Embed Size (px)
Citation preview

Operations Research
fur Wirtschaftsinformatiker
Vorlesungsskript
von
Richard Mohr
Fachhochschule Esslingen, SS 2005

INHALTSVERZEICHNIS i
Inhaltsverzeichnis
1 Lineare Optimierung 1
1.1 Graphische Losung des linearen Optimierungsproblems . . . . . . . . . . . 1
1.2 Austauschverfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.3 Simplexverfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.4 Bestimmung einer zulassigen Basislosung . . . . . . . . . . . . . . . . . . . 13
1.5 Sonderfalle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
1.5.1 Probleme, die keine Losung besitzen . . . . . . . . . . . . . . . . . 17
1.5.2 Probleme mit unbeschranktem zulassigem Bereich . . . . . . . . . . 18
1.5.3 Probleme mit mehreren optimalen Basislosungen . . . . . . . . . . 19
1.5.4 Probleme mit degenerierter optimaler Basislosung . . . . . . . . . . 20
1.6 Erganzungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
1.6.1 Gleichungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
1.6.2 Opportunitatskosten . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2 Transportprobleme 29
2.1 Problemstellung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
2.2 Transportalgorithmus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
2.2.1 Rechenschema . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
2.2.2 Nord-West-Ecken-Regel . . . . . . . . . . . . . . . . . . . . . . . . 34
2.2.3 Optimalitatstest . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
2.2.4 Fiktive Quellen und Senken . . . . . . . . . . . . . . . . . . . . . . 43
2.2.5 Abweichende Problemstellungen . . . . . . . . . . . . . . . . . . . . 46
2.3 Umladeprobleme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
2.4 Zuordnungsproblem . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
3 Dynamische Optimierung 56
3.1 Darstellung mehrstufiger Entscheidungsprozesse . . . . . . . . . . . . . . . 57
3.2 Losungsprinzip der dynamischen Optimierung . . . . . . . . . . . . . . . . 59
3.3 Stochastische Probleme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
4 Nichtlineare Optimierung 70
4.1 Losungsverfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79

ii INHALTSVERZEICHNIS
5 Warteschlangentheorie 86
5.1 Klassifizierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
5.2 Modellierung von Wartesystemen . . . . . . . . . . . . . . . . . . . . . . . 90
5.3 Das Wartesystem M|M|1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
5.3.1 Gleichgewichtsfall des Systems M|M|1 . . . . . . . . . . . . . . . . . 97
5.4 Ausblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
5.4.1 Endlicher Warteraum . . . . . . . . . . . . . . . . . . . . . . . . . . 104
5.4.2 Das Wartesystem M|M|s . . . . . . . . . . . . . . . . . . . . . . . . 106
5.4.3 Das Wartesystem M|Ek|1 . . . . . . . . . . . . . . . . . . . . . . . . 108
5.4.4 Einschwingverhalten . . . . . . . . . . . . . . . . . . . . . . . . . . 110
5.4.5 Simulation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112
6 Simulation 114
6.1 Begriff Simulation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114
6.2 Erzeugen und Testen von Zufallszahlen . . . . . . . . . . . . . . . . . . . . 115
6.2.1 Erzeugung und Test gleichverteilter Zufallszahlen . . . . . . . . . . 115
6.2.2 Erzeugung diskret verteilter Zufallszahlen . . . . . . . . . . . . . . 118
6.2.3 Erzeugung kontinuierlich verteilter Zufallszahlen . . . . . . . . . . . 119
6.3 Beispiele . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123
6.3.1 Satzgewinn beim Tennis . . . . . . . . . . . . . . . . . . . . . . . . 123
6.3.2 Simulation eines M|M|1-Warteschlangenmodells . . . . . . . . . . . 125
6.3.3 Ein Entscheidungsproblem . . . . . . . . . . . . . . . . . . . . . . . 127
Literaturverzeichnis 123
Index 124

1
1 Lineare Optimierung
Ein Programm zur linearen Optimierung ist fester Bestandteil jedes Software-Pakets zum
Thema Operations Research. Hier soll nur die grundsatzliche Vorgehensweise erlautert
werden. Zunachst wollen wir fur den Fall von zwei Variablen einen grahpischen Losungs-
weg skizzieren. Bei der Formulierung des allgemeinen Losungsverfahrens benotigen wir
eine Umformulierung des Gauß-Algorithmus zur Losung linearer Gleichungssysteme, das
sogenannte”Austauschverfahren“. Dies wird in einem Unterabschnitt bereitgestellt.
1.1 Graphische Losung des linearen Optimierungs-
problems
Zunachst machen wir uns die Problematik an einem einfachen Beispiel klar:
Eine Schuhfabrik stellt Damen- und Herrenschuhe her. Der beim Verkauf erzielte Gewinn
(Deckungsbeitrag) betrage bei Herrenschuhen 32 C, bei Damenschuhen nur 16 C. Die
Herstellung der Schuhe unterliegt bestimmten (stark vereinfachten) Nebenbedingungen,
welche die monatlich zur Verfugung stehende Zahl der Arbeitsstunden und Maschinenlauf-
zeiten sowie die in diesem Zeitraum verfugbare Ledermenge betreffen. Diese Annahmen
sind in der folgenden Tabelle zusammengefasst:
Damenschuh Herrenschuh verfugbar
Herstellungszeit [h] 20 10 800
Maschinenbearbeitung [h] 4 5 200
Lederbedarf [dm2] 6 15 450
Gewinn [ C] 16 32
Wir fuhren als Variable ein:
x1 = Zahl der produzierten Damenschuhe
x2 = Zahl der produzierten Herrenschuhe .
Damit konnen wir unsere Optimierungsaufgabe wie folgt formulieren:
20x1 + 10x2 ≤ 800 (1) g1 : 20x1 + 10x2 = 80
4x1 + 5x2 ≤ 200 (2) g2 : 4x1 + 5x2 = 200
6x1 + 15x2 ≤ 450 (3) g3 : 6x1 + 15x2 = 450
x1 ≥ 0 (4) g4 : x1 = 0
x2 ≥ 0 (5) g5 : x2 = 0
16x1 + 32x2 = Max! .

2 1 Lineare Optimierung
Die ersten drei Ungleichungen berucksichtigen die zu beachtenden Nebenbedingungen, die
beiden weiteren Ungleichungen den Tatbestand, dass die Zahl der produzierten Schuhe
nicht negativ sein kann. Die letzte Zeile gibt die zu maximierende Zielfunktion an.
Da unser Problem nur zwei Variable enthalt, kann es graphisch in der (x1, x2)-Ebene gelost
werden. Die Menge der Punkte (x1, x2), die eine der linearen Ungleichungen
ai1x1 + ai2x2 ≤ bi
erfullt, besteht aus einer Halbebene, d.h. aus allen Punkten oberhalb oder unter der Grenz-
gerade gi (je nach Vorzeichen der ai1, ai2)
ai1x1 + ai2x2 = bi .
Die funf Ungleichungen unseres Beispiels definieren auf diese Weise funf Halbebenen. Ein
zulassiger Punkt muss demnach im Durchschnitt dieser funf Halbebenen liegen.
A B
C
D
E
10
10
g1
g2
g316x1 + 32x2 = const.
Eckpunkte des zulassigen Bereichs
A(0|0) : (4) ∩ (5)
B(40|0) : (1) ∩ (5)
C(1003|40
3) : (1) ∩ (2)
D(25|20) : (2) ∩ (3)
E(0|30) : (3) ∩ (4)
Die Zielfunktion z = 16x1 + 32x2 ist zu maximieren.
Die Gerade 16x1 + 32x2 = c enthalt alle Punkte mit konstantem Gewinn c.
Damit c maximal wird, verschieben wir diese Gerade moglichst weit parallel nach oben, so
dass noch mindestens ein zulassiger Punkt darauf liegt. Man erkennt unschwer, dass der
Punkt D(25|20) zu optimalem Gewinn fuhrt:
z = 16 · 25 + 32 · 20 = 1040 .

1.1 Graphische Losung des linearen Optimierungsproblems 3
Aus der graphischen Losung entnehmen wir noch eine zusatzliche Information. Der Losungs-
punkt liegt auf den beiden Geraden g2, g3 wahrend g1 nicht tangiert wird. Dies bedeutet,
dass die verfugbare Maschinenzeit und die Ledermenge aufgebraucht sind, wahrend bei
den Arbeitsstunden noch freie Kapazitat vorhanden ist.
Dieses Verfahren lasst sich auf beliebig viele Ungleichungen anwenden.
m Lineare Ungleichungen in zwei Variablen
a11 · x1 + a12 · x2 ≤ b1
a21 · x1 + a22 · x2 ≤ b2
......
......
...
am1 · x1 + am2 · x2 ≤ bm
Die Losungsmenge jeder Ungleichung ist eine
Halbebene – je nach Vorzeichen von ai2 der
Bereich”unter“ oder
”uber“ der Grenzgerade
ai1 · x1 + ai2 · x2 = ci .
Die Festlegung”unter“ oder
”uber“ geschieht am besten durch eine Punktprobe. So kann
man zum Beispiel durch Einsetzen des Koordinatenursprungs in die Ungleichung uber-
prufen, ob dieser Punkt zur gesuchten Halbebene gehort.
Bemerkung: Auch Ungleichungen der Form1
ak1 · x1 + ak2 · x2 ≥ bk
lassen sich durch Multiplikation mit dem Faktor (−1) in die gewunschte Form bringen.
−ak1 · x1 − ak2 · x2 ≤ − bk
Als Losungsmenge eines solchen linearen Un-
gleichungssystems ergibt sich ein durch Gera-
denstucke begrenztes Gebiet (zulassiger Bereich)
in der (x, y)-Ebene. Die Eckpunkte ergeben sich
als Schnitt von zwei Geraden, d.h. als Losung ei-
nes linearen Gleichungssystems in zwei Variablen.
ai · x + bi · y = bi
aj · x + bj · y = bj
Um Eckpunkt des Gebiets zu sein, mussen auch
alle ubrigen Ungleichungen erfullt sein.
x
y
Optimierung der Zielfunktion z(x1, x2) = c1 · x1 + c2 · x2 + d!= Max
Die Zielfunktion ist eine lineare Funktion der Variablen x1 und x2. Ihre Niveaulinien
z(x1, x2) = constant bestehen aus einer Schar paralleler Geraden.
1Die Darstellungsform des Ungleichungssystems ist leider nicht einheitlich geregelt.

4 1 Lineare Optimierung
Die optimale Lage der Geraden
c1 · x1 + c2 · x2 = γ
ergibt sich durch Parallelverschiebung.
Ist die Losungsmenge des Ungleichungssystems beschrankt, so liegt die optimale Losung
in einem Eckpunkt. Sind zwei benachbarte Eckpunkte Losung des Optimierungsproblems,
so auch die gesamte Verbindungsstrecke.
Rechenstrategie: Man berechnet die Zielfunktion an allen Eckpunkten, vergleicht deren
Werte und bestimmt so den optimalen Punkt (x∗1|x∗2).
1.2 Austauschverfahren
In diesem Abschnitt wollen wir einen Algorithmus fur die Losung von linearen Glei-
chungssystemen entwickeln. Der im Folgenden dargestellte Algorithmus entspricht inhalt-
lich dem bekannten Gauß-Algorithmus, ergibt aber formal eine andere Datenorganisation.
Die grundlegenden Schritte seien bei der Losung eines 2× 2-Systems erlautert.
a11x1 + a12x2 = b1 (1)
a21x1 + a22x2 = b2 (2)
Die direkte Anwendung des Gauß-Algorithmus fuhrt auf die folgenden Umformungen: a11 a12 b1
a21 a22 b2
∼
1 a12
a11
b1a11
a21 a22 b2
| ·(−a21)
¾∼
1 a12
a11
b1a11
0 a22 − a12a21a11
b2 − b1a21a11
Wir erhalten dasselbe Ergebnis, wenn wir das aus der Schule bekannte”Einsetzverfahren“
anwenden. Dazu losen wir die erste Gleichung nach x1 auf.
a11x1 + a12x2 = b1 ; x1 = b1a11
− a12a11
x2
Eingesetzt in die zweite Gleichung ergibt sich:
a21
(b1a11
− a12a11
x2
)+ a22x2 = b2 bzw. 0 ·x1 +
(a22 − a12a21
a11
)·x2 = b2− b1a21
a11
Dies entspricht genau der zweiten Zeile des Matrix-Schemas.
Wir wollen nun analog zum Vorgehen beim Invertieren einer Matrix das lineare Gleichungs-
system vollstandig nach den Variablen xi auflosen. Bezeichnen wir die Koeffizienten des
neuen Schemas mit αij bzw. βk, so erhalten wir: 1 α12 β1
0 α22 β2
∼
1 α12 β1
0 1β2α22
|·(−α12)
¾
∼ 1 0 β1 − β2α12
α22
0 1β2α22

1.2 Austauschverfahren 5
Dieser Schritt entspricht wieder dem Auflosen der zweiten Gleichung nach x2 und anschlie-
ßendem Einsetzen in die erste Gleichung.
α22x2 = β2 ; x2 =β2α22
; x1 + α12
(β2α22
)= β1 ;
x1 + 0 · x2 = β1 − α12β2α22
In der letzten Spalte steht nun die Losung des linearen Gleichungssystems. Wir begreifen
die Division durch das Element a11 bzw. α22 und anschließendes Einsetzen in die verblie-
benene Gleichungen als einen Rechenschritt. Die Rechenregeln fur das Umstellen wollen
wir im Folgenden allgemein formulieren. a11 a12 b1
a21 a22 b2
∼
1 a12
a11
b1a11
0 a22 − a12a21a11
b2 − b1a21a11
1 α12 β1
0 α22 β2
∼
1 0 β1 − β2α12
α22
0 1β2α22
Das eingerahmte Element nennt man Pivotelement. Bezogen auf dieses Element apq erge-
ben sich die folgenden Regeln.
Rechenregeln
a) Das Pivotelement geht in 1 uber.
b) Die ubrigen Elemente der Pivotzeile sind durch das Pivotelement zu dividieren.
c) Die verbleibenden Elemente der Pivotspalte sind mit 0 zu belegen.
d) Die restlichen Elemente werden nach der sogenannten Rechteckregel transformiert.
Ist apq das Pivotelement, so ergeben sich die neuen Elemente durch:
a′ik = 1apq
aik aiq
apk apq
= aik − aiq · apkapq
i 6= p ; k 6= q .
Dieses Schema,”Austauschverfahren“ genannt, lasst sich auch auf nichtquadratische Sys-
teme ubertragen. Zur Unterscheidung zum Gauß-Algorithmus benutzen wir eine andere
außere Form.
Beispiel 1.1:x1 − x2 + 3x3 = 5
2x1 + 3x2 + x3 = −10
x1 x2 x3 b
1 −1 3 5
2 3 1 −10
x1 x2 x3 b
1 −1 3 5
0 5 −5 −20
x1 x2 x3 b
1 0 2 1
0 1 −1 −4

6 1 Lineare Optimierung
Als lineares Gleichungssystem geschrieben erhalt man aus dem letzten Tableau:
x1 + 0 · x2 + 2x3 = 1
0 · x1 + x2 − x3 = −4bzw. mit x3 = t
x1 = 1 − 2t
x2 = −4 + t
x3 = t
Es ist uns gelungen, die Variablen x1 und x2 in Abhangigkeit von x3 darzustellen. Wir
nennen in Zukunft diese Variable, deren Spalten in obigem Schema Einheitsvektoren sind,
Basisvariable. Es ist ublich, diese Variable in der ersten Spalte des Schemas zu notieren.
Das Austauschverfahren eignet sich auch zur Inversion einer Matrix.
Beispiel 1.2:y1 = 2x1 + x2
y2 = 5x1 + 3x2
BV x1 x2 y1 y2
y1 2 1 1 0
y2 5 3 0 1
BV x1 x2 y1 y2
x1 1 12
12
0
y2 0 12
−52
1
BV x1 x2 y1 y2
x1 1 0 3 −1
x2 0 1 −5 2
Nun wird auch die Bezeichnung”Austauschverfahren“ plausibel. Die Basisvariablen y1, y2
wurden gegen die Basisvariablen x1, x2 ausgetauscht.
Das Austauschverfahren lasst sich auch auf ein eindeutig bestimmtes lineares Gleichungs-
system anwenden.
Beispiel 1.3: x1 + 2x2 + 3x3 + 4x4 = 3
5x1 + 6x2 + 7x3 + 8x4 = 7
7x1 + 6x2 + 6x3 + 4x4 = 7
8x1 + 4x2 − 5x4 = 1
BV x1 x2 x3 x4 bi
1 2 3 4 3
5 6 7 8 7
7 6 6 4 7
8 4 0 −5 1
∼
BV x1 x2 x3 x4 bi
x1 1 2 3 4 3
0 -4 −8 −12 −8
0 −8 −15 −24 −14
0 −12 −24 −37 −23
∼
BV x1 x2 x3 x4 bi
x1 1 0 −1 −2 −1
x2 0 1 2 3 2
0 0 1 0 2
0 0 0 −1 1
∼
BV x1 x2 x3 x4 bi
x1 1 0 0 −2 1
x2 0 1 0 3 −2
x3 0 0 1 0 2
0 0 0 -1 1
∼
BV x1 x2 x3 x4 bi
x1 1 0 0 0 −1
x2 0 1 0 0 1
x3 0 0 1 0 2
x4 0 0 0 1 −1
⇒
x1 = −1
x2 = 1
x3 = 2
x4 = −1

1.3 Simplexverfahren 7
Bemerkung: Unter numerischen Gesichtspunkten wird man wegen Rundungsfehlern bei der
Auswahl der Pivotelemente nicht unbedingt entlang der”Hauptdiagonale“ vorgehen. Man
versucht durch Vertauschen von Zeilen (und gegebenenfalls auch Spalten) ein betragsmaßig
großes Element als Pivotelement festzulegen.
1.3 Simplexverfahren
Optimierungsprobleme fur mehr als zwei Variable lassen sich prinzipiell wie im Abschnitt
1.1 losen. Auch hier muss der optimale Punkt eine”Ecke“ des zulassigen Bereichs sein.
Bei n Variable werden die zulassigen Bereiche durch”Hyperebenen“ im IRn begrenzt. Um
diese Eckpunkte zu bestimmen mussen zunachst n lineare Gleichungen (entstanden aus n
linearen Ungleichungen durch Ubergang zum Gleichheitszeichen) gelost werden. Anschlie-
ßend ist zu uberprufen, ob auch die ubrigen Ungleichungen erfullt sind. Danach muss
die Zielfunktion in allen zulassigen Eckpunkten berechnet werden um das Optimum zu
bestimmen. Da die Anzahl der Eckpunkte rasch mit der Anzahl der Variablen und der
Nebenbedingungen wachst, ist diese Vorgehensweise nicht effektiv2. Ein sinnvolles Verfah-
ren sollte nur wenige Eckpunkte uberprufen und gezielt den optimalen Punkt suchen. Es
sollte
• nie von einer Ecke zu einer anderen mit geringerem Zielfunktionswert ubergehen;
• ein Abbruchkriterium besitzen, welches es gestattet zu entscheiden, ob der gegenwartig
uberprufte Eckpunkt optimal ist oder weiter gesucht werden soll, oder ob das Pro-
blem unlosbar ist.
Das bekannteste Verfahren, dass obige Kriterien erfullt, ist das Simplexverfahren. Es wird
im Folgenden vorgestellt.
Die Grundidee des Verfahrens wollen wir an dem eingangs behandelten Beispiel der Opti-
mierung der Schuhproduktion deutlich machen. (vgl. Abschnitt 1.1)
Die Zielfunktion z = 16x1 + 32x2 war unter den nachfolgenden Nebenbedingungen zu
maximieren. Zunachst wollen wir uns nur mit den Ungleichungen beschaftigen.
Durch Einfuhrung von drei”Schlupfvariablen“ x3, x4, x5 kann das Ungleichungssystem
in ein Gleichungssystem uberfuhrt werden. Fur alle Variable gilt dann die einheitliche
Zusatzbedingung xi ≥ 0.
2Bei n Entscheidungsvariablen und m Ungleichungen gibt es(mn
)potenzielle Schnittpunkte der zu-
gehorigen ”Hyperebenen“. (Zahlenbeispiel:(103
)= 120 !)

8 1 Lineare Optimierung
20x1 + 10x2 ≤ 800
4x1 + 5x2 ≤ 200
6x1 + 15x2 ≤ 450
x1,2 ≥ 0
⇔
20x1 + 10x2 + x3 = 800
4x1 + 5x2 + x4 = 200
6x1 + 15x2 + x5 = 450
xi ≥ 0
Die Schnittpunkte der Begrenzungsgeraden
g1 : 20x1 + 10x2 = 800 bzw. x3 = 0
g2 : 4x1 + 5x2 = 200 bzw. x4 = 0
g3 : 6x1 + 15x2 = 450 bzw. x5 = 0
g4 : x1 = 0 bzw. x1 = 0
g5 : x2 = 0 bzw. x2 = 0
werden dadurch beschrieben, dass man zwei der funf Variablen x1, x2, . . . , x5 zu Null
macht und die restlichen Variablen aus dem linearen Gleichungssystem bestimmt. Das
Austauschverfahren gestattet nun diese Losungen aus dem umgeformten Schema einfach
abzulesen. Dazu macht man drei Variable zu Basisvariablen und setzt die Nichtbasisvaria-
blen zu Null. Der zugehorige Wert fur die Basisvariablen lasst sich dann aus der rechten
Spalte ablesen. Ob ein Schnittpunkt zum zulassigen Bereich gehort kann am Vorzeichen
der rechten Spalte abgelesen werden. Sind alle Werte positiv, so gehort der Eckpunkt zum
zulassigen Bereich.
BV x1 x2 x3 x4 x5 bi
x3 20 10 1 0 0 800
x4 4 5 0 1 0 200
x5 6 15 0 0 1 450
⇔ L1(0|0|800|200|450) : g4 ∩ g5 bzw. A(0|0)
BV x1 x2 x3 x4 x5 bi
x1 1 12
120
0 0 40
x4 0 3 −15
1 0 40
x5 0 12 − 310
0 1 210
⇔ L2(40|0|0|40|210) : g1 ∩ g5 bzw. B(40|0)
BV x1 x2 x3 x4 x5 bi
x1 1 0 116
0 − 124
3114
x4 0 0 −18
1 −14
−1212
x2 0 1 − 140
0 112
1712
⇔ L3(3114|171
2|0|−121
2|0) : g1∩g3 unzulassig!
Tauscht man im vorangegangenen System x4 gegen x2 aus, so ergibt sich:

1.3 Simplexverfahren 9
BV x1 x2 x3 x4 x5 bi
x1 1 12
120
0 0 40
x4 0 3 −15
1 0 40
x5 0 12 − 310
0 1 210
⇔ L2(40|0|0|40|210) : g1 ∩ g5 bzw. B(40|0)
BV x1 x2 x3 x4 x5 bi
x1 1 0 112
−16
0 3313
x2 0 1 − 115
13
0 1313
x5 0 0 12
−4 1 50
⇔ L4(3313|131
3|0|0|50) : g2 ∩ g3 bzw. C(331
3|131
3)
Wie kann man nun im Vorfeld sicher stellen, dass bei einem Austausch der zulassige Bereich
nicht verlassen wird? Soll die q-te Variable Basisvariable werden, so mussen wir aus der
q-ten Spalte des Tableaus eine geeignete Zeile auswahlen. Zunachst nehmen wir an, dass –
wie in obigem Beispiel – nur positive Werte in der ausgewahlten Spalte vorkommen. Wir
betrachten nun die Quotienten von Elementen der rechten Seite und der Pivotspalte
biaiq
in obigem Beispiel: 4012
= 80, 403 = 13
1
3, 210
12 = 171
2.
Wir wahlen nun diejenige Zeile p mit dem kleinsten Quotienten
bpapq
≤ biaiq
fur i = 1, 2, . . . n ; 0 ≤ biaiq
− bpapq
; 0 ≤ bi − aiqbpapq
.
Auf der rechten Seite des Ungleichheitszeichens steht genau die Rechteckregel fur die
Transformation der rechten Seite bi .
Tritt nun in der Pivotspalte auch ein negatives Element akq auf, so ist der Ausdruck
akqbpapq
negativ. Damit kann das transformierte Element
b′k = bk − akqbpapq
nur großer werden. D. h. bei der Suche nach dem kleinsten Quotienten mussen nur die
positiven Elemente der Pivotspalte einbezogen werden.
Ein negatives Element in der Pivotspalte selbst kommt niemals als Pivotelement in Frage.
Die rechte Seite bp der Pivotzeile muss ja durch apq dividiert werden und wurde dadurch
negativ. Es ergabe sich ein unzulassiger Punkt! Somit sind negative Eintrage in der Pivot-
spalte nicht zum Austausch geeignet.
Regel: Sind in einer Pivotspalte alle Elemente negativ, fuhrt ein Austausch stets zu einem
unzulassigen Punkt. Fur die positiven Elemente der Pivotspalte untersuchen wir die Quo-
tienten der Elemente der rechten Seite und den verbleibenden Elementen der Pivotspalte.
Als Pivotzeile wird der Index mit dem minimalen Quotienten bestimmt.

10 1 Lineare Optimierung
Obige Auswahlregel fur die Pivotzeile stellt sicher, dass nur”Eckpunkte“ des zulassigen
Bereichs errechnet werden. Nur solche Schnittpunkte der begrenzenden”Hyperebenen“
werden berechnet, die tatsachlich Eckpunkte des zulassigen Bereichs sind.
Es ware schon, den Wert der Zielfunktion nicht fur samtliche”Eckpunkte“ des zulassigen
Gebiets berechnen zu mussen. Dazu benutzen wir einen Suchalgorithmus fur die Pivotspal-
te, der eine Zunahme der Zielfunktion garantiert. Wir nehmen die Zielfunktion als weitere
Gleichung in unser Tableau auf. Wir stellen die Zielfunktion
z = c1x1 + c2x2 + . . . + cnxn
um und fugen z − c1x1 − c2x2 − . . . − cnxn = 0 als letzte Zeile im Tableau an.
Nichtbasisvariable Basisvariable
BV x1 x2 . . . xn xn+1 xn+2 . . . xn+m z bi
xn+1 a11 a12 . . . a1n 1 0 . . . 0 0 b1
xn+2 a21 a22 . . . a2n 0 1 . . . 0 0 b2
... ... ... . . . ... 0 0 .. . 0 0 ...xn+m am1 am2 . . . amn 0 0 . . . 1 0 bm
−c1 −c2 . . . −cn 0 0 . . . 0 1 0
Die Variable z wird
als Basisvariable inter-
pretiert. Da z die Ba-
sis nie verlasst, lassen
wir die letzte Spalte weg
und erhalten das folgen-
de Rechenschema:
BV x1 x2 . . . xn−1 xn xn+1 xn+2 . . . xn+m−1 xn+m bi
xn+1 a1,1 a1,2 . . . a1,n−1 a1,n 1 0 . . . 0 0 b1
xn+2 a2,1 a2,2 . . . a2,n−1 a2,n 0 1 . . . 0 0 b2
... ... ... . . . ... ... 0 0 ... 0 0 ...
xn+m−1 am−1,1 am−1,2 . . . am−1,n−1 am−1,n 0 0 . . . 1 0 bm−1
xn+m am,1 am,2 . . . am,n−1 am,n 0 0 . . . 0 1 bm
z −c1 −c2 . . . −cn−1 −cn 0 0 . . . 0 0 zw
Soll im nachsten Auistauschschritt wieder ein zulassiger Randpunkt erreicht werden, muss
das Pivotelement apq positiv sein. Nach Voraussetzung (zulassiger Randpunkt) sind samt-
liche bi positiv. Damit tritt eine Zunahme des Zielwerts zw nur dann ein, wenn cq postiv
ist. (D. h. wenn der Eintrag in der letzten Zeile negatives Vorzeichen hat.)
zw′ = zw − (−cq) · bpapq
= zw +cq · bpapq
Wir haben damit eine Kriterium gefunden, das bei der Auswahl der Spalte eine Zunahme
des Zielfunktionswerts garantiert. Zusammen mit der zuvor behandelten Strategie bei der
Auswahl der Zeile lasst sich der Simplex-Algorithmus wie folgt formulieren.
Voraussetzung: Das Ausgangstableau stellt eine zulassige Basislosung dar, d. h. alle Ein-
trage bi sind positiv.

1.3 Simplexverfahren 11
1. Schritt: Sind alle Eintrage in der z-Zeile positiv, so lasst sich durch einen Austausch-
schritt keine Zunahme des Zielwerts zw erreichen, d. h. die Basislosung ist bereits optimal.
Ansonsten bestimmen wir diejenige Spalte q mit dem kleinsten (negativen) Wert in der
z-Zeile. Stehen mehrere Spalten zur Wahl, so wahlen wir eine beliebige Spalte aus.
Die ausgewahlte Spalte ergibt die Pivotspalte. Die zugehorige Variable xq wird neu in die
Basis aufgenommen.
2. Schritt: Sind in der Pivotspalte alle Elemente negativ, so wurde ein Austausch zu einem
unzulassigen Punkt fuhren. Der Algorithmus ist in einer solchen Situation abzubrechen.
Ansonsten betrachten wir fur positive aiq die Quotiienten
bkakq
; akq > 0 .
Die Zeile p mit kleinstem Quotienten wird Pivotzeile. Die zur Zeile p gehorende Basisva-
riable verlasst die Basis.
3. Schritt: Wir fuhren nun zum Pivotelement apq gehorigen Austauschschritt durch.
a) Die Pivotzeile ist durch das Pivotelement apq zu dividieren.
b) Die vom Pivotelement verschiedenen Elemente der Pivotspalten werden Null.
c) Die ubrigen Elemente des Tableaus werden mittels der Rechteckregel transformiert.
a′ik = aik − aqkaipapq
Diese Regel ist auch auf die b-Spalte und die z-Zeile anzuwenden.
Wir wenden nun den Algorithmus auf unser Ausgangsbeispiel an.
BV x1 x2 x3 x4 x5 bi
x3 20 10 1 0 0 800
x4 4 5 0 1 0 200
x5 6 15 0 0 1 450
z −16 −32 0 0 0 0
⇔ S1(0|0|800|200|450) : g4∩g5 bzw. A(0|0)
Begrundung fur die Auswahl des Pivotelements a32 = 15 : Der kleinste Eintrag in der
z-Zeile ist -32, d. h. die zweite Spalte ist auszuwahlen. Die Quotienten zwischen b-Spalte
und Elementen der Pivotspalte ergeben: 80010
= 80, 2005
= 40, 45015
= 30 . Damit ist die
dritte Zeile auszuwahlen.
BV x1 x2 x3 x4 x5 bi
x3 16 0 1 0 −23
500
x4 2 0 0 1 −13
50
x225
1 0 0 115
30
z −165
0 0 0 3215
960
⇔ S2(0|30|500|50|0) : g3 ∩ g4 bzw. E(0|30)

12 1 Lineare Optimierung
Begrundung fur die Auswahl des Pivotelements a21 = 2 : Der einzige negative Eintrag
in der z-Zeile ist −165, d. h. die erste Spalte ist auszuwahlen. Die Quotienten zwischen
b-Spalte und Elementen der Pivotspalte ergeben: 50016
= 3114, 50
2= 25, 30
0.4= 75 . Damit ist
die zweite Zeile auszuwahlen.
BV x1 x2 x3 x4 x5 bi
x3 0 0 1 −8 2 100
x1 1 0 0 12
−16
25
x2 0 1 0 −15
215
20
z 0 0 0 85
83
1040
⇔ S3(25|20|100|0|0) : g2 ∩ g3 bzw. D(25|20)
Im letzten Tableau sind alle Elemente der z-Zeile positiv, d. h. ein weiterer Austausch-
schritt wurde zu einer Verringerung des Zielwerts fuhren. Wir haben damit die optimale
Losung gefunden. Die obigen Umformungen lassen sich mittels der Skizze auf Seite 2 ver-
anschaulichen.
Wie kann man nun sicher sein, dass der Algorithmus stets den optimalen Punkt findet?
Dazu wollen wir uns zunachst Gedanken uber die Struktur des zulassigen Bereichs eines
linearen Ungleichungssystems machen. Der auf Seite 2 skizzierte zulassige Bereich hat die
Eigenschaft, dass mit zwei Punkten aus dieser Menge auch die gesamte Verbindungsgerade
zur Menge gehort. Eine solche Menge nennt man konvex. Beim Nachweis fur die Existenz
eines optimalen Punkts spielt diese Eigenschaft eine zentrale Rolle. Ist das zulassige Ge-
biet nicht konvex, so kann der oben beschriebene Algorithmus nicht in allen Fallen den
optimalen Punkt finden.
Lauft z. B. im nebenstehend skizzierten Bereich
der Algorithmus in den Punkt P , so kann er sich
nicht mehr von diesem Punkt”losen“ um den
eventuell besseren Punkt P ∗ zu erreichen. Der
Algorithmus hat zwar ein relatives, aber nicht
das absolute Optimum erreicht.
Lineare Ungleichungssysteme mit beliebig vie-
len Variablen bestimmen ein konvexes Gebiet.
Dazu die folgende Uberlegung:
P
P ∗
c1x1 + c2x2 = const.
x1
x2
Erfullt x und y die Ungleichung
a · x =n∑
i=1
aixi ≤ c
a · y =n∑
i=1
aiyi ≤ c

1.4 Bestimmung einer zulassigen Basislosung 13
so auch der Verbindungsvektor z = x+ (1− λ)(y− x
)= (1− λ)x+ λy ; 0 ≤ λ ≤ 1
a · z = (1− λ) a · x+ λ a · y ≤ (1− λ)c + λc = c
D. h. der durch eine lineare Ungleichung bestimmte Bereich ist konvex. Da der Schnitt
konvexer Mengen wieder konvex ist, ist der zulassige Bereich eines Ungleichungssystems –
interpretiert als Schnittmenge der zu den einzelnen Ungleichungen gehorenden Mengen –
stets eine konvexe Menge. Wenn einige Zusatzbedingungen erfullt sind, kann man zeigen,
dass eine lineare Zielfunktion in einem konvexen Gebiet stets ein globales Optimum besitzt.
Auf Problemsituationen gehen wir in Abschnitt 1.5 ein.
1.4 Bestimmung einer zulassigen Basislosung
Ausgangspunkt des Simplex-Algorithmus ist die Kenntnis einer zulassigen Basislosung.
Bei unseren bisher betrachteten Beispielen war der Nullpunkt im zulassigen Bereich und
konnte daher als Startpunkt fur den Simplex-Algorithmus benutzt werden. Dies ist immer
dann der Fall, wenn bei den zu betrachtenden Ungleichungen
ai1x1 + ai2x2 + . . . + ainx2 ≤ bi
alle bi positiv sind. Treten jedoch Ungleichungen der Form
2x1 + x2 ≥ 7 ; −2x1 − x2 ≤ − 7
auf, so erhalt man in der b-Spalte negative Eintrage und der Nullpunkt gehort nicht zum
zulassigen Bereich.
Wir wollen uns die Problematik an einem einfachen Beispiel klarmachen.
Die Zielfunktion z = x1 + 3x2 ist unter den folgenden Nebenbedingungen zu maximieren.
g1 : x1 + 2x2 ≥ 8
g2 : 2x1 + x2 ≥ 7
g3 : x1 + x2 ≤ 6
x1,2 ≥ 0
⇔
−x1 − 2x2 + x3 = −8
−2x1 − x2 + x4 = −7
x1 + x2 + x5 = 6
xi ≥ 0

14 1 Lineare Optimierung
BV x1 x2 x3 x4 x5 bi
x3 -1 −2 1 0 0 −8
x4 −2 −1 0 1 0 −7
x5 1 1 0 0 1 6
z −1 −3 0 0 0 0
BV x1 x2 x3 x4 x5 bi
x1 1 2 −1 0 0 8
x4 0 3 −2 1 0 9
x5 0 -1 1 0 1 −2
z 0 −1 −1 0 0 8
BV x1 x2 x3 x4 x5 bi
x1 1 0 1 0 2 4
x4 0 0 1 1 3 3
x2 0 1 −1 0 −1 2
z 0 0 −2 0 −1 10
Um zu einem zulassigen Punkt zu kommen,
mussen wir erreichen, dass samtliche Eintrage in
der b-Spalte positiv werden. Wir wahlen zunachst
die erste Zeile als Pivotzeile aus. Befinden sich in
dieser Zeile negative Eintrage, so ist sichergestellt,
dass der Austauschschritt zu einem positiven b-
Glied fuhrt. (Die Elemente der Pivotzeile werden
durch das Pivotelement dividiert!)
Zwischen den in der ersten Zeile stehenden Ele-
menten −1 und −2 entscheiden wir uns fur −1;
hier wird – analog zur Strategie beim direkten
Simplex-Algorithmus – der Quotient zwischen Zei-
lenglied und entspechendem Eintrag in der z-
Spalte minimal.
Der nach dem ersten Austauschschritt verbleiben-
de negative Eintrag −2 in der b-Spalte wird durch
den Austausch x5 → x2 beseitigt.
Wir haben nun einen Punkt des zulassigen Bereichs erreicht. Da jedoch ein Koeffizient der
z-Zeile noch negativ ist, muss der originare Simplex-Algorithmus angewandt werden.
BV x1 x2 x3 x4 x5 bi
x1 1 0 0 −1 −1 1
x3 0 0 1 1 3 3
x2 0 1 0 1 2 5
z 0 0 0 2 5 16
In der nebenstehenden Skizze
konnen die Iterationsschritte nach-
vollzogen werden. Die ersten beiden
Schritte P0 → P1 → P2 fuhren
zu einer zulassigen Basislosung.
Die Optimierung der Zielfunktion
erfolgt im dritten Schritt. P2 → P3
1
1
P0
P1(8|0)
P2(4|2)
P3(1|5)
x
y
x + 3y = 16g1
g2 g3

