Embed Size (px)
Citation preview

Peer to Peer (1)

References
This discussion is based on the papers and websites in the P2P File Sharing section
Acknowledgements: Many of the figures are from other presentations especially from the original authors.

Client-Server Model
Let’s look at the Client-Server modelServers are centrally maintained and administeredClient has fewer computing resources than a serverThis is the way the web worksNo interaction between clients

Client Server Model
Disadvantages of the client-server modelo Reliability
—The network depends on a possibly highly loaded server to function properly.
—Server needs to be replicated to some extent to provide better reliability.
o Scalability—More users imply more demand for computing
power, storage space and bandwidth

Peer-to-Peer Model
All nodes have same functional capabilities and responsibilitiesNo reliance on central services or resources.A node acts as both as a “server” and client.Considered more scalable

Peer-to-Peer Model
Peer-to-peer systems provide access to information resources located on computers throughout network.
Algorithms for the placement and subsequent retrieval of information is a key aspect of the design of P2P systems.

The Promise of P2P Computing
High capacity through parallelism:o Many diskso Many network connectionso Many CPUs
Reliability:o Many replicaso Geographic distribution
Automatic configuration Useful in public and proprietary settings

Why P2P?
P2P potentially can eliminating the single-source bottleneck
P2P can be used to distribute data and control and load-balance requests across the Net
P2P potentially eliminates the risk of a single point of failure
P2P infrastructure allows direct access and shared space, and this can enable remote maintenance capability

Brief History
Generation 1 of P2P Systemso Napster music exchange
Generation 2o Freenet, Gnuetella, Kazaa, BitTorrent
Generation 3o Characterized by the emergence of
middleware layers for the application-independent management of distributed resources on a global scale
—Pastry, Tapestry, Chord, Kademlia

Environment Characteristics for Peer-to-Peer Systems
Unreliable environments Peers connecting/disconnecting – network
failures to participation Random Failures e.g. power outages,
cable and DSL failures, hackers Personal machines are much more
vulnerable than servers

Evaluating Peer-to-Peer Systems
A node’s database:o What does a node need to save in order to operate
properly/efficiently Success rate (if the file is in the network, what
are the changes that a search will find it) Lookup cost:
o Timeo Communication (bandwidth usage)
Join/departure cost Fault Tolerance – Resilience to faults Resilience to denial of service attacks, security.

Issues in File Sharing Services
Publish – How to insert a new file into the network
Lookup – Find a specific file Retrieval – Getting a copy of a file

P2P File Sharing Software
Allows a user to open up a directory in their file systemo Anyone can retrieve a file from directoryo Like a Web server
Allows the user to copy files from other users’ open directories:o Like a Web client
Allows users to search nodes for content based on keyword matches:o Like Google

Napster: How Did It Work
Application-level, client-server protocol over point-to-point TCP
Centralized directory server Steps:
o Connect to Napster servero Give server keywords to search the full list with.o Select “best” of correct answers.
—One approach is select based on the response time of a pings.
– Shortest response time is chosen.
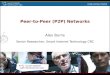
Napster: How Did It Work
File list and IP address is uploaded
1.napster.com centralized directory

Napster: How Did It Work
napster.com centralized directory
Queryand
results
User requests search at server.
2.

Napster: How Did It Work
pingspings
User pings hosts that apparently have data.
Looks for best transfer rate.
3.napster.com centralized directory

Napster: How Did It Work
napster.com centralized directory
Retrievesfile
User choosesserver
4.
Napster’s centralized server farm had difficult time keeping up with traffic

