Embed Size (px)
Citation preview

OPTIMIZING CODES FOR SOURCE SEPARATION IN COMPRESSED VIDEO RECOVERYAND COLOR IMAGE DEMOSAICING
Alankar Kotwal1 and Ajit Rajwade2
1Department of Electrical Engineering, 2Department of Computer Science and EngineeringIndian Institute of Technology Bombay
ABSTRACTThere exist several applications in image processing (eg:video compressed sensing [5] and color image demosaic-ing) which require separation of constituent images givenmeasurements in the form of a coded superposition of thoseimages. Physically practical code patterns in these applica-tions are non-negative and do not obey the nice coherenceproperties of Gaussian codes, which can adversely affect re-construction performance. The contribution of this paper isto design code patterns for these applications by minimizingthe coherence given a fixed dictionary. Our method explic-itly takes into account the structure of those code patterns asrequired by these applications: (1) non-negativity, (2) block-diagonal nature, and (3) circular shifting. In particular, thelast property enables accurate patchwise reconstruction.
Index Terms— video compressed sensing, color image de-mosaicing, source separation, coherence, patchwise recovery
1. INTRODUCTION AND RELATED WORK
COMPRESSED sensing is a fast way of sampling sparsecontinuous time signals. Its success with images has
inspired efforts to apply it to video. Indeed, [5] achieves com-pression across time by combining T input frames {Xi}Ti=1
linearly, weighted by the sensing matrices φi into the outputY :
Y =
T∑i=1
φiXi (1)
The sparsifying basis here is a 3D dictionary D learned onvideo patches. Any set of frames {Xi}Ti=1 can then be repre-sented as a sum of its projections αj on the K atoms in D:
Xi =
K∑j=1
Djiαj (2)
where Dji is the ith frame in the jth 3-D dictionary atom Dji.The input images are recovered by solving the following op-timization problem:
minα‖α‖0 subject to
∥∥∥∥∥∥Y −T∑i=1
φi
K∑j=1
Djiαj
∥∥∥∥∥∥2
≤ ε (3)
The drawback here, though, is that the 3D dictionary imposesa smoothness assumption on the scene. Since a linear com-bination of dictionary atoms cannot ‘speed’ an atom up, thetypical speeds of objects moving in the video must be roughlythe same as the dictionary. Therefore, the dictionary fails tosparsely represent sudden scene changes caused by, say, light-ing or occlusion. Other than that, dictionaries are learned onclasses of patches and a dictionary learned on outdoor scenes,for instance, may not work as well on an indoor scene.We treat each of the coded snapshots as a coded mixtureof sources, each sparse in some basis. We aim to designcodes with this structure and low coherence, making themideal for compressed video. Most current approaches to thisproblem have their limitations: firstly, they do not accountfor the special structure of the sensing matrices used in [5]or for demosaicing, a framework which this paper expresslydeals with. The method in [3] involves a step that requiresa Cholesky-type decomposition of a ‘reduced’ Gram matrix,and the non-linear reduction process is not guaranteed to keepthe Gram matrix positive-semidefinite. Besides, the methodsin all of [2, 3, 9] optimize objective functions that are someaverage normalized dot products of dictionary columns, andminimizing averages doesn’t guarantee minimizing the max-imum (coherence, in this case) of the quantities forming thisaverage. Some authors have taken an information-theoreticroute to this problem [1, 10, 12]. These papers design sensingmatrices Φ such that the mutual information between a set ofsmall patches {Xi}ni=1 and their corresponding projections{Yi}ni=1 where Yi = ΦXi, is maximized. Computing thismutual information first requires estimation of the probabilitydensity function of X and Y using Gaussian mixture models,for instance. This can be expensive and is an iterative pro-cess. Moreover these learned GMMs for a class of patchesmay not be general enough. Other techniques [11] exploitadditional structure like periodicity, and rigid or analyticalmotion models and cannot be used in the general case.There are obvious applications for this in the fields of fastvideo sensing and the general problem of coded source sepa-ration. Besides, this will find applications in improving multi-spectral imaging and image demosaicing, where inputs arecoded linear combinations of images sparse in some domainand need to be solved for in a source-separation framework.

