Embed Size (px)
Citation preview

PACTree: A High Performance Persistent Range Index Using PAC Guidelines
Wook-Hee Kim, R. Madhava Krishnan, Xinwei Fu, Sanidhya Kashyap, and Changwoo Min

Talk outline
2
• Background
• Packed Asynchronous Concurrency (PAC) Guidelines
• PACTree : A High Performance Persistent Range Index Using PAC Guidelines
• Evaluation
• Conclusion

Talk outline
3
• Background
• Packed Asynchronous Concurrency (PAC) Guidelines
• PACTree : A High Performance Persistent Range Index Using PAC Guidelines
• Evaluation
• Conclusion

Non-Volatile Memory (NVM) is now available!
4
• Intel Optane DCPMM is the first commercially available NVM in the market.• Byte-addressable like DRAM and durable storage like SSD• Huge capacity
• 3TB per socket (e.g., 4-socket server = 12TB NVM + 6TB DRAM)
• Direct access to NVM using load/store bypassing the storage stack

NVM Hardware: Intel DC Persistent Memory
5
Persistent domain (ADR)IMC: Integrated Memory ControllerWPQ: Write Pending QueueAIT: Address Indirection Table
UPINUMA 0
NUMA 1
Core Core
L1/L2 $ L1/L2 $
Last Level Cache (LLC)
Mesh Interconnect
IMC IMC
DRAM
WPQ
NVM
Per-NUMANVM device
(e.g., /dev/pmem1)
Optane DIMMXPController
XPPrefetcher
3D-XpntMedia
Directory Cache Coherence Info
AIT Data
XPBuffer
XPLine: 256 bytes
From CPUIMC
WPQ
DDR-TCache line: 64 bytes
UPI: Ultra Path Interconnect

• Previous studies focus on hardware aspects of NVM• Yang et al.[FAST’20], Wang et al.[Micro’20], Gugnani et al.[VLDB’21]
• The limited bandwidth and slow latency of NVM is the fundamental limiting factor in designing storage systems.
NVM is not a slow DRAM
6
01234
Sequential ReadLatency
Random ReadLatency
No
rmal
ized
to
DR
AM
La
ten
cy
DRAM NVM
0
0.5
1
Read Write (clwb) Write(ntstore)
No
rmal
ized
to
DR
AM
b
and
wid
th
DRAM NVM[1] Yang et al., An Empirical Guide to the Behavior and Use of Scalable Persistent Memory, FAST’20
Let’s investigate performance properties of NVM (Optane) and explore their implications for core storage system design -- index.

Talk outline
7
• Background
• Packed Asynchronous Concurrency (PAC) Guidelines
• PACTree : A High Performance Persistent Range Index Using PAC Guidelines
• Evaluation
• Conclusion

NVM Software stack
8
NVM Program
NVM Hardware
Load/Store
NVM Allocator
NVM File System
mmapmapping
File System
API

Packed Asynchronous Concurrency (PAC) guidelines
9
Guidelines on NVM System Software
Findings on NVM Hardware
Guidelines on Index StructuresGuidelines on Concurrency Control
mmapmapping
NVM Program
NVM Hardware
Load/Store
NVM Allocator
NVM File System
File System
API

Packed Asynchronous Concurrency (PAC) guidelines
10
• Finding on NVM hardware
• FH5. Cache coherence protocol impedes NUMA scalability.
• Guidelines on NVM system software
• GS1. Persistent memory allocation is very expensive.
• Guidelines on persistent index algorithm
• GA1. Lookup operation should consume minimal NVM bandwidth.
• Guidelines on concurrency control of a persistent index
• GC2. Minimize the blocking time of structural modification operations.

