Embed Size (px)
Citation preview

OPTIMIZING INFORMATION EXTRACTION PROGRAMS OVER EVOLVING TEXT
by
Fei Chen
A dissertation submitted in partial fulfillment of
the requirements for the degree of
Doctor of Philosophy
(Computer Science)
at the
UNIVERSITY OF WISCONSIN–MADISON
2010

c© Copyright by Fei Chen 2010
All Rights Reserved

i
To my mother and father

ii
ACKNOWLEDGMENTS
I owe my deepest gratitude to my two advisors, AnHai Doan and Raghu Ramakrishnan. I am
extremely lucky to work with both of them, and am very thankful that they shared their knowl-
edge, passion and vision in databases with me. I especially thank Raghu for providing me with
the funding for the first four years, which allowed me to focus on my research. I am also deeply
grateful to Raghu for introducing me to AnHai and the DBLife project that inspired this disserta-
tion. It is with AnHai that I learnt so much about how to become a good researcher. He taught me
numerous lessons about writing academic papers and presenting research ideas. His intellectual
acuity always challenged me to think deeper and harder, and that always brought out my best ideas.
Without his encouragement and constant guidance this dissertation would not have been possible.
I am also greatly indebted to Jun Yang for working with AnHai and me on the Cyclex and
Delex projects and providing insightful feedback. I would also like to thank Luis Gravano for his
valuable comments on the Delex project. Special thanks go to Jeffery F. Naughton, C. David Page,
and Jignesh M. Patel for being on my Ph.D committee.
This research also benefits tremendously from many graduate and post-doctoral students. I
would like to thank Byron Gao for our discussions and his help on the Delex project. I owe
many thanks to several students on the DBLife project team: Xiaoyong Chai, Ting Chen, Pedro
DeRose, Chaitanya Gokhale, Warren Shen, and Ba-Quy Vuong. Thank you for your feedback
and support. I also thank fellow students Akanksha Baid, Spyridon Blanas, Bee-Chung Chen,
Lei Chen, Eric Chu, Yeye He, Allison Holloway, Willis Lang, SangKyun Lee, Junghee Lim, Eric
Paulson, Christine Reilly, Chong Sun, Khai Tran and Chen Zeng for their friendship and support.
Last but not least, I thank my parents for their unconditional support and love all these years,
and for their encouragement to pursue my interests. It is to them that I dedicate this dissertation.

iii
TABLE OF CONTENTS
Page
LIST OF FIGURES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . v
1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.1 State of the Art . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 IE over Evolving Text . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.3 Limitations of the Current Solutions . . . . . . . . . . . . . . . . . . . . . . . . . 31.4 Overview of Our Solutions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.4.1 Recycling for Single-IE-Blackbox Programs . . . . . . . . . . . . . . . . 41.4.2 Recycling for Complex IE Programs . . . . . . . . . . . . . . . . . . . . . 61.4.3 Recycling for CRF-Based IE Programs . . . . . . . . . . . . . . . . . . . 7
1.5 Contributions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91.6 Outline . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2 Recycling for Single-IE-Blackbox Programs . . . . . . . . . . . . . . . . . . . . . . 11
2.1 Problem Definition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112.2 The Cyclex Solution Approach . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142.3 The Page Matchers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.3.1 Suffix Tree Basics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162.3.2 ST: The Suffix-Tree Matcher . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.4 The Reuser + Extraction Module . . . . . . . . . . . . . . . . . . . . . . . . . . . 232.5 The Cost-Based Matcher Selector . . . . . . . . . . . . . . . . . . . . . . . . . . 282.6 Empirical Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 302.7 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
3 Recycling for Complex IE Programs . . . . . . . . . . . . . . . . . . . . . . . . . . 35
3.1 Problem Definition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 353.2 Capturing IE Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 383.3 Reusing Captured IE Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
3.3.1 Scope of Mention Reuse . . . . . . . . . . . . . . . . . . . . . . . . . . . 42

iv
Page
3.3.2 Overall Processing Algorithm . . . . . . . . . . . . . . . . . . . . . . . . 423.3.3 IE Unit Processing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 453.3.4 Identifying Reuse With Matchers . . . . . . . . . . . . . . . . . . . . . . 46
3.4 Selecting a Good IE Plan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 473.4.1 Space of Alternatives . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 483.4.2 Searching for Good Plans . . . . . . . . . . . . . . . . . . . . . . . . . . 493.4.3 Cost Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
3.5 Putting It All Together . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 553.6 Empirical Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 563.7 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
4 Recycling for CRF-Based IE Programs . . . . . . . . . . . . . . . . . . . . . . . . . 64
4.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 644.1.1 Conditional Random Fields for Information Extraction . . . . . . . . . . . 654.1.2 Problem Definition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 674.1.3 Challenges and Solution Outlines . . . . . . . . . . . . . . . . . . . . . . 69
4.2 Modeling CRFs for Reusing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 704.3 Capturing CRF IE Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 744.4 Reusing Captured Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 774.5 Putting It All Together . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 814.6 Empirical Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 814.7 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
5 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
6 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
6.1 Contributions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 886.2 Future Directions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
LIST OF REFERENCES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
APPENDICES
Appendix A: xlog Programs for Delex Experiments . . . . . . . . . . . . . . . . . . 99

v
LIST OF FIGURES
Figure Page
1.1 Two pages of the same URL, retrieved at different times . . . . . . . . . . . . . . . . 4
2.1 The Cyclex architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.2 An example of inserting a suffix . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.3 An example of prefix links . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.4 Data flow of Cyclex . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
2.5 Data sets and extractors for our experiments . . . . . . . . . . . . . . . . . . . . . . . 29
2.6 Runtime of Cyclex versus the three algorithms that use different page matchers . . . . 31
2.7 Runtime decomposition of different plans . . . . . . . . . . . . . . . . . . . . . . . . 32
2.8 Accuracy of cost models as a function of (a) number of snapshots k, (b) sample size|S|, (c) α, (d) β . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
2.9 Ratio of runtimes as a function of α and β . . . . . . . . . . . . . . . . . . . . . . . . 34
3.1 (a) A multi-blackbox IE program P in xlog, and (b) an execution plan for P . . . . . . 36
3.2 (a) An execution tree T , and (b) IE units of T . . . . . . . . . . . . . . . . . . . . . . . 38
3.3 Movement of data between disk and memory during the execution of IE unit U onpage p1. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
3.4 An illustration of executing an IE unit. . . . . . . . . . . . . . . . . . . . . . . . . . . 45
3.5 IE chains and sharing the work of matching across them. . . . . . . . . . . . . . . . . 48
3.6 Cost model parameters. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53

vi
Figure Page
3.7 Data sets and IE programs for our experiments . . . . . . . . . . . . . . . . . . . . . 56
3.8 The execution plan used in our experiments for the “award” IE task. . . . . . . . . . . 57
3.9 Runtime of No-reuse, Shortcut, Cyclex, and Delex. . . . . . . . . . . . . . . . . . 58
3.10 Runtime decomposition of No-reuse, Shortcut, Cyclex and Delex. . . . . . . . . . . 59
3.11 Performance of the optimizer. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
3.12 Sensitivity analysis. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
3.13 Runtime comparison wrt number of mentions. . . . . . . . . . . . . . . . . . . . . . . 61
3.14 Runtime comparison on a learning based IE program. . . . . . . . . . . . . . . . . . . 63
4.1 (a) An example of using CRFs to extract persons and locations, and (b) an example ofthe Viterbi algorithm. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
4.2 An example of a path matrix. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
4.3 An illustration of right contexts. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
4.4 An illustration of left contexts. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
4.5 An illustration of capturing CRF contexts from a path matrix. . . . . . . . . . . . . . 76
4.6 Data sets for our experiments. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
4.7 Stanford NER in xlog. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
4.8 Runtime of No-reuse, Cyclex, Delex, and CRFlex. . . . . . . . . . . . . . . . . . . 83
4.9 Runtime decomposition of No-reuse, Cyclex, Delex, and CRFlex. . . . . . . . . . . 84
A.1 xlog Programs for 6 IE tasks in Figure 3.7.(b). IE blackboxes are in bold. . . . . . . . 105
A.2 The xlog program of “actor”. IE blackboxes are in bold. . . . . . . . . . . . . . . . . 105

ABSTRACT
OPTIMIZING INFORMATION EXTRACTION PROGRAMS OVER EVOLVING TEXT
Fei Chen
Under the supervision of Associate Professor AnHai Doan and Dr. Raghu Ramakrishnan
At the University of Wisconsin-Madison
Information extraction (IE) is the problem of extracting structured data from unstructured text.
Examples of structured data are entities such as organizations and relationships such as “company
X is acquired by company Y.” Examples of unstructured text are emails, Web pages, and blogs.
Most current IE approaches have considered only static text corpora, over which we typically
have to apply IE only once. Many real-world text corpora however are evolving, in that documents
can be added, deleted and modified. An example of evolving text is Wikipedia. Therefore, to
keep extracted information up to date, we often must apply IE repeatedly, to consecutive corpus
snapshots. How to efficiently execute such repeated IE?
In this dissertation I describe solutions that efficiently execute such repeated IE by recycling
previous IE efforts. Specifically, given a current corpus snapshot U , these solutions first identify
text portions of U that also appear in the previous corpus snapshot V . Since these solutions have
already executed the IE program over V , they can now recycle the IE results of these parts, by
combining these results with the results of executing IE over the remaining parts of U , to produce
the complete IE results for U . We describe three systems that deal with successively more complex
IE programs. The first system, Cyclex, recycles for IE programs that contain a single IE black-
box. The second system, Delex, recycles for IE programs that consist of multiple IE blackboxes.
The third system, CRFlex, also considers multi-blackbox IE programs, but some of these black-
boxes are based on a leading statistical learning model: Conditional Random Fields. I present
experiments on real-world data that validate the proposed solutions.

1
Chapter 1
Introduction
Information extraction (IE) is the problem of extracting structured data from unstructured text.
Examples of structured data are entities such as persons, locations, organizations, and relationships
such as “company X is acquired by company Y.” Examples of unstructured text are emails, Web
pages, and blogs.
This dissertation studies optimizing IE over evolving text: the problem of how to execute IE
programs efficiently over text corpora that are evolving, in that documents can be added, deleted,
and modified. An example of evolving text is Wikipedia.
We begin in this chapter by reviewing state-of-the-art IE solutions, and showing that these IE
solutions only consider static text. Then we show that evolving text is pervasive and that many IE
applications consider IE over evolving text (Section 1.2). Next, we show that the current solution of
IE over evolving text is not satisfactory (Section 1.3). We then outline our solutions (Section 1.4).
Finally, we list our contributions (Section 1.5) and outline the rest of this dissertation (Section 1.6).
1.1 State of the Art
Information extraction has received much attention in the database, AI, Web, and KDD com-
munities (see [22, 3, 33, 18] for recent tutorials). The vast majority of works consider how to
improve extraction accuracy (e.g., with novel techniques such as CRFs [22]). But recent works
also consider how to improve extraction time. They fall roughly into three groups:

2
• The first group (e.g., [4, 50]) efficiently selects a subset of documents that are likely to contain
the structured data of interest. Then it only applies IE programs to the selected subset of
documents, instead of to the entire text corpus.
• The second group (e.g., [20, 15, 67]) considers the problem of efficiently matching patterns
against documents, which is a common problem in IE tasks. It builds an inverted index over
the documents to reduce the number of documents considered for each pattern. Alteratively,
when there are many patterns to be matched, it builds an index over the patterns to reduce
the number of patterns considered for each document.
• The third group (e.g., [62, 67]) considers IE programs as workflows that consist of multiple
operators. Then it exploits relational style optimization to change the order of evaluating
these operators to reduce extraction time.
These proposed solutions have made significant progress in deploying IE programs efficiently
over large text corpora. However, these solutions have considered only static text corpora, over
which we typically have to apply IE only once. In practice, text corpora are often evolving. There-
fore, to keep extracted information up to date, we often must apply IE repeatedly to consecutive
corpus snapshots. We now list a few examples of IE applications over evolving text.
1.2 IE over Evolving Text
Community Information Management (CIM): CIM systems [32] extract, manage, and keep
track of structured information related to a community on the Web. For example, DBLife [31] is a
structured portal for the database community that we have been developing. It extracts and tracks
information about researchers, organizations, papers, conferences, and talks. To this end, DBLife
operates over a text corpus of 10,000+ URLs. Each day it re-crawls these URLs to generate a 120+
MB corpus snapshot, and then applies IE to this snapshot to extract the aforementioned structured
data. In order to monitor the latest community information (e.g., which database researchers have
been mentioned where in the past 24 hours), it must re-crawl all the URLs to generate a new corpus
snapshot and then re-apply IE.

3
Enterprise Information Management: As another example, Impliance is a system built at IBM
Almaden that aims to manage all information within an enterprise [7]. It crawls the enterprise
intranet, and applies IE programs to each document obtained to extract information such as, “who
is mentioned in this document.” In order to infer the latest information over the intranet, Impliance
must regularly re-crawl the intranet and then re-apply IE.
Social Media Monitoring: Recently, there is growing interest in monitoring social media, such
as blogs, Wikipedia, and Twitter. For example, YAGO [70] is a system that extracts structures from
Wikipedia and stores these extracted structures into a database. In order to keep the database up
to date as Wikipedia evolves, it must regularly re-crawl Wikipedia and re-extract structures. See
[6, 19, 34, 13, 51] for other examples of evolving text corpora.
1.3 Limitations of the Current Solutions
Despite their pervasiveness, no satisfactory solution has been proposed currently for IE over
evolving text. Given such a corpus, the common solution is to apply IE to each corpus snapshot
in isolation, from scratch. This solution is simple, but highly inefficient, with limited applicability.
For example, in DBLife reapplying IE from scratch takes 8+ hours each day, leaving little time left
for higher-level data analysis. As another example, time-sensitive applications (e.g., stock, auction,
intelligence analysis) often want to refresh information quickly, by re-crawling and re-extracting,
say, every 30 minutes. In such cases, applying IE from scratch is inapplicable if it already takes
more than 30 minutes. Finally, this solution is ill-suited for interactive debugging of IE applications
over evolving corpora, because such debugging often requires applying IE repeatedly to multiple
corpus snapshots. Thus, given the growing need for IE over evolving text corpora, it has now
become crucial to develop efficient IE solutions for these settings.
1.4 Overview of Our Solutions
The key idea behind our solutions is to exploit IE efforts spent on previous corpus snapshots to
reduce the extraction time on the current corpus snapshot. We now outline our solutions.

4
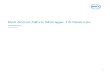
Cimple Project Meetings
CS 310 at 4pm on Jun 20, to discuss
CIM and IR.
Will meet in CS 105 at 2pm this
Thursday.
p q
u1
u2
v1
v2
v3
Cimple Project Meetings
Will meet in CS 105 at 2pm this
Thursday.
Figure 1.1 Two pages of the same URL, retrieved at different times
1.4.1 Recycling for Single-IE-Blackbox Programs
We start by considering IE programs that have a single blackbox or an extractor. We consider
how to execute extractors over evolving text efficiently. We have developed Cyclex as a solution
to this problem. The key idea underlying Cyclex is to recycle previous IE results, given that con-
secutive snapshots of a text corpus often contain much overlapping data. The following example
illustrates this idea:
Example 1.1. Consider a tiny corpus of a single URL that lists project meetings. Figure 1.1 shows a
snapshot of this corpus, which is just a single data page p (of the above URL), crawled today. Suppose that
we have applied an extractor E to this snapshot, to extract the tuple (CS 105,2pm) which is a mention of a
meeting. Suppose tomorrow we crawl the above URL to obtain another corpus snapshot, which is the page
q shown in Figure 1.1. Then to extract meetings from q, current solutions would apply extractor E to q from
scratch, and produce tuples (CS 105,2pm) and (CS 310,4pm).
In contrast, Cyclex tries to recycle the IE results of p. Specifically, it starts by “matching” q with p, to
find text regions of q that also appear in p. Suppose it finds two regions v1 and v2 of q that also appear as
u1 and u2 of p, respectively (see Figure 1.1). Cyclex then does not apply E to v1 and v2, but instead copies
over the mentions of u1 and u2. Cyclex then applies E only to v3, the sole region of q that does not appear
in p. The savings come from not having to apply E to the entire page q.
While promising, realizing the above idea raises difficult challenges. The first challenge is that
we cannot simply just copy mentions over, e.g., from regions u1 and u2 of page p to v1 and v2 of
page q, as discussed in Example 1.1. To see why, suppose a particular extractor E is such that
it only extracts meetings if a page has fewer than five lines (otherwise it produces no meetings).
Then none of the mentions of page p can be copied over to page q, which has more than five lines.

5
In general, which mentions can be copied “safely” depends on certain properties of extractor E.
Thus, we must model certain properties of extractor E, so that we can (a) exploit these properties
to reuse certain mentions, and (b) prove that reusing will produce the same set of mentions as
applying IE from scratch. In Cyclex, we define a small set of such properties, show that many
practical extractors exhibit these properties (see Section 2.1), and develop incremental re-extraction
techniques by exploiting these properties.
Our second challenge is how to “match” two pages, e.g., p and q in Example 1.1, to find
overlapping text regions. We first develop ST, a powerful suffix-tree based matcher, and prove
that this matcher achieves the most complete result, i.e., finds all largest possible overlapping
regions. We then show that an entire spectrum of matchers exists, with matchers trading off the
completeness of the result for runtime efficiency (see Section 2.3). Since no matcher is always
optimal, we provide Cyclex with a set of alternative matchers (more can be added easily), and a
way to select a good one, as discussed below.
Since dynamic text corpora can easily contain tens of thousands or millions of data pages,
we must also develop efficient solutions for reusing mentions and applying extractor E to non-
overlapping text, in the presence of a large amount of disk-resident data. We must also consider
how to efficiently interleave these steps with the step of matching data pages (see Section 2.4).
Finally, addressing the above challenges results in a space of execution plans, where the plans
differ mainly on the page matcher employed. Thus, in the final challenge we must develop a cost
model and use it to select the optimal plan. Unlike RDBMS settings, our cost model is extraction-
specific. In particular, it tries to model the rate of change of the text corpus, and the run time and
result size of extractors and matchers, among others (see Section 2.5).
We conduct extensive experiments over two real-world data sets that demonstrate that Cyclex
can dramatically cut the runtime of re-applying IE from scratch by 50-90%. This suggests that
recycling past IE efforts can be highly beneficial.

6
1.4.2 Recycling for Complex IE Programs
The Cyclex work clearly established that recycling IE results for evolving text corpora is highly
promising. The work itself however suffers from a major limitation: it considers only IE programs
that contain a single IE blackbox. Real-world IE programs, in contrast, often contain multiple IE
blackboxes connected in a compositional “workflow.” As a simple example, a program to extract
meetings may employ an IE blackbox to extract locations (e.g., “CS 105”), another IE blackbox to
extract times (e.g., “3 pm”), then pairs locations and times and keeps only those that are within 20
tokens of each other (thus producing (“CS 105”, “3 pm”) as a meeting instance in this case).
The IE blackboxes are either off-the-shelf (e.g., downloaded from public domains or purchased
commercially) or hand-coded (e.g., in Perl or Java), and they are typically “stitched together” using
a procedural (e.g., Perl) or declarative language (e.g., UIMA, Gate, xlog [37, 28, 67]). Such multi-
blackbox IE programs could be quite complex, for example, 45+ blackboxes stacked in five levels
in DBLife, and 25+ blackboxes stacked in seven levels in Avatar [33]. Since Cyclex is not aware
of the compositional nature of such IE programs (effectively treating the whole program as a large
blackbox), its utility is severely limited in such settings.
To remove this limitation, we develop Delex, a solution for effectively executing multi-blackbox
IE programs over evolving text data. Like Cyclex, Delex aims at recycling IE results. However,
compared with Cyclex, developing Delex is fundamentally much harder, for three reasons.
First, since the target IE programs for Delex are multi-blackbox and compositional, we face
many new and difficult problems. For example, how should we represent multi-blackbox IE pro-
grams, e.g., how to stitch together IE blackboxes? How to translate such programs into execution
plans? At which level should we reuse such plans? We show for instance that reusing at the level
of each IE blackbox (i.e., storing its input/output for subsequent reuse), like Cyclex does, is sub-
optimal in the compositional setting. Once we have decided on the level of reuse, what kind of
data should we capture and store for subsequent reuse? Can we reuse across IE blackboxes? These
are examples of problems that Cyclex did not face.
Second, since a target IE program now consists of many blackboxes, all attempting reuse at the
same time, Delex faces a far harder challenge of coordinating their execution and reuse to ensure

7
efficient movement of large quantities of data between disk and memory. In contrast, Cyclex only
had to worry about the efficient execution of a single IE blackbox.
Finally, the main optimization challenge in Cyclex is to decide which matcher to assign to the
sole IE blackbox. A matcher encodes a way to find overlapping text regions between the current
corpus snapshot and the past ones, for the purpose of recycling IE results. Thus, the Cyclex plan
space is bounded by the (relatively small) number of matchers. In contrast, Delex can assign to
each IE blackbox in the program a different matcher. Hence, it must search a blown-up plan space
(exponential in the number of blackboxes). To exacerbate the search problem, optimization in
this case is “non-decomposable;” i.e., we cannot just optimize parts of a plan, then glue the parts
together to obtain an optimized whole.
We conduct extensive experiments with both rule-based and learning-based IE programs over
two real-world data sets to demonstrate the utility of our approach. We show in particular that
Delex can cut the runtime of Cyclex by as much as 71%.
1.4.3 Recycling for CRF-Based IE Programs
So far, we have developed the efficient recycling algorithm Delex for IE programs that consist
of multiple IE blackboxes. If we can open up some of these blackboxes and understand more
about them, can we develop a more efficient recycling algorithm? We study this problem in this
section. In particular, we focus on IE programs that contain IE blackboxes based on a statistical
learning model: Conditional Random Fields (CRFs). We open up these CRF-based IE blackboxes
and explore whether we can develop a more efficient recycling algorithm. CRF-based IE is a
state-of-the-art IE solution that has been successfully applied to many IE tasks, including name
entity extraction [38, 54], table extraction [61], and citation extraction [60]. Therefore, a recycling
solution for CRF-based IE is a practical extension of Delex.
CRF-based IE reduces information extraction to a sequence labeling problem. Given a docu-
ment d, an IE program P that contains a CRF-based IE blackbox F first converts d into a sequence
of tokens x1...xT . Then F takes x1...xT as input and outputs a label from a set Y of labels for each
token. Y consists of the set of entity types to be extracted and a special label “other” for tokens

8
that do not belong to any of the entity types. The output of F is a label sequence y1...yT , where yi
is the label of xi.
We consider how to execute P efficiently over evolving text. To address this problem, a simple
solution is to treat all CRF-based IE blackboxes as general IE blackboxes and then apply Delex
to P . However, we found that this solution does not work well when the text corpus changes
frequently. The main reason is that the properties we use to guarantee safe reuse for general IE
blackboxes are not very effective for CRF-based IE blackboxes. Although they can guarantee the
correctness, they are also very strict in that they lead to very limited reuse opportunities.
This suggests that we should exploit properties that are specific to CRFs. We develop the
solution CRFlex, which captures this intuition. We now discuss the challenges in designing this
solution.
The first challenge is what properties of CRF models we can exploit for reuse. Compared to
the properties of general IE blackboxes, identifying properties of CRFs that could be exploited for
reuse is fundamentally much harder. The main reason is that CRFs operate based on the depen-
dency in the labels of adjacent tokens. To this end, we show that under certain conditions, a token’s
label does not depend on the labels of its adjacent tokens. This allows us to break a token sequence
into several independent pieces and recycle the IE results of each piece independently.
The second challenge is what results to capture for each CRF-based IE blackbox and how to
capture these results while executing P . The CRF properties we identify define small windows
surrounding each token such that the label of the token output by the CRF-based IE blackbox only
depends on tokens in those windows. However, the length of these windows may vary from one
token to another. Therefore, we must identify and capture these windows so that we can exploit
them for safe reuse in the subsequent snapshots. We show how to exploit the intermediate results
of CRF-based blackboxes to identify these windows efficiently. Our theoretical and experimental
results both show that the overhead of capturing is insignificant.
Finally, how can we efficiently reuse the captured results? Similar to Cyclex and Delex, CR-
Flex first finds overlapping regions and then exploits the CRF properties to identify copy regions,

9
which are overlapping regions where we can safely copy results. As we will show later (Sec-
tion 4.2), in order to properly exploit the CRF properties, CRFlex must interleave re-applying the
CRF-based IE blackbox with exploiting the CRF properties to identify the copy regions. The chal-
lenge is that these two steps are dependent upon each other. Without re-applying the CRF-based IE
blackbox, we cannot exploit the CRF properties, and thus cannot identify the copy regions. At the
same time, without identifying the copy regions, we also do not know which regions are non-copy
regions to which we should re-apply the CRF-based IE blackbox. We develop an approach that
explores this dependency constraint to interleave the two steps carefully.
Our experiments over real-world datasets and a CRF-based IE program show that CRFlex cuts
the runtime of Delex by as much as 52%.
1.5 Contributions
In summary, we have made the following contributions:
• The most important contribution of this dissertation is a framework that provides efficient
solutions for IE over evolving text. In particular, the framework advocates the idea of recy-
cling the IE results over previous corpus snapshots. As far as we know, this dissertation is
the first in-depth solution to the problem of IE over evolving text.
• We show how to model common properties of general IE blackboxes and CRF-based IE
blackboxes, and how to exploit these properties for safely reusing previous IE results.
• We show that a natural tradeoff exists in finding overlapping text regions from which we can
recycle past IE results. An approach to finding overlapping regions is called a matcher. We
show that an entire spectrum of matchers exists, with matchers trading off the completeness
of the results for runtime efficiency. Since no matcher is always optimal, our solutions
provide a set of alternative matchers (more can be added easily), and employ a cost model to
make an informed decision in selecting a good matcher.

