Embed Size (px)
Citation preview

Philip Jackson and Martin RussellPhilip Jackson and Martin Russell
Electronic Electrical and Computer Engineering
Models of speech Models of speech dynamics in a segmental-dynamics in a segmental-
HMM recognizer using HMM recognizer using intermediate linear intermediate linear
representationsrepresentations
http://web.bham.ac.uk/p.jackson/balthasar/
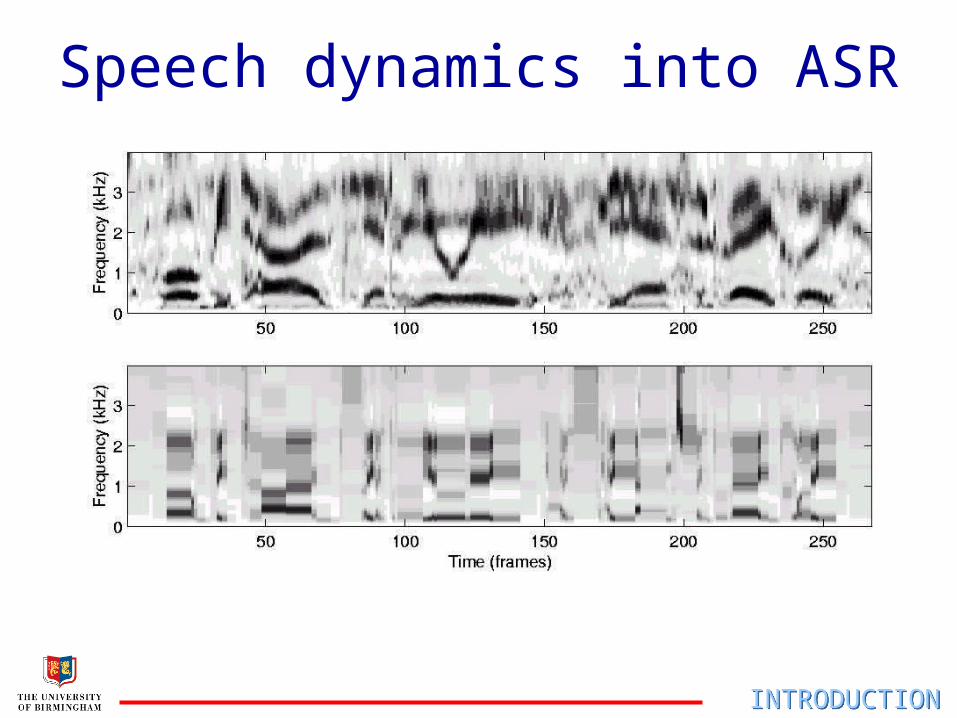
Speech dynamics into ASR
INTRODUCTIONINTRODUCTION
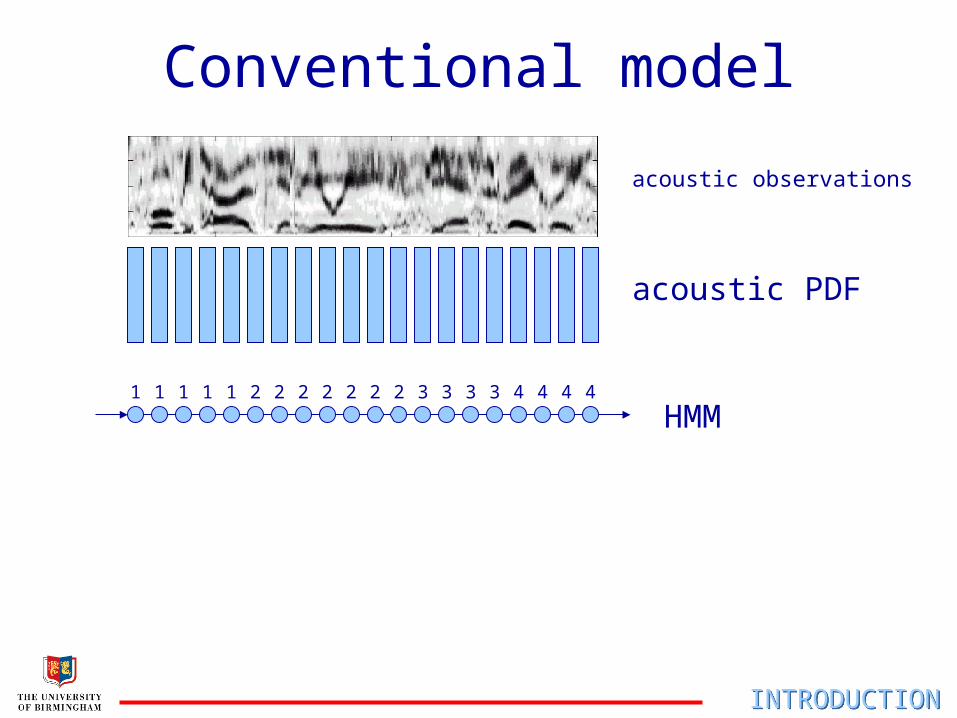
Conventional model
INTRODUCTIONINTRODUCTION
1
acoustic observations
HMM
acoustic PDF
1 11 1 2 3 42 2222 3 33 4 4 42
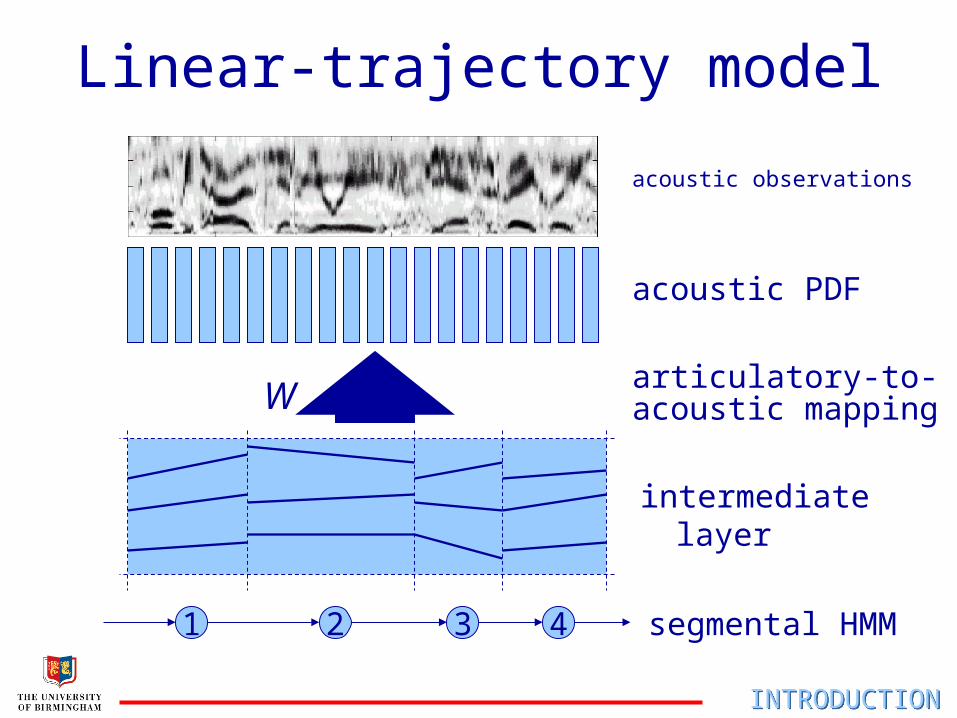
