Embed Size (px)
Citation preview

ONLINE Q-LEARNER USING MOVING PROTOTYPESONLINE Q-LEARNER USING MOVING PROTOTYPES
byby
Miguel Ángel Soto SantibáñezMiguel Ángel Soto Santibáñez

Reinforcement LearningReinforcement Learning
What does it do?What does it do?
Tackles the problem of learning control strategies for Tackles the problem of learning control strategies for autonomous agents. autonomous agents.
What is the goal?What is the goal?
The goal of the agent is to The goal of the agent is to learn learn anan action policy action policy that that maximizes the total reward it will receive from any starting maximizes the total reward it will receive from any starting state.state.

Reinforcement LearningReinforcement Learning
What does it need?What does it need?
This method assumes that training information is available in This method assumes that training information is available in the form of a real-valued reward signal given for each state-the form of a real-valued reward signal given for each state-action transition. action transition.
i.e. (s, a, r)i.e. (s, a, r)
What problems?What problems?
Very often, reinforcement learning fits a problem setting Very often, reinforcement learning fits a problem setting known as a known as a Markov decision processMarkov decision process (MDP). (MDP).

Reinforcement Learning vs. Dynamic programmingReinforcement Learning vs. Dynamic programming
reward functionreward function
r(s, a) r(s, a) r r
state transition function state transition function
δδ(s, a) (s, a) s’ s’

Q-learningQ-learning
An off-policy control algorithmAn off-policy control algorithm..
Advantage:Advantage:
Converges to an optimal policy in both deterministic and Converges to an optimal policy in both deterministic and nondeterministic MDPs.nondeterministic MDPs.
Disadvantage:Disadvantage:
Only practical on a small number of problems.Only practical on a small number of problems.

Q-learning AlgorithmQ-learning Algorithm
Initialize Initialize Q(s, a)Q(s, a) arbitrarily arbitrarily Repeat (for each episode)Repeat (for each episode) Initialize Initialize ss Repeat (for each step of the episode)Repeat (for each step of the episode)
Choose Choose aa from from ss using an exploratory policy using an exploratory policy Take action Take action aa, observe , observe rr, , s’s’
Q(s, a)Q(s, a) Q(s, a)Q(s, a) + α[ + α[rr + γ max + γ max Q(s’, a’)Q(s’, a’) – – Q(s, a)Q(s, a)] ]
a’a’
ss s’s’

Introduction to Q-learning AlgorithmIntroduction to Q-learning Algorithm
• An episode: { (sAn episode: { (s11, a, a11, r, r11), (s), (s22, a, a22, r, r22), … (s), … (snn, a, ann, r, rnn), }), }
• s’: s’: δδ(s, a) (s, a) s’ s’
• Q(s, a):Q(s, a):
• γ, α :γ, α :

A Sample ProblemA Sample Problem
A
B
r = 8r = 0
r = - 8

StatesStates and and actionsactions
11 22 33 44 55
66 77 88 99 1010
1111 1212 1313 1414 1515
1616 1717 1818 1919 2020
states: actions:
N
S
E
W

The The Q(s, a)Q(s, a) function function
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
N
S
W
E
states
actions

Q-learning AlgorithmQ-learning Algorithm
Initialize Initialize Q(s, a)Q(s, a) arbitrarily arbitrarily Repeat (for each episode)Repeat (for each episode) Initialize Initialize ss Repeat (for each step of the episode)Repeat (for each step of the episode)
Choose Choose aa from from ss using an exploratory policy using an exploratory policy Take action Take action aa, observe , observe rr, , s’s’
Q(s, a)Q(s, a) Q(s, a)Q(s, a) + α[ + α[rr + γ max + γ max Q(s’, a’)Q(s’, a’) – – Q(s, a)Q(s, a)] ]
a’a’
ss s’s’

Initializing the Initializing the Q(s, a)Q(s, a) function function
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
N 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
S 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
W 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
E 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
states
actions

