Embed Size (px)
Citation preview

OPTIMIZATION OF BIG DATA PROCESSING IN
PRIVATE CLOUD ENVIRONMENT 1Bhavika A Tailor,
2Prof HetalA Joshiara
1ME Student,
2Assistant Professor
Department of Computer Engineering,L.D College of Engineering, Gujarat Technological University.
Abstract-- Big data is emerging technology which is a massive volume of both structured and unstructured data that is so large. Hadoop
framework is used for processing and storing big data. Running Hadoop jobs in the cloud environment is beneficial because it provides flexible,
scalable, elastic, multitenant and on-demand infrastructure. Despite its potential benefits, it is a challenging task of running Hadoop jobs inside the
cloud environment. Performance of Hadoop cluster on cloud is affected due to virtualization, diversification of model, technologies, and tools.
Default Schedulers of the Hadoop framework are designed for a cluster environment. These schedulers only consider either time of arrival or the
maximum capacity guaranteed. These schedulers do not take scheduling decision based on the type of job and resource usage pattern. In this
research work, we have proposed scheduling algorithm which making job scheduling decisions based on job characteristics and resource(like
CPU, Memory, Network Bandwidth)usage pattern of virtual machines (DataNodes) with a purpose to reduce job execution time and improve
resources utilization.
Keywords-- Big data, Hadoop, Scheduling, cloud, Job characteristics, Node monitoring.
I.INTRODUCTION
Big data is a massive volume of data that is so huge like terabytes, petabytes of data generated through various kind of social media and
networking sites like facebook, twitter, Sensor devices, Scientific instruments, mobile devices, and mobile networks, web sites click and
various kind of transactions likes banking, e-commerce web site transaction. The velocity of big data generation is fast and required fast
processing like online data analytics. Big data is in variety of forms like structured, semi-structured and unstructured data like text,
images,pictures, numbers, audio, video, sensor data, social media data, static data, streaming data.Processing and storing these huge data on
the distributed hardware clusters need a powerful computation model like Hadoop [6].
Hadoop is an open source, a scalable, fault-tolerant framework written in Java. It is used for processing and storing big data. It performs
automatic parallelization and distribution of work. It consists of main three key components: HDFS(Hadoop distributed file system) is used
for storing data, Map reduce is used for data processing and YARN(Yet Another Resource Negotiation) is used for resource management.
Hadoop is basically designed for a cluster environment. On the downside, the cluster can be used by a single big data application,
resources cannot be scaled independently. It is challenging to manage, scale and upgrade the cluster.So, Hadoop jobs with huge computing
requirement are preferred to be executed on cloud due to the benefits like easy provision of infrastructure, scalability, pay-per-use,
flexibility, elasticity. Deployment of the cluster on cloud is affected by virtualization and multi-tenancy factor which affects the
performance of the job. Schedulers that are provided by Hadoop consider either time of arrival or the maximum capacity guaranteed. All the
schedulers are not considered parameters related to machine performance and job characteristics [11].
To solve this problem, Job scheduling and execution time of Hadoop job running on cloud can be optimized and make it suitable for a
cloud environment by making scheduling decision dynamic based on resource utilization pattern (CPU, Memory and Network Bandwidth)
of virtual machine and type of job if it is CPU or IO intensive. Our proposed algorithm makesa scheduling decision dynamically based on
job characteristics and current resource utilization pattern of computing nodes. Whenever a new job request will come, it will assign to the
appropriate computing nodes (Virtual machine)based on resource utilization pattern.The main aim of our proposed work is to improve job
execution time and improve resource utilization of virtual machines.
II. RELATED WORK
Xinzhu Lu Et al[2]
proposed a heartbeat mechanism for MapReduce Task Scheduler using Dynamic Calibration (HMTSDC) to address the
unbalanced node computation capacity problem in a heterogeneous MapReduce environment. HMTSDC uses two mechanisms to
dynamically adapt and balance tasks assigned to each compute node: 1) using heartbeat to dynamically estimate the capacity of the compute
nodes, and 2) using data locality of replicated data blocks to reduce data transfer between nodes.
