Embed Size (px)
Citation preview

IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 16, NO. 8, NOVEMBER 2008 1503
Phantom Materialization: A Novel Method toEnhance Stereo Audio Reproduction on Headphones
Jeroen Breebaart, Member, IEEE, and Erik Schuijers
Abstract—Loudspeaker reproduction systems are subject toa compromise between spatial realism and cost. By simulatingloudspeaker reproduction on headphones, the resulting spatialrealism is limited accordingly, despite the virtually unlimitedspatial imaging capabilities of binaural audio rendering tech-nology. More particularly, phantom imaging as often used forstereo audio material intended for loudspeaker reproduction issubject to various restrictions in terms of loudspeaker positioningin simulated space. As a consequence, phantom imaging shouldpreferably be avoided when simulating virtual loudspeakers overheadphones, especially if head tracking is incorporated or if awide sound stage is desired. A novel method is described to extractphantom sound sources from stereo audio content and convertthese to sound sources in a virtual listening environment.
Index Terms—Audio systems, head-related transfer functions(HRTFs), headphones, loudspeakers, perceptual quality, phantomimaging, position measurement, spatial audio, sound localization,virtual audio reproduction.
I. INTRODUCTION
D URING the last two decades, headphones as audio repro-duction systems have gained significant interest. Since the
introduction of the portable cassette players in the early 1980s,mobile music players have become extremely popular, espe-cially among youngsters. Since then, mobile players have devel-oped quite rapidly. During the mid 1980s, the analog, magnetictape storage medium was replaced by optical storage methods(CDs) with content stored in digital format that significantly im-proved the audio quality. Around the year 2000, flash memorywas introduced to store music in a digital, compressed format,resulting in a significant increase in storage capacity expressedin hours of content. Very recently, mobile players have been ex-tended with video playback capabilities as well. Given the largeavailability of video content accompanied by surround-soundaudio, it can be expected that 3-D sound positioning will find itsway in the mobile domain in the near future.
Mobility and social constraints in most cases dictate head-phones as a reproduction device on mobile players. In contrastto loudspeaker playback, stereo audio content reproduced overheadphones is perceived inside the head [1]. The absence of theeffect of the acoustical pathway from sources at certain phys-ical positions to the eardrums causes the spatial image to sound
Manuscript received December 20, 2007; revised July 07, 2008. Current ver-sion published October 17, 2008The associate editor coordinating the review ofthis manuscript and approving it for publication was Dr. Susanto Rahardja.
J. Breebaart is with Philips Research (HTC 34 MS 61), 5656 AE Eindhoven,The Netherlands (e-mail: [email protected]).
E. Schuijers is with Philips Applied Technologies (HTC 5), 5656 AE Eind-hoven, The Netherlands (e-mail: [email protected]).
Digital Object Identifier 10.1109/TASL.2008.2002983
unnatural, since the cues that determine the perceived azimuth,elevation, and distance of a sound source are essentially missingor very inaccurate.
To resolve the unnatural sound stage caused by inaccurate orabsent sound source localization cues on headphones, varioussystems have been proposed to simulate a virtual loudspeakersetup. The idea is to superimpose sound source localization cuesonto each loudspeaker signal. The technology for such binauralaudio rendering on headphones has attracted quite some interestin various research areas and has found its way to consumerelectronic devices.
It is well known that accurate synthesis process of virtualsources over headphones is not straightforward. In particular,it has shown to be very difficult to match the perceived andintended sound source position and distance using a generic,nonindividualized system [2]. Another challenge is related tothe effect of head movements. In normal listening conditions,head rotations will result in a change of stationary sound sourcepositions relative to the orientation of the head. When usingheadphones, on the other hand, the position of virtual soundsources moves along with head rotations. The absence of theeffect of head rotations in virtual auditory displays has a detri-mental effect on naturalness [3], [4] and sound source localiza-tion abilities [5]–[8]. One method to resolve this inconsistencythat has been proposed is to measure the orientation of the headby means of a so-called head tracker, and modify the parametersof the synthesis process accordingly to simulate sound sourcepositions that have stationary physical locations.
For music or movie content, there is an additional challengethat is often not mentioned explicitly. By simulation of a virtualloudspeaker setup, the constraints and limitations that apply tothe suboptimal reproduction system will also limit the spatialimage quality in the virtual environment on top of the difficultiesthat exist for binaural synthesis in general.
In the next section, limitations and constraints of loudspeakerreproduction will be discussed in more detail. Subsequently, thegeneral challenges for binaural synthesis will be outlined, fol-lowed by a discussion on the consequences of combining thetwo: the synthesis of virtual loudspeaker setups. Finally, an al-ternative solution for binaural synthesis is described that re-solves some of the problems associated with virtual loudspeakersetups.
II. STEREOPHONIC COMPROMISE
The aim of an audio or recording engineer is to provide anartistically meaningful and preferably realistic reproduction ofa certain event or recording, given the limitations of a certaintarget reproduction system. Basically, two approaches can be
1558-7916/$25.00 © 2008 IEEE

1504 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 16, NO. 8, NOVEMBER 2008
pursued (cf. [9]). The first approach, referred to as there andthen, aims at an accurate reproduction of the spatial characteris-tics that were present during the recording. The idea is to createthe illusion that the listener is situated in the same room as therecording was made, for example in a concert hall. The secondmethod, referred to as here and now, aims at placing various au-ditory objects in the reproduction room, i.e., in the same roomthe listener is situated during playback.
One of the major challenges that audio engineers are facing isthat the target reproduction system is suboptimal and restrictedin terms of spatial imaging capabilities. These restrictionsfollow from various cost and esthetic considerations. The mostpopular loudspeaker reproduction system is based on two-channel stereophony, using two loudspeakers ideally positionedat 30 and 30 azimuth and at equal distance from thelistener. Under these circumstances, the listener is positionedin the so-called sweet spot. Given this setup, a technique re-ferred to as amplitude panning can position a phantom soundsource between the two loudspeakers. Thus, in the contextof this paper, the term phantom source reflects a perceivedsound source at a position in between the loudspeakers that iscreated using panning techniques. For a phantom source gen-erated using amplitude panning, the employed inter-channellevel differences (ICLDs) result in inter-aural time differences(ITDs) and inter-aural level differences (ILDs) at the level ofthe listener’s eardrums that roughly correspond to those of thedesired phantom sound source position [10]. However, thereare indications that the match between sound source localiza-tion cues resulting from a phantom source and those from areal source can differ significantly, especially in the mid- andhigh-frequency range [10]–[12].