2. METHOD AND ANALYSIS
2.1. Our framework
We propose to use a recovery method different from the oneused in [5], within the same acquisition framework. Our sig-nals are acquired according to Eq. 1, but we use a basis D tomodel each frame in the input data. The dictionary Ψ spar-sifying the video sequence, thus, is a block-diagonal matrixwith the n× n sparsifying basis D on the diagonal. Thus,
Y =(φ1D . . . φTD
) (α1 . . . αT
)T(4)
Given a Y , we recover the input {Xi}Ti=1 through the DCTcoefficients α by solving the optimization problem
arg minα‖α‖1, Y = ΦΨα, α =
(α1 α2 . . . αT
)T(5)
2.2. Calculation of coherence for our matrices
Our aim, then, is to optimize the sensing matrices φi for co-herence. As in Eq. 4, we have the effective dictionary
ΦΨ =(φ1D φ2D . . . φTD
)(6)
The coherence of a dictionary D, with ith column di, is
µ = maxi6=j
| 〈di, dj〉 |√〈di, di〉 〈dj , dj〉
(7)
This expression contains max and abs functions that agradient-based scheme cannot handle. We soften the maxand convert the abs to a square using, for large enough θ,
maxi{t2i }ni=1 ≈
1
θlog
n∑i=1
eθt2i (8)
We will call the index varying from 1 to T as µ or ν, and theindex varying from 1 to n as α, β or γ. The µth block of Φ isthus φµ. Let the βth diagonal element of φµ be φµβ . Definethe αth column ofDT to be dα. Then, it can be shown [7] thatthe dot product between the βth column of the µth block andthe γth column of the ν th block is
Mµν(βγ) =
∑nα=1 φµαφναdα(β)dα(γ)√(∑n
α=1 φ2µαd
2α(β)
)(∑nτ=1 φ
2ντd
2τ (γ))
(9)
Using Eq. 8, the squared soft coherence C is
C =1
θlog
T∑µ=1
n∑β=1
[µ−1∑ν=1
n∑γ=1
eθM2µν(βγ) +
β−1∑γ=1
eθM2µµ(βγ)
](10)
The first term above corresponds to all (µ > ν) blocks thatare ‘below’ the block diagonal. The second term correspondsto (µ = ν) blocks on the block diagonal. Here, we consideronly (β > γ) below-diagonal elements for the maximum. De-riving expressions for the gradient of this quantity [7], we doadaptive projected gradient descent with a multi-start strategyto combat the non-convexity of the problem.
Fig. 1: Motivation behind circularly-shifted optimization
2.3. Time complexity and the need for something more
The size of Φ to be optimized above is n × nT , and eachdot product needs O(n) operations, warranting the calcula-tion of O(n3T 2) quantities. Optimizing this rapidly becomesintractable as n increases. The performance of gradient de-scent on this non-convex problem also worsens as the dimen-sionality of the search-space (O(nT )) increases. We observethat it is intractable to design codes that are more than 20×20in size in any reasonable time. This implies that we needsomething more to make designing codes possible.
2.4. Circularly-symmetric coherence minimization
This leads us to designing smaller masks and tiling them tofit the image size we’re dealing with. A small coherence forthe designed patch guarantees good reconstruction for patchesexactly aligned with the code block; however, other patchessee a code that is a circular shift of the original code. Fig 1provides a visual explanation. The big outer square denotesthe image. On top of the image we show tiled designed codes.Now, the patch in red clearly multiplies with the exact de-signed code; however the patch in green multiplies with acode shifted in both the coordinates circularly.This points to designing sensing matrices that have small co-herence in all their circular permutations (note that these per-mutations happen in two dimensions and must be handled assuch). To this end, we modify the above objective function:
C =1
θlog
∑ζ∈perm(Φ)
T∑µ=1
n∑β=1
[µ−1∑ν=1
n∑γ=1
eθM(ζ)2µν (βγ)
+
β−1∑γ=1
eθM(ζ)2µµ (βγ)
] (11)
where M (ζ)µν (βγ) represents the normalized dot product be-
tween the βth column of the µth block and the γth column ofthe ν th block, resulting from the instance ζ among the circularpermutations of Φ. Derivatives of this expression are found asin the non-circular case, except that the µ, ν, β and γ param-eters are subjected to the appropriate circular permutation.

