Embed Size (px)
Citation preview

Page 1
Learning and Inference in Natural Language From Stand Alone Learning Tasks to Structured
Representations
Dan RothDepartment of Computer Science
University of Illinois at Urbana-Champaign
Joint work with my students: Vasin Punyakanok, Wen-tau Yih, Dav Zimak
Biologically Inspired ComputingSendai, Japan, Nov. 2004

Page 2
We have concentrated on developing the theoretical basis within which to address some of the obstacles and on developing an experimental paradigm so that realistic
experiments can be performed to validate the theoretical basis.The emphasis is on large-scale real-world problems
in natural language understanding and visual recognition
The group develops theories and systems pertaining to intelligent behavior using a unified methodology.
At the heart of the approach is the idea that learning has a central role in intelligence.
Cognitive Computation Group

Page 3
Cognitive Computation Group Foundations
Learning Theory: Classification; Multi-Class Classification; Ranking Knowledge Representation: Relational Representations, Relational
Kernels Inference approaches: structural mappings
Intelligent Information Access Information Extraction Named Entities and Relations Matching Entities Mentions within and across documents and data
bases
Natural Language Processing Semantic Role Labeling Question answering Semantics
Software Basic tools development: SNoW, FEX; shallow parser, pos tagger,
semantic parser, …
Some of our work on understanding the role of learning in supporting reasoning in
the natural language domain

Page 4
Comprehension(ENGLAND, June, 1989) - Christopher Robin is alive and well. He lives in
England. He is the same person that you read about in the book, Winnie the Pooh. As a boy, Chris lived in a pretty home called Cotchfield Farm. When Chris was three years old, his father wrote a poem about him. The poem was printed in a magazine for others to read. Mr. Robin then wrote a book. He made up a fairy tale land where Chris lived. His friends were animals. There was a bear called Winnie the Pooh. There was also an owl and a young pig, called a piglet. All the animals were stuffed toys that Chris owned. Mr. Robin made them come to life with his words. The places in the story were all near Cotchfield Farm. Winnie the Pooh was written in 1925. Children still love to read about Christopher Robin and his animal friends. Most people don't know he is a real person who is grown now. He has written two books of his own. They tell what it is like to be famous.
1. Who is Christopher Robin? 2. When was Winnie the Pooh written?
3. What did Mr. Robin do when Chris was three years old?4. Where did young Chris live? 5. Why did Chris write two books of
his own?

Page 5
Illinois’ bored of education board
...Nissan Car and truck plant is ……divide life into plant and animal kingdom
(This Art) (can N) (will MD) (rust V) V,N,N
The dog bit the kid. He was taken to a veterinarian a hospital
Tiger was in Washington for the PGA Tour
What we Know: Stand Alone Ambiguity Resolution

Page 6
Comprehension(ENGLAND, June, 1989) - Christopher Robin is alive and well. He lives in
England. He is the same person that you read about in the book, Winnie the Pooh. As a boy, Chris lived in a pretty home called Cotchfield Farm. When Chris was three years old, his father wrote a poem about him. The poem was printed in a magazine for others to read. Mr. Robin then wrote a book. He made up a fairy tale land where Chris lived. His friends were animals. There was a bear called Winnie the Pooh. There was also an owl and a young pig, called a piglet. All the animals were stuffed toys that Chris owned. Mr. Robin made them come to life with his words. The places in the story were all near Cotchfield Farm. Winnie the Pooh was written in 1925. Children still love to read about Christopher Robin and his animal friends. Most people don't know he is a real person who is grown now. He has written two books of his own. They tell what it is like to be famous.
1. Who is Christopher Robin? 2. When was Winnie the Pooh written?
3. What did Mr. Robin do when Chris was three years old?4. Where did young Chris live? 5. Why did Chris write two books of
his own?

Page 7
Inference

Page 8
Global decisions in which several local decisions play a role but there are mutual dependencies on their outcome.
Learned classifiers for different sub-problems
Incorporate classifiers’ information, along with constraints, in making coherent decisions – decisions that respect the local classifiers as well as domain & context specific constraints.
Global inference for the best assignment to all variables of interest.
Inference with Classifiers

