Embed Size (px)
Citation preview

Peter J. Russell • Paul E. Hertz • Beverly McMillan
www.cengage.com/biology/russell
Chapter 3Biological Molecules
(Sections 4-5)

3.4 Proteins
• Proteins perform many vital functions in living organisms:• Structural support; enzymes; movement; transport;
recognition and receptor molecules; regulation of proteins and DNA; hormones; antibodies; toxins and venoms
• Proteins are macromolecules – polymers of amino acid monomers, which contain both an amino and a carboxyl group
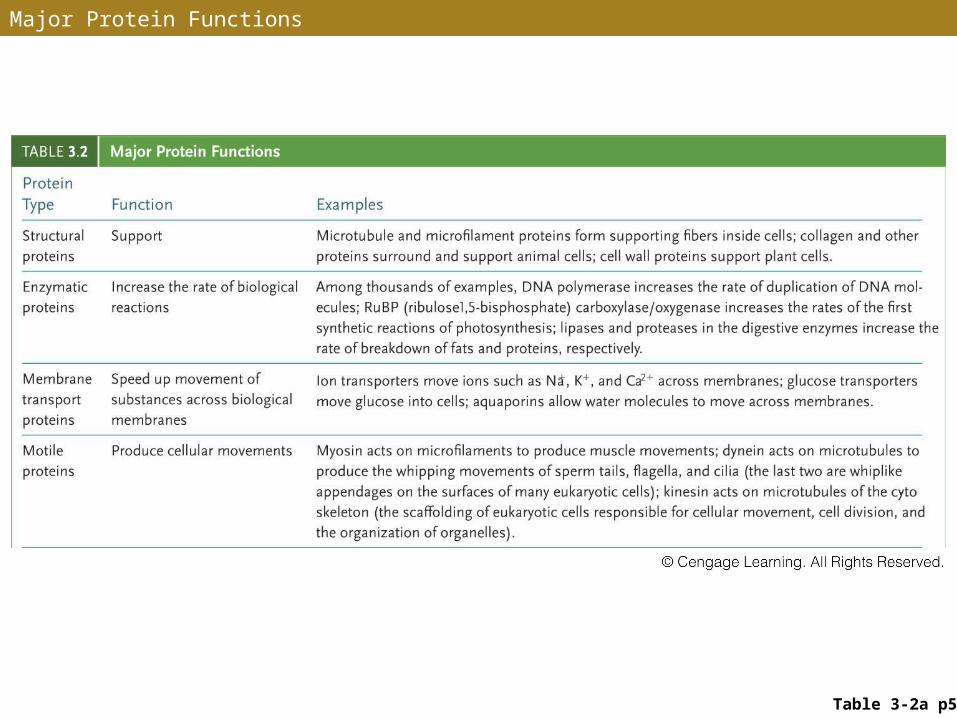
Major Protein Functions
Table 3-2a p55
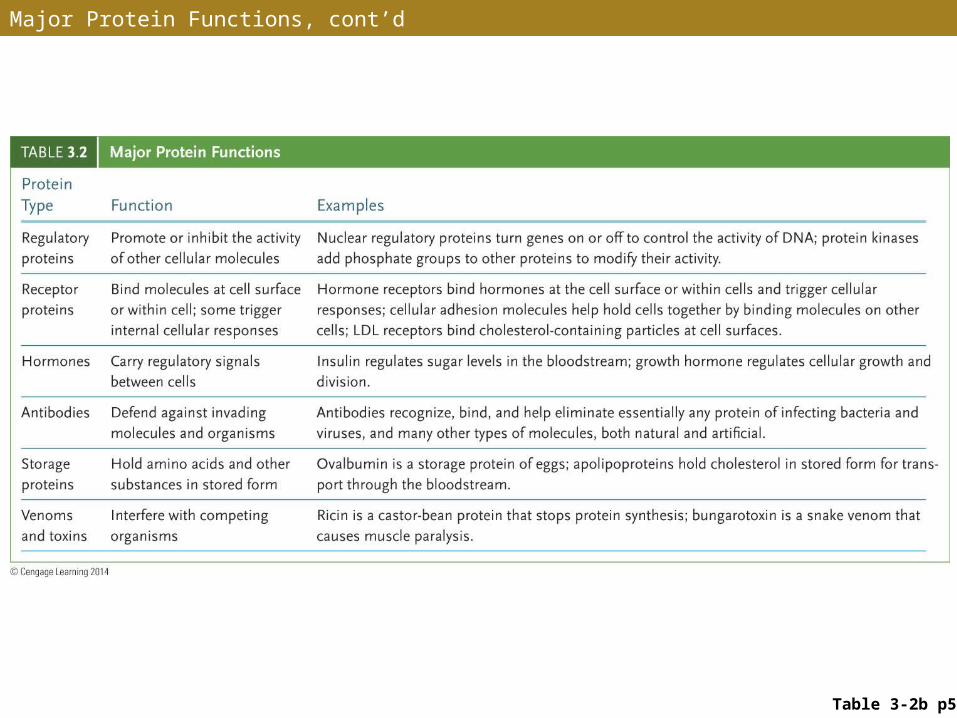
Major Protein Functions, cont’d
Table 3-2b p55
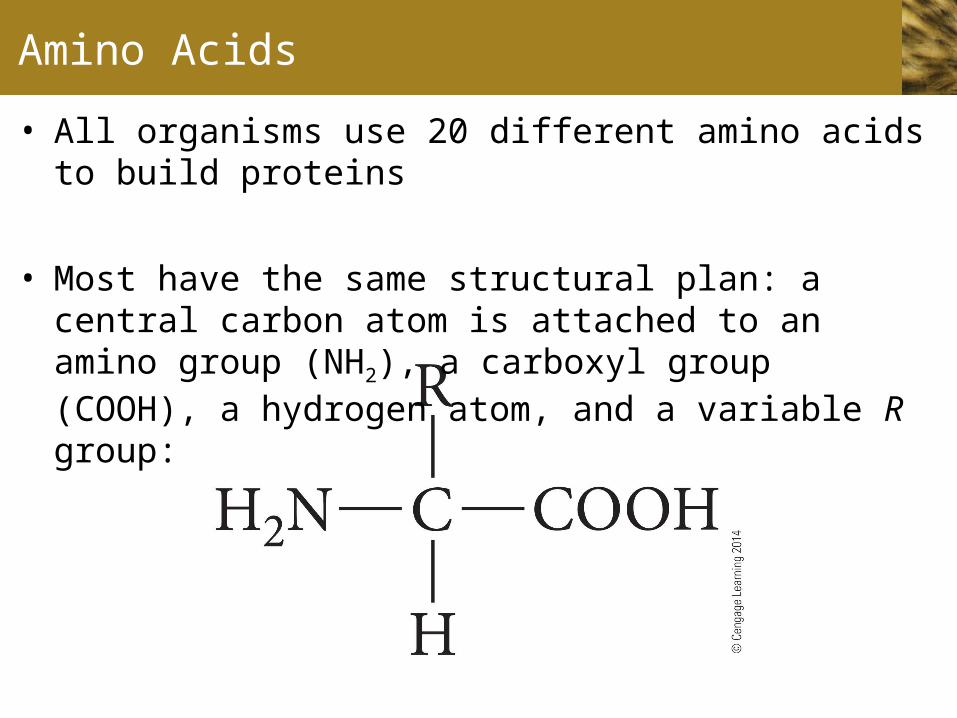
Amino Acids
• All organisms use 20 different amino acids to build proteins
• Most have the same structural plan: a central carbon atom is attached to an amino group (NH2), a carboxyl group (COOH), a hydrogen atom, and a variable R group:

Amino Acids (cont.)
• One amino acid, proline, differs slightly in that it has a ring structure that includes the central carbon atom – the central carbon bonds to a —COOH group on one side and to an =NH (imino) group at the other side
• All amino acids can act as acids or bases – the amino group can produce a basic reaction by accepting H+, or the carboxyl group can produce an acidic reaction by releasing H+

