Embed Size (px)
Citation preview

Overlay and P2P Networks Applications continued and Summary
Prof. Sasu Tarkoma
18.2.2013

Contents
Today CDNs Some advanced topics Summary and conclusions

Content Delivery Networks (CDN)
Geographically distributed network of Web servers around the globe (by an individual provider, E.g. Akamai).
Improve the performance and scalability of content retrieval. Allow several content providers to replicate their content in a
network of servers.

Motivation
Network cost Huge cost involved in setting up clusters of servers around the globe and corresponding increase in network traffic
Economic cost
Higher cost per service rate making them inaccessible to lower and medium level customers
Social cost
Monopolization of revenue

CDN Technology
Intelligent wide area traffic management Direct clients’ requests to optimal site based on topological proximity
Two types of redirection: DNS redirection or URL rewriting Cache
Saves useful contents in cache nodes.
Two cache policies: least frequently used standard and least recently used standard.
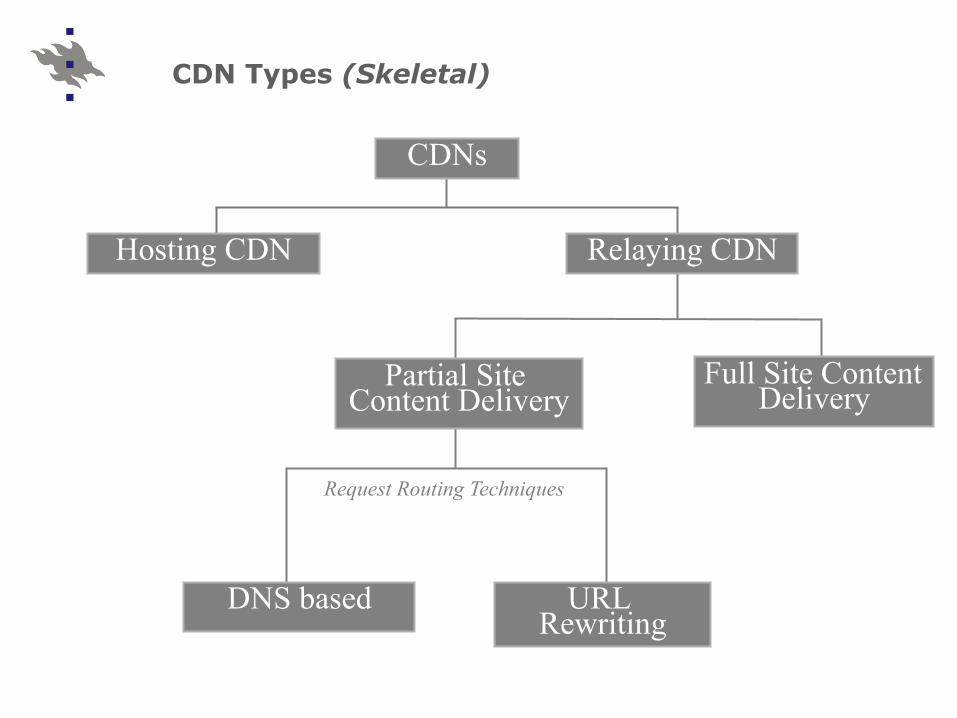
CDN Types (Skeletal)
CDNs
Hosting CDN Relaying CDN
Partial Site Content Delivery
Full Site Content Delivery
URL Rewriting
DNS based
Request Routing Techniques

7
CDN
Replicate content on many servers Challenges
How to replicate content Where to replicate content How to find replicated content How to choose among known replicas How to direct clients towards replica
DNS, HTTP redirect, anycast, etc. Akamai

8
Server Selection
Service and content is replicated in many places in network How to direct clients to a particular server?
As part of routing à anycast, cluster load balancing As part of application à HTTP redirect As part of naming à DNS
Which server to use?
Best performance à to improve client performance Based on Geography? RTT? Throughput? Load?
Lowest load à to balance load on servers Any active node à to provide availability
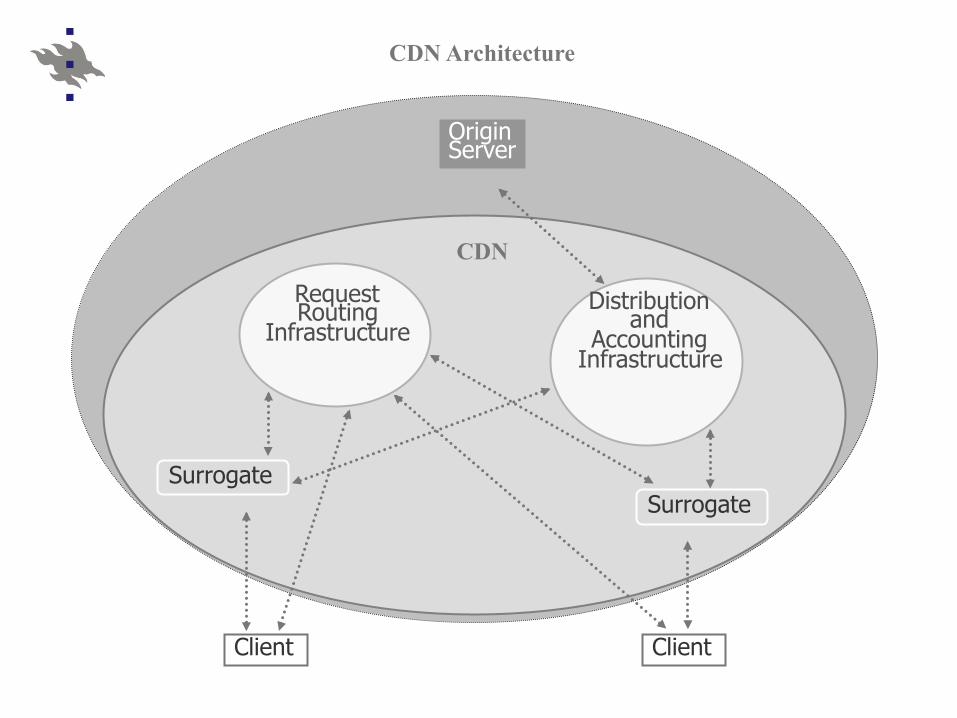
CDN Architecture
Surrogate Surrogate
Request Routing
Infrastructure Distribution
and Accounting
Infrastructure
CDN
Origin Server
Client Client