10
• Our approaches can deal with large text corpora by exploiting many database techniques,
such as cost-based optimization and hash joins.
• Our approaches can deal with complex IE programs that consist of multiple IE blackboxes
by exploiting the compositional nature of these IE programs. We show how to model these
complex IE programs for recycling, how to implement the recycling process efficiently, and
how to find a good execution plan in a vast plan space with different recycling alternatives.
• We have developed a powerful suffix-tree-based matcher that detects all overlapping regions
between two documents. This matcher can be exploited by many other applications that need
to compare two documents.
1.6 Outline
Chapters 2-4 describe Cyclex, Delex, and CRFlex, respectively. They elaborate on the ideas
outlined in Section 1.4. Chapter 5 reviews existing solutions and discusses how they relate to ours.
Finally, Chapter 6 concludes the dissertation and discusses directions for future research.
Parts of this dissertation have been published in conferences. In particular, Cyclex is described
in an ICDE-08 paper [16], and Delex is described in a SIGMOD-09 paper [17].

11
Chapter 2
Recycling for Single-IE-Blackbox Programs
We begin our study by developing an efficient recycling solution for single-IE-blackbox pro-
grams. IE blackboxes are fundamental building blocks of IE programs. We will consider how to
recycle for complex IE programs that consist of multiple IE blackboxes in Chapter 3, and how to
recycle for IE blackboxes that are based on specific statistical learning models in Chapter 4.
This chapter is organized as follows. We first formally define our problem in Section 2.1. Then
we provide an overview of our solution, Cyclex, in Section 2.2. Sections 2.3–2.5 describe our
solution. Section 2.6 presents an empirical evaluation. Finally, Section 2.7 concludes this chapter.
2.1 Problem Definition
Data Sources, Pages, & Corpus Snapshots: Let S = {S1, . . . , Sn} be a set of data sources
considered by an application A. We assume that A crawls these sources at regular intervals to
retrieve sets of data pages. For example, DBLife considers 10,000+ data sources, each specified
with a URL, and crawls these URLs (each to a pre-specified depth) each day to retrieve a set of
14,000+ Web pages. We will refer to Pi — the set of data pages retrieved at time i — as the i-th
snapshot of the evolving text corpus S.
Entities, Attributes, & Mentions: Data pages often mention entities, which are real-world con-
cepts, such as person, paper, and meeting. We represent each entity type e with a set of attributes
a1, . . . , ak, which can be atomic (e.g., meeting room) or set-valued (e.g., topics).
Given a data page p, we refer to a consecutive sequence of characters in p as a string, or a
text fragment, or a region (we will use these notions interchangeably). We use p[i..j] to denote the

12
string s that starts with the i-th character and ends with the j-th characters of p. In this case, we
will also say s.start = i and s.end = j.
A mention of an atomic (set-valued) attribute a is then a string in p (a set of strings in p) that
refers to a. We can now define an entity mention as follows:
Definition 2.1 (Entity mention). Let p be a data page, and a1, . . . , ak be the attributes of an entity
type e. Then a mention of an instance of entity type e is a tuple m = (m1, . . . , mk), where
each mi, i ∈ [1, k], is either a mention of ai in page p, or the special value “nil,” indicating
that a mention of ai cannot be extracted from p. We also define m.start = minki=1 mi.start and
m.end = maxki=1 mi.end.
Example 2.1. Suppose the entity type “meeting” has three attributes: room, time, and topics. Then
tuple (CS 310, 4pm, {CIM,IR}) is a mention of “meeting” in page q of Figure 1.1. String s = “CS
310” (where s.start = 25 and s.end = 30) is a mention of attribute “room.” “4pm” is a mention
of “time,” and the set of strings {“CIM,” “IR”} is a mention of “topics.”
Extractors: Real-world IE applications extract mentions of one or multiple entity types from data
pages. As a first step, in this chapter we consider extracting mentions of a single entity type e (e.g.,
meeting). To extract such mentions, current applications usually employ an extractor E, which is
typically a learning-based program, or a set of extraction rules encoded in, say, a Perl script [33].
We assume that E extracts mentions from each data page in isolation, e.g., extracting meetings as
in Figure 1.1. Such per-page extractors are pervasive (e.g., constituting 94% of extractors in the
current DBLife, see [33, 67] for many examples). Hence, we start with such extractors, leaving
more complex extractors (e.g., those that extract mentions that span multiple pages) for future
work. We can now define extractors considered in this chapter as follows:
Definition 2.2 (Extractors). Let a1, . . . , ak be the attributes of an entity type e. Then an extractor
E : p → M takes as input a data page p and produces as output a set M of mentions of e in page
p, where each mention is of the form (m1, . . . , mk) as described in Definition 2.1.
Modeling Properties of Extractors: Recall from the introduction that we must model certain
properties of extractors, so that we can reuse mentions and prove the correctness of our algorithm.

13
We now describe two such properties: scope and context. To motivate scope, we observe that
attribute mentions of an entity often appear in close proximity in text pages. Consequently, an
extractor often starts by extracting attribute mentions, then combines the mentions and prunes
those combinations that span more than a maximal length α.
Example 2.2. Suppose we apply E to page q in Figure 1.1 to extract (room,time). E may start
by extracting all room mentions: “CS 310,” “CS 105,” then all time mentions: “4pm,” “2pm.” E
then pairs room and time mentions, and prunes pairs that are not found within, say, a length of
100 characters. Thus, E returns only the pairs (CS 310,4pm) and (CS 105,2pm).
Thus, we can formalize the notion of scope as follows:
Definition 2.3 (Extractor scope). An extractor E has scope α iff for any mention m produced by
E we have (m.end−m.start) < α.
To motivate context, we observe that when extracting mentions, many extractors examine only
small “context windows” to both sides of a mention, as the following example illustrates:
Example 2.3. Let E be an extractor for (room,time,topics). Suppose E produces string X as a
topic if (a) X matches a pre-defined word (e.g., “IR”), and (b) the word “discuss” or “topic”
occurs within a 30-character distance, either to the left or to the right of X . Then we say that the
context of topic mentions is 30 characters. That is, once E has extracted X as a topic, then no
matter how we perturb the text outside a 30-character window of X (on both sides), E would still
recognize X as a valid topic mention.
Let m be a mention produced by an extractor E in page p. Then we formalize the notion of
context as follows:
Definition 2.4 (β-context of mention & extractor context). The β-context of m (or context for
short when there is no ambiguity) is the string p[(m.start − β)..(m.end + β)], i.e., the string of
m being extended on both sides by β characters. Extractor E has a context β iff for any m and p′
obtained by perturbing the text of p outside the β-context of m, applying E to p′ still produces m
as a mention.

14
We assume that each extractor E comes with a scope α and a context β. These values can be
supplied by whoever implementing E or knowing how E works (e.g., the application builder, after
examining E’s description or code). As we show in the experiments, α and β do not have to be
“tight” in order for us to benefit from recycling IE results. However, the “tighter” (i.e., smaller)
these values are, the larger the benefits.
The Generality of Our IE Model: So far we have defined extractor scope and context at the
character level (see Definitions 2.1-2.1), and in this chapter, for ease of exposition, we will limit
our discussion to only the character level. However, Cyclex can be easily generalized to work with
scope/context at higher-granularity levels (e.g., word, sentence, paragraph), should that be more
appropriate for the target extractors.
Problem Definition: We can now describe our problem as follows. Let P1, . . . , Pn be consecutive
snapshots of a text corpus, E be an extractor with scope α and context β, and M1, . . . ,Mn be the
set of mentions extracted by E from P1, . . . , Pn, respectively. Let Pn+1 be the corpus snapshot
immediately following Pn. Then develop a solution to extract the set of mentions Mn+1 from Pn+1
in a minimal amount of time, by utilizing P1, . . . , Pn, α, β, and M1, . . . , Mn. In the rest of the
chapter we describe Cyclex, our solution to this problem.
2.2 The Cyclex Solution Approach
To describe Cyclex, we begin with two notions:
Definition 2.5 (Old region & maximally old region). A region r in a data page p of snapshot Pn+1
is an old region if it occurs in a page q of snapshot Pn. r is a maximally old region if it cannot be
extended on either side and still remains an old region.
To extract mentions from Pn+1, Cyclex then considers each page p in Pn+1 and “matches,” i.e.,
compares p with pages in Pn, to find old regions of p. Next, it uses the old regions to identify copy
regions and extraction regions of p (see Section 2.4). Cyclex then applies extractor E only to the
extraction regions, and copies over the mentions of the copy regions.

15
Pn , Pn+1
Pn-w, P
n-w+1, …, P
n
Mn-w,Mn-w+1
, … , Mn
Cost Model
Matcher Selector
Mn+1
Matchers
Page Matcher
Reuser
Extraction Module
Figure 2.1 The Cyclex architecture
Since pages retrieved (in consecutive snapshots) from the same URL often share much over-
lapping data, to find old regions of p, Cyclex currently matches p only with q, the page in Pn that
shares the same URL with p. (If q does not exist, then Cyclex declares that p has no old regions.)
Section 2.6 shows that the choice of matching pages with the same URL already significantly re-
duces IE time. Considering more complex choices (e.g., matching p with all pages in Pn) is an
ongoing research.
We call algorithms that match p and q to find old regions in p page matchers. Sections 2.3
shows that such matchers span an entire spectrum, trading off result completeness for runtime,
and that no matcher is always optimal. For example, the ST matcher described below returns all
maximally old regions, thus providing the most opportunities for recycling past IE results. But it
may also incur more runtime than matchers that return only some old regions. So, a priori we do
not know if it would be better than these other matchers.
The above result leads to the Cyclex architecture in Figure 2.1. Given snapshot Pn+1, the
matcher selector employs a cost model (that utilizes statistics computed over the past w snapshots)
to select a page matcher from a library of matchers. The page matcher then finds old regions of
pages in Pn+1. Next, the extraction module applies extractor E to extraction regions of pages in
Pn+1, and the reuser copies over mentions of the copy regions. Cyclex then combines the results
of both the extraction module and the reuser to produce the final IE result for Pn+1. The next three
sections describe the matchers (Section 2.3), the reuser and extraction module (Section 2.4, and
the matcher selector (Section 2.5) in detail.

16
2.3 The Page Matchers
Recall from Section 2.2 that a page matcher compares pages p and q to find old regions of p.
We have provided the current Cyclex with three page matchers: DN, UD, and ST (more matchers
can be easily plugged in as they become available). DN incurs zero runtime, as it immediately
declares that page p has no old region. Cyclex with DN thus is equivalent to applying IE from
scratch to Pn+1.
UD employs an Unix-diff-command like algorithm [58], which splits pages p and q into lines,
then employs a heuristic to find common lines. Thus, UD is relatively fast (takes time linear in
|p| + |q|), but finds only some old regions. We omit further description for space reason, but refer
the reader to [58].
ST is a novel suffix-tree based matcher that we have developed, which finds all maximal old
regions of p using time linear in |p| + |q|. ST and DN thus represent the two ends of a spectrum
of matchers that trade off the result completeness for runtime efficiency, while UD represents an
intermediate point on this spectrum.
In the rest of this section we describe ST in detail. Roughly speaking, ST inserts all suffixes
of q and p into one suffix tree T [40]. As we insert each suffix of p, T helps us identify the longest
prefix of this suffix that also appears in q. To realize this intuition, however, we must handle a
number of intricacies, so that we can locate all maximal old regions without slowing down ST to
quadratic time.
2.3.1 Suffix Tree Basics
The suffix tree for a string q is a tree T with |q| leaves, each describing a suffix of q. T must
satisfy the following: (1) Each non-root internal node has at least two children. (2) Each edge is
labeled with a nonempty substring of q, and no two edges out of a node can have labels beginning
with the same character. (3) The path label of a node is the concatenation of all edge labels on the
path from the root to this node; each suffix of q corresponds to the path label of a leaf. (4) Each
non-root internal node with path label λu (where λ is a single character and u is a string) has a

17
suffix link to the node with path label u; the root has a suffix link to itself. Figure 2.2.a shows the
suffix tree for “ababbabaab$,” where symbol $ terminates the string. Suffix links are showed as
dotted lines.
To construct a suffix tree for q, we insert all suffixes of q one by one into an initially empty
tree. For example, the suffixes of “ababbabaab$” are “ababbabaab$,” “babbabaab$,” “abbabaab$,”
. . ., “b$.” Let si denote q[i..|q|], the i-th suffix of q. Conceptually, to insert si, we first look up si,
matching si against edge labels as we go down the tree until no more characters can be matched.
If lookup stops at a node, we insert si as a leaf below that node; if lookup stops in the middle of
an edge, we add a new node to split the edge right before the point where it diverges from si, and
then insert si as a leaf of the new node.
Unfortunately, if we insert every si by starting the lookup from the root, we would end up with
a quadratic-time algorithm. The secret to more efficient suffix-tree construction is to exploit the
suffix links, which allow us to leverage the matching work we have already done when inserting
si−1. We now sketch the construction algorithm below.
Suppose we have just inserted si−1 as a leaf child of node αi−1; note that αi−1 is the only
possibly new internal node created during the insertion of si−1. Next, we want to insert si into the
suffix tree, and ensure that αi−1’s suffix link is properly set up. To this end, we follow a series of
up, across, and down moves in the suffix tree. Suppose αi−1’s path label is λu, where λ is a single
character; note that u is a prefix of si. First, we go up from αi−1 to its parent θ, whose path label
is λu′, where u′ is a prefix of u. Then, following the suffix link of θ, we go across to θ′, whose
path label is u′. Next, starting from θ′, we go down the tree, matching u − u′, the substring of u
that follows u′. We end up with node β with path label u, to which we set the suffix link of αi−1.
If β does not currently exist in the tree, we create β by splitting the edge right where the matching
of u − u′ stops; we then add si (which, as we recall, begins with u) as a child of β. On the other
hand, if β already exists in the tree, we continue to go down the tree from β, matching si − u, the
substring of si that follows u, and insert si at the point where matching stops; this process may
create a new internal node. It can be shown that this construction algorithm is linear in the size of
the string [40].

18
$baababb
a
b
a
$ba
$
$baabab
ab$
$baa
babaab$
ab$
babaab$
$
b
a
8
9
3 16 5
2
74
10
b
a
b
a
$baabab
ab$
$baa
babaab$
babaab$
b
a
3 16 5
2
4
b
$baababb
a
$baabab
ab$
$baa
babaab$
ab$babaab$
b
a
3 16 5
2
74
b
a
b
$baababb
(a) (b) (c)
Figure 2.2 An example of inserting a suffix
Figure 2.2.b shows the suffix tree before inserting s7 of “ababbabaab$.” The only new internal
node in the tree now is α6 (the dark node). The path label for the dark node is “aba” and u is “ba.”
First, we go up from the dark node to its parent θ. Then we follow the suffix link of θ and go across
to θ′ (the dotted node). Notice that we skip looking up the first “b” in s7 by following the suffix
link. Next, from the dotted node, we go down the tree, matching the substring of u that follows
“b.” The matching stops in the middle of the edge with label “ab” out from the dotted node, which
leads to splitting the edge and creating a new node β. In Figure 2.2.c, β is the dark node. We then
insert the leaf corresponding to s7 as the child of β. Finally, we set up the suffix link from α6 to β.
2.3.2 ST: The Suffix-Tree Matcher
ST starts by building a suffix tree T for q, the old page, as described in Section 2.3.1. Next,
it inserts the suffixes of p, the new page, one by one, into T , and reports each maximal old region
as soon as it is detected. To carry out this second step, we make important extensions to both the
insertion procedure and the suffix tree structure. First, we augment suffix-tree nodes with prefix
links, which are crucial to finding old regions efficiently. We also show how to set up these links
during construction. Second, we show how to detect maximal old regions without introducing
additional performance overhead. We describe these two extensions next.
Finding Old Regions Using Prefix Links: By inserting s′i, the i-th suffix of p, into T , we can
easily find the longest common prefix between s′i and any suffixes that have been already inserted.

19
(a)(c)
$c
$aaaaba
baabaaabaaaa$
1
a
baaaa$
4
$a
8
a
a
baaa
5c$
$ca c$
1 2
c$
1
baabaaabaaaa$
2
abaaabaaaa$
$c
a
(b)
Figure 2.3 An example of prefix links
Let hi denote this string, which corresponds to node α′i, the parent of the leaf corresponding to s′i.
On the other hand, what we are looking for, ri, is the longest common prefix between s′i and any
suffix of q, the old page. Unfortunately, ri may not be the same as hi, because the suffix tree at this
time additionally contains suffixes s′1, . . . , s′i−1 of p, inserted earlier than s′i.
However, it is not difficult to see that ri must be a prefix of hi, because hi by definition cannot
be shorter than any common prefix between s′i and suffixes of q. To find ri, we need to locate
the last node on the path from the root to α′i with at least one descendant leaf corresponding to
a suffix of q. Efficiently finding this node, which we denote by δi, turns out to be quite tricky.
One might think that we should encounter δi as we go down T when inserting s′i. However, recall
from Section 2.3.1 that we use suffix links to avoid quadratic-time construction; thus, we reach α′i
without starting from the root, and possibly without passing through δi.
To ensure the efficiency of locating δi, we add a prefix link for each node of T . The prefix link of
node γ, denoted Lp(γ), points to its lowest ancestor with at least one descendant leaf corresponding
to a suffix of q. If γ itself has at least one descendant leaf corresponding to a suffix of q, we do not
explicitly store a prefix link, but we implicitly understand that Lp(γ) points to γ itself.
We construct prefix links as follows. Suppose we have created the suffix tree T for q. Then
there are no explicit prefix links yet (i.e., every node’s prefix link implicitly points to itself) because
every node leads to a suffix of q. Now, for every new leaf γ we create (for a suffix of p), we let Lp(γ)
point to the same node as γ’s parent’s prefix link. For an internal node γ created by splitting an
edge pointing to node γ′, if Lp(γ′) points to γ′ itself, we let Lp(γ) point to γ itself; otherwise, we set
Lp(γ) = Lp(γ′). For example, Figure 2.3.a shows the suffix tree for q = “ac$.” Figure 2.3.b shows

20
the prefix links (in solid arrows) after we insert the first two suffixes of p = “baabaaabaaaa$.” The
black leaves are corresponding to the suffixes of q. For those nodes which have a prefix link to
itself, we do not show the links.
With prefix links, we now show how to find the longest common prefix between a suffix s′i of
p and any suffix of q, while inserting s′i into the suffix tree. After a leaf has been created for s′i, we
check the node δi pointed to by the prefix link of the leaf’s parent. The path label of δi gives us
the largest possible old region matching a prefix of s′i. For example, Figure 2.3.c shows the state
of the suffix tree before we inserting s′9, the ninth suffix of p, “aaaa$.” We omit the irrelevant part
of the tree (in triangle) and links from the figure. Following the standard suffix-tree construction
algorithm, we first use the suffix link (in dotted arrow) of the parent node of α8 to go across to θ′.
Then we go down the tree and match the substring of u = “aaa” that follows “aa.” The matching
stops in the middle of the edge with label “abaaaa$,” which leads to splitting the edge and creating
a new internal node α′9 with path label “aaa.” The leaf for s′9 is then inserted below α′9. The prefix
links of α′9 and the leaf point to the same node pointed to by the prefix link (in solid arrow) of leaf
5. We then use the prefix link of α′9 to find “a,” the longest common prefix between s′9 and any
suffix of q.
Detecting Maximally Old Regions: So far, we have seen how to find, for each suffix of p, the
longest common prefix between it and all suffixes of q. However, these prefix matches are not
necessarily maximally old regions (cf. Definition 2.5). Although such matches cannot be extended
any further to the right, it may be possible to extend them to the left. How do we then find the
globally maximally old regions?
We make two observations. First, any maximally old region must be the longest common prefix
between some suffix of p and suffixes of q. The second observation is captured by the following
lemma:
Lemma 2.1. Let p[i − 1..j] be the longest common prefix between s′i−1, the (i − 1)-th suffix of p,
and any suffix of q. Let p[i..k] be the longest common prefix between s′i and any suffix of q. Then,
p[i..k] is a maximally old region if and only if k > j.

21
Proof. If k > j, p[i− 1..k] cannot be a substring of q, as p[i− 1..j] is already the longest common
prefix between s′i−1 and any suffix of q. Hence p[i..k] cannot be extended further to the left.
Furthermore, p[i..k] cannot be extended further to the right either because it is already the longest
common prefix between s′i and any suffix of q. Therefore, p[i..k] is a maximally old region.
If p[i..k] is a maximally old region, p[i − 1..k] cannot be a substring of q, which implies that
j < k.
The above observations lead to a simple, efficient method for identifying all maximally old
regions in a streaming fashion while we process suffixes of p one by one. After processing the i-th
suffix of p and finding the longest common prefix ri between it and q’s suffixes, we compare the
end position of ri with that of ri−1 (identified while processing the (i− 1)-th suffix of p). As long
as the end position has advanced, we output ri as a maximally old region.
The complete psudocode for ST is listed in Algorithm 2.1.
Runtime Complexity: We conclude this section by stating the complexity of our suffix-tree
matching algorithm in the following theorem. The dominating cost, in terms of both time and
space, comes from standard suffix tree construction. Our implementation uses balanced search
trees to manage parent-child relationships in the suffix tree, which implies that an additional time
cost factor c = O(log A), where A is the size of the alphabet. Other alternatives with c = O(1) also
exist, but we have found our implementation to work well when A is very large. This is probably
because suffix trees with balanced search trees to manage parent-child relationships take smaller
space and thus lead to fewer cache misses.
Theorem 2.1. ST takes O((|p|+ |q|)c) time and O(|p|+ |q|) space, where c is the cost of looking
up a child of a node in the suffix tree.
Proof. First, we prove that ST takes O((|p| + |q|)c) time. ST proceeds in two phases. In the first
phase, it builds a suffix tree T (line 3) for q using O(|q|c) time [40]. In the second phase, ST finds
the maximally old regions while it is inserting each suffix of p into T (line 4-26). Except the step of
locating α′i (line 9), each of the other steps takes O(1) time. Therefore, line 2-8 and line 10-26 take
O(|p|) time. [40] shows that the total time of locating all α′i (line 9) is dominated by the total time

22
Algorithm 2.1 ST1: Input: old data page q, new data page p
2: Output: all maximal old regions R in p
3: T ⇐ buildSuffixTree(q)
4: //initialization
5: R ⇐ ∅6: α′0 ⇐ T.root
7: for each suffix s′i of p do
8: //locate the node corresponding to the longest common prefix of s′i and any suffixes in T and set up the suffix link of α′i−1
9: α′i ⇐ longestCommonPrefix(s′i,T ,α′i−1)
10: if α′i is a new node created by splitting an edge pointed to γ then
11: //set up the prefix link of α′i12: if Lp(γ) = γ then
13: Lp(α′i) ⇐ α′i14: else
15: Lp(α′i) ⇐ Lp(γ)
16: end if
17: end if
18: Insert leaf η′i as a child of α′i19: Lp(η′i) ⇐ Lp(α′i)
20: //find ri, the longest common prefix of s′i and any suffix of q, using prefix link of α′i21: ri ⇐ p[i..i + pathLength(T.root, Lp(α′i))− 1]
22: //compare the ending positions of ri and ri−1 to check if ri is a maximal old region
23: if ri.end > ri−1.end or i = 1 then
24: R ⇐ R⋃{ri}
25: end if
26: end for
of locating the children of all nodes visited in T . The total number of nodes visited is O(|p|+ |q|)and the cost of locating the children of each node is c. Therefore, line 9 takes O((|p| + |q|)c)time. Hence, the total time of the second phase is O((|p|+ |q|)c) and the overall runtime of ST is
O((|p|+ |q|)c).Now, we prove that ST takes O(|p| + |q|) space. The space taken by ST is used to store the
suffix tree and the ending position of the longest common prefix between the most recently inserted
suffix of p and all suffixes of q. The latter only needs O(1) space. A standard suffix tree for a string
of length l has at most 2l number of nodes and takes O(l) space [40]. A suffix tree augmented with
prefix links has one prefix link per node. Therefore, the augmented tree still takes O(l) space. ST

23
builds a suffix tree T with prefix links to store all suffixes of p and q. Therefore, T has at most
2(|p|+ |q|) number of nodes and takes O(|p|+ |q|) space. Hence, the overall space taken by ST is
O(|p|+ |q|).
2.4 The Reuser + Extraction Module
Suppose Cyclex has selected a page matcher M (see Section 2.2). We now describe how M
works in conjunction with the reuser and the extraction module to recycle mentions and extract
new ones. We face two key challenges. First, since corpus snapshots often are large, we must
handle disk-resident data efficiently. Second, we must employ scope α and context β to identify
precise text regions from which it is “safe” to copy mentions or to apply extractor E. To address
these challenges, we proceed in the following three steps.
1. Find Copy Regions: We begin by reading pages from disk-resident Pn+1 in a sequential
manner. For each page p, we find q ∈ Pn which shares the same URL with p. (If no such q exists,
we simply apply extractor E to p.) Next, we apply M to p and q (in memory) to find old regions
(see Section 2.3).
Not all mentions in old regions (if we find any) are safe to be copied. This is illustrated by the
following example.
Example 2.4. Let q = “Dr. John Doe is a CS prof.”. Suppose extractor E declares string n to
be a person name if it is two capitalized words preceded by “Dr. ”. Then E has context β = 3,
and produces “John Doe” as a mention of q. Now consider p = “John Doe is a CS professor”.
Suppose M declares o = “John Doe is a CS prof” to be an old region of p. Then since “John Doe”
is a mention (of q) in o, we may think that it will also be a mention of p. However, this is incorrect
because applying E to p would produce no mention.
In general, we can copy a mention only if both the mention (e.g., “John Doe”) and its context
(e.g., “Dr.”) are contained in an old region. Specifically, if p[c..c + k] is an old region because it
matches q[c′..c′ + k], then we copy a mention m only if it is contained in the region q[c′ + β..c′ +
k − β]. We refer to such regions, from which it is safe to copy mentions, as copy regions. We now

24
describe finding copy regions, distinguishing two cases: disjoint old regions, and overlapping old
regions.
• Old regions are disjoint: Let r1, . . . , rk be old regions of p (discovered by matcher M ). We
represent each ri as a tuple (idp, idq, sp, sq, l), where idp and idq are IDs of p and q, sp and sq are
the start positions of the old region in p and q, respectively, and l is the length of the old region.
Suppose old regions represented by r1, . . . , rk are disjoint. Then we simply construct for each
ri a copy region hi which is a tuple (idp, idq, s′p, s
′q, l
′), where s′p = sp + β, s′q = sq + β, and
l′ = l − 2β. Next, we insert hi into a memory-resident table H .
• Old regions are overlapping: In this case we extend the above algorithm so that we copy each
mention in the overlapping regions only once. First, we construct a set of copy region candidates
by chopping β characters at both ends of each old region, as we described in the disjoint case. Let
the resulting set of regions be r′1, . . . , r′k. This step gives us a set of regions where we are sure that
if a mention is contained in one of those regions, it will be extracted by E from p, and thus it can
be safely copied. However, since regions r′1...r′k can overlap, a mention can be contained in more
than one region and copied more than once. The following two steps ensure that any mentions
contained in at least one of r′1...r′k will be copied exactly once.
Let a and b be two overlapping regions from r′1, . . . , r′k. Then a corresponds to a copy region
candidate p[i..j] and b corresponds to another copy region candidate p[k..l] such that i < k <
j < l. Then we discard a and b and generate instead the following regions: (1) regions c, d, e that
corresponds to p[i..k − 1], p[k..j], p[j + 1..l], respectively. These regions are created so that we
can avoid copying mentions in region d twice. (2) regions f, g that corresponds to p[k − α..k +
α], p[j−α..j +α], respectively. These regions are created to catch any mention that may cross the
splitting points k and j and thus is not contained in any of the above regions.
We insert the tuples corresponding to these regions into table H . Figure 2.4 shows the data
flows of Cyclex for the step of finding copying regions in phase I.
2. Find Extraction Regions & Apply Extractor E: Let c1, . . . , ct be the copy regions of p,
identified as in Step 1. We now find extraction regions, those regions of p on which we must apply
extractor E, to ensure the correctness of Cyclex.