Q-learning AlgorithmQ-learning Algorithm
Initialize Initialize Q(s, a)Q(s, a) arbitrarily arbitrarily Repeat (for each episode)Repeat (for each episode) Initialize Initialize ss Repeat (for each step of the episode)Repeat (for each step of the episode)
Choose Choose aa from from ss using an exploratory policy using an exploratory policy Take action Take action aa, observe , observe rr, , s’s’
Q(s, a)Q(s, a) Q(s, a)Q(s, a) + α[ + α[rr + γ max + γ max Q(s’, a’)Q(s’, a’) – – Q(s, a)Q(s, a)] ]
a’a’
ss s’s’

An episodeAn episode
11 22 33 44 55
66 77 88 99 1010
1111 1212 1313 1414 1515
1616 1717 1818 1919 2020

Q-learning AlgorithmQ-learning Algorithm
Initialize Initialize Q(s, a)Q(s, a) arbitrarily arbitrarily Repeat (for each episode)Repeat (for each episode) Initialize Initialize ss Repeat (for each step of the episode)Repeat (for each step of the episode)
Choose Choose aa from from ss using an exploratory policy using an exploratory policy Take action Take action aa, observe , observe rr, , s’s’
Q(s, a)Q(s, a) Q(s, a)Q(s, a) + α[ + α[rr + γ max + γ max Q(s’, a’)Q(s’, a’) – – Q(s, a)Q(s, a)] ]
a’a’
ss s’s’

Calculating new Q(s, a) valuesCalculating new Q(s, a) values
]0)0(*5.00[*10),( 12 EsQ
0),( 12 EsQ
1st step:
2nd step: ]0)0(*5.00[*10),( 13 NsQ
0),( 13 NsQ
3rd step:]0)0(*5.00[*10),( 8 WsQ
0),( 8 WsQ
4th step:
]0)0(*5.08[*10),( 7 NsQ
8),( 7 NsQ
)],()','([),(),( max'
asQasQrasQasQa

The The Q(s, a)Q(s, a) function after the first episode function after the first episode
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
N 00 00 00 00 00 00 -8-8 00 00 00 00 00 00 00 00 00 00 00 00 00
S 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
W 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
E 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
states
actions

A second episodeA second episode
11 22 33 44 55
66 77 88 99 1010
1111 1212 1313 1414 1515
1616 1717 1818 1919 2020

Calculating new Calculating new Q(s, a)Q(s, a) values values
)],()','([),(),( max'
asQasQrasQasQa
]0}0,0,0,8max{*5.00[*10),( 12 NsQ
0),( 12 EsQ
1st step:
2nd step: ]0)0(*5.00[*10),( 7 EsQ
0),( 7 EsQ
3rd step:]0)0(*5.00[*10),( 8 EsQ
0),( 8 EsQ
4th step:
]0)0(*5.08[*10),( 9 EsQ
8),( 9 EsQ

The The Q(s, a)Q(s, a) function after the second episode function after the second episode
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
N 00 00 00 00 00 00 -8-8 00 00 00 00 00 00 00 00 00 00 00 00 00
S 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
W 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
E 00 00 00 00 00 00 00 00 88 00 00 00 00 00 00 00 00 00 00 00
states
actions

The The Q(s, a)Q(s, a) function after a few episodes function after a few episodes
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
N 00 00 00 00 00 00 -8-8 -8-8 -8-8 00 00 11 22 44 00 00 00 00 00 00
S 00 00 00 00 00 00 0.50.5 11 22 00 00 -8-8 -8-8 -8-8 00 00 00 00 00 00
W 00 00 00 00 00 00 -8-8 11 22 00 00 -8-8 0.50.5 11 00 00 00 00 00 00
E 00 00 00 00 00 00 22 44 88 00 00 11 22 -8-8 00 00 00 00 00 00
states
actions

