Embed Size (px)
DESCRIPTION
Pattern Matching Using n -grams With Algebraic Signatures. Witold Litwin [1] , Riad Mokadem1, Philippe Rigaux1 & Thomas Schwarz [2] [1] Université Paris Dauphine [2] Santa Clara University. n -gram Search. New pattern matching idea Matches algebraic signatures - PowerPoint PPT Presentation
Citation preview

1
Pattern Matching Using n-grams With Algebraic Signatures
Witold Litwin[1], Riad Mokadem1, Philippe Rigaux1 & Thomas Schwarz[2]
[1] Université Paris Dauphine[2] Santa Clara University

2
n-gram Search• New pattern matching idea• Matches algebraic signatures • Preprocesses both : pattern & string (record)
– String preprocessing is a new idea • To the best of our knowledge
• Provides incidental protection of stored data• Important for P2P & grid systems
• Fast processing• Especially useful for DBs & longer patterns
– ASCII, Unicode, DNA…– Should be then often faster than Boyer-Moore– Possibly the fastest known in this context

3
Algebraic Signature
• Symbols of the alphabet are elements of a Galois Field– GF (256) usually
• We choose there one primitive element – Usually = 2
• The algebraic signature of the string of i symbols p1… pi is the sum:
p’i = p1 +…+pi i.
• Here the addition and the multiplication are the operations in GF.

4
Algebraic Signature
• In our GF (2f) where f = 8,16:p + q = p – q = p XOR q
• One method for multiplying is :p*q = antilog (( log p + log q) mod 255)
• The division is then :p / q = antilog (( log p - log q) mod 255)
• The log and antilog are encoded in log and antilog tables with 2f elements each. – Entry 0 is for element 0 of the GF and is by
convention set to 2f - 1.

5
Cumulative Algebraic Signature
• We encode every symbol pi in a string into
the signature of the prefix p1…pi
• The value of a CAS symbol now encodes also the knowledge of values of all the previous ones
• Matching a single symbol means prefix matching

6
Application of CASs• Protection against involuntary data disclosure • On P2P & Grid Servers especially• Numerous CAS encoded string matching
algorithms– Prefix match with O (1) complexity– Pattern match by signature only
• Karp – Rabin like, linear O (L) complexity
– Longest common string search– Longest common prefix search– …

7
CAS Properties
• O (K) encoding and decoding speed• For encoding, for instance:
p’i = p’i-1 + pi i = CAS ( pi-1) + pi i
• Fast n – gram signature calculus– For Sk,l = pk…pl with k > 1 and l – k = n :
AS ( Sk,l ) = AS (S l - k+1) = (p’l XOR p’k - 1) / k-1
• Logarithmic Algebraic Signature (LAS) LAS ( Sk,l ) = log AS ( Sk,l ) =
= ( log (p’l XOR p’k - 1) – (k-1)) mod 2f – 1

8
The n-gram SearchKey ideas
• Design a sublinear pattern match search– With speed about L / K
• Apply to CAS encoded DB– New idea for string search algorithm with
preprocessing – Justified for a DB
• Store once, search many times

9
The n-gram SearchKey ideas
• Preprocess the pattern to create a jump table– As in Boyer – Moore
• Use n –grams with n > 1 to increase the discriminative power of an attempt – Comparison of a sample from the pattern
• a single symbol for BM• an LAS of an n – gram for a CAS-encoded string

10
The n-gram SearchKey ideas
• If the alphabet uses m symbols, the probability that a symbol matches is 1/m– Assuming all symbols equally likely
• For usual ASCII pattern matching m = 20-25
• For DNA m = 4
• A single symbol may often match without the whole pattern matching
• e.g., ¼ times for DNA on the average
• Leading to small jumps, – by m symbols on the average

11
The n-gram SearchKey ideas
• The probability of an n - gram matching may be : min ( 1/ 2f , 1 / mn )
• In our examples it can reach 1 / 256– More discriminative sampling– Longer jumps
• By almost K or 256 symbols in general
• Useful for longer strings– DNA, text, images…

12
ASCII Exemple Usual Alphabet
2-grams => 5 jumps
1-gram => 6 jumps

13
DNA Exemple4-letter Alphabet
3 jumps
4 jumps4 jumps
11 jumps

14
The n-gram Search Preprocessing
• Encode every record (string) into its CAS– Done for incidental protection anyhow for SDDS-2006
• Encode the terminal n - gram of the searched pattern SK into its LAS in variable V
• Fill up the jump table T for every other n - gram in SK – calculate every LAS – for each LAS, store in T its rightmost offset with
respect to the end of SK

15
The n-gram Search Jump Table
• For GF (256), every n – gram Si, i+n-1 in the pattern and i = LAS (Si, i+n-1):– T ( i ) = the offset – T ( i ) = K – n + 1 otherwise
• Remainder : LAS (0) = 255• T can be also hash table
– See the paper– Slower to use but possibly more memory efficient
• Probably more useful for a larger GF