Napster
There are centralized indexes but users supplied the files which were stored and accessed on their personal computer
Napster became very popular for music exchange
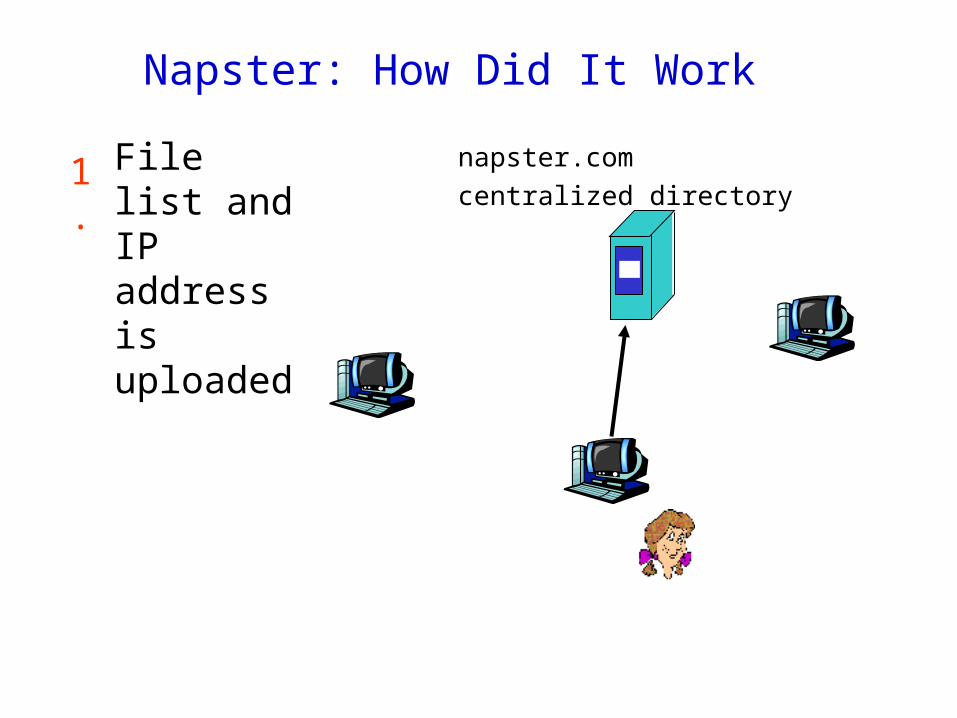
Napster
History:o 5/99: Shawn Fanning (freshman,
Northeasten U.) founds Napster Online music service
o 12/99: first lawsuito 3/00: 25% UWisc traffic Napstero 2/01: US Circuit Court of
Appeals: Napster knew users violating copyright laws
o 7/01: # simultaneous online users:Napster 160K, Gnutella: 40K,
Morpheus (KaZaA): 300K
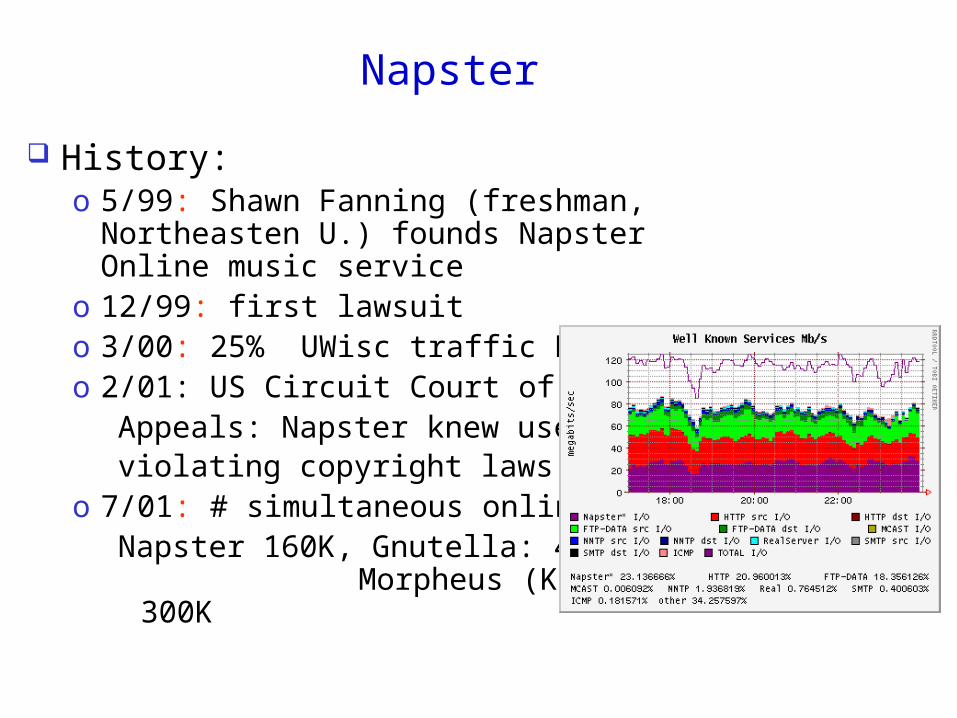
Napster
Judge orders Napster to pull plug in July ‘01
Other file sharing apps take over!
gnutellanapsterfastrack (KaZaA)
8M
6M
4M
2M
0.0bit
s per
sec