Second, the area of feasible phantom source positions is quitelimited. Basically, phantom sources can only be positioned at anarc between the two loudspeakers. The angle between the twoloudspeakers has an upper limit of about 60 [13], and hence theresulting frontal image is limited in terms of width. However,even for such limited aperture angle of the speakers, the per-ceived phantom source position is not fully deterministic and de-pends on the temporal and spectral characteristics of the sourcesignals [11], [14].
Third, in order for amplitude panning to work correctly, theposition of the listener is very restricted. The sweet spot is usu-ally quite small. As soon as the listener moves outside the sweetspot, panning techniques fail and audio sources are perceived atthe position of the closest loudspeaker [15].
A fourth restriction applies to the orientation of the listener.If due to head or body rotations both speakers are not positionedsymmetrically on both sides of the median plane, the conversionfrom inter-channel relations to correct inter-aural cues fails, andthe perceived position of phantom sources is wrong or becomesambiguous [16]–[20].
A fifth potential issue is the spectral coloration that is in-duced by amplitude panning. Due to dissimilar path-lengthdifferences to both ears and the resulting comb-filter effects,phantom sources may suffer from pronounced spectral modifi-cations compared to a real sound source at the desired position[17], [21]. It has also been shown that speech intelligibility issignificantly improved for a real (center) loudspeaker source
compared to a phantom source, which may also be attributedto the presence of comb-filter effects in the phantom-sourcecase [22].
A final, more generic potential problem of loudspeaker re-production is that the room-acoustic properties in which the re-production system is placed will be superimposed on the room-acoustic properties of the recording. In the case of a here andnow type recording, this is a desired property, but for record-ings that were mixed according to the there and then principle,the reproduction room acoustics may interfere with those cap-tured by the recording.
III. VIRTUAL CHALLENGES
If the panning techniques to create phantom sources onloudspeaker systems are used on headphones, the auditoryobjects are perceived inside the head [1], [10], [23], [24]. Thisis because the simple, frequency-independent level and/or timedifferences between the audio channels only approximate thesound-source localization cues that appear in the real world.Inter-aural level differences and inter-aural time differences de-pend on azimuth and elevation of a sound source in a complexway, due to path-length differences, diffraction, reflections, andhead-shadow effects. In order to create a realistic virtual soundsource, the acoustical pathway from a certain sound sourceposition to both eardrums must be modeled in great detail.The most common method to describe and process virtualsound sources is by means of head-related transfer functions(HRTFs) [25]–[28]. Typically, HRTFs come in pairs (one foreach ear) and due to their strong dependence on position, theyare typically measured at a very fine spatial resolution (typi-cally 5 to 10 spacing, cf. [29], [30]). Besides dependenceon azimuth and elevation, HRTFs vary also as a function ofdistance [31], [32]. The large amount of data, associated withan HRTF database, and the required processing power are themain challenges in binaural audio processing [2], especially onmobile devices with limited processing power and battery life.
Another difficulty is the dependence of HRTFs on the specificanthropometric properties of each individual [33], [34]. If sig-nals are processed with individualized HRTFs in anechoic con-ditions and a fixed head orientation/position, listeners cannotdiscriminate between a real sound source and a virtual soundsource [26], [28]. Despite such accurate reproduction of virtualsources, subjects show localization errors and front/back confu-sions with generic [35] as well as with individualized HRTFs,especially for positions on the so-called cones of confusion thathave virtually identical ITD and ILD cues [32], [35], [36]. Ifnon-individual HRTFs are used, sound source localization per-formance degrades [33], [37], [38]. Interestingly, if head ro-tations are allowed during sound stimulation using a physicalsound source, or if the effect of head rotations is taken intoaccount in the synthesis process of virtual sources, the local-ization accuracy of human sound source localization increasesconsiderably (especially in terms of front/back reversals), bothfor individual as well as non-individual HRTFs [5], [35], [38].Moreover, there is some evidence that if head rotations are in-cluded in the binaural synthesis, non-individualized and indi-vidualized HRTFs give approximately equal localization per-formance [5]–[8]. This observation seems to suggest that HRTF

BREEBAART AND SCHUIJERS: PHANTOM MATERIALIZATION 1505
personalization is only required in the case that the effect of headrotations are not taken into account in the synthesis process.
If anechoic HRTFs are employed, the perceived distance ofthe virtual source is often very limited. The addition of a room-acoustic model, involving early reflections (i.e., the first part ofthe time-domain reverb impulse response that mainly containsdistinct peaks) is known to increase the out-of-head percept andrealism of a virtual sound source [35], [39], [40]. The additionof late reverberation (the remainder of the impulse response thatis in most cases described in terms of statistical properties suchas the decay time and modal density) does not seem to haveany effect on externalization [35]. The incorporation of roomacoustics, however, may interfere with those captured by therecording itself and hence may have negative effects as well,especially for there and then types of content.
IV. USER PERSPECTIVE
When binaural synthesis techniques are used to simulate afixed virtual loudspeaker setup using headphones, all restric-tions that are valid for loudspeaker systems on the one hand,and the difficulties associated with binaural synthesis on theother hand will all apply simultaneously. In other words, a lis-tener may find him or herself with his or her head tightenedto a chair without being able to move or change orientation.The pinnae of the listener’s ears are replaced by those fromsomeone else. The acoustical properties of the virtual listeningroom may interfere with those captured by the recording. Thesound stage is quite narrow due to the compromised loudspeakersetup, phantom sources have a somewhat diffuse image and maysuffer from comb-filter artefacts, and it is quite difficult to de-termine whether the virtual loudspeakers are placed in front orbehind the listener. This is not a very desirable user perspectiveand chances are that this approach does not provide the desiredimmersive and realistic listening experience.
Given all observations described above, we can formulate aset of design recommendations for headphone enhancement al-gorithms to playback audio produced for loudspeakers.
1) Incorporate head tracking. Head tracking is currently theonly known factor to resolve front/back reversals. A secondimportant advantage of the incorporation of the proprio-ceptive sense is that it relaxes the need for individualizedHRTFs and all associated measurement challenges that aredifficult to realize for consumer-oriented devices.
