Embed Size (px)
Citation preview

Optimizing Applications on Blue WatersBlue Waters Institute June 5, 2014
April 18, 2023
Victor AnisimovNCSA Science and Engineering Applications Support

Overview• Hardware• Topology Aware Scheduling• Balanced Injection: Sharing the Network• Compilers• Libraries• Profiling: Finding Hot Spots in the Code• File System and I/O Performance Optimization• Training materials:
cp -pr /u/staff/anisimov/training_bw .
2Performance Optimization on Blue Waters

Hardware Overview
3Performance Optimization on Blue Waters

Blue Waters – Configuration
• GPU: NVIDIA K20X (Kepler GK110)
• CPU: AMD 6276 Interlagos (2.3 – 2.6 GHz)
• 3D Torus Network Topology
• 22,640 XE6 nodes (Dual CPU), 64 GB RAM each
• 4,224 XK7 nodes (CPU+GPU), 32 GB RAM each
• File system 26.4 PB, Aggregate I/O bandwidth 1 TB/s
4Performance Optimization on Blue Waters

Node Characteristics
Number of Cores 32 cores(2 AMD 6276 Interlagos )
Peak Performance 313 Gflops/sec
Memory Size 64 GB per node
Memory Bandwidth(Peak)
102.4 GB/sec
Cray XE6 Blade has 2 Compute nodes
Performance Optimization on Blue Waters 5
Y
X
Z

• Compute node contains• XE6: 2 Processors
• Processor has 2 numa nodes• Numa node has 4 Bulldozer
modules• Each Buldozer module has
single FP-unit and 2 integer cores
AMD 6276 Interlagos ProcessorS
hared
L3 C
ache
Sh
ared L
3 Cach
e
NB/HT LinksNB/HT LinksMemory Memory
ControllerController
Sh
ared L
3 Cach
eS
hared
L3 C
ache
NB/HT LinksNB/HT LinksMemory Memory
ControllerController
Numa node
Processor socket
Performance Optimization on Blue Waters 6

Job Submitting Performance Options: XE6BW node: 64 GB RAM, 16 Bulldozer cores, 32 cores, 4 NUMA domains•aprun enumerates cores from 0 to 31; each pair represents a BD core
• BD core consists of 2 compute cores sharing single FP unit
• Default task placement – fill up from 0 to 31
• -N16 will use cores 0,1,…,15 utilizing only 8 FP units
• -N16 -d2 will utilize cores 0,2,4,6,8,10,12,14,…,24,26,28,30 and 16 FP units
•aprun options to specify particular number of tasks per XE6 node• -N1 1 process
• -N2 -cc 0,16 2 processes
• -N4 -d8 4 processes, one per NUMA node(cache optimal)
• -N8 -d4 8 processes, two per NUMA node
• -N16 -d2 16 processes, interleaved, 16 BD cores
• -N32 32 processes (may improve performance over -N16)
7Performance Optimization on Blue Waters

Test 01: Optimal MPI task placement• Question:
• When 16 cores do better job than 32 cores?
• How to optimally use fewer than 32 cores per XE6 node?
• Running the test:• Show task placement: export MPICH_CPUMASK_DISPLAY=1
• cc app.c; qsub run• aprun -n32 ./a.out (Time = 7.613)
• aprun -n16 ./a.out (Time = 5.995)
• aprun -n16 -d2 ./a.out (Time = 5.640)
• Take home lesson: Contention will degrade performance. Test different task placements and choose the optimal one before starting the production computations.
8Performance Optimization on Blue Waters

3D Torus in XY plane
9Performance Optimization on Blue Waters
PCIe
Gen
2
PCIe
Gen
2
Y
X
Z