Amino Acids (cont.)
• Some side groups are polar and some are nonpolar
• Among the polar side groups, some carry a positive or negative charge and some act as acids or bases
• Many side groups contain reactive functional groups, such as —NH2, —OH, —COOH, or —SH, which interact with other atoms in the same protein or outside the protein
• Sulfhydryl groups (in cysteines) can produce disulfide linkages (—S—S—) that help hold proteins in their 3-D shape
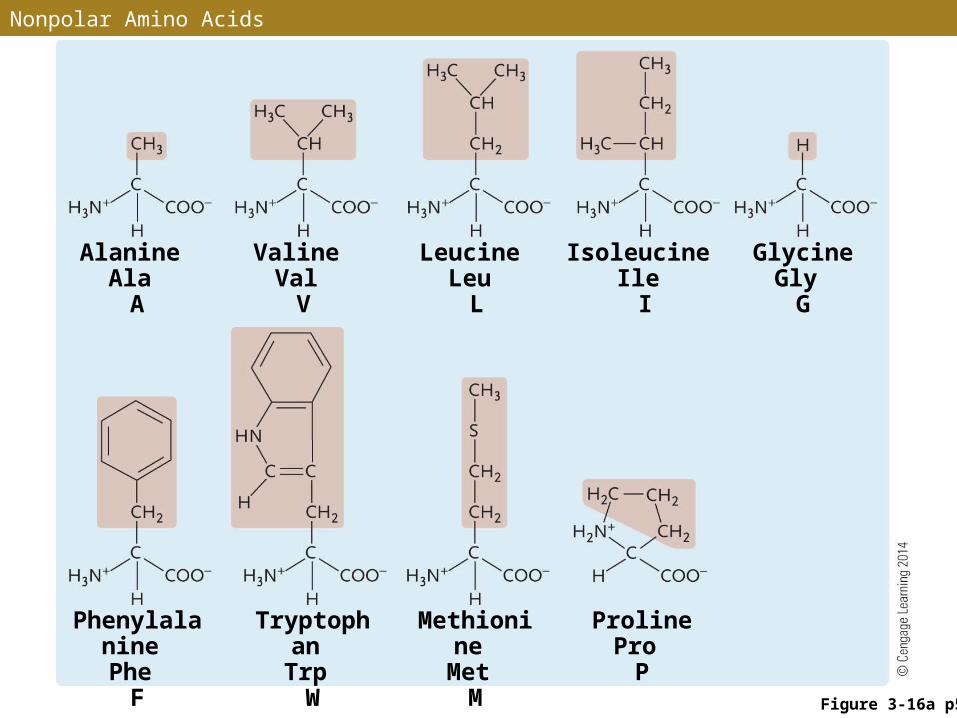
Alanine Ala
A
Valine Val
V
Leucine Leu
L
Isoleucine Ile
I
Glycine Gly
G
Proline Pro
P
Phenylalanine Phe
F
Tryptophan Trp W
Methionine Met
M
Nonpolar Amino Acids
Figure 3-16a p56
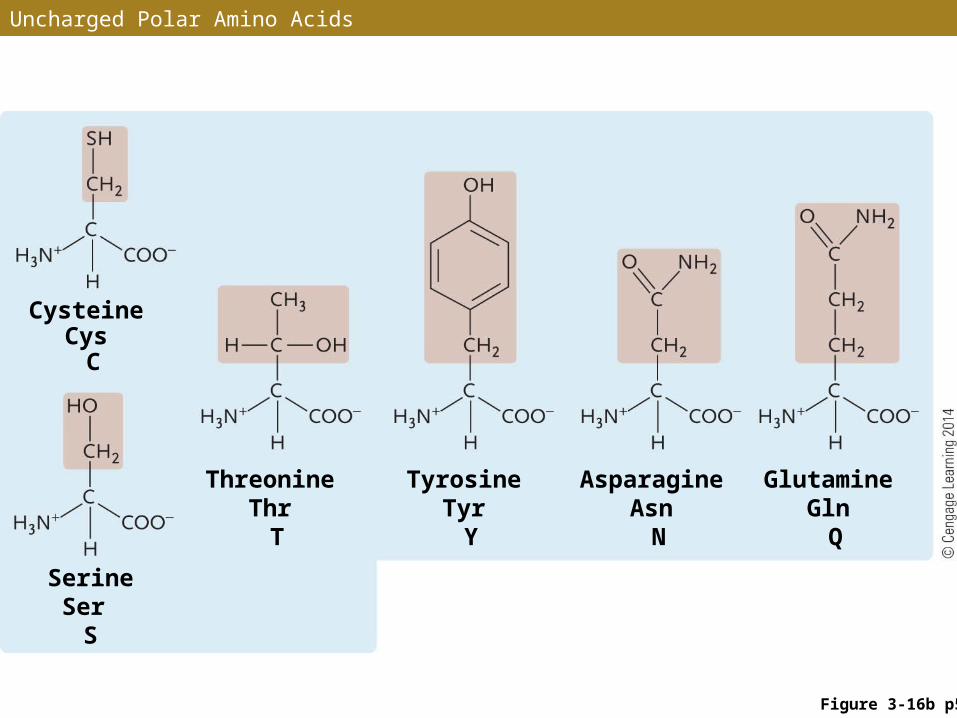
Uncharged Polar Amino Acids
Figure 3-16b p56
Serine Ser
S
Threonine Thr
T
Tyrosine Tyr
Y
Asparagine Asn
N
Glutamine Gln
Q
Cysteine Cys
C
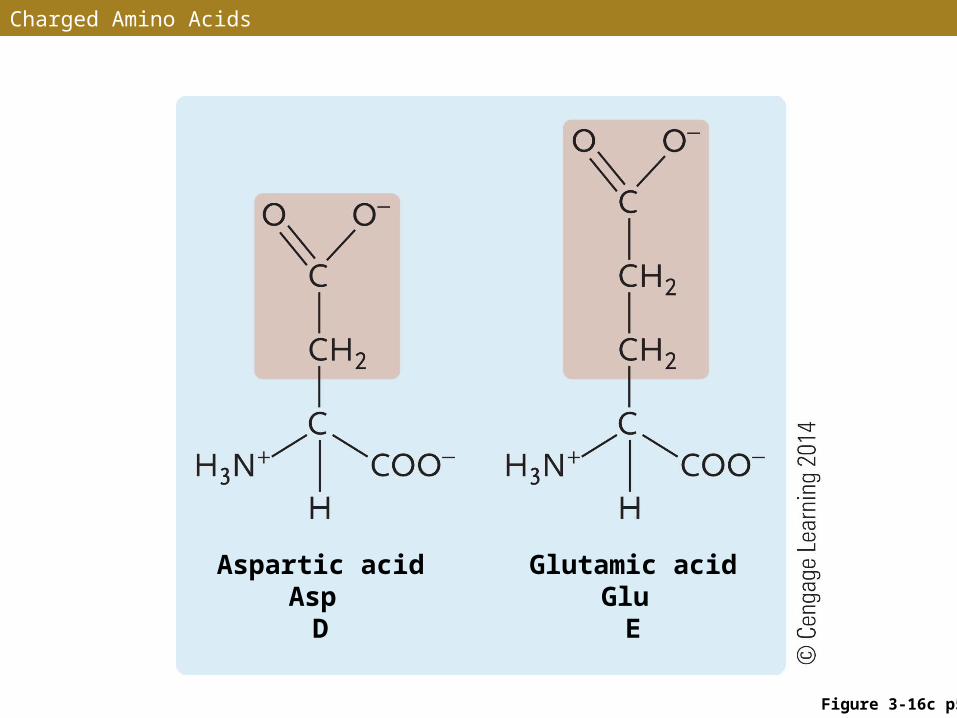
Charged Amino Acids
Figure 3-16c p56
Aspartic acid Asp
D
Glutamic acid Glu
E
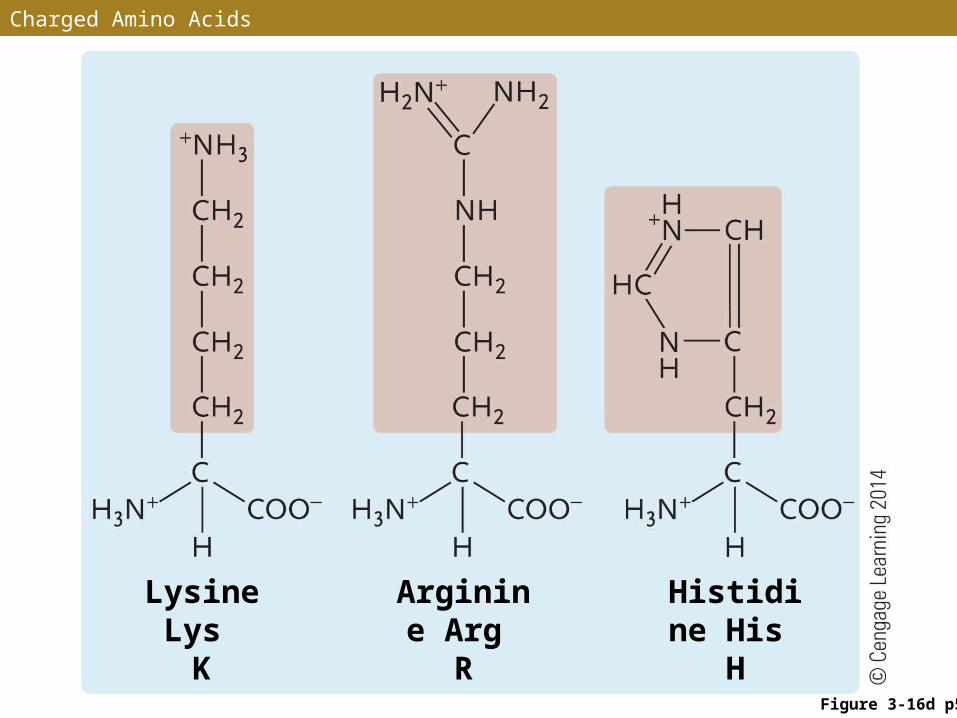
Charged Amino Acids
Figure 3-16d p56
Lysine Lys
K
Arginine Arg
R
Histidine His H
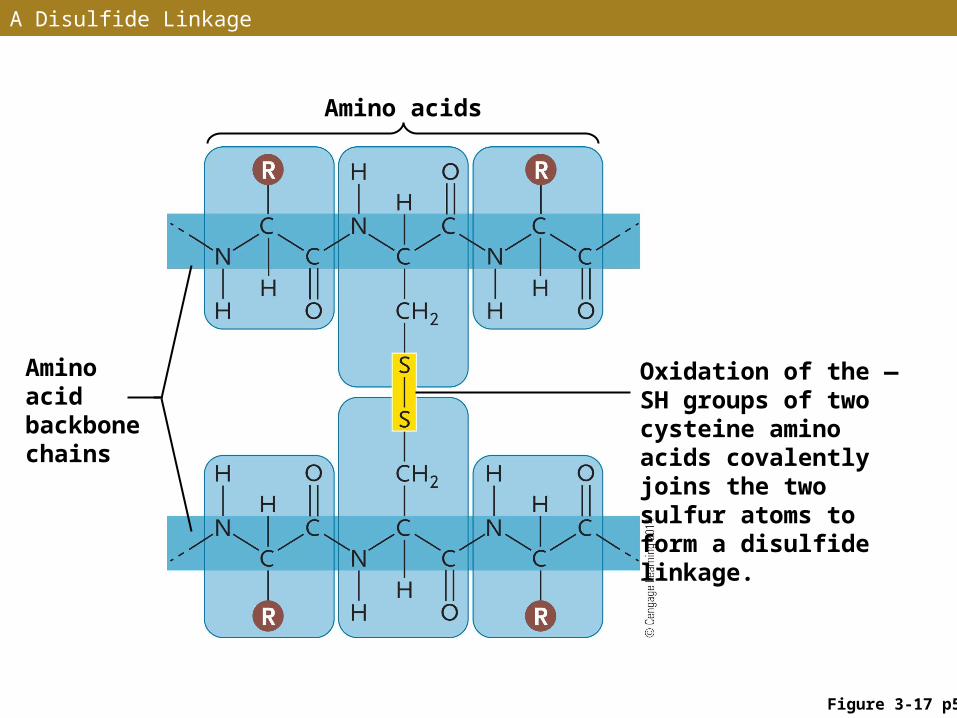
A Disulfide Linkage
Figure 3-17 p57
Amino acids
Amino acid backbone chains
Oxidation of the —SH groups of two cysteine amino acids covalently joins the two sulfur atoms to form a disulfide linkage.