11
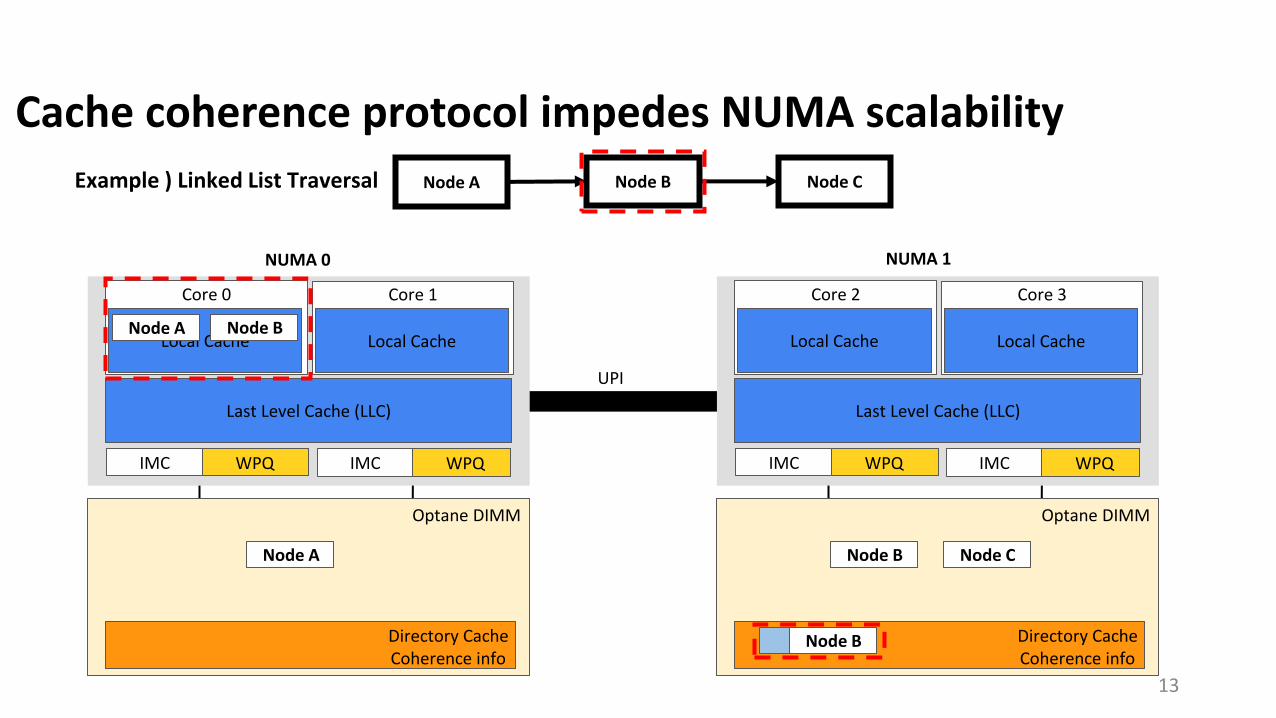
Cache coherence protocol impedes NUMA scalability
Core 1Core 0
Local Cache
Last Level Cache (LLC)
NUMA 0
Optane DIMM
Node A Node B Node C
NUMA 1
UPI
Directory CacheCoherence info
Node A
Local Cache
IMC WPQWPQIMC
Core 3Core 2
Local Cache
Last Level Cache (LLC)
Optane DIMM
Directory CacheCoherence info
Node B
Local Cache
IMC WPQWPQIMC
Node C
Example ) Linked List Traversal

12
Cache coherence protocol impedes NUMA scalability
Core 1Core 0
Local Cache
Last Level Cache (LLC)
NUMA 0
Optane DIMM
Node A Node B Node C
NUMA 1
UPI
Directory CacheCoherence info
Node A
Local Cache
IMC WPQWPQIMC
Core 3Core 2
Local Cache
Last Level Cache (LLC)
Optane DIMM
Directory CacheCoherence info
Node B
Local Cache
IMC WPQWPQIMC
Node C
Node A
Example ) Linked List Traversal
13
Cache coherence protocol impedes NUMA scalability
Core 1Core 0
Local Cache
Last Level Cache (LLC)
NUMA 0
Optane DIMM
Node A Node B Node C
NUMA 1
UPI
Directory CacheCoherence info
Node A
Local Cache
IMC WPQWPQIMC
Core 3Core 2
Local Cache
Last Level Cache (LLC)
Optane DIMM
Directory CacheCoherence info
Node B
Local Cache
IMC WPQWPQIMC
Node C
Node A Node B
Node B
Example ) Linked List Traversal

14
Cache coherence protocol impedes NUMA scalability
Core 1Core 0
Local Cache
Last Level Cache (LLC)
NUMA 0
Optane DIMM
Node A Node B Node C
NUMA 1
UPI
Directory CacheCoherence info
Node A
Local Cache
IMC WPQWPQIMC
Core 3Core 2
Local Cache
Last Level Cache (LLC)
Optane DIMM
Directory CacheCoherence info
Node B
Local Cache
IMC WPQWPQIMC
Node C
Node A Node B
Node B
Node C
Node C
Directory
NVM Write for Directory Cache Coherence Info
Remote NVM Read incurs NVM Writes due to the directory based cache coherence protocol
Example ) Linked List Traversal