Cray 3D Torus Topology VMD image of 3D torus
•Torus is a periodic box in 3D•XK nodes – red•Service nodes – blue•Compute nodes – gray•Slower – Y, X, Z – Faster •Routing X, then Y, then Z•Routing path depends on application placement on 3D torus
10
Reference: Bob Fiedler, Cray Inc.: https://bluewaters.ncsa.illinois.edu/documents/10157/12008/AdvancedFeatures_PRAC_WS_2013-02-27.pdf
Performance Optimization on Blue Waters
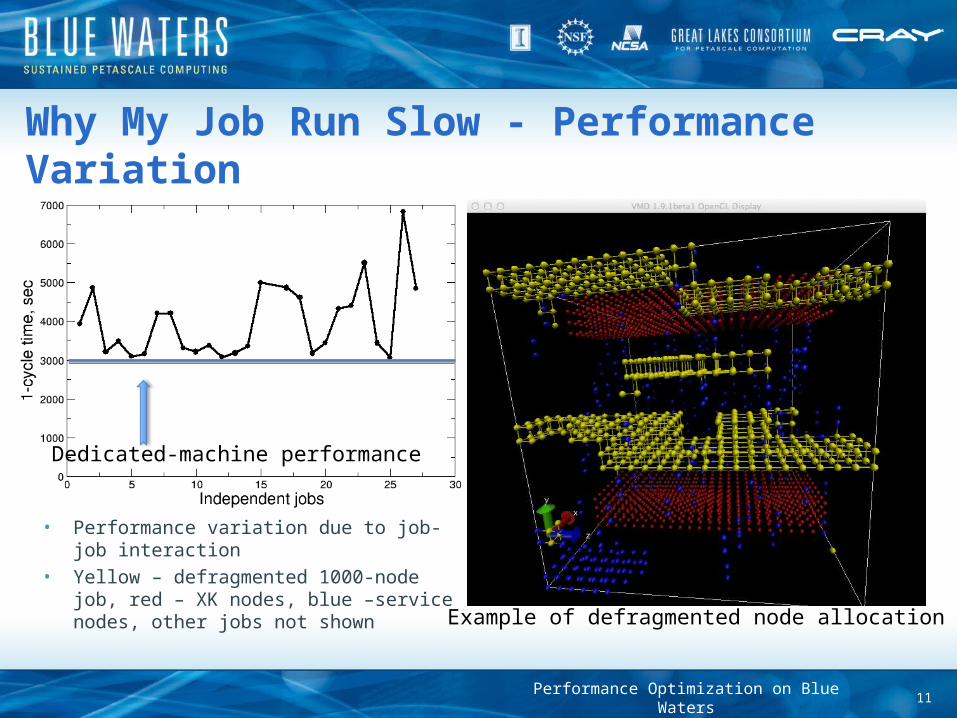
Why My Job Run Slow - Performance Variation
• Performance variation due to job-job interaction
• Yellow – defragmented 1000-node job, red – XK nodes, blue –service nodes, other jobs not shown
11
Example of defragmented node allocation
Dedicated-machine performance
Performance Optimization on Blue Waters

Moab: Nodesets
Available Shapes and Sizes (number of nodes in them):
Sheets: 1100, 2200, 6700, 8200, 12300Bars: 6700Cubes: 3300
Yellow: Job placement in a cube nodeset
12
Specifying a nodeset in PBS script:
#PBS -l nodes=3360:ppn=32
#PBS -l nodeset=ONEOF:FEATURE:c1_3300n:c2_3300n:c3_3300n:
c5_3300n:c6_3300n:c7_3300n
Performance Optimization on Blue Waters

Moab: Hostlist
Yellow – Job placement in 3D torus
#PBS -l nodes=1000:ppn=32
#PBS -l hostlist=1152+1153+1154+1155+1156+…+8207^
13Performance Optimization on Blue Waters

Test 02: Optimal job placement on 3D torus
• Challenge: Chose a pair of adjacent nodes on 3D torus. Find the application performance on 0-1, Y-Y, and Z-Z links.
• Runnig the test:• Show node ids and X,Y,Z coordinates: getnodexyz.sh• cc app.c; qsub run
• Example of 0-1, Z-Z, Y-Y links• aprun -n64 -L 24124,24125 ./a.out• aprun -n64 -L 24125,24126 ./a.out• aprun -n64 -L 24108,24178 ./a.out• (non-local) aprun -n64 -L 23074,24102 ./a.out• Try your own node ids to test your understanding
• Take home lesson: Different links have different network bandwidth: 0-1 > Z-Z = X-X > Y-Y
14
YX
Z
node 0node 1
Performance Optimization on Blue Waters

Congestion Protection
• Network congestion is a condition that occurs when the volume of traffic on the high-speed network (HSN) exceeds the capacity to handle it.
• To "protect" the network from data loss, congestion protection (CP) globally “throttles” injection bandwidth per-node.
• If CP happens often, application performance degrades.
• At job completion you might see the following message reported to stdout:
Application 61435 network throttled: 4459 nodes throttled, 25:31:21 node-secondsApplication 61435 balanced injection 100, after throttle 63
• Throttling disrupts the work on the entire machine.
http://lh5.google.ca/abramsv/R9WYOKtLe1I/AAAAAAAALO4/FLefbnOq5rQ/s1600-h/495711679_52f8d76d11_o.jpg
Performance Optimization on Blue Waters 15

