Embed Size (px)
Citation preview

Journal of lntelligent and Robotic Systems 3: 293-303, 1990. 293 �9 1990 Kluwer Academic Publishers. Printed in the Netherlands.
Parallel Processing in Knowledge-Based Diagnostic Systems M U K H T A R HUSSA1N a n d J A T I N D E R S I N G H BEDI Department of Electrical and Computer Engb~eering, Wayne State University, Detroit, MI 48202, U.S.A.
(Received: I1 November 1988; revised: 9 March 1990)
Abstract. This paper highlights the use of the parallel processing concept in knowledge-based diagnostic systems. A MIMD machine connected in a cubic mesh fashion using Parlog has been suggested to implement such systems. An algorithm supporting the concurrent execution of multiple conflict set rules of the same production system program is presented. A specific application to communication systems maintenance utilizing these principles has been discussed.
Key words. Parallel processing, production systems, knowledge engineering, artificial intelligence, database.
1. Introduction
The diagnosis of component failures is an intellectually challenging activity which requires the human expert to maintain and reason a large collection of related facts. Electronic systems diagnosis involves the identification and isolation of faulty com- ponents and assemblies. The principles of artificial intelligence are being successfully applied to bear the expertise of the systems architect to each problem [1]. The central focus of recent research is to investigate a highly parallel non-Von Neumann machine architecture [2, 3] which can be adapted for all kinds of operations required for knowledge-based diagnostic systems. The concept of parallel processing can be effectively applied at the hardware/software system level or at the algorithmic and programming level. For instance, a high-speed Prolog machine has been suggested [4] which carries out the direct execution of knowledge-based diagnostic systems.
In knowledge-based systems, knowledge is used to solve problems, i.e. to determine new facts based upon what is already known. Knowledge must be represented for quick and easy retrieval, for use in reasoning or for solving a specific problem, and for efficient storage. Selecting an appropriate knowledge representation technique is important because research has shown that the problem-solving strategy depends heavily upon this representation [5]. Some common techniques include semantic networks, production rules, and frames, but all these techniques suffer from problems. They fail to provide the generality which is needed by real-world knowledge. This generality is important so that these techniques can be applied universally to all forms of knowledge rather than being specific to a certain domain. Production rules are thought to be unnatural means of representing real-world knowledge for certain domains [6]. Semantic networks are passive structures and need a net manipulator for their operation. Moreover, no universally accepted semantics exists for its formalism

294 MUKHTAR HUSSAIN AND JATINDER SINGH BEDI
[7]. The frame concept suffers from updating anomalies which often arise in an unnormalised database [8]. Frames do not represent the smallest item of knowledge. Their deletion can only be affected if all the knowledge contained within them is removed.
Bell [8] has suggested two approaches to overcome some of the problems being faced by existing techniques. Firstly, the disjoint approach, in which a total know- ledge base is made up of three consistuent knowledge representation techniques. The knowledge domain can be dissected into fragments which are easily realizable by production rules. A global knowledge base is built with a combination of three sub-knowledge bases, each constituent base exhibiting homogeneity with respect to the knowledge representation. The second approach is the fused approach. In this, we have a heterogenous amalgam of three methods to suit the application in hand. However, in this approach, the subordinate knowledge base cannot be identified. A single knowledge base exists and such a base draws on the salient characteristics of the above-mentioned techniques. The inference engine consists of problem-solving strategies that use knowledge from the knowledge base to search for a solution from the search space which consists of a set of all possible solutions.