2) Convert phantom sources to virtual sources. If stereoaudio content contains phantom sources, reproduction ofthis audio content will result in virtual phantom sourcesif reproduced over a stereophonic virtual loudspeakersetup. The necessity of phantom imaging to overcome thequality versus cost compromise of loudspeaker systemsis in many cases not required with headphone-based sys-tems. By selecting the appropriate HRTFs, sound sourcescan be positioned anywhere around the listener withoutthe restrictions associated with phantom imaging. This isespecially important when head tracking is incorporated;a change in the orientation of the listener’s head violatesthe restrictions imposed by amplitude panning and hencethe combination of head tracking and phantom imaging
should be avoided. Thus, phantom sources will have to beconverted to (virtual) sound sources at the intended spatialposition.
3) Minimize virtual reproduction-room acoustic interferenceor at least provide user control. Early reflections are re-quired for externalized sound sources, but late reverbera-tion is not. To minimize interference between the acous-tical properties of the recording and the reproduction room,it is recommended to use early reflections only, and pos-sibly provide means to add late reverberation if desired bythe listener.
V. MATERIALIZE THE PHANTOM
For many applications, phantom sound sources are difficultto circumvent. A significant portion of recorded stereo music,especially in the popular category, is produced using amplitudepanning as main spatial imaging method. Hence, playback ofsuch material over two virtual loudspeakers will result in “vir-tual phantom” sources as depicted in the left panel of Fig. 1.Using amplitude panning, the left and right virtual loudspeakersproduce a virtual phantom sound source which is subject to thevarious drawbacks described in Section II. The preferred virtualplayback scenario is shown in the right panel of Fig. 1. The vir-tual phantom source is replaced by a virtual source using HRTFsthat correspond to an azimuth angle conforming to the per-ceived azimuth angle of the virtual phantom source shown inthe left panel of Fig. 1. This process is referred to as “phantommaterialization.”
The main challenge of the development of such a scheme isto decompose a set of signals into one or more phantom sourcesignals, including their corresponding perceived positions, anda residual signal, that represents signal components that do notfit in the amplitude panning model, such as room reflections andreverberation or effects that may have been added to certain ele-ments in a stereo mix that modify their spatial attributes. Since itis not a priori known how many phantom sources are present ina certain audio segment, and (blind) separation of such sourcesis very difficult, the proposed decomposition method is basedon recent trends in spatial audio processing and compression. Ithas been shown that the spatial image of an auditory scene canbe captured by interpreting individual time/frequency tiles of asignal as pseudo auditory objects [41]–[47] that have a certainperceived position and a perceived width. The perceived posi-tion depends on sound-source localization cues (e.g., inter-auraltime and level differences) while the perceived width predomi-nantly depends on the coherence of the underlying stereo signalpair.
The proposed method applied to stereo signals is outlinedin Fig. 2. A spatial analysis stage decomposes the stereo inputsignal into various time/frequency tiles. For each time/fre-quency tile, an estimated perceived position angle of thephantom source is derived based on analysis of sound-sourcelocalization cues. Subsequently, for each time/frequency tile,the stereo input signal is decomposed into three intermediatesignals:
• a phantom source signal that is constructed from thestereo input signal;

1506 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 16, NO. 8, NOVEMBER 2008
Fig. 1. Two virtual loudspeakers result in a virtual phantom source at an azimuth angle � resulting from amplitude panning techniques (left panel). The virtualphantom source is replaced by a virtual source at the same position (right panel).
Fig. 2. Outline of the proposed analysis followed by synthesis steps to materialize virtual phantom sources.
• a residual signal for the left input channel representingcomponents that are not associated with the phantomsource signal ;
• a residual signal for the right input channel rep-resenting components that are not associated with thephantom source signal .
The idea to extract phantom sources from stereo or multi-channel content has been part of extensive research in the past(cf. [46], [48]–[51]). This current decomposition method differshowever from earlier proposals that focus on extraction of pri-mary and ambience signals. In earlier approaches, the primarysignal is assumed to be directional, while the ambience signalis assumed to be unidirectional to create a sense of spacious-ness. The risk with such approach is that if the input signals donot fit the underlying model for the primary components, the re-sulting signals may erroneously be interpreted as ambience. Inthe current residual approach, on the other hand, the idea is toenhance the spatial image for signal components that fit in anamplitude-panning model, while leaving other components (theresidual signals) untouched.
The three intermediate signals and the position angleof the phantom source are conveyed to a spatial synthesisstage that employs HRTFs to the three intermediate signals togenerate the desired virtual sound sources, and subsequentlyconverts the resulting stereo binaural signal to the time domain.Each individual time/frequency tile of the signal is convolvedwith HRTFs of the corresponding azimuth angle , while theresidual components and are processed with HRTFs
of predetermined positions. These predetermined positionsare preferably equal to the positions of the loudspeakers intwo-channel stereophonic listening.
A. Spatial Analysis
The spatial analysis stage comprises a time/frequency anal-ysis transform to obtain the required processing bands. Theseprocessing bands preferably follow a nonlinear frequency reso-lution according to the equivalent rectangular bandwidth (ERB)scale [52] to mimic the assumed perceptual spatial decompo-sition. Various methods based on Fourier transforms [44], [53]or filter banks [46], [54] have been proposed in the past. In thecurrent implementation, the two input signals, and(sampled at 44.1-kHz sampling frequency), were segmented in1024-sample, 50% overlapping frames. Each segment was sub-sequently windowed using a square-root Hanning window, andtransformed to the frequency domain using a -pointdiscrete Fourier transform (DFT) to result in frequency-domainrepresentations . Finally, the various frequency bins
were grouped into processing bandsto approximate the ERB-scale resolution.