Page 9
Overview Stand Alone Learning
Modeling Representational Issues. Computational Issues
Inference Making Decisions under General Constraints Semantic Role Labeling
How to train Components of Global Decisions Tradeoff that depends on easiness of learning
components. Feedback to learning is (indirectly) given by the
reasoning stage. There may not be a need (or even a possibility) to learn
exactly, but only to the extent that is supports Reasoning.
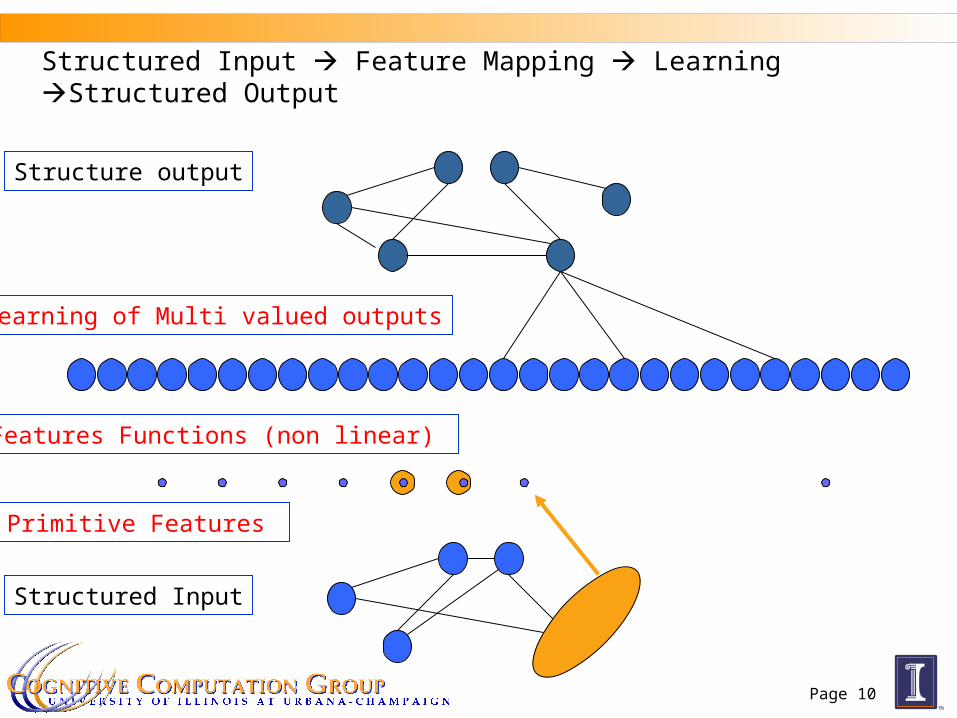
Page 10
Structured Input Feature Mapping Learning Structured Output
Structured Input
Primitive Features
Features Functions (non linear)
Structure output
Learning of Multi valued outputs

Page 11
Illinois’ bored of education board
...Nissan Car and truck plant is ……divide life into plant and animal kingdom
(This Art) (can N) (will MD) (rust V) V,N,N
The dog bit the kid. He was taken to a veterinarian a hospital
Tiger was in Washington for the PGA Tour
Stand Alone Ambiguity Resolution

Page 12
Disambiguation Problems Middle Eastern ____ are known for their sweetness Task: Decide which of { deserts , desserts } is more likely in the given context.
Ambiguity: modeled as confusion sets (class labels C )
C={ deserts, desserts}C={ Noun,Adj.., Verb…}C={ topic=Finance, topic=Computing}C={ NE=Person, NE=location}

Page 13
Learning to Disambiguate Given
a confusion set C={ deserts, desserts} sentence (s)
Middle Eastern ____ are known for their sweetness
Map into a feature based representation : S { 1(s), 2(s), …}
Learn a function FC that determines which of C={ deserts, desserts} is more likely in a given context.
FC (x)= w ¢ (x) Evaluate the function on future C sentences

Page 14
S= I don’t know whether to laugh or cry [x x x x]Consider words, pos tags, relative location in windowGenerate binary features representing presence of:
a word/pos within window around target word don’t within +/-3 know within +/-3 Verb at -1 to within +/- 3 laugh within +/-3 to a +1
conjunctions of size 2, within window of size 3 words: know__to; ___to laugh pos+words: Verb__to; ____to Verb
Example: Representation
The sentence is represented as a set of its active features
S= (don’t at -2 , know within +/-3,… ____to Verb,...)
Hope: S=I don’t care whether to laugh or cry has almost the same representation
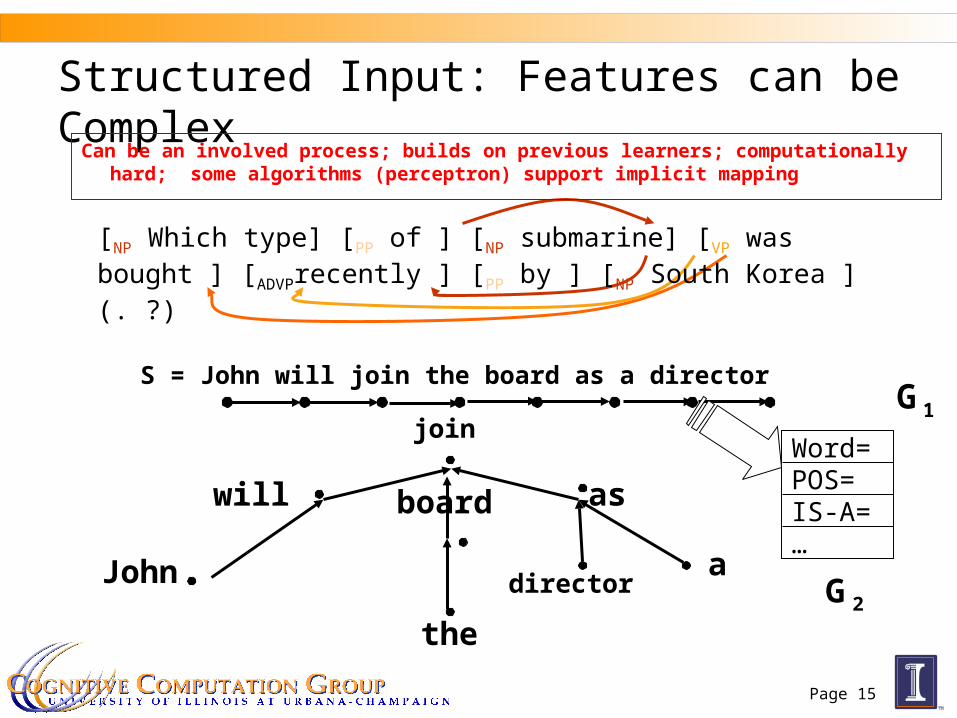
Page 15
Structured Input: Features can be Complex
join
John
will
the
board as
adirector
2G
[NP Which type] [PP of ] [NP submarine] [VP was bought ] [ADVPrecently ] [PP by ] [NP South Korea ] (. ?)
S = John will join the board as a director 1G
Word=POS=IS-A=…
Can be an involved process; builds on previous learners; computationally hard; some algorithms (perceptron) support implicit mapping