Types of congestion events• There are two main forms of congestion: many-to-one and long-path.
The former is easy to detect and correct. The latter is harder to detect and may not be correctable.
• Many-to-one congestion occurs in some algorithms and can be corrected. See “Modifying Your Application to Avoid Gemini Network Congestion Errors” on balanced injection section on the portal.
• Long-path congestion is typically due to a combination of communication pattern and node allocation. It can also be due to a combination of jobs running on the system.
• We monitor for cases of congestion protection and try to determine the most likely cause.
Performance Optimization on Blue Waters 16

Congestion on a Shared, Torus Network• HSN uses dimension ordered
routing: X-then-Y-then-Z between two locations on the torus. Note that AB≠BA.
• Shortest route can sometimes cause traffic to pass through geminis used by other jobs.
• Non-compact node allocations can have traffic that passes through geminis used by other jobs.
• I/O traffic can lead to network hot-spots.
• We are working with Adaptive and Cray on eliminating some of the above causes of congestion with better node allocation: shape, location, etc.
A
B
Performance Optimization on Blue Waters 17

Balanced Injection
• Balanced Injection (BI) is a mechanism that attempts to reduce compute node injection bandwidth in order to prevent throttling and which may have the effect of improving application performance for certain communication patterns.
• BI can be applied “per-job” using an environment variable or with user accessible API.
• export APRUN_BALANCED_INJECTION=63
• Can be set from 1-100 (100 = no BI).
• There isn’t a linear relation of BI to application performance.
• MPI-based applications have “balanced injection” enabled in collective MPI calls that locally “throttle” injection bandwidth.
Performance Optimization on Blue Waters 18

Compilers
19Performance Optimization on Blue Waters

Available Compilers• Cray Compilers - Cray Compiling Environment (CCE)
• Fortran 2003, Co-arrays, UPC, PGAS, OpenACC• GNU Compiler Collection (GCC)• Portland Group Inc (PGI) Compilers
• OpenACC• Intel Compilers (to be available soon)• All compilers provide Fortran, C, C++, OpenMP support• Use cc, CC, ftn wrappers for C, C++, and FORTRAN
• So which compiler do I choose?• Experiment with various compilers• Work with BW staff• Mixing libraries created by different compilers may cause issues
20Performance Optimization on Blue Waters

Compiler Choices – Relative Strength• CCE – outstanding Fortran, very good C, and okay C++
• Very good vectorization• Very good Fortran language support; only real choice for
coarrays• C support is very good, with UPC support• Very good scalar optimization and automatic parallelization• Clean implementation of OpenMP 3.0 with tasks• Cleanest integration with other Cray tools (Performance tools,
debuggers, upcoming productivity tools)• No inline assembly support• Excellent support from Cray (bugs, issues, performance etc)
21Performance Optimization on Blue Waters

Compiler Choices – Relative Strength• PGI – very good Fortran, okay C and C++
• Good vectorization• Good functional correctness with optimization
enabled• Good automatic prefetch capabilities• Company (NVIDIA) focused on HPC market• Excellent working relationship with Cray• Slow bug fixing
22Performance Optimization on Blue Waters

Compiler Choices – Relative Strength• GNU – good Fortran, outstanding C and C++
• Obviously, the best gcc compatibility• Scalable optimizer was recently rewritten and is very
good• Vectiorization capabilities focus mostly on inline
assembly• Few releases have been incompatible with each
other and require recompilation of modules (4.3, 4.4, 4.5)
• General purpose application, not necessarily HPC
23Performance Optimization on Blue Waters

Recommended CCE Compilation Options• Use default optimization levels
• It’s the equivalent of most other compilers -O3 or -fast
• Use -O3, fp3 (or -O3 -hfp3 or some variation)• -O3 gives slightly more than -O2
• -hfp3 gives a lot more floating point optimizations, esp 32 bit
• If an application is intolerant of floating point reassociation, try lower hfp number, try hfp1 first, only hfp0 if absolutely necessary
• Might be needed for tests that require strict IEEE conformance
• Or applications that have validated results from diffferent compiler
• Do not suggest using -Oipa5, -Oaggress and so on; higher numbers are not always correlated with better performance
• Compiler feedback : -rm (fortran), -hlist=m ( C )
• If don’t want OpenMP : -xomp or -Othread0 or -hnoomp
• Manpages : crayftn, craycc, crayCC
24Performance Optimization on Blue Waters

Starting Point for PGI Compilers• Suggested Option : -fast• Interprocedural analysis allows the compiler to perform
whole program optimizations : -Mipa=fast(,safe)• If you can be flexible with precision, also try -Mfprelaxed• Option -Msmartalloc, calls the subroutine mallopt in the
main routine, can have a dramatic impact on the performance of program that uses dynamic allocation of memory
• Compiler feedback : -Minfo=all, -Mneginfo• Manpages : pgf90, pgcc, pgCC
25Performance Optimization on Blue Waters

