Embed Size (px)
Citation preview

PetastormPetastorm: A Light-Weight Approach to Building ML Pipelines @Uber
Yevgeni Litvin ([email protected]),
Uber ATG

Deep-learning for self driving vehiclesComplex upstream API
Cluster processing
● Huge row sizes (multi MBs)● Huge datasets (tens+ TB)
Learning curve
Many datasets Raw AV data AP
I
HDF5
TFRecords
Png files
Maps
API
Labels
API
Autonomous Vehicle
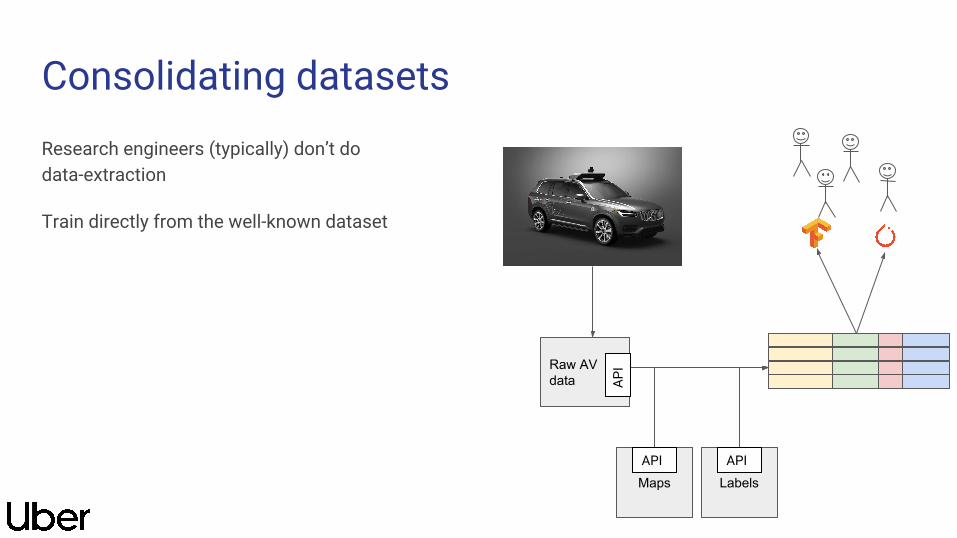
Consolidating datasetsResearch engineers (typically) don’t do data-extraction
Train directly from the well-known dataset
Raw AV data
LabelsMaps
API
API API

Uber ATG MissionIntroduce self-driving technology to the Uber network in order to make transporting people and goods safer, more efficient, and more affordable around the world.

About myself...Yevgeni Litvin
Work on data platform and onboard integration of models

Our talk todayEnabling “One Dataset” approach
File formats
Petastorm as an enabling tool
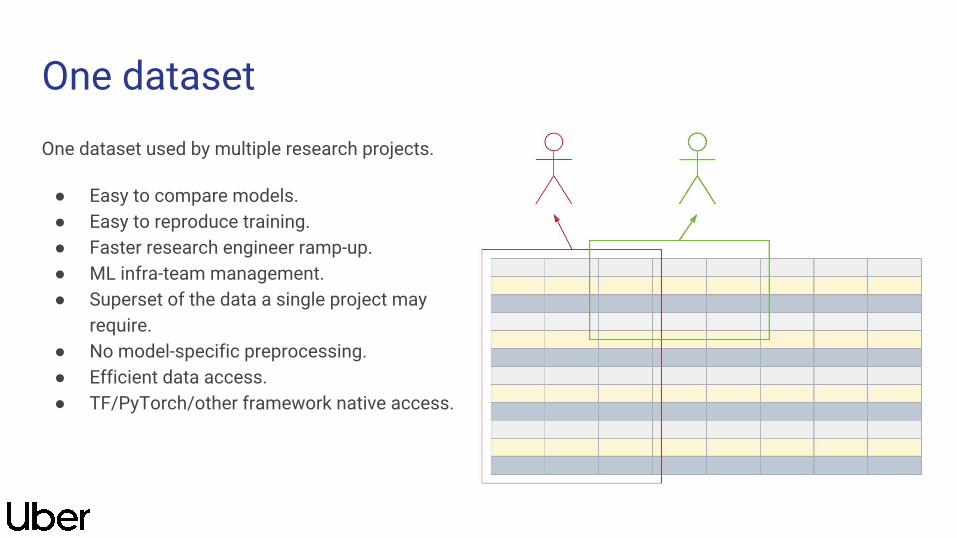
One datasetOne dataset used by multiple research projects.
● Easy to compare models.● Easy to reproduce training.● Faster research engineer ramp-up.● ML infra-team management.● Superset of the data a single project may
require.● No model-specific preprocessing.● Efficient data access.● TF/PyTorch/other framework native access.

