Embed Size (px)
Citation preview

Operating SystemsCMPSC 473
Virtual Memory Management (4)
November 18 2010 – Lecture 22Instructor: Bhuvan Urgaonkar

Allocating Kernel Memory
• Treated differently from user memory• Often allocated from a free-memory
pool– Kernel requests memory for structures of
varying sizes– Some kernel memory needs to be
contiguous

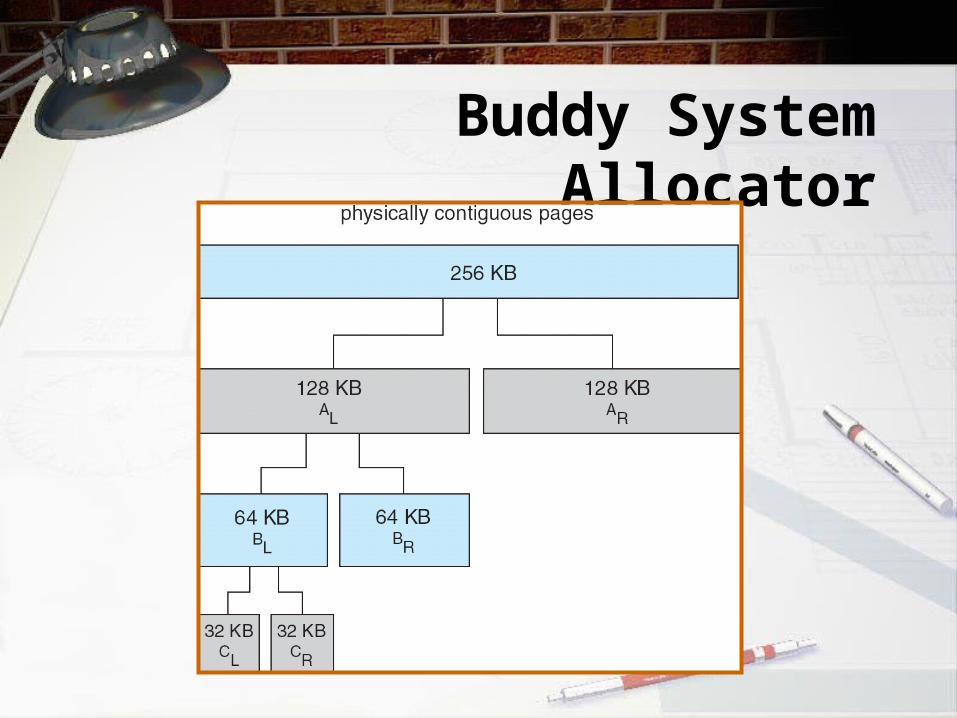
Buddy System
• Allocates memory from fixed-size segment consisting of physically-contiguous pages
• Memory allocated using power-of-2 allocator– Satisfies requests in units sized as power of 2– Request rounded up to next highest power of 2– When smaller allocation needed than is available,
current chunk split into two buddies of next-lower power of 2
• Continue until appropriate sized chunk available
Buddy System Allocator

Slab Allocator• Alternate strategy• Slab is one or more physically contiguous pages• Cache consists of one or more slabs• Single cache for each unique kernel data structure
– Each cache filled with objects – instantiations of the data structure
• When cache created, filled with objects marked as free• When structures stored, objects marked as used• If slab is full of used objects, next object allocated from
empty slab– If no empty slabs, new slab allocated
• Benefits include no fragmentation, fast memory request satisfaction

Slab Allocation

How does malloc work?• Your process has a heap spanning
from virtual address x to virtual address y– All your “malloced” data lives
here• malloc() is part of a user-level
library that keeps some data structures, say a list, of all the free chunks of space in the heap
• When you call malloc, it looks through the list for a chunk that is big enough for your request, returns a pointer to it, and records the fact that it is not free anymore as well as how big it is

malloc (contd.)• When you call free() with the same pointer,
free() looks up how big that chunk is and adds it back into the list of free chunks()
• If you call malloc() and it can't find any large enough chunk in the heap, it uses the brk() syscall to grow the heap, i.e. increase address y and cause all the addresses between the old y and the new y to be valid memory – brk() must be a syscall; there is no way to do the
same thing entirely from userspace

brk() system callNAMEbrk, sbrk - change the amount of space allocated for the calling
process's data segment
SYNOPSIS#include <unistd.h>int brk(void *endds);void *sbrk(intptr_t incr);
DESCRIPTIONThe brk() and sbrk() functions are used to change dynamically the
amount of space allocated for the calling process's data segment (see exec(2)). The
change is made by resetting the process's break value and allocating the
appropriate amount of space. Thebreak value is the address of the first location beyond the end of
the data segment. Theamount of allocated space increases as the break value increases.
Newly allocated space is set to zero. If, how-ever, the same memory space is reallocated to
the same process its
contents are undefined ……

Memory-Mapped Files
• Memory-mapped file I/O allows file I/O to be treated as routine memory access by mapping a disk block to a page in memory
• A file is initially read using demand paging. A page-sized portion of the file is read from the file system into a physical page. Subsequent reads/writes to/from the file are treated as ordinary memory accesses.
• Simplifies file access by treating file I/O through memory rather than read() write() system calls
• Also allows several processes to map the same file allowing the pages in memory to be shared



• Reading from and writing to a memory-mapped file avoids the extra copy that occurs when using the read() and write system calls where data must be copied to and from a user-space buffer
• Aside from any potential page faults, reading from and writing to a memory-mapped file does not incur any system call or context switch overhead
mmap vs. read/write: advantages

• When multiple processes map the same object into memory, data is shared among all the processes• Read-only and shared writable mappings are
shared in their entirety• Private writable mappings have their not-yet COW
pages shared
• Seeking around the mapping involves trivial pointer manipulations. There is no need for the lseek() system call
mmap advantages (contd.)

• Memory mappings are always at granularity of page => Wastage for small files
• Very large number of various-sized mappings can cause fragmentation of address space making it hard to find large free contiguous regions
• Overhead in creating and maintaining the mappings and associated data structures inside kernel
mmap vs. read/write:
disadvantages

Memory Mapped Files

Quiz • Q1: Explain the difference between internal and external
fragmentation. What is the most internal fragmentation if address spaces > 4kB, 4kB <= page size <= 8kB
• Q2: Consider a paging system with the page table stored in memory– If a memory ref. takes 200 nsec, how long does a paged
memory ref. take?– If we add TLBs, and TLB hit ratio is 90%, what is the
effective mem. ref. time? Assume TLB access takes 0 time
• Q3: How much memory is needed to store an entire page table for 32-bit address space if– Page size = 4kB, single-level page table– Page size = 4kB, 3-level page table, p1=10, p2=10, d=12

Quiz • Q4: Consider a demand-paging system with the following time-
measured utilizations: CPU util = 20%, Paging disk (swap device) = 97.7%, Other I/O devices = 5%. For each of the following, say whether it will (or is likely to) improve CPU utilization. Explain your answer.– Install a faster CPU– Install a bigger swap device– Increase the degree of multi-programming– Decrease the degree of multi-programming– Install more main memory– Install a faster hard disk (on which the swapping device resides)– Increase the page size

Quiz • Q5: Consider a system with the following #memory refs vs. LRU queue position curve
If the following two computers cost the same, which would you buy1. CPU = 1GHz, RAM = 400pages2. CPU = 2GHz, RAM = 500pages
Assume memory access time of 100 cycles and swap access time of 100,000 cycles. Ignore memory needed to store page tables, ignore the TLB.
0 1000
1000





