1.4 Bestimmung einer zulassigen Basislosung 15
Die am vorangegangenen Beispiel deutlich gewordene Strategie verlauft analog zum ori-
ginaren Simplex-Algorithmus, wenn man die Bedeutung der z-Zeile und b-Spalte miteinan-
der vertauscht. Entsprechend verandert sich auch die Reihenfolge bei der Wahl von Pivot-
zeile und Pivotspalte. Man nennt deshalb diese Strategie zur Bestimmung einer zulassigen
Basislosung”dualer Simplex-Algorithmus“.
Voraussetzung: Das Ausgangstableau stellt eine Basislosung dar.
1. Schritt: Sind alle Eintrage in der b-Zeile positiv, so liegt bereits eine zulassige Basislosung
vor.
Ansonsten bestimmen wir diejenige Zeile p mit dem kleinsten (negativen) Wert in der
b-Spalte. Stehen mehrere Spalten zur Wahl, so wahlen wir eine beliebige Spalte aus.
Die ausgewahlte Zeile ergibt die Pivotzeile. Die zur Zeile p gehorende Basisvariable verlasst
die Basis.
2. Schritt: Sind in der Pivotzeile alle Elemente positiv, so besitzt das Problem keine zulassi-
ge Basislosung. Der Algorithmus ist in einer solchen Situation abzubrechen.
Ansonsten betrachten wir fur negative api die Quotienten
ziapi
; api < 0 .
Die Spalte q mit kleinstem Quotienten wird Pivotspalte. Die zugehorige Variable xq wird
neu in die Basis aufgenommen.
3. Schritt: Wir fuhren nun zum Pivotelement apq gehorigen Austauschschritt durch.
a) Die Pivotzeile ist durch das Pivotelement apq zu dividieren.
b) Die vom Pivotelement verschiedenen Elemente der Pivotspalten werden Null.
c) Die ubrigen Elemente des Tableaus werden mittels der Rechteckregel transformiert.
a′ik = aik − aqkaipapq
Diese Regel ist auch auf die b-Spalte und die z-Zeile anzuwenden.
An einem abschließenden Beispiel soll die Effizienz des Verfahrens demonstriert werden.
Beispiel 1.4: Zielfunktion: z = z(x1, x2, x3) = 4x1 + 5x2 + 9x3!= Max
Ungleichungssystem:
x1 + x2 − 3x3 ≤ 1 (1)
−x1 + 3x2 − x3 ≤ 3 (2)
3x1 − x2 − x3 ≤ 3 (3)
3x1 − 5x2 + 3x3 ≤ 3 (4)
−5x1 + 3x2 + 3x3 ≤ 3 (5)
x1 + x2 + x3 ≥ 1 (6)
xi ≥ 0 (7), (8), (9)
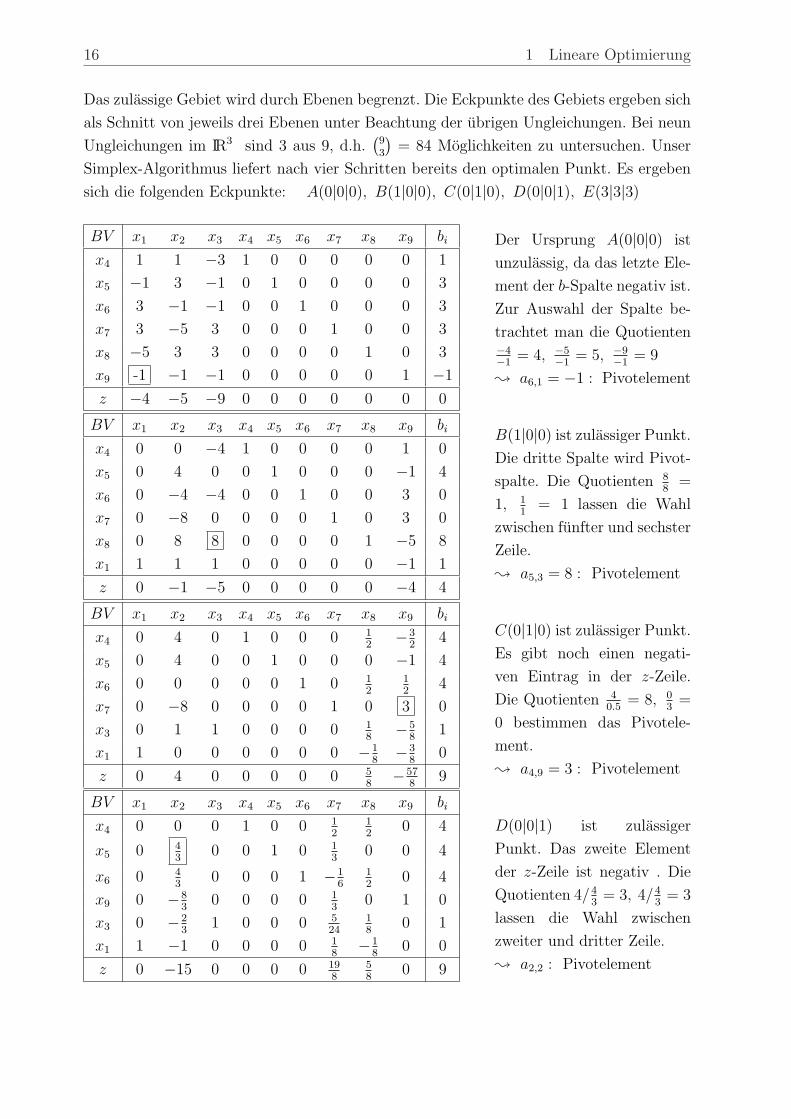
16 1 Lineare Optimierung
Das zulassige Gebiet wird durch Ebenen begrenzt. Die Eckpunkte des Gebiets ergeben sich
als Schnitt von jeweils drei Ebenen unter Beachtung der ubrigen Ungleichungen. Bei neun
Ungleichungen im IR3 sind 3 aus 9, d.h.(93
)= 84 Moglichkeiten zu untersuchen. Unser
Simplex-Algorithmus liefert nach vier Schritten bereits den optimalen Punkt. Es ergeben
sich die folgenden Eckpunkte: A(0|0|0), B(1|0|0), C(0|1|0), D(0|0|1), E(3|3|3)
BV x1 x2 x3 x4 x5 x6 x7 x8 x9 bi
x4 1 1 −3 1 0 0 0 0 0 1
x5 −1 3 −1 0 1 0 0 0 0 3
x6 3 −1 −1 0 0 1 0 0 0 3
x7 3 −5 3 0 0 0 1 0 0 3
x8 −5 3 3 0 0 0 0 1 0 3
x9 -1 −1 −1 0 0 0 0 0 1 −1
z −4 −5 −9 0 0 0 0 0 0 0
BV x1 x2 x3 x4 x5 x6 x7 x8 x9 bi
x4 0 0 −4 1 0 0 0 0 1 0
x5 0 4 0 0 1 0 0 0 −1 4
x6 0 −4 −4 0 0 1 0 0 3 0
x7 0 −8 0 0 0 0 1 0 3 0
x8 0 8 8 0 0 0 0 1 −5 8
x1 1 1 1 0 0 0 0 0 −1 1
z 0 −1 −5 0 0 0 0 0 −4 4
BV x1 x2 x3 x4 x5 x6 x7 x8 x9 bi
x4 0 4 0 1 0 0 0 12
−32
4
x5 0 4 0 0 1 0 0 0 −1 4
x6 0 0 0 0 0 1 0 12
12
4
x7 0 −8 0 0 0 0 1 0 3 0
x3 0 1 1 0 0 0 0 18
−58
1
x1 1 0 0 0 0 0 0 −18
−38
0
z 0 4 0 0 0 0 0 58
−578
9
BV x1 x2 x3 x4 x5 x6 x7 x8 x9 bi
x4 0 0 0 1 0 0 12
12
0 4
x5 0 43
0 0 1 0 13
0 0 4
x6 0 43
0 0 0 1 −16
12
0 4
x9 0 −83
0 0 0 0 13
0 1 0
x3 0 −23
1 0 0 0 524
18
0 1
x1 1 −1 0 0 0 0 18
−18
0 0
z 0 −15 0 0 0 0 198
58
0 9
Der Ursprung A(0|0|0) ist
unzulassig, da das letzte Ele-
ment der b-Spalte negativ ist.
Zur Auswahl der Spalte be-
trachtet man die Quotienten−4−1
= 4, −5−1
= 5, −9−1
= 9
; a6,1 = −1 : Pivotelement
B(1|0|0) ist zulassiger Punkt.
Die dritte Spalte wird Pivot-
spalte. Die Quotienten 88
=
1, 11
= 1 lassen die Wahl
zwischen funfter und sechster
Zeile.
; a5,3 = 8 : Pivotelement
C(0|1|0) ist zulassiger Punkt.
Es gibt noch einen negati-
ven Eintrag in der z-Zeile.
Die Quotienten 40.5
= 8, 03
=
0 bestimmen das Pivotele-
ment.
; a4,9 = 3 : Pivotelement
D(0|0|1) ist zulassiger
Punkt. Das zweite Element
der z-Zeile ist negativ . Die
Quotienten 4/43
= 3, 4/43
= 3
lassen die Wahl zwischen
zweiter und dritter Zeile.
; a2,2 : Pivotelement

1.5 Sonderfalle 17
BV x1 x2 x3 x4 x5 x6 x7 x8 x9 bi
x4 0 0 0 1 0 0 12
12
0 4
x2 0 1 0 0 34
0 14
0 0 3
x6 0 0 0 0 −1 1 −12
12
0 0
x9 0 0 0 0 2 0 1 0 1 8
x3 0 0 1 0 12
0 38
18
0 3
x1 1 0 0 0 34
0 38
−18
0 3
z 0 0 0 0 454
0 498
58
0 54
Der Punkt E(3|3|3) ist bereits der
optimale Punkt, da alle Eintrage in
der z-Zeile positiv sind. Ein weite-
rer Austauschschritt wurde zu ei-
nem kleineren Wert der Zielfunkti-
on fuhren. Der optimale Wert der
Zielfunktion ergibt sich aus dem
Eintrag im”Kreuzungspunkt“ von
z-Zeile und b-Spalte mit 54.
1.5 Sonderfalle
Im Folgenden untersuchen wir einige Sonderfalle, die beim Losen linearer Optimierungs-
probleme auftreten konnen. Wir versuchen vor allem aufzuzeigen, woran diese bei der
Anwendung des Simplex-Algorithmus erkennbar sind.
Die verschiedenen Falle wollen wir uns an ausgewahlten Beispielen klarmachen und im
Zweidimensionalen durch eine Skizze verdeutlichen.
1.5.1 Probleme, die keine Losung besitzen
Beispiel 1.5:
x1 + x2 ≤ 10 (A)
x1 − x2 ≥ 10 (B)
x1 + 4x2 ≥ 25 (C)
xi ≥ 0
z = 2x1 + x2!= Max.
Wir versuchen mittels des dualen Simplex-Algorithmus eine zulassige Losung zu finden:
BV x1 x2 x3 x4 x5 bi
x3 1 1 1 0 0 10
x4 −1 1 0 1 0 −10
x5 −1 -4 0 0 1 −48
z −1 −1 0 0 0 0
BV x1 x2 x3 x4 x5 bi
x3 0.75 0 1 0 0.25 −2
x4 -1.25 0 0 1 0.25 −22
x2 0.25 1 0 0 −0.25 12
z −0.75 0 0 0 −0.25 12
BV x1 x2 x3 x4 x5 bi
x3 0 0 1 0.6 0.4 −15.2
x1 1 0 0 −0.8 −0.2 17.6
x2 0 1 0 0.2 −0.2 7.6
z 0 0 0 −0.6 −0.4 25.2
In der ersten Zeile der b-Spalte befindet sich
noch ein negativer Wert. Die als Pivotele-
ment in Frage kommenden Werte sind alle
positiv. Somit kann kein weiterer Austausch-
schritt durchgefuhrt werden und der Algo-
rithmus bricht ab.

18 1 Lineare Optimierung
Die Geltungsbereiche der drei Unglei-
chungen (A, B, C) sind in der neben-
stehenden Skizze verschieden schraf-
fiert. Sie macht deutlich, dass alle
drei Ungleichungen nicht gleichzeitig
erfullbar sind.
Beobachtung: Sich widersprechende
Ungleichungen machen sich dadurch
bemerkbar, dass der duale Simplex-
Algorithmus zur Bestimmung einer
zulassigen Ausgangslosung abbricht.
x1
x2
P1
P2
P3
AB
C
1.5.2 Probleme mit unbeschranktem zulassigem Bereich
Bei solchen Bereichen kann eine endliche optimale Losung nicht garantiert werden.
Beispiel 1.6:
−x1 + x2 ≤ 10 (A)
x1 − x2 ≤ 10 (B)
xi ≥ 0
z = x1 + 2x2!= Max.
BV x1 x2 x3 x4 bi
x3 −1 1 1 0 10
x4 1 −1 0 1 10
z −1 −2 0 0 0
BV x1 x2 x3 x4 bi
x2 −1 1 1 0 10
x4 0 0 1 1 20
z −3 0 2 0 20
Das umgeformte Tableau ist nicht optimal, da die z-Zeile noch den negativen Wert −3
enthalt. Trotzdem kann in der ersten Spalte kein Pivotelement bestimmt werden, da dort
keine positiven Koeffizienten stehen. Die Variable x1 kann beliebig vergroßert werden;
dabei wachst auch die Zielfunktion z = 20 + 3x1 − 2x2 unbeschrankt an.
Verandern wir die Zielfunktion, so lasst sich ein optimaler Wert bestimmen!
Beispiel 1.7:
−x1 + x2 ≤ 10 (A)
x1 − x2 ≤ 10 (B)
xi ≥ 0
z = − 2x1 + x2!= Max.
BV x1 x2 x3 x4 bi
x3 −1 1 1 0 10
x4 1 −1 0 1 10
z 2 −1 0 0 0
BV x1 x2 x3 x4 bi
x2 −1 1 1 0 10
x4 0 0 1 1 20
z 1 0 1 0 10
Das Tableau ist op-
timal; es existiert ein
Optimum in der Ecke
P (0|10). Dort ist
z = 10

1.5 Sonderfalle 19
Der Geltungsbereiche der zwei Un-
gleichungen (A, B) ist in der ne-
benstehenden Skizze schraffiert. Er ist
unbeschrankt und kann fur manche
Zielfunktionen (z1(x1, x2)) zu beliebig
großen Werten fuhren. Fur andere Ziel-
funktionen (z2(x1, x2)) kann dagegen
ein Optimum existieren.
Beobachtung: Bei unbeschrankten
zulassigen Gebieten kann der Simplex-
Algorithmus abbrechen, ohne eine op-
timale Losung gefunden zu haben.
x1
x2 z2 = −2x1 + x2
z1 = x1 + 2x2
A
B
P
Eine solche Situation zeigt sich darin, dass es zwar noch negative Eintrage in der z-Zeile
vorliegen, aber trotzddem kein weiterer Austauschschritt vollzogen werden kann. (Z. B.
wenn in der zugehorigen Spalte nur negative Eintrage stehen.)
In der Praxis durften haufig Eingabefehler die Ursache fur solche Verhaltensweisen sein.
1.5.3 Probleme mit mehreren optimalen Basislosungen
Beispiel 1.8:
4x1 + 3x2 ≤ 48 (A)
4x1 + x2 ≤ 40 (B)
x1 + 3x2 ≤ 30 (C)
xi ≥ 0
z = 4x1 + 3x2!= Max.
BV x1 x2 x3 x4 x5 bi
x3 4 3 1 0 0 48
x4 4 1 0 1 0 40
x5 1 3 0 0 1 30
z −4 −3 0 0 0 0
BV x1 x2 x3 x4 x5 bi
x3 0 2 1 −1 0 8
x1 1 14
0 14
0 10
x5 0 114
0 −14
1 20
z 0 −2 0 1 0 40
BV x1 x2 x3 x4 x5 bi
x2 0 1 12
−12
0 4
x1 1 0 −18
38
0 9
x5 0 0 −118
98
1 9
z 0 0 1 0 0 48
Mit dem Punkt P1(9|4) wurde ein optimaler
Punkt gefunden. Wegen der 0 in der vierten Spal-
te der Zielfunktionszeile kann ein weiterer Aus-
tauschschritt vorgenommen werden, ohne dass
sich der Wert der Zielfunktion andert. Wir tau-
schen noch x4 gegen x5 aus und erhalten einen
weiteren optimalen Wert.

20 1 Lineare Optimierung
BV x1 x2 x3 x4 x5 bi
x2 0 1 −19
0 49
8
x1 1 0 13
0 −13
6
x4 0 0 −119
1 89
8
z 0 0 1 0 0 48
Durch diesen weiteren Austauschschritt ergab sich
eine weitere zulassige Losung P2(6|8) mit demsel-
ben Wert fur die Zielfunktion.
Ein weiterer moglicher Austauschschritt (grau un-
terlegt) ergabe wieder die ursprungliche Losung
P1(9|4).
Aus nebenstehender Skizze wird deut-
lich, dass die Begrenzungsgerade fur die
Ungleichung (A) parallel zur Isoquan-
te der Zielfunktion verlauft. Damit sind
die Punkte auf der Strecke zwischen P1
und P2 ebenfalls optimal.
Beobachtung: Sind im Optimaltableau
Zielfunktionskoeffizienten von Nichtba-
sisvariablen Null, so existieren meh-
rere optimale Losungen. Man erhalt
die Eckpunkte durch weitere Aus-
tauschschritte. Alle Konvexkombina-
tionen optimaler Punkte sind wieder
optimal.
x1
x2
C
AB
P1
P2
z = const.
1.5.4 Probleme mit degenerierter optimaler Basislosung
Es sind Falle denkbar, dass fur einen optimalen Eckpunkt mehrere Tableaus existieren.
Damit erhalt man kein wohlbestimmtes Ende des Simplex-Algorithmus.
Beispiel 1.9:
4x1 + 3x2 ≤ 48 (A)
4x1 + x2 ≤ 40 (B)
x1 + 3x2 ≤ 30 (C)
x1 + x2 ≤ 14 (D)
xi ≥ 0
z = 3x1 + 4x2!= Max.
BV x1 x2 x3 x4 x5 x6 bi
x3 4 3 1 0 0 0 48
x4 4 1 0 1 0 0 40
x5 1 3 0 0 1 0 30
x6 1 1 0 0 0 1 14
z −3 −4 0 0 0 0 0
BV x1 x2 x3 x4 x5 x6 bi
x3 3 0 1 0 −1 0 18
x4113
0 0 1 −13
0 30
x213
1 0 0 13
0 10
x623
0 0 0 −13
1 4
z −53
0 0 0 43
0 40

1.5 Sonderfalle 21
BV x1 x2 x3 x4 x5 x6 bi
x3 0 0 1 0 12
−92
0
x4 0 0 0 1 32
−112
8
x2 0 1 0 0 12
−12
8
x1 1 0 0 0 −12
32
6
z 0 0 0 0 12
52
50
BV x1 x2 x3 x4 x5 x6 bi
x6 0 0 −29
0 −19
1 0
x4 0 0 −119
1 89
0 8
x2 0 1 −19
0 49
0 8
x1 1 0 13
0 −13
0 6
z 0 0 59
0 79
0 50
BV x1 x2 x3 x4 x5 x6 bi
x5 0 0 2 0 1 −9 0
x4 0 0 −3 1 0 8 8
x2 0 1 −1 0 0 4 8
x1 1 0 1 0 0 −3 6
z 0 0 −1 0 0 7 50
Die erste Komponente der b-Spalte ist Null.
Damit kann ein weiterer Austauschschritt
durchgefuhrt werden, ohne dass sich der
Wert der Zielfunktion andert. Tauschen wir
x3 gegen x6 aus, so ergibt ein weiterer op-
timaler Punkt mit denselben Werten fur
x1, x2.
Das obere Tableau kann als Schnitt der Ge-
raden C und D gedeutet werden, wahrend
sich das untere Tableau als Schnitt von A
und C interpretieren lasst. Die jeweils ande-
re Schlupfvariable nimmt dort den Wert Null
an. Dies bedeutet, dass ein Schnittpunkt mit
mehr als zwei Geraden vorliegt.
Tauschen wir nochmals x5 gegen x6 aus, so
erhalt man wieder eine optimale Losung. Der
negative Koeffizient in der z-Zeile stort nicht,
da er bei einer Nichtbasisvariablen steht. Das
entstehende Tableau ergibt sich beim Schnitt
der Geraden A und D.
Aus nebenstehender Skizze wird deut-
lich, dass die Begrenzungsgerade fur die
Ungleichung (A, C, D) sich im Punkt
P2 schneiden. Deswegen erhalten wir
fur den Punkt P2(6|8) drei verschiedene
”Zustande“ des Tableaus.
Beobachtung: Nimmt im Optimalta-
bleau eine Basisvariable den Wert Nulla
an (b-Spalte besitzt eine Null!), so kann
man zum selben Schnittpunkt weitere
Zustande des Tableaus mit optimalem
Wert der Zielfunktion erzeugen. Da-
durch besteht die Gefahr, dass der Al-
gorithmus in einen”Zyklus“ gerat. Dies
muss gegebenenfalls beim Programmie-
ren”abgefangen“ werden.
aHat eine Basisvariable den Wert Null, soist eine weitere Ungleichung ”zusatzlich“genauerfullt.
x1
x2
C
AB
D
z = 50P1
P2

22 1 Lineare Optimierung
1.6 Erganzungen
1.6.1 Gleichungen
Kommen bei einem Optimierungsproblem auch Gleichungen vor, so sind verschiedene
Losungsmoglichkeiten offen. Zunachst kann man diese linearen Gleichungen dazu benut-
zen, die Anzahl der Variablen zu reduzieren. Diese Transformation der Variablen kann
dazu fuhren, dass die Voraussetzung xi ≥ 0 verletzt wird und dann noch eine zusatzliche
Verschiebung des Koordinatensystems notwendig macht. Als zweite Moglichkeit bietet sich
an, die Gleichung zunachst wie eine Ungleichung zu behandeln und bei der Anwendung des
Simplex-Algorithmus die zugehorige Schlupfvariable zur Nichtbasisvariablen zu erklaren.
Diese wird dann stets Null gesetzt und so die Gleichung erfullt. Die geringste Abweichung
vom gewohnten Vorgehen ergibt sich bei folgendem Trick: Man behandelt die Gleichung
wie eine Ungleichung und bewertet sie kunstlich in der Zielfunktion mit einem”großen“
negativen Wert. Dies soll an folgendem Beispiel erlautert werden.
Beispiel 1.10:
5x1 + 2x2 + 3x3 ≤ 96 (A)
x1 + 5x2 ≤ 96 (B)
x1 + x2 ≤ 24 (C)
x1 − x3 = 4 (D)
xi ≥ 0
z = 5x1 + 8x2 + x3!= Max.
Nach Einfuhrung der Schlupfvariablen x4 . . . x7 ergibt sich das folgende lineare Gleichungs-
system:
5x1 + 2x2 + 3x3 + x4 = 96 (A)
x1 + 5x2 + x5 = 96 (B)
x1 + x2 + x6 = 24 (C)
x1 − x3 + x7 = 4 (D)
xi ≥ 0
Um den Simplex-Algorithmus zu”zwingen“ die Variable x7 zu Null zu machen, modifizie-
ren wir die Zielfunktion wie folgt:
z = 5x1 + 8x2 + x3 − 100x7!= Max.
Der ubliche Simplex-Algorithmus ergibt das gesuchte Optimum.
BV x1 x2 x3 x4 x5 x6 x7 bi
x4 5 2 3 1 0 0 0 96
x5 1 5 0 0 1 0 0 96
x6 1 1 0 0 0 1 0 24
x7 1 0 −1 0 0 0 1 4
z −5 −8 −1 0 0 0 100 0

1.6 Erganzungen 23
BV x1 x2 x3 x4 x5 x6 x7 bi
x4 4.6 0 3 1 −0.4 0 0 57.6
x2 0.2 1 0 0 0.2 0 0 19.2
x6 0.8 0 0 0 −0.2 1 0 4.8
x7 1 0 −1 0 0 0 1 4
z −3.4 0 −1 0 1.6 0 100 153.6
BV x1 x2 x3 x4 x5 x6 x7 bi
x4 0 0 7.6 1 −0.4 0 −4.6 39.2
x2 0 1 0.2 0 0.2 0 −0.2 18.4
x6 0 0 0.8 0 −0.2 1 −0.8 1.6
x1 1 0 −1 0 0 0 1 4
z 0 0 −4.4 0 1.6 0 103.4 167.2
BV x1 x2 x3 x4 x5 x6 x7 bi
x4 0 0 0 1 1.5 −9.5 3 24
x2 0 1 0 0 0.25 −0.25 0 18
x3 0 0 1 0 −0.25 1.25 −1 2
x1 1 0 0 0 −0.25 1.25 0 6
z 0 0 0 0 0.5 5.5 99 176
1.6.2 Opportunitatskosten
Zum Abschluss wollen wir das Resultat einer linearen Optimierungsaufgabe interpretieren.
Die Bedeutung der Koeffizienten soll an folgendem Beispiel im Abschlusstableau veran-
schaulicht werden.
Beispiel 1.11:
x1 + x2 ≤ 8 (A)
2x1 + x2 ≤ 14 (B)
x1 + 2x2 ≤ 14 (C)
xi ≥ 0
z = 4x1 + 3x2!= Max.
;
BV x1 x2 x3 x4 x5 bi
x3 1 1 1 0 0 8
x4 2 1 0 1 0 14
x5 1 2 0 0 1 14
z −4 −3 0 0 0 0
BV x1 x2 x3 x4 x5 bi
x3 0 0.5 1 −0.5 0 1
x1 1 0.5 0 0.5 0 7
x5 0 1.5 0 −0.5 1 7
z 0 −1 0 2 0 28
BV x1 x2 x3 x4 x5 bi
x2 0 1 2 −1 0 2
x1 1 0 −1 1 0 6
x5 0 0 −3 1 1 4
z 0 0 2 1 0 30
Wir wollen nun die Koeffizienten der z-Zeile des Schlusstableaus interpretieren. Zu den
Schlupfvariablen x3, x4, x5 gehoren die Koeffizienten 2, 1, 0. Dies bedeutet, dass die Un-

24 1 Lineare Optimierung
gleichungen (A) und (B) aktiv sind, wahrend (C) keine Rolle spielt. Hatte x3 den Wert
1, so erhohte sich der Wert der Zielfunktion um 2. Dies bedeutet, dass eine Erhohung der
Grenze fur die Ungleichung (A) um eine Einheit einen Zuwachs fur die Zielfunktion um
zwei Einheiten nach sich zieht. In der nachfolgenden Skizze ist die zu dieser Veranderung
gehorende Vergroßerung des zulassigen Gebiets dunkel schraffiert. Die zur Zielfunktion
gehorende Gerade 4x1 + 3x2 = 30 kann vom Punkt P1 in den Punkt P1 verschoben wer-
den. Entsprechend ergabe sich bei der Erhohung der Grenze fur die Ungleichung (B) ein
Zuwachs von einer Einheit fur die Zielfunktion. Dies fuhrt jedoch nur so lange zu einer
Erhohung der Zielfunktion, wie die ubrigen Restriktionen nicht greifen. In unserem Bei-
spiel hatte eine Erhohung der Restriktion (A) um mehr als 43
keine Auswirkung mehr.
In der Skizze wurde dies eine Parallelverschiebung von (A) in den Punkt P ∗ bedeuten.
Wird umgekehrt die Restriktion (A) um eine Einheit verkleinert, so vermindert sich die
Zielfunktion um 2. Man nennt diese Großen, die als entgangener Gewinn gedeutet werden
konnen, Opportunitatskosten.
A B
C
C
AP1
P2
P1
P2
z1 z2
Begrenzungsgeraden
mod. Begrenzungsgeraden
Zielfunktion
x1
x2
P ∗

1.6 Erganzungen 25
Die zur nichtaktiven Ungleichung (C) gehorende Variable x5 hat den Wert 4 (dritte Kom-
ponente der b-Spalte). Dies bedeutet, dass eine Verkleinerung der Grenze fur die Unglei-
chung (C) um vier Einheiten keinen Einfluss auf die optimale Losung hat. In der Skizze
ist diese Begrenzung mit C gekennzeichnet.
Erhohung von (A) um 1 Einheit
BV x1 x2 x3 x4 x5 bi
x3 1 1 1 0 0 9
x4 2 1 0 1 0 14
x5 1 2 0 0 1 14
z −4 −3 0 0 0 0
BV x1 x2 x3 x4 x5 bi
x3 0 0.5 1 −0.5 0 2
x1 1 0.5 0 0.5 0 7
x5 0 1.5 0 −0.5 1 7
z 0 −1 0 2 0 28
BV x1 x2 x3 x4 x5 bi
x2 0 1 2 −1 0 4
x1 1 0 −1 1 0 5
x5 0 0 −3 1 1 1
z 0 0 2 1 0 32
Erhohung von (A) um 2 Einheiten
BV x1 x2 x3 x4 x5 bi
x3 1 1 1 0 0 10
x4 2 1 0 1 0 14
x5 1 2 0 0 1 14
z −4 −3 0 0 0 0
BV x1 x2 x3 x4 x5 bi
x3 0 0.5 1 −0.5 0 3
x1 1 0.5 0 0.5 0 7
x5 0 1.5 0 −0.5 1 7
z 0 −1 0 2 0 28
BV x1 x2 x3 x4 x5 bi
x3 0 0 1 −13
−13
23
x1 1 0 0 23
−13
143
x2 0 1 0 −13
23
143
z 0 0 0 53
23
3223
Verminderung von (A) um 0.5 Einheiten
BV x1 x2 x3 x4 x5 bi
x3 1 1 1 0 0 7.5
x4 2 1 0 1 0 14
x5 1 2 0 0 1 14
z −4 −3 0 0 0 0
BV x1 x2 x3 x4 x5 bi
x3 0 0.5 1 −0.5 0 0.5
x1 1 0.5 0 0.5 0 7
x5 0 1.5 0 −0.5 1 7
z 0 −1 0 2 0 28
BV x1 x2 x3 x4 x5 bi
x2 0 1 2 −1 0 1
x1 1 0 −1 1 0 6.5
x5 0 0 −3 1 1 5.5
z 0 0 2 1 0 29
Verminderung von (C) um 4 Einheiten
BV x1 x2 x3 x4 x5 bi
x3 1 1 1 0 0 8
x4 2 1 0 1 0 14
x5 1 2 0 0 1 10
z −4 −3 0 0 0 0
BV x1 x2 x3 x4 x5 bi
x3 0 0.5 1 −0.5 0 1
x1 1 0.5 0 0.5 0 7
x5 0 1.5 0 −0.5 1 3
z 0 −1 0 2 0 28
BV x1 x2 x3 x4 x5 bi
x2 0 1 2 −1 0 2
x1 1 0 −1 1 0 6
x5 0 0 −3 1 1 0
z 0 0 2 1 0 30

26 1 Lineare Optimierung
Wir formuliern allgemein:
Die Zielfunktionskoeffizienten der Nichtbasisvariablen im optimalen Simplextableau-
geben an, um wieviele Einheiten sich der Zielfunktionswert andert, wenn
• bei einer Entscheidungsvariablen eine Einheit eines bisher nicht produzierten
Erzeugnisses produziert wird.
• bei einer Schlupfvariablen eine bisher voll ausgelastete Restriktion um eine
Einheit verandert wird. (unter Beachtung der ubrigen Beschrankungen!)
Beispiel 1.12: Ein Unternehmen stellt drei Produkttypen I, II, II her. Zur Produktion
wird ein Rohstoff verwendet; jedes Produkt muss zwei Fertigungsstellen durchlaufen. Roh-
stoffmenge und die beiden Fertigungsstellen sind durch Kapazitatsschranken begrenzt.
Verfugbare Kapazitaten und die Deckungsbeitrage fur die Produkte sind der folgenden
Tabelle zu entnehmen:
Produkttyp verfugbare
I II III Kapazitat
Fertigungsstelle A 4 h1/ME1 22 h1/ME2 7 h1/ME3 180 h1
Fertigungsstelle B 1 h2/ME1 4 h2/ME2 1 h2/ME3 30 h2
Rohstoff 1 kg/ME1 5 kg/ME2 2 kg/ME3 30 kg
Deckungsbeitrage 8 C/ME1 35 C/ME2 13 C/ME3
Die Entscheidungsvariablen x1, x2, x3 bezeichnen produzierten Mengen in Mengeneinhei-
ten MEi3. Damit ergibt sich das folgende Optimierungsproblem:
z = 8x1 + 35x2 + 13x3!= Max unter den Nebenbedingungen:
4x1 + 22x2 + 7x3 ≤ 180
x1 + 4x2 + x3 ≤ 30
x1 + 5x2 + 2x3 ≤ 50
xi ≥ 0
Der Simplexalgorithmus fuhrt zu den folgenden Tableaus.
3Die Mengeneinheiten (ME) werden entsprechend dem Produktionstyp indiziert. Damit ist aus derAngabe einer Einheit sofort ewrsichtlich, um welches Produkt es sich handelt. Analog sind die ubrigenEinheiten-Indicex zu verstehen (z. B. 12 h1 = 12 Stunden in der Fertigungsstelle 1 usw.).