Surrogate server placement problem
Given N possible locations at edge of the Internet, we are able to place K (K<N) surrogate servers, how to place them to minimize the total cost?
This is the: Minimum K-Median Problem Given N points, we must select K (centers), and then assign
each input point j to the selected center that is closest to it. The goal is to select K centers so as to minimize the sum of the assignment costs.
This is NP-Hard Many heuristics algorithms to solve this (tree, greedy ,…)
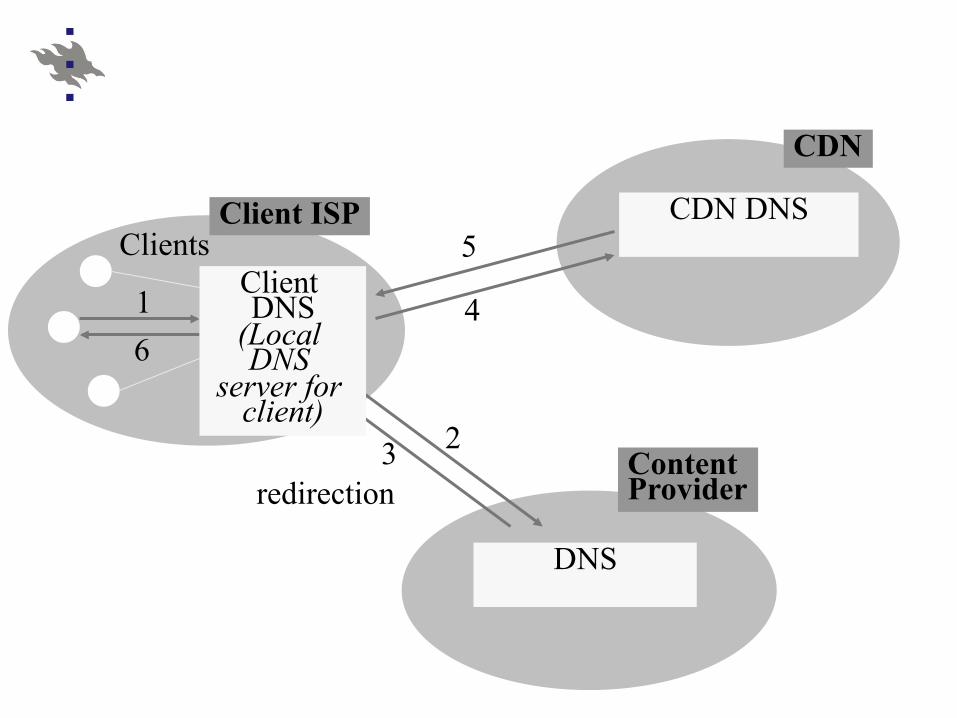
DNS
CDN DNS
CDN
Client ISP Clients
1 6
2 3
5
4
redirection Content Provider
Client DNS
(Local DNS
server for client)
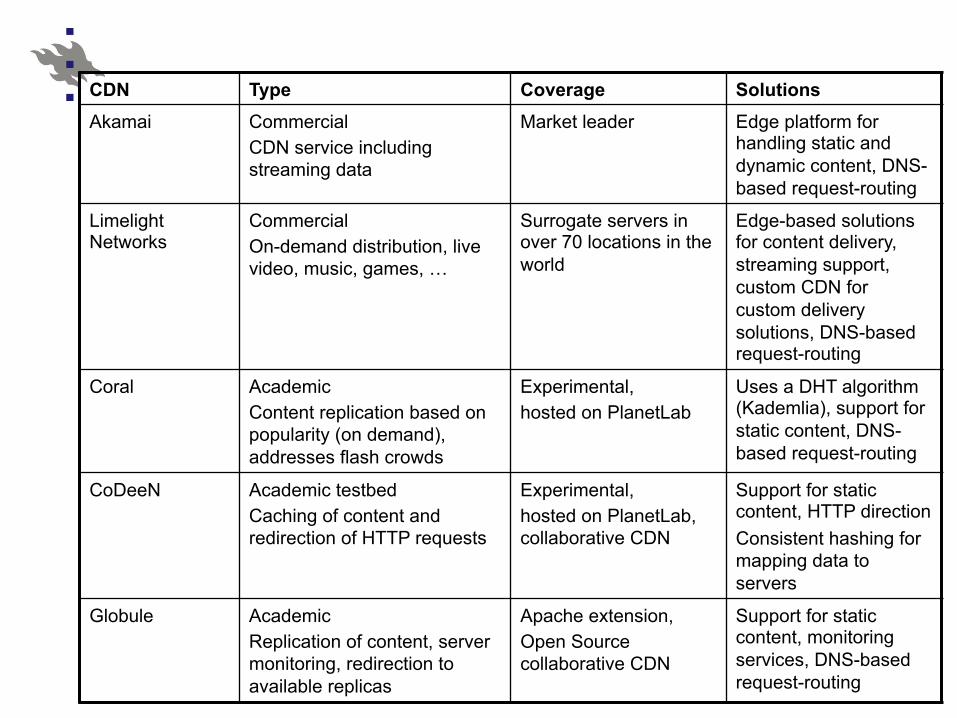
CDN Type Coverage Solutions Akamai Commercial
CDN service including streaming data
Market leader Edge platform for handling static and dynamic content, DNS-based request-routing
Limelight Networks
Commercial On-demand distribution, live video, music, games, …
Surrogate servers in over 70 locations in the world
Edge-based solutions for content delivery, streaming support, custom CDN for custom delivery solutions, DNS-based request-routing
Coral Academic Content replication based on popularity (on demand), addresses flash crowds
Experimental, hosted on PlanetLab
Uses a DHT algorithm (Kademlia), support for static content, DNS-based request-routing
CoDeeN Academic testbed Caching of content and redirection of HTTP requests
Experimental, hosted on PlanetLab, collaborative CDN
Support for static content, HTTP direction Consistent hashing for mapping data to servers
Globule Academic Replication of content, server monitoring, redirection to available replicas
Apache extension, Open Source collaborative CDN
Support for static content, monitoring services, DNS-based request-routing