Additional PGI Compiler Options
• -default64 : Fortran driver option for -i8 and -r8• -i8, -r8 : Treats INTEGER and REAL variables in
Fortran as 8 bytes (use ftn -default64 option to link the right libraries)
• -byteswapio : Reads big endian files in fortran• -Mnomain : Uses ftn driver to link programs with
the main program (written in C or C++) and one or more subroutines (written in fortran)
26Performance Optimization on Blue Waters

Starting Point for GNU Compilers
• -O3 –ffast-math –funroll-loops• Compiler feedback : -ftree-vectorizer-verbose=2• Manpages : gfortran, gcc, g++
27Performance Optimization on Blue Waters

Test 03: Manual code optimization
• Challenge: Find and fix two programming blunders in the test code. Modify app2.c and app3.c so their runtime T(app1) > T(app2) > T(app3).
• Runnig the test:• cc -hlist=m -o app1.x app1.c
• cc -hlist=m -o app2.x app2.c
• cc -hlist=m -o app3.x app3.c
• qsub run
• Target: T(app1)=5.665s, T(app2)=0.242s, T(app3)=0.031s
28Performance Optimization on Blue Waters

Test 03: Solution
29Presentation Title
app1.c
app2.c
app3.c

Libraries
30Performance Optimization on Blue Waters

Libraries: Where to Start
• Libraries motto: Reuse rather than reinvent• Libraries are tailored to Programming Environment
• Choose programming environment PrgEnv-[cray,gnu,pgi] • Load library module: module load <libname>• See actual path: module show <libname>• Location path: ls –l $CRAY_LIBSCI_PREFIX_DIR/lib
• Use compiler wrappers: ftn, cc, CC
• For most applications, using default settings work very well• OpenMP threaded BLAS/LAPACK libraries are available
• The serial version is used if “OMP_NUM_THREADS” is not set or set to 1
31Performance Optimization on Blue Waters

PETSc (Argonne National Laboratory)• Programmable, Extensible Toolkit for Scientific
Computing• Widely-used collection of many different types of linear
and non-linear solvers• Actively under development; very responsive team• Can also interface with numerous optional external
packages (e.g., SLEPC, HYPRE, ParMETIS, …)• Optimized version installed by Cray, along with many
external packages• Use “module load petsc[/version]”
32Performance Optimization on Blue Waters

Other Numerical Libraries
• ACML (AMD Core Math Library)• BLAS, LAPACK, FFT, Random Number Generators
• Trilinos (from Sandia National Laboratories)• Somewhat similar to PETSc, interfaces to a large
collection of preconditioners, solvers, and other computational tools
• GSL (GNU Scientific Library)• Collection of numerous computational solvers and tools for
C and C++ programs• See all available modules “module avail”
33Performance Optimization on Blue Waters

Cray Scientific Library (libsci)
• Contains optimized versions of several popular scientific software routines
• Available by default; see available versions with “module avail cray-libsci” and load particular version “module load cray‑libsci[/version]”
• BLAS, BLACS
• LAPACK, ScaLAPACK
• FFT, FFTW
• Unique to Cray (affects portability)• CRAFFT, CASE, IRT
34Performance Optimization on Blue Waters

Cray Accelerated LibrariesCray LibSci accelerated BLAS, LAPACK, and ScaLAPACK libraries
PrgEnv-cray or PrgEnv-gnu Programming Environment
module add craype-accel-nvidia35
call libsci_acc_init()
… (your code) …
call libsci_acc_finalize()
The Library interface automatically initiates appropriate execution mode (CPU, GPU, Hybrid).
When BLAS or LAPACK routines are called from applications built with the Cray or GNU compilers, Cray LibSci automatically loads and links libsci_acc libraries upon execution if it determines performance will be enhanced.
Execution control from source code:
routine_name invokes automated method
routine_name_cpu executed on host CPU only
routine_name_acc executed on GPU only
See “man intro_libsci_acc” for more information.
35Performance Optimization on Blue Waters

Cray Accelerated Libraries, continuedLibsci_acc is not thread safe. It will fail when called concurrently from OpenMP threads.
ENVIRONMENT VARIABLES
CRAY_LIBSCI_ACC_MODE
Specifies execution mode for libsci_acc routine:
0 Use automated mode. Adds slight overhead. This is the default.
1 Forces all supported auto-tuned routines to execute on the accelerator.
2 Forces all supported routines to execute on the CPU if the data is located within host processor address space.
LIBSCI_ACC_BYPASS_FUNCTION
Specifies the execution mode for FUNCTION.
0 Use automated mode. Adds slight overhead. This is the default.
1 Call the version that handles data addresses resident on the GPU.
2 Call the version that handles data addresses resident on the CPU.
3 For SGEMM, DGEMM, CGEMM, ZGEMM, this will call accelerated version.
Warning: Passing a wrong CPU / GPU address will cause the program to crash.
36Performance Optimization on Blue Waters