Page 16
A feature is a function over sentences, which maps a sentence to a set of properties of the sentence. : S {0,1} or [0,1]
There is a huge number of potential features (~105); Out of these – only a small number is actually active in each example.
Representation: List only features that are active (non zero) in example
When the number of features is fixed, the collection of examples is {1(s), 2(s), … n(s)} = {0,1}n. No need to fix number of features (on-line algorithms). infinite attribute domain { 1(s), 2(s), …} = {0,1}1
Some algorithms can make use of variable size input.
Notes on Representation
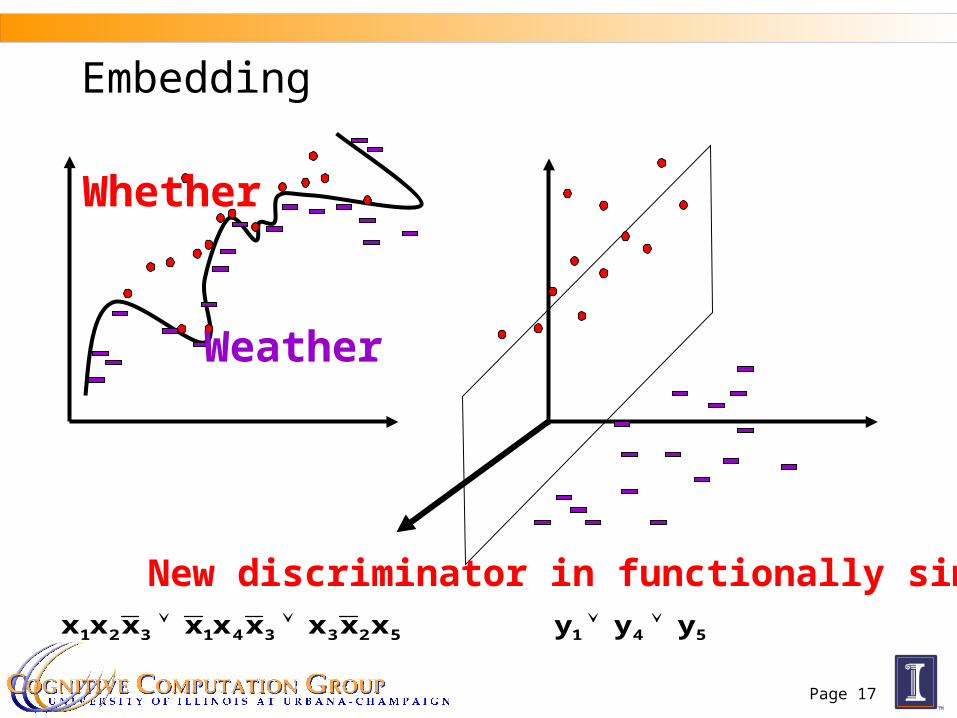
Page 17
Weather
Whether
523341321 xxxxxxxxx 541 yyy
New discriminator in functionally simpler
Embedding

Page 18
The number of potential features is very large
The instance space is sparse
Decisions depend on a small set of features (sparse)
Want to learn from a number of examples that is small relative to the dimensionality
Natural Language: Domain Characteristics

Page 19
Focus: Two families of on-line algorithms Examples x 2 {0,1}n; Hypothesis w 2 Rn;
Prediction: sgn{w ¢ x - }
Additive weight update algorithm (Perceptron, Rosenblatt, 1958. Variations exist)
Multiplicative weight update algorithm (Winnow, Littlestone, 1988. Variations exist)
(demotion) 1)x (if 1- w w,xbut w 0Class If
)(promotion 1)x (if 1 w w,xwbut 1Class If
iii
iii
(demotion) 1)x (if /2w w,xbut w 0Class If
)(promotion 1)x (if 2w w,xwbut 1Class If
iii
iii
Algorithm Descriptions