Napster’s Downfall
Napster’s developers argued they were not liable for infringement of the copyrightso Why? They were not participating in the copying
process which was performed entirely between users’ machines.
This argument was not accepted by the courtso Why? The index servers were deemed an essential
part of the process Since the index servers were located at well-
known addresses, their operators were unable to remain anonymous.o Makes for an easy lawsuit target

Napster’s Downfall
A more fully distributed file sharing service spreads the responsibility across all of the users o Makes the pursuit of legal remedies difficult

Napster: Discussion
Locates files quickly Vulnerable to censorship and technical
failure Popular data become less accessible
because of the load of the requests on a central server
People started to look for more distributed solutions to file-sharing as a result of Napster’s failure.

Gnutella
Napster’s legal problems motivated Gnutella where there is not a use of centralized indexes
The focus is on a decentralized method of searching for fileso Central directory server no longer the bottlenecko More difficult to “pull plug”
Each application instance serves to:o Store selected fileso Route queries from and to its neighboring peerso Respond to queries if file stored locallyo Serve files

Gnutella
Gnutella history:o 3/14/00: release by AOL, almost immediately withdrawno Became open sourceo Many iterations to fix poor initial design (poor design
turned many people off) Issues:
o How much traffic does one query generate?o How many hosts can it support at once?o What is the latency associated with querying?o Is there a bottleneck?

Gnutella: Searching
Searching by flooding:• A Query packet might ask, "Do you have any content
that matches the string ‘Homer"? o If a node does not have the requested file, then 7
(default set by Gnutella) of its neighbors are queried. o If the neighbors do not have it, they contact 7 of
their neighbors.o Maximum hop count: 10 (this is called time-to-live
TTL)o Reverse path forwarding for responses (not files)

Gnutella: Searching
Downloading• Peers respond with a “QueryHit” (contains contact info)• File transfers use direct connection using HTTP
protocol’s GET method • When there is a firewall a "Push" packet is used –
reroutes via Push path

Gnutella: Searching

Gnutella: Searching

Gnutella: Discovering Peers
A peer has to know at least one other peer to send requests to.
Addresses of some peers have been published on a website.
When a peer enters the network, it contacts a designated peer and receives a list of other peers that have recently entered the network.

Gnutella: Discussion
Robust: The failure of peer is not a failure of Gnutella.
Performance: Flooding leads to poor performance
Free riders: Those who get data but do not share data.
The model of Gnutella just presented was found not be workable.
This led to models that and some peer nodes have indexes.

KaZaA: The Service
More than 3 million up peers sharing over 3,000 terabytes of content
More popular than Napster ever was MP3s & entire albums, videos, games Optional parallel downloading of files Automatically switches to new download
server when current server becomes unavailable
Provides estimated download times

KaZaA: The Service
A user can configure the maximum number of simultaneous uploads and maximum number of simultaneous downloads
Queue management at server and cliento Frequent uploaders can get priority in server queue
Keyword searcho User can configure “up to x” responses to keywords
Responses to keyword queries come in waves; stops when x responses are found

KaZaA: The Technology
Proprietary Control data encrypted Everything in HTTP request and response
messages

KaZaA: Architecture
Each peer is either a supernode or is assigned to a supernode
o 56 min avg connecto Each SN has about 100-
150 childreno Roughly 30,000 SNs
Each supernode has TCP connections with 30-50 supernodes
o 23 min avg connect
supernodes

KaZaA: Architecture
Nodes that have more connection bandwidth and are more available are designated as supernodes
Each supernode acts as a mini-Napster hub, tracking the content and IP addresses of its descendants
A supernode tracks only the content of its children.
Considered a cross between Napster and Gnutella

KaZaA: Finding Supernodes
List of potential supernodes included within software download
New peer goes through list until it finds operational supernodeo Connects, obtains more up-to-date list, with 200 entrieso Nodes in list are “close” to ON.o Node then pings 5 nodes on list and connects with the
one If supernode goes down, node obtains updated
list and chooses new supernode

KaZaA Queries
Node first sends query to supernodeo Supernode responds with matcheso If x matches found, done.
Otherwise, supernode forwards query to subset of supernodeso If total of x matches found, done.
Otherwise, query further forwardedo Probably by original supernode rather than
recursively

Freenet: History
Final year (undergraduate) project at Edinburgh University, Scotland, 1999.
Around the time of Napster One of the goals was to provide users
with anonymity; circumvent censorship. Other goals include filesharing, high availability and reliability (through decentralization), efficiency and scalability.