Akamai
Clients fetch html document from primary server URLs for replicated content are replaced in html Client resolves aXYZ.g.akamaitech.net hostname Akamai.net name server returns NS record for
g.akamaitech.net G.akamaitech.net nameserver choses server
in region Should try to choose server that has file in
cache - How to choose? Uses aXYZ name and consistent hash
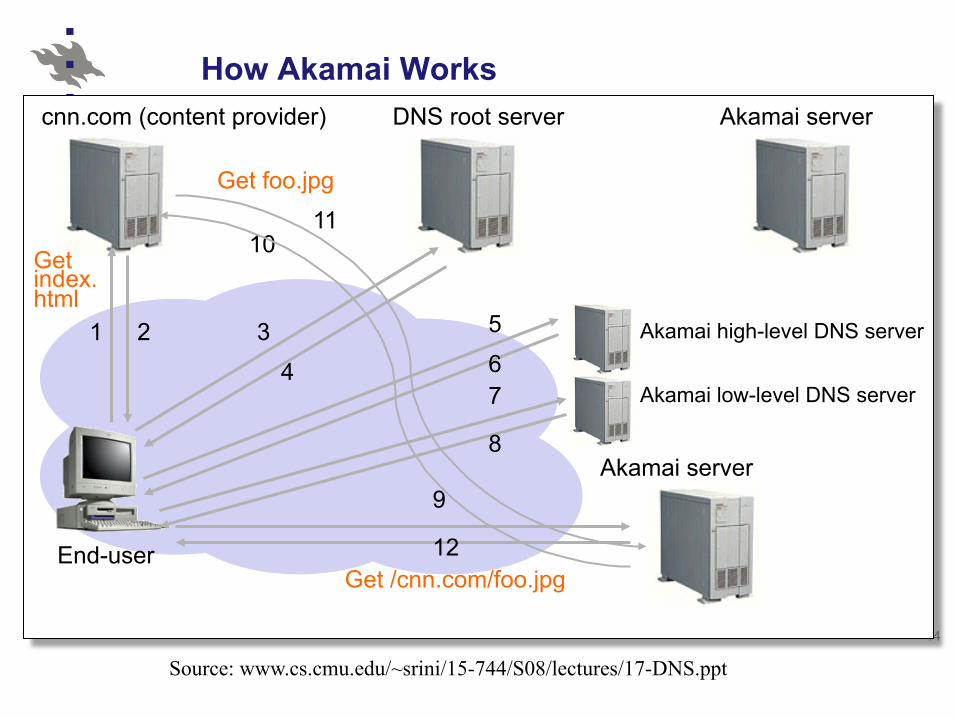
14
How Akamai Works
End-user
cnn.com (content provider) DNS root server Akamai server
1 2 3
4
Akamai high-level DNS server
Akamai low-level DNS server
Akamai server
10
67
8
9
12
Get index.html
Get /cnn.com/foo.jpg
11
Get foo.jpg
5
Source: www.cs.cmu.edu/~srini/15-744/S08/lectures/17-DNS.ppt

Question
Consistent hashing is extensively used in CDN and DHTs Are there alternatives? Simply taking hashval mod N is not good due to remapping
when N changes Linear hashing predates consistent hashing and it can be
used to solve this

Linear Hashing
Use a family of hash functions h0, h1, h2, ... Each function’s range is twice that of its
predecessor When all the pages at one level (the current
hash function) have been split, a new level is applied
Splitting occurs gradually
Current hash function, then you know if a bucket has been split from a split counter
Pages are split when overflows occur – but not
necessarily the page with the overflow (use overflow bucket as a temporary measure)
Splitting in a round robin fashion

Linear Hashing II
Use a family of hash functions h0, h1, h2, ...
hi(key) = h(key) mod(2iN) N = initial number of buckets
h is some hash function
hi+1 doubles the range of hi
Keep track of the next bucket to split and the current level: half of a split bucket is moved to the new bucket
When all buckets split, go to the next level

