Embed Size (px)
Citation preview

6/4/2014
1
Patterns in parallel computing
Oregon State University EECSJune 4, 2014
Copyright © 2006, Intel Corporation. All rights reserved. Prices and availability subject to change without notice.*Other brands and names are the property of their respective owners
1
,
Michael Wrinn, Ph.D.Research DirectorUniversity Research Office, Intel
Disclaimer: the views expressed in this talk are those of the speaker, not his employer. This is an academic style talk, not intended to address details of any particular Intel product or plan.
Parallel Programming Principle and Practice
Lecture 5 —shared memory
programming with OpenMP
Ji H iJin, Hai
School of Computer Science and Technology
Huazhong University of Science and Technology
Example Problem:Numerical Integration
3
Parallel Pi: OpenMP solution
4
Case Study: AkariLogic puzzle from Nikoli
Goal: Place chess rooks on open squares such that• No two rooks attack each other• Numbered squares surrounded by specified number of rooks
• All open squares are “covered” by one or more rooks• Black squares block attack of rooks
Copyright © 2006, Intel Corporation. All rights reserved. Prices and availability subject to change without notice.*Other brands and names are the property of their respective owners
5 5
Akari Algorithm
Input: board size and list of number and black squares
Sort numbered squares by value; plain black squares after numbered
Place rooks around all “4” squares• Get next numbered square in list• Try all rook combinations around square, via recursive call
Copyright © 2006, Intel Corporation. All rights reserved. Prices and availability subject to change without notice.*Other brands and names are the property of their respective owners
6
– “3” square => 4 combinations– “2” square => 6 combinations– “1” square => 4 combinations
• If no more numbered squares, compile list of all open squares• Using backtracking:
– Try rook in/out next open square from list– Solution reached when no more open squares
6

6/4/2014
2
Search Tree – placeThree() example
Copyright © 2006, Intel Corporation. All rights reserved. Prices and availability subject to change without notice.*Other brands and names are the property of their respective owners
7 7
Conventional analysis: where to parallelize?
What might Hotspot Analysis show?• If move generation is fast, very little
time in BT()• Likely DeadEnd() or Solution() (at
leafs of search tree) would report most execution time
Typically not much parallelism to be
function BT(c){if (DeadEnd(c)) return;if (Solution(c)) Output(c);elseforeach (s = next moves from c) {
BT(s);}
}
Copyright © 2006, Intel Corporation. All rights reserved. Prices and availability subject to change without notice.*Other brands and names are the property of their respective owners
8
Typically not much parallelism to be exploited in checking partial solutions
Example: Akari solver• countBlanks() is 96% of serial time• Simple for-loop over board squares
– 360 squares for dataset used
8
Akari Execution – Hotspot Parallelism
int board::countBlanks(){// find total number of blanks and non-covered squaresint i, c = 0;
#pragma omp parallel for reduction(+:c)for (i = 0; i < rows*cols; ++i)
if (B[0][i] == ' ' || B[0][i] == 'n' || B[0][i] == 'N' )
Copyright © 2006, Intel Corporation. All rights reserved. Prices and availability subject to change without notice.*Other brands and names are the property of their respective owners
9 9
Code version Time (sec) Speedupserial 29.557 1.0parallel (32 cores)
36.841 0.8
++c;return c;
}
Architecting Parallel Software:Design patterns in practice
A brief look at work developed by• Kurt Keutzer, UC Berkeley• Tim Mattson, Intel
many contributors at UC Berkeley UIUC Intel
Copyright © 2006, Intel Corporation. All rights reserved. Prices and availability subject to change without notice.*Other brands and names are the property of their respective owners
10
• many contributors at UC Berkeley, UIUC, Intel
How do we fix the parallel programming problem?