One of the optimal policiesOne of the optimal policies
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
N 00 00 00 00 00 00 -8-8 -8-8 -8-8 00 00 11 22 44 00 00 00 00 00 00
S 00 00 00 00 00 00 0.50.5 11 22 00 00 -8-8 -8-8 -8-8 00 00 00 00 00 00
W 00 00 00 00 00 00 -8-8 11 22 00 00 -8-8 0.50.5 11 00 00 00 00 00 00
E 00 00 00 00 00 00 22 44 88 00 00 11 22 -8-8 00 00 00 00 00 00
states
actions
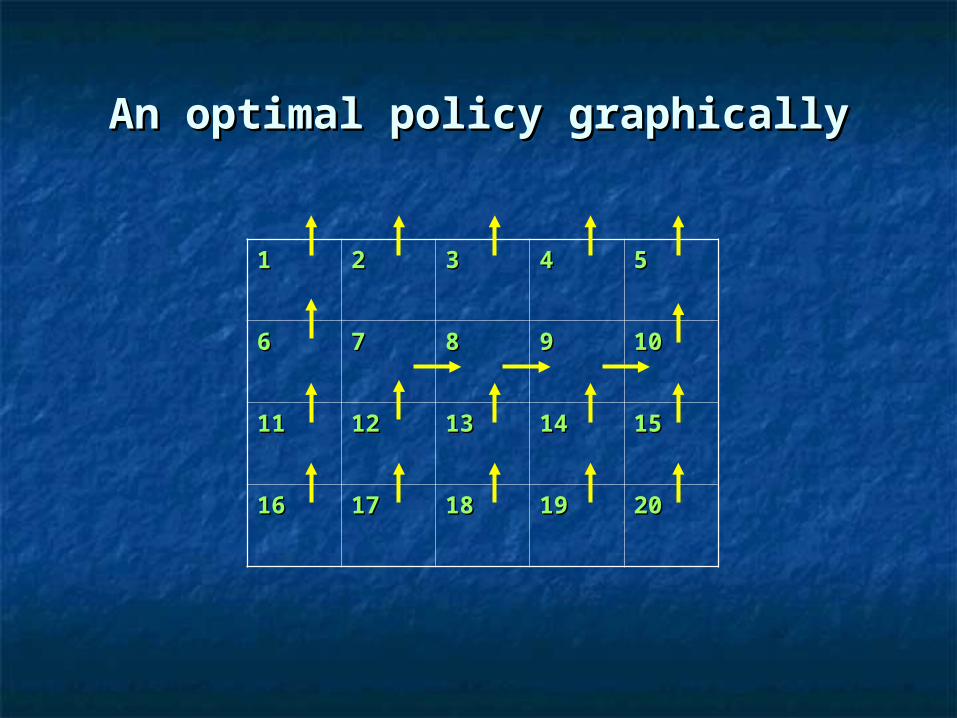
An optimal policy graphicallyAn optimal policy graphically
11 22 33 44 55
66 77 88 99 1010
1111 1212 1313 1414 1515
1616 1717 1818 1919 2020

Another of the optimal policiesAnother of the optimal policies
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
N 00 00 00 00 00 00 -8-8 -8-8 -8-8 00 00 11 22 44 00 00 00 00 00 00
S 00 00 00 00 00 00 0.50.5 11 22 00 00 -8-8 -8-8 -8-8 00 00 00 00 00 00
W 00 00 00 00 00 00 -8-8 11 22 00 00 -8-8 0.50.5 11 00 00 00 00 00 00
E 00 00 00 00 00 00 22 44 88 00 00 11 22 -8-8 00 00 00 00 00 00
states
actions

Another optimal policy graphicallyAnother optimal policy graphically
11 22 33 44 55
66 77 88 99 1010
1111 1212 1313 1414 1515
1616 1717 1818 1919 2020

The problem with tabular Q-learningThe problem with tabular Q-learning
What is the problem?What is the problem?
Only practical in a small number of problems because:Only practical in a small number of problems because:
a)a) Q-learning can require many thousands of training Q-learning can require many thousands of training iterations to converge in even modest-sized problems.iterations to converge in even modest-sized problems.
b)b) Very often, the memory resources required by this Very often, the memory resources required by this method method become too large.become too large.

SolutionSolution
What can we do about it?What can we do about it?
Use generalization.Use generalization.
What are some examples?What are some examples?
Tile coding, Radial Basis Functions, Fuzzy function Tile coding, Radial Basis Functions, Fuzzy function approximation, Hashing, Artificial Neural Networks, LSPI, approximation, Hashing, Artificial Neural Networks, LSPI, Regression Trees, Kanerva coding, etc.Regression Trees, Kanerva coding, etc.