Peptide Bonds
• Covalent peptide bonds link amino acids into polypeptide chains – the subunits of proteins
• A peptide bond is formed by a dehydration synthesis reaction between the NH2 group of one amino acid and the COOH group of another amino acid
• The growing polypeptide chain has an N-terminal end and a C-terminal end – new amino acids are linked only to the C-terminal end
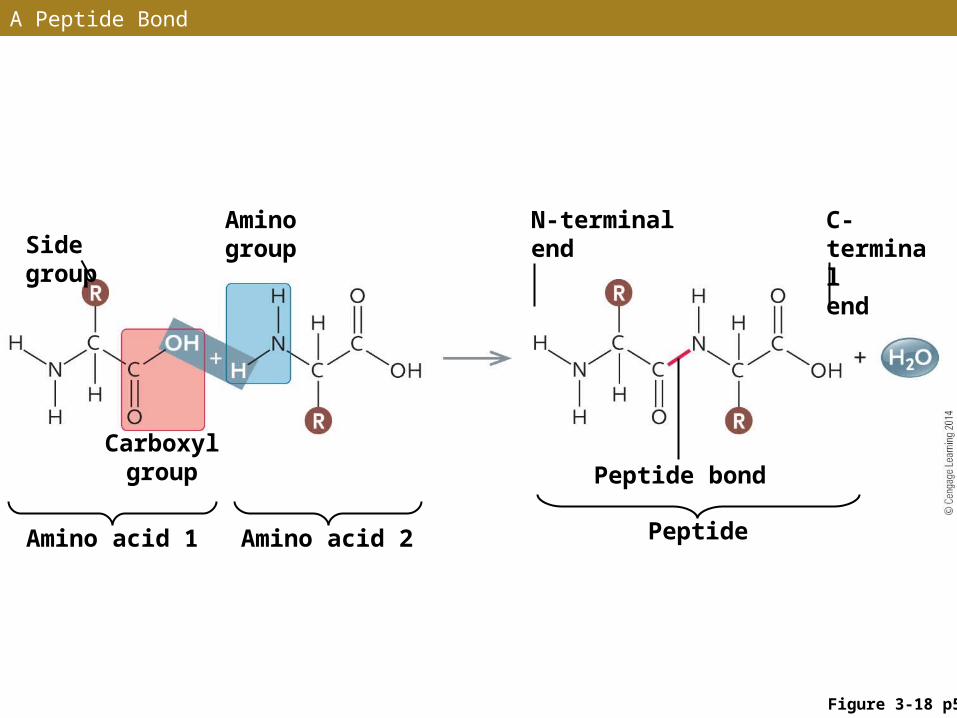
A Peptide Bond
Figure 3-18 p57
Side groupAmino group
N-terminal end
C-terminal end
Peptide bond
Amino acid 1 Amino acid 2 Peptide
Carboxyl group

Four Levels of Protein Structure
• Primary structure is the unique sequence of amino acids forming a polypeptide
• Secondary structure is produced by the twists and turns of the amino acid chain
• Tertiary structure is the folding of the amino acid chain, with its secondary structures, into the overall 3Dshape of a protein
• Quaternary structure, when present, is formed from more than one polypeptide chain
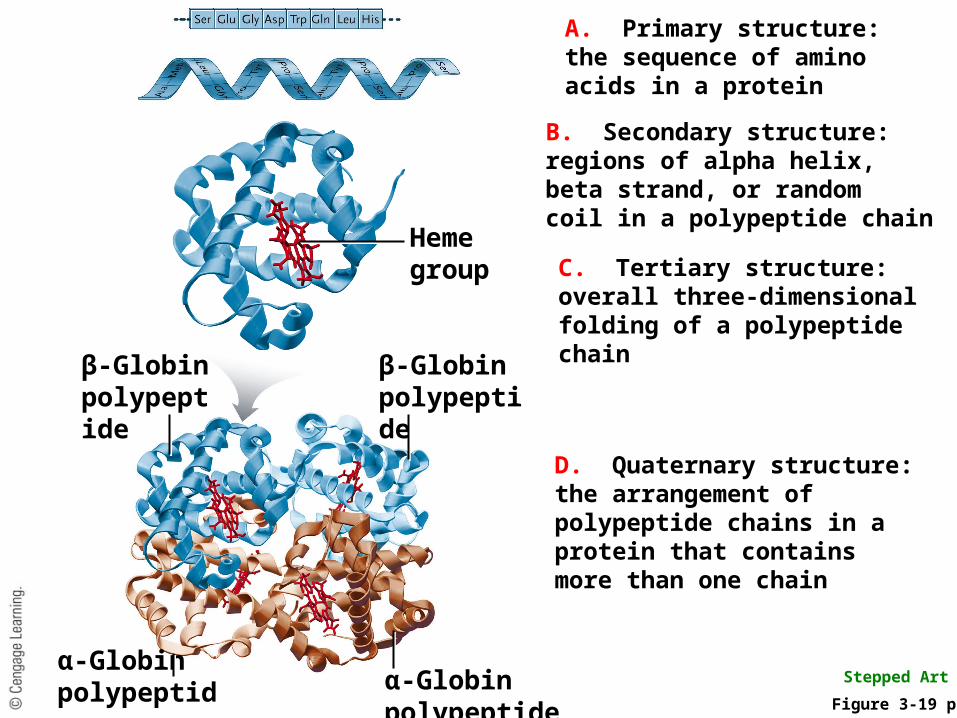
Heme groupC. Tertiary structure:overall three-dimensionalfolding of a polypeptidechain
Figure 3-19 p58
Stepped Art
A. Primary structure:the sequence of aminoacids in a protein
B. Secondary structure:regions of alpha helix,beta strand, or randomcoil in a polypeptide chain
D. Quaternary structure:the arrangement ofpolypeptide chains in a protein that containsmore than one chain
β-Globin polypeptide
α-Globin polypeptideα-Globin polypeptide
β-Globin polypeptide
ANIMATION: Secondary and Tertiary Structure
To play movie you must be in Slide Show ModePC Users: Please wait for content to load, then click to play
Mac Users: CLICK HERE

Primary Structure
• Primary structure of a protein is the precise sequence in which amino acids are linked
• Changing even a single amino acid alters secondary, tertiary, and quaternary structures – which can alter or destroy the biological function of a protein
• Example: Substitution of a single amino acid in hemoglobin produces an altered form responsible for sickle-cell disease
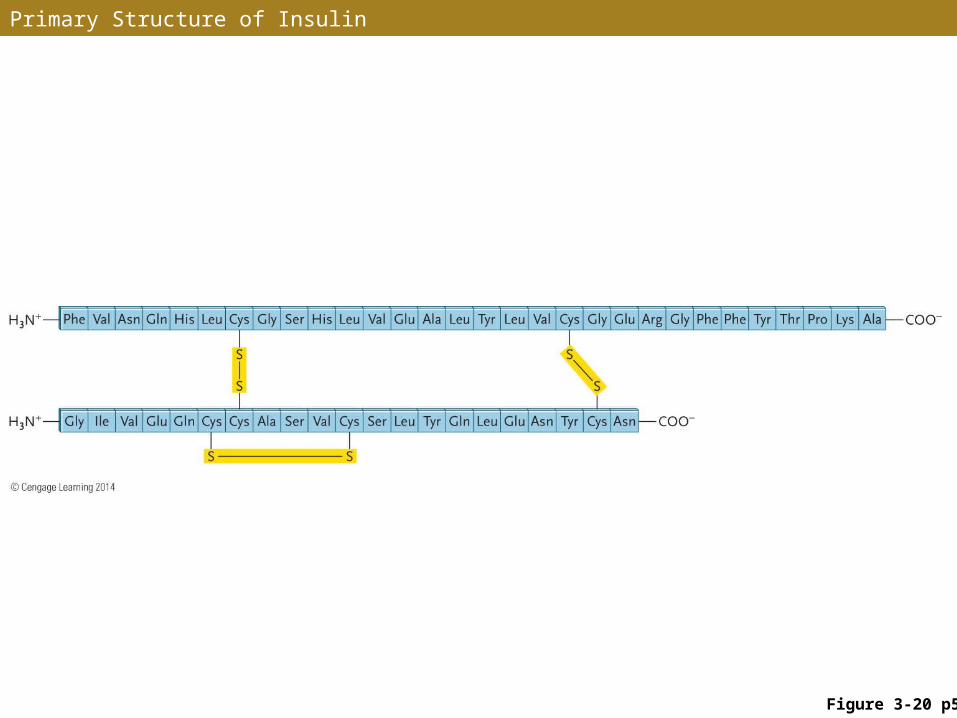
Primary Structure of Insulin
Figure 3-20 p58
ANIMATION: Peptide Bond Formation
To play movie you must be in Slide Show ModePC Users: Please wait for content to load, then click to play
Mac Users: CLICK HERE

Secondary Structure
• The amino acid chain (primary structure) is folded into arrangements that form the protein’s secondary structure
• The alpha (α) helix is twisted into a regular right-hand spiral
• The beta (β) strand zigzags in a flat plane, forming a sheet
• Most proteins have segments of both arrangements

