 4.
8. DISCUSSION
ANOVA and post-hoc analysis reveals both multi-statemodels yielding increased recall over the 2-state model(F2,1332 = 30.62, p < 10−13), and increased f-score(F2,1332 = 11.28, p < 10−4) with no significant differ-ence in precision. Interestingly, the most significant re-call increases from addition of the melodic contour stateswithin styles include hardbop (F2,297 = 15.68, p < 10−6),postbop (F2,432 = 12.22, p < 10−5), and swing styles(F2,177 = 6.73, p < 10−3).
These increases in recall within a style also corre-late well with a high proportion of occurrences of phraseboundaries with no temporal discontinuity. These accountfor 22% of all phrase boundaries in hardbop, 18% in post-bop, and 29% in swing, while accounting for 17%, 7%,and 4% in bebop, cool, and free jazz, respectively. We be-lieve this suggests that incorporating ground-truth melodiccontour allows the model to account for the relationship
(a) 2-State
(b) 5-State
(c) 7-State
Figure 4. Audio-based HMM segmentation results bystyle. Significant (p < 0.005) increases in recall and f-score observed in Hardbop, Postbop, and Swing.
between contours indicative of phrase boundaries and theirassociated timbral and harmonic shifts.
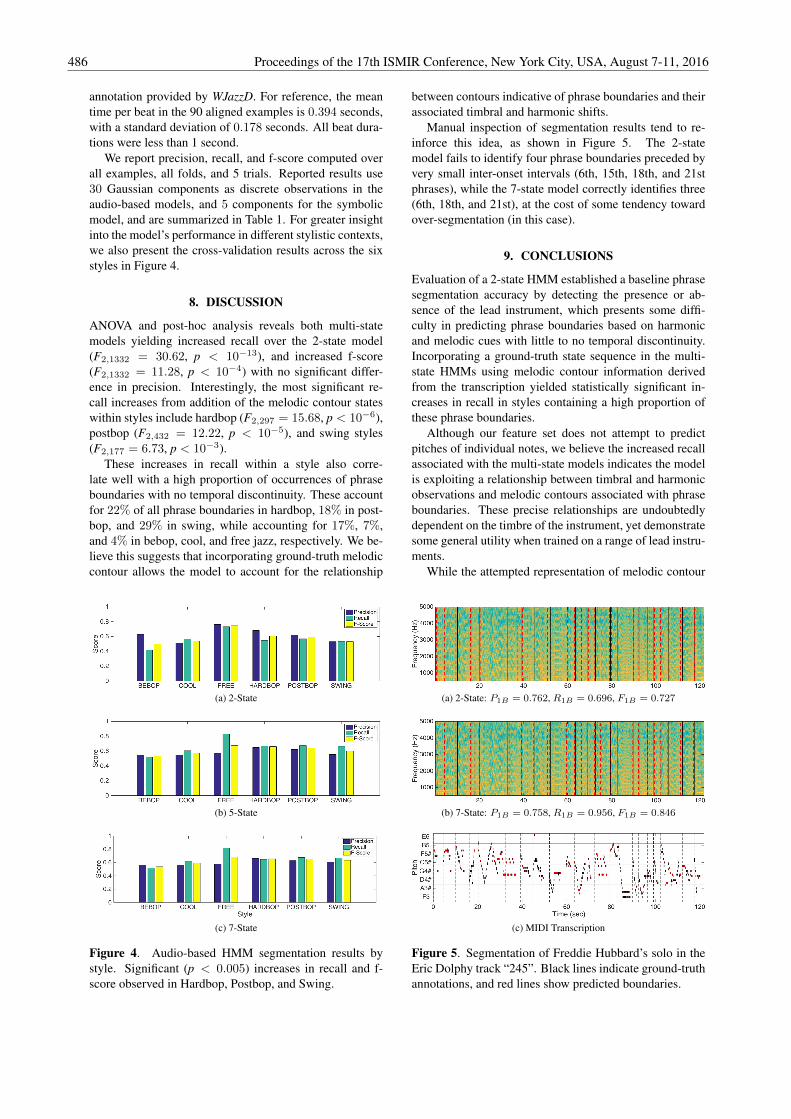
Manual inspection of segmentation results tend to re-inforce this idea, as shown in Figure 5. The 2-statemodel fails to identify four phrase boundaries preceded byvery small inter-onset intervals (6th, 15th, 18th, and 21stphrases), while the 7-state model correctly identifies three(6th, 18th, and 21st), at the cost of some tendency towardover-segmentation (in this case).