Page 20
Dominated by the sparseness of the function space Most features are irrelevant advantage to
multiplicative # of examples required by multiplicative
algorithms depends mostly on # of relevant features
Generalization bounds depend on ||w||.
Lesser issue: Sparseness of features space Very few active features advantage to additive. Generalization depend on ||x||
[Kivinen/Warmuth 95]
Generalization
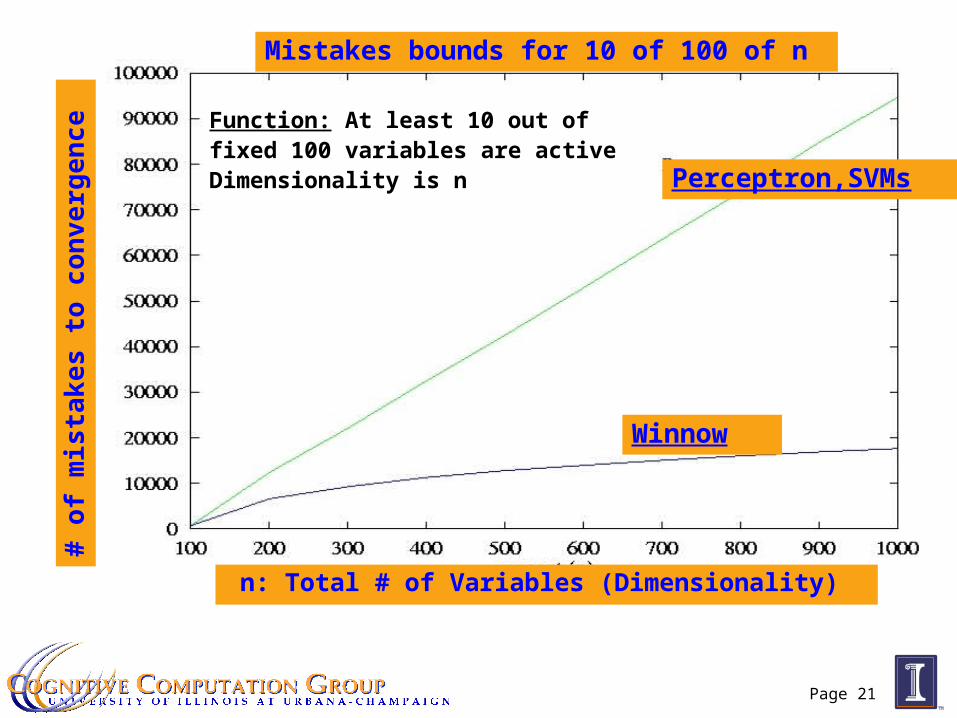
Page 21
Function: At least 10 out of fixed 100 variables are activeDimensionality is n Perceptron,SVMs
n: Total # of Variables (Dimensionality)
Winnow
Mistakes bounds for 10 of 100 of n#
of
mis
takes t
o c
on
verg
en
ce

Page 22
Multiclass Classification in NLP Name/Entity Recognition
Label people, locations, and organizations in a sentence [PER Sam Houston],[born in] [LOC Virginia], [was a
member of the] [ORG US Congress].
Decompose into sub-problems Sam Houston, born in Virginia... (PER,LOC,ORG,?) PER
(1) Sam Houston, born in Virginia... (PER,LOC,ORG,?) None
(0) Sam Houston, born in Virginia... (PER,LOC,ORG,?) LOC
(2)
Input : {0,1}d or Rd
Output: {0,1,2,3,...,k}

Page 23
Solving Multi-Class via Binary Learning
Decompose; use Winner-Take-All y = argmax wi ¢ x + ti
wi, x Rn , ti R (Pairwise classification also possible) Key issue: how to train the binary classifiers
wi Via Kessler Construction - comparative training - allows learning voroni diagrams.
Equivalently: learn in nk-dimension
1-vs-all:not expressive enough

Page 24
Detour – Basic Classifier: SNoW A learning architecture that supports several linear
update rules (Winnow, Perceptron, naïve Bayes) Allows regularization; pruning; many options True multi-class classification [Har-Peled, Roth, Zimak, NIPS
2003] Variable size examples; very good support for large
scale domains like NLP both in terms of number of examples and number of features.
Very efficient (1-2 order of magnitude faster than SVMs)
Integrated with an expressive Feature EXtraction Language (FEX)
[Dowload from: http://L2R.cs.uiuc.edu/~cogcomp ]

Page 25
Summary: Stand Alone Classification Theory is well understood
Generalization bounds Practical issues
Essentially all work is done with linear representations Features: generated explicitly or implicitly (Kernels) Tradeoff here is relatively understood Success on a large number of large scale classification
problems
Key issues: Features
How to decide what are good features How to compute/extract features (intermediate
representations) Supervision: learning protocol

Page 26
Overview Stand Alone Learning
Modeling Representational Issues. Computational Issues
Inference Making Decisions under General Constraints Semantic Role Labeling
How to train Components of Global Decisions Tradeoff that depends on easiness of learning
components. Feedback to learning is (indirectly) given by the
reasoning stage. There may not be a need (or even a possibility) to learn
exactly, but only to the extent that is supports Reasoning.

Page 27
Comprehension(ENGLAND, June, 1989) - Christopher Robin is alive and well. He lives in
England. He is the same person that you read about in the book, Winnie the Pooh. As a boy, Chris lived in a pretty home called Cotchfield Farm. When Chris was three years old, his father wrote a poem about him. The poem was printed in a magazine for others to read. Mr. Robin then wrote a book. He made up a fairy tale land where Chris lived. His friends were animals. There was a bear called Winnie the Pooh. There was also an owl and a young pig, called a piglet. All the animals were stuffed toys that Chris owned. Mr. Robin made them come to life with his words. The places in the story were all near Cotchfield Farm. Winnie the Pooh was written in 1925. Children still love to read about Christopher Robin and his animal friends. Most people don't know he is a real person who is grown now. He has written two books of his own. They tell what it is like to be famous.
1. Who is Christopher Robin? 2. When was Winnie the Pooh written?
3. What did Mr. Robin do when Chris was three years old?4. Where did young Chris live? 5. Why did Chris write two books of
his own?