An α Helix
• Amino acid side groups extend outward from the twisted backbone
• Stabilized by regularly spaced hydrogen bonds
• Forms rigid, rodlike structures
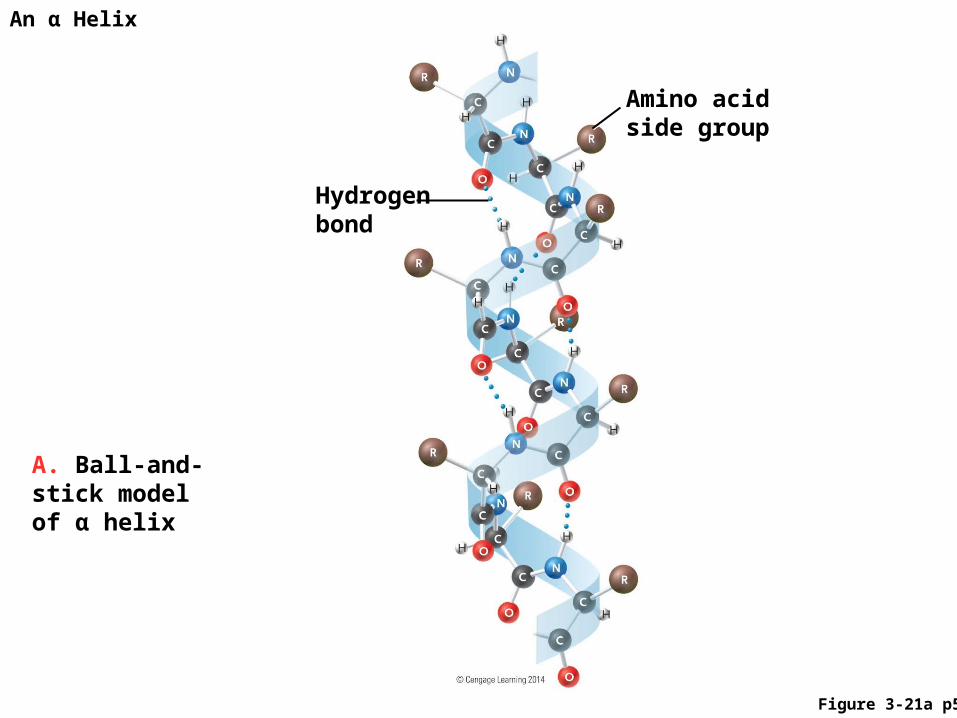
An α Helix
A. Ball-and-stick model of α helix
Amino acid side group
Hydrogen bond
Figure 3-21a p59
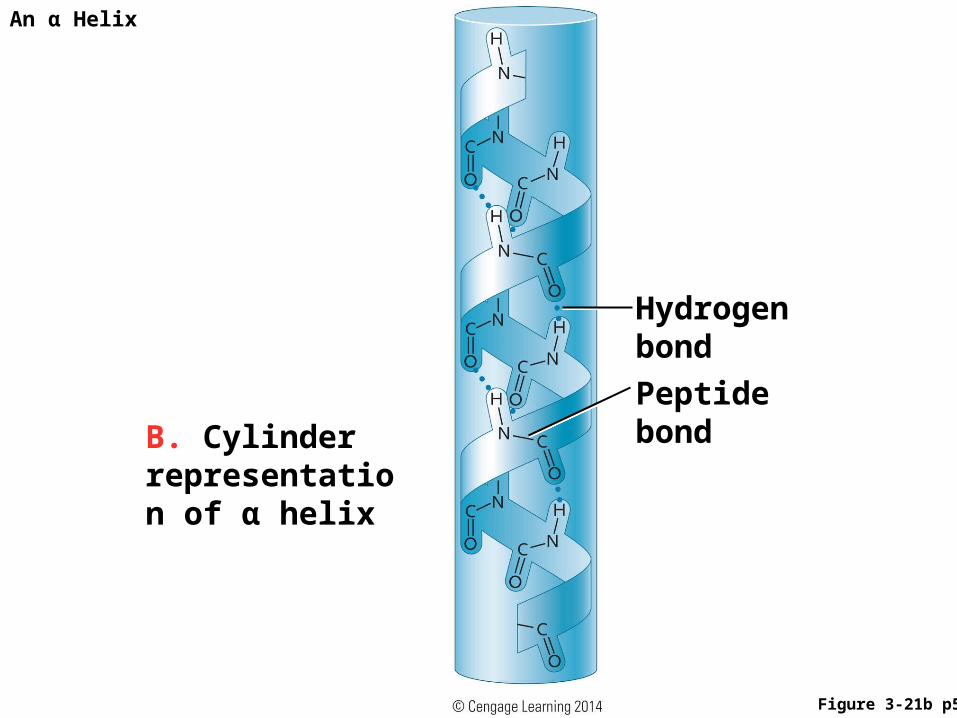
An α Helix
B. Cylinder representation of α helix
Peptide bond
Hydrogen bond
Figure 3-21b p59
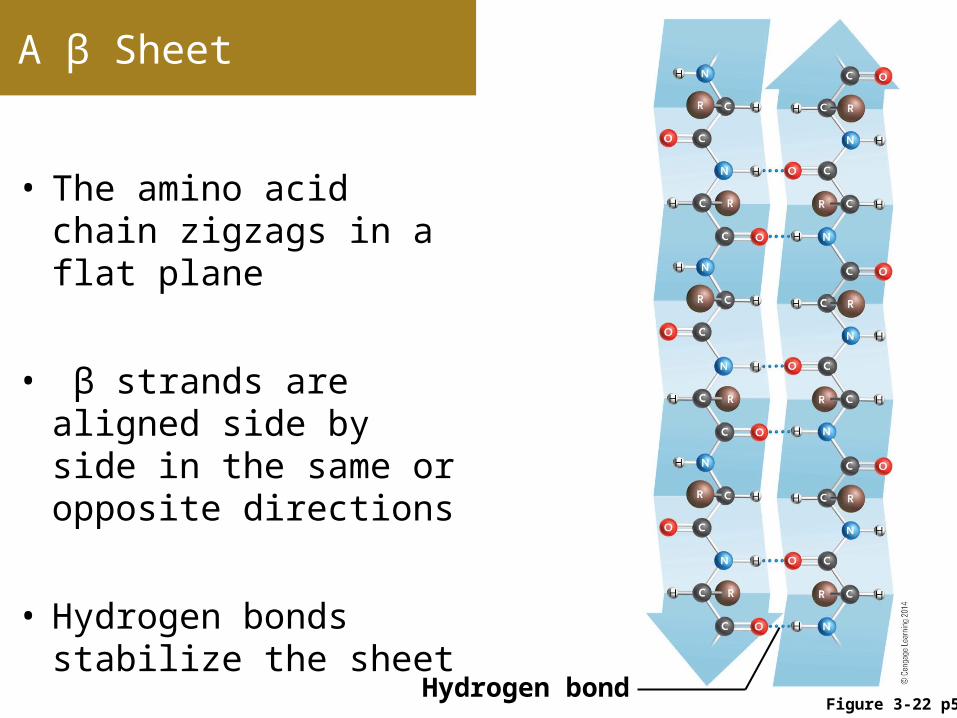
A β Sheet
• The amino acid chain zigzags in a flat plane
• β strands are aligned side by side in the same or opposite directions
• Hydrogen bonds stabilize the sheet
Figure 3-22 p59Hydrogen bond

The Random Coil
• A random coil has an irregularly folded arrangement
• Segments of random coil provide flexible sites that allow α-helical or β-strand segments to bend or fold back on themselves
• Segments of random coil act as “hinges” that allow major parts of proteins to move with respect to one another

Tertiary Structure
• Tertiary structure gives a protein its overall three-dimensional shape, or conformation
• The positions of secondary structures, disulfide linkages, and hydrogen bonds play major roles in folding each protein into its tertiary structure
• Attractions between positively and negatively charged side groups and polar or nonpolar associations also contribute to tertiary structure
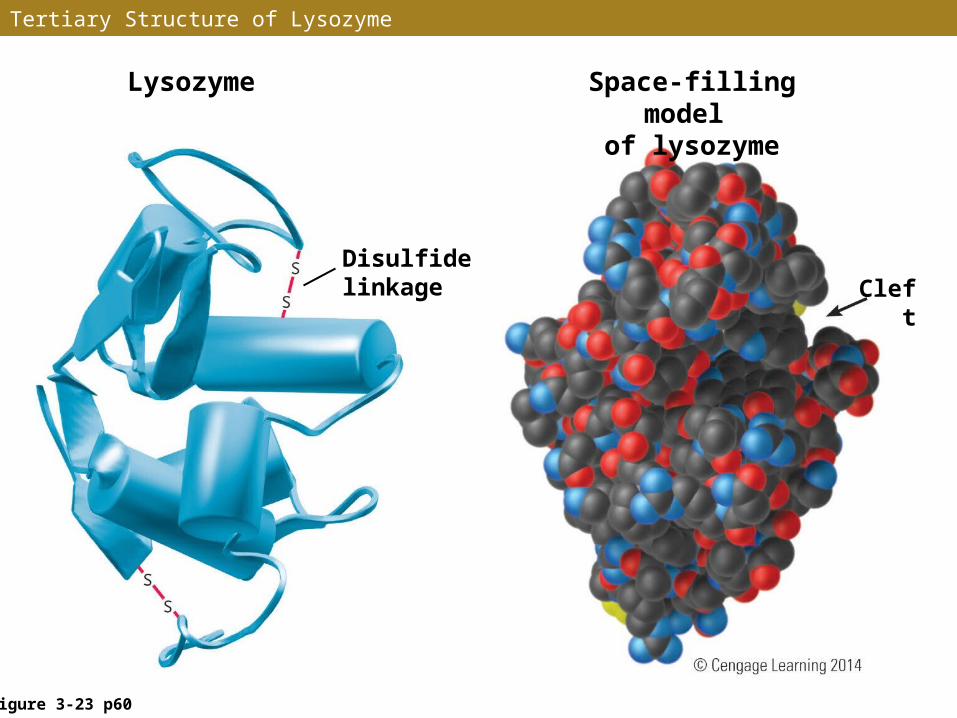
Tertiary Structure of Lysozyme
Figure 3-23 p60
Lysozyme
Disulfide linkage
Space-filling model of lysozyme
Cleft

