Embed Size (px)
Citation preview

IEICE TRANS. ??, VOL.Exx–??, NO.xx XXXX 200x1
PAPERSpliTable: Toward Routing Scalability Through Distributed BGPRouting Tables
Akeo MASUDA†,Member, Cristel PELSSER††, Nonmember, and Kohei SHIOMOTO†, Fellow
SUMMARYThe Internet has grown extremely fast in the last two decades. The
number of routes to be supported by the routers has become very large.Moreover, the number of messages exchanged to distribute the routes hasincreased even faster. In this paper, we propose SpliTable, a scalable way tosupport the Internet routes in a Service Provider network. In our proposal,BGP route selection is done by distributed servers on behalf of the routers.They are called route selection servers. The selected routes are then storedin distributed routing tables. Each router maintains only its share of Internetroutes, not the routes for each Internet prefix as it is the case today. Weadapted the concept of Distributed Hash Tables (DHT) for that purpose.
We show analytically that our proposal is more scalable in the num-ber of routes supported in each router than current iBGP route distributionsolutions. Moreover, the number of control messages exchanged with ourproposal is bounded contrary to current sparse iBGP route distribution so-lutions which may never converge. We confirm these findings in an evalu-ation of a prototype implementation.key words: Scalable routing, BGP, DHT
1. Introduction
The rapid growth of the Internet impacts the scalability ofits routing infrastructure. In the last two decades, the num-ber of routes to be supported by the routers has become verylarge. Moreover, predictions say that this number will con-tinue to increase in the future[1]. In addition to the numberof routes, the number of messages exchanged to distributethe routes has increased even faster. In [2], Huston and Ar-mitage have studied the increase in BGP routing entries andin number of BGP messages. They predicted a growth ofthe routing entries by a factor 2 while the amount of BGPadvertisements will increase by a factor 4, in 5 years time.
The large number of routes and messages to be pro-cessed has an negative impact on BGP convergence timeleading to long connectivity losses. Feldmann et al. [3] haveshown that BGP processing time is largely affected by therate of BGP update messages and the number of BGP peers.They have shown that BGP processing time plays a signifi-cant role in BGP convergence time. Long BGP convergencetimes in turn affect the traffic [4].
Inside a SP network, the Internet routes are redis-tributed to the routers via iBGP. Traditionally, a full-meshof iBGP sessions where established for that purpose. In or-der to reduce the load of the routers, solutions requiring the
Manuscript received January 1, 2008.Manuscript revised January 1, 2008.Final manuscript received January 1, 2008.
†NTT Corporation, Musashino-Shi, 180-8585 Japan.††Internet Initiative Japan, Chiyoda-ku, 101-0051 Japan.DOI: 10.1587/trans.E0.??.1
establishment of fewer iBGP sessions are now used. Thesesolutions make use of Route-Reflectors (RRs) and confeder-ations. We call them sparse iBGP topologies. These topolo-gies are more scalable in the number of routes stored inthe routers than an iBGP full-mesh. However, this num-ber is still large. To be able to forward packets to everypossible destination, each router maintains all the Internetroutes in its Forwarding Information Base (FIB). Secondly,BGP requires that each router also maintains tables withthe routes received from and sent to each of its BGP peers.These tables are called the Adj-RIB-Ins and Adj-RIB-outs.The number of adjacencies routing tables increases with thenumber of BGP peers thus leading to an increased numberof routes stored per Internet prefix in the router. To keep upwith the increase, network operators regularly have to per-form costly upgrades of the routers. It is unclear whetheradvances in hardware will be able to keep up with the in-creasing load and capacity.
In addition to maintaining large routing tables, thenumber of BGP messages exchanged with a sparse iBGPtopology is considerable. In some situations, the amountof messages required to distribute the routes is not evenbounded. The iBGP protocol may not converge [5].
In this paper, we propose a solution to reduce the num-ber of routing entries in the routers of a SP network and thenumber of BGP messages exchanged between the routersof the SP network. In our proposal, the distribution of theInternet routes inside the local AS is sure to converge. Wesolve the scalability issue of iBGP. By focusing on the singleAS case, our solution provides a mean for network adminis-trators to deploy a scalable Internet routing solution in theirnetwork without requiring changes in their customer, peerand provider networks, and, a fortiori to the global Internet.The adoption of our proposal in an AS is transparent to theexternal ASs.
In essence, we propose to split the Internet routing tableon multiple routers of the AS. Each router does not maintainroutes for every prefix locally, anymore. We call our pro-posal SpliTable, whose first concept was addressed in [6].We propose to use distributed servers and a method to dis-tribute the load on these servers. The servers select routes onbehalf of the routers. Normal routers do not have to maintainAdj-RIB-Ins and Adj-RIB-outs anymore. The same routesare selected for all the routers of a Point of Presence (PoP).For a prefix, two routes are selected for each PoP. With tworoutes per PoP, our solution is resilient in the face of the fail-ure of one of the routes. We use a DHT, called Kademlia,
Copyright c� 200x The Institute of Electronics, Information and Communication Engineers

2IEICE TRANS. ??, VOL.Exx–??, NO.xx XXXX 200x
to implement the distributed routing table concept. Oncethe routes are selected at the servers, they are stored in theDHT. Each router of a PoP maintains a portion of the In-ternet routes selected for the PoP. In addition, it maintains acache of routes that are currently in use to forward the traf-fic. Once a packet arrives, if there is no entry for its flowin the cache, the corresponding route is retrieved from theDHT. Since the routes of a PoP are stored in the PoP itself,quick route retrieval upon packet arrival is ensured.
We developed prototypes to conceptually prove the fea-sibility of the proposed architecture and measure its benefits.We implemented prototypes for the Route Selection Servers(RSS), ASBRs and internal routers. ASBRs relay the eBGPmessages learned on eBGP sessions to the RSSs. RSSs per-form per PoP BGP route selection and inject the resultingroutes in the DHT. ASBRs resolve the route for a packetby means of the DHT and then forward the packet. RSS,internal routers and ASBRs participate in the DHT. Theystore a portion of the routes computed for their PoP. We usethe prototype to measure the scalability improvements madepossible by our proposal. In this paper, we describe the de-sign and implementation of our prototypes. We also showsome preliminary performance results of our proposal withthe prototypes deployed in a sample network.
The paper is structured as follows. First, we introducethe related work. Then, in section 3, we present SpliTable,our proposal. We describe our prototype implementation insection 4. We analyze the scalability of SpliTable with re-gard to the size of the routing tables and the amount of con-trol messages required to distribute the routes, in section 5.We show some preliminary results concerning the scalabil-ity of the proposal in a simple network in section 6. Finally,we conclude the paper and highlight future directions forthis work.
2. Related work
One of the most popular approach to tackle the scalabilityissue of BGP is the Locator/ID Separation Protocol (LISP)[7]. The authors propose to stop advertising in BGP the pre-fixes allocated to the ASs located at the border of the In-ternet. The hosts in these ASs are assigned an identifier.There is a mapping function that associates an IP address toa host’s identifier. This IP address can be reached based onthe BGP routes. Packets destined to the host are encapsu-lated to reach the node with the IP returned by the mappingfunction. The node with this IP address knows how to reachthe destination host. It decapsulates the packets and for-wards them to the host. The difficulty of this approach liesin its deployment in the Internet. A large number of ASsat the border of the Internet has to adopt the solution to seean impact on the scalability. Moreover, ASs that adopt thesolution still have to be reachable from hosts in ASs that donot adopt it.
In contrast, our proposal is designed to give scalabilitybenefits immediately to the SP even the deployment is lim-ited to its AS. We believe this aspect is important consider-
ing the realistic, incremental deployment of a new Internetarchitecture.
In [8], Krioukov et al. study the trade-offs in usingcompact routing in the Internet. In compact routing, the sizeof the routing table is reduced by aggregating the routes.This leads to longer routes and, thus, an increase in resourceconsumption. This phenomenon is called path stretch. Vir-tual Aggregates [9] is an example of a compact routing solu-tion applied to a single AS[9]. We describe VA and compareit to our proposal in section 5.
In [10] the use of Route Servers (RSs) is proposed. RSsselect a BGP route on behalf of other routers in the AS. Themotivation of these works is to be able to perform smarterBGP route selection than in the routers. We also rely on thisRS concept. We see an additional benefit in this concept. Itmay relieve the routers from the necessity of storing a largenumber of routes in their own tables. Our contribution withregard to our RSSs is that we propose in this paper a meansto distribute the routing selection and storage load amongthe RSSs.
There are several proposals of the routing architecturethat make use of DHT technology. LISP-DHT[11] alsoaims to tackle the interdomain routing scalability issue. Itis different in the sense that DHT is used for the resolutionof the RLOC-EID mapping information required in LISP,and it is designed to work in the global Internet. Ourproposal uses DHT to share the route itself, and it works ina single AS. ROFL[12] is a suggestion of a routing based onaddresses that only contain end-IDs. Here, routing is donewith a mechanism similar to Chord ring. However ROFLdoes not address scalability issues. Authors admit that inpresent, performance including scalability is far from ideal.