2. Diagnostic Strategies - A Review
Diagnosis is a method of employing knowledge over a certain area for specific analysis and synthesis techniques in order to explain any abnormal situation. It also reasons about the explanation, applying it to reach a treatment or to expand domain know- ledge. Generally, such systems enable their users to report abnormal situations or a malfunctioning of the equipment in the form of known symptoms. The main difficulty in diagnosis is in tracing the fault through the network until a component is found that is not producing the right output and yet which is getting the right input. The diagnosis strategy should not only ensure correct diagnosis but also must meet the requirements of repair and preventive maintenance, and should have a reasoning process to explain why and how a decision was made. This will help in tutoring the new technicians. The following diagnostic strategies are available in current know- ledge based diagnostic systems [1, 9, 10]:
(a) Traditional Approach Test generation [1] is the traditional approach to trouble shooting digital circuitry. Given a specified fault, it is capable of determining a set of input values that will detect the fault. A theory of the components enables us to correlate the faults to a set of inputs. It determines which faults to consider or which components to suspect generally, tests for complex integrated circuits and for boards full of ICs is an activity which is vital to the automatic test industry. The generation of such tests for hybrid circuits, i.e. containing analog and digital circuitry, is even more difficult. In this domain, several different reasoning techniques have to be applied which will be based on the description of what the circuit is supposed to do, how the circuit is built, and

PARALLEL PROCESSING IN KNOWLEDGE-BASED DIAGNOSTIC SYSTEMS 295
how the parts contribute to the overall function of the circuit. It will not be possible to reproduce all such forms of reasoning until we have methods for describing most of the information found in a high-quality documentation package for a circuit. However, it may be possible to solve simple diagnostic problems by mapping directly from symptoms to repairs. Symptoms can be obtained from the trouble reports generated by test equipment connected in the system to monitor the behaviour of the system. In this case, the search space is not built a-priori but is built as needed.
(b) Discrepancy Detection and Candidate Generation Technique This technique [9] simply looks for mismatches between the values it expected from the correct operation and those actually obtained. This allows the detection of a wide range of faults. It allows the systematic isolation of possible faulty devices without having to precompute fault dictionaries and diagnosis trees. This approach can deal with complex structures due to its suitability to hierarchical descriptions.
(c) Model-Based Reasoning Technique Human experts do not simply apply heuristic rules to map data to obtain intermediate conclusions, but frequently reason about some problems using the knowledge of the structure of a piece of equipment. The strategy must provide a database capability for storing the structural model and must provide advanced query and influence mechan- isms for reasoning with such data. Two types of descriptions, structure and behaviour, are important in model-based reasoning [9].
(d) Heuristic Search With the passage of experience, some humans can diagnose more quickly than others. This is basically because of domain-specific knowledge which has been attained over a period of time. This is called heuristic. Humans are very good at this. When diagnosing a particular fault, they know the most likely fault and/or what to check first.
(e) Meta-rules These are the basic blocks of IF-THEN rules [11], or hypothesis refinement pro- cedures which rely on an exhaustive mapping of causality relations and basic actions in the three-dimensional space. If the database does not say explicitly [12] about a fact, then the opposite of that can be taken as true. For example, in a company records, if it is not said that Mr X is a temporary employee, then it is taken for granted that he is a permanent employee. To use rules like this, a system would need a linguistic expression that denotes its own database.
3. Parallel Processing Concept
Advanced computer architectures are centered around the concept of parallel process- ing which is needed in expert systems to meet the outgrowing requirement of a large number of computations. To achieve the desired efficiency, reliability, and response time in production system based expert systems, parallel processing can be applied at

296 MUKHTAR HUSSAIN AND JATINDER SINGH BEDI
the hardware/software system level or at the algorithmic and programming level. The major source of inefficiency in production systems is the matching phase [13], thus fast matches are required for well-implemented knowledge-based systems.