Freenet:Key Management
Files are stored according to an associated keyo Cluster information about similar keys
Keys are used to locate a document anywhere
Keys are used to form a URI Two similar keys don’t mean the
subjects of the file are similar

Freenet: Routing Tables
Each node maintains a common stackid – file identifiernext_hop – another node that stores
the file idfile – file identified by id being stored
on the local node Forwarding of query for file id
o If file id stored locally, then stop—Forward data back to upstream requestor—Requestor adds file to cache, adds entry in
routing tableo If not, search for the “closest” id in the stack,
and forward the message to the corresponding next_hop
o If data is not found, failure is reported back—Requestor then tries next closest match in
routing table
id next_hop file
……

Freenet:Messages
Random 64 bit ID used for loop detection
—Each node maintains the list of query IDs that have traversed it help to avoid looping messages
TTL—TTL is decremented each time the query message
is forwarded

Freenet:Query
API: file = query(id); Upon receiving a query for document id
o Check whether the queried file is stored locally—If yes, return it—If not, forward the query message
Notes:o Each query is associated with a TTL that is
decremented each time the query message is forwarded; to obscure distance to originator:
—TTL can be initiated to a random value within some bounds
—When TTL=1, the query is forwarded with a finite probability
o Each node maintains the state for all outstanding queries that have traversed it help to avoid cycles
o When file is returned it is cached along the reverse path

Freenet: Routing Example
Copies of the requested file may be cached along the request path for scalability and robustness
4 n1 f412 n2 f12 5 n3
9 n3 f9
3 n1 f314 n4 f14 5 n3
14 n5 f1413 n2 f13 3 n6
n1 n2
n3
n4
4 n1 f410 n5 f10 8 n6
n5
query(10)
1
2
3
4
4’
5

Freenet: Insert
API: insert(id, file); Two steps
o Search for the file to be inserted— If found, report collision— If number of nodes exhausted report clear
o If not found, insert the file

Freenet: Insert
Searching: like query Insertion
o Follow the forward path; insert the file at all nodes along the path
o A node probabilistically replace the originator with itself; obscure the true originator

Freenet: Insert Example
Assume query returned failure along “gray” path; insert f10
4 n1 f412 n2 f12 5 n3
9 n3 f9
3 n1 f314 n4 f14 5 n3
14 n5 f1413 n2 f13 3 n6
n1 n2
n3
n4
4 n1 f411 n5 f11 8 n6
n5
insert(10, f10)

Freenet: Insert Example
10 n1 f10 4 n1 f412 n2
3 n1 f314 n4 f14 5 n3
14 n5 f1413 n2 f13 3 n6
n1
n3
n4
4 n1 f411 n5 f11 8 n6
n5
insert(10, f10)
9 n3 f9
n2orig=n1

Freenet: Insert Example
n2 replaces the originator (n1) with itself
10 n1 f10 4 n1 f412 n2
10 n1 f10 9 n3 f9
10 n2 10 3 n1 f314 n4
14 n5 f1413 n2 f13 3 n6
n1 n2
n3
n4
4 n1 f411 n5 f11 8 n6
n5
insert(10, f10)
orig=n2

Freenet: Insert Example
n2 replaces the originator (n1) with itself
10 n1 f10 4 n1 f412 n2
10 n1 f10 9 n3 f9
10 n2 10 3 n1 f314 n4
10 n2 f1014 n5 f1413 n2
n1 n2
n3
n4
10 n4 f10 4 n1 f411 n5
n5
Insert(10, f10)

Insert Conflict
If the same GUID already exists, reject insert
Previous file propagation prevents attempts to supplant file already in network.

Freenet: Ensuring Anonymity
Nodes can lie randomly about the requests and claim to be the origin or the destination of a request
TTL values are fuzzy It is difficult to trace back a document to
its original node Similarly, it is difficult to discover which
node inserted a given document.