3. SpliTable Architecture
In this section, we describe our proposal for the scalableredistribution of Internet routes inside an AS. Our proposal,SpliTable, relies on a distributed route selection mechanismand a DHT to split the routing table on the routers of the AS.
3.1 Distributed Route Selection
We introduce Route Selection Servers (RSSs) in the AS.Each server is responsible of BGP path selection for a sub-set of the external prefixes. It receives all the external BGPmessages for these prefixes. Prefixes are assigned to a RSSas follows. Each RSS is assigned an ID. The set of RSSIDs is noted R. There is a function that maps each prefix toa key. Route selection servers’ identifiers and prefix’s keysbelong to the same domain K. Thus, R ⊆ K. Each RSSwith ID ri is responsible for prefixes with key k comprisedin rj < k ≤ ri, where rj , ri ∈ R and rj is the largest ID,that is smaller than ri, assigned to a RSS.
In order for the AS Border Routers (ASBRs) to sendall the routes they learn on eBGP sessions to the appropriateRSSs, each ASBR has an iBGP session with each RSS. TheASBRs discover the RSSs that are present in the AS, as well

MASUDA et al.: SPLITABLE: TOWARD ROUTING SCALABILITY THROUGH DISTRIBUTED BGP ROUTING TABLES3
!"#
$""%$#
$&
$'$(
$""#)
$""%*+,*-.,/0*12-*34#004%5$""#)*+,*-.,/0*12-*346004#)5
47
4&846
!99*-2:;.,*12-*34#004%5*<-.*,.=;*;2*$""%!99*-2:;.,*12-*346004#)5*<-.*,.=;*;2*$""#).>
?4
.>?4
.>?4
.>?4$<
$@
$.$1
Fig. 1 Route Selection Servers prefix allocation.
as their ID, by means of the IGP.In figure 1, the ID of a route selection server is the num-
ber used in its label. Thus, the ID of RSS5 is 5. Moreover,the key of a prefix is the index used in its label. For example,P2 has key 2. In figure 1, RSS5 receives all the routes forprefix P2. The advertisements concerning P6 and P9 aresent to RSS10.
Traditionally, the BGP routes are redistributed to therouters of an AS on iBGP sessions. Then, each router per-forms the selection of its own routes. This is changed withour proposal. Routers do not perform their own selectionanymore. Thus, the current route selection procedure has tobe adapted.
The current BGP Decision Process (DP) is shown intable 1. The 4th and the 5th rules of the DP make use ofthe location of the router in the topology. These rules ensurehot-potato routing. Hot-potato routing consists in sendingtraffic as soon as possible outside of the AS to reduce theinternal cost of carrying interdomain traffic. We provide anetwork of reference for illustrating the BGP route selectionin Figure 2. The considered AS is divided into Points ofPresence (PoPs). A PoP is a set of routers that are presentin the same location, for example in the same city or thesame building. Figure 3 illustrates the traditional BGP routeselection at the routers in PoP “PoP-SW” assuming a full-mesh of iBGP sessions. Here we show how the best route toprefix P1 will be selected among the four routes that the AShas learned. Each column represents a BGP route candidateidentified by the NH of the route. Each line represents anattribute of the route that is compared based on each of thesix rules of the DP. The last column shows the routes thatremain after each rule of the DP. In the first four process,no routes were evicted since the values are the same.Routeswith Rd and Rc as Next-Hop (NH) are eliminated at the 5thrule of the DP. The cost to reach the NH is higher for theseroutes than for routes with NHs Ra and Rb. Then, whencomparing routes with NHs Ra and Rb based on the 6thrule, Rb has a higher ID than Ra. Thus, it is eliminated andRa is selected as best route for R7, R8 and R9.
We note that, as in Figure 2, in deployed SP networks,the IGP cost of inter-PoP links is usually higher than intra-PoP link costs. This common design [13] ensures that trafficoriginated in and destined to the same PoP stays in the PoP.This design has the following consequence: all the routersin the PoP perform a consistent route selection. If an exter-nal route is received at a router of the PoP, this route will
Table 1 Simplified BGP decision process (DP)Sequence of rules
1 Highest Loc pref 4 eBGP over iBGP2 Shortest AS-path 5 Lowest IGP cost to NH3 Lowest MED 6 Tie-break
!"
!#
!$
!%!& '"
'"
()*'
()*'
()*'
()*''+',-.
'+',-/
"00
"
"
"0 "
"
"0
!1
!2
!3!"0
!"#
!""
'+',4. '+',4/
"00
"00 "00
"0 "0
"
"
"
"
!5
!6
!7
!8
!44%
!9
Fig. 2 Reference network.
NH Ra Rb Rc Rd result(winner)
1) Loc_pref 50 50 50 50 (tie)2) AS-path length 2 2 2 2 (tie)3) MED max value max value max value max value (tie)4) eBGP/iBGP iBGP iBGP iBGP iBGP (tie)5) IGP cost (to NH) from R7, R8: 101
from R9: 102from R7, R8: 101
from R9: 102from R7, R8: 201
from R9: 202from R7, R8: 201
from R9: 202Ra, Rb
6) Tie break(lower router ID)
Router_id(Ra) Router_id(Rb) Ra
Fig. 3 Traditional route selection.
be selected. Otherwise, all the routers of the PoP select thesame route, learned on an eBGP session in a different PoP.In this example of the route selection for the packest arrivedat the routers in the PoP-SW, all the routers select the sameroute, Ra as the NH for P1. Similarly, all the routers in“PoP-SE” select the route with Rc as NH, according to thetraditional route selection process.
In our proposal, route selection is done at the RSSs in-stead of at the individual routers. However, in order to favorhot-potato routing, the location of the router that will use theroute is considered in the route selection process.
Route selection is consistent for all the routers in a PoPbecause they are in the same location. Thus, it is sufficientfor the RSS to select the same route for all the routers inthe PoP. The RSS only computes routes for one router ofthe PoP. We call this selection “per PoP route selection”. Inour proposal, each router advertises the identifier of its PoPin the IGP. This enables the RSSs to identify the nodes of aPoP.
First, there are no changes concerning the rules 1 to3, in table 1. The 4th rule of the BGP decision processbecomes: “If the NH of the route is directly connected toone of the routers of the PoP for which the selection is per-formed, select this route”. In the 5th rule, the route selectionserver will keep the routes with NHs that are the closest tothe considered PoP. Since intra-PoP paths have lower IGPcost than inter-PoP paths [13], the 5th rule of the DP canrely on the IGP cost from any node in the PoP to the route’sNH. This cost is computed from the link costs distributed bythe IGP. Finally, there are no changes in the application ofthe tie-breaking rules.
Figure 4 illustrates the per PoP route selection per-
4IEICE TRANS. ??, VOL.Exx–??, NO.xx XXXX 200x
NH Ra Rb Rc Rd result(winner)
1) Loc_pref 50 50 50 50 (tie)2) AS-path length 2 2 2 2 (tie)3) MED max value max value max value max value (tie)4) Direct connection to the PoP n/a n/a n/a n/a (tie)5) IGP cost(to NH) from R7: 102 from R7: 102 from R7: 202 from R7: 202 Ra, Rb6) Tie break(lower router ID)
Router_id(Ra) Router_id(Rb) Ra
Route selection done by RSS for routers in PoP-SW (R7, R8, R9) for P1
NH Ra Rb Rc Rd result(winner)
1) Loc_pref 50 50 50 50 (tie)2) AS-path length 2 2 2 2 (tie)3) MED max value max value max value max value (tie)4) Direct connection to the PoP available available n/a n/a Ra, Rb5) IGP cost(to NH) from R2: 2 from R2: 1 Rb
Route selection done by RSS for routers in PoP-NW (R1, R2, R3) for P1
Fig. 4 Per PoP route selection.
formed at route selection server RSS5 for prefix P1 in thenetwork of Figure 2. Here we show per PoP route selectionfor PoP “PoP-SW” and “PoP-NW”. In the route selection for“PoP-NW”, first elimination of the candidate happens withthe 4th rule. Ra andRb are directly connected to the routersin the PoP, while the others are not. Finally, Rb remains tobe the best route to P1, by the 5th rule.
As it is already widely recommended in traditionaliBGP topologies, in order to avoid forwarding loops[14],encapsulation is also required to avoid such loops with ourproposal.
In order to allow fast restoration and load balancing ofthe traffic from a PoP on multiple ASBRs, we enable theRSSs to select for each PoP multiple routes to a given pre-fix. We observe here that multiple routes’ selection per PoPenables the routers of “PoP-NW” in figure 2 to use both Raand Rb for the traffic destined to P1, should the RSS adver-tise the two best NHs to the routers of the PoP.
