Embed Size (px)
Citation preview

OVERVIEW OF DATA EXPLORATION TECHNIQUES
Stratos Idreos, Olga Papaemmanouil, Surajit Chaudhuri SIGMOD 2015, Melbourne

USER INTERACTION
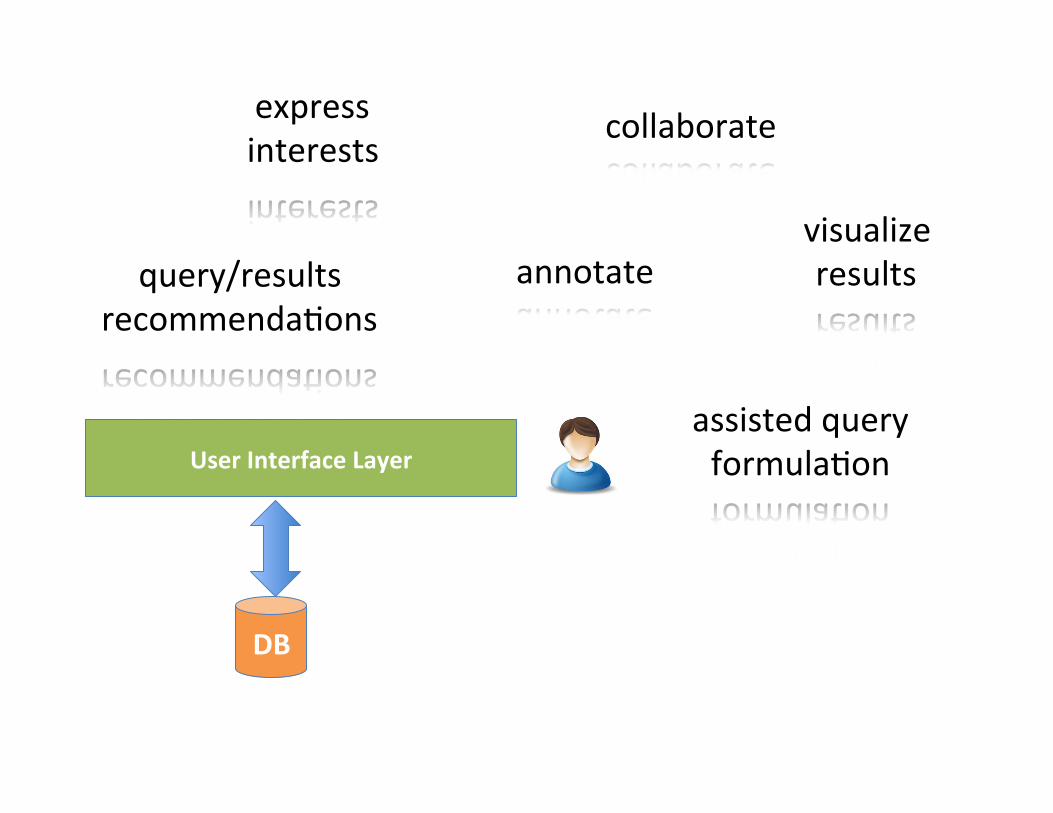
DB
User Interface Layer
visualize results
express interests
assisted query formulaSon
collaborate
annotate query/results recommendaSons
DB
User Interface Layer

DB
User Interface Layer
Data Visualiza=on

DB
User Interface Layer
Data Visualiza=on
Explora=on Interface
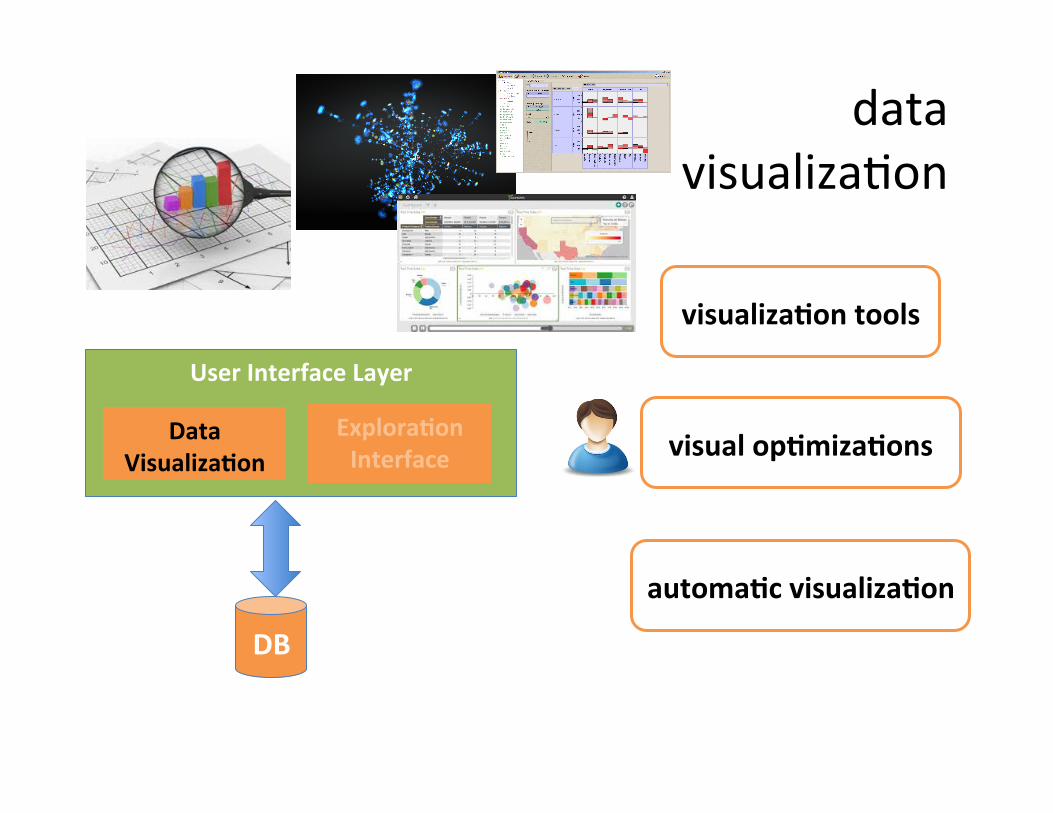
data visualizaSon
visualiza=on tools
automa=c visualiza=on
visual op=miza=ons
User Interface Layer
Data Visualiza=on
Explora=on Interface
DB
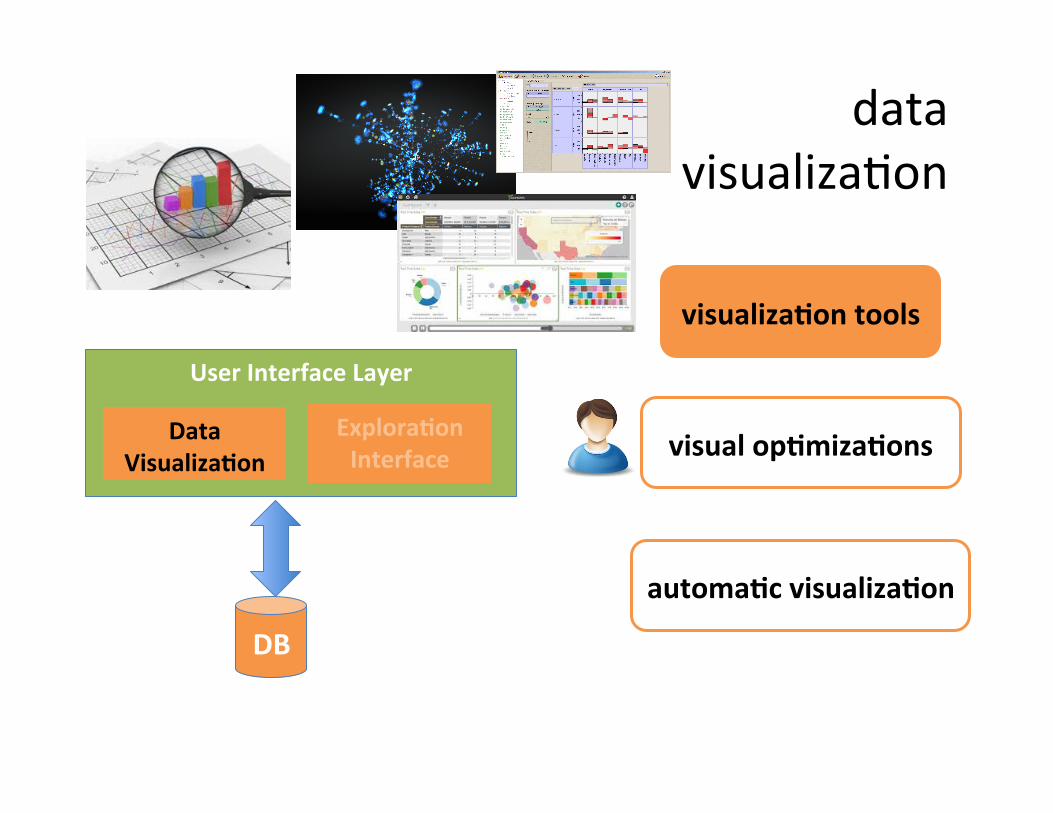
data visualizaSon
visualiza=on tools
automa=c visualiza=on
visual op=miza=ons
User Interface Layer
Data Visualiza=on
Explora=on Interface
DB