1.6 Erganzungen 27
BV x1 x2 x3 x4 x5 x6 bi
x4 4 22 4 1 0 0 180
x5 1 4 1 0 1 0 30
x6 1 5 2 0 0 1 50
z −8 −35 −13 0 0 0 0
BV x1 x2 x3 x4 x5 x6 bi
x4 −1.5 0 −1.5 1 −5.5 0 15
x2 0.25 1 0.25 0 0.25 0 7.5
x6 −0.25 0 0.75 0 −1.25 1 12.5
z 0.75 0 −4.25 0 8.75 0 262.5
BV x1 x2 x3 x4 x5 x6 bi
x4 −2 0 0 1 −8 2 40
x213
1 0 0 23
−13
103
x3 −13
0 1 0 −53
43
1623
z −23
0 0 0 53
173
33313
BV x1 x2 x3 x4 x5 x6 bi
x4 0 6 0 1 −4 0 60
x1 1 3 0 0 2 −1 10
x3 0 1 1 0 −1 1 20
z 0 2 0 0 3 5 340
Zur Deutung der Koeffizienten der Zielfunktionszeile schreiben wir die letzte Zeile des
Tableaus als Gleichung:
2x2 + 3x5 + 5x6 + z = 340 ; z = 340− 2x2 − 3x5 − 5x6
Verandert man nun irgendeine Nichtbasisvariable um eine Einheit, so verandert sich der
Deckungsbeitrag z genau in Hohe des entsprechenden Zielfunktionskoeffizienten. Im folgen-
den Tableau erhohen wir die Schranken fur die beiden letzten Bedingungen um 1 Einheit.
Rechentechnisch bedeutet dies fur die Variablen x5 und x6 den Wert −1 .
BV x1 x2 x3 x4 x5 x6 bi
x4 4 22 4 1 0 0 180
x5 1 4 1 0 1 0 31
x6 1 5 2 0 0 1 51
z −8 −35 −13 0 0 0 0
BV x1 x2 x3 x4 x5 x6 bi
x4 0 6 0 1 −4 0 56
x1 1 3 0 0 2 −1 11
x3 0 1 1 0 −1 1 20
z 0 2 0 0 3 5 348

28 1 Lineare Optimierung
Der optimale Wert hat sich auf z = 340− 3 · (−1)− 5 · (−1) = 348 erhoht.
Fuhren wir einen weiteren Austauschschritt durch, um zu Erzwingen, dass sich x2 6= 0
ergibt, so erhalten wir:
BV x1 x2 x3 x4 x5 x6 bi
x4 −2 0 0 1 −8 2 34
x213
1 0 0 23
−13
113
x3 −13
0 1 0 −53
43
1613
z −23
0 0 0 53
173
34023
Fur die zulassigen Produktionsmengen erhielten wir x1 = 0, x2 = 113, x3 = 151
3. Der Wert
der Zielfunktion hat sich um den entsprechenden Betrag vermindert:
z = 348− 2 · 113 = 3402
3

29
2 Transportprobleme
Transportmodelle stellen eine spezielle, aber sehr wichtige Klasse von linearen Optimie-
rungsaufgaben dar. Es handelt sich dabei nicht nur um Probleme auf dem Transportsektor,
sondern um einen formalen Typ von Optimierungsaufgaben, die sich auch in anderen Be-
reichen (z. B. Produktionsplanung) ergeben.
Zur Optimierung von Transportmodellen ist das zuvor behandelte Verfahren, das Simplex-
Verfahren, relativ aufwendig. Unter Ausnutzung der speziellen Struktur verwendet man
Spezialverfahren, die mit weniger Aufwand das Optimum ergeben.
2.1 Problemstellung
Ein Gut ist an m Standorten in den Mengen a1, a2, . . . am vorhanden und soll zu n Orten
in den Mengen b1, b2, . . . bn transportiert werden. Dabei wird zunachst unterstellt, dass
die Summe der Bestande genau der Summe der Bedarfsmengen entspricht. Die Transport-
kosten sollen linear mit den versandten Mengen ansteigen. Die Kosten fur den Transport
je Einheit des Guts von jedem Liefer- zu jedem Bedarfsort seien bekannt. Gesucht ist
derjenige Transportplan, der zu minimalen Kosten fuhrt.
Fur die mathematische Formulierung des Problems fuhren wir folgende Großen ein:
ai : Bestand am Lieferort i ; i = 1, 2, . . . m
bj : Bedarf am Bedarfsort j ; j = 1, 2, . . . n
cij : Transportkosten je Einheit vom Lieferort i zum Bedarfsort j
xij : Transportmenge vom Lieferort i zum Bedarfsort j (Entscheidungsvariable)
K : gesamte Transportkosten (Entscheidungskriterium)
Die zu minimierende Zielfunktion ergibt sich als Summe der Produkte aus Transportkosten
je Einheit und transportierte Menge auf allen moglichen Routen.
K =m∑
i=1
n∑j=1
cij · xij!= Min
Die Annahme, dass im gesamten System die verfugbare Menge der benotigten Menge ent-
spricht, wird durch die folgende Beziehung zwischen den Großen ai und bj wiedergegeben:
m∑i=1
ai =n∑
j=1
bj (?)
Diese”Gleichgewichtsbedingung“ wird implizit eingehalten, wenn sicher gestellt wird, dass
von jedem Lieferort genau die dort verfugbare Menge abtransportiert und an jedem Be-

30 2 Transportprobleme
darfsort genau die dort benotigte Menge angeliefert wird. Daraus ergibt sich fur jeden
Liefer- bzw. Bedarfsort eine Gleichung der folgenden Art.
n∑j=1
xij = ai ; i = 1, 2, . . . m : Lieferort
m∑i=1
xij = bj ; j = 1, 2, . . . n : Bedarfsort
Wegen der Gleichgewichtsbedingung (?) sind die obigen (n+m) Gleichungen linear abhangig,
d. h. es genugt, wenn wir nur (n + m− 1) dieser Nebenbedingungen berucksichtigen.
Da nur nichtnegative Mengen sinnvoll sind, muss zusatzlich gelten:
xij ≥ 0 ; i = 1, 2, . . .m, j = 1, 2, . . . n
Es handelt sich um ein spezielles lineares Optimierungsproblem. Dies soll an folgendem
Zahlenbeispiel verdeutlicht werden.
Wir wollen annehmen, dass von drei Fabrikationsstatten eines Unternehmens vier Abneh-
mer zu beliefern sind. In der nachstehenden Tabelle sind die Transportkosten je Mengen-
einheit auf jeder moglichen Route sowie die Produktions- und Bedarfsmengen festgehalten.
Abnehmer Nr.
1 2 3 4
Fabrik Nr. Transportkosten/Einheit Kapazitat
1 5 5 2 7 9
2 8 3 1 8 15
3 2 4 4 5 14
Bedarf 10 12 9 7∑
38
Die Summe der Produktionsmengen betragt ebenso wie die Summe der Verbrauchsmen-
gen 38 Einheiten. Mit den angegebenen Daten lasst sich das folgende Transportmodell
formulieren:
Die Funktion
K = 5x11 + 5x12 + 2x13 + 7x14 +
8x21 + 3x22 + 1x23 + 8x24 +
2x31 + 4x32 + 4x33 + 5x34
ist zu minimieren unter den Nebenbedingungen
x11 + x12 + x13 + x14 = 9
x21 + x22 + x23 + x24 = 15
x31 + x32 + x33 + x34 = 14
Fabrik-Restriktionen

2.1 Problemstellung 31
x11 + x21 + x31 = 10
x12 + x22 + x32 = 12
x13 + x23 + x33 = 9
x14 + x24 + x34 = 7
Kunden-Restriktionen
und den Nichtnegativitatsbedingungen
xij ≥ 0 ; i = 1, 2, . . . 3, j = 1, 2, . . . 4
Formuliern wir dieses Problem im Stile des vorangegangenen Abschnitts, so erhalten wir
ein Tableau mit 12 Entscheidungsvariablen und 6 Schlupfvariablen1. Zunachst mussen
wir das Minimum-Problem in ein Maximumproblem umformulieren. Wenn wir von allen
Koeffizienten der Kostenmatrix dieselbe Zahl addieren oder subtrahieren, so verandert sich
unser Ausgangsproblem nicht. Wenn wir das Vorzeichen der Koeffizienten verandern, so
ergibt sich ein aquivalentes Maximumproblem.
F (x) = c · [x11 + x12 + . . . + x34]−K(x)
= (c− 5)x11 + (c− 5)x12 + (c− 2)x13 + (c− 7)x14 + (c− 8)x21 + (c− 3)x22 + . . .
(c− 1)x23 + (c− 8)x24 + (c− 2)x31 + (c− 4)x32 + (c− 4)x33 + (c− 5)x34
!= Maximum
Weiter besteht das Tableau aus 6 Gleichungszeilen fur die (Un)gleichungen sowie der z-
Zeile. Da die 6 (Un)gleichungen genau erfullt sind, mussen die entsprechenden Eintrage in
der z-Zeile mit großen”Straffaktoren“ versehen werden. Wegen der Straffaktoren werden
die 6 Schlupfvariable stets Nichtbasisvariable. Damit mussen von den 12 Entscheidungsva-
riablen stets 6 Basis- und 6 Nichtbasisvariable sein. Das nachfolgende Tableau zeigt diesen
Austausch von Basisvariablen. Fur die Konstante wurde c = 10 gewahlt und die Schlupf-
variablen mit dem Straffaktor 50 versehen. Weiter wurde die letzte Kindenrestriktion nicht
ins Tableau aufgenommen.
BV x1,1 x1,2 x1,3 x1,4 x2,1 x2,2 x2,3 x2,4 x3,1 x3,2 x3,3 x3,4 x13 x14 x15 x16 x17 x18 bi
x13 1 1 1 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 9
x14 0 0 0 0 1 1 1 1 0 0 0 0 0 1 0 0 0 0 15
x15 0 0 0 0 0 0 0 0 1 1 1 1 0 0 1 0 0 0 14
x16 1 0 0 0 1 0 0 0 1 0 0 0 0 0 0 1 0 0 10
x17 0 1 0 0 0 1 0 0 0 1 0 0 0 0 0 0 1 0 12
x18 0 0 1 0 0 0 1 0 0 0 1 0 0 0 0 0 0 1 9
z −5 −5 −8 −3 −2 −7 −9 −2 −8 −6 −6 −5 50 50 50 50 50 50 0
1Die 3 Fabrik- und 7 Kundenrestriktionen sind linear unabhangig. Deshalb sind nur 6 Gleichungen zuberucksichtigen.

32 2 Transportprobleme
BV x1,1 x1,2 x1,3 x1,4 x2,1 x2,2 x2,3 x2,4 x3,1 x3,2 x3,3 x3,4 x13 x14 x15 x16 x17 x18 bi
x13 1 1 1 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 9
x14 0 0 −1 0 1 1 0 1 0 0 −1 0 0 1 0 0 0 −1 6
x15 0 0 0 0 0 0 0 0 1 1 1 1 0 0 1 0 0 0 14
x16 1 0 0 0 1 0 0 0 1 0 0 0 0 0 0 1 0 0 10
x17 0 1 0 0 0 1 0 0 0 1 0 0 0 0 0 0 1 0 12
x2,3 0 0 1 0 0 0 1 0 0 0 1 0 0 0 0 0 0 1 9
z −5 −5 1 −3 −2 −7 0 −2 −8 −6 3 −5 50 50 50 50 50 59 81
BV x1,1 x1,2 x1,3 x1,4 x2,1 x2,2 x2,3 x2,4 x3,1 x3,2 x3,3 x3,4 x13 x14 x15 x16 x17 x18 bi
x13 1 1 1 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 9
x14 0 0 −1 0 1 1 0 1 0 0 −1 0 0 1 0 0 0 −1 6
x15 −1 0 0 0 −1 0 0 0 0 1 1 1 0 0 1 −1 0 0 4
x3,1 1 0 0 0 1 0 0 0 1 0 0 0 0 0 0 1 0 0 10
x17 0 1 0 0 0 1 0 0 0 1 0 0 0 0 0 0 1 0 12
x2,3 0 0 1 0 0 0 1 0 0 0 1 0 0 0 0 0 0 1 9
z 3 −5 1 −3 6 −7 0 −2 0 −6 3 −5 50 50 50 58 50 59 161
BV x1,1 x1,2 x1,3 x1,4 x2,1 x2,2 x2,3 x2,4 x3,1 x3,2 x3,3 x3,4 x13 x14 x15 x16 x17 x18 bi
x13 1 1 1 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 9
x2,2 0 0 −1 0 1 1 0 1 0 0 −1 0 0 1 0 0 0 −1 6
x15 −1 0 0 0 −1 0 0 0 0 1 1 1 0 0 1 −1 0 0 4
x3,1 1 0 0 0 1 0 0 0 1 0 0 0 0 0 0 1 0 0 10
x17 0 1 1 0 −1 0 0 −1 0 1 1 0 0 −1 0 0 1 1 6
x2,3 0 0 1 0 0 0 1 0 0 0 1 0 0 0 0 0 0 1 9
z 3 −5 −6 −3 13 0 0 5 0 −6 −4 −5 50 57 50 58 50 52 203
BV x1,1 x1,2 x1,3 x1,4 x2,1 x2,2 x2,3 x2,4 x3,1 x3,2 x3,3 x3,4 x13 x14 x15 x16 x17 x18 bi
x13 1 0 0 1 1 0 0 1 0 −1 −1 0 1 1 0 0 −1 −1 3
x2,2 0 1 0 0 0 1 0 0 0 1 0 0 0 0 0 0 1 0 12
x15 −1 0 0 0 −1 0 0 0 0 1 1 1 0 0 1 −1 0 0 4
x3,1 1 0 0 0 1 0 0 0 1 0 0 0 0 0 0 1 0 0 10
x1,3 0 1 1 0 −1 0 0 −1 0 1 1 0 0 −1 0 0 1 1 6
x2,3 0 −1 0 0 1 0 1 1 0 −1 0 0 0 1 0 0 −1 0 3
z 3 1 0 −3 7 0 0 −1 0 0 2 −5 50 51 50 58 56 58 239

2.2 Transportalgorithmus 33
BV x1,1 x1,2 x1,3 x1,4 x2,1 x2,2 x2,3 x2,4 x3,1 x3,2 x3,3 x3,4 x13 x14 x15 x16 x17 x18 bi
x13 1 0 0 1 1 0 0 1 0 −1 −1 0 1 1 0 0 −1 −1 3
x2,2 0 1 0 0 0 1 0 0 0 1 0 0 0 0 0 0 1 0 12
x3,4 −1 0 0 0 −1 0 0 0 0 1 1 1 0 0 1 −1 0 0 4
x3,1 1 0 0 0 1 0 0 0 1 0 0 0 0 0 0 1 0 0 10
x1,3 0 1 1 0 −1 0 0 −1 0 1 1 0 0 −1 0 0 1 1 6
x2,3 0 −1 0 0 1 0 1 1 0 −1 0 0 0 1 0 0 −1 0 3
z −2 1 0 −3 2 0 0 −1 0 5 7 0 50 51 55 53 56 58 259
BV x1,1 x1,2 x1,3 x1,4 x2,1 x2,2 x2,3 x2,4 x3,1 x3,2 x3,3 x3,4 x13 x14 x15 x16 x17 x18 bi
x1,4 1 0 0 1 1 0 0 1 0 −1 −1 0 1 1 0 0 −1 −1 3
x2,2 0 1 0 0 0 1 0 0 0 1 0 0 0 0 0 0 1 0 12
x3,4 −1 0 0 0 −1 0 0 0 0 1 1 1 0 0 1 −1 0 0 4
x3,1 1 0 0 0 1 0 0 0 1 0 0 0 0 0 0 1 0 0 10
x1,3 0 1 1 0 −1 0 0 −1 0 1 1 0 0 −1 0 0 1 1 6
x2,3 0 −1 0 0 1 0 1 1 0 −1 0 0 0 1 0 0 −1 0 3
z 1 1 0 0 5 0 0 2 0 2 4 0 53 54 55 53 53 55 268
Damit erhalten wir als optimale Losung:
x1,1 = 0 x1,2 = 0 x1,3 = 6 x1,4 = 3
x2,1 = 0 x2,2 = 12 x2,3 = 3 x2,4 = 0
x3,1 = 10 x3,2 = 0 x3,3 = 0 x3,4 = 4
Die minimalen Kosten K(x∗) ergeben sich aus dem Maximum F (x∗) durch
K(x∗) = c ·∑
xi,j − F (x∗) = 10 · 38− 262 = 112
Die allgemeine Theorie sagt, dass das Optimum stets an einem Eckpunkt angenommen
wird. Dies bedeutet, dass wir bei unserem Optimierungsalgorithmus stets voraussetzen
konnen, dass hochstens (n+m− 1) Entscheidungsvariable (im obigen Beispiel 6) ungleich
Null sind. Oder anders ausgedruckt: beim optimalen Transport werden nur (n + m − 1)
Wege (=Entscheidungsvariable ungleich Null) benotigt. Daher genugt es bei dem nun
zu besprechenden speziellen Transportalgorithums eine Strategie zu entwickeln, die nur
(n + m− 1) Transportwege ins Kalkul einbezieht.
2.2 Transportalgorithmus
Der Ablauf des Rechenverfahrens entspricht im Prinzip dem des Simplex-Algorithmus.
Man berechnet zunachst eine zulassigen Basislosung. Dann fuhrt man einen Optimalitats-
test durch und geht gegebenenfalls zu einer besseren Basislosung uber. Hier soll nur eine
heuristische Vorgehensweise dargestellt werden, bei der im Wesentlichen nur Addition und
Subtraktion benotigt wird.

34 2 Transportprobleme
2.2.1 Rechenschema
Die Durchfuhrung der einzelnen Rechenschritte erfolgt in einem speziellen Tableau, das
fur unser obiges Zahlenbeispiel angeschrieben wird.
1 2 3 4 ai
5 5 2 7
1x11 x12 x13 x14 9
8 3 1 8
2x21 x22 x23 x24 15
2 4 4 5
3x31 x32 x33 x34 14
bj 10 12 9 7∑
38
Die Kopfzeile enthalt die Indizes der Bedarfsorte, die Kopfspalte die der Lieferorte. In der
letzten Spalte bzw. Zeile sind die Liefer- bzw. Bedarfsmengen eingetragen. Das Innere des
Feldes ist in 3 ·4 Kastchen aufgeteilt. In der linken oberen Ecke eines Kastchens werden die
Kostenkoeffizienten cij eingetragen. Die Liefermenge xij vom Lieferort i zum Bedarfsort
j wird im entsprechenden Kastchen unten rechts eingetragen. Wird von i nach j nichts
transportiert, so bleibt das zugehorige Feld leer. Wie wir sehen werden, sind immer genau
m + n − 1 Felder belegt. Durch Aufsummieren der Zeilen- bzw. Spaltenwerte kann die
Einhaltung der Nebenbedingunen uberpruft werden.
2.2.2 Nord-West-Ecken-Regel
Zunachst wollen wir uberlegen, wie eine Basislosung des Transportproblems aussieht, d.
h. wieviele der insgesamt m · n Entscheidungsvariablen ungleich Null sind. Aus der allge-
meinen Fragestellung bei linearen Optimierungsproblemen wissen wir, dass die Anzahl der
Basisvariablen (Zahl der Variablen mit positiven Werten) gleich der Zahl der Nebenbe-
dingungen ist. Ein Transportproblem besitzt m + n Nebenbedingungen, von denen jedoch
eine wegen der Gleichgewichtsbedingung
m∑i=1
ai =n∑
j=1
bj
uberflussig ist. Es liegen also m + n − 1 linear unabhangige Nebenbedingungen vor. Bei
einer nichtentarteten Basislosung nehmen daher (m+n− 1) Variable Werte ungleich Null
an; die ubrigen sind Null. Zur Bestimmung einer solchen zulassigen Losung gibt es mehrere

2.2 Transportalgorithmus 35
Methoden. Hier sei nur die einfachste Methode, die sogenannte Nord-West-Ecken- Regel
erlautert.
Das Verfahren beginnt damit, dass man zuerst dem linken oberen Feld (nordwestliche
Ecke!) diejenige Menge zuordnet, die auf dieser Route maximal transportiert werden kann.
Diese Menge ist gleich dem Minimum von a1 und b1. Bei unserem Beispiel ist dieses
Minimum gleich a1, also 9 Einheiten. Wir tragen diese Menge in unser Tableau ein. Damit
ist die erste Zeile erledigt und wir gehen in die erste Spalte der zweiten Zeile. Wenn wir
hier die Erganzung zu b1 eintragen, ist auch die erste Spalt erledigt. Dabei ist zu beachten,
dass durch diesen Eintrag nicht die zweite Zeilenbedingung verletzt wird. Wir konnen
also in Feld (2,1) das Minimum der notwendigen Differenz zu b1 und dem Wert von a2
eintragen, also min(a2, b1−a1)=min(15,1). Damit ist die Nebenbedingung der ersten Zeile
und Spalte erfullt und wir konnen zum Feld (2,2) ubergehen. Hatte sich bei der Belegung
des ersten Feldes (1,1) als Minimum min(a1, b1) = b1 ergeben, so hatte man in der oben
beschriebenen Prozedur nur die Bedeutung von Zeile und Spalte vertauscht.
Wichtig ist, dass bei jedem Schritt die maximal mogliche Menge zugeordnet wird. Damit
ist gewahrleistet, dass bei jedem Schritt genau eine Zeilen- oder Spaltenbedingung erfullt
wird. Tritt einmal, außer bei der Belegung des rechten unteren Feldes, der Fall ein, dass
mit einer Zuteilung gleichzeitig eine Zeilen- und Spaltenbedingung erfullt wird, so liegt
eine Entartung vor2. Ansonsten erhalt man bei dieser Vorgehensweise genau m + n − 1
belegte Felder.
Im Entartungsfall werden zunachst weniger Felder belegt. Wir markieren dann noch”Null-
felder“ um formal (m + n − 1) linear unabhangige Basislosungen zu erhalten. Dies ist
Voraussetzung fur die spater zu behandelnde”Stepping-Stone-Methode“ bei der Losung
des Optimierungsproblems.
1 2 3 4 ai
5 5 2 7
19 9
8 3 1 8
21 12 2 15
2 4 4 5
37 7 14
bj 10 12 9 7∑
38
Es handelt sich, wie man leicht kontrollieren kann, um eine zulassige Basislosung. Die
2Entartung: auch eine der Basisvariablen nimmt den Wert Null an.

36 2 Transportprobleme
Zielfunktion fur diese Losung hat den Wert
K = 5 · 9 + 8 · 1 + 3 · 12 + 1 · 2 + 4 · 7 + 5 · 7 = 154 .
2.2.3 Optimalitatstest
Wir wollen nun feststellen, ob sich die gefundene Losung noch verbessern lasst. Zu die-
sem Zweck berechnen wir fur jedes nicht besetzte Feld die Anderung der Zielfunktion
K, die sich beim Transport einer Einheit uber die betreffende Route ergeben wurde. Da-
bei ist zu beachten, dass eine Veranderung der Besetzung in einem zunachst leeren Feld
Veranderungen in anderen Feldern nach sich ziehen wird. Es sind ja die diversen Zeilen-
und Spaltenbedingungen einzuhalten. Innerhalb einer Zeile (Spalte) kann die Zuteilung
zu einem Feld nur erhoht werden, wenn bei einem anderen Feld derselben Zeile (Spal-
te) eine entsprechende Verminderung erfolgt. Da bei jeder Veranderung aber stets eine
Zeilen- und Spaltenbedingung beruhrt wird, kann eine zulassige Umverteilung nur auf ei-
nem geschlossenen Verteilweg erfolgen. Die Konstruktion eines geschlossenen Verteilwegs
fur ein bestimmtes Nichtbasisfeld erfolgt so, dass man von einem Feld ausgehend abwech-
selnd in horizontaler bzw. vertikaler Richtung ausschließlich Basisfelder (d. h. besetzte
Felder)”anspringt“, bis man am Ende wieder zum Ausgangsfeld zuruckkommt. Ist man
vom Ausgangsfeld waagrecht auf ein Basisfeld gesprungen, so muss der Rucksprung zum
Ausgangsfeld vertikal erfolgen und umgekehrt. Fur jedes Nichtbasisfeld (leeres Feld) exis-
tiert genau ein solcher geschlossener Verteilweg. Man uberlegt sich nun zunachst, welche
Stationen bei einem solchen geschlossenen Weg anzusteuern sind. Da durch die Belegung
eines vorher leeren Feldes mit einem positiven Wert ein neues Basisfeld entsteht, muss ein
anderes Feld auf dem geschlossenen Verteilweg die Basis verlassen, d. h. zu Null werden.
Da alle angesprungenen Felder um dieselbe Große verandert werden, ergibt sich die auf
der”neuen“ Route mogliche Transportmenge aus dem Minimum der beim Ansprung zu
reduzierenden Felder. Damit ist auch gewahrleistet, dass ein bisher belegtes Feld zu Null
wird, d. h. die Basis verlasst.
Das folgende Tableau zeigt, welche Felder beim geschlossenen Verteilweg anzuspringen
sind, wenn das Feld (1,4) X verandert werden soll. Die anzuspringenden Felder sind
grau unterlegt. Dabei sind die dunkelgrau unterlegten Felder zu vermindern, wahrend die
hellgrauen Felder vergroßert werden.
Prinzipiell waren auch noch andere Umverteilungen moglich, bei denen Nichtbasisfelder
angesprungen werden. Die hier beschriebene Methode garantiert, dass auch bei dieser
”Selbstbeschrankung“ das Optimum erreicht wird. Damit ist es moglich fur alle leeren
Felder genau einen moglichen Verteilweg anzugeben und die dabei entstehenden Kosten
zu bestimmen.

2.2 Transportalgorithmus 37
1 2 3 4 ai
5 5 2 7
19 X 9
8 3 1 8
21 12 2 15
2 4 4 5
37 7 14
bj 10 12 9 7∑
38
Die Veranderung des Zielfunktionswerts K bei Belegung des betreffenden Feldes um eine
Einheit erhalt man, indem man die Kostenkoeffizienten der angesprungenen Felder ab-
wechselnd addiert und subtrahiert – je nachdem ob das betreffende Feld vergroßert oder
verkleinert wird. Fur unser Feld (1,4) ergibt sich:
∆1,4 = 7− 5 + 8− 1 + 4− 5 = + 8
Das angewandte Bewertungsverfahren wird auch als”Stepping-Stone-Methode“ bezeich-
net, wohl weil es dem Uberqueren eines Baches auf herausragenden Steinen ahnelt.
Fur die anderen Nichtbasisfelder (leeren Felder) ergeben sich folgende Wege und Kosten-
differenzen.
Feld geschlossener Verteilweg Kostendifferenz
(1, 2) (1, 2) ; (1, 1) ; (2, 1) ; (2, 2) ; (1, 2) ∆1,2 = 5− 5 + 8− 3 = +5
(1, 3) (1, 3) ; (1, 1) ; (2, 1) ; (2, 3) ; (1, 3) ∆1,3 = 2− 5 + 8− 1 = +4
(2, 4) (2, 4) ; (2, 3) ; (3, 3) ; (3, 4) ; (2, 4) ∆2,4 = 8− 1 + 4− 5 = +6
(3, 1) (3, 1) ; (3, 3) ; (2, 3) ; (2, 1) ; (3, 1) ∆3,1 = 2− 4 + 1− 8 = −9
(3, 2) (3, 2) ; (3, 3) ; (2, 3) ; (2, 2) ; (3, 2) ∆3,2 = 4− 4 + 1− 3 = −2
Da es sich bei der vorliegenden Fragestellung um ein Minimierungsproblem handelt,
signalisieren die negativen ∆-Werte noch vorhandene Verbesserungsmoglichkeiten. Aus
den Feldern mit negativer Bewertung wahlen wir das mit dem absolut hochsten Betrag3
aus. Dem neuen Basisfeld soll nun die maximal mogliche Menge zugeordnet werden. Dies
ist die kleinste Transportmenge, die in einem waagrecht angesprungenen Feld auf dem
3Diese Auswahlverfahren garantiert keineswegs das schnellste Erreichen des Optimum. Es gibt auf-wendigere, dafur aber effizientere Auswahlverfahren. Ebenso kann bereits beim Bestimmen einer erstenBasislosung die Kostenmatrix berucksichtigt werden.

38 2 Transportprobleme
zugehorigen Verteilweg zur Verfugung steht.
min(x3,3; x2,1) = min(7; 1) = 1
Die neue Basislosung erhalt man, indem man das ermittelte Minimum (1) in das neue Ba-
sisfeld einsetzt und die auf dem geschlossenen Verteilweg angesprungenen Felder verandert.
Dabei werden die waagrecht angesprungenen Felder um diese Menge vermindert und die
vertikal angesprungenen Felder entsprechend erhoht. Das waagrecht angesprungene Feld
mit der kleinsten Menge wird zu Null und scheidet damit aus der Basis aus. Alle nicht auf
dem Verteilweg liegenden Felder bleiben unverandert.
Man beginnt nun wieder mit dem Optimaltitatstest und setzt das Verfahren so lange fort,
bis keine negativ bewerteten Felder mehr vorhanden sind. Das betreffende Tableau stellt
dann die optimale Losung des Transportproblems dar. Wir wollen diese Schritte fur unser
Ausgangsproblem nochmals im Zusammenhang darstellen. Dabei wird auch der theore-
tische Hintergrund sichtbar. Es werden stets genau 4+3-1 = 6 Transportwege benutzt.
Dies entspricht genau der Anzahl der Freiheitsgrade des zugehorigen linearen Gleichungs-
systems. Bei n Kunden und m Lieferanten gibt es zunachst n · m Variable. Bei einem
geschlossenen Trtansportproblem mussen (n + m− 1) Nebenbedingungen erfullt sein. Da-
her besitzt das Problem n ·m−(n+m−1) Freiheitsgrade. Damit konnen n ·m−(n+m−1)
Variable Null gesetzt werden. Die ubrigen (n + m − 1) sind dann Basisvariable, die i. A.
Werte ungleich Null annehmen.
1 2 3 4 ai
5 5 2 7
19 5 4 8 9
8 3 1 8
21 12 2 6 15
2 4 4 5
3-9 -2 7 7 14
bj 10 12 9 7∑
38
K1 = 5 · 9 + 8 · 1 + 3 · 12 + 1 · 2 + 4 · 7 + 5 · 7 = 154 .
Die Bewertungen sind in die rechte untere Ecke der Nichtbasisfelder (Felder ohne Trans-
port) eingetragen. Wir wahlen unter den negativ bewerteten Feldern dasjenige mit dem
hochsten Absolutbetrag, also Feld (3,1), aus. Auf dem zugehorigen Verteilweg liegen die
Basisfelder (3,3), (2,3) und (2,1). Sie sind in der Skizze grau unterlegt. Bei den dunkelgrau
unterlegten Feldern wird die umzuverteilende Menge abgezogen; das hellgrau unterlegte

2.2 Transportalgorithmus 39
Feld wird um die entsprechende Menge vergroßert. Die umzuverteilende Menge bestimmt
sich aus dem Minimum der dunkelgrau unterlegten Felder: min(x3,3; x2,1) = min(7;1) = 1
Die Variable x2,1 verschwindet damit aus der Basis. Dafur wird x3,1 Basisvariable.
Die Bewertungen der neuen Basislosung sind wieder in der rechten unteren Ecke der Nicht-
basisfelder vermerkt.
1 2 3 4 ai
5 5 2 7
19 -4 -5 -1 9
8 3 1 8
29 12 3 6 15
2 4 4 5
31 -2 6 7 14
bj 10 12 9 7∑
38
K2 = 5 · 9 + 3 · 12 + 1 · 3 + 2 · 1 + 4 · 6 + 5 · 7 = 145 .
Feld (1,3) zeigt die hochste Einsparung pro umverteilte Einheit. Die Felder auf dem zu-
gehorigen Verteilweg sind grau unterlegt. Die zu verteilende Menge bestimmt sich wieder
aus dem Minimum der dunkelgrau unterlegten Felder: min(x1,1; x3,3) = min(9;6) = 6
1 2 3 4 ai
5 5 2 7
13 1 6 -1 9
8 3 1 8
24 12 3 1 15
2 4 4 5
37 3 5 7 14
bj 10 12 9 7∑
38
K3 = 5 · 3 + 2 · 6 + 3 · 12 + 1 · 3 + 2 · 7 + 5 · 7 = 115 .
Das einzige Feld mit negativer Bewertung ist (1,4). Es konnen maximal min(x1,1; x3,4) =
min(3;7) = 3 Einheiten umverteilt werden. Der Umverteilweg ist wieder grau unterlegt.
x1,1 verlasst die Basis.

40 2 Transportprobleme
1 2 3 4 ai
5 5 2 7
11 1 6 3 9
8 3 1 8
25 12 3 2 15
2 4 4 5
310 2 4 4 14
bj 10 12 9 7∑
38
Im letzen Tableau sind nur noch positive Bewertungen zu finden, d. h. das Tableau re-
prasentiert die optimale Losung x∗.
x∗1,3 = 6 Einheiten x∗1,4 = 3 Einheiten
x∗2,2 = 12 Einheiten x∗2,3 = 3 Einheiten
x∗3,1 = 10 Einheiten x∗3,4 = 4 Einheiten
Alle anderen x∗i,j sind Null!
;
K∗ = 2 · 6 + 7 · 3 + 3 · 12 + 1 · 3 + 2 · 10 + 5 · 4 = 112 .

2.2 Transportalgorithmus 41
Die nachfolgende Skizze soll die sechs Transportwege von den drei Fabriken Fi zu den vier
Kunden Kj nochmals deutlich machen. Die Pfeile reprasentieren die transporte von den
Fabriken Fi zu den Kunden Kj. Liegt kein Entartungsfall vor, so sind zur Beschreibung
genau (m + n− 1) Pfeile notwendig.
F1 F2 F3
K4 K3 K2 K1
O 7 K ¸ 6i
3 6 3 12 4 10
Mit etwas Phantasie konnen wir versuchen, die gegenseitige Lage der Kunden und Fabriken
auf einer fiktiven Landkarte aufzuzeichnen. Es ist”auffallig“, dass jede der drei Fabriken
zwei Kunden in ihrer”Nahe beliefert. Wenn wir jede Fabrik zwischen zwei Kunden plat-
zieren, erhalten wir folgende Landkarte. Dabei ist die von der Fabrik Fi zum Kunden Kj
transportierte Menge auf dem Verbindungsweg in quadratischen Kastchen vermerkt.

42 2 Transportprobleme
K1
10
F3
4
K4 3 F1 6
K2
12
F2
3
K3
optimale Losung
K212
F1
9
K1
1
F2
2
K3
7
F3
7
K4
Startlosung
An dieser Stelle ergeben sich Verbin-
dungen zur sogenannten Graphentheo-
rie. Ein Graph besteht aus einer Kno-
tenmenge (Fabriken und Kunden) und
einer Menge von verbindenden Kan-
ten (Transportwege). Die hier interes-
sierende Struktur besitzt fur n Knoten
genau n − 1 Kanten. Werden zusatz-
lich geschlossene Wege (Zyklen) aus-
geschlossen, so bezeichnet man diese
Struktur als Baum.
Man kann zeigen, dass sich jede Ba-
sislosung des Transportproblems als
Baum darstellen lasst. Dies folgt aus
der Tatsache, dass zu den n − 1 li-
near unabhangigen Nebenbedingungen
des Transportproblems n − 1 Basisva-
riable gehoren. Diese sind als Kanten in
einem Graph deutbar.
Fur die Startlosung in unserem Beispiel
hat der zugehorige Baum die nebenste-
hende Struktur.
Aus einer vorgebenen Struktur von
Knoten und Kanten, die abwechselnd
als Fabriken und Kunden gedeutet wer-
den, lassen sich auch die zur Erfullung
der Nebenbedingungen notwendigen
Transportmengen bestimmen. Wegen
der Nichtnegativitatsbedingung sind
naturlich nicht alle Baume als Trans-
portprobleme bei vorgegebenen Re-
striktionen deutbar.

2.2 Transportalgorithmus 43
2.2.4 Fiktive Quellen und Senken
Haufig ist die zur Anwendung des Transportalgorithmus notwendige Bedingung
m∑i=1
ai =n∑
j=1
bj
nicht erfullt. Die im System verfugbare Menge ist also entweder großer (Fall 1) oder kleiner
(Fall 2) als die insgesamt benotigte Menge. Man kann diese Ungleichheit jedoch mit einem
einfachen Trick beheben, indem man fiktive Abnehmer bzw. Fabriken einfuhrt.
Fall 1: Uberkapazitat
Die liefernden Fabriken produzieren mehr als die Kunden abnehmen konnen. Wir fuhren
deshalb einen fiktiven Kunden ein, der den Uberschuss der Produktion aufnimmt. Die beim
fiktiven Kunden gelandeten Mengen verbleiben in Wirklichkeit bei den Produzenten als
Lagerbestand. Wenn wir die Transportkosten zum fiktiven Abnehmer mit Null bewerten
hat dieser Trick keinerlei Einfluss auf unser Optimierungsproblem.
In unserem oben diskutierten Beispiel wollen wir annehmen, dass die Fabrik Nr. 3 statt
14 Einheiten nun 17 Einheiten produziere. Wir fuhren deshalb einen fiktiven Kunden Nr.
5 ein, dessen Bedarfsmenge der Differenz
m∑i=1
ai −n∑
j=1
bj = 41 − 38 = 3
entspricht. Wenn wir die zugehorigen Kostenkoeffizienten Null setzen, ergibt sich mit der
Nord-West-Ecken-Regel die folgende zulassige Basislosung.
1 2 3 4 5 ai
5 5 2 7 0
19 9
8 3 1 8 0
21 12 2 15
2 4 4 5 0
37 7 3 17
bj 10 12 9 7 3∑
41
Die Optimierung kann nun wie im Standardfall durchgefuhrt werden und liefert als opti-
male Losung:

44 2 Transportprobleme
1 2 3 4 5 ai
5 5 2 7 0
16 3 9
8 3 1 8 0
212 3 15
2 4 4 5 0
310 7 17
bj 10 12 9 7 3∑
41
Fur minimalen Kosten K∗ ergibt sich daraus:
K∗ = 2 · 6 + 0 · 3 + 3 · 12 + 1 · 3 + 2 · 10 + 5 · 7 = 106 .
Die dem fiktiven Kunden K5 zugeteilten drei Mengeneinheiten verbleiben in Wirklichkeit
in der Fabrik F1 als Lagerbestand.
Dieses Minimum fallt kleiner aus als beim ursprunglichen Transportproblem ohne den
fiktiven Kunden Nr. 5. Durch Uberkapazitat ergibt sich zusatzlicher planerischer Spiel-
raum, der zu einer Minimierung der Kosten fuhrt. Dabei werden die eventuell anfallenden
Lagerkosten nicht berucksichtigt.
Fall 2: Unterkapazitat
Die liefernden Fabriken produzieren weniger als die Kunden abnehmen konnen. Wir fuhren
deshalb eine fiktive Fabrik ein, die den Fehlbedarf erzeugt. Die den Kunden von der fiktiven
Fabrik gelieferten Mengen sind fur die entsprechenden Kunden Fehlmengen. Wenn wir die
Transportkosten von der fiktiven Fabrik zum Abnehmer mit Null bewerten, hat dieser
Trick keinerlei Einfluss auf unser Optimierungsproblem.
In unserem oben diskutierten Beispiel wollen wir annehmen, dass die Kunde Nr. 1 statt
10 Einheiten nun 14 Einheiten abnimmt. Wir fuhren deshalb eine fiktive Fabrik Nr. 4 ein,
dessen Produktionsmenge der Differenz
n∑j=1
bj −m∑
i=1
a1 = 42 − 38 = 4
entspricht. Wenn wir die zugehorigen Kostenkoeffizienten Null setzen, ergibt sich mit der
Nord-West-Ecken-Regel die folgende zulassige Basislosung.

2.2 Transportalgorithmus 45
1 2 3 4 ai
5 5 2 7
19 9
8 3 1 8
25 10 15
2 4 4 5
32 9 3 14
0 0 0 0
44 4
bj 14 12 9 7∑
42
Wir optimieren wieder mit dem Standardverfahren und erhalten als optimale Losung das
Tableau:
1 2 3 4 ai
5 5 2 7
16 3 9
8 3 1 8
212 3 15
2 4 4 5
314 14
0 0 0 0
44 4
bj 14 12 9 7∑
42
Fur minimalen Kosten K∗ ergibt sich daraus:
K∗ = 2 · 6 + 7 · 3 + 3 · 12 + 1 · 3 + 2 · 14 + 0 · 4 = 100 .
Die dem Kunden K4 von der fiktiven fabrik F4 zugeteilten vier Mengeneinheiten sind in
Wirklichkeit der Fehlbestand beim Abnehmer K4.
Auch hier ergibt sich durch die Auswahl des Kunden, der mit Fehlmengen bedacht wird, ein
zusatzlicher planerischer Spielraum. Dies fuhrt ebenso zur Kostenreduktion, wenn eventu-
elle Fehlbedarfskosten nicht berucksichtigt werden.