Linear-trajectory model
INTRODUCTIONINTRODUCTION
2 3 41
W
acoustic observations
articulatory-to-
intermediate layer
segmental HMM
acoustic PDF
acoustic mapping

Multi-level Segmental HMM
• segmental finite-state process
• intermediate “articulatory” layer– linear trajectories
• mapping required– linear transformation– radial basis function network
INTRODUCTIONINTRODUCTION

Estimation of linear mapping
Matched sequences andT1x
YXW
,1Ty
YWXD min
THEORYTHEORY

Linear-trajectory equations
Defined as:
,iii ttt cmf
THEORYTHEORY
21 t
tif
t
ic

Training the model parameters
For optimal least-squares estimates (acoustic domain):
,s
11
)(1
ˆi
i
t
tti t
Tyc
1 2
1
1
1 )(ˆ
i
i
i
i
t
tt
t
tti
tt
tttym
THEORYTHEORY
midpoint
slope

11
)(1
ˆi
i
t
ttki tW
Tyc
THEORYTHEORY
midpoint
slope
For optimal least-squares estimates (articulatory domain):
,s
1 2
1
1
1 )(ˆ
i
i
i
i
t
tt
t
tt k
itt
tttW ym
Training the model parameters

11
)(1
ˆi
i
t
ttikii tDWD
Tyc
1 2
1
1
1 )(ˆ
i
i
i
i
t
tt
t
tt iki
itt
tttDWD ym
THEORYTHEORY
midpoint
slope
For optimal maximum-likelihood estimates (articulatory domain):
,s
Training the model parameters

Tests on MOCHA
• S. British English, at 16kHz (Wrench, 2000)
– MFCC13 acoustic features, incl. zero’th
– articulatory x- & y-coords from 7 EMA coils– PCA9+Lx: first nine articulatory modes plus
