Embed Size (px)
DESCRIPTION
Guía Estadística para la Investigación
Citation preview

Esta obra esta bajo una licencia reconocimiento-no comercial 2.5
Colombia de creativecommons. Para ver una copia de esta licencia,
visite http://creativecommons.org/licenses/by/2.5/co/ o envié una
carta a creative commons, 171second street, suite 30 San
Francisco, California 94105, USA
PAQUETES ESTADÍSTICOS
PARA MODELAR SERIES DE
TIEMPO
Autores:
Mónica Yolanda Mogollón Plazas
Director Unidad Informática: Henry Martínez Sarmiento
Tutor Investigación: Alejandro Nieto
Coordinadores: Alvaro Schneider Guevara
Juan Felipe Reyes Rodríguez
Coordinador Servicios Web: Miguel Ibañez
Analista de Infraestructura y Comunicaciones: Alejandro Bolivar
Analista de Sistemas de
Información: MesiasAnacona Obando
UNIVERSIDAD NACIONAL COLOMBIA
FACULTAD DE CIENCIAS ECONÓMICAS UNIDAD DE INFORMÁTICA Y COMUNICACIONES
BOGOTÁ D.C. JUNIO 2010

PAQUETES ESTADISTICOS PARA
LA MODELACIÓN DE SERIES DE
TIEMPO
Director Unidad Informática: Henry Martínez Sarmiento
Tutor Investigación: Alejandro Nieto
Auxiliares de Investigación:
CAMILO ALBERTO ZAPATA MARTÍNEZ JORGE LEONARDO LEMUS CASTIBLANCO
DAVID FELIPE BELTRAN SÁNCHEZ LILIANA CAROLINA HERRERA PRIETO
DAVID CAMILO SANCHEZ ZAMBRANO WILLIAM CAMILO CASTRO LOPEZ
DIEGO ARMANDO POVEDA ZAMORA CINDY LORENA PABON GÓMEZ
EDGAR ANDRÉS GARCIA HERNÁNDEZ MONICA YOLANDA MOGOLLON PLAZAS
IVAN ALBEIRO CABEZAS MARTÍNEZ SANDRA MIREYA AGUILAR MAYORGA
JAVIER ALEJANDRO ORTIZ VARELA SANDRA MILENA CASTELLANOS PÁEZ
JORGE ALBERTO TORRES VALLEJO JOSÉ SANTIAGO APARICIO CASTRO LAURA VANESSA HERNANDEZ CRUZ JUAN CARLOS TARAPUEZ ROA
Este trabajo es resultado del esfuerzo de todo el equipo
perteneciente a la Unidad de Informática.
Se prohíbe la reproducción parcial o total de este documento,
por cualquier tipo de método fotomecánico y/o electrónico,
sin previa autorización de la Universidad Nacional de
Colombia.
UNIVERSIDAD NACIONAL COLOMBIA
FACULTAD DE CIENCIAS ECONÓMICAS
UNIDAD DE INFORMÁTICA Y COMUNICACIONES BOGOTÁ D.C.
JUNIO 2010

PAQUETES Estadísticos PARA MODELAR SERIES DE TIEMPO
UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS
UNIDAD DE INFORMÁTICA Y COMUNICACIONES 3
TABLA DE CONTENIDO
TABLA DE CONTENIDO ......................................................................................................... 3
1. RESUMEN ........................................................................................................................... 4
2. ABSTRACT......................................................................................................................... 4
3. INTRODUCCIÓN ............................................................................................................. 5
4. Es el programa diseñado para series? Presencia del componente Arima.......................... 6
5. Metodología Box Jenkins: comparación de procedimientos............................................ 11
Descripción de la serie a modelar........................................................................................ 11
Antes de comenzar: Transformación de la serie y pruebas de raíz unitaria. ...................... 11
Etapa 1: identificación. .......................................................................................................... 18
Función de autocorrelación.................................................................................................. 19
Criterios de información. ................................................................................................. 26
Etapa 2: Estimación. .......................................................................................................... 26
6. CONCLUSIONES ............................................................................................................ 32
7. BIBLIOGRAFIA ................................................................................................................. 33

PAQUETES Estadísticos PARA MODELAR SERIES DE TIEMPO
UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS
UNIDAD DE INFORMÁTICA Y COMUNICACIONES 4
1. RESUMEN
Los modelos estadísticos para administrar series de tiempo son en la actualidad
herramientas prácticas para acercarse a la modelación de series económicas, para variables
que se cree tienen cambios en el tiempo permanentes. La mayoría de paquetes estadísticos
en el mercado ofrecen algún componente para modelos Arima, pero no todos ofrecen la
misma gama de pruebas sobre los supuestos o capacidad de pronósticos. En este informe se
propone completar el informe pasado sobre las diferencias en la modelación Arima a través
de al metodología Box Jenkins para los programas Stata 10, Winrats7.2, Matlab 7,9, Eviews 9,
R y Jmulti. El criterio para evaluar la capacidad del programa en series es la gama de
funcionalidades para llevar a cabo la metodología Box Jenkins. Se podrá observar que
mientras unos programas son especializados en series y por tanto ofrecen un comando para
ejecutar la estimación y las pruebas de ruido blanco, otros permiten no tiene comandos
directos aunque permiten programar.
2. ABSTRACT
Statistical models to manage univariates time series are currently practical tools to bring
economic series, for which expected changes in time have a permanent impact. Most
statistical packages in the market offer some component for Arima models, but not all offer
the same range of evidence on the assumptions and forecasting capability.The criterion to
assess the programme capacity in series is the range of functionality for the Box Jenkins
methodology.In this report the propose is to study the differences in the Arima modeling
through the Box Jenkins methodology for Stata 10, Winrats7.2, Matlab 7.9, Eviews 9, R and
Jmulti programs. It will see programmes are specialized in series, and therefore to provide a
command to run the estimation and the white noise tests, others allow has no direct
commands while programming.