Test 04: Speed up matrix multiplication by using OpenMP-threaded AMD Core Math Library
Challenge: Speed up application by using threaded library
Running the testmodule swap PrgEnv-cray PrgEnv-pgimodule add acmlcc -lacml -Wl,-ydgemm_ -o app1.x app.c
/opt/acml/5.3.1/pgi64_fma4/lib/libacml.a(dgemm.o): definition of dgemm_
cc -lacml -Wl,-ydgemm_ -mp=nonuma -o app2.x app.c/opt/acml/5.3.1/pgi64_fma4/lib/libacml.a(dgemm.o): definition of dgemm_
export OMP_NUM_THREADS=32aprun -n1 -cc none -d32 ./app1.x
aprun -n1 -cc none -d32 ./app2.x
aprun -n1 -d32 ./app2.x
Output: Time = 2.938, Time = 0.213, Time = 0.302
Take home lesson: Reuse instead of reinvent. “-Wl,-ydgemm_” tells where dgemm() was resolved from. “-cc none” allows OpenMP threads to migrate.
37Performance Optimization on Blue Waters

Profiling
38Performance Optimization on Blue Waters

The Cray Performance Analysis Tools
Supports traditional post-mortem performance analysis• Automatic identification of performance problems
o Indication of causes of problemso Suggestions of modifications for performance improvement
• pat_build: provides automatic instrumentation • CrayPAT run-time library collects measurements (transparent to the user)• pat_report performs analysis and generates text reports • pat_help: online help utility
To start working with CrayPAT:o module load perftoolso http://docs.cray.com/books/S-2376-612/S-2376-612.pdf
Performance Optimization on Blue Waters 39

Application Instrumentation with pat_build• Supports two categories of experiments−asynchronous experiments (sampling) capture values
from the call stack or the program counter at specified intervals or when a specified counter overflows
−Event-based experiments (tracing) count some events such as the number of times a specific system call is executed
• While tracing provides most detailed information, it can be very heavy if the application runs on a large number of cores for a long period of time
• Sampling (-S, default: -Oapa = sampling +HWPC + MPI tracing) can be useful as a starting point, to provide a first overview of the work distribution
Performance Optimization on Blue Waters 40

Example Runtime Environment Variables
• Optional timeline view of program available• export PAT_RT_SUMMARY=0 (minimize volume of tracing data)
• Request hardware performance counter information:• export PAT_RT_PERFCTR=1 (FLOP count)
Performance Optimization on Blue Waters 41

• blas Basic Linear Algebra subprograms• caf Co-Array Fortran (Cray CCE compiler only)• hdf5 manages extremely large data collection• heap dynamic heap• io includes stdio and sysio groups• lapack Linear Algebra Package• math ANSI math• mpi MPI• omp OpenMP API • pthreads POSIX threads• shmem SHMEM• sysio I/O system calls• system system calls• upc Unified Parallel C (Cray CCE compiler only)
For a full list, please see pat_build(1) man page
Predefined Trace Wrappers (-g tracegroup)
Performance Optimization on Blue Waters42

Example Experiments• > pat_build –O apa
• Gets top time consuming routines• Least overhead
• > pat_build –u –g mpi ./my_program• Collects information about user functions and MPI
• > pat_build –w ./my_program• Collections information for MAIN• Lightest-weight tracing
• > pat_build –g netcdf,mpi ./my_program• Collects information about netcdf routines and MPI
Performance Optimization on Blue Waters 43

Steps to Collecting Performance Data• Access performance tools software
% module load perftools
• Build application keeping .o files (CCE: -h keepfiles)
% make clean ; make
• Instrument application for automatic profiling analysiso You should get an instrumented program a.out+pat
% pat_build a.out
• Run application to get top time consuming routines % aprun … a.out+pat (or qsub <pat script>)
Performance Optimization on Blue Waters 44

Steps to Collecting Performance Data (2)
• You should get a performance file (“<sdatafile>.xf”) or multiple files in a directory <sdatadir>
• Generate report
% pat_report <sdatafile>.xf > sampling_report
Performance Optimization on Blue Waters 45