Answer
Yes, linear hashing can be used but it is not so convenient as consistent hashing
Consistent hashing allows buckets to be added in any
order, whereas Litwin’s Linear Hashing (LH*) scheme requires buckets to be added one at a time in sequence
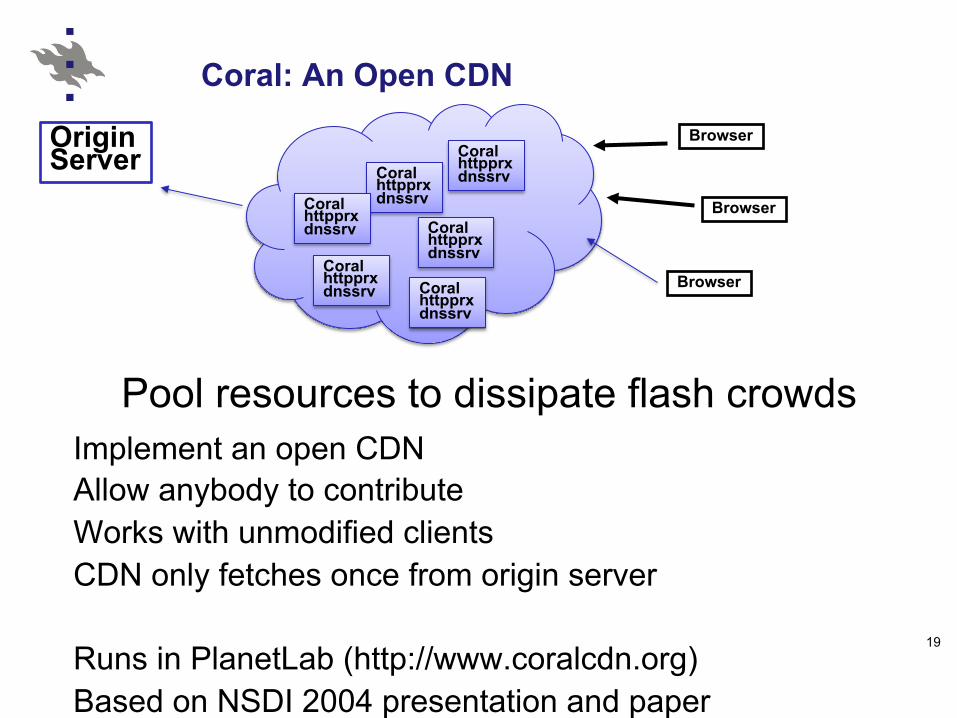
Coral: An Open CDN
Implement an open CDN Allow anybody to contribute Works with unmodified clients CDN only fetches once from origin server Runs in PlanetLab (http://www.coralcdn.org) Based on NSDI 2004 presentation and paper
Origin Server
Coral httpprx dnssrv
Coral httpprx dnssrv Coral
httpprx dnssrv
Coral httpprx dnssrv
Coral httpprx dnssrv
Coral httpprx dnssrv
Browser
Browser
Browser
Pool resources to dissipate flash crowds
19

Using CoralCDN
Rewrite URLs into “Coralized” URLs www.x.com → www.x.com.nyud.net:8090
Coral distributes the load
Who might “Coralize” URLs? Web server operators Coralize URLs Coralized URLs posted to portals, mailing lists Users explicitly Coralize URLs
20

Resolver Browser
Coral dns srv http prx Coral
dns srv http prx
Coral dns srv http prx
Coral dns srv http prx
Coral dns srv http prx
4 (get proxies) 4
2 5
3 probe client)
9 Found
8,11 looking up URL
1 6: proxy list
7 use proxy 10 cache and return www.x.com
.nyud.net
Coral dns srv http prx Coral
dns srv http prx
DNS Redirection
Return proxy, preferably one near client
Cooperative Web Caching

Coral Server Discovery
1. Each Coral server inserts its IP network prefix as key, its IP address as value
2. DNS server does DHT lookup on client IP prefix to find nearby Coral server
Details (multiple prefixes): Each Coral server uses traceroute to find nearby
routers Registers itself under IP of each nearby router Coral DNS server traceroutes to client Looks up each router IP address in mapping

Hierarchical DHT
A hierarchy of DHTs, with clustering at lower levels DHT based on XOR metric
Nearby (< 20 ms) Coral nodes form an L2 DHT L1: 60 ms L0: global Search in L2 DHT first If nearby copy exists, will find it first Only search L1, L0 if miss in lower level

Finding URLs
Look up the URL in a DHT key=URL, value=IP addr of Coral cache that has the URL
Coral cache fetches the page from that other cache
If DHT had more than one value for key, fetch
page from more than one In case one is down or slow

Coral lacks… Central management A priori knowledge of network topology
Anybody can join system Any special tools (e.g., BGP feeds)
Coral has… Large number of vantage points to probe topology Distributed index in which to store network hints Each Coral node maps nearby networks to self
Challenges for DNS Redirection

Internet Indirection Infrastructure (i3)
• A DHT - based overlay network – Based on Chord
• Aims to provide more flexible communication model than current IP addressing
• Also a forwarding infrastructure – i3 packets are sent to identifiers – each identifier is routed to the i3 node responsible for
that identifier – the node maintains triggers that are installed by
receivers – when a matching trigger is found the packet is
forwarded to the receiver

