Embed Size (px)
Citation preview

PageNUCA: PageNUCA: Selected Policies for Page-Selected Policies for Page-grain Locality Management grain Locality Management
in Large Shared CMP in Large Shared CMP CachesCaches
Mainak Chaudhuri, IIT KanpurMainak Chaudhuri, IIT Kanpur
[email protected]@iitk.ac.in

PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
Talk in one slideTalk in one slide Large shared caches in CMPs are Large shared caches in CMPs are
designed as a collection of a number designed as a collection of a number of smaller banksof smaller banks
The banks are distributed across the The banks are distributed across the floor of the chip and connected to floor of the chip and connected to the cores by some point-to-point the cores by some point-to-point interconnect giving rise to a NUCAinterconnect giving rise to a NUCA
We explore page-grain dynamic We explore page-grain dynamic data migration in a NUCA and data migration in a NUCA and compare it with block-grain compare it with block-grain migration and OS-assisted static migration and OS-assisted static bank-to-page mapping techniques bank-to-page mapping techniques (first touch and application-directed)(first touch and application-directed)

PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
SketchSketch PreliminariesPreliminaries
– Why page-grainWhy page-grain– Hypothesis and observationsHypothesis and observations
Dynamic page migrationDynamic page migration Dynamic cache block migrationDynamic cache block migration OS-assisted static page mappingOS-assisted static page mapping Simulation environmentSimulation environment Simulation resultsSimulation results An analytical modelAn analytical model SummarySummary
PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
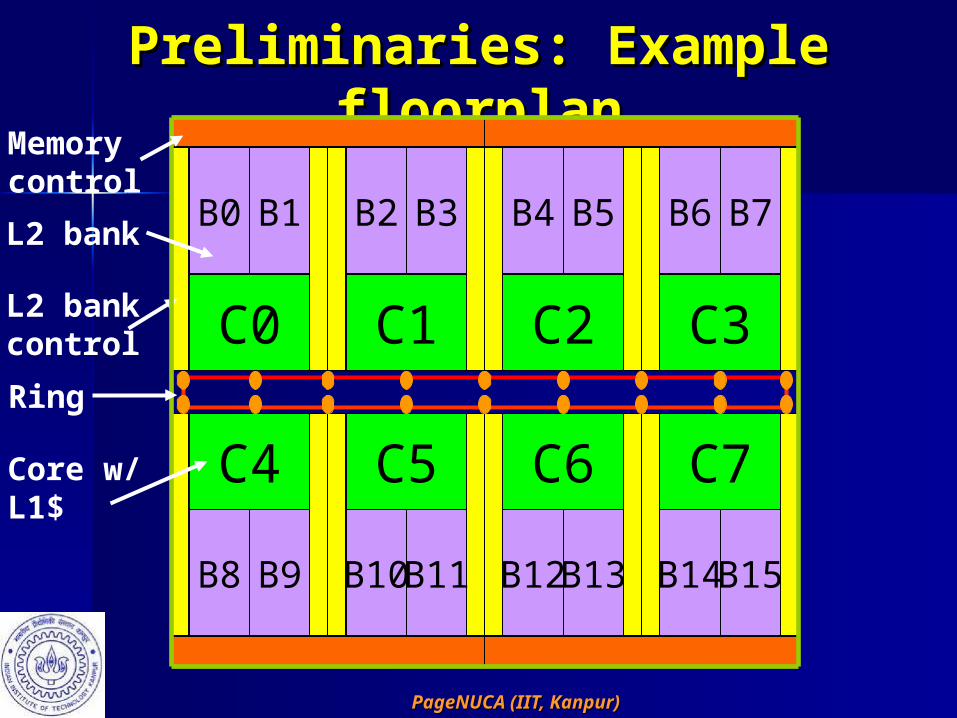
Preliminaries: Example Preliminaries: Example floorplanfloorplan
C0
B0 B1
L2 bankcontrol C1
B2 B3
C2
B4 B5
C3
B6 B7
C4
B8 B9
C5
B10B11
C6
B12B13
C7
B14B15
Memorycontrol
L2 bank
Ring
Core w/L1$

PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
Preliminaries: Baseline Preliminaries: Baseline mappingmapping Virtual address to physical address Virtual address to physical address
mapping is demand-based L2 cache-mapping is demand-based L2 cache-aware bin-hoppingaware bin-hopping– Good for reducing L2 cache conflictsGood for reducing L2 cache conflicts
An L2 cache block is found in a unique An L2 cache block is found in a unique bank at any point in timebank at any point in time– Home bank maintains the directory entry Home bank maintains the directory entry
of each block in the bank as an extended of each block in the bank as an extended statestate
– Home bank is a function of physical Home bank is a function of physical address coming out of the L1 cache address coming out of the L1 cache controllercontroller
– Home bank may change as a block Home bank may change as a block migratesmigrates
– Replication not explored in this workReplication not explored in this work

PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
Preliminaries: Baseline Preliminaries: Baseline mappingmapping Physical address to bank mapping is Physical address to bank mapping is
page-interleavedpage-interleaved– Bank number bits are located right next Bank number bits are located right next
to the page offset bitsto the page offset bits– Delivers performance and energy-Delivers performance and energy-
efficiency similar to the more popular efficiency similar to the more popular block-interleaved schemeblock-interleaved scheme
Private L1 caches are kept coherent Private L1 caches are kept coherent via a home-based MESI directory via a home-based MESI directory protocolprotocol– Every L1 cache request is forwarded to Every L1 cache request is forwarded to
the home bank first for consulting the the home bank first for consulting the directory entrydirectory entry
– The cache hierarchy maintains inclusionThe cache hierarchy maintains inclusion

PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
Preliminaries: Why page-grainPreliminaries: Why page-grain Past research has explored block-grain Past research has explored block-grain
data migration and replication in NUCAsdata migration and replication in NUCAs– See paper for a detailed accountSee paper for a detailed account
Learning dynamic reference patterns at Learning dynamic reference patterns at coarse-grain requires less storagecoarse-grain requires less storage
Can pipeline the transfer of multiple Can pipeline the transfer of multiple cache blocks (amortizes the overhead)cache blocks (amortizes the overhead)
Page-grain is particularly attractivePage-grain is particularly attractive– Contiguous physical data exceeding a page Contiguous physical data exceeding a page
may include completely unrelated virtual may include completely unrelated virtual pages (we compare two ends of spectrum)pages (we compare two ends of spectrum)
– Success in NUMAs (Origin 2000 and Wildfire)Success in NUMAs (Origin 2000 and Wildfire)
PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
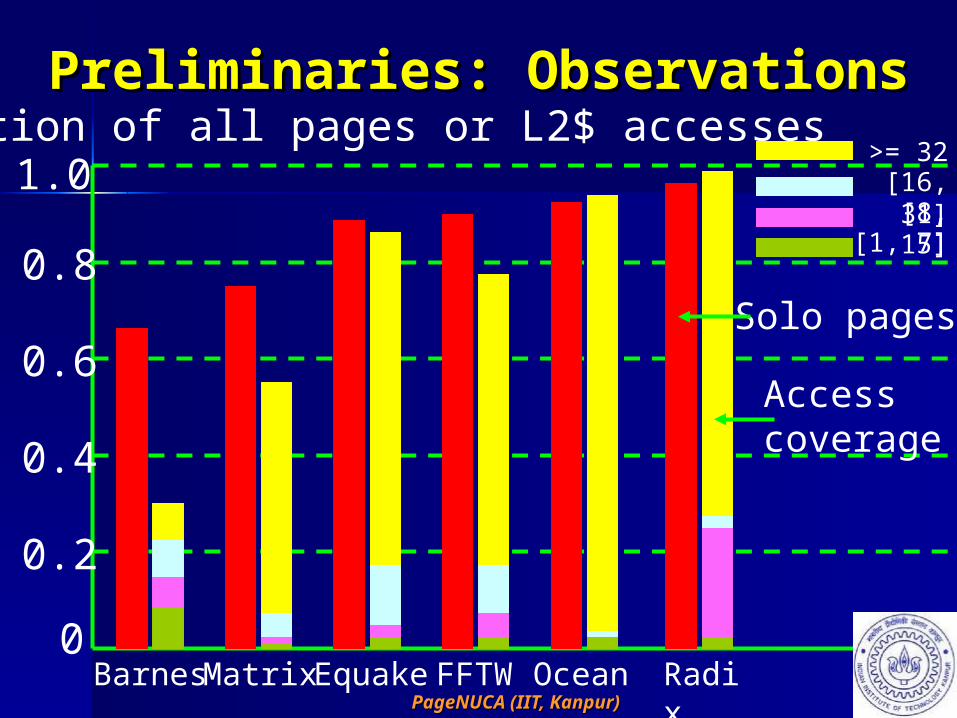
Preliminaries: ObservationsPreliminaries: Observations>= 32
[16, 31][8, 15][1, 7]
Fraction of all pages or L2$ accesses
0
0.2
0.4
0.6
0.8
1.0
BarnesMatrixEquakeFFTW Ocean Radix
Solo pages
Accesscoverage

PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
Preliminaries: ObservationsPreliminaries: Observations For five out of six applications, more For five out of six applications, more
than 75% of pages accessed in a than 75% of pages accessed in a 0.1M-cycle sample period are solo0.1M-cycle sample period are solo
For five out of six applications, more For five out of six applications, more than 50% L2 cache accesses are than 50% L2 cache accesses are covered by these solo pagescovered by these solo pages
Major portion of L2 cache accesses Major portion of L2 cache accesses are covered by solo pages with 32 are covered by solo pages with 32 or more accessesor more accesses– Potential for compensating migration Potential for compensating migration
overhead by enjoying subsequent overhead by enjoying subsequent reusesreuses

PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
SketchSketch PreliminariesPreliminaries
– Why page-grainWhy page-grain– Hypothesis and observationsHypothesis and observations
Dynamic page migrationDynamic page migration Dynamic cache block migrationDynamic cache block migration OS-assisted static page mappingOS-assisted static page mapping Simulation environmentSimulation environment Simulation resultsSimulation results An analytical modelAn analytical model SummarySummary

PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
Dynamic page migrationDynamic page migration Fully hardwired solution composed of Fully hardwired solution composed of
four central algorithmsfour central algorithms– When to migrate a pageWhen to migrate a page– Where to migrate a candidate pageWhere to migrate a candidate page– How to locate a cache block belonging to How to locate a cache block belonging to
a migrated pagea migrated page– How the physical data transfer takes How the physical data transfer takes
placeplace Definition: an L2 cache bank B is local Definition: an L2 cache bank B is local
to a core C if B is in {x | RTWD (x, C) ≤ to a core C if B is in {x | RTWD (x, C) ≤ RTWD (y, C) for all y ≠ x} = LOCAL(C)RTWD (y, C) for all y ≠ x} = LOCAL(C)– A core can have multiple local banksA core can have multiple local banks
PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
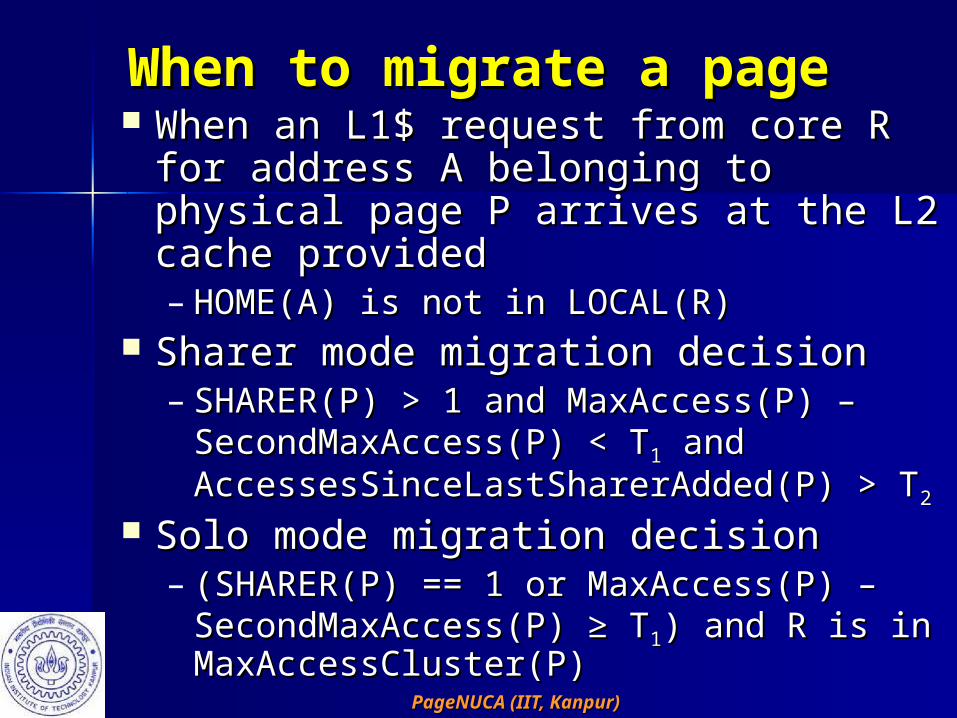
When to migrate a pageWhen to migrate a page When an L1$ request from core R When an L1$ request from core R
for address A belonging to physical for address A belonging to physical page P arrives at the L2 cache page P arrives at the L2 cache provided provided – HOME(A) is not in LOCAL(R)HOME(A) is not in LOCAL(R)
Sharer mode migration decisionSharer mode migration decision– SHARER(P) > 1 and MaxAccess(P) – SHARER(P) > 1 and MaxAccess(P) –
SecondMaxAccess(P) < TSecondMaxAccess(P) < T11 and and AccessesSinceLastSharerAdded(P) > TAccessesSinceLastSharerAdded(P) > T22
Solo mode migration decisionSolo mode migration decision– (SHARER(P) == 1 or MaxAccess(P) – (SHARER(P) == 1 or MaxAccess(P) –
SecondMaxAccess(P) ≥ TSecondMaxAccess(P) ≥ T11) and R is in ) and R is in MaxAccessCluster(P)MaxAccessCluster(P)

PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
When to migrate a pageWhen to migrate a page Hardware supportHardware support
– Page access counter table (PACT) per L2 Page access counter table (PACT) per L2 cache bank and associated logiccache bank and associated logic
– PACT is a set-associative cache that PACT is a set-associative cache that maintains several information about a pagemaintains several information about a page
– Valid, tag, LRU statesValid, tag, LRU states– Saturating counters keeping track of access Saturating counters keeping track of access
count from a topologically close cluster of count from a topologically close cluster of cores (pair of adjacent)cores (pair of adjacent)
– Max. and second max. counts, max. clusterMax. and second max. counts, max. cluster– Sharer bitvector and population countSharer bitvector and population count– Count of accesses since last sharer addedCount of accesses since last sharer added

PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
When to migrate a pageWhen to migrate a page PACT organizationPACT organization
PageSet 0
PageSet 2
PageSet N-1
PageSet 1
k ways
Psz/Bsz
L2 cache bank
k ways012
N-1PACT

PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
Where to migrate a pageWhere to migrate a page Consists of two sub-algorithmsConsists of two sub-algorithms
– Find a destination bank of migrationFind a destination bank of migration– Find an appropriate “region” in the Find an appropriate “region” in the
destination bank for holding the migrated destination bank for holding the migrated pagepage
Find a destination bank D for a Find a destination bank D for a candidate page P for solo mode candidate page P for solo mode migrationmigration– Definition: load on a bank is defined as the Definition: load on a bank is defined as the
number of pages mapped on to that bank number of pages mapped on to that bank either by OS or dynamically by migrationeither by OS or dynamically by migration
– Set D to the least loaded bank among Set D to the least loaded bank among LOCAL(R) where R is the requesting core LOCAL(R) where R is the requesting core for the current transactionfor the current transaction

PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
Where to migrate a pageWhere to migrate a page Find a destination bank D for a Find a destination bank D for a
candidate page P for sharer mode candidate page P for sharer mode migrationmigration– Ideally we want D to minimize Ideally we want D to minimize
ΣΣii a aii(P)*RTWD (x, S(P)*RTWD (x, Sii(P)) where i ranges over (P)) where i ranges over the sharers of P (read out from PACT), athe sharers of P (read out from PACT), aii(P) (P) is the number of accesses from the iis the number of accesses from the ith th
sharer to page P, and Ssharer to page P, and Sii(P) is the i(P) is the ith th sharersharer– Simplification: assume aSimplification: assume aii(P) == a(P) == ajj(P)(P)– Maintain a “Proximity ROM” of size 2Maintain a “Proximity ROM” of size 2#C#C per per
L2 cache bank indexed by the sharer L2 cache bank indexed by the sharer vector of P and returning top four solutions vector of P and returning top four solutions of the minimization problem; cancel of the minimization problem; cancel migration if HOME(P) is one of these fourmigration if HOME(P) is one of these four
– Set D to the one with least loadSet D to the one with least load

PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
Where to migrate a pageWhere to migrate a page Find a region in destination bank D for Find a region in destination bank D for
migrated page Pmigrated page P– A design decision: migration is done by A design decision: migration is done by
swapping the contents of page frame P’ swapping the contents of page frame P’ mapping to D with those of P in HOME(P); mapping to D with those of P in HOME(P); no gradual migration => saves powerno gradual migration => saves power
– Look for an invalid entry in PACT(D) => Look for an invalid entry in PACT(D) => unused index range covering a page in D; unused index range covering a page in D; generate a frame id P’ outside physical generate a frame id P’ outside physical address range mapping to that index address range mapping to that index rangerange
– If not found, let P’ be the LRU page in a If not found, let P’ be the LRU page in a randomly picked non-MRU set in PACT(D)randomly picked non-MRU set in PACT(D)

PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
How to locate a cache block in How to locate a cache block in L2$L2$ The migration process is confined The migration process is confined
within the boundaries of the L2 cache within the boundaries of the L2 cache onlyonly– Not visible to OS, TLBs, L1 caches, Not visible to OS, TLBs, L1 caches,
external memory system (may contain external memory system (may contain other CMP nodes)other CMP nodes)
– Definition: OS-generated physical address Definition: OS-generated physical address (OS PA) is the address assigned to a page (OS PA) is the address assigned to a page at the time of a page faultat the time of a page fault
– Definition: L2 cache address (L2 CA) of a Definition: L2 cache address (L2 CA) of a cache block is the address of the block cache block is the address of the block within the L2 cachewithin the L2 cache
– Appropriate translation must be carried Appropriate translation must be carried out between OS PA and L2 CA at L2 cache out between OS PA and L2 CA at L2 cache boundaries boundaries
PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
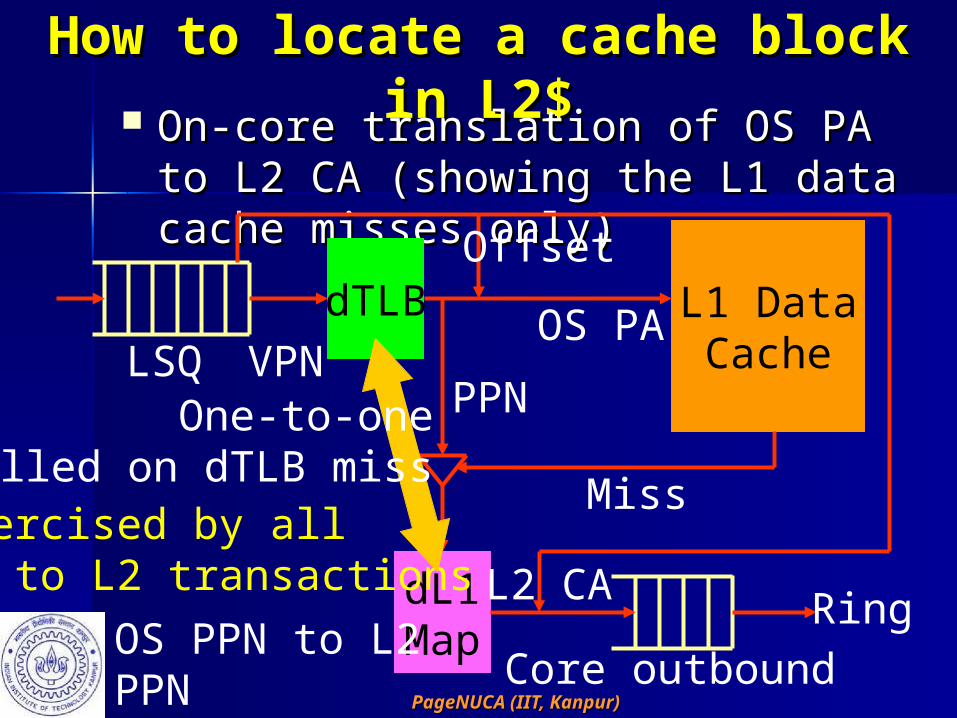
How to locate a cache block in How to locate a cache block in L2$L2$ On-core translation of OS PA to L2 On-core translation of OS PA to L2
CA (showing the L1 data cache CA (showing the L1 data cache misses only)misses only)
dTLB L1 DataCache
dL1Map
LSQ VPN
Offset
OS PA
PPN
Miss
L2 CA RingCore outbound
OS PPN to L2 PPN
Exercised by allL1 to L2 transactions
One-to-oneFilled on dTLB miss
PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
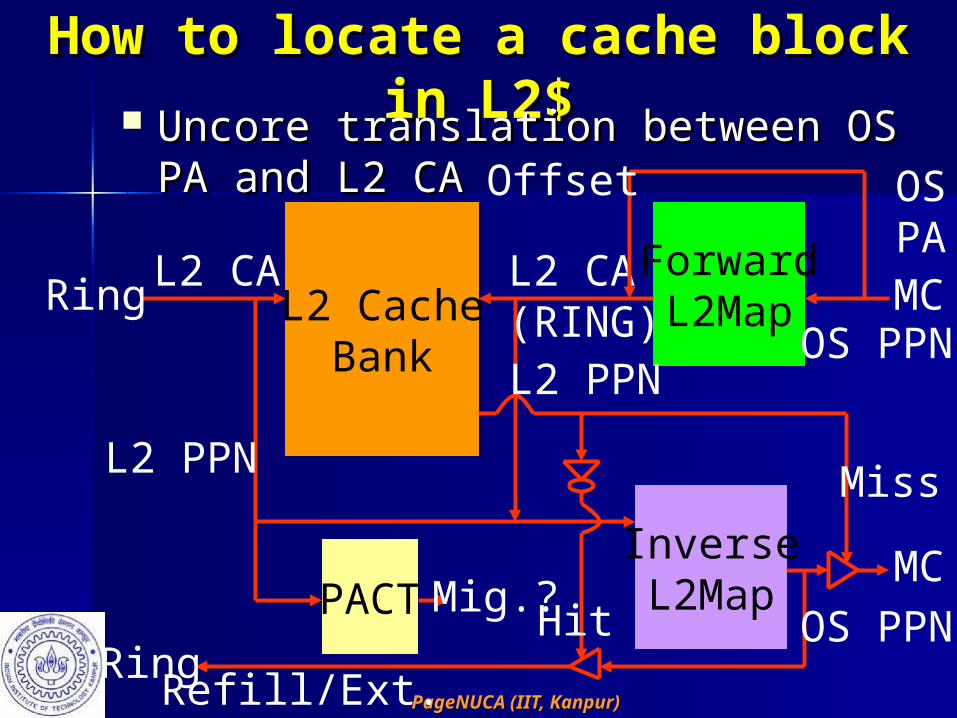
How to locate a cache block in How to locate a cache block in L2$L2$ Uncore translation between OS PA Uncore translation between OS PA
and L2 CAand L2 CA
L2 CacheBank
ForwardL2Map
InverseL2MapPACT
Ring
Ring
L2 CA
L2 PPN
Mig.?
MC
MC
OS PPN
L2 CA(RING)L2 PPN
Miss
Offset
OS PPN
OSPA
Refill/Ext.
Hit
PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
How to locate a cache block in How to locate a cache block in L2$L2$ Storage overheadStorage overhead
– L1Maps: instruction and data per core; L1Maps: instruction and data per core; organization same as iTLB and dTLB; organization same as iTLB and dTLB; filled at the time of TLB miss from filled at the time of TLB miss from forward L2Map (if not found, filled with forward L2Map (if not found, filled with identity)identity)
– Forward and inverse L2Maps per L2 Forward and inverse L2Maps per L2 cache bank: organized as a set-cache bank: organized as a set-associative cache; sized to achieve associative cache; sized to achieve small volume of replacementssmall volume of replacements
Invariant: Map(P, Q) Invariant: Map(P, Q) єє fL2Map(HOME(P)) iff Map(Q, P) fL2Map(HOME(P)) iff Map(Q, P) єє iL2Map(HOME(Q))iL2Map(HOME(Q))

PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
How to locate a cache block in How to locate a cache block in L2$L2$ Implications on miss pathsImplications on miss paths
– L1Map lookup can be hidden under the L1Map lookup can be hidden under the write to outbound queue in the local write to outbound queue in the local switchswitch
– L2 cache miss path gets lengthened L2 cache miss path gets lengthened because on a miss, the request must be because on a miss, the request must be routed to the original home bank over routed to the original home bank over the ring for allocating the MSHR and the ring for allocating the MSHR and going through the proper MCgoing through the proper MC
– On an L2 cache refill or external On an L2 cache refill or external intervention, the transaction arrives at intervention, the transaction arrives at the original home bank and must be the original home bank and must be routed to its migrated bank (if any)routed to its migrated bank (if any)

PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
How data is transferredHow data is transferred Page P from bank B is being swapped Page P from bank B is being swapped
with page P’ from bank B’with page P’ from bank B’– Note that these are L2 CAsNote that these are L2 CAs– Step1: iL2Map(B) produces OS PA of P Step1: iL2Map(B) produces OS PA of P
(call it Q) and iL2Map(B’) produces OS (call it Q) and iL2Map(B’) produces OS PA of P’ (call it Q’); swap these two PA of P’ (call it Q’); swap these two entriesentries
– Step2: fL2Map(HOME(Q)) must have Step2: fL2Map(HOME(Q)) must have Map(Q, P) and fL2Map(HOME(Q’)) must Map(Q, P) and fL2Map(HOME(Q’)) must have Map(Q’, P’); swap these two entrieshave Map(Q’, P’); swap these two entries
– Step3: Send the new forward maps i.e. Step3: Send the new forward maps i.e. Map(Q, P’) and Map(Q’, P) to the sharing Map(Q, P’) and Map(Q’, P) to the sharing cores of P and P’ [obtained from PACT(B) cores of P and P’ [obtained from PACT(B) and PACT(B’)] so that they can update and PACT(B’)] so that they can update their L1Mapstheir L1Maps

PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
How data is transferredHow data is transferred Page P from bank B is being swapped Page P from bank B is being swapped
with page P’ from bank B’with page P’ from bank B’– Step4: Sharing cores acknowledge L1Map Step4: Sharing cores acknowledge L1Map
updateupdate– Step5: Start the pipelined transfer of data Step5: Start the pipelined transfer of data
blocks, coherence states, and directory blocks, coherence states, and directory entryentry
– Banks B and B’ stop accepting any request Banks B and B’ stop accepting any request until the migration is completeuntil the migration is complete
– Migration protocol may evict cache blocks Migration protocol may evict cache blocks from B or B’ to make room for the from B or B’ to make room for the migrated blocks (perfect swap may not be migrated blocks (perfect swap may not be possible)possible)
– Cycle-free virtual lane dependence graph Cycle-free virtual lane dependence graph guarantees freedom from deadlockguarantees freedom from deadlock

PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
SketchSketch PreliminariesPreliminaries
– Why page-grainWhy page-grain– Hypothesis and observationsHypothesis and observations
Dynamic page migrationDynamic page migration Dynamic cache block migrationDynamic cache block migration OS-assisted static page mappingOS-assisted static page mapping Simulation environmentSimulation environment Simulation resultsSimulation results An analytical modelAn analytical model SummarySummary

PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
Dynamic cache block migrationDynamic cache block migration Modeled as a special case of page-Modeled as a special case of page-
grain migration where the grain is a grain migration where the grain is a single L2 cache blocksingle L2 cache block– PACT is replaced by BACT and is now PACT is replaced by BACT and is now
tightly coupled with the L2 cache tag array tightly coupled with the L2 cache tag array (doesn’t require separate tags and LRU (doesn’t require separate tags and LRU states)states)
– TT11 and T and T22 are retuned for best performance are retuned for best performance– Destination bank selection algorithm is Destination bank selection algorithm is
similar except the load on a bank is the similar except the load on a bank is the number of cache blocks fills to the banknumber of cache blocks fills to the bank
– Destination set is selected by first looking Destination set is selected by first looking for the next round-robin set with an invalid for the next round-robin set with an invalid way and resorting to a random selection if way and resorting to a random selection if none found none found

PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
Dynamic cache block migrationDynamic cache block migration The algorithm for locating a cache block The algorithm for locating a cache block
in the L2 cache is similarin the L2 cache is similar– The per-core L1Map is now a replica of the The per-core L1Map is now a replica of the
forward L2Map so that on an L1 cache miss forward L2Map so that on an L1 cache miss request can be routed to the correct bankrequest can be routed to the correct bank
– As an optimization, we store the target set As an optimization, we store the target set and way also in the L1Map so that the L2 and way also in the L1Map so that the L2 cache tag access latency can be eliminated cache tag access latency can be eliminated (races with migration are resolved by (races with migration are resolved by NACKing the racing L1 cache request)NACKing the racing L1 cache request)
– The forward and inverse L2Maps get bigger The forward and inverse L2Maps get bigger (same organization as the L2 cache)(same organization as the L2 cache)
– The inverse L2Map shares the tag array The inverse L2Map shares the tag array with the L2 cachewith the L2 cache

PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
SketchSketch PreliminariesPreliminaries
– Why page-grainWhy page-grain– Hypothesis and observationsHypothesis and observations
Dynamic page migrationDynamic page migration Dynamic cache block migrationDynamic cache block migration OS-assisted static page mappingOS-assisted static page mapping Simulation environmentSimulation environment Simulation resultsSimulation results An analytical modelAn analytical model SummarySummary

PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
OS-assisted first touch OS-assisted first touch mappingmapping The OS-assisted techniques (static or The OS-assisted techniques (static or
dynamic) change the default VA to PA dynamic) change the default VA to PA mapping to indirectly achieve a “good” mapping to indirectly achieve a “good” PA to L2 cache bank mappingPA to L2 cache bank mapping– Contrast with the hardware techniques Contrast with the hardware techniques
that keep the VA to PA mapping that keep the VA to PA mapping unchanged and introduce a new PA to unchanged and introduce a new PA to shadow PA indirectionshadow PA indirection
– First touch mapping is a static technique First touch mapping is a static technique where the OS assigns a PA to a virtual where the OS assigns a PA to a virtual page such that the PA is mapped to a bank page such that the PA is mapped to a bank local to the core touching the page for the local to the core touching the page for the first timefirst time
– Resort to a spill mechanism if all local page Resort to a spill mechanism if all local page frames are exhausted (e.g., pick the frames are exhausted (e.g., pick the globally least loaded)globally least loaded)

PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
OS-assisted application-OS-assisted application-directeddirected The application can provide a one-The application can provide a one-
time (manually coded) hint to the OS time (manually coded) hint to the OS about the affinity of data structuresabout the affinity of data structures– The hint is sent through special system The hint is sent through special system
calls just before the first parallel section calls just before the first parallel section beginsbegins
– Completely private data structures can Completely private data structures can provide accurate hintsprovide accurate hints
– Shared pages provide hints such that Shared pages provide hints such that they are placed round-robin within the they are placed round-robin within the local banks of the sharing coreslocal banks of the sharing cores
– Avoid flushing the re-mapped pages from Avoid flushing the re-mapped pages from cache hierarchy or copying in memory by cache hierarchy or copying in memory by leveraging the hardware page-grain map leveraging the hardware page-grain map tablestables

PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
SketchSketch PreliminariesPreliminaries
– Why page-grainWhy page-grain– Hypothesis and observationsHypothesis and observations
Dynamic page migrationDynamic page migration Dynamic cache block migrationDynamic cache block migration OS-assisted static page mappingOS-assisted static page mapping Simulation environmentSimulation environment Simulation resultsSimulation results An analytical modelAn analytical model SummarySummary

PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
Simulation environmentSimulation environment Single-node CMP with eight OOO coresSingle-node CMP with eight OOO cores
– Private L1 caches: 32KB 4-way LRUPrivate L1 caches: 32KB 4-way LRU– Shared L2 cache: 1MB 16-way LRU banks, Shared L2 cache: 1MB 16-way LRU banks,
16 banks distributed over a bidirectional 16 banks distributed over a bidirectional ringring
– Round-trip L2 cache hit latency from L1 Round-trip L2 cache hit latency from L1 cache: maximum 20 ns, minimum 7.5 ns cache: maximum 20 ns, minimum 7.5 ns (local access), mean 13.75 ns (assumes (local access), mean 13.75 ns (assumes uniform access distribution) [65 nm uniform access distribution) [65 nm process, M5 for ring with optimally placed process, M5 for ring with optimally placed repeaters]repeaters]
– Ring widths evaluated: 1024 bits, 512 bits, Ring widths evaluated: 1024 bits, 512 bits, 256 bits (area based on wiring pitch:30 256 bits (area based on wiring pitch:30 mmmm22, 15 mm, 15 mm22, 7.5 mm, 7.5 mm22))
– Off-die DRAM latency: 70 ns row miss, 30 Off-die DRAM latency: 70 ns row miss, 30 ns row hitns row hit

PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
Simulation environmentSimulation environment Shared memory applicationsShared memory applications
– Barnes, Ocean, Radix from SPLASH-2; Barnes, Ocean, Radix from SPLASH-2; Matrix (sparse solver using iterative Matrix (sparse solver using iterative CG) from DIS; Equake from SPEC; FFTWCG) from DIS; Equake from SPEC; FFTW
– All optimized with array-based queue All optimized with array-based queue locks and tree barrierslocks and tree barriers
Multi-programmed workloadsMulti-programmed workloads– Mix of SPEC 2000 and BioBenchMix of SPEC 2000 and BioBench– We report average turn-around time We report average turn-around time
(i.e. average CPI) for each application (i.e. average CPI) for each application to commit a representative set of one to commit a representative set of one billion dynamic instructions (identified billion dynamic instructions (identified using SimPoint)using SimPoint)
PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
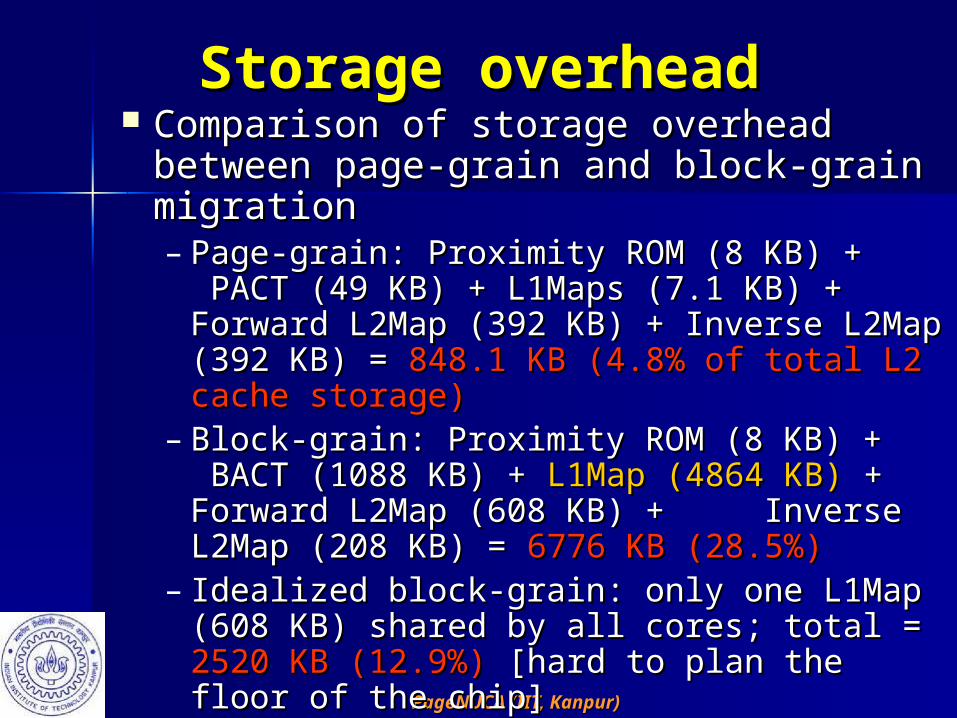
Storage overheadStorage overhead Comparison of storage overhead Comparison of storage overhead
between page-grain and block-grain between page-grain and block-grain migrationmigration– Page-grain: Proximity ROM (8 KB) + Page-grain: Proximity ROM (8 KB) +
PACT (49 KB) + L1Maps (7.1 KB) + PACT (49 KB) + L1Maps (7.1 KB) + Forward L2Map (392 KB) + Inverse L2Map Forward L2Map (392 KB) + Inverse L2Map (392 KB) = (392 KB) = 848.1 KB (4.8% of total L2 848.1 KB (4.8% of total L2 cache storage)cache storage)
– Block-grain: Proximity ROM (8 KB) + Block-grain: Proximity ROM (8 KB) + BACT (1088 KB) + BACT (1088 KB) + L1Map (4864 KB)L1Map (4864 KB) + + Forward L2Map (608 KB) + Inverse Forward L2Map (608 KB) + Inverse L2Map (208 KB) = L2Map (208 KB) = 6776 KB (28.5%)6776 KB (28.5%)
– Idealized block-grain: only one L1Map (608 Idealized block-grain: only one L1Map (608 KB) shared by all cores; total = KB) shared by all cores; total = 2520 KB 2520 KB (12.9%)(12.9%) [hard to plan the floor of the chip][hard to plan the floor of the chip]

PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
SketchSketch PreliminariesPreliminaries
– Why page-grainWhy page-grain– Hypothesis and observationsHypothesis and observations
Dynamic page migrationDynamic page migration Dynamic cache block migrationDynamic cache block migration OS-assisted static page mappingOS-assisted static page mapping Simulation environmentSimulation environment Simulation resultsSimulation results An analytical modelAn analytical model SummarySummary
PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
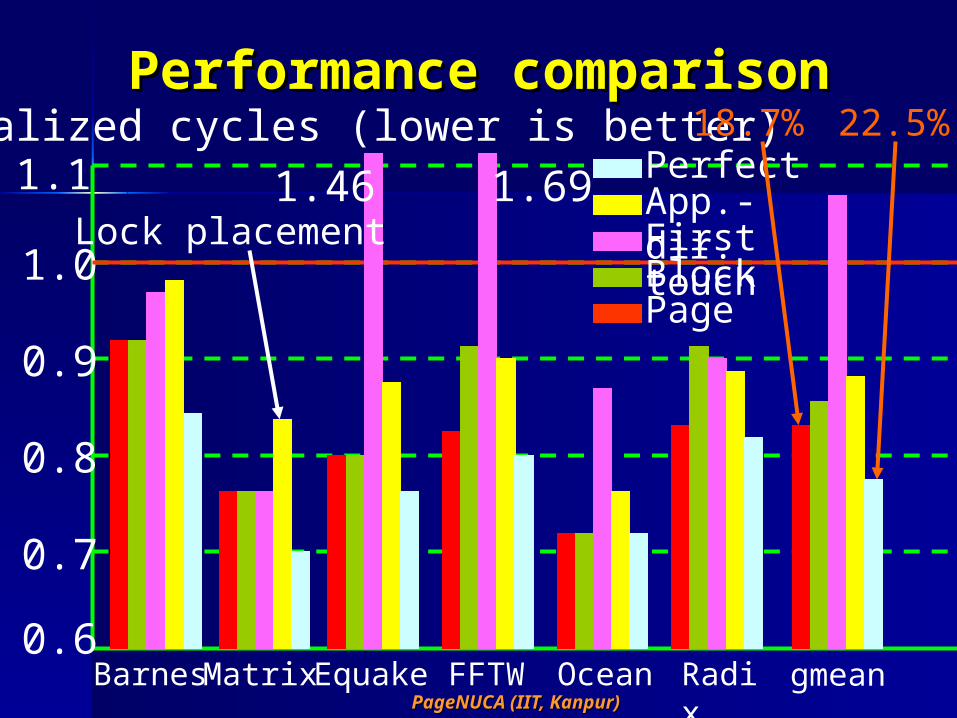
Performance comparisonPerformance comparison
Page
Normalized cycles (lower is better)
0.6
0.7
0.8
0.9
1.0
1.1
BarnesMatrixEquake FFTW Ocean Radix
gmean
1.46 1.69
BlockFirst touch
App.-dir.Perfect
18.7% 22.5%
Lock placement
PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
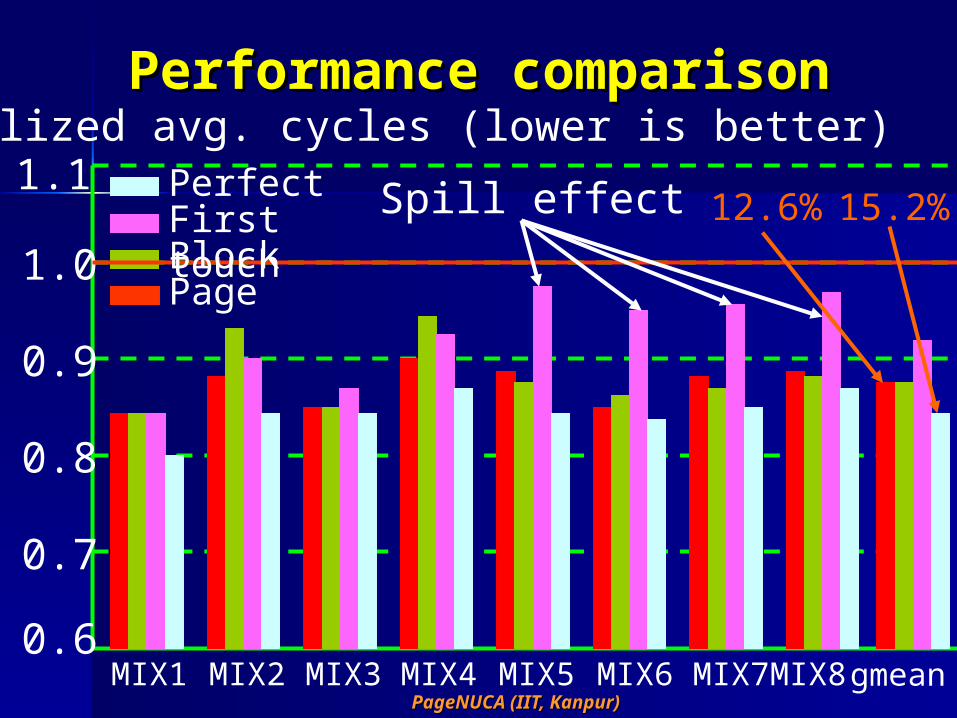
Performance comparisonPerformance comparison
Page
Normalized avg. cycles (lower is better)
0.6
0.7
0.8
0.9
1.0
1.1
MIX1 MIX2 MIX3 MIX4 MIX5 MIX6
gmean
BlockFirst touch
Perfect12.6% 15.2%Spill effect
MIX7
MIX8

PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
Performance analysisPerformance analysis Why page-grain sometimes Why page-grain sometimes
outperforms block-grain (counter-outperforms block-grain (counter-intuitive)intuitive)– Pipelined block transfer during page Pipelined block transfer during page
migration helps amortize the cost and migration helps amortize the cost and allows page migration to be more allows page migration to be more aggressively tuned for Taggressively tuned for T11 and T and T22
– The degree of aggression gets reflected The degree of aggression gets reflected in local L2 cache access percentage: in local L2 cache access percentage:
Base Page Block FT APBase Page Block FT AP
ShMem 21.0% 81.7% 72.6% 43.1% ShMem 21.0% 81.7% 72.6% 43.1% 54.1%54.1%
MProg 21.6% 85.3% 84.0% 69.6%MProg 21.6% 85.3% 84.0% 69.6%

PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
Performance analysisPerformance analysis Impact of ring bandwidthImpact of ring bandwidth
– Results presented till now assume a Results presented till now assume a bidirectional data ring of width 1024 bidirectional data ring of width 1024 bits in each directionbits in each direction
– A 256-bit data ring causes a 3.6% A 256-bit data ring causes a 3.6% increase in execution time of page increase in execution time of page migration for shared memory migration for shared memory applications and 1.3% increase in applications and 1.3% increase in execution time of multiprogrammed execution time of multiprogrammed workloadsworkloads
– Block migration is more tolerant to ring Block migration is more tolerant to ring bandwidth variationbandwidth variation

PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
L1 cache prefetchingL1 cache prefetching Impact of a 16 read/write stream Impact of a 16 read/write stream
stride prefetcher per corestride prefetcher per core
L1 Pref. Page Mig. BothL1 Pref. Page Mig. Both
ShMem 14.5% 18.7% 25.1%ShMem 14.5% 18.7% 25.1%
MProg 4.8% 12.6% 13.0%MProg 4.8% 12.6% 13.0%

PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
Energy SavingsEnergy Savings Energy savings originate fromEnergy savings originate from
– Reduced execution timeReduced execution time Potential show stoppersPotential show stoppers
– Extra dynamic interconnect energy due Extra dynamic interconnect energy due to migrationto migration
– Extra leakage in added SRAMsExtra leakage in added SRAMs– Extra dynamic energy in consulting the Extra dynamic energy in consulting the
additional tables and logicadditional tables and logic

PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
Energy SavingsEnergy Savings Good newsGood news
– Dynamic page migration is most Dynamic page migration is most energy-efficient among all the optionsenergy-efficient among all the options
– Saves 14% energy for shared memory Saves 14% energy for shared memory applications and 11% for applications and 11% for multiprogrammed workloads compared multiprogrammed workloads compared to baseline static NUCAto baseline static NUCA
– Extra leakage in large tables kills block Extra leakage in large tables kills block migration: saves only 4% and 2% migration: saves only 4% and 2% energy for shared memory and energy for shared memory and multiprogrammed workloadsmultiprogrammed workloads

PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
SketchSketch PreliminariesPreliminaries
– Why page-grainWhy page-grain– Hypothesis and observationsHypothesis and observations
Dynamic page migrationDynamic page migration Dynamic cache block migrationDynamic cache block migration OS-assisted static page mappingOS-assisted static page mapping Simulation environmentSimulation environment Simulation resultsSimulation results An analytical modelAn analytical model SummarySummary
PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
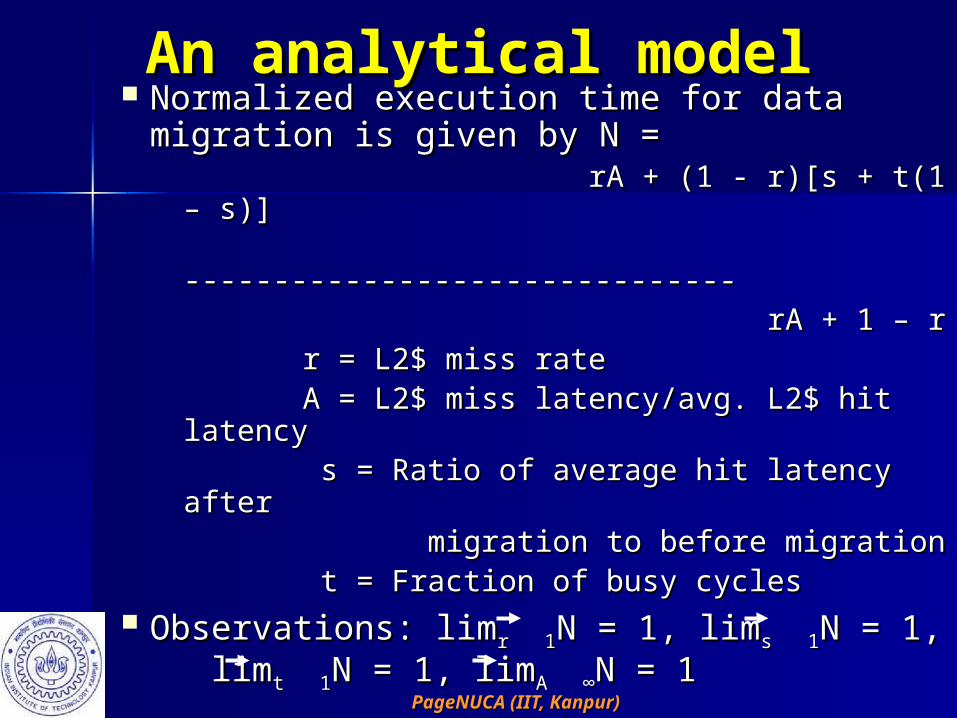
An analytical modelAn analytical model Normalized execution time for data Normalized execution time for data
migration is given by N = migration is given by N = rA + (1 - r)[s + t(1 – s)]rA + (1 - r)[s + t(1 – s)] -------------------------------------------------------------- rA + 1 – rrA + 1 – r r = L2$ miss rater = L2$ miss rate A = L2$ miss latency/avg. L2$ hit A = L2$ miss latency/avg. L2$ hit
latencylatency s = Ratio of average hit latency afters = Ratio of average hit latency after migration to before migration migration to before migration t = Fraction of busy cyclest = Fraction of busy cycles
Observations: limObservations: limr 1r 1N = 1, limN = 1, lims 1s 1N = N = 1, lim1, limt 1t 1N = 1, limN = 1, limA ∞A ∞N = 1N = 1

PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
SketchSketch PreliminariesPreliminaries
– Why page-grainWhy page-grain– Hypothesis and observationsHypothesis and observations
Dynamic page migrationDynamic page migration Dynamic cache block migrationDynamic cache block migration OS-assisted static page mappingOS-assisted static page mapping Simulation environmentSimulation environment Simulation resultsSimulation results An analytical modelAn analytical model SummarySummary

PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
SummarySummary Explored hardwired and OS-assisted Explored hardwired and OS-assisted
page migration in CMPspage migration in CMPs Page migration reduces execution Page migration reduces execution
time by 18.7% for shared memory time by 18.7% for shared memory applications and 12.6% for applications and 12.6% for multiprogrammed workloadsmultiprogrammed workloads
Storage overhead of page migration Storage overhead of page migration is less than 5%is less than 5%
Performance-optimized block Performance-optimized block migration algorithms come close to migration algorithms come close to page migration, but require at least page migration, but require at least 13% extra storage13% extra storage

PageNUCA (IIT, Kanpur)PageNUCA (IIT, Kanpur)
AcknowledgmentsAcknowledgments Intel Research CouncilIntel Research Council
– Financial supportFinancial support Gautam DoshiGautam Doshi
– Moral support, useful “tele-brain-Moral support, useful “tele-brain-storming”storming”
Vijay Degalahal, Jugash ChandarlapatiVijay Degalahal, Jugash Chandarlapati– HSPICE simulations for leakage modelingHSPICE simulations for leakage modeling
Sreenivas SubramoneySreenivas Subramoney– Detailed feedback on early manuscriptDetailed feedback on early manuscript
Kiran Panesar, Shubhra Roy, Manav Kiran Panesar, Shubhra Roy, Manav SubodhSubodh– Initial connectionsInitial connections

PageNUCA: PageNUCA: Selected Policies for Page-Selected Policies for Page-grain Locality Management grain Locality Management
in Large Shared CMP in Large Shared CMP CachesCaches
Mainak Chaudhuri, IIT KanpurMainak Chaudhuri, IIT [email protected]@iitk.ac.in
[Presented at HPCA’09][Presented at HPCA’09]
THANK YOU!

![MAINAK PODDAR AND AJAY SINGH THAKUR … · arXiv:1603.04629v3 [math.CV] 23 Jul 2016 GROUP ACTIONS AND NON-KAHLER COMPLEX MANIFOLDS¨ MAINAK PODDAR AND AJAY SINGH THAKUR Abstract](https://img.pdfslide.us/doc/110x75/5e5e9bc25aca8024455c1b60/mainak-poddar-and-ajay-singh-thakur-arxiv160304629v3-mathcv-23-jul-2016-group.jpg)



