16
ASCII Exemple
Dauphine
V = ne’’
70
71
……
1in’’
……
5au’’
……
3ph’’
……
7255
Notation :
xy’’ = LAS (xy)

17
The n-gram Search Processing
• Calculate LAS of the current n-gram in the string– Start with the n-gram SK-n+1,K – Continue depending on jump calculus
• Attempt to match V– If .true then calculate LAS of the entire current
possibly matching substring • of length K and ending with the current n-gram
• If .true, then resolve the possible collision– Either attempt to match all the K symbols– Or match enough of terminal n-grams or symbols to
decrease the probability of collision to a very small value

18
The n-gram Search Processing
• Otherwise– Go to T using LAS of the n-gram– Jump by the number of symbols found in T
• Update the “current” position for n-gram to attempt the match
– Re-attempt the match as above• Unless the n-gram to attempt is beyond the end of
the string

19
ASCII Exemple Again
2-grams => 5 jumps
1-gram => 6 jumps

20
DNA Exemple Again
3 jumps
4 jumps4 jumps
11 jumps

21
n-grams / BM
• Average shifts with n-grams can be typically longer
• Calculate an attempt & jump may be more expensive as well– About twice as long at first approach– The precise analysis remains to be done
• Rule of thumb: If shifts are more than 2 times longer, n-grams with n > 1 or should be faster than BM.

22
Experimental Results
• Searching large data of:– DNA– Typical ASCII – XML Documents
• Patterns of 6 to 500 symbols (bytes)
• 1.8 GHZ P3 and 2.4 GHZ DualCore AMD Turion 64 Processors

23
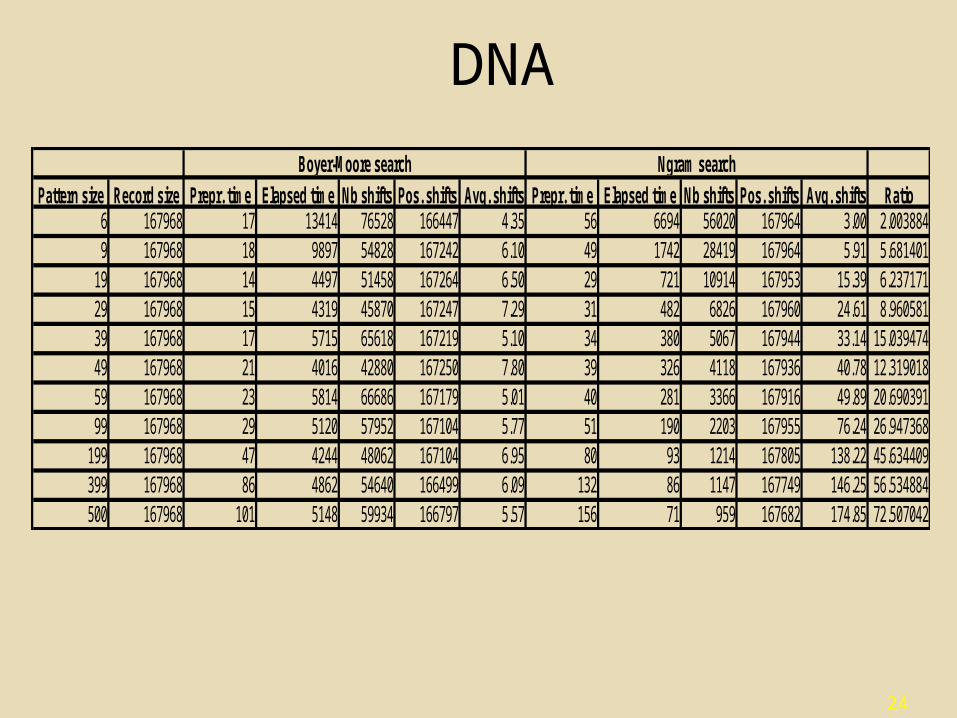
Results Compared to BM
• DNA• Up to 72 times faster
• Typical ASCII • Up to about 11 times faster
• XML Documents• Up to more than 5 times faster
• Search faster for longer pattern– Average shifts are longer
24
Pattern size Record size Prepr. time Elapsed time Nb shifts Pos. shifts Avg. shifts Prepr. time Elapsed time Nb shifts Pos. shifts Avg. shifts Ratio6 167968 17 13414 76528 166447 4.35 56 6694 56020 167964 3.00 2.0038849 167968 18 9897 54828 167242 6.10 49 1742 28419 167964 5.91 5.681401
19 167968 14 4497 51458 167264 6.50 29 721 10914 167953 15.39 6.23717129 167968 15 4319 45870 167247 7.29 31 482 6826 167960 24.61 8.96058139 167968 17 5715 65618 167219 5.10 34 380 5067 167944 33.14 15.03947449 167968 21 4016 42880 167250 7.80 39 326 4118 167936 40.78 12.31901859 167968 23 5814 66686 167179 5.01 40 281 3366 167916 49.89 20.69039199 167968 29 5120 57952 167104 5.77 51 190 2203 167955 76.24 26.947368
199 167968 47 4244 48062 167104 6.95 80 93 1214 167805 138.22 45.634409399 167968 86 4862 54640 166499 6.09 132 86 1147 167749 146.25 56.534884500 167968 101 5148 59934 166797 5.57 156 71 959 167682 174.85 72.507042
Boyer-Moore search Ngram search
DNA