A great amount of research has gone into this and many architectures have been suggested to improve the speed. Eshera and Barash [2] have proposed reconfigurable mesh-connected array architecture to accommodate the inference network such that rules are distributed and processed in parallel on the different processing elements in the array. Gupta et al. [4] have proposed a highly parallel multiprocessor, data-driven computer architecture. In this, the goals are inferred by parallel inference processors called inference cells. All the inference cells put together form a parallel inference engine (PIE). The PIE contains the goal pool, unifying processor, task processor, knowledge base manager, and the system activity manager. Prolog has been chosen due to its semantic clarity, argument matching, automatic back tracking control, and internal database management facility [4]. The main aim of all these proposed techniques has been to reduce the time spent in the matching operation. In production systems, however, the number of state changes during each cycle is small (maybe 3 to 5), hence we may not be able to achieve the desired efficiency. Firing rules in parallel is needed so that the number of changes in each cycle is sufficient enough to utilize the power of parallel processing provided by the proposed systems. Furthermore, we need to carry out load balancing so that no processor remains idle due to an inefficient distribution of load. A processor may be designated to control the load flow in a justifiable manner, i.e. no processor should be overloaded nor should it remain idle. Sugie [14] has suggested some techniques to improve the load-dispatch strategies to get the desired load balancing. Shapiro [15] has suggested the use of concurrent programming and parallel execution. However, this language is considered to be unsafe, as the local bindings that are made are not valid until commitment has taken
place. In Parlog [16], a goal can only be attempted to be reduced by a clause if the input
arguments for that predicate can be unified with the head of the clause without causing any instantiation in the goal being evaluated. Parlog is safe, as it does not permit the binding of goal parent variables in the guard. It is important to note that we should not only restrict ourselves to achieve enhanced performance by using multiprocessor architecture but also use improved programming languages along with it to get the real fruit of parallel processing. The application at hand is another important aspect to be looked at. How much parallelism is available in the problem to be solved, and how can it be determined?; are two of the crucial factors which will affect the overall system performance. Real-time fault diagnosis and systems main- tenance is a good candidate for the application of parallel processing.
Some researchers [17] have suggested the use of connectionist models to solve problems in parallel. A connectionist model consists of many simple, richly inter- connected neuron-like computing units that cooperate to solve problems in parallel. The distributed connectionist production system interpreters use distributed repre- sentation. These models perform matching and variable binding by massively parallel

PARALLEL PROCESSING IN KNOWLEDGE-BASED DIAGNOSTIC SYSTEMS 297
constraint satisfaction. The capacity of its working memory is dependent on the similarity of the items being stored. Connectionist models are good at performing pattern matching in cases where there is no perfect match and the objective is to find the best partial match. In other words, we try to find the global energy minimum and become satisfied if we obtain an acceptable local energy minimum to satisfy as many constraints as possible. Due to this reason, the connectionist approach may not be suitable in fault diagnosis systems. These models are too restricted and have been worked with a limited class of production systems. Moreover, the neural network field has not yet matured and systems have not been developed using neurons as computing elements.
4. Matching Algorithms for Production Systems
The Rete match algorithm [18] is considered to be the best algorithm for matching applications. It utilizes memory support and condition relationships and compiles the left-hand side of the production rules into a discrimination network in the form of an augmented data flow network. Database operators are used as the operators in the data flow network. The algorithm has the advantage that a large amount of stored data minimizes the number of times two working memory elements will be repeatedly compared and similar rules will apply to similar networks, allowing the sharing of network structures. However, the sharing of a network structure is not advantageous in a parallel environment due to contention and/or communication cost [4, 19]. Another algorithm, TREAT [20], has been developed to overcome this difficulty. This algorithm is based on conflict-set support. Here the conflict set is explicitly retained across the production system cycles. This helps in limiting the search for a new instantiation to those instantiations that contain newly asserted working memory elements. The TREAT algorithm exploits condition membership, memory support, and conflict support. Moreover, it can be effectively used for other production system languages due to use of joint optimization. Simulation results have shown that TREAT always outperforms the Rete algorithm and is a better production system algorithm in both time and space, and works well in parallel processing environments.