JASC: Journal of Applied Science and Computations
Volume VI, Issue V, May/2019
ISSN NO: 1076-5131
Page No:2683

Chi-Ting Chen Et al[3]
proposed novel dynamic grouping and integrated neighboring search (DGNS) algorithm, which consider the node
ability on both Map Reduce and HDFS layer and balance the resource utilization and improve the performance and data locality in a
heterogeneous environment. The performance of the proposed algorithm was compared with that of the default FCFS job scheduling
policies of Hadoop.
Ibrahim AbakerTargioHashem Et al[4]
proposed model based on the combination of two main models, namely, completion time and cost, to
fulfill the performance objectives and maximize the efficiency of a Hadoop cluster in the cloud. A scheduling algorithm is proposed based
on the adopted earliest finish time algorithm to establish the relationship between resource allocation and job scheduling.
Godwin Caruana Et al[7]
proposed gSched, Proposed algorithm establishes the estimated time to compute each task on each participating
node. This is based on the performance characteristics of nodes and task characteristics. gSched employs a machine learning approach to
allocate tasks to appropriate computing nodes based on their characteristics from the same task to establish the most appropriate nodes for
tasks to be scheduled. This enables gSched to better utilize Hadoop cluster resources and minimize job execution time.
Yi Yao Et al[8]
proposed OPERA,A new opportunistic resource allocation approach,which leverages the knowledge of the actual runtime
resource utilization to determine the availability of system resources and dynamically re-assigns idle resources to the waiting tasks. The
primary goal of this design is to break the barriers among the encapsulated resource containers and share the reserved resources among
different tasks such that the overall resource utilization and system throughput can be improved.
AdepuSree LakshmiEt al[10]
design a dynamic capacity scheduler which schedules MapReduce application considering job and VM
characteristics. The proposed work is done in three modules 1.Job resource requirements classification 2. Virtual machine state
classification 3. Scheduling based on above two classifications of job and VM state and assign job to the appropriate virtual machine.
Wei Yan Et al[14]
is proposed maximum node hit rate priority algorithm (MNHRPA) and it can achieve load balancing by dynamic
adjustment of data allocation based on nodes’ computing power and load. This algorithm can effectively reduce tasks’ completion time and
achieve load balancing of the cluster compared with Hadoop's default algorithm.
III. APACHE HADOOP
Hadoop is an open source framework that allows distributed processing of large data sets across the cluster of commodity hardware.
Hadoop is a scalable and fault tolerant framework written in Java. It is used for processing and storing big data.
It consists of the main three components:
a) HDFS: It is used for storing data.
b) Map Reduce: It is used for data processing
c) YARN: It is used for resource management.
Shown in fig 1. The Master node is a Name Node and slave node is a Data Node in Hadoop HDFS. The Name Node store metadata in
HDFS. Data Node store actual data and complex computation in HDFS. In MapReduce parallel processing name node is known as Job
tracker and slave node is known as Task tracker. Every slave node has a Task Tracker daemon and a Data Node that synchronizes the
processes with the Job Tracker and Name Node respectively [6].
When even user sends a job request to Job tracker its divided task into the
map and the reduce tasks. Job tracker assigns these tasks to Task tracker. All Task tracker execute all tasks assigned to them in parallel.
After completion of their tasks returns the result to the master node. Reduce process reorganize data and collect the result then send to the
user.
Hadoop is essentially intended for the cluster environment. On the downside, the cluster is suitable for a single big data application.
Resources cannot be scaled independently in the cluster. It is hard to manage, scale and upgrade the cluster Hadoop having huge processing
prerequisite are like to be executed on the cloud because of advantages like easy provision of the framework, adaptability, pay-per-use,
scalability,flexibility[11].
JASC: Journal of Applied Science and Computations
Volume VI, Issue V, May/2019
ISSN NO: 1076-5131
Page No:2684

Fig. 1 Sequence in Hadoop framework[5]
IV PROPOSED ALGORITHM
In our proposed work, the usage pattern of the data nodes is checked periodically. CPU utilization, Memory utilization and Network
bandwidth of data nodes are fetched. The total utilization of resources is calculated by considering the weighting factors of each resource.