With per PoP route selection, all the nodes in the PoPuse the same routes. Thus, per PoP route selection makespossible a split of a PoP’s routing table. Each router of thePoP maintains only a portion of the routing table. When arouter needs a route that is not present locally, it requests itfrom another node in its PoP. Since all the routers in a PoPare in the same location, retrieving a route from a neighbor-ing node is fast. In the next section, we will describe howroutes are distributed in a PoP and how route retrieval is per-formed.
3.2 Distributed Routing Tables
In this section, we present our proposal for maintaining dis-tributed routing tables inside a PoP. We also describe howrouting information is retrieved from this distributed routerepository.
First, we list the set of properties that is desired from arouting system. We will show in section 5 that our proposalverifies these properties.
• Maintaining routes in the routers should consume lessmemory than current BGP’s routing tables’ sizes.
• Distributing the routes on the routers and retrieving the
routes necessary to forward traffic should consume lessbandwidth and CPU than current iBGP route distribu-tion.
• Retrieving a routing entry upon packet arrival shouldonly take a few tens of milliseconds.
In the development of our proposal, we rely on the fol-lowing assumptions:
• A large amount of the traffic received at an ASBR isdestined to a small number of destinations.
This assumption is motivated by the findings expressed in[15] and [16].
Due to this property of the traffic, we first note thatthe amount of active routes in the ASBRs is small. Thus, anASBR does not need to maintain all the routes locally. In ourproposal, ASBRs only maintain their share of routes and thesubset of active routes in their tables. Second, there may besome benefit in replicating routes for popular destinationsin order to retrieve this information quickly. Our secondassumption is:
• The routes to popular destinations are stable.
This assumption is confirmed by the work of Rexford et al.[16]. This assumption implies that the routes active for along period at an ASBR are not likely to change often. Theycan be maintained in a cache. There is no need for regu-lar pulling of these routes at short timescales to check forchanges.
In our proposal, we choose to store the routes in a Dis-tributed Hash Table (DHT). DHTs provide a framework forthe distribution of the routes on multiple nodes. We chooseto use Kademlia [17] due to the following properties of thisDHT:
1. The search functionality in Kademlia is based on theXOR metric. As we will show later in this section, thismetric is suitable for searching for a prefix.
2. The information is replicated on multiple nodes. Repli-cation provides robustness in the face of the failure ofa DHT element. In our case, routes are still available ifa network element fails, if the DHT graph is not parti-tioned.
3. In Kademlia, replication increases with the popularityof the information. It requires less messages and ittakes less time to retrieve popular information. Thisproperty is suitable to the popular destinations trendsobserved in the Internet traffic [16].
Kademlia is currently used as a file tracker in BitTor-rent, the widely deployed peer-to-peer network for file shar-ing. It enables to quickly find a list of nodes that participatein the torrent for the distribution of the searched file.
In Kademlia, nodes are assigned an identifier (ID).Moreover, each piece of information is assigned a key. Keysand node IDs belong to the same domain, the set of natu-rals that can be represented in 160 bits. The key identifiesa piece of information. It is used to retrieve the information

MASUDA et al.: SPLITABLE: TOWARD ROUTING SCALABILITY THROUGH DISTRIBUTED BGP ROUTING TABLES5
Fig. 5 Store a (key,value) pair in Kademlia.
from the DHT. In our proposal, a piece of information is aroute to be used in a given PoP.
The key is used to locate the nodes that will store the re-lated piece of information. In Kademlia, node IDs and keysare compared to determine in which node to store the infor-mation. A piece of information will be stored in k nodes.k is called the replication parameter. These nodes have theIDs that are closest to the key based on the XOR metric.Figure 5 illustrates the storing action of a (key, value) pairin Kademlia as well as the use of the XOR metric. Eachnode maintains a list of contacts. For each contact, it knowsthe node ID, its IP address and the port on which it can bereached.
In figure 5, node R8 wants to store v with key 10111in the system. Let assume in this example that k = 2. R8looks in its own contact data structure for the closest nodesto 10111 (23 in decimal representation). The closest nodesto key 23 are R20 and R22, in the b3 list. According to theXORmetric,R22 is the closest node to key 23 since only thelast bit of its ID, 10110 differs from the key, 10111. Simi-larly, R20 is the second closest node. The third bit of its IDdiffers from key 23. As k = 2,R8 contacts these two nodes.R8 asks these nodes if they know closer nodes to the key 23.This is done by sending a findNode request. These nodesdo not know closer nodes. They know the existence of R24.However, R24 is farther away than R20 and R22. The sec-ond bit ofR24’s ID already differs from the key. Both nodesreturnR20 andR22 as closest nodes. Thus,R8 asks them tostore v, by sending them a store request. Finally, the closestnodes are added to the contacts of R8. Here no new nodesare added since they were already known. However, timersfor these contacts are reset.
Now, assume that R20, in figure 5 wants to retrievethe value for key 23. It first looks for the (key,value) pairlocally. If this fails, it searches for the k closest nodes to 23in its contacts. These are nodes R20 and R22 according tothe XOR metric. Thus, it asks R22 for the value with key23. R22 looks in its own data structure. If it finds the value,it returns it. Otherwise it returns the k closest nodes to 23,which are R20 and R22. In the latter case, the search failed.
The searched information is not present in the system.We observe that the XOR metric is appropriate for IP
destination and prefix comparison. IP packets are currentlyrouted according to the longest match prefix. Let’s assumethat an ASBR has routes for 66/8 and 66.249/16. Today,when an IP packet with destination address 66.249.89.147is received, the ASBR routes the packet according to theroute for prefix 66.249/16. The XOR metric is consistentwith this practice. With the XOR metric, the longest matchprefix 66.249/16will be closer to the IP destination than theother prefix. It will thus be preferred.
We will now explain how we propose to adapt Kadem-lia to our purpose. In our proposal, S is a RSS and R20 isan ASBR, in figure 5. First, we consider the node ID assign-ment. We also define the keys to store a route in the systemand to retrieve it. These concepts are particularly importantas they determine the efficacy of the store and retrieval pro-cedures. In Kademlia, the ID of a node is 160 bits long. Inour proposal, we set the ID of a node to its PoP identifier towhich a hash value is concatenated.
< nodeid >::=< PoPid >< hash >
where the PoPid is 32 bits long and < hash > is 128 bitslong. < hash > is obtained by applying MD5 on a ran-domly generated number.
In this paper, the DHT is used to store routes. A routeis a (key, value) pair where the key is 160 bits long. Wedenote the key of a route as kr. The format of this key is:
kr ::=< PoPid >< prefix >< mask >< padding > .
< PoPid > identifies the PoP for which the route is des-tined. It is 32 bits long. < prefix > is a 32 bits IPv4 prefixand < mask > is the mask for the IPv4 prefix. The maskis also 32 bits long. < padding > is 64 bits long. All these64 bits are set to 0. The format of the value component isv ::=< version >< length >< NH1 >< pref1 > ... <NHn >< prefn > where < length >::= n. The valuemay consist of multiple NHs to which the traffic destined tothe prefix may be sent. A preference is assigned to each NH.Setting multiple NHs in a route enables an ASBR to performrestoration upon a failure as well as to load balance the traf-fic on multiple paths during normal network operation. Inthis paper, we consider n = 2.
We do not apply any modifications to Kademlia’s storeprocedure. Our definitions of kr and nodeid ensure thatroutes destined to a PoP will preferably be stored in nodesof the PoP. This is because for a node in a PoP and a routedestined to this PoP, the first 32 bits of the node ID and theroute’s key are identical.
Upon a packet arrival, the ASBR (for example R20 infigure 5) has to retrieve a matching route in order to forwardthe packet. However, the matching prefixes for the packet’sdestination are not known in advance. A fortiori, the mostspecific matching prefix is not known. Thus, kr cannot bebuilt. We define a different key to retrieve a route from thesystem. This key is denoted kd:

6IEICE TRANS. ??, VOL.Exx–??, NO.xx XXXX 200x
Algorithm 1 retrieveRoute(kd)1: repeat2: {search for a less specific prefix if a matching route is not found for
the initial kd}3: Nnew=N=a {first search in the local node}4: {InitializeNnew in order to not overrideN in the first execution of
the loop}5: repeat6: {search for the most specific prefix for kd}7: N=Nnew
8: (Nnew, P )=findMatchingRouteInClosestNodes(N ,kd)9: if (P �= ∅) then10: r=mostSpecificNewestRoute(P, r)11: installInFIB(r)12: end if13: until (Nnew ⊆ N )14: kd=resetLastIPAndMaskNonZeroBits(kd)15: until (defined r)16: replicate(r)
kd ::=< PoPid >< IP >< mask >< padding > .