Back in 1982…
window-‐based “sophis=cated” browser for rela=onal DBs
TIMBER
(1,1) (M,1)
(1,i) ith tuple goes here
DB
browser for mulSple relaSons/tuples rich query language for icon-‐oriented DBs visual editor of text objects browser for geographical data
TIMBER, VLDB’82
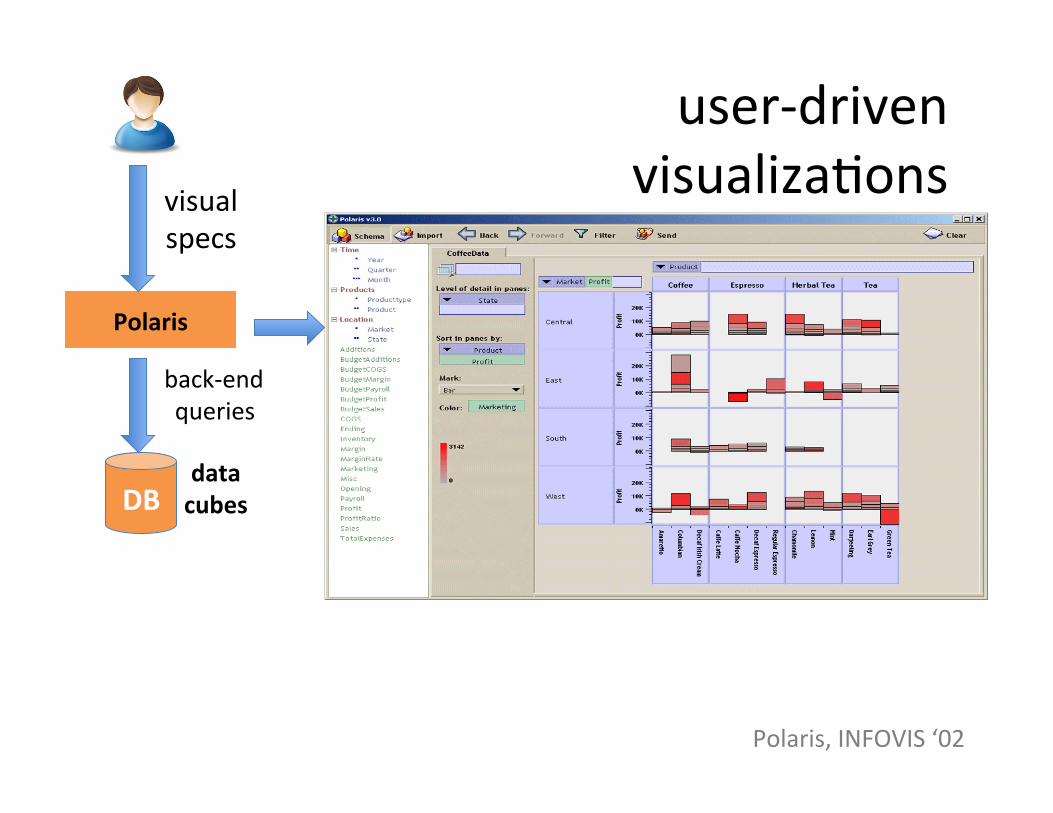
user-‐driven visualizaSons
data cubes
Polaris
DB
back-‐end queries
visual specs
Polaris, INFOVIS ‘02
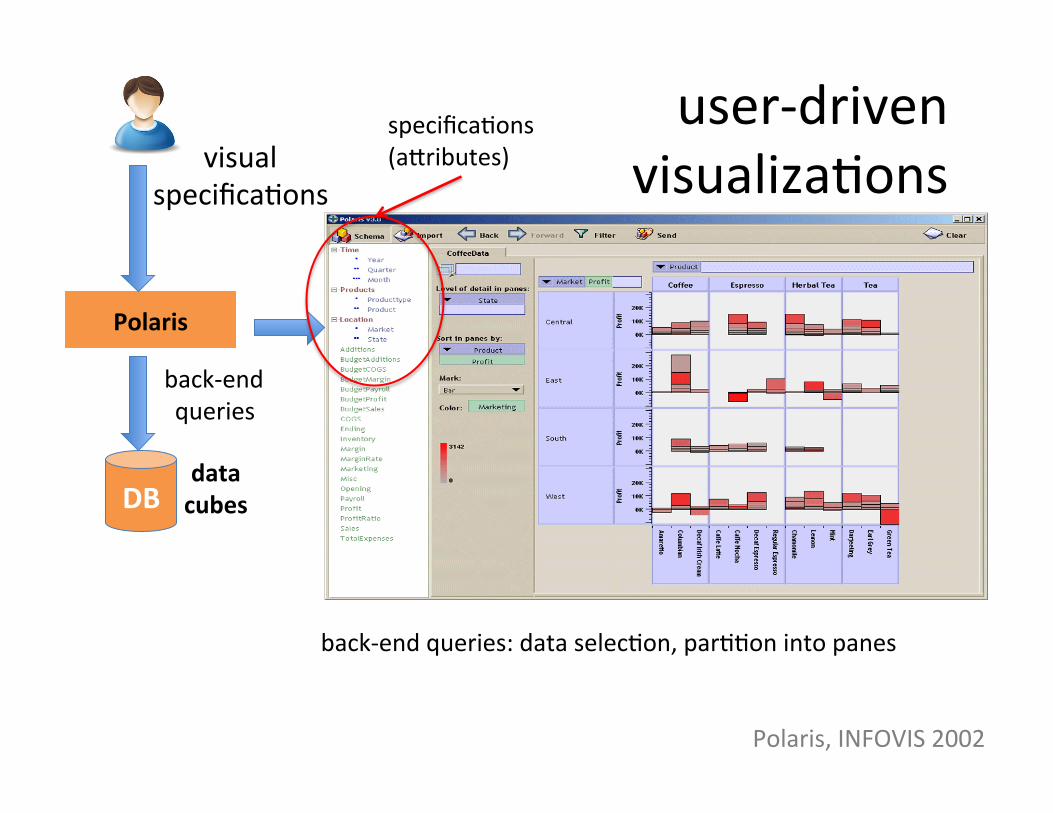
user-‐driven visualizaSons
data cubes
Polaris
back-‐end queries: data selecSon, parSSon into panes
visual specificaSons
back-‐end queries
specificaSons (abributes)
DB
Polaris, INFOVIS 2002