We build the underutilized queue of the data nodes by calculating the median of total utilization of resources of data nodes. The Weighting
factor of CPU, Memory and Network Bandwidth are adaptive based on Job type (CPU or IO intensive). Whenever the request will come
then it will be served with these underutilized data nodes i.e., Virtual machines. Here weighting factors w1, w2, and w3 are adaptive based
on the type of job.w1 in the CPU intensive job accounted for a relatively high and w2 in the I/O intensive job accounted for relatively high.
Ex. If the job is CPU intensive than set values 0.7 for w1, 0.2 for w2 and 0.1 for w3. If the job is IO intensive than set values 0.2 for w1, 0.7
for w2 and 0.1 for w3.where w1, w2 and w3 are resources’ weight coefficient they represent respectively the important proportion CPU,
memory and Network bandwidth.According to the definition, it can be known that w1 +w2 +w3=1.
Algorithm 1: Job classification
For all the job in the job queue
If the job.type== cpu_intensive
CPU_intensive[] job_id
Else if job.type == IO_intensive
IO_intensive[] job_id
End if
End for
Algorithm 2: Node_Monitoring
For every periodic interval
For all the data node (VMs)
CPU_util[] getCPUUtilization()
Mem_util[] getMemoryUtilization()
Net_bandwidth [] getNetworkBandwidth()
End for
JASC: Journal of Applied Science and Computations
Volume VI, Issue V, May/2019
ISSN NO: 1076-5131
Page No:2685
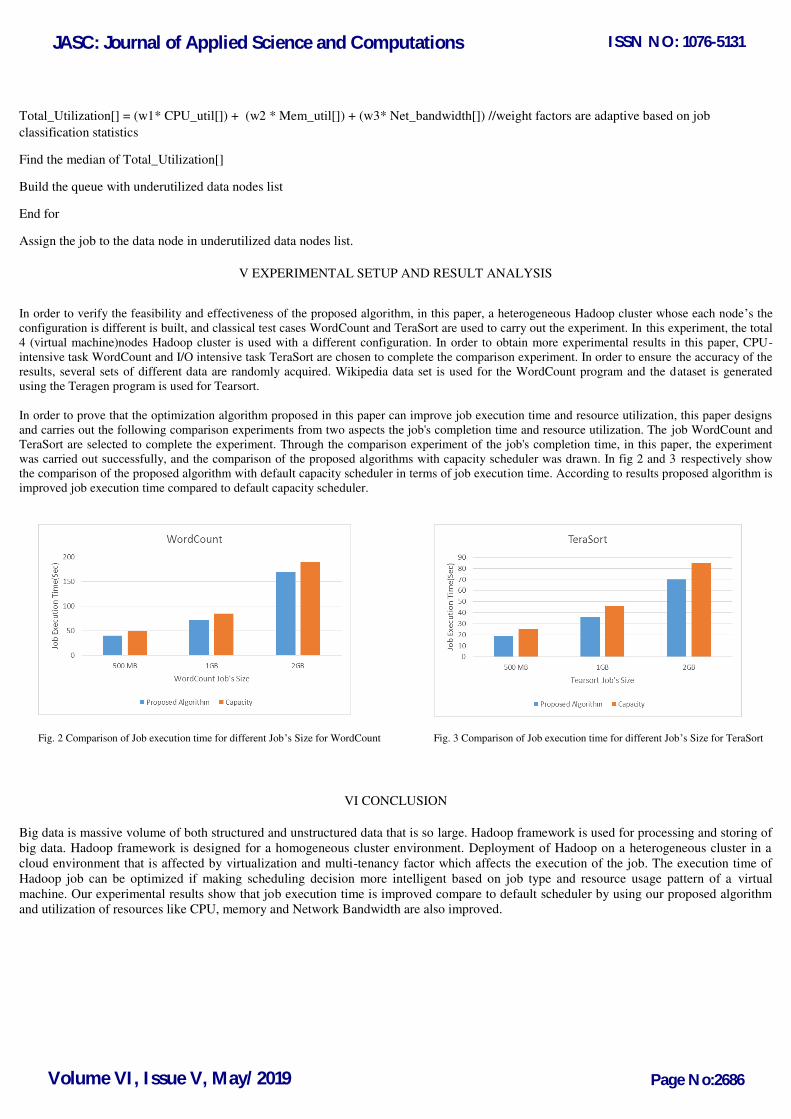
Total_Utilization[] = (w1* CPU_util[]) + (w2 * Mem_util[]) + (w3* Net_bandwidth[]) //weight factors are adaptive based on job
classification statistics
Find the median of Total_Utilization[]
Build the queue with underutilized data nodes list
End for
Assign the job to the data node in underutilized data nodes list.