the laryngograph log energy
METHODMETHOD
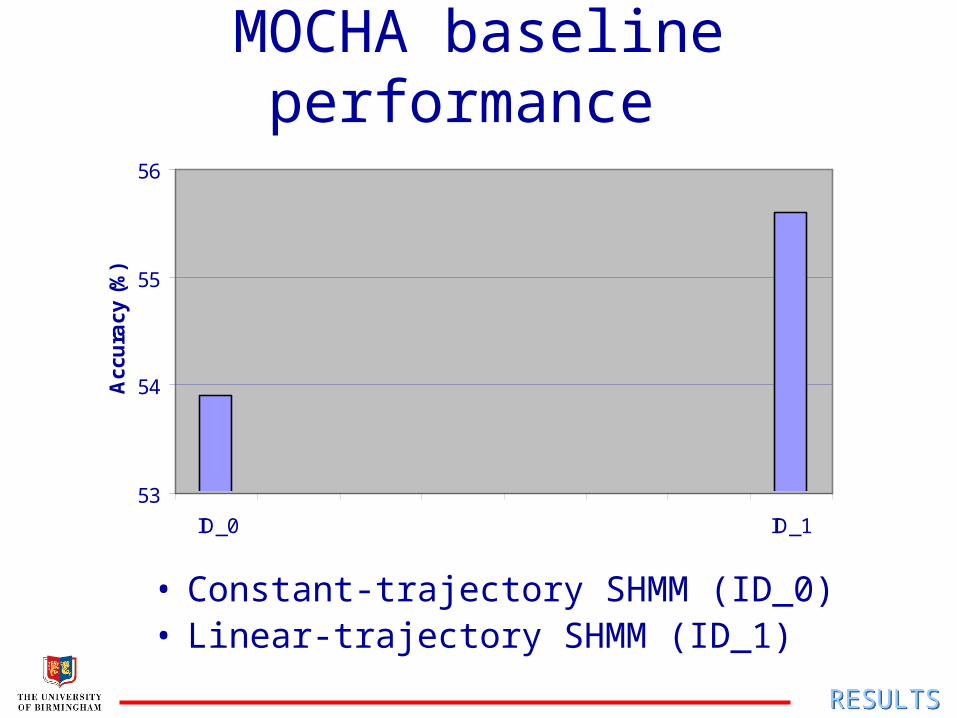
MOCHA baseline performance
53
54
55
56
ID_0 ID_1
Mappings
Acc
ura
cy (
%)
RESULTSRESULTS
• Constant-trajectory SHMM (ID_0)• Linear-trajectory SHMM (ID_1)
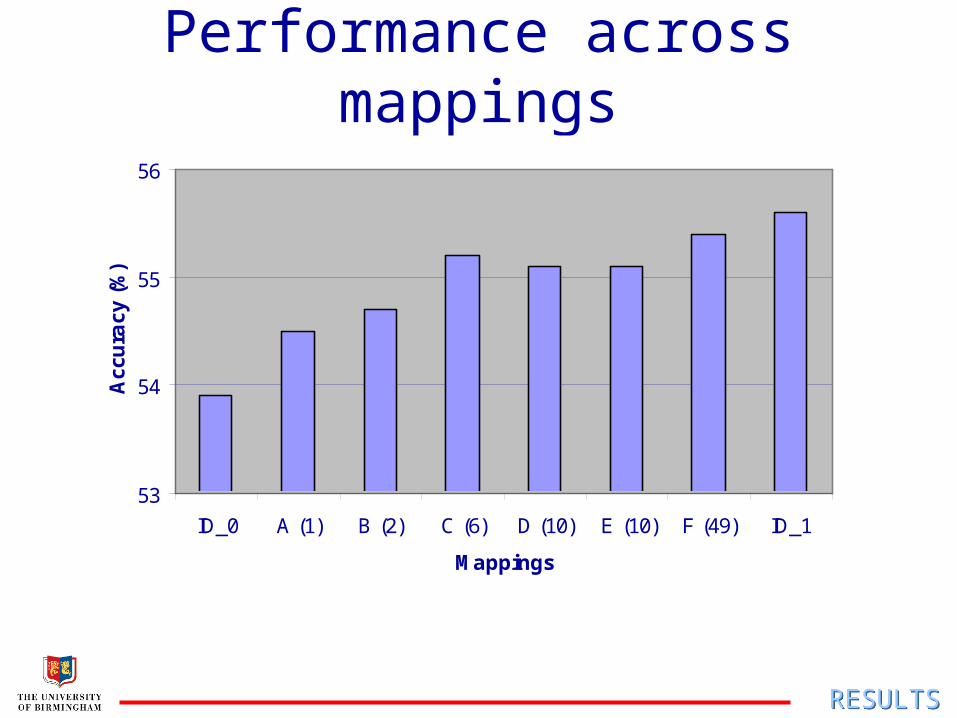
Performance across mappings
53
54
55
56
ID_0 A (1) B (2) C (6) D (10) E (10) F (49) ID_1
Mappings
Acc
ura
cy (
%)
RESULTSRESULTS
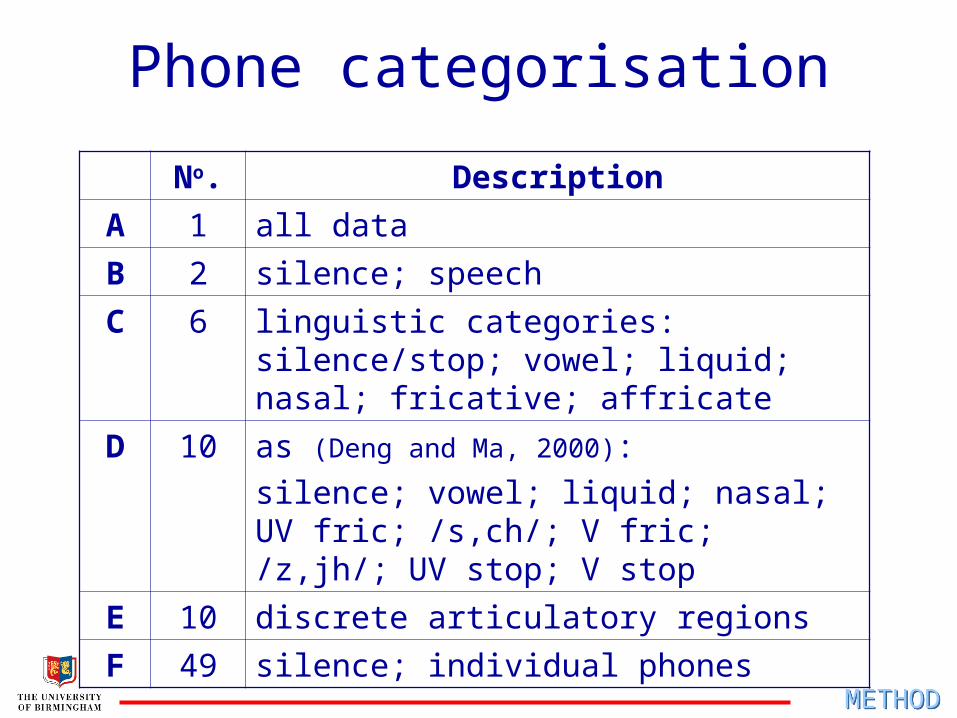
Phone categorisation
No. Description
A 1 all data
B 2 silence; speech
C 6 linguistic categories: silence/stop; vowel; liquid; nasal; fricative; affricate
D 10 as (Deng and Ma, 2000):silence; vowel; liquid; nasal; UV fric; /s,ch/; V fric; /z,jh/; UV stop; V stop