PAQUETES Estadísticos PARA MODELAR SERIES DE TIEMPO
UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS
UNIDAD DE INFORMÁTICA Y COMUNICACIONES 5
3. INTRODUCCIÓN
Los paquetes estadísticostienen diferentes especialidades que es necesario reconocer para
hacer una elección adecuada a la hora de analizar una base de datos con un modelo
econométrico específico. En el caso de la modelación de series de tiempo univariadas todos
los paquetes analizados ofrecen algún componente o conjunto de herramientas para ajustar
un modelo Arima, evaluar sus supuestos y hacer predicciones. Sin embargo la diferencia
entre paquetes radica en que algunos son diseñados para los modelos de series de tiempo
como puede ser WinRats y JMulti, mientras que otros son tienen un rango más amplio de
aplicación dentro del campo estadístico, y esto hace que sus herramientas para series sean
muy básicas, o que sea necesario programar las iteraciones para estimación, que puede
tomar tiempo de aprendizaje y elaboración al investigador.
El procedimiento más común para estimar y escoger un proceso Arma es a través de la
metodología Box Jenkins. Es muy usadaya que a través de un proceso por etapas, conduce a
una modelación que permite obtener el mejor modelo para el pronóstico. Por tanto si un
programa permite efectuar todas las etapas Box-Jenkins con la mayor facilidad y el mayor
rango de pruebas para decidir, será un criterio de capacidad adecuada del programa para la
aplicación de herramientas econométricas a series de tiempo univariadas.
Esta metodología propone en primer lugar transformar la serie objeto de análisis para que
pueda ser estimado un proceso estocástico con las propiedades Arma. La serie tiene que ser
estacionaria por supuesto para lo cual se pueden aplicar transformaciones de varianza y de
nivel. El segundo paso es identificar un modelo, un proceso que no es muy preciso y
depende tanto de la intuición del investigador como de las herramientas que dispone, en
este caso las pruebas y graficas que arroje cada programa. Después de identificado un
modelo Arima, se procede a estimar los coeficientes, y es posible que difieran dependiendo
del método de estimación utilizado. Finalmente se verifican los supuestos sobre los
residuales, se corrigen los modelos si es necesario, y con el modelo (o los modelos)
resultantes se efectúan las predicciones, que es el fin último de todo el proceso1. El modelo
escogido será el que mejor ofrezca pronósticos de acuerdo a criterios estadísticos.
El propósito es entonces evaluarcomo se puede ejecutar la metodología Box Jenkins para
series de tiempo, en cada paquete estadístico Stata 10, Winrats7.2,Matlab 7.9, Eviews 9, R y
Jmulti y dar un conclusión sobre los paquetes que serian mas prácticos y equipados para este
tipo de modelos.
1Esta metodología fue planteada por primera vez en Box, George and Jenkins, Gwilym (1970) Time series analysis: Forecasting and control , San Francisco: Holden-
Day.
PAQUETES Estadísticos PARA MODELAR SERIES DE TIEMPO
UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS
UNIDAD DE INFORMÁTICA Y COMUNICACIONES 6
4. Es el programa diseñado para series? Presencia del
componente Arima
Antes de abordar los procedimientos de la metodología Box-Jenkins debemos saber si los paquetes en estudio ofrecen en su interfaz gráfica o en su conjunto de comandos los
procedimientos ya programados para la estimación de modelos Arima y sus correspondientes pruebas.
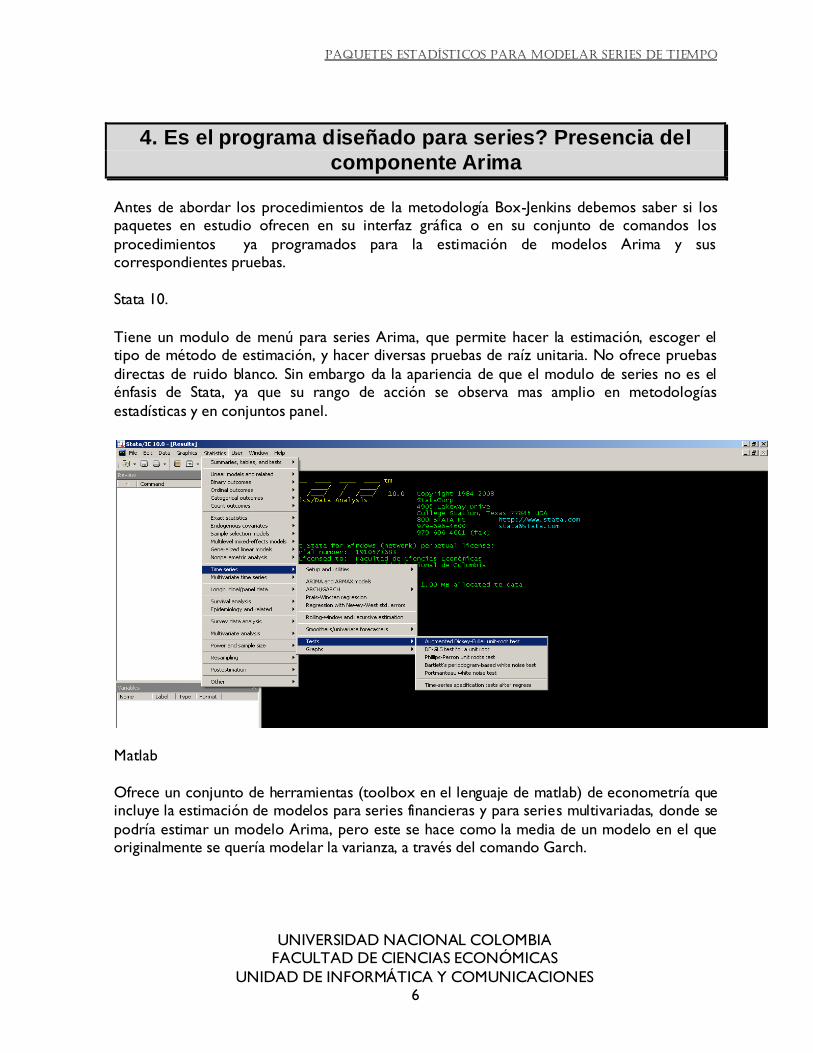
Stata 10.
Tiene un modulo de menú para series Arima, que permite hacer la estimación, escoger el tipo de método de estimación, y hacer diversas pruebas de raíz unitaria. No ofrece pruebas
directas de ruido blanco. Sin embargo da la apariencia de que el modulo de series no es el énfasis de Stata, ya que su rango de acción se observa mas amplio en metodologías
estadísticas y en conjuntos panel.
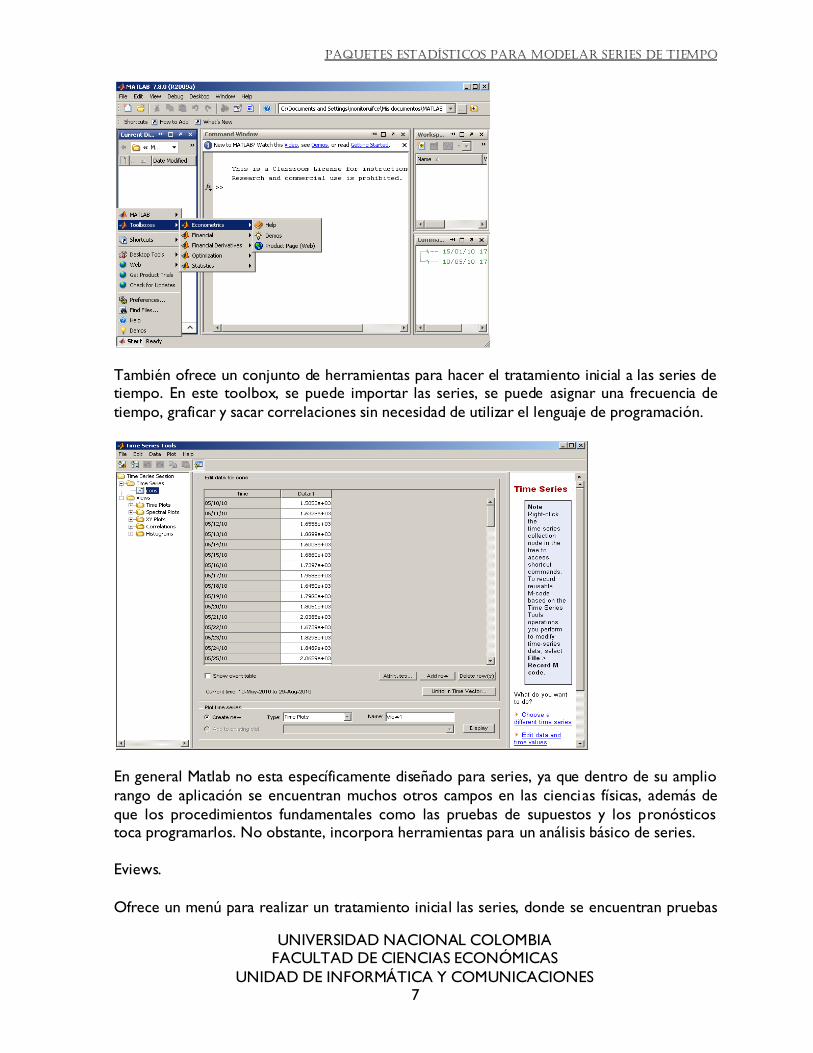
Matlab
Ofrece un conjunto de herramientas (toolbox en el lenguaje de matlab) de econometría que incluye la estimación de modelos para series financieras y para series multivariadas, donde se
podría estimar un modelo Arima, pero este se hace como la media de un modelo en el que originalmente se quería modelar la varianza, a través del comando Garch.
PAQUETES Estadísticos PARA MODELAR SERIES DE TIEMPO
UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS
UNIDAD DE INFORMÁTICA Y COMUNICACIONES 7
También ofrece un conjunto de herramientas para hacer el tratamiento inicial a las series de tiempo. En este toolbox, se puede importar las series, se puede asignar una frecuencia de
tiempo, graficar y sacar correlaciones sin necesidad de utilizar el lenguaje de programación.
En general Matlab no esta específicamente diseñado para series, ya que dentro de su amplio
rango de aplicación se encuentran muchos otros campos en las ciencias físicas, además de
que los procedimientos fundamentales como las pruebas de supuestos y los pronósticos toca programarlos. No obstante, incorpora herramientas para un análisis básico de series.
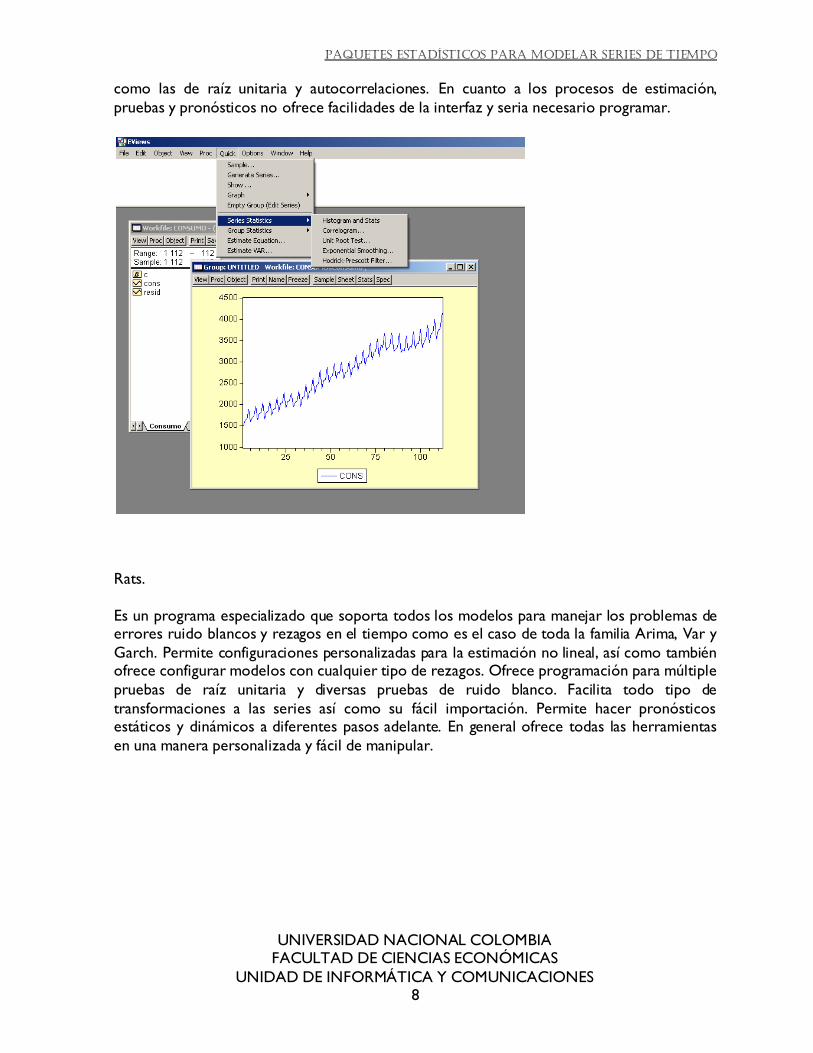
Eviews.
Ofrece un menú para realizar un tratamiento inicial las series, donde se encuentran pruebas
PAQUETES Estadísticos PARA MODELAR SERIES DE TIEMPO
UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS
UNIDAD DE INFORMÁTICA Y COMUNICACIONES 8
como las de raíz unitaria y autocorrelaciones. En cuanto a los procesos de estimación,
pruebas y pronósticos no ofrece facilidades de la interfaz y seria necesario programar.
Rats.
Es un programa especializado que soporta todos los modelos para manejar los problemas de errores ruido blancos y rezagos en el tiempo como es el caso de toda la familia Arima, Var y
Garch. Permite configuraciones personalizadas para la estimación no lineal, así como también ofrece configurar modelos con cualquier tipo de rezagos. Ofrece programación para múltiple
pruebas de raíz unitaria y diversas pruebas de ruido blanco. Facilita todo tipo de
transformaciones a las series así como su fácil importación. Permite hacer pronósticos estáticos y dinámicos a diferentes pasos adelante. En general ofrece todas las herramientas
en una manera personalizada y fácil de manipular.