Denaturation
•Unfolding a protein from its active conformation so that it loses its structure and function (caused by chemicals, changes in pH, or high temperatures) is called denaturation
•Experiments by Christian Anfinsen showed that breaking the disulfide linkages holding the protein ribonuclease in its functional state caused it to unfolded and lose enzyme activity
•For some proteins, denaturation is permanent – for others, denaturation is reversible (renaturation)
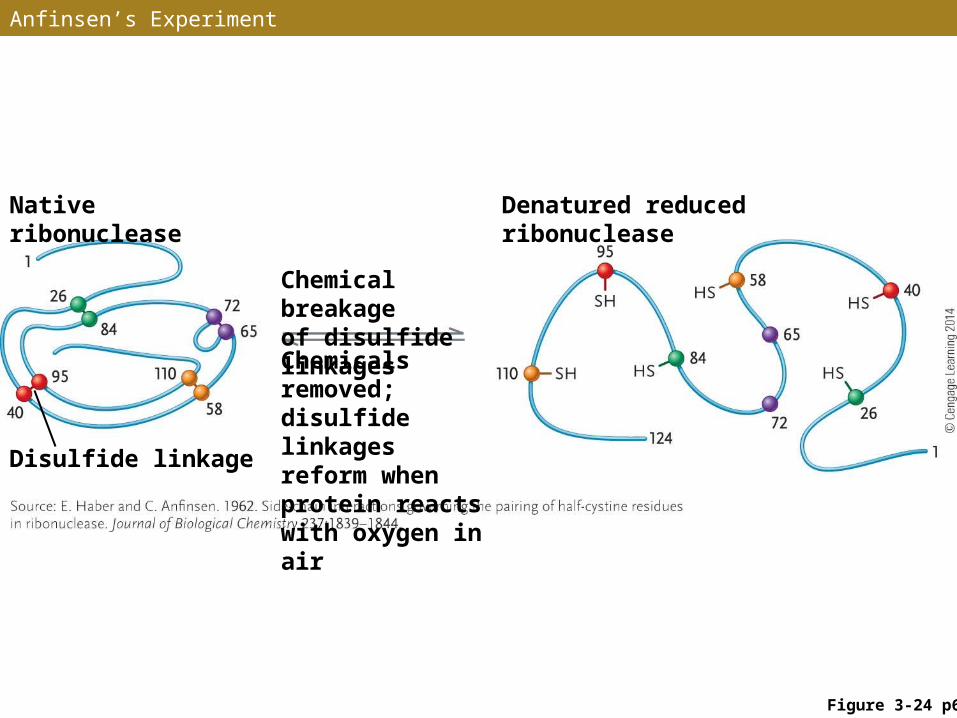
Anfinsen’s Experiment
Figure 3-24 p61
Native ribonuclease Denatured reduced ribonuclease
Chemical breakage of disulfide linkages
Chemicals removed; disulfide linkages reform when protein reacts with oxygen in air
Disulfide linkage

Chaperonins
• Proteins fold gradually as they are assembled – as successive amino acids are linked into the primary structure, the chain folds into increasingly complex structures
• For many proteins, “guide” proteins called chaperone proteins or chaperonins bind temporarily with newly synthesized proteins, directing their conformation toward the correct tertiary structure and inhibiting incorrect arrangements
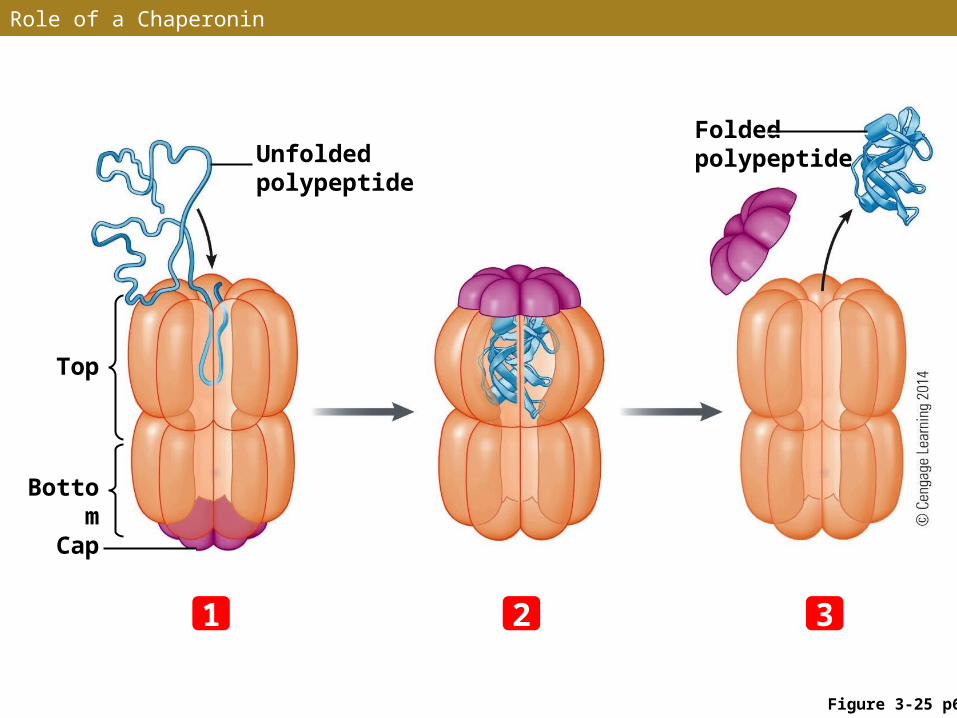
Role of a Chaperonin
Figure 3-25 p62
Unfolded polypeptide
Folded polypeptide
Top
Bottom
Cap
21 3

Tertiary Structure (cont.)
• Tertiary structure determines a protein’s function
• The distribution and 3-D arrangement of side groups, in combination with their chemical properties, determine the overall chemical activity of the protein
• Tertiary structure also determines the solubility of a protein, depending on the arrangement of polar (hydrophilic) and nonpolar (hydrophobic) segments

Tertiary Structure (cont.)
• Tertiary structure of most proteins is flexible, allowing them to undergo limited conformational changes
• Conformational changes are important to the function of enzymes, and to proteins involved in cellular movements or transport of substances across cell membranes

Quaternary Structure
•Some complex proteins, such as hemoglobin and antibody molecules, have quaternary structure – the presence and arrangement of two or more polypeptide chains
•Hydrogen bonds, polar and nonpolar attractions, and disulfide linkages hold the multiple polypeptide chains together
•Chaperonins promote correct association of the individual amino acid chains and inhibit incorrect formations

Functional Domains
•In many proteins, folding of the amino acid chain (or chains) produces large subdivisions called domains
•In proteins with multiple functions, individual functions are often located in different domains
•Domains with similar functions are found in different proteins
•3-D arrangement of amino acid chains within and between domains produces highly specialized regions called motifs
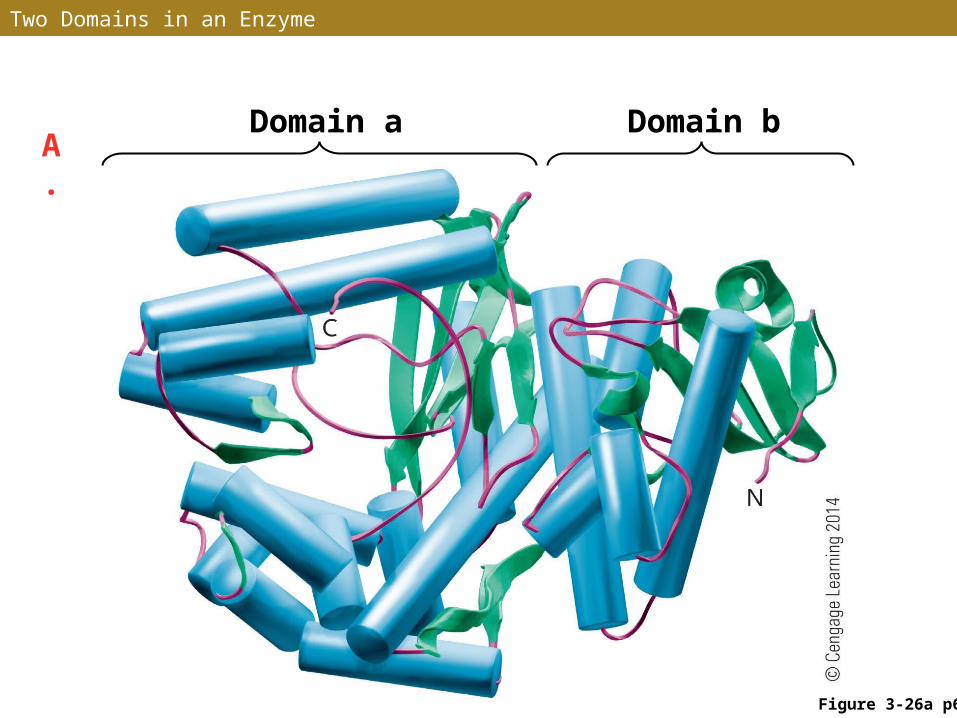
Two Domains in an Enzyme
A. Domain a Domain b
Figure 3-26a p63
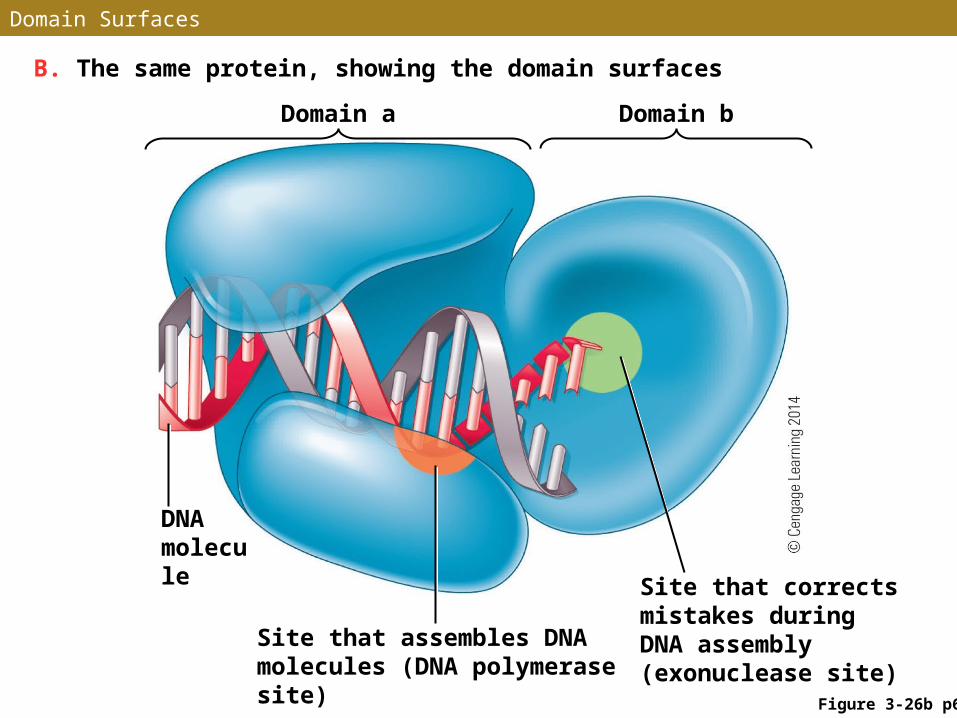
Domain Surfaces
Figure 3-26b p63
B. The same protein, showing the domain surfaces
Domain a Domain b
DNA molecule
Site that assembles DNA molecules (DNA polymerase site)
Site that corrects mistakes during DNA assembly (exonuclease site)