15
Cache coherence protocol impedes NUMA scalability
• Such coherence write traffic could be significant!• Example 1) 100% 64-byte random read of 870MB
• NVM read: 870MB, NVM write: 481MB (55%!)
• A tentative solution is to change the cache coherence protocol to snoop coherence at BIOS. • Ultimately, the directory information should not be
stored in NVM.
• Snoop coherence shows much higher performance.• Example 2) 100% random lookup on a persistent B+tree
0
2
4
6
8
10
12
14 28 56 84 112
Thro
ugh
pu
t (M
op
s)
Number of Threads
Directory Snoop
100% random lookup on persistent B+-tree

• Let's compare the NVM bandwidth consumption in two representative index design, B+-tree and Trie, using an example of a lookup of a key “AAC”
Lookup operation should consume minimal NVM bandwidth
16
0
1
2
3
4
Performance PM Read
No
mal
ize
d t
o B
+-tr
ee
B+-tree Trie
A A
A C D
B
C
B+-tree
Trie
…
…
ATrie : 4 Byte
Access in a packed fashion to save the limited NVM bandwidth
A A D
A A C
A A A A A C A A D
BCA
B+-tree : 9 Byte
Performance NVM Read

Talk outline
17
• Background
• Packed Asynchronous Concurrency (PAC) Guidelines
• PACTree : A High Performance Persistent Range Index Using PAC Guidelines
• Evaluation
• Conclusion

• A high-performance persistent index should provide
Key take away from PAC Guidelines
18
Asynchronous ConcurrencyPacked Access to NVM
A A
A C D
B
C
A
Saving bandwidth Decoupling slow NVM latency

19
A B
AA CA AB BB
AAA
AAB
ACA
ACC
BAB
BAC
BBB
BBC
PACTree: a persistent index based on the PAC guidelines
ABA
Search Layer(PDL-ART)
Data Layer(B+-tree style
leaf nodes)

AAA < ABA < ACA
20
A B
AA CA AB BB
AAA
AAB
ACA
ACC
BAB
BAC
BBB
BBC
Lookup operation
ABA
Find the key ‘ABA’
A < ABA < B
AAA < ABA < ACA
Jump node
Target node

AAA < ABB < ACA
21
A B
AA CA AB BB
AAA
AAB
ACA
ACC
BAB
BAC
BBB
BBC
Asynchronous Update: Data layer update
Insert the key ‘ABB’
A < ABB < B
ABA

22
A B
AA CA AB BB
AAA
AAB
ACA
ACC
BAB
BAC
BBB
BBC
ABB
ABA
Asynchronous Update: Data layer update done
Insert the key ‘ABB’
A < ABB < B
ABA < ABB < ACA
SMO Log
ABA
AAA < ABB < ACA

23
A B
AA CA AB BB
AAA
AAB
ACA
ACC
BAB
BAC
BBB
BBC
ABB
ABA
Asynchronous Update: Search layer update
Insert the key ‘ABB’
A < ABB < B
ABA < ABB < ACA
BA
Background Thread
SMO Log
AAA < ABB < ACA
AAA < ABB < ACA
24
A B
AA CA AB BB
AAA
AAB
ACA
ACC
BAB
BAC
BBB
BBC
ABB
ABA
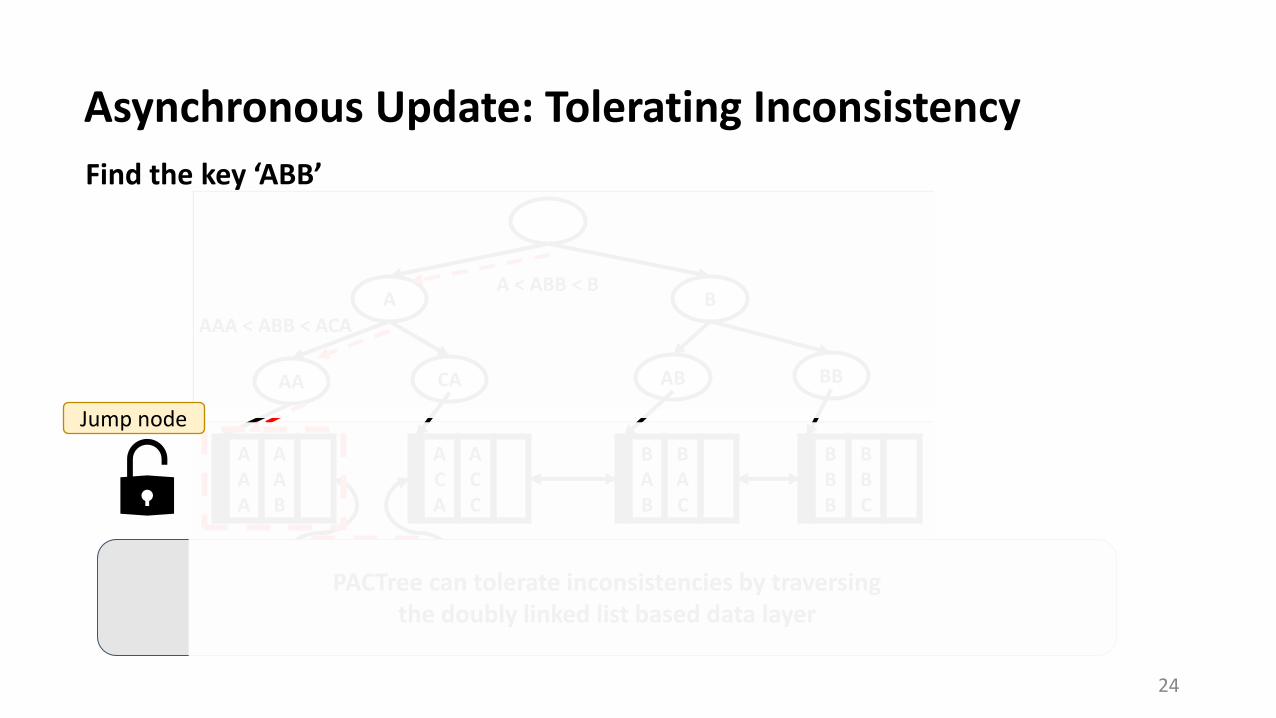
Asynchronous Update: Tolerating Inconsistency
Find the key ‘ABB’
A < ABB < B
AAB < ABA
ABA < ABB < ACA
Target nodePACTree can tolerate inconsistencies by traversing
the doubly linked list based data layer
Jump node