< PoPid > is the identifier of the PoP in which the packetis received. < IP > is the packet’s IP destination address.It is 32 bits long. The mask is composed of 32 bits set to1. Finally, the < padding > is 64 bits long. All these 64bits are set to 0. The presence of < PoPid > at the head ofthe key enables to contain route search in the PoP and, thus,quickly find the route computed for the PoP.
Since the key of the stored route and the key to look upfor a route are different, we cannot use Kademlia’s look upprocedure. Our proposed route retrieval method is shownin algorithm 1. Let a be the ASBR receiving a packet, inalgorithm 1 and 2. Moreover, N is the set of the next nodesto contact to search for the route.
In algorithm 1, we first search for a prefix matching thekey kd. If such a specific route cannot be found, we searchfor a less specific route. This is done by setting the last nonzero bit of the IP address and the corresponding tailing bitsof the mask to 0, in line 14. This is the purpose of the outermost loop (lines 1-15). For a given kd, in algorithm 1, lines5-13, we first look in the local node for the most specific andnewest matching route for kd (line 8). We also search forthe closest nodes to the key kd (line 8). If a matching prefixis found, it is installed in the Forwarding Information Base(FIB) (line 11). Thus, we note that as soon as a route for amatching prefix is found it is installed in the FIB. This en-ables the ASBR to forward packets quickly even though theroute is not the final, most specific route. The search contin-ues to find the most specific route. For that purpose, the kclosest nodes known locally, the nodes in N , are contactedin the next run of the inner loop (line 8). These nodes in turnlocally search for the most specific and newest route. In ad-dition, they respond with a list of k closest nodes. Details forfindMatchingRouteInClosestNodes are providedin algorithm 2.
During a route search, when routes are received frommultiple nodes, line 8 in Alg. 1, the set of “most spe-cific matching routes” is identified. From this set, the
Algorithm 2 findMatchingRouteInClosestNodes(N ,kd)1: if (|N | = 1 andN = a) then2: Nresult=getClosestNodes(kd)3: Presult=getMostSpecificRoute(kd)4: else5: for (n ∈ N ) do6: (Nnew, Pnew)=sendFindRoute(kd, n)7: Nresult=Nresult ∪Nnew
8: Presult=Presult ∪ Pnew
9: end for10: end if11: return (Nresult, Presult)
method mostSpecificNewestRoute only returns theroute with the newest version number (line 10). The ver-sion number of a route is important here. Each time a RSScomputes a route, it attaches a version number to the route.Popular routes are replicated in the DHT. When the RSS re-computes a route, it deletes the old routes present in the kclosest nodes. However, it is not able to delete the otherreplications. These copies timeout. In the mean time, theversion number ensures that the stale routes are not used toforward traffic once the route search is terminated.
In this section, we presented our proposal, SpliTable.We showed how to distribute the load on multiple RSSswhile ensuring full visibility of the routes for a prefix at aRSS. Together with encapsulation, this ensures correctness[5]. Then, we presented our modifications to Kademlia inorder to support the distributed storage of IP routes and theirretrieval upon packet arrivals. Now, we will describe ourprototype implementation. We describe the functions thatwe implemented in the different nodes, the RSSs and theASBRs. We show the feasibility of our proposal.
4. Prototype Implementation
In this section, we show how we have implemented therequired functionalities in the RSS and ASBR prototypes.Running example of the prototype will be shown later insection 6.
4.1 Software architecture
The prototype consists of RSSs and the RSS clients. RSSclients are ASBRs that are capable of the protocol proposedin this paper. Some of the routers may work as an RSS andan ASBR at the same time.
As shown in Fig. 6, RSSs and the ASBRs are com-posed of two modules that we have developed: the BGPmodule and the DHT module. The BGP module is a slightmodification of an existing open source routing software,Quagga (ver. 0.99.11) [18]. The DHT module is developedbased on one of the existing open source implementation ofKademlia, Entangled (release 0.1) [19].
Usually, network entities negotiate which protocol touse between them by advertising the functions they are ca-pable of to their neighbor. In our prototype, we use the ca-pability feature of the BGP OPEN message to negotiate the

MASUDA et al.: SPLITABLE: TOWARD ROUTING SCALABILITY THROUGH DISTRIBUTED BGP ROUTING TABLES7
RSSRSS Client (ASBR)
BGP module
DHT module
RS selection
BGP routes(eBGP) BGP routes
(iBGP)
RSS Client (ASBR)
eBGPiBGP
Route decision
BGP module
DHT module
RS selection
eBGPiBGP
Route decision
RSS Client (ASBR)
BGP module
DHT module
BGP modulePacketarrival findVALUE
findNODE, STORE
DHT module
Fig. 6 Prototype architecture: RSS and RSS Client modules
“RSS” and “RSS client” capabilities [20]. We assign thecode 250 to the “RSS Capability” and code 251 to the “RSSClient Capability”. The RSS ID and the PoP ID are set inthe 32 bit field of the capability value of RSS Capability andthe RSS Client Capability, respectively.
Network operators can choose which nodes to launchas an RSS or as an ASBR via command line or configurationfiles. The PoP ID and the RSS ID, in the case of an RSS, areset by the operator.
Here we describe how the functionalities of RSSs andASBRs are achieved by the development of BGP and DHTmodule.
4.2 Implementation of a RSS
An RSS sets up iBGP sessions with all the ASBRs in theAS in order to collect all the BGP routes that the RSS isresponsible for. The Quagga implementation of the ASBRis changed to relay BGP routes to the right RSS. ASBRs se-lect the RSS responsible for the prefix advertised and simplysend the BGP advertisement to this RSS. There is no BGProute selection at the ASBR anymore.
An RSS computes routes for each prefix, as is ex-plained in 3.1. Per-PoP route selection is performed by theRSS. Then, the routes are delivered to the ASBRs of thePoP. This is done by storing the routes in the DHT. The IDof the ASBRs and the key of the routes ensure storage ofthe routes in their respective PoP. After the BGP module inthe RSS carries out the per-PoP route calculation, it handlesthe generated route information to the DHT module runningin that RSS in order to distribute it to the ASBRs. In ourprototype, the external BGP routes are generated in a file,and the DHT module of the ASBRs periodically checks ifthe file has been updated. The DHT module of the RSSdelivers the route information to some ASBRs of the ap-propriate PoP through the Kademlia’s “findNODE” and“STORE” procedures. This does not require changes tothe store implementation of Entangled.
4.3 Implementation of an ASBR
The BGP module provides the capabilities for an ASBR toset up eBGP sessions with peer ASBRs outside of the AS.
This is already provided by Quagga. However, we changedthe following functions of the Quagga implementation, tosupport the distributed route calculation at the RSSs.
When an ASBR learns a BGP route on the eBGP ses-sion, it determines the RSS in charge of the prefix and itsimply forwards the message to this RSS. ASBRs do not runthe BGP path selection, and they do not store the route in theFIB. There is no FIB in the ASBRs anymore, only a cachewith the routes currently in use for packet forwarding. Theydo not even create the adj-RIB-in/out database. ASBRs onlytransfers the messages received from the peers to the RSSs,and vice versa for external BGP route distribution.
The support of iBGP sessions between ASBRs andRSSs is also provided by the standart Quagga implemen-tation. As mentioned in 3.1, RSSs are assigned an ID. TheID is used when the ASBRs determine which RSS the BGProute should be sent. In the implementation, we defined theRSS ID as being a 32 bits IPv4 address. The decimal rep-resentation of prefix keys and RSS IDs is used to comparethem, in order to identify the RSS in charge of a given pre-fix. For example, an RSS ID A.B.C.D will be converted toa decimal numberA∗2563+B∗2562+C∗256+D. Accord-ing to the result of this calculation, ASBRs sends the BGProute to the selected RSS. Note that path selection is madeby the RSSs. Therefore, the attributes of the BGP routes aretransmitted unchanged to the RSS.
4.3.1 Distributed routing tables
Ingress ASBRs forward packets that are received fromneighboring ASs to the egress ASBRs of the AS. As ex-plained above, routing information for packet forwarding iscomputed by the RSSs and stored in the DHT by the RSSs.The set of routes for the ASBRs in a PoP will be distribut-edly maintained among the ASBRs of the PoP. We use aradix tree as the data structure, in the DHT module. Theroute key kr is composed of the identifier of the PoP forwhich the route was selected, the route’s prefix and its mask.This key is used to determine the set of nodes in the DHTthat will store the route for the PoP. These nodes are in thePoP. The value stored for each route’s key contains the Next-Hop (NH) of the best route (i.e. the address of the egressASBR for the best route) for that prefix, the NH of the sec-ond best route, the last publication time, the original publi-cation time and, the node ID of the RSS who published theroute. The original publication time indicates the time whenthe route was selected. Thus, when different routes werefound for a destination prefix, it will be used to determinewhich route is the newer selection that should be used. Thepersistence of the key-value pairs is ensured through period-ical re-publication of the pairs by the RSSs. The last publi-cation time corresponds to the latest re-publication. This isprovided by the original Kademlia implementation.