Protein Combinations
• Proteins link with lipids to form lipoproteins, which form parts of cell membranes
• Proteins link with carbohydrates to form glycoproteins, which function as enzymes, antibodies, recognition and receptor molecules, and parts of extracellular supports
• Proteins link with nucleic acids to form nucleoproteins, which form structures such as chromosomes

STUDY BREAK 3.4
1. What gives amino acids their individual properties?
2. What is a peptide bond and what type of reaction results in its formation?
3. What are functional domains of proteins and how are they formed?

3.5 Nucleotides and Nucleic Acids
• Nucleic acids are macromolecules assembled from repeating monomers called nucleotides
• DNA (deoxyribonucleic acid) stores hereditary information responsible for inherited traits in all eukaryotes and prokaryotes and in a large group of viruses
• RNA (ribonucleic acid) is the hereditary molecule of another large group of viruses – three major types of RNA are involved in protein synthesis

Nucleotides
• A nucleotide, the monomer of nucleic acids, consists of three parts linked together by covalent bonds:• A nitrogenous base formed from rings of carbon and
nitrogen atoms• A five-carbon, ring-shaped sugar• One to three phosphate groups
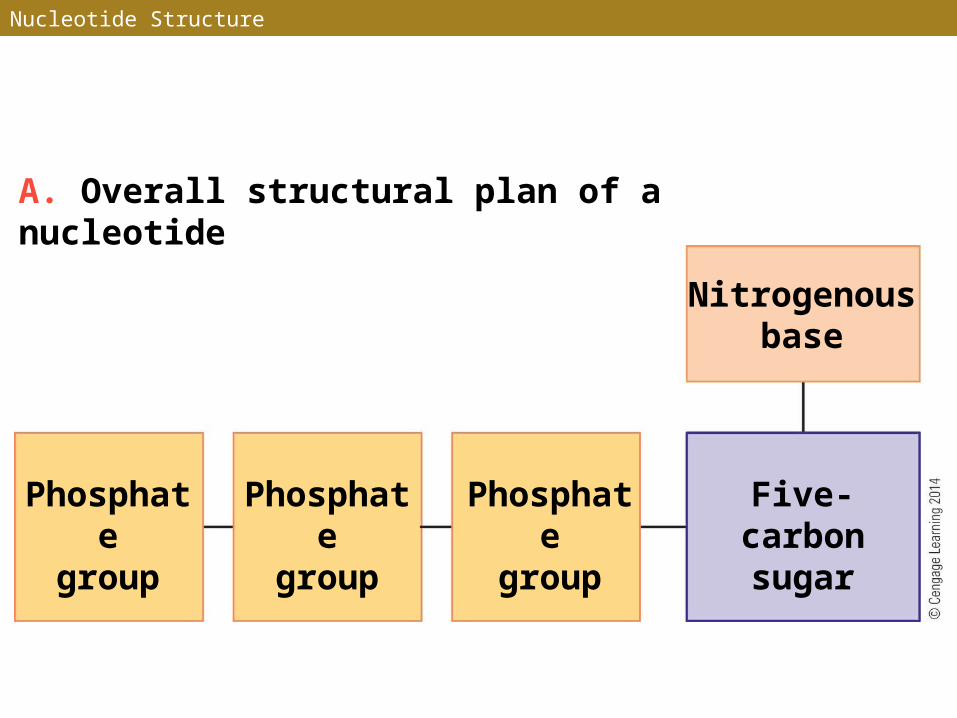
Nucleotide Structure
A. Overall structural plan of a nucleotide
Nitrogenousbase
Phosphategroup
Five-carbonsugar
Phosphategroup
Phosphategroup
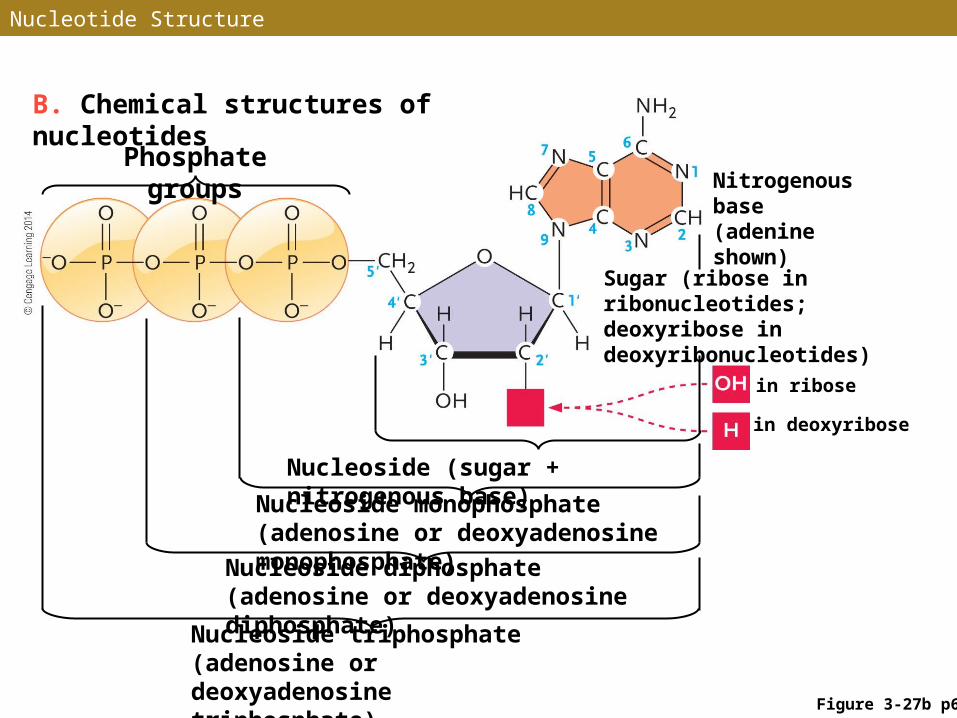
Figure 3-27b p64
B. Chemical structures of nucleotides
Phosphate groupsNitrogenous base (adenine shown)
Sugar (ribose in ribonucleotides; deoxyribose in deoxyribonucleotides)
Nucleoside (sugar + nitrogenous base)
Nucleoside monophosphate (adenosine or deoxyadenosine monophosphate)
Nucleoside diphosphate (adenosine or deoxyadenosine diphosphate)
Nucleoside triphosphate (adenosine or deoxyadenosine triphosphate)
in deoxyribose
in ribose
Nucleotide Structure

Two Types of Nitrogenous Bases
• Pyrimidines• Nitrogenous bases with one carbon-nitrogen ring • Uracil (U), thymine (T), and cytosine (C)
• Purines• Nitrogenous bases with two carbon–nitrogen rings• Adenine (A) and guanine (G)
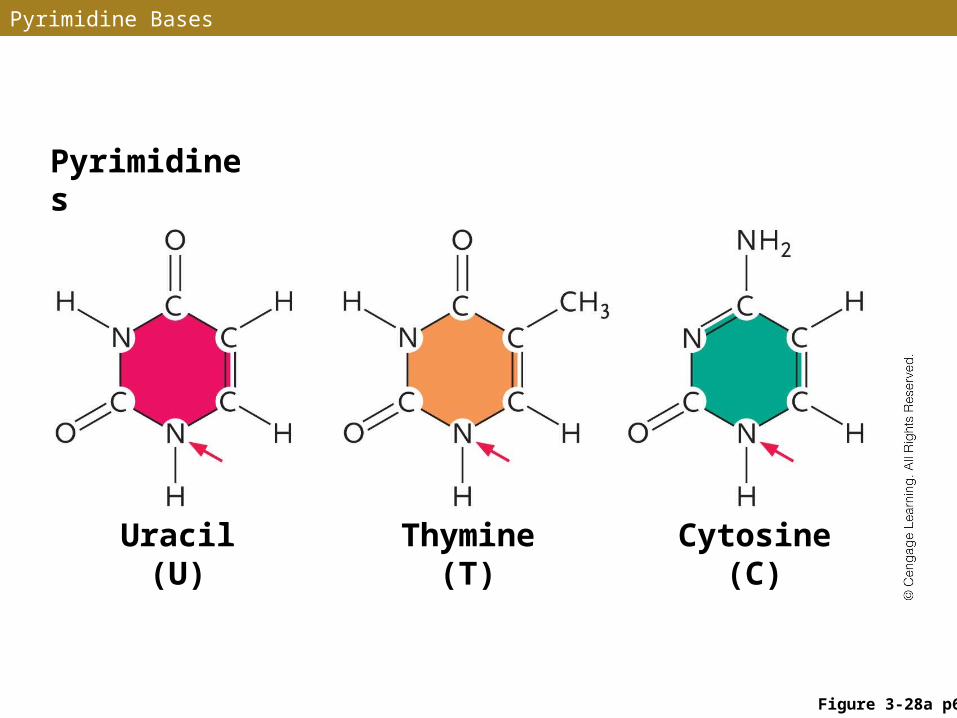
Pyrimidine Bases
Pyrimidines
Uracil (U) Thymine (T) Cytosine (C)
Figure 3-28a p64