46 2 Transportprobleme
Bemerkung: Die in den beiden vorangegangenen Beispielen angegebene Strategie umfasst
den Fall, dass die anfallenden Lagerkosten im Fall 1 und die entstehenden Fehlmengenkos-
ten beim Fall 2 fur alle Produktionsstatten bzw. Abnehmer gleich hoch sind. Sind diese
Kosten unterschiedlich, so muss ein entsprechender Eintrag in die Kostenmatrix gemacht
werden. Es sind dann die Gesamtkosten, d. h. Transport- und Lagerhaltungskosten bzw.
Fehlmengenkosten zu minimieren.
2.2.5 Abweichende Problemstellungen
In der Praxis unterliegen Transportprobleme haufig zusatzlichen einschrankenden Bedin-
gungen, welche mit dem Transportalgorithmus nicht unmittelbar berucksichtigt werden
konnen. Durch Manipulation der Kostenmatrix lassen sich jedoch einige dieser Restriktio-
nen auf einfache Weise erfassen. Dies sei an zwei Beispielen erlautert.
Eine oder mehrere Routen sollen nicht benutzt werden
Wir ersetzen die Kostenkoeffizienten der gesperrten Routen durch fiktive, sehr hohe Werte.
Der Algorithmus liefert uns dann die optimale Losung, welche die betreffenden Felder
(wegen der hohen Kosten) nicht belegt.
Zur Illustration nehmen wir bei unserem Eingangsbeispiel an, dass die Route von der Fa-
brik F2 zum Kunden K2 gesperrt ist. Wir ersetzen den entspechenden Kostenkoeffizienten
c2,2 durch den Wert 30 und erhalten das folgende Tableau.
1 2 3 4 ai
5 5 2 7
19 9
8 30 1 8
21 12 2 15
2 4 4 5
37 7 14
bj 10 12 9 7∑
38
Durch Anwendung des Optimierungs-Algorithmus ergibt sich die Losung:

2.2 Transportalgorithmus 47
1 2 3 4 ai
5 5 2 7
19 9
8 30 1 8
29 6 15
2 4 4 5
310 3 1 14
bj 10 12 9 7∑
38
Wie zu erwarten war, ist das Feld (2,2) nicht belegt. Die minimalen Kosten K∗ bestimmen
sich zu:
K∗ = 5 · 9 + 1 · 9 + 8 · 6 + 2 · 10 + 4 · 3 + 5 · 1 = 139 .
Diese zusatzliche Bedingung, eine Route nicht zu benutzen, schrankt den planerischen
Spielraum ein und fuhrt deshalb zu hoheren Kosten.
Bevorzugte Belieferung eines Kunden bei Fehlbedarf
Falls die Gesamtproduktion der Fabriken den Gesamtverbrauch der Kunden nicht decken
kann, soll ein bestimmter Kunde unter allen Umstanden vollstandig beliefert werden.
Der formale Ausgleich zwischen Angebot und Nachfrage erfolgt wieder durch Einfuhrung
einer fiktiven Fabrik. Die von dieser Fabrik gelieferten Mengen stellen in Wirklichkeit Fehl-
mengen beim belieferten Kunden dar. Wir konnen somit die Forderung nach vollstandiger,
realer Belieferung eines bestimmten Kunden umwandeln in ein Verbot der Route von der
fiktiven Fabrik zu diesem Kunden. Wir erzwingen die Einhaltung dieser Bedingung (ana-
log zur vorangegangenen Problematik) dadurch, indem wir das betreffende Kostenfeld mit
einem fiktiven hohen Wert belegen.
Dies sei wieder am Eingangsbeispiel erlautert. Soll z. B. der Kunde K4 vollstandig beliefert
werden, so mussen wir die Route von der fiktiven Fabrik F4 zum Kunden K4 sperren. Wir
weisen deshalb dem Kostenkoeffizienten c4,4 den Wert 50 zu.

48 2 Transportprobleme
1 2 3 4 ai
5 5 2 7
16 3 9
8 3 1 8
212 3 15
2 4 4 5
314 14
0 0 0 50
44 4
bj 14 12 9 7∑
42
Das optimale Tableau hat die folgende Gestalt:
1 2 3 4 ai
5 5 2 7
14 5 9
8 3 1 8
210 5 15
2 4 4 5
312 2 14
0 0 0 50
42 2 4
bj 14 12 9 7∑
42
Wie zu erwarten war, ist das Feld (4,4) nicht belegt. Fur die minimalen Kosten K∗ gilt:
K∗ = 2 · 4 + 7 · 5 + 3 · 10 + 1 · 5 + 2 · 12 + 5 · 2 0 · 2 + 0 · 2 = 112 .
Bemerkung In manchen Situationen ist auch die folgende Uberlegung bezuglich der Kos-
tenmatrix hilfreich: Addiert oder subtrahiert man bei der Kostenmatrix von samtlichen
Elementen einer Zeile oder Spalte dieselbe Zahl, so erhalt man ein aquivalentes Optimie-
rungsproblem. Dadurch verandern sich die Kosten aller Wege von einer Fabrik bzw. zu
einem Kunden um denselben Betrag. Die Auswahl der Entscheidungsvariablen wird davon
nicht beruhrt, da ja die gesamte Kapazitat einer Fabrik bzw. Nachfrage eines Kunden
gleichmaßig betroffen ist.

2.3 Umladeprobleme 49
2.3 Umladeprobleme
Wir betrachten nun ein Transportproblem mit Zwischenlagern Zr. Mit einem kleinen Trick
konnen wir diese Fragestellung mit den zuvor behandelten Methoden losen. Wir betrach-
ten die Zwischenlager gleichzeitig als Fabriken und Kunden. Fur jedes Zwischenlager muss
die”aufgenommene“ Menge gleich der
”abgegebenen“ Menge sein. Ein fiktiver Trans-
port innerhalb desselben Zwischenlagers ist vorgesehen und wird in der Kostenmatrix mit
Null bewertet. Diese Durchflussmenge kann zudem beschrankt sein. Wir erlautern diese
Vorgehensweise an unserem Eingangsbeispiel auf Seite 30, indem wir zwei Zwischenla-
ger hinzufugen. Transporte zwischen Z1 und Z2 seien verboten. Dies wird durch einen
entsprechend hohen Eintrag (20) in der Kostenmatrix erreicht.
Abnehmer Nr. Zwischenlager Nr.
1 2 3 4 1 2
Fabrik/Lager Nr. Transportkosten/Einheit Kapazitat
1 5 5 2 7 1 1 9
2 8 3 1 8 2 1 15
3 2 4 4 5 1 2 14
1 2 1 3 4 0 20 10
2 1 2 1 3 20 0 50
Bedarf 10 12 9 7 10 50∑
98
Das Standardverfahren zur Optimierung ergibt das nachfolgende Tableau.
K1 K2 K3 K4 Z1 Z2 ai
5 5 2 7 1 1
F1 9 9
8 3 1 8 2 1
F2 2 9 4 15
2 4 4 5 1 2
F3 4 10 14
2 1 3 4 0 20
Z1 10 10
1 2 1 3 20 0
Z2 6 7 37 50
bj 10 12 9 7 10 50∑
98

50 2 Transportprobleme
Der Eintrag 37 im Feld (5,5) stellt einen fiktiven Transport innerhalb des Zwischlagers
Z2 dar, um die Kapazitat von 50 zu erfullen. Da die Kostenmatrix an dieser Stelle den
Eintrag Null hat, ist dies ohne Einfluss auf die Transportkosten. Der Eintrag von 50 fur
die Kapazitat von Z2 soll eine fur unsere Fragestellung unbeschrankte Aufnahmekapa-
zitat ausdrucken. Die vorgegebene Kapazitat von 10 fur Z1 wird voll ausgeschopft. Die
minimalen Kosten K∗ bestimmen sich zu:
K∗ = 1 · 9 + 3 · 2 + 1 · 9 + 1 · 4 + 2 · 4 + 1 · 10 + 1 · 10 + 1 · 6 + 3 · 7 + 0 · 37 = 83 .
2.4 Zuordnungsproblem
Das Zuordnungsproblem stellt eine spezielle Variante der linearen Optimierung dar, welche
bereits in das Gebiet der kombinatorischen Optimierung hinein reicht. Diese Fragestellung
lasst sich wie folgt skizzieren:
Fur die Erledigung von n Aufgaben stehen genauso viele Mittel (Arbeiter, Maschinen, etc.)
zur Verfugung. Grundsatzlich kann jedes Mittel zur Erfullung jeder Aufgabe eingesetzt
werden. Doch ist nicht jedes Mittel fur jede Aufgabe gleich gut geeignet. Diese spezifische
Eignung sei quantitativ fassbar und wird durch eine Matrix analog der Kostenmatrix
ausgedruckt. Gesucht ist diejenige Zuordnung der n Mittel zu den n Aufgaben, bei der
die Summe der Eignungskoeffizienten ihr Optimum erreicht. Dabei ist zu berucksichtigen,
dass jede Aufgabe erledigt werden muss und jedes Mittel genau einmal eingesetzt werden
kann.
Intuitiv wurde man zunachst versuchen, jeder Aufgabe das fur sie am besten geeignete
Mittel zuzuordnen. Da es aber bei dieser Strategie in der Regel Zielkonflikte gibt (ein Mit-
tel ist z. B. fur mehrere Aufgaben am besten geeignet) fuhrt diese Vorgehensweise in der
Regel zu keiner optimalen Losung. Auch der Gedanke, die beste Losung durch Aufzahlen
aller Moglichkeiten und anschließendem Kostenvergleich zu ermitteln, lasst sich bei große-
ren Problemen in der Praxis nicht durchfuhren. Die Anzahl der zulassigen Losungen fur
ein n · n-Problem betragt n! und ubersteigt damit auch fur leistungsfahige Rechner die
Kapazitat. (z.B. 20! = 2 432 902 008 176 640 000) Die Notwendigkeit eines effizienten
Optimierungsverfahren kann wohl nicht eindringlicher demonstriert werden.
Mathematische Formulierung
Z : Entscheidungskriterium
ci,j : Eignungskoeffizienten
(Eignung des Mittels i = 1, 2, . . . , n fur die Aufgabe j = 1, 2, . . . , n)
xi,j : Entscheidungsvariable i, j = 1, 2, . . . , n

2.4 Zuordnungsproblem 51
Wir setzen wieder voraus, dass die Eignungskoeffizienten alle nicht negativ sind. (Andern-
falls lasst sich dies durch Addition einer Konstanten zur gesamten Eignungsmatrix errei-
chen.) Die xi,j sind Auswahlvariable, die nur die Werte Null und Eins annehmen konnen.
Wir legen fest:
xi,j = 1 ⇔ wenn das Mittel i der Aufgabe j zugeordnet wird, andernfalls xi,j = 0
Damit lasst sich die Aufgabenstellung wie folgt beschreiben:
Man bestimme das Minimum der Funktion
Z =n∑
i=1
n∑j=1
ci,j · xi,j
unter den Nebenbedingungen
n∑i=1
xi,j = 1 fur alle j = 1, 2, . . . , n
n∑j=1
xi,j = 1 fur alle i = 1, 2, . . . , n
xi,j =
1
0
Die Nebenbedingungen bewirken, dass nur solche Losungen des Zuordnungsproblems zu-
lassig sind, bei denen jede Zeile und jede Spalte der Entscheidungsmatrix genau mit einem
Einselement belegt ist. Dies entspricht der Forderung, dass jede Aufgabe mit genau einem
Mittel erledigt wird.
Beispiel 2.1: Zur Eignungsmatrix
C = (cij) =
2 5 1 3
4 4 5 2
5 2 1 1
2 1 4 5
stellt die Entscheidungsmatrix
X = (xi,j) =
0 1 0 0
1 0 0 0
0 0 1 0
0 0 0 1
entspricht der Zuordnung
Mittel 1 2 3 4
m m m mAufgabe 2 1 3 4
eine zulassige Losung dar – in jeder Zeile und Spalte steht genau eine Eins.
Der (keineswegs optimale) Wert der Zielfunktion fur diese Losung betragt:
Z = 5 + 4 + 1 + 5 = 15

52 2 Transportprobleme
In der oben formulierten Gestalt kann das Zuordnungsproblem als spezielles Transport-
problem interpretiert werden. Man setzt m = n und ai = 1 fur i = 1, 2, . . . , n sowie bj = 1
fur j = 1, 2, . . . , n. Die grundsatzlich mogliche Losung des Zuordnungsproblems mit dem
Transportalgorithmus ist jedoch vergleichsweise muhsam. Ein spezieller Algorithmus fur
das Zuordnungsproblem ist wesentlich schneller.
Die Losung des Zuordnungsproblems besteht in der Aufgabe, aus den n · n Koeffizienten
der Eignungsmatrix C diejenigen n Elemente auszuwahlen, deren Summe das erreichbare
Minimum darstellt. Dabei mussen die ci,j so gewahlt werden, dass aus jeder Zeile und jeder
Spalte genau ein Element stammt. Man geht nun von der folgenden Idee aus: Unter der
Voraussetzung ci,j ≥ 0 ist das Minimum erreicht, wenn es gelingt, n Nullelemente ci,j = 0
zu finden. Diese Idee allein bringt uns noch nicht weiter, denn es werden wohl in den
wenigsten Fallen n Nullelemente in der Eignungsmatrix stehen. Zuhilfe kommt uns hier
die schon erwahnte Tatsache, dass die Addition einer Konstanten zu allen Koeffizienten
einer Spalte bzw. Zeile ein aquivalentes Minimierungsproblem ergibt. Wir versuchen nun
mit dieser Erkenntnis unsere Beispielmatrix umzuformen.
Beispiel 2.2: C = (cij) =
2 5 1 3
4 4 5 2
5 2 1 1
2 1 4 5
Wir subtrahieren von der ersten Spalte die Zahl Zwei, von den ubrigen Spalten wird Eins
abgezogen.
C1 = (cij) =
0 4 0 2
2 3 4 1
3 1 0 0
0 0 3 4
Es sind zwar genugend Nullen entstanden, aber leider nicht in der verwertbaren Anord-
nung. Die in der zweiten Zeile befindet sich keine Null. Deshalb subtrahieren wir noch von
der zweiten Zeile die Zahl Eins.
C2 = (cij) =
0 4 0 2
1 2 3 0
3 1 0 0
0 0 3 4
Die als Basiselemente ausgewahlten Variablen sind eingerahmt. Dies entspricht der folgen-
den Entscheidungsmatrix:

2.4 Zuordnungsproblem 53
X = (xi,j) =
1 0 0 0
0 0 0 1
0 0 1 0
0 1 0 0
entspricht der Zuordnung
Mittel 1 2 3 4
m m m mAufgabe 1 4 3 2
Das Minimum erhalten wir durch Einsetzen der Zuordnung in die ursprungliche Eignungs-
matrix:
Z∗ = 2 + 2 + 1 + 1 = 6
Es stellt sich nun die Frage, ob diese Strategie stets zum Ziel fuhrt. Wie wir beim nachsten
Beispiel sehen werden, muss diese Subtraktionsmethode noch etwas modifiziert werden.4
Beispiel 2.3: C = (cij) =
8 7 2 5 3
3 5 11 12 7
10 8 6 4 6
2 1 6 9 8
15 14 11 9 12
Schritt 1: Von allen Elementen einer jeden Zeile subtrahieren wir das kleinste Element
der betreffenden Zeile. Es sind dies der Reihe nach die Zahlen 2, 3, 4, 1, 9. Damit ergibt
sich in jeder Zeile mindestens ein Nullelement.
C1 = (cij) =
6 5 0 3 1
0 2 8 9 4
6 4 2 0 2
1 0 5 8 7
6 5 2 0 3
Schritt 2: Von allen Elementen einer jeden Spalte (der durch Schritt 1 umgeformten
Matrix) subtrahieren wir das kleinste Element der betreffenden Spalte. Es sind dies der
Reihe nach die Zahlen 0, 0, 0, 0, 1. Schritt 2 wird nur fur solche Spalten aktuell, die noch
keine Null enthalten. Damit ergibt sich auch in der vierten Spalte ein Nullelement.
C2 = (cij) =
6 5 0 3 0
0 2 8 9 3
6 4 2 0 1
1 0 5 8 6
6 5 2 0 2
Schritt 3: Es ist nun zu prufen, ob in jeder Spalte und Zeile genau eine Null ausgewahlt
werden kann, d. h. ob n linear unabhangige Entscheidungsvariable mit Eins belebt werden
4In der Literatur wird dieses Verfahren als ungarische Methode bezeichnet; benannt nach den ungari-schen Mathematikern Egervary und Konig.

54 2 Transportprobleme
konnen. Dies ist bei der Matrix C2 nicht der Fall. Die weiß eingerahmten Nullen sind
linear unabhangig, wahrend die beiden grau unterlegten Nullen davon abhangig sind.
Die Prufung auf lineare Unabhangigkeit erfolgt
mittels eines sogenannnten Deckliniensystems. Die
ausgewahlten Nullen werden mit horizontalen und
vertikalen”Decklinien“ uberdeckt. Werden dazu
genau n Linien benotigt, so liegt lineare Un-
abhangigkeit vor. In unserem Fall ist dies offen-
sichtlich nicht der Fall. Es reichen vier Linien aus
um alle Nullelemente zu uberdecken.6 5 2 0 2
1 0 5 8 6
6 4 2 0 1
0 2 8 9 3
6 5 0 3 0
Schritt 4: Durch geschicktes Subtrahieren mussen weitere Nullen erzeugt werden. Wir
gehen dazu nach folgendem Schema vor:
• Man sucht das kleinste von keiner Linie bedeckte Element und subtrahiert diese Zahl
von allen Elementen der Eignungsmatrix. (bei unserem Beispiel: 1)
• Um die auf den Deckungslinien vorhandenen Nullen nicht zu verlieren, addiert man
zu allen Elementen auf den Linien dieselbe Zahl. Dies hat zur Konsequenz, dass
alle Elemente, die nur auf einer Linie (vertikal oder horizontal) stehen unverandert
bleiben und die Elemente auf den Kreuzungspunkten um die im vorangegangenen
Schritt bestimmte Zahl (bei unserem Beispiel: 1) vergroßert werden.
C3 = (cij) =
7 5 0 4 0
0 1 7 9 2
6 3 1 0 0
2 0 5 9 6
6 4 1 0 1
6 4 1 0 1
2 0 5 9 6
6 3 1 0 0
0 1 7 9 2
7 5 0 4 0
Schritt 4 ergab eine zusatzliche Null. Der Test fur die lineare Unabhangigkeit mittels
Decklinien verlauft positiv. Wir wahlen die weiß unterlegten Nullen als Basis fur unsere
Entscheidungsmatrix
X =
0 0 1 0 0
1 0 0 0 0
0 0 0 0 1
0 1 0 0 0
0 0 0 1 0
entspricht der Zuordnung
Mittel 1 2 3 4 5
m m m m mAufgabe 3 1 5 2 4

2.4 Zuordnungsproblem 55
Die Kostensumme fur das Optimum ergibt sich zu:
Z∗ = 2 + 3 + 6 + 1 + 9 = 21
Falls sich keine n linear unabhangige”Nullvektoren“ ergeben, sind die Schritte 3 und 4 zu
wiederholen.
Maximierung statt Minimierung
Ein Zuordnungsproblem, dessen Zielfunktion zu maximieren ist, kann mit den vorhande-
nen Hilfsmitteln dadurch gelost werden, dass man die Maximierungsaufgabe durch eine
aquivalente Minimierungsaufgabe ersetzt.
z =∑i,j
xi,j · ci,j!= Max ⇔ z =
∑i,j
xi,j · (−ci,j)!= Min
Die Eignungsmatrix des aquivalenten Minimierungsproblems ist die mit dem Fakltor (−1)
multiplizierte Eignungsmatrix der Maximierungsaufgabe. Um wieder eine Matrix mit po-
sitiven Koeffizienten zu erhalten, addieren wir eine genugend große positive Konstante zu
allen Koeffizienten der Eignungsmatrix.
Beispiel 2.4: Gesucht ist eine Zuordnung, so dass die Bewertungsfunktion z bzgl. der
nachfolgenden Eignungsmatrix maximal wird.
z =∑i,j
xi,j · ci,j =!= Max
C = (cij) =
3 2 5
−1 2 3
6 4 4
; (−1) · C =
−3 −2 −5
1 −2 −3
−6 −4 −4
(−1) · C + 6 ·
1 1 1
1 1 1
1 1 1
= C =
3 4 1
7 4 3
0 2 2
Zeilen- und Spaltenreduktion ergibt bereits die optimale Matrix:
3 4 1
7 4 3
0 2 2
;
2 3 0
4 1 0
0 2 2
; C∗ =
2 2 0
4 0 0
0 1 2
Die zugehorige Entscheidungsmatrix
X =
0 0 1
0 1 0
1 0 0
entspricht der Zuordnung
Mittel 1 2 3
m m mAufgabe 3 2 1
Das Maximum der Bewertungsfunktion z ergibt sich zu: z = 6 + 2 + 5 = 13

56 3 Dynamische Optimierung
3 Dynamische Optimierung
Mit Hilfe der bisher entwickelten Verfahren sind wir in der Lage, sogenannte einstufige
Entscheidungsprozesse zu optimieren. Einstufig heißen Entscheidungsprobleme, wenn es
moglich ist, sie in zeitlicher und sachlicher Hinsicht von anderen Entscheidungsproblemen
zu isolieren. In zunehmendem Maße sieht man sich jedoch mit immer komplexeren Proble-
men konfrontiert, welche eine Abfolge von einander wechselseitig beeinflussenden Entschei-
dungen notwendig macht. Die dynamische Optimierung (DO) bietet Losungsmoglichkeiten
fur Entscheidungsprobleme bei denen eine Folge voneinander abhangiger Entscheidungen
getroffen werden muss. Die Folge dieser Entscheidungen soll ein Optimum fur den Ge-
samtprozess ergeben. Das Besondere an der dynamischen Optimierung liegt also in der
sequentiellen Losung eines in mehrere Perioden (Stufen) aufgeteilten Entscheidungsprozes-
ses, wobei auf jeder Stufe nur die dort existierende Entscheidungsalternativen betrachtet
werden. Bei diesen Stufen muss es sich nicht immer um zeitlich strukturiertes Problem
handeln.
Die Problematik derartiger Entscheidungen liegt darin, dass die Optimalitat einer jeden
Einzelentscheidung nicht unmittelbar, sondern erst im Zusammenhang mit den ubrigen
Entscheidungen beurteilt werden kann. Fur Anwender ist die dynamische Optimierung ein
weitaus schwierigeres Teilgebiet des Operation Research als etwa die lineare Optimierung.
Die Grunde hierfur liegen sowohl in der geeigneten Modellwahl als auch in der Auwahl des
geeigneten Losungsverfahrens fur die Optimierung.
Beispiel 3.1: Wir betrachten ein Bestellmengenproblem. Hierbei sind die Stufen, in die
der Losungsprozess unterteilt werden kann, Zeitperioden. Die Einkaufsabteilung eines Un-
ternehmens muss fur vier aufeinanderfolgende Perioden eine bestimmte, in jeder Periode
gleiche Menge eines Rohstoffes bereitstellen.
Die Einkaufspreise unterliegen saisonalen Schwankungen; sie
seien aber fur jede Periode bekannt und konnen der neben-
stehenden Tabelle entnommen werden. Der Lieferant kann,
Periode k 1 2 3 4
Preis qk 7 9 12 8
Bedarf bk 1 1 1 1
bei vernachlassigbarer Lieferzeit, in einer Periode maximal den Bedarf fur zwei Perioden
liefern. Die Lagerkapazitat ist ebenfalls auf den Bedarf von zwei Perioden beschrankt. Zu
Beginn der Periode 1 sei das Lager leer; am Ende der vierten Periode soll der Bestand
wieder Null betragen.
Problemstellung: Welche Mengen sind zu den verschiedenen Zeitpunkten einzukaufen, so
dass moglichst geringe Beschaffungskosten entstehen?

3.1 Darstellung mehrstufiger Entscheidungsprozesse 57
3.1 Darstellung mehrstufiger Entscheidungsprozesse
Der Einfachheit halber wollen wir von einer zeitlichen Strukturierung der Entscheidungs-
prozesse ausgehen. Wir betrachten einen Entscheidungsprozess in den diskreten Zeitpunk-
ten i ; i = 0, 1, 2, . . . , n und verwenden zu seiner Beschreibung die folgenden Begriffe:
a) Der Zustand des Prozesses zum Zeitpunkt i wird durch die Zustandsvariablen
z1i , z2
i , . . . , zMi , zusammengefasst im Zustandsvektor zi, beschrieben. Die Zustands-
variablen mussen so gewahlt werden, dass in ihren Werten zu jedem Zeitpunkt die
gesamte Vorgeschichte des Prozesses festgeschrieben ist. Weiter darf es keine Rolle
spielen, auf welche Weise der Prozess in diesen Zustand gelangt ist.
b) Zwischen den Zeitpunkten i− 1 und i konnen wir den Prozess durch eine Entschei-
dung beeinflussen. Zur Beschreibung dieser Entscheidung dienen die Entscheidungs-
variablen x1i , x2
i , . . . , xNi , zusammengefasst im Entscheidungsvektor xi. Durch die
Entscheidung xi geht das System vom Zustand zi−1 in den Zustand zi uber. Da der
Endzustand zi der Stufe i vom Anfangszustand zi−1 und von der Entscheidung xi
abhangt, konnen wir formal schreiben:
zi = hi( zi−1, xi)
c) Auf der Stufe i liefert der Prozess einen Beitrag Ki zum Gesamtkriterium K. Analog
zum Verhalten des Zustands zi unterstellen wir, dass Ki eine gegebene Funktion gi
des Anfangszustands zi−1 und der Entscheidung xi ist:
Ki = gi( zi−1, xi)
In der folgenden Skizze sind diese Strukturelemente mit Hilfe einer Zustands- und einer
Entscheidungsvariablen veranschaulicht.
SystemAnfangszustand zi−1 Endzustand zi = hi( zi−1, xi)
Beitrag zum Kriterium
Ki = gi( zi−1, xi)
Entscheidung
xi
- -
?
?

58 3 Dynamische Optimierung
Die Verkettung der Stufen (Perioden) uber den gesamten Prozessverlauf soll die nachfol-
gende Skizze deutlich machen.
1 2 i n−1 n
? ? ? ? ?
? ? ? ? ?- - - - - - - -
x1 x2 xi xn−1 xn
K1 K2 Ki Kn−1 Kn
z0 z1 z3 zi−1 zi zn−2 zn−1 zn. . . . . .
Fur unser Eingangsbeispiel ergibt sich folgende Konkretisierung als Graph. An den Ent-
scheidungspfeilen ist die Entscheidungsvariable xi und Beitrag Ki zum Entscheidungskri-
terium als Wertepaar (xi, Ki) vermerkt. Die Zustande zi sind in den Knoten vermerkt.
R
µ µ
µ
R
R
µ
R- -
-
-
-
-0 0
1
0
1
00
1
2
-
1 2 3 4 k
(2,14)
(1,7) (1,9)
(1,9)
(2,18)
(2,18)
(0,0)
(1,12)
(1,12)
(2,24)
(0,0)
(0,0)
(1,8)
(0,0)
Die Darstellung spiegelt folgende Gegebenheiten wieder:
• Jeder Knoten des Graphen entspricht einem Zustand, den das betrachtete System
(in unserem Fall das Lager) in der Periode k = 0, , 1, . . . , 4 annehmen kann.
• Jeder Pfeil veranschaulicht den durch eine Entscheidung xi (Zukauf) und eine Storgroße
bi (Abgang) hervorgerufenen Ubergang des Systems von einem Zustand zi−1 in einen
Zustand zi. Dieser Ubergang wird durch die Beziehung
zi = hi(zi−1, xi, bi)
dargestellt. (In unserem Beispiel ist bi konstant.)

3.2 Losungsprinzip der dynamischen Optimierung 59
3.2 Losungsprinzip der dynamischen Optimierung
Eine Folge von Entscheidungen, die einen Zustand z0 in einen Zustand zn uberfuhrt,
bezeichnet man als eine Politik. Eine Politik, die diese Anderung unter Minimierung der
Zielfunktion K erreicht, nennt man eine optimale Politik.
Da die Entscheidung auf der Stufe i nicht nur den Einzelertrag Ki, sondern auch die
anderen Zustande und damit die Beitrage zur Zielfunktion aller Stufen beeinflusst, fin-
det man die optimale Gesamtpolitik im Allgemeinen nicht dadurch, dass man auf jeder
Stufe des Prozesses den Einzelbeitrag Ki optimiert. Ein Wegweiser fur das Auffinden des
Gesamtoptimums ist das Bellmansche Optimaltitatsprinzip. Es lautet verkurzt:
Jede Unterpolitk einer optimalen Gesamtpolitik ist in ihrem Teilbereich wieder optimal.
oder in der Sprechweise der Mathematik ausgedruckt:
Satz: Sei x∗1, x∗2, . . . , x∗i−1, x∗i , . . . , x∗n eine optimale Gesamtpolitik, die den Anfangszu-
stand z0 in den Endzustand zn uberfuhrt. Sei ferner z∗i−1 der Zustand, den das System
bei optimaler Politik in der Periode i− 1 annimmt. Dann gilt:
• Die Folge von Entscheidungen xi, . . . , x∗n ist eine optimale Teilpolitik, die das System
vom Zustand z∗i−1 in Stufe i− 1 in den vorgegebenen Endzustand uberfuhrt.
• Die Folge von Entscheidungen x∗1, . . . , x∗i−1 ist eine optimale Teilpolitik, die das Sys-
tem vom Anfangsstand z0 in den Zustand z∗i−1 in Stufe i− 1 uberfuhrt.
Diese Optimalitatsprinzip wird rekursiv angewendet. Man bildet dabei entweder vom be-
kannten Ausgangszustand (Vorwartsrechnung) oder vom geforderten Endzustand (Ruckwarts-
rechnung, haufiger angewandt) ausgehend sukzessive optimale Unterpolitiken, zu deren
Konstruktion nur optimale Unterpolitiken niedrigerer Ordnung benutzt werden.
Fur jede Einzelentscheidung xi in der Periode i, die den Zustand zi−1 in den Zustand zi
uberfuhrt, bestimmen wir eine Bewertungsfunktion Fi−1(zi−1). Sie berechnet sich aus dem
aktuellen Beitrag Ki(xi, zi−1) und dem im vorangegangenen Schritt bestimmten Optimum
F ∗i (zi).
Fi−1(zi−1) = Fi∗(zi) + Ki(xi, zi−1)
Anschließend wird wieder das Optimum von Fi−1(zi−1) bestimmt.
Zur Illustration wollen wir unser Eingangsbeispiel durch”Ruckwartsrechnen“ optimieren.
Schritt 1: i = 4 Die Entscheidungsvaria-
ble x4 ist in Abhangigkeit der moglichen
Zustande z3 so festzulegen, dass der Endzu-
stand erreicht wird. Die optimale Entschei-
dung ist mit ∗ markiert.
z3 x4 z4 K4(z3, x4)) F3(z3) optimal
1 0 0 0 0 ∗0 1 0 8 8 ∗

60 3 Dynamische Optimierung
Schritt 2: i = 3 Die Entscheidungs-
variable x3 ist in Abhangigkeit der
moglichen Zustande z2 so festzulegen,
dass der Endzustand erreicht wird.
Die optimale Entscheidung ist mit ∗markiert.
z2 x3 z3 K3(z2, x3) F ∗3 (z3) F2(z2) optimal
2 0 1 0 0 0 ∗1 1 1 12 0 12
1 0 0 0 8 8 ∗0 2 1 24 0 24
0 1 0 12 8 20 ∗
Schritt 3: i = 2 Die Entscheidungs-
variable x2 ist in Abhangigkeit der
moglichen Zustande z1 so festzulegen,
dass der Endzustand erreicht wird.
Die optimale Entscheidung ist mit ∗markiert.
z1 x2 z2 K2(z1, x2) F ∗2 (z2) F1(z1) optimal
1 2 2 18 0 18
1 1 1 9 8 17 ∗1 0 0 0 20 20
0 2 1 18 8 26 ∗0 1 0 9 20 29
Schritt 4: i = 1 Die Entscheidungs-
variable x1 ist in Abhangigkeit vom
Startzustand z0 so festzulegen, dass
der Endzustand erreicht wird. Die op-
timale Entscheidung ist mit ∗ mar-
kiert.
z0 x1 z1 K1(z0, x1) F ∗1 (z1) F0(z0) optimal
0 2 1 14 17 31 ∗0 1 0 7 26 33
Die Verkettung dieser Entscheidungen fuhrt zu der optimalen Gesamtpolitik
x1 = 2; x2 = 1; x3 = 0; x4 = 1 mit dem Optimum F ∗0 (z0) = 31
R
µ
µ
-
-
-
µ
-
µ
- -
R
R R
0 0
1
0
1
00
1
2
-
1 2 3 4 k
(2,14)
(1,7) (1,9)
(1,9)
(2,18)
(2,18)
(0,0)
(1,12)
(1,12)
(2,24)
(0,0)
(0,0)
(1,8)
(0,0)

3.2 Losungsprinzip der dynamischen Optimierung 61
Im vorangegangenen Beispiel haben wir die optimale Teilpolitik durch Auflisten aller Falle
bestimmt. Dies ist bei ganzzahligen Entscheidungsvariablen mit eingeschranktem Bereich
moglich. Sind die Entscheidungsvariable reelle Großen, so ist fur jede Stufe ein geeignetes
Optimierungsverfahren bereit zu stellen. Dies sei am nachfolgenden Beispiel erlautert.
Von einem Wirtschaftsgut werde jeweils zu Beginn einer Periode eine gewisse Menge ver-
kauft. Anschließend wachse der verbleibende Bestand bis zum Beginn der nachsten Periode
mit dem Faktor a > 1 an. Die Zustandsvariablen zi ≥ 0 sollen den Bestand am Ende der
Periode i beschreiben. Die Entscheidungsvariable xi gibt die in dieser Periode verkaufte
Menge an. Dann gilt der Zusdammenhang:
zi = a · (zi−1 − xi) mit 0 ≤ xi ≤ zi−1 , i = 1, 2, . . . , n
Der Einfachheit wollen wir zn = 0 voraussetzen. Der durch den Verkauf in der Periode i
erzielte Gewinn werde durch gi(zi−1, xi) beschrieben. Bei vorgegebenem Anfangsbestand
z0 ergibt sich daraus die folgende Problemstellung:
zi = a · (zi−1 − xi) mit 0 ≤ xi ≤ zi−1 , i = 1, 2, . . . , n
zn = 0
G(z0, x1, x2, . . . , xn) =n∑
i=1
gi(zi−1, xi)!= Max
Zahlenbeispiel: a = 2 ; n = 3 ; z0 = 1 ; gi(zi−1, xi) =√
xi (D.h. der Gewinn hangt nur
von xi ab.)
Wir schreiben die Ubergangsgleichungen und die zu optimierenden Ausdrucke exlizit an.
z0 = 1
z1 = 2 · (z0 − x1) 0 ≤ x1 ≤ z0 g1(z0, x1) =√
x1
z2 = 2 · (z1 − x2) 0 ≤ x2 ≤ z1 g2(z1, x2) =√
x2
z3 = 2 · (z2 − x3) 0 ≤ x3 ≤ z2 g3(z2, x3) =√
x3
Eine mogliche”Politik“ sei im nachfolgenden Tableau dargestellt.
Zustandsvariable zi Entscheidungsvariable xi Gewinnfunktion gi(xi)
z0 = 1
z1 = 2 ·(1− 1
2
)= 1 x1 = 1
2
√12
z2 = 2 ·(1− 1
2
)= 1 x2 = 1
2
√12
z3 = 2 · (1− 1) = 0 x3 = 1√
1
G(12, 1
2, 1) =
√12
+√
12
+ 1 ≈ 2.41 . . .