For each processing band , the following transformation ofthe signals and was used
(1)
(2)
BREEBAART AND SCHUIJERS: PHANTOM MATERIALIZATION 1507
Here, represents the phantom-source signal and asingle, out-of-phase residual signal according to
(3)
(4)
A single, out-of-phase residual signal was found to re-sult in a more robust estimate of a residual component thanour attempts to estimate independent residual signals and
. The angle represents a “sine-cosine pan law” param-eter, also referred to as “tangent pan law” parameter [14], [55],[56] and has a value between 0 and 90 . The inverse relation-ship between and gives a better insightin the employed signal model
(5)
The solution for follows from an energetic analysis underthe constraints that and are independent and isminimized for each band independently (see [44] and [46] formore details)
(6)
with
(7)
The variable denotes the normalized cross-correlation coef-ficient of the signals and in processing band
(8)
with the real part of the complex conjugate ofdenoting all bins that are grouped in parameter band
and the energy in the left and right input signalsfor processing band , respectively
(9)
The parameter is given by
(10)
The amplitude-panning parameter is mapped to a perceivedposition parameter for a given (predetermined) virtual loud-speaker setup with a left-channel loudspeaker positioned at anangle and a right-channel loudspeaker at an angle (typi-cally 30 and 30 , respectively)
(11)
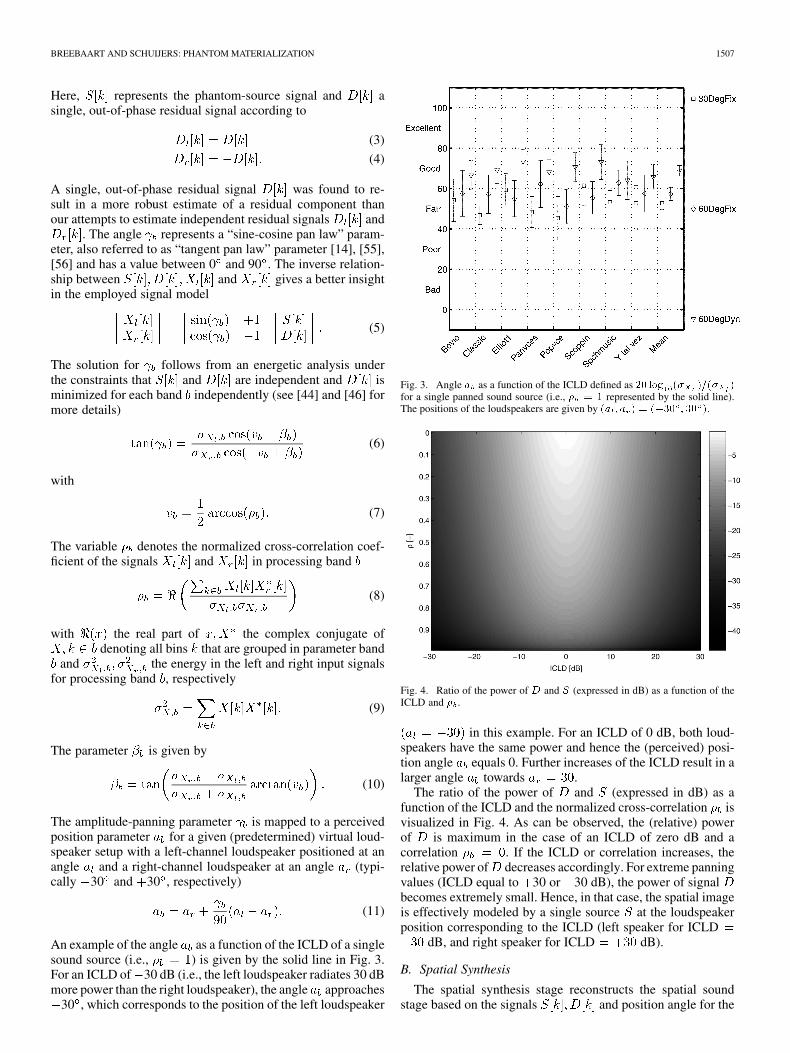
An example of the angle as a function of the ICLD of a singlesound source (i.e., ) is given by the solid line in Fig. 3.For an ICLD of 30 dB (i.e., the left loudspeaker radiates 30 dBmore power than the right loudspeaker), the angle approaches
30 , which corresponds to the position of the left loudspeaker
Fig. 3. Angle � as a function of the ICLD defined as �� ��� �� ���� �for a single panned sound source (i.e., � � represented by the solid line).The positions of the loudspeakers are given by �� � � � � ��� � � �.
Fig. 4. Ratio of the power of � and � (expressed in dB) as a function of theICLD and � .
in this example. For an ICLD of 0 dB, both loud-speakers have the same power and hence the (perceived) posi-tion angle equals 0. Further increases of the ICLD result in alarger angle towards .
The ratio of the power of and (expressed in dB) as afunction of the ICLD and the normalized cross-correlation isvisualized in Fig. 4. As can be observed, the (relative) powerof is maximum in the case of an ICLD of zero dB and acorrelation . If the ICLD or correlation increases, therelative power of decreases accordingly. For extreme panningvalues (ICLD equal to 30 or 30 dB), the power of signalbecomes extremely small. Hence, in that case, the spatial imageis effectively modeled by a single source at the loudspeakerposition corresponding to the ICLD (left speaker for ICLD
dB, and right speaker for ICLD dB).
B. Spatial Synthesis
The spatial synthesis stage reconstructs the spatial soundstage based on the signals and position angle for the

1508 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 16, NO. 8, NOVEMBER 2008
Fig. 5. Aperture of the reconstructed soundstage. The angles � and � repre-sent the modified positions of the left and right loudspeaker, respectively.
signal , and the positions corresponding to the residuals( and ), which may be modified versions of and ,respectively. These modified position angles may result from adesired modification in the sound-stage aperture (by increasingthe angle between the two loudspeakers placed at and ),or a sound-stage angular offset resulting from a head-trackeraccording to
(12)
(13)
(14)
with a sound-stage aperture scale factor and a sound-stageoffset angle. The sound-stage aperture is visualized in Fig. 5.
The synthesis process comprises generation of three sourcesfor each parameter band: a source at an azimuth angle ,a source at an azimuth angle , and a source at anazimuth angle . A conventional method to create such virtualsound sources is by means of convolution using HRTFs. Thisprocess could in principle be employed on subband signals aswell. Alternatively, in the FFT domain, convolution can be ef-ficiently implemented by multiplication with HRTFs providedthat zero-padding is employed to the signal frames to resolvethe cyclic behavior of the Fourier transform. Recently, however,it has been shown that HRTF processing can be efficiently im-plemented in a lossy parametric form [46], [57] without nega-tive perceptual consequences. The parametric representation isespecially suitable for the application described here since 1)in contrast to many other approaches, no zero padding is re-quired, and 2) the parametric HRTF description closely matchesthe processing-band approach that is pursued here. This meansthat the spatial analysis and spatial synthesis can be employed inthe same (transform) domain without creating audible time-do-main aliasing distortion.
Using the parametric approach, pairs of HRTFs are describedby the following parameters that are defined for each processingband independently:
1) an (average) level parameter of the left-ear HRTF ;2) an (average) level parameter of the right-ear HRTF ;3) an average phase difference parameter ;with the azimuth angle and the elevation angle. The (av-
erage) level parameters describe the spectral en-velopes of the HRTFs (and hence the inter-aural level differ-ences). The phase difference parameter provides a step-wise constant approximation of the inter-aural time difference.