5. Development of COSMES (An Expert System for Communication System Maintenance)
The application of expert systems in communication systems maintenance has proven its worth [21, 22] through field tests and actual use. COSMES [23] is being developed to carry out the analysis of reports for switching equipment and telephone repair and maintenance. The block layout of the COSMES is given in Figure 1. The output of an existing computer system is currently used to create a set of maintenance messages for the craft personnel to analyze, localize, and monitor the quality of transmission. This acts as input to the expert system. It also acquires information from a generalized database for determining faults in cables. Test requests can be generated from trouble
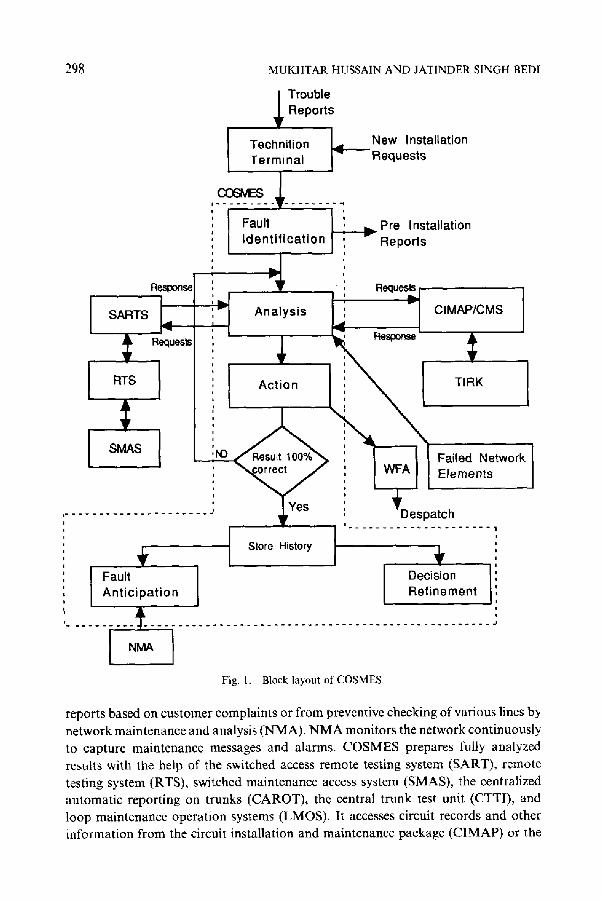
298 MUKHTAR HUSSAIN AND JATINDER SINGH BEDI
~ Trouble Reports
L New Installation TerminaITechniti~ 1" Requests
, . ~ s _~ .......... I *
Fault I '! . . - ' Pre Installation Identification ~ Reports
J
I I ~o ~.~..,Uo0o/o~ I ..... !1 Failed Network
,- . . . . . . . . . . . . . . . . . . . . j , ~Yes VDespatch
§ r J . . . . . . . . . . . . . . . . . . . . .
I Fa~litci patio n L Deflns~ieOne nt [
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . J II. l Fig. 1. Block layout of COSMES.
reports based on customer complaints or from preventive checking of various lines by network maintenance and analysis (NMA). NMA monitors the network continuously to capture maintenance messages and alarms. COSMES prepares fully analyzed results with the help of the switched access remote testing system (SART), remote testing system (RTS), switched maintenance access system (SMAS), the centralized automatic reporting on trunks (CAROT), the central trunk test unit (CTTI), and loop maintenance operation systems (LMOS). It accesses circuit records and other information from the circuit installation and maintenance package (CIMAP) or the

PARALLEL PROCESSING IN KNOWLEDGE-BASED DIAGNOSTIC SYSTEMS 299
circuit maintenance system (CMS) and from the trunk integrated record-keeping system (TIRK). COSMES can also interact with the work and force administration system (WFA) and even prepares dispatch schedules. The resulting report contains complete, specific, and easy-to-understand instructions. However, all this is done off-line. To perform all these tasks (including fault diagnosis of switchboards) on-line and to remove some of the existing packages being used for maintenance, information about the structure of switchboards is required. For types of faults being encountered with specific symptoms, we need to utilize a multiprocessor system with a high-level programming language like Parlog and Bell's fused approach for knowledge represen- tation. Moore [24] has discussed the problem of building a knowledge base for an on-line system. The requirements of a real-time expert system have also been pointed out by Sauers [25], In next section, we discuss the possibility of determining the parallelism in the application under consideration and propose an alogrithm to achieve it.
6. Parallel Processing in Knowledge-Based Communication Systems Maintenance Expert Systems
Communication systems maintenance requires a large number of rules and data items for its smooth functioning. The following must be taken in consideration for provid- ing reliable and efficient service to the customers:
(a) Unlike conventional expert systems, the real-time expert system should not carry out exhaustive searches of rule bases.
(b) Use of a distributed multiprocessor system in which each memory module is physically associated to each processor.