Page 28
Identifying Phrase Structure
Classifiers1. Recognizing “The beginning of NP”2. Recognizing “The end of NP” (or: word based classifiers: BIO
representation)Also for other kinds of phrases…
Some Constraints1. Phrases do not overlap2. Order of phrases3. Length of phrases
Use classifiers to infer a coherent set of phrases
He reckons the current account deficit will narrow to only # 1.8 billion in
September
[NP He ] [VP reckons ] [NP the current account deficit ] [VP will narrow ]
[PP to ] [NP only # 1.8 billion ] [PP in ] [NP September ]
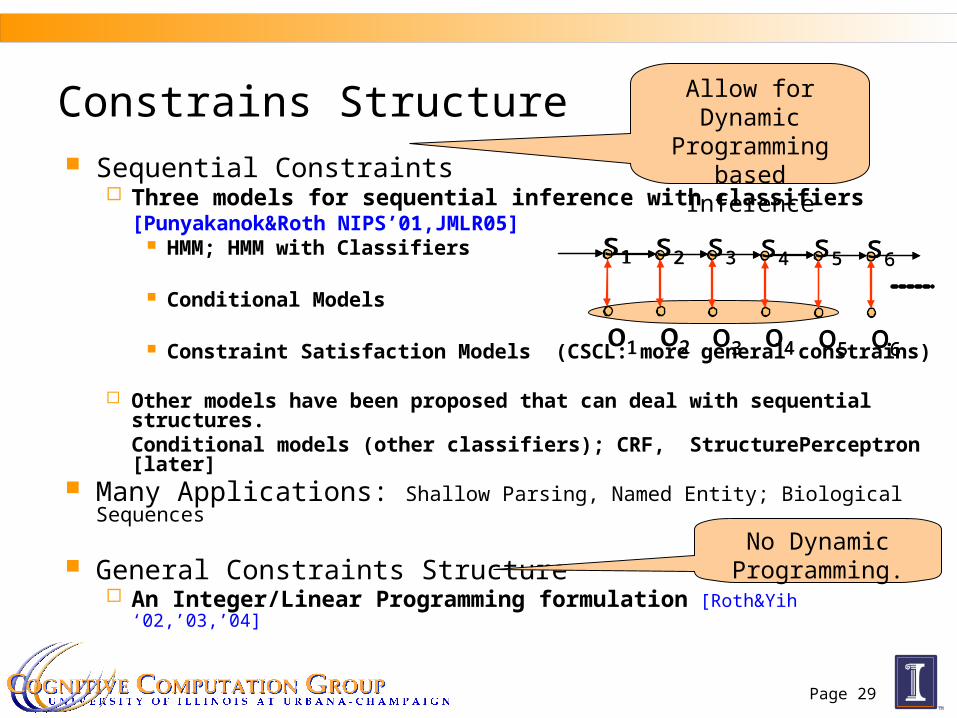
Page 29
Constrains Structure Sequential Constraints
Three models for sequential inference with classifiers[Punyakanok&Roth NIPS’01,JMLR05]
HMM; HMM with Classifiers
Conditional Models
Constraint Satisfaction Models (CSCL: more general constrains)
Other models have been proposed that can deal with sequential structures.Conditional models (other classifiers); CRF, StructurePerceptron [later]
Many Applications: Shallow Parsing, Named Entity; Biological Sequences
General Constraints Structure An Integer/Linear Programming formulation [Roth&Yih ‘02,’03,’04]
s1
o1
s2
o2
s3
o3
s4
o4
s5
o5
s6
o6
s1
o1
s2
o2
s3
o3
s4
o4
s5
o5
s6
o6
Allow for Dynamic Programming
based Inference
No Dynamic Programming.

Page 30
Identifying Entities and Relations
J.V. Oswald was murdered at JFK after his assassin, K. F. Johns…
Identify:
J.V. Oswald was murdered at JFK after his assassin, K. F. Johns…location
personperson
Kill (X, Y)
Identify named entities Identify relations between entities Exploit mutual dependencies between named
entities and relation to yield a coherent global detection.
Some knowledge (classifiers) may be known in advanceSome constraints may be
available only at decision time

Page 31
Inference with Classifiers Scenario:
Global decisions in which several local decisions / components play a role, but there are mutual dependencies on their outcome.
Assume: Learned classifiers for different sub-problems Constraints on classifiers’ labels (known during
training or only at evaluation time).
Goal: Incorporate classifiers’ predictions, along with the
constraints, in making coherent decisions – that respect the classifiers as well as domain/context specific constrains.
Formally: Global inference for the best assignment to all
variables of interest.