9. CONCLUSIONS
Evaluation of a 2-state HMM established a baseline phrasesegmentation accuracy by detecting the presence or ab-sence of the lead instrument, which presents some diffi-culty in predicting phrase boundaries based on harmonicand melodic cues with little to no temporal discontinuity.Incorporating a ground-truth state sequence in the multi-state HMMs using melodic contour information derivedfrom the transcription yielded statistically significant in-creases in recall in styles containing a high proportion ofthese phrase boundaries.
Although our feature set does not attempt to predictpitches of individual notes, we believe the increased recallassociated with the multi-state models indicates the modelis exploiting a relationship between timbral and harmonicobservations and melodic contours associated with phraseboundaries. These precise relationships are undoubtedlydependent on the timbre of the instrument, yet demonstratesome general utility when trained on a range of lead instru-ments.
While the attempted representation of melodic contour
(a) 2-State: P1B = 0.762, R1B = 0.696, F1B = 0.727
(b) 7-State: P1B = 0.758, R1B = 0.956, F1B = 0.846
(c) MIDI Transcription
Figure 5. Segmentation of Freddie Hubbard’s solo in theEric Dolphy track “245”. Black lines indicate ground-truthannotations, and red lines show predicted boundaries.
486 Proceedings of the 17th ISMIR Conference, New York City, USA, August 7-11, 2016

in the model topology indicates some promise, we believethere are likely better alternatives to modeling contour thanarbitrary quanitzation of ground truth inter-pitch intervals.Future work should examine the potential of assemblingobserved contours from a smaller set of contour primitivesover longer time scales than note pair transitions. Fur-thermore, though our approach avoided relying high-levelpitch estimates derived from the audio because of strongpotential for propagation of errors, we will investigate theuse of mid-level pitch salience functions in future featuresets.
More generally, we believe that the availability of well-aligned audio and symbolic data can allow the use of super-vised methods as a precursor to more scalable audio-basedmethods, and aid in the creation of mid-level features use-ful for a wide range of MIR problems.
10. REFERENCES
[1] Jakob Aeßler, Klaus Frieler, Martin Pfleiderer, andWolf-Georg Zaddach. Introducing the jazzomat project- jazz solo analysis using music information retrievalmethods. In In: Proceedings of the 10th InternationalSymposium on Computer Music Multidisciplinary Re-search (CMMR) Sound, Music and Motion, Marseille,Frankreich., 2013.
[2] Emilios Cambouropoulos. Music, Gestalt, and Com-puting: Studies in Cognitive and Systematic Musicol-ogy, chapter Musical rhythm: A formal model fordetermining local boundaries, accents and metre in amelodic surface, pages 277–293. Springer Berlin Hei-delberg, Berlin, Heidelberg, 1997.
[3] Tuomas Eerola and Petri Toiviainen. MIDI Toolbox:MATLAB Tools for Music Research. University ofJyvaskyla, Jyvaskyla, Finland, 2004.
[4] D.P.W. Ellis. Aligning midi files to music au-dio, web resource, 2013. http://www.ee.columbia.edu/˜dpwe/resources/matlab/alignmidi/. Accessed 2016-03-11.
[5] Sheng Gao, N. C. Maddage, and Chin-Hui Lee. Ahidden markov model based approach to music seg-mentation and identification. In Information, Commu-nications and Signal Processing, 2003 and Fourth Pa-cific Rim Conference on Multimedia. Proceedings ofthe 2003 Joint Conference of the Fourth InternationalConference on, volume 3, pages 1576–1580 vol.3, Dec2003.
[6] M. Levy and M. Sandler. Structural segmentation ofmusical audio by constrained clustering. Trans. Au-dio, Speech and Lang. Proc., 16(2):318–326, February2008.
[7] Marcelo Rodrguez Lpez and Anja Volk. Melodic seg-mentation: A survey. Technical Report UU-CS-2012-015, Department of Information and Computing Sci-ences, Utrecht University, 2012.
[8] Jouni Paulus, Meinard Muller, and Anssi Klapuri. Stateof the art report: Audio-based music structure analy-sis. In Proceedings of the 11th International Society forMusic Information Retrieval Conference, ISMIR 2010,Utrecht, Netherlands, August 9-13, 2010, pages 625–636, 2010.
[9] Geoffroy Peeters, Amaury La Burthe, and XavierRodet. Toward automatic music audio summary gen-eration from signal analysis. In In Proc. InternationalConference on Music Information Retrieval, pages 94–100, 2002.
[10] Mark Sandler and Jean-Julien Aucouturier. Segmenta-tion of musical signals using hidden markov models. InAudio Engineering Society Convention 110, May 2001.
[11] David Temperley. The cognition of basic musical struc-tures. MIT Press, 2004.
Proceedings of the 17th ISMIR Conference, New York City, USA, August 7-11, 2016 487





