The time complexity for determining this quantity isO(n5T 2),with the extraO(n2) arising from n2 permutations. However,we don’t need to optimize masks having very high values ofn; we can get away with keeping n a small constant such thatn × n patches are sparse in some chosen basis. Thereforethe effective dimension of the optimization problem in such ascheme is, in terms of the variables that matter, O(T 2) and ismore scalable in terms of the size of the input image.It is worth mentioning that this simple idea has been largelyignored in literature. Previous attempts [2, 3, 9] minimizecoherence for full-sized matrices, and are not as scalable forlarge images because they involve optimization problems ofdimensions of the order of image size. Sensing matrices canbe designed at the patch level as well, for instance using in-formation theoretic techniques as in [1, 10, 12], but the meth-ods therein are not designed to account for overlapping recon-struction. To the best of our knowledge, ours is the first pieceof work to handle this important issue in a principled manner.
3. VALIDATION AND RESULTS
3.1. Coherence minimization
The distribution of coherences of a uniform random matrix ofthe type we’re interested in is shown in Fig 2. It is interest-ing to note that the resulting minimum coherence is close forall random starts, and therefore the corresponding designedmatrices are nearly equally good.
2 3 4 5 6 7 8 9 10
T
0.75
0.8
0.85
0.9
0.95
Co
he
ren
ce
Coherence distribution for positive random codes
Fig. 2: Distribution of coherences for 8× 8 random positivecodes as a function of T
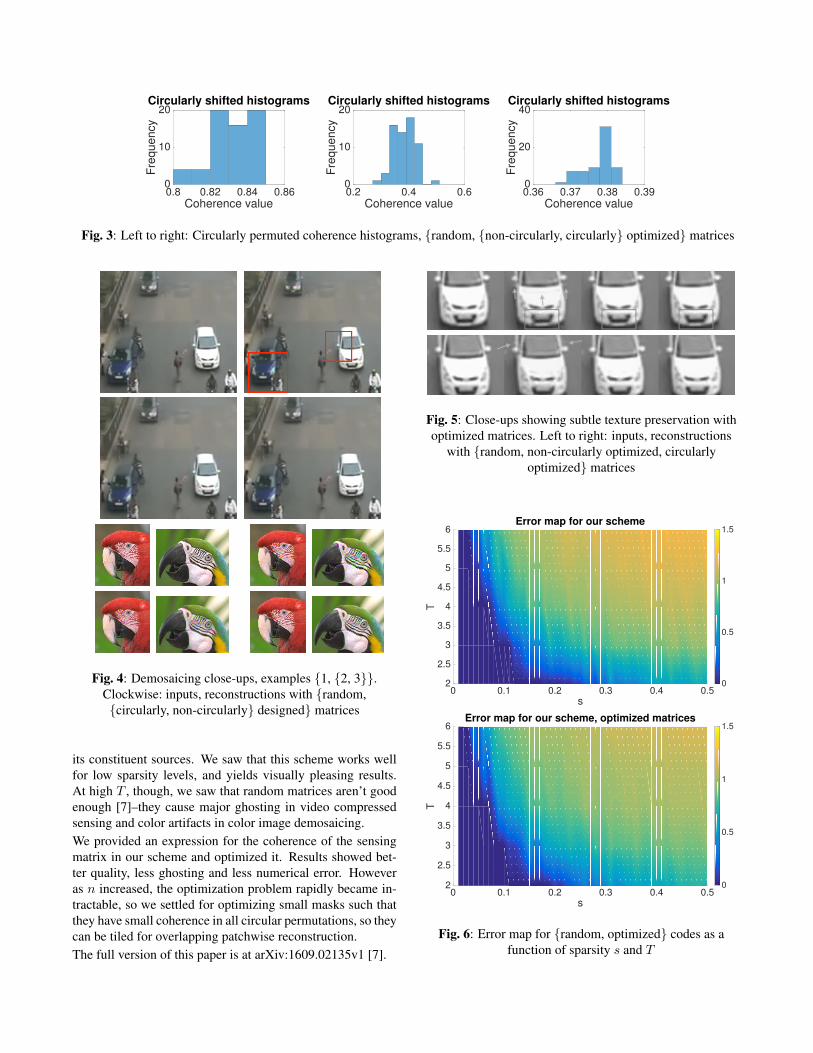
To show coherence improvement between positive randomcodes, and codes designed with and without circular permuta-tions, we plot a histogram of coherences of Φ(ζ)D in Fig. 3 forall circular permutations ζ, with 8×8 codes and T = 2. Notethat though the coherences of non-circularly designed matri-ces are much lower than positive random matrices, the max-imum coherence among all permutations is quite large. Thecircularly-designed matrices, however, have permuted coher-ences clustered around a low value. We then expect goodreconstruction with all circular permutations.