Page 32
Setting
Inference with classifiers is not a new idea. On sequential constraint structure:
HMM, PMM [Punyakanok&Roth], CRF[Lafferty et al.], CSCL[Punyakanok&Roth]
On general structure: Heuristic search Attempts to use Bayesian Networks [Roth&Yih’02] have
problems
The Proposed Integer linear programming (ILP) formulation General: works on non-sequential constraint structure Expressive: can represent many types of constraints Optimal: finds the optimal solution Fast: commercial packages are able to quickly solve
very large problems (hundreds of variables and constraints)

Page 33
Problem Setting (1/2)
x4 x5 x6 x7 x8
x1 x2 x3C(x1,x4) C(x2,x3,x6,x7,x8)
Random Variables X:
Conditional Distributions P (learned by classifiers) Constraints C– any Boolean function defined on partial assignments (possible weights W
on constraints) Goal: Find the “best” assignment
The assignment that achieves the highest global accuracy.
This is an Integer Programming ProblemX*=argmaxX PX subject to constraints C(+ WC)
Everything is Linear

Page 34
Integer Linear Programming
A set of binary variables, x = (x1,…, xd) A cost vector p Rd, Cost matrices C1RdRt ; C2RdRr, t, r: # of (inequality, equality) constraints; d - # of
variables.
The ILP solution x* is the vector that maximizes the cost function,
x* = argmax x {0,1}d px
Subject to C2x> b1; and C1x = b2, where b1, b2Rd and x{0,1}d

Page 35
Problem Setting (2/2) Very general formalism; Connections to a large number of well studied
optimisation problems and a variety of applications.
Justification: direct argument for the appropriate “best
assignment” Relations to Markov Random Fields (but better
computationally)
Significant modelling and computational advantages

Page 36
Semantic Role Labeling
For each verb in a sentence1. identify all constituents that fill a semantic role2. determine their roles
• Agent, Patient or Instrument, …• Their adjuncts, e.g., Locative, Temporal or Manner
PropBank project [Kingsbury & Palmer02] provides a large human-annotated corpus of semantic verb-argument relations.
Experiment: CoNLL-2004 shared task [Carreras & Marquez 04]
No parsed data in the input

Page 37
Example
A0 represents the leaver,
A1 represents the thing left,
A2 represents the benefactor,
AM-LOC is an adjunct indicating the location of the action,
V determines the verb.

Page 38
Argument Types
A0-A5 and AA have different semantics for each verb as specified in the PropBank Frame files.
13 types of adjuncts labeled as AM-XXX where ARG specifies the adjunct type.
C-ARG is used to specify the continuity of the argument ARG.
In some cases, the actual agent is labeled as the appropriate argument type, ARG, while the relative pronoun is instead labeled as R-ARG.

Page 39
Examples
C-ARG
R-ARG

Page 40
Algorithm
I. Find potential argument candidates (Filtering) II. Classify arguments to types III. Inference for Argument Structure
Cost Function Constraints Integer linear programming (ILP)

Page 41
I. Find Potential Arguments
An argument can be any set of consecutive words
Restrict potential arguments Classify BEGIN(word)
BEGIN(word) = 1 “word begins argument”
Classify END(word) END(word) = 1 “word ends argument”
Argument (wi,...,wj) is a potential argument iff
BEGIN(wi) = 1 and END(wj) = 1
Reduce set of potential arguments (PotArg)
I left my nice pearls to her
I left my nice pearls to her[ [ [ [ [ ] ] ] ] ]

Page 42
II. Arguments Type Likelihood
Assign type-likelihood How likely is it that arg a is type t? For all a POTARG , t T
P (argument a = type t )
I left my nice pearls to her[ [ [ [ [ ] ] ] ] ]
I left my nice pearls to her0.3 0.2 0.2 0.3
0.6 0.0 0.0 0.4
A0 C-A1 A1 Ø

Page 43
Details – Phrase-level Classifier
Learn a classifier (SNoW) ARGTYPE(arg) P(arg) {A0,A1,...,C-A0,...,AM-LOC,...} argmaxt{A0,A1,...,C-A0,...,LOC,...} wt P(arg)
Estimate Probabilities Softmax over SNoW activations P(a = t) = exp(wt P(a)) / Z

Page 44
What is a Good Assignment?
Likelihood of being correct P(Arg a = Type t)
if t is the correct type for argument a
For a set of arguments a1, a2, ..., an
Expected number of arguments that are correct
i P( ai = ti )
The solution is the assignment with the maximum expected number of correct arguments.

Page 45
Inference
Maximize expected number correct T* = argmaxT i P( ai = ti )
Subject to some constraints Structural and Linguistic (R-A1A1)
0.3 0.2 0.2 0.3
0.6 0.0 0.0 0.4
0.1 0.3 0.5 0.1
0.1 0.2 0.3 0.4
I left my nice pearls to her
I left my nice pearls to her
Cost = 0.3 + 0.4 + 0.5 + 0.4 = 1.6 Non-OverlappingCost = 0.3 + 0.4 + 0.3 + 0.4 = 1.4 BlueRed & N-OCost = 0.3 + 0.6 + 0.5 + 0.4 = 1.8 Independent Max