25
Page Matcher M
Old Regions
Extraction
Regions
Copy
RegionsExtractor E
Reuser
Phase I
Phase II
q
pPn
Pn+1
Mn+1
Mn
N
H
Figure 2.4 Data flow of Cyclex
To obtain extraction regions, at a first glance, it appears that we can simply remove copy regions
from p. However it is not difficult to construct examples where this would “remove too much,” thus
dropping mentions that we should have found for p. In general, we can prove that if p[c..c + k] is
an old region, then it is safe to remove only region p[c + γ..c + k − γ], where γ = 2β + α − 1.
We now describe finding extraction regions for two cases: disjoint old regions, and overlapping
old regions.
• Old regions are disjoint: Let R be the set of disjoint old regions of p. We begin by initializing
c, the start position of the next extraction region, to 1. Then we scan regions of R sequentially,
in increasing value of their start positions. For each r ∈ R, we create p[c..(r.sp − 1 + γ)] as an
extraction region. Then we update c = r.sp + r.l − γ. The last extraction region ends at position
|p|.• Old regions are overlapping: In this case, the extraction regions identified by the above algo-
rithm might not be minimal in the sense that if we remove some parts of the extraction regions,
we can still guarantee correctness of Cyclex. Hence,we waste the time of applying E over the
additional regions.
To ensure that an identified extraction region is not contained in any old region, we extend
the algorithm for disjoint old regions case as follows. First, we repeatly concatenate any two
overlapping old regions p[i..j] and p[k..l] if the length of the overlapping part is larger than γ.
Without loss of generality, suppose i < k < j < l. Since j− k ≥ γ + 1, the maximal length of the

26
β-context of any mention extracted by E, the β-context of any mention across the two old regions
p[i..j] and p[k..l] is either contained in p[i..j] or p[k..l], and thus the mention will be copied. Hence,
we can ignore the adjacent boundaries of p[i..j] and p[k..l] when identifying extraction regions. We
refer to the concatenated regions as super old regions. Let the set of super old regions be R′. Any
mention such that both itself and its context is contained in a region r′ ∈ R′ will be copied.
Next, we create a set of extraction regions to catch any mention that will not be copied. For
each r′ corresponding to p[i..j] in R′, we create a removal region p[i+γ..j−γ]. Since the length of
the overlapping part of any two regions in R′ is at most γ, the removal regions created at this step
are disjoint. Let the set of removal regions be D. Finally, we remove D form p and the remaining
set of regions are the extraction regions.
Once we have identified all extraction regions of a page p, we apply extractor E to these
regions. To guarantee correctness of Cyclex, among all extracted mentions, we only retain those
such that both the mentions and their contexts are contained in an extraction region. We then insert
the retained mentions into a memory-resident table N . N is flushed to the disk-resident table Mn+1
(which stores all mentions extracted from Pn+1) whenever it is full. Figure 2.4 shows the data flow
of Cyclex for the step of finding extraction regions and applying extractor E in phase I.
3. Copy Mentions from Copy Regions: We repeat step 1 and step 2 until we have processed all
pages p in Pn+1. At this point, we have extracted mentions from all extraction regions. We have
also stored all copy regions (actually, only the start- and end-positions of these regions, not the
regions themselves) in table H . Now we must copy to N any mention that (a) exists in Mn (the IE
result over the previous snapshot Pn) and (b) can be found in a region stored in H .
Since Mn can be large, we assume it is on disk. Furthermore, since each application may want
to store the mentions in a particular order (for further processing, e.g., mention disambiguation),
we do not assume any particular order for mentions in Mn. Rather, we proceed as follows. We
perform a sequential scan of Mn. For each mention m of Mn, we immediately probe m against
regions of table H (implemented as a hash table, with key idq, sq and l). In case of a hit, m appears
in one of the copy regions, thus, we construct an appropriate mention m′ of p (that correspond to

27
m), then insert m′ into table N . Figure 2.4 shows the data flow of Cyclex for the step of copying
mentions in phase II.
The following theorem states the correctness of Cyclex:
Theorem 2.2 (Correctness of Cyclex). Let Mn+1 be the set of mentions obtained by applying
extractor E from scratch to snapshot Pn+1. Then Cyclex is correct in that when applied to Pn+1 it
produces exactly Mn+1.
Proof. Let M ′n+1 be the set of mentions produced by applying Cyclex to Pn+1. Let Mn be the set
of mentions produced by applying E to Pn.
We first prove that M ′n+1 ⊆ Mn+1. Let m be a mention in M ′
n+1 and p be the page that contains
m. Cyclex produces m in one of the following ways:
Case 1: If Cyclex produces m by copying mentions from a copy region r, there must exist a
mention m′ in Mn and a region r′ in a data page q ∈ Pn such that m = m′, r contains the β-context
of m, r′ contains the β-context of m′, and r matches r′. Therefore the β-context of m matches the
β-context of m′. This implies the β-context of m′ is contained in r, and thus in p. Hence, p can be
obtained by perturbing the text of q outside the β-context of m′. From the definition of β-context,
it follows that applying E to p from scratch also produces m′. Since m′ = m, producing m′ is
equivalent to producing m. Hence, applying E to p from scratch produces m.
Case 2: If Cyclex produces m by applying E to an extraction region r in page p, r must contain
the β-context of m. Since p can be generated by perturbing the text of r outside the β-context of
m, from the definition of β-context, it follows that applying E to p from scratch also produces m.
Case 3: If Cyclex produces m by applying E to the entire data page p (i.e., there does not exist
q ∈ Pn such that q shares the same URL with p), then obviously applying E to p produces m.
In summary, no matter how Cyclex produces m, applying E to p ∈ Pn+1 from scratch also
produces m. Therefore M ′n+1 ⊆ Mn+1.
Similarly, we can prove Mn+1 ⊆ M ′n+1. Given that M ′
n+1 ⊆ Mn+1 and Mn+1 ⊆ M ′n+1, it
follows that M ′n+1 = Mn+1.

28
2.5 The Cost-Based Matcher Selector
We now describe how the matcher selector employs a cost model to select the best matcher
(one that minimizes Cyclex’s runtime).
Our cost model captures the three execution steps of Section 2.4. We model the elapsed time of
each step as a weighted sum of I/O and CPU costs. The weights are measured empirically, allowing
us to account for varying execution characteristics across steps, implementations, and platforms.
With the weights, we can reasonably capture completion times of highly tuned implementations
that overlap I/O with CPU computation (in this case, the dominated cost component will be com-
pletely masked and therefore have weight 0) as well as simple implementations that do not exploit
parallelism.
Let m be the number of pages in Pn+1, mb be the total size of Pn+1 on disk (in blocks), and
l be the average page size (in bytes). Let n be the number of mentions in the previous mention
table Mn, and nb be the total size of Mn on disk (in blocks). Let b be the number of buckets in
the in-memory hash table H (cf. Section 2.4). We model the completion time of a Cyclex plan on
Pn+1 as:
w1,IO ·mb · f + w1,mat ·m · l · f + w1,ex ·m · l · f · g (2.1)
+w2,IO · nb + w2,find · n · m · f · hb
(2.2)
+w3,IO ·mb(1− f) + w3,ex ·m · l · (1− f), (2.3)
where f is the fraction of pages in Pn+1 with a match in Pn; g measures, on average, what fraction
of the text within a matched page still needs re-extraction; and h is the average number of tuples
inserted into hash table H per matched page. The w’s are weights, whose numeric subscripts
reflect which phases incur the associated costs.
Line (2.1) models the completion time of the first execution step. This includes I/O cost of
reading in matching pages from Pn+1 and Pn, CPU cost of matching the pairs of pages to identify
copy regions, and the CPU cost of applying E to extraction regions. Line (2.2) models the second

29
35M180MAvg Size per Snapshot
303810155Avg # Page per Snapshot
2030# Snapshots
21 days1 dayTime Interval
925980# Data Sources
WikipediaDBLifeData Sets
10400talk (speaker, time, location, topics)
793affiliation (researcher name, organization)
332researcher (first name, mid name, last name)
βαExtractors for DBLife
10250award (actor name, award, movie, role)
496play (actor name, movie)
335actor (first name, mid name, last name)
βαExtractors for Wikipedia
Figure 2.5 Data sets and extractors for our experiments
step. This includes I/O cost of reading in Mn, and CPU cost of probing H to determine whether to
copy each mention. The term m·f ·hb
estimates the number of hash table entries per bucket. Finally,
Line (2.3) models I/O cost of reading in unmatched pages in Pn+1, and CPU cost of applying E to
them. In all three steps, we ignore the cost of writing out mentions in Pn+1, since this cost is the
same for all matcher choices.
As a special case for DN, which simply runs E over the entire Pn+1, Lines (2.1) and (2.2) are
always 0, and f = 0 on Line (2.3). For UD and ST, f is the same. In general, however, the hatted
parameters f , g, h, and w’s need be estimated, and their values may differ across alternatives. On
the other hand, unhatted parameters do not need to be estimated, because their exact values are
directly available from either the corpus metadata (for m, mb, l, n, and nb) or the execution context
(for b).
We estimate the parameters using a small sample S of Pn as well as the past k snapshots, for
a pre-specified k. Section 2.6 demonstrates empirically that small |S| and k are sufficient for our
applications of Cyclex, meaning that parameter estimation and cost-based plan selection adds very
little overhead to the overall cost.

30
2.6 Empirical Evaluation
We now empirically evaluate the utility of Cyclex. Figure 2.5 describes two real-world data
sets and six extractors used in our experiments. DBLife consists of 30 consecutive one-day snap-
shots from DBLife system [31], and Wikipedia dataset consists of 20 consecutive snapshots obtain
from Wikipedia.com. The DBLife extractors extract mentions of academic entities and their rela-
tionships, and the three Wikipedia extractors extract mentions of entertainment entities and rela-
tionships (see the figure). Although these extractors may not be the state-of-the-art IE solutions to
extract these entities and relationships, there are real-world IE systems (e.g. DBLife) that employ
such extractors. Our goal is to evaluate the utility of Cyclex for the extractors used in those IE
systems.
We obtained extractor scopes and contexts by analyzing the extractors. For example, “talk”
extractor detects speakers, time and topics by matching a set of regular expressions. The length
of extraction context for these attribute is 0. Then “talk” detects location attribute by (a) detecting
a set of keywords such as “Location: ,” “Room: ” etc., and (b) extracting 1-2 capitalized words
immediately following the detected keyword as the location. We thus set the context β of “talk” to
be the maximal length of all keywords.
Runtime Comparison: For each of the above six extraction tasks, Figure 2.6 shows the run-
time of Cyclex vs. DNplan, STplan, and UDplan, three plans that employ matchers DN, ST, and
UD, respectively, over all consecutive snapshots (the X axis). The runtimes of DNplan are signif-
icantly higher than those of the other three plans. Hence, to clearly show the differences in the
runtimes among all plans in one figure, we only plot the curves of STplan, UDplan, and Cyclex,
and summarize the trends of the curves of DNplan. Note that for each snapshot, Cyclex employs
a cost model to pick and execute the best among the above three plans. Cyclex’s runtime includes
statistic collection, optimization, and execution times.
The results show that in all cases except “actor,” UDplan, STplan, and Cyclex drastically cut
runtime of DNplan (which always applies extraction from scratch to the current snapshot), by
50-90%. This suggests that recycling past IE efforts can be highly beneficial.

31
researcher
0
500
1000
1500
2000
2500
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
runtime (s)
affiliation
0500
100015002000250030003500
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
runtime (s)
talk
020004000600080001000012000
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
runtime (s)
DNplan STplan UDplan Cyclex
play
200
400
600
800
1000
1200
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
runtime (s)
award
500
1500
2500
3500
4500
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
runtime (s)
actor
50
100
150
200
250
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
runtime (s)
Figure 2.6 Runtime of Cyclex versus the three algorithms that use different page matchers
Next, the results show that none of DNplan, STplan, and UDplan is uniformly better than
the others. For example, for “actor,” where the changes between two consecutive snapshots are
substantial and the extraction cost is fairly low, DNplan outperforms UDplan and STplan. In
contrast, for “play” and “award,” where the change of data is still substantial but extraction is very
expensive, STplan is the winner. For DBLife cases, where the consecutive snapshots change little
and matching regions detected by UD and ST are quite similar, UDplan is the winner.

32
Others
0
200
400
600
800
DNplan UDplan STplan Cyclex DNplan UDplan STplan Cyclex DNplan UDplan STplan Cyclex
runtime (s) affiliation3027
talk11198
researcher2261
0
200
400
600
800
1000
DNplan UDplan STplan Cyclex DNplan UDplan STplan Cyclex DNplan UDplan STplan Cyclex
runtime (s) play award3885actor
Match Extraction Copy Opt
Figure 2.7 Runtime decomposition of different plans
The above results underscore the importance of optimization to select the best plan for a partic-
ular extraction situation. They also show that Cyclex handles this optimization well. It successfully
picks the fastest plan in all six cases, while incurring only a modest overhead of 4-13% the runtime
of the fastest plan.
Contributions of Components: Figure 2.7 shows the decomposition of runtime of various plans
(numbers in the figure are averaged over five random snapshots per IE task). “Match” is time to
match pages, “Extraction” is time to apply IE, “Copy” is time to copy mentions, “Opt” is opti-
mization time of Cyclex, and “Others” is the remaining time (to read file indices, doing scoping,
etc.).
The results show that matching and extracting dominate runtimes, hence we should focus on
optimizing these components. The suffix-tree matcher ST clearly spends more time finding old
regions than the Unix-diff matcher UD. However, the figure shows that this effort clearly pays off
in certain cases, such as “play” and “award,” where IE is expensive and the consecutive snapshots
change substantially. Here, STplan saves significant time avoiding IE. Finally, the results show
that the overhead of Cyclex (statistic collection, etc.) remains insignificant compared to the overall
runtime.
We also found that DNplan (i.e., applying IE from scratch) incurs very little IO time in most
tasks (less than 3% of total runtimes, numbers not shown due to space reasons) Thus, it is important
to optimize CPU time, as we do in this work.

33
play
55
70
85
100
100 150 200 250 300 350 400 450 500
accuracy (%)
α
play
55
70
85
100
10 20 30 40 50 60 70 80 90
# sampled pages
accuracy (%)
play
55
70
85
100
2 3 4 5 6 7 8 9 10
# snapshots
accuracy (%)affiliation
55
70
85
100
2 3 4 5 6 7 8 9 10
# snapshots
accuracy (%)
(a)
affiliation
55
70
85
100
10 20 30 40 50 60 70 80 90
# sampled pages
accuracy (%)
(b)
affiliation
55
70
85
100
100 150 200 250 300 350 400 450 500
α
accuracy (%)
(c)
affiliation
55
70
85
100
10 20 40 60 80 100 120 140 160
β
accuracy (%)
(d)
play
55
70
85
100
10 20 40 60 80 100 120 140 160
β
accuracy (%)
Figure 2.8 Accuracy of cost models as a function of (a) number of snapshots k, (b) sample size|S|, (c) α, (d) β
Sensitivity Analysis: Finally, we examined the sensitivity of Cyclex wrt the main input param-
eters: k and |S|, the number of snapshots and size of sample used in statistic estimation, and the
scope and context values.
Figure 2.8.a plots the “accuracy” of Cyclex as a function of k, where “accuracy” is the fraction
of snapshots where Cyclex picks the correct (i.e., fastest) plan. We show results for “affiliation”
and “play” only, results for other IE tasks show similar phenomenons.
Figure 2.8.b-d plots the “accuracy” of Cyclex in a similar fashion against changes in the sample
size |S|, scope α, and context β, respectively.
The results show that Cyclex only needs a few recent snapshots (3) and a small number of
sample size (30 pages) to do well. Regarding scope and context, the results show that for “affili-
ation,” Cyclex performs well even when we increased α and β significantly, by 5 and 100 times,
respectively. For “play,” Cyclex performs well until α was increased by 4 times. As α increases,
the difference between the fastest plan, STplan, and the second fastest plan, UDplan, becomes

34
smaller and smaller, thus causing the optimizer to mistakenly select the second fastest plan on
certain snapshots.
affiliation
0
5
10
15
20
100 150 200 250 300 350 400 450 500
α
runtime ratio (%)
affiliation
0
5
10
15
20
10 20 40 60 80 100 120 140 160
β
runtime ratio (%) play
20
30
40
50
60
10 20 40 60 80 100 120 140 160
β
runtime ratio (%)
play
25
35
45
55
65
75
100 150 200 250 300 350 400 450 500
α
runtime ratio (%)
(a)
(b)
STplan UDplan
Figure 2.9 Ratio of runtimes as a function of α and β
In the final experiment, Figure 2.9 shows the runtime ratio of STplan and UDplan as a function
of α and β. The runtime ratio is the ratio of the runtime of these plans over the runtime of DNplan.
The results show that this ratio changes only slowly, as we increase α and β. This suggests that a
rough estimation of α and β does increase the runtime of the various plans, but only in a graceful
fashion.
2.7 Summary
A growing number of real-world applications must deal with IE over dynamic text corpora.
We have shown that executing such IE in a straightforward manner is very expensive, and have
developed Cyclex, an efficient solution that recycles past IE results. As far as we know, Cyclex
is the first in-depth solution in this direction. Our extensive experiments over two real-world data
sets demonstrate that Cyclex can dramatically cut the runtime of re-applying IE from scratch by
50-90%. This suggests that recycling past IE results can be highly beneficial.

35
Chapter 3
Recycling for Complex IE Programs
The Cyclex work clearly established that recycling IE results for evolving text corpora is highly
promising. The work itself however suffers from a major limitation: it considers only IE programs
that contain a single IE “blackbox.” Real-world IE programs, in contrast, often contain multiple
IE blackboxes connected in a compositional “workflow.” Since Cyclex is not aware of the compo-
sitional nature of such IE programs (effectively treating the whole program as a large blackbox),
its utility is severely limited in such settings.
To remove this limitation, in this chapter we describe Delex, a solution for effectively executing
multi-blackbox IE programs over evolving text data.
We first formally define our problem in Section 3.1. Sections 3.2–3.5 describe Delex. Sec-
tion 3.6 presents an empirical evaluation. Finally, Section 3.7 concludes this chapter.
3.1 Problem Definition
We now briefly describe xlog (see [67] for a detailed discussion), then build on it to define the
problem considered in this chapter.
Compositional, Multi-Blackbox IE Programs: As discussed in Section 4.1, Cyclex has clearly
demonstrated the potential of recycling IE. However, it handles only single-blackbox IE programs,
which severely limits its applicability. Thus, in this chapter, we build on Cyclex to develop an
efficient solution for multi-blackbox IE programs.
To do so, we must first decide how to represent such programs. Many possible representations
exist (e.g., [37, 28, 67]). As a first step, in this chapter we will use xlog [67], a recently developed

36
(a)
extractAbstract(d,abstract)
σapproxMatch(abstract, “relevance feedback”)
σimmBefore(title,abstract)
extractTitle(d,title)
docs(d)docs(d)
(b)
R1: titles(d,title) :- docs(d), extractTitle(d,title).
R2: abstracts(d,abstract) :- docs(d), extractAbstract(d,abstract).
R3: talks(d,title,abstract) :- titles(d,title), abstracts(d,abstract),
immBefore(title,abstract), approxMatch(abstract,“relevance feedback”).
Figure 3.1 (a) A multi-blackbox IE program P in xlog, and (b) an execution plan for P .
declarative IE representation. Extending our work to other IE representations is a subject for future
research.
xlog is a Datalog variant with embedded procedural predicates. Like Datalog, each xlog pro-
gram consists of multiple rules p :− q1, . . . , qn, where the p and qi are predicates. For example,
Figure 3.1.a shows an xlog program P with three rules R1, R2, and R3, which extract talk titles
and abstracts from seminar announcement pages. Currently xlog does not yet support negation or
recursion.
xlog predicates can be intensional or extensional, as in Datalog, but can also be procedural. A
procedural predicate, or p-predicate for short, q(a1, . . . , an, b1, . . . , bm) is associated with a proce-
dure g (e.g., written in Java or Perl) that takes as input a tuple (a1, . . . , an) and produces as output
tuples of the form (a1, . . . , an, b1, . . . , bm). For example, extractT itle(d, title) is a p-predicate in
P that takes a document d and returns a set of tuples (d, title), where title is a talk title appearing
in d. We define p-functions similarly. We single out a special type of p-predicate that we call IE
predicate, defined as:
Definition 3.1 (IE predicate). An IE predicate q extracts one or more output text spans from a
single input span. Formally, q is a p-predicate q(a1, . . . , an, b1, . . . , bm), where there exist i and j
such that (a) ai is either a document or a text span variable, (b) bj is a span variable, and (c) for
any output tuple (u1, . . . , un, v1, . . . , vm), ui contains vj (i.e., q extracts span vj from span ui).

37
In Figure 3.1.a, extractT itle(d, title) is an IE predicate that extracts title span from document
d. The p-predicate extractAbstract(d, abstract) is another IE predicate, whereas immBefore
(title, abstract) (a p-predicate that evaluates to true if title occurs immediately before abstract)
is not.
Thus, an xlog program cleanly encapsulates multiple IE blackboxes using IE predicates, and
then stitches them together using Datalog. To execute such a program, we must translate (and
possibly optimize) it to obtain an execution plan that mixes relational operators with blackbox
procedures. Figure 3.1.b shows a possible execution plan T for program P in Figure 3.1.a. T
extracts all titles and abstracts from d, and keeps only those (title, abstract) pairs where the title
occurs immediately before the abstract. Finally, T retains only talks whose abstracts contain the
phrase “relevance feedback” (allowing for misspelling and synonym matching).
Problem Definition: We are now in a position to define the problem considered in this chapter.
PROBLEM DEFINITION Let P1, . . . , Pn be consecutive snapshots of a text corpus, P be
an IE program written in xlog, E1, . . . , Em be the IE blackboxes (i.e., IE predicates) in P , and
(α1, β1), . . . , (αm, βm) be the estimated scopes and contexts for the blackboxes, respectively. De-
velop a solution to execute P over corpus snapshot Pn+1 with minimal cost, by reusing extraction
results over P1, . . . , Pn.
To address this problem, a simple solution is to detect identical pages, then reuse IE results on
those. This reuse-at-page-level solution however provides only limited reuse opportunities, and
does not work well when the text corpus changes frequently.
Another solution is to apply Cyclex to the whole program P , effectively treating it as a single
IE blackbox. We however found that this reuse-at-whole-program-level solution does not work
well either (see Section 3.6). The main reason is that estimating “tight” α and β for the whole IE
program P is very difficult. Whether we do so directly, by analyzing the behavior of P (which
tends to be a large and complex program), or indirectly, by using the (αi, βi) of its component
blackboxes, we often end up with large α and β, which limits reuse opportunities.