ANIMATION: Subunits of DNA
To play movie you must be in Slide Show ModePC Users: Please wait for content to load, then click to play
Mac Users: CLICK HERE
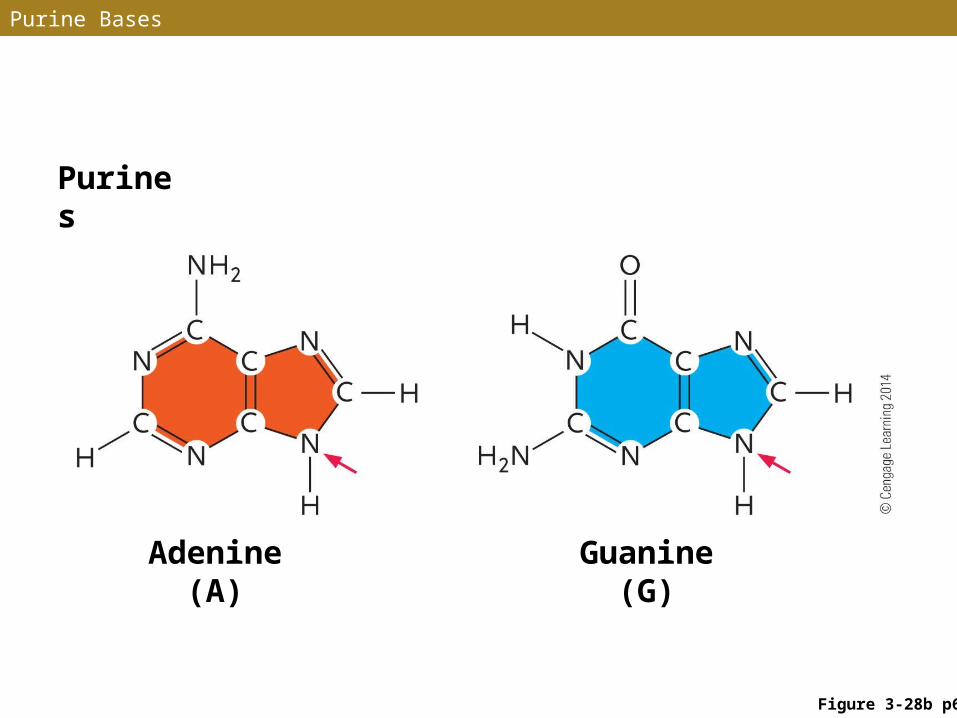
Purine Bases
Purines
Adenine (A)
Guanine (G)
Figure 3-28b p64

Linkage of Nucleotides
• Nitrogenous bases link covalently to a five-carbon sugar:• Deoxyribose in DNA deoxyribonucleotides• Ribose in RNA ribonucleotides
• The two sugars differ only in the chemical group bound to the 2 carbon (—H in deoxyribose, —OH in ribose)′
• In unlinked nucleotides: 1, 2, or 3 phosphate groups bond to the ribose or deoxyribose sugar at the 5 carbon′

Nucleosides and Nucleotide Phosphates
• A structure containing only a nitrogenous base and a five-carbon sugar is a nucleoside
• A nucleotide is a nucleoside phosphate
• Examples: • Adenosine monophosphate (AMP)• Adenosine diphosphate (ADP)• Adenosine triphosphate (ATP)

DNA and RNA
• DNA and RNA consist of polynucleotide chains, with one nucleotide linked to the next by a phosphodiester bond
• One nucleotide is linked to the next by a bridging phosphate group between the 5 carbon of one sugar and the 3 carbon ′ ′of the next sugar
• Alternating sugar and phosphate groups forms the backbone of a nucleic acid chain
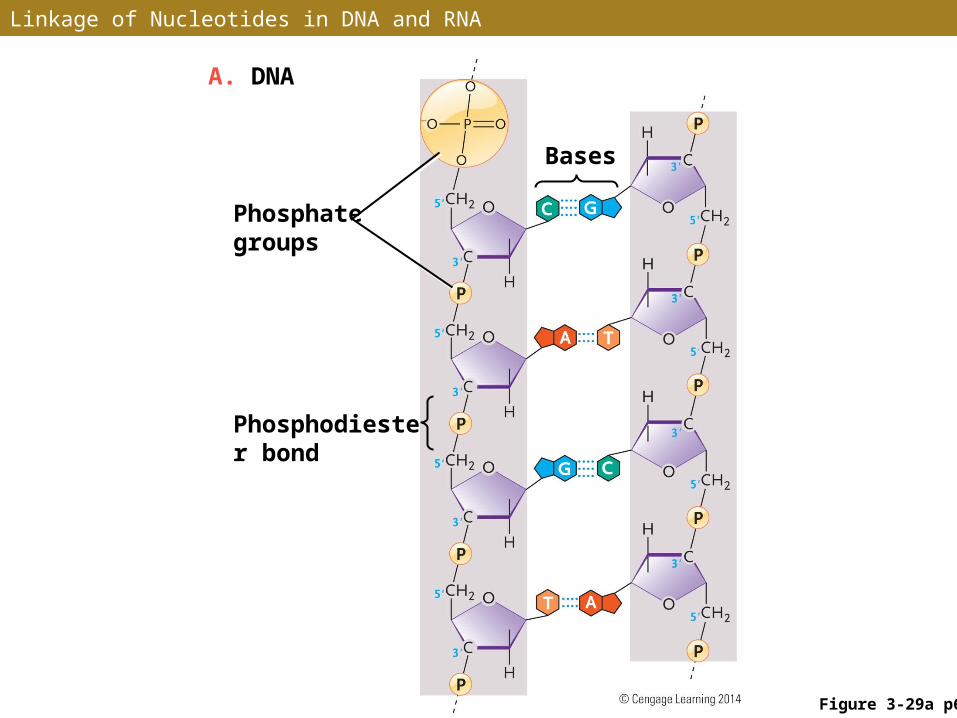
Linkage of Nucleotides in DNA and RNA
Figure 3-29a p65
A. DNA
Bases
Phosphate groups
Phosphodiester bond
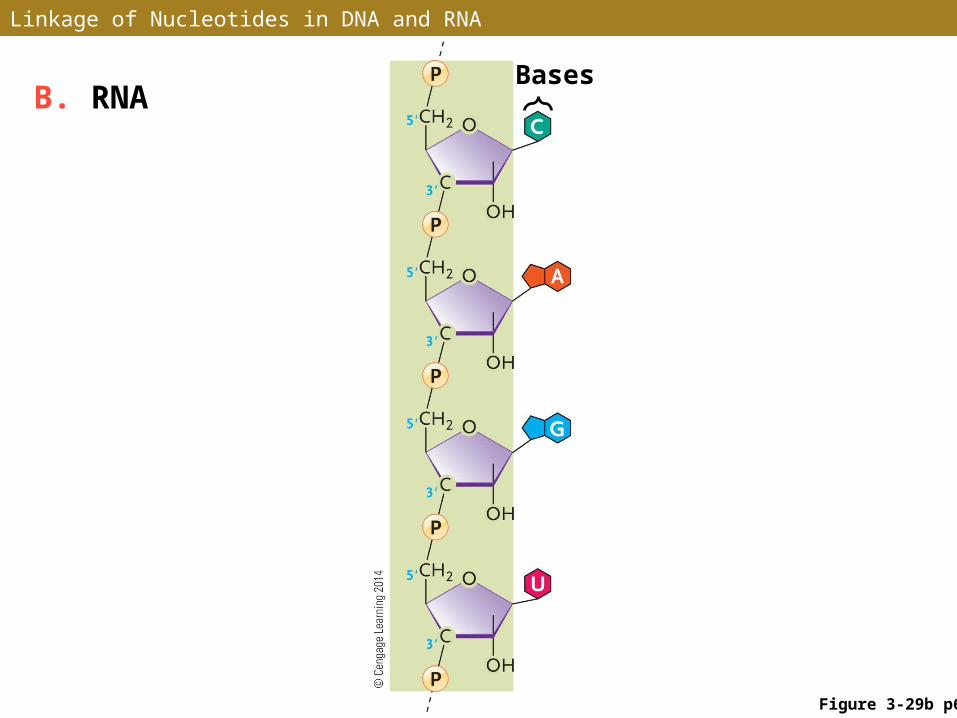
Linkage of Nucleotides in DNA and RNA
Figure 3-29b p65
BasesB. RNA

The DNA Molecule
• The DNA molecule is a double helix (double-stranded) consisting of two nucleotide chains wrapped around each other in a spiral that resembles a twisted ladder
• The sides of the ladder are the sugar-phosphate backbones of the two chains
• The rungs of the ladder are nitrogenous bases which extend inward from the sugars toward the center of the helix
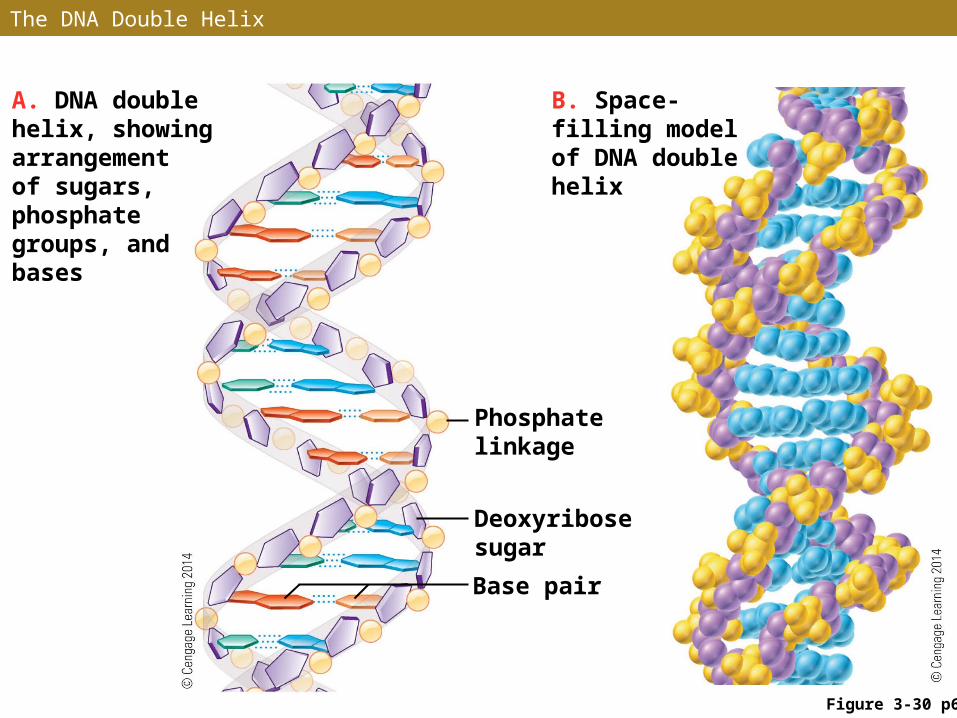
The DNA Double Helix
A. DNA double helix, showing arrangement of sugars, phosphate groups, and bases
Phosphate linkage
Deoxyribose sugar
Base pair
B. Space-filling model of DNA double helix
Figure 3-30 p65