3.2. Demosaicing
To demonstrate the utility of this scheme, we show resultson demosaicing RGB images. The demosaicing problem in-volves interpolating pixel-sensed RGB data acquired from acamera to estimate the original scene. Traditional approachesto demosaicing involve the use of the Bayer pattern. Re-covery algorithms, like Matlab’s demosaic function, takeapproaches like [8], a gradient-corrected bilinear interpo-lated approach. However, a case has recently been madefor panchromatic demosaicing [4], where we sense a codedlinear combination of the three channels. However, the Bayerpattern has very high coherence, so it is unsuitable for com-pressive recovery. Here, we design the mosaic patterns byminimizing coherence.As Fig. 4 show, results from the designed case are more faith-ful to the ground-truth than the random reconstructions are.The random reconstructions show (more) color artifacts thanours, especially in areas where the input image varies a lot.Notice the artifacts near car headlights (green blotches) andthose in the densely-varying area near the eyes of the parrotsin Fig. 4. Using our optimized matrices reduces the magni-tude of these color artifacts. Better reconstructions are whenwe use circularly-optimized matrices. Full-scale color imagedemosaicing results live in [7].
3.3. Results on video data
Next, we validate the superiority of our matrices on videodata. We design 8 × 8 codes (both with and without the cir-cular permutations), reconstructing patchwise with overlap-ping patches. We show close-ups that illustrate the superior-ity of our matrices. Note, in the car video sequence in Fig. 5,better reconstruction of the numberplate and headlight areain our case. Further, notice the presence of major ghostingand degradation in the random case (marked by arrows andboxes), while our reconstructions remain free of these arti-facts. Adding circular optimization further improves imagequality especially in the bonnet area, where the non-circularreconstruction is splotchy. Full-scale results live in [7].We do a numerical comparison between our designed codesand random codes for various values of s = ‖x‖0/n and T .We randomly generate T s-sparse (in 2D DCT) 8 × 8 sig-nals {xi}Ti=1, combine them using random matrices to get y1
and using our designed codes to get y2. Average relative rootmean square errors on recovering the input signals from y1
and y2 as a function of s and T are shown in Fig. 6. On anaverage, we see that we perform better than the random case.The RRMSE error difference is not very significant, though itdoes produce significant changes in subtle texture.
4. CONCLUSION
We cast the video compressed sensing problem as one of sep-aration of a coded linear combination of sparse signals into
0.8 0.82 0.84 0.86Coherence value
0
10
20
Fre
quency
Circularly shifted histograms
0.2 0.4 0.6Coherence value
0
10
20
Fre
quency
Circularly shifted histograms
0.36 0.37 0.38 0.39Coherence value
0
20
40
Fre
quency
Circularly shifted histograms
Fig. 3: Left to right: Circularly permuted coherence histograms, {random, {non-circularly, circularly} optimized} matrices
Fig. 4: Demosaicing close-ups, examples {1, {2, 3}}.Clockwise: inputs, reconstructions with {random,{circularly, non-circularly} designed} matrices
its constituent sources. We saw that this scheme works wellfor low sparsity levels, and yields visually pleasing results.At high T , though, we saw that random matrices aren’t goodenough [7]–they cause major ghosting in video compressedsensing and color artifacts in color image demosaicing.We provided an expression for the coherence of the sensingmatrix in our scheme and optimized it. Results showed bet-ter quality, less ghosting and less numerical error. Howeveras n increased, the optimization problem rapidly became in-tractable, so we settled for optimizing small masks such thatthey have small coherence in all circular permutations, so theycan be tiled for overlapping patchwise reconstruction.The full version of this paper is at arXiv:1609.02135v1 [7].