i3 II
• An i3 identifier may be bound to a host, object, or a session
• i3 has been extended with ROAM – Robust Overlay Architecture for Mobility – Allows end hosts to control the placement of
rendezvous-points (indirection points) for efficient routing and handovers
– Legacy application support • user level proxy for encapsulating IP packets to i3
packets
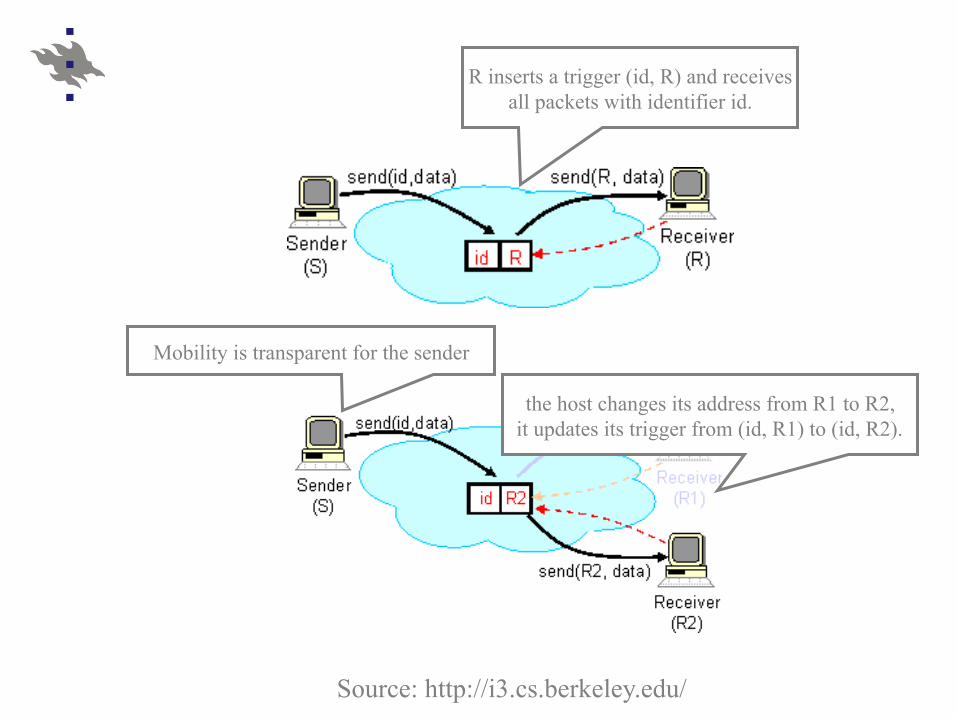
Source: http://i3.cs.berkeley.edu/
R inserts a trigger (id, R) and receives all packets with identifier id.