62 3 Dynamische Optimierung
t
z3
z2
z1
z0z0
z1
z2
z3
2
1x1
x2
x3
Lasst sich der Gewinn durch”geschicktere“ Wahl von x1 , x2 noch optimieren?
Wir optimieren durch Ruckwartsrechnen und benutzen dabei die Beziehung:
Fi−1(zi−1) = F ∗i (zi) + gi(zi−1, xi)
Nun gilt: F3(z3) = F3(0) = F ∗3 (0) = 0
Schritt 1
F2(z2) = F ∗3 (z3) + g3(z2, x3)
= 0 +√
x3
;F ∗
2 (z2) = max0≤x3≤z2
√x3
=√
z2 , x3 = z2
Schritt 2
F1(z1) = F ∗2 (z2) + g2(z1, x2)
=√
z2 +√
x2 mit z2 = 2(z1 − x2) erhalt man daraus
=√
2 · (z1 − x2) +√
x2
F ∗1 (z1) = max
0≤x2≤z1
√2 · (z1 − x2) +
√x2
Nebenrechnung: w(u) =√
c · (t− u) +√
u!= max in 0 ≤ u ≤ t
w′(u) = −c2√
c(t− u)+ 1
2√
u!= 0 ;
c2√
c(t− u)= 1
2√
u
c√
u =√
c(t− u)
c2u = c(t− u) ;
umax = tc + 1
wmax =
√c ·
(t− t
c + 1
)
︸ ︷︷ ︸= c2t
c + 1
+√
tc + 1 =
√t
c + 1 · (c + 1) =√
(c + 1)t

3.2 Losungsprinzip der dynamischen Optimierung 63
damit gilt:
F ∗1 (z1) =
√3z1 , x2 = z1
3Schritt 3
F0(z0) = F ∗1 (z1) + g1(z0, x1)
=√
3z1 +√
x1 mit z1 = 2(z0 − x1) erhalt man daraus
=√
6 · (z0 − x1) +√
x1
F ∗0 (z0) = max
0≤x1≤z0
√6 · (z0 − x1) +
√x1
Mittels obiger Nebenrechnung (c = 6) erhalt man:
F ∗0 (z0) =
√7z0 , x1 = z0
7Die optimale
”Politik“ ist im nachfolgenden Tableau dargestellt.
Zustandsvariable zi Entscheidungsvariable xi Gewinnfunktion gi(xi)
z0 = 1
z1 = 2 ·(1− 1
7
)= 12
7 x1 = z07 = 1
7
√17
z2 = 2 ·(
127 − 4
7
)= 16
7 x2 = z13 = 4
7
√47
z3 = 2 ·(
167 − 16
7
)= 0 x3 = z2 = 16
7
√167
Der optimale Gewinn errechnet sich zu:
Gmax(17, 4
7, 16
7 ) = F ∗0 (1) =
√7 · 1 =
√17
+√
47
+√
167≈ 2.65 . . .
Solche Fragestellungen konnen auch mit der Technik, das Maximum einer Funktion meh-
rerer Variabler zu bestimmen, angegangen werden. Dazu stellen wir die Gewinnfunktion
direkt in Abhangigkeit der Entscheidungsvariablen dar. Bei obigem Beispiel setzen wir
dazu die Transformationsgleichungen
z0 = 1
z1 = 2 · (z0 − x1) 0 ≤ x1 ≤ z0 g1(x1) =√
x1
z2 = 2 · (z1 − x2) 0 ≤ x2 ≤ z1 g2(x2) =√
x2
z3 = 2 · (z2 − x3)!= 0 0 ≤ x3 ≤ z2 g3(x3) =
√x3
ineinander ein:
z2 = 2 · (z1 − x2) = 2 · [2 · (z0 − x1)− x2] = 4− 4x1 − 2x2
Da x3 = z2 (alles wird in der dritten Periode verkauft!) erhalten wir die Gewinnfunktion
in Abhangigkeit der beiden Entscheidungsvariablen x1, x2.
F (x1, x2) =√
x1 +√
x2 +√
x3 =√
x1 +√
x2 +√
4− 4x1 − 2x2
da alle Verkaufe xi ≥ 0 sein mussen, gilt fur die beiden Entscheidungsvariablen x1, x2 die

64 3 Dynamische Optimierung
Einschrankung:
x1 ≥ 0 , 0 ≤ x2 ≤ 2− 2x1
Wir bestimmen die optimale Politik indem wir die partiellen Ableitungen Null setzen.
∂F∂x1
= 12√
x1+ −4
2√
4− 4x1 − 2x2
;
4√
x1 =√
4− 4x1 − 2x2
16x1 = 4− 4x1 − 2x2
20x1 + 2x2 = 4
∂F∂x2
= 12√
x2+ −2
2√
4− 4x1 − 2x2
;
2√
x2 =√
4− 4x1 − 2x2
4x2 = 4− 4x1 − 2x2
4x1 + 6x2 = 4
Als Losung des linearen Gleichungssystems
10x1 + x2 = 2
2x1 + 3x2 = 2
erhalt man die bekannten Werte x1 = 17 , x2 = 4
7 .
Die nachfolgenden Bilder sollen dieses Optimierungsprinzip deutlich machen. Auf die Pro-
blematik nichtlinearer Optimierung werden wir im nachsten Abschnitt genauer eingehen.

3.2 Losungsprinzip der dynamischen Optimierung 65

66 3 Dynamische Optimierung
3.3 Stochastische Probleme
Wir betrachten erneut unser Bestellmodell und beschranken uns auf die ersten drei Peri-
oden. Nun nehmen wir an, dass der Bedarf bi jeder Periode i gleich 1 ist mit der Wahr-
scheinlichkeit p1 = 0.6 und gleich 0 mit der Wahrscheinlichkeit p0 = 0.4 . Lagerbestand
und Liefermenge sind wie bisher auf zwei Einheiten beschrankt.
Periode k 1 2 3
Preis ck 7 9 12
Bedarf bk 1 0 1 0 1 0
Wahrscheinlichkeit 0.6 0.4 0.6 0.4 0.6 0.4
Wir unterstellen ferner, dass fur die Produktion bei nicht ausreichendem Bestand Fehl-

3.3 Stochastische Probleme 67
mengenkosten in Hohe von 20 Einheiten entstehen. Eine am Ende des Planungszeitraums
eventuell vorhandene Restmenge sei nicht verwertbar.
Bei stochastischen Modellen der dynamischen Optimierung ist es ublich eine Poltik zu
bestimmen, die den Kostenerwartungswert (Beschaffungs- und Fehlmengenkosten) mini-
miert. Der nachfolgende Graph soll die diversen Entscheidungen veranschaulichen.
0 0
1
2
0
1
2
0
1
2
-
-
-
U
U
-
-
-
U
U
¸
µ
µ
R
µ
±
-
-
-
U
U
¸
µ
-0
¸
1
º
2
-1
µ2
R0
-0
µ1
-0
-1
R0
-0
-0
Da die entstehenden Kosten nicht allein von Entscheidungen, sondern auch vom Zufall
(dem stochastischen Bedarf) abhangen, enthalt der Graph zwei Arten von Knoten. Zu-
standsknoten, in denen eine Entscheidung zu treffen ist, nennt man deterministisch; sie
sind als Kreise dargestellt. Die quadratischen Knoten nennt man stochastisch; die von
ihnen ausgehenden Pfeile entsprechen einer zufallsabhangigen Nachfrage.
Ausgehend von einem Zustand zi−1 gelangen wir durch eine Entscheidung xi eindeutig
zu einem stochastischen Knoten (dicker Pfeil). Von dort erreichen wir uber die zufalls-
abhangige Nachfrage bi einen von zwei moglichen deterministischen Knoten zi. Von je-
dem stochastischen Knoten (Quadrat) gehen zwei Pfeile aus (dunner Pfeil). Der obere
Pfeil symbolisiert den mit der Wahrscheinlichkeit p0 = 0.4 auftretenden Bedarf bi = 0,
der untere Pfeil kennzeichnet den mit der Wahrscheinlichkeit p1 = 0.6 anfallenden Bedarf

68 3 Dynamische Optimierung
bi = 1. In jeder Stufe i = 1, 2, , 3 kann man von jedem Zustand zi−1 durch eine Entschei-
dung xi in hochstens zwei Folgezustande gelangen.
zi = zi−1 + xi − bi
Mit diesen Ubergangen sind die deterministischen Beschaffungskosten ci · xi und die fol-
genden zufallsabhangigen Fehlmengenkosten verbunden:
fi(zi−1, xi, bi) =
20 falls zi−1 = xi = 0 und bi = 1
0 sonst
Im Laufe der Ruckwartsrechnung berechnen wir fur jeden Entscheidungsknoten zi−1 den
minimalen Kostenerwartungswert F ∗i−1(zi−1) gemaß der Beziehung:
F ∗i−1(zi−1) = min
xi
ci · xi +
1∑
k=0
pk · [ fi(zi−1, xi, k) + F ∗i (zi) ]
Die folgenden Tabellen geben den Losungsgang fur unser Ausgangsproblem wieder. Im
Gegensatz zu Abschnitt 3.2 sind zu jedem Anfangszustand zi−1 und jeder Entscheidung xi
zwei mogliche Endzustande zi (mit den Wahrscheinlichkeiten pk) ins Kalkul einzubeziehen.
Die Bewertung Fi−1 ergibt sich dann aus dem mit den Wahrscheinlichkeiten gewichteten
arithmetischen Mittel der beiden Wege. Die optimale Entscheidung ist wieder mit ∗ mar-
kiert.
Schritt 1: i = 3
z2 x3 z3 c3 · x3 pk f3(z2, x3, b3) F ∗3 (z3) F2(z2) optimal
2 0 2 0 0.4 0 0
2 0 1 0 0.6 0 00 *
1 0 1 0 0.4 0 0
1 0 0 0 0.6 0 00 *
0 1 1 1 · 12 0.4 0 0
0 1 0 1 · 12 0.6 0 012 *
0 0 0 0 0.4 0 0
0 0 0 0 0.6 20 012 *

3.3 Stochastische Probleme 69
Schritt 2: i = 2
z1 x2 z2 c2 · x2 pk f2(z1, x2, b2) F ∗2 (z2) F1(z1) optimal
2 0 2 0 0.4 0 0
2 0 1 0 0.6 0 00 *
1 1 2 1 · 9 0.4 0 0
1 1 1 1 · 9 0.6 0 09
1 0 1 0 0.4 0 0
1 0 0 0 0.6 0 127.2 *
0 2 2 2 · 9 0.4 0 0
0 2 1 2 · 9 0.6 0 018
0 1 1 1 · 9 0.4 0 0
0 1 0 1 · 9 0.6 0 1216.2 *
0 0 0 0 0.4 0 12
0 0 0 0 0.6 20 1224
Schritt 3: i = 1
z0 x1 z1 c1 · x1 pk f1(z0, x1, b1) F ∗1 (z1) F0(z0) optimal
0 2 2 2 · 7 0.4 0 0
0 2 1 2 · 7 0.6 0 7.218.32 *
0 1 1 1 · 7 0.4 0 7.2
0 1 0 1 · 7 0.6 0 16.219.6
0 0 0 0 0.4 0 16.2
0 0 0 0 0.6 20 16.228.2
In der nebenstehenden Ab-
bildung sind die optimalen
Teilpolitiken fett gezeichnet.
Bei Stufe 1 sind auf jeden
Fall zwei Mengeneinheiten
zu beschaffen. Im Anschluss
an die zufallige Realisation
einer Nachfrage ist auf Stu-
fe 2 sowohl in z1 = 2 als
auch in z1 = 1 die Entschei-
dung x2 = 0 zu treffen. Fur
z1 = 0 stellt x2 = 1 die
optimale Teilpolitik dar. Auf
Stufe 3 ist jede (hinsichtlich
der Nebenbedingungen sinn-
volle) Entscheidung optimal.
0 0
1
2
0
1
2
0
1
2
-
-
-
U
U
-
-
-
U
U
¸
µ
µ
R
µ
±
-
-
-
U
U
¸
µ-0
1
2
1
µ2
R0
0
µ1
0
1
0
0
0
¸
-
1 2 3 i
º--
-
- -
-
R

70 4 Nichtlineare Optimierung
4 Nichtlineare Optimierung
Bisher haben wir uns ausschließlich mit linearen Optimierungsaufgaben beschaftigt, d.
h. Fragestellungen bei denen Zielfunktion und Nebenbedingungen lineare Funktionen von
x1, x2, . . . , xn sind. In der Realitat sind aber auch Optimierungsaufgaben, bei denen Ziel-
funktion und/oder Nebenbedingungen nichtlinear eingehen, nicht allzu selten. Fur solche
Probleme ist die Differentialrechnung das klassische Instrument zur Berechnung von Ex-
tremwerten. Fur einfache Modelle der Unternehmensforschung kann damit das Optimum
explizit berechnet werden. Bereits bei mittlerer Große und mittlerem Komplexitatsgrad der
Entscheidungsmodelle scheitert die Differentialrechnung jedoch. Der Wert dieser Metho-
den liegt heute mehr in der theoretischen Fundierung moderner Optimierungsalgorithmen.
Beispiele fur haufig vernachlassigte nichtlineare Beziehungen sind:
• der Einfluss der Großendegression in der Fertigung bei Entscheidungen uber das
Produktionsprogramm
• mangelnde Additivitat einzelner Faktoren bei Mischungsproblemen
• wechselseitige Beeinflussung von Verkaufsmengen und -preisen, woraus die Nichtli-
nearitat des Umsatzes resultiert
• abnehmende Ertragszuwachse, z. B. im Absatzbereich (doppelter Werbeeinsatz er-
gibt nicht unbedingt den doppelten Ertrag), bei Rationalisierungsmaßnahmen etc.
In vielen Fallen ist das Ausmaß und/oder der Einfluss der Nichtlinearitat auf das Ergebnis
gering, so dass die Losung des linearisierten Modells als hinreichend gute Naherung des
Problems angesehen werden darf. Es bleiben jedoch genugend Problemstellungen, die eine
explizite Berucksichtigung von Nichtlinearitaten erforderlich machen.
Eine formale Beschreibung eines allgemeinen Optimierungsproblems lautet:
Man maximiere (oder minimiere) die Zielfunktion
z = z(x1, x2, . . . , xn)
wobei die Variablen x1, x2, . . . , xn die m Nebenbedingungen
gi(x1, x2, . . . , xn)
≤≥=
bi ; i = 1, 2, . . . ,m
erfullen mussen.

71
Bemerkung: Speziell wird bei der linearen Optimierung gefordert, dass die Zielfunktion
die Bauart
z(x1, x2, . . . , xn) =n∑
j=1
cj · xj
und alle Nebenbedingungen von der Art
gi(x1, x2, . . . , xn) =n∑
j=1
ai,j · xj
sind. Weiterhin wird Nichtnegativitat fur alle Variablen angenommen.
Alle Optimierungsprobleme, die nicht diese spezielle Form haben, bezeichnen wir als nicht-
lineare Probleme. In dieser allgemeinen Definition von”nichtlinear“ sind auch alle ganzzah-
ligen, kombinatorischen Optimierungsaufgaben enthalten. Ganzzahlige Problemstellungen
unterscheiden sich jedoch von den ubrigen nichtlinearen Problemen insoweit, dass eine
gemeinsame Behandlung keine Vorteile hatte. Wir beschranken uns daher im Folgenden
auf nichtlineare Optimierungsaufgaben im engeren Sinne, also auf solche, die nichtlineare,
aber kontinuierliche Funktionen enthalten. Ganzzahlige, kombinatorische Optimierungs-
probleme werden separat betrachtet.
Derzeit existiert kein, dem Simplex-Algorithmus entsprechendes Verfahren, das samtliche
nichtlineare Optimierungsaufgaben zuverlassig lost. Alle praktisch einsetzbaren Verfah-
ren stellen relativ strenge Forderungen an die Art und die zulassige Anzahl nichtlinearer
Funktionen. Aber selbst bei starken Beschrankungen kann nicht die Wirksamkeit und
Zuverlassigkeit des Simplex-Algorithmus erreicht werden. Der Grund hierfur liegt in der
erheblichen grundsatzlichen Verkomplizierung von Optimierungsaufgaben beim Auftreten
nichtlinearer Funktionen. Zur Verdeutlichung wollen wir nochmals die grundsatzlichen Ei-
genschaften linearer Optimierungsprobleme deutlich machen:
a) Die Menge der zulassigen Losungen bilden einen konvexen Bereich des n-dimensionalen
Raumes, welcher endlich viele Ecken besitzt.
b) Die optimale Losung liegt auf dem Rand des zulassigen Gebiets. Es gibt einen Eck-
punkt (Basislosung) mit Optimalitat.
c) Es gibt außer dem globalen Optimum keine lokalen Optima.
d) Sofern die zulassige Losungsmenge nicht leer ist und die Zielfunktion auf dem zulassi-
gen Bereich beschrankt ist, existiert stets eine globale optimale Losung.
Die folgenden Beispiele mit zwei Variablen sollen diese Schwierigkeiten bei nichtlinearen
Problemen deutlich machen.

72 4 Nichtlineare Optimierung
Beispiel 4.1: Optimum liegt zwar auf dem Rand, aber nicht in einem Eckpunkt des
zulassigen Bereichs.
Minimiere die Zielfunktion : z(x1, x2) = (x1 − 1)2 + (x2 − 1)2 − 0.4
unter der Nebenbedingung : g1(x1, x2) = x1 + x2 ≤ 1
Das Problem besitzt ein globales Minimum
bei (0.5, 0.5) mit z(0.5, 0.5) = 0.1 .

73
Beispiel 4.2: Optimum liegt im Inneren des zulassigen Bereichs.
Minimiere die Zielfunktion : z(x1, x2) = (x1 − 1)2 + (x2 − 1)2 − 0.4
unter der Nebenbedingung : g1(x1, x2) = x1 + x2 ≤ 3
Das Problem besitzt ein globales Minimum
bei (1, 1) mit z(1, 1) = −0.4 .
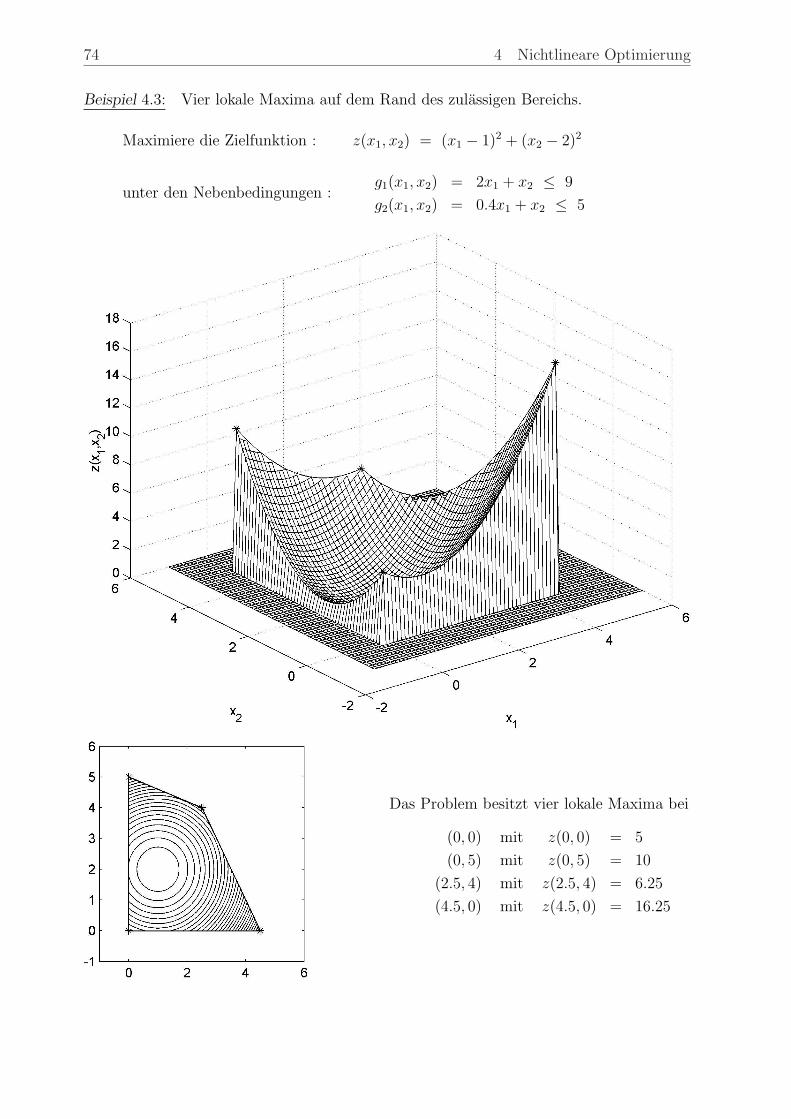
74 4 Nichtlineare Optimierung
Beispiel 4.3: Vier lokale Maxima auf dem Rand des zulassigen Bereichs.
Maximiere die Zielfunktion : z(x1, x2) = (x1 − 1)2 + (x2 − 2)2
unter den Nebenbedingungen :g1(x1, x2) = 2x1 + x2 ≤ 9
g2(x1, x2) = 0.4x1 + x2 ≤ 5
Das Problem besitzt vier lokale Maxima bei
(0, 0) mit z(0, 0) = 5
(0, 5) mit z(0, 5) = 10
(2.5, 4) mit z(2.5, 4) = 6.25
(4.5, 0) mit z(4.5, 0) = 16.25

75
Beispiel 4.4: Unendlich viele lokale Maxima im Inneren des zulassigen Bereichs.
Maximiere die Zielfunktion : z(x1, x2) = sin[(x1 − 1)2 + (x2 − 2)2
]+ 1.1
unter den Nebenbedingungen :g1(x1, x2) = 2x1 + x2 ≤ 8
g2(x1, x2) = −2(x1 − 1)2 + x2 ≤ 2
Das Problem besitzt lokale Maxima, die
durch Minima voneinander getrennt sind.
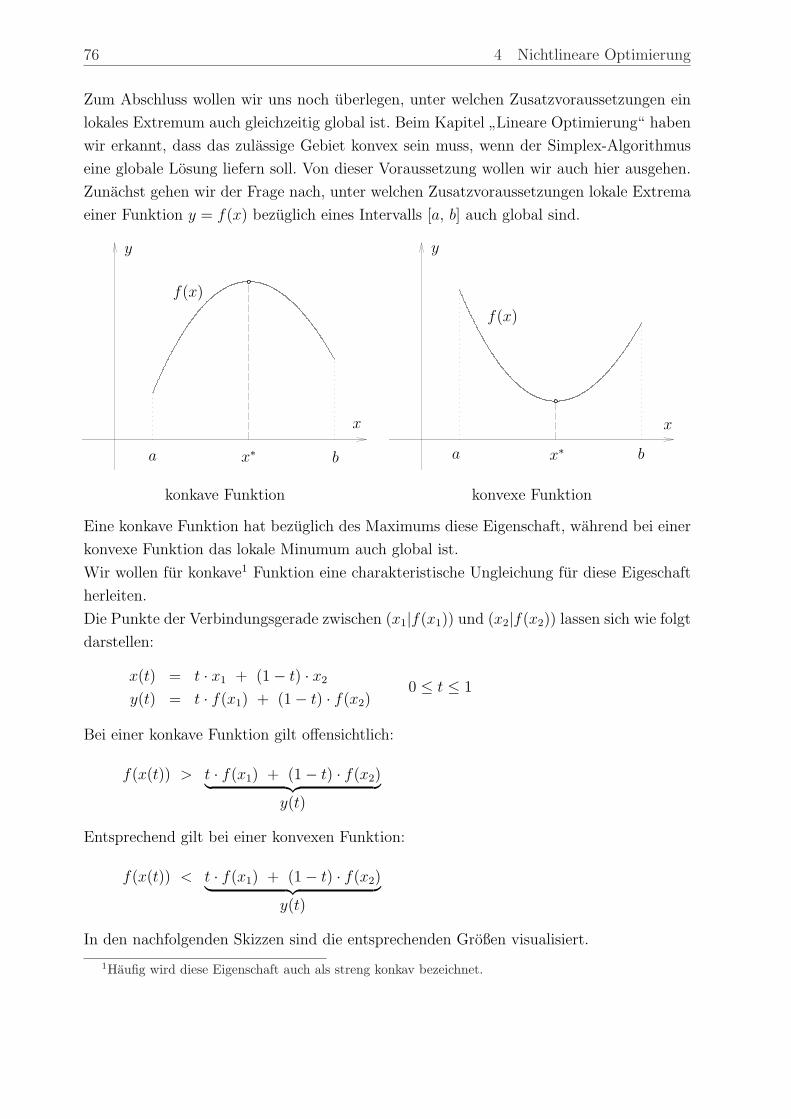
76 4 Nichtlineare Optimierung
Zum Abschluss wollen wir uns noch uberlegen, unter welchen Zusatzvoraussetzungen ein
lokales Extremum auch gleichzeitig global ist. Beim Kapitel”Lineare Optimierung“ haben
wir erkannt, dass das zulassige Gebiet konvex sein muss, wenn der Simplex-Algorithmus
eine globale Losung liefern soll. Von dieser Voraussetzung wollen wir auch hier ausgehen.
Zunachst gehen wir der Frage nach, unter welchen Zusatzvoraussetzungen lokale Extrema
einer Funktion y = f(x) bezuglich eines Intervalls [a, b] auch global sind.
a bx∗
x
y
f(x)
konkave Funktion
a x∗ b
x
y
f(x)
konvexe Funktion
Eine konkave Funktion hat bezuglich des Maximums diese Eigenschaft, wahrend bei einer
konvexe Funktion das lokale Minumum auch global ist.
Wir wollen fur konkave1 Funktion eine charakteristische Ungleichung fur diese Eigeschaft
herleiten.
Die Punkte der Verbindungsgerade zwischen (x1|f(x1)) und (x2|f(x2)) lassen sich wie folgt
darstellen:
x(t) = t · x1 + (1− t) · x2
y(t) = t · f(x1) + (1− t) · f(x2)0 ≤ t ≤ 1
Bei einer konkave Funktion gilt offensichtlich:
f(x(t)) > t · f(x1) + (1− t) · f(x2)︸ ︷︷ ︸y(t)
Entsprechend gilt bei einer konvexen Funktion:
f(x(t)) < t · f(x1) + (1− t) · f(x2)︸ ︷︷ ︸y(t)
In den nachfolgenden Skizzen sind die entsprechenden Großen visualisiert.
1Haufig wird diese Eigenschaft auch als streng konkav bezeichnet.

77
a x1 x(t) x2 b
x
y
f(x)
f(x1)
y(t)
f(x2)
f(x(t))
konkave Funktion
a x1 x(t) x2 b
x
f(x(t))
f(x2)
y(t)
f(x1)
y
f(x)
konvexe Funktion

78 4 Nichtlineare Optimierung
Fur Funktionen mehrerer Variabler f(x) wird die Eigenschaft konvex und konkav mit
denselben Ungleichungen erklart.
Bei der Optimierung von Funktionenn f(x) mehrerer Variabler spielen naturgemaß die
partiellen Ableitungen von f(x) eine zentrale Rolle. Zur ubersichtlichen Darstellung fassen
wir samtliche partiellen Ableitungen zu einem Vektor zusammen und bezeichnen diesen
Vektor mit ∇f(x); gesprochen Gradient von f .
∇f(x) =
∂f∂x1
(x)
∂f∂x2
(x)
...∂f∂xn
(x)
Der Gradientenvektor ist fur jeden Punkt des Definitionsbereichs von f erklart. Fur n = 2
kann der Gradient von f anschaulich gedeutet werden. Die zu optimierende Funktion
z = f(x) stellt dann eine Flache im Raum dar. Der Vektor ∇f(x) gibt dann in der
(x1, x2)-Ebene die Richtung des starksten Anstiegs an. In der folgenden Skizze sind fur die
Funktion
z = f(x1, x2) =√
1− x21 − 2.5x2
2
in der (x1, x2)-Ebene neben den Hohenlinien einige Gradienten eingezeichnet.
z = sqrt1− x2 − 2.5y2
x
y

4.1 Losungsverfahren 79
Es ist anschaulich klar, dass der Definitionsbereich von f(x) (Inneres einer Ellipse!)
konvex ist. Ebenso kann man durch Nachrechnen erkenne, dass die Funktion f(x) fur
x1, x1 ∈ D(f) die Eigenschaft
x(t) = (1− t) · x1 + t · x2; f(x(t)) > t · f(x1) + (1− t) · f(x2)︸ ︷︷ ︸y(t)
erfullt und damit konkav ist. Fur solche Funktionen gilt nun der Satz:
Satz: Es sei f(x) eine auf einer konvexen Menge erklarten Menge X ∈ IRn definierte
konkave Funktion. Dann gilt:
a) Ein lokales Maximum f(x∗) ist zugleich globales Maximum von f auf X.
b) Ist f(x) zweimal stetig differenzierbar, so stellt ∇f(x) = 0 eine notwendige und
zugleich hinreichende Bedingung fur ein globales Maximum dar.
Eine analoge Aussage gilt fur kovexe Funktionen bezuglich des Minimums.
Der obere Satz ist eine reine Existenzausssage. Er hat aber auch fur den Anwender ei-
ne gewisse Bedeutung. Liefert ein Naherungsverfahren unter den Voraussetzungen dieses
Satzes eine Losung, so kann man sicher sein, dass diese auch global ist. In allen anderen
Fallen mussen wir versuchen durch Zusatzbetrachtungen, Variation der Startbedingungen
des Algorithmus etc. eine globale Losung zu rechtfertigen.
4.1 Losungsverfahren
Wir versuchen hier nur einen Uberblick uber diverse Grundgedanken zu geben, die zu
Losungsverfahren fur nichtlineare Optimierungsprobleme fuhren. Zunachst seien einige
Spezialfalle erwahnt, die einer expliziten Losung zuganglich sind. Dabei sei die Nichtlinea-
ritat auf die Zielfunktion beschrankt. Der zulassige Bereich fur die Losungen bilde – wie
im linearen Fall – ein von Hyperebenen beschranktes konvexes Gebiet im IRn.
a) Probleme mit trennbarer Zielfunktion
Eine Zielfunktion von n Variablen heißt trennbar, wenn sie als Summe von n Funk-
tionen dargestellt werden kann, die jeweils nur von einer Variablen xj abhangen.
z = f(x1, x2, . . . , xn) =n∑
i=1
fi(xi)
Erfullen die Zielfunktionen fi zusatzlich Bedingungen ( z. B. konvex oder konkav),
so lassen sich die entsprechenden Optimierungsaufgaben auf die Einzelfunktionen
zuruckspielen.

80 4 Nichtlineare Optimierung
b) Probleme mit quadratischer Zielfunktion
Eine Zielfunktion heisst quadratisch, wenn sie nur Glieder erster und zweiter Ord-
nung enthalt.
z = f(x1, x2, . . . , xn) =n∑
i=1
ci xi +n∑
i=1
n∑j=1
di,j xi xj
In vektorieller Schreibweise lasst sich die Zielfunktion in die Form bringen:
z = f(x1, x2, . . . , xn) = cT · x + xT · D · x
Hierbei ist D eine symmetrische (n, n)-Matrix. Da partielle Ableitungen quadra-
tischer Ausdrucke linear sind, kann man dieses Optimierungsproblem unter einfa-
chen Zusatzvoraussetzungen (Matrix muss positiv semidefinit sein) durch Einfuhrung
zusatzlicher Schlupfvariabler auf den Simplex-Algorithmus zuruckspielen.
c) Probleme mit hyperbolischer Zielfunktion
z = f(x1, x2, . . . , xn) =
c0 +n∑
i=1
ci xi
d0 +n∑
i=1
di xi
Man spricht von einer hyperbolischen Zielfunktion, wenn die Zielfunktion als Quoti-
ent zweier linearer Ausdrucke dargestellt werden kann.
Zielfunktionen dieser Art treten in den Fallen auf, in denen relative Kriterien zu
optimieren sind, z. B bei Rentabilitat.
Durch einen kleinen Trick lasst sich dieses Problem auf eine lineare Fragestellung
zuruckfuhren. Man erweitert den Quotienten mit einer Hilfsvariablen t > 0 und
fuhrt neue Variable ein:
z = f(x1, x2, . . . , xn) =
c0 · t +n∑
i=1
ci xi · t
d0 · t +n∑
i=1
di xi · t
mit der zusatzlichen Nebenbedingung
d0 · t +n∑
i=1
di xi · t = 1
und den neuen Variablen yj = xj · t ergibt sich ein lineares Optimierungsproblem
z = f(y1, y2, . . . , yn, t) = c0 · t +n∑
i=1
ci yi

4.1 Losungsverfahren 81
Bezuglich der Losung allgemeiner nichtlinearer Optimierungsaufgaben wollen wir uns auf
wenige Grundgedanken beschranken. Im Zweidimensionalen wird die zu optimierende Ziel-
funktion F (x1, x2) durch eine Flache im IR3 dargestellt. Der Gradient von F ergibt einen
zweidimensionalen Vektor, der im Definitionsgebiet in Richtung des starksten Anstiegs
auf der Flache weist (Falllinie). Wir versuchen nun das Maximum iterativ zu erreichen.
Dazu bestimmen wir ausgehend von einer Naherung xn die Richtung des Gradienten und
bestimmen auf dieser Geraden den Punkt xn+1 mit maximalem Wert der Zielfunktion als
nachste Naherung. Auf diese Weise konnen wir den Gipfel des Berges ersteigen.
Soll das Minimum bestimmt werden, so geht man in Richtung des negativen Gradienten
zur nachsten Naherung.
Beispiel 4.5: Quadratische Zielfunktion mit globalem Minimum im Inneren des zulassigen
Bereichs.
Minimiere die Zielfunktion : z(x1, x2) = (x1 − 1)2 + 2(x2 − 2)2
unter den Nebenbedingungen :g1(x1, x2) = 2x1 + x2 ≤ 9
g2(x1, x2) = 0.4x1 + x2 ≤ 5

82 4 Nichtlineare Optimierung
Das Problem besitzt vier lokale Maxima und
ein globales Minimum bei
(0, 0) mit z(0, 0) = 9
(0, 5) mit z(0, 5) = 19
(2.5, 4) mit z(2.5, 4) = 10.25
(4.5, 0) mit z(4.5, 0) = 20.25
(1, 2) mit z(1, 2) = 0
Zur Losung gehen wir von einem Naherungspunkt in Richtung des negativen Gradienten
zur nachsten Naherung. Bereits nach zwei Iterationen haben wir das globale Minimum
erreicht.
xn grad(F (xn)) xn + t · [−grad(F (xn))] optimaler t-Wert xn+1
(1.6
1.2
) (1.2
−3.2
) (1.6
1.2
)+ t ·
(−1.2
3.2
)0.25
(1.3
2
)
(1.3
2
) (0.6
0
) (1.3
2
)+ t ·
(−0.6
0
)0.5
(1
2
)
Die folgende Skizze zeigt die Iteration in der (x1, x2)-Ebene.

4.1 Losungsverfahren 83
Wenden wir dasselbe Prinzip unverandert zur Bestimmung des maximalen Wertes an, so
erreichen wir schnell den Rand des zulassigen Bereichs und der Prozess bricht ab. Der
Algorithmus berucksichtigt nicht die Berandung des zulassigen Gebiets.
xn grad(F (xn)) xn + t · [grad(F (xn))] optimaler t-Wert xn+1
(0.95
1.95
) (−0.1
−0.2
) (0.95
1.95
)+ t ·
(−0.1
−0.2
)1
(0.85
1.75
)
(0.85
1.75
) (−0.3
−1
) (0.85
1.75
)+ t ·
(−0.3
−1
)1
(0.55
0.75
)
(0.55
0.75
) (−0.3
−1
) (0.85
1.75
)+ t ·
(−0.9
−5
)0.15
(0.415
0
)
Die folgende Skizze zeigt, wie schnell die Iteration zu einem Randpunkt fuhrt. Ein vernunf-
tiger Algorithmus muss die aus den Nebenbedingungen stammenden”zulassigen Richtun-
gen“ mit einbeziehen. Nur so sind die lokalen Maxima in den Eckpunkten erreichbar.

84 4 Nichtlineare Optimierung
Zum Abschluss wollen wir noch die Tucken bei der An-
wendung von Software (z. B. Excel, MATLAB) auf unser
Beispiel deutlich machen.
Bei der Suche nach dem Maximum ergeben sich bei obi-
gem Beispiel je nach Startwert verschiedene Losungen.
Solche Programme erkennen haufig nur lokale Extrema.
Aus diesem Grund ist es meist sehr wichtig zu wissen, in
welchem Bereich das zu bestimmende Optimum liegen
muss. Ein Anhaltspunkt liefert haufig auch ein verein-
fachtes lineares Modell.
x0 x∗ F (x∗)
(0.1
0.1
) (0
0
)9
(1
4
) (0
5
)19
(4
1
) (4.5
0
)20.25
Nachfolgendes Tabellenkalkulationsblatt (Excel) soll die Vorgehensweise erlautern. In Zelle
B6 ist die Zielfunktion in Abhangigkeit von x1, x2, d. h. von Zelle B5 bzw. C5 einzugeben.
Die Koeffizienten der Ungleichungen geben wir in den Zellbereich B9:C10 ein; die Schran-
ken tragen wir in D9:D10 ein. In der Berechnungtabelle B12:C13 berechnen wir die linken
Seiten der Ungleichungen.

4.1 Losungsverfahren 85
A B C D
1 Nichtlineare
2 Optimierung
3
4 Variable x1 x2
5 Werte 0 5,00000001486873
6 Funktion =(B5-1)ˆ2+2*(C5-2)ˆ2
7
8 Ungleichungen ai1 ai2 di
9 2 1 9
10 0,4 1 5
11
12 Berechnung =B5*B9 =C5*C9 =SUMME(B12:C12)
13 =B5*B10 =C5*C10 =SUMME(B13:C13)
Nun wird fur die Zelle B7 (Zielfunktion) der”Solver“ aufgerufen. In die Solver-Dialog-Box
machen wir folgende Eintrage:
Zielzelle : $B$6
Zielwert : Max anklicken
Veranderbare Zelle : $B$5: $C$5
Nebenbedingungen :$D$12: $D$13 <= $D$9: $D$10
$B$5: $C$5 >= 0
Wenn wir in die Zellen B5:C5 die verschiedenen Startwerte eintragen und anschließend
den Solver aufrufen, ergeben sich die erwahnten drei lokalen Maxima.