Experiments have shown that if the processing bands are suf-ficiently small, such step-wise approximation does not result inaudible differences compared to the original HRTFs [46]. Usingsuch parametric representation, the synthesis process of a bin-aural signal pair for a virtual source with signalwithin a subband or FFT domain comprises multiplication ofthe signal with a complex-valued scalar
(15)
(16)
The phase difference is expressed in radians and is di-vided symmetrically across the two output signals, which re-quires to be an estimate of the unwrapped phase differ-ence between the respective HRTFs.
Applying the parametric method in the current context, thebinaural output signals given the decomposition ofthe input signals into , and the position data ,and are given by
(17)
(18)
The values for and are typically stored ina (parametric) HRTF database for a discrete set of virtual soundsource positions. The spatial resolution of such a database is typ-ically one parameter set for 5 to 15 in azimuth and/or eleva-tion. If parameters are required for an azimuth and/or elevationangle that is not present in the database, (bi)linear interpolationis employed.
Finally, the time-domain output signals are obtained by aninverse DFT, windowing with a square-root Hanning windowand overlap-add (using 50% overlapping frames).
C. Evaluation
1) Stimuli and Method: A listening test was conducted toevaluate the subjective implications for the processing schemeas described above. Subjects had to rate three different pro-cessing configurations:
1) a standard stereo virtual loudspeaker setup with vir-tual speakers positioned at 30 and 30 (labeled as“30DegFix”);
2) a “widened” stereo virtual loudspeaker setup with vir-tual speakers positioned at 60 and (labeled as“60DegFix”);
3) the phantom materialization method using resultingin 60 and 60 (“60DegDyn”).
Nine subjects were asked to provide scores for a set of itemsfor each of the processing methods above on a 100-point scale ina double-blind listening test. The 100-point scale had equidis-tant anchors labelled “Excellent,” “Good,” “Fair,” “Poor,” and“Bad.” The test procedure provided means to switch between
BREEBAART AND SCHUIJERS: PHANTOM MATERIALIZATION 1509
TABLE ILISTENING TEST EXCERPTS
processing methods in real time and to loop user-definable seg-ments within the excerpts. The (unprocessed) stereo signal wasprovided as “reference.” Subjects were instructed to rate the per-ceived quality of the processed items, and only use the “ref-erence” to allow identification of artefacts, sound source col-oration or unnatural spatial attributes introduced by the pro-cessing and to perform a cross-check whether these artefacts areabsent or present in the unprocessed content. In other words, theresulting rates can only be interpreted as relative scores acrossthe employed processing methods, but do not indicate any ab-solute quality rating for the processing itself (compared to thecase without any processing). The subjects were seated in asound-isolated listening room using Stax reference headphones.
Eight excerpts were used that covered a wide variety ofcontent and stereo imaging, including classical music, popularmusic, speech, and speech with background music or back-ground ambience. A short description of each excerpt is givenin Table I. The audio excerpts had a duration between 9 and30 s and were sampled at 44.1 kHz, 16 bits.
Anechoic dummy-head HRTF measurements were employedto generate virtual sound sources. No head tracking was em-ployed in the test. The HRTFs were sampled at a 6 azimuth andelevation resolution. Subsequently, the HRTFs were equalizedfor the diffuse-field and transformed to the parametric domain(cf. [46], [57]). In total, 28 parameter bands were employed tocover the audible frequency range using a spectral spacing thatis identical to that employed in MPEG Surround [46], [58]. Spa-tial positions in-between HRTF measurement positions wereobtained by means of linear interpolation of the HRTF param-eters. A simple early-reflections stage was incorporated to in-crease the percept of distance. This stage operated on a monodown mix in parallel to the HRTF processing stage and con-sisted of a band-pass filter, a delay, a set of first-order all-passsections connected in series and a Lauridsen decorrelator [59] tocreate stereo output. The resulting early-reflections signal wasadded to the output of the HRTF processing stage with a gainof 6 dB. This level gave an audible but subtle increase in theperceived distance while minimizing the interference with thespatial attributes of the various excerpts.
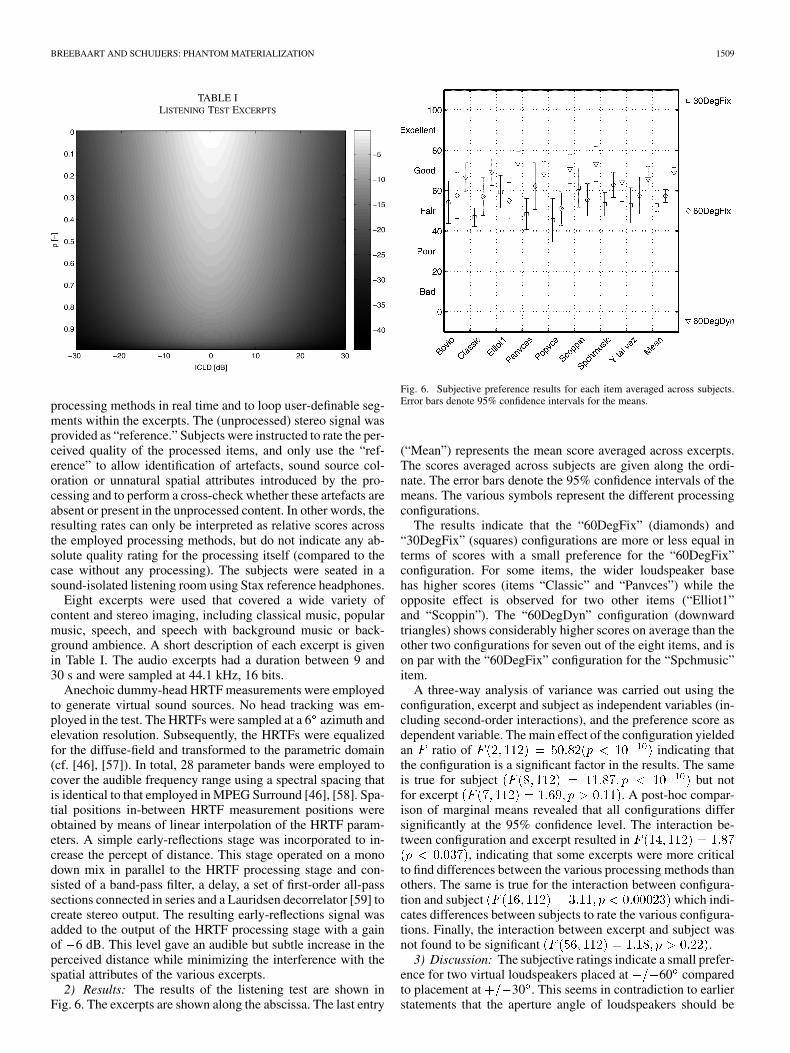
2) Results: The results of the listening test are shown inFig. 6. The excerpts are shown along the abscissa. The last entry
Fig. 6. Subjective preference results for each item averaged across subjects.Error bars denote 95% confidence intervals for the means.