38
3E
4EZ
Y3E
4E
σ π
3
π
σ π
3
π
U V
(a) (b)
1E 2E 1E 2E
Figure 3.2 (a) An execution tree T , and (b) IE units of T .
These problems suggest that we should try to reuse at a finer granularity: regions in a page
instead of whole page, and at a finer level: program components instead of whole program. The
Delex solution captures this intuition. In the rest of the chapter we describe Delex in detail.
3.2 Capturing IE Results
We will explain Delex in a bottom-up fashion. Let T be an execution plan of the target IE
program P (see Problem Definition). In this section we consider what to capture for reuse, when
executing T on a corpus snapshot Pn.
Section 3.3 then discusses how to reuse the captured result when executing T on Pn+1. Section
3.4 describes how to select such a plan T in a cost-based fashion. Section 3.5 puts all of these
together and describes the end-to-end Delex solution.
In what follows we describe how to decide on the level of reuse, what to capture, and how to
store the captured results, when executing T on snapshot Pn.
Level of Reuse: Recall that we want to reuse at the granularity of program components, instead of
the whole program. The question is which components. A natural choice would be the individual
IE blackboxes. For example, given the execution tree1 T in Figure 3.2.a, the four IE blackboxes
E1, . . . , E4 would become “reuse units,” whose input and output would be captured for subsequent
reuse.
Reusing at the IE-blackbox level however turns out to be suboptimal. To explain, consider for
instance blackbox E1 (Figure 3.2.a), and let σ(E1) denote the edge of T that applies the selection
1In the rest of the chapter we will use “tree,” “execution tree,” and “execution plan” interchangeably.

39
operator σ to the output of E1. Instead of storing the output of E1, we can store that of σ(E1).
Doing so does not affect reuse (as we will see below), but is better in two ways. First, it would
incur less storage space, because σ(E1) often produces far fewer output tuples than E1. Second,
less storage space in turn reduces the time of writing to disk (while executing T on Pn) and reading
from disk (for reuse, while executing T on Pn+1). Consequently, we reuse at the level of IE units,
defined as:
Definition 3.2 (IE Unit). Let X = N1 ← N2 ← · · · ← Nk denote a path on tree T that applies
Nk−1 to Nk, Nk−2 to Nk−1, and so on. We say X is an IE unit of T iff (a) Nk is an IE blackbox,
(b) N1, . . . , Nk−1 are relational operators σ and π, and (c) X is maximal in that no other path
satisfying (a) and (b) contains X .
For example, tree T in Figure 3.2.a consists of four IE units U, V, Y , and Z, as shown in
Figure 3.2.b.
In essence, each IE unit can be viewed as a generalized IE blackbox, with similar notions of
scope α and context β. In this setting, it is easy to prove that we can set the (α, β) of an IE unit
N1 ← N2 ← · · · ← Nk to be exactly those of the IE blackbox Nk. This property is desirable and
explains why we do not include join operator ./ in the definition of IE unit: doing so would prevent
us from guaranteeing the above “wholesale transfer” of (α, β) values.
IE Results to Capture: Next we consider what to capture for each IE unit U of tree T . Concep-
tually, each such unit U (which is an IE blackbox E augmented with σ and π operators, whenever
possible) can be viewed as extracting a set of mentions from a text region of a document. Formally,
we can write U : (did, s, e, c) → {(did,m, c′)}, where
• did is the ID of a document d,
• s and e are the start and end positions of a text region S in d,
• c denotes the rest of the input parameter values (see the example below),
• m denotes a mention (of a target relation) extracted from text region S, and
• c′ denotes the rest of the output values.

40
Example 3.1. Consider a hypothetical IE unit σallcap(title)(extractT itle(d,maxlength, title,
numtitles)), which extracts all titles not exceeding maxlength from document d, selects only
those in all capital letters, and outputs them as well as the number of such titles.
Here, for the input tuple, did is the ID of document d, s and e are the positions of the first and
last characters of d (because text region S is the entire document d), and c denotes maxlength.
For the output tuple, m is an extracted title, and c′ denotes numtitles.
In order to reuse the results of U later, at the minimum we should record all mentions m
produced by U (recall that given an input tuple (did, s, e, c), U produces as output a set of tuples
(did,m, c′)). Then, whenever we want to apply U to a region S in a page p, we can just copy
over all mentions of a region S ′ in some page q in a past snapshot, which we have recorded
when applying U to S ′, provided that S matches S ′ and that it is safe to copy the mentions (see
Section 3.1).
This is indeed what Cyclex does. In the Delex context, however, it turns out that since we
employ multiple IE blackboxes that can be “stacked” on top of one another, we must record more
information to guarantee correct reuse, as the following example illustrates.
Example 3.2. Consider a page p = “Midwest DB Courses: CS764 (Wisc), CS511 (Illinois)”.
Suppose we have applied an IE unit V to p to remove the headline (by ignoring all text before
“:”), and then applied another IE unit U to the rest of the page to extract locations “Wisc” and
“Illinois”.
Suppose the next day the page is modified into p′ = “Midwest DB Courses This Year CS764
(Wisc), CS511 (Illinois)”, where character “:” has been omitted (and some new text has been
added). Consequently, V does not remove anything from p′, and p′ ends up sharing the region
S = “Midwest DB Courses” with p. Thus, when applying U to p′, we will attempt to copy over
mentions found in this region. Since no such mention was recorded, however, we will conclude that
applying U to region S in p′ produces no mention. This conclusion is incorrect, since “Midwest”
is a valid location mention in S.

41
The problem is that no mention has been recorded in region S for U and p, not because U
failed to extract any such mentions from S, but rather because U has never been applied to S. U
can only take as input whichever regions V outputs, and V did not output S when it operated on p.
Thus, we must record not only the previously extracted mentions, but also the text regions that
an IE unit has operated over. Specifically, for an IE unit U : (did, s, e, c) → {(did,m, c′)}, we
record all pairs (s, e) and the mentions m associated with those. It is easy to see that we must
record c as well, for otherwise we do not know the exact conditions under which a mention m was
produced, and hence cannot recycle it appropriately.
Storing Captured IE Results: We now describe how to store the above intermediate results
while executing tree T on a corpus snapshot Pn. Our goal is to produce, at the end of the run on
Pn, two reuse files InU and On
U for each IE unit U in tree T .
During the run, whenever U takes as input a tuple (did, s, e, c), we append a tuple (tid, did, s, e,
c), where tid is a tuple ID (unique within InU ), to In
U , to capture the region that U operates on.
Whenever U produces as output a tuple (did,m, c′), we append a tuple (tid, itid, m, c′) to OnU , to
capture the mentions extracted by U . Here, tid is a tuple ID (unique within OnU ), and itid is the
ID of the tuple in InU that specifies the text region from which m is extracted. Hence, tuples are
appended to InU and On
U in the order they are generated. After executing T over Pn, each IE unit U
is associated with two reuse files InU and On
U that store intermediate IE results for U for later reuse.
To avoid excessive disk writes caused by individual append operations, we use one block of
memory per reuse file to buffer the writes. Whenever a block fills up, we flush the buffered tuples
to the end of the corresponding reuse file. The memory overhead during execution is 2|T | blocks
(one per file), where |T | is the number of IE units in T . The I/O overhead, same as the total storage
requirement for reuse files, is exactly∑
U∈T (B(InU) + B(On
U)) blocks, where B(InU) and B(On
U)
represent the number of blocks occupied by InU and On
U , respectively. Although it is conceivable
for an IE unit to produce more mentions than the size of the input document, in practice the number
of mentions is usually no more (and often far smaller) than the input size. Therefore, both the total
storage and the I/O overhead are usually bounded by O(|T |B(Pn)), where B(Pn) denotes the size
of Pn in blocks.

42
3.3 Reusing Captured IE Results
We have described how to capture IE results in reuse files while executing a tree T on snapshot
Pn. We now describe how to use these results to speed up executing T over the subsequent snapshot
Pn+1.
3.3.1 Scope of Mention Reuse
As discussed earlier, to reuse, we must match each page p ∈ Pn+1 with pages in the past
snapshots, to find overlapping regions. Many such matching schemes exist. Currently, we match
each page p only with the page q in Pn at the same URL as p. (If q does not exist then we declare
p to have no overlapping regions.) This simplification is based on the observation that pages
with the same URL often change relatively slowly across consecutive snapshots, and hence often
share much overlapping data. Extending Delex to handle more general matching schemes, such as
matching within the same Web site, or matching over all pages of all past snapshots, is an ongoing
work.
3.3.2 Overall Processing Algorithm
Within the above reuse scope, we now discuss how to process Pn+1. Since Pn+1 can be quite
large (tens of thousands or millions of pages), we will scan it only once, and process each page in
turn in memory in a streaming fashion.
In particular, to process tree T on a page p ∈ Pn+1 (once it has been brought into memory), we
need page q ∈ Pn (the previous snapshot) with the same URL, as well as all intermediate IE results
that we have recorded while executing tree T on q. These IE results are scattered in various reuse
files (Section 3.2), which can be large and often do not fit into memory. Consequently, we must
ensure that in accessing intermediate IE results, we do not probe the reuse files randomly. Rather,
we want to read them sequentially and access IE results in that fashion.
The above observation led us to the following algorithm. Let q1, q2, . . . , qk be the order in
which we processed pages in Pn. That is, we first executed T on q1, then on q2, and so on. The way

43
)( 1qOn
U
1p
)( 1qIn
U
1q
)( 1qIn
U
)( 1qOn
U
)( 2qIn
U nUI
)( 2qOn
U nUO
nP)( 1
1pI
n
U
+
)( 11pO
n
U
+
1+nUI
1+nUO
)( 11pO
n
U
+
)( 11pI
n
U
+
1+nP
2B
1B
3B
4B
5B
6B
IE Unit U
Matcher M
L
L
Figure 3.3 Movement of data between disk and memory during the execution of IE unit U onpage p1.
we wrote reuse files, as described earlier in Section 3.2, ensures that the IE results in each reuse
file are stored in the same order. For example, InU stores all input tuples (for U ) on page q1 first,
then all input tuples on page q2, and so on.
Consequently, we will process pages in Pn+1 following the same order. That is, let pi be the
page with same URL as qi, i = 1, . . . , k. Then we process p1, then p2, and so on. (If a page
p ∈ Pn+1 does not have a corresponding page in Pn, then we can process it at any time, by simply
running extraction on it.) By processing in the same order, we only need to scan each reuse file
sequentially once.
Figure 3.3 illustrates the above idea. Suppose we are about to process page p1 ∈ Pn+1. First,
we read p1 and q1 into memory (buffers B1 and B2 in the figure).
Next, we execute T on p1 in a bottom-up fashion. Consider the execution tree T in Figure 3.2.b.
We start with executing IE unit U . To do so, we bring all intermediate IE results recorded while
executing U on q1 (back when we processed Pn) into memory. Specifically, let InU(q1) denote the
input tuples for U on page q1. Since q1 is the first page in Pn, InU(q1) must appear at the beginning
of file InU , and hence can be immediately brought into memory (buffer B3 in Figure 3.3). Similarly,
OnU(q1)—the tuples output by U on page q1—must occupy the beginning of file On
U and can be
immediately read into memory (buffer B4 in Figure 3.3).
The details of how to execute IE unit U on p1 will be presented next in Section 3.3.3. Roughly
speaking, we identify overlapping regions between q1 and p1, and leverage InU(q1) and On
U(q1) for
reuse. Note that InU(q1) and On
U(q1) store only the start and end positions of regions in q1, so we
need q1 in memory to access these regions. During the execution of U on p1, we produce the

44
input and output tuples of U , In+1U (p1) and On+1
U (p1), in memory (buffers B5 and B6 in Figure 3.3,
respectively). As described in Section 3.2, these tuples are also appended to reuse files In+1U and
On+1U .
Once we are done with U (for p1), memory reserved for InU(q1), On
U(q1), and In+1U (p1) can
be discarded; however, On+1U (p1) will be retained in memory until it is consumed by the parent
operator or IE unit of U in T (in this case, the join operator in Figure 3.2.b).
Next, we move on to IE unit V . We read in InV (q1) and On
V (q1) from the corresponding reuse
files InV and On
V , and generate In+1V (p1) and On+1
V (p1) in memory. Again, once V finishes, only
On+1V (p1) needs to stay in memory to provide input to V ’s parent in T . This process continues until
we have executed the entire T .
Once the entire T finishes execution on p1, we move on to process T on page p2, then p3,
and so on. Note that each time we process a page pi, the intermediate IE results of qi will be at
the start of the unread portion of the reuse files, and thus can be read in easily. Consequently,
we only have to scan each reuse file once during the entire run over Pn+1. The total number of
I/Os is thus∑
U∈T (B(InU) + B(On
U) + B(In+1U ) + B(On+1
U )) + B(Pn) + B(Pn+1), i.e., one pass
over the current and previous corpus snapshots and all reuse files for the two snapshots. At any
point in time (say, when executing IE unit U on page pi), we only need to keep in memory pi,
qi, InU(qi), On
U(qi), In+1U (pi), On+1
U (pi), as well as On+1U ′ (pi) for any child U ′ of U . Therefore,
the maximum memory requirement for the algorithm (not counting memory needed for buffering
writes to reuse files discussed in Section 3.2, or by the IE units and relational operators themselves)
is O(maxi(B(pi) + B(qi) + (F (T ) + 1) maxU∈T (B(InU (qi)), B(On
U (qi)), B(In+1U (pi)), B(On+1
U (pi)))))
blocks, where F (T ) is the maximum fan-in of T . In practice, under the reasonable assumption
that the total size of the extracted mentions is linear in the size of the input page, the memory
requirement comes down to O((F (T ) + 1) maxi(B(pi) + B(qi))).

45
�� ��
���� ����
Extraction
regions
Copy
regions
Matching
Figure 3.4 An illustration of executing an IE unit.
3.3.3 IE Unit Processing
We now describe in more detail how to execute an IE unit U on a particular page p (in snapshot
Pn+1), whose previous version is q (in snapshot Pn). The overall algorithm is depicted in Figure
3.4.
We start with In+1U (p), the set of input tuples to U . Each input tuple (tid, did, s, e, c) ∈ In+1
U (p)
represents a text region [s, e] of page p to which we want to apply U , with additional input param-
eter values c. There are two cases. If U has a child in T , this set is produced by the execution
of the child. If U is a leaf in T , which operates directly on page p, there is only one input tuple
(did, s, e, c), where did is the ID of p, s and e are set to 0 and the length of p, and c denotes all
other input parameters.
To identify reuse opportunities, we consult InU(q), which contains the input tuples to U when it
executed on q. This set is read in from the reuse file InU as discussed in Section 3.3.2. Each tuple
in InU(q) has the form (tid′, did′, s′, e′, c′), where did′ is the ID of q, and c′ records the values of
additional input parameters that U took when applied to region [s′, e′] of q. To find results to reuse
for input tuple (did, s, e, c) ∈ In+1U (p), we “match” the region [s, e] of p with regions of q encoded
by tuples in InU(q) with c′ = c. This matching is done using one of the matchers to be described
later in Section 3.3.4 (Section 3.4 discusses how to select a good matcher).
We repeat the matching step for each input tuple in In+1U (p) to find its matching input tuples
in InU(q). From the corresponding pairs of matching regions in p and q as well as the scope and
context properties of U (Section 3.1), we derive the extraction regions and copy regions. Because

46
of space constraint, we do not discuss the derivation process further, but instead refer the reader to
[16] for details.
Extraction regions require new work: we run U over these regions of p. Copy regions represent
reuse. If a copy region is derived from input tuple (tid′, did′, s′, e′, c′) ∈ InU(q), we find the joining
output tuples (with the same tid′) in OnU(q). Recall that On
U(q) contains the output tuples of U
when it executed on q, and this set is read in from the reuse file OnU as discussed in Section 3.3.2.
The OnU(q) tuples with tid′ represent the mentions extracted from region [s′, e′] of q, which can be
reused by U to produce output tuples for the corresponding copy region.
Regardless of how U produces its output tuples (through reuse or new execution), they are
appended to the reuse file On+1U (as described in Section 3.2), and kept in memory until consumed
by a parent operator or IE unit in T (as described in Section 3.3.2).
3.3.4 Identifying Reuse With Matchers
Delex currently employs four matchers—DN, UD, ST, and RU—for matching regions be-
tween two pages (more matchers can be easily plugged in as they become available). We describe
the first three matchers here only briefly, since they come from Cyclex. Then, we focus on RU, a
novel contribution of Delex that allows sharing the work of matching across IE units.
Given two text regions R (of page p ∈ Pn+1) and S (of page q ∈ Pn) to match, DN immediately
declares that the two regions have no matching portions, incurring zero running time. Using DN
thus amounts to applying IE from scratch to R. UD employs a Unix-diff-command like algorithm
[58]. It is relatively fast (takes time linear in |R|+ |S|), but finds only some matching regions. ST
is a suffix-tree based matcher, which finds all matching regions of R using time linear in |R|+ |S|.We do not discuss these Cyclex matchers further; see [16] for more details.
The development of RU is based on the observation that we can often avoid repeating much
of the matching work for different IE units. This opportunity does not arise in Cyclex because
Cyclex considers only a single IE blackbox. To illustrate the idea in a multi-blackbox setting,
consider again executing tree T of Figure 3.2.b on page p ∈ Pn+1, and suppose that we execute

47
IE units U , V , Y , and Z, in that order. During U ’s execution we would have matched page p with
page q ∈ Pn with the same URL to find overlapping regions on which we can reuse mentions.
Now consider executing V . Here, we would need to match p and q again; clearly, we should
take advantage of the matching work we have already performed on behalf of U . Next, consider
executing Y . Here, we often have to match a region R of p with a set of regions S1, . . . , Sk of
q (as described in Section 3.3.3) to detect overlapping regions (on which we can reuse mentions
produced by Y on page q). However, since we have already matched p with q while executing U ,
we should be able to leverage that result to quickly find all overlapping regions between R of p and
Si of q.
In general, since all regions to be matched by IE units of an execution tree come from two pages
(one from Pn and the other from Pn+1), and since IE units often match successively smaller regions
that are extracted from longer regions (matched by lower IE units), it follows that higher-level IE
units can often reuse matching results of lower ones, as described earlier.
We now briefly describe RU, a novel matcher that draws on this idea. While T executes on
a page p, RU keeps track of all triples (R, S,O), whenever a ST or UD matcher has matched a
region R of p with a region S of q and found overlapping regions O. Now suppose an IE unit X
calls RU to match two regions R′ and S ′. RU computes the intersection of R′ with all recorded
R regions, the intersection of S ′ with all recorded S regions, and then uses these intersections and
the recorded overlapping regions O to quickly compute the set of overlapping regions for R′ and
S ′. We omit further details for space reasons.
The four matchers in Delex make different trade-offs between result completeness and runtime
efficiency. The next section discusses how Delex assigns appropriate matchers to IE units, thereby
selecting a good IE plan.
3.4 Selecting a Good IE Plan
Given an execution tree T , we now discuss how to select appropriate matchers for T using
a cost-based approach. We first describe the space of alternatives, then our cost-driven search
strategy, and finally the cost model itself.

48
Z
Y
U
C1
V
C4C2 C3
π
C1 C2U V
U1 VU2 U3
UD DN ST
(a) (b)
Figure 3.5 IE chains and sharing the work of matching across them.
3.4.1 Space of Alternatives
For each corpus snapshot, we consider assigning a matcher to each IE unit of tree T , and then
use the so-augmented tree to process pages in the snapshot. Let |T | be the number of IE units in
T , and k be the number of matchers available to choose (Section 3.3.4). We would have a total of
up to k|T | alternatives. For ease of exposition, we will refer to such an alternative as an IE plan
whenever there is no ambiguity.
Note that we could make the choice of matchers at even finer levels, such as whenever we must
match two regions (while executing T on a page p). However, such low-level assignments would
produce a vast plan space that is practically unmanageable. Hence, we assign matchers only at the
IE-unit level. Even at this level, the plan space is already huge, ranging from 1 million plans for
10 IE units and four possible matchers, to 1 billion plans for 15 IE units, and beyond.
Furthermore, for most plans in this space, optimization is not “decomposable,” in that “gluing”
the locally optimized subplans together does not necessarily yield a globally optimized plan. The
following example illustrates this point.
Example 3.3. Consider a plan of two IE units A(B), where we apply A to the output of B. When
optimizing A and B in isolation, we may find that matcher UD works best for both. So the best
global plan appears to be applying UD to both units. However, when optimizing A(B) as whole,
we may find that applying ST to A and RU to B produces a better plan. The reason is that for
A ST may be more expensive (i.e., takes longer to run) than UD, but it generates more matching
regions, and B can just use RU to recycle these regions at a very low cost.

49
For the above reasons, we did not look for an exact algorithm that finds the optimal plan.
Rather, as a first step, in this chapter we develop a greedy solution that can quickly find a good
plan in the above huge plan space. We now describe this solution.
3.4.2 Searching for Good Plans
Our solution breaks tree T into smaller pieces, finds a good plan for some initial pieces, and
iteratively builds on them to find a good plan to cover other pieces until the entire T is covered. To
describe the solution, we start with the concept of IE chain:
Definition 3.3 (IE Chain). An IE chain is a path in tree T such that (a) the path contains a sequence
of IE units A1, · · · , Ak, (b) the path begins with A1 and ends with Ak, (c) between each pair of
adjacent IE units Ai and Ai+1, there are no other IE units, and Ai extracts mentions from regions
output by Ai+1, and (d) the chain is maximal in that we can not add another IE unit to its beginning
or end and obtain another chain satisfying the above properties.
For example, an IE execution tree extractTopics(extractAbstract(d, abstract)) is itself a
chain because the IE unit extractAbstract extracts abstracts from a document d, and then feeds
them to IE unit extractTopics, which in turn extracts topic strings from the abstract.
Note that the above definition allows two adjacent IE units to be connected indirectly by re-
lational operators that do not belong to any IE units. For example, the chain C1 in Figure 3.5.a
consists of the sequence of IE units Z, Y , U , where Y and U are connected by project-join (and Y
extracts mentions from a text region output by U ).
It is relatively straightforward to partition any execution tree T into a set of IE chains. Fig-
ure 3.5.a shows for example a partition of such a tree into two chains C1 and C2. Note that this
is also the only possible partition created by Definition 3.3, given that Y extracts mentions only
from a text region output by U (not from any text region output by V ). In general, given a tree T ,
Definition 3.3 creates a unique partition of T into IE chains.
We define the concept of IE chain because, within each chain, it is relatively easy to find a
good local plan, as we will see later. Unfortunately, we cannot just find these locally optimal plans
independently, and then assemble them together to form a good global plan. The reason is that

50
chains can reuse results of other chains, and this reuse often leads to a substantially better plan
(than one that does not exploit reuse across chains), as the following example illustrates.
Example 3.4. Suppose we have found a good plan for chain C1 in Figure 3.5.a, and this plan
applies matcher ST for IE unit U . That is, for each page p in snapshot Pn+1, U applies ST to
match p with q, the page with the same URL in Pn. Assuming that the running time of matcher RU
is negligible (which it is in practice), the best local plan for chain C2 is to apply matcher RU in IE
unit V . Since V must also match p and q, RU will enable V to recycle matching results of U , with
negligible cost.
Thus, optimality of IE chains is clearly “interdependent.” To take such interdependency into
account and yet keep the search still manageable, we start with one initial chain, find a good plan
for it in isolation, then extend this plan to cover a next chain, taking into account cross-chain reuse,
and so on, until we have covered all chains. Our concrete algorithm is as follows (Algorithm 3.1
shows the full pseudo code).
1. Sort the IE Chains: Using the cost model (see the next subsection), we estimate the cost of
each IE chain if extraction were to be performed from the scratch in all IE units of the chain. We
then sort the chains in decreasing order of this cost. Without loss of generality, let this order be
C1, . . . , Ch.
2. Find a Good Plan g for the First Chain: Since the first chain is the most expensive, we give
it the maximum amount of freedom in choosing matchers. To do so, we enumerate the following
set of plans for the first chain C1 (based on the heuristics that we explain below):
1. a plan that assigns matcher DN to all IE units of C1;
2. all plans that assign ST to an IE unit U of C1, RU to all “ancestor” IE units of U , and DN to
all “descendant” IE units of U ;
3. all plans that assign UD to an IE unit U of C1, RU to all “ancestor” IE units of U , and DN
to all “descendant” IE units of U .
We then use the cost model to select the best plan g from the above set.

51
Since the cost of RU is negligible in practice (as remarked earlier), it is easy to prove that the
above set of plans dominates the set M of plans where each plan employs matchers ST and UD at
most once, i.e., at most one IE unit in the plan is assigned a matcher that is either ST or UD. Thus,
the plan we select will be the best plan from M.
We do not examine a larger set of plans because any plan outside M would contain at least
either two ST matchers, or two UD matchers, or an ST matcher together with a UD matcher. Since
the cost of these matchers are not negligible, our experiments suggest that plans with two or more
such matchers tend to incur high overhead. In particular, they usually underperform plans where
we apply just one such expensive matcher relatively early on the chain, and then apply only RU
matcher afterward. For this reason, we currently consider only the plan space M.
3. Extend Plan g to Cover the Second Chain: First, we repeat the above Step 2 (but replacing
C1 with C2), to find a good plan g′ for the second chain C2.
Next, let U be the bottom IE unit of chain C1. Suppose the best plan g for C1 assigns either
matcher ST or UD to U . Then we can potentially reuse the results of this matcher for C2 (if C2
is executed later than C1 in T ). Hence, we consider a reuse-across-chains plan g′′ that assigns
matcher RU to all IE units of C2 (and directing them to reuse from IE unit U of C1).
We then compare the estimated cost of g′ and g′′, and select the cheaper one as the best plan
found for chain C2.
4. Cover the Remaining Chains Similarly: We then repeat Step 3 to cover the remaining
chains. In general, for a chain Ci, we could have as many reuse-across-chains plans as the number
of chains in the set {C1, . . . , Ci−1} that assign matcher ST or UD to their bottom IE units.
Example 3.5. Figure 3.5.b depicts a situation where we have found the best plans for chains
C1, C2, and C3. These plans have assigned matchers UD, DN, and ST to the bottom IE units
U1, U2, and U3, respectively. Then, when considering chain C4, we will create two reuse-across-
chains plans: the first one reuses the results of matcher UD of U1, and the second reuses the results
of matcher ST of U3 (see the figure).