user-‐driven visualizaSons
data cubes
Polaris
back-‐end queries: data transformaSons (group, sort, aggregate within each pane)
visual specificaSons
back-‐end queries
transformaSons (group by, sort)
DB
Polaris, INFOVIS 2002

data cubes
Polaris
visual specificaSons
back-‐end queries
mappings (shape, size, color)
back-‐end queries: graphical transformaSons (renter and visualize)
DB
user-‐driven visualizaSons
Polaris, INFOVIS 2002

collaboraSve exploraSon
Sky View
live annotaSons
exploraSon for sky objects/paberns
AstroShelf, SIGMOD ‘12

Sky View
Live Annota=ons
subscripSons to interesSng objects
exploraSon for sky objects/paberns
AstroShelf, SIGMOD ‘12
collaboraSve exploraSon

Sky View
Live Annota=ons
stream based noSficaSons
collaboraSve exploraSon
exploraSon for sky objects/paberns
AstroShelf, SIGMOD ‘12

data visualizaSon
visualiza=on tools
automa=c visualiza=on
visual op=miza=ons
User Interface Layer
Data Visualiza=on
Explora=on Interface
DB

automaSc visualizaSon
review views
request views
manual, repeSSve exploraSon for best visualizaSon(s)
interesSng? insigheul?
User Interface Layer
Data Visualiza=on
DB

filter across charts, recommend, rank
search, select, promote, discard,
save, share VizDeck
DB
model “good” charts
saved decks/replay logs
auto-‐ranked visualizaSons
VizDeck, SIGMOD ‘12

automaSc visualizaSons
aggregaSons/ single-‐abribute
group-‐by
sales over Sme % sales/ region user query
Q1 Q2 … Qn
uSlity DB
informa=ve queries visualizaSon
engine high deviaSon
from overall dataset
SeeDB, PVLDB‘13

data visualizaSon
visualiza=on tools
automa=c visualiza=on
visual op=miza=ons
User Interface Layer
Data Visualiza=on
Explora=on Interface
DB
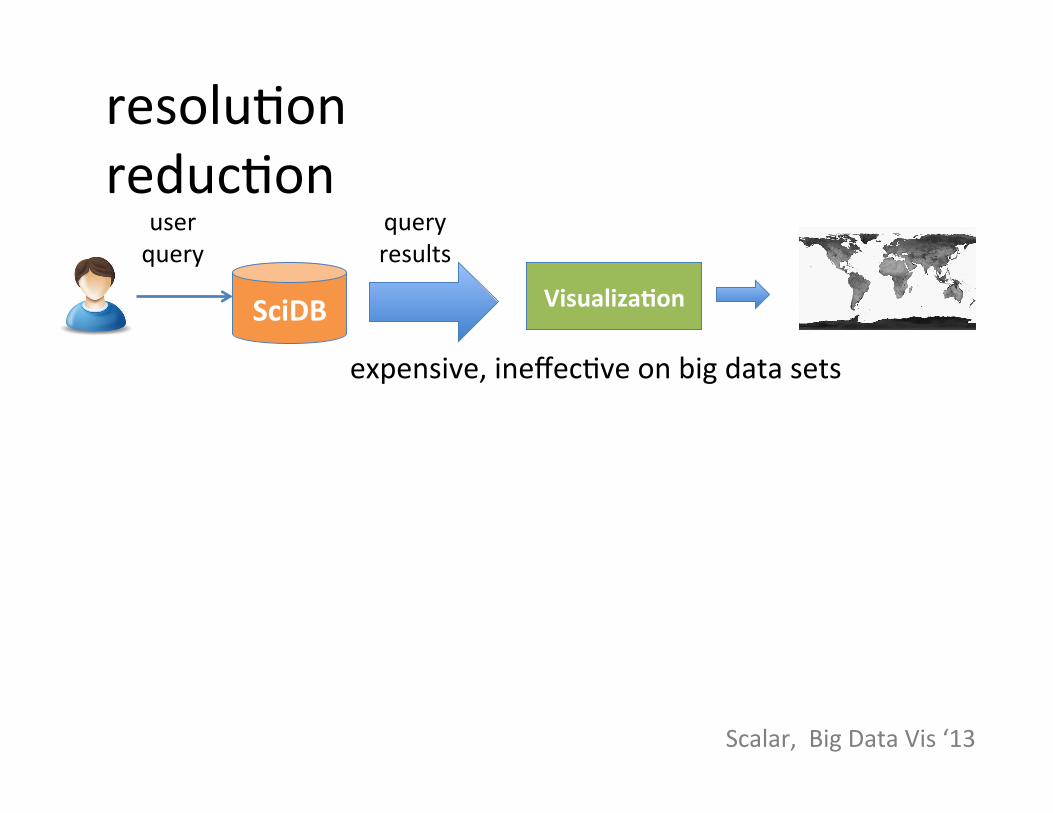
resoluSon reducSon
SciDB
user query
query results
expensive, ineffecSve on big data sets
Visualiza=on
Scalar, Big Data Vis ‘13