ShortcomingsShortcomings
• Tile codingTile coding: Curse of Dimensionality.: Curse of Dimensionality.
• Kanerva codingKanerva coding: Static prototypes.: Static prototypes.
• LSPILSPI: Require a priori knowledge of the Q-function.: Require a priori knowledge of the Q-function.
• ANNANN: Require a large number of learning experiences.: Require a large number of learning experiences.
• Batch + Regression treesBatch + Regression trees: Slow and requires lots of memory.: Slow and requires lots of memory.

Needed propertiesNeeded properties
1)1) Memory requirements Memory requirements should not explode exponentiallyshould not explode exponentially with the dimensionality of the problem.with the dimensionality of the problem.
2)2) It should It should tackle the pitfallstackle the pitfalls caused by the usage of “ caused by the usage of “static static prototypesprototypes”. ”.
3)3) It should try to It should try to reducereduce the the number of learning experiencesnumber of learning experiences required to generate an acceptable policy.required to generate an acceptable policy.
NOTE: NOTE: All this All this withoutwithout requiring requiring a prioria priori knowledge of the Q-functionknowledge of the Q-function..

Overview of the proposed methodOverview of the proposed method
1) The proposed method limits the number of prototypes 1) The proposed method limits the number of prototypes available to describe the Q-function (available to describe the Q-function (as Kanerva codingas Kanerva coding).).
2) The Q-function is modeled using a regression tree (2) The Q-function is modeled using a regression tree (asas the the batch method proposed by batch method proposed by Sridharan and TesauroSridharan and Tesauro).).
3) 3) But prototypes are not staticBut prototypes are not static, as in Kanerva coding, but , as in Kanerva coding, but dynamic. dynamic.
4) The proposed method has the capacity to update the Q-4) The proposed method has the capacity to update the Q-function once for every available learning experience (it can function once for every available learning experience (it can be an be an online learneronline learner). ).

Changes on the normal regression treeChanges on the normal regression tree

Basic operations in the regression treeBasic operations in the regression tree
Rupture Rupture
MergingMerging

Impossible MergingImpossible Merging

Rules for a sound treeRules for a sound tree
parent
childrenchildren
parent

Impossible MergingImpossible Merging
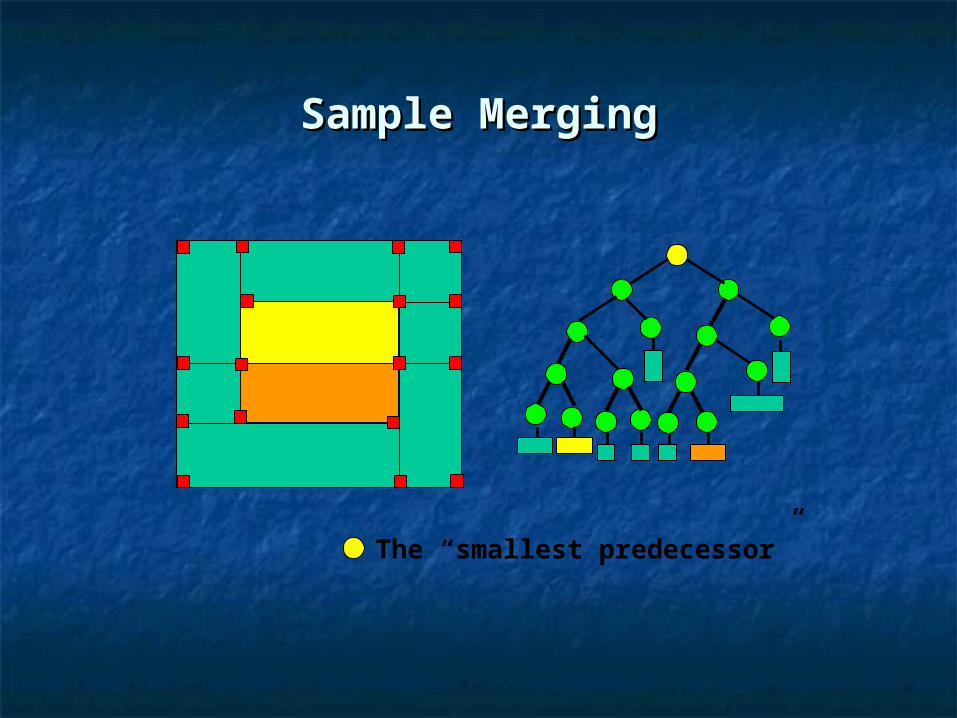
Sample MergingSample Merging
The “smallest predecessor”

