Embed Size (px)
Citation preview

1/2/01 1
Performance Impact ofMultithreaded Java ServerApplications
Yue Luo, Lizy K. JohnLaboratory of Computer ArchitectureECE DepartmentUniversity of Texas at Austin

2
Outline
• Motivation• VolanoMark Benchmark• Methodology• Results• Conclusion• Further Work Needed

3
Motivation
• Performance under the presence of a largenumber of threads is crucial for a commercialJava server.– Java applications are shifting from client-side to server-
side.– Server needs to support multiple simultaneous client
connections.– No select() or poll() or asynchronous I/O in Java– Current Java programming paradigm: one thread for
one connection.

4
VolanoMark Benchmark
• VolanoMark is a 100% Pure Java serverbenchmark characterized by long-lasting networkconnections and high thread counts.– Based on real commercial software.– Server benchmark.– Long-lasting network connections and high thread
counts.– Two threads for each client connection.
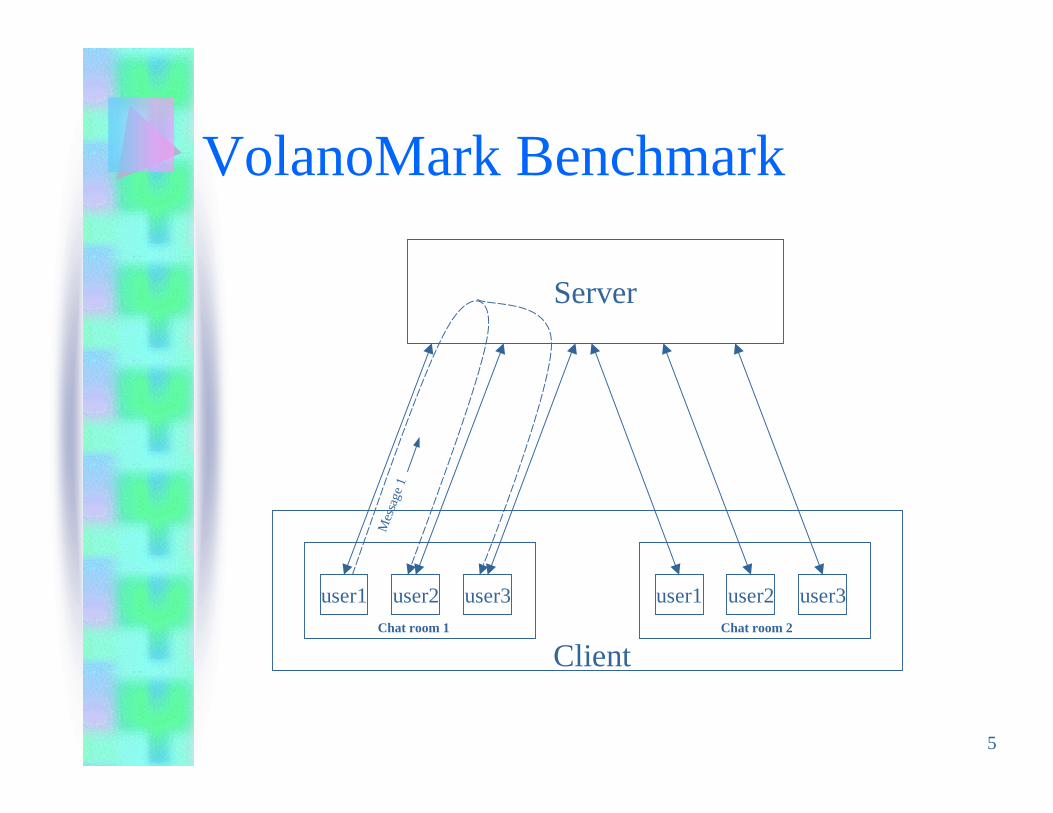
5
VolanoMark Benchmark
user1 user2 user3 user1 user2 user3
Server
Mes
sage
1
Chat room 1 Chat room 2
Client

6
Methodology
• Performance counters used to study OSand user activity on Pentium III system.
• Monitoring Tools -- Pmon– Developed in our lab. Better controlled.– Device driver to read performance counters– Low overhead

7
Platform Parameters• Hardware
– Uni-processor– CPU Frequency: 500MHz– L1 I Cache: 16KB, 4-way, 32 Byte/Line, LRU– L2 Cache: 512KB, 4-way, 32 Byte/Line, Non-blocking– Main Memory: 1GB
• Software– Windows NT Workstation 4.0– Sun JDK1.3.0-C with HotSpot server (build 2.0fcs-E,
mixed mode)

8
Monitoring Issues
• Synchronize measurements with clientconnections to skip starting and shutdownprocess– Add wrapper to the client.– The wrapper starts an extra connection immediately
before starting the client to trigger measurement.