the host changes its address from R1 to R2, it updates its trigger from (id, R1) to (id, R2).
Mobility is transparent for the sender
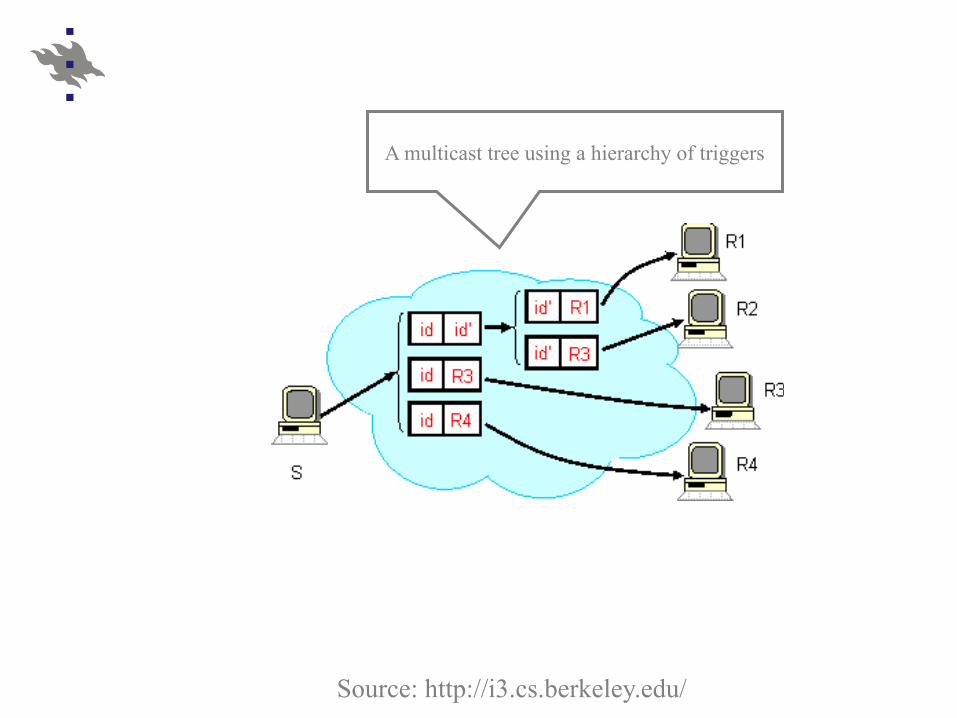
Source: http://i3.cs.berkeley.edu/
A multicast tree using a hierarchy of triggers
Source: http://i3.cs.berkeley.edu/
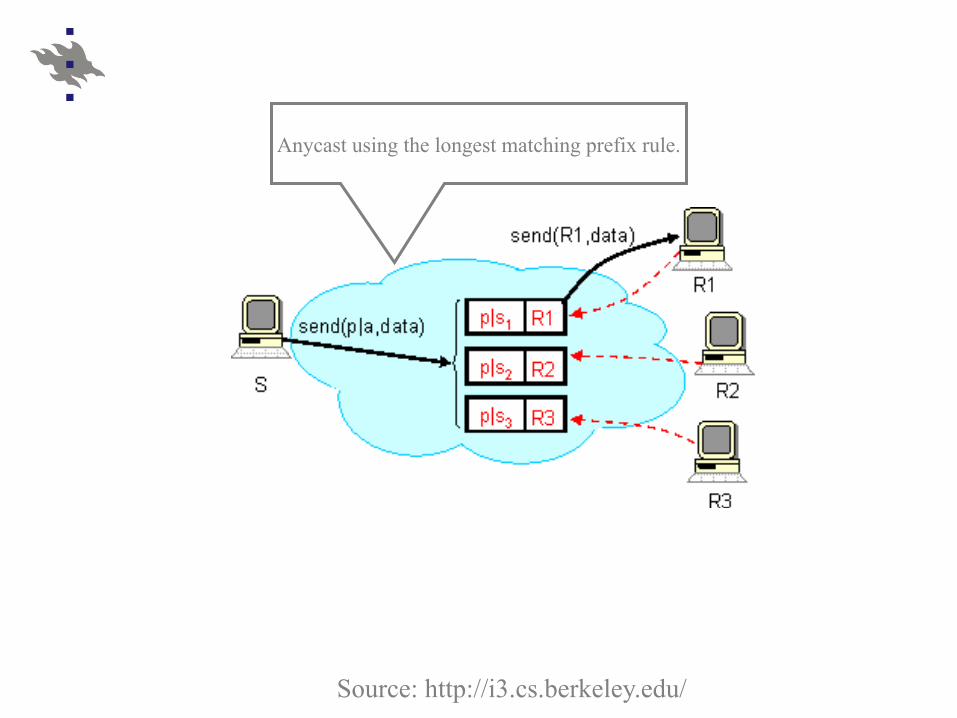
Anycast using the longest matching prefix rule.
Source: http://i3.cs.berkeley.edu/
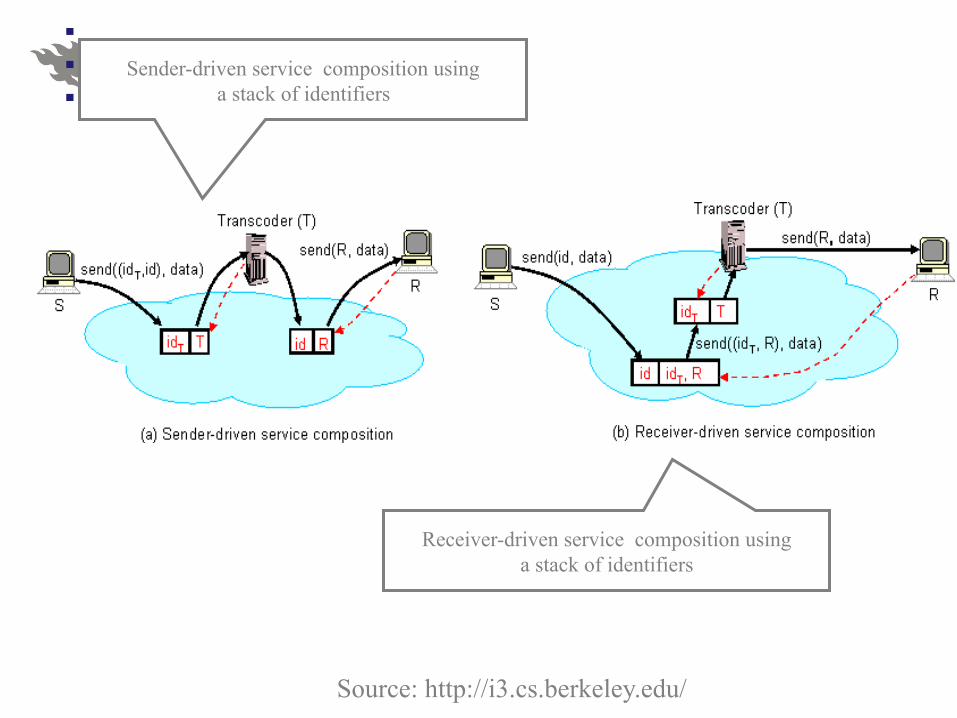
Sender-driven service composition using a stack of identifiers
Receiver-driven service composition using a stack of identifiers