PAQUETES Estadísticos PARA MODELAR SERIES DE TIEMPO
UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS
UNIDAD DE INFORMÁTICA Y COMUNICACIONES 9
R.
Para el programa de licencia libre R, siempre se desarrollan de manera continua paquetes que contienen funciones para los modelos econométricos recientes. Los modelos Arima no
son la excepción, dentro de la comunidad de R se han desarrollado paquetes como farma, tseries,fseries, que permiten la manipulación dentro del kernel de series de tiempo. Sin
embargo estas librerías requieren a su vez una lista larga de otras librerías lo que hace el
inicio del trabajo un esfuerzo innecesario por parte del investigador para cargar la información necesaria. Por otro lado los paquetes desarrollados aunque ofrecen
herramientas avanzadas para la estimación no proveen muchas funciones de predicción.
Jmulti.
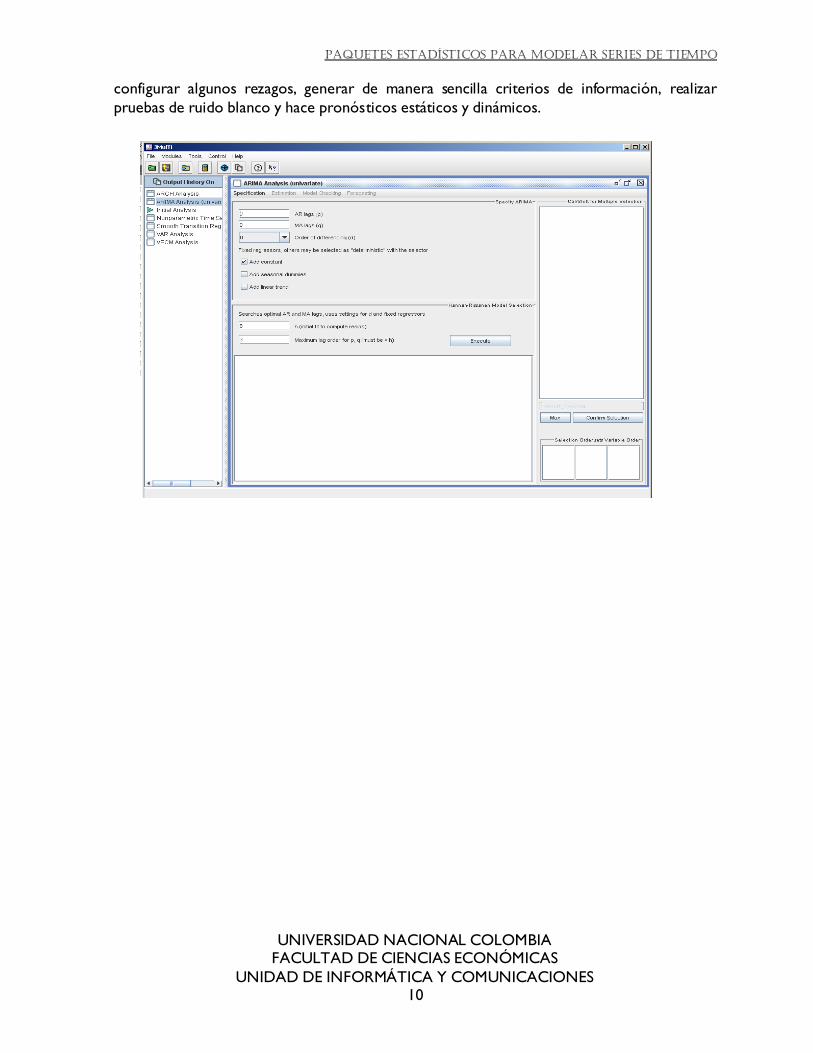
Es un programa especializado en modelación de series pero su mayor fuerte son los
modelos de sistemas de ecuaciones Var. Para los modelos Arima ofrece un módulo que contiene pestañas para representar paso a paso las etapas de la modelación. Permite
PAQUETES Estadísticos PARA MODELAR SERIES DE TIEMPO
UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS
UNIDAD DE INFORMÁTICA Y COMUNICACIONES 10
configurar algunos rezagos, generar de manera sencilla criterios de información, realizar
pruebas de ruido blanco y hace pronósticos estáticos y dinámicos.
PAQUETES Estadísticos PARA MODELAR SERIES DE TIEMPO
UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS
UNIDAD DE INFORMÁTICA Y COMUNICACIONES 11
5. Metodología Box Jenkins: comparación de
procedimientos.
Descripción de la serie a modelar.
Para la comparación de las etapas de la metodología Box Jenkins, utilizamos la serie del consumo trimestral ajustada en estaciones, para Alemania de 1960-1 a 1982-42.
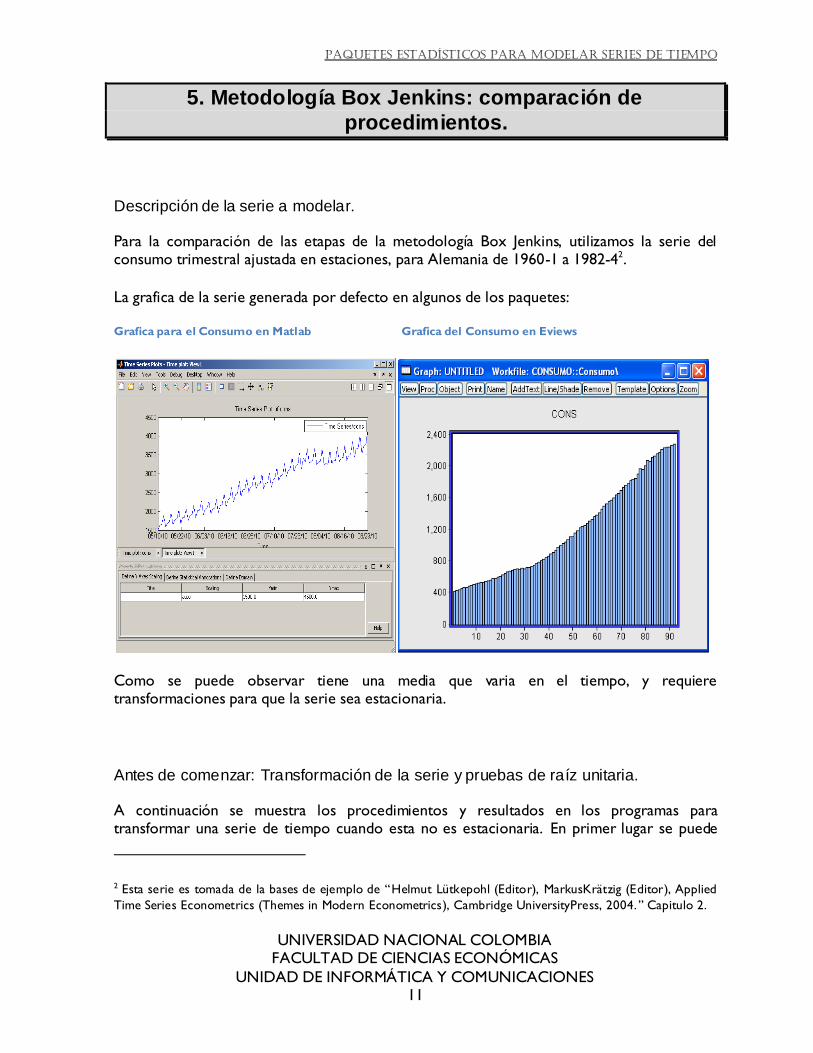
La grafica de la serie generada por defecto en algunos de los paquetes:
Grafica para el Consumo en Matlab Grafica del Consumo en Eviews
Como se puede observar tiene una media que varia en el tiempo, y requiere transformaciones para que la serie sea estacionaria.
Antes de comenzar: Transformación de la serie y pruebas de raíz unitaria.
A continuación se muestra los procedimientos y resultados en los programas para transformar una serie de tiempo cuando esta no es estacionaria. En primer lugar se puede
2 Esta serie es tomada de la bases de ejemplo de “Helmut Lütkepohl (Editor), MarkusKrätzig (Editor), Applied
Time Series Econometrics (Themes in Modern Econometrics), Cambridge UniversityPress, 2004.” Capitulo 2.
PAQUETES Estadísticos PARA MODELAR SERIES DE TIEMPO
UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS
UNIDAD DE INFORMÁTICA Y COMUNICACIONES 12
aplicar pruebas de raíz unitaria como una herramienta estadística que permitiría verificar si
una serie es estacionaria.
La prueba DickeyFuller contrasta la hipótesis de que el coeficiente Ƴ de la siguiente regresión sea igual a cero. Si ese coeficiente es cero quiere decir que el proceso tiene raíz
unitaria, es decir que el rezago de la serie no provee información suficiente para explicar la
diferencia de la variable, en este caso la variable depende de su valor anterior más un error aleatorio. En caso contrario, la serie tendría rezagos que permiten explicar el valor actual. Si
la prueba es aumentada, tenemos una constante y un término de tendencia.
Para las series, se testea la hipótesis nula con el estadístico t, de que el proceso tenga raíz
unitaria. También se testea la existencia de tendencia.
En primer lugar se hace una transformación logarítmica de manera que se estabiliza la varianza. Posteriormente se realiza la prueba de raíz unitaria. En todos los programas esta
transformación es fácil de realizar, aplicando la función logarítmica sobre la serie u objeto.
A continuación se muestra una comparación de las pruebas disponibles mas comunes
(comandos o procedimientos listos para usar) para identificar la raíz unitaria, en los paquetes Rats, Eviews y Matlab. Es posible en los programas conducidos por comandos crear las
pruebas que no existan. Todas la pruebas buscan testear una ecuación, pero varían en la forma como especifican el error de dicha ecuación.
Presencia de un comando de raíz unitaria para cada prueba.
Paquete
Estadistico/matemático
Dickey -
Fuller
Dickey-
Fuller
aumentada
Kwaitowsky Phillips-
Pherron
Schmidt
& Phillips
Rats x x x x
Eviews x x x x
Matlab x x x
Stata x x x
R x x x x
JMulti x x x x
La prueba más usada es la prueba DickeyFuller. En todos los programas se correrán con cero rezagos de la diferencia. El propósito de esta prueba es solo comparativo, es decir para
observar los procedimientos
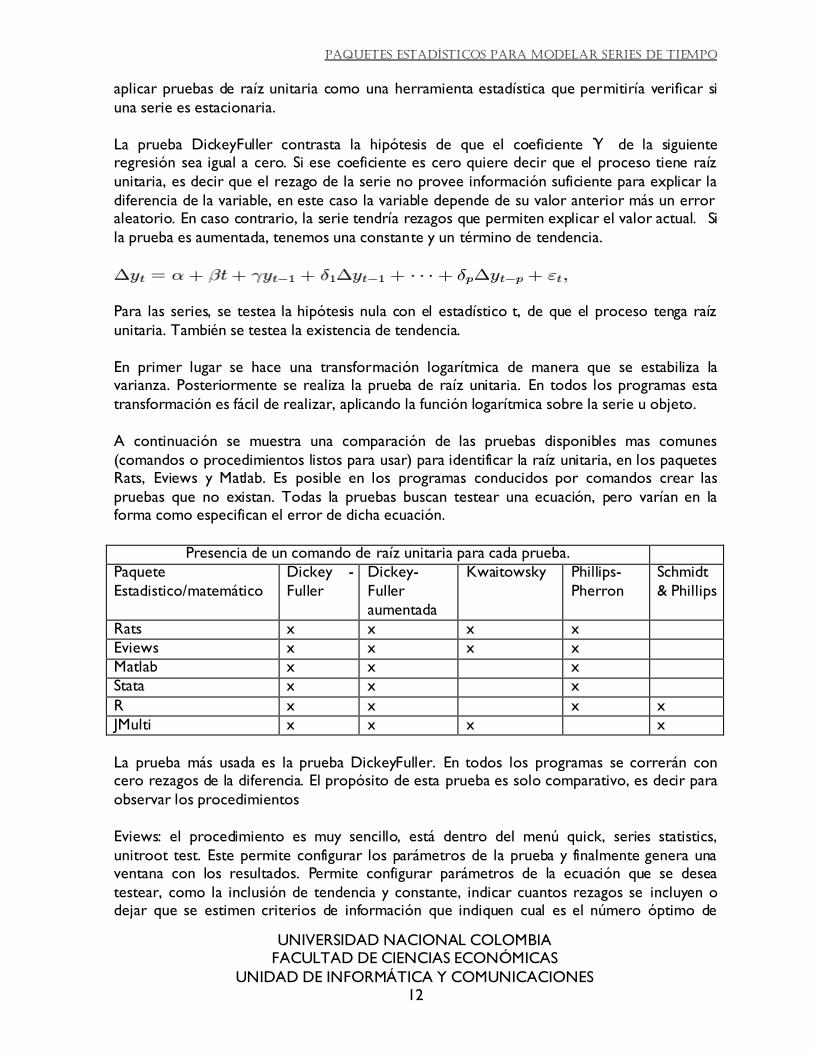
Eviews: el procedimiento es muy sencillo, está dentro del menú quick, series statistics,
unitroot test. Este permite configurar los parámetros de la prueba y finalmente genera una ventana con los resultados. Permite configurar parámetros de la ecuación que se desea
testear, como la inclusión de tendencia y constante, indicar cuantos rezagos se incluyen o dejar que se estimen criterios de información que indiquen cual es el número óptimo de
PAQUETES Estadísticos PARA MODELAR SERIES DE TIEMPO
UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS
UNIDAD DE INFORMÁTICA Y COMUNICACIONES 13
rezagos a incluir.
Dentro de los resultados se muestran los valores críticos de la función de distribución
calculada en diferentes niveles de significancia. Pero además muestra los resultados de la regresión, y las pruebas de inferencia para los parámetros de la ecuación.
Resultados.