• Avoid counter overflow– Counting interval: 3sec
9
Results
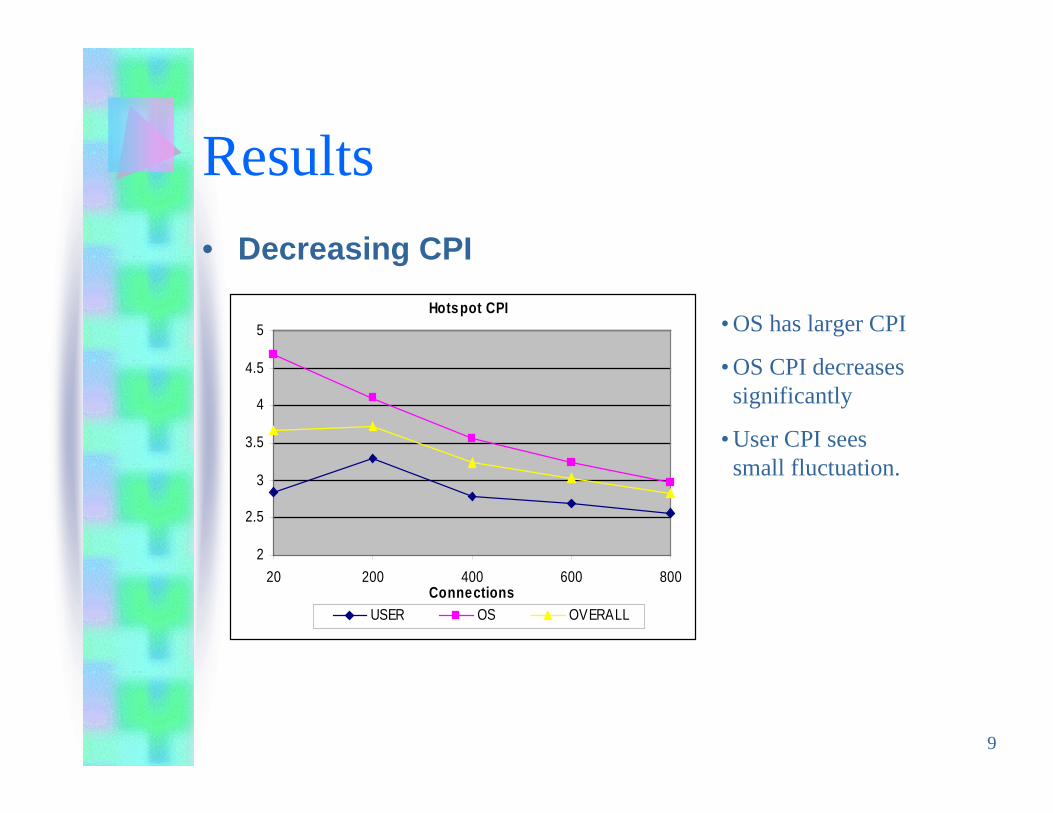
• Decreasing CPI
• OS has larger CPI
• OS CPI decreasessignificantly
• User CPI seessmall fluctuation.
Hotspot CPI
2
2.5
3
3.5
4
4.5
5
20 200 400 600 800Connections
USER OS OVERALL
10
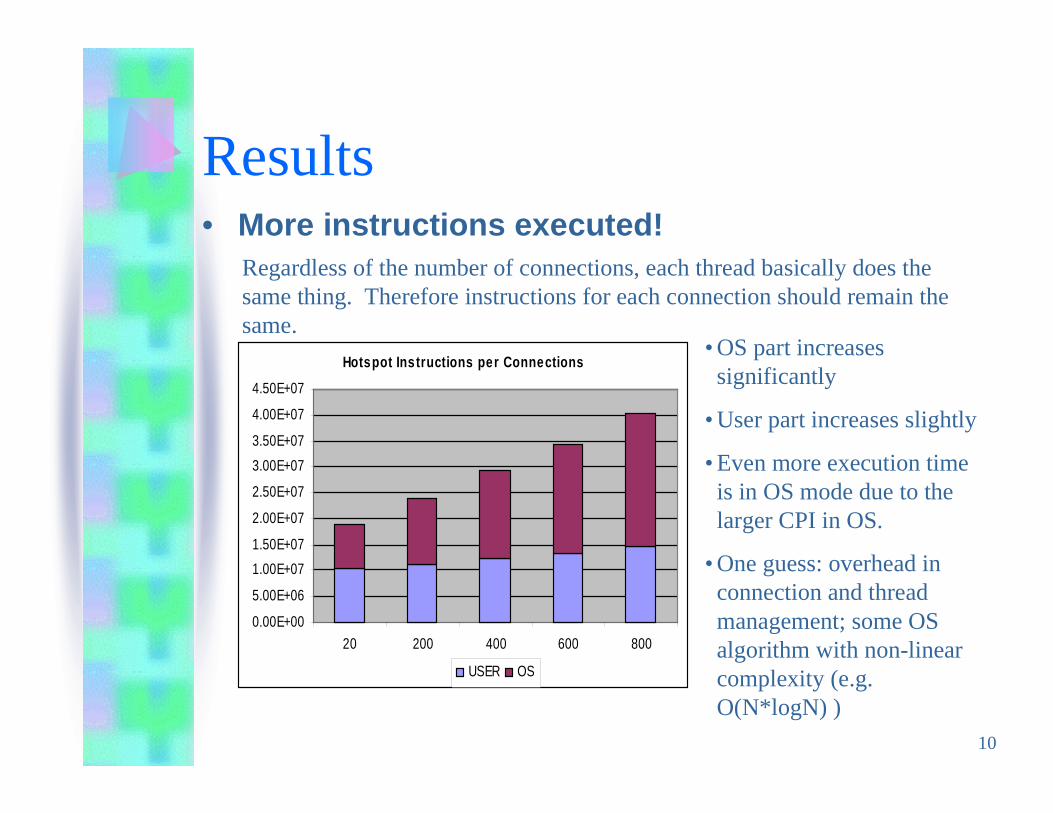
Results• More instructions executed!
• OS part increasessignificantly
• User part increases slightly
• Even more execution timeis in OS mode due to thelarger CPI in OS.
• One guess: overhead inconnection and threadmanagement; some OSalgorithm with non-linearcomplexity (e.g.O(N*logN) )
Hotspot Instructions per Connections
0.00E+00
5.00E+06
1.00E+07
1.50E+07
2.00E+07
2.50E+07
3.00E+07
3.50E+07
4.00E+07
4.50E+07
20 200 400 600 800
USER OS
Regardless of the number of connections, each thread basically does thesame thing. Therefore instructions for each connection should remain thesame.