V EXPERIMENTAL SETUP AND RESULT ANALYSIS
In order to verify the feasibility and effectiveness of the proposed algorithm, in this paper, a heterogeneous Hadoop cluster whose each node’s the
configuration is different is built, and classical test cases WordCount and TeraSort are used to carry out the experiment. In this experiment, the total
4 (virtual machine)nodes Hadoop cluster is used with a different configuration. In order to obtain more experimental results in this paper, CPU-
intensive task WordCount and I/O intensive task TeraSort are chosen to complete the comparison experiment. In order to ensure the accuracy of the
results, several sets of different data are randomly acquired. Wikipedia data set is used for the WordCount program and the dataset is generated
using the Teragen program is used for Tearsort.
In order to prove that the optimization algorithm proposed in this paper can improve job execution time and resource utilization, this paper designs
and carries out the following comparison experiments from two aspects the job's completion time and resource utilization. The job WordCount and
TeraSort are selected to complete the experiment. Through the comparison experiment of the job's completion time, in this paper, the experiment
was carried out successfully, and the comparison of the proposed algorithms with capacity scheduler was drawn. In fig 2 and 3 respectively show
the comparison of the proposed algorithm with default capacity scheduler in terms of job execution time. According to results proposed algorithm is
improved job execution time compared to default capacity scheduler.
Fig. 2 Comparison of Job execution time for different Job’s Size for WordCount
Fig. 3 Comparison of Job execution time for different Job’s Size for TeraSort
VI CONCLUSION
Big data is massive volume of both structured and unstructured data that is so large. Hadoop framework is used for processing and storing of
big data. Hadoop framework is designed for a homogeneous cluster environment. Deployment of Hadoop on a heterogeneous cluster in a
cloud environment that is affected by virtualization and multi-tenancy factor which affects the execution of the job. The execution time of
Hadoop job can be optimized if making scheduling decision more intelligent based on job type and resource usage pattern of a virtual
machine. Our experimental results show that job execution time is improved compare to default scheduler by using our proposed algorithm
and utilization of resources like CPU, memory and Network Bandwidth are also improved.
JASC: Journal of Applied Science and Computations
Volume VI, Issue V, May/2019
ISSN NO: 1076-5131
Page No:2686

REFERENCES
[1] Yi Yao, Han Gao,JiayinWangy, Bo Shengy and NingfangMi, “New Scheduling Algorithms for Improving Performance and Resource
Utilization in Hadoop YARN Clusters”, IEEE Transactions on Cloud Computing, 2018.
[2] Xinzhu Lu and KeatkeongPhang, “An Enhanced Hadoop Heartbeat Mechanism for MapReduce Task Scheduler Using Dynamic
Calibration”, IEEE China Communications,2018,93-110.
[3] Chi-Ting Chen, Ling-Ju Hung, Sun-Yuan Hsieh, RajkumarBuyya and Albert Y. Zomaya,” Heterogeneous Job Allocation Scheduler for
Hadoop MapReduce Using Dynamic Grouping Integrated Neighboring Search”, IEEE Transactions on Cloud Computings,2017.