When a packet arrives at the border of the AS, the DHTmodule of the ASBR retrieves the routing information fromthe DHT. We modified the implementation of Entangled toperform our route retrieval algorithm (Algorithms 1 and 2).

8IEICE TRANS. ??, VOL.Exx–??, NO.xx XXXX 200x
Table 2 Items of statistics
BGP module Memory consumption for each informationNumber of iBGP sessionsNumber of iBGP messages sent per sessionNumber of total iBGP messages sent/receivedNumber of UPDATE messages on iBGP sessionNumber of UPDATE messages on eBGP sessionRoute decision result
DHT module Number of sent RPCs for each DHT procedureElapsed time for each DHT procedureNumber of routes maintained (total and per radix tree)Memory size consumed to maintain the routes(total and per radix tree)Number of entries in the k-bucketsMemory size consumed by k-buckets
Modifications were required to enable the retrieval of theroute for the most specific prefix that matches a packetsdestination, instead of a strict match provided by standardKademlia implementations.
4.4 Measurement functions
Our aim is not only to prove that our concept is feasible andimplementable, but also to carry out measurements in thefuture. We thus have added to our prototype a capabilityto output various items of information that are recorded ormeasured while running the system. The generated statisticsshow us important performance criteria that can be used forthe evaluation of the proposed architecture. Items of statis-tics that the prototype can show are listed in table 2. Notethat we modified Quagga to output these statistics for bothour prototype implementation and for the regular BGP be-havior. For example, because the prototype monitors the“memory consumption” in the RSS, the RSSs clients andthe standard BGP implementation, we are able to know andcompare the memory size required for routers running theoriginal BGP, and those running our proposed protocol.
Measurements are important to validate our proposal.Since in our proposal ASBRs do not maintain locally a routefor every prefix, they need some time to retrieve the routefrom the DHT. Thus, packet might be forced to wait un-til the ASBR retrieves the route for that packet’s destina-tion. As the retrieval time in DHT depends on the numberof peers, this issue may be critical to ensure good forward-ing performance with a large number of ASBRs in the PoP.In the future, we plan to evaluate the importance of this issueby using our prototype implementation.
In this section, we have shown the implementation ofthe prototype. The prototype was implemented in order notonly to make a proof of the concept, but also to evaluate andvalidate our proposal in terms of performance. In the nextsection we will give analytical evalutation that clarifies howmuch we can benifit from our proposal. Running exampleand sample measurement results are addressed in section 6.
5. Scalability analysis
In this section, we compare traditional iBGP route distri-
Table 3 Variables and example value for each notation.n 200 (20) number of nodes in the ASp 320000 number of external prefixesq 16 (3) average number of iBGP peers per node (in sparse
iBGP topology)r 3 (1.9) average number of eBGP peers per ASBRs 20 (3) number of RSSa 160 (20) number of ASBRsl 20 (3) number of PoPsm 8400 number of eBGP messages (per hour)k 2 replication factor in the DHTt 3 min cache timeout (in minutes)d 18000 maximum number of destinations per “t” intervalc 4050 maximum number of cache misses per “t” interval
bution and the Virtual Aggregate (VA) solution proposedby Francis et al. [9] to our solution. Concerning tradi-tional iBGP, we consider both full-mesh iBGP topologiesand sparse iBGP topologies. For each of these techniques,we quantify the routing information stored in each node andprovide an upper bound on the number of control messagesexchanged to distribute the routing information.
We define the following variables: p is the number ofexternal prefixes learned by the AS, n is the number of nodesin the AS, q is the average number of iBGP peers of a node ina sparse iBGP topology. And, s is the number of RSSs in theAS, with our proposal. It is assumed that q < s and n > s.p is an upper bound for the number of prefix advertisementreceived at each ASBR. An overview of the variables usedto compute the upper bound on the number of routes in thetables and control messages exchanged is provided in table3. We assign a value to each variable. These are the valuesused for the generation of figures 7 and 8. These valuesare only provided as an example of the values that may beobserved in a real SP network. Numbers in the bracketsare used for evaluation assuming a much practical case witha sample topology modeling an network that is actually inservice. Evaluation is addressed in section6.
We computed the average number of iBGP peers q intable 3 based on a iBGP topology composed of 2 RRs perPoP. Each node in the PoP has an iBGP session with the RRsof its PoP. There is a full-mesh of iBGP sessions in the PoP.And, all the RRs of the AS are connected in a full-meshof iBGP sessions. This design follows one of the recom-mendations in [21]. m encompasses the eBGP churn. Thevalue assigned to m in table 3, is the average number ofroute changes observed per hour at the routers participat-ing in linx interconnection point. We computed this averagebased on one day’s BGP updates data (March 24th, 2009),collected by the routeviews project (http://archive.routeviews.org/bgpdata/). The values for t, d,c are assigned according to the findings of Iannone et al.in [15]. The authors assumed that the Internet traffic at thebound of a university is routed according to the entries of acache. For each flow, they installed a routing entry in thecache. For different timeouts, they determined the numberof routing entries required in the cache to route all the traf-fic. They also measured to number of cache miss for eachtimeout value. In our proposal, the ASBRs request a route
MASUDA et al.: SPLITABLE: TOWARD ROUTING SCALABILITY THROUGH DISTRIBUTED BGP ROUTING TABLES9
Table 4 Table sizesBGP table sizes
Technique Adj-RIB (in+out) FIBFull-mesh p(2r + 2n− 3) pSparse p(2r + 2q − 1) pVA p(2r + 2q − 1) (2lp/n) + 2(127
−2 ∗ 127(l/n))SpliTable (at RSS) (p/s)(ar + 2l) –
DHT table sizes (SpliTable)DHT table Routing cache
At ASBR pkl/n + (a/l)dl/n d+(a/l)(1440/t)cl/n
At RSS pkl/n + (a/l)dl/n –+(a/l)(1440/t)cl/n
entry from the DHT upon a packet arrival. Once the routeentry is received it is stored in a cache and can be used toroute subsequent packets. As the study in [15] analyses thepacket trace collected at the egress point of a campus, thiscan be seen as a behavior of a single stub network from theSP point of view. Thus, if we assume a simplified modelthat one stub network is connected to each of the ASBRs,we can rely on the numbers observed in[15] for assigningnumbers of d and c, the destination addresses arrived andcache misses at an ASBR.
In VA, a router may act as Aggregation Points Routers(APR) for a Virtual Prefix (VP). A VP is an aggregate ofprefixes. It is not necessarily part of the Internet routes. TheAPR advertises the VP in iBGP. The APR installs in its FIBthe routes for the prefixes that are more specific than its VP.However, the other routers do not. They only install the VPin their FIB. They will thus route the traffic to the APR. TheAPR will then relay the route along the most specific route.This enables to reduce the size of the FIB in the routers.They do not have to install all the most specific routes intheir FIB. However, it does not enable to reduce the sizeof the Adj-RIB-Ins and Adj-RIB-outs as a router still haveto advertise all the Internet routes to its BGP peers. Sincethe traffic is first sent to an APR and then along the mostspecific route, traffic may follow a longer path than in tra-ditional iBGP. This is called the path stretch. If there areAPRs for each VP in each PoP as suggested in [22], thepath stretch is limited. In order to avoid forwarding loops,packets are encapsulated at the APRs. The destination of theencapsulating tunnel is the NH of most specific route.
5.1 Number of routes
In this section, we look at the number of routes stored in thenodes with a full-mesh, a sparse iBGP topology, VA and ourproposal (SpliTable). First, we show in table 4 the formulasused to compute the number of routers stored in the nodesof an AS for each of the techniques.
We see in table 4 that the number of routes in the Adj-RIBs with a full-mesh is proportional to the number of nodesin the AS. This is not scalable. Sparse iBGP topologies andVA are much more scalable. We also observe that for VA,only the size of the FIB is reduced compared to traditionaliBGP topologies.