ANIMATION: DNA Structure

DNA Base Pairs
• The two nucleotide chains of a DNA double helix are held together by hydrogen bonds between the base pairs
• A base pair consists of one purine and one pyrimidine
• Adenine pairs only with thymine (A–T), forming two stabilizing hydrogen bonds
• Guanine pairs only with cytosine (G–C), forming three hydrogen bonds
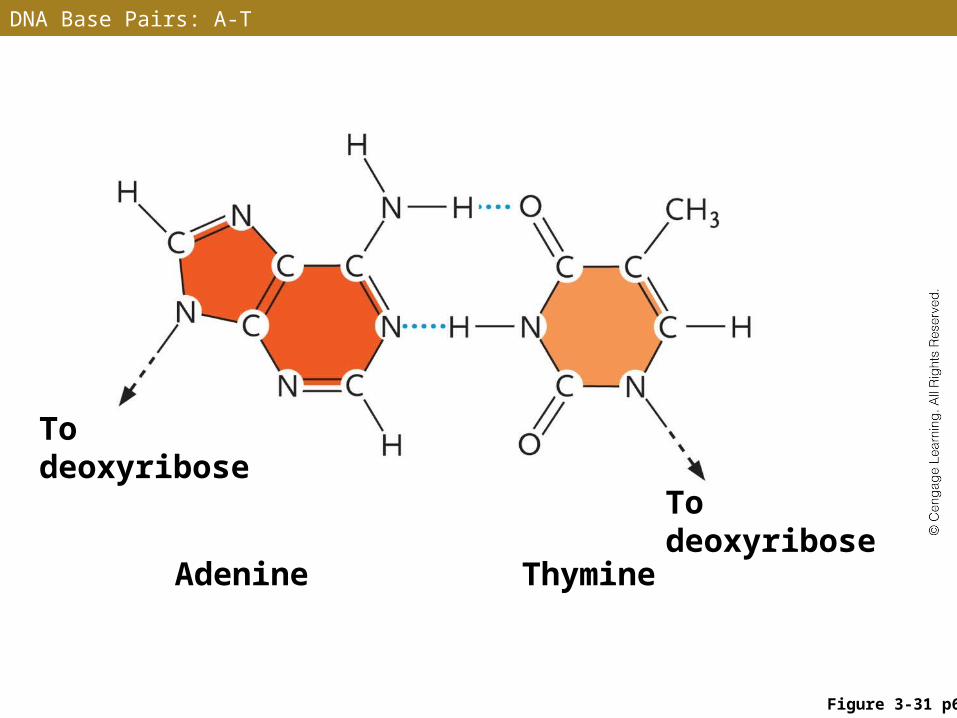
DNA Base Pairs: A-T
To deoxyribose
To deoxyribose
Adenine Thymine
Figure 3-31 p66
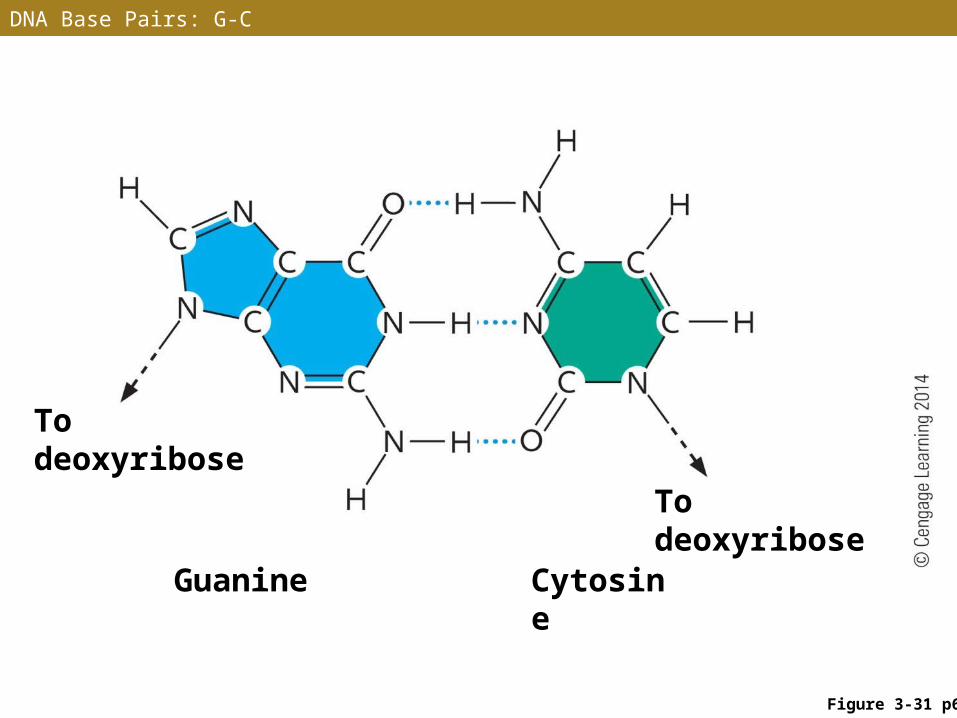
DNA Base Pairs: G-C
To deoxyribose
To deoxyribose
Cytosine Guanine
Figure 3-31 p66

Complementary Base Pairing
• Formation of A–T and G–C pairs allows the sequence of one nucleotide chain to determine the sequence of its partner in the double helix
• The nucleotide sequence of one chain is said to be complementary to the nucleotide sequence of the other chain
• In DNA replication, one nucleotide chain is used as a template for the assembly of a complementary chain according to the A–T and G–C base-pairing rules
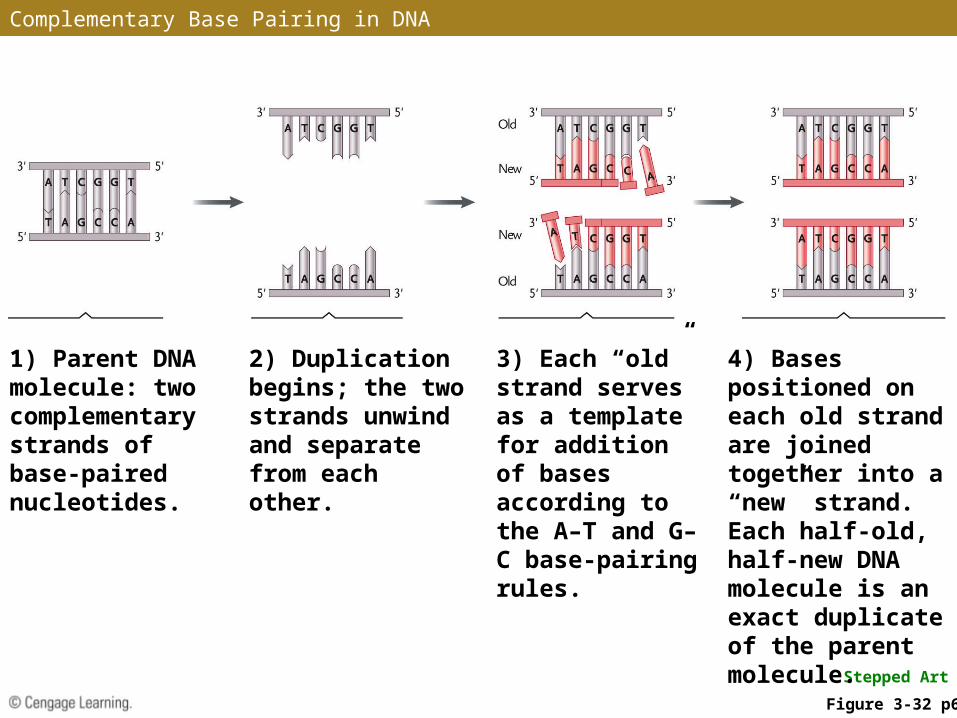
Stepped Art
1) Parent DNA molecule: two complementary strands of base-paired nucleotides.
2) Duplication begins; the two strands unwind and separate from each other.
3) Each “old” strand serves as a template for addition of bases according to the A–T and G–C base-pairing rules.
4) Bases positioned on each old strand are joined together into a “new” strand. Each half-old, half-new DNA molecule is an exact duplicate of the parent molecule.
Figure 3-32 p66
Complementary Base Pairing in DNA
ANIMATION: DNA Replication in Detail

RNA Molecules
• RNA molecules exist mainly as single polynucleotide chains (single-stranded) – however, RNA molecules can fold back on themselves to form double-helical regions
• “Hybrid” double helices (an RNA chain paired with a DNA chain) are formed temporarily when RNA copies DNA
• In RNA, the uracil (U) base takes the place of thymine (T), forming A–U base pairs

STUDY BREAK 3.5
1. What is the monomer of a nucleic acid macromolecule?
2. What are the chemical differences between DNA and RNA?





