25
ASCII
Pattern size Record size Prepr. time Elapsed time Nb shifts Pos. shifts Avg. shifts Prepr. time Elapsed time Nb shifts Pos. shifts Avg. shifts Ratio6 160832 18 9818 60342 159936 5.30 42 6427 53761 160829 2.99 1.5276189 160832 16 7593 46428 159770 6.88 52 1664 27107 160826 5.93 4.563101
14 160832 12 2804 33760 159891 9.47 25 952 14885 160819 10.80 2.94537825 160832 14 1932 22916 159916 13.96 31 528 7633 160811 21.07 3.65909127 160832 14 1651 18812 159914 17.00 29 492 7018 160828 22.92 3.35569172 160832 22 1094 12334 159869 25.92 46 232 2642 160805 60.86 4.715517
108 160832 28 1066 11668 159924 27.41 52 165 1870 160733 85.95 6.460606157 160832 36 873 10058 159938 31.80 65 107 1333 160828 120.65 8.158879172 160832 39 834 9508 159803 33.61 71 96 1214 160752 132.42 8.687500207 160832 46 700 7590 159837 42.12 79 81 1034 160718 155.43 8.641975251 160832 51 812 9326 159720 34.25 90 81 1035 160783 155.35 10.024691502 160832 88 703 8456 159897 37.82 155 60 781 160671 205.72 11.716667
Boyer-Moore search Ngram search

26
Boyer-Moore search Ngram search
Pattern size Record size Prepr. time Elapsed time Nb shifts Pos. shifts Avg. shifts Prepr. time Elapsed time Nb shifts Pos. shifts Avg. shifts Ratio
5 1119392 11 39684 486654 1105079 4.54 29 33830 560243 1119388 2.00 1.173042
7 1119392 10 29964 363532 1103455 6.07 29 17128 282339 1119388 3.96 1.749416
10 1119392 13 20835 244306 1104955 9.05 43 10102 161595 1119384 6.93 2.062463
11 1119392 11 21537 263710 1092465 8.29 31 9086 143455 1119387 7.80 2.370350
13 1119392 12 20053 223080 1065458 9.55 40 7237 112626 1119387 9.94 2.770900
27 1119392 14 11672 134974 1089086 16.14 36 3496 47727 1119384 23.45 3.338673
51 1119392 19 9719 105588 1089559 20.64 43 2440 27498 1119366 40.71 3.983197
186 1119392 40 4687 34028 1108639 65.16 82 1391 9094 1119298 123.08 3.369518
237 1119392 49 4307 37738 1108658 58.76 95 802 8119 1119327 137.87 5.370324
386 1119392 74 4647 32918 1108691 67.36 133 913 8072 1119024 138.63 5.089814
567 1119392 103 3385 30560 1108574 72.55 183 819 6312 1118932 177.27 4.133089
XML

27
Related Work• Implemented in SDDS-2006• Applies best to
– longer patterns• where many jumps occur
– alphabets much smaller than the size of GF used
• Instead of shifts of size m in the average, one reaches almost min (K, 2f) per shift– up to almost 256 for DNA or ASCII with GF (256) – up to almost 64K for DNA or Unicode with GF (64K)
• instead of 4 or 25 respectively
– For Boyer-Moore especially

28
Related Work
• In SDDS 2006 & P2P or Grid System in general
• Wish to hide what is searched for ?• Use the signature only based search
– Usually slower since linear only

29
Conclusion
• A new pattern matching algorithm• Uses algebraic signatures• Preprocesses both the pattern and the string• Appears particularly efficient
– For databases– For longer patterns
• Possibly faster in this context than any other algorithm known know
• But all this are only preliminray results

30
Future Work• Performance Analysis
– Theoretical• Jump Length
– Median, Average…
– Experimental• Actual text
– Non uniform symbol distribution
• DNA– Actual DNA strings

31
Future Work• Variants
– Jump Table– Partial Signatures of n –grams
• Symbol pi encodes the n –gram signature up to pi-
n+1 …pi
– No more XORing & Division to find this signature– Faster unsuccessful attempt to match
– Approximate Match• Tolerating match errors
– E.g., and at most 1 symbol






