PAQUETES Estadísticos PARA MODELAR SERIES DE TIEMPO
UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS
UNIDAD DE INFORMÁTICA Y COMUNICACIONES 14
Null Hypothesis: LCONS has a unit root
Exogenous: None
LagLength: 0 (Fixed) t-Statistic Prob.* Augmented Dickey-Fuller test statistic 15.60972 1.0000
Test criticalvalues: 1% level -2.590622
5% level -1.944404
10% level -1.614417 *MacKinnon (1996) one-sided p-values.
Augmented Dickey-Fuller Test Equation
Dependent Variable: D(LCONS)
Method: LeastSquares
Date: 05/28/10 Time: 13:22
Sample (adjusted): 2 92
Includedobservations: 91 afteradjustments Variable Coefficient Std. Error t-Statistic Prob. LCONS(-1) 0.002663 0.000171 15.60972 0.0000 R-squared -0.061761 Meandependentvar 0.018678
Adjusted R-squared -0.061761 S.D. dependentvar 0.010960
S.E. of regression 0.011294 Akaikeinfocriterion -6.118200
Sum squaredresid 0.011479 Schwarzcriterion -6.090608
Log likelihood 279.3781 Hannan-Quinncriter. -6.107068
Durbin-Watson stat 1.957701
Matlab: Tiene un comando llamado dfARDTest que realiza la prueba de DickeyFuller.
Asume por hipótesis nula que el proceso tiene raíz unitaria sin tendencia. Se debe crear una
matriz que contenga los resultados de la prueba. Esta es la escritura para efectuar la prueba
[H,pValue,TestStat,CriticalValue] = dfARTest(Y,Lags,Alpha,TestType)
Se le tiene que indicar al comando los rezagos, el nivel de significancia, el tipo de Test (si es para Arima, y que estadístico se utiliza, t o f). La prueba genera una decisión lógica llamada
H, que es igual a 1 si se rechaza la hipótesis a un nivel de significancia dado. Genera también los t estadísticos, p-valor y los valores críticos asociados a la decisión H.
Los resultados son muestran solo los elementos que se señalan en los comandos. De todos
los programas es el que menos resultados muestra, con solo un valor crítico y solo un
estadístico.
H = 0

PAQUETES Estadísticos PARA MODELAR SERIES DE TIEMPO
UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS
UNIDAD DE INFORMÁTICA Y COMUNICACIONES 15
pValue =
0.9990 TestStat =
15.6097 CriticalValue =
-1.9445
Rats: estima tiene una variada oferta de pruebas de raíz unitaria, y que ofrece como programas externos dentro de su página de internet. Se llama a un archivo externo llamado dfunit, que ejecuta una prueba Dickey-Fuller.Ofrece realizar el procedimiento de la prueba
tanto desde un menú, como el que se ve en la siguiente gráfica, como desde un programa externo que se descarga de la página Estima, que permite configurar los rezagos, el tipo de
hipótesis que se genera, los rezagos que se incluyen, las distribuciones del estadístico de
prueba, y la inclusión de términos constantes.
source(noecho) dfunit.src
@dfunit(lags=0) dlx;
Los resultados son:
Dickey-Fuller Unit Root Test, Series DLX
Regression Run From 1960:03 to 1982:04
Observations 91 With intercept
Using 0 lags on the differences
Sig Level Crit Value 1%(**) -3.50296
5%(*) -2.89320 10% -2.58344
T-Statistic -8.29546**
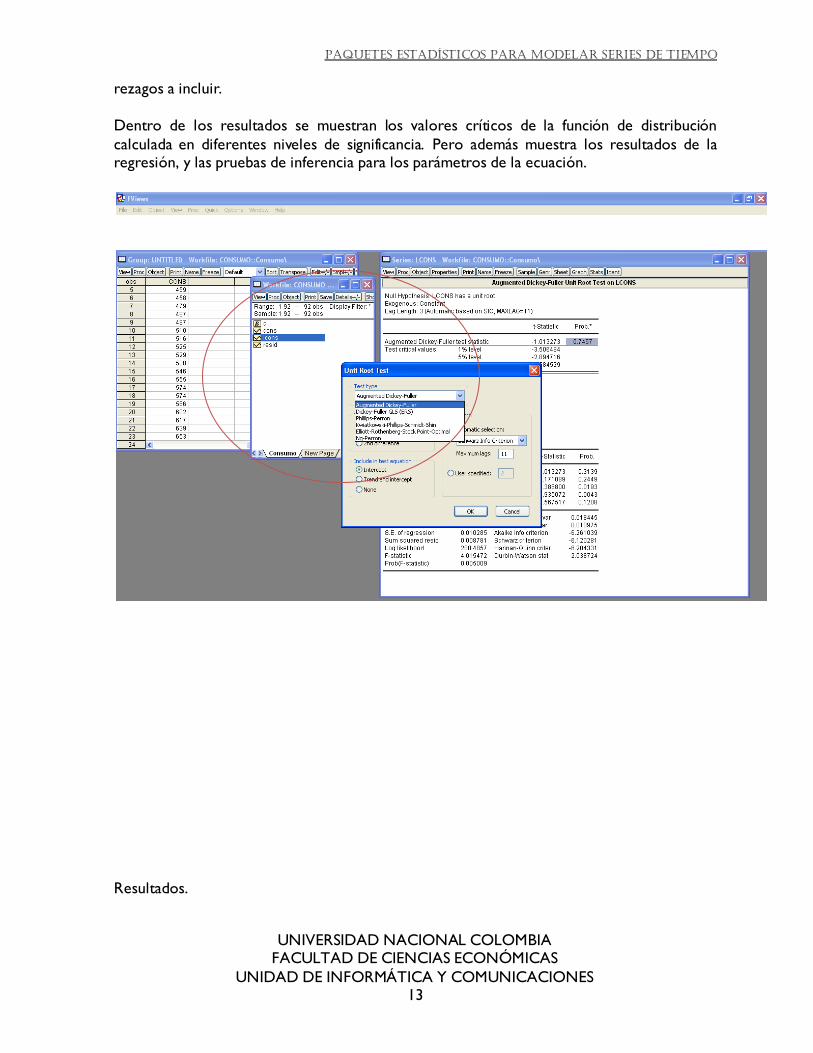
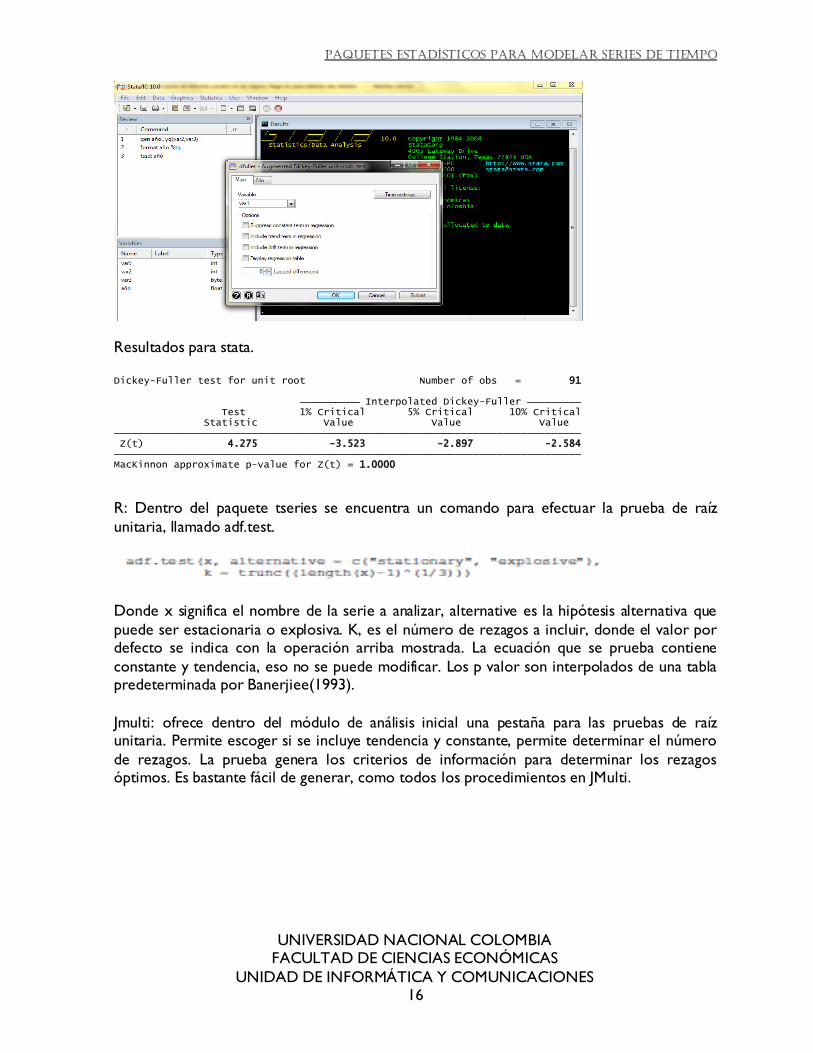
Stata: se puede ejecutar a través del menú, que genera la programación en la ventana de resultados. El comando utilizado es dfuller. Permite ajustar si tiene constante o tendencia, y
cuantos rezagos se incluyen. En los resultados se observan, si se desea los resultados de la regresión. Se encuentran los valores de la distribución generada para distintos niveles de
significancia.
PAQUETES Estadísticos PARA MODELAR SERIES DE TIEMPO
UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS
UNIDAD DE INFORMÁTICA Y COMUNICACIONES 16
Resultados para stata.
R: Dentro del paquete tseries se encuentra un comando para efectuar la prueba de raíz
unitaria, llamado adf.test.
Donde x significa el nombre de la serie a analizar, alternative es la hipótesis alternativa que
puede ser estacionaria o explosiva. K, es el número de rezagos a incluir, donde el valor por defecto se indica con la operación arriba mostrada. La ecuación que se prueba contiene
constante y tendencia, eso no se puede modificar. Los p valor son interpolados de una tabla predeterminada por Banerjiee(1993).
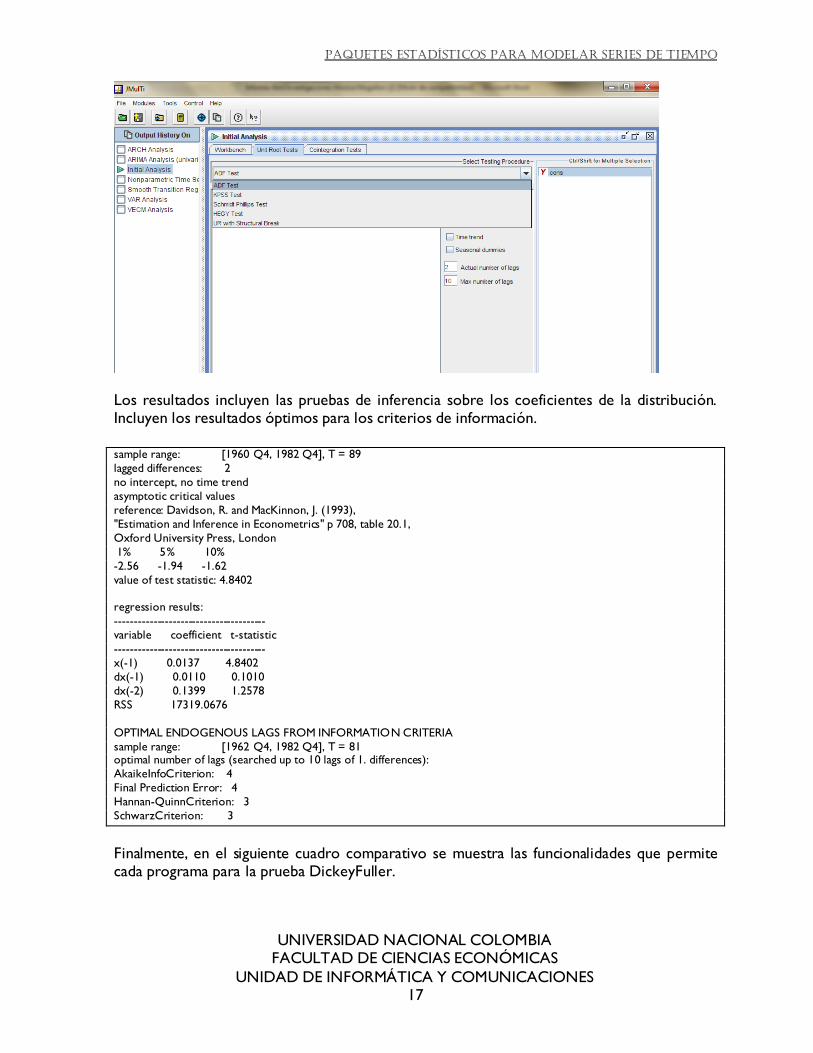
Jmulti: ofrece dentro del módulo de análisis inicial una pestaña para las pruebas de raíz unitaria. Permite escoger si se incluye tendencia y constante, permite determinar el número
de rezagos. La prueba genera los criterios de información para determinar los rezagos óptimos. Es bastante fácil de generar, como todos los procedimientos en JMulti.
MacKinnon approximate p-value for Z(t) = 1.0000 Z(t) 4.275 -3.523 -2.897 -2.584 Statistic Value Value Value Test 1% Critical 5% Critical 10% Critical Interpolated Dickey-Fuller
Dickey-Fuller test for unit root Number of obs = 91
PAQUETES Estadísticos PARA MODELAR SERIES DE TIEMPO
UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS
UNIDAD DE INFORMÁTICA Y COMUNICACIONES 17
Los resultados incluyen las pruebas de inferencia sobre los coeficientes de la distribución. Incluyen los resultados óptimos para los criterios de información.
sample range: [1960 Q4, 1982 Q4], T = 89
lagged differences: 2
no intercept, no time trend
asymptotic critical values
reference: Davidson, R. and MacKinnon, J. (1993),
"Estimation and Inference in Econometrics" p 708, table 20.1,
Oxford University Press, London
1% 5% 10%
-2.56 -1.94 -1.62
value of test statistic: 4.8402
regression results:
---------------------------------------
variable coefficient t-statistic
---------------------------------------
x(-1) 0.0137 4.8402
dx(-1) 0.0110 0.1010
dx(-2) 0.1399 1.2578
RSS 17319.0676
OPTIMAL ENDOGENOUS LAGS FROM INFORMATION CRITERIA
sample range: [1962 Q4, 1982 Q4], T = 81 optimal number of lags (searched up to 10 lags of 1. differences):
AkaikeInfoCriterion: 4
Final Prediction Error: 4
Hannan-QuinnCriterion: 3
SchwarzCriterion: 3
Finalmente, en el siguiente cuadro comparativo se muestra las funcionalidades que permite cada programa para la prueba DickeyFuller.