(“Mean”) represents the mean score averaged across excerpts.The scores averaged across subjects are given along the ordi-nate. The error bars denote the 95% confidence intervals of themeans. The various symbols represent the different processingconfigurations.
The results indicate that the “60DegFix” (diamonds) and“30DegFix” (squares) configurations are more or less equal interms of scores with a small preference for the “60DegFix”configuration. For some items, the wider loudspeaker basehas higher scores (items “Classic” and “Panvces”) while theopposite effect is observed for two other items (“Elliot1”and “Scoppin”). The “60DegDyn” configuration (downwardtriangles) shows considerably higher scores on average than theother two configurations for seven out of the eight items, and ison par with the “60DegFix” configuration for the “Spchmusic”item.
A three-way analysis of variance was carried out using theconfiguration, excerpt and subject as independent variables (in-cluding second-order interactions), and the preference score asdependent variable. The main effect of the configuration yieldedan ratio of indicating thatthe configuration is a significant factor in the results. The sameis true for subject but notfor excerpt . A post-hoc compar-ison of marginal means revealed that all configurations differsignificantly at the 95% confidence level. The interaction be-tween configuration and excerpt resulted in
, indicating that some excerpts were more criticalto find differences between the various processing methods thanothers. The same is true for the interaction between configura-tion and subject which indi-cates differences between subjects to rate the various configura-tions. Finally, the interaction between excerpt and subject wasnot found to be significant .
3) Discussion: The subjective ratings indicate a small prefer-ence for two virtual loudspeakers placed at 60 comparedto placement at 30 . This seems in contradiction to earlierstatements that the aperture angle of loudspeakers should be

1510 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 16, NO. 8, NOVEMBER 2008
limited to 60 (cf. [13]) to obtain correct phantom sourceimaging. The degradation of phantom source image quality isconfirmed by informal retrospective listening to the variousitems and processing configurations. For the 120 apertureangle (“60DegFix”), phantom sources tend to sound more “in-side” the head and are elevated compared to the correspondingimages resulting from the other two processing configurations.On the other hand, the “30DegFix” configuration has a quitenarrow spatial extent, which may cause lower preference scores.Possibly, the preference for a wider sound stage for “60DegFix”counteracts the corresponding degradation in phantom-imagingaccuracy and “out-of-head” localization.
The phantom materialization method resulted in equal orhigher scores than the two other (conventional) processingmethods. Especially for those items that consisted of a mix-ture of multiple sound sources at discrete spatial positions, thequality difference is most prominent (items “Elliot1,” “Popvce,”and “Scoppin”). These observations support the notion that spa-tial analysis and synthesis methods can overcome limitations offixed virtual loudspeaker setups. More specifically, the resultscan be explained at least qualitatively by considering two maineffects: 1) the overall spatial extent (or sound stage width),and 2) the spatial naturalness or imaging quality of the varioussound sources. By widening or narrowing the sound stagewithout the use of spatial analysis and synthesis techniques,these two effects seem to be counteracting. On the other hand,the use of phantom materialization results in a positive-sumresult: a more natural and simultaneously wider sound stage.In fact, informal tests revealed that if the orientation of thelistener with respect to the loudspeaker setup is changed (whichcould be the result of the incorporation of a head tracker), thedifferences are even more pronounced in favor of the phantommaterialization method. This observation suggests that theproposed method results in even more natural sound stageimaging when head-tracking is employed.
VI. CONCLUSION
Playback of conventional stereo content over headphonesis usually perceived “inside” the head. A more natural repro-duction can be obtained using so-called virtual loudspeakersemploying HRTFs. However, when a conventional stereospeaker setup is simulated over headphones, all correspondingcompromises that are associated with such a reproductionsystem will limit the spatial accuracy in the virtual listeningenvironment as well. In this paper, an approach was presentedthat exploits the extended spatial imaging capabilities forheadphone reproduction. A stereo signal is decomposed intoa number of (phantom) sound sources with correspondingperceived positions. Subsequently, a spatial synthesis stepmaterializes the (virtual) phantom sources by synthesis of theestimated phantom–source signals using HRTFs correspondingto the perceived positions. A listening test was conducted toillustrate the potential of the phantom materialization method.The results indicate that 1) subjects prefer a larger spatial extentof the sound stage and 2) subjects prefer materialized sourcesrather than (virtual) phantom sources in a virtual listening testsetup. The angular approach of the proposed method is verysuitable for applications that include head tracking.
ACKNOWLEDGMENT
The authors would like to thank their colleagues O. Ouweltjesand A. van Leest, the associate editor, and the anonymous re-viewers for their very helpful comments and contributions inimproving this manuscript.
REFERENCES
[1] J. Blauert, Spatial Hearing: The Psychophysics of Human Sound Lo-calization. Cambridge, MA: MIT Press, 1997.
[2] D. R. Begault, “Challenges to the successful implementation of 3-Dsound,” J. Audio Eng. Soc., vol. 39, pp. 864–870, 1991.
[3] J. M. Loomis, C. Hebert, and J. G. Cincinelli, “Active localization ofvirtual sounds,” J. Acoust. Soc. Amer., vol. 88, pp. 1757–1764, 1990.
[4] E. M. Wenzel, “What perception implies about implementation of in-teractive virtual acoustic environments,” in Proc. 101st AES Conv., LosAngeles, CA, 1996, CD-ROM.
[5] F. L. Wightman and D. J. Kistler, “Resolution of front-back ambiguityin spatial hearing by listener and source movement,” J. Acoust. Soc.Amer., vol. 105, pp. 2841–2853, 1999.