(c) Use of a highly concurrent language like Parlog or concurrent Prolog. (d) Development of a highly parallel algorithm for the unification process. (e) Subdividing the application under discussion into subsets in such a way that a
maximum number of resources can be utilized and no processor remains idle at any particular time. We should be able to figure out where the problem contains parallelism and how it can be split into or apportioned across the multiprocessor system.
All these points need very careful study. The first three points are not really difficult to implement, but the remaining two points need further consideration. Yasuura [26] has indicated in his work that there is difficulty in designing very efficient parallel algorithms for unification. Unification is a process in which we try to find sub- stitutions of terms for variables to make two expressions identical. He has suggested to use hardware to achieve the desired efficiency.
The communication system maintenance problem has enough parallelism which can be exploited if carefully planned. To start with, either we get computer-generated reports which show the status of the system or the customer complaints of a fault. Based on this information, we formulate several hypotheses. For example, if a

300 MUKHTAR HUSSAIN AND JATINDER SINGH BEDI
customer complaint that he cannot send or receive data (CRD/CSD), then two hypotheses can be generated. The first one being the fault in the customer's equipment and the second may be that the line is grounded or short circuiting. This is the first stage where we can do operations in parallel. The analysis of the computer generated report is done by matching the standard values with the observed values during system monitoring. We can divide the knowledge base and put it into the processor's own memory module and carry out a comparison in parallel.
The second level is to determine the truth of a particular hypotheses, for which certain tests have to be generated and some parameters need to be measured. Again, we need to compare these values with standard values. Based on these results, we can assign a certainty value to a particular hypotheses. During hypotheses testing, goal pools are generated. These goals have a subgoal. The process of unification is thus there. We can use parallel processing very effectively at this level.
We have to also ensure that the overheads generated to achieve this parallelism do not exceed a certain level, otherwise the system performance may be reduced to a sequential level performance. Hence, we must keep the process simple enough to reduce the overheads and efficient enough to achieve a reduction in computing time. The suggested flow chart of the proposed algorithm is given in Figure 2. The trouble history is updated if the fault has been detected correctly. This increases the system confidence value with the passage of time, as in the case of human experts. A priority organizer is needed so that we can test the generated hypotheses in a manner that the obvious ones are tested first followed by those that are not so obvious. In other words, we can make sets of plausible hypotheses and try to check set by set, that the most obvious set is tested first. However, the process will not be sequential. Depending upon the computing power available, we test a set of most important hypotheses before the other formulated hypotheses. Normally, with a communication systems maintenance problem, a set of symptoms gives rise to more than two or three hypotheses. The work on a real-time expert system is under way. The main objective is to provide a reliable, uninterrupted, and efficient service to customers.