E 10 discrete articulatory regions
F 49 silence; individual phonesMETHODMETHOD

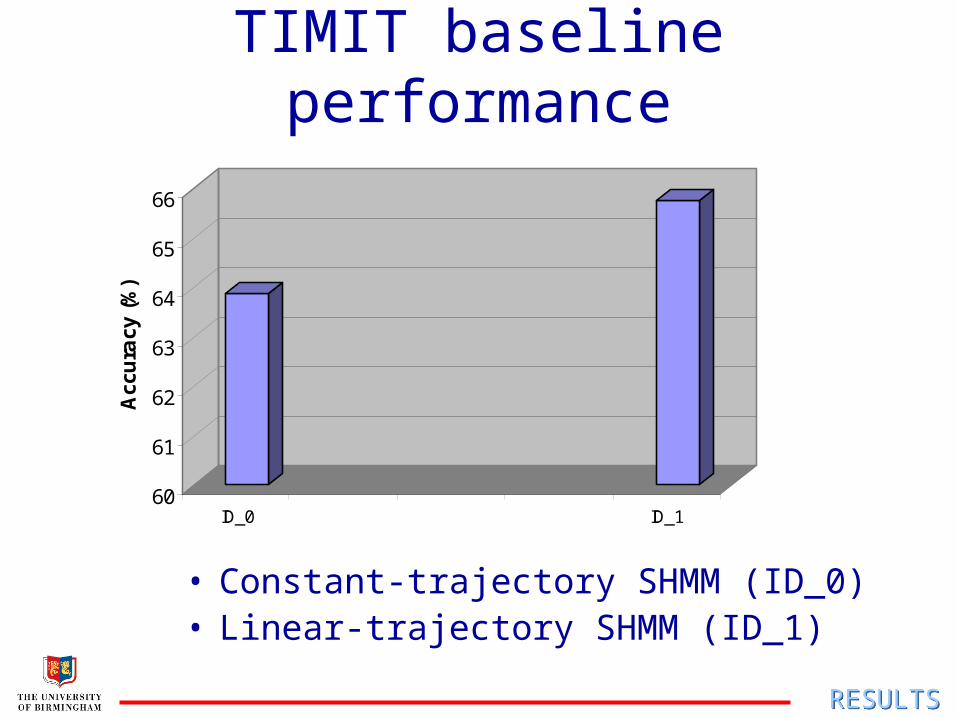
Tests on TIMIT
• N. American English, at 8kHz
– MFCC13 acoustic features, incl. zero’th
a) F1-3: formants F1, F2 and F3, estimated by Holmes formant tracker
b) F1-3+BE5: five band energies added
c) PFS12: synthesiser control parameters
METHODMETHOD
60
61
62
63
64
65
66
Acc
ura
cy (
%)
ID_0 ID_1
Features
TIMIT baseline performance
• Constant-trajectory SHMM (ID_0)• Linear-trajectory SHMM (ID_1)
RESULTSRESULTS
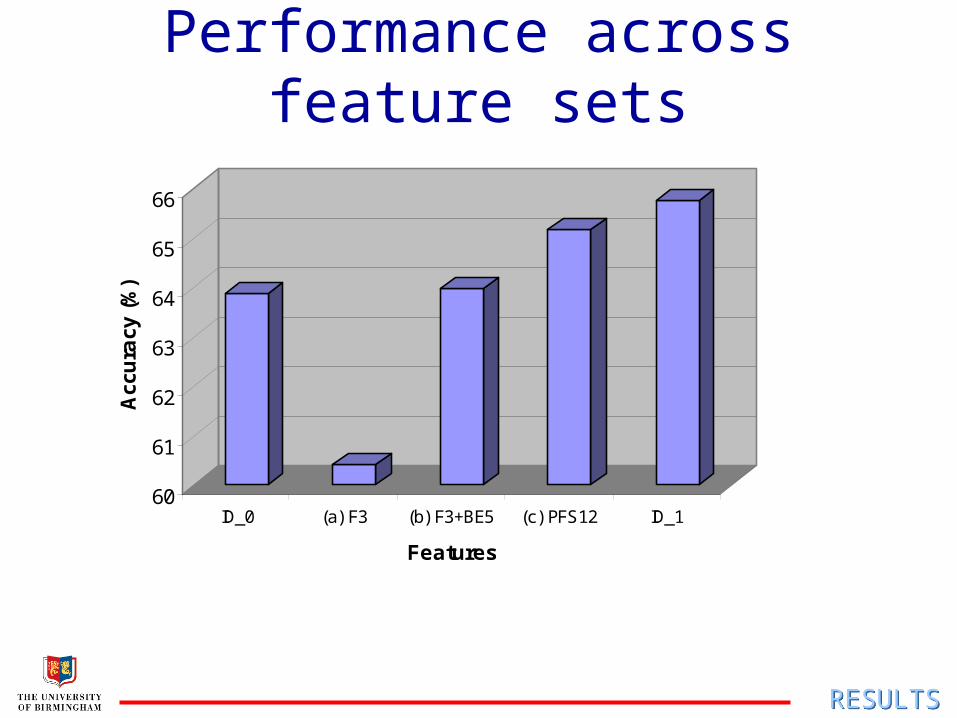
Performance across feature sets
RESULTSRESULTS
60
61
62
63
64