[6] U. Horbach, A. Karamustafaoglu, R. Pellegrini, P. Mackensen, and G.Theile, “Design and applications of a data-based auralization systemfor surround sound,” in Proc. 106th AES Conv., Munich, Germany,1999, CD-ROM.
[7] P. J. Minnaar, S. K. Olesen, F. Christensen, and H. Møller, “The impor-tance of head movements for binaural room synthesis,” in Proc. ICAD,Espoo, Finland, Jul. 2001, pp. 21–25.
[8] P. Mackensen, “Head Movements, an Additional cue in Localization.,”Ph.D. dissertation, Technische Univ. Berlin, Berlin, Germany, 2004.
[9] F. Rumsey, “Spatial quality evaluation for reproduced sound: Termi-nology, meaning and a scene-based paradigm,” J. Acoust. Soc. Amer.,vol. 50, pp. 651–666, 2002.
[10] S. P. Lipshitz, “Stereo microphone techniques; are the purists wrong?,”J. Audio Eng. Soc., vol. 34, pp. 716–744, 1986.
[11] D. Griesinger, “Stereo and surround panning in practice.,” in Proc.112th AES Conv., Munich, Germany, 2002, CD-ROM.
[12] E. Benjamin and P. Brown, “The effect of head diffraction on stereolocalization in the mid-frequency range,” in Proc. 122nd AES Conv.,Vienna, Austria, 2007, CD-ROM.
[13] J. C. Bennett, K. Barker, and F. O. Edeko, “A new approach to theassessment of sterephonic sound system performance,” J. Audio Eng.Soc., vol. 33, pp. 314–321, 1985.
[14] V. Pulkki and M. Karjalainen, “Localization of amplitude-panned vir-tual sources I: Stereophonic panning,” J. Audio Eng. Soc., vol. 49, pp.739–752, 2001.
[15] H. A. M. Clark, G. F. Dutton, and P. B. Vanderlyn, “The ‘Stereosonic’recording and reproduction system: A two-channel systems for do-mestic tape records,” J. Audio Eng. Soc., vol. 6, pp. 102–117, 1958.
[16] G. Theile and G. Plenge, “Localization of lateral phantom sources,” J.Audio Eng. Soc., vol. 25, pp. 196–200, 1977.
[17] V. Pulkki, M. Karjalainen, and V. Valimaki, “Localization, coloration,and enhancement of amplitude-panned virtual sound sources,” in Proc.16th AES Conf., Rovaniemi, Finland, 1999, pp. 257–278.
[18] G. Martin, W. Woszczyk, J. Corey, and R. Quesnel, “Sound sourcelocalization in a five-channel surround sound reproduction system,” inProc. 107th AES Conv., New York, 1999, CD-ROM.
[19] V. Pulkki, “Localization of amplitude-panned virtual sources II:Two-and three-dimensional panning,” J. Audio Eng. Soc., vol. 49, pp.753–767, 2001.
[20] J. Corey and W. Woszczyk, “Localization of lateral phantom imagesin a 5-channel system with and without simulated early reflections,” inProc. 113th AES Conv., Los Angeles, 2002, CD-ROM.
[21] V. Pulkki, “Coloration of amplitude-panned virtual sources,” in Proc.110th AES Conv., Amsterdam, The Netherlands, 2001, CD-ROM.
[22] B. Shirley, P. Kendrick, and C. Churchill, “The effect of stereo crosstalkon intelligibility: Comparison of a phantom stereo image and centralloudspeaker source,” J. Audio Eng. Soc., vol. 55, pp. 852–863, 2007.
[23] B. Sayers, “Acoustic image lateralization judgments with binauraltones,” J. Acoust. Soc. Amer., vol. 36, pp. 923–926, 1964.
[24] W. A. Yost, “Lateral position of sinusoids presented with interauralintensive and temporal differences,” J. Acoust. Soc. Amer., vol. 70, pp.397–409, 1981.
[25] F. L. Wightman and D. J. Kistler, “Headphone simulation of free-fieldlistening. I. Stimulus synthesis,” J. Acoust. Soc. Amer., vol. 85, pp.858–867, 1989.

BREEBAART AND SCHUIJERS: PHANTOM MATERIALIZATION 1511
[26] F. L. Wightman and D. J. Kistler, “Headphone simulation of free-fieldlistening. II: Psychophysical validation,” J. Acoust. Soc. Amer., vol. 85,pp. 868–878, 1989.
[27] W. M. Hartmann and A. Wittenberg, “On the externalization of soundimages,” J. Acoust. Soc. Amer., vol. 99, pp. 3678–3688, 1996.
[28] E. H. A. Langendijk and A. W. Bronkhorst, “Fidelity of three-dimen-sional-sound reproduction using a virtual auditory display,” J. Acoust.Soc. Amer., vol. 107, pp. 528–537, 2000.
[29] T. Ajdler, L. Sbaiz, and M. Vetterli, “The plenacoustic function on thecircle with application to HRTF interpolation,” in Proc. ICASSP, 2005,pp. 273–276.
[30] T. Ajdler, L. Sbaiz, and M. Vetterli, “Head related transfer functionsinterpolation considering acoustics,” in Proc. 118th AES Conv.,Barcelona, Spain, May 2005.
[31] D. S. Brungart, N. I. Durlach, and W. M. Rabinowitz, “Auditory local-ization of nearby sources. II. Localization of a broadband source,” J.Acoust. Soc. Amer., vol. 106, pp. 1956–1968, 1999.
[32] B. G. Shinn-Cunningham, S. Santarelli, and N. Kopco, “Tori of confu-sion: Binaural localization cues for sources within reach of a listener,”J. Acoust. Soc. Amer., vol. 107, pp. 1627–1636, 2000.
[33] H. Møller, M. F. Sørensen, C. B. Jensen, and D. Hammershøi, “Bin-aural technique: Do we need individual recordings?,” J. Audio Eng.Soc., vol. 44, pp. 451–469, 1996.
[34] H. Møller, D. Hammershøi, C. B. Jensen, and M. F. Sørensen, “Eval-uation of artifical heads in listening tests,” J. Audio Eng. Soc., vol. 47,pp. 83–100, 1999.
[35] D. R. Begault, E. M. Wenzel, and M. R. Anderson, “Direct comparisonof the impact of head tracking, reverberation, and individualized head-related transfer functions on the spatial perception of a virtual speechsource,” J. Audio Eng. Soc., vol. 49, pp. 904–916, 2001.