86 5 Warteschlangentheorie
5 Warteschlangentheorie
Warteschlangensituationen trifft man uberall an: Autos vor einer Ampel, Kunden vor
einer Kasse, Anrufe bei einer Telefonzentrale und Maschinen, die auf eine Reparatur war-
ten. Jedes Wartesystem besteht aus den Komponenten Inputprozess, Warteschlange und
Servicesystem. Warteschlangenmodelle werden mit Hilfe der charakteristischen Eigenschaf-
ten dieser drei Komponenten klassifiziert.
Kundenquelle-ankommende
Kunden-abgefertigte
Kunden
Wartesystem
Warte-schlange
Bedienungs-station
Die obige Abbildung zeigt den prinzipiellen Aufbau eines Wartesystems mit einer Bedie-
nungsstation, die aus zwei parallelen Schaltern besteht.
5.1 Klassifizierung
In diesem Abschnitt wollen wir, ohne auf konkrete Rechenstrukturen einzugehen, Warte-
schlangensysteme charakterisieren.
a) Inputprozess
Als Modell stellen wir uns dafur eine Quelle vor, die Einheiten (Kunden, Autos,
Maschinen etc.) fur unser System liefert. Dabei unterscheiden wir:
• Unbeschrankte Quelle (offenes System)
Beschrankte Quelle (geschlossenes System)
Beispiel fur offenes System: Kunde - Bankschalter

5.1 Klassifizierung 87
Beispiel fur geschlossenes System: Maschinenpark - Servicemonteur
• Einzelankunfte oder Gruppenankunfte
Beispiel fur Einzelankunfte: Friseur
Beispiel fur Gruppenankunfte: Restaurant
• Zeiten zwischen zwei Ankunften sind statistisch von einander abhangig oder
unabhangig
• Die Wahrscheinlichkeitsverteilung der Zwischenzeiten ist zeitunabhangig
( stationar ) oder hangt von der Zeit ab ( nichtstationar ).
Ein nichtstationarer Inputprozess liegt vor, wenn sich Zeiten des Hochbetriebs
mit Flauten abwechseln.
• Manchmal hangen die Inputprozesse auch vom jeweiligen Zustand der Warte-
schlange ab.
Beispiel fur einen vom Systemzustand abhangigen Inputprozess: Falls die War-
teschlange zu lang ist, tritt ein potentieller Kunde mit einer bestimmten Wahr-
scheinlichkeit nicht ins System ein. Als Spezialfall ist hier auch ein beschrankter
Warteraum enthalten.
b) Warteschlange
Hier wird die Reihenfolge der Bedienung sowie das Kundenverhalten in der Schlange
charakterisiert.
• Auswahlordnungen fur den Service, die von der Reihenfolge des Eintreffens
abhangen:
FIFO : first in, first out
LIFO : last in, first out
SIRO : service in random order
• Prioritatensystem
Die ankommenden Einheiten werden fur die Bedienungsreihenfolge in Rangklas-
sen eingeteilt. Die Prioritat der Bedienung kann auch”absolut“ erklart sein, d.
h. eine Einheit hoheren Ranges unterbricht sogar den laufenden Service einer
niedrigeren Einheit.
Der Rang einer Einheit kann sowohl extern vorgegeben werden (z. B. Stamm-
kunden werden vorgezogen), er kann aber auch intern an die zu erwartende
Servicezeit gebunden werden.
• Ungeduldige Kunden in der Warteschlange
Kunden verlassen ohne Service mit einer gewissen Wahrscheinlichkeit die War-
teschlange, wenn diese zu lang ist.

88 5 Warteschlangentheorie
c) Servicesystem
Ein Servicesystem besteht aus mehreren gekoppelten Servicestellen ( = Kanalen )
• Servicestellen
Eine entscheidende Kenngroße einer Servicestelle ist die Wahrscheinlichkeits-
verteilung der Servicezeiten. Zur Klassifizierung dienen die Eigenschaften:
– alle Kunden sind in Bezug auf die Servicezeit vom selben Typ bzw. verhal-
ten sich unterschiedlich.
– alle Servicestellen des Systems verhalten sich gleich oder besitzen ein un-
terschiedliches Serviceverhalten
– Servicezeiten sind vom jeweiligen Systemzustand unabhangig oder abhangig.
(Bei Andrang schnellere Abfertigung!)
– die Servicezeitverteilung ist stationar oder hangt von der Zeit ab
• Struktur von Servicesystemen
– Parallelschaltung von Servicestellen: Die Abfertigungsrate des Gesamtsys-
tems ergibt sich als Summe der einzelnen Abfertigungsraten.
– Reihenschaltung
Falls zwischen den Servicestellen Warteschlangen beliebiger Lange moglich
sind, ist die Gesamtabfertigungsrate des Systems gleich der Abfertigungsra-
te derjenigen Servicestelle, die den Engpass bildet. Bei beschranktem War-
teraum zwischen den verschiedenen Servicestationen konnen durch”Ruck-
stau“ Blockierungseffekte auftreten, die die Leistung des Gesamtsystems
unter die Engpassleistung drucken.
Reihenschaltungen sind erheblich schwerer zu analysieren als Parallelschal-
tungen.
• Stochastische Netzwerke
Aus der Parallel- und Reihenschaltung von Servicestellen konnen beliebig kom-
plizierte Netzwerke aufgebaut werden. Hier hilft in der Regel nur die Simulation
der Anordnung.
Zur groben Klassifikation von Wartesystemen benutzt man das folgende Schema:
A|B|s : (d|e|f)
Jedes Symbol dieses Codes steht fur die Auspragung eines Unterscheidungsmerkmals von
Wartesystemen.

5.1 Klassifizierung 89
A : Wahrscheinlichkeitsverteilung des Inputprozesses
B : Wahrscheinlichkeitsverteilung der Servicezeiten
s : Anzahl der parallel geschalteten Servicestellen
d : Angabe der Schlangendisziplin (FIFO etc.)
e : e < ∞ oder e = ∞ gibt die Schlangenkapazitat an
f : f < ∞ oder f = ∞ signalisiert, ob der Input beschrankt ist oder nicht
Im Falle d=FIFO, e=f=∞ beschrankt man sich darauf, die ersten drei Merkmale anzuge-
ben.
Fur A und B kommen folgende gebrauchliche Wahrscheinlichkeitsverteilungen in Frage:
M : exponentiell verteilte Zwischenzeiten; beim Input ergibt sich ein Poisson-Strom
(M = Markov-Eigenschaft)
E : Input genugt einer Erlangverteilung (Summe von Exponentialverteilungen)
D : konstante Servicezeit bzw. aquidistanter Input (D = deterministic)
G : allgemeine Verteilung bei Servicezeit bzw. Input (G = general)
Beispiel 5.1: Das Kurzel M|D|2 : (FIFO|∞|∞) bedeutet:
Input : Zwischenankunftszeiten sind exponential verteilt
Service : konstante Servicezeiten; zwei parallele Kanale
Schlangendisziplin : FIFO (first in, first out)
Schlangenkapazitat : unbeschrankt
System : unbeschrankt
Leistungen der Warteschlangentheorie
Eine Warteschlangenanalyse wird bei Entscheidungen fur einen Systementwurf benotigt.
Um Entscheidungen uber Geschwindigkeit, Anzahl und Anordnung von Servicestationen,
den Wartraum und die Auswahlordnung eines Systems treffen zu konnen, benotigen wir
detaillierte Informationen uber das Verhalten von solchen Warteschlangensystemen. Wir
versuchen deswegen Maßzahlen zu berechnen, die die Leistungsfahigkeit solcher Systeme
widerspiegelt. Haufig verwendete Leistungskennzahlen sind Erwartungswert (entspricht
Mittelwert) und Varianz der Warteschlangenlange und der Wartezeit. Ebenso bestimmt
man Parameter, die den Ausnutzungsgrad der Servicestellen und den maximal moglichen
Durchfluss.

90 5 Warteschlangentheorie
Die Warteschlangentheorie liefert uns fur viele Systemvarianten analytisch gewonnene For-
meln fur die oben erwahnten Parameter. Fur komplexere Systeme, die in der Praxis durch-
aus relevant sind, bietet nur die Simulation einen Ausweg.
5.2 Modellierung von Wartesystemen
Wir nehmen an, dass das Wartesystem zum Zeitpunkt 0 leer sei und zu den Zeitpunkten
T1, T2, . . . mit 0 < T1 < T2 < . . . Kunden einzeln ankommen und sich in die Warte-
schlange einreihen. (Kunden treten in das Wartesystem ein, wobei das Wartesystem die
Warteschlange und die Bedienungsstation umfasst.) Setzen wir noch T0 = 0, so bezeichnen
wir mit Zn = Tn−Tn−1 die Zwischenankunftszeit des n-ten Kunden. Sn sei die Bedienungs-
zeit oder Servicezeit des n-ten Kunden. Als aktuelle Wartezeit W qn des Kunden n in der
Schlange bezeichnen wir die Zeitspanne zwischen Ankunft und Beginn der Bedienung.
Wn = W qn + Sn
ist dann die Gesamtzeit des n-ten Kunden im Wartesystem, auch Verweilzeit genannt. Fur
den Zeitpunkt Dn , zu dem der Kunde das Wartesystem verlasst gilt:
Dn = Tn + W qn + Sn
Sei L(t) die Anzahl der Kunden im Wartesystem zum Zeitpunkt t ≥ 0. Im Falle eines
Bedienungsschalters gilt dann fur die Anzahl Lq(t) der Kunden in der Schlange
Lq(t) =
L(t)− 1, falls L(t) ≥ 1
0, falls L(t) = 1.
Die Großen Tn, Zn, Sn, Wn, W qn ; n = 1, 2, . . . sowie L(t), Lq(t) ; t ≥ 0 stellen
Zufallsgroßen dar. Bei einem Wartesystem sind in der Regel die Verteilungen von Zn und
Sn gegeben und die Verteilungen von W qn und L(t) gesucht. Wir werden im Folgenden nur
Wartesysteme betrachten, bei denen Zn und Sn jeweils unabhangige, identisch verteilte
Zufallsgroßen sind und damit durch je ein Zufallsvariable Z (”die Zwischenankunftszeit“)
bzw. S (”die Bedienungszeit“) beschrieben werden konnen. Außerdem sollen Z und S
voneinander stochastisch unabhangig sein. Diese Voraussetzung ist oft in der Praxis nicht
gegeben. In diesem Fall muss auf die Simulation des Systems zuruckgegriffen werden.
L(t)| t ≥ 0 ist ein sogenannter stochastischer Prozess. Jede Realisation von L(t)| t ≥0 entspricht einer Treppenfunktion, die zu den Zeitpunkten Tn und Dn Sprungstellen
besitzt. Vereinbaren wir, dass diese Treppenfunktion”rechtsseitig“ stetig ist, dann ist
L(Tn) − 1 die Anzahl der Kunden, die der n-te ankommende Kunde im Wartesystem
vorfindet. L(Dn) ist die Anzahl der im System zuruckbleibenden Kunden, wenn der n-te
Kunde das Wartesystem verlasst.

5.3 Das Wartesystem M|M|1 91
1
2
3
T1 T2T3 D1 D2 T4 D3
t
W1
W2
W3
Die obige Skizze illustriert einen solchen”stochastischen Prozess“. Sie zeigt vier Ankunfte
zu den Zeiten T1, T2, T3, T4. Zu den Zeiten D1, D2, D3 verlasst jeweils ein Kunde das
System. Die Doppelpfeile sollen die zugehorigen Verweildauern Wi deutlich machen.
5.3 Das Wartesystem M|M|1Beim Wartesystem M|M|1 sind die Zwischenankunftszeit und die Bedienzeit exponential-
verteilte Zufallsvariable. Wir wollen versuchen fur dieses”einfache“ System ein mathema-
tisches Modell zu entwickeln. Dabei werden wir wieder auf die aus der Wahrscheinlichkeits-
theorie bekannten Possion-Verteilung treffen. Mit Hilfe der Wahrscheinlichkeitsrechnung
lasst sich zeigen, dass die Anzahl der Ereignisse in einem festen Zeitraum T bei einem
exponentialverteilten Ankunftsstrom einer Poisson-Verteilung genugt.
Die Zeiten zwischen zwei Ereignissen seien exponentialverteilt mit der Dichtefunktion
f(t) = λe−λt. Wir fragen nach der Anzahl der Ereignisse in einem festen Zeitraum T .
pλ(k) sei die Wahrscheinlichkeit dafur, dass im Zeitraum [0, T ] genau k Ereignisse statt-
finden.
• kein Ereignis in [0, T ]:
pλ(0) =∞∫T
λe−λτdτ =[− e−λτ
]∞T
= e−λT
• genau ein Ereignis in [0, T ]: es ist zu falten

92 5 Warteschlangentheorie
kein Ereignis in [0, T ]
?
ein Ereignis in [0, T ]
pλ(1) =T∫0
e−λτ · λe−λ(T−τ)dτ = λe−λTT∫0
1dτ = λe−λT[τ]T
0= λTe−λT
• genau zwei Ereignisse in [0, T ]: es ist zu falten
ein Ereignis in [0, T ]
?
ein Ereignis in [0, T ]
pλ(2) =T∫0
λτe−λτ · λe−λ(T−τ)dτ = λ2e−λTT∫0
τdτ = λ2e−λT[τ 2
2
]T
0=
(λT )2
2 e−λT
• Vermutung: Poisson-Verteilung mit dem Parameter λT
Wir fuhren den Nachweis mit vollstandiger Induktion. Es ist noch der Induktionss-
schritt durchzufuhren.
Es gelte pλ(k) =(λT )k
k!e−λT .
Wir bestimmen die Wahrscheinlichkeit fur genau k + 1 Ereignisse in [0, T ]: es ist zu
falten
k Ereignisse in [0, T ]
?
ein Ereignis in [0, T ]
pλ(k + 1) =T∫0
λkτ k
k!e−λτ · λe−λ(T−τ)dτ = λk+1
k!e−λT
T∫0
τ kdτ
= λk+1
k!e−λT
[τ k+1
k + 1
]T
0=
(λT )k+1
(k + 1)!e−λT
Diese Verteilung besitzt den Erwartungswert E(X ) = λT mit der Bedeutung
”durchschnittliche Anzahl der Anrufe im Beobachtungszeitraum [0, T ]“.
Daraus errechnet sich wieder die”Ankunftsrate“ λ =
E(X )T .
Der Kehrwert TE(X )
hat die Bedeutung”durchschnittliche Zeit zwischen zwei
Ankunften“.
Wir wollen hier alternativ versuchen, diese Verteilungen aus folgenden Forderungen A1,
A2, A3 abzuleiten. Dabei formulieren wir ein Differenzialgleichungssystem fur die Wahr-
scheinlichkeiten p(k). Dieser Weg hat den Vorteil, dass prinzipiell auch die”Einschwing-
vorgange“ fassbar sind. Im Gegensatz dazu beschreibt die obere Uberlegung nur den sta-
tionaren Fall!

5.3 Das Wartesystem M|M|1 93
A1 Die Wahrscheinlichkeit P , dass ein Kunde in einem beliebigen Zeitintervall ∆t ein-
trifft sei proportional zu Intervalllange und unabhangig vom Zeitpunkt t sowie der
Situation in der Warteschlange; d. h. es gelte
P = λ ·∆t ; λ : Ankunftsrate
Die Wahrscheinlichkeit, dass ein weiterer Kunde in diesem Zeitintervall eintrifft sei
Null.
A2 Die Wahrscheinlichkeit P , dass ein Kunde in einem beliebigen Zeitintervall ∆t ab-
gefertigt wird, sei wieder proportional zu Intervalllange und unabhangig vom Zeit-
punkt t sowie der Situation in der Warteschlange; d. h. es gelte
P = µ ·∆t ; µ : Bedienungsrate
Die Wahrscheinlichkeit, dass mehr als ein Kunde in diesem Zeitintervall abgefertigt
wird, sei ebenfalls Null.
Im Falle eines leeren Wartesystems setzen wir die Wahrscheinlichkeit fur das Abfer-
tigen gleich Null.
Die Voraussetzungen A1 und A2 besagen insbesondere, dass die Kunden einzeln ankommen
und abgefertigt werden. Das”Eintreffen eines Kunden“ und das
”Abfertigen eines Kunden“
bezeichnen wir im Folgenden im Sinne der Wahrscheinlichkeitsrechnung als ein Ereignis.
Die dritte Forderung lautet dann:
A3 Die Anzahl der in disjunkten Zeitintervallen auftretenden Ereignisse”Eintreffen ei-
nes Kunden“ seien unabhangige Zufallsgroßen. D. h. die Anzahl der zuvor eingetrof-
fenen Kunden beeinflusst nicht die Ankunft der nachfolgenden Kunden. Dasselbe
gelte fur die Ereignisse”Abfertigen eines Kunden“.
Wir wollen nun unter den Voraussetzungen A1 bis A3 alle moglichen Zustandsanderungen
untersuchen. Sind zum Zeitpunkt t ≥ 0 genau j ≥ 0 Kunden im Wartesystem, d. h. es
gelte
L(t) = j
so sagen wir, das System befinde sich zur Zeit t im Zustand j. Die wahrend eines Zeitin-
tervalls ∆t moglichen”Zustandsubergange“ sind in der nachfolgenden Tabelle aufgelistet.
Bei den Wahrscheinlichkeiten wurden nur die linearen Glieder in ∆t berucksichtigt.

94 5 Warteschlangentheorie
Zustand
zur Zeit t
Zustand
zur Zeit t+∆t
Bedeutung des
Zustandsubergangs
Wahrscheinlichkeit des
Zustandsubergangs
j ≥ 0 j + 1ein neuer Kunde ist
angekommenλ ·∆t
j + 1 jein Kunde wurde
abgefertigtµ ·∆t
j ≥ 1 j
weder ein neuer Kunde ange-
kommen noch ein neuer Kunde
abgefertigt oder
ein neuer Kunde ist angekom-
men und ein Kunde wurde im
selben Intervall abgefertigt.
1− (λ ·∆t + µ ·∆t) 1
j = 0 j = 0kein neuer Kunde ist
angekommen1− λ ·∆t
Mittels obiger Tabelle konnen wir nun fur die Wahrscheinlichkeiten pj(t) und pj(t + ∆t)
eine Differenzengleichung angeben. Dabei werden wieder nur die linearen Glieder in ∆t
berucksichtigt.2
p0(t + ∆t) =
keine Veranderung︷ ︸︸ ︷(1− λ∆t) · p0(t) +
eine Abfertigung︷ ︸︸ ︷µ∆t · p1(t)
pj(t + ∆t) = λ∆t · pj−1︸ ︷︷ ︸eine Ankunft
+ (1− λ∆t− µ∆t) · pj(t)︸ ︷︷ ︸keine Veranderung
+ µ∆t · pj+1(t)︸ ︷︷ ︸eine Abfertigung
; j = 1, 2, . . .
Obiges System lasst sich auch als Differenzenquotient anschreiben:
p0(t + ∆t)− p0(t)∆t = −λ · p0(t) + µ · p1(t)
pj(t + ∆t)− pj(t)∆t = λ · pj−1 + − (λ + µ) · pj(t) + µ · pj+1(t) ; j = 1, 2, . . .
1Es gilt exakt :
(1− λ ·∆t) · (1− µ ·∆t) + (λ ·∆t) · (µ ·∆t) = 1− (λ + µ) ·∆t + 2λ · µ · (∆t)2
Wenn wir die Glieder zweiter Ordnung in ∆t vernachlassigen, so erhalten wir den obigen Tabelleneintrag.2Hintergrund ist der Satz von der totalen Wahrscheinlichkeit: Seinen B1, B2, . . . Br paarweise dis-
junkte Ereignisse mit ∪rk=1Bk = Ω . Dann gilt fur ein beliebiges Ereignis A
P (A) =r∑
k=1
P (A|Bk) · P (Bk)︸ ︷︷ ︸P (A ∩Bk)

5.3 Das Wartesystem M|M|1 95
Der Grenzubergang ∆t → 0 liefert dann das folgende System von Differenzialgleichungen,
wobei wir wie ublich die Ableitung nach der Zeit mit einem Punkt bezeichnen.
p0(t) = −λ · p0(t) + µ · p1(t)
pj(t) = λ · pj−1 + − (λ + µ) · pj(t) + µ · pj+1(t) ; j = 1, 2, . . .
Zu obigen Differenzialgleichungen mussen noch Startwerte vorgegeben werden. Wenn wir
standardmaßig annehmen, dass wir mit einem leeren System starten, so erhalt man die
Anfangsbedingungen:
p0(0) = 1
pj(0) = 0 ; j = 1, 2, . . .
Aus den obigen Uberlegungen konnen die Verteilungsfunktionen des Ankunfts- und Ab-
gangsprozesses sowie die Verteilung der Wartezeiten bestimmt werden. Exemplarisch wol-
len wir die Verteilungsfunktion fur den Ankunftsprozess ableiten.
Es sei qj(t) die Wahrscheinlichkeit dafur, dass bis zum Zeitpunkt t genau j Klienten ange-
kommen sind. Wir erhalten das zugehorige Differenzialgleichungssystem, indem wir oben
µ = 0 und pj(t) = qj(t) setzen.
q0(t) = −λ · q0(t) q0(0) = 1
qj(t) = λ · qj−1(t) − λ · qj(t) qj(0) = 0 ; j = 1, 2, . . .
Wir losen nun sukzessive das System.
Fall j = 0
Das Anfangswertproblem q0(t) = −λ · q0(t) ; q0(0) = 1 besitzt die Losung:
q0(t) = e−λt
Fall j = 1
Zu losen ist das Problem q1(t) = λ · e−λt − λ · q1(t) ; q1(0) = 0 .
Fur die homogene Losung erhalten wir wieder q1,h(t) = Ce−λt .
Wegen”Resonanz“ machen wir fur die partikulare Losung den Ansatz:
q1,p = A · t · e−λt ; q1p = A · e−λt + A · t · e−λt(−λ)
In die Differenzialgleichung eingesetzt, ergibt sich eine Bestimmungsgleichung fur A:
A · e−λt + A · t · e−λt(−λ) = λ · e−λt + (−λ) · A · t · e−λt ; A = λ
Nun mussen wir noch die Losung q1(t) = Ce−λt + λt · e−λt an die Anfangsbedingung
q1(0) = 0 anpassen.
q1(0) = C!= 0 ; C = 0 ⇒ q1(t) = λt · e−λt

96 5 Warteschlangentheorie
Fall j = 2
Als Losung des Problems q2(t) = λ · (λt)e−λt − λ · q2(t) ; q2(0) = 0 erhalten wir mit
derselben Losungsstrategie:
q2(t) =(λt)2
2!· e−λt
Wir vermuten nun, dass sich auch fur j ≥ 2 eine Poisson-Verteilung ergibt. Der Nachweis
wird durch vollstandige Induktion erbracht.
Fur j = 1, 2 haben wir oben bereits den Nachweis erbracht. Es gelte nun
qj(t) =(λt)j
j!· e−λt ; j = 0, 1, 2, . . . n
Wir wollen nun zeigen, dass
qn+1(t) =(λt)n+1
(n + 1)!· e−λt
die Differentialgleichung
qn+1(t) = λqn(t) − λqn+1(t) = λ · (λt)n
n!· e−λt − λqn+1(t)
erfullt. Dazu differenzieren wir den Ausdruck
qn+1(t) = ddt
(λt)n+1
(n + 1)!· e−λt
=
(λt)n
n!· λ · e−λt
︸ ︷︷ ︸λqn(t)
+(λt)n+1
(n + 1)!· e−λt · (−λ)
︸ ︷︷ ︸−λqn+1(t)
Damit haben wir den Nachweis erbracht, dass der Ankunftsprozess einer Poisson-Verteilung
mit dem Parameter λt genugt. Man spricht dann auch von einem Poisson-Prozess oder
einem Poisson-Strom.
Die Anzahl der im Mittel pro Zeiteinheit ankommenden Kunden bezeichnen wir als An-
kunftsrate. Fur das Wartesystem M|M|1 ist die Ankunftsrate gleich dem Erwartungswert
einer Poisson-verteilten Zufallsvariablen fur t = 1, also gleich λ.
Fur die Zwischenankunftszeit Z gilt mit obigen Uberlegungen
P (Z > t) = P (in [0, t] ist kein Kunde angekommen) = q0(t) = e−λt .
Fur die Verteilungsfunktion F (t) von Z ergibt sich somit
F (t) = P (Z ≤ t) = 1− e−λt ,
d. h. die Zwischenankunftszeit Z ist exponentialverteilt mit dem Parameter λ . Der Er-
wartungswert von Z ist somit 1λ
(vgl. Wahrscheinlichkeitsrechnung).

5.3 Das Wartesystem M|M|1 97
Analog zum Ankunftsprozess kann der sogenannte Bedienungsprozess betrachtet werden.
Die Bedienungsrate, d. h. die Anzahl der im Mittel pro Zeiteinheit abgefertigten Kunden,
ist gleich µ. Auch die Bedienungszeit S ist exponentialverteilt mit dem Parameter µ. Dies
fuhrt wieder zum Erwartungswert 1µ
.
Der Quotient der beiden Parameter
ρ = λµ
wird Verkehrsintensitat genannt; er ist ein Maß fur die Auslastung des Systems.
Wir haben damit verifiziert, dass die Bedingungen A1, A2, A3 zum Wartesystem M|M|1fuhren, d. h. die Zwischenankunftszeit Z und die Bedienungszeit S sind exponentialver-
teilte Zufallsgroßen mit den Parametern λ bzw. µ . Man kann auch umgekehrt zeigen, dass
aus diesem Sachverhalt die Bedingungen A1, A2, A3 folgen.
5.3.1 Gleichgewichtsfall des Systems M|M|1Die Bestimmung der Verteilungsfunktion fur die Verweildauer wurde die Losung des ur-
sprunglichen Differenzialgleichungssystems mit unendlich vielen Funktionen pj(t) erfor-
dern.
p0 = −λp0 + µp1
p1 = λp0 − (λ + µ)p1 + µp2
p2 = λp1 − (λ + µ)p2 + µp3
p3 = λp2 − (λ + µ)p3 + µp4
p4 = λp3 − (λ + µ)p4 + µp5
...
Dies ist sehr aufwendig und nur naherungsweise losbar. Wir betrachten deshalb hier den
stationaren Fall, der sich rechentechnisch dadurch ergibt, dass man die im obigen Diffe-
renzialgleichungssystem auftretenden Ableitungen zu Null setzt.
Bezeichnen wir die stationaren Wahrscheinlichkeiten mit πj, so erhalten wir mit dieser
Uberlegung das folgende lineare Gleichungssystem
0 = −λπ0 + µπ1
0 = λπ0 − (λ + µ)π1 + µπ2
0 = λπ1 − (λ + µ)π2 + µπ3
0 = λπ2 − (λ + µ)π3 + µπ4
0 = λπ3 − (λ + µ)π4 + µπ5
...

98 5 Warteschlangentheorie
Durch sukzessives Ineinander-Einsetzen erhalten wir
π1 = λµ π0
π2 =λ + µ
µ π1 − λµ π0 =
λ + µµ
(λµ
)π0 − λ
µ π0 =(
λµ
)2
π0
π3 =λ + µ
µ π2 − λµ π1 =
λ + µµ
(λµ
)2
π0 −(
λµ
)2
π0 =(
λµ
)3
π0
π4 =λ + µ
µ π3 − λµ π2 =
λ + µµ
(λµ
)3
π0 −(
λµ
)3
π0 =(
λµ
)4
π0
...
Allgemein ergibt sich
πk =(
λµ
)k
π0 bzw. mit ρ = λµ < 1 πk = ρkπ0 .
Der Wert fur π0 ergibt sich aus der Normierungseigenschaft:
1 =∞∑
k=0
πk = π0 ·∞∑
k=0
ρk = π0 · 11− ρ ; π0 = 1− ρ
Damit erhalten wir fur die stationaren Wahrscheinlichkeiten:
πk = (1− ρ) · ρk ; k = 0, 1, 2, . . . mit ρ = λµ
Damit lassen sich alle fur das System wichtige Kennzahlen bestimmen. Exemplarisch wol-
len wir dies fur die Erwartungswerte der Anzahl der Kunden im System L bzw. der Lange
der Warteschlange Lq durchfuhren.
E(L) =∞∑
k=1
k · (1− ρ)ρk
= ρ · (1− ρ) ·∞∑
k=1
kρk−1
= ρ · (1− ρ) · ddρ
∞∑k=0
ρk
= ρ · (1− ρ) · ddρ
1
1− ρ
= ρ · (1− ρ) · 1(1− ρ)2
= ρ · 11− ρ = λ
µ− λ

5.3 Das Wartesystem M|M|1 99
E(Lq) =∞∑
k=1
(k − 1) · (1− ρ)ρk
=∞∑
k=1
k · (1− ρ)ρk −∞∑
k=1
(1− ρ)ρk
=ρ
1− ρ − (1− ρ) ·∞∑
k=0
ρk + (1− ρ)
=ρ
1− ρ − ρ = λ2
µ(µ− λ)
Sind W die mittlere Verweildauer im System und Wq die mittlere Wartezeit, dann sind
die Beziehungen
W = 1λ· L bzw. Wq = 1
λ· Lq
plausibel; denn 1λ
ist der Erwartungswert der Zwischenankunftszeit.
Die fur den Umgang mit stationaren M|M|1-Systemen wichtigen Definitionen und Bezie-
hungen sind nochmals in den folgenden Tabellen zusammengestellt.
Symbol Bedeutung
λ mittlere Ankunftsrate
1λ
mittlere Zwischenankunftszeit
µ mittlere Abfertigungsrate
1µ mittlere Servicezeit
ρ = λµ Servicequotient
α Ausnutzungsgrad des Servicesystems
L Anzahl der Einheiten im Gesamtsystem
Lq Anzahl der Einheiten in der Schlange
W Verweilzeit einer Einheit im Gesamtsystem
Wq Verweilzeit (Wartezeit) einer Einheit in der Schlange
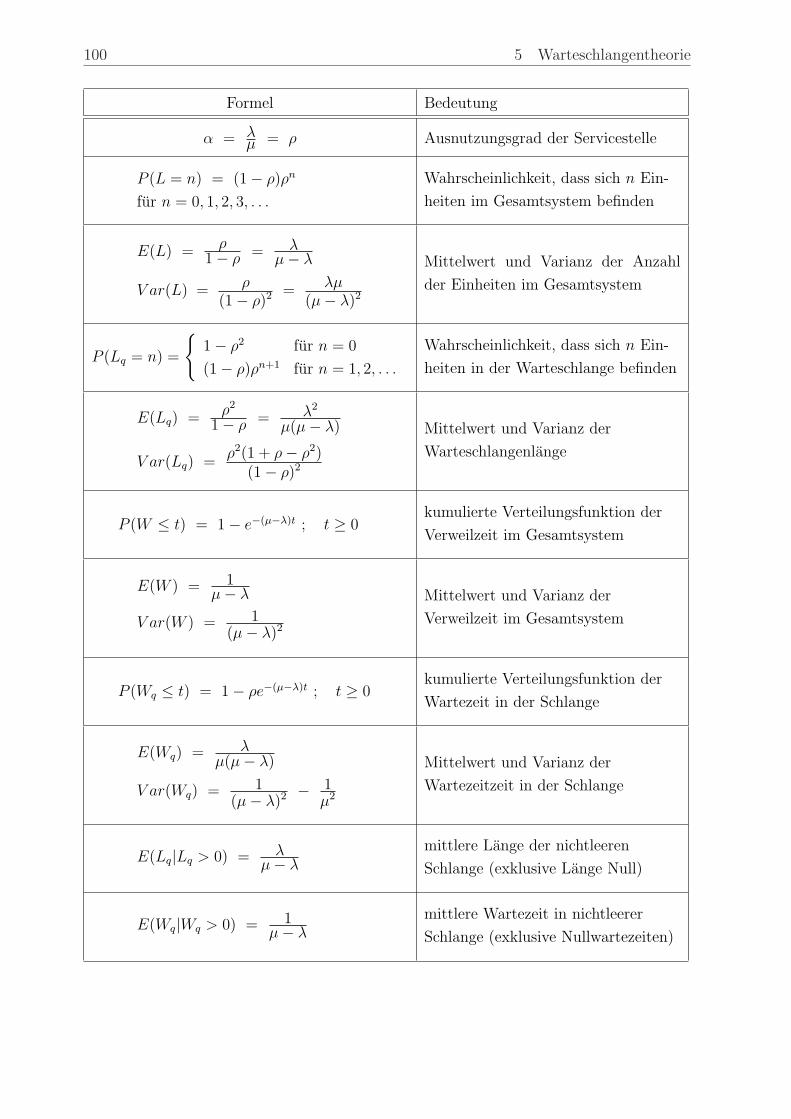
100 5 Warteschlangentheorie
Formel Bedeutung
α = λµ = ρ Ausnutzungsgrad der Servicestelle
P (L = n) = (1− ρ)ρn
fur n = 0, 1, 2, 3, . . .
Wahrscheinlichkeit, dass sich n Ein-
heiten im Gesamtsystem befinden
E(L) =ρ
1− ρ = λµ− λ
V ar(L) =ρ
(1− ρ)2 =λµ
(µ− λ)2
Mittelwert und Varianz der Anzahl
der Einheiten im Gesamtsystem
P (Lq = n) =
1− ρ2 fur n = 0
(1− ρ)ρn+1 fur n = 1, 2, . . .
Wahrscheinlichkeit, dass sich n Ein-
heiten in der Warteschlange befinden
E(Lq) =ρ2
1− ρ = λ2
µ(µ− λ)
V ar(Lq) =ρ2(1 + ρ− ρ2)
(1− ρ)2
Mittelwert und Varianz der
Warteschlangenlange
P (W ≤ t) = 1− e−(µ−λ)t ; t ≥ 0kumulierte Verteilungsfunktion der
Verweilzeit im Gesamtsystem
E(W ) = 1µ− λ
V ar(W ) = 1(µ− λ)2
Mittelwert und Varianz der
Verweilzeit im Gesamtsystem
P (Wq ≤ t) = 1− ρe−(µ−λ)t ; t ≥ 0kumulierte Verteilungsfunktion der
Wartezeit in der Schlange
E(Wq) = λµ(µ− λ)
V ar(Wq) = 1(µ− λ)2 − 1
µ2
Mittelwert und Varianz der
Wartezeitzeit in der Schlange
E(Lq|Lq > 0) = λµ− λ
mittlere Lange der nichtleeren
Schlange (exklusive Lange Null)
E(Wq|Wq > 0) = 1µ− λ
mittlere Wartezeit in nichtleerer
Schlange (exklusive Nullwartezeiten)

5.3 Das Wartesystem M|M|1 101
In der nachfolgenden Tabelle sind fur einige Kombinationen von λ und µ die Zahlenwerte
fur die interessante Großen zusammengestellt. Dabei uberrascht, wie unerwartet groß die
Schlangenlange und Wartezeit bei einer mittleren Auslastung 50 % und 80 % bereits
werden. (P ∗ ist dabei die Wahrscheinlichkeit, dass ein Kunde warten muss.)
λ µ ρ P ∗ E(L) E(W ) E(Lq) E(Wq)
1 1.2 0.833 0.694 5 5 4.17 4.17
1 1.5 0.667 0.444 2 2 1.33 1.33
1 2 0.5 0.25 1 1 0.5 0.5
1 3 0.333 0.111 0.5 0.5 0.167 0.167
1 5 0.2 0.04 0.25 0.25 0.05 0.05
0.9 1 0.9 0.81 9 10 8.1 9
0.8 1 0.8 0.64 4 5 3.2 4
0.5 1 0.5 0.25 1 2 0.5 1
0.3 1 0.3 0.09 0.429 1.43 0.129 0.429
0.1 1 0.1 0.01 0.111 1.11 0.0111 0.111
Beispiel 5.2: An einem Ausgabeschalter kommen Arbeiter mit einem mittleren Abstand
von vier Minuten, um das notwendige Werkzeug in Empfang zu nehmen. Eine Werkzeug-
ausgabe dauert im Mittel drei Minuten. Sowohl bei den Ankunften wie bei der Ausgabe-
dauer kann Exponentialverteilung unterstellt werden.
Losung: Die Voraussetzungen des M|M|1-Modells sind gegeben.
• Wie lange muss ein Arbeiter durchschnittlich warten?
4 = 1λ
; λ = 14
3 = 1µ ; µ = 1
3
ρ = λµ = 3
4 = 0.75
E(Wq) = λµ(µ− λ)
=14
13
(13 − 1
4
) = 9
• Wie lange ist die durchschnittliche Wartezeit, exklusive Null-Wartezeiten?
E(Wq|Wq > 0) = 1µ− λ
= 113 − 1
4
= 12

102 5 Warteschlangentheorie
• Wie lange braucht ein Arbeiter im Mittel insgesamt, um ein Werkzeug zu holen?
E(W ) = 1µ− λ
= 113 − 1
4
= 12
• Wieviele Arbeiter stehen im Mittel vor dem Schalter, wobei der gerade Bediente
mitgerechnet werden soll?
E(L) = λµ− λ
=14
13 − 1
4
= 3
• Wie lange ist die durchschnittliche Schlangenlange, wobei der gerade Bediente nicht
mitgerechnet wird?
E(Lq) = λ2
µ(µ− λ)= E(Wq) · λ = 9 · 1
4 = 2.25
• Wie groß ist die Wahrscheinlichkeit, dass mehr als drei Arbeiter am Schalter stehen
(der Bediente mitgerechnet)?
Wir berechnen die Wahrscheinlichkeit, dass mehr als drei Arbeiter anstehen, uber
die Gegenwahrscheinlichkeit.
P = (1− ρ) + (1− ρ)ρ + (1− ρ)ρ2 + (1− ρ)ρ3
= (1− ρ) (1 + ρ + ρ2 + ρ3)
= 14
[1 + 3
4 +(
34
)2
+(
34
)3]≈ 0.68
In 32% der Falle stehen mehr als drei Arbeiter am Schalter.
• Wie groß ist die Wahrscheinlichkeit, dass ein Arbeiter langer als 10 Minuten warten
muss?
P (Wq > 10) = 1 − P (Wq ≤ 10)
= 1 − [1− ρe−(µ−λ)·10
]
= ρe−(µ−λ)·10
= 34 · e
−( 13− 1
4)·10 ≈ 0.33
• Welchen Prozentsatz der Zeit ist der Mann am Schalter durchschnittlich beschaftigt?
α = λµ = 0.75
75 % der Zeit ist der Mann am Schalter beschaftigt.
• Wurde die mittlere Abholzeit großer als 15 Minuten werden, so wurde die Firma
einen zweiten Mann fur die Werkzeugausgabe anstellen. Auf welchen Wert musste
die Ankunftsfrequenz steigen, damit dieser Fall eintritt?
Fur diese Grenzfrequenz λ∗ ergibt sich die Bestimmungsgleichung:

5.3 Das Wartesystem M|M|1 103
15 = E(W ) = 1µ− λ∗ = 1
13 − λ∗
; λ∗ = 415 bzw. 1
λ∗ = 154 = 3.75
D. h. die mittlere Zwischenankunftszeit musste auf 3.75 Minuten sinken.
Das”Ubergangsverhalten“ eines Wartesystems im Gleichgewichtsfall (Ubergang von ei-
nem Zustand in einen anderen) kann auch in Form eines sogenannten Ubergangsgraphen
veranschaulicht werden. Die Zustande des Wartesystems (Anzahl der im System befindli-
chen Kunden) entsprechen dabei den Knoten und die moglichen unmittelbaren Ubergange
von einem Zustand in den anderen den Pfeilen. Die Ubergangsraten stellen die Bewertung
der Pfeile dar. Bei einem unendlichen Warteraum besitzt der Ubergangsgraph unendlich
viele Knoten und Pfeile. Die folgende Skizze soll diese Situation veranschaulichen.
0 1 2 j−1 j j+1
- -
¾ ¾
- -
¾ ¾
λ λ
µ µ
λ λ
µ µ
Aus dem Ubergangsgraphen erhalt man durch die folgende Plausibilitatsbetrachtung auf
einfache Weise das Gleichungssystem fur die stationaren Wahrscheinlichkeiten.
Wir betrachten zunachst einen Zustand bzw. Knoten j ≥ 1. Von den Zustanden j− 1 und
j +1 ist jeweils ein Ubergang in den Zustand j moglich und zwar mit den Ubergangsraten
λ bzw. µ. Die (stationare) Wahrscheinlichkeit, dass sich das System im Zustand j−1 bzw.
j + 1 befindet ist πj−1 bzw. πj+1. Damit ist die”Gesamteingangsrate“ fur den Zustand
bzw. Knoten j gleich
λπj−1 + µπj+1
Befindet sich das System im Zustand j, so sind umgekehrt Ubergange in die Zustande
j − 1 bzw. j + 1 moglich und zwar mit den Ubergangsraten µ bzw. λ. Die (stationare)
Wahrscheinlichkeit, dass sich das System im Zustand j befindet ist πj. Folglich ist die
”Gesamtausgangsrate“ gleich
(λ + µ) · πj
Da im Gleichgewichtsfall fur jeden Zustand die Gesamteingangsrate gleich der Gesamt-
ausgangsrate sein muss ergibt sich
λπj−1 + µπj+1 = (λ + µ) · πj ; j = 1, 2, 3, . . . .
Fur den Knoten j = 0 wer halt man die Bilanzgleichung
λπ0 = µπ1
Diese Gleichungen sind mit dem Gleichungssystem auf Seite 97 identisch.