52
Algorithm 3.1 Searching for Execution Plan1: Input: IE execution tree T
2: Output: execution plan G
3: C ⇐ partition T //C is a set of chains
4: C1, · · · , Ch ⇐ sort C in decreasing order of cost estimate
5: g1 ⇐ findBest(C1)
6: G ⇐ {g1}7: for 2 ≤ i ≤ h do
8: g′i ⇐ findBest(Ci)
9: B ⇐ bottom IE units for all chains in G
10: if (any U ∈ B has the raw data page as input and is assigned ST or UD) then
11: g′′i ⇐ assign RU to all IE units of Ci reusing the matching results of U
12: gi ⇐ select g′i or g′′i with the smaller cost estimate
13: G ⇐ G ∪ {gi}14: else
15: G ⇐ G ∪ {g′i}16: end if
17: end for
Procedure FindBest(Ci)1: Input: chain Ci = A1(A2(· · · (Ak) · · · ))2: Output: best execution plan for Ci in Mi, where Mi is the set of plans each having at most one IE unit Aj , 1 ≤ j ≤ k,
assigned matcher ST or UD.
3: M′i ⇐ ∅
4: g ⇐ assign DN to each Aj , 1 ≤ j ≤ k
5: M′i ⇐M′
i ∪ {g}6: for 1 ≤ j ≤ k do
7: g ⇐ assign ST to Aj , RU to Am, 1 ≤ m < j, and DN to An, j < n ≤ k
8: M′i ⇐M′
i ∪ {g}9: g ⇐ assign UD to Aj , RU to Am, 1 ≤ m < j, and DN to An, j < n ≤ k
10: M′i ⇐M′
i ∪ {g}11: end for
12: for each g ∈M′i, estimate its cost using the cost model
13: return the g with the smallest cost estimate
Once we have covered all the chains, we have found a reasonable plan for execution tree T .
Our experiments in Section 3.6 show that such plans prove quite effective on our real-world data
sets.

53
a Average number of input tuples in IU per page
b Size of IU on disk (in blocks)
c Size of OU on disk (in blocks)
d Size of all pages on disk (in blocks) in a snapshot
l Average length of a region encoded by an input tuple
m Number of pages in a single snapshot
v Number of buckets in the in-memory hash table of copy regions
(a) Meta data statistics
f Fraction of pages with an earlier version in the previous snapshot
s Number of times a matcher is invoked on a region encoded by an input tuple
g After matching region R, the ratio of resulting extraction regions to R (in length)
h Number of copy regions generated from matching a region
(b) Selectivity statistics
Figure 3.6 Cost model parameters.
3.4.3 Cost Model
We now describe how to estimate the runtime of an execution plan. Since the difference among
all plans is how they execute the IE units of tree T (Section 3.4.1), we focus on the cost incurred by
executing IE units, and ignore other costs. Therefore, we estimate the cost of a plan to be∑
U∈T tU ,
where tU denotes the elapsed time of executing the IE unit U .
For an IE unit U , we further model tU as the sum of the elapsed time of the steps involved in
executing U (Section 3.3.3). We model the elapsed time of each step as a weighted sum of I/O
and CPU costs to capture the elapsed times of highly tuned implementations that overlap I/O with
CPU computation (in which case, the dominated cost component will be completely masked and
therefore have weight 0) as well as simple implementations that do not exploit parallelism.
To model tU , our cost model employs three categories of parameters. The first category of
parameters (listed in Figure 3.6.a) are the meta data of data pages and intermediate results. For
these parameters, we use subscript n to represent the value of the parameter on snapshot n. For
example, an denotes the average number of input tuples in InU(q) for a page q ∈ Pn.
The second category of parameters (listed in Figure 3.6.b) are selectivity statistics of a matcher.
The last category of parameters are I/O and CPU cost weights w, whose subscripts reflect which

54
step incur the associated costs. For all parameters, we use hatted variables to represent parameters
are estimated.
We now describe tU as follows. tU consists of 4 cost components in executing U . The first cost
component is the cost of identifying regions encoded by input tuples (tid, did, s, e, c) ∈ In+1U and
(tid′, did′, s′, e′, c′) ∈ InU where c = c′. We model the cost component as:
w1,IO · bn + w1,find · an · an+1 ·mn+1 · f (3.1)
The term w1,IO · bn models the I/O cost of reading in InU into buffer. The term an · an+1 ·mn+1 · f
models the total number of comparisons between arguments c and c′ for input tuples in InU and
In+1U respectively.
The second cost component is the cost of matching the regions identified in the first step. We
model this component as:
w2,IO · dn · f + w2,mat · an+1 ·mn+1 · f · s · l (3.2)
This model accounts for the I/O cost of reading in pages in Pn and the CPU cost of applying
matchers. The term dn · f estimates the size (in disk blocks) of raw data pages in Pn that share the
same URL, since we only match same URL pages (see Section 3.3.1). The term an+1 ·mn+1 · f · sestimates the total number of times we apply the matcher when executing U on Pn+1.
The third cost component is the cost of applying U to all extraction regions. We model this
component as:
w3,ex · (an+1 ·mn+1 · (1− f) · l + an+1 ·mn+1 · f · l · g) (3.3)
We will apply U to those input tuples (in In+1U ) on pages in Pn+1 that do not have an earlier version
in Pn. The term an+1 ·mn+1 ·(1− f) · l estimates the total length of regions encoded in those tuples.
In addition, we also need to apply U to the extraction regions on pages Pn+1 that do have an earlier
version in Pn. The term an+1 ·mn+1 · f · l · g estimates the length of these extraction regions. In
particular, g measures, on average, the fraction of a region we still need to apply U after we match
it using a matcher.

55
The last cost component is the cost of reusing output tuples for copy regions. We model this
component as:
w4,IO · cn + w4,copy · an ·mn · an+1 ·mn+1 · f · hv
(3.4)
The formula models the I/O cost of reading in OnU and the CPU cost of probing the copy regions to
determine whether to copy each mention. Delex stores the copy regions in a hash table to facilitate
fast lookups. The term an+1·mn+1·f ·hv
estimates the number of hash table entries per bucket.
Notice that we ignore the costs of reading the raw data pages in Pn+1 and writing out the
intermediate results and the final target relation, since these costs are the same for all plans.
Given the cost model, we then estimate the parameters using a small sample S of Pn+1 as well
as the past k snapshots, for a pre-specified k. Since our parameter estimation techniques are similar
to those in Cyclex, we do not discuss the details any further.
3.5 Putting It All Together
We now describe the end-to-end Delex solution. Given an IE program P written in xlog, we
first employ the techniques described in [67] to translate and optimizes P into an execution tree T ,
and then pass T to Delex.
Given a corpus snapshot Pn+1, Delex first employs the optimization technique described in
Section 3.4 to assign matchers to the IE units of T . Next, Delex executes the so-augmented tree
T on Pn+1, employing the reuse algorithm described in Section 3.3 and the reuse files it produced
for snapshot Pn. During execution, it captures and stores intermediate IE results (for reuse in the
subsequent snapshot Pn+2), as described in Section 3.2.
Note that Delex executes essentially the same plan tree T on all snapshots. The only aspect of
the plan that changes across snapshots is the matchers assigned to the IE units. Our experiments
in Section 3.6 show that for our real-world data sets this scheme already performs far better than
current solutions (e.g., applying IE from scratch, running Cyclex, reusing IE results on duplicate

56
35M180MAvg Size per Snapshot
303810155Avg # Page per Snapshot
1515# Snapshots
21 days2 daysTime Between Snapshots
925980# Data Sources
WikipediaDBLifeData Sets
(a) Data sets for our experiments.
12
5
9
β (in char.)
205395advise (advisor, advisee, topics)
94583chair (person, chairType, conference)
1551talk (speaker, topics)
α (in char.)# IE “Blackboxes”IE Program for DBLife
15
7
7
β (in char.)
106252blockbuster (movie)
305066award (actor, movie, role, award )
227054play (actor, movie)
α (in char.)# IE “Blackboxes”IE Program for Wikipedia
(b) IE programs for our experiments.
Figure 3.7 Data sets and IE programs for our experiments
pages). Exploring more complex schemes, such as re-optimizing the IE program P for each snap-
shot or re-assigning the matchers for different pages, is a subject of ongoing work. The following
theorem states the correctness of Delex:
Theorem 3.1 (Correctness of Delex). Let Mn+1 be mentions of the target relation R obtained by
applying IE program P from scratch to snapshot Pn+1. Then Delex is correct in that when applied
to Pn+1 it produces exactly Mn+1.
Proof. Let U be an IE blackbox in P and OUn+1 be the output of U produced by re-applying U from
scratch to Pn+1. In the similar way we have shown in Cyclex, we can show that Delex produces
exactly OUn+1 for U when it is applied to Pn+1. Since Delex produces the correct output for each
IE blackbox in P , it is easy to show that Delex produces exactly Mn+1.
3.6 Empirical Evaluation
We now empirically evaluate the utility of Delex. Figure 3.7 describes two real-world data sets
and six IE programs used in our experiments. DBLife consists of 15 snapshots from the DBLife

57
exBioSection(d,bioSection)
docs(d)
exActor(bioSection,p,actor)
namePatterns(p)
exAwardItem(awardSection,awardItem)
exAwardSection(d,awardSection)
exAward(awardItem,m,a,movie2,award)
awardPatterns(a) docs(d)
exRole(d,m,movie1,role)
moviePatterns(m)
(movie1,role,award)
match(movie1,movie2)
moviePatterns(m)
docs(d)
π
σ
Figure 3.8 The execution plan used in our experiments for the “award” IE task.
system [31], and Wikipedia consists of 15 snapshots from Wikipedia.com (Figure 3.7.a). The three
DBLife IE programs extract mentions of academic entities and their relationships, and the three
Wikipedia IE programs extract mentions of entertainment entities and relationships (Figure 3.7.b).
Figure 3.8 shows for example the execution plan used in our experiments for the “award” IE task
(with IE blackboxes shown in bold font). The above IE programs are rule-based. However, we also
experimented with an IE program consisting of multiple learning-based blackboxes, as detailed at
the end of this section.
We obtained the scope α and context β of each IE blackbox and the entire IE program by
analyzing the IE blackboxes and their relationships. The appendix describes this analysis in detail.
Runtime Comparison: For each of the six IE tasks in Figure 3.7.b, Figure 3.9 shows the runtime
of Delex vs. that of other possible baseline solutions over all consecutive snapshots. We consider
three baselines: No-reuse, Shortcut, and Cyclex. No-reuse re-executes the IE program over all
pages in a snapshot; Shortcut detects identical pages, then reuses IE results on those; and Cyclex
treats the whole IE program as a single IE blackbox.
On DBLife, No-reuse incurred much more time than the other solutions. Hence, to clearly
show the differences in the runtimes of all solutions, we only plot the runtime curves of Shortcut,
Cyclex, and Delex on DBLife (the left side of Figure 3.9). Since in each snapshot both Cyclex and

58
talk
200
550
900
1250
1600
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15snapshot
runtime(s) Runtime of No-reuse varies from 14685 seconds to 15231 seconds
chair
200
550
900
1250
1600
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15snapshot
runtime(s) Runtime of No-reuse varies from 14526 seconds to 14702 seconds
advise
200
700
1200
1700
2200
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15snapshot
runtime(s) Runtime of No-reuse varies from 17462 seconds to 18252 seconds
award
300
750
1200
1650
2100
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15snapshot
runtime(s)
blockbuster
150
300
450
600
750
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15snapshot
runtime(s)
play
100
450
800
1150
1500
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15snapshot
runtime(s)
No-reuse Shortcut Cyclex Delex
Figure 3.9 Runtime of No-reuse, Shortcut, Cyclex, and Delex.
Delex employ a cost model to select and execute a plan, their runtime includes statistic collection,
optimization, and execution times.
Figure 3.9 shows that, in all cases, No-reuse (i.e., rerunning IE from the scratch) incurs large
runtimes, while Shortcut shows mixed performance. On DBLife, where 96-98% of pages re-
main identical on consecutive snapshots, it performs far better than No-reuse. But on Wikipedia,
where many pages tend to change (only 8-20% pages remain identical on consecutive snapshots),
Shortcut is only marginally better than No-reuse. In all cases, Cyclex performs comparably or
significantly better than Shortcut.
Delex however outperforms all of the above solutions. For “talk” task, where the IE program
contains a single IE blackbox, Delex performs as well as Cyclex. For all the remaining tasks,
where the IE program contains multiple IE blackboxes, Delex significantly outperforms Cyclex,
cutting runtime by 50-71%. These results suggest that Delex was able to exploit the compositional
nature of multi-blackbox IE programs to enable more reuse, thereby significantly speeding up
program execution.
Contributions of Components: Figure 3.10 shows the runtime decomposition of the above
solutions (numbers in the figure are averaged over five random snapshots per IE task). “Match”
is the total time of applying all matchers in the execution tree. “Extraction” is the total time to

59
Match Extract ion Copy Opt Others
blockbuster
0306090120150
No-reuse Shortcut Cyclex Delex
runtime(s)505 491 386 203
play
0306090120150
No-reuse Shortcut Cyclex Delex
runtime(s)870 865 751
award
0306090120150
No-reuse Shortcut Cyclex Delex
runtime(s)1575 1496 1575 312
talk
020406080100
No-reuse Shortcut Cyclex Delex
runtime(s)11552 904 414 414
chair
020406080100
No-reuse Shortcut Cyclex Delex
runtime(s)14658 878 755 473
advise
020406080100
No-reuse Shortcut Cyclex Delex
runtime(s)14805 1151 1068 458
Figure 3.10 Runtime decomposition of No-reuse, Shortcut, Cyclex and Delex.
apply all IE extractors. “Copy” is the total time to copy mentions. “Opt” is the optimization time
of Cyclex and Delex. Finally, “Others” is the remaining time (to apply relational operators, read
file indices, etc.).
The results show that matching and extracting dominate runtimes. Hence we should focus on
optimizing these components, as we do in Delex. Furthermore, Delex spends more time on match-
ing and copying than Cyclex and Shortcut in complex IE programs (e.g., “play” and “award”).
However, this effort clearly pays off (e.g., reducing the extraction time by 37-85%). Finally, the
results show Delex incurs insignificant overhead (optimization, copying, etc.) compared to its
overall runtime.
We also found that in certain cases the best plan (one that incurs the least amount of time)
employs RU matchers, and that the optimizer indeed selected such plans (e.g., for “chair” and
“advise” IE tasks), thereby significantly cutting runtime (see the left side of Figure 3.9). This
suggests that reusing across IE units can be highly beneficial in our Delex context.
Effectiveness of the Delex Optimizer: To evaluate the Delex optimizer, we enumerate all
possible plans in the plan space, and then compare the runtimes of the best plan versus the one
selected by the optimizer. To conduct the experiment, we first selected the “play” IE task, whose

60
play
0
400
800
1200
1600
3 6 9 12 15snapshot
runtime(s)
best plan plan picked by Delex bad plan
play
1
3
5
7
9
3 6 9 12 15snapshot
rank
Figure 3.11 Performance of the optimizer.
play
02505007501000
10 20 30 40 50# sampled pages
runtime(s) play
02505007501000
2 3 4 5 6#snapshot
runtime(s)
Cyclex Delex
Figure 3.12 Sensitivity analysis.
plan space contains 256 plans, thereby enabling us to enumerate and run all plans. We then ranked
the plans in increasing order of their actual runtimes. Figure 3.11.a shows the positions in this
ranking for the plan selected by the optimizer, over five snapshots. The results show that the
optimizer consistently selected a good plan (ranked number five or three). Figure 3.11.b shows
the runtime of the actual best plan, the selected plan, and the worst plan, again over the same five
snapshots. The results show that the selected plan performs quite comparably to the best plan, and
that optimization is important, given the significantly varying runtimes of the plans.
Sensitivity Analysis: Next, we examined the sensitivity of Delex with respect to the main input
parameters: number of snapshots, size of sample used in statistics estimation, and the scope and
context values.
Figure 3.12.a plots the runtime of the plans selected by the optimizers of Delex and Cyclex as
a function of sample size, only for “play” (results for other IE tasks show similar phenomenons).
Figure 3.12.b plots the runtime of the plans selected by the optimizer of Delex and Cyclex as a
function of the number of snapshots.
The results show that in both cases Delex only needs a few recent snapshots (3) and a small
sample size (30 pages) to do well. Furthermore, even when using statistics over only the last 2
snapshots, and a sample size of 10 pages, Delex can already reduce the runtime of Cyclex by

61
play
0
2000
4000
6000
8000
20 40 60 80 100 120# of mentions (k)
runtime (s)
No-reuse Shortcut Cyclex Delex
Figure 3.13 Runtime comparison wrt number of mentions.
25%. This suggests that while collecting statistics is crucial for optimization, we can do so with a
relatively small number of samples over very recent snapshots.
We also conducted experiments to examine the sensitivity of Delex with respect to the α and β
of IE “blackboxes” (figure omitted for space reasons). We found that the runtime of Delex grows
gracefully when α and β of IE “blackboxes” increase. Consider for example a scenario in our
experiments: randomly selecting an IE blackbox in the “play” task and increasing its α and β to
examine the change in Delex’s time. When we increased α from 52 to 150, the averaged runtime
of Delex over five randomly selected snapshots only increases by 15% (from 216 seconds to 248
seconds). When we further increased α to 250 (five times of the original α), the averaged runtime
of Delex over the same five snapshots increases by only 38% (from 216 seconds to 298 seconds).
We observe a similar phenomenon for β. The results suggest that a rough estimation of the α and
β of the IE blackboxes does increase the runtime of Delex, but in a graceful fashion.
Impact of Capturing IE Results: We also evaluated the impact of capturing IE results on Delex.
To do so, we varied the number of mentions extracted by the IE blackboxes and then examined
the runtimes of Delex and the baseline solutions. For example, given the IE program “play,” we
changed the code of each IE blackbox in “play” so that a mention extracted by the IE blackbox is
output multiple times. Then we applied Delex and the baseline solutions to this revised IE program
of “play.” Figure 3.13 plots these runtimes on “play” as a function of the total number of mentions
extracted by all IE blackboxes.
The results show Delex continues to outperform the baseline solutions by large margins as the
total number of mentions grows. This suggests that Delex scales well with respect to the number
of extracted mentions (and thus the size of captured IE results). Furthermore, we found that as

62
the number of mentions grows by 400% (from 22K to 110K), the time Delex spends on capturing
and reusing the IE results only grows by 88% (from 17 seconds to 32 seconds). Additionally, the
overhead of capturing and reusing IE results incurred by Delex remains to occupy an insignificant
portion (3% - 8%) of its overall runtime. This suggests that the overhead of capturing IE results
does increase as the number of extracted mentions increases, but only in a graceful manner.
Learning-based IE Programs: Finally, we wanted to know how well Delex works on IE pro-
grams that contain learning-based IE blackboxes. To this end, we experimented with an IE program
proposed by a recent work [76] to automatically construct infoboxes (tabular summaries of an ob-
ject’s key attributes) in Wikipedia pages. This IE program extracts name, birth name, birth date,
and notable roles for each actor. To do this, it employs a maximal entropy (ME) classifier to seg-
ment a raw data page into sentences, then employs four conditional random field (CRF) models –
one for each attribute – to extract the appropriate values from each of the sentences.
To apply Delex, we first converted the above IE program into an xlog program that consists
of five IE blackboxes. These blackboxes capture the ME classifier and the four CRF models,
respectively. Then we derived α and β for each of the blackboxes. For example, given a delimit
character in a raw data page, the ME classifier examines its context (i.e., surrounding characters) to
determine if the delimit character is indeed the end of a sentence. Given this, we can set αME to be
the maximal number of characters in a sentence, and βME to be the maximal number of characters
in the contexts examined by the ME classifier (321 and 16 in our experiment, respectively). It is
more difficult to derive tight values of αCRF and βCRF for the four CRF models, as these models
are quite complex. However, we can always set them to the length of the CRF model’s longest
input string, i.e., the longest sentence, and this is what we did in the current experiment.
Figure 3.14 shows the runtime of Delex and the three baseline solutions on the above xlog
program running on Wikipedia. The results show that both Shortcut and Cyclex only perform
marginally better than No-reuse, due to significant change of pages across snapshots and large α
(17824 characters) of the entire IE program. However, Delex significantly outperforms all three
solutions. In particular, Delex reduces the runtime of Cyclex by 42-53%. This suggests that
Delex can benefit from exploiting the compositional nature of multi-blackbox learning-based IE

63
No-reuse Shortcut Cyclex Delex
actor
700
1000
1300
1600
1900
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15snapshot
runtime(s)
Figure 3.14 Runtime comparison on a learning based IE program.
programs, even though we are not able to derive tight α and β for some learning-based IE black-
boxes (e.g. the complex CRF models) in the programs.
3.7 Summary
A growing number of real-world applications involve IE over dynamic text corpora. Recent
work on Cyclex has shown that executing such IE in a straightforward manner is very expensive,
and that recycling past IE results can lead to significant performance improvements. Cyclex,
however, is limited in that it handles only IE programs that contain a single IE blackbox. Real-
world IE programs, in contrast, often contain multiple IE blackboxes connected in a workflow.
To address the above problem, we have developed Delex, a solution that effectively executes
multi-blackbox IE programs over evolving text data. As far as we know, Delex is the first in-
depth solution to this important problem. Our extensive experiments over two real-world data sets
demonstrate that Delex can cut the runtime of Cyclex by as much as 71%. This suggests that
exploiting the compositional nature of multi-blackbox IE programs can be highly beneficial.

64
Chapter 4
Recycling for CRF-Based IE Programs
So far, we have developed the efficient recycling algorithm Delex for IE programs consisting
of multiple IE blackboxes. If we can open up some of these blackboxes and understand more
about them, can we develop a more efficient recycling algorithm? We study this problem in this
chapter. In particular, we study IE programs that contain IE blackboxes based on a statistical
learning model, Conditional Random Fields (CRFs). We open up these CRF-based IE blackboxes
and explore whether we can develop a more efficient recycling algorithm. CRF-based IE is a
state-of-the-art IE solution that has been successfully applied to many IE tasks, including name
entity extraction [38, 54], table extraction [61], and citation extraction [60]. Therefore, a recycling
solution for CRF-based IE is a practical extension of Delex.
We first review CRF-based IE and introduce our problem in Section 4.1. Sections 4.2–4.5
describe our solution CRFlex. Section 4.6 presents an empirical evaluation. Finally, Section 4.7
concludes this chapter.
4.1 Introduction
In this section, we first briefly review CRF-based IE. Then we formally define our problem.
Finally we discuss the challenges in recycling for CRF-based IE and outline our solution.

65
4 9 10 16 18 25
1 6 7 14 17 27
1 2 13 16 19 24
1 2 3 4 5 6
P
L
O
d: Tom Cruise was born in NY.
NYinbornwasCruiseTom
x6x5x4x3x2x1
LOOOPP
y6y5y4y3y2y1
Entity TypeName
LOCATIONNY
PERSONTom Cruise
x:
y:
M:
(a)
(b)
Figure 4.1 (a) An example of using CRFs to extract persons and locations, and (b) an example ofthe Viterbi algorithm.
4.1.1 Conditional Random Fields for Information Extraction
CRF-based IE reduces information extraction to a sequence labeling problem. Given a doc-
ument d, a CRF-based IE program P first converts d into a sequence of tokens x1...xT1. Then
P employs a CRF model F that takes x1...xT as input and outputs a label from a set Y of labels
for each token. Y consists of the set of entity types to be extracted and a special label “other” for
tokens that do not belong to any of the entity types. The output of F is a label sequence y1...yT ,
where yi is the label of xi. Finally, P considers the labels of consecutive tokens to extract mentions.
Example 4.1. Figure 4.1.a illustrates an example of using CRFs to extract PERSON and LOCA-
TION entities from a document d. A CRF-based IE program P first converts d into a sequence x
of tokens. Then it tags each token with one of the labels in Y = {PERSON(P), LOCATION(L),
OTHER(O)}, and outputs the label sequence y. Finally, P outputs a set of name mentions M ,
where each mention consists of the longest sequence of tokens with the same labels P or L.
To label token sequences accurately, CRFs capture the dependency in the labels. For example,
while New York is a location, New York Times is an organization. In particular, the most popular
CRF models used for IE assume a linear-chain dependency in labels. This implies that the label yi
1Besides token sequences, there are many other types of sequences (e.g., line sequences). Our solution can begenerally applied to all types of sequences. For simplicity of discussion, we will focus on token sequences.