[36] F. L. Wightman and D. J. Kistler, “Individual differences in humansound localization behavior,” J. Acoust. Soc. Amer., vol. 99, pp.2470–2500, 1996.
[37] E. M. Wenzel, M. Arruda, D. J. Kistler, and F. L. Wightman, “Lo-calization using nonindividualized head-related transfer functions,” J.Acoust. Soc. Amer., vol. 94, pp. 111–123, 1993.
[38] A. Bronkhorst, “Localization of real and virtual sound sources,” J.Acoust. Soc. Amer., vol. 98, pp. 2542–2553, 1995.
[39] D. R. Begault, “Perceptual effects of synthetic reverberation on 3-Daudio systems,” in Proc. 91th AES Conv., New York, 1991, CD-ROM.
[40] B. G. Shinn-Cunningham, “The perceptual consequences of creating arealistic, reverberant 3-D audio display.,” in Proc. Int. Congr. Acoust.,Kyoto, Japan, Apr. 2004, CD-ROM.
[41] F. Baumgarte and C. Faller, “Why binaural cue coding is better thanintensity stereo coding,” in Proc. 112th AES Conv., Munich, Germany,2002, CD-ROM.
[42] C. Faller and F. Baumgarte, “Binaural cue coding applied to stereo andmulti-channel audio compression,” in Proc. 112th AES Conv., Munich,Germany, 2002, CD-ROM.
[43] F. Baumgarte and C. Faller, “Binaural cue coding—part I: Psychoa-coustic fundamentals and design principles,” IEEE Trans. SpeechAudio Process., vol. 11, no. 6, pp. 509–519, Nov. 2003.
[44] J. Breebaart, S. van de Par, A. Kohlrausch, and E. Schuijers, “Para-metric coding of stereo audio,” EURASIP J. Appl. Signal Process., vol.9, pp. 1305–1322, 2004.
[45] J. Breebaart, “Analysis and synthesis of binaural parameters for effi-cient 3D audio rendering in MPEG surround,” in Proc. ICME’07, Bei-jing, China, 2007, pp. 1878–1881.
[46] J. Breebaart and C. Faller, Spatial Audio Processing: MPEG Surroundand Other Applications. Chichester, U.K.: Wiley, 2007.
[47] V. Pulkki, “Spatial sound reproduction with directional audio coding,”J. Audio Eng. Soc., vol. 55, pp. 503–516, 2007.
[48] C. Avendano and J.-M. Jot, “Frequency-domain techniques for stereoto multichannel upmix,” in Proc. 22nd AES Conf., Espoo, Finland,2002, CD-ROM.
[49] R. Irwan and R. M. Aarts, “Two-to-five channel sound processing,” J.Audio Eng. Soc., vol. 50, pp. 914–926, 2002.
[50] M. M. Goodwin and J. M. Jot, “Binaural 3-D audio rendering basedon spatial audio scene coding,” in Proc. 123rd AES Conv., New York,2007, CD-ROM.
[51] J. Merimaa, M. M. Goodwin, and J. M. Jot, “Correlation-based am-bience extraction from stereo recordings,” in Proc. 123rd AES Conv.,New York, 2007, CD-ROM.
[52] B. R. Glasberg and B. C. J. Moore, “Auditory filter shapes in for-ward masking as function of level,” J. Acoust. Soc. Amer., vol. 71, pp.946–949, 1982.
[53] J. Breebaart, S. van de Par, A. Kohlrausch, and E. Schuijers, “High-quality parametric spatial audio coding at low bit rates,” in Proc. 116thAES Conv., Berlin, Germany, 2004, CD-ROM.
[54] E. Schuijers, J. Breebaart, H. Purnhagen, and J. Engdegard, “Low com-plexity parametric stereo coding,” in Proc. 116th AES Conv., Berlin,Germany, 2004, CD-ROM.
[55] A. D. Blumlein, “Audio Eng. Soc.,” U.K. Patent 394,325 (1931), 1986,NY, Reprinted in Stereophonic Techniques.
[56] B. Bernfeld, “Attempts for better understanding of the directionalstereophonic listening mechanism,” in Proc. 44th AES Conv., Rot-terdam, The Netherlands, 1973, CD-ROM.
[57] J. Breebaart, L. Villemoes, and K. Kjörling, “Binaural rendering inMPEG Surround,” in EURASIP J. Appl. Signal Process., 2008, vol.2008, article ID 732895.
[58] J. Rödén, J. Breebaart, J. Hilpert, H. Purnhagen, E. Schuijers, J. Kop-pens, K. Linzmeier, and A. Hölzer, “A study of the MPEG Surroundquality versus bit-rate curve,” in Proc. 123rd AES Conv., New York,2007, CD-ROM.
[59] H. Lauridsen, “Experiments concerning different kinds of room-acous-tics recording,” Ingenioren, vol. 47, 1954, CD-ROM.
Jeroen Breebaart (M’06) was born in The Netherlands. He studied biomed-ical engineering at the Technical University Eindhoven, Eindhoven, The Nether-lands. He received the Ph.D. degree in mathematical models of human spatialhearing from the Institute for Perception Research (IPO), Eindhoven, in 2001.
From 2001 to 2007, he was a Researcher in the Digital Signal ProcessingGroup of Philips Research in The Netherlands. During this period, his mainfield of research comprised spatial hearing, parametric stereo and multichannelaudio coding, automatic audio content analysis, and audio signal processingtools. He is currently extending is research scope towards biometrics for secureand convenient identification as member of the Information and System SecurityGroup at Philips Research. He has published several papers on binaural detec-tion, binaural modeling, and spatial audio coding. He also contributed to thedevelopment of parametric stereo coding algorithms as currently standardizedin MPEG-4 and 3GPP, the recently finalized MPEG Surround standard and theupcoming MPEG standard for spatial audio object coding.
Erik Schuijers was born in The Netherlands in 1976. He received the M.Sc. de-gree in electrical engineering from Eindhoven University of Technology, Eind-hoven, The Netherlands, in 1999.
In 2000, he joined the Signal Processing Group of Philips Applied Technolo-gies, Eindhoven. His main activity has been the research and development ofparametric audio coding tools, such as MPEG-4 parametric audio, parametricstereo and MPEG surround spatial audio coding. Recently, his activities have ex-panded to other audio signal processing areas, such as multichannel and binauralaudio reproduction and improving audio quality for analog broadcast transmis-sions.





