Page 46
LP Formulation – Linear Cost
Cost function
a POTARG P(a=t) = a POTARG , t T P(a=t) x{a=t}
Indicator variablesx{a1=A0}, x{a1= A1}, …, x{a4= AM-LOC}, x{P4=} {0,1}
Total Cost = p(a1= A0)· x(a1= A1) + p(a1= )· x(a1= ) +… + p(a4= )· x(a4= )
Corresponds to Maximizing expected
number of correct phrases

Page 47
Binary values a POTARG , t T , x{a = t} {0,1}
Unique labels a POTARG , t T x{a = t} = 1
No overlapping or embeddinga1 and a2 overlap x{a1=Ø} + x{a2=Ø} 1
Linear Constraints (1/2)

Page 48
No duplicate argument classesa POTARG x{a = A0} 1
R-ARG a2 POTARG , a POTARG x{a = A0} x{a2 = R-A0}
C-ARG a2 POTARG ,
(a POTARG) (a is before a2 ) x{a = A0} x{a2 = C-A0}
Many other possible constraints: Exactly one argument of type Z If verb is of type A, no argument of type B
Linear Constraints (2/2) Any Boolean rule can be encoded as a linear constraint.
If the is an R-ARG phrase, there is an ARG Phrase
If the is an C-ARG phrase, there is an ARG before it

Page 49
Discussion Inference approach used also for simultaneous named
entities and relation identification (CoNLL’04) A few other problems in progress
Global inference helps ! All constraints vs. only non-overlapping constraints: error reduction > 5% ; > 1% absolute F1 A lot of room for improvement (additional constraints) Easy and fast: 70-80 Sentences/Second (using Xpress-
MP)
Modeling and Implementation details: http://L2R.cs.uiuc.edu/~cogcomp http://www.scottyih.org/html/publications.html#ILP

Page 50
Overview Stand Alone Learning
Modeling Representational Issues. Computational Issues
Inference Semantic Role Labeling Making Decisions under General Constraints
How to train Components of Global Decisions Tradeoff that depends on easiness of learning
components. Feedback to learning is (indirectly) given by the
reasoning stage. There may not be a need (or even a possibility) to learn
exactly, but only to the extent that is supports Reasoning.
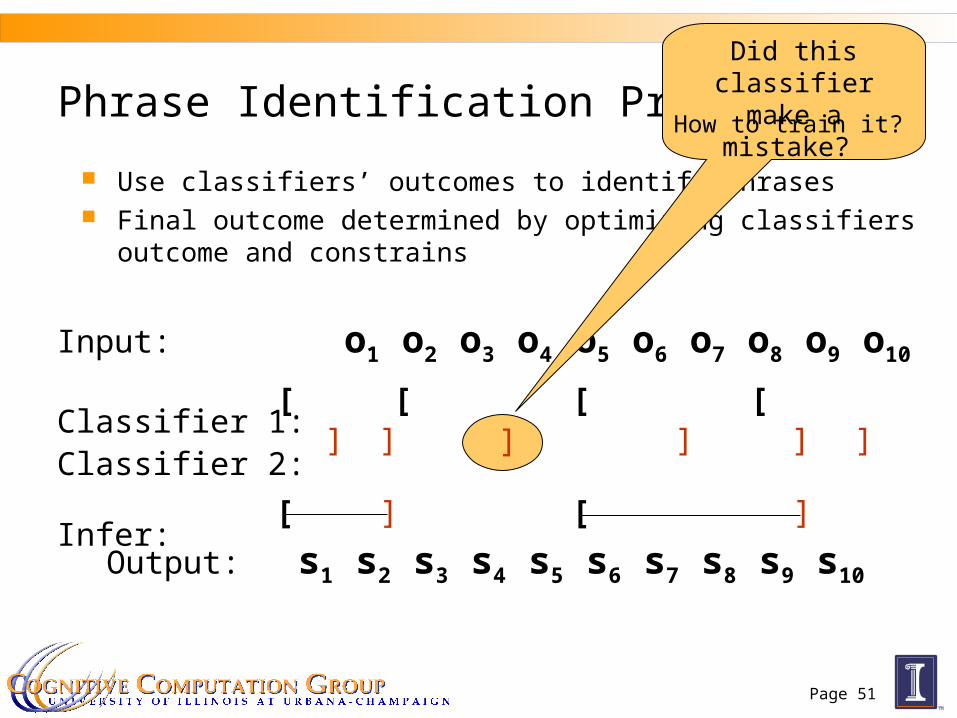
Page 51
Input: o1 o2 o3 o4 o5 o6 o7 o8 o9 o10
Classifier 1:Classifier 2:
Infer:
Phrase Identification Problem
Use classifiers’ outcomes to identify phrases Final outcome determined by optimizing classifiers outcome
and constrains
[ [ [ []] ] ] ] ]
Output: s1 s2 s3 s4 s5 s6 s7 s8 s9 s10
[ ] ][
Did this classifier make a
mistake? How to train it?