Example: HW counter data
46
PAPI_TLB_DM Data translation lookaside buffer misses PAPI_L1_DCA Level 1 data cache accesses PAPI_FP_OPS Average Rate of Floating point operations per single MPI task MFLOPS (aggregate) Total FLOP rate of the entire job
FLOP rate shows the efficiency of hardware utilization========================================================================USER------------------------------------------------------------------------ Time% 98.3% Time 4.434402 secs Imb.Time -- secs Imb.Time% -- Calls 0.001M/sec 4500.0 calls PAPI_L1_DCM 14.820M/sec 65712197 misses PAPI_TLB_DM 0.902M/sec 3998928 misses PAPI_L1_DCA 333.331M/sec 1477996162 refs PAPI_FP_OPS 445.571M/sec 1975672594 ops User time (approx) 4.434 secs 11971868993 cycles 100.0%Time Average Time per Call 0.000985 sec CrayPat Overhead : Time 0.1% HW FP Ops / User time 445.571M/sec 1975672594 ops 4.1%peak(DP) HW FP Ops / WCT 445.533M/sec Computational intensity 0.17 ops/cycle 1.34 ops/ref MFLOPS (aggregate) 1782.28M/sec TLB utilization 369.60 refs/miss 0.722 avg uses D1 cache hit,miss ratios 95.6% hits 4.4% misses D1 cache utilization (misses) 22.49 refs/miss 2.811 avg hits========================================================================
Performance Optimization on Blue Waters

Example: Time spent in User and MPI functions
47
Table 1: Profile by Function
Samp % | Samp | Imb. | Imb. |Group | | Samp | Samp % | Function | | | | PE='HIDE’ 100.0% | 775 | -- | -- |Total|-------------------------------------------| 94.2% | 730 | -- | -- |USER||------------------------------------------|| 43.4% | 336 | 8.75 | 2.6% |mlwxyz_|| 16.1% | 125 | 6.28 | 4.9% |half_|| 8.0% | 62 | 6.25 | 9.5% |full_|| 6.8% | 53 | 1.88 | 3.5% |artv_|| 4.9% | 38 | 1.34 | 3.6% |bnd_|| 3.6% | 28 | 2.00 | 6.9% |currenf_|| 2.2% | 17 | 1.50 | 8.6% |bndsf_|| 1.7% | 13 | 1.97 | 13.5% |model_|| 1.4% | 11 | 1.53 | 12.2% |cfl_|| 1.3% | 10 | 0.75 | 7.0% |currenh_|| 1.0% | 8 | 5.28 | 41.9% |bndbo_|| 1.0% | 8 | 8.28 | 53.4% |bndto_||==========================================| 5.4% | 42 | -- | -- |MPI||------------------------------------------|| 1.9% | 15 | 4.62 | 23.9% |mpi_sendrecv_|| 1.8% | 14 | 16.53 | 55.0% |mpi_bcast_|| 1.7% | 13 | 5.66 | 30.7% |mpi_barrier_|===========================================
Computation intensity
Communication intensity
vs.
Performance Optimization on Blue Waters

Test 05: Obtain FLOP count and User/MPI time• Challenge: What is application FLOP count? Use CrayPat
to perform profiling experiment and compare the result with manual count.
• Running the test:• module add perftools• cc -c app.c // compile the application• cc -o app.x app.o // link the application• pat_build app.x // instrument the application• qsub run // submit the job• aprun -n16 -d2 ./app.x+pat• pat_report app.x+pat*.xf > report.out
• Results:• MPI: 88.9%; USER: 11.1%; communication intensive job• FLOP count = 2 GF (hint – convert FLOP rate to FLOP count)
48Performance Optimization on Blue Waters
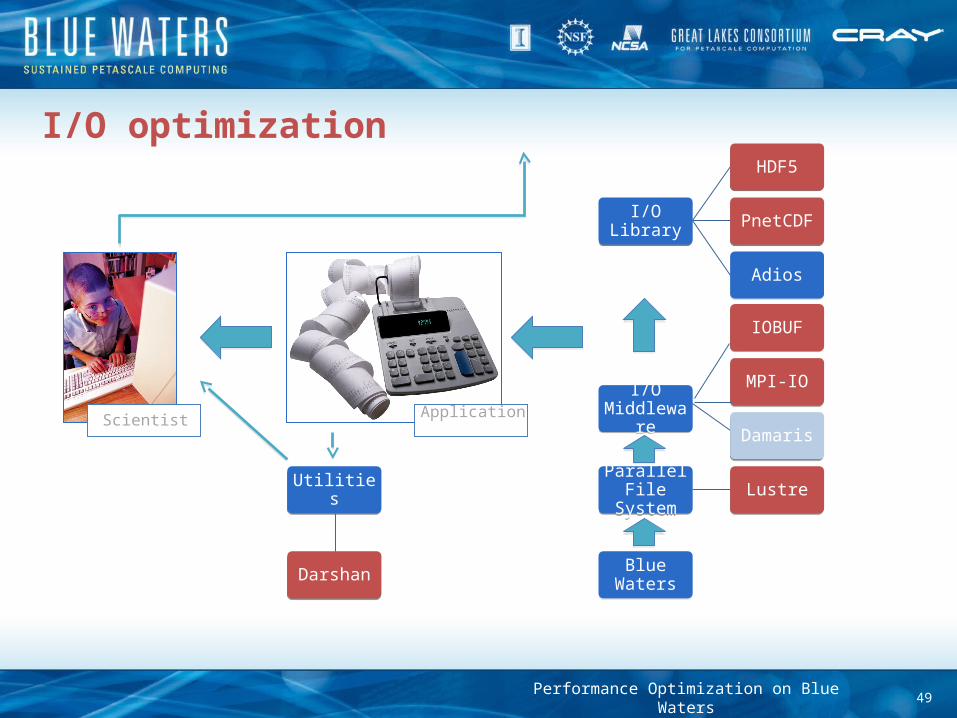
I/O optimization
Application…
I/O LibraryI/O Library
HDF5HDF5
PnetCDFPnetCDF
AdiosAdios
I/O Middleware
I/O Middleware
MPI-IOMPI-IO
DamarisDamaris
Parallel File System
Parallel File System LustreLustre
Scientist…
UtilitiesUtilities
DarshanDarshan Blue WatersBlue Waters
IOBUFIOBUF
Performance Optimization on Blue Waters 49