resoluSon reducSon
SciDB
user query
query results
Visualiza=on
user query
reduced results
modified query plans filter/aggregate/sample
at given resoluSon
Visualiza=on
Data Reduc=on
SciDB
Scalar, Big Data Vis ‘13

approximate visualizaSons
DB
Visualiza=on
SELECT X, AVG(Y) FROM R(X,Y) GROUP BY X
reduced results
original chart
approximate chart
same group ordering
user query
Sampling
Blais et al, PVLDB ‘15

approximate visualizaSons
DB
Visualiza=on
SELECT X, AVG(Y) FROM R(X,Y) GROUP BY X
reduced results
approximate chart
user query
Sampling
clear ordering less samples
Blais et al, PVLDB ‘15

approximate visualizaSons
DB
Visualiza=on
SELECT X, AVG(Y) FROM R(X,Y) GROUP BY X
reduced results
approximate chart
user query
Sampling
correct order? sample more
min # samples for correct order?
Blais et al, PVLDB ‘15

approximate visualizaSons
DB
Visualiza=on
SELECT X, AVG(Y) FROM R(X,Y) GROUP BY X
reduced results
approximate chart
user query
#samples Group 1 Group 2 Group 3 Group 4
1 [60,90] [20,50] [10,40] [40,70]
20 [64,84] [30,48] [15,35] [45,65]
21 [66,84], I [30,48] [17,35] [46,64]
70 [66,84], I [40,47] [17,32], I [46,53]
sampling phases/ confidence intervals
Sampling
Blais et al, PVLDB ‘15

visualizaSon management
DB
user query
query results
Visualiza=on
overlapping user queries
replicated db opera=ons
memory opera=ons on big data
Ermac, PVLDB ‘14

visualizaSon management
DB
user query
query results
Visualiza=on
DVMS
visual specifica=ons
logical visual plans è physical query plans
transforma=ons to pixel space visual op=miza=ons reduced
rendering =me
Ermac, PVLDB ‘14

exploraSon interfaces
automa=c explora=on
novel query interfaces
assisted query formula=on
User Interface Layer
Data Visualiza=on
Explora=on Interface
DB

exploraSon interfaces
automa=c explora=on
novel query interfaces
assisted query formula=on
User Interface Layer
Data Visualiza=on
Explora=on Interface
DB
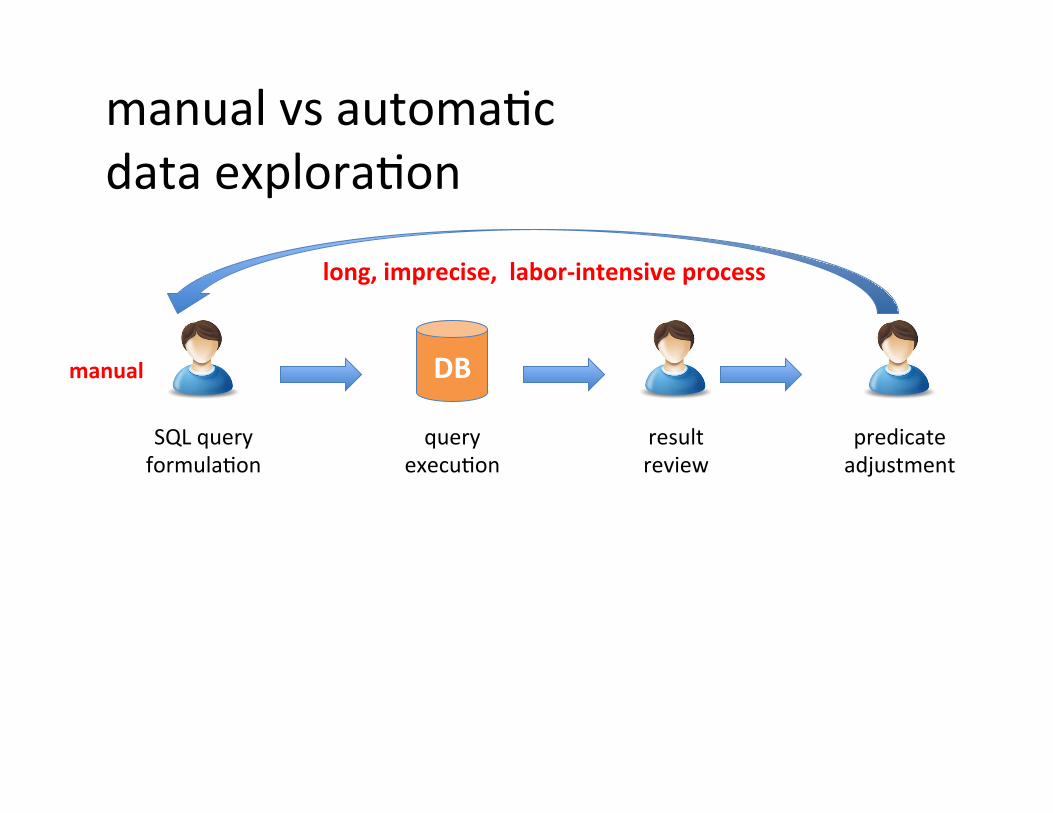
manual vs automaSc data exploraSon
SQL query formulaSon
result review
predicate adjustment
query execuSon
long, imprecise, labor-‐intensive process
DB manual

manual vs automaSc data exploraSon
SQL query formulaSon
result review
predicate adjustment
query execuSon
long, imprecise, labor-‐intensive process
DB
capture user interests
op=mize query execu=on
reduce user effort
recommend data/queries
manual
auto

manual vs automaSc data exploraSon
SQL query formulaSon
result review
predicate adjustment
query execuSon
long, imprecise, labor-‐intensive process
DB
capture user interests
op=mize query execu=on
reduce user effort
recommend data/queries
manual
auto

explore by example
effecSveness vs efficiency sampling areas? sampling size?
DB
User Model Samples Space
Explora=on decision
tree classifier
relevant
irrelevant
sample extrac=on
AIDE, SIGMOD’14/ VLDB’15

explore by example
Abrib
ute B
Abribute A
relevant areas to predict
AIDE, SIGMOD’14/ VLDB’15