Page 52
Learning Structured Output
Input variables, x = (x1,…, xd) 2 X; Output variables y = (y1,…, yd) 2 Y
A set of constrains C(Y) µ Y A cost function f(x,y) that assigns a score to each possible output. The cost function is linear in the components of y = (y1,…, yd):
f(x, (y1,…, yd) ) = i fi(x, y) Each scoring function (classifier) is linear over some feature space
fi(x,y) = wi (x,y) Therefore the overall cost function is linear
We seek a solution y* that maximizes the cost function, Subject to the constrain s C(Y)
y* = argmax C(y) i (x,y)

Page 53
Learning and Inference Structured Output Inference is the task of determining an optimal assignment y
given an assignment x.
For sequential structure of constraints, polynomial-time algorithms such as Viterbi or CSCL [Punyakanok&Roth, NIPS’01] can be used.
For general structure of constraints, we proposed a formalism that uses Integer Linear Programming (ILP).
Irrespective of the inference chosen, there are several ways to learn the scoring function parameters.
These differ in whether or not the structure-based inference process is leveraged during training.
Learning Local Classifiers: Decouple Learning from Inference. Learning Global Classifiers: Interleave inference with learning.

Page 54
Learning Local and Global Classifiers
Learning Local Classifiers: No knowledge of the inference used during learning.
For each example (x, y) ∈ D, the learning algorithm must ensure that each component of y produces the correct output.
Global constraint are enforced only at evaluation time.
Learning Global Classifiers: Train to produce correct global output.
Feedback from the inference process determines which classifiers to provide feedback to; together, the classifiers and the inference yield the desired result.
At each step a subset of the classifiers are updated according to inference feedback.
Conceptually similar to CRF and Collin’s Perceptron; we provide an online algorithm with a more general inference procedure.,

Page 55
Relative Merits
Learning Local Classifiers = L+I Learning Global Classifier = Inference based Training
(IBT)
Claim: With a fixed number of examples:1. If the local classification tasks are separable, then L+I outperforms IBT.2. If the task is globally separable, but not locally separable then IBT outperforms L+I only with sufficient examples.
This number correlates with the degree of the separability of the local classifiers. (The more strict the constrains are, the larger IBT’s example is)

Page 56
Relative Merits
Learning Local Classifiers = L+I Learning Global Classifier = Inference based Training
(IBT) LO: learning a stand alone component
Results on the SRL task:In order to get to the region In which IBT is good, we reduced the number of features usedby the individuals classifiers
Page 57
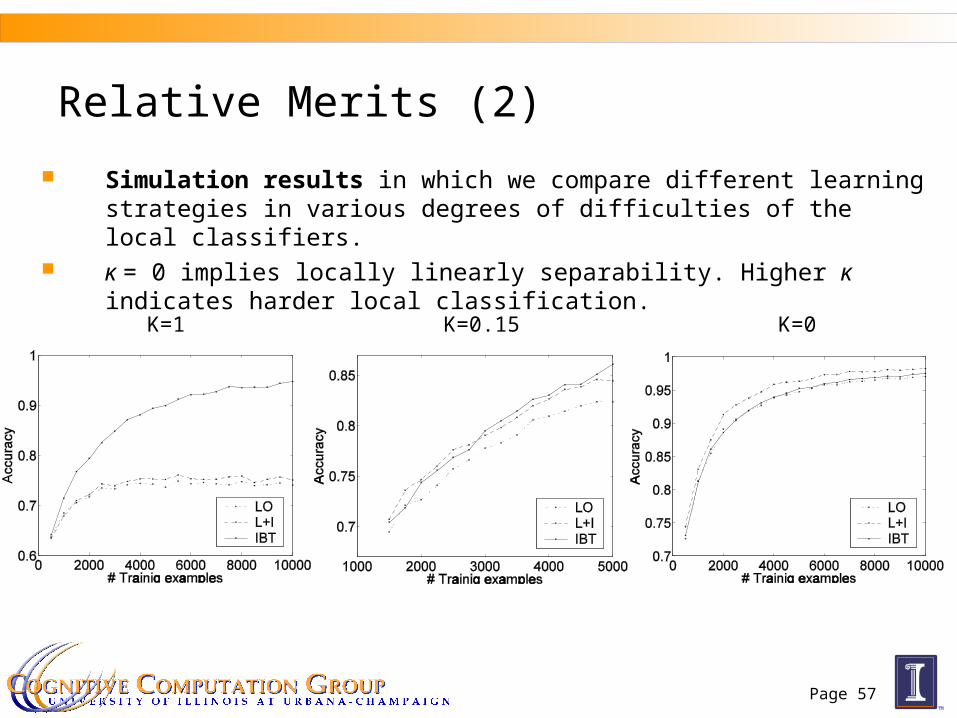
Relative Merits (2)
Simulation results in which we compare different learning strategies in various degrees of difficulties of the local classifiers.
κ = 0 implies locally linearly separability. Higher κ indicates harder local classification.
K=0.15K=1 K=0

Page 58
Summary Stand alone learning
Learning itself is well understood
Learning & Inference with General Global Constraints
Many problems in NLP involve several interdependent components and requires applying inference to obtain the best global solution
Need to incorporate linguistics and other constraints into NLP reasoning
A general paradigm for inference over learned components, based on (ILP) over general learners and expressive constraints.
Preliminary understanding of relative merits of different training approaches. In practical situations, decoupling training from inference is advantageous.
• Features: how to map to a high dimensional space• Learning protocol (weaker forms of supervision)
What are the components?
What else do we do wrong: Developmental Issues
Page 59
Questions? Thank you





