PAQUETES Estadísticos PARA MODELAR SERIES DE TIEMPO
UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS
UNIDAD DE INFORMÁTICA Y COMUNICACIONES 18
Configuración de la Prueba DickeyFuller
Paquete
Estadístico/matemático
Rats Eviews Matlab Stata R JMulti
Especificar número de
rezagos
x x x x x x
Calcular número óptimo de rezagos
x x
Especificar presencia de constante y tendencia
x x x x
Especificar hipótesis nula x
Mostrar resultados de la regresión
x x x
Mostrar varios valores críticos a diferentes niveles
de significancia
x x x x x
Dado que en todos los resultados se obtuvo raiz unitaria, procedemos a tomar la primera diferencia de la serie. Esta transformación se obtiene con facilidad en stata, rats, jmulti,
eviews, a través de operaciones sobre la serie. Con una mayor dificultad en matlab y R. a continuación se observa cómo se genera una variable diferenciada en eviews.
La programación para matlab sería:
>>dlcons=diff(lcons)
Etapa 1: identificación.
Después de tomar la serie transformada para cumplir las condiciones de estacionariedad

PAQUETES Estadísticos PARA MODELAR SERIES DE TIEMPO
UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS
UNIDAD DE INFORMÁTICA Y COMUNICACIONES 19
necesarias para este tipo de modelos Arima, procedemos a identificar un modelo. Existen
dos procedimientos para este fin: uno más intuitivo a través de las gráficas de autocorrelación y a través de la optimización de criterios de información.
Función de autocorrelación
La función de autocorrelación permite observar el comportamiento de la relación entre las observaciones para diferentes periodos del tiempo. Si estas correlaciones son
permanentemente mayores que cero, se puede decir que son procesos Permite detectar si una serie es estacionaria o no. Si las autocorrelaciones decaen rápidamente a cero, la serie
es estacionaria.
Además las gráficas de autocorrelación son una herramienta para identificar de manera
intuitiva los órdenes de un modelo Arima. La gráfica de autocorrelación simple permite identificar el número de rezagos de medias móviles. La grafica de autocorrelación parcial
permite identificar el número de rezagos autorregresivos.
Los procedimientos en cada programa varían, pero en general se muestran los mismos resultados, solo que cambia su presentación visual.
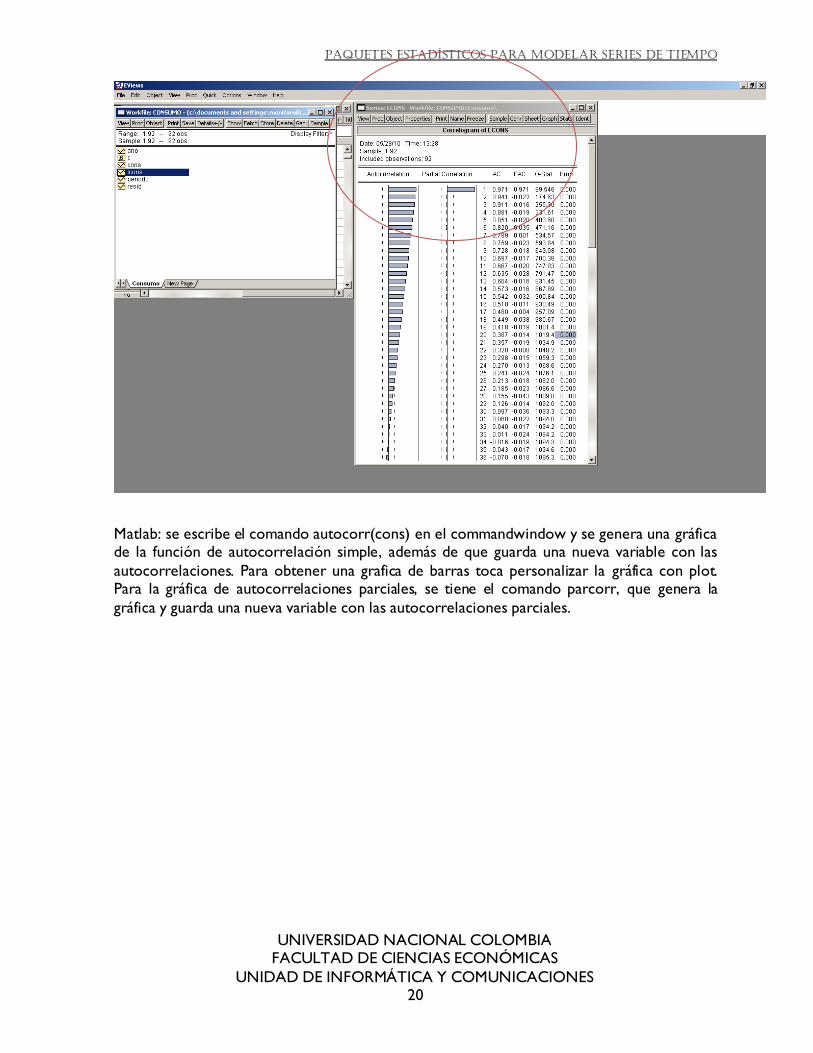
Eviews: una vez se tiene la serie en un Workfile, se ingresa al menú Quick, Series Satistics, Correlogram. Es un procedimiento sencillo y los resultados son bastante completos, además
la grafica esta editada y lista para presentar. Genera tanto la gráfica de autocorrelación parcial como la simple. Además muestra una tabla con los números exactos de las
correlaciones.
PAQUETES Estadísticos PARA MODELAR SERIES DE TIEMPO
UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS
UNIDAD DE INFORMÁTICA Y COMUNICACIONES 20
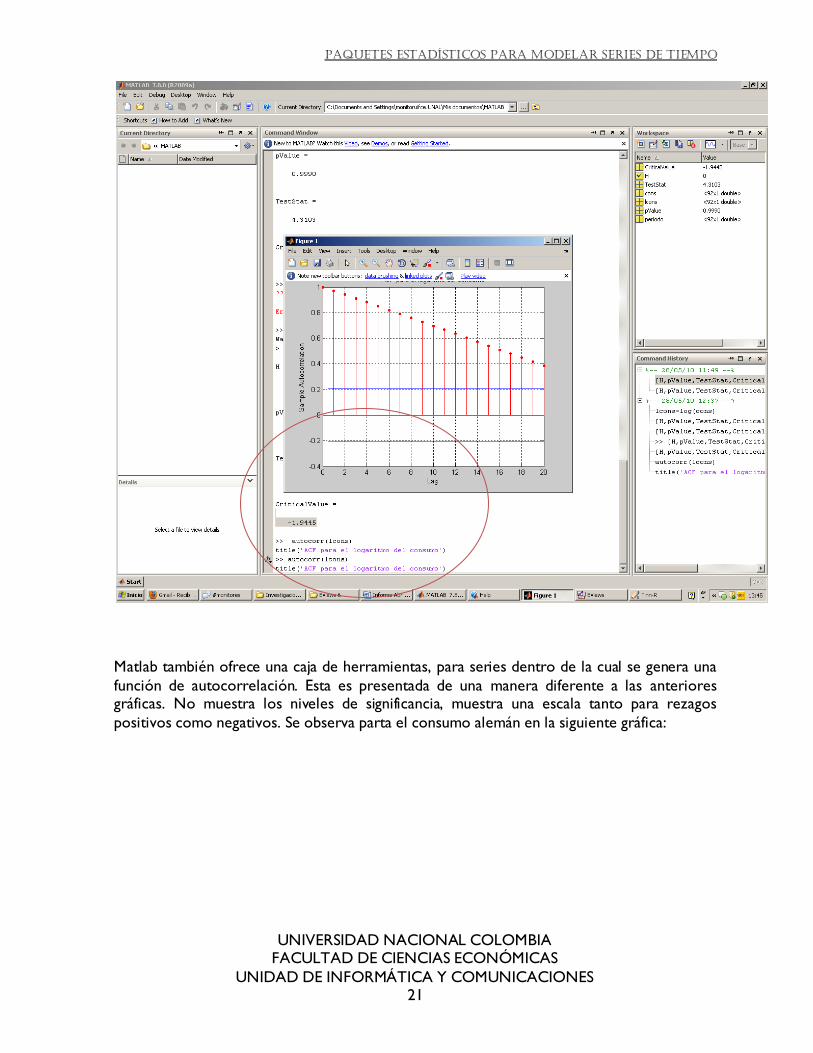
Matlab: se escribe el comando autocorr(cons) en el commandwindow y se genera una gráfica de la función de autocorrelación simple, además de que guarda una nueva variable con las
autocorrelaciones. Para obtener una grafica de barras toca personalizar la gráfica con plot. Para la gráfica de autocorrelaciones parciales, se tiene el comando parcorr, que genera la
gráfica y guarda una nueva variable con las autocorrelaciones parciales.
PAQUETES Estadísticos PARA MODELAR SERIES DE TIEMPO
UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS
UNIDAD DE INFORMÁTICA Y COMUNICACIONES 21
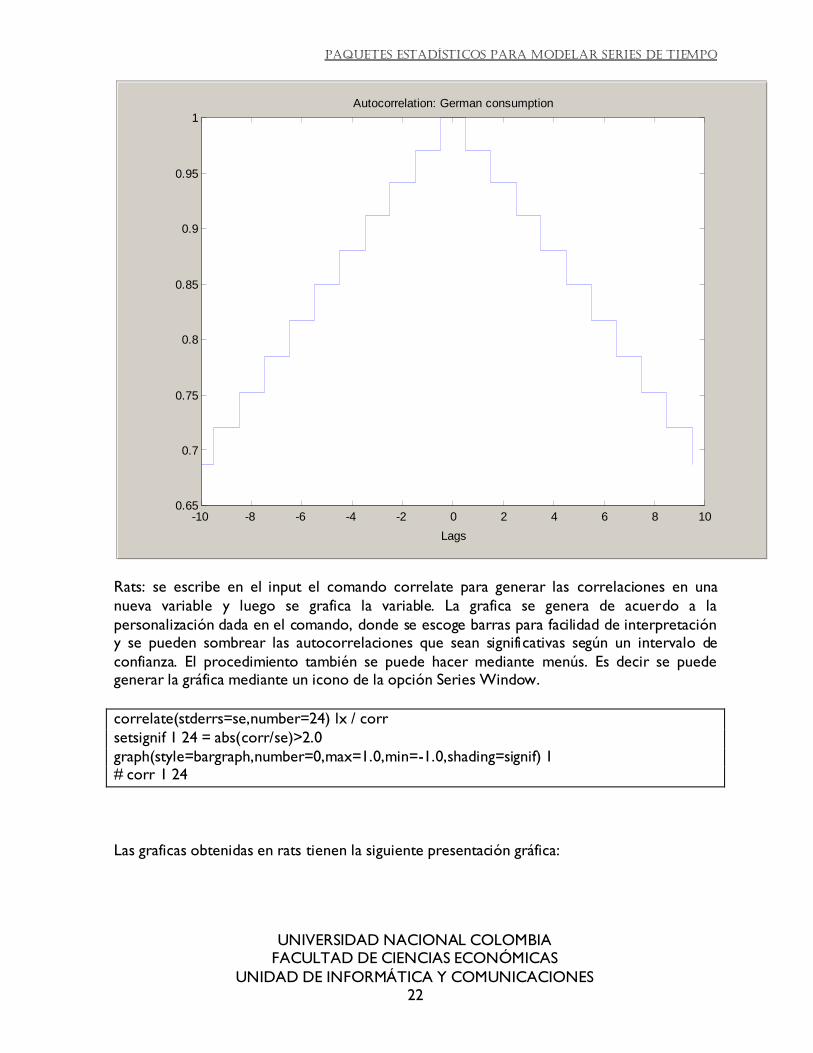