Focus on software architecture and time‐tested designs that have been shown to work …
Given a good design, a
programmer can create
11
Design patterns are a way to put these approaches into
writing.
can create quality software
regardless of the language
Graph Algorithms
Dynamic Programming
Dense Linear Algebra
Sparse Linear Algebra
Unstructured Grids
Structured Grids
Model View Controller
Iterative Refinement
Map Reduce
Layered Systems
Arbitrary Static Task Graph
Pipe and Filter
Agent and Repository
Process Control
Event Based, Implicit Invocation
Puppeteer
Graphical Models
Finite State Machines
Backtrack Branch and Bound
N-Body Methods
Circuits
Spectral Methods
Monte Carlo
Structural Patterns Computational Patterns
Our Pattern Language 2011
Task ParallelismRecursive splitting
Data ParallelismPipeline
Discrete Event Geometric DecompositionSpeculation
SPMDStrict data par
Fork/JoinActorsMaster/workerGraph partitioning
Distributed-ArrayShared-Data
Shared-QueueShared Hash Table
MIMD Thread PoolSIMD Task Graph
Parallel Execution Patterns
Algorithm Strategy Patterns
Implementation Strategy Patterns
Data structureProgram structure
Loop-Par.BSPTask-Queue
Msg PassCollective CommMutual exclusion
CoordinationAdvancing “program counters”
Task-GraphData FlowDigital Circuits
Pt-2-pt syncCollective syncTrans Mem
6/4/2014
3
Our Pattern Language
Applications
StructuralPatterns
ComputationalPatterns
Parallel Algorithm Strategy Patterns
Implementation Patterns
Execution Patterns
•Pipe-and-Filter
•Agent-and-Repository
•Process-Control
•Event-Based/Implicit-Invocation
Identify the SW Structure
Structural Patterns
•Puppeteer
•Model-View-Controller
•Iterative-Refinement
•Map-Reduce
•Layered-Systems
•Arbitrary-Static-Task-Graph
These define the software structure but do not describe what is computed
Analogy: Layout of Factory Plant Analogy: Machinery of the Factory
Filter 2Filter 3
Filter 1
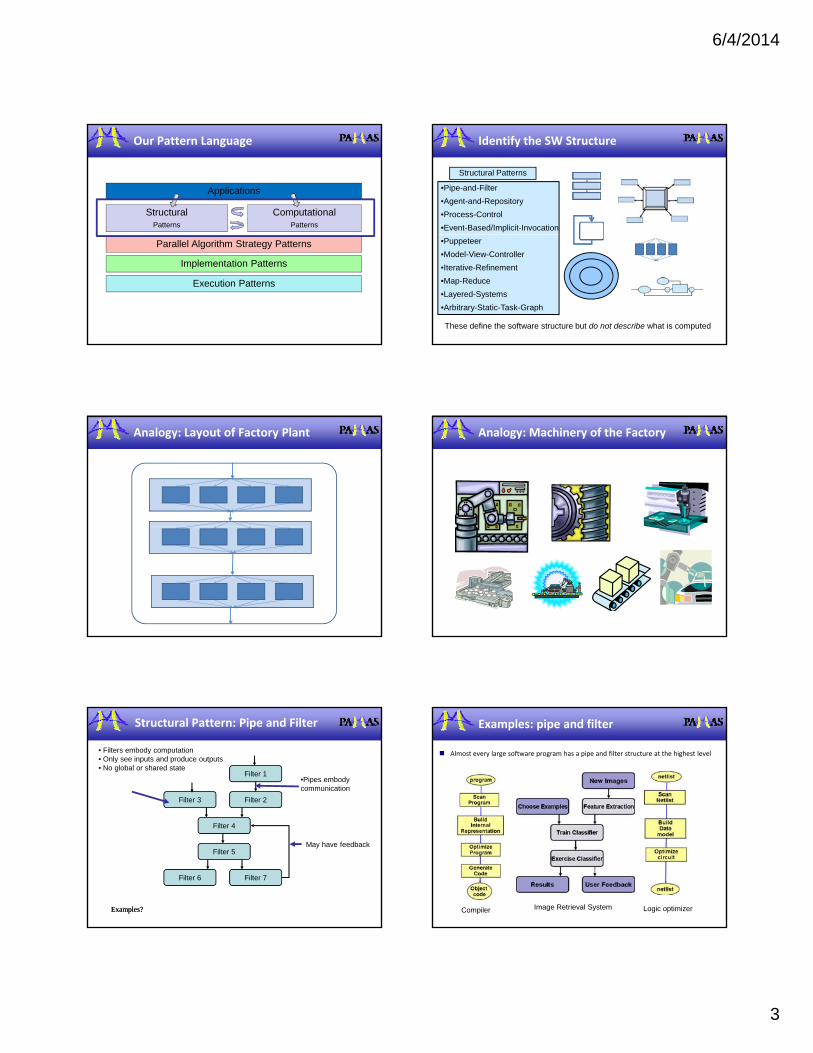
Structural Pattern: Pipe and Filter
• Filters embody computation• Only see inputs and produce outputs• No global or shared state
•Pipes embody communication
Filter 6
Filter 5
Filter 4
Filter 7
May have feedback
Examples?Examples?