Summary
Key applications Kademlia and Mainline DHT (XOR geometry) PAST and SCRIBE (Pastry) Akamai (consistent hashing)
Amazon (Dynamo, consistent hashing, ring geometry) Coral (XOR geometry)

Synthesis
We have covered building blocks for decentralized distributed systems Unstructured: Bittorrent, flooding, limited flooding, Bloom filter
summaries, depth-first search with backtracking, layered Structured: consistent hashing and DHTs, small world and location
swapping, network proximity, content placement, rendezvous Security: asymmetric and symmetric techniques, Sybil attack Additional techniques: gossip, anti-entropy, vector clocks, … Applications: Search, file exchange, secure and high performance
storage, multicast, DNS replacement, CDN, Future Internet?
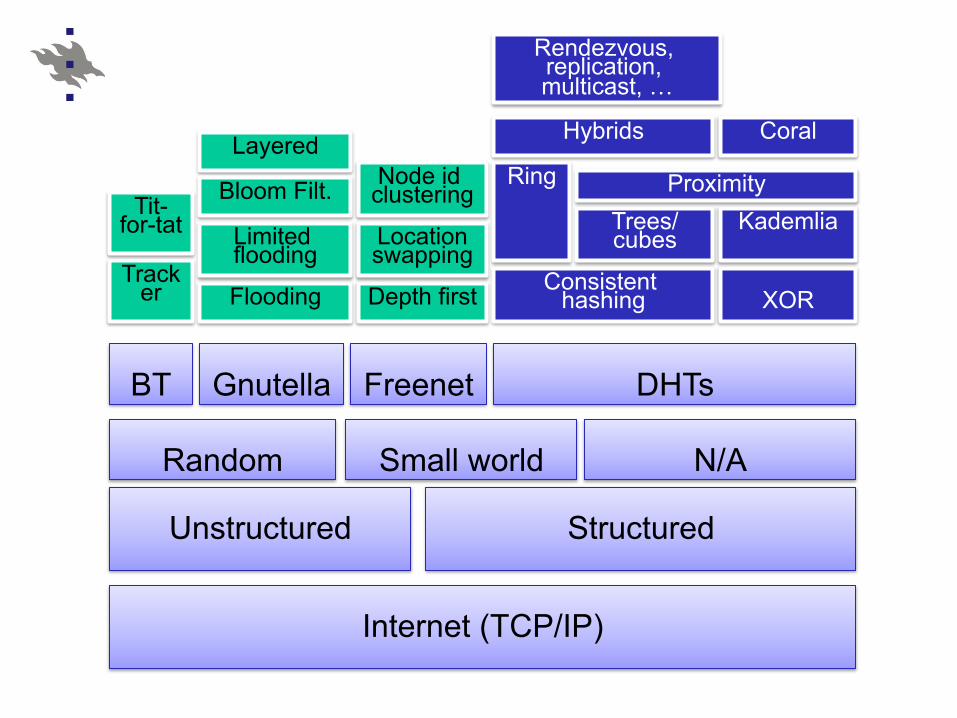
Internet (TCP/IP)
Unstructured
Structured
Small world
Random
N/A
BT
DHTs
Freenet
Flooding
Limited flooding
Layered
Bloom Filt.
Gnutella
Tracker
Tit-for-tat
Depth first
Location swapping
Node id clustering
Consistent hashing
XOR
Kademlia
Coral
Ring
Trees/cubes
Rendezvous, replication, multicast, …
Proximity
Hybrids
Internet (TCP/IP)
Cluster
Wide-area
(unstructured)
Search
Storage
Rendezvous
Search
Storage
Rendezvous
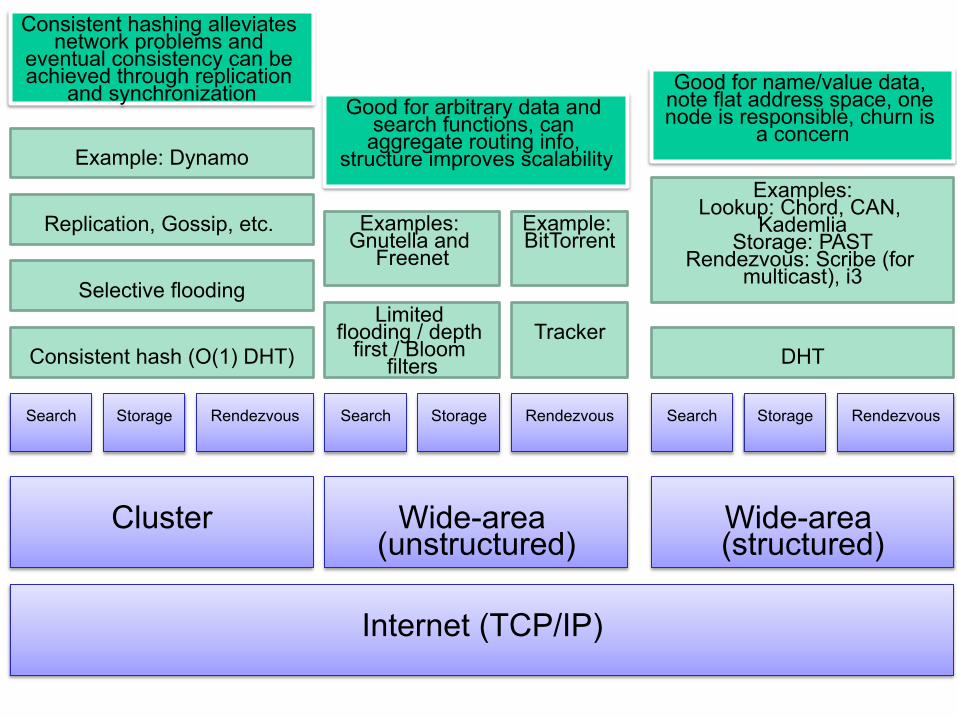
Consistent hash (O(1) DHT)
Selective flooding
Replication, Gossip, etc.
Example: Dynamo
Limited flooding / depth
first / Bloom filters
Examples: Gnutella and
Freenet
Tracker
Example: BitTorrent
Wide-area (structured)
Search
Storage
Rendezvous
DHT
Examples: Lookup: Chord, CAN,
Kademlia Storage: PAST
Rendezvous: Scribe (for multicast), i3
Good for name/value data, note flat address space, one node is responsible, churn is
a concern Good for arbitrary data and
search functions, can aggregate routing info,
structure improves scalability
Consistent hashing alleviates network problems and
eventual consistency can be achieved through replication
and synchronization

Current research involving overlays
Virtualized cloud systems and data centers Cluster-based data analytics and processing Social networks Data dissemination (live video, subscriptions) Control plane for Future Internet proposals
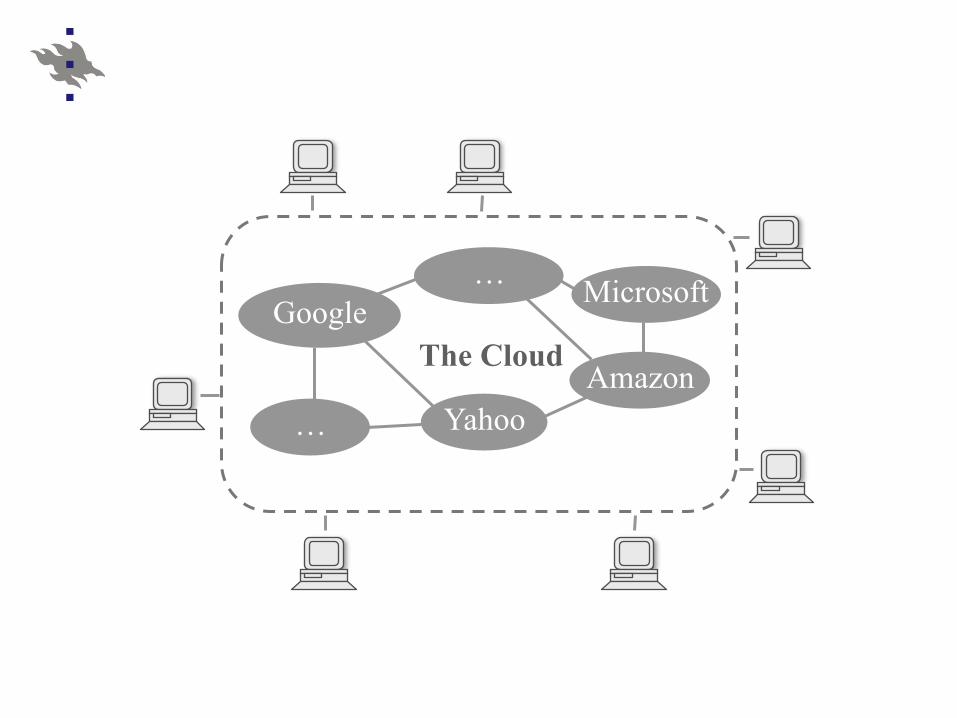
The Cloud
… Google Microsoft
Amazon Yahoo …