0
10
20
30
40
50
60
70
80
sparse VA SpliTable(ASBR) SpliTable(RSS)
Tabl
e Si
ze (m
illio
n en
tries
) in 2010 (320,000 prefixes)
in 2020 (2,000,000 prefixes)
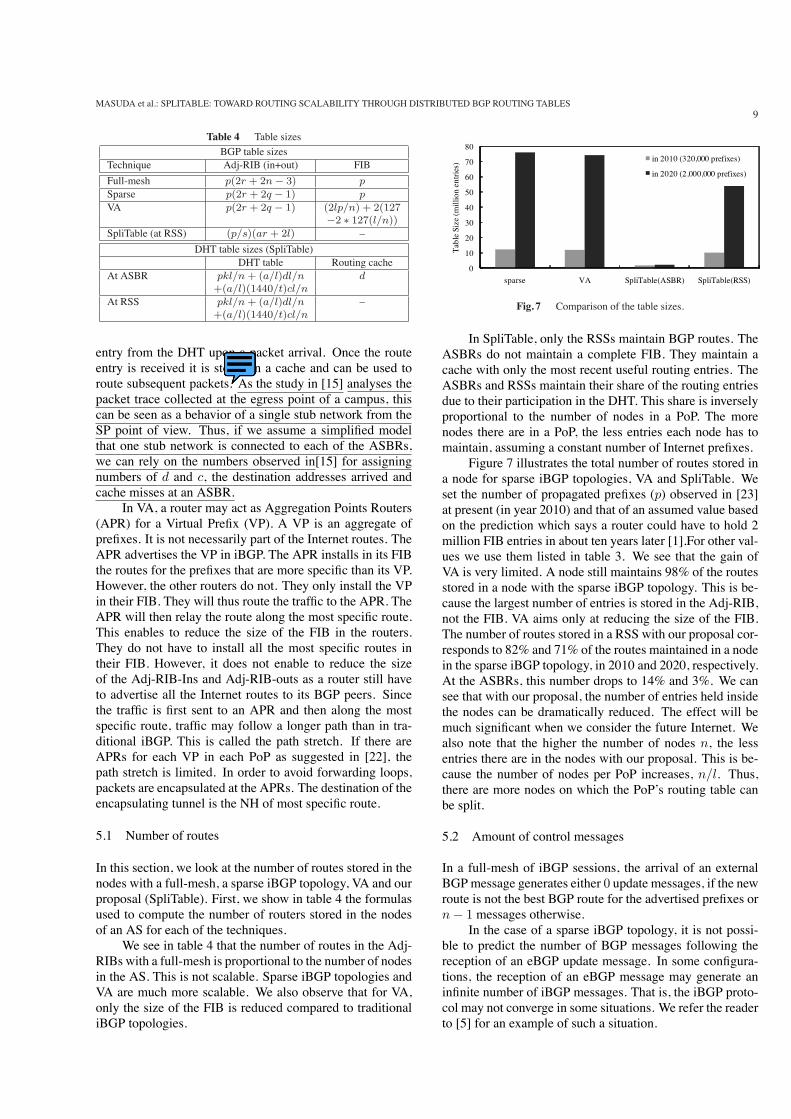
Fig. 7 Comparison of the table sizes.
In SpliTable, only the RSSs maintain BGP routes. TheASBRs do not maintain a complete FIB. They maintain acache with only the most recent useful routing entries. TheASBRs and RSSs maintain their share of the routing entriesdue to their participation in the DHT. This share is inverselyproportional to the number of nodes in a PoP. The morenodes there are in a PoP, the less entries each node has tomaintain, assuming a constant number of Internet prefixes.
Figure 7 illustrates the total number of routes stored ina node for sparse iBGP topologies, VA and SpliTable. Weset the number of propagated prefixes (p) observed in [23]at present (in year 2010) and that of an assumed value basedon the prediction which says a router could have to hold 2million FIB entries in about ten years later [1].For other val-ues we use them listed in table 3. We see that the gain ofVA is very limited. A node still maintains 98% of the routesstored in a node with the sparse iBGP topology. This is be-cause the largest number of entries is stored in the Adj-RIB,not the FIB. VA aims only at reducing the size of the FIB.The number of routes stored in a RSS with our proposal cor-responds to 82% and 71% of the routes maintained in a nodein the sparse iBGP topology, in 2010 and 2020, respectively.At the ASBRs, this number drops to 14% and 3%. We cansee that with our proposal, the number of entries held insidethe nodes can be dramatically reduced. The effect will bemuch significant when we consider the future Internet. Wealso note that the higher the number of nodes n, the lessentries there are in the nodes with our proposal. This is be-cause the number of nodes per PoP increases, n/l. Thus,there are more nodes on which the PoP’s routing table canbe split.
5.2 Amount of control messages
In a full-mesh of iBGP sessions, the arrival of an externalBGPmessage generates either 0 update messages, if the newroute is not the best BGP route for the advertised prefixes orn− 1 messages otherwise.
In the case of a sparse iBGP topology, it is not possi-ble to predict the number of BGP messages following thereception of an eBGP update message. In some configura-tions, the reception of an eBGP message may generate aninfinite number of iBGP messages. That is, the iBGP proto-col may not converge in some situations. We refer the readerto [5] for an example of such a situation.
10IEICE TRANS. ??, VOL.Exx–??, NO.xx XXXX 200x
Table 5 Control messages
Technique BGP DHT (store, DHT (retrieve)update, remove)
Full-mesh 24m(n− 1) 0 0Sparse infinite 0 0VA infinite 0 0
SpliTable 24m 48ml(min((n/l) a(d + (1440/t)c)+k, 129k)) ∗(2 ∗min(n/l,
24 ∗ 128k) + 1)
1
10
100
1,000
10,000
100,000
Full-mesh SpliTable
Num
ber o
f mes
sage
s (m
illio
n)
n=200 n=400
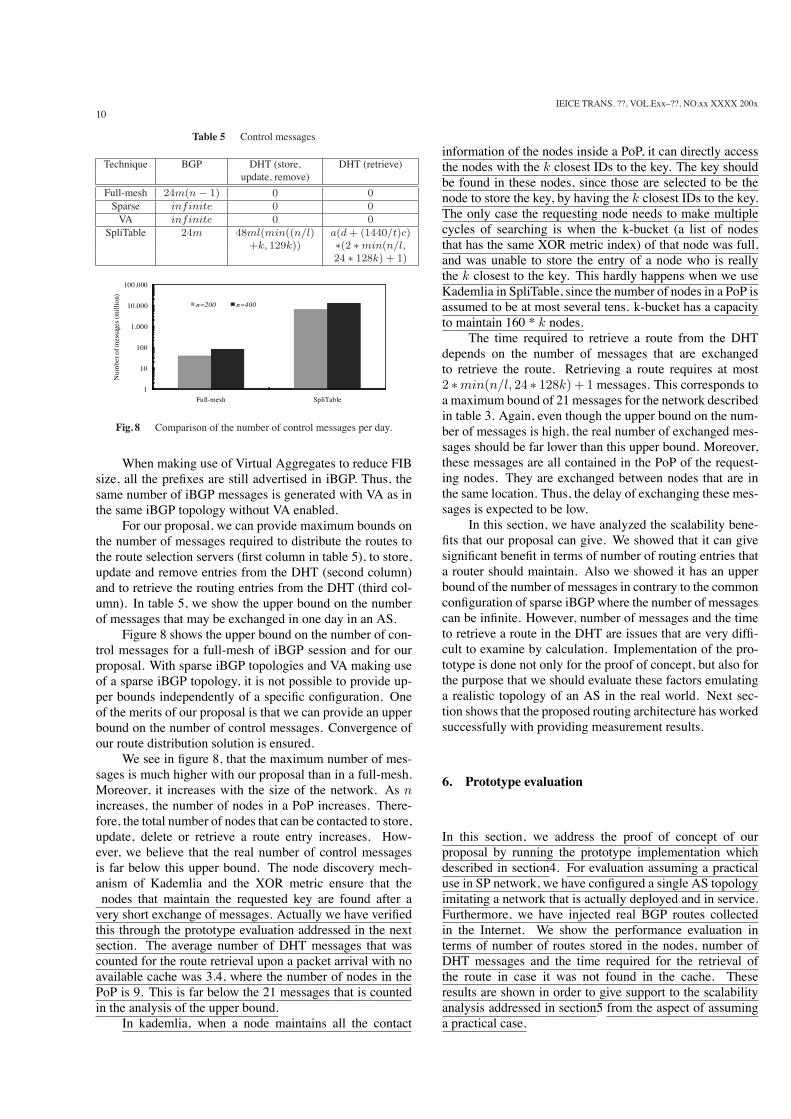
Fig. 8 Comparison of the number of control messages per day.
When making use of Virtual Aggregates to reduce FIBsize, all the prefixes are still advertised in iBGP. Thus, thesame number of iBGP messages is generated with VA as inthe same iBGP topology without VA enabled.
For our proposal, we can provide maximum bounds onthe number of messages required to distribute the routes tothe route selection servers (first column in table 5), to store,update and remove entries from the DHT (second column)and to retrieve the routing entries from the DHT (third col-umn). In table 5, we show the upper bound on the numberof messages that may be exchanged in one day in an AS.
Figure 8 shows the upper bound on the number of con-trol messages for a full-mesh of iBGP session and for ourproposal. With sparse iBGP topologies and VA making useof a sparse iBGP topology, it is not possible to provide up-per bounds independently of a specific configuration. Oneof the merits of our proposal is that we can provide an upperbound on the number of control messages. Convergence ofour route distribution solution is ensured.