Talk outline
25
• Background
• Packed Asynchronous Concurrency (PAC) Guidelines
• PACTree : A High Performance Persistent Range Index Using PAC Guidelines
• Evaluation
• Conclusion

Evaluation Environment
26
• Two Socket Real NVM machine • 2 x Intel Xeon Platinum 8280 processors (28 physical/56 logical cores) per socket,
• 3.0 TB of DCPMM (256GB x 6 (1.5TB) per-socket), and 768 GB of DRAM
• Workloads• YCSB Workloads
• Write intensive, Read intensive, and Scan workload
• Competitors• FPTree [SIGMOD’17] : DRAM/NVM hybrid B+-tree
• FAST-FAIR [ FAST’18] : Persistent B+-tree supporting non-blocking read
• BzTree [VLDB’18] : Lock-free persistent B+-tree

Evaluation result: Throughput of YCSB
Write Intensive Workload (YCSB A) Read Intensive Workload (YCSB B)
0
5
10
15
20
25
30
35
1 28 56 84 112
Th
rou
gh
pu
t(M
op
s)
Number of Threads
PACTree
FAST-FAIR
BzTree
FPTree
0
10
20
30
40
50
60
70
1 28 56 84 112
Th
rou
gh
pu
t (M
op
s)
Number of Threads
PACTree
FAST-FAIR
BzTree
FPTree
27
Our ApproachOur Approach
PACTree shows better scalability and performance than other persistent indexes
+ +

Evaluation Result: Tail Latency of YCSB
28
0
500
1000
1500
99 99.9 99.99 99.999
Late
ncy
(u
s)
Percentage (%)
PACTree FP-Tree Bz-Tree FAST-FAIR
0
50
100
150
99 99.9 99.99 99.999
Late
ncy
(u
s)
Percentage (%)
PACTree FP-Tree Bz-Tree FAST-FAIR
Write Intensive Workload (Workload A) Read Intensive Workload (Workload C)
PACTree shows low tail latency
in both write intensive workload and read intensive workload
Our ApproachOur Approach
+ +

Talk outline
29
• Background
• Packed Asynchronous Concurrency (PAC) Guidelines
• PACTree : A High Performance Persistent Range Index Using PAC Guidelines
• Evaluation
• Conclusion

Conclusion
30
• PAC guideline: design guidelines for persistent index• Access in a packed fashion to save the limited NVM bandwidth
• Exploit asynchronous concurrency control to decouple the long NVM latency from the critical path.
• PACTree: high-performance persistent index designed under the PAC guideline• Packed Access to NVM using Trie-based Search Layer
• Asynchronous update for Search Layer and Data Layer
• PAC guidelines can be applied to other NVM software design• Performance critical system software (e.g., File systems, Database systems)
• In-memory storage systems that use NVM as large volatile memory





