Abrib
ute B
Abribute A
x
x x
x x
x x
x x
√
√
explore by example
√
uniform sampling across domain
AIDE, SIGMOD’14/ VLDB’15

√
√
discover relevant area
√ √
x √
Abrib
ute B
Abribute A
√
explore by example
predicted relevant area
sampling around relevant objects
AIDE, SIGMOD’14/ VLDB’15
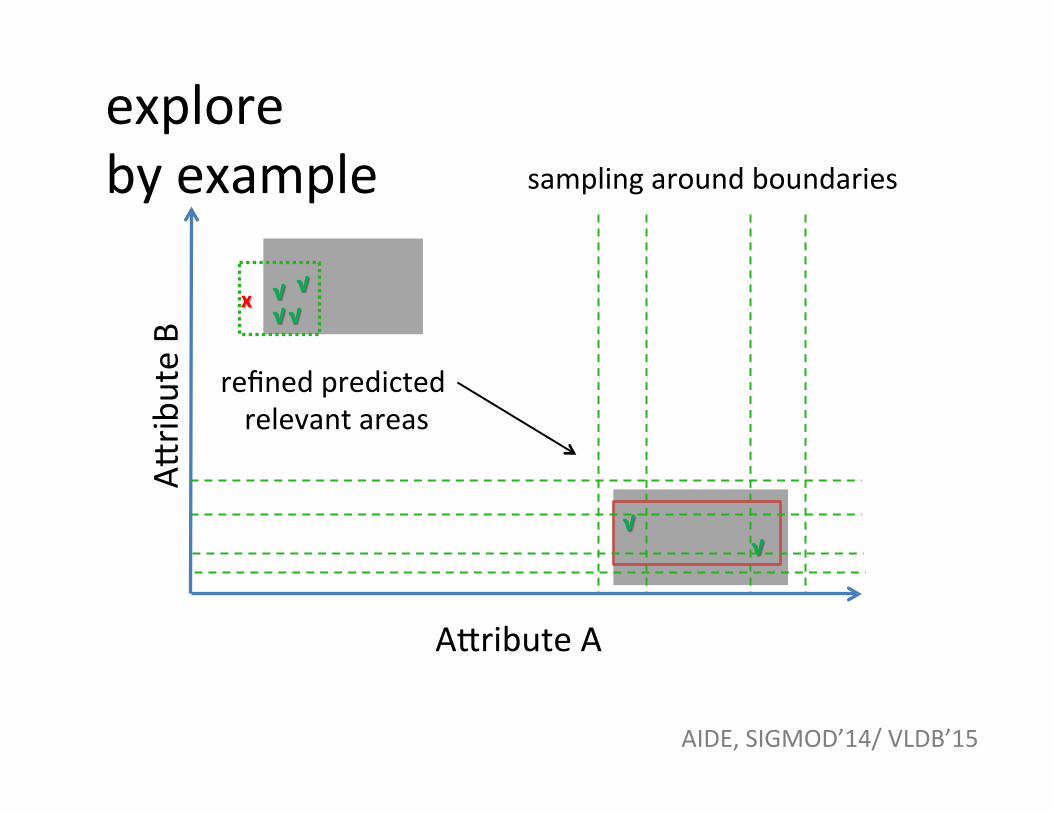
√ √ √
x √
Abrib
ute B
Abribute A
√ √
refined predicted relevant areas
explore by example sampling around boundaries
AIDE, SIGMOD’14/ VLDB’15

result recommendaSons
query
DB addi=onal results
interes=ng queries
DB
results YMALDB
YMALDB, VLDBJ ’13

result recommendaSons
query
DB addi=onal results
interes=ng queries
DB
results YMALDB
rank faSets
freq(result)/ freq(DB)
query extract query faSets
selecSon predicates based on original query
expand adributes
add abributes from table schema
top-‐k queries
YMALDB, VLDBJ ’13

result recommendaSons
query
DB addi=onal results
interes=ng queries
DB
results
rank faSets
freq(result)/ freq(DB)
YMALDB
query extract query faSets
selecSon predicates based on original query
expand adributes
add abributes from table schema
top-‐k queries
!tle, year, genre of Scorsese movies
!tle, year, genre, country of Scorsese movies
many Scorsese movies are related to Italy
+ =
YMALDB, VLDBJ ’13

exploraSon interfaces
automa=c explora=on
novel query interfaces
assisted query formula=on
User Interface Layer
Data Visualiza=on
Explora=on Interface
DB

keyword-‐based query suggesSons
SQL query (tedious)
keywords (intuiSve) DB
relevant & irrelevant data
relevant data
keyword search DB
relevant data
how we can discover relevant queries?
SQLSUGG, ICDE’11

Template Repository “database gray”
template on Stle/authors? template on Stle?
suggested queries
Template Matcher
SQL Query
Generator
keywords Sample Results/
Visualiza=on
ranked
templates
keyword-‐based query suggesSons
SQLSUGG, ICDE’11

suggested queries
Template Matcher
SQL Query
Generator
keywords Sample Results/
Visualiza=on
ranked
templates
Paper
=tle year
Paper
=tle year
id=p_id
Template 1 Template 2
Author Template Repository
template generaSon
keyword-‐based query suggesSons
SQLSUGG, ICDE’11

template relevance = f (en=ty relevance & importance)
suggested queries
Template Matcher
SQL Query
Generator
keywords Sample Results/
Visualiza=on
ranked
templates
Template Repository
enSty relevance èkeyword frequency in enSty enSty importanceè importance of data nodes
relevant template?
keyword-‐based query suggesSons
SQLSUGG, ICDE’11

equi-‐join inference
inference algorithm
informa=ve
tuple
Cartesian
product
goal join
predicate
minimize user effort discover all posi=ves eliminate all nega=ves
goal predicate:
table A A1 A2 B1 B2
table B sample
BonifaS et al, EDBT’14

equi-‐join inference
inference algorithm
informa=ve
tuple
Cartesian
product
table A table B goal join
predicate
A1 A2 B1 B2
(A1, B1) (A1, B2) (A2, B1)
(A1, B1) (A1, B2)
(A1, B1) (A2, B1)
(A1, B1) (A2, B2)
prune predicates with uninformaSve tuples label tuple that prunes as many predicates as possible
sample
candidate predicates
BonifaS et al, EDBT’14

graphical query specificaSon
answers
non-‐answers
result visualizaSon
DataPlay, PVLDB ’13

graphical query specificaSon
answers
non-‐answers
pivot relaSon
query /visualizaSon recommendaSons
add, remove query constraints
result visualizaSon
seman=c query tuning by local syntac=c modifica=ons
DataPlay, PVLDB ’13

graphical query specificaSon
answers
non-‐answers
result visualizaSon
search limited to local modifica=ons
pivot relaSon
query correcSons
add, remove results
DataPlay, PVLDB ’13