In the proposed architecture, each node of the PIE is connected to all other nodes and each node can communicate with any other node in a unit time delay. The database will be partitioned into a finite set of smaller databases, stored in the processor's own memory module and will be functionally independent of other databases. The partioning will be done based on the relationship between hypotheses and symptoms. We will store the names of rule bases associated with each symptom in slots in each individual symptom frame. We will thus have one rule base for each testable hypotheses. This will counter the problem of hypotheses coherence which may have been present otherwise. This will also help in speeding up the searching and fetching of relevant data. A garbage collection unit [27] is needed to reduce the unuseful information in the goal pool. The goal pool becomes larger with every inference step. We must reduce it by eliminating intermediate data which is not needed any more. A global memory will store the operating system and user programs. The block diagram of the proposed architecture is given in Figure 3. The host computer accepts input
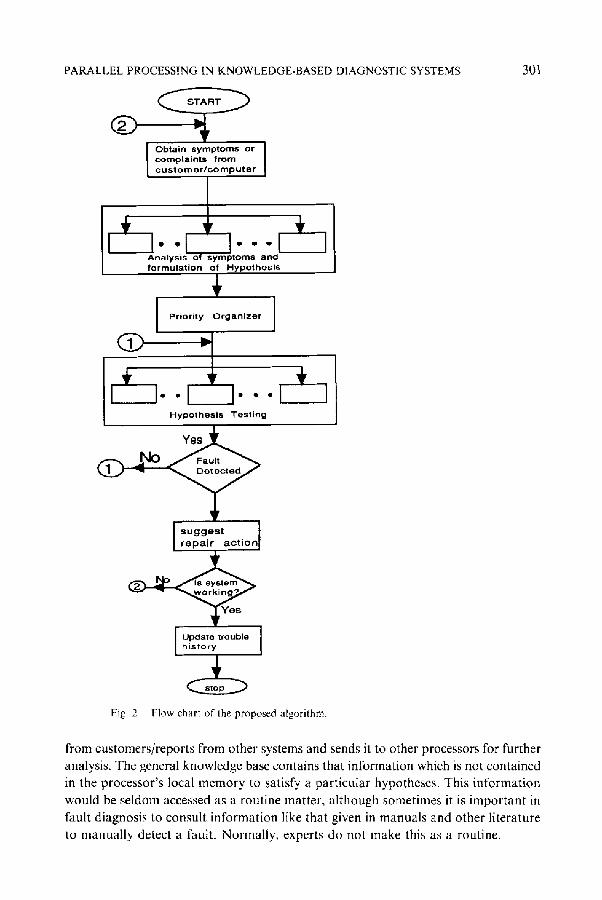
PARALLEL PROCESSING IN KNOWLEDGE-BASED DIAGNOSTIC SYSTEMS
Q -, I Obtain symptoms or I
complaints from customer/computer
II b~
I Priority Organizer
. .
Hypothesis Testing
su .est .
Update trouble I history
Fig. 2. Flow chart of the proposed algorithm.
301
from customers/reports from other systems and sends it to other processors for further analysis. The general knowledge base contains that information which is not contained in the processor's local memory to satisfy a particular hypotheses. This information would be seldom accessed as a routine matter, although sometimes it is important in fault diagnosis to consult information like that given in manuals and other literature to manually detect a fault. Normally, experts do not make this as a routine,

302
C o Global m Memory m u
n Hi c Garbage a Collection t Unit o r
MUKHTAR HUSSAIN AND JATINDER SINGH BEDI
Host Computer
Multiprocessor System
General K!owledge base Manager
Priority Organizer
General Knowledge Base
Fig. 3. Block diagram of the proposed parallel machine.
7. Conclusion Tremendous effort is being spent in research on developing new models for parallel execution in knowledge-based systems. Concurrent Prolog- or Parlog-like languages are finding their way into these types of systems duc to their semantic clarity, automatic backtracking control, and their excellent management of internal data- bases. However, a lot of work is still needed to develop efficient parallel algorithms for the unification process which is so important in production system-based expert systems. The data flow concept is also being utilized in this area which would enable us to achieve a high degree of parallelism while executing knowledge-based diagnostic systems. Due to powerful emerging techniques of knowledge representation systems, it is now much simpler to guarantee a reasonable reponse time and good fault coverage for the developed systems. The knowledge-based systems capture the diag- nostic reasoning of the best qualified human experts in a particular domain, A successfully implemented service advisory system would allow a technician with only a brief training to conduct expert guided service procedures, Reduction of service time, overall maintenance cost, and improved and uniformly applied service strategies are some of the benefits of using knowledge-based diagnostic systems utilizing parallel processing.

PARALLEL PROCESSING IN KNOWLEDGE-BASED DIAGNOSTIC SYSTEMS 303
References
1. Pau, L.F., 1986, Survey of expert systems for fault detection, test generation and maintenance, Expert System 3, No. 2. pp. 100-I 1.
2. Eshera, M.A. and Barash, S.C., 1989, Parallel rule-based fuzzy inference on mesh-connected systolic arrays, IEEE Exl~ert, Winter, pp. 27-35.
3. Nakamura, K. and Kobayashi, S., 1988, A fault diagnosis system based on parallel interaction, in International Workship cm Artificial Intelligence for Industrial Application. pp. 100-114.
4. Gupta, S.K., Singh, R., and Joseph, J., 1987, A data driven model for parallel execution of rule based expert systems in Prolog machine, in Proc 30th Midwest Svmposiun~ on Circuits and Systems, Syracuse, N.Y., 17-18 Aug., pp. 871-874.