66
of xi is directly influenced only by labels yi−1 and yi+1 (besides by xi). Once yi−1 is fixed, yi−2 has
no influence on yi. In this chapter, we focus on linear-chain CRFs. Extending our work to other
CRF models is a subject for future research.
To capture such dependency in the labels of adjacent tokens, CRFs employ a set of feature
functions {fk(yi−1, yi, xi)}Kk=1. These feature functions indicate the properties of xi, given its label
yi and the previous label yi−1. For example, in the previous example, two possible feature functions
can be:
f1(yi−1, yi, xi) = [xi matches a state name] · [yi = LOCATION ],
f2(yi−1, yi, xi) = [xi starts with a capitalized character] · [yi−1 =PERSON] · [yi =PERSON],
where [p] = 1 if the predicate p is true and 0 otherwise.
Each function fk is associated with a weight λk, which is obtained during the training phase.
With these feature functions and their weights, CRFs model the conditional distribution of the
label sequence y = y1...yT given the token sequence x = x1...xT as
p(y|x) =1
Z(x)exp{
T∑i=1
K∑
k=1
λk · fk(yi−1, yi, xi)} (4.1)
where Z(x) is a normalizing constant, which equals to
∑y
exp{T∑
i=1
K∑
k=1
λk · fk(yi−1, yi, xi)}. (4.2)
During the inference phase, to label the input token sequence x, we compute the most likely
labeling
y∗ = argmaxyp(y|x) (4.3)
A brute force approach to find y∗ is to enumerate all possible y, which requires time exponential
in the sequence length. Fortunately, for linear-chain CRFs, the Viterbi algorithm can find y∗ in a
more efficient way. We now briefly describe this algorithm.

67
Viterbi Algorithm: The Viterbi algorithm is a dynamic programming algorithm for finding the
most likely label sequences. It operates in two phases: forward phase and backward phase. In
the forward phase, it computes a two dimensional V matrix. Each cell (y, i) of V stores the best
labeling score of the sequence from 1 to i with the ith position labeled y. The Viterbi algorithm
computes score V (y, i) recursively as follows:
V (y, i) =
maxy′{V (y′, i− 1) +K∑
k=1
λk · fk(y′, y, i)} if i > 0
0 if i = 0
While computing score V (y, i), it also keeps track of which y′ is used to compute V (y, i) by
adding an edge from cell (y′, i − 1) to cell (y, i). In the end of the forward phase, it fills in all
cells of the V matrix and adds all edges that indicate which previous labels are used to compute
the V scores. Then y∗ corresponds to the path traced from the cell that stores maxyV (y, T ). In
the backward phase, the Viterbi algorithm backtracks by following the edges added in the forward
phase to restore y∗.
Example 4.2. Continuing Example 4.1, Figure 4.1.b illustrates the V matrix computed over the
token sequence x in Figure 4.1.a. The first row, second row, and third row contain the scores for
label P, L, and O respectively. Each column contains the scores for a given position. We also
plot all the edges that keep track of which previous labels are used to compute the V scores. For
example, the edge cell(P, 1) → cell(L, 2) indicates V (P, 1) is used to compute V (L, 2). Finally,
the path of the best labeling is highlighted in bold.
The running time of the Viterbi algorithm is O(T |Y|2), where T is the length of the input token
sequence and |Y| is the size of Y .
4.1.2 Problem Definition
CRF-Based IE Programs: We consider how to execute a CRF-based IE program P efficiently
over evolving text. Like the IE programs considered by Delex (Chapter 3), P is a multi-blackbox
IE program, represented in xlog. Some of these blackboxes employ CRF models for extraction.

68
1 2 3 4 5 6
P
L
O
Figure 4.2 An example of a path matrix.
We call such IE blackboxes CRF-based IE predicates. A CRF-based IE predicate takes input as a
text span and a sequence of tokens contained in the text span and outputs the labels of the tokens.
In order to reuse efficiently for CRF predicates2, we assume that these predicates expose some
intermediate results to CRFlex. In particular, we assume that CRF predicates output the paths
created by the Viterbi algorithm. These paths are stored in a path matrix. For example, Figure 4.2
illustrates the path matrix that stores all the paths created in Example 4.2. Furthermore, CRF
predicates also take an additional input argument, a vector that stores the scores of position 0 in the
V matrix. The CRF predicate uses this vector to initialize the V matrix according to Equation 4.1.1.
We now formally define CRF predicates as follows:
Definition 4.1 (CRF-based IE predicate). A CRF-based IE predicate F labels a sequence of tokens
using a CRF model. Formally, F is a p-predicate q(a1, a2, a3, . . . , an, b1, b2, . . . , bm), where (a) a1
is either a document or a text span variable, (b) a2 is a token sequence variable, (c) a3 is a score
vector variable, (d) b1 is a label sequence variable, (e) b2 is a path matrix variable, and (f) for any
output tuple (u1, u2, u3, . . . , un, v1, v2, . . . , vm), u2 is a token sequence contained by u1, v1 is the
sequence of labels of u2 output by F with initializing the scores of position 0 to u3, and v2 is the
path matrix output by F during its execution over u1.
Example 4.3. Consider a CRF predicate
applyCRFs(textSpan, tokenSequence, initialScores, labelSequence, paths)
that represents the CRF predicate used in Example 4.1. An instant input to applyCRFs is (d, x, [0, 0,
0]), where d, x are illustrated in Figure 4.1.a, and [0, 0, 0] represents the scores for position 0 in
2In the rest of the chapter, we use “CRF-based IE predicate” and “CRF predicate” interchangeably.

69
the V matrix illustrated in Figure 4.1.b. This input tuple results in an output tuple (y,G), where y
is illustrated in Figure 4.1.a, and G is the matrix illustrated in Figure 4.2.
A CRF-based IE program is an IE program that contains one or more CRF predicates. We can
now define our problem formally as follows:
PROBLEM DEFINITION Let P1, . . . , Pn be consecutive snapshots of a text corpus, P be an
IE program written in xlog. Let F1, . . . , Fl be the CRF-based IE predicates in P , with the esti-
mated scopes and contexts (α1, β1), . . . , (αl, βl), respectively. Furthermore, let E1, . . . , Em be the
non-CRF-based IE predicates in P with the estimated scopes and contexts (α′1, β′1), . . . , (α
′m, β′m),
respectively. Develop a solution to execute P over corpus snapshot Pn+1 with minimal cost, by
reusing extraction results over P1, . . . , Pn.
To address this problem, a simple solution is to treat all F1, . . . , Fl, together with E1, . . . , Em
as general IE blackboxes, and then apply Delex to P . We found, however, that this solution does
not work well when the text corpus changes frequently. The main reason is that estimating “tight”
αi and βi for Fi is very difficult. As discussed before (Section 4.1.1), the Viterbi algorithm used
for CRF inference considers the entire sequence together to output the best labels. Therefore, we
have to set αi and βi to the maximal length of the text spans covering the entire token sequences.
These values are often very large and limit reuse opportunities.
This suggests that we should exploit properties that are specific to CRFs. In this chapter,
we present CRFlex as a solution that captures this intuition. We now discuss the challenges in
designing this solution.
4.1.3 Challenges and Solution Outlines
The first challenge is what properties of CRFs we can exploit for reuse. As we discussed
before, the general scope and context provide limited reusing opportunities for CRF predicates. To
address this problem, we identify an important property of CRFs: CRF context. Similar to mention
contexts identified in Cyclex, the CRF context of a token x specifies small windows surrounding
x, such that no matter how we perturb tokens outside these windows, the label of x remains the
same. Compared to mention contexts, however, identifying CRF contexts is fundamentally much

70
harder. The main reason is that CRFs operate based on the dependency in the labels of adjacent
tokens. To this end, we show that, under certain conditions, a token’s label does not depend on the
labels of its adjacent tokens. This allows us to break a sequence into several independent pieces
and recycle the results of each piece independently.
The second challenge is what results to capture for each CRF predicate and how to capture
these results. As we will show later (Section 4.2), CRF contexts vary from one token to another.
Therefore, we must identify, capture, and store these contexts in Pn, so that we can exploit them in
Pn+1 for safe reuse. To this end, we develop a solution that efficiently infers the CRF contexts from
the path matrix output by the CRF predicate. In addition, we show how to store these contexts to
reduce the I/O overhead.
Finally, how can we efficiently reuse the captured results? Similar to Cyclex and Delex, CR-
Flex first finds overlapping regions and then exploits the CRF contexts to identify copy regions.
As we will show later (Section 4.4), in order to exploit CRF contexts properly, CRFlex must inter-
leave re-applying the CRF predicate with exploiting the CRF contexts to identify the copy regions.
The challenge is that these two steps are dependent upon each other. Without re-applying the CRF
predicate, we cannot exploit the CRF contexts, and thus cannot identify the copy regions. At the
same time, without identifying the copy regions, we also do not know the extraction regions, and
thus do not know to which regions we should re-apply the CRF predicate. We develop a solution
that explores this dependency constraint to interleave the two steps carefully.
In the rest of this chapter, we describe our solution CRFlex in detail. We first present prop-
erties of CRFs we exploit for safe reuse in Section 4.2. Then we describe how to capture results
efficiently for future reuse in Section 4.3, and reuse the captured results in Section 4.4.
4.2 Modeling CRFs for Reusing
We now discuss how to model CRF predicates for safe reuse. Our goal is to model some
properties so that we can safely recycle the labels output by CRF predicates. In CRFlex, we
identify such a property of CRF predicates: CRF context. Like mention contexts, the CRF context
of a token xi specifies windows surrounding xi, such that, given these windows, the tokens outside

71
1 2 3 4 5 6 7 8
L1
L2
L3
Figure 4.3 An illustration of right contexts.
1 2 3 4 5 6 7 8
L1
L2
L3
Figure 4.4 An illustration of left contexts.
those windows are irrelevant to the label of xi. Unlike mention contexts, the CRF context of xi
also specifies the labels of certain tokens in those windows. We first introduce right context, which
specifies a window after a token. Then we introduce left context, which specifies both a window
before a token and the label of a certain token in that window. Finally, we introduce CRF context
based on right context and left context.
To motivate right contexts, we observe that the tokens that are far away after a token xi have
little influence on xi’s label, as illustrated by the following example:
Example 4.4. Figure 4.3 illustrates the path matrix G of an eight-token sequence and three possible
labels L1, L2, and L3. Notice that G(L1, 1) can reach all cells in column 3 by following the
highlighted paths between column 1 and 3. Since the best labeling path must contain one of those
3 cells in column 3, no matter what follows the third token, the best labeling path must contain
G(L1, 1). Therefore, L1 is the best label of x1 no matter how we perturb the tokens after x3. We
call token sequence x2...x3 the right context of x1. Similarly, we can find the right context for each
token in the token sequence. As another example, Figure 4.3 illustrates that G(L3, 4) can reach all
cells in column 6 by following the highlighted paths between column 4 and 6. Therefore, the right
context of x4 is x5...x6.
Let x = x1...xT be a token sequence, xi be a token in x, and y be the label of xi produced by
applying a CRF predicate F to x. Furthermore, let G denote the path matrix output by F on x.
Then we formalize the notion of right context as follows:
Definition 4.2 (Right context). The right context of a token xi is the token sequence xi+1...xi+ν ,
i.e., the consecutive ν tokens after xi in x, such that i + ν is the first column of G where all cells
can be reached by G(y, i) through the paths stored in G.

72
The nice property of right context is that the tokens outside the right context of xi are irrelevant
to the label of xi. That is, for any token sequence x′ obtained by perturbing the tokens of x after
the right context of xi, applying F to x′ still produces the same label y of xi.
To motivate left contexts, we observe that the tokens that are far away before a token also
have little influence on its label. In particular, we observe that if a cell G(y, i) can reach all cells
in some column j of G, then no matter how we perturb the tokens of x before xi, under certain
conditions, all labels of tokens after xj remain the same. We formulate this observation in the
following lemma.
Lemma 4.1. Let xj be the first token after xi such that all cells in column j of G can be reached
by G(y, i). Let x′ be any token sequence obtained by perturbing tokens of x before xi. Let G ′ be
the path matrix output by F over x′. Suppose the positions of xi and xj become i′ and j′ in x′. If
G ′(y, i′) can reach all cells in column j′ of G ′, then the labels of tokens after xj in x remain the
same.
Proof. Let W (u, v, a, b) denote the max score of a sequence starting at position a with label u and
ending at position b with label v. Let V denote the score matrix computed by F over x. Then it is
easy to show that, given that G(y, i) can reach any cell in and after column j of G, for any k ≥ j
and any y′ ∈ Y , V (y′, k) = V (y, i) + W (y, y′, i, k).
Let V ′ denote the score matrix computed by F over x′. In the similar way, we can show
that V ′(y′, k′) = V ′(y, i′) + W (y, y′, i′, k′), where i′ and k′ are the positions of xi and xk in x′
respectively.
We can also show that W (u, v, a, b) and the path traced by it remain the same no matter how
we perturb tokens outside token sequence xa...xb. Therefore, W (y, y′, i, k) = W (y, y′, i′, k′) and
the paths traced by them are exactly the same.
Hence, V ′(y′, k′)−V (y′, k) = V ′(y, i)−V (y, i′) = δ. This indicates the V scores of the tokens
after xj are only increased by a constant δ. Therefore, the ranking of scores of different labels for
the same token remains the same. Therefore, the best label for the last token xT remains the same.
Furthermore, the paths traced by V (y′, k) and V ′(y′, k′) after xi are exactly the same path as
the path traced by W (y′, y, i, k), and thus contain the same edges. Since the best label of the last

73
token xT remains the same and all the paths between xj and xT remain the same, the best labeling
path also remains the same at and after xj . Hence, the labels of all tokens after xj (including the
label of xj) remain the same.
We can now define the left context of a token xi as follows:
Definition 4.3 (Left context). The left context of a token xi is the token sequence xi−µ...xi−1 and
the label λ of xi−µ, such that G(λ, i − µ) can reach all cells in column i through the paths in G,
and no cell in a column after i− µ can reach all cells in column i. We represent the left context as
a tuple (xi−µ...xi−1, λ). Furthermore, we call xi−µ...xi−1 the left context window of xi.
By Lemma 4.1, we can show that for any token sequence x′ obtained by perturbing the tokens
of x before the left context window xi−µ...xi−1 of xi, as long as the cell of the path matrix for label
λ and token xi−µ can still reach all cells for xi, applying F to x′ still produces the same label y of
xi.
Example 4.5. Figure 4.4 illustrates the same path matrix as the one illustrated in Figure 4.3.
Notice that G(L1, 2) can reach all cells in column 4 by following the highlighted paths between
column 2 and 4. Therefore, the left context of x4 is x2...x3 and label L1. Let x′ be a token sequence
resulted from perturbing the tokens of x before x2, and G ′ be the path matrix created by F over x′.
Then if the cell of G ′ for label L1 and token x2 can still reach all cells for token x4, the label of x4
remains the same.
We now define CRF context. Intuitively, the CRF context of a token xi consists of its left
context and its right context. Formally:
Definition 4.4 (CRF context). The CRF context of a token xi is the token sequence xi−µ...xi+ν
and the label λ of xi−µ, such that xi−µ...xi−1 is its left context window and xi+1...xi+ν is the right
context window. We represent the CRF context as a tuple (xi−µ...xi+ν , λ).
The nice property of CRF context is that no matter how we perturb the tokens of x outside
xi−µ...xi+ν , as long as the label λ of xi−µ can still reach all possible labels of xi, applying F to the
perturbed token sequence still produces the same label y of xi.

74
Example 4.6. From Example 4.4 and Example 4.5, we know that the left context of x4 is (x2...x3, L1)
and the right context is x5...x6. Therefore, the CRF context of x4 is (x2...x6, L1).
4.3 Capturing CRF IE Results
In this section, we discuss what results to capture for a CRF-based IE program P and how to
capture them while running P on the current snapshot Pn.
Like Delex, CRFlex captures both input tuples and output tuples for each non-CRF IE pred-
icate in P . Additionally, CRFlex also captures results for each CRF predicate. We first discuss
what results to capture for a CRF predicate F , and then discuss how to capture and store them.
Capturing IE Results: In order to reuse the results of F safely, we need to capture: (a) the token
sequences F has operated over, (b) the CRF contexts of tokens in these token sequences, and (c)
labels output by F .
We can capture the token sequences and the labels from the input and output tuples of F .
Capturing the CRF contexts raises a challenge since F does not output CRF contexts directly. Our
solution is to exploit the path matrices output by F and infer the CRF contexts from the paths
stored in these matrices. We now describe this solution in detail.
Given the path matrix G output by F over a token sequence x, we scan G once and identify the
CRF contexts of all tokens in x.
The key step in identifying the CRF contexts is to identify a cell in each column i of G that
can reach all cells in a column after i. To do so, we use a matrix R of the same size of G to keep
track of the reachability of each cell of G. Initially, R is empty. Then we update R as we scan
G column by column. When we scan column j of G, each cell R(y, i) is either empty or stores a
label y′ if G(y′, i) can reach G(y, j) by following the paths stored in G. If all cells in column i of R
contain the same label y′, this indicates G(y′, i) can reach all cells in column j of G. The concrete
algorithm is as follows:
1. Initialize R: Initially, each cell of R is empty.

75
2. Scan Column 1 of G and Update R: Since no edge points to any cell in column 1 of G, we
set R(y, 1) = y for each y ∈ Y , indicating G(y, 1) can reach itself.
3. Scan Column 2 of G and Update R: We first make a copy R′ of R. Then we scan column
2 of G. For each cell G(y, 2) in column 2, if there is an edge from G(y′, 1) to G(y, 2), then we set
R(y, 1) = R′(y′, 1). This indicates that G(R(y, 1), 1) can reach G(y, 2). Finally, we set R(y, 2) = y
for each possible label y ∈ Y .
4. Check R to Identify Left and Right Contexts: Now we check if all cells in any column
before column 2 of R store the same label. In this case, there is only one column before 2, which
is column 1. So if all cells in column 1 of R contain the same label y, this indicates G(y, 1) can
reach all cells in column 2. Hence we identify x2 as the right context of x1. Furthermore, x1 and
its label y form the left context of x2.
5. Scan the Rest of the Columns of G and Update R Similarly: We repeat step 3-4 for the rest
of the columns of G. In general, before we begin to scan a column j, we first make a copy R′ of
R. Then while we are scanning column j, if there is an edge from G(y′, j − 1) to G(y, j), then we
set R(y, k) = R′(y′, k) for each k < j. Next, we set R(y, j) = y for each possible label y ∈ Y .
Finally, we check if there is any column k of R such that all cells in column k store the same label
y. If so, xk+1...xj is the right context of xk. Furthermore, xk...xj−1 and y forms the left context of
xj . After we finish scanning G, we can combine the left contexts and the right contexts to find the
CRF contexts.
Example 4.7. Figure 4.5 illustrates an example of capturing CRF contexts. The matrix in the
first row is the path matrix over token sequence x1...x5 with 3 possible labels L1, L2, and L3.
The matrices in the second and third row are the reachability matrices when we scan column 1 to
column 5 of the path matrix respectively. First, we scan the first column of the path matrix and set
the reachability matrix to R1. Then we scan the second column of the path matrix and update the
reachability matrix. This results in matrix R2. After we scan the third column of the path matrix
and update the reachability matrix, all cells in the first column of the reachability matrix contain
the same label L1. This indicates that the right context of x1 is x2...x3, and the left context of x3 is

76
1 2 3 4 5
L1
L2
L3
L1
L2
L3
L1
L2
L3R1
L1 L1
L1 L2
L3 L3R2
L1 L1 L1
L1 L2 L2
L1 L1 L3
R3x1’s right context = x2 ...x3x3’s left context = (x1 ...x2, L1)
L1 L1 L1 L1
L1 L1 L3 L2
L1 L1 L3 L3
L1 L1 L1 L1 L1
L1 L1 L3 L3 L2
L3 L1 L3 L3 L3R5
L1
L2
L3
x2’s right context = x3...x4x4’s left context = (x2 ...x3,L1)
R4
Figure 4.5 An illustration of capturing CRF contexts from a path matrix.
x1...x2 and L1, which is the label of x1. Then we cover the rest of the columns in the path matrix
similarly.
Capturing CRF contexts incurs overhead of O(TD|Y|) in time and O(T |Y|) in memory space,
where T is the length of x and D is the length of the longest right context. In our experiments, we
found that D is generally 2-3 tokens.
Storing the Captured IE Results: We now discuss how to discover and capture the above results
while running F over Pn.
Our goal is to generate three files at the end of the run on Pn: InF that stores the input token
sequences to F , OnF that stores the labels output by F , and Cn
F that scores all CRF contexts.
Formally, we can write each CRF predicate F : (did, s, e, x, S) → (y,G), where
• did is the ID of a document d,
• s and e are the start and end positions of a text span t in d,
• x is the token sequence contained in t,
• S is the initialization score vector,

77
• y is the resulting label sequence, and
• G is the resulting path matrix..
Then for each input tuple (did, s, e, x, S), we append a tuple (tid, did, s, e, p) to InF , where
• tid is the tuple ID unique in InF , and
• p is a sequence of tuples (si, ei), where si and ei are the start and end positions of xi in d
respectively.
For each output tuple (y,G), we append a set of tuples {(otid, itid, i, y)} to OnF and a set of
tuples {(ctid, itid, i, µ, ν)} to CnF , where
• otid is the tuple ID unique in OnF ,
• ctid is the tuple ID unique in CnF ,
• itid is the ID of the input tuple that results in the output tuple (y,G),
• i is the position of token xi in x,
• y is the label of xi, and
• µ and ν are the lengths of the left and right context window of xi respectively.
The overall process is the same as in Delex: we process pages in Pn, append the results gener-
ated from each page to the three files, and store these files I/O efficiently on disk while executing
F . Pleaser refer to Chapter 3 for a detailed discussion.
4.4 Reusing Captured Results
We now describe how to use the captured results to speed up executing P over snapshot Pn+1.
The overall processing algorithm is the same as the one used in Delex, which we summarize
as follows. Please refer to Section 3.3.2 for a detailed discussion. We assume that we match each
page p ∈ Pn+1 with pages in Pn, to find overlapping regions, from which we can reuse previous
IE results. To reuse, we need Pn+1, Pn and all intermediate IE results we captured over Pn. These
intermediate IE results are stored in various reuse files (Section 4.3 and Section 3.2). To ensure
sequential access to these results during reuse, the IE results in each reuse file are stored in the same

78
order. Particularly, let q1, q2, . . . , qk be the order in which we processed pages in Pn. Then in each
reuse file, we stored all tuples on page q1 first, then all tuples on page q2, and so on. Consequently,
we will process pages in Pn+1 following the same order. That is, let pi be the page with the same
URL as qi, i = 1, . . . , k. Then we process p1, then p2, and so on. When we execute P over a page
p1, we execute the predicates of P in a bottom-up fashion of the execution plan tree (Section 3.1).
Please refer to Section 3.3.3 for a detailed discussion on how to execute a non-CRF-based IE
predicate. In what follows, we discuss how to execute the CRF predicates.
Suppose we are going to execute a CRF predicate F on a particular page p (in snapshot Pn+1),
whose previous version is q (in snapshot Pn). We first read in InF (q), On
F (q) and CnF (q) from the
corresponding reuse files InF , On
F and CnF . Then we execute F in three steps as follows:
1. Match Input Sequences: We start with In+1F (p), the set of input tuples to F . Each input tuple
(tid, did, s, e, p) ∈ In+1F (p) represents a text region [s, e] of page p that contains token sequence x
(whose positions are encoded by p). Then, we consult InF (q), which contains the input tuples to F
when it executed on q. This set is read in from the reuse file InF as discussed above. Each tuple in
InF (q) has the form (tid′, did′, s′, e′, p′), where did′ is the ID of q, and p′ records the positions of
tokens in x′ (contained in region [s′, e′] of q), to which we applied F .
Our goal is to find matching token sequences between x and x′. We call such matching token
sequences matching regions, in a similar way as we defined in Delex and Cyclex.
There are two ways to find matching regions between x and x′. One way is to match region
p[s, e] of p with region q[s′, e′] of q. The matching is done using one of the matchers employed
by Delex (Section 3.3.4). Then we join the resulting matching regions with p and p′ to identify
matching token sequences. Another way is to match the sequence x directly with sequence x′ of q.
We call this matching algorithm a token matcher. As we have shown in Cyclex and Delex, none
of these matchers is always optimal. So CRFlex considers all matchers employed by Delex and
the token matcher. Then it uses a cost model to select matchers, as Delex does. Please refer to
Section 3.4 for how to select a matcher.
We repeat the matching step for each input tuple in In+1F (p) to find its matching regions. For
each matching region between x on p and x′ on q, we store in memory a tuple (tid, tid′, s, s′, l),

79
where tid and tid′ are the tuple IDs of the tuples that encodes x and x′ respectively, s and s′ are the
start positions of the matching regions in x and x′, respectively, and l is the length of the matching
region. We store these tuples in buffer Rn+1F (p).
2. Apply F & Identify Copy Regions: Given the set of matching regions, we then identify copy
regions and apply F to find the labels of extraction regions, which are regions that are not copy
regions.
To identify copy regions, we must check the CRF context of each token in the matching region.
Given that token x in x on page p matches token x′ in x′ on page q, we must check if the CRF
context of x is the same as the CRF context of x′. Recall that the CRF context of x′ also includes
the label of the first token in the left context window of x′ (see Section 4.2). This implies that
we must check if that token’s match in x also has the same label. This suggests that we must first
re-apply F to x to output the labels of some tokens. Then we can check the CRF contexts of tokens
in the matching regions and determine the copy regions. We proceed in the following steps:
• a. Determine the First Extraction Region: Let r be the first matching region in x, and r′ be r’s
match in x′. We consult CnF (q) to locate the first token x′i in x′ such that its left context window
x′i−µ...x′i−1 is totally contained in r′. Let xj be the match of x′i. Then the first extraction region is
x1...xj .
• b. Apply F to the Extraction Region: We apply F to token sequence x1...xj with score vector
S, where all elements of S are set to 0.
• c. Output the Labels and Identify the CRF Contexts: From the path matrix G output in step b.,
we apply the same approach described in Section 4.3 to identify the left and right contexts of tokens
in the extraction region x1...xj . Let xk be the last token with its right context window xk+1...xk+ν
totally contained in the extraction region. Then we can output the labels of x1...xk. Furthermore,
we check if the left context of xj is the same as the left context of x′i. If so, we go to step d. to
determine the copy region. Otherwise, we go to step e. to continue applying F .
• d. Determine the First Copy Region: We first locate the last token x′g in x′ such that its right
context window x′g+1...x′g+ν′ is totally contained in region r′. Let xh be the match of x′g in x. Then
xj...xh is the first copy region. We output a tuple (tid, tid′, s, s′, l) that encodes this copy region,