Freenet: Discussion
What’s wrong with Freenet?o Not well tested in the wild – scalability, resilience.
Insertion flooding is one way to take out the network.o Anonymity guarantees not that strong – “Most non-
trivial attacks would probably be successful in identifying someone making requests on Freenet.”
o No search mechanism – a standard search would allow attacks to take out specific content holders
o Suffers from problems of establishing initial network connection.
o Does not always guarantee that a file is found, even if the file is in the network

Freenet: Discussion
Primary Pointso Prevention of censorship and protection of
privacy is an important and active field of research.
o Freenet is a (successful?) implementation of a system that resists information censorship
o Freenet is an ongoing project that still has plenty of flaws
o There may be a tradeoff between network efficiency and anonymity, robustness.

BitTorrent
Problems:o Traditional Client/Server Sharing
—Performance deteriorates rapidly as the number of clients increases
o Free-riding in P2P network —Free riders only download without contributing to
the network.
BitTorrent: Started in 2002 by B. Cohen Focus: Efficient fetching and not
searching
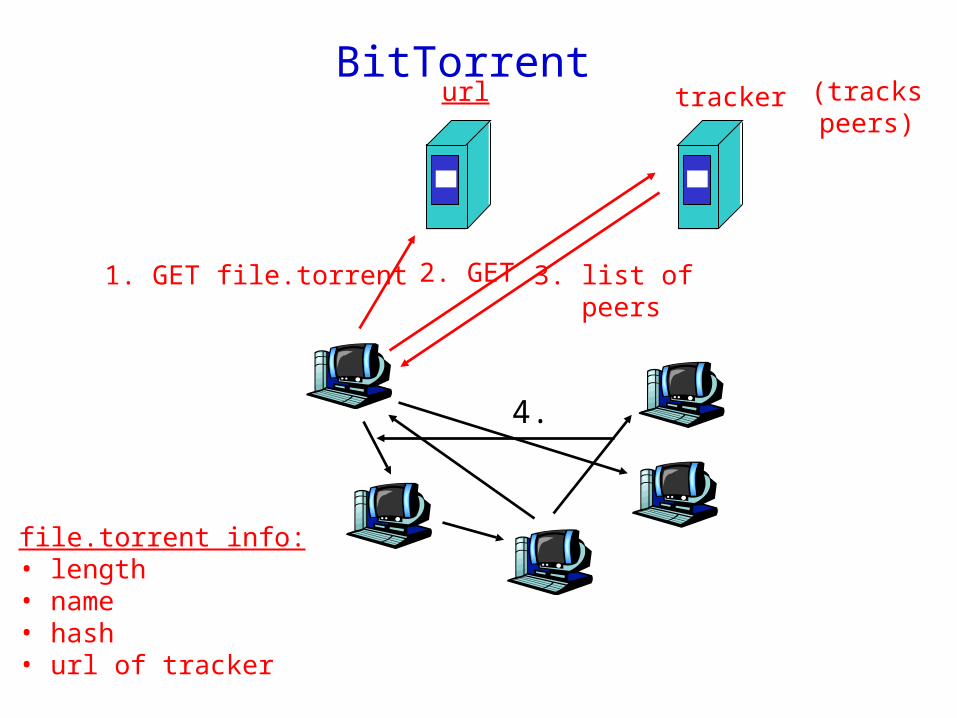
BitTorrenturl tracker
1. GET file.torrent
file.torrent info:• length• name• hash• url of tracker
2. GET 3. list of peers
4.
(tracks peers)

BitTorrent: Pieces
File is broken into pieceso Typically piece is 256 KByteso Upload pieces while downloading pieces
Tit-for-tato Bit-torrent uploads to at most four peerso Among the uploaders, upload to the four
that are downloading to you at the highest rates
o Sometimes it allows for free loaders

Summary
P2P is a major portion of Internet traffic.o Has exceeded web traffic
There are different approaches to structuring P2P applications.
There is a good deal of concern about future scalability and traffic which leading to a lot research from academia and industry.

Interesting Notes
P2P traffic significantly outweighs web traffic
P2P traffic continues to grow The focus of P2P file sharing is NOT MP3’s
o Many free software projects use BitTorrent to download software
BitTorrent is the dominant P2P application in use.o Microsoft is jealous – they are developing
their own version called Avalanche


















![F-Secure H2 2012 Threat Report case study of the affiliate marketing and peer-to-peer ... are widely used by many e-commerce websites[3]. ... P2P file sharing service Abusing a P2P](https://img.pdfslide.us/doc/110x75/5aaaf9837f8b9a693f8b4dd5/f-secure-h2-2012-threat-report-case-study-of-the-affiliate-marketing-and-peer-to-peer.jpg)