[4] Ibrahim AbakerTargioHashem, Nor BadrulAnuar, Mohsen Marjani, Abdullah Gani, Arun Kumar Sangaiah and
AdewoleKayodeSakariyah,” Multi-objective scheduling of MapReduce jobs in big data processing.”, Springer, Science Business Media
New York,2017.
[5] Ehab Mohamed and Zheng Hong,”Hadoop -Map Reduce job scheduling algorithm survey”, IEEE 7th International Conference on
Cloud Computing and Big Data, 2016,237-242.
[6] Bhavin J. Mathiya and Vinodkumar L. Desai, “Apache Hadoop Yarn Parameter Configuration Challenges and Optimization”,IEEE
International Conference on Soft-Computing and Network Security (ICSNS -2015), Feb 25 – 27, 2015.
[7] Godwin Caruana, Maozhen Li Man Qi, Mukhtaj Khan and Omer Rana,” gSched: a resource aware Hadoop scheduler for heterogeneous
cloud computing environments”, John Wiley & Sons, Ltd. concurrency and computation: practice and experience, 2016.
[8] Yi Yao, Han Gao, Jiayin Wang, NingfangMi, Bo Sheng,” OPERA: Opportunistic and Efficient Resource Allocation in Hadoop YARN
by Harnessing Idle Resources”, IEEE 2016.
[9] Rashmi S, Dr AnirbanBasu,” Deadline constrained Cost Effective Workflow Scheduler for Hadoop clusters in Cloud Datacenter.”, IEEE
International Conference on Computational Systems and Information Systems for Sustainable Solutions, 2016,409-415.
[10] AdepuSree Lakshmi, N. Subhash Chandra and M. BalRaju,” Optimized Capacity Scheduler for MapReduce Applications in Cloud
Environments”, Springer Nature Singapore V. E. Balas et al. (eds.), Data Management, Analytics and Innovation,Advances in
Intelligent Systems and Computing 808, 2018.
[11] Jayalakshmi D S,,SyedaRabiyaAlam and R Srinivasan,”Approaches to Deployment of Hadoop on Cloud Platforms: Analysis and
Research Issues”, 2nd IEEE International Conference On Recent Trends in Electronics Information & Communication Technology
(RTEICT), May 19-20, 2017,1985-1990.
[12]Bhavin J. Mathiya and Vinodkumar L. Desai,” Apache Hadoop Yarn MapReduce Job Classification Based on CPU Utilization and
Performance Evaluation on Multi-cluster Heterogeneous Environment”. Proceedings of International Conference on ICT for
Sustainable Development, Advances in Intelligent Systems and Computing,springer ,2016.
[13] MohdUsama, Mengchen Liu, Min Chen,” Job schedulers for Big data processing in Hadoop environment: testing real-life schedulers
using benchmark programs”, Digital Communications and Networks3, 2017 260–273.
[14] Wei Yan, ChunLin Li, ShuMeng Du, XiJun Mao,” An Optimization Algorithm for Heterogeneous Hadoop Clusters Basedon
Dynamic Load Balancing,”IEEE 17th International Conference on Parallel and Distributed Computing, Applications and
Technologies”, 2016, 250-255.
[14] Chao Tian, HaojieZhou,Yongqiang He, Li Zha,” A Dynamic MapReduce Scheduler for Heterogeneous Workloads”, IEEE Eighth
International Conference on Grid and Cooperative Computing, 2009, 218-224.
[15] Tharam Dillon, Chen Wu and Elizabeth Chang,”Cloud Computing: Issues and Challenges”, 24th
IEEE International Conference on
Advanced Information Networking and Applications, 2010, 27-33.
[16] SwathiPrabhu, Anisha P Rodrigues, Guru Prasad M S and Nagesh H R “Performance Enhancement of HadoopMapReduce Framework
for AnalyzingBigData” IEEE,2015.
JASC: Journal of Applied Science and Computations
Volume VI, Issue V, May/2019
ISSN NO: 1076-5131
Page No:2687





