11
Results
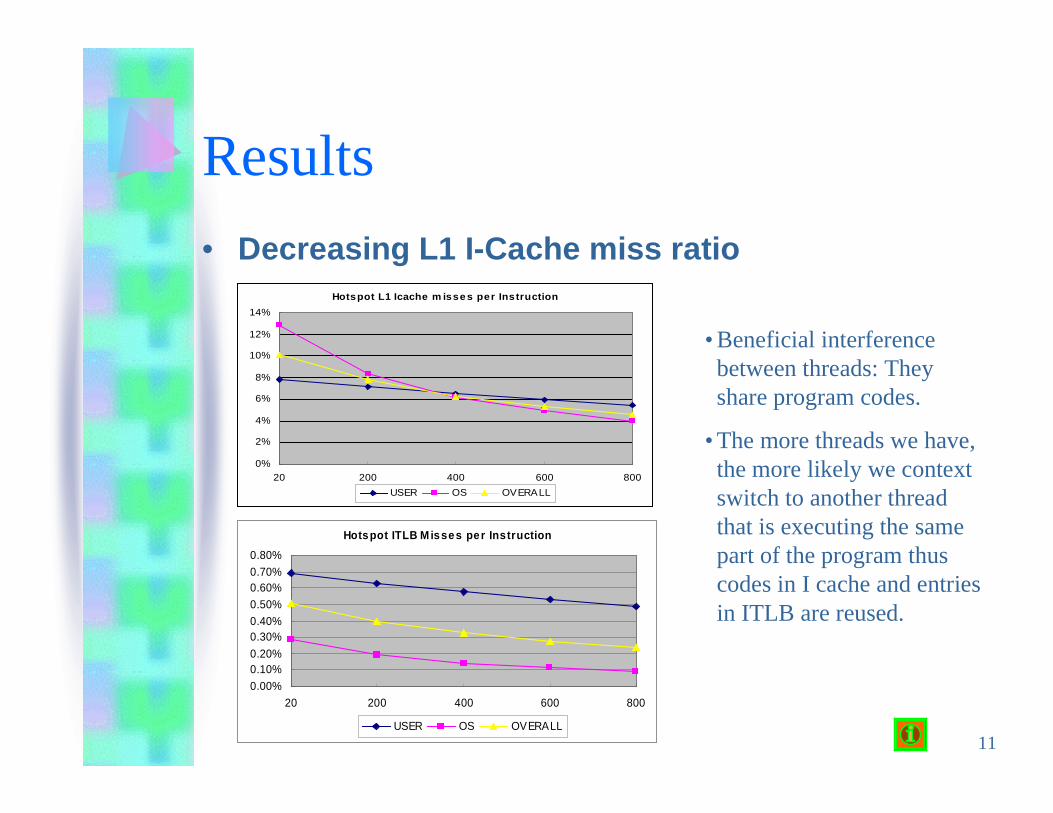
• Decreasing L1 I-Cache miss ratio
• Beneficial interferencebetween threads: Theyshare program codes.
• The more threads we have,the more likely we contextswitch to another threadthat is executing the samepart of the program thuscodes in I cache and entriesin ITLB are reused.
Hotspot L1 Icache m isse s per Instruction
0%
2%
4%
6%
8%
10%
12%
14%
20 200 400 600 800
USER OS OVERALL
Hotspot ITLB M isses per Instruction
0.00%
0.10%0.20%
0.30%0.40%
0.50%
0.60%0.70%
0.80%
20 200 400 600 800
USER OS OVERALL
12
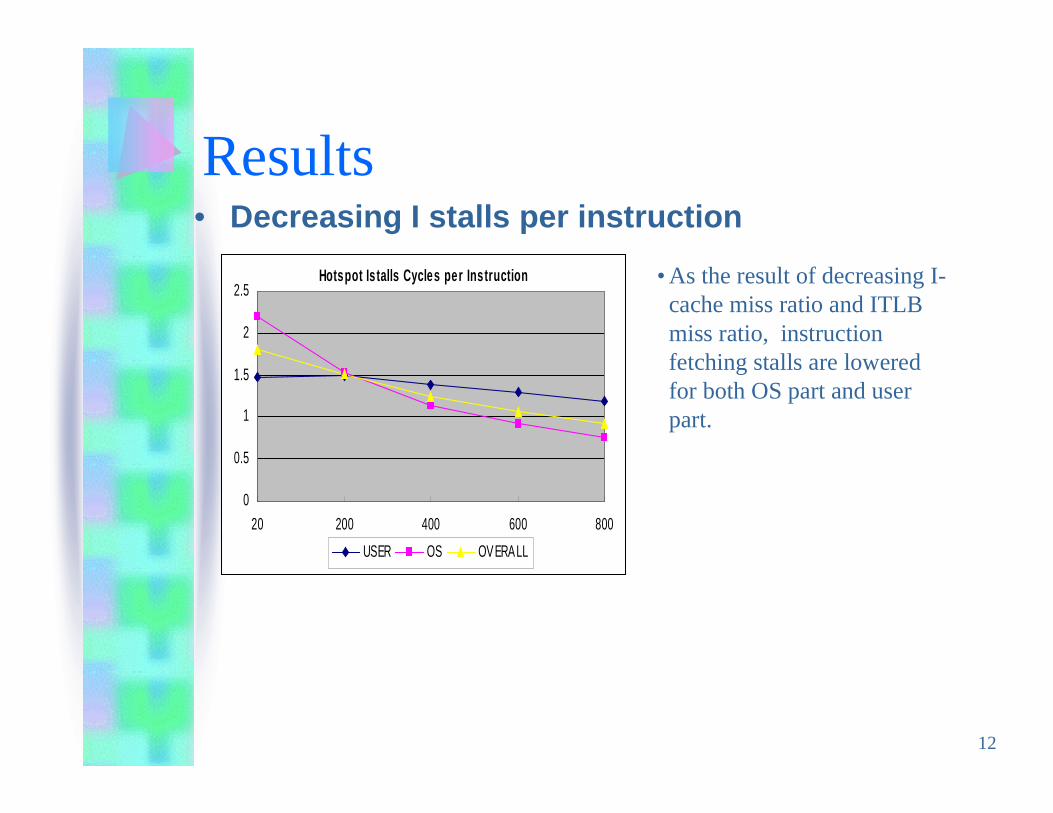
Results• Decreasing I stalls per instruction
• As the result of decreasing I-cache miss ratio and ITLBmiss ratio, instructionfetching stalls are loweredfor both OS part and userpart.