Lustre File System: Striping
• File striping: single files are distributed across a series of OSTs • File size can grow to the aggregate size of available
OSTs (rather than a single disk)• Accessing multiple OSTs concurrently increases I/O
bandwidth
LogicalPhysical
Performance Optimization on Blue Waters 50
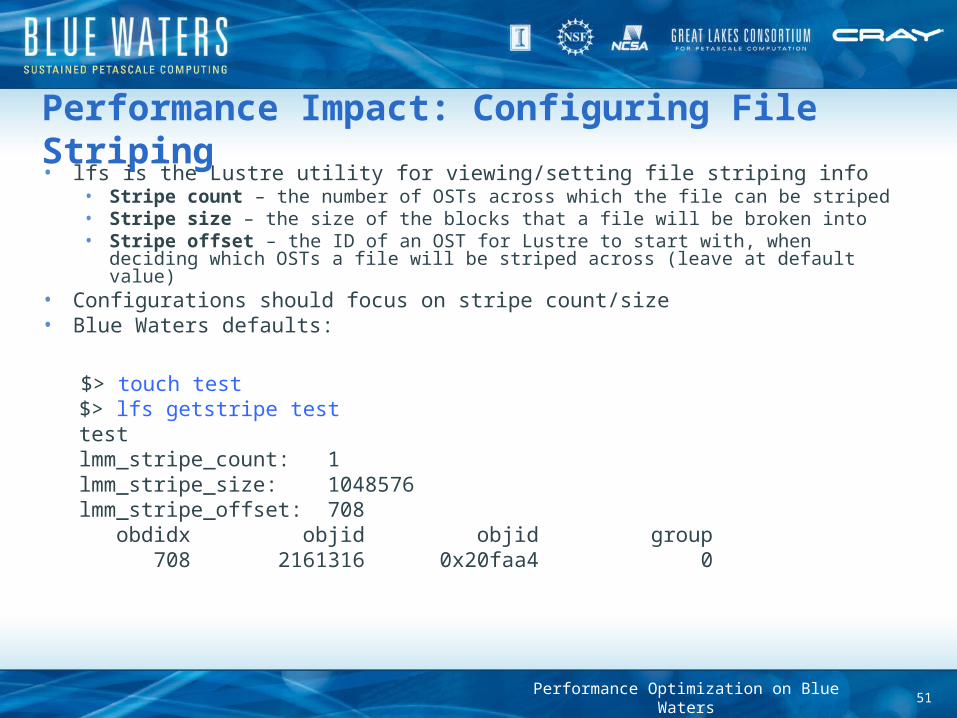
Performance Impact: Configuring File Striping• lfs is the Lustre utility for viewing/setting file striping info
• Stripe count – the number of OSTs across which the file can be striped• Stripe size – the size of the blocks that a file will be broken into• Stripe offset – the ID of an OST for Lustre to start with, when deciding which
OSTs a file will be striped across (leave at default value)• Configurations should focus on stripe count/size • Blue Waters defaults:
$> touch test $> lfs getstripe test test lmm_stripe_count: 1 lmm_stripe_size: 1048576 lmm_stripe_offset: 708 obdidx objid objid group 708 2161316 0x20faa4 0
Performance Optimization on Blue Waters 51