Examples: pipe and filter
Almost every large software program has a pipe and filter structure at the highest level
Logic optimizerImage Retrieval SystemCompiler
6/4/2014
4
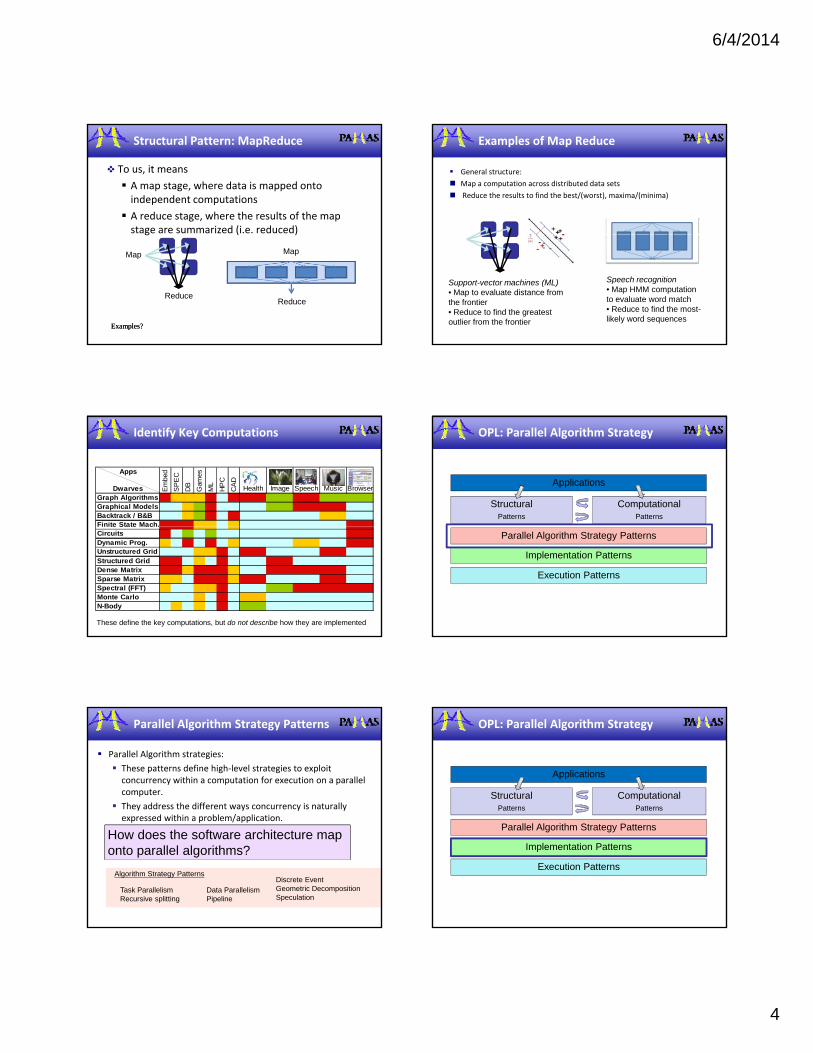
Structural Pattern: MapReduce
To us, it means
A map stage, where data is mapped onto independent computations
A reduce stage, where the results of the map stage are summarized (i.e. reduced)g ( )
Map
Reduce
Map
Reduce
Examples?Examples?