Hotspot Is talls Cycles per Instruction
0
0.5
1
1.5
2
2.5
20 200 400 600 800
USER OS OVERALL
13
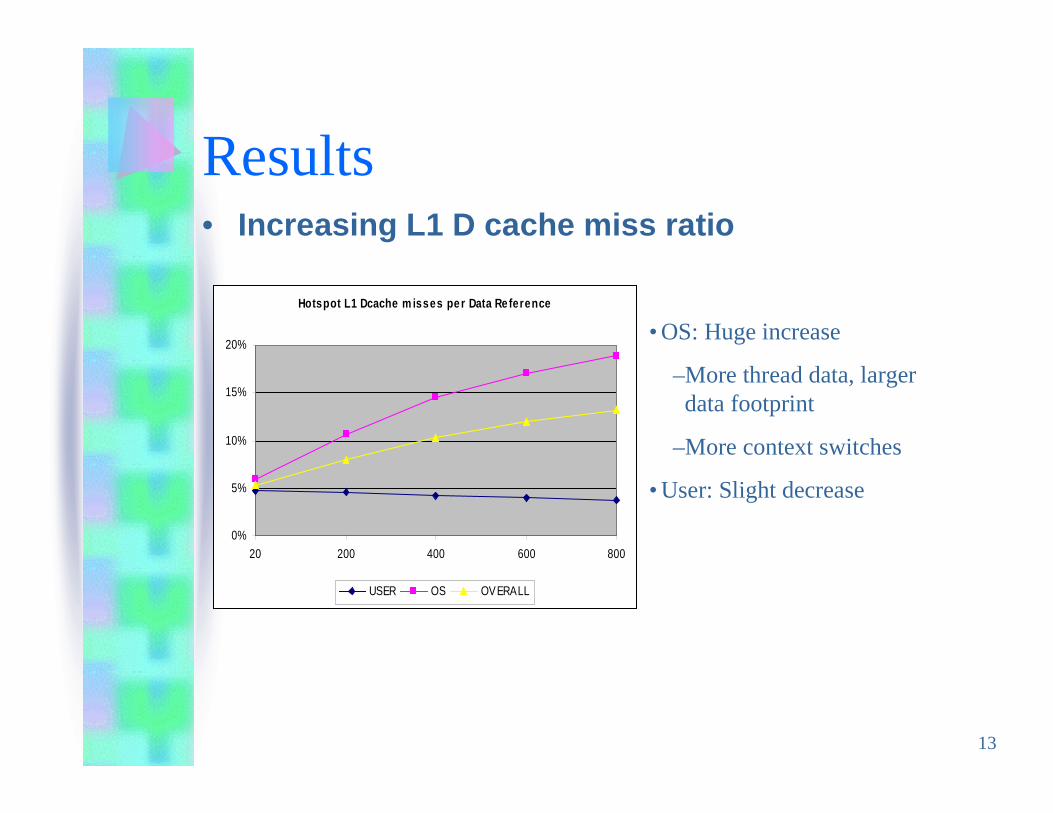
Results• Increasing L1 D cache miss ratio
• OS: Huge increase
–More thread data, largerdata footprint
–More context switches
• User: Slight decrease
Hotspot L1 Dcache m isses pe r Data Re ference
0%
5%
10%
15%
20%
20 200 400 600 800
USER OS OVERALL
14
Hots pot Cache M isses per Connection
0.00E+00
1.00E+06
2.00E+06
3.00E+06
4.00E+06
5.00E+06
6.00E+06
20 200 400 600 800
OS D-CACHE
USER D-CACHE
OS I-CACHE
USER I-CACHE