Apache ParquetEfficient column-subset reads.
Atomic read unit: one column from a row group (a chunk).
Random access to a row-group.
Natively supported by Apache Spark, Hive and other big-data tools.
No tensor support

PetastormScalable
Native TensorFlow, PyTorch
Shuffling
Sharding
Queries, Indexing
Parquet partitions
Local caching
N-grams (windowing)

Research engineer experienceBefore: After:
Data extraction(Query upstream systems,
ETL at scale)
Train
Evaluate
Deploy
Train
Evaluate
Deploy

Apache Parquet as a dataframe with tensors
Two integration alternativesTrain from existing org Parquet stores (native types, no tensors)
nd-arrays, scalars
(e.g. images, lidar point
clouds)
Apache Parquet store
FogHorse
Hedgehog
non-Petastorm, Apache Parquet store

Extra schema informationFrameSchema = Unischema('FrameSchema', [ UnischemaField('timestamp', np.int32, (), ScalarCodec(IntegerType()), nullable=False), UnischemaField('front_cam', np.uint8, (1200, 1920, 3), CompressedImageCodec('png'), nullable=False), UnischemaField('label_box', np.uint8, (None, 2, 2), NdarrayCodec(), nullable=False),])
Stored with Parquet store
Defines tensor serialization format
Runtime types validation
Needed for wiring natively into Tensorflow graph

Generating a dataset
with materialize_dataset(spark, output_url, FrameSchema, rowgroup_size_mb):
rows_rdd = sc.parallelize(range(rows_count))\ .map(row_generator)\ .map(lambda x: dict_to_spark_row(FrameSchema, x))
spark.createDataFrame(rows_rdd, FrameSchema.as_spark_schema()) \ .write \ .parquet(output_url)
def row_generator(x): return {'timestamp': ..., 'front_cam': np.asarray(...), 'label_box: np.asarray(...)}
1. Configure row-group size spark and writes Petastorm metadata at the end
2. Encode tensors and convert to a spark Row
3. Spark schema from Unischema

Pythonwith make_reader('hdfs:///tmp/hello_world_dataset') as reader:
for sample in reader: print(sample.id) plt.imshow(sample.image1)
[Out 0] 0
# Reading from non-Petastorm dataset (only native Apache Parquet types)with make_batch_reader('hdfs:///tmp/hel...') as reader:
for sample in reader: print(sample.id)
[Out 1] [0, 1, 2, 3, 4, 5]

Tensorflow
# tf tensors
with make_reader('hdfs:///tmp/dataset') as reader:
data = tf_tensors(reader)
predictions = my_model(data.image1, data.image2)
Substitute with make_batch_reader to read non-Petastorm dataset
Connect Petastorm Reader object intoTF graph

PyTorchfrom petastorm.pytorch import DataLoader
with DataLoader(make_reader(dataset_url)) as train_loader:
sample = next(iter(train_loader))
print(sample['id'])

Real examplewith make_reader('hdfs:///path/to/uber/atg/dataset', schema_fields=[AVSchema.lidar_xyz]) as reader:
sample = next(reader)
plt.plot(sample.returns_xyz[:, 0], sample.returns_xyz[:, 1], '.')

Reader architecture
Uses Apache Arrow
Reading workers (threads or processes)
Row-groups filtered, shuffled
Output rows as np.array, tf.tensor or tf.data.Dataset

Petastorm row predicate
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
carcarcar
pedestriancarcar
bicyclecar
...
...
...
...
...
...
...
...
...
...
...
...
carcarcarcarcarcar
User defined row filter
Optimizations in_lambda(['object_type'], lambda object_type: object == 'car'))

Transform
[[1,2,3], [4], [5,6]][[1], [4,5,6]]
[[10]]
User defined row update
On thread/process pool
def modify_row(row): row['list_of_lists_as_tensor'] = \ foo_to_tensor(row['list_of_lists'])
del row['data_as_list_of_lists']
0, 0, ... 01, 1, ... 03, 3, ... 1
4, 3, ... 11, 2, ... 03, 5, ... 1
0, 8, ... 31, 4, ... 21, 3, ... 1

Local cache
Slow/expensive links
In-memory cache
make_reader(..., cache_type=’local-disk’)

Sharding
Distributed training
Quick experimentation
make_reader(..., cur_shard=3, shard_count=10)

NGrams (windowing)
Sorted datasets
Efficient IO/decoding
Cons: RAM wasteful shuffling
t=0 t=1 t=2
t=1 t=2 t=3
t=2 t=3 t=4
t=0
t=1
t=2
t=3
t=4

Conclusion
Petastorm developed to support “One Dataset” workflow.
Uses Apache Parquet as the store format:
- Tensors support- Provides set of tools needed for deep-learning training/evaluation
Organization data-warehouse (non-Petastorm, native Parquet types)
(still lot’s of work left to be done… we are hiring!)

Thank you!
Github: https://github.com/uber/petastorm






![M. Billaud-Friess ,A.Nouyand O. Zahm€¦ · canonical tensors, Tucker tensors, Tensor Train tensors [27,40], Hierarchical Tucker tensors [25] or more general tree-based Hierarchical](https://img.pdfslide.us/doc/110x75/606a2ea8ed4bc80bc83876de/m-billaud-friess-anouyand-o-zahm-canonical-tensors-tucker-tensors-tensor-train.jpg)






