65
66
Acc
ura
cy (
%)
ID_0 (a) F3 (b) F3+BE5 (c) PFS12 ID_1
Features
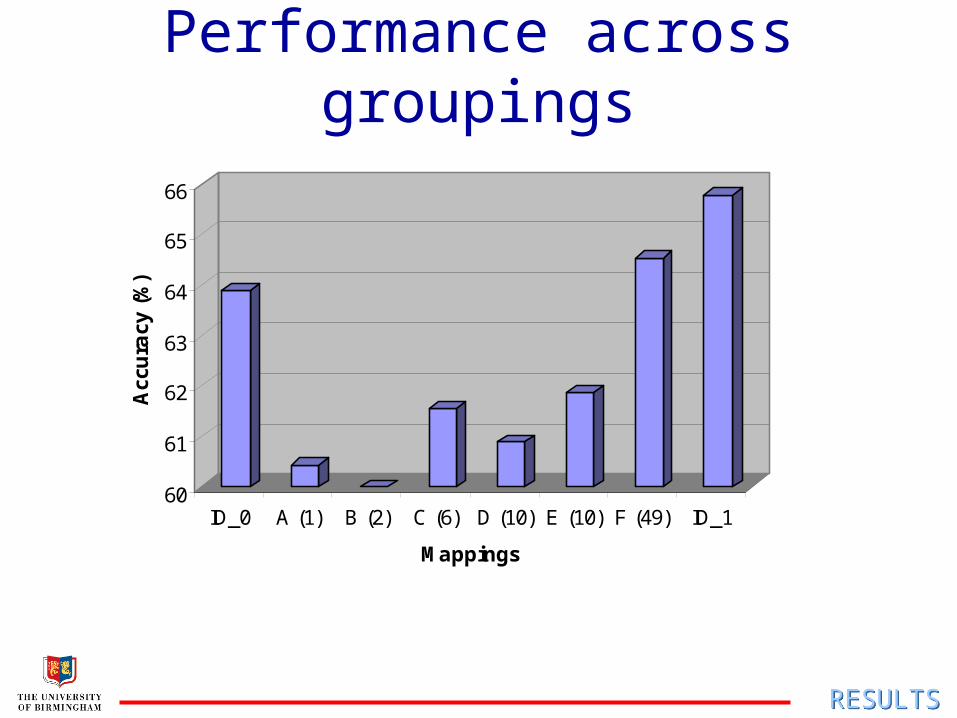
Performance across groupings
RESULTSRESULTS
60
61
62
63
64
65
66
Acc
ura
cy (
%)
ID_0 A (1) B (2) C (6) D (10) E (10) F (49) ID_1
Mappings
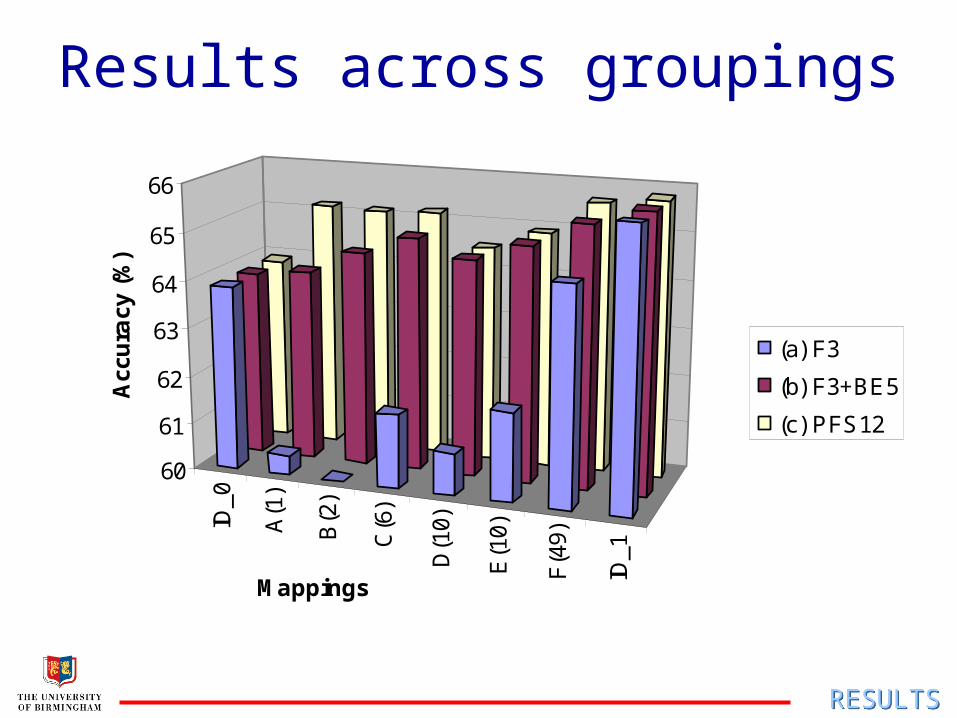
Results across groupings
RESULTSRESULTS
ID_0
A(1
)
B(2
)
C(6
)
D(1
0)
E(1
0)
F(4
9)
ID_1
60
61
62
63
64
65
66
Acc
ura
cy (
%)
Mappings
(a) F3
(b) F3+BE5
(c) PFS12
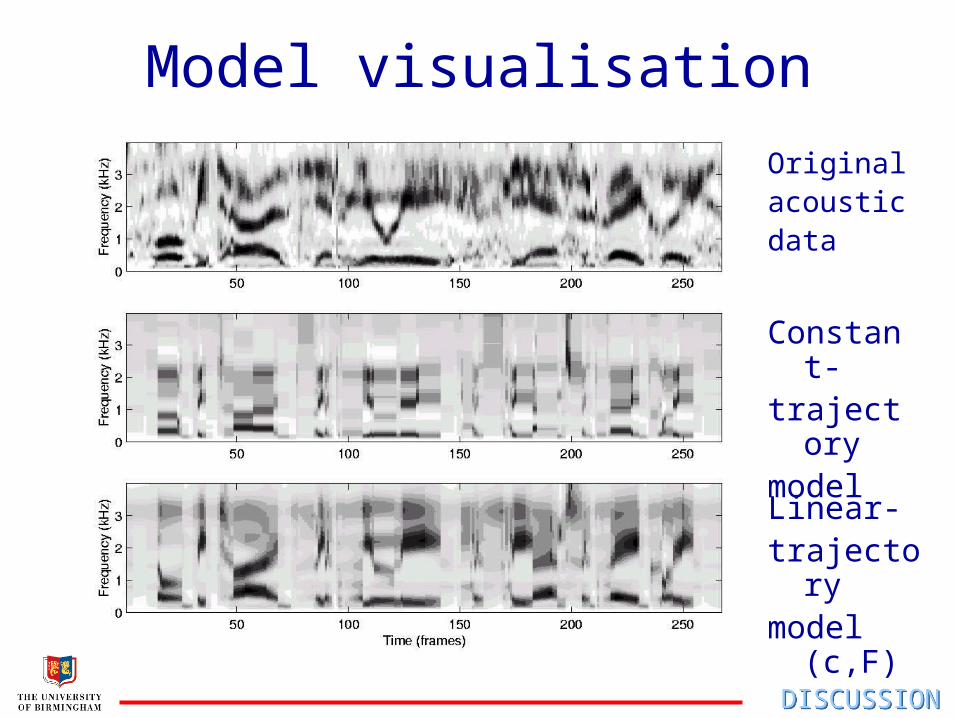
Model visualisation
Originalacousticdata
Constant-trajectorymodel
Linear-trajectorymodel (c,F)
DISCUSSIONDISCUSSION

Conclusions• Developed framework for speech
dynamics in an intermediate space• Linear traj. + piecewise linear mapping
bounded by performance of linear traj. in acoustic space
• Near optimal performance achieved– For more than 3 formant parameters– For 6 or more linear mappings
• Formants and articulatory parameters gave qualitatively similar results
• What next?
SUMMARYSUMMARY

• Complete experiments with lang. model• Include segment duration models• Derive pseudo-articulatory
representations by unsupervised (embedded) training
• Implement non-linear mapping (i.e., RBF)
• Further information:– here and now– [email protected]– web.bham.ac.uk/p.jackson/balthasar
SUMMARYSUMMARY
Further work





