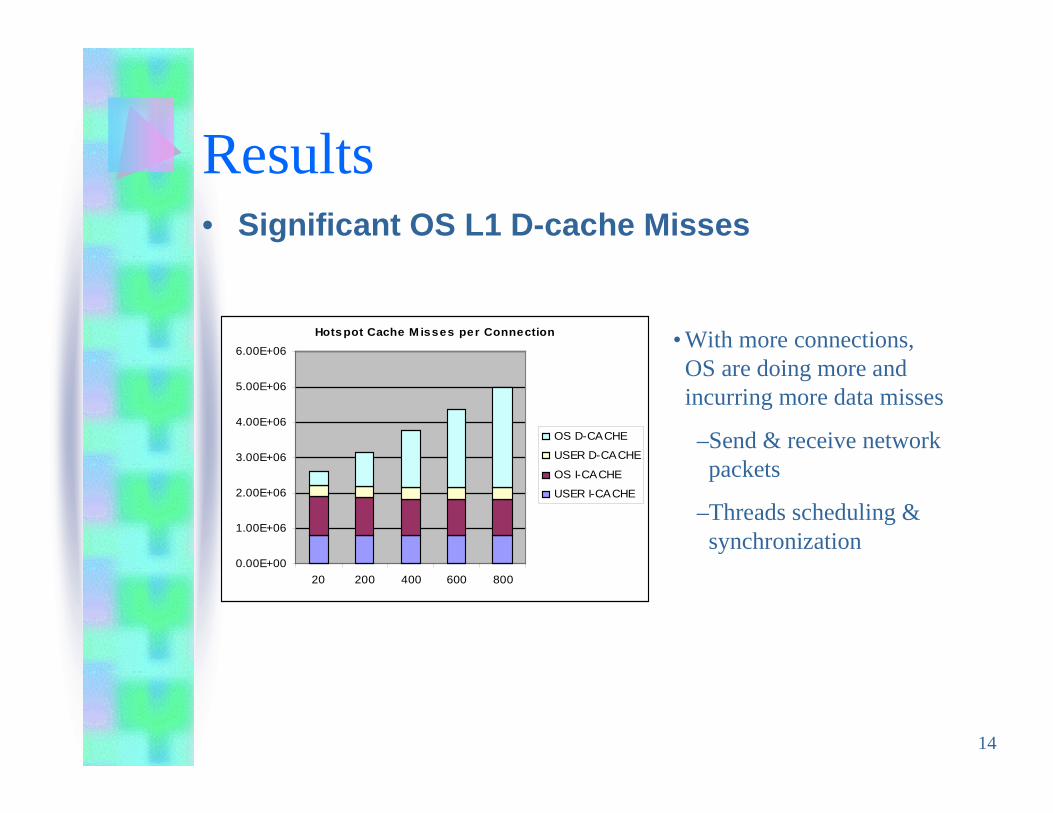
• With more connections,OS are doing more andincurring more data misses
–Send & receive networkpackets
–Threads scheduling &synchronization
Results• Significant OS L1 D-cache Misses
15
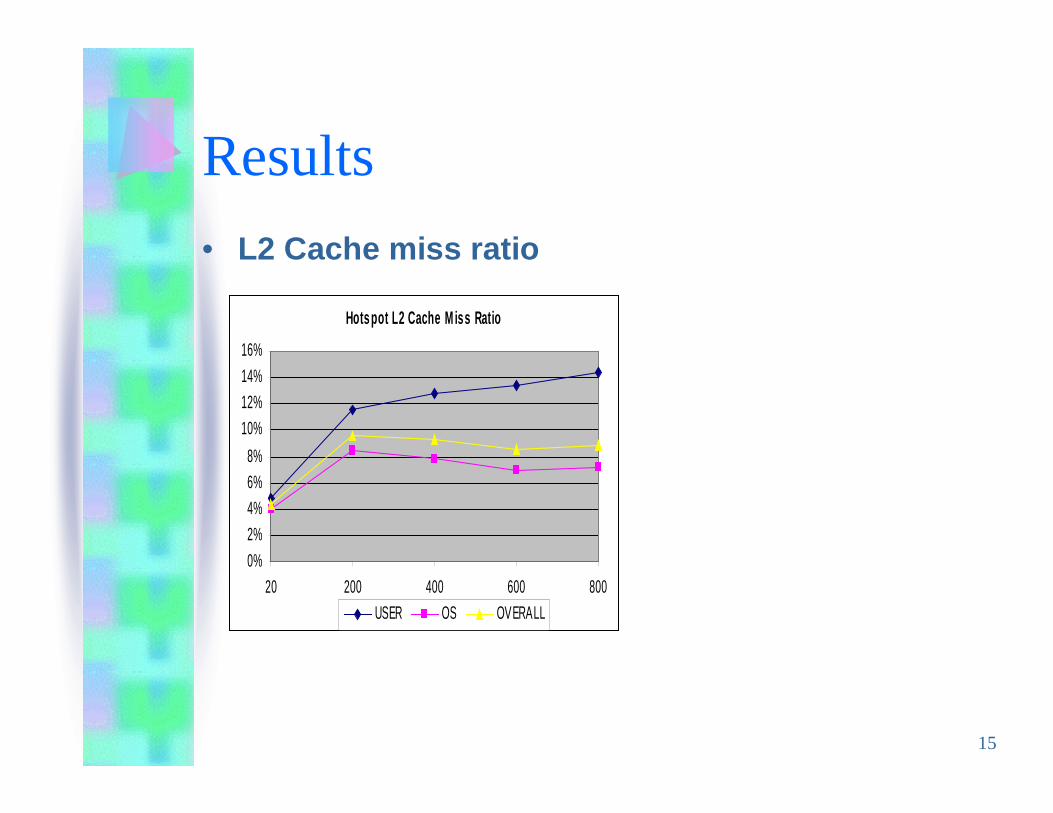
Results
• L2 Cache miss ratio
Hots pot L2 Cache M iss Ratio
0%
2%
4%
6%
8%
10%
12%
14%
16%
20 200 400 600 800
USER OS OVERALL
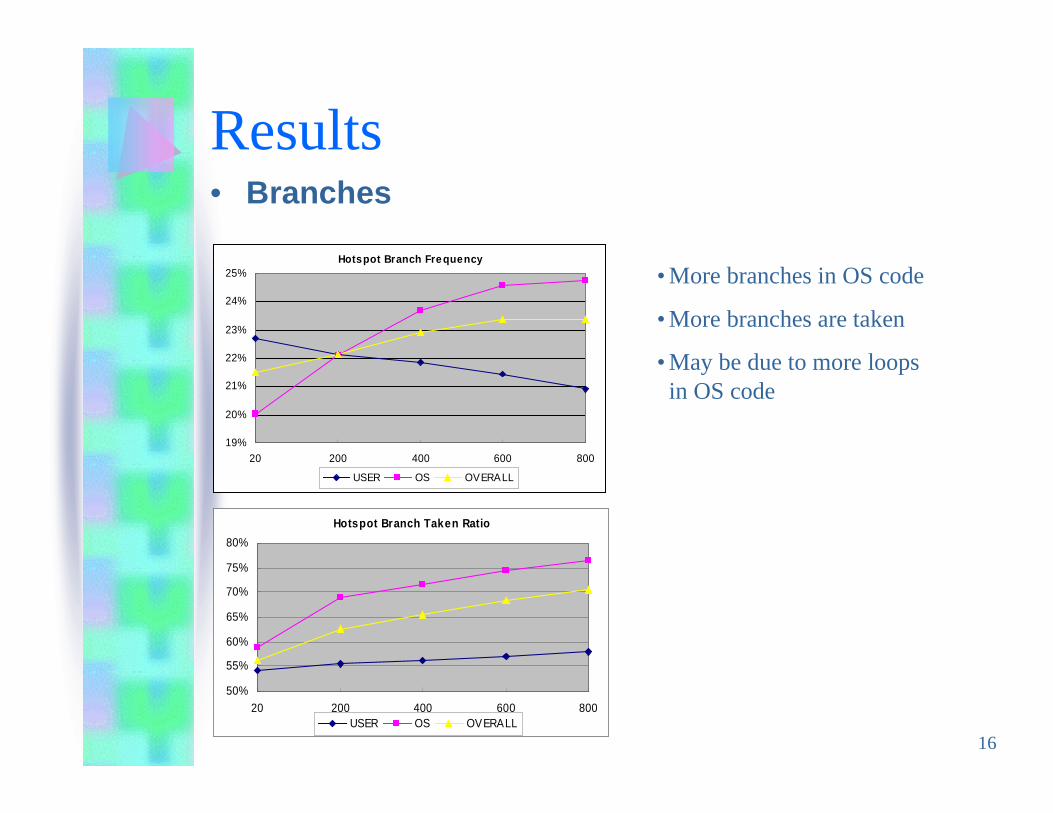
16
• More branches in OS code
• More branches are taken
• May be due to more loopsin OS code
Hotspot Branch Fre quency