Fig. 5: Close-ups showing subtle texture preservation withoptimized matrices. Left to right: inputs, reconstructions
with {random, non-circularly optimized, circularlyoptimized} matrices
0 0.1 0.2 0.3 0.4 0.5
s
2
2.5
3
3.5
4
4.5
5
5.5
6
T
Error map for our scheme
0
0.5
1
1.5
0 0.1 0.2 0.3 0.4 0.5
s
2
2.5
3
3.5
4
4.5
5
5.5
6
T
Error map for our scheme, optimized matrices
0
0.5
1
1.5
Fig. 6: Error map for {random, optimized} codes as afunction of sparsity s and T

5. REFERENCES
[1] William R. Carson, Minhua Chen, Miguel R. D.Rodrigues, Robert Calderbank, and Lawrence Carin.Communications-inspired projection design with appli-cation to compressive sensing. SIAM Journal on Imag-ing Sciences, 5(4):1185–1212, 2012.
[2] J. M. Duarte-Carvajalino and G. Sapiro. Learning tosense sparse signals: Simultaneous sensing matrix andsparsifying dictionary optimization. IEEE Transactionson Image Processing, 18(7):1395–1408, July 2009.
[3] M. Elad. Optimized projections for compressed sensing.IEEE Transactions on Signal Processing, 55(12):5695–5702, Dec 2007.
[4] K. Hirakawa and P. J. Wolfe. Spatio-spectral color filterarray design for optimal image recovery. IEEE Trans-actions on Image Processing, 17(10):1876–1890, Oct2008.
[5] Y. Hitomi, J. Gu, M. Gupta, T. Mitsunaga, and S. K. Na-yar. Video from a single coded exposure photograph us-ing a learned over-complete dictionary. In 2011 Interna-tional Conference on Computer Vision, pages 287–294,Nov 2011.
[6] Alankar Kotwal. Implementation. http://bitbucket.org/alankarkotwal/coded-sourcesep/.
[7] Alankar Kotwal and Ajit Rajwade. Optimizingcodes for source separation in compressed video re-covery and color image demosaicing: long version,arXiv:1609.02135v1 [cs.CV]. 2016.
[8] Rico Malvar, Li wei He, and Ross Cutler. High-Quality Linear Interpolation for Demosaicing of Bayer-Patterned Color Images. In International Conference ofAcoustic, Speech and Signal Processing, May 2004.
[9] M. Mordechay and Y. Y. Schechner. Matrix optimiza-tion for poisson compressed sensing. In Signal and In-formation Processing (GlobalSIP), 2014 IEEE GlobalConference on, pages 684–688, Dec 2014.
[10] F. Renna, M. R. D. Rodrigues, M. Chen, R. Calderbank,and L. Carin. Compressive sensing for incoherent imag-ing systems with optical constraints. In 2013 IEEE In-ternational Conference on Acoustics, Speech and SignalProcessing, pages 5484–5488, May 2013.
[11] A. Veeraraghavan, D. Reddy, and R. Raskar. Codedstrobing photography: Compressive sensing of highspeed periodic videos. IEEE Transactions on Pat-tern Analysis and Machine Intelligence, 33(4):671–686,April 2011.
[12] Yair Weiss, Hyun Sung Chang, and William T. Freeman.Learning Compressed Sensing. In Allerton Conferenceon Communication, Control, and Computing, 2007.





