We see in figure 8, that the maximum number of mes-sages is much higher with our proposal than in a full-mesh.Moreover, it increases with the size of the network. As nincreases, the number of nodes in a PoP increases. There-fore, the total number of nodes that can be contacted to store,update, delete or retrieve a route entry increases. How-ever, we believe that the real number of control messagesis far below this upper bound. The node discovery mech-anism of Kademlia and the XOR metric ensure that thenodes that maintain the requested key are found after avery short exchange of messages. Actually we have verifiedthis through the prototype evaluation addressed in the nextsection. The average number of DHT messages that wascounted for the route retrieval upon a packet arrival with noavailable cache was 3.4, where the number of nodes in thePoP is 9. This is far below the 21 messages that is countedin the analysis of the upper bound.
In kademlia, when a node maintains all the contact
information of the nodes inside a PoP, it can directly accessthe nodes with the k closest IDs to the key. The key shouldbe found in these nodes, since those are selected to be thenode to store the key, by having the k closest IDs to the key.The only case the requesting node needs to make multiplecycles of searching is when the k-bucket (a list of nodesthat has the same XOR metric index) of that node was full,and was unable to store the entry of a node who is reallythe k closest to the key. This hardly happens when we useKademlia in SpliTable, since the number of nodes in a PoP isassumed to be at most several tens. k-bucket has a capacityto maintain 160 * k nodes.
The time required to retrieve a route from the DHTdepends on the number of messages that are exchangedto retrieve the route. Retrieving a route requires at most2 ∗min(n/l, 24 ∗ 128k) + 1 messages. This corresponds toa maximum bound of 21 messages for the network describedin table 3. Again, even though the upper bound on the num-ber of messages is high, the real number of exchanged mes-sages should be far lower than this upper bound. Moreover,these messages are all contained in the PoP of the request-ing nodes. They are exchanged between nodes that are inthe same location. Thus, the delay of exchanging these mes-sages is expected to be low.
In this section, we have analyzed the scalability bene-fits that our proposal can give. We showed that it can givesignificant benefit in terms of number of routing entries thata router should maintain. Also we showed it has an upperbound of the number of messages in contrary to the commonconfiguration of sparse iBGP where the number of messagescan be infinite. However, number of messages and the timeto retrieve a route in the DHT are issues that are very diffi-cult to examine by calculation. Implementation of the pro-totype is done not only for the proof of concept, but also forthe purpose that we should evaluate these factors emulatinga realistic topology of an AS in the real world. Next sec-tion shows that the proposed routing architecture has workedsuccessfully with providing measurement results.
6. Prototype evaluation
In this section, we address the proof of concept of ourproposal by running the prototype implementation whichdescribed in section4. For evaluation assuming a practicaluse in SP network, we have configured a single AS topologyimitating a network that is actually deployed and in service.Furthermore, we have injected real BGP routes collectedin the Internet. We show the performance evaluation interms of number of routes stored in the nodes, number ofDHT messages and the time required for the retrieval ofthe route in case it was not found in the cache. Theseresults are shown in order to give support to the scalabilityanalysis addressed in section5 from the aspect of assuminga practical case.
MASUDA et al.: SPLITABLE: TOWARD ROUTING SCALABILITY THROUGH DISTRIBUTED BGP ROUTING TABLES11
R1
R4R2
R5
R3
R11
R10
R15
R18
R19
R17
RSS
RSS
RSS
R12
R13
R14
R20
R16R6
R8
R9
R7
eBGP(EQUINIX)
eBGP(DIXIE)
eBGP(LINX)
PoP1
PoP2
PoP3
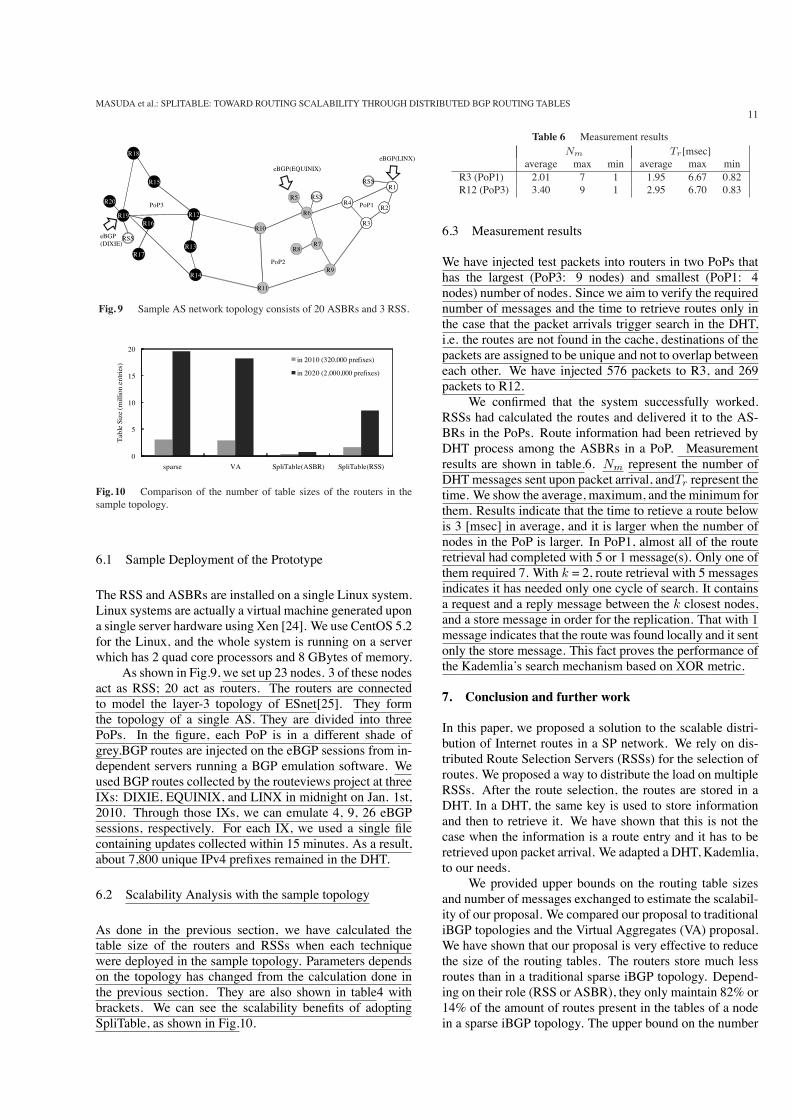
Fig. 9 Sample AS network topology consists of 20 ASBRs and 3 RSS.
0
5
10
15
20
sparse VA SpliTable(ASBR) SpliTable(RSS)
Tabl
e Si
ze (m
illio
n en
tries
) in 2010 (320,000 prefixes)
in 2020 (2,000,000 prefixes)
Fig. 10 Comparison of the number of table sizes of the routers in thesample topology.
6.1 Sample Deployment of the Prototype
The RSS and ASBRs are installed on a single Linux system.Linux systems are actually a virtual machine generated upona single server hardware using Xen [24]. We use CentOS 5.2for the Linux, and the whole system is running on a serverwhich has 2 quad core processors and 8 GBytes of memory.
As shown in Fig.9, we set up 23 nodes. 3 of these nodesact as RSS; 20 act as routers. The routers are connectedto model the layer-3 topology of ESnet[25]. They formthe topology of a single AS. They are divided into threePoPs. In the figure, each PoP is in a different shade ofgrey.BGP routes are injected on the eBGP sessions from in-dependent servers running a BGP emulation software. Weused BGP routes collected by the routeviews project at threeIXs: DIXIE, EQUINIX, and LINX in midnight on Jan. 1st,2010. Through those IXs, we can emulate 4, 9, 26 eBGPsessions, respectively. For each IX, we used a single filecontaining updates collected within 15 minutes. As a result,about 7,800 unique IPv4 prefixes remained in the DHT.
6.2 Scalability Analysis with the sample topology
As done in the previous section, we have calculated thetable size of the routers and RSSs when each techniquewere deployed in the sample topology. Parameters dependson the topology has changed from the calculation done inthe previous section. They are also shown in table4 withbrackets. We can see the scalability benefits of adoptingSpliTable, as shown in Fig.10.
Table 6 Measurement resultsNm Tr[msec]
average max min average max minR3 (PoP1) 2.01 7 1 1.95 6.67 0.82R12 (PoP3) 3.40 9 1 2.95 6.70 0.83
6.3 Measurement results
We have injected test packets into routers in two PoPs thathas the largest (PoP3: 9 nodes) and smallest (PoP1: 4nodes) number of nodes. Since we aim to verify the requirednumber of messages and the time to retrieve routes only inthe case that the packet arrivals trigger search in the DHT,i.e. the routes are not found in the cache, destinations of thepackets are assigned to be unique and not to overlap betweeneach other. We have injected 576 packets to R3, and 269packets to R12.