80
where tid and tid′ are the tuple IDs of the input tuples that encode x and x′ respectively, s and s′
are the start positions of the copy region in x and x′, respectively, and l is the length of the copy
region. We then go to step g.
• f. Continue Applying F After an Extraction Region: Let xk be the last token whose right
context is contained in the last extraction region. Let y be its label. We then use the same approach
described in step a. to determine the end of the next extraction region. Let this extraction region
be xk+1...xl. We apply F to xk+1...xl with score vector S, where S is set such that except for the
score of label y, the initial scores of all other labels are 0. In this way, we enforce F to start with
label y for the next extraction region. Then we go to step d. and continue.
• g. Apply F After a Copy Region: Suppose we have found a copy region xj...xh. We then follow
the similar approach in step f. to determine the next extraction region. The only difference here is
that the extraction region starts at xh+1, and initial score vector S is set such that, except for the
label of xh, all other labels’ scores are 0.
• e. Cover the Rest of x: We repeat step a. to g. for the rest of the token sequence.
3. Copy Labels and CRF Contexts: We now have obtained a set of copy regions and labels
of non-copy regions. In the last step, we copy the labels and CRF contexts of the tokens in the
copy regions. Specifically, for each tuple (tid, tid′, s, s′, l) that encodes a copy region, we consult
OnV (q) to find the joining output tuples (with the same tid′), and consult Cn
V (q) to find joining
CRF contexts (with the same tid′). This step is similar to the copy step of Delex. Please refer to
Section 3.3.3 for a detailed discussion.
We conclude this section by showing the correctness of CRFlex.
Theorem 4.1 (Correctness of CRFlex). Let Mn+1 be the set of mentions obtained by applying a
CRF-based IE program P from scratch to snapshot Pn+1. Then CRFlex is correct in that when
applied to Pn+1 it produces exactly Mn+1.
Proof. Let F be a CRF-based IE blackbox in P and OFn+1 be the output of F produced by re-
applying F from scratch to Pn+1. In the similar way we have shown in Cyclex, we can show that
CRFlex produces exactly OFn+1 for F when it is applied to Pn+1. Therefore, CRFlex produces the

81
35M180MAvg Size per Snapshot
303810155Avg # Page per Snapshot
1515# Snapshots
21 days2 daysTime Interval
925980# Data Sources
WikipediaDBLifeData Sets
Figure 4.6 Data sets for our experiments.
correct output for each CRF-based IE blackbox. Since CRFlex and Delex behave in the same way
for all non-CRF-based blackboxes, CRFlex produces the correct output for each non-CRF-based
blackbox as Delex does. Hence, CRFlex produces exactly Mn+1.
4.5 Putting It All Together
We now describe the end-to-end CRFlex solution. Given a CRF-based IE programP written in
xlog, we first employ the techniques described in [67] to translate and optimize P into an execution
tree T , and then pass T to CRFlex.
Given a corpus snapshot Pn+1, CRFlex first employs the optimization technique described in
Section 3.4 to assign matchers to the IE predicates, including the CRF predicates. Next, CRFlex
executes the so-augmented tree T on Pn+1, employing the reuse algorithm described in Section 4.4
and the reuse files it produced for snapshot Pn. During execution, it captures and stores intermedi-
ate IE results (for reuse in the subsequent snapshot Pn+2), as described in Section 4.3.
4.6 Empirical Evaluation
We now empirically evaluate the utility of CRFlex. Figure 4.6 describes two real-world data
sets used in our experiments. DBLife consists of 15 snapshots from the DBLife system [31], and
Wikipedia consists of 15 snapshots from Wikipedia.com.
We experimented with an open source real-world CRF-based IE program, the Stanford CRF-
based Name Entity Recognizer (NER) [38]. Given a document, NER labels sequences of tokens
in a document as the names of PERSON, ORGANIZATION, or LOCATION entities. The CRF

82
stanfordNER(d, token, entityType) :- docs(d), stanfordNERTokenize(d,x),
applyCRFs(d,x,y), outputLabels(x,y,token,entityType)
(a)
docs(d)
applyCRFs(d,x,y)
stanfordNERTokenize(d,x)
outputLabels(x,y,token,entityType)
(b)
Figure 4.7 Stanford NER in xlog.
model employed by NER uses a variety of feature functions, such as the prefixes and suffixes of
a token, as well as conjunctions of these feature functions. To apply Delex and CRFlex to NER,
we first converted NER into an xlog program. The resulting program and its execution plan are
illustrated in Figure 4.7. Given a document d, stanfordNERTokenize converts d into a sequence
x of tokens. Then applyCRFs takes d and x as input, employs a CRF model to label x, and outputs
the label sequence y. We analyzed the program and set α and β of the entire IE program and all IE
blackboxes. In particular, we set αstanfordNERTokenize to 25 characters, and βstanfordNERTokenize
to 2 characters. αapplyCRFs, βapplyCRFs, and the α, β of the entire IE program are all set to the
maximal length of the entire document.
Runtime Comparison: Figure 4.8 shows the runtime of CRFlex vs. that of other possible
baseline solutions over all consecutive snapshots. We consider three baselines: No-reuse, Cyclex,
and Delex. No-reuse re-executes NER over all pages in a snapshot; Cyclex treats the whole NER
program as a single IE blackbox for reuse; and Delex is aware of the blackboxes in the IE program,
but not aware that the blackbox applyCRFs is based on CRFs.
Figure 4.8 shows that, in all cases, No-reuse (i.e., rerunning IE from scratch) incurs large
runtimes, while Cyclex and Delex shows mixed performance. On DBLife, where 96-98% of
pages remain identical on consecutive snapshots, they perform far better than No-reuse. But on
Wikipedia, where many pages tend to change (only 8-20% pages remain identical on consecutive
snapshots), they perform only slightly better than No-reuse.

83
DBLife
0
275
550
825
1100
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15snapshot
runtime (s)
No-reuse Cyclex Delex CRFlex
Wikipedia
0
175
350
525
700
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15snapshot
runtime(s)
Figure 4.8 Runtime of No-reuse, Cyclex, Delex, and CRFlex.
CRFlex, however, performs comparably or significantly better than all of the above solutions.
On DBLife, where most of the pages remain identical, CRFlex performs as well as Cyclex and
Delex. On Wikipedia, where many pages tend to change, CRFlex significantly outperforms the
other three solutions, cutting runtime by nearly 52%. These results suggest that CRFlex is able
to exploit the properties of CRFs to enable more reuse, thereby significantly speeding up program
execution.
Contributions of Components: Figure 4.9 shows the runtime decomposition of the above solu-
tions (numbers in the figure are averaged over five random snapshots on each data set). “Match”
is the total time of applying all matchers in the execution tree. “CRFs” is the total time to apply
CRF-based IE blackboxes. “Non-CRFs” is the total time to apply all non-CRF-based IE black-
boxes. “Copy” is the total time to copy results. “Opt” is the optimization time of Cyclex, Delex,
and CRFlex. Finally, “Others” is the remaining time (to apply relational operators, read file in-
dices, etc.).
The results show that matching and extracting dominate runtimes. In particular, 67-90% of
overall runtime is for CRF-based IE in all 4 solutions. Hence, we should focus on optimizing
these components, as we do in CRFlex. Furthermore, CRFlex spends more time on matching
and copying than Cyclex and Delex on Wikipedia, where pages change frequently. However, this

84
DBLife
0
200
400
600
800
1000
No-reuse Cyclex Delex CRFlex
runtime (s) Wikipedia
0
100
200
300
400
500
No-reuse Cyclex Delex CRFlex
runtime (s)
Match CRFs Non-CRFs Copy Opt Others
Figure 4.9 Runtime decomposition of No-reuse, Cyclex, Delex, and CRFlex.
effort clearly pays off (e.g., reducing the extraction time of No-reuse, Cyclex, and Delex by 47-
52%). Finally, the results show CRFlex incurs insignificant overhead (optimization, copying, etc.)
compared to its overall runtime.
4.7 Summary
A growing number of real-world applications involve IE over evolving text corpora. Recent
work on Cyclex and Delex has shown that executing such IE in a straightforward manner is very
expensive, and that recycling past IE results can lead to significant performance improvements.
Cyclex and Delex, however, are limited in that they are not aware that some IE blackboxes are
based on statistical learning models. However, learning-based IE programs have been successfully
applied to many real-world applications.
To address the above problem, we have developed CRFlex, a solution for efficiently executing
IE programs based on CRFs, a state-of-the-art learning model. As far as we know, CRFlex is the
first in-depth solution for this important problem. Our experiments over real-world datasets and
a CRF-based IE program show that CRFlex cuts the runtime of Delex by as much as 52%. This
suggests that exploiting the properties of CRFs can be highly beneficial.

85
Chapter 5
Related Work
Information Extraction: The problem of information extraction has received much attention
(see [22, 3, 33, 18] for recent tutorials). Numerous rule-based extractors (e.g., those relying on
regular expressions or dictionaries [30, 62, 46, 52, 69]) and learning-based extractors (e.g., those
employing CRFs, SVMs, and Mokov Networks [72, 26, 14, 12, 2, 76, 65, 10]) have been devel-
oped. Our work can handle both types of extractors.
Much work has tried to improve the accuracy and runtime of these extractors [35, 63]. But
recent work has also considered how to combine and manage such extractors in large-scale IE
applications [3, 33, 1]. Our work fits into this emerging direction.
Once we have extracted entity mentions, we can perform additional analysis, such as mention
disambiguation (a.k.a. record linkage, e.g., [5, 8, 23, 25, 55, 64, 74, 43]). Thus, such analysis is
higher level and orthogonal to our current work.
While we have focused on IE over unstructured text, our work is related to wrapper construc-
tion, the problem of inferring a set of rules (encoded as a wrapper) to extract information from
template-based Web pages [24]. Since wrappers can be viewed as extractors (as defined in Chapter
2), our techniques can potentially also apply to wrapper contexts. In this context, the knowledge
of page templates may help us develop even more efficient IE algorithms.
Finally, optimizing IE programs and developing IE-centric cost models have also been consid-
ered in several recent papers [67, 50, 42, 4]. These efforts however have considered only static
corpus contexts, not dynamic ones as we do in this dissertation.

86
Evolving Text: Several recent works have also considered evolving text data, but in different
problem contexts. The work [47, 57, 56] considers how to repair a wrapper (so that it continues
to extract semantically correct data) as the underlying page templates change, the work [29] con-
siders how to build robust wrappers over evolving text, the work [77] considers how to efficiently
recrawl evolving text to improve the freshness of extracted data, and the work [48] considers how
to incrementally update an inverted index, as the indexed Web pages change.
Recent work [78, 41] has also exploited overlapping text data, but again in different problem
contexts. These works observe that document collections often contain overlapping text. They then
consider how to exploit such overlap to “compress” the inverted indexes over these documents,
and how to answer queries efficiently over such compressed indexes. In contrast, we exploit the IE
results over the overlapping text regions to reduce the overall extraction time.
Detecting Matching Regions: The problem of finding matching text regions is related to detecting
duplicated Web pages. Many algorithms have been developed in this area (e.g., [36, 68, 11]).
But when applied to our context they do not guarantee to find all largest possible overlapping
regions, in contrast to the suffix-tree based algorithm developed in this work. Several suffix tree
algorithms have been widely used to find matching substrings in a given input string [40]. Here we
have significantly extended these algorithms, to develop one that can efficiently detect all maximal
matching regions (i.e., substrings) between two given strings, in time linear in the total length of
these two strings.
CRFs: CRF-based IE has received much attention recently. Most works [44, 21, 53, 66, 71, 54,
59, 27, 45, 49] have considered how to improve extraction accuracy of CRF-based IE programs.
Recent work [73] has considered how to implement CRF-based IE programs over RDBMS, and
then exploit RDBMS to improve extraction time. However, this work has only considered static
text corpora, not evolving text corpora as we do.
View Maintenance: Our work is also related to incremental view maintenance [39, 79, 9, 75]
– namely, if changes to the input of a dataflow program are small, then incrementally computing
changes to the result can be more efficient than recomputing the dataflow from scratch. But the
works differ in many important ways. First, our inputs are text documents instead of tables. Most

87
work on view maintenance assumes that changes to the inputs (base tables) are readily available
(e.g., from database logs), while we also face the challenge of how to characterize and efficiently
detect portions of the input texts that remain unchanged. Most importantly, view maintenance only
needs to consider a handful of standard operators with well-defined semantics. In contrast, we
must deal with arbitrary IE blackboxes.

88
Chapter 6
Conclusions
Evolving text is pervasive, and there are many applications that consider IE over evolving
text. The current solution is to re-apply IE programs to each corpus snapshot from scratch and in
isolation. This approach is inefficient and has limited applicability. To this end, this dissertation
has developed a set of solutions that execute IE programs over evolving text efficiently. In this
chapter, we summarize the key contributions of the dissertation and discuss directions for future
research.
6.1 Contributions
We have made the following contributions:
• The most important contribution of this dissertation is a framework that provides efficient
solutions for IE over evolving text. In particular, the framework advocates the idea of recy-
cling the IE results over previous corpus snapshots. As far as we know, this dissertation is
the first in-depth solution to the problem of IE over evolving text.
• We show how to model common properties of general IE blackboxes and CRF-based IE
blackboxes, and how to exploit these properties for safely reusing previous IE results.
• We show that a natural tradeoff exists in finding overlapping text regions from which we can
recycle past IE results. An approach to finding overlapping regions is called a matcher. We
show that an entire spectrum of matchers exists, with matchers trading off the completeness
of the results for runtime efficiency. Since no matcher is always optimal, our solutions

89
provide a set of alternative matchers (more can be added easily), and employ a cost model to
make an informed decision in selecting a good matcher.
• Our approaches can deal with large text corpora by exploiting many database techniques,
such as cost-based optimization and hash joins.
• Our approaches can deal with complex IE programs that consist of multiple IE blackboxes
by exploiting the compositional nature of these IE programs. We show how to model these
complex IE programs for recycling, how to implement the recycling process efficiently, and
how to find a good execution plan in a vast plan space with different recycling alternatives.
• We have developed a powerful suffix-tree-based matcher that detects all overlapping regions
between two documents. This matcher can be exploited by many other applications that need
to compare two documents.
6.2 Future Directions
Handling More General Matching Schemes: To recycle IE results, we must match each page
in the current snapshot with pages in the past snapshots to find overlapping regions. Many such
matching schemes exist. Currently, we match each page p in snapshot Pn+1 only with the page
q in snapshot Pn at the same URL as p. However, in some cases, it is desirable to match p with
other pages as well. For example, bloggers and online news editors often quote other articles on a
particular subject, and then make their own comments about the subject. Therefore, news and blog
articles, of different URLs or even from different Web sites, often contain overlapping regions. In
this case, if we allow matching pages across URLs (e.g., matching within the same Web sites or
matching over all pages of all previous snapshots), we can find more overlapping regions, and thus
save more IE efforts. The key challenge is how to match pages across URLs efficiently and how to
access IE results of all previous snapshots efficiently for reuse.
Maintaining the Quality of IE Programs over Evolving Text: In this dissertation, we have
considered the problem of how to execute the same IE programs repeatedly over evolving text.

90
However, due to the heterogeneous nature of unstructured text, IE programs themselves also need
to evolve continuously over time to adapt to the changes in the incoming text. For instance, when
documents in newer formats come, IE programs need to incorporate new parsers accordingly.
Hence, IE systems must constantly monitor the source text, and detect and deal with any possible
changes. Manually monitoring, detecting, and adapting is very expensive and not scalable. The
key challenge here is to develop techniques to automatically monitor and adapt IE programs.
Optimizing Information Integration over Evolving Text: Another direction is to optimize the
runtime of programs that consist of not only IE but also Information Integration (II) blackboxes
over evolving text. Many applications require II together with IE. For example, II can be used to
decide if two extracted text fragments “UW-Madison” and “University of Wisconsin, Madison”
refer to the same entity. To optimize the total runtime of those programs, ideally we should op-
timize the runtime of II as well as that of IE. The key challenge is to identify the properties of II
blackboxes that we can exploit for efficient and correct reuse.

91
LIST OF REFERENCES
[1] http://langrid.nict.go.jp.
[2] Eugene Agichtein and Venkatesh Ganti. Mining reference tables for automatic text seg-mentation. In KDD ’04: Proceedings of the 10th International Conference on KnowledgeDiscovery and Data Mining, pages 20–29, 2004.
[3] Eugene Agichtein and Sunita Sarawagi. Scalable information extraction and integration (tu-torial). In KDD ’06: Proceedings of the 12th International Conference on Knowledge Dis-covery and Data Mining, 2006.
[4] Yevgeny (Eugene) Agichtein. Extracting relations from large text collections. PhD Thesis,2005. Adviser-Gravano, Luis.
[5] Rohit Ananthakrishna, Surajit Chaudhuri, and Venkatesh Ganti. Eliminating fuzzy duplicatesin data warehouses. In VLDB ’02: Proceedings of the 28th International Conference on VeryLarge Data Bases, pages 586–597, 2002.
[6] Nilesh Bansal, Fei Chiang, Nick Koudas, and Frank Wm. Tompa. BlogScope: a systemfor online analysis of high volume text streams. In VLDB ’07: Proceedings of the 33rdInternational Conference on Very Large Data Bases, 2007.
[7] B. Bhattacharjee, V. Ercegovac, J. Glider, R. Golding, G. Lohman, V. Markl, H. Pirahesh,J. Rao, R. Rees, F. Reiss, E. Shekita, and G. Swart. Impliance: a next generation informa-tion management appliance. In CIDR ’07: Proceedings of the 3rd Biennial Conference onInnovative Data Systems Research, pages 351–362, 2007.
[8] Mikhail Bilenko, Raymond Mooney, William Cohen, Pradeep Ravikumar, and StephenFienberg. Adaptive name matching in information integration. IEEE Intelligent Systems,18(5):16–23, 2003.
[9] Jose A. Blakeley, Per-Ake Larson, and Frank Wm Tompa. Efficiently updating materializedviews. SIGMOD Record, 15(2):61–71, 1986.
[10] Vinayak Borkar, Kaustubh Deshmukh, and Sunita Sarawagi. Automatic segmentation of textinto structured records. SIGMOD Record, 30(2):175–186, 2001.

92
[11] Andrei Z. Broder. Identifying and filtering near-duplicate documents. In COM ’00: Pro-ceedings of the 11th Annual Symposium on Combinatorial Pattern Matching, pages 1–10,2000.
[12] Razvan Bunescu and Raymond J. Mooney. Collective information extraction with relationalmarkov networks. In ACL ’04: Proceedings of the 42nd Annual Meeting on Association forComputational Linguistics, page 438, 2004.
[13] Yuhan Cai, Xin Luna Dong, Alon Halevy, Jing Michelle Liu, and Jayant Madhavan. Per-sonal information management with SEMEX. In SIGMOD ’05: Proceedings of the 31stInternational Conference on Management of Data, pages 921–923, 2005.
[14] Mary Elaine Califf and Raymond J. Mooney. Relational learning of pattern-match rules forinformation extraction. In AAAI ’99/IAAI ’99: Proceedings of the 16th National Confer-ence on Artificial Intelligence and the 11th Innovative Applications of Artificial IntelligenceConference, pages 328–334, 1999.
[15] Amit Chandel, P. C. Nagesh, and Sunita Sarawagi. Efficient batch top-k search for dictionary-based entity recognition. In ICDE ’06: Proceedings of the 22nd International Conference onData Engineering, pages 28–38, 2006.
[16] Fei Chen, AnHai Doan, Jun Yang, and Raghu Ramakrishnan. Efficient information extractionover evolving text data. In ICDE ’08: Proceedings of the 24th International Conference onData Engineering, pages 943–952, 2008.
[17] Fei Chen, Byron J. Gao, AnHai Doan, Jun Yang, and Raghu Ramakrishnan. Optimizingcomplex extraction programs over evolving text data. In SIGMOD ’09: Proceedings of the35th International Conference on Management of Data, pages 321–334, 2009.
[18] Laura Chiticariu, Yunyao Li, Sriram Raghavan, and Frederick R. Reiss. Enterprise informa-tion extraction: recent developments and open challenges (tutorial). In SIGMOD ’10: Pro-ceedings of the 36th International Conference on Management of Data, pages 1257–1258,2010.
[19] Junghoo Cho and Hector Garcia-Molina. Effective page refresh policies for web crawlers.ACM Transaction on Database Systems, 28(4), 2003.
[20] Junghoo Cho and Sridhar Rajagopalan. A fast regular expression indexing engine. In ICDE’02: Proceedings of the 18th International Conference on Data Engineering, page 419, 2002.
[21] Yejin Choi, Claire Cardie, Ellen Riloff, and Siddharth Patwardhan. Identifying sources ofopinions with conditional random fields and extraction patterns. In HLT ’05: Proceedingsof the Conference on Human Language Technology and Empirical Methods in Natural Lan-guage Processing, pages 355–362, 2005.

93
[22] W. Cohen and A. McCallum. Information extraction from the World Wide Web (tutorial).In KDD ’03: Proceedings of the 9th International Conference on Knowledge Discovery andData Mining, 2003.
[23] William Cohen and Jacob Richman. Learning to match and cluster entity names. In SIGIR’01 Workshop on Mathematical/Formal Methods in Information Retrieval, 2001.
[24] William W. Cohen, Matthew Hurst, and Lee S. Jensen. A flexible learning system for wrap-ping tables and lists in HTML documents. In WWW ’02: Proceedings of the 11th Interna-tional Conference on World Wide Web, pages 232–241, 2002.
[25] William W. Cohen, Pradeep Ravikumar, and Stephen E. Fienberg. A comparison of stringdistance metrics for name-matching tasks. In IIWeb ’03: Proceedings of IJCAI-03 Workshopon Information Integration on the Web, pages 73–78, 2003.
[26] William W. Cohen and Sunita Sarawagi. Exploiting dictionaries in named entity extraction:combining semi-markov extraction processes and data integration methods. In KDD ’04:Proceedings of the 10th International Conference on Knowledge Discovery and Data Mining,pages 89–98, 2004.
[27] Michael Collins. Discriminative training methods for hidden markov models: theory and ex-periments with perceptron algorithms. In EMNLP ’02: Proceedings of the 2002 Conferenceon Empirical Methods in Natural Language Processing, pages 1–8, 2002.
[28] Hamish Cunningham, Diana Maynard, Kalina Bontcheva, and Valentin Tablan. GATE: anarchitecture for development of robust hlt applications. In ACL ’02: Proceedings of the 40thAnnual Meeting on Association for Computational Linguistics, pages 168–175, 2002.
[29] Nilesh N. Dalvi, Philip Bohannon, and Fei Sha. Robust web extraction: an approach basedon a probabilistic tree-edit model. In SIGMOD ’09: Proceedings of the 35th InternationalConference on Management of Data, pages 335–348, 2009.
[30] Pedro DeRose, Warren Shen, Fei Chen, AnHai Doan, and Raghu Ramakrishnan. Buildingstructured web community portals: a top-down, compositional, and incremental approach.In VLDB ’07: Proceedings of the 33rd International Conference on Very Large Data Bases,pages 399–410, 2007.
[31] Pedro DeRose, Warren Shen, Fei Chen, Yoonkyong Lee, Douglas Burdick, AnHai Doan,and Raghu Ramakrishnan. DBLife: a community information management platform forthe database research community (demo). In CIDR ’07: Proceedings of the 3rd BiennialConference on Innovative Data Systems Research, pages 169–172, 2007.
[32] AnHai Doan, Raghu Ramakrishnan, Fei Chen, Pedro DeRose, Yoonkyong Lee, Robert Mc-Cann, Mayssam Sayyadian, and Warren Shen. Community information management. IEEEData Engineering Bulletin, 29(1):64–72, 2006.