Sample MergingSample Merging
List 1

Sample MergingSample Merging
The node to be inserted

Sample MergingSample Merging
List 1
List 1.1 List 1.2

Sample MergingSample Merging

Sample MergingSample Merging

Sample MergingSample Merging

The agentThe agent
Detectors’Signals
Actuators’SignalsAgent
Reward

ApplicationsApplications
BOOK STORE

Results first applicationResults first application
TabularTabular
Q-learningQ-learning
MovingMoving
PrototypesPrototypes
BatchBatch
MethodMethod
PolicyPolicy
QualityQuality
BestBest BestBest WorstWorst
ComputationalComputational
ComplexityComplexity
O(O(nn)) O(O(nn log( log(nn)) ))
O(O(n2n2))
O(O(n3n3))
Memory Memory
UsageUsage
BadBad BestBest WorstWorst

Results first application (details)Results first application (details)
TabularTabular
Q-learningQ-learning
MovingMoving
PrototypesPrototypes
BatchBatch
MethodMethod
PolicyPolicy
QualityQuality
$2,423,355$2,423,355 $2,423,355$2,423,355 $2,297,10$2,297,10
00 Memory Memory
UsageUsage
10,202 10,202
prototypesprototypes413 413
prototypesprototypes11,975 11,975
prototypesprototypes

Results second applicationResults second application
MovingMoving
PrototypesPrototypes
LSPILSPI(least-squares (least-squares
policy iteration)policy iteration)
PolicyPolicy
QualityQuality
BestBest WorstWorst
ComputationalComputational
ComplexityComplexity
O(O(nn log( log(nn)) ))
O(O(n2n2))
O(O(nn))
Memory Memory
UsageUsage
WorstWorst BestBest

Results second application (details)Results second application (details)
MovingMoving
PrototypesPrototypes
LSPILSPI(least-squares (least-squares
policy iteration)policy iteration)
PolicyPolicy
QualityQuality
forever (succeeded)forever (succeeded)
forever (succeeded)forever (succeeded)
forever (succeeded)forever (succeeded)
26 time steps (failed)26 time steps (failed)
170 time steps (failed)170 time steps (failed)
forever (succeeded)forever (succeeded)
Required Required Learning Learning
ExperiencesExperiences
216 216
324324
216216
1,902,6211,902,621
183,618 183,618
648648
Memory Memory
UsageUsage
about 170 prototypesabout 170 prototypes
about 170 prototypesabout 170 prototypes
about 170 prototypesabout 170 prototypes
2 weight parameters2 weight parameters
2 weight parameters2 weight parameters
2 weight parameters2 weight parameters

Results third applicationResults third application
Reason for this experiment:Reason for this experiment:
Evaluate the performance of the proposed method in a Evaluate the performance of the proposed method in a scenario that we consider ideal for this method, namely one, scenario that we consider ideal for this method, namely one, for which there is no application specific knowledge available.for which there is no application specific knowledge available.
What took to learn a good policy:What took to learn a good policy:
• Less than 2 minutes of CPU time.Less than 2 minutes of CPU time.• Less that 25,000 learning experiences. Less that 25,000 learning experiences. • Less than 900 state-action-value tuples.Less than 900 state-action-value tuples.

Swimmer first movieSwimmer first movie

Swimmer second movieSwimmer second movie

Swimmer third movieSwimmer third movie

Future WorkFuture Work
• Different types of Different types of splitssplits..
• Continue Continue characterizationcharacterization of the method Moving Prototypes. of the method Moving Prototypes.
• Moving prototypes + Moving prototypes + LSPILSPI. .
• Moving prototypes + Moving prototypes + Eligibility tracesEligibility traces..





