5. Newell, A. and Simon, H., 1972, Human Problem Solving, Prentice-Hall, N.J. 6. Davis. R. and King, J., 1976, All Overview q/' Production Systems, Machine Intelligence, Vol. 8, Wiley,
New York. 7. Woods, W.A., 1975, What's in a Link: Foundations [or Semantic Networks, in Representation and
Understanding, Academic Press, New York. 8. Bell, D.A. and O'Hare, G.M., 1985, The co-existence approach to knowledge representation, s
Systems 2, No. 4 pp. 230-237. 9. Davis, R., Shorbe, H., Hamsher, W.. Wieckert, K., and Shirley, M., 1982, Diagnosis based on
description of structure and function, in Proe. Amer. Assoc. Art(h'eial Intelligence, pp. 91-10l. [0. Davis, R., 1983, Diagnosis via causal reasoning: paths of interaction and the locality principle, in Proc.
o[' Amer. Assoc. Art(/ieial hltelligenee. I1. Davis, R., 1980, Metarules: Reasoning about control, Art(ficial Intelligence 15, 179-222. 12. Nilsson, N.J., 1986, Principles q['Art(I~eial Intelligence, Morgan Kaufmann, U.S.A. 13. Gupta, A., 1984, Implementing OPS5 production systems on DADO, Carnegie Mellon University,
internal report, CM U-CS-84-115. 14. Sugie, M. and Yoneyama, M., 1988, Analysis of parallel inference machines to achieve dynamic load
balancing, hTt. Workshop on Artfeial h~tell~,,enee fi~r hutustrial Applications, pp. 511 516. 15. Shapiro, E,, 1986, Concurrent Prolog: a progress report, IEEE Computer, pp. 44-58. 16. Greogry, S., 1987, Parallel Logic Programming in Parlog, Addison-Wesley. New York. 17. Touretzky, D.S., and Hinton, G,E.. [988. A distributed connectionist production system, Cognitive
Science 12, 423 466. 18. Forgy, C.L., 1982, Rete: A fast algorithm for the many pattern/many object pattern matching prob-
lem, Artificial Intelligence 19, 17-37. 19. Stolofo, J.S. and Miranker, D.P., 1984, DADO: A parallel processor for expert systems, Proe q/'h~t.
Coq[i on Parallel Processing, IEEE Computer Society Press. pp. 74-82. 20. Miranker, D.P., 1988, TREAT: A better match algorithm for At production systems, Technical report,
Department of Computer Sciences, University of Texas at Austin. 21. Goyal, S.K., Prerau, D.S, Lemon, A.V., Gunderson, A.S., and Riuke, R.E., 1985. COMPASS: An
expert system for telephone switch maintenance, Expert Systems 2, I12-126. 22. Miller, F.D. and Copp, D.H., Vesander. G.T., and Zeilurshi, J.E., 1984, The ACE experiment,
AT&T Lab., Whiff;any, NJ. 23. Hussain, M. and Bedi, J.S., 1987, COSMES - An expert system for communication system main-
tenancc, Proe ESD/SMI Cwference on Expert O'stems.fin" Advanced Manu/~wturing Technology, 9 I I June, MI, U.S.A,, pp. 185-198.
24. Moore, R.L. and Krammer, M.A., Expert Systems in On-line Process Control, Lisp Machine, Inc., Los Angeles, pp. 839-867.
25. Sauers, R. and Walsh, R., 1983. On the requirements of future expert systems, in Proe 8th lnt. Con[i on AL Karlsruhe, W. Germany.
26. Yasure, H., 1984, On parallel computational complexity of unification, in Pr~c. Int. Cotl[~ 5th Gener- ation Computer Systems, pp. 235-243.
27. Singh, R. and Joseph, J., 1988, Multiprocessor parallel garbage collector architecture, algorithm and its performance analysis, in 30th Midwest Symposium on Circuits and Systems, pp. 867-870.





