104 5 Warteschlangentheorie
5.4 Ausblick
Das im vorangegangenen Abschnitt behandelte Warteschlangenmodell stellt die mathema-
tisch einfachste Spielart dieser Problemstellung dar. Wir stellen hier noch einige Erweite-
rungen vor.
5.4.1 Endlicher Warteraum
Der zur Aufnahme der Warteschlange bestimmte Raum sei nun auf r Platze beschrankt.
Mit der zuletzt entwickelten Modellvorstellung eines Ubergangsgraphen fur den stationaren
Fall konnen wir die Zustandswahrscheinlichkeiten leicht ausrechnen.
0 1 2 r−2 r−1 r
- -
¾ ¾
- -
¾ ¾
λ λ
µ µ
λ λ
µ µ
Fur die Kanten j des Graphen ergeben sich die folgenden Bilanzgleichungen:
Fall j = 0
λπ0 = µπ1
Fall 0 < j < r
λπj−1 + µπj+1 = (λ + µ) · πj ; j = 1, 2, 3, . . . , r
Fall j = r
λ πr−1 = µπr
Als Losung erhalten wir wieder fur j < r den Ausdruck
πj = π0ρj ; mit ρ = λ
µ .
Auch fur j = r erhalten wir dieselbe Beziehung aus
πr = λµpr−1
Der”Anfangswert“ π0 ergibt sich wieder aus der Normierungsbedingung.
1 =r∑
k=0
= π0 ·r∑
k=0
ρk = π0 · 1− ρr+1
1− ρ ; π0 =1− ρ
1− ρr+1

5.4 Ausblick 105
Damit gilt:
πk =1− ρ
1− ρr+1 · ρk ; k = 0, 1, 2, . . . , r
Bemerkung: da es sich nur um endlich viele Zustande handelt, ist die Konvergenzbedin-
gung ρ < 1 nicht mehr notwendig. Fur ρ = 1 sind die obigen Formeln entsprechend zu
modifizieren.
Interessant ist noch der Anteil der Kunden, die wegen fehlendem Warteraum abgewiesen
werden. Der letzte Platz im Warteraum ist mit der Wahrscheinlichkeit πr besetzt. Damit
wird ein potentieller Kunde mit der Wahrscheinlichkeit
α = 1− πr = 1 − 1− ρ1− ρr+1 · ρr =
1− ρr
1− ρr+1
abgewiesen. Man nennt α auch den Erfassungsgrad.
Die Parameter zur Beschreibung des Wartesystems errechnen sich durch Auswertung von
endlichen Summen. Exemplarisch sei der Erwartungswert fur die Anzahl der Einheiten im
System angegeben.
E(L) =r∑
k=1
k · πk =r∑
k=1
k · 1− ρ1− ρr+1 ρk
=(1− ρ)ρ1− ρr+1 ·
r∑k=1
k · ρk−1
=(1− ρ)ρ1− ρr+1 · d
dρ
1− ρr+1
1− ρ
=(1− ρ)ρ1− ρr+1 · 1− (r + 1)ρr + rρr+1
(1− ρ)2
=ρ
[1− (r + 1)ρr + rρr+1
](1− ρ)(1− ρr+1)
Um den Einfluss eines begrenzten Warteraums zu demonstrieren, greifen wir das vorange-
gangene Beispiel nochmals auf.
Beispiel 5.3: Erganzend zum Beispiel 5.2 auf Seite 101 nehmen wir einen endlichen War-
teraum an. Insgesamt seien r Positionen (einschließlich der Schalterposition) verfugbar.
Dann ergeben sich fur die Zustandswahrscheinlichkeiten im stationaren Zustand:
πk = 1− 0.751− 0.75r+1 · 0.75k
Fur den Erwartungswert von L und Auslastungsgrad α erhalten wir:
E(L) =0.75
[1− (r + 1)0.75r + r0.75r+1
](1− 0.75)(1− 0.75r+1)
α = 1− 0.75r
1− 0.75r+1

106 5 Warteschlangentheorie
Die folgende Tabelle soll den Einfluss des endlichen Warteraums demonstrieren.
r L α π0 π1 π2 π3 π4 π5 π6 π7
4 1.4443 0.8963 0.3278 0.2458 0.1844 0.1383 0.1037 0 0 0
5 1.7009 0.9278 0.3041 0.2281 0.1711 0.1283 0.0962 0.0722 0 0
6 1.9217 0.9487 0.2885 0.2164 0.1623 0.1217 0.0913 0.0685 0.0513 0
7 2.1100 0.9629 0.2778 0.2084 0.1563 0.1172 0.0879 0.0659 0.0494 0.0371
∞ 3 1 0.2500 0.1875 0.1406 0.1055 0.0791 0.0593 0.0445 0.0334
5.4.2 Das Wartesystem M|M|sWir wollen jetzt annehmen, dass s parallele identische Bedienungsschalter zur Verfugung
stehen, um die ankommenden Kunden zu bedienen. Die Zwischenankunftszeit Z und die
Bedienungszeit S an einem Schalter seien wieder exponentialverteilt mit den Parametern
λ und µ. Wenn wir uns auf den Gleichgewichtsfall beschranken, konnen wir die Zustands-
wahrscheinlichkeiten wieder aus dem Ubergangsgraphen entnehmen. Dabei ist zu beachten,
dass die Bedienungsraten fur die Knoten j < s jeweils linear mit j anwachsen. Fur j ≥ s
erhalten wir dann die konstante Bedienungsrate s · µ.
0 1 2 s−2 s−1 s s+1
- - -
¾ ¾ ¾
- -
¾ ¾
λ λ
µ 2µ (s− 1)µ sµ
λ λ λ
sµ
Die Wahrscheinlichkeiten πk lassen sich wieder aus den Bilanzgleichungen fur die einzelnen
Knoten bestimmen.
λπ0 = µπ1
λπj−1 + (j + 1)µπj+1 = (λ + jµ)πj fur j = 1, 2, . . . , s− 1
λπj−1 + sµπj+1 = (λ + sµ)πj fur j = s, s + 1, s + 2, . . .
Aus den Bilanzgleichungen ergeben sich nach einiger Zwischenrechnung:
π0 = 1
1 +s−1∑j=1
ρj
j!+
ρs
(s− 1)! · (s− ρ)
πj =ρj
j!· π0 fur j = 1, 2, . . . , s− 1
πj =ρj
s! · sj−s · π0 fur j = s, s + 1, s + 2, . . .

5.4 Ausblick 107
Die Wahrscheinlichkeit, dass ein zufallig Ankommender warten muss, bestimmt sich daraus
zu
P ∗ =∞∑
k=s
πk = π0
∞∑
k=s
ρk
s! · sk−s =ρs
(s− 1)! · (s− ρ)· π0
Die Parameter des Wartesystems errechnen sich daraus durch Auswertung der entspre-
chenden Reihen.
E(L) =∞∑
k=0
k · πk =ρs+1
(s− 1)! · (s− ρ)2 · π0 + ρ ; E(W ) = 1λ· E(L)
E(Lq) =∞∑
k=s
(k − s) · πk =ρs+1
(s− 1)! · (s− ρ)2 · π0 ; E(Wq) = 1λ· E(Lq)
Beispiel 5.4: Das Beispiel 5.2 auf Seite 101 wollen wir nochmals aufgreifen und jetzt
annehmen, dass s identische Schalter zu Abfertigung vorhanden sind. Wir errechnen die
entsprechenden Wahrscheinlichkeiten zu:
π0 = 1
1 +s−1∑j=1
0.75j
j!+ 0.75s
(s− 1)! · (s− 0.75)
πj = 0.75j
j!· π0 fur j = 1, 2, . . . , s− 1
πj = 0.75j
s! · sj−s · π0 fur j = s, s + 1, s + 2, . . .
Die folgende Tabelle soll den Einfluss mehrer Servicestationen demonstrieren.
s E(L) P ∗ π0 π1 π2 π3 π4 π5 π6 π7
1 3 0.75 0.2500 0.1875 0.1406 0.1055 0.0791 0.0593 0.0445 0.0334
2 0.8727 0.2045 0.4545 0.3409 0.1278 0.0479 0.0180 0.0067 0.0025 0.0009
3 0.7647 0.0441 0.4706 0.3529 0.1324 0.0331 0.0083 0.0021 0.0005 0.0001
Zusatzlich zu den bisherigen Angaben wollen wir noch unterstellen, dass ein Mann an der
Werkzeugausgabe Kosten in Hohe von 100 EUR pro Zeiteinheit verursacht. Wir nehmen
weiter an, dass die Produktionsausfallkosten eines Arbeiters wahrend der Abholung bei
150 EUR liegen. Daraus ergibt sich die folgende Kostentafel:
Anzahl der Schalter s = 1 s = 2 s = 3
Kosten der Schalter 1 · 100 2 · 100 3 · 100
Produktionsausfallkosten 3 · 150 0.8727 · 150 0.7647 · 150
Gesamtkosten 550 330.90 414.70
Offenbar ist es optimal, die Werkzeugausgabe mit zwei Schaltern zu bestucken.

108 5 Warteschlangentheorie
5.4.3 Das Wartesystem M|Ek|1Die Annahme, dass die Bedienzeit exponentialverteilt ist, fuhrt haufig zu unrealistischen
Modellen. Die sogenannte Erlang-Verteilung besitzt neben dem Erwartungswert einen
zusatzlichen Parameter zur Modellierung der Bedienzeiten. Diese Verteilung besitzt noch
den Vorzug, dass sich die Warteschlangenparameter noch explizit berechnen lassen. Die
Dichtefunktion lautet:
fk(t) =
0 fur t < 0
(kµ)k
(k − 1)!· e−kµt · tk−1 fur t ≥ 0
.
Fur k = 1 ergibt sich wieder die Exponential-Verteilung.
Die nachfolgende Skizze zeigt diese Dichtefunktionen fur einige ausgewahlte Parameter.
1
1
1µ
k = 1
k = 3
k = 6
k = 9
t
Die Erlang-Verteilung entsteht als Summe von k Exponenzial-Verteilungen. Fur Freunde
der Integralrechnung sei der Nachweis hier skizziert.
• Die Dichtefunktion der Summe von zwei Exponential-Verteilungen mit demselben
Parameter µ ergibt sich aus dem nachfolgenden Faltungsintegral.
f2(t) =t∫
0
(µe−µτ ) · (µe−µ(t−τ)) dτ = µ2e−µtt∫
0
1 dτ = µ2 · e−λt[τ]t
0= µ2 · t · e−λt
• Fur die Dichtefunktion der Summe von drei Exponential-Verteilungen mit demselben
Parameter µ ergibt sich:
f3(t) =t∫
0
(µ2τe−µτ )·(µe−µ(t−τ)) dτ = µ3e−λtt∫
0
τ dτ = µ3 ·e−µt[τ 2
2
]t
0=
µ3t2
2!·e−λt
• Vermutung:
Es gelte fn(t) =µntn−1
(n− 1)!· e−µt .

5.4 Ausblick 109
Der Induktionsschluss ist noch durchzufuhren.
fn+1(t) =
t∫
0
(µnτn−1
(n− 1)!e−µτ
)· (µe−µ(t−τ)) dτ
=µn+1
(n− 1)!· e−λt ·
t∫
0
τn−1 dτ
=µn+1
(n− 1)!· e−λt ·
[τn
n
]t
0
=µn+1tn
n!· e−µt
Soll der Erwartungswert der Summe von n Zu-
fallsvariablen gleich bleiben, so muss der Er-
wartungswert des einzelnen Summanden auf den
n-ten Teil gesetzt. Damit ist gewahrleistet, dass
der Erwartungswert konstant bleibt.
en(t) =(nµ)n · tn−1
(n− 1)!· e−nµt
E(X + . . . + X ) = 1µ
V ar(X + . . . + X ) = 1kµ2
Im Gegensatz zur Exponential-Verteilung kann die Erlang-Verteilung mit Hilfe von zwei
Parametern an empirisch vorgefundene Verteilungen angepasst werden. Insbesondere ist
es moglich, den Mittelwert (Erwartungswert) und die Varianz unabhangig voneinander zu
manipulieren. Sogar der deterministische Fall kann durch k →∞ hergeleitet werden.
Die wichtigsten Formeln fur das System M|Ek|1
Formel Bedeutung
α = λµ = ρ Ausnutzungsgrad der Servicestelle
E(L) = k + 12k
· ρ2
1− ρ + ρMittelwert der Anzahl der Einheiten
im Gesamtsystem
E(Lq) = k + 12k
· ρ2
1− ρ = k + 12k
· λ2
µ(µ− λ)Mittelwert der Warteschlangenlange
E(W ) = k + 12k
· λµ(µ− λ)
+ 1µ = E(Wq) + 1
µMittelwert der Verweilzeit im Gesamt-
system
E(Wq) = k + 12k
· λµ(µ− λ)
=E(Lq)
λMittelwert der Wartezeit in der
Schlange

110 5 Warteschlangentheorie
Beispiel 5.5: Ein Friseur hat sich selbstandig gemacht und arbeitet noch alleine. Fur
einen Haarschnitt benotigt er durchschnittlich 15 Minuten bei einer Standardabweichung
von 5 Minuten. Es sind die interessierenden Großen zu bestimmen, wenn die Kunden im
durchschnittlichen Abstand von 20 Minuten eintreffen.
Zur Losung nehmen wir beim Inputprozess Exponential-Verteilung an und versuchen eine
Erlang-Verteilung an die empirischen Daten der Servicestelle anzupassen.
λ = 3 Kunde/Stunde µ = 4 Kunde/Stunde
Bestimmung des Parameters k der Erlang-Verteilung:
V ar(X + . . . + X ) = 1kµ2 ;
(560
)2
= 1k · 42 ; k = 9
E(Lq) = k + 12k
· λ2
µ(µ− λ)= 10
18 · 32
4 · (4− 3)= 5
4
E(L) = E(Lq) + λµ = 5
4 + 34 = 2
E(Wq) =E(Lq)
λ=
543 = 5
12 bzw. 25 Minuten
E(W ) = E(Wq) + 1µ = 5
12 + 14 = 2
3 bzw. 40 Minuten
5.4.4 Einschwingverhalten
Fur endliche Warteraume wird das auf Seite 95 hergeleitete Differenzialgleichungssystem
fur exponential verteilte Wartesysteme endlich. Es ist lediglich die letzte Gleichung zu
modifizieren. Fur r Warteplatze erhalten wir das folgende System homogener linearer
Differenzialgleichungen mit konstanten Koeffizienten.
p0(t) = −λ · p0(t) + µ · p1(t)
pj(t) = λ · pj−1 + − (λ + µ) · pj(t) + µ · pj+1(t) ; j = 1, 2, . . . , r − 1
pr(t) = −λpr−1(t) − µpr(t)
bzw. in Matrix-Form
p0
p1
p2
...
pr−1
pr
=
−λ µ 0 0 0 · · ·λ −(λ + µ) µ 0 0 · · ·0 λ −(λ + µ) µ 0 · · ·...
......
. . .
λ −(λ + µ) µ 0
0 λ −(λ + µ) µ
0 0 λ −µ
·
p0
p1
p2
...
pr−1
pr

5.4 Ausblick 111
Fur s gleiche Kanale ist das Differenzialgleichungssystem entsprechend zu modifizieren.
(vgl. Abschnitt 5.4.2)
p0(t) = −λ · p0(t) + µ · p1(t)
pj(t) = λ · pj−1 + − (λ + j · µ) · pj(t) + (j + 1) · µ · pj+1(t) ; j = 1, 2, . . . , s− 1
pj(t) = λ · pj−1 + − (λ + s · µ) · pj(t) + s · µ · pj+1(t) ; j = s, (s + 1), . . . , r − 1
pr(t) = −λpr−1(t) − s · µpr(t)
bzw. in Matrix-Form
p0
p1
p2
...
pr−1
pr
=
−λ µ 0 0 0 · · ·λ −(λ + µ) 2µ 0 0 · · ·0 λ −(λ + 2µ) 3µ 0 · · ·...
......
. . .
λ −(λ + sµ) sµ 0
0 λ −(λ + sµ) sµ
0 0 λ −sµ
·
p0
p1
p2
...
pr−1
pr
Solche Systeme sind numerisch unproblematisch. Wenn wir als Anfangsbedingung
p0(0) = 1, pj(0) = 1; j = 1, 2, . . . r wahlen, ergibt sich das folgende Einschwingverhal-
ten der Losungskurven des Diffferenzialgleichungssystems.

112 5 Warteschlangentheorie
5.4.5 Simulation
Bei vielen praktischen Problemen treffen die in den vorangegangenen Abschnitten gemach-
ten Annahmen nicht zu. Die Verteilungsstrukturen der Ankunfte und der Bedienungszeiten
konnen sehr vielfaltig sein.
Ebenso ist zu beachten, dass die analytisch abgeleiteten Formeln nur fur den stationaren
Zustand gelten. Viele Prozesse erreichen diesen stationaren Zustand gar nicht (nur kurz-
fristiges Offnen der Servicestation).
Haufig trifft auch die”FIFO-Regel“ nicht zu. Ebenso konnen Problemstellungen mit meh-
reren sequentiellen Servicestationen auftreten.
In solchen Fallen empfiehlt sich die Losung mittels stochastischer Simulation. Man er-
zeugt fur Zwischenankunfts-, Bedienungszeiten etc. Zufallswerte und errechnet die daraus
resultierenden Mittelwerte.
Beispiel 5.6: Simulation eines M|M|1-Warteschlangenmodell mit den Parameterwerten
λ = 109
und µ = 107.
In den Spalten B und D stehen die Zufallswerte fur die Zwischenankunfts- bzw. Bedie-
nungszeit. Daraus errechnet man die Ankunftszeit in Spalte C. In Spalte E und F wird
der Beginn und das Ende der Bedienung eingetragen: die Bedienung des ersten Kunden
kann naturlich unmittelbar nach seinem Eintreffen (T1 = 1, 5276) beginnen. Nach einer
Bedienungdauer von 1,0959 verlasst er das System zum Zeitpunkt D1 = 2, 6235. Jeder
weitere Kunde kann jedoch erst bedient werden, wenn der vorherige Kunde abgefertigt ist.
Es gilt also stets:
E(i) = max(C(i), F (i− 1)
In Spalte G notieren wir die Warte- und in Spalte H die Verweilzeit (Warte- einschließlich
Bedienzeit) jedes Kunden. In der vorletzten Zeile (∅) sind die Mittelwerte der Simulation
angegeben. Die theoretischen Werte fur den stationaren Fall sind in der letzten Zeile (E(?))
angefugt.
Es zeigen sich starke Unterschiede zum stationaren Fall. Ebenso erhalt man starke Unter-
schiede bei verschiedenen Laufen. Dies liegt an der”kleinen“ Datenmenge. Eine Stabilisie-
rung wurde sich erst bei mehreren tausend Kunden einstellen. Im Ergebnis bedeutet dies,
dass solche Simulationen mit einem Tabellenkalkulationsprogramm wenig aussagekraftig
sind.

5.4 Ausblick 113
A B C D E F G H
Nr.Zwischen-ank.-Zeit
Ankunfts-Zeit
Bedienungs-Dauer
Bedienungs-Beginn
Bedienungs-Ende
Warte-Zeit
Verweil-Zeit
1 1,5276 1,5276 1,0959 1,5276 2,6235 0,0000 1,0959
2 0,4541 1,9817 0,6750 2,6235 3,2985 0,6418 1,3168
3 0,4081 2,3898 0,5575 3,2985 3,8560 0,9087 1,4662
4 0,2312 2,6210 0,0029 3,8560 3,8589 1,2350 1,2379
5 0,4545 3,0755 0,0926 3,8589 3,9515 0,7834 0,8760
6 0,8779 3,9534 1,4938 3,9534 5,4471 0,0000 1,4938
7 0,0601 4,0134 0,2571 5,4471 5,7043 1,4337 1,6908
8 3,2626 7,2761 1,3768 7,2761 8,6529 0,0000 1,3768
9 0,1008 7,3769 2,0737 8,6529 10,7266 1,2760 3,3497
10 0,4430 7,8199 0,0557 10,7266 10,7823 2,9067 2,9624
11 0,5028 8,3227 1,3076 10,7823 12,0898 2,4596 3,7671
12 1,0559 9,3786 0,0496 12,0898 12,1394 2,7112 2,7608
13 0,6614 10,0400 0,2066 12,1394 12,3460 2,0994 2,3060
14 0,1097 10,1497 0,3589 12,3460 12,7049 2,1962 2,5551
15 0,0869 10,2367 0,4702 12,7049 13,1750 2,4682 2,9384
16 4,3214 14,5580 0,6373 14,5580 15,1954 0,0000 0,6373
17 0,0816 14,6397 0,3144 15,1954 15,5098 0,5557 0,8701
18 0,3439 14,9835 0,8018 15,5098 16,3116 0,5263 1,3281
19 0,4824 15,4659 1,2683 16,3116 17,5799 0,8456 2,1140
20 1,7232 17,1891 0,6291 17,5799 18,2090 0,3908 1,0199
21 0,2116 17,4007 0,4154 18,2090 18,6244 0,8083 1,2237
22 0,0653 17,4659 0,6461 18,6244 19,2705 1,1585 1,8045
23 1,7798 19,2458 0,5335 19,2705 19,8040 0,0247 0,5582
24 0,7276 19,9734 1,6673 19,9734 21,6406 0,0000 1,6673
25 3,7575 23,7309 0,4568 23,7309 24,1878 0,0000 0,4568
26 1,4353 25,1662 0,1971 25,1662 25,3633 0,0000 0,1971
27 0,7430 25,9093 1,3996 25,9093 27,3088 0,0000 1,3996∑
25,9093 19,0405 25,4298 44,4703
∅ 0,9596 0,7052 0,9418 1,6470
E(?) 1λ = 0.9 1
µ = 0.7 2,7222 3,5000

114 6 Simulation
6 Simulation
6.1 Begriff Simulation
Aus Sicht des Operationsresearch beschaftigt sich die Simulation mit der Nachahmung
der Realitat durch Modelle auf einem Rechner. Das”Durchspielen“ komplexer Zusam-
menhange auf einem Rechner empfiehlt sich, wenn entweder ein Ausprobieren in der Rea-
litat zu teuer ist oder sich aus anderen Grunden verbietet (Zerstorung etc.).
Besonders nutzlich ist die Simulation in folgenden Situationen:
• Ein vollstandiges mathematisches Modell ist nicht verfugbar.
• Die verfugbaren analytischen Methoden setzen vereinfachende Annahmen voraus,
die den Kern des eigentlichen Problems verfalschen.
• Es ist zu kostspielig reale Experimente durchzufuhren.
• Die Beobachtung eines realen Systems ist zu gefahrlich (Reaktorverhalten) oder mit
irreversiblen Konsequenzen verbunden (Konkurs des Unternehmens)
• Eine Simulation kann zur Kontrolle eines analytischen Ansatzes sinnvoll sein.
Trotz der universellen Einsetzbarkeit der Simulation muss auf spezielle Gefahrenmomente
aufmerksam gemacht werden.
• Die Simulation sollte (als alleiniges) Losungsverfahren nur eingesetzt werden, wenn
analytische Methoden nicht verfugbar sind.
• Bedingt durch die einfache Realisationsmoglichkeit besteht die Gefahr, auch weni-
ger wichtige Einzelheiten in die Modellierung aufzunehmen. Es ist im Sinn einer
Selbstbeschrankung auf eine sorgfaltige, klare Modellierung zu achten.
• Simulation kann sich haufig nicht wie andere Methoden des Operations Research auf
erprobte und standardisierte Kalkule stutzen (Simplex-Methode, Gradiententech-
niken, etc.). Deshalb kommt der Korrektheitsprufung des Rechenprogramms und
des zugrundeliegenden Modells besondere Bedeutung zu. Eine Prufung fur bekannte
Sonderfalle ist unabdingbar.
• Der Output eines Simulationslaufs lasst sich als Realisation entsprechender Zufalls-
variabler interpretieren. Die Auswertung der Stichprobe hinsichtlich der Schatzung

6.2 Erzeugen und Testen von Zufallszahlen 115
von Parameterwerten fuhrt zu statistischen Aussagen etwa der Art, dass der Er-
wartungswert der Outputvariablen mit einer Wahrscheinlichkeit von 0.9 im Intervall
[a, b] liegt. Mit einer solchen Aussage ist aber stets das Risiko verbunden, dass der
Erwartungswert tatsachlich außerhalb liegt.
6.2 Erzeugen und Testen von Zufallszahlen
Zur Durchfuhrung von Simulationen werden viele Zufallszahlen benotigt. Beim Einsatz
von Computern stammen sie in der Regel nicht aus aktuellen Beobachtungen realer Zu-
fallsexperimente (beispielsweise die Impulse eines Geigerzahlers), sondern sie werden vom
Rechner”erzeugt“. Diese vom Rechner erzeugte Zahlen nennt man
”Pseudozufallszahlen“.
Sie werden bei Bedarf erzeugt und sind reproduzierbar. Pseudozufallszahlen sollen sich
in ihrem Verhalten praktisch nicht von echten Zufallszahlen unterscheiden. Wir sprechen
deshalb der Einfachheit halber im Folgenden nur noch von Zufallszahlen.
Ublicherweise wird die Erzeugung von Zufallszahlen fur eine vorgegebene Verteilung auf
einem Rechner in zwei Stufen vorgenommen. Zunachst werden durch sogenannte Zufalls-
zahlengeneratoren (0 1)-gleichverteilte Zufallszahlen erzeugt. Anschließend werden diese so
transformiert, dass sie einer vorgegebenen Verteilung entsprechen.
6.2.1 Erzeugung und Test gleichverteilter Zufallszahlen
Die gangigsten Verfahren und Ideen sind in der nachfolgenden Liste zusammengestellt.
• Physikalische Generatoren
– Zerfallsprozesse beim radioaktivem Zerfall: Zerplatzen der Kerne erfolgt rein
zufallig; die Anzahl der gespaltenen Kerne pro Zeiteinheit genugt einer Expo-
nentialverteilung.
– Rauschvorgange in Rohren
Diese Moglichkeit wird in Zukunft durch die einfachen und billigen Speichermoglich-
keiten (CD-Rom, DVD) wohl an Bedeutung gewinnen.
• Ziffernfolge bei Dezimaldarstellung der Zahl π
Die Ziffernfolge bei der Naherungsberechnung der transzendenten Zahl π genugt kei-
nerlei Gesetzmaßigkeit. Sie sind”zufallig“. Ziffern-Blocke bei der Berechnung konnen
als Zufallszahlen dienen.
π = 3. 14159︸ ︷︷ ︸Y1
26535︸ ︷︷ ︸Y2
89793︸ ︷︷ ︸Y3
23846︸ ︷︷ ︸Y4
26433︸ ︷︷ ︸Y5
83279︸ ︷︷ ︸Y6
50288︸ ︷︷ ︸Y7
41971︸ ︷︷ ︸Y8
69399︸ ︷︷ ︸Y9
37510︸ ︷︷ ︸Y10
. . .

116 6 Simulation
Nach Division durch 105 ergeben sich Standard-Zufallszahlen zwischen 0 und 1.
Zi = Yi
105
• lineare Kongruenzoperatoren
Yn+1 = [a · Yn + r] mod m ; n = 0, 1, 2, 3, . . .
Hierbei bedeutet mod m : Rest der sich bei ganzzahliger Division durch m ergibt.
Wird ein Startwert Y0 gewahlt, so ergibt sich eine Folge von Zahlen zwischen 0 und
m− 1. Standardzufallszahlen ergeben sich nach Division durch m: zi = Yim
Einen solchen linearen Kongruenzoperator bezeichnen wir mit
C(m, a, r, Y0)
Einfachstbeispiel fur linearen Kongruenzoperator:
Yn+1 = [7 · Yn + 3] mod 32 Y0 = 1
Y1 = [7 · 1 + 3] mod 32 = 10
Y2 = [7 · 10 + 3] mod 32 = 9
Y3 = [7 · 9 + 3] mod 32 = 2
Y4 = [7 · 2 + 3] mod 32 = 17
Y5 = [7 · 17 + 3] mod 32 = 26
Y6 = [7 · 26 + 3] mod 32 = 25
Y7 = [7 · 25 + 3] mod 32 = 18
Y8 = [7 · 18 + 3] mod 32 = 1Der lineare Kongruenzoperator erzeugt zum Startwert Y0 = 1
8”zufallige“ Zahlen zwischen 0 und 31.
Normierung auf 1 ergibt:Yi 10 9 2 17 26 25 18 1
Zi1032
932
232
1732
2632
2532
1832
132
An diesem Beipiel wird klar: Von totaler Zufalligkeit kann keine Rede sein. Die Zahlenfolge
muss periodisch werden, da nur endlich viele Reste moglich sind. Wenn m und a entspre-
chend gewahlt werden, ergeben sich lange Perioden und angenaherte Gleichverteilung.
Vorschlage:
• m = 2k oder m = 2k ± 1

6.2 Erzeugen und Testen von Zufallszahlen 117
• a = 4 · n + 1 oder a ≈ 2k−2 · 12
(√5− 1
)
• r ungerade; oft r = 0
• Y0 ungerade
Zur Bestimmung von geeigneten Werten von a, r und m werden sowohl zahlentheoretische
Uberlegungen als auch umfangreiche statistische Tests herangezogen.
Qualitatskontrolle der Pseudo-Zufallszahlen
Forderungen:
• Periode sollte moglichst groß sein!
• Die relative Haufigkeit der standardisierten Pseudo-Zufallszahlen zi, die in einem
Teilintervall von [0, 1] liegen, sollte ungefahr gleich der Intervallbreite sein:
h(zi : z ≤ zi ≤ z + ∆z) ≈ ∆z
• Aus der Lage der Pseudo-Zufallszahl zi sollte keine wesentliche Information uber die
Lage der folgenden Zahl zi+1 ableitbar sein. (Verallgemeinerung: zi 7→ zi+k)
Dazu interpretieren wir die Paare aufeinanderfolgender Pseudo-Zufallszahlen als
zweidimensionale Stichprobe: (zi, zi+1) ; i = 1, 2, 3, . . . , n− 1
Sind die Merkmale stochastisch voneinander unabhangig, so multiplizieren sich die
Wahrscheinlichkeiten, d.h. es musste gelten:
h( (zi, zi+1) : z ≤ zi ≤ z + ∆z; z ≤ zi+1 ≤ z + ∆z ) ≈ ∆z ·∆z
Durchfuhrung fur C(231 − 1, 75 + 3, 0, 225 + 1)
• Die Frage nach der Wiederholung kann teilweise aus Erkenntnissen der Zahlentheorie
oder durch”Ausprobieren“ beantwortet werden. Im konkreten Fall wiederholt sich
der Startwert nach 109 < Laufen.
• Zur Uberprufung der Gleichverteilung wurden 100.000 Pseudo-Zufallszahlen erzeugt.
Das Intervall [0, 1] wurde in 20 gleichgroße Teilintervalle geteilt (Klasseneinteilung!!)
und nachgerechnet, wieviel Pseudo-Zufallszahlen im jeweiligen Teilintervall liegen.
Bei absoluter Gleichverteilung mussten jeweils 5.000 Zahlen in jedem Teilintervall
liegen. Dies wird naturlich nicht genau der Fall sein – zufallige Abweichungen mussen
zugelassen werden. Die typische Messgroße fur Abweichungen von Soll- und Ist-Wert
ist die Summe der Abweichungsquadrate. Der Statistiker spricht vom sogenannten
χ2-Test.

118 6 Simulation
Prufgroße:
χ2ber = 1
n
N∑i=1
(Hi − npi)2
pi
Hi : absolute Haufigkeiten
pi : theoretische Wahrscheinlichkeiten; hier pi = 120
N : Anzahl der Klassen; hier N = 20
n : Stichprobenzahl; hier n = 1000.000
Die theoretische Schranke zum Vertrauensniveau 0.99 ist: χ219 = 36.2
• Zum Test der Zahlenpaare (zi, zi+1) auf Unabhangigkeit unterteilen wir das Ein-
heitsquadrat in 100 Teilquadrate und bestimmen wieviele der Zahlenpaare in je-
dem Quadratchen liegen. Die gemessenen Haufigkeiten werden mit den theoretischen
Wahrscheinlichkeiten verglichen und die entsprechende Prufgroße berechnet.
Prufgroße:
χ2ber = 1
n
N∑i=1
(Hi − npi)2
pi
Hi : absolute Haufigkeiten
pi : theoretische Wahrscheinlichkeiten; hier pi = 1100
N : Anzahl der Klassen; hier N = 100
n : Stichprobenzahl; hier n = 1000.000
Die theoretische Schranke zum Vertrauensniveau 0.99 ist: χ299 = 134.6
Der Statistiker spricht hier vom χ2-Anpassungstest.
6.2.2 Erzeugung diskret verteilter Zufallszahlen
Bernoulli-verteilte Zufallszahlen
Bernoulli-verteilte Zufallszahlen x mit vorgegebener Wahrscheinlichkeit p erhalt man durch
wiederholtes Erzeugen von im Intervall (0 1)-gleichverteilter Zufallszahlen z auf folgende
Weise:
Im Falle z ≤ p nimmt x den Wert 1 ansonsten den Wert 0 an.
Binomial-verteilte Zufallszahlen B(k, n, p)
Man erhalt sie einfach dadurch, dass man jeweils n Bernoulli-veteilte Zufallszahlen gene-
riert und die Ergebnisse aufsummiert.