19%
20%
21%
22%
23%
24%
25%
20 200 400 600 800
USER OS OVERALL
Hotspot Branch Taken Ratio
50%
55%
60%
65%
70%
75%
80%
20 200 400 600 800USER OS OVERALL
Results• Branches
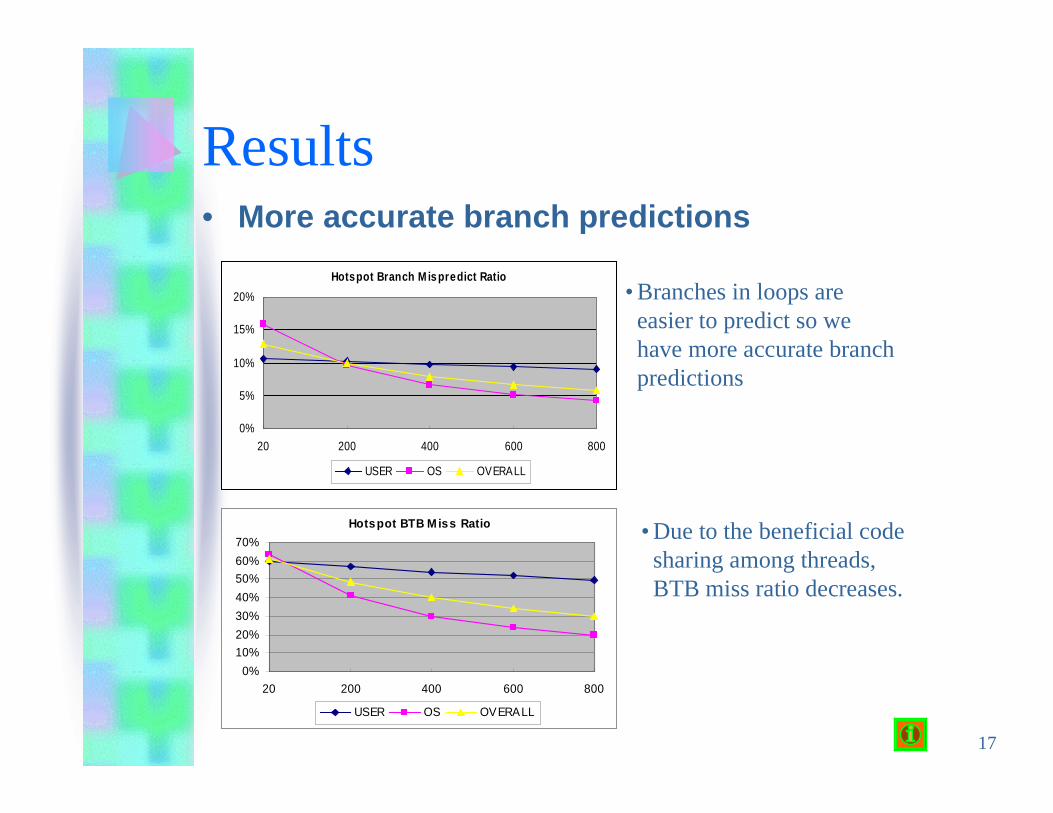
17
• Branches in loops areeasier to predict so wehave more accurate branchpredictions
Hotspot Branch M is predict Ratio
0%
5%
10%
15%
20%
20 200 400 600 800
USER OS OVERALL
Hotspot BTB M iss Ratio
0%
10%
20%
30%
40%
50%
60%
70%
20 200 400 600 800
USER OS OVERALL
• Due to the beneficial codesharing among threads,BTB miss ratio decreases.