Examples of Map Reduce
General structure:
Map a computation across distributed data sets
Reduce the results to find the best/(worst), maxima/(minima)
Speech recognition• Map HMM computation to evaluate word match• Reduce to find the most-likely word sequences
Support-vector machines (ML)• Map to evaluate distance from the frontier • Reduce to find the greatest outlier from the frontier
Identify Key Computations
Finite State Mach.
Apps
Dwarves Em
bed
SP
EC
DB
Gam
es
ML
HP
C
CA
D
Health Image Speech Music BrowserGraph AlgorithmsGraphical ModelsBacktrack / B&B
Structured GridDense MatrixSparse MatrixSpectral (FFT)Monte CarloN-Body
Dynamic Prog.Unstructured Grid
Finite State Mach.Circuits
These define the key computations, but do not describe how they are implemented
OPL: Parallel Algorithm Strategy
Applications
StructuralPatterns
ComputationalPatterns
Parallel Algorithm Strategy Patterns
Implementation Patterns
Execution Patterns
Parallel Algorithm Strategy Patterns
Parallel Algorithm strategies:
These patterns define high‐level strategies to exploit concurrency within a computation for execution on a parallel computer.
They address the different ways concurrency is naturally expressed within a problem/applicationexpressed within a problem/application.
How does the software architecture map onto parallel algorithms?
Task ParallelismRecursive splitting
Data ParallelismPipeline
Discrete Event Geometric DecompositionSpeculation
Algorithm Strategy Patterns
OPL: Parallel Algorithm Strategy
Applications
StructuralPatterns
ComputationalPatterns
Parallel Algorithm Strategy Patterns
Implementation Patterns
Execution Patterns

6/4/2014
5
Implementation Strategy Patterns
Implementation strategies:
These are the structures that are realized in source code to support (a) how the program itself is organized and (b) common data structures specific to parallel programming.
How do parallel algorithms map onto sourceHow do parallel algorithms map onto source code in a parallel programming language?
SPMDStrict data par
Fork/JoinActorsMaster/workerGraph partitioning
Distributed-ArrayShared-Data
Shared-QueueShared Hash Table
Implementation Strategy Patterns
Data structureProgram structure
Loop-Par.BSPTask-Queue
OPL: Parallel Algorithm Strategy
Applications
StructuralPatterns
ComputationalPatterns
Parallel Algorithm Strategy Patterns
Implementation Patterns
Execution Patterns
Parallel Execution Patterns
Parallel Execution Patterns:
These are the approaches often embodied in a runtime system that supports the execution of a parallel program.
How is the source code realized as an executing program running on the target parallel processor?
MIMD Thread PoolSIMD Task Graph
Parallel Execution PatternsMsg PassCollective CommMutual exclusion
CoordinationAdvancing “program counters”
Task-GraphData FlowDigital Circuits
Pt-2-pt syncCollective syncTrans Mem
Compelling Application:Fast, Robust Pediatric MRI
Pediatric MRI is difficult:
Children cannot sit still, breathhold
Low tolerance for long exams
Anesthesia is costly and risky
Like to accelerate MRI acquisition
Advanced MRI techniques exist, but require d t d t i t l ith fdata‐ and compute‐ intense algorithms for image reconstruction
Reconstruction must be fast, or time saved in accelerated acquisition is lost in computing reconstruction
Slow reconstruction times are a non‐starter for clinical use
SW architecture of image reconstruction Game‐Changing Speedup
100X faster reconstruction
Higher‐quality, faster MRI
This image: 8 month‐old patient with cancerous mass in liver
256 x 84 x 154 x 8 data size
Serial Recon: 1 hour
P ll l R 1 i t Parallel Recon: 1 minute
Fast enough for clinical use
Software currently deployed at Lucile Packard Children's Hospital for clinical study of the reconstruction technique

6/4/2014
6
Software Design Patterns: earlier lesson
Early days OO
Perception: Object oriented? Isn’t that just an academic thing?