query recommendaSons
query Charles DB
results queries selected query
Charles, CIDR ’13

query recommendaSons
query Charles DB
results queries selected query
<5 >5
<5 >5 <20 <30 <5 >5 >20 >30
weight weight, height different data parSSons
quality: simplicity, breadth, balance
Charles, CIDR ’13

query refinement
Merlin DB condi=onal
query
select species from birds where color= {red: 80%, blue: 20%}
ranked results by match probability
sensi=vity of user predicates
query refinements w/ quality improvement
rank species
1 Bluebird
2 Blue Jay
adr sensi=vity
color 18.6
adr quality score
size 83.3
legcolor 57.1
remaining adributes
result quality if added in the query
impact on ranking
Merlin, ICDE ’14

exploraSon interfaces
automa=c explora=on
novel query interfaces
assisted query formula=on
User Interface Layer
Data Visualiza=on
Explora=on Interface
DB
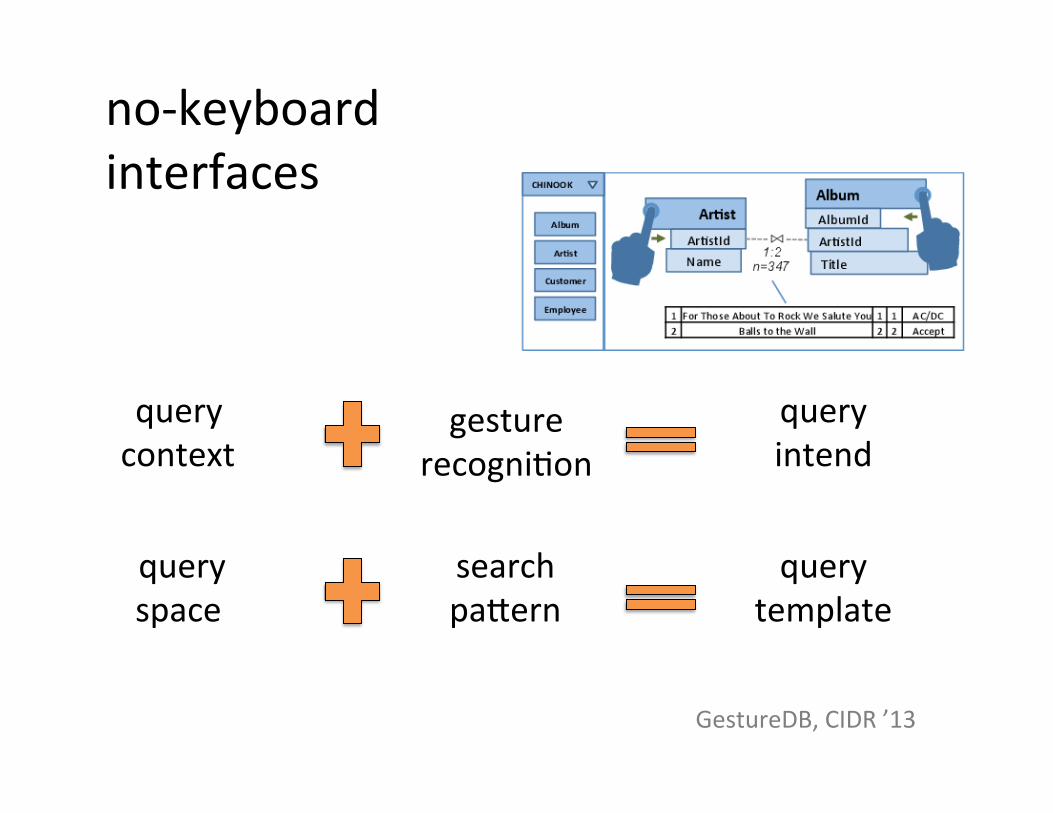
no-‐keyboard interfaces
gesture recogniSon
query context
query intend
query space
search pabern
query template
GestureDB, CIDR ’13

no-‐keyboard interfaces
DB
touch recogniSon
gesture recogniSon
map touch to operators
novel database kernel
touch input
quick response
dbTouch, CIDR ’13

MIDDLEWARE TECHNIQUES
InteracSve ExploraSon through Data Prefetching & Query ApproximaSon
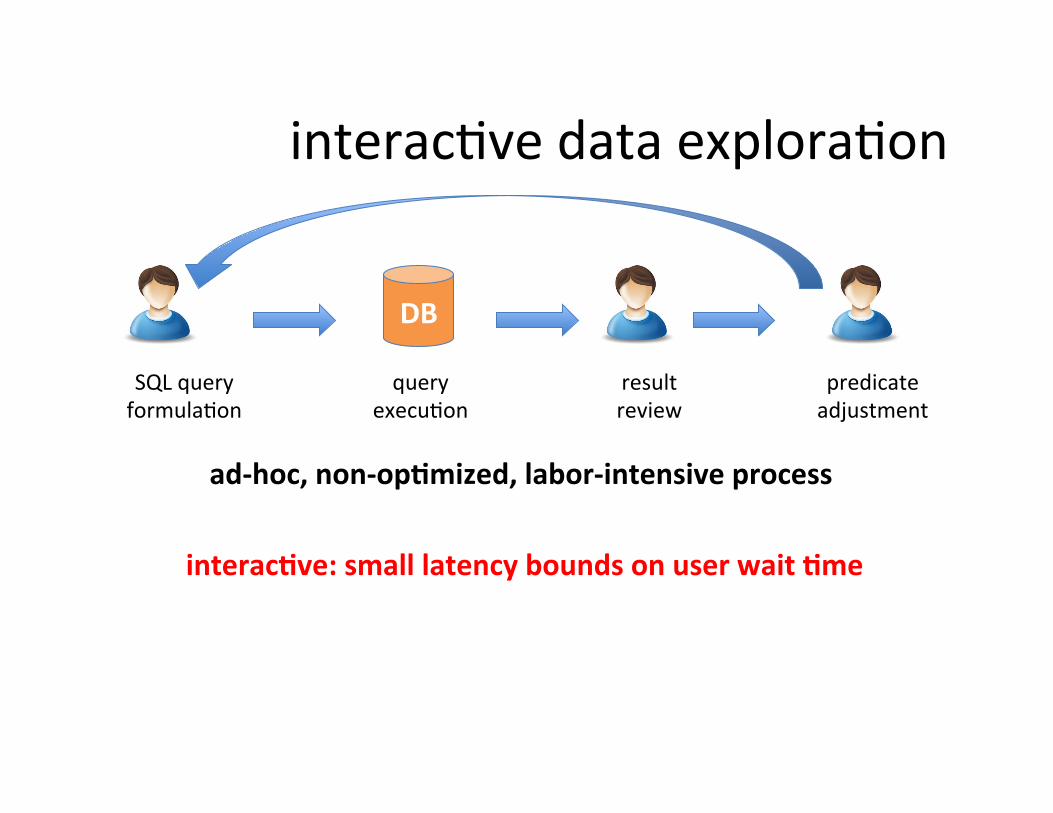
SQL query formulaSon
result review
predicate adjustment
query execuSon
interacSve data exploraSon
ad-‐hoc, non-‐op=mized, labor-‐intensive process
interac=ve: small latency bounds on user wait =me
DB