Matlab también ofrece una caja de herramientas, para series dentro de la cual se genera una
función de autocorrelación. Esta es presentada de una manera diferente a las anteriores gráficas. No muestra los niveles de significancia, muestra una escala tanto para rezagos
positivos como negativos. Se observa parta el consumo alemán en la siguiente gráfica:
PAQUETES Estadísticos PARA MODELAR SERIES DE TIEMPO
UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS
UNIDAD DE INFORMÁTICA Y COMUNICACIONES 22
Rats: se escribe en el input el comando correlate para generar las correlaciones en una
nueva variable y luego se grafica la variable. La grafica se genera de acuerdo a la
personalización dada en el comando, donde se escoge barras para facilidad de interpretación y se pueden sombrear las autocorrelaciones que sean significativas según un intervalo de
confianza. El procedimiento también se puede hacer mediante menús. Es decir se puede generar la gráfica mediante un icono de la opción Series Window.
correlate(stderrs=se,number=24) lx / corr
setsignif 1 24 = abs(corr/se)>2.0
graph(style=bargraph,number=0,max=1.0,min=-1.0,shading=signif) 1 # corr 1 24
Las graficas obtenidas en rats tienen la siguiente presentación gráfica:
-10 -8 -6 -4 -2 0 2 4 6 8 100.65
0.7
0.75
0.8
0.85
0.9
0.95
1
Autocorrelation: German consumption
Lags
PAQUETES Estadísticos PARA MODELAR SERIES DE TIEMPO
UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS
UNIDAD DE INFORMÁTICA Y COMUNICACIONES 23
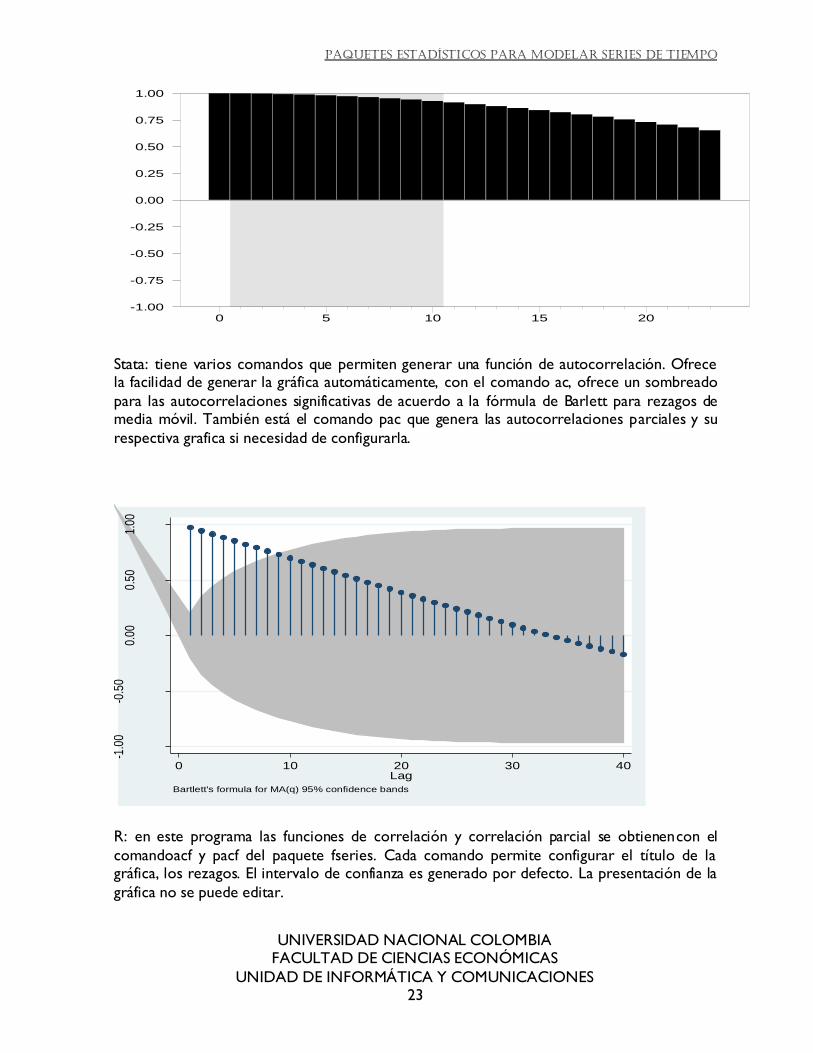
Stata: tiene varios comandos que permiten generar una función de autocorrelación. Ofrece la facilidad de generar la gráfica automáticamente, con el comando ac, ofrece un sombreado
para las autocorrelaciones significativas de acuerdo a la fórmula de Barlett para rezagos de media móvil. También está el comando pac que genera las autocorrelaciones parciales y su
respectiva grafica si necesidad de configurarla.
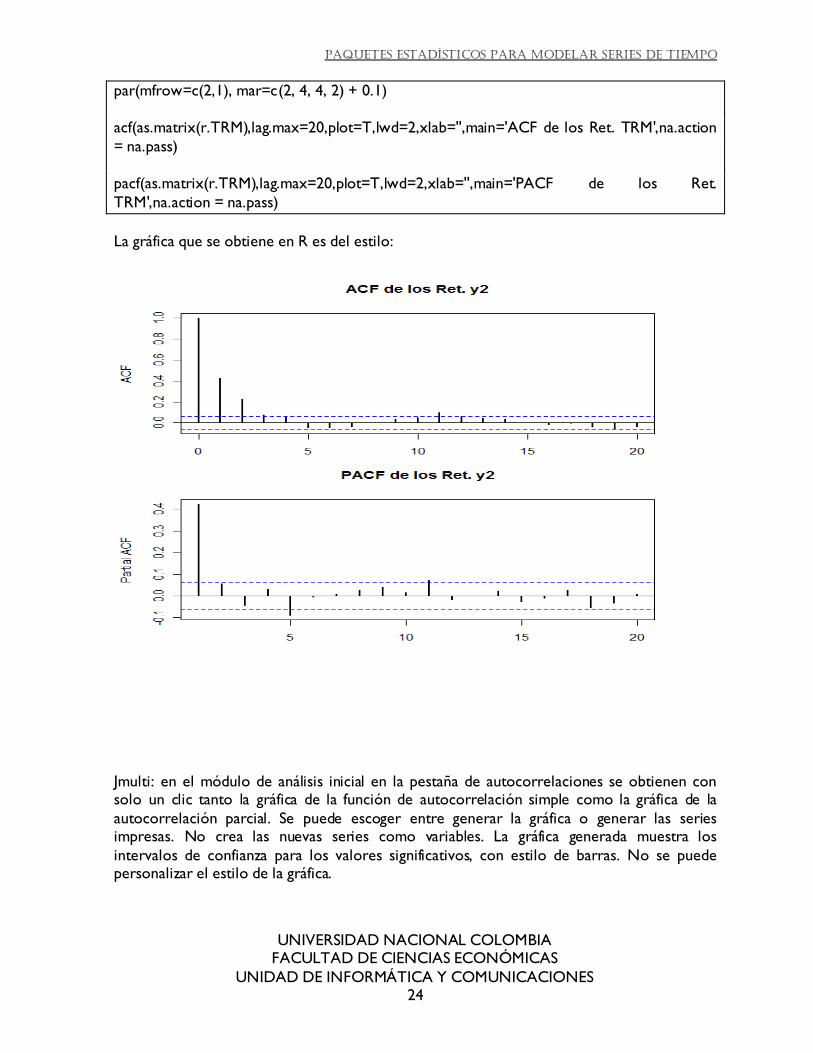
R: en este programa las funciones de correlación y correlación parcial se obtienencon el
comandoacf y pacf del paquete fseries. Cada comando permite configurar el título de la gráfica, los rezagos. El intervalo de confianza es generado por defecto. La presentación de la
gráfica no se puede editar.
0 5 10 15 20-1.00
-0.75
-0.50
-0.25
0.00
0.25
0.50
0.75
1.00
-1.0
0-0
.50
0.00
0.50
1.00
Aut
ocor
rela
tions
of l
ogco
ns
0 10 20 30 40Lag
Bartlett's formula for MA(q) 95% confidence bands
PAQUETES Estadísticos PARA MODELAR SERIES DE TIEMPO
UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS
UNIDAD DE INFORMÁTICA Y COMUNICACIONES 24
par(mfrow=c(2,1), mar=c(2, 4, 4, 2) + 0.1)
acf(as.matrix(r.TRM),lag.max=20,plot=T,lwd=2,xlab='',main='ACF de los Ret. TRM',na.action
= na.pass)
pacf(as.matrix(r.TRM),lag.max=20,plot=T,lwd=2,xlab='',main='PACF de los Ret.
TRM',na.action = na.pass)
La gráfica que se obtiene en R es del estilo:
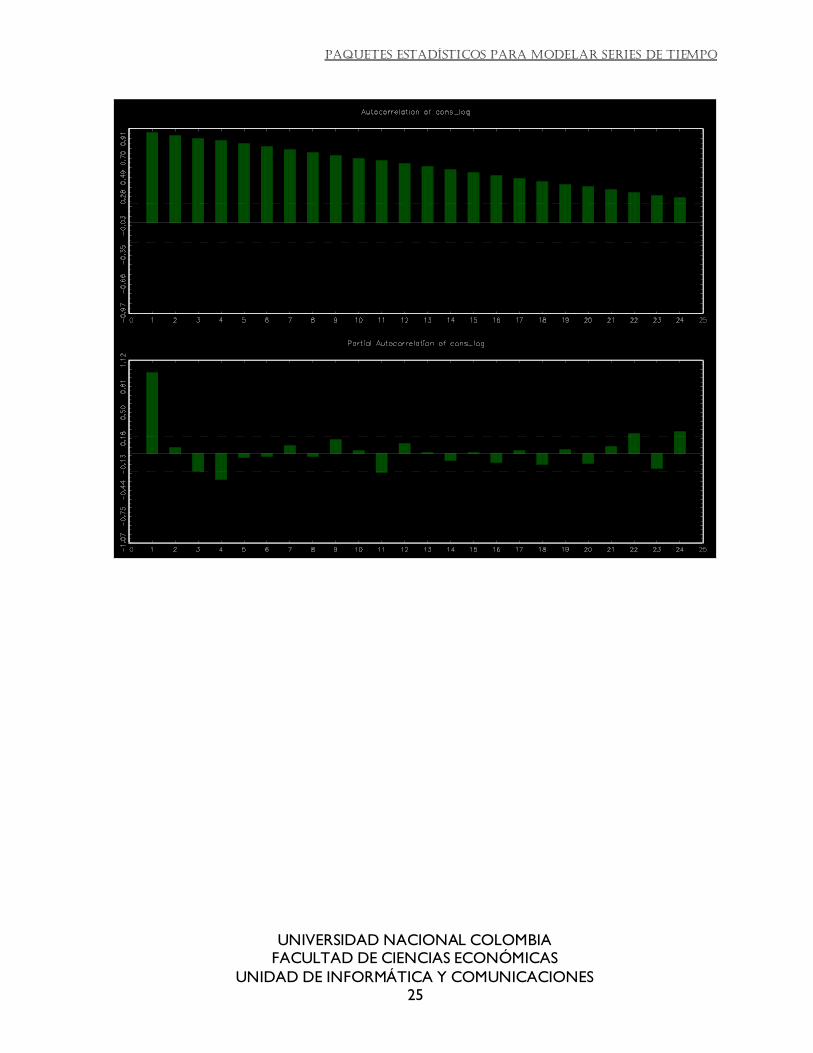
Jmulti: en el módulo de análisis inicial en la pestaña de autocorrelaciones se obtienen con solo un clic tanto la gráfica de la función de autocorrelación simple como la gráfica de la
autocorrelación parcial. Se puede escoger entre generar la gráfica o generar las series impresas. No crea las nuevas series como variables. La gráfica generada muestra los
intervalos de confianza para los valores significativos, con estilo de barras. No se puede personalizar el estilo de la gráfica.
PAQUETES Estadísticos PARA MODELAR SERIES DE TIEMPO
UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS
UNIDAD DE INFORMÁTICA Y COMUNICACIONES 25