Results• More accurate branch predictions
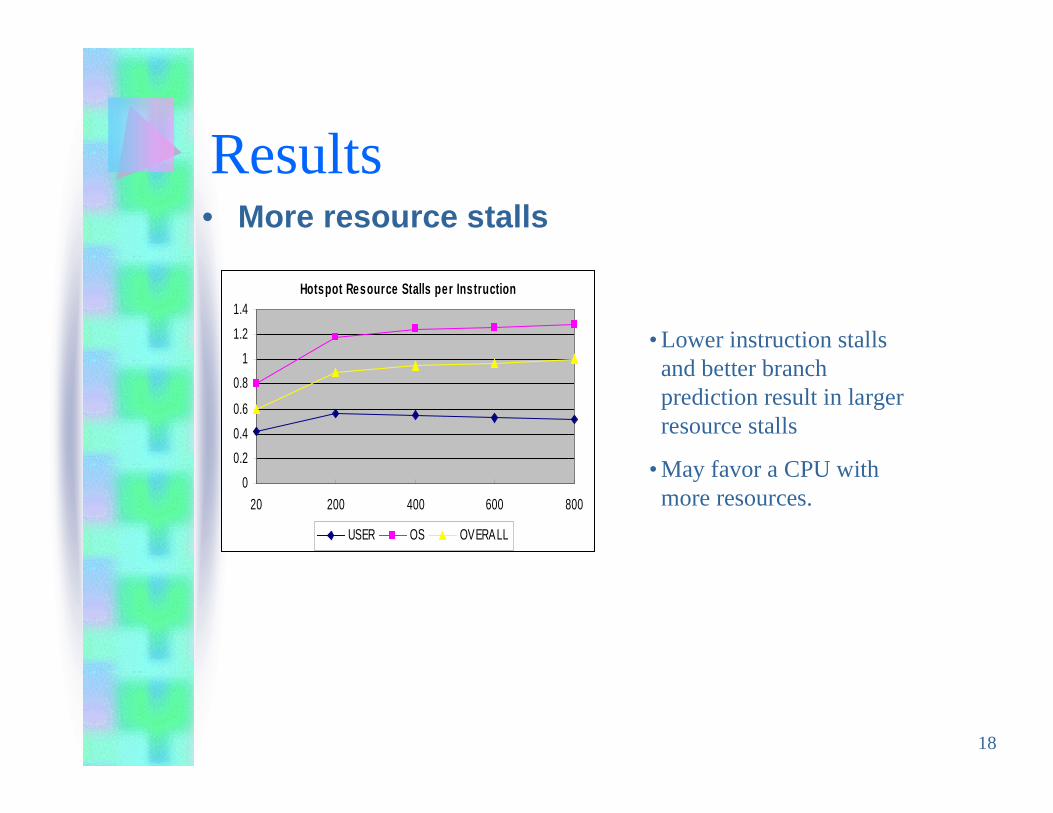
18
• Lower instruction stallsand better branchprediction result in largerresource stalls
• May favor a CPU withmore resources.
Hotspot Resource Stalls per Instruction
0
0.2
0.4
0.6
0.8
1
1.2
1.4
20 200 400 600 800
USER OS OVERALL
Results• More resource stalls

19
Conclusions• Multi-threading is an excellent approach to support multiple
simultaneous client connections. Heavy multithreading is morecrucial to Java server applications due to its lack of I/Omultiplexing APIs.
• Thread creation and synchronization as well as networkconnection management are the responsibility of the operatingsystem. With more concurrent connections, more OS activity isinvolved in the server execution.
• Threads usually share program code; thus instruction cache, ITLBand BTB will all benefit when the system context switch from onethread to another thread executing the same part of code. Multi-threading also benefits branch predictors.
• Each thread will incur some code and data overheads especiallyin operating system mode. Given enough memory resources, thenonlinearly increasing overheads are the biggest impediment toperformance scalability. Further tuning of the application andoperating system may alleviate this problem.

20
Further work needed
• More complex benchmark needed (eg SPECjbb2000) to validate the results. We need todistinguish characterization of multi-threadedserver applications from that of VolanoMark.
• Find why much more instructions areexecuted in OS with more connections and tryto reduce them.