6.2 Erzeugen und Testen von Zufallszahlen 119
Zufallszahlen, die einer empirischen Verteilung genugen
In okonomischen Simulationsrechnungen benotigt man oft diskrete Zufallszahlen, die einer
empirisch ermittelten Verteilung genugen.
Beispiel 6.1: Fur die wochentliche Nachfrage nach einem Produkt wurden in der Vergan-
genheit die folgenden Haufigkeiten registriert:
Nachfragemenge 0 1 2 3 4 5
Haufigkeit 5 10 20 4 5 6
relative Haufigkeit 0.1 0.2 0.4 0.08 0.1 0.12
Die simulierten Absatzmengen sollen in ihren Wahrscheinlichkeiten den bisher beobachte-
ten relativen Haufigkeiten entsprechen. Unter Verwendung von im Intervall (0, 1) gleich-
verteilten Zufallszahlen zi lassen sich diskrete Zufallszahlen, die den vorgegebenen relativen
Haufigkeit entsprechen, wie folgt ermitteln:
Man unterteilt das Intervall (0, 1) entsprechend den relativen Haufigkeiten in disjunkte
Teilintervalle (0, 0.1), [0.1, 0.3), [0.3, 0.7), [0.7 0.78), [0.78, 0.88), [0.88, 1). Fallt eine
Zufallszahl zi in das k-te Intervall (mit k = 0, 1, . . . , 5), so erhalt man die simulierte
Zufallszahl xi = k.
gleichverteilt: zi
Nachfrage: xi
( ))[ )[ )[ )[ )[
| || | | | |0 1 2 3 4 5
0 10.1 0.3 0.7 0.78 0.88
Viele Software-Pakete bieten entsprechende Generatoren auch fur kompliziertere Vertei-
lungsstrukturen an.
6.2.3 Erzeugung kontinuierlich verteilter Zufallszahlen
Transformation mittels Umkehrung der Verteilungsfunktion
Wir wollen uns die Problemstellung an Hand der Exponentialverteilung klar machen.
Mit der Wahrscheinlichkeit
∆P = F (x + ∆x)− F (x)
soll die erzeugte Zufallszahl im Bereich [x, x + ∆x] liegen. Dazu erzeugen wir (0, 1)-
gleichverteilte Zufallszahlen und bilden sie mit der Umkehrfunktion der Verteilungsfunk-
tion
xi = F−1(zi)
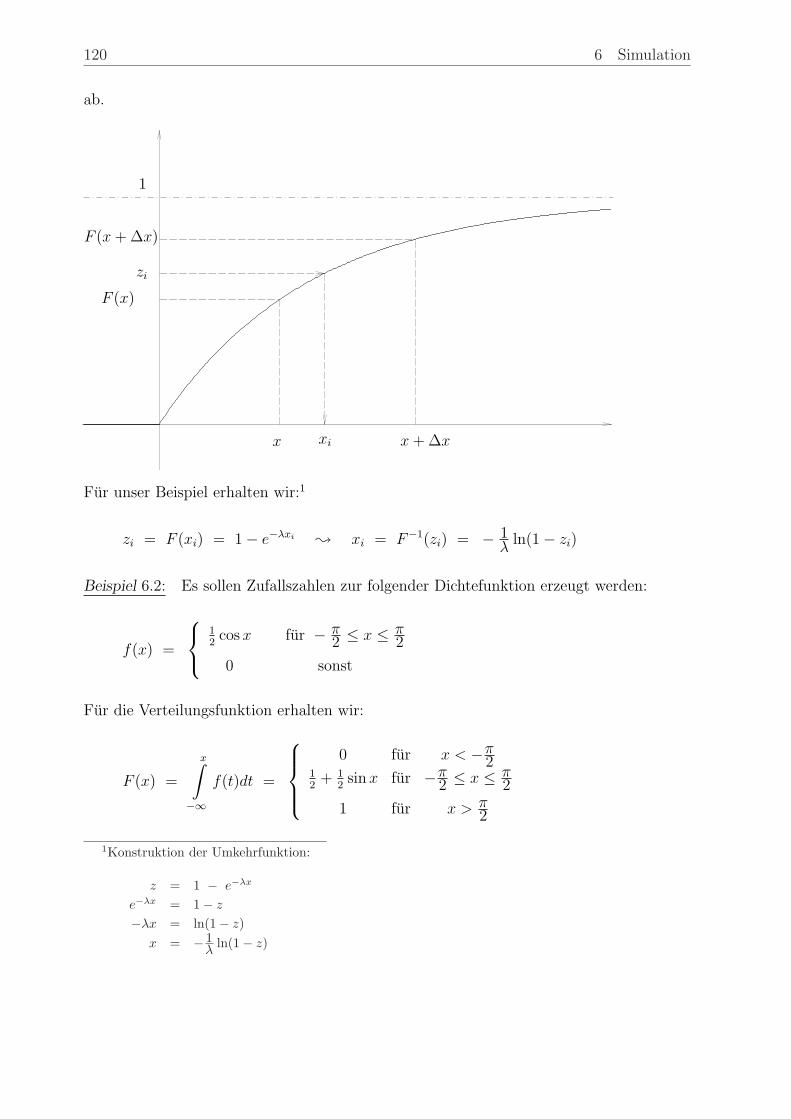
120 6 Simulation
ab.
x x + ∆xxi
zi
F (x)
F (x + ∆x)
1
Fur unser Beispiel erhalten wir:1
zi = F (xi) = 1− e−λxi ; xi = F−1(zi) = − 1λ
ln(1− zi)
Beispiel 6.2: Es sollen Zufallszahlen zur folgender Dichtefunktion erzeugt werden:
f(x) =
12cos x fur − π
2 ≤ x ≤ π2
0 sonst
Fur die Verteilungsfunktion erhalten wir:
F (x) =
x∫
−∞
f(t)dt =
0 fur x < −π2
12
+ 12sin x fur −π
2 ≤ x ≤ π2
1 fur x > π2
1Konstruktion der Umkehrfunktion:
z = 1 − e−λx
e−λx = 1− z
−λx = ln(1− z)x = − 1
λln(1− z)

6.2 Erzeugen und Testen von Zufallszahlen 121
x
1
π2−π
2
f(x)
−π2
π2
x1
z1
z2
x2
1
x
F (x)
Fur die Umkehrfunktion erhalten wir:
z = 12 + 1
2 sin x
2z − 1 = sin x
x = arcsin(2z − 1)
; xi = arcsin(2zi − 1)
Verwerfmethode
Oft ist es rechentechnisch sehr aufwendig oder gar explizit gar nicht moglich, die Umkeh-
rung der Verteilungsfunktion zu bestimmen. Eine anylytisch sehr einfache Methode, die
ausnutzt, dass (0, 1)-gleichverteilte Zufallszahlen ohne großen Aufwand erzeugt werden
konnen, ist als Verwerfmethode bekannt. Sie benotigt nur die Dichte f(x) der gewunsch-
ten Verteilung, die auf einem (zunachst als beschrankt angenommenen) Intervall stetig,
positv und beschrankt und außerhalb gleich Null sein soll. Das Maximum von f(x) sei c.
Wir unterwerfen nun zwei (0, 1)-gleichverteilte Zufallszahlen z1, z2 der Transformation
X = a + (b− a)z1
Y = cz2
Die Paare (X,Y ) sind nun im Rechteck (a, b) × (0, c) gleichverteilt. Liegt fur eine Rea-
lisation (z1, z2) der Punkt (X, Y ) nicht oberhalb des Funktionsgraphen von f(x), d. h.
gilt
Y ≤ f(X) bzw. z2 ≤ 1
c· f(a + [b− a]z1)
so wird
x = a + (b− a)z1
als nachste Zufallszahl verwendet. Liegt dagegen das Paar (X,Y ) oberhalb der Funktions-
kurve, so werden die beiden erzeugten Zufallszahlen z1, z2 verworfen.
Die so konstruierten Zufallszahlen entsprechen dem Zuwachs der Verteilungsfunktion von
F (x). Wie aus der folgenden Skizze entnommen werden kann, arbeitet diese Methode
ineffizient, wenn der Flacheninhalt des Rechtecks A = c · (b− a) erheblich großer als 1 ist.

122 6 Simulation
c
a b
x
(X, Y )
(X, Y )
f(x)
y
Bei unbeschranktem Intervall ist der x-Bereich zunachst einer Transformation zu unter-
werfen.
Erzeugung von Zufallszahlen fur spezielle stetige Verteilungen
Standard-Normalverteilung
Aus zwei (0, 1)-gleichverteilten Zufallszahlen z1, z2 erhalt man zwei Zufallszahlen fur die
Standard-Normalverteilung durch die folgende Transformation
x1 =√−2 ln(z1) · sin(2πz2)
x2 =√−2 ln(z1) · cos(2πz2)
Erlang-Verteilung
Die bei Warteschlangenproblemen haufig auftretende Erlang-Verteilung mit den Parame-
tern λ und n ergibt sich als die Wahrscheinlichkeitsverteilung der Summe von n unabhangi-
gen, identisch mit dem Parameter λ verteilten exponentiellen Zufallsvariablen. Sie besitzt
die Dichtefunktion
f(x) = λnxn−1e−λ
(n− 1)!
Eine einfache Methode zur Erzeugung derart verteilter Zufallszahlen x geht von n expo-
nentiell verteilten Zufallszahlen u1, u2, . . . un aus, die wiederum aus (0, 1)-gleichverteilten
Zufallszahlen z1, z2, . . . zn erzeugt werden konnen.
x =n∑
k=1
uk = − 1λ
n∑
k=1
ln(zk)
Fur große Werte von n ist diese Methode allerdings nicht zu empfehlen. In diesem Fall
ist die Verwerfmethode gunstiger, da bei ihr die Zahl der benotigten (0, 1)-gleichverteilten
Zufallszahlen nicht von n abhangt.

6.3 Beispiele 123
6.3 Beispiele
Die Vorgehensweise soll an drei Beispielen deutlich gemacht werden. Dabei spielen Si-
mulationen mit diskreten und kontinuierlichen Zufallsvariablen eine Rolle. Die Beispiele
sind bewusst so angelegt, dass sie auch noch einer expliziten Berechnung mit Hilfsmitteln
der Wahrscheinlichkeitsrechnung zuganglich sind. Diese Berechnungen sind angefugt, ob-
wohl sie teilweise uber den hier vorausgesetzten Kenntnisstand in diesem Teilgebiet der
Stochastik hinausgehen.
6.3.1 Satzgewinn beim Tennis
Beim Tennis wird ein Satzgewinn erzielt, wenn von einem Spieler sechs Spiele mit einem
Vorsprung von mindestens zwei Spielen gewonnen werden. Fur den Fall, dass ein Spielstand
von 5:5 auftritt, wird der Satz so lange fortgesetzt, bis einer der beiden Spieler einen
Vorsprung von zwei gewonnenen Spielen erreicht hat.
Von zwei Spielern A und B sei bekannt, dass A im Durchschnitt zwei von drei Spielen
gegen B gewinnt: Dabei nehmen wir an, dass aufeinanderfolgende Spiele unabhangig von-
einander ablaufen. Beim Stand von 5:5 soll nun die Wahrscheinlichkeit ermittelt werden,
mit der Spieler A gewinnt. Wir wollen nun eine Reihe von Satzverlaufen simulieren. Die
dabei beobachtete relative Haufigkeit des Satzgewinns von A lasst sich als Schatzwert fur
die gesuchte Wahrscheinlichkeit verwenden. Wir bestimmen zunachst die theoretischen
Wahrscheinlichkeiten, dass der Spieler A bzw. B gewinnt. Ebenso wollen wir den Erwar-
tungswert fur die Anzahl der Spiele pro Satz berechnen (unter der Bedingung, dass 5 : 5
Spielstand auftritt).
a) Wahrscheinlichkeit pE, dass das Spiel nach einer Zweier-Runde – bei vorherigem
Gleichstand – beendet wird.
pE = 23
23 + 1
313 = 5
9
b) Wahrscheinlickeit, dass Spieler A bzw. B gewinnt.
pA =23
23
23
23 + 1
313
= 45 pB =
13
13
23
23 + 1
313
= 15
c) Erwartungswert fur die Spiellange
Die Wahrscheinlichkeit, dass der Satz nach einer Zweier-Runde beendet wird ist pE =59. Die Anzahl der benotigten Zweier-Runden genugt einer geometrischen Verteilung.
pZ(k) = 59
(49
)k−1

124 6 Simulation
Fur deren Erwartungwert L (Anzahl der Zweier-Runden) gilt:
L =∞∑
k=1
k · pZ(k) =∞∑
k=1
k59
(49
)k−1
= . . . = 95
D. h. 95· 2 = 3.6 Runden sind nach dem Gleichstand 5 : 5 noch zu erwarten.
LS = 10 + 95 · 2 = 13.6
Wir gehen von einer (0, 1)-gleichverteilten Zufallszahl zi aus und bestimmen daraus den
Spielgewinn fur A bzw. B je nachdem ob zi ≤ 23
gilt.
Nr. Zufallszahl Spielgewinn Matchstand Satzgewinner Satzlange
1 0.7222 B 5 : 6
2 0.4615 A 6 : 6
3 0.0258 A 7 : 6
4 0.3495 A 8 : 6 A 14
5 0.7626 B 5 : 6
6 0.1824 A 6 : 6
7 0.2178 A 7 : 6
8 0.0145 A 8 : 6 A 14
9 0.1887 A 6 : 5
10 0.6957 B 6 : 6
11 0.8013 B 6 : 7
12 0.7728 B 6 : 8 B 14
13 0.6448 B 5 : 6
14 0.5845 A 6 : 6
15 0.6857 B 6 : 7
16 0.5457 A 7 : 7
17 0.7688 B 7 : 8
18 0.8506 B 7 : 9 B 16
19 0.5123 A 6 : 5
20 0.5261 A 7 : 5 A 12
21 0.5704 A 6 : 5
22 0.0541 A 7 : 5 A 12
23 0.7373 B 5 : 6
24 0.5448 A 6 : 6
25 0.5144 A 7 : 6...
......
......
...

6.3 Beispiele 125
Unsere Simulation fur sechs Satze ergab die folgenden Werte:
a) Relative Haufigkeit fur den Satzgewinn von Spieler A bzw. B
hA = 46 = 2
3 hB = 26 = 1
3
b) Mittlere Satzlange
LS = 14 + 14 + 14 + 16 + 12 + 126 = 82
6 = 13.6
Die Simulation”traf “ den theoretischen Wert der Satzlange relativ gut.
13.6 ↔ 13.6
Die Abweichungen bei der Gewinnwahrscheinlichkeit sind relativ groß.(
45 , 1
5
)↔
(23 , 1
3
)
Angesichts der geringen Zahl von Simulationslaufen ist dies auch nicht weiter verwunder-
lich. Bei Erhohung der Simulationszahl ergaben sich folgende Werte:2
Anzahl der Laufe hA hB LS
20 0.7000 0.3000 13.1000
50 0.8000 0.2000 13.4000
100 0.7700 0.2300 13.5800
1000 0.8110 0.1890 13.5640
10000 0.8041 0.1959 13.5692
100000 0.7996 0.2004 13.5885
6.3.2 Simulation eines M|M|1-Warteschlangenmodells
Eine M|M|1-Warteschlangenmodell mit den Parameterwerten λ = 109
und µ = 107
soll
simuliert werden. Die theoretischen Werte ergeben sich zu:
mittlere Zwischenankunftszeit Z = 1λ
= 1109
= 0.9
mittlere Bedienzeit Z = 1µ = 1
107
= 0.7
mittlere Verweilzeit W = 1µ− λ
= 1107 − 10
9
= 3.15
mittlere Wartezeit Wq = λµ(µ− λ)
=109
107
(107 − 10
9
) = 2.45
2Die Simulation erfolgte mit dem Zufallszahlengenerator von MATLAB fur (0, 1)-gleichverteilte Zu-fallszahlen; Startstellung: rand(’seed’,0)

126 6 Simulation
A B C D E F G H
Nr.Zwischen-ank.-Zeit
Ankunfts-Zeit
Bedienungs-Dauer
Bedienungs-Beginn
Bedienungs-Ende
Warte-Zeit
Verweil-Zeit
1 1,5276 1,5276 1,0959 1,5276 2,6235 0,0000 1,0959
2 0,4541 1,9817 0,6750 2,6235 3,2985 0,6418 1,3168
3 0,4081 2,3898 0,5575 3,2985 3,8560 0,9087 1,4662
4 0,2312 2,6210 0,0029 3,8560 3,8589 1,2350 1,2379
5 0,4545 3,0755 0,0926 3,8589 3,9515 0,7834 0,8760
6 0,8779 3,9534 1,4938 3,9534 5,4471 0,0000 1,4938
7 0,0601 4,0134 0,2571 5,4471 5,7043 1,4337 1,6908
8 3,2626 7,2761 1,3768 7,2761 8,6529 0,0000 1,3768
9 0,1008 7,3769 2,0737 8,6529 10,7266 1,2760 3,3497
10 0,4430 7,8199 0,0557 10,7266 10,7823 2,9067 2,9624
11 0,5028 8,3227 1,3076 10,7823 12,0898 2,4596 3,7671
12 1,0559 9,3786 0,0496 12,0898 12,1394 2,7112 2,7608
13 0,6614 10,0400 0,2066 12,1394 12,3460 2,0994 2,3060
14 0,1097 10,1497 0,3589 12,3460 12,7049 2,1962 2,5551
15 0,0869 10,2367 0,4702 12,7049 13,1750 2,4682 2,9384
16 4,3214 14,5580 0,6373 14,5580 15,1954 0,0000 0,6373
17 0,0816 14,6397 0,3144 15,1954 15,5098 0,5557 0,8701
18 0,3439 14,9835 0,8018 15,5098 16,3116 0,5263 1,3281
19 0,4824 15,4659 1,2683 16,3116 17,5799 0,8456 2,1140
20 1,7232 17,1891 0,6291 17,5799 18,2090 0,3908 1,0199
21 0,2116 17,4007 0,4154 18,2090 18,6244 0,8083 1,2237
22 0,0653 17,4659 0,6461 18,6244 19,2705 1,1585 1,8045
23 1,7798 19,2458 0,5335 19,2705 19,8040 0,0247 0,5582
24 0,7276 19,9734 1,6673 19,9734 21,6406 0,0000 1,6673
25 3,7575 23,7309 0,4568 23,7309 24,1878 0,0000 0,4568
26 1,4353 25,1662 0,1971 25,1662 25,3633 0,0000 0,1971
27 0,7430 25,9093 1,3996 25,9093 27,3088 0,0000 1,3996∑
25,9093 19,0405 25,4298 44,4703
∅ 0,9596 0,7052 0,9418 1,6470
E(?) 1λ = 0.9 1
µ = 0.7 2,4500 3,1500
In den Spalten B und D stehen die Zufallswerte fur die Zwischenankunfts- bzw. Bedie-
nungszeit. Daraus errechnet man die Ankunftszeit in Spalte C. In Spalte E und F wird
der Beginn und das Ende der Bedienung eingetragen: die Bedienung des ersten Kunden
kann naturlich unmittelbar nach seinem Eintreffen (T1 = 1, 5276) beginnen. Nach einer
Bedienungdauer von 1,0959 verlasst er das System zum Zeitpunkt D1 = 2, 6235. Jeder
weitere Kunde kann jedoch erst bedient werden, wenn der vorherige Kunde abgefertigt ist.

6.3 Beispiele 127
Es gilt also stets:
E(i) = max(C(i), F (i− 1)
In Spalte G notieren wir die Warte- und in Spalte H die Verweilzeit (Warte- einschließlich
Bedienzeit) jedes Kunden. In der vorletzten Zeile (∅) sind die Mittelwerte der Simulation
angegeben. Die theoretischen Werte fur den stationaren Fall sind in der letzten Zeile (E(?))
angefugt.
Es zeigen sich starke Unterschiede zum stationaren Fall. Ebenso erhalt man starke Unter-
schiede bei verschiedenen Laufen. Dies liegt an der”kleinen“ Datenmenge. Eine Stabilisie-
rung wurde sich erst bei mehreren tausend Kunden einstellen. Im Ergebnis bedeutet dies,
dass solche Simulationen mit einem Tabellenkalkulationsprogramm3 wenig aussagekraftig
sind.
6.3.3 Ein Entscheidungsproblem
Viele Anwendungen fur die Simulation ergeben sich bei Entscheidungsproblemen im Zu-
sammenhang mit Wartesystemen. Ein OR-Spezialist habe nach seinem Einkauf in einem
Supermarkt die Wahl, sich an einer von zwei Kassen anzustellen. An jeder Kasse werde ge-
rade mit der Bedienung eines Kunden begonnen, aber kein Kunde warte zusatzlich. Es sei
bekannt, dass die Bedienungszeiten unabhangige, exponentialverteilte Zufallsgroßen sind,
und zwar an Kasse 1 mit dem Parameter µ1 = 0.2 und an Kasse 2 mit µ2 = 0.15. D. h. die
mittlere Bedienzeiten betragen 5 bzw. 203
Einheiten. Ferner wisse der OR-Spezialist, dass
in Kurze ein Inspektor eintreffen wird, der zuerst Kasse 1 und dann Kasse 2 kontrollieren
wird. Bei der Kontrolle muss die Bedienung an der jeweiligen Kasse fur die Dauer von 20
Einheiten unterbrochen werden. (Die Kontrolle finde auch wahrend der Bedienzeit statt, d.
h. der Kontrolleur warte nicht bis der aktuelle Kunde bedient wurde.) Die Dauer bis zum
Eintreffen des Inspektors sei wieder exponentialverteilt mit dem Parameter λ = 0.05 und
unabhangig von den Bedienungszeiten der Kunden. Vor welcher Kasse soll sich unser OR-
Spezialist anstellen, wenn er keine Moglichkeit hat, spater zu wechseln? Ist es gunstiger,
sich an Kasse 1 anzustellen, an der die mittlere Servicezeit kurzer ist als an Kasse 2, aber
gleichzeitig eine großere Gefahr besteht, durch Kassenkontrolle aufgehalten zu werden?
Zunachst wollen wir wieder mit Hilfe der Wahrscheinlichkeitsrechnung eine Entscheidung
treffen, indem wir fur die beiden Varianten die Erwartungswerte bestimmen. Ist P1 bzw.
P2 die Wahrscheinlichkeit, dass wahrend der Abfertigung des OR-Spezialisten an Kasse 1
bzw. 2 keine Kontrolle stattfindet, so erhalten wir die Erwartungswerte
L1 = 2 · 5 · P1 + (2 · 5 + 20) · (1− P1)
L2 = 2 · 203 · P2 +
(2 · 20
3 + 20)· (1− P2)
3Die Simulation wurde mit dem Tabellenkalkulationsprogramm Excel vorgenommen.

128 6 Simulation
Berechnung von P1
a) Wir bestimmen zunachst die Dichtefunktion f1(t) fur die Gesamtwartezeit. Sie ist
die Summe zweier identischer, exponentiell verteilter Zufallsvariabler.4 Die Dichte-
funktion ergibt sich durch Auswertung des entsprechenden Faltungsintegrals.
f1(t) =∞∫−∞
fµ1(τ)fµ1(t− τ)dτ
= µ21
t∫0
e−µ1τ · e−µ1(t−τ)dτ
= µ21e−µ1t
t∫0
1dτ
= µ21te
−µ1t
b) Wahrscheinlichkeit, dass der Inspektor im Zeitintervall [t, t + ∆t] nicht zu Kasse 1
kommt:
∆P = [f1(t) ·∆t] · [1− (1− e−λt)]
= f1(t) · e−λt ·∆t
Damit ergibt sich fur P1:
P1 =∞∫0
µ21te
−µ1t · e−λtdt
= µ21
∞∫0
te−(µ1+λ)tdt
= µ21
[−te−(µ1+λ)t
µ1 + λ
]∞
0
+ 1µ1 + λ
∞∫0
e−(µ1+λ)tdt
= µ21
[− e−(µ1+λ)t
(µ1 + λ)2
]∞
0
=µ2
1
(µ1 + λ)2
= 0.22
(0.2 + 0.05)2 = 0.64
Berechnung von P2
a) Fur die Dichtefunktion f2(t) der Gesamtwartezeit ergibt sich analog:
f2(t) = µ22te
−µ2t
b) Bei der Berechnung von P2 ist zu beachten, dass in den ersten 20 Einheiten der
Inspektor nicht an der zweiten Kasse auftauchen kann, die Kontrolle von Kasse 1
4Es ergibt sich eine Erlang-Verteilung mit dem Parameter n = 2.

6.3 Beispiele 129
nimmt ja diese Zeit in Anspruch. Fur die folgende Zeit ist die um 20 Einheiten
”verschobene“ Verteilungsfunktion der Ankunftszeit zu berucksichigen.
P2 = µ22
20∫
0
te−µ2tdt + µ22
∞∫
20
te−µ2t · e−λ(t−20)dt = I1 + I2
I1 = µ22
20∫0
te−µ2tdt
= µ22
[e−µ2t
µ22
· (−1− µ2t)
]20
0
= 1− e−20µ2(1 + 20µ2)
= 1− 4e−3
I2 = µ22
∞∫20
te−µ2t · e−λ(t−20)dt
= µ22e
20λ∞∫20
te−(λ+µ2)tdt
= µ22e
20λ
[e−(λ+µ2)t
(λ + µ2)2 · (−1− (λ + µ2)t)
]∞
20
=µ2
2
(λ + µ2)2 · e20λ · [e−20(λ+µ2)(1 + 20(λ + µ2))
]
=µ2
2
(λ + µ2)2 · e−µ2(1 + 20(λ + µ2))
= 0.152
0.22 5e−4
P2 = I1 + I2
= 1− e−20µ2(1 + 20µ2) +µ2
2
(λ + µ2)2 · e−µ2(1 + 20(λ + µ2))
= 1− 4e−3 + 0.152
0.22 5e−4 ≈ 0.9407
Bestimmung der Erwartungswerte
W1 = 2µ1· P1 +
(2µ1
+ 20)· (1− P1)
= 10 · 0.64 + 30 · 0.36 = 17.2
W2 = 2µ2· P2 +
(2µ2
+ 20)· (1− P2)
= 403 · 0.9407 . . . + 100
3 · 0.0593 . . . ≈ 14.516

130 6 Simulation
Die Simulation dieser Entscheidungssituation kann so vorgenommen werden, dass die
zufalligen Bedienzeiten des wartenden Kunden und des OR-Spezialisten sowie die zufallige
Dauer bis zum Eintreffen des Inspektors durch exponentialverteilte Zufallszahlen bestimmt
werden. Das einmalige”Durchspielen“ dieser Entscheidungssituation fur Kasse 1 oder 2
stellt einen Simulationslauf dar. Aus einer Vielzahl von Simulationslaufen lasst sich dann
abschatzen, wie groß der Erwartungswert der Verweildauer bis zum Ende der Bedienung
des OR-Spezialisten ist. In den folgenden beiden Tabellen sind jeweils 10 Simulationslaufe5
eingetragen.
Bedienzeit des
wartenden
Kunden an
Bedienzeit des
OR-Spezialisten
an
Dauer bis zur
Ankunft des
Inspektors
Verweildauer des
OR-Spezialisten
an
Kasse 1 Kasse 2 Kasse 1 Kasse 2 Kasse 1 Kasse 2
Parameter µ1=0.2 µ2=0.15 µ1=0.2 µ2=0.15 λ=0.05
7.5943 4.2363 3.2034 7.4269 52.4322 10.7978 11.6631
15.2833 2.6584 11.9317 3.0524 9.1889 47.2150 5.7108
1.9367 32.4451 2.1239 1.8611 2.4500 24.0605 54.3063
1.9335 6.3909 4.3854 0.0600 25.9869 6.3188 6.4509
0.3377 18.0361 1.7749 6.7129 16.5834 2.1126 24.7490
4.7921 5.8234 0.4698 9.3214 5.3185 5.2618 15.1448
3.2752 2.5050 1.3577 0.1174 14.7741 4.6330 2.6224
0.9258 3.5291 6.6884 2.1654 28.7287 7.6143 5.6946
16.8235 0.4807 15.2389 1.8881 25.8265 52.0624 2.3688
14.6440 1.1136 1.5321 2.8563 20.4739 16.1760 3.9699
Mittelwert 6.7546 7.7219 4.8706 3.5462 20.1763 17.6252 13.2681
Erwartungs-
wert5 6.6 5 6.6 20 17.2 14.516
Varianz 41.626 100.187 24.851 10.063 208.572 326.883 255.730
Aus den ersten 10 Simulationslaufen erhalten wir Werte fur die Verweildauer, die relativ
nahe an den theoretisch errechneten liegen. Aus diesem Simulationslauf ergibt sich ganz
klar eine Praferenz fur Kasse 2. Beim zweiten Simulationslauf ergibt sich das umgekehrte
Bild. Der Unterschied zu den theoretischen Werten ist betrachtlich.
Auffallig ist weiter, dass die Varianz bei beiden Laufen an der Kasse 1 großer ist. Ein
Risiko liebender Entscheidungstrager wird sich daher – in der Hoffnung auf einen schnellen
Einkauf – eher an Kasse 1 anstellen.
5Die Zufallszahlen wurden mit MATLAB gewonnen. Es wurde der eingebaute Zufallszahlengeneratorfur Exponentialverteilungen benutzt.
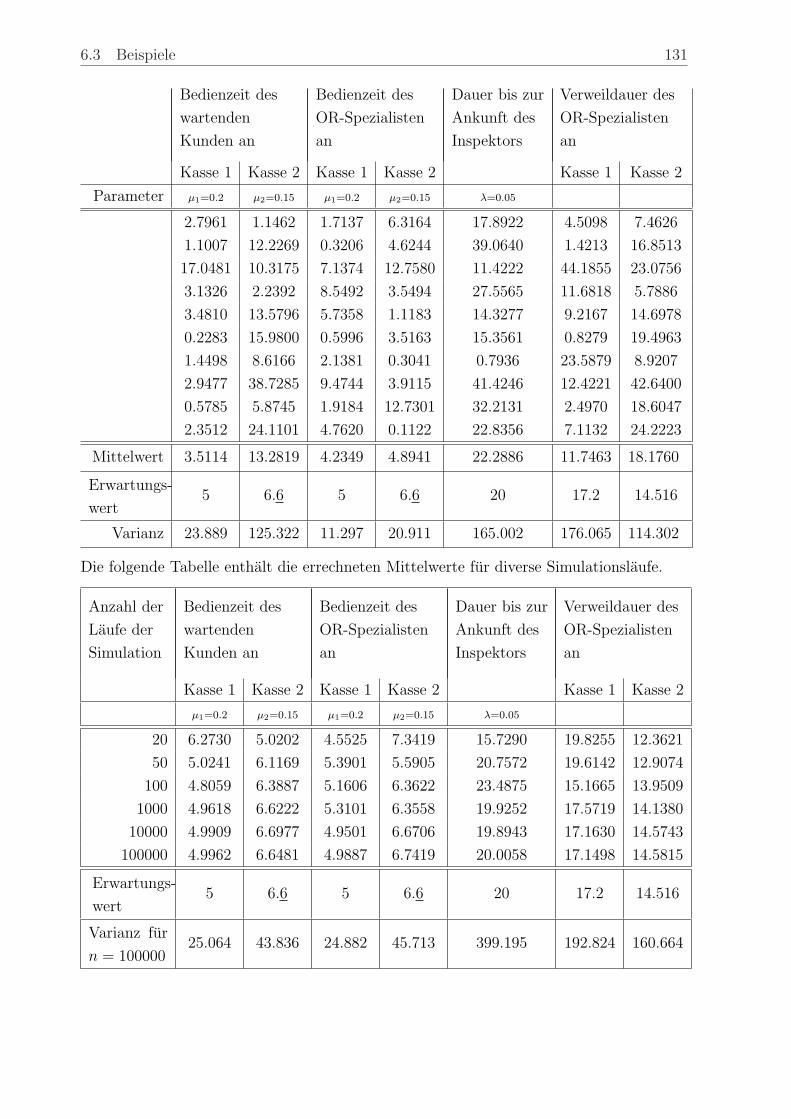
6.3 Beispiele 131
Bedienzeit des
wartenden
Kunden an
Bedienzeit des
OR-Spezialisten
an
Dauer bis zur
Ankunft des
Inspektors
Verweildauer des
OR-Spezialisten
an
Kasse 1 Kasse 2 Kasse 1 Kasse 2 Kasse 1 Kasse 2
Parameter µ1=0.2 µ2=0.15 µ1=0.2 µ2=0.15 λ=0.05
2.7961 1.1462 1.7137 6.3164 17.8922 4.5098 7.4626
1.1007 12.2269 0.3206 4.6244 39.0640 1.4213 16.8513
17.0481 10.3175 7.1374 12.7580 11.4222 44.1855 23.0756
3.1326 2.2392 8.5492 3.5494 27.5565 11.6818 5.7886
3.4810 13.5796 5.7358 1.1183 14.3277 9.2167 14.6978
0.2283 15.9800 0.5996 3.5163 15.3561 0.8279 19.4963
1.4498 8.6166 2.1381 0.3041 0.7936 23.5879 8.9207
2.9477 38.7285 9.4744 3.9115 41.4246 12.4221 42.6400
0.5785 5.8745 1.9184 12.7301 32.2131 2.4970 18.6047
2.3512 24.1101 4.7620 0.1122 22.8356 7.1132 24.2223
Mittelwert 3.5114 13.2819 4.2349 4.8941 22.2886 11.7463 18.1760
Erwartungs-
wert5 6.6 5 6.6 20 17.2 14.516
Varianz 23.889 125.322 11.297 20.911 165.002 176.065 114.302
Die folgende Tabelle enthalt die errechneten Mittelwerte fur diverse Simulationslaufe.
Anzahl der
Laufe der
Simulation
Bedienzeit des
wartenden
Kunden an
Bedienzeit des
OR-Spezialisten
an
Dauer bis zur
Ankunft des
Inspektors
Verweildauer des
OR-Spezialisten
an
Kasse 1 Kasse 2 Kasse 1 Kasse 2 Kasse 1 Kasse 2
µ1=0.2 µ2=0.15 µ1=0.2 µ2=0.15 λ=0.05
20 6.2730 5.0202 4.5525 7.3419 15.7290 19.8255 12.3621
50 5.0241 6.1169 5.3901 5.5905 20.7572 19.6142 12.9074
100 4.8059 6.3887 5.1606 6.3622 23.4875 15.1665 13.9509
1000 4.9618 6.6222 5.3101 6.3558 19.9252 17.5719 14.1380
10000 4.9909 6.6977 4.9501 6.6706 19.8943 17.1630 14.5743
100000 4.9962 6.6481 4.9887 6.7419 20.0058 17.1498 14.5815
Erwartungs-
wert5 6.6 5 6.6 20 17.2 14.516
Varianz fur
n = 10000025.064 43.836 24.882 45.713 399.195 192.824 160.664

132 LITERATURVERZEICHNIS
Literaturverzeichnis
[1] Domschke, W. und Drexl, A.: Einfuhrung in Operations Research. Springer-Verlag,
Berlin 2002
[2] Domschke, W. und Drexl, A.: Ubungsbuch Operations Research. Springer-Verlag,
Berlin 1995
[3] Durr, W. und Kleibohm, K.: Operations Research 3. Aufl., Hanser-Verlag,
Munchen/Wien 1992
[4] Leiser, W.: Angewandte Wirtschaftsmathematik. Schafer-Poeschel Verlag, Stuttgart
2000
[5] Mohr, R.: Statistik fur Ingenieure und Naturwissenschaftler. Expert-Verlag, Rennin-
gen 2003
[6] Neumann, K. und Morlock, M.: Operations Research. Hanser-Verlag, Munchen/Wien
1999
[7] Stingl, P.: Operations Research. Fachbuch Verlag im Hanser-Verlag, Munchen 2002
[8] Zimmermann, H.: Operations Research Methoden und Modelle. Vieweg-Verlag,
Braunschweig/Wiesbaden 1987
[9] Zimmermann, W. und Stache, U.: Operationsresearch. 10. Aufl., Oldenbourg Verlag,
Munchen/ Wien 2001

Index
Uberkapazitat, 43
Abbruchkriterium, 7
Abfertigungsrate, 99
Ankunftsrate, 92, 93, 99
Ausnutzungsgrad, 99
Austauschverfahren, 4
Basisfeld, 37, 39
Basislosung, 10, 13
entartet, 20
Bedienungsrate, 93, 99
χ2-Test, 118
dynamische Optimierung, 56
stochastische Probleme, 66
Eignungsmatrix, 50, 51
Erlang-Verteilung, 89, 108, 110
Exponentialverteilung, 89
Faltung, 91
FIFO, 87
Gesamtpolitik, 59
Gradient, 81, 84
Graph, 42, 58
Input-Prozess, 86
Kanten, 42, 58
Knoten, 42, 58
deterministischer, 67
stochastischer, 67
Kongruenzoperator, 116
konvex, 13
Kostenmatrix, 34, 36, 37
Reduktion der, 48
LIFO, 87
lineare Gleichungen, 22
lineare Optimierung
graphische Losung, 1
Zielfunktion, 2
zulassiger Punkt, 2
lineare Ungleichungen, 2, 3, 7
Markov-Eigenschaft, 89
Matrixinversion, 4
nichtlineare Optimierung, 70
Zielfunktion, 70
Nord-West-Ecken-Regel, 34
Opportunitatskosten, 23
Optimalitatstest, 36
Optimierung
dynamische, 56
nichtlineare, 70
Pivotelement, 5, 10
Poisson-Verteilung, 92
Rechteckregel, 5, 9, 10
Servicequotient, 99
Servicesystem, 88
Sevicesystem, 86
Simplexverfahren, 10
duales, 15
Simulation, 114
SIRO, 87
Stepping-Stone-Methode, 37
Teilpolitik, 59
Transportalgorithmus, 33
fiktive Quellen, 43, 47
gesperrte Routen, 46
Restriktionen, 30
133

134 INDEX
Ubergangsgraph, 103, 104, 106
Umladeprobleme, 49
ungarische Methode, 53
Unterkapazitat, 44
Verweilzeit, 99
Verwerfmethode, 121
Warteschlange, 86, 87
Differenzialgleichungssystem, 95
endlicher Warteraum, 104
Gleichgewichtsfall, 97
M|Ek|s, 108
M|M|s, 106
M|M|1, 91, 97
Simulation, 112
Wartesystem, 86
Zielfunktion
hyperbolische, 80
konkav, 79
konkave, 76
konvexe, 76, 79
quadratische, 80
trennbare, 79
Zufallszahlen, 115
Bernoulli-verteilte, 118
Binomial-verteilte, 118
Erlang-Verteilung, 122
gleichverteilte, 115
Standard-Normalverteilung, 122
Transformation, 119
zulassiger Bereich, 3, 16–18
Zuordnungsproblem, 50
Maximierung, 55
Zustand, 57
Zustandsvariable, 57





