PAQUETES Estadísticos PARA MODELAR SERIES DE TIEMPO
UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS
UNIDAD DE INFORMÁTICA Y COMUNICACIONES 26
Criterios de información.
Los criterios de información permiten generar un criterio estadístico para escoger el número óptimo de rezagos y puede ser menos subjetivo que la interpretación de las
funciones de autocorrelación parcial. Los criterios son una función de la varianza del error y del número de parámetros incluidos dentro del modelo ARMA, promediados por algún
número que depende del tamaño de la muestra. Entre menos parámetros se tendrán más
grados de libertad y la varianza será menor. Lutkepohl(2004) La idea es escoger el número de parámetros que arroje el menor criterio, es decir tiene los parámetros óptimos para una
varianza del error menor.
Por el criterio AIC, aplicado a 12 rezagos en media móvil y en autorregresivos.
, , donde k es el número de parámetros.
A continuacion se muestra una tabla comparativa que muestra la disponibilidad del cálculo de los criterios de información en cada programa como un comando específico. También se
menciona el comando necesario y que tipo de resultado genera.
Programa/criterio Ackaicke Schwartz Perzonalizar criterios
Comando necesario
Rats x x x @bjautofit
Eviews
Matlab
Stata
R
JMulti x x
Los resultados obtenidos en Jmulti para la variable logaritmo del consumo, se obtienen en el modulo de Arima, en la primera pestaña, a través del metodo Hannan Kinnon.
original variable: cons_log
order of differencing (d): 0 adjusted sample range: [1962 Q4, 1982 Q4], T = 81
optimal lags p, q (searched all combinations where max(p,q) <= 3) Akaike Info Criterion: p=3, q=0 Hannan-Quinn Criterion: p=3, q=0
Schwarz Criterion: p=3, q=0
Etapa 2: Estimación.
Los modelos Arima son ecuaciones no lineales que requiere un proceso de optimizaciones
iteradas para poder hallar un estimador. El estimador que se muestra es aquel que converge de una iteración a otra. Existen varias funciones que se pueden optimizar y varios algoritmos
que se pueden seguir para lograrlo.Se considera convergencia cuando el cambio de una iteración a otra es pequeño. Se calcula un cambio relativo entre los estimadores de cada

PAQUETES Estadísticos PARA MODELAR SERIES DE TIEMPO
UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS
UNIDAD DE INFORMÁTICA Y COMUNICACIONES 27
estimación
Matlab: a través del comando garchspec, se especifican los órdenes de la media, que
corresponde al modelo arima. Luego se utiliza el comando ajustarchfitpara ajustar un modelo, incluyendo la opción de estimar media, ya que el comando es para estimar la
varianza de los retornos.
Los resultados que se obtienen son los coeficientes estimados y el criterio de convergencia
C.
Coeff =
Comment: 'Mean: ARMAX(3,0,0); Variance: GARCH(0,0) '
Distribution: 'Gaussian' R: 3
C: 0.0097 AR: [-0.0950 0.2519 0.3119]
VarianceModel: 'GARCH'
K: 1.0204e-004
Rats: tiene un comando de gran potencial por su nivel de precisión llamado Boxjenk. Estima
coeficientes de acuerdo al método y algoritmo designado. Tiene entre sus opciones de configuración:
Constant: establece si se incluye constante
Ar: número de órdenes autorregresivos.
Ma: número de órdenes de media móvil
Diff: número de diferencias sobre la variable.
Sdiff= número de diferencias estacionales sobre la variable.
Sar, Sma: órdenesestacionales
Method=gauss,bfgs,simplex,genetic,initial. El método es el algoritmo que se usa para
optimizar la función. Los primeros dos hacen derivadas de la función y tienes diferentes transformaciones para acercarse al parámetro. Los dos últimos no hacen
derivadas sino que hacen evaluaciones en la función.
Función a optimizar: por defecto es mínimos cuadrados. Pero se puede escoger
máxima verosimilitud con la opción maxl.
El comando boxjenks también permite guardar los residuales, guarda los estimadores,
guarda la información sobre los estimadores.
Para nuestro caso los resultados mostrados, dado que no se modifica la configuración
predeterminada, es decir el método de estimación es Gauss, y la función es mínimos cuadrados. El valor de convergencia es 0.000010, es un alto nivel de precisión. Hace