middleware opSmizaSons
query
results middleware
prefetching
query approxima=on
DB
specula=ve query execu=on
result reuse
structure-‐aware prefetching
online processing
sample-‐based processing

sample-‐based processing
approximate results
query sampling
• accuracy vs response Smes • sample construcSon & selecSon • error approximaSon
Samples DB

off-‐line data synopses
approximate results + confidence bounds
query Synopses
DB
Aqua
transformed query
join synopses: sample disSnguished joins
congressional samples: biased sampling for group-‐by queries
incremental maintenance: equi-‐depth & compressed histograms
samples histograms
Aqua, SIGMOD ’99

offline sampling
on frequent columns sets
DB
disk in-‐memory
samples across 1000s machines
select avg(sessionTime) FROM table WHERE city=“SF” WITHIN 1 SEC
online sample selecSon
Results 190+/-‐ 5.89 (95% confidence)
parallel query execu=on on mul=ple samples across
mul=ple machines
BlinkDB, EuroSys ’13
online sampling selecSon

data impressions
approximate results
DB Level 1
query & =me/error bounds
adapSve sampling to exploraSon focus
impressions during data loading
mulS layer sampling and processing to meet user bounds
Level 2
Level 3
SciBORG, CIDR ’11

middleware opSmizaSons
query
results middleware
prefetching
query approxima=on
DB
specula=ve query execu=on
result reuse
structure-‐aware prefetching
online processing
sample-‐based processing

speculaSve query execuSon
1. predict follow-‐up queries 2. execute queries 3. cache results
DB
Query Formula=on user wait =me
Query Execu=on
Result Review
=me

speculaSve query execuSon
1. predict follow-‐up queries 2. execute queries 3. cache results
DB
Query Formula=on user wait =me
Query Execu=on
Result Review
=me

speculaSve query execuSon
1. predict follow-‐up queries 2. execute queries 3. cache results
DB
Query Formula=on user wait =me
Query Execu=on
Result Review
=me
explora=on space reduc=on
query enumera=on
query ranking

cube exploraSon
SELECT AVG (iops) FROM events WHERE month=“m1” AND week=“w1” GROUP BY zone
location
itme
month
zone center rack
week
hour
user query
explora=on space reduc=on
DICE, ICDE ’14

cube exploraSon
SELECT AVG (iops) FROM events WHERE month=“m1” AND week=“w1” GROUP BY zone
WHERE month=“m1”
WHERE month=“m1” AND week=“w1 AND hour=“h1”
WHERE month=“m1” AND week=“w2”
parent
child
sibling
user query
explora=on space reduc=on
cube explora=on operators
location
itme
month
zone center rack
week
hour
DICE, ICDE ’14

Q(month=“m1”)
Q(month = “m12”)
Q(hour =“h1”)
Q(hour =“ h24”)
Q(week=“w2”)
Q(week=“w3”)
specula=ve queries
…
…
…
cube exploraSon explora=on
space reduc=on query
enumera=on
SELECT AVG (iops) FROM events WHERE month=“m1” AND week=“w1” GROUP BY zone
user query
location
itme
month
zone center rack
week
hour
DICE, ICDE ’14
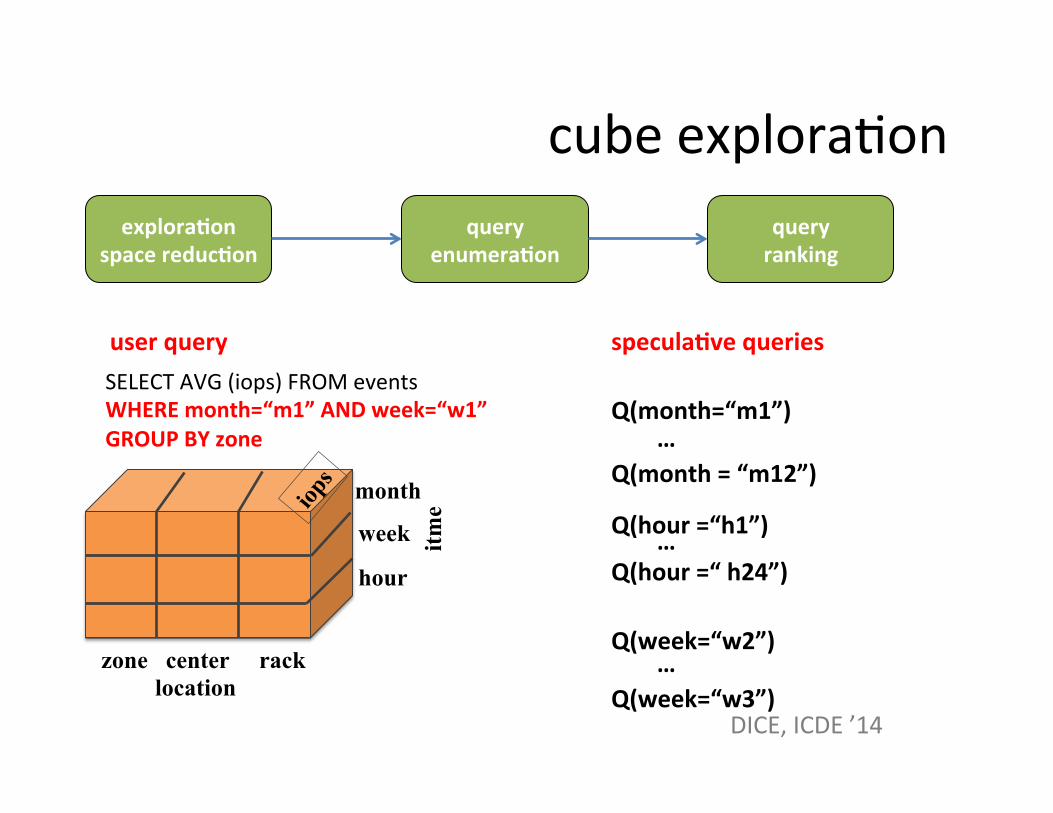
Q(month=“m1”)
Q(month = “m12”)
Q(hour =“h1”)
Q(hour =“ h24”)
Q(week=“w2”)
Q(week=“w3”)
specula=ve queries
…
…
…
cube exploraSon explora=on
space reduc=on query
enumera=on
SELECT AVG (iops) FROM events WHERE month=“m1” AND week=“w1” GROUP BY zone
user query
query ranking
location
itme
month
zone center rack
week
hour
DICE, ICDE ’14