We confirmed that the system successfully worked.RSSs had calculated the routes and delivered it to the AS-BRs in the PoPs. Route information had been retrieved byDHT process among the ASBRs in a PoP. Measurementresults are shown in table.6. Nm represent the number ofDHTmessages sent upon packet arrival, andTr represent thetime. We show the average, maximum, and the minimum forthem. Results indicate that the time to retieve a route belowis 3 [msec] in average, and it is larger when the number ofnodes in the PoP is larger. In PoP1, almost all of the routeretrieval had completed with 5 or 1 message(s). Only one ofthem required 7. With k = 2, route retrieval with 5 messagesindicates it has needed only one cycle of search. It containsa request and a reply message between the k closest nodes,and a store message in order for the replication. That with 1message indicates that the route was found locally and it sentonly the store message. This fact proves the performance ofthe Kademlia’s search mechanism based on XOR metric.
7. Conclusion and further work
In this paper, we proposed a solution to the scalable distri-bution of Internet routes in a SP network. We rely on dis-tributed Route Selection Servers (RSSs) for the selection ofroutes. We proposed a way to distribute the load on multipleRSSs. After the route selection, the routes are stored in aDHT. In a DHT, the same key is used to store informationand then to retrieve it. We have shown that this is not thecase when the information is a route entry and it has to beretrieved upon packet arrival. We adapted a DHT, Kademlia,to our needs.
We provided upper bounds on the routing table sizesand number of messages exchanged to estimate the scalabil-ity of our proposal. We compared our proposal to traditionaliBGP topologies and the Virtual Aggregates (VA) proposal.We have shown that our proposal is very effective to reducethe size of the routing tables. The routers store much lessroutes than in a traditional sparse iBGP topology. Depend-ing on their role (RSS or ASBR), they only maintain 82% or14% of the amount of routes present in the tables of a nodein a sparse iBGP topology. The upper bound on the number

12IEICE TRANS. ??, VOL.Exx–??, NO.xx XXXX 200x
of messages required to distribute the routes in the DHT andto retrieve them from the DHT is very high. However, weare convinced that this upper bound largely overestimatesthe number of control messages that will be observed in realnetwork operation.
We have also shown a prototype design and an experi-mental deployment of our proposal. We confirmed the pro-posal had successfully worked, and through the experimentwe retrieved some measurement results such as number ofmessages and time required for a retrieval of the route incase the destination was not found in the router’s cache.
Our future work using the prototype which we de-scribed in this paper will focus on the evaluation regardingthe overall number of control messages and time to resolve aroute.This is expected to be done by taking consideration ofthe performance of the cache, using packet traces collectedin the Internet.
Acknowledgments
We would like to thank Akinori Isogai at NTT Network Ser-vice Systems Laboratories for his support to this work in theprototype evaluation.
References
[1] D. Meyer, L. Zhang, and K. Fall, “Report from the IAB workshopon routing and addressing,” RFC 4984, September 2007.
[2] G. Huston and G. Armitage, “Projecting future IPv4 router require-ments from trends in dynamic BGP behaviour,” ATNAC, Australia,December 2006.
[3] A. Feldmann, H. Kong, O. Maennel, and A. Tudor, “Measuring BGPpass-through times,” PAM, pp.267–277, 2004.
[4] F. Wang, Z. Mao, J. Wang, L. Gao, and R. Bush, “A measurementstudy on the impact of routing events on end-to-end internet pathperformance,” ACM SIGCOMM 2006, September 2006.
[5] T. Griffin and G. Wilfong, “On the correctness of iBGP configura-tion,” ACM SIGCOMM 2002, August 2002.
[6] C. Pelsser, A. Masuda, and K. Shiomoto, “Scalable Support of In-terdomain Routes in a Single AS,” IEEE GLOBECOM 2009, 2009.
[7] D. Farinacci, V. Fuller, D. Meyer, and D. Lewis, “Locator/ID Sepa-ration Protocol (LISP),” January 2010. Internet draft, draft-ietf-lisp-06.txt, work in progress.
[8] D. Krioukov, K. Claffy, K. Fall, and A. Brady, “On compact rout-ing for the internet,” ACM SIGCOMM Computer CommunicationReview (CCR), vol.37, no.3, 2007.
[9] P. Francis, X. Xu, H. Ballani, D. Jen, R. Raszuk, and L. Zhang,“FIB suppression with Virtual Aggregation,” Internet Draft, draft-ietf-grow-va-02.txt, work in progress, March 2010.
[10] M. Caesar, D. Caldwell, N. Feamster, J. Rexford, A. Shaikh, andJ. van der Merwe, “Design and implementation of a routing controlplatform,” Networked Systems Design and Implementation (NSDI),May 2005.
[11] L. Mathy and L. Iannone, “LISP-DHT: towards a DHT to map iden-tifiers onto locators,” CoNEXT ’08: Proceedings of the 2008 ACMCoNEXT Conference, New York, NY, USA, pp.1–6, ACM, 2008.
[12] M. Caesar, T. Condie, J. Kannan, K. Lakshminarayanan, and I. Sto-ica, “ROFL: routing on flat labels,” SIGCOMM Comput. Commun.Rev., vol.36, no.4, pp.363–374, 2006.
[13] G. Iannaccone, C.N. Chuah, S. Bhattacharyya, and C. Diot, “Feasi-bility of IP restoration in a tier 1 backbone,” IEEE Network, vol.18,no.2, pp.13–19, Mar-Apr 2004.
[14] O. Bonaventure, C. Filsfils, and P. Francois, “Achieving sub-50 mil-liseconds recovery upon BGP peering link failures,” IEEE/ACMTransactions on Networking, vol.15, no.5, pp.1123 – 1135, Octo-ber 2007.
[15] L. Iannone and O. Bonaventure, “On the cost of caching locator/IDmappings,” CoNEXT ’07: Proceedings of the 2007 ACM CoNEXTconference, December 2007.
[16] J. Rexford, J. Wang, Z. Xiao, and Y. Zhang, “BGP routing stabil-ity of popular destinations,” Proc. Internet Measurement Workshop,2002.
[17] P. Maymounkov and D. Mazieres, “Kademlia: A peer-to-peer infor-mation system based on the XOR metric,” International workshopon Peer-To-Peer Systems (IPTPS 2002), March 2002.
[18] “Quagga Routing Software Suite.” http://www.quagga.net.[19] “Entangled - DHT and Tuple Space based on Kademlia.” http:
//entangled.sourceforge.net/.[20] R. Chandra and J. Scudder, “Capabilities advertisement with BGP-
4,” RFC 3392, November 2002.[21] R. Zhang and M. Bartell, BGP Design and Implementation, first ed.,
Cisco Press, December 2003.[22] P. Francis, “A configuration-only approach to shrinking FIBs,” Pre-
sentation at NANOG42’ meeting, February 2008.[23] “BGPRouting Table Analysis Reports.” http://bgp.potaroo.
net/.[24] “Xen hypervisor.” http://www.xen.org/.[25] “Energy Sciences Network.” http://www.es.net/.
AkeoMasuda received the B.S degree fromthe University of Tokyo, Japan, in 1997. He re-ceived the M. Science and Ph. D degree fromWaseda University, Japan. He is with the Net-work Service Systems Laboratories in NTT Cor-poration since 1997, and is a visiting researcherat Waseda University. His research interests in-clude IP-QoS, optical networks, network virtu-alization, inter-domain routing, and wireless ac-cess protocols. He is a member of IEICE.
Cristel Pelsser received her Master de-gree in computer science from the FUNDP inBelgium in 2001. She then obtained her PhDin applied sciences from the UCL, in Belgium,in 2006. From 2007 to 2009, she held a post-doctorate position at NTT Network Service Sys-tems Laboratories in Japan. She is now a re-searcher at Internet Initiative Japan (IIJ). Hercurrent research interests are in Internet routingand web applications scaling.
Kohei Shiomoto is a Senior Research Engi-neer, Supervisor, Group Leader at NTTNetworkService Systems Laboratories, Tokyo, Japan.He joined the Nippon Telegraph and TelephoneCorporation (NTT), Tokyo, Japan in April 1989.He has been engaged in R&D of high-speednetworking including ATM, IP, (G)MPLS, andIP+Optical networking in NTT labs. From Au-gust 1996 to September 1997 he was a visitingscholar at Washington University in St. Louis,MO, USA. Since April 2006, he has been lead-
ing the IP Optical Networking Research Group in NTT Network ServiceSystems Laboratories. He received the B.E., M.E., and Ph.D degrees in

MASUDA et al.: SPLITABLE: TOWARD ROUTING SCALABILITY THROUGH DISTRIBUTED BGP ROUTING TABLES13
information and computer sciences from Osaka University, Osaka in 19871989, and 1998, respectively. He is a Fellow of IEICE, a member of IEEE,and ACM.





