PAQUETES Estadísticos PARA MODELAR SERIES DE TIEMPO
UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS
UNIDAD DE INFORMÁTICA Y COMUNICACIONES 28
inferencia sobre los estimadores.
Box-Jenkins - Estimation by LS Gauss-Newton
Convergence in 2 Iterations. Final criterion was 0.0000000<= 0.0000100
Dependent Variable LCONS
Quarterly Data From 1960:04 To 1982:04
Usable Observations 89 Degrees of Freedom 86
Centered R**2 0.999547 R Bar **2 0.999537
Uncentered R**2 0.999998 T x R**2 89.000
Mean of Dependent Variable 6.9577491350
Std Error of Dependent Variable 0.5118883190
Standard Error of Estimate 0.0110169426
Sum of Squared Residuals 0.0104380801
Log Likelihood 276.48090
Durbin-Watson Statistic 2.189968
Q(22-3) 40.027842
Significance Level of Q 0.00324489
Variable CoeffStd Error T-Stat Signif
*******************************************************************************
1. AR{1} 1.020470711 0.103421930 9.86706 0.00000000
2. AR{2} 0.255006837 0.147228673 1.73205 0.08685067
3. AR{3} -0.273620199 0.104731130 -2.61260 0.01060409
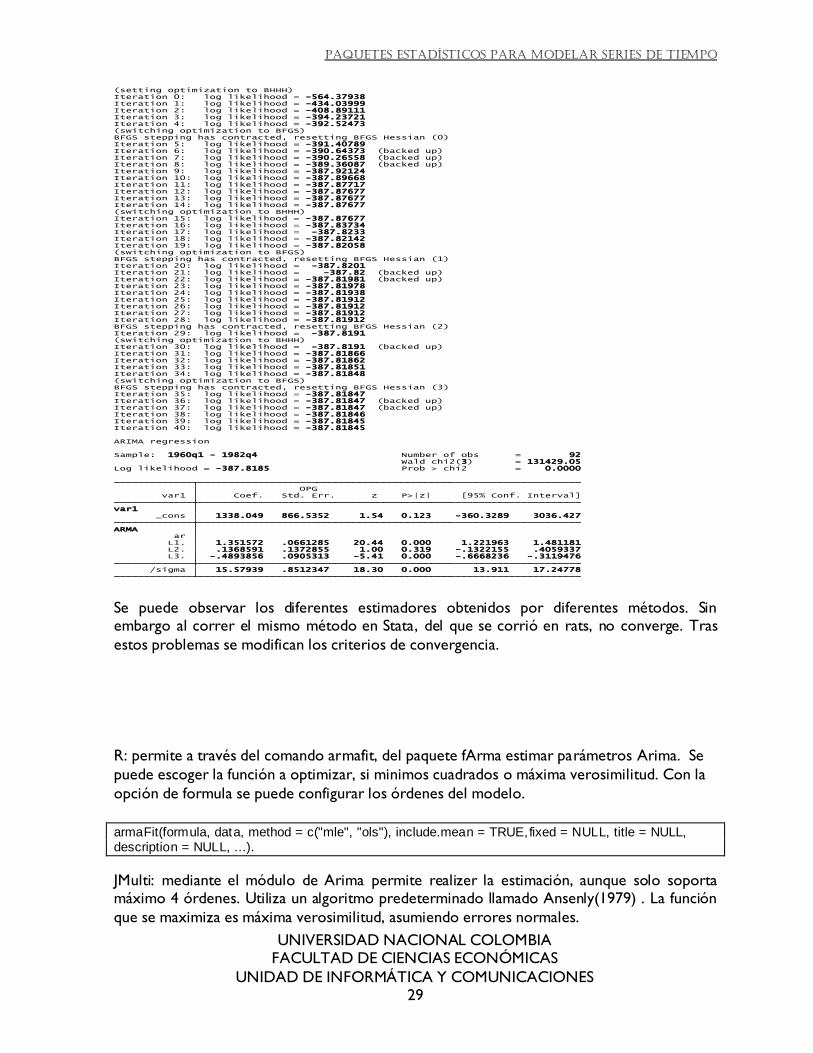
Stata: el comando de estimación se denomina arima. Permite personalizar cualquier nivel de órden para el modelo. El método o algoritmo utilizado por defecto es Berndt-Hall-Hall-
Hausman (BHHH). Se puede personalizar el método con la opción tecnique. También es posible cambiar el nivel de convergencia. En los resultados se muestra por defecto las
iteraciones. También hace inferencias sobre los estimadores. La función maximizada es máxima verosimilitud y no se puede modificar.
PAQUETES Estadísticos PARA MODELAR SERIES DE TIEMPO
UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS
UNIDAD DE INFORMÁTICA Y COMUNICACIONES 29
Se puede observar los diferentes estimadores obtenidos por diferentes métodos. Sin embargo al correr el mismo método en Stata, del que se corrió en rats, no converge. Tras
estos problemas se modifican los criterios de convergencia.
R: permite a través del comando armafit, del paquete fArma estimar parámetros Arima. Se
puede escoger la función a optimizar, si minimos cuadrados o máxima verosimilitud. Con la
opción de formula se puede configurar los órdenes del modelo.
armaFit(formula, data, method = c("mle", "ols"), include.mean = TRUE,fixed = NULL, title = NULL, description = NULL, ...).
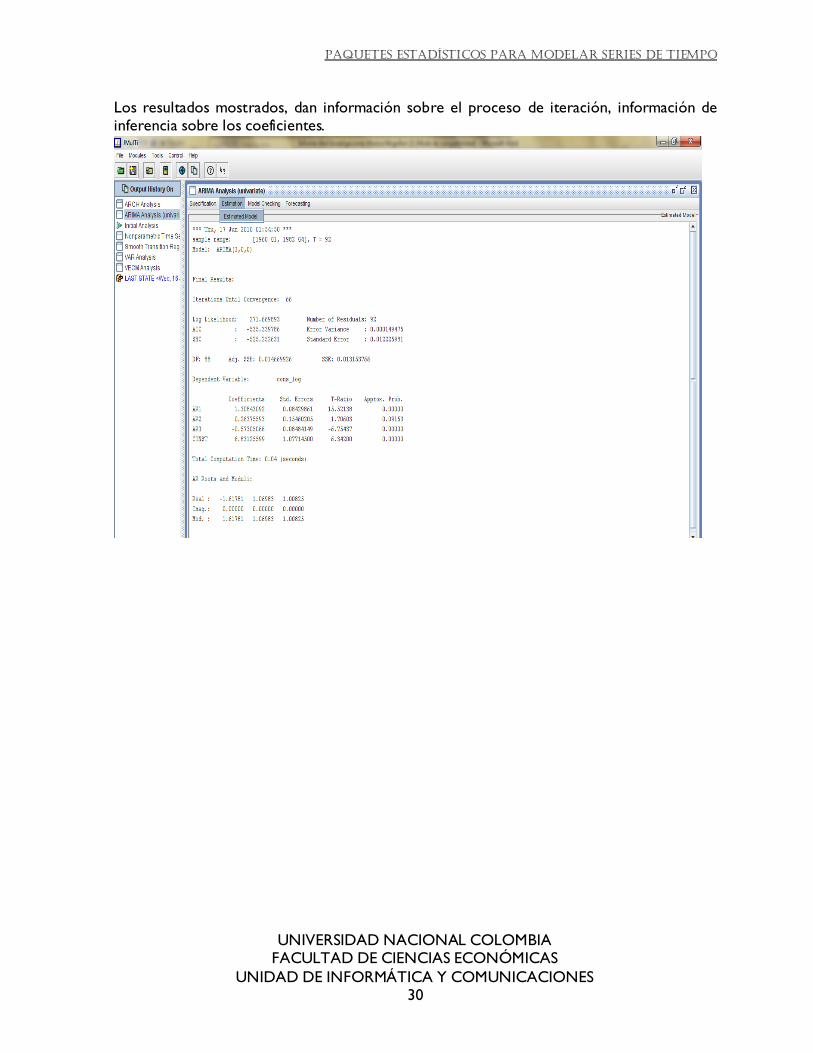
JMulti: mediante el módulo de Arima permite realizer la estimación, aunque solo soporta máximo 4 órdenes. Utiliza un algoritmo predeterminado llamado Ansenly(1979) . La función
que se maximiza es máxima verosimilitud, asumiendo errores normales.
/sigma 15.57939 .8512347 18.30 0.000 13.911 17.24778 L3. -.4893856 .0905313 -5.41 0.000 -.6668236 -.3119476 L2. .1368591 .1372855 1.00 0.319 -.1322155 .4059337 L1. 1.351572 .0661285 20.44 0.000 1.221963 1.481181 ar ARMA _cons 1338.049 866.5352 1.54 0.123 -360.3289 3036.427var1 var1 Coef. Std. Err. z P>|z| [95% Conf. Interval] OPG
Log likelihood = -387.8185 Prob > chi2 = 0.0000 Wald chi2(3) = 131429.05Sample: 1960q1 - 1982q4 Number of obs = 92
ARIMA regression
Iteration 40: log likelihood = -387.81845 Iteration 39: log likelihood = -387.81845 Iteration 38: log likelihood = -387.81846 Iteration 37: log likelihood = -387.81847 (backed up)Iteration 36: log likelihood = -387.81847 (backed up)Iteration 35: log likelihood = -387.81847 BFGS stepping has contracted, resetting BFGS Hessian (3)(switching optimization to BFGS)Iteration 34: log likelihood = -387.81848 Iteration 33: log likelihood = -387.81851 Iteration 32: log likelihood = -387.81862 Iteration 31: log likelihood = -387.81866 Iteration 30: log likelihood = -387.8191 (backed up)(switching optimization to BHHH)Iteration 29: log likelihood = -387.8191 BFGS stepping has contracted, resetting BFGS Hessian (2)Iteration 28: log likelihood = -387.81912 Iteration 27: log likelihood = -387.81912 Iteration 26: log likelihood = -387.81912 Iteration 25: log likelihood = -387.81912 Iteration 24: log likelihood = -387.81938 Iteration 23: log likelihood = -387.81978 Iteration 22: log likelihood = -387.81981 (backed up)Iteration 21: log likelihood = -387.82 (backed up)Iteration 20: log likelihood = -387.8201 BFGS stepping has contracted, resetting BFGS Hessian (1)(switching optimization to BFGS)Iteration 19: log likelihood = -387.82058 Iteration 18: log likelihood = -387.82142 Iteration 17: log likelihood = -387.8233 Iteration 16: log likelihood = -387.83734 Iteration 15: log likelihood = -387.87677 (switching optimization to BHHH)Iteration 14: log likelihood = -387.87677 Iteration 13: log likelihood = -387.87677 Iteration 12: log likelihood = -387.87677 Iteration 11: log likelihood = -387.87717 Iteration 10: log likelihood = -387.89668 Iteration 9: log likelihood = -387.92124 Iteration 8: log likelihood = -389.36087 (backed up)Iteration 7: log likelihood = -390.26558 (backed up)Iteration 6: log likelihood = -390.64373 (backed up)Iteration 5: log likelihood = -391.40789 BFGS stepping has contracted, resetting BFGS Hessian (0)(switching optimization to BFGS)Iteration 4: log likelihood = -392.52473 Iteration 3: log likelihood = -394.23721 Iteration 2: log likelihood = -408.89111 Iteration 1: log likelihood = -434.03999 Iteration 0: log likelihood = -564.37938 (setting optimization to BHHH)
PAQUETES Estadísticos PARA MODELAR SERIES DE TIEMPO
UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS
UNIDAD DE INFORMÁTICA Y COMUNICACIONES 30
Los resultados mostrados, dan información sobre el proceso de iteración, información de inferencia sobre los coeficientes.
PAQUETES Estadísticos PARA MODELAR SERIES DE TIEMPO
UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS
UNIDAD DE INFORMÁTICA Y COMUNICACIONES 31
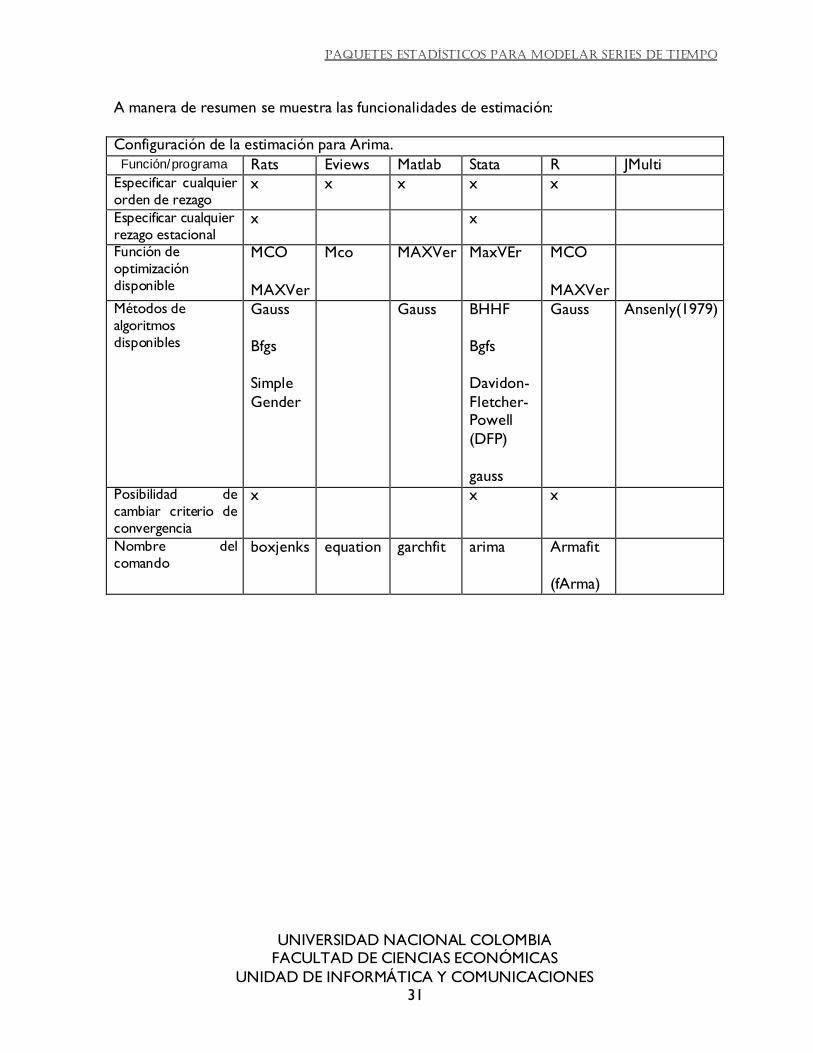
A manera de resumen se muestra las funcionalidades de estimación:
Configuración de la estimación para Arima.
Función/programa Rats Eviews Matlab Stata R JMulti Especificar cualquier orden de rezago
x x x x x
Especificar cualquier rezago estacional
x x
Función de optimización disponible
MCO
MAXVer
Mco MAXVer MaxVEr MCO
MAXVer
Métodos de algoritmos disponibles
Gauss
Bfgs
Simple
Gender
Gauss BHHF
Bgfs
Davidon-
Fletcher-Powell
(DFP)
gauss
Gauss Ansenly(1979)
Posibilidad de cambiar criterio de convergencia
x x x
Nombre del comando
boxjenks equation garchfit arima Armafit
(fArma)

PAQUETES Estadísticos PARA MODELAR SERIES DE TIEMPO
UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS
UNIDAD DE INFORMÁTICA Y COMUNICACIONES 32
6. CONCLUSIONES
Se generan herramientas para la escogencia estratégica de paquetes para el análisis de series
de tiempo univariadas. Cada paquete tiene fortalezas y debilidades. Pero se encuentra que
Rats es el paquete mas flexible y completo en cuanto a modelación Arima, porque ofrece
multiples pruebas de raíz unitaria con amplia flexibilidad para modificarlas, ofrece posibilidad
de modificar gráficos con precisión, y en la estimación ofrece la posibilidad de cambiar
métodos y funciones de optmización. Asi como de personalizar cualquier modelo deseado.
Entre los programas menos útiles para Arima se encuentra Matlab, porque no ofrece
facilidad en el tratamiento de series, no ofrece un comando específico de estimación, genera
resultados muy simples al investigador, no permite mayores configuraciones con facilidad. Se
podría programar nuevas funciones de maximización pero requiere de más aprendizaje del
lenguaje de matlab.
JMulti a pesar de ofrecer un proceso organizado y sencillo, en realidad no ofrece flexibilidad
en la escogencia de métodos y modelos. Además en la estimación puede generar resultados
muy diferentes a todos los programas porque utiliza un algoritmo poco popular. Su fuerte
no son los modelos Arima.
En cuanto a Eviews, ofrece facilidades en las pruebas de raíz unitaria y en las funciones de
autocorrelación, pero en la hora de la estimación no es muy preciso. Finalmente Stata
terminó con bastantes bondades salvo el defecto de la difícil importación de datos de series
de tiempo.

PAQUETES Estadísticos PARA MODELAR SERIES DE TIEMPO
UNIVERSIDAD NACIONAL COLOMBIA FACULTAD DE CIENCIAS ECONÓMICAS
UNIDAD DE INFORMÁTICA Y COMUNICACIONES 33
7. BIBLIOGRAFIA
Helmut Lütkepohl (Editor), Markus Krätzig (Editor), Applied Time Series Econometrics (Themes in Modern
Econometrics), Cambridge University Press, 2004.” Capitulo 2.
Michael N. Mitchell. Strategically using General Purpose Statistics Packages:A Look at Stata, SAS and
SPSS.Statistical Consulting Group.UCLA Academic Technology Services.Technical Report Series
DiethelmWuertz(2009) ARMA Time Series Modelling.Package „fArma‟. Version 2100.76
User Guide. (2009) Rats 7,2. Estima.Cap 7 Arima.
User Guide, (2009) And Help. Stata Press.





