Usage: specialists
Now
Perception: OO=programming
Isn’t this how it was always done?
Copyright © 2006, Intel Corporation. All rights reserved. Prices and availability subject to change without notice.*Other brands and names are the property of their respective owners
31
Usage: specialists only. Mainstream regards with indifference or anxiety.
Performance: not so good.
Usage: cosmetically widespread, some key concepts actually deployed.
Performance: so-so, masked by CPU advances until now.
1994
Then
Perception: Parallel programming? Isn’t that just an HPC thing?
Usage: specialists
Soon
Perception: PP=programming
Isn’t this how it was always done?
Parallel Design Patterns: does history rhyme?(a prediction from 2011)
Copyright © 2006, Intel Corporation. All rights reserved. Prices and availability subject to change without notice.*Other brands and names are the property of their respective owners
32
Usage: specialists only. Mainstream regards with indifference or anxiety.
Performance: very good, for the specialists.
Usage: widespread, key concepts actually deployed.
Performance: broadly sufficient. Application domains greatly expanded.
2011
UC BerkeleyComputational Characteristics
of (big data) application areas (2014)
Web
Sea
rch
Soc
ial N
etw
orks
Dat
abas
e
Big
Dat
a A
naly
tics
Vis
ualiz
atio
n
Gen
om
ics
UA
V &
Wea
rabl
eV
isio
n
Big
Dat
a M
ultim
edia
Adv
ertis
ing
Fin
ance
Graph Algorithms
Graphical Models
Apps
Patterns
33
G ap ca ode s
Backtrack / B&B
Finite State Machines
Circuits
Dynamic Programming
N-Body
Unstructured Grid
Structured Grid
Dense Matrix
Sparse Matrix
Spectral (FFT)
Monte Carlo
Forrest Iandola [email protected]
Genomics - Architecture for doing all in a dayApril 31, 2014
34
Gans Srinivasa, Sr Principal EngineerKarthik Gururaj, Mohammad Ghodrat, Mishali Naik, Paolo Narvaez
and Genomics Team
DCG‐HSS
Overview
Secondary Analysis DNA/RNA pipeline + More
Systems Biomedicine Development of
Personalized TreatmentsPrimary Analysis
FASTQFor
individual
BAMFor
individual
HCHC Variant
S
Big DataStarts here
Joint Genotyping
Pathway networks to predict various drug responses (Graph
models, Bayesian models & ML)
Cell response &methylation data
Models for Drug Treatment and Response
HCHCHCHCHCHCHCHCHC
Store
Pop/DisStudyPop/DisStudy
Imaging, Parallelism,Statistical work,Accelerated Algorithms
+imaging +ML + Drug Sensitivity Assays +Mechanistic learning and systems +Correlation work and Knowledge systems
Various Algorithms, Big Data, Parallelism, Accelerated Algorithms, Statistical and Math puzzles, In memory Processing
Heterogeneous Computing –Xeon+Accelerators+GPU+Memory computing / Data Store
DNA Pipeline: BWA+GATK: Whole Genome Sample: ~65x CoverageCollaborating with our Partners and Medical community
Step # of Threads
Runtime (hours)
Read Alignment (bwamem)
24 7
View (samtools) 24 2
Sort + Index (samtools) 24 3MarkDuplicates(picardtools) + Index
1 11
RealignerTargetCreator(GATK)
24 1
IndelRealigner* (GATK) + I d
24 6.5
Step Tool # of Threads
Runtime(hours)
Read Alignment (bwa) 16 8Sampe (bwa) 1 24Import (samtools) 1 11Sort + Index (samtools) 1 14.5MarkDuplicates(picardtools) + Index
1 11.5
UnifiedGenotyper* (GATK) 16 7.5
SomaticIndelDetector(GATK)
1 3
RealignerTargetCreator 16 0.8
Redesign of Mark Duplicates
+Merge Bam Align
30-36hours
SW HW
36
Process level Parallelism
Thread-level Parallelism
Index
BaseRecalibrator(GATK) 24 1.3PrintReads* (GATK) + Index + Flagstat
24 12.3
TOTAL (hours) 44
g g(GATK)IndelRealigner* (GATK) + Index
1 17.5
BaseRecalibrator*(GATK) 1 62
PrintReads* (GATK) + Index + Flagstat
1 25
TOTAL (hours) 177Algorithmic Improvement
6X improvement so far and 4X without major code change and rest with code changes.