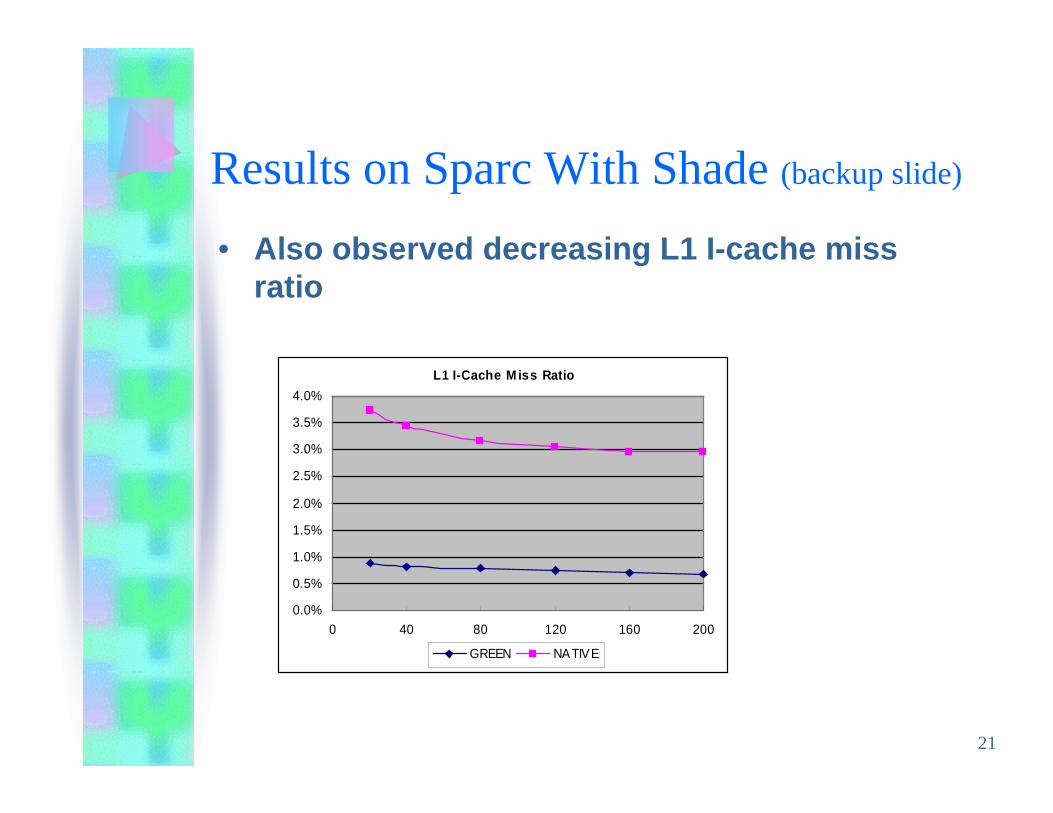
21
L1 I-Cache M iss Ratio
0.0%
0.5%
1.0%
1.5%
2.0%
2.5%
3.0%
3.5%
4.0%
0 40 80 120 160 200
GREEN NATIVE
Results on Sparc With Shade (backup slide)
• Also observed decreasing L1 I-cache missratio
22
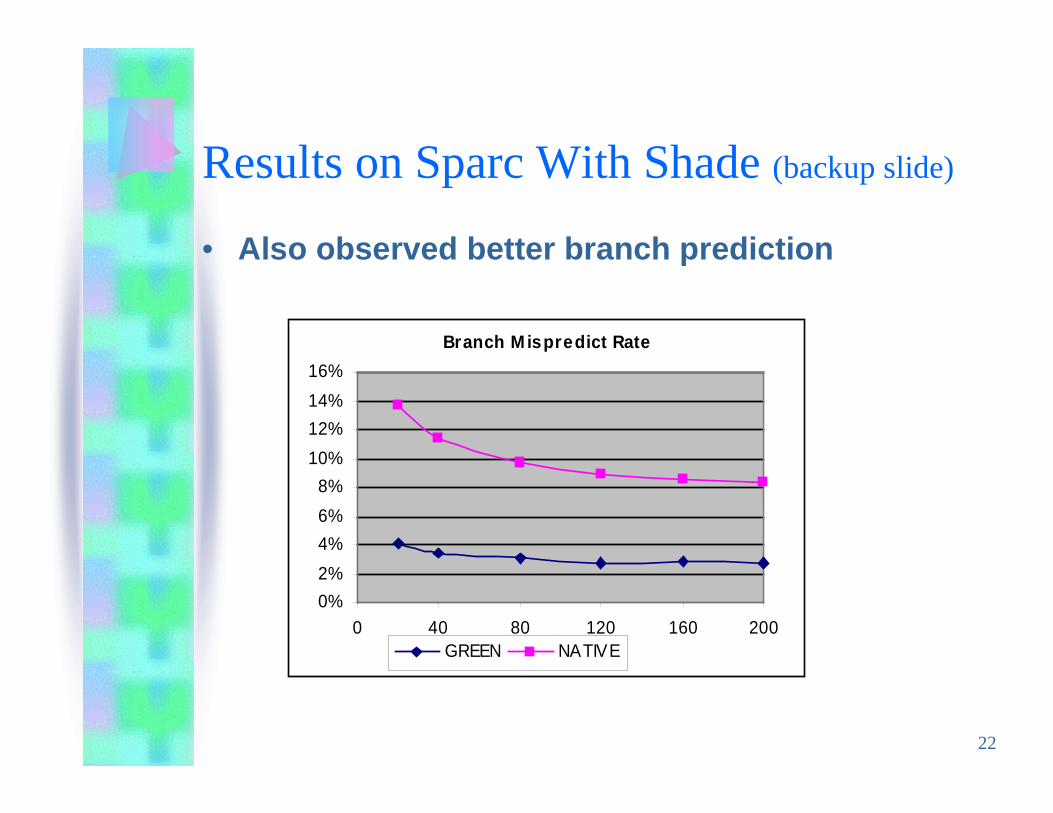
Results on Sparc With Shade (backup slide)
• Also observed better branch prediction
Branch M ispredict Rate
0%
2%
4%
6%
8%
10%
12%
14%
16%
0 40 80 120 160 200GREEN NATIVE

















![[Developer Shed Network] Server Side - PHP - Using PHP With Java](https://img.pdfslide.us/doc/110x75/577cd32c1a28ab9e7896dd99/developer-shed-network-server-side-php-using-php-with-java.jpg)