94
[33] AnHai Doan, Raghu Ramakrishnan, and Shivakumar Vaithyanathan. Managing informationextraction: state of the art and research directions (tutorial). In SIGMOD ’06: Proceedingsof the 32nd International Conference on Management of Data, pages 799–800, 2006.
[34] Jenny Edwards, Kevin McCurley, and John Tomlin. An adaptive model for optimizing per-formance of an incremental web crawler. In WWW ’01: Proceedings of the 10th InternationalConference on World Wide Web, pages 106–113, 2001.
[35] Oren Etzioni, Michael Cafarella, Doug Downey, Stanley Kok, Ana-Maria Popescu, TalShaked, Stephen Soderland, Daniel S. Weld, and Alexander Yates. Web-scale informationextraction in Knowitall (preliminary results). In WWW ’04: Proceedings of the 13th Interna-tional Conference on World Wide Web, pages 100–110, 2004.
[36] Min Fang, Narayanan Shivakumar, Hector Garcia-Molina, Rajeev Motwani, and Jeffrey D.Ullman. Computing iceberg queries efficiently. In VLDB ’98: Proceedings of the 24rdInternational Conference on Very Large Data Bases, 1998.
[37] D. Ferrucci and A. Lally. UIMA: an architectural approach to unstructured information pro-cessing in the corporate research envrionment. Natural Language Engineering, 10(3-4):327–348, 2004.
[38] Jenny Rose Finkel, Trond Grenager, and Christopher Manning. Incorporating non-local in-formation into information extraction systems by gibbs sampling. In ACL ’05: Proceedingsof 43rd Annual Meeting of the Association for Computational Linguistics, pages 290–294,1997.
[39] A. Gupta and I.S. Mumick. Materialized Views: Techniques, Implementations and Applica-tions. MIT Press, 1999.
[40] D. Gusfield. Algorithms on strings, trees, and sequences. Cambridge : Cambridge UniversityPress, 1997.
[41] Michael Herscovici, Ronny Lempel, and Sivan Yogev. Efficient indexing of versioned docu-ment sequences. In ECIR’07: Proceedings of the 29th European Conference on IR Research,pages 76–87, 2007.
[42] Alpa Jain, AnHai Doan, and Luis Gravano. SQL queries over unstructured text batabases.In ICDE ’07: Proceedings of the 23rd International Conference on Data Engineering, pages1255–1257, 2007.
[43] N. Koudas, S. Sarawagi, and D. Srivastava. Record linkage: similarity measures and algo-rithms (tutorial). In SIGMOD ’06: Proceedings of the 32nd International Conference onManagement of Data, 2006.

95
[44] Trausti Kristjansson, Aron Culotta, Paul Viola, and Andrew McCallum. Interactive informa-tion extraction with constrained conditional random fields. In AAAI ’04: Proceedings of the19th National Conference on Artifical Intelligence, pages 412–418, 2004.
[45] Taku Kudo, Kaoru Yamamoto, and Yuji Matsumoto. Applying conditional random fields tojapanese morphological analysis. In EMNLP ’04: Proceedings of the 2004 Conference onEmpirical Methods in Natural Language Processing, pages 230–237, 2004.
[46] W. Lehnert, J. McCarthy, S. Soderland, E. Riloff, C. Cardie, J. Peterson, F. Feng, C. Dolan,and S. Goldman. UMass/Hughes: description of the circus system used for tipster text. InProceedings of a workshop on held at Fredericksburg, Virginia, pages 241–256, 1993.
[47] Kristina Lerman, Steven N. Minton, and Craig A. Knoblock. Wrapper maintenance: a ma-chine learning approach. Journal of Artificial Intelligence Research, 18:2003, 2003.
[48] Lipyeow Lim, Min Wang, Sriram Padmanabhan, Jeffrey Scott Vitter, and Ramesh Agarwal.Dynamic maintenance of web indexes using landmarks. In WWW ’03: Proceedings of the12th International Conference on World Wide Web, pages 102–111, 2003.
[49] Yan Liu, Jaime Carbonell, Peter Weigele, and Vanathi Gopalakrishnan. Segmentation condi-tional random fields (SCRFs): a new approach for protein fold recognition. In RECOMB ’05:Proceeding of the 9th International Conference on Computer Biology, pages 14–18, 2005.
[50] Panagiotis G. lpeirotis, Eugene Agichtein, Pranay Jain, and Luis Gravano. To search or tocrawl? Towards a query optimizer for text-centric tasks. In SIGMOD ’06: Proceedings ofthe 32nd International Conference on Management of Data, pages 265–276, 2006.
[51] Michael Mathioudakis and Nick Koudas. TwitterMonitor: trend detection over the twitterstream. In SIGMOD ’10: Proceedings of the 36th International Conference on Managementof Data, pages 1155–1158, 2010.
[52] Diana Maynard, Valentin Tablan, Cristian Ursu, Hamish Cunningham, and Yorick Wilks.Named entity recognition from diverse text types. In Recent Advances in Natural LanguageProcessing 2001 Conference, Tzigov Chark, 2001.
[53] Andrew Mccallum and David Jensen. A note on the unification of information extraction anddata mining using conditional-probability, relational models. In IJCAI 03: Proceedings ofthe 18th International Joint Conference on Artificial Intelligence, 2003.
[54] Andrew McCallum and Wei Li. Early results for named entity recognition with conditionalrandom fields, feature induction and web-enhanced lexicons. In CoNLL ’03: Proceedings ofthe 7th Conference on Natural Language Learning, 2003.
[55] Andrew Mccallum and Ben Wellner. Toward conditional models of identity uncertainty withapplication to proper noun coreference. In NIPS ’03: Proceedings of the sixteenth Interna-tional Conference on Advances in Neural Information Processing Systems, pages 905–912,2003.

96
[56] Robert McCann, Bedoor K. AlShebli, Quoc Le, Hoa Nguyen, Long Vu, and AnHai Doan.Maveric: mapping maintenance for data integration systems. In VLDB ’05: Proceedings ofthe 31st International Conference on Very Large Data bases, pages 1018–1029, 2005.
[57] Xiaofeng Meng, Dongdong Hu, and Chen Li. Schema-guided wrapper maintenance for web-data extraction. In WIDM ’03: Proceedings of the 5th ACM International Workshop on WebInformation and Data Management, pages 1–8, 2003.
[58] Eugene W. Myers. An O(ND) difference algorithm and its variations. Algorithmica,1(1):251–256, 1986.
[59] Fuchun Peng, Fangfang Feng, and Andrew McCallum. Chinese segmentation and new worddetection using conditional random fields. In COLING ’04: Proceedings of the 20th Interna-tional Conference on Computational Linguistics, page 562, 2004.
[60] Fuchun Peng and Andrew McCallum. Accurate information extraction from research papersusing conditional random fields. In HLT-NAACL ’04: Proceedings of the Human LanguageTechnology Conference and North American Chapter of the Association for ComputationalLinguistics, 2004.
[61] David Pinto, Andrew McCallum, Xing Wei, and W. Bruce Croft. Table extraction usingconditional random fields. In SIGIR ’03: Proceedings of the 26th Annual International Con-ference on Research and Development in Informaion Retrieval, pages 235–242, 2003.
[62] Frederick Reiss, Sriram Raghavan, Rajasekar Krishnamurthy, Huaiyu Zhu, and Shivaku-mar Vaithyanathan. An algebraic approach to rule-based information extraction. In ICDE’08: Proceedings of the 24th International Conference on Data Engineering, pages 933–942,2008.
[63] Sunita Sarawagi. Information extraction. Foundations and Trends in Databases, 1(3):261–377, 2008.
[64] Sunita Sarawagi and Anuradha Bhamidipaty. Interactive deduplication using active learning.In KDD ’02: Proceedings of the 8th International Conference on Knowledge Discovery andData Mining, pages 269–278, 2002.
[65] Sandeepkumar Satpal and Sunita Sarawagi. Domain adaptation of conditional probabilitymodels via feature subsetting. In PKDD 2007: Proceedings of the 11th European conferenceon Principles and Practice of Knowledge Discovery in Databases, pages 224–235, 2007.
[66] Fei Sha and Fernando Pereira. Shallow parsing with conditional random fields. In NAACL’03: Proceedings of the 2003 Conference of the North American Chapter of the Associationfor Computational Linguistics, pages 134–141, 2003.

97
[67] Warren Shen, AnHai Doan, Jeffrey F. Naughton, and Raghu Ramakrishnan. Declarativeinformation extraction using datalog with embedded extraction predicates. In VLDB ’07:Proceedings of the 33rd International Conference on Very Large Data Bases, pages 1033–1044, 2007.
[68] N. Shivakumar and H. Garcia-Molina. SCAM: a copy detection mechanism for digital docu-ments. In DL ’95: Proceedings of the Second Annual Conference on the Theory and Practiceof Digital Libraries, 1995.
[69] Stephen Soderland. Learning information extraction rules for semi-structured and free text.Maching Learning, 34(1-3):233–272, 1999.
[70] Fabian M. Suchanek, Gjergji Kasneci, and Gerhard Weikum. YAGO: a core of semanticknowledge. In WWW ’07: Proceedings of the 16th international conference on World WideWeb, pages 697–706, 2007.
[71] Charles Sutton, Andrew McCallum, and Khashayar Rohanimanesh. Dynamic conditionalrandom fields: factorized probabilistic models for labeling and segmenting sequence data.Journal Machine Learning Research, 8:693–723, 2007.
[72] Koichi Takeuchi and Nigel Collier. Use of support vector machines in extended named en-tity recognition. In COLING ’02: Proceedings of the 6th Conference on Natural LanguageLearning, pages 1–7, 2002.
[73] Daisy Zhe Wang, Eirinaios Michelakis, Michael J. Franklin, Minos N. Garofalakis, andJoseph M. Hellerstein. Probabilistic declarative information extraction. In ICDE ’10: Pro-ceedings of the 26th International Conference on Data Engineering, pages 173–176, 2010.
[74] Ben Wellner, Andrew McCallum, Fuchun Peng, and Michael Hay. An integrated, conditionalmodel of information extraction and coreference with application to citation matching. InUAI ’04: Proceedings of the 20th Conference on Uncertainty in Artificial Intelligence, pages593–601, 2004.
[75] Jennifer Widom. Research problems in data warehousing. In CIKM ’95: Proceedings ofthe 4th International Conference on Information and Knowledge Management, pages 25–30,1995.
[76] Fei Wu and Daniel S. Weld. Autonomously semantifying wikipedia. In CIKM ’07: Pro-ceedings of the 16th International Conference on Information and Knowledge Management,pages 41–50, 2007.
[77] Mohan Yang, Haixun Wang, Lipyeow Lim, and Min Wang. Optimizing content freshness ofrelations extracted from the web using keyword search. In SIGMOD ’10: Proceedings of the36th International Conference on Management of Data, pages 819–830, 2010.

98
[78] Jiangong Zhang and Torsten Suel. Efficient search in large textual collections with redun-dancy. In WWW ’07: Proceedings of the 16th International Conference on World Wide Web,pages 411–420, 2007.
[79] Yue Zhuge, Hector Garcıa-Molina, Joachim Hammer, and Jennifer Widom. View mainte-nance in a warehousing environment. SIGMOD Record, 24(2):316–327, 1995.

99
Appendix A: xlog Programs for Delex Experiments
In this section, we show how to derive α and β of individual IE blackboxes and entire IE pro-
grams used in our experiments. This includes the three DBLife IE programs and three Wikipedia IE
programs listed in Figure 3.7.(b), and one learning-based IE program “actor”. Their xlog programs
are showed in Figure A.1 and Figure A.2.
talk: The IE program “talk” consists of 1 IE blackbox exTalk that takes input as a data page d,
a name pattern n and a topic pattern t. It then extracts mentions of talk relationship as follows.
First it detects speaker mentions by finding occurrences of n in d. Then it detects topic mentions
by finding occurrences of t in d. Next, it detects keywords such as “seminar”,“lecture”, and “talk”.
Finally, it pairs up a speaker mention and a topic mention if they span at most 155 characters, and
a detected keyword either immediately precedes or is contained in the text spanned by the mention
pair. Therefore, we set α to 155 and β to 9, the maximal length of a keyword.
chair: The IE program “chair” contains 3 IE blackboxes exPerson, exConference and exChair-
Type. We derive their α and β as follows.
exPerson takes input as a data page d and a name pattern n. It then extracts person mentions
by detecting occurrences of n in d. Therefore, we set αexPerson to the maximal length of a person
mention and βexPerson to 0.
exConference operates similarly as exPerson. Accordingly, we set αexConference to the maximal
length of a conference mention and βexConference to 0.
exChairType takes input as a data page d and a chair-type pattern c. It then extracts a chair-
type mention by (a) detecting all occurrences of c , and (b) outputting an occurrence of c if it is
immediately followed by a keyword “chair”. Therefore, we set αexChairType to the maximal length
of a chair-type mention, and βexChairType to the length of the keyword “chair”.
Finally, the IE program “chair” outputs a chair mention by “stitching” a person mention, a
conference mention and a chair-type mention together, if (a) the conference mention precedes the
chair-type mention, (b) the chair-type mention precedes the person mention, and (c) the chair-type
mention and person mention span at most 20 characters. Therefore, we can set α of the entire IE

100
program to the maximal length of the text spanned by a chair mention. Since any text spanned by
a chair mention begins with the conference mention, and ends with the person mention, we set β
= max(βexConference, βexPerson).
advise: The IE program “advise” contains 5 IE blackboxes: exAdvisor, exAdvisee, exNameList,
exCoauthors, and exWorkOn. We derive their α and β as follows.
exAdvisor takes as input a data page d and a name pattern n. It then extracts an advisor mention
by (a) detecting all occurrences of n , and (b) outputting an occurrence of n if it is preceded by a
keyword such as “professor” or “prof.”. Therefore, we set αexAdvisor to the maximal length of an
advisor mention, and βexAdvisor to the maximal distance between the beginning of the keyword and
the beginning of the advisor mention.
exAdvisee operates similarly as exAdvisor, except that the keywords used are “student”, “PhD”
etc. Therefore, αexAdvisee and βexAdvisee are set in a similar manner.
exNameList takes as input a data page d and a name list pattern l. It then extracts a list of names
by detecting occurrences l in d. Therefore, we set αexNameList to the maximal length of a name
list, and βexNameList to 0.
exCoauthors takes as input a name list, and a pair of name patterns n1 and n2. It then extracts
coauthor mentions by (a) detecting occurrences of n1 and n2 and (b) “stitching” occurrences of
n1 and n2 together. Therefore, we set αexCoauthor to the maximal length of a text spanned by the
coauthor mention, and βexCoauthor to 0.
exWorkOn takes as input a data page d, a name pattern n and a topic pattern t. It then extracts
mentions of work-on relationship in three steps. First, it detects person mentions by finding occur-
rences of n in d. Then it detects topic mentions by finding occurrences of t in d. Finally, it pairs
up person and topic mentions if they span at most 60 characters. Therefore, we set αexWorkOn to
60, and βexWorkOn to 0.
Finally, the IE program “advise” outputs a mention of advise relationship by stitching the advi-
sor mention, advisee mention and work-on mention together, if (a) the advisor mention and advisee
mention approximately match the two names in a coauthor mention, and (b) the text spanned by
one of the names in the matched coauthor mention is the same text spanned by the name in the

101
work-on mention. Therefore, we set α of the entire IE program to the maximal length of the text
spanned by an advise mention. Furthermore, we set β of the entire IE program to be maxi(βi),
where i ∈ {exAdvisor, exAdvisee, exNameList, exCoauthors,
exWorkOn}.
blockbuster: The IE program “blockbuster” extracts famous movies from a data page. It contains
2 IE blackboxes exCareerSection and exMovie. We derive their α and β as follows.
exCareerSection extract career sections from a Wikipedia page by (a) detecting all sections
delimited by the section heading markups, then (b) outputting a section if keyword “career” is
present in the section title preceding the section. Therefore we set the context βexCareerSection to
the maximal distance between the the beginning of the section title and the beginning of the section.
Then we set αexCareerSection to the maximal number of characters in a career section.
exMovie takes input as a career section and a movie name pattern. It then extracts movie
mentions by detecting occurrences of the name patterns in the career section. Therefore we set the
context βexMovie to 0, and scope αexMovie to the maximal length of a movie name.
Finally, we set α of the entire IE program to the maximal length of a movie mention, and β to
the max of βexCareerSection and βexMovie.
play: The IE program “play” extracts who plays in which movies relationships from data pages.
It contains 4 IE blackboxes: exIntro, exActor, exCareerSection and exMovie. We derive their α and
β as follows.
exIntro extracts the introduction paragraphs from a Wikipedia page by (a) detecting all para-
graphs, and (b) outputting paragraphs that precede the first section heading markup. Therefore,
we set the context βexIntro to the maximal length of a section markup, and scope αexIntro to the
maximal length of an introduction paragraph.
exActor takes as input introduction paragraphs p and an actor name pattern n. It then outputs
actor mentions by finding occurrences of n in p. Therefore, we set αexActor to the maximal length
of spanned by an actor mention, and βexActor to 0.
exCareerSection and exMovie operate exactly the same as those in “blockbuster”. Therefore
their α and β are same as before.

102
Finally, the IE program stitches the actor mentions and movie mentions together. Therefore,
we set α of the entire IE program to the longest text spanned a paired actor and movie mention,
and β to be the longest βi.
award: The IE program “award” contains 6 IE blackboxes: exAwardSection, exBioSection, ex-
AwardItem exAward, exActor and exRole. We derive their α and β as follows.
exAwardSection extracts the award section from a Wikipedia page by (a) detecting all sections
delimited by the section heading markups, then (b) outputting a section if the keyword “award” is
present in the section heading preceding the section. Therefore we set the context βexAwardSection
to the maximal distance between the beginning of the section heading and the beginning of the
section. Furthermore,we set αexAwardSection to the maximal number of characters in any award
section.
exBioSection operates similarly as exAwardSection, thus αexBioSection and βexBioSection are es-
timated in a similar manner.
exAwardItem takes input as an award section, detects list item markups and outputs all list
items in the award section. Therefore we set αexAwardItem to the maximal length of a list item and
βexAwardItem to the maximal length of list item markups .
exAward takes input as an award list item i, a movie pattern m, and an award pattern a. It
then extracts movie and award mention pairs from i by (a) detecting all movie mentions by finding
occurrences of m, (b) detecting all award mentions by finding occurrences of a , and (c) pairing up
all movie mentions and award mentions. Therefore, we set αexAward to the maximal length of the
text spanned by a movie and award mention pair, and βexAward to 0.
exActor and exRole operates similarly as exAward. Thus, their scope and scope are estimated
in a similar manner.
Finally, we derive the α and β of the entire IE program using above α and β of the individual
IE blackboxes. Specifically, we set α of “award” to the maximum length of text spanned by an
award mention, and β of “award” to be the maximum of all βi.
actor: The IE program “actor”(shown in Figure A.2) is a learning-based IE program that extracts
mentions of actor entities from Wikipedia pages. It captures exactly the extraction workflow of

103
KYLIN, a machine learning system recently proposed by [76] to automatically construct infoboxes
for Wikipedia pages.
Following the workflow of KYLIN, “actor” operates in three steps. First, given a Wikipedia
page d, rule R1 extracts sentences from d using the IE blackbox exSentence. As in KYLIN, we im-
plemented exSentence using the sentence detector from openNLP library (http://opennlp.sourcefor
ge.net). This sentence detector employs a maximal entropy (ME) classifier to detect delimits of
sentences. Next, each rule from R2 − R5 employs an IE blackbox (in bold) to extract attribute
values of a distinct attribute from a sentence, if the sentence is predicted to contain some values of
that attribute at all. As in KYLIN, we implemented each IE blackbox in R2−R5 as a distinct con-
ditional random field (CRF) model, trained for each attribute, to extract the values of that attribute.
Specifically, we used the implementation from http://crf.sourceforge.net/ for the CRFs. Finally,
rule R6 “stitches” the attribute values extracted by R2 −R5 to produce actor mentions.
We now describe how to derive the α and β of each IE blackbox and the entire IE program. IE
blackbox exSentence takes input as a data page d, and extracts sentences from d by (a) identifying
candidate delimits such as “!”, “.” and “?”, (b) capturing features from the tokens surrounding those
delimits, and (c) employing an ME classifier to determine if candidate delimits are actual sentence
delimits based on the captured features. Obviously, as long as the tokens surrounding a candidate
delimit remain the same, the features captured from the tokens will also remain the same, and
thus the classification of the candidate delimit remains the same. Hence, we can set βME to the
maximal number of characters in the surrounding tokens. Furthermore, we can set scope αME to
the maximal number of characters in a sentence. In our experiment, we set βME to 16 and αME to
321.
Each of the four IE blackboxes exName, exBirthName, exBirthDate and exNotableRoles
employs a CRF model to extract attribute values from a sentence by (a) capturing features of each
token in the sentence, then (b) finding the most likely sequence of labels (indicating if a token is
part of an attribute value) of the sentence using the trained CRF model. The CRF models are very
complex and thus hard to derive tight values of αCRF and βCRF . However, it is always true that if
a given sentence remains the same, the sequence of labels of this sentence and thus the extracted

104
attribute values will remain the same. Therefore, we can set αCRF and βCRF to the length of the
CRF model’s longest input string, i.e., the longest sentence.
Finally, we estimate the α and β of the entire IE program using those of the IE blackboxes.
The scope α of the IE program is set to the length of the longest string spanned by an actor
mention. Additionally, for an actor mention m in page p, the string p[(m.start−βCRF )..(m.end+
βCRF )] must contain all sentences from which the attribute values of m are extracted. Therefore,
if p[(m.start − βCRF )..(m.end + βCRF )] remains the same, we can guarantee the same attribute
values will be extracted. Furthermore, if p[(m.start − βCRF − βME)..(m.end + βCRF + βME)]
remains the same, we can guarantee the same sentences spanned by m will also be extracted.
Therefore β is set to βME + βCRF . In our experiment, we set α to 17824 and β to 337.

105
R1: talk(d,speaker,topics) :- docs(d), namePatterns(n), topicPatterns(t), R1: careerSections(d,careerSection) :- docs(d), exCareerSection(d,careerSection).
exTalk(d,n,t,speaker,topics).
R2: blockbuster(d,movie) :- careerSections(careerSection), moviePatterns(m),
(a) talk exMovie(careerSection,m,movie) .
R1: people(d,person) :- docs(d), namePatterns(n), exPerson(d,n,person). (d) blockbuster
R2: conferences(d,conference):- docs(d), conferencePatterns(f), R1: introParagraphs(d,intro) :- docs(d), exIntro(d, intro).
exConference(d,f,conference).
R2: actors(d,actor) :- introParagraphs(d, intro), namePatterns(n), exActor(intro,n,actor).
R3: chairTypes(d,chairType) :- docs(d), chairTypePatterns(c),
exChairType(d,c,chairType). R3: careerSections(d, careerSection) :- docs(d), exCareerSection(d, careerSection).
R4: chair(d, person, conference, chairType) :- people(d,person), R4: movies(d,movie) :- careerSections(d,careerSection), moviePatterns(m),
conferences(d,conference), exMovie(carSection,m,movie).
chairTypes(d, chairType),
isBefore(conference,chairType), R5: play(d,actor,movie) :- actors(d,actor), movies(d,movie).
isBefore(chairType,person),
spanChar(chairType, person) < 20. (e) play
(b) chair R1: awardSections(d,awardSection) :- docs(d), exAwardSection(d,awardSection).
R1: advisors(d,advisor) :- docs(d), namePatterns(n), exAdvisor(d,n,advisor). R2: bioSections(d,bioSection) :- docs(d), exBioSection(d,bioSection).
R2: advisees(d,advisee) :- docs(d), namePatterns(n), exAdvisee(d,n,advisee) R3: awardItems(d,awardItem) :- awardSections(d,awardSection),
exAwardItem(awardSection,awardItem).
R3: nameLists(d,nameList) :- docs(d), nameListPatterns(l), exNameList(d,l,nameList).
R4: movieAwards(d,movie,award) :- awardItems(d,awardItem),
R4: coauthors(d,author1,author2) :- docs(d), nameLists(d,nameList), moviePatterns(m), awardPatterns(a),
namePatterns(n1), namePatterns(n2) exAward(awardItem,m,a,movie,award).
exCoauthor(nameList,n1,n2,author1,author2).
R5: actors(d,actor) :- bioSections(d, bioSection), namePatterns(n),
R5: workOn(d,person,topics) :- docs(d), namePatterns(n), topicPatterns(t), exActor(bioSection,n,actor).
exWorkOn(d,n,t,person,topics).
R6: roles(d,movie,role) :- docs(d), moviePatterns(m), exRole(d,m,movie,role).
R6: advise(d,advisor,advisee,topics) :- advisors(d,advisor), advisees(d,advisee)
coauthors(d,author1,author2), R7: award(d,actor,movie,role,award) :- roles(d,movie,role),
approMatch(advisor, author1), movieAwards(d,movie1,award),
approMatch(advisee, author2), match(movie,movie1),
distChar(author2, person) =0 actors(d,actor).
(c) advise (f) award
Figure A.1 xlog Programs for 6 IE tasks in Figure 3.7.(b). IE blackboxes are in bold.
R1: sentences(d,sentence) :- docs(d), exSentence(d,sentence).
R2: names(d,name) :- sentences(d,sentence), containingName(sentence),
exName(sentence,name).
R3: birthNames(d,birthName) :- sentences(d,sentence), containingBirthName(sentence),
exBirthName(sentence,birthName).
R4: birthDates(d,birthDate) :- sentences(d,sentence), containingBirthDate(sentence),
exBirthDate(sentence,birthDate).
R5: notableRoles(d,notableRoles) :- sentences(d,sentence), containingNotableRole(sentence),
exNotableRoles(sentence,notableRoles).
R6: actor(d,name,birthName,birthDate,notableRoles) :- names(d,name),
birthNames(d,birthName),
birthDates(d,birthDate),
notableRoles(d,notableRoles)
Figure A.2 The xlog program of “actor”. IE blackboxes are in bold.


![Optimizing Hardware for Distributed Imagery Processing: A ...PDAD18].pdfother matching algorithms, automated tie point extraction, 3D point extraction, Orthophoto production, ... Dell](https://img.pdfslide.us/doc/110x75/5e7c2f2dcdd2397e633cb649/optimizing-hardware-for-distributed-imagery-processing-a-pdad18pdf-other.jpg)









![Estimating OGIP and Reserves with Crystal Ball [optimizing extraction of results with VBA]](https://img.pdfslide.us/doc/110x75/568bdd7f1a28ab2034b60271/estimating-ogip-and-reserves-with-crystal-ball-optimizing-extraction-of-results.jpg)