Query Formula=on user wait =me, t
Result Review
DB
Specula=ve Execu=on
Query Execu=on
74
=me
cube exploraSon
DICE, ICDE ’14

Query Formula=on user wait =me, t
Result Review
DB
Specula=ve Execu=on
Query Execu=on
75
QUERY Probability Exec Time Q1 0.3 22
Q2 0.25 20
Q3 0.25 35
Q4 0.15 70
Q5 0.05 35
maximize query probability total speculaSon Sme < t
=me
cube exploraSon
DICE, ICDE ’14

result reuse
DB
Query 1
Execu=on
Query 2
• idenSfy (likely) overlapping results • cache them • reduce query execuSon Sme (user wait Sme)
Query 3
Execu=on
prefetching window prefetching window
=me
Execu=on

semanSc windows user-‐defined
window properSes
SW2
SW3
SW4
SW1
2D exploraSon space
overlapping results/windows
window prefetching
which order?
Kalinin et al, SIGMOD ’14

semanSc windows
uSlity-‐based result ranking
& result prefetching
SW2
SW3
SW4
SW1
2D exploraSon space
user-‐defined window properSes
overlapping results/windows
Kalinin et al, SIGMOD ’14

semanSc windows
online performance vs
query compleSon Sme
SW1
extend & prefetch
adjust prefetching size to output progress
SW2
Kalinin et al, SIGMOD ’14

data diversificaSon
query
DB
diversified results k representa=ve tuples with
max total pairwise distance
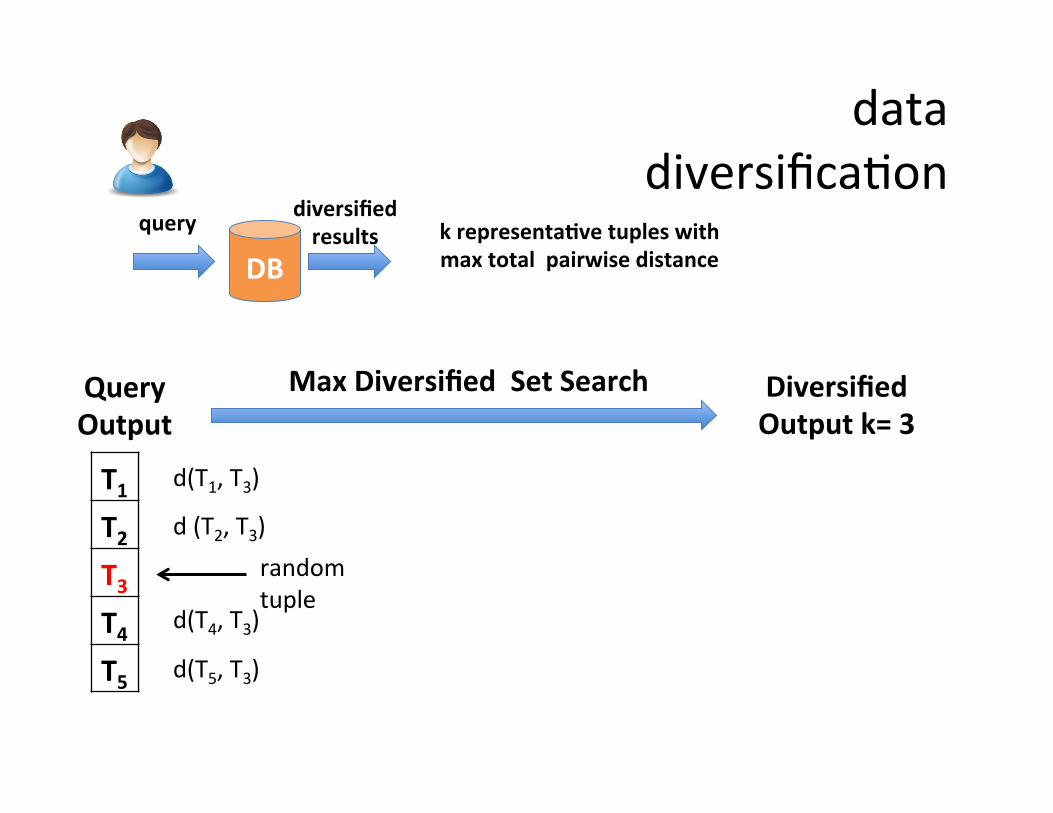
data diversificaSon
d(T1, T3) T1 T2 T3 T4 T5
random tuple
d (T2, T3)
d(T4, T3)
d(T5, T3)
Query Output
Diversified Output k= 3
Max Diversified Set Search
query
DB
diversified results k representa=ve tuples with
max total pairwise distance

data diversificaSon
d(T1, T3) T1 T2 T3 T4 T5
random tuple
d (T2, T3)
d(T4, T3)
d(T5, T3)
T1 T2 T3 T4 T5
d (T2, T1)+ d(T2,T3)
d (T4, T1)+d(T4, T3)
d (T5, T1)+d(T5, T3)
Query Output
Diversified Output k= 3
Max Diversified Set Search
query
DB
diversified results k representa=ve tuples with
max total pairwise distance

data diversificaSon
d(T1, T3) T1 T2 T3 T4 T5
random tuple
d (T2, T3)
d(T4, T3)
d(T5, T3)
T1 T2 T3 T4 T5
d (T2, T1)+ d(T2,T1)
d (T4, T1)+d(T4, T3)
d (T5, T1)+d(T5, T3)
T1 T2 T3 T4 T5
Query Output
Diversified Output k= 3
Max Diversified Set Search
query
DB
diversified results k representa=ve tuples with
max total pairwise distance

interacSve data diversificaSon
Q1
Q2
Q3 w
w
w w ¢
¢ ¢
¢ ¢
¢
¢
w
w
¢
overlapping diversified results
long Time-‐To-‐Insight
¢ ¢ ¢
¢
¢ ¢ ¢
¢ ¢ ¢
¢
¢
¢
w
w
w
w
w
w w
• cache diversified results and use most promising • regression model predicts max diversificaSon of a set
DivIDE, SSDBM’14

DB query
Cached Diversified Results
reusable results
query results
divide search space
reusable diversified results
new query results
model based output selec=on
diversified results
• search space pruning through regression model • best/first fit search for max total diversificaSon
among cached and new results
DivIDE, SSDBM’14
interacSve data diversificaSon

structure-‐aware prefetching • prefetching for interacSve spaSal query sequences • model structures of past spaSal queries in graph • idenSfy guiding structure in past two queries : iteraSve pruning • cache the predicted next locaSon
SCOUT, VLDB’12





