Grading
Course grading will be based on the final exam and the assignments.
Assignments give bonus points for the exam
Max exam points 60, max bonus points 12 Course exam 27.2.2013 16:00 CK112 Final exam on 19.4.2013 16:00 in A111

Exam
Four essay questions, answer three, 18 max points, max 6 points per answer
Example questions: Q1: A) Compare Gnutella and Kademlia. What are the key
differences and similarities of the systems. B) Consider the structure and routing functions of the
systems. C) How is content placed on the overlay nodes in these two systems?
Q2: A) What problem does BitTorrent solve?
B) Compare BitTorrent to HTTP. C) What are the key metrics in BitTorrent data delivery? Briefly consider the significance of each metric.
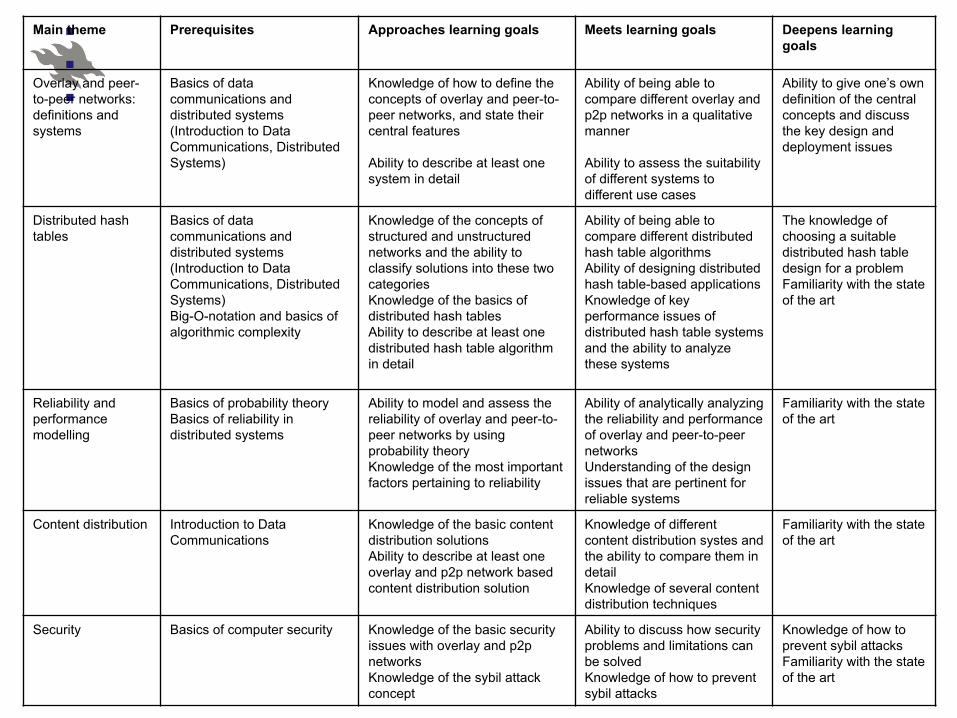
Main theme Prerequisites Approaches learning goals Meets learning goals Deepens learning goals
Overlay and peer-to-peer networks: definitions and systems
Basics of data communications and distributed systems (Introduction to Data Communications, Distributed Systems)
Knowledge of how to define the concepts of overlay and peer-to-peer networks, and state their central features Ability to describe at least one system in detail
Ability of being able to compare different overlay and p2p networks in a qualitative manner Ability to assess the suitability of different systems to different use cases
Ability to give one’s own definition of the central concepts and discuss the key design and deployment issues
Distributed hash tables
Basics of data communications and distributed systems (Introduction to Data Communications, Distributed Systems) Big-O-notation and basics of algorithmic complexity
Knowledge of the concepts of structured and unstructured networks and the ability to classify solutions into these two categories Knowledge of the basics of distributed hash tables Ability to describe at least one distributed hash table algorithm in detail
Ability of being able to compare different distributed hash table algorithms Ability of designing distributed hash table-based applications Knowledge of key performance issues of distributed hash table systems and the ability to analyze these systems
The knowledge of choosing a suitable distributed hash table design for a problem Familiarity with the state of the art
Reliability and performance modelling
Basics of probability theory Basics of reliability in distributed systems
Ability to model and assess the reliability of overlay and peer-to-peer networks by using probability theory Knowledge of the most important factors pertaining to reliability
Ability of analytically analyzing the reliability and performance of overlay and peer-to-peer networks Understanding of the design issues that are pertinent for reliable systems
Familiarity with the state of the art
Content distribution Introduction to Data Communications
Knowledge of the basic content distribution solutions Ability to describe at least one overlay and p2p network based content distribution solution
Knowledge of different content distribution systes and the ability to compare them in detail Knowledge of several content distribution techniques
Familiarity with the state of the art
Security Basics of computer security Knowledge of the basic security issues with overlay and p2p networks Knowledge of the sybil attack concept
Ability to discuss how security problems and limitations can be solved Knowledge of how to prevent sybil attacks
Knowledge of how to prevent sybil attacks Familiarity with the state of the art

After this course
Seminars on overlays & related topics M.Sc. Thesis
Many topics in this area

Course development ideas
More focus design of systems Instructed group work on designing a large-scale system Design & partial implementation
Have a nice Spring!
Remember course feedback





