Setting Striping Patterns$> lfs setstripe -c 5 -s 32m test$> lfs getstripe testtestlmm_stripe_count: 5lmm_stripe_size: 33554432lmm_stripe_offset: 1259 obdidx objid objid group 1259 2162557 0x20ff7d 0 1403 2165796 0x210c24 0 955 2163063 0x210177 0 1139 2161496 0x20fb58 0 699 2161171 0x20fa13 0
•Note: a file’s striping pattern is permanent, and set upon creation• lfs setstripe creates a new, 0 byte file• The striping pattern can be changed for a directory; every new file or directory
created within will inherit its striping pattern• Simple API available for configuring striping – portable to other Lustre systems
Performance Optimization on Blue Waters 52

IOBUF – I/O Buffering Library
• Optimize I/O performance with minimal effort• Asynchronous prefetch
• Write back caching
• stdin, stdout, stderr disabled by default
• No code changes needed• module load iobuf
• Recompile & relink the code
• Ideal for sequential read or write operations
ApplicationApplicationIOBUFIOBUF
Linux IO infrastructureLinux IO infrastructureFile Systems / LustreFile Systems / Lustre
Performance Optimization on Blue Waters 53

IOBUF – I/O Buffering Library
• Globally (dis)enable by (un)setting IOBUF_PARAMS
• Fine grained control• Control buffer size, count, synchronicity, prefetch
• Disable iobuf per file
Example:
export IOBUF_PARAMS='*:verbose'
export IOBUF_PARAMS='*.in:count=4:size=32M,*.out:count=8:size=64M'
Performance Optimization on Blue Waters 54

IOBUF – MPI-IO Sample Verbose Output
Performance Optimization on Blue Waters 55

I/O Utility: Darshan
• Darshan was developed at Argonne• It is “a scalable HPC I/O characterization tool…
designed to capture an accurate picture of application I/O behavior… with minimum overhead”
• I/O Characterization• Sheds light on the intricacies of an application’s I/O • Useful for application I/O debugging• Pinpointing causes of extremes• Analyzing/tuning hardware for optimizations
• http://www.mcs.anl.gov/research/projects/darshan/
Performance Optimization on Blue Waters 56

Darshan Specifics
• Darshan collects per-process statistics (organized by file)• Counts I/O operations, e.g. unaligned and sequential
accesses• Times for file operations, e.g. opens and writes• Accumulates read/write bandwidth info• Creates data for simple visual representation
• More• Requires no code modification (only re-linking)• Small memory footprint• Includes a job summary tool
Performance Optimization on Blue Waters 57

Summary Tool Example Output
Performance Optimization on Blue Waters 58

Performance Optimization on Blue Waters 59

Test 06: Use Darshan to perform I/O analysis• Challenge: How much time the application spends in write
operation?• Running the test:
• module unload perftools• module load darshan• ftn app.f90 // compile the application• qsub run // submit the job
• export DARSHAN_LOGPATH=./• aprun -n16 -d2 ./a.out input.psf input.pdb
• darshan-job-summary.pl *.gz // get job summary• darshan-parser *.gz > darshan.log // get darshan log
• Results:• Calculation time = 10.6 seconds• IO write time = 6.0 seconds
60Performance Optimization on Blue Waters

Test 06: Three possible solutions
• Look in Darshan job-summary PDF file (figure above): 6.2 sec• Get from Darshan log for coor.xyz.0: CP_F_CLOSE_TIMESTAMP -
CP_F_OPEN_TIMESTAMP = 1401918203.0 – 1401918197.5 = 5.5 sec• Manually put timers in designated spots in the source code: 6.0 sec
61Presentation Title

Good I/O Practices• Opening a file for writing/appending is expensive, so:
• If possible, open files as read-only• Avoid large numbers of small writeswhile(forever){ open(“myfile”); write(a_byte); close(“myfile”); }
• Be gentle with metadata (or suffer its wrath)• limit the number of files in a single directory
• Instead opt for hierarchical directory structure• ls contacts the metadata server, ls –l communicates with every OST
assigned to a file (for all files)• Avoid wildcards: rm –rf *, expanding them is expensive over many files• It may even be more efficient to pass metadata through MPI than have all
processes hit the MDS (calling stat)• Avoid updating last access time for read-only operations (NO_ATIME)
Performance Optimization on Blue Waters 62

Thanks to
Kalyana Chadalavada, Robert Brunner, Manisha Gajbe,
Galen Arnold for contributing to this
presentation63
Acknowledgements