6/4/2014
7
Pair HMM Acceleration using AVX
• Computation kernel and bottleneck in GATK Haplotype Caller
• AVX enables 8 floating point SIMD operations in parallel
• 2 Ways to vectorize HMM computation
• Intra-Sequence – Parallelize computation within one HMM matrix operation. Run multiple (8) computations concurrently along diagonal
• Inter-Sequence – Perform multiple (8) HMM matrix operations at once
37
Time (seconds) Speedup C++/Java
Serial C++ 1540 1x / 9x
1 core with AVX (Intra) 340 4.5x / 40.7x
1 core with AVX (Inter) 285 5.4x / 48.6x
24 cores with AVX (Inter) 14.3 108x / 970x
24 cores hybrid (Inter) 15.7 98x / 882x
38
UC BerkeleyEvaluating Hardware Choices
SoftwareRadio
Computer Vision
Machine Learning
Cancer Genomics
Graph Processing
Multimedia Analysis
Interactive Cloud
What to target?What are productivity/cost/performance
39
CPU FPGA
Memories, Interconnects, I/O
ASICGPU
Racks (10s kW) Mobiles (1W)Embedded (10 kW‐1W)
tradeoffs?
UC Berkeley
High‐level pattern constrains space of reasonable low‐level mappings
(Insert latest OPL chart showing path)
40
UC Berkeley
Specializers: Pattern‐specific and platform‐specific compilers
App 1 App 2 App 3
Dense Sparse Graph Trav.
Clusters CPU GPU
Allow maximum efficiency and expressibility in specializersby avoiding mandatory intermediary layers
41
postcript on patterns in big data
Copyright © 2006, Intel Corporation. All rights reserved. Prices and availability subject to change without notice.*Other brands and names are the property of their respective owners
42

6/4/2014
8
Graph abstraction:essential for data driven problems
43
Flashback to 1998
Why?
First Google advantage: a Graph Algorithm & a System to Support it!
Example 1: PageRank
Twister
Hadoop5.5 hrs
1 hr
40M Webpages, 1.4 Billion Links
GraphLab8 min
Hadoop results from [Kang et al. '11]Twister (in-memory MapReduce) [Ekanayake et al. ‘10]
Hadoop 95 Cores 7.5 hrs
DistributedGraphLab
32 EC2 machines
80 secs
Example 2: Never Ending Learner Project (CoEM)
0.3% of Hadoop time
2 orders of mag faster 2 orders of mag cheaper
34.8 Billion TrianglesExample 3: Triangle Counting on Twitter Graph
64 Machines
1636 Machines423 Minutes
Hadoop[WWW’11]
15 Seconds
S. Suri and S. Vassilvitskii, “Counting triangles and the curse of the last reducer,” WWW’11
Why??Wrong Abstraction!(Broadcast O(degree2) messages per Vertex)
Wrapping up (pontificating)...
Patterns:• use ‘em• use the right ones• beware hasty/naive parallelization (pattern understanding
will help you here)will help you here)
Patterns facilitate good design; their utility continues to grow